PDLight: A Deep Reinforcement Learning Traffic Light Control Algorithm with Pressure and Dynamic Light Duration
Abstract
Existing ineffective and inflexible traffic light control at urban intersections can often lead to congestion in traffic flows and cause numerous problems, such as long delay and waste of energy. How to find the optimal signal timing strategy is a significant challenge in urban traffic management. In this paper, we propose PDlight, a deep reinforcement learning (DRL) traffic light control algorithm with a novel reward as PRCOL (Pressure with Remaining Capacity of Outgoing Lane). Serving as an improvement over the pressure used in traffic control algorithms, PRCOL considers not only the number of vehicles on the incoming lane but also the remaining capacity of the outgoing lane. Simulation results using both synthetic and real-world data-sets show that the proposed PDlight yields lower average travel time compared with several state-of-the-art algorithms, PressLight and Colight, under both fixed and dynamic green light duration.
Introduction
Traffic congestion is one of the major problems in today’s metropolitan transportation networks. Effective traffic signal control plays a significant role in alleviating traffic congestion, reducing the average travel time, improving throughput of a traffic network. However, the optimization of traffic lights scheduling at urban road intersections is a challenging task, especially how to intelligently adapt to real-time traffic demands.
Traditional traffic signal control systems usually use fixed phase and time schedule, which can only adjust the traffic flow at the intersection in a known traffic pattern. With increasing availability of large volumes of sensors, it is now potential to make significant improvements in traffic signal control by collecting abundant real-time traffic data(Zhu et al. 2019). The solutions utilizing reinforcement learning (RL) algorithms for online optimization of traffic signal control are proposed in (Wu et al. 2017; Chacha Chen et al. 2020; Laval and Zhou 2019; Guo et al. 2019). It is shown that a potential reduction of up to in vehicle delays can be achieved when compared to fixed-time actuation (Mousavi et al. 2017).
When the traffic pattern changes dramatically, the state-of-the-art RL algorithms may be unable to make full use of the real-time traffic condition data and give an ineffective adjustment scheme, resulting in longer waiting time of vehicles. Recently, the concept of ”max press” (MP) from the traffic field has been utilized as the reward for control model optimization (Wei et al. 2019a; Chacha Chen et al. 2020). The pressure is defined as the difference between the number of vehicles on incoming lanes and the number of vehicles on outgoing lanes. However, all the studies above ignore the consideration of road carrying capacity. For example, if there has no vacant space on outgoing lane, the waiting vehicles on the corresponding incoming lane will not be able to pass the intersection even in the green light time. The reward used in such cases will be unable to reflect the effectiveness of the selected action. This will result in an unnecessary waste of green light resources and increase the waiting time of all vehicles that fail to pass.
To enhance the capacity of urban road network in a dynamic way, our idea is that the computation of the pressure should consider not only the vehicles on the incoming lanes but also the capacity of the outgoing lanes. An RL agent is assigned for each intersection in the traffic network, which observes the real-time traffic state of its own intersection at each time step. Then according to the observed traffic condition, the agent selects an action from the action space and executes it until the next time step. After the execution, state parameters obtained from the traffic conditions such as the number of vehicles on the lane will be given. The performance of the selected action will be judged by the reward and the policy will be optimized. To summarize, the main contributions are:
-
•
We propose PRCOL, a more rigorous way of calculating pressure to capture the real-time feature of the incoming and outgoing lanes condition. This approach avoids the phenomenon that vehicles cannot completely pass the intersection due to limited outgoing lane capacity.
-
•
We use the PRCOL as the reward function and design an RL algorithm to control the traffic light in the road network of multi-intersections.
-
•
We perform simulation experiments under two synthetic data-sets and two real-world data-sets, Hangzhou and New-York. We consider two cases when the traffic duration is Fixed or Dynamic. The results demonstrate that the proposed PRCOL can reduce the travel time of vehicles and increase the throughput of the network.
Related Work
Since RL algorithm can learn from the interaction with the environment and adapt to the rapidly changing traffic environment, it achieves better performance than the traditional approaches. There has been a large volume of published studies of RL algorithms in the field of traffic signal control.
As fundamental elements in the RL algorithm, the setting of reward and action will have a significant impact on its performance. Variables which are more easily observed, such as queue length and average delay, are often used as reward parameters, such as in (Zang et al. 2020; Zheng et al. 2019; de Oliveira Boschetti et al. 2006; Wei et al. 2019b; Chu et al. 2019; Wei et al. 2018; Genders and Razavi 2020; Joo and Lim 2020). However, these heuristic setting may cause high sensitivity performance and increased learning process. (Wei et al. 2019a) and (Chacha Chen et al. 2020) propose a reward setting approach based on max pressure (MP) inspired by relevant research in the field of transportation(Lioris, Kurzhanskiy, and Varaiya 2016). The “pressure” is defined as the difference between the number of vehicles on incoming lanes and outgoing lanes. The MP does not take into account the carrying capacity of the lanes, so that excessive traffic flow may cause system failure. In this paper, we design a novel pressure, PRCOL, and use it as the reward for the RL algorithm.
There are usually three action options for traffic light control problems. A simple way is to have the agents choose whether to switch to the next phase in a cycle-based signal plan(Xu et al. 2020; de Oliveira Boschetti et al. 2006; Wei et al. 2018), which is not flexible enough to cope with changing traffic conditions. A most widely-used approach is to select the green phases for next state (Wei et al. 2019a; Chacha Chen et al. 2020; Zang et al. 2020; Zheng et al. 2019; Wei et al. 2019b; Kim and Jeong 2020; Chu et al. 2019; Genders and Razavi 2020). However, fixed action duration may cause unnecessary delay when the vehicle’s required pass time and green phase duration do not match. In other approaches, the agents can choose the duration of green lights to adapt to the changing traffic flow(Liang et al. 2019; Joo and Lim 2020). In the experiment, a more flexible approach is used, which can adjust the duration of the traffic light according to the real-time traffic conditions.
Problem Definition
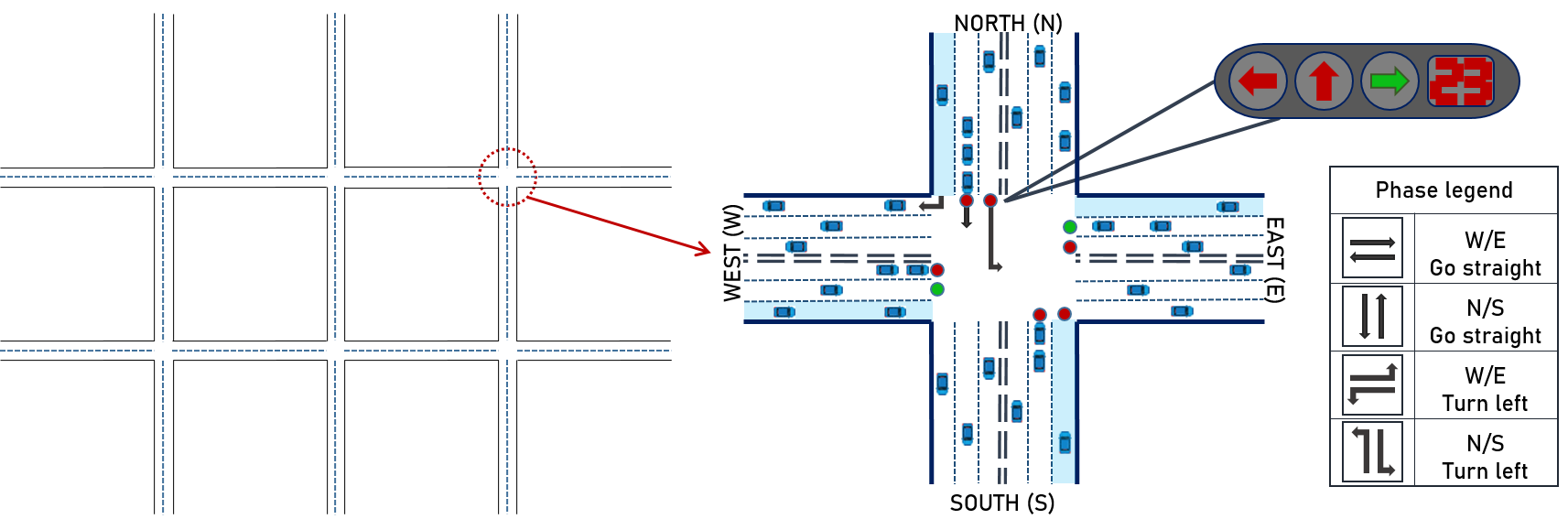
This paper studies the dynamic control of traffic light phase at a multi-intersection scene. Every single intersection is set as a two-way six-lane intersection, as shown in Fig.1. Each intersection has four approaches in different directions (”W”, ”E”, ”N”, ”S”), which are divided into three lanes (turn left, turn right, go straight). The green light directions are combined in pairs in a way that does not cause conflict, and are divided into four phases, as given in Fig. 1.
Incoming/outgoing approach and lane.
Incoming and outgoing approaches are defined as the roads on which vehicles approach and leave the intersection. In our setting, each intersection has approaches. There are three lanes on each approach, representing three different travel directions: turning left, turning right and going straight.
Traffic movement and phase.
A traffic movement is a route that vehicles take through an intersection. The traffic movement from lane to lane is expressed as (,). There are types of moving traffic at an intersection. Two non-conflicting movements is combined as a light phase, and there are phases in an intersection, as shown in Figure.1.
PRCOL.
In this paper, the pressure algorithm (Wei et al. 2019b) has been improved, and the impact of the maximum carrying capacity of the lane on the pressure calculation is taken into consideration. Our proposed pressure index is named as PRCOL(Pressure with Remaining Capacity of Outgoing Lane). The PRCOL of a traffic movement is determined by the number of vehicles on the incoming and outgoing lanes, which is calculated by the following equation:
| (1) |
where is the PRCOL of traffic movement , and is the number of vehicles on the incoming and outgoing lane respectively. The is the maximum number of vehicles that can fit in a lane. There is a one-to-one correspondence between pressures and traffic movements.
PDlight Algorithm
In the RL algorithm, the agent making decisions in the process of interacting with the environment is usually regarded as a Markov Decision Process (MDP), represented by . In this MDP, there is a set of states , a set of actions , a transfer probability , a reward function , and a discount factor .
In PDlight algorithm, an agent is set for each intersection in the road network. Each agent controls the traffic light of its intersection. For the communication and coordination between the agents, we adopt the graph attention networks proposed by (Wei et al. 2019b).
Fo each agent, the state reflects the observation of the traffic situation at a certain time of the intersection. To be more specific, the state is a dimension vector representing the number of vehicles on the 12 incoming lanes. For the agent, to choose an action is to control the traffic light for the intersection. There are possible traffic light phases, as shown in Fig. 1. The phase with the minimum intersection pressure calculated by the PRCOL is selected as the green light of the next time step. Considering that the duration of the traffic light may change, we also include this duration into the action space. The choice of reward is based on the PRCOL, which is defined as:
| (2) |
where is the PRCOL of the traffic movement , which is defined in Eq.1. The total reward for an action is:
| (3) |
where is the index of traffic movements.
Unlike the primary pressure algorithms, the PRCOL takes into account the difference between the apparent pressure and the actual capacity of the vehicle. As a more accurate way of reward calculating, it can avoid conflicts caused by the number of vehicles trying to pass exceeding the maximum carrying capacity of the outgoing lane.
At each intersection, the agent observes the road environment at time , obtains the vehicle queue length on each lane and the current traffic light phase, and takes these obtained traffic flow characteristics as the current state. Then, the agent predicts the Q-value of all phases that can be chosen. The Q function is used to predict the expected future reward for a given state and action:
| (4) |
where is the discount factor, evaluated in the interval between and , representing the importance of the future state. As approaches , the agent will focus on the reward for the future state.
The goal of action selection is to maximize the reward , that is, to choose the phase in time step with the highest Q-value. Then, the agent will calculate the maximum number of vehicles that can move across the intersection. The loss function expressed as follow is calculated and the parameters of the Q network are updated by gradient descent.
| (5) |
where is the target function, and is the primary function.
PDlight algorithm uses Deep Q-Network (DQN) to control the traffic lights at each intersection. As one of the classical reinforcement learning algorithms, DQN combines Q-learning with deep neural network, which is used to approximate the Q-value function to avoid the “curse of dimensionality”. In the complex and unknown environment, DQN interacts with the environment by selecting actions and obtaining rewards in a trial-and-error manner, so as to perceive the invisible environment and learn the optimal strategy. The pseudocode of PDlight algorithm is shown in Algorithm 1.
Experiment and Analysis
In this section, PDlight algorithm is performed on four data-sets which include both synthetic and real-world traffic data. The experiments are conducted on CityFlow(Zhang et al. 2019), a large-scale traffic simulator.
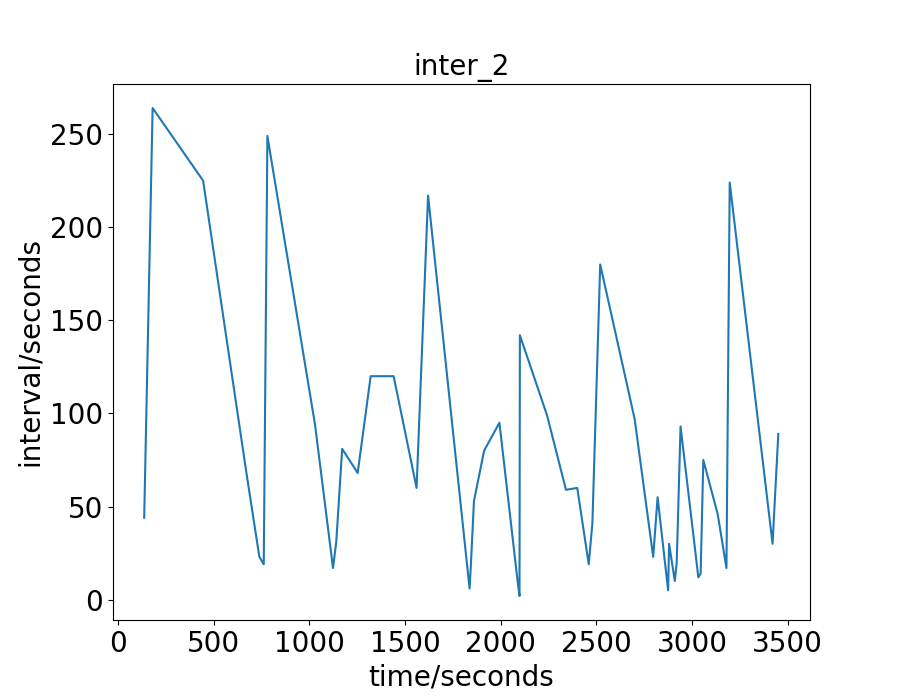
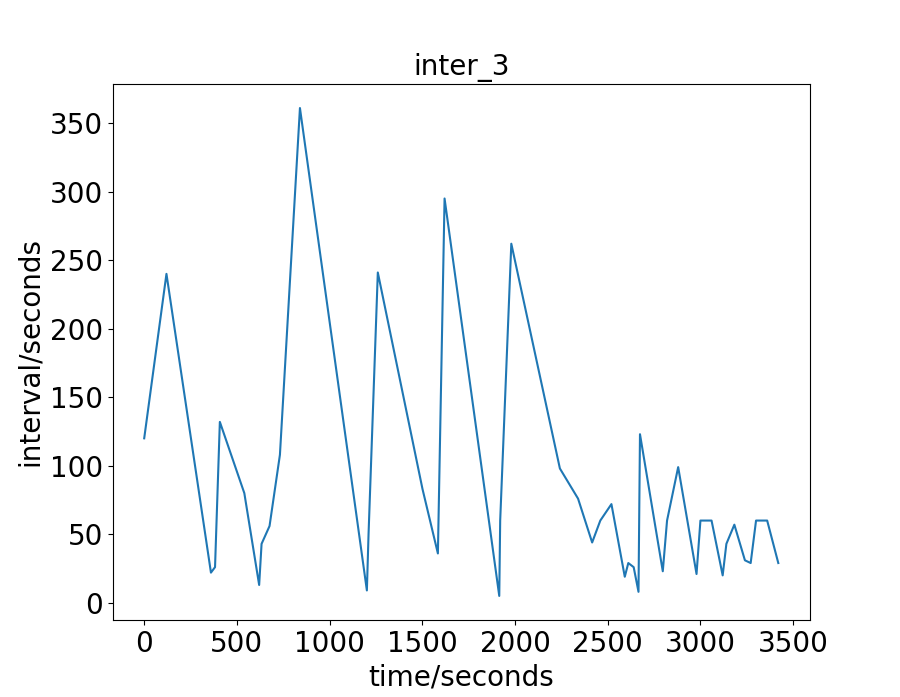
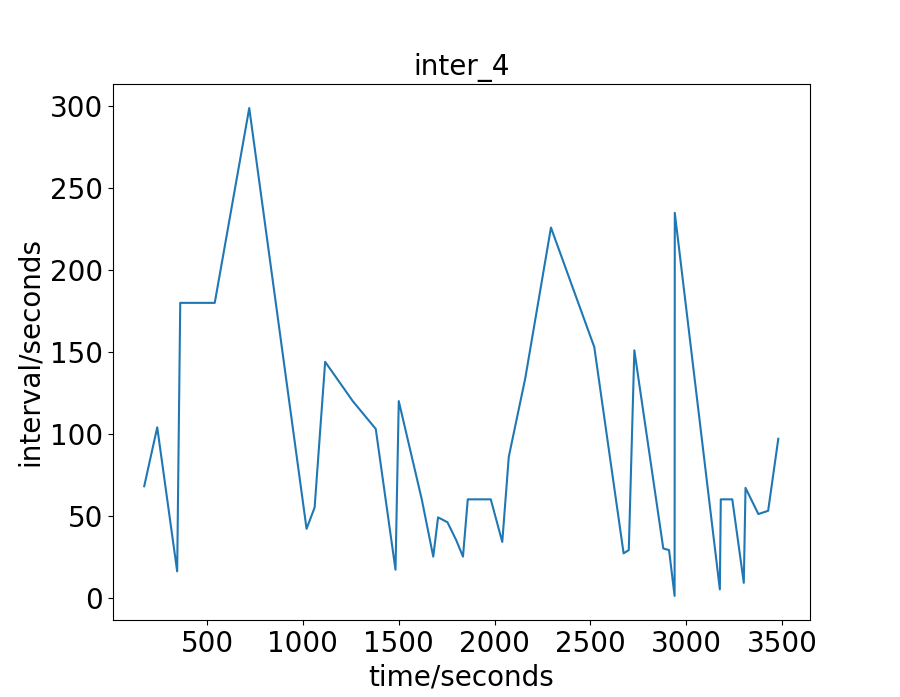
Data-sets
We use two kinds of data-sets, synthetic and real-world. The synthetic data-set enables us to learn the property of different algorithms since the traffic can be designed manually and regularly. The real-world data-sets enable us to test the performance of different algorithms on real traffic flow, which can be more irregular and unpredictable. For all the four data-sets, the topology of the road network is similar to the road presented in Fig. 1.
For the synthetic data-set, there are intersections (The first and the second represent there are roads on the WE and NS direction respectively. For the following Hangzhou and New-York data-sets, we use the similar notation.). The trajectories of vehicles are generated manually. The lane length of the WE lane and NS lane is both . We use two traffic flow, Syn-Light and Syn-Heavy, to test the performance under different traffic conditions. To facilitate the analysis, we assume that in both the two data-sets all vehicles can only go straight. Therefore, there are four allowed directions for the traffic: NS, SN, WE, EW. For Syn-Light, the interval between two vehicles is 20 seconds for all of the four directions. For the Syn-Heavy data-set, the interval is set as 10 seconds for the first and third 900 seconds. Then at the second 900 seconds, the NS and SN traffic flow interval is set to 2 seconds while the WE and EW traffic interval is still 10s. At the last 900 seconds, the WE and EW traffic flow interval is set to 2 seconds while the NS and SN interval remains 10s. Such setting is expected to model the case of rush time, when the traffic becomes heavy.
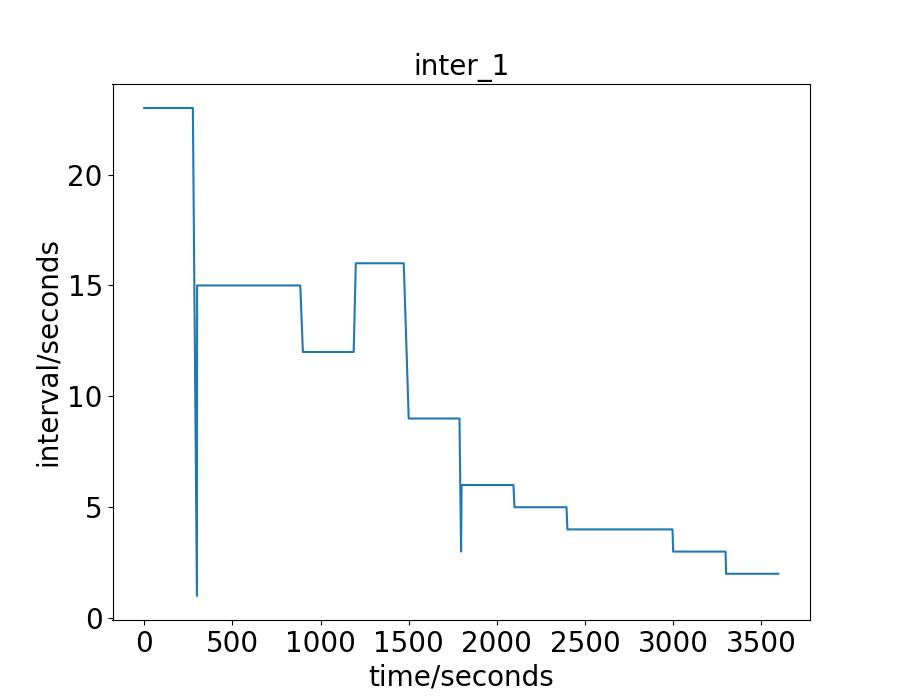
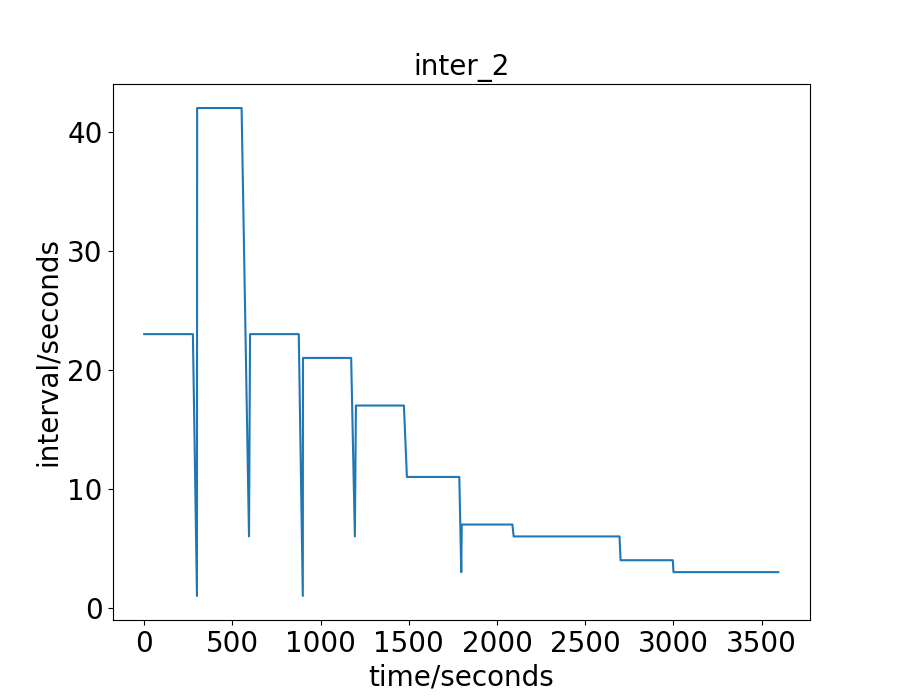
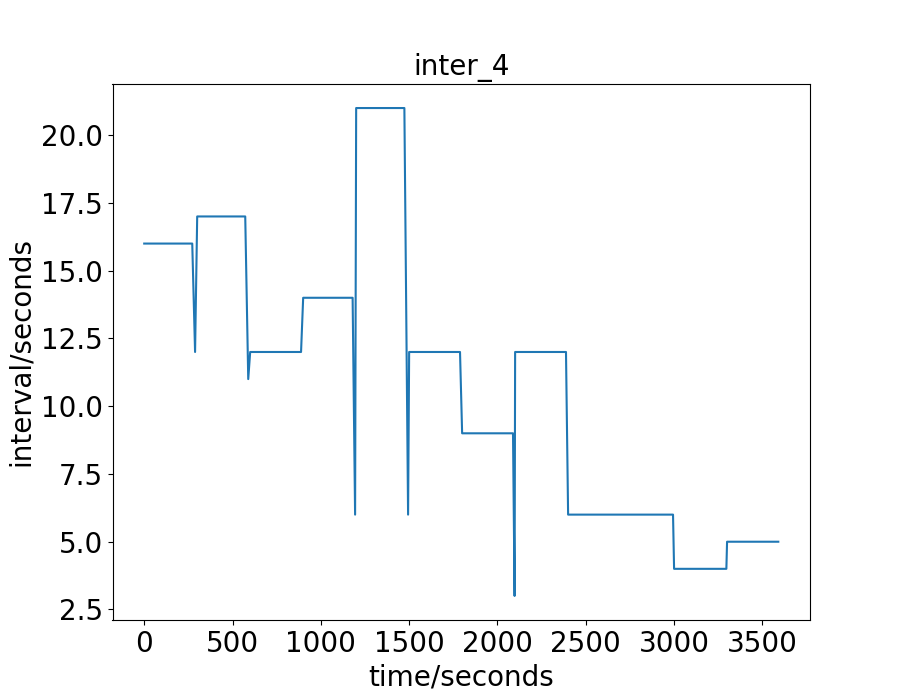
The real-world data-sets are the traffic flow of an hour in the city of Hangzhou and New-York. For the Hangzhou data-set, there are intersections. The lane length for the WE and NS direction is and respectively. The vehicle trajectory is captured from the surveillance camera. For the New-York data-set, there are intersections. The lane length for the WE and NS direction is and respectively. The vehicle trajectory is open-source 111https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page. For these two real-world data-sets, the traffic is more irregular and complicate than the synthetic data-sets. To have a more intuitive understand of these real-world two data-sets, we draw their vehicles’ arrival interval on some intersections, as shown in Fig. 2 and 3. The x-axis is the time a vehicle enters the road network, and the y-axis is the interval between this vehicle and the next one. For the Hangzhou data-set, the traffic is light in the beginning and becomes heavier later. For the New-York data-set, the traffic presents no distinct characteristics .
| Average Travel Time | Throughput | |||||||
| Syn-Light | Syn-Heavy | Hangzhou | New-York | Syn-Light | Syn-Heavy | Hangzhou | New-York | |
| FixedTime | 115.36 | 197.75 | 557.68 | 1846.21 | 2094 | 5220 | 3410 | 200 |
| MaxPressure | 116.32 | 196.84 | 406.35 | 421.27 | 2096 | 6080 | 4394 | 2373 |
| CoLight | 94.92 | 197.10 | 358.71 | 177.50 | 2109 | 6366 | 4360 | 2699 |
| PressLight | 98.40 | 219.82 | 390.42 | 848.51 | 2107 | 6009 | 4359 | 1243 |
| PDLight | 89.24 | 190.10 | 340.66 | 176.80 | 2112 | 6428 | 4485 | 2710 |
| Average Travel Time | Throughput | |||||||
| Syn-Light | Syn-Heavy | Hangzhou | New-York | Syn-Light | Syn-Heavy | Hangzhou | New-York | |
| FixedTime | 115.36 | 197.75 | 557.68 | 1846.21 | 2094 | 5220 | 3410 | 200 |
| MaxPressure | 116.32 | 196.84 | 406.35 | 421.27 | 2096 | 6080 | 4394 | 2373 |
| CoLight | 95.13 | 195.31 | 417.77 | 177.95 | 2109 | 6386 | 4183 | 2712 |
| PressLight | 98.52 | 208.46 | 380.69 | 897.26 | 2107 | 6402 | 4348 | 1206 |
| PDLight | 89.69 | 194.25 | 352.53 | 174.51 | 2112 | 6446 | 4584 | 2721 |
Experiment Settings
Regarding the calculation of the proposed PRCOL in Eq. (1), the number of vehicles on the incoming lane and the number of vehicles on the outgoing lane can be measured by some sensors or camera in practice. There are also APIs in CityFlow that can give these measurements. For , the maximum number of vehicles that can fit in the outgoing lane, we assume that the length of the outgoing lane is , the average length of the vehicle is and the minimum gap between two vehicles is . The then can be simply calculate as . In the experiment, for all the four data-sets, we take and .
We consider two settings of traffic light duration: Fixed and Dynamic. For the Fixed traffic light duration, the duration is set as 10 seconds for all green lights. For the Dynamic traffic light duration, we adjust the duration of green light according to the real-time traffic condition. To be more specific, we first define the number of vehicles to pass as
| (6) |
where is the number of remaining empty space of the outgoing lane. We assume there are vehicles waiting before the intersection statically and their gap is the minimum gap . With the acceleration as and the maximum speed as , we can calculate the total time for all the vehicles to pass the intersection. In the experiment, we take and . For both the Fixed and Dynamic traffic light duration, a yellow light of seconds is added to clear the traffic and avoid collision whenever the green light swift to another phase.
In algorithm 1, the episode length is set as seconds. In the Fixed traffic light duration, each is seconds. And in the Dynamic traffic light duration, the ranges from to seconds. Note that the actual episode may last longer than one hour in the Dynamic setting. In the experiment, we take decreasing from to . The discount factor for calculating the accumulated reward is set as . The maximal sample size is . The Q network parameters are updated with the learning rate as . The target Q network is updated every steps.
Baseline
To demonstrate the effectiveness of the proposed PRCOL, we use both classic traffic light control algorithms and recently developed RL algorithms as baselines.
For the classic traffic light control algorithms, we consider the following two widely used ones:
-
•
FixedTime: Set green light for all phases periodically with a given order.
-
•
MaxPressure (Varaiya 2013): Set the green light for the phase with the maximum pressure.
Recently, some RL algorithms have been proposed for more advanced traffic light control strategies. In this paper, we use one state-of-the-art framework CoLight proposed in (Wei et al. 2019b). We compare the following three RL algorithms:
-
•
CoLight (Wei et al. 2019b). A multi-intersection traffic control algorithm, which uses graph attention networks for the communication among intersections. This algorithm can handle the traffic signal control in a road network containing many intersections. Follow the same setting of (Wei et al. 2019b), the queue length of the incoming lane is used as the reward.
-
•
PressLight (Wei et al. 2019a). A recently developed RL algorithm with pressure as the reward function. In this paper, we use the CoLight framework with pressure as the reward function to accentuate the effectiveness of the proposed PRCOL.
-
•
PDLight. The CoLight framework is adopted for the agent and the proposed PRCOL is used to calculate the reward.
For the RL algorithms, considering the randomness of the initial value of neural networks, we run each experiment three times with random initial values.
Evaluation Metrics
To evaluate the performance of a traffic light control strategy, we use both the travel time and throughput as metrics.
-
•
Average Travel Time. In the experiment, we record and , the time when a vehicle enters and leaves the road network. The travel time for that vehicle is then . Since not all vehicles can leave the network in the given one hour, for those left in the network, we calculate their travel time as . We use the average travel time for all vehicles as the final result.
-
•
Throughput. The throughput is defined as the number of vehicles passed the road network in the give one hour. Each vehicle has a pre-determined destination and only the vehicles that have reached the destination are counted as passed.
Result
In Table 1, we give the average travel time for all vehicles and the throughput under Fixed green light duration. In Table 2, we give the average travel time for all vehicles and the throughput under Dynamic green light duration. It can be seen that under both traffic light settings, the proposed PDlight achieves the lowest average travel time and the highest throughput.
Case Study
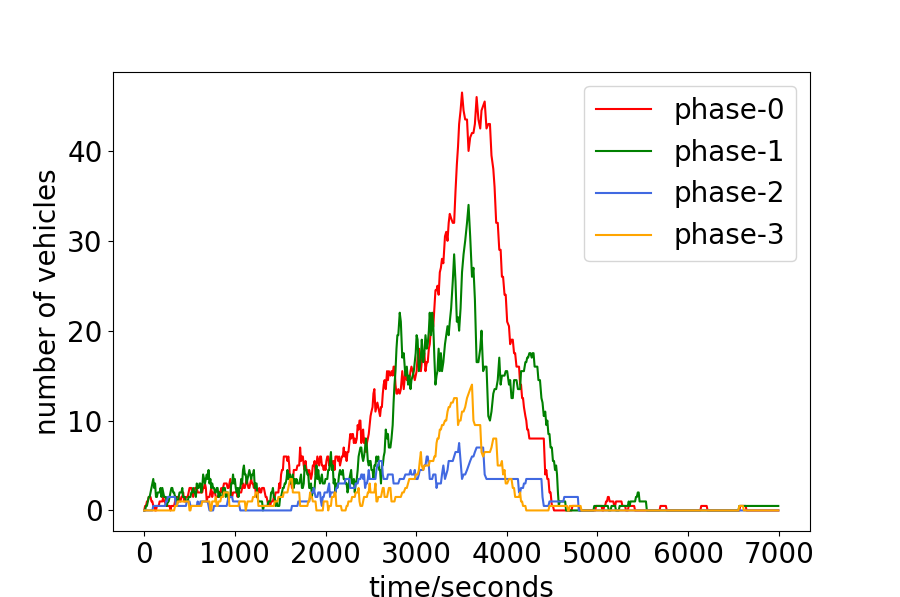
The average travel time and throughput has demonstrated the superior of the proposed PDLight. To gain a more comprehensive understanding of the algorithm, we will analyze the action chosn by the PDlight algorithm in detail.
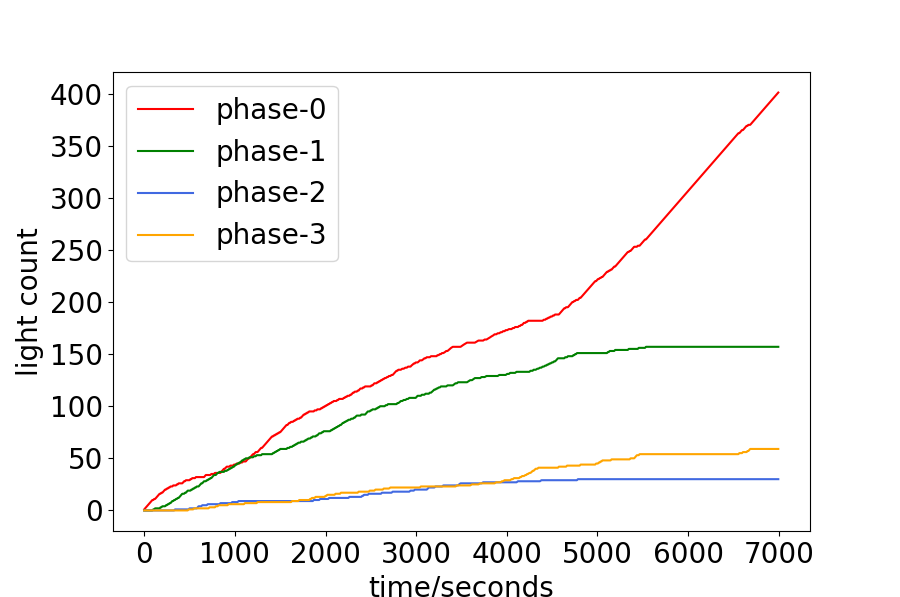
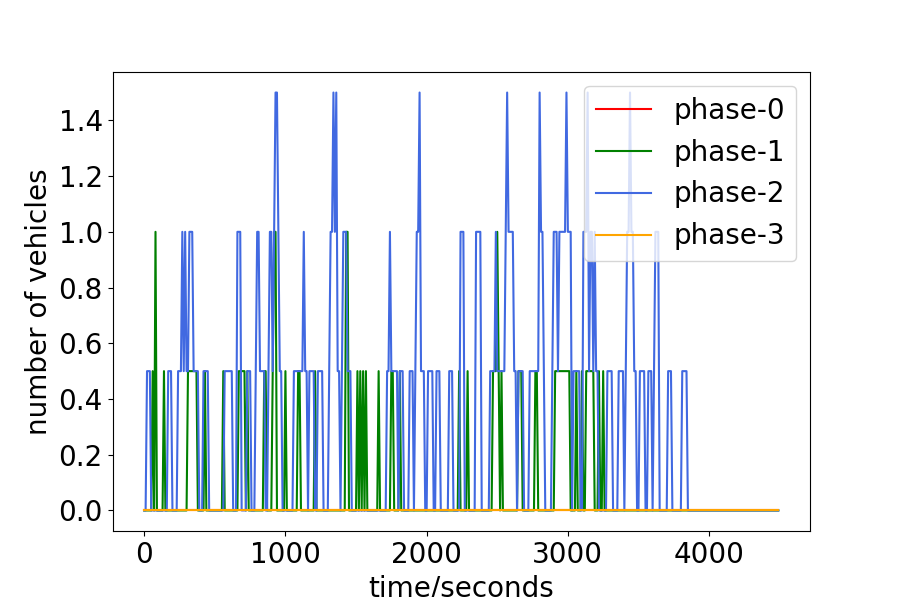
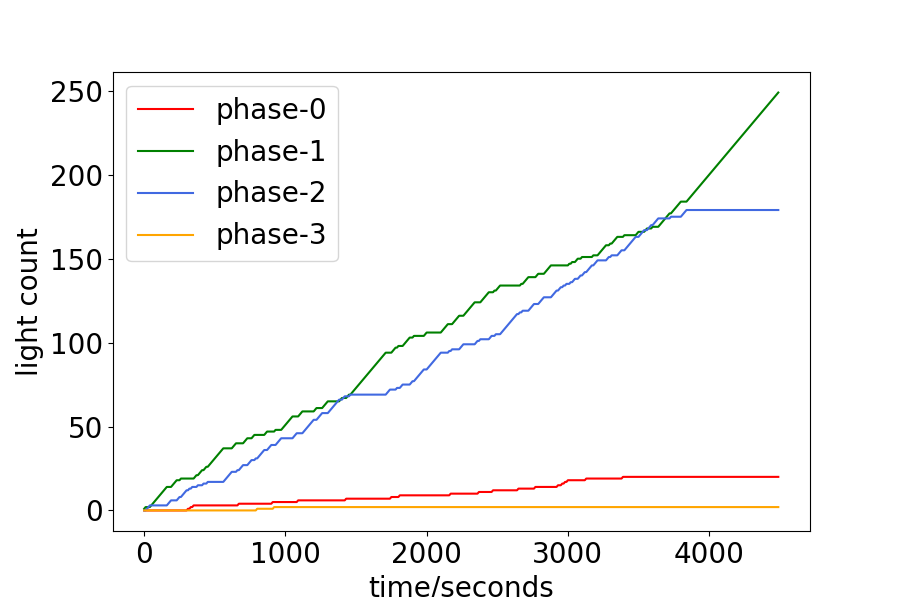
The PDlight aims to control the traffic light in the complex and dynamic traffic environment according to the real-time traffic condition, and thus we analyze the relationship between the traffic condition and the choice of traffic light. The number of vehicles of the four phases and the accumulated number each phase has been chosen are shown in Fig. 4. Since each phase corresponds to two directions, the number of vehicles is calculated by their average. (For example, phase-0 means the traffic flow goes straight in W/E will be allowed, as show in 1, and the number of vehicles of phase-0 is the average of the number in the west-to-east lane and the east-to-west lane.) From 4.(a) and 4.(b), or 4.(c) and 4.(d), it can be seen that the more vehicles of one phase, the more time it will be chosen, such as phase-0 of the Hangzhou data-set and phase-1 and phase-2 of the New-York data-set. Quantitatively, we calculate the frequency that the phase with the maximum real-time number of vehicles has been chosen in Hangzhou and New-York data-sets as 0.518 and 0.549 respectively.
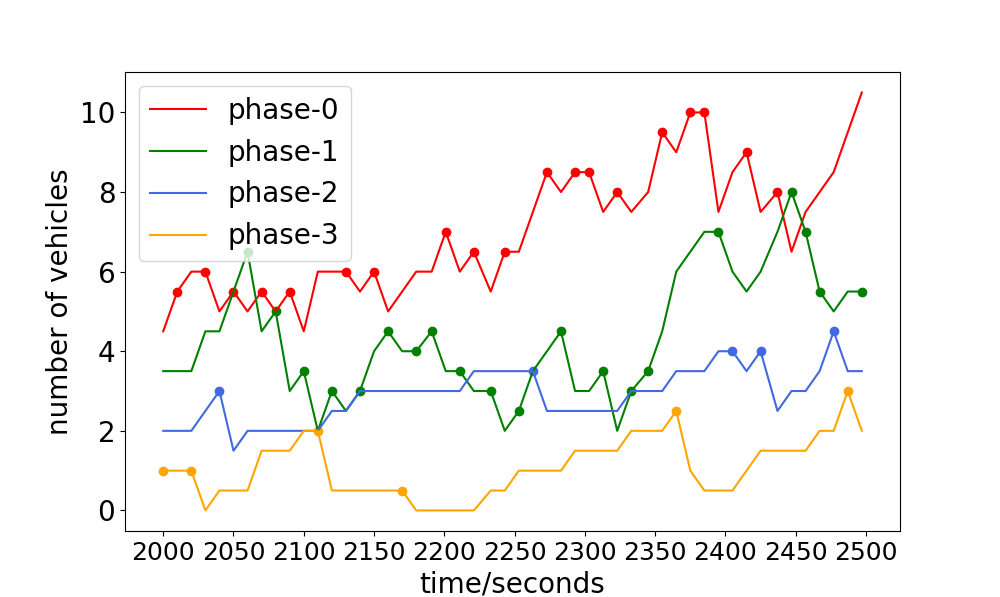
The experiments have shown that with more than , the phase with the maximum number of vehicles is chosen, but When will the algorithm choose the phase not with the maxinum number of vehicles? To answer this question, the number of vehicles and the choice of traffic light are drawn in Fig. 5. The point on each curve means one choice of the corresponding phase. It can be seen that for the phase-2 or phase-3, the interval between two choices is relatively long, compared to phase-0 and phase-1. One rational explanation for this can be stated as follows. The aim of traffic light control is to minimize the average travel time of all vehicles. For a same interval, green light on the phase with more number of vehicles means less average results. Therefore, the phase with maximum number of vehicles will be chosen priorly. However, if the vehicles of one phase have been waiting long enough, it will be reasonable to set the green light for this phase since some extremely huge numbers may have a deep impact on the result.
Verification of the dynamic green light duration
We mention earlier that we consider two traffic light duration: Fixed and Dynamic. The Fixed green light is commonly seen in the daily life. The Dynamic green light duration is also by some previous work. In this subsection, we investigate the future of the duration of green lights.
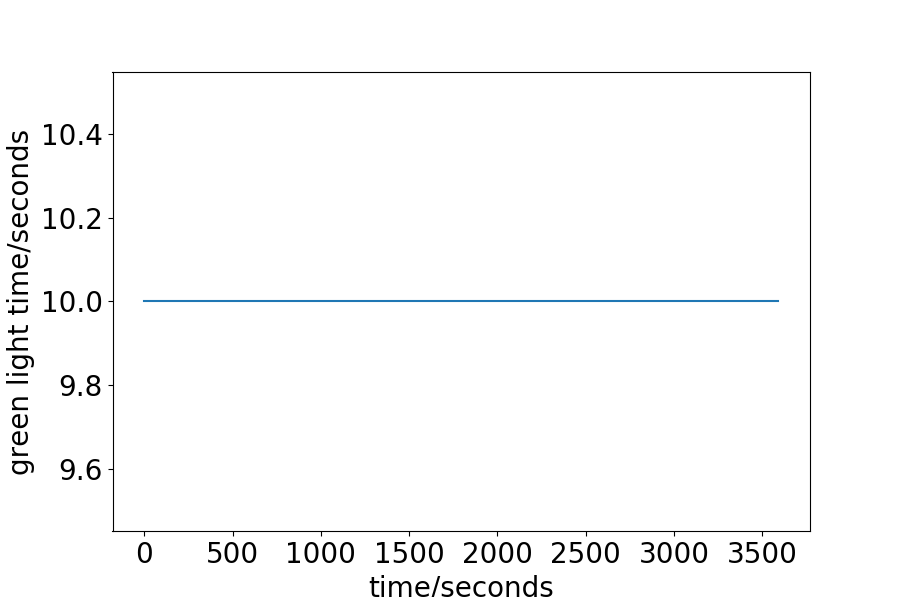
We first give the exact green light time during the process in Fig. 6. For the Synthetic-Light data-set, the interval between two vehicles is set to 20 seconds, and the number of vehicles to pass is relatively small, so the green light is always 10 seconds. For the Hangzhou data-set, as has been discussed, there is a trend for decreasing intervals, or increasing vehicles. The green light time, given this property, also shows some increasing trend. For the approximate first half an hour, the green light is always set to 10 seconds, which is in consist with the analysis of the data-set aforementioned. For the second half an hour, since the interval becomes smaller, more vehicle enters the road network, and the green light time is set longer than before. This explanation is also adaptive to the Synthetic Heavy data-set. For the New-York data-set, the green light is also set as 10 seconds constantly. The analysis in Fig.3 shows no clear trend as the Hanzhou or Synthetic data-sets. The range of the intervals is wide, from less than 5 to more than 350 seconds. One can also notice that the small interval is less frequent than the large interval. The average interval is calculated to be 42.55 seconds, which is considerably large.
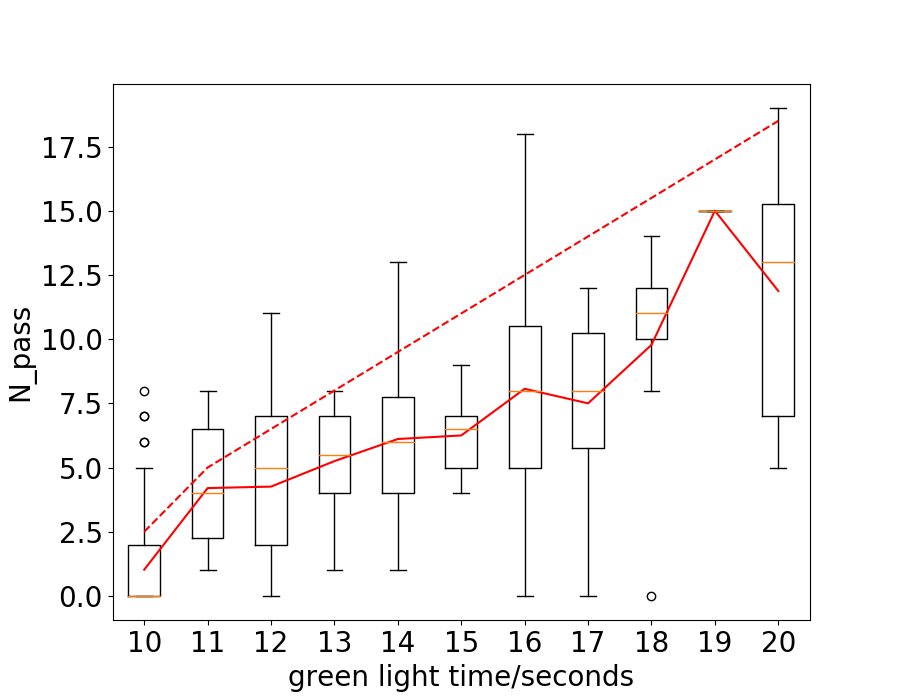
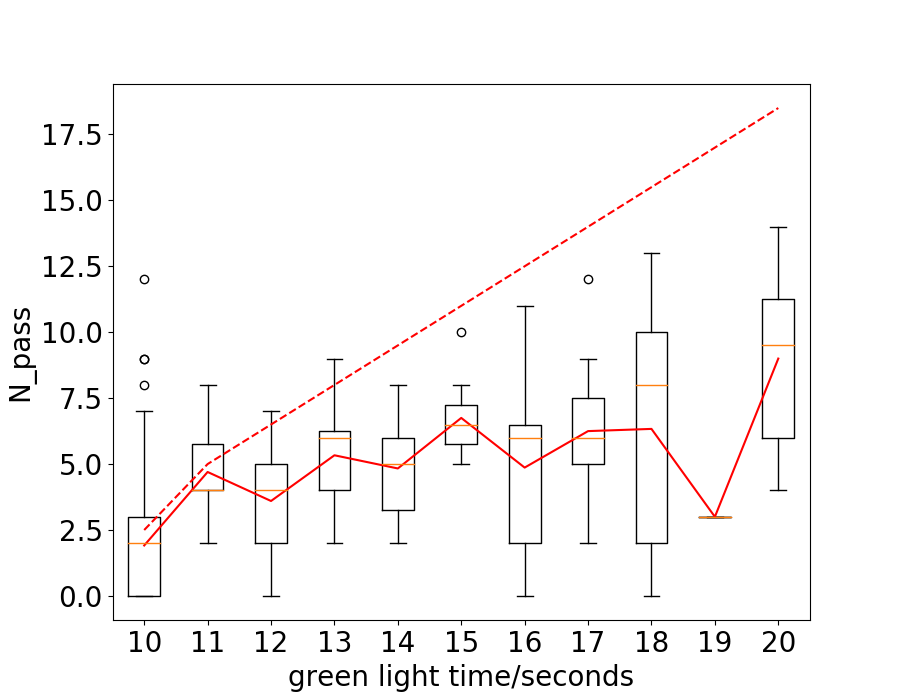
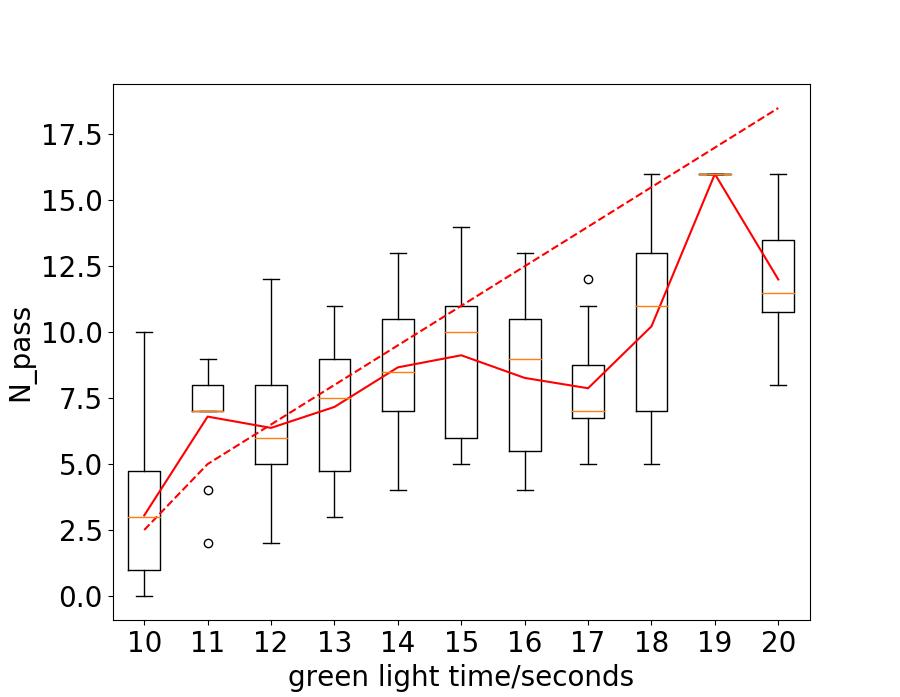
The duration of the green light is decided by , the number of vehicles we assume will pass the intersection. It is natural to ask what is the real number of vehicles passing the intersection with the given green light time. To answer this question, we take Hangzhou data-set as an example and draw the curve of passed vehicles vs green light time in Fig. 7. The solid and dotted red lines represent the number of vehicles passed the intersection ideally and practically. It can be seen that the solid line goes as roughly approximate trend as the dotted line, while always lower than the dotted line. The similar trend validates our assumption and the decision of green light time. The gap between the two lines may be caused by the complex traffic condition in practice. It is noticeably that the vehicles on one lane may change to another while driving and the distance between two vehicles is hardly equal to the minimal threshold for safety. This can also help explain why the gap between the solid and dotted line increases as the duration of green light increases, since longer green light means more uncertainty and bigger difference between ideal and practice.
Conclusion
In this paper, we propose PDlight, a traffic light control algorithm with a novel PRCOL as the reward. The new pressure PRCOL considers not only the vehicles on the incoming lanes but also the capacity of the outgoing lanes. Experiment results on synthetic and real-world data-sets show that the average travel time of all vehicles in the road network is shorten and that the total trough output is larger. A deep analysis of the decision of traffic signal reveals what the PDlight has learned and can help to design traffic light control algorithms.
Broader Impact
Traffic light control is an important technology in intelligent traffic system. The research results in this paper can effectively reduce vehicles’ travel time and increase network’s throughput, so as to reduce congestion and environmental pollution.
References
- Chacha Chen et al. (2020) Chacha Chen, H. W.; Xu, N.; Zheng, G.; Yang, M.; Xiong, Y.; Xu, K.; and Li, Z. 2020. Toward A Thousand Lights: Decentralized Deep Reinforcement Learning for Large-Scale Traffic Signal Control. In Proceeding of the Thirty-fourth AAAI Conference on Artificial Intelligence (AAAI’20). New York, NY.
- Chu et al. (2019) Chu, T.; Wang, J.; Codecà, L.; and Li, Z. 2019. Multi-agent deep reinforcement learning for large-scale traffic signal control. IEEE Transactions on Intelligent Transportation Systems 21(3): 1086–1095.
- de Oliveira Boschetti et al. (2006) de Oliveira Boschetti, D.; Bazzan, A.; da Silva, B.; Basso, E.; and Nunes, L. 2006. Reinforcement Learning based Control of Traffic Lights in Non-stationary Environments: A Case Study in a Microscopic Simulator. In EUMAS. Lisbon, Portugal.
- Genders and Razavi (2020) Genders, W.; and Razavi, S. 2020. Policy Analysis of Adaptive Traffic Signal Control Using Reinforcement Learning. Journal of Computing in Civil Engineering 34(1): 04019046.
- Guo et al. (2019) Guo, M.; Wang, P.; Chan, C.-Y.; and Askary, S. 2019. A Reinforcement Learning Approach for Intelligent Traffic Signal Control at Urban Intersections. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC). Auckland, New Zealand.
- Joo and Lim (2020) Joo, H.; and Lim, Y. 2020. Reinforcement Learning for Traffic Signal Timing Optimization. In 2020 International Conference on Information Networking (ICOIN). Barcelona, Spain.
- Kim and Jeong (2020) Kim, D.; and Jeong, O. 2020. Cooperative traffic signal control with traffic flow prediction in multi-intersection. Sensors 20(1): 137.
- Laval and Zhou (2019) Laval, J. A.; and Zhou, H. 2019. Large-scale traffic signal control using machine learning: some traffic flow considerations. ArXiv preprint arXiv:1908.02673.
- Liang et al. (2019) Liang, X.; Du, X.; Wang, G.; and Han, Z. 2019. A deep reinforcement learning network for traffic light cycle control. IEEE Transactions on Vehicular Technology 68(2): 1243–1253.
- Lioris, Kurzhanskiy, and Varaiya (2016) Lioris, J.; Kurzhanskiy, A.; and Varaiya, P. 2016. Adaptive max pressure control of network of signalized intersections. IFAC-PapersOnLine 49(22): 19–24.
- Mousavi et al. (2017) Mousavi, S. S.; Schukat, M.; Corcoran, P.; and Howley, E. 2017. Traffic Light Control Using Deep Policy-Gradient and Value-Function Based Reinforcement Learning. ArXiv 11(7): 417–423.
- Varaiya (2013) Varaiya, P. 2013. The Max-Pressure Controller for Arbitrary Networks of Signalized Intersections, 27–66. New York, NY: Springer New York. ISBN 978-1-4614-6243-9. doi:10.1007/978-1-4614-6243-9˙2. URL https://doi.org/10.1007/978-1-4614-6243-9˙2.
- Wei et al. (2019a) Wei, H.; Chen, C.; Zheng, G.; Wu, K.; Gayah, V.; Xu, K.; and Li, Z. 2019a. PressLight: Learning Max Pressure Control to Coordinate Traffic Signals in Arterial Network. In In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’19). Anchorage, AK, USA.
- Wei et al. (2019b) Wei, H.; Xu, N.; Zhang, H.; Zheng, G.; Zang, X.; Chen, C.; Zhang, W.; Zhu, Y.; Xu, K.; and Li, Z. 2019b. Colight: Learning network-level cooperation for traffic signal control. In Proceedings of the 2019 ACM on Conference on Information and Knowledge Management (CIKM’19). Beijing, China.
- Wei et al. (2018) Wei, H.; Zheng, G.; Yao, H.; and Li, Z. 2018. Intellilight: A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 2018 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’18). London, UK.
- Wu et al. (2017) Wu, C.; Kreidieh, A.; Parvate, K.; Vinitsky, E.; and Bayen, A. M. 2017. Flow: A Modular Learning Framework for Autonomy in Traffic. ArXiv preprint arXiv:1710.05465.
- Xu et al. (2020) Xu, M.; Wu, J.; Huang, L.; Zhou, R.; Wang, T.; and Hu, D. 2020. Network-wide Traffic Signal Control based on the Discovery of Critical Nodes and Deep Reinforcement Learning. Journal of Intelligent Transportation Systems 24(1): 1–10.
- Zang et al. (2020) Zang, X.; Yao, H.; Zheng, G.; Xu, N.; Xu, K.; and Li, Z. 2020. MetaLight: Value-based Meta-reinforcement Learning for Traffic Signal Control. In Proceeding of the Thirty-fourth AAAI Conference on Artificial Intelligence (AAAI’20). New York, NY.
- Zhang et al. (2019) Zhang, H.; Feng, S.; Liu, C.; Ding, Y.; Zhu, Y.; Zhou, Z.; Zhang, W.; Yu, Y.; Jin, H.; and Li, Z. 2019. CityFlow: A Multi-Agent Reinforcement Learning Environment for Large Scale City Traffic Scenario. ArXiv preprint arXiv:1905.05217.
- Zheng et al. (2019) Zheng, G.; Xiong, Y.; Zang, X.; Feng, J.; Wei, H.; Zhang, H.; Li, Y.; Xu, K.; and Li, Z. 2019. Learning Phase Competition for Traffic Signal Control. In Proceedings of the 2019 ACM on Conference on Information and Knowledge Management (CIKM’19). Beijing, China.
- Zhu et al. (2019) Zhu, L.; Yu, F. R.; Wang, Y.; Ning, B.; and Tang, T. 2019. Big Data Analytics in Intelligent Transportation Systems: A Survey. IEEE Transactions on Intelligent Transportation Systems 20(1): 383–398.