People Tracking and Re-Identifying in Distributed Contexts: Extension Study of PoseTReID
Abstract
In our previous paper, we introduced PoseTReID which is a generic framework for real-time 2D multi-person tracking in distributed interaction spaces where long-term people’s identities are important for other studies such as behavior analysis, etc. In this paper, we introduce a further study of PoseTReID framework in order to give a more complete comprehension of the framework. We use a well-known bounding box detector YOLO (v4) for the detection to compare to OpenPose which was used in our last paper, and we use SORT and DeepSORT to compare to centroid which was also used previously, and most importantly for the re-identification, we use a bunch of deep leaning methods such as MLFN, OSNet, and OSNet-AIN with our custom classification layer to compare to FaceNet which was also used earlier in our last paper. By evaluating on our PoseTReID datasets, even though those deep learning re-identification methods are designed for only short-term re-identification across multiple cameras or videos, it is worth showing that they give impressive results which boost the overall tracking performance of PoseTReID framework regardless the type of tracking method. At the same time, we also introduce our research-friendly and open source Python toolbox pyppbox, which is purely written in Python and contains all sub-modules which are used in this study along with real-time online and offline evaluations for our PoseTReID datasets. This pyppbox is available on GitHub https://github.com/rathaumons/pyppbox .
Index Terms:
People Re-Identification, People Tracking, People Tracking Dataset, People Tracking Framework, Python ToolboxI Introduction
Previously in our last paper [1], we introduced PoseTReID framework which was designed for both short-term and long-term people tracking in distributed people interaction spaces or various ecological applications either indoor like in malls, outdoor like in smart cities, or both like in amusement parks. We used OpenPose [2] for people detection, centroid tracker for people tracking, and FaceNet [3] for both short-term and long-term people re-identification. We also introduced PoseTReID datasets [1] which were used for evaluating the results. The overall tracking performance results of PoseTReID in our last paper outperformed the state-of-art tracker-only STAF [4] in almost every scenario except in the surveillance video where the camera’s position is a bit too high and too far for FaceNet to re-identify.
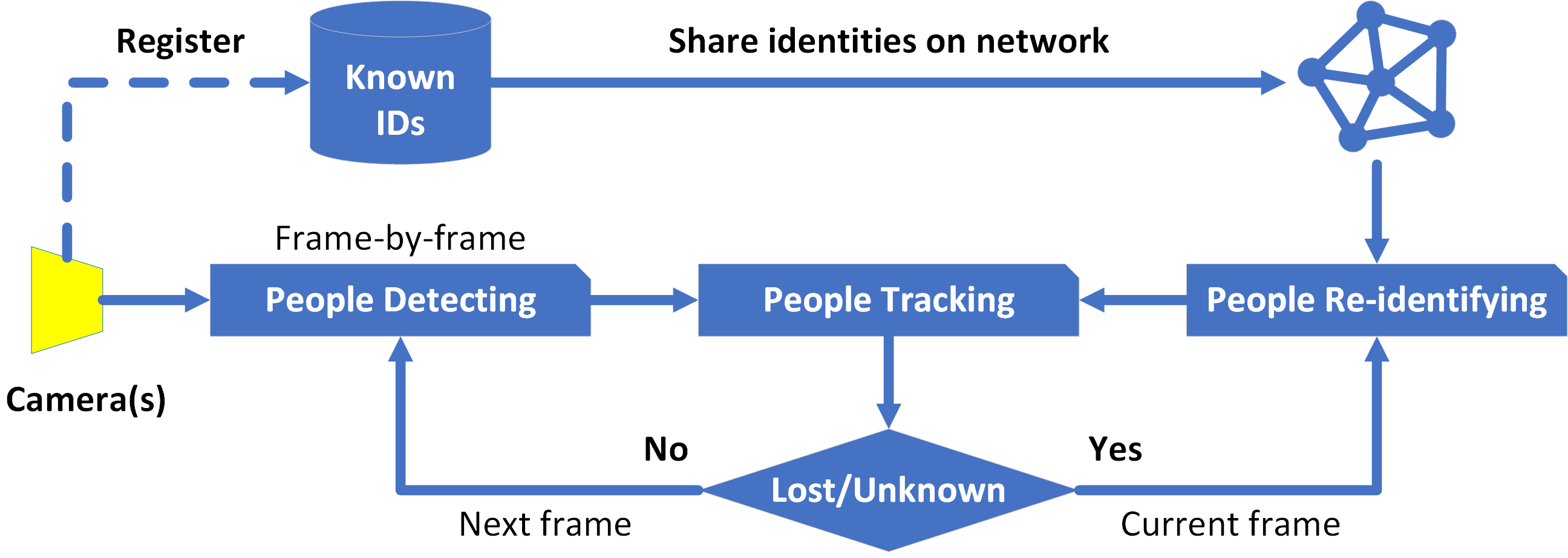
As an extension of our last paper, in this paper, we give a more complete comprehensive study of PoseTReID framework and show the potential of the overall tracking performance with a selection of different detector, tracker, and re-identifier modules with some other improvements we made. The details are described in the next section.
II Experimental Study
We still stick with our context like we mentioned in our previous paper; there is basically a need for (1) long-term people re-identification and (2) body features and poses for interactions. However, in this paper, we give a more complete and general comprehensive study as an extension of our previous work by comparing various detectors, trackers, and re-identifiers which are described in this section.
II-A Detector
II-A1 OpenPose
OpenPose [2] is a real-time deep learning-based multi-person system that can jointly detect human body, hands, feet as keypoints, as well as facial landmarks. With a dedicated GPU, OpenPose can perform multi-person detection on RGB streams in real-time. OpenPose only produces frame by frame detection, and it does not have any official or stable built-in tracker yet.
II-A2 YOLO
YOLO (You Only Look Once) [5] is a fast real-time object detector which uses only a single neural network to detect the whole image. The network divides input image into small regions and then predicts classes and gives them bounding boxes and probabilities. The original authors kept improving until v3 [6], and we started to see different authors from version v4 [7].
II-B Tracker
II-B1 Centroid
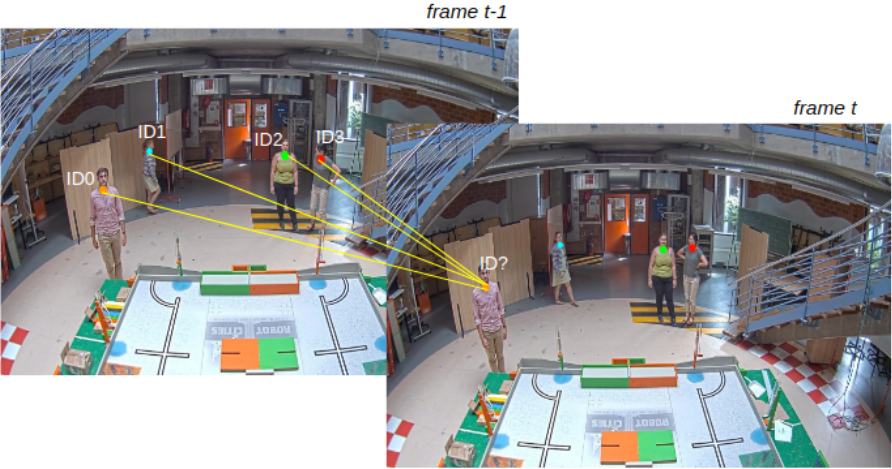
Centroid or Euclidean distance is a simple, yet highly effective object tracking. It was implemented in our last paper on top of OpenPose where neck was chosen as the represent point of every detected person because neck point is one of the most stable and visible nodes given by OpenPose detection.
| (1) |
For every detected person at a frame t, we compute the Euclidean distance between each pair of existing centroids (necks), .
II-B2 SORT
SORT (Simple Online and Realtime Tracking) [9] is a well-known open source of a visual multiple object tracking framework based on rudimentary data association and state estimation techniques. It is a real-time and online bounding box tracker where requires only previous and current inputs from the bounding detector. SORT performs well, but it does not handle occlusion or re-identify object after it disappears and reappears.
We add SORT to our comparison study to see how it performs with other modules in our PoseTReID framework.
II-B3 DeepSORT
DeepSORT (Simple Online and Realtime Tracking with a Deep Association Metric) [10] is designed as an upgrade over SORT, which integrates a deep association metric as an internal re-identifier in the aim of solving occlusion and reducing the number of identity switches. However, DeepSORT is much computational heavier than SORT.
We also add DeepSORT to our comparison study to see how it performs with other modules in our PoseTReID framework.
II-C Re-Identifier
In our PoseTReID framework, the re-identifier has 3 rules [1] for handling occlusion and duplicated ID as follows:
-
•
When a new or unknown person is detected, meaning the tracking needs an ID, re-identifying (ReID) is applied to this person only.
-
•
When the same ID is allocated or found on multiple persons, re-identifying (ReID) is applied again on all people having the same ID.
-
•
A speed limit threshold might be or be not used: When the distance between frames of the same ID is greater than the limit, ReID is applied again. This last rule is not used in this paper.
II-C1 FaceNet
FaceNet [3] is an end-to-end learning which learns to create euclidean space by mapping faces, and the face similarity can be measured by the corresponded distances. The model needs to be first trained on large datasets such as CASIA-WEBFACE [11], MS-Celeb-1M [12], VGGFace2 [13], etc.
We use pre-trained VGGFace2 model for training the characters in our PoseTReID datasets. In our previous paper, our PoseTReID with the combination of OpenPose as detector, Centroid as tracker, and FaceNet as re-identifier, outperformed others in almost all scenarios except the Hard-Surveillance complexity where FaceNet was struggle to re-identify the characters. We looked into that issue, and we later identified that our classification model did not perform well enough. This time, we tweak our classification model by changing the SVM [14] kernel function from linear to radial basis function:
| (2) |
Where is the length scale of the kernel.
We also add more face data of every character for training our classifier model (About 600 faces per character and approximately 2,957 images in total for the 5 characters in our PoseTReID datasets).
II-C2 MLFN
MLFN [15] proved that the effectiveness of person re-identification can be achieved by modeling discriminative and view-invariant factors of person appearance at both high and low semantic levels. The authors proposed Multi-Level Factorisation Net which models the visual appearance of a person into latent discriminative factors at multiple semantic levels without extra manual annotation. MLFN achieves state-of-the-art results on many popular datasets.
We use the pre-trained MLFN model (Provided by torchreid [16]) with our custom classification layer for training the characters in our PoseTReID datasets. Similar to FaceNet module, we extract 30 images of full body crop of all characters, and then train with the same SVM configuration.
II-C3 OSNet
OSNet [17] is a lightweight yet effective deep learning person re-identification model. Similar to MLFN, OSNet also relies on discriminative features which capture different spatial scales and encapsulate an arbitrary combination of multiple scales which are addressed as homogeneous and heterogeneous scales omni-scale features by the authors. Omni-Scale Network (OSNet) is omni-scale feature learning using a residual block composed of multiple convolutional streams while a novel unified aggregation gate is introduced to dynamically fuse multi-scale features with input-dependent channel-wise weights.
We also use some pre-trained model and weights with our custom classification layer for training the characters in our PoseTReID datasets. The same to MLFN module, we use the same 30 images of full body crop of all characters, and then train with the same SVM configuration.
II-C4 OSNet-AIN
OSNet-AIN [18] is pretty much like OSNet which can distinguish similar-looking people, yet generalizable for deployment across datasets without any adaptation. To improve this generalisable feature learning, the authors introduced instance normalisation (IN) layers into OSNet by optimally formulating an efficient differentiable architecture search algorithm. They achieved state-of-the-art performance yet having much smaller model than other existing reID models.
We also use the best pre-trained model and weight with our custom classification layer for training the characters in our PoseTReID datasets. The same to OSNet module, we use the same 30 images of full body crop of all characters, and then train with the same SVM configuration.

II-D Datasets
In our last paper [1], we explained why we used our own synthetic datasets not other popular datasets like [19][20]. Surprisingly soon later, we started to see booming growth in synthetic datasets such as MOTSynth-MOT-CVPR22 [21].
To evaluate the results, we use our PoseTReID datasets simulated by a 3D video game, GTA V [22] which is a great tool for creating controlled environment datasets for people tracking, face and body recognition and re-identification, vehicle analysis, and especially the scenarios where real world situations are costly and hard to establish. Resolutions, duration, and more details can be found in our last paper [1].
To understand the results in section III better, you may need to understand the complexities of PoseTReID datasets a bit here. The datasets have two complexities for people tracking which are illustrated in figures 4 and 5. “Normal” complexity videos feature 3 characters who never leave but always stay in camera field of view. Two of the characters make a single occlusion by passing in front of one another. This normal complexity has only two camera positions as shown in figure 4 (Left image as “Low” position, and right image as “High” position).

“Hard” complexity videos feature 5 characters. Two of the characters leave and reappear again in the camera field of view, and they also make several occlusions on their ways in and out. This hard complexity is made by four camera position configurations as shown in 5: (1) “Low” position as the top-left frame, (2) “Frontal” position as the top-right frame which has the highest occlusion probability, (3) “High” position as the bottom-left, and (4) “Surveillance” position as the bottom-right image which is hard for face re-identification to recognize faces.

III Quantitative Results and Discussion
Be noticed that our pyppbox has a layer which manages and handles various types of inputs for various types of trackers which are used in this experiment. For example, SORT and DeepSORT trackers, which require input as a set of bounding boxes from detector, can also be used together with OpenPose which is a pose or keypoints detector. To deal with this, pyppbox simply generates a bounding box from keypoints. Refer to pyppbox documentation for more details.
Before discussing any result from the table, be noticed that, in DT (Detector) column in table I and II, “FN” refers to false negative meaning that the detector fails to detect a person, while “FP” refers to false positive meaning that the detector detects a none person as a person.
| DT | Tracker | Result | ReIDer | ReID Count | Incorrect ID | Result |
|---|---|---|---|---|---|---|
| OpenPose (FN=0, FP=2) | Centroid | 100% | +FaceNet | 6 | 2 | 99.85% |
| +MLFN | 3 | 0 | 100% | |||
| +OSNet-AINa | 3 | 0 | 100% | |||
| +OSNetb | 3 | 0 | 100% | |||
| +OSNetc | 3 | 0 | 100% | |||
| SORT | 85.27% | +FaceNet | 15 | 3 | 99.78% | |
| +MLFN | 12 | 3 | 99.78% | |||
| +OSNet-AINa | 12 | 3 | 99.78% | |||
| +OSNetb | 12 | 3 | 99.78% | |||
| +OSNetc | 12 | 3 | 99.78% | |||
| DeepSORT | 84.54% | +FaceNet | 21 | 5 | 99.63% | |
| +MLFN | 16 | 2 | 99.85% | |||
| +OSNet-AINa | 16 | 2 | 99.85% | |||
| +OSNetb | 16 | 2 | 99.85% | |||
| +OSNetc | 16 | 2 | 99.85% | |||
| YOLO v4 (FN=0, FP=0) | Centroid | 99.85% | +FaceNet | 19 | 13 | 99.04% |
| +MLFN | 3 | 2 | 99.85% | |||
| +OSNet-AINa | 3 | 2 | 99.85% | |||
| +OSNetb | 3 | 2 | 99.85% | |||
| +OSNetc | 3 | 2 | 99.85% | |||
| SORT | 99.85% | +FaceNet | 19 | 13 | 99.04% | |
| +MLFN | 3 | 2 | 99.85% | |||
| +OSNet-AINa | 3 | 2 | 99.85% | |||
| +OSNetb | 3 | 2 | 99.85% | |||
| +OSNetc | 3 | 2 | 99.85% | |||
| DeepSORT | 99.19% | +FaceNet | 24 | 13 | 99.04% | |
| +MLFN | 12 | 2 | 99.85% | |||
| +OSNet-AINa | 12 | 2 | 99.85% | |||
| +OSNetb | 12 | 2 | 99.85% | |||
| +OSNetc | 12 | 2 | 99.85% |
-
a
OSNet-AIN: Multi-source domain generalization MS+D+C→M
-
b
OSNet: Multi-source domain generalization MS+D+C→M
-
c
OSNet: Same-domain generalization M
Here are the details of each parameter of every module used in this experiment:
-
•
Detectors:
-
–
OpenPose (Model: BODY_25, Model res: -1x256)
-
–
YOLO v4 (Model res: 416x416, NMS: 0.45, Conf: 0.5)
-
–
-
•
Trackers:
-
–
Centroid (Max dist: 50)
-
–
SORT (Max age: 1, min hits: 3, IoU: 0.3)
-
–
DeepSORT (NN: 100, NMS: 0.5, Max dist: 0.1)
-
–
-
•
Re-Identifiers:
-
–
FaceNet (Min conf: 0.75)
-
–
MLFN (Min conf: 0.35, Base only)
-
–
OSNet-AIN x1.0 (Min conf: 0.35, MS+D+C→M)
-
–
OSNet x1.0 (Min conf: 0.35, MS+D+C→M)
-
–
OSNet x1.0 (Min conf: 0.35, M)
-
–
The result in percentage (%) is the score of having correct IDs by comparing to ground truth. Be noticed that the ground truth of our datasets was manually checked and verified to make sure that every character or person has only one unique ID across all frames of each video, unlike other datasets which use the tracking results of SORT [9] as the baseline score or the ground truth. Thus, our scoring measures how well the tracking system can keep track of the exact same person across all frames in the same video.
| DT | Tracker | Result | ReIDer | ReID Count | Incorrect ID | Result |
|---|---|---|---|---|---|---|
| OpenPose (FN=2, FP=27) | Centroid | 71.77% | +FaceNet | 47 | 198 | 94.59% |
| +MLFN | 45 | 100 | 97.26% | |||
| +OSNet-AINa | 45 | 101 | 97.24% | |||
| +OSNetb | 46 | 103 | 97.18% | |||
| +OSNetc | 36 | 101 | 97.24% | |||
| SORT | 72.24% | +FaceNet | 221 | 332 | 90.92% | |
| +MLFN | 90 | 110 | 96.99% | |||
| +OSNet-AINa | 92 | 113 | 96.91% | |||
| +OSNetb | 91 | 111 | 96.96% | |||
| +OSNetc | 93 | 116 | 96.83% | |||
| DeepSORT | 41.17% | +FaceNet | 238 | 344 | 90.60% | |
| +MLFN | 105 | 112 | 96.93% | |||
| +OSNet-AINa | 114 | 111 | 96.96% | |||
| +OSNetb | 113 | 108 | 97.04% | |||
| +OSNetc | 104 | 109 | 97.02% | |||
| YOLO v4 (FN=28, FP=10) | Centroid | 41.85% | +FaceNet | 150 | 166 | 95.46% |
| +MLFN | 36 | 64 | 98.25% | |||
| +OSNet-AINa | 43 | 76 | 97.92% | |||
| +OSNetb | 47 | 83 | 97.73% | |||
| +OSNetc | 44 | 78 | 97.86% | |||
| SORT | 41.88% | +FaceNet | 215 | 189 | 94.83% | |
| +MLFN | 76 | 63 | 98.27% | |||
| +OSNet-AINa | 79 | 56 | 98.46% | |||
| +OSNetb | 82 | 61 | 98.33% | |||
| +OSNetc | 79 | 59 | 98.38% | |||
| DeepSORT | 40.68% | +FaceNet | 316 | 294 | 91.96% | |
| +MLFN | 85 | 311 | 91.50% | |||
| +OSNet-AINa | 87 | 57 | 98.44% | |||
| +OSNetb | 92 | 63 | 98.27% | |||
| +OSNetc | 89 | 61 | 98.33% |
-
a
OSNet-AIN: Multi-source domain generalization MS+D+C→M
-
b
OSNet: Multi-source domain generalization MS+D+C→M
-
c
OSNet: Same-domain generalization M
Table I shows the comparison results on “Normal” complexity and “High” camera position video which has 455 frames and 1,365 detection count (Sum of IDs in all frames) according to the ground truth. OpenPose has 0 FN but 2 FPs while YOLO v4 has 0 FN and 0 FP. For detection alone, YOLO v4 outperforms OpenPose here.
For tracker-only (Without ReIDer) results in table I, the combination of (OpenPose + Centroid) has the highest score 100% despite OpenPose having 2 FP meaning that the false positive detection given by OpenPose here does not interfere with the actual persons that exist in the ground truth. It is obvious that “Centroid” with neck point can achieve 100% here in this scenario due to the fact that the necks do not overlap each other during the occlusion. The combinations of (OpenPose + SORT) and of (OpenPose + DeepSORT) have similar results around 85% because one of the persons or characters is assigned by a new ID after occlusion. DeepSORT is designed to deal with occlusion yet fails to do so here, which is somehow similar to yet slightly worse than SORT due to the fact that DeepSORT needs first 3 frames for initializing. “ID switch” does not occur in any combination of YOLO, and similar to the combination of OpenPose, DeepSORT is slightly worse than others because it needs extra frame for its initialization.
For overall tracking results with ReIDer in table I, all combinations achieve over 99%, which are more or less the same. By applying the tweak for FaceNet as mentioned in section II-C1, the combination of (OpenPose + Centroid + FaceNet) achieves up to 99.85% vs. 96.85% from the same combination in our last paper, see table III. However, by comparing to combinations with other ReIDers, each combination with FaceNet has the highest “ReID Count” among its own group of the same tracker, meaning that FaceNet is more struggling to re-identify the characters than other ReIDers.
| Complexity | Set | Result |
|---|---|---|
| Normal-High | Prev. [1] (STAF [4]) | 85.05% |
| Prev. [1] (OpenPose + Centroid) | 100% | |
| Prev. [1] (OpenPose + Centroid + FaceNet) | 96.85% | |
| Curr. (OpenPose + Centroid + FaceNet) | 99.85% | |
| Curr. (OpenOose + DeepSORT + MFLN) | 99.85% | |
| Curr. (YOLO v4 + SORT + OSNet-AIN a ) | 99.85% | |
| Hard-Surveillance | Previous [1] (STAF [4]) | 86.22% |
| Prev. [1] (OpenPose + Centroid) | 85.96% | |
| Prev. [1] (OpenPose + Centroid + FaceNet) | 40.71% | |
| Curr. (OpenPose + Centroid + FaceNet) | 94.59% | |
| Curr. (OpenOose + DeepSORT + MFLN) | 91.50% | |
| Curr. (YOLO v4 + SORT + OSNet-AIN a ) | 98.46% |
-
a
OSNet-AIN: Multi-source domain generalization MS+D+C→M
Hard-Surveillance video used in table II has much longer duration (876 frames) and many more occlusions. There are totally 3,660 detection count (Sum of all IDs in all frames). For detector comparison here, we can say that OpenPose performs more accurate than YOLO v4 as OpenPose has only 2 vs. 28 FNs. For the results of tracker-only (Without ReIDer) here, we can say that SORT outperforms others while DeepSORT still does not perform as it is supposed to.
On Hard-Surveillance video, the combination of (OpenPose + Centroid + FaceNet) achieves up to 94.59% vs. 40.71% from the same combination in our last paper, see table III, meaning the improved classification layer now is much better and it gives fewer incorrect IDs to the tracker in this scenario where the camera position is very high and not ideal for face recognition. In contrast, the tracker-only result here (OpenPose + Centroid) can only achieve 71.77% (Table II) vs. 85.96% in our last paper (See table III), and this happens because in our last paper, we implemented everything in C++ (Except FaceNet) where OpenPose could run much faster even with higher model resolution (Higher model resolution gives better detection and stability).
When it comes to Hard-Surveillance, the gaps between overall tracking performance of using FaceNet as re-identifier and using other deep re-identifiers are noticeably bigger according to table II. FaceNet is more struggling to re-identify than other re-identifiers as some characters in the video do not always turn their faces to the camera especially when they walk back in the camera field of view after they exit. This allows the whole body discriminative models to have a greater advantage over FaceNet.
For computing power consumption and framerate (fps), we did all experiments on a laptop (Intel i7-8750H, DDR4 32 GB of RAM, and RTX 2080 Max-Q, 8 GB of VRAM) running on Microsoft Windows 11 64-bit, and the average framerate was about 12 fps for (OpenPose + Centroid/SORT), 9 fps for (OpenPose + DeepSORT), 30 fps for (YOLO v4 + Centroid/SORT), and 20 fps for (YOLO v4 + DeepSORT), regardless the re-identifier module as it is fast and only causes framerate to drop about a few frames when it is used.
IV Conclusion
Our detailed comprehensive study of PoseTReID framework in this paper really shows the potential of the overall tracking performance with various types of detectors, trackers, and re-identifiers where good re-identifier does make PoseTReID framework very robust regardless the type of tracking method. On top of that, the adjustment on our custom classification layer has proved to help boost the accuracy performance of re-identifier as well as the overall tracking performance of PoseTReID framework.
We believe that our Python toolbox pyppbox is a right step forward to help research community and attract more young researchers in the related fields.
Acknowledgment
The authors would like to gratefully thank to the supports of Belgium Wallonie Win2Wal program, under APTITUDE project.
References
- [1] R. Siv, M. Mancas, S. Sreng, S. Chhun, and B. Gosselin, “People tracking and re-identifying in distributed contexts: Posetreid framework and dataset,” in 2020 12th International Conference on Information Technology and Electrical Engineering (ICITEE), 2020, pp. 323–328.
- [2] Z. Cao, T. Simon, S. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1302–1310.
- [3] F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 815–823.
- [4] Y. Raaj, H. Idrees, G. Hidalgo, and Y. Sheikh, “Efficient online multi-person 2d pose tracking with recurrent spatio-temporal affinity fields,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4620–4628.
- [5] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779–788.
- [6] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” 2018. [Online]. Available: https://arxiv.org/abs/1804.02767
- [7] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” 2020. [Online]. Available: https://arxiv.org/abs/2004.10934
- [8] G. Bradski, “The OpenCV Library,” Dr. Dobb’s Journal of Software Tools, 2000.
- [9] A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in 2016 IEEE International Conference on Image Processing (ICIP), 2016, pp. 3464–3468.
- [10] N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in 2017 IEEE International Conference on Image Processing (ICIP), 2017, pp. 3645–3649.
- [11] D. Yi, Z. Lei, S. Liao, and S. Z. Li, “Learning face representation from scratch,” arXiv preprint arXiv:1411.7923, 2014.
- [12] Y. Guo, L. Zhang, Y. Hu, X. He, and J. Gao, “Ms-celeb-1m: A dataset and benchmark for large-scale face recognition,” in European Conference on Computer Vision. Springer, 2016, pp. 87–102.
- [13] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman, “Vggface2: A dataset for recognising faces across pose and age,” in 2018 13th IEEE International Conference on Automatic Face Gesture Recognition (FG 2018), 2018, pp. 67–74.
- [14] M. Hearst, S. Dumais, E. Osuna, J. Platt, and B. Scholkopf, “Support vector machines,” IEEE Intelligent Systems and their Applications, vol. 13, no. 4, pp. 18–28, 1998.
- [15] X. Chang, T. M. Hospedales, and T. Xiang, “Multi-level factorisation net for person re-identification,” 2018. [Online]. Available: https://arxiv.org/abs/1803.09132
- [16] K. Zhou and T. Xiang, “Torchreid: A library for deep learning person re-identification in pytorch,” arXiv preprint arXiv:1910.10093, 2019.
- [17] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” 2019. [Online]. Available: https://arxiv.org/abs/1905.00953
- [18] ——, “Learning generalisable omni-scale representations for person re-identification,” 2019. [Online]. Available: https://arxiv.org/abs/1910.06827
- [19] P. Dendorfer, H. Rezatofighi, A. Milan, J. Shi, D. Cremers, I. Reid, S. Roth, K. Schindler, and L. Leal-Taixé, “CVPR19 tracking and detection challenge: How crowded can it get?” arXiv:1906.04567 [cs], Jun. 2019, arXiv: 1906.04567. [Online]. Available: http://arxiv.org/abs/1906.04567
- [20] P. Dendorfer, H. Rezatofighi, A. Milan, J. Shi, D. Cremers, I. Reid, S. Roth, K. Schindler, and L. Leal-Taixé, “Mot20: A benchmark for multi object tracking in crowded scenes,” 2020. [Online]. Available: https://arxiv.org/abs/2003.09003
- [21] M. Fabbri, G. Braso, G. Maugeri, O. Cetintas, R. Gasparini, A. Osep, S. Calderara, L. Leal-Taixe, and R. Cucchiara, “Motsynth: How can synthetic data help pedestrian detection and tracking?” 2021. [Online]. Available: https://arxiv.org/abs/2108.09518
- [22] R. N. Limited, “Grand theft auto v,” https://www.rockstargames.com/V/, 2015, pC.