Performance Heterogeneity in Graph Neural Networks:
Lessons for Architecture Design and Preprocessing
Abstract
Graph Neural Networks have emerged as the most popular architecture for graph-level learning, including graph classification and regression tasks, which frequently arise in areas such as biochemistry and drug discovery. Achieving good performance in practice requires careful model design. Due to gaps in our understanding of the relationship between model and data characteristics, this often requires manual architecture and hyperparameter tuning. This is particularly pronounced in graph-level tasks, due to much higher variation in the input data than in node-level tasks. To work towards closing these gaps, we begin with a systematic analysis of individual performance in graph-level tasks. Our results establish significant performance heterogeneity in both message-passing and transformer-based architectures. We then investigate the interplay of model and data characteristics as drivers of the observed heterogeneity. Our results suggest that graph topology alone cannot explain heterogeneity. Using the Tree Mover’s Distance, which jointly evaluates topological and feature information, we establish a link between class-distance ratios and performance heterogeneity in graph classification. These insights motivate model and data preprocessing choices that account for heterogeneity between graphs. We propose a selective rewiring approach, which only targets graphs whose individual performance benefits from rewiring. We further show that the optimal network depth depends on the graph’s spectrum, which motivates a heuristic for choosing the number of GNN layers. Our experiments demonstrate the utility of both design choices in practice.
1 Introduction
Graph Neural Networks (GNNs) have found widespread applications in the social, natural and engineering sciences (Zitnik et al., 2018; Wu et al., 2022; Shlomi et al., 2020). Notable examples include graph classification and regression tasks, which arise in drug discovery (Zitnik et al., 2018), protein function prediction (Gligorijević et al., 2021), and the study of chemical reactions (Jin et al., 2017; Coley et al., 2019), among others.
Most state of the art GNNs are based on message-passing or transformer-type architectures. In both cases, careful model design and parameter choices are crucial for competitive performance in downstream tasks. A growing body of literature studies the relationship of model and data characteristics in graph learning and their impact on such design choices. This includes the study of challenges in encoding long-range dependencies, which arise in shallow architectures due to under-reaching (Barceló et al., 2020) and in deep architectures due to over-smoothing and over-squashing effects (Alon and Yahav, 2021; Li et al., 2018). A second perspective evaluates a model’s (in)ability to encode certain structural functions due to limitations in representational power (Xu et al., 2018). Some recent works have studied model and data characteristics through classical complexity lenses, such as generalization (Garg et al., 2020; Le and Jegelka, 2024; Franks et al., 2024) and trainability (Kiani et al., 2024). While these results offer valuable theoretical insights, their ability to directly guide design choices for specific datasets and tasks is often limited. As a result, model design usually relies on manual hyperparameter tuning in practice.
In this work, we study the interplay of model and data characteristics from a different perspective. We analyze the performance of a model on individual graphs with the goal of understanding variations in optimal model design within data sets. We introduce heterogeneity profiles as a tool for systematically evaluating individual performance across graphs in a dataset. The analysis of the profiles of several classification and regression benchmarks for both message-passing and transformer-based architectures reveals significant performance heterogeneity in graph-level learning. We then investigate how data and model characteristics drive this heterogeneity. A natural idea in this context is that the topological properties of the graphs, along with their variation across the dataset, might explain the observed heterogeneity. However, our results indicate that graph topology alone cannot explain heterogeneity. We then analyze the datasets with the Tree Mover’s Distance (Chuang and Jegelka, 2022), a similarity measure that compares graphs using both topological and feature information. Using this lens, we show that common graph-level classification benchmarks contain examples that are more “similar” to graphs of a different label than to graphs with the same label. The prediction stability of typical GNN architectures therefore makes it hard to classify these examples correctly.
Using these insights, we study data pre-processing and model design choices with an eye towards heterogeneous graph-level effects. We first revisit graph rewiring, a pre-processing technique that perturbs the edges of input graphs with the goal of mitigating over-smoothing and over-squashing. We find that while some graphs benefit, the individual performance of others drops significantly as a result of rewiring. Although we observe notable differences between rewiring techniques, the general observation is consistent across approaches and data sets. Motivated by this observation, we introduce a new “selective” rewiring approach that rewires only graphs that based on their topology are likely to benefit. We further show that the optimal GNN depth varies between the graphs in a dataset and depends on the spectrum of the input graph; hence, aligning spectra across graphs allows for choosing a GNN depth that is close to optimal across the data set. We illustrate the utility of both intervention techniques in experiments on several common graph benchmarks.
1.1 Related work
Performance heterogeneity The interplay of model and data characteristics in graph learning was previously studied by Li et al. (2023); Liang et al. (2023), albeit only for node-level tasks. Li et al. (2023) establish a link between a graph’s topological characteristics and node-level performance heterogeneity. To the best of our knowledge, no such study has been conducted for graph-level tasks. As we discuss below, performance heterogeneity is linked to model generalization. Size generalization in GNNs has been studied in (Yehudai et al., 2021; Maskey et al., 2022; Le and Jegelka, 2024; Jain et al., 2024). For a more comprehensive overview of generalization results for GNNs, see also (Jegelka, 2022).
Beyond graph learning, performance heterogeneity has been studied through the lens of example difficulty (Kaplun et al., ) by analyzing a model’s performance on individual instances in the test data.
Graph Rewiring Several rewiring approaches have been studied in the context of mitigating over-smoothing and over-squashing effects, most of which are motivated by topological graph characteristics that can be used to characterize both effects. Notable examples include rewiring based on the spectrum of the Graph Laplacian (Karhadkar et al., 2023; Arnaiz-Rodr´ıguez et al., 2022), discrete Ricci curvature (Topping et al., 2022; Nguyen et al., 2023; Fesser and Weber, 2024a), effective resistance (Black et al., 2023), and random sparsification (Rong et al., 2019). When applied in graph-level tasks, these preprocessing routines are applied to all input graphs. In contrast, Barbero et al. (2023) propose a rewiring approach that balances mitigating over-smoothing and over-squashing and preserving the structure of the input graph. A more nuanced analysis of the effectiveness of standard rewiring approaches has been given in (Tortorella and Micheli, 2022; Tori et al., 2024).
1.2 Summary of contributions
Our main contributions are as follows:
-
1.
We introduce graph-level heterogeneity profiles for analyzing performance variations of GNNs on individual graphs in graph-level tasks. Our analysis suggests that both message-passing and transformer-based GNNs display performance heterogeneity in classification and regression tasks.
-
2.
We provide evidence that topological properties alone cannot explain graph-level heterogeneity. Instead, we use the notion of the Tree Mover’s Distance to establish a link between class-distance ratios and performance heterogeneity.
-
3.
We use these insights to derive lessons for architecture choices and data preprocessing. Specifically, we show that the optimal GNN depth for individual graphs depends on their spectrum and can vary across the data set. We propose a selective rewiring approach that aligns the graphs’ spectra. In addition, we propose a heuristic for the optimal network depth based on the graphs’ Fiedler value.
2 Background and Notation
Following standard convention, we denote GNN input graphs as with node attributes and edges , where is the set of vertices of .
2.1 Graph Neural Networks
Message-Passing Graph Neural Networks Message-Passing (MP) (Gori et al., 2005; Hamilton et al., 2017) has become one of the most popular learning paradigms in graph learning. Many state of the art GNN architectures, such as GCN (Kipf and Welling, 2017), GIN (Xu et al., 2018) and GAT (Veličković et al., 2018), implement MP by iteratively updating their nodes’ representation based on the representations of their neighbors. Formally, let denote the representation of node at layer . Then the updated representation in layer (i.e., after one MP iteration) is given by
.
Here, denotes an aggregation function (e.g., averaging) defined on the neighborhood of the anchor node , and an update function (e.g., an MLP) that computes the updated node representation. We refer to the number of MP iterations as the depth of the GNN. Node representations are initialized by the node attributes in the input graph.
Transformer-based Graph Neural Networks Several transformer-based GNN (GT) architectures have been proposed as an alternative to MPGNNs (Müller et al., 2023). They consist of stacked blocks of multi-head attention layers followed by
fully-connected feed-forward networks. Formally, a single attention head in layer computes node feature as
.
Here, the matrices the matrices , , are linear projections
of the node features; the softmax is applied row-wise.
Multi-head attention concatenates several such single-attention heads and projects their output into the feature space of . Notable instances of GTs include Graphormer (Ying et al., 2021) and GraphGPS (Rampášek et al., 2022).
A more detailed description of the GNN architectures used in this study can be found in Appendix A.1.
Graph Rewiring The topology of the input graph(s) has significant influence on the training dynamics of GNNs. Two notable phenomena in this context are over-smoothing and over-squashing. Over-smoothing (Li et al., 2018) arises when the representations of dissimilar nodes become indistinguishable as the number of layers increases. In contrast, over-squashing (Alon and Yahav, 2021) is induced by “bottlenecks” in the information flow between distant nodes as the number of layers increases. Both effects can limit the GNN’s ability to accurately encode long-range dependencies in the learned node representations, which can negatively impact downstream performance. Graph rewiring was introduced as a pre-processing routine for mitigating over-smoothing and over-squashing by perturbing the edges of the input graph(s). A plethora of rewiring approaches, which leverage a variety of topological graph characteristics, have been introduced. In this paper we consider two rewiring approaches: FOSR (Karhadkar et al., 2023), which leverages the spectrum of the Graph Laplacian, and BORF (Nguyen et al., 2023; Fesser and Weber, 2024a), which utilizes discrete Ricci curvature. We defer a more detailed description of both approaches to Appendix A.2.
2.2 Tree Mover’s Distance
The Tree Mover’s Distance (short: TMD) is a similarity measure on graphs that jointly evaluates feature and topological information Chuang and Jegelka (2022). Like an MPGNN, it views a graph as a set of computation trees. A node’s computation tree is constructed by adding the node’s neighbors to the tree level by level. TMD compares graphs by characterizing the similarity of their computation trees via hierarchical optimal transport: The similarity of two trees , is computed by comparing their roots , and then recursively comparing their subtrees. We provide a formal definition of the TMD in Appendix A.4.
3 Establishing Graph-level Heterogeneity
In this section, we establish the existence of performance heterogeneity in common graph classification and regression tasks in both message-passing and transformer-based GNNs. We further provide empirical evidence that topological features alone are not sufficient to explain these observations.
3.1 Heterogeneity Profiles
To analyze performance heterogeneity, we compute heterogeneity profiles that show the average individual test accuracy over 100 trials for each graph in the dataset. For each dataset considered, we apply a random train/val/test split of 50/25/25 percent. We train the model for 300 epochs on the training dataset and keep the model checkpoint with the highest validation accuracy (see Appendix D for additional training details and hyperparameter choices). We then record this model’s error on each of the graphs in the test dataset in an external file. We repeat this procedure until each graph has been in the test dataset at least 100 times. For the graph classification tasks, we compute the average graph-level accuracy (higher is better, denoted as ), and for each regression task the graph-level MAE (lower is better, denoted as ).
3.2 Heterogeneity in MPNNs and GTs
Figure 1 shows heterogeneity profiles for two graph classification benchmarks (Enzymes and Proteins) and one graph regression task (Peptides-struct). Profiles are shown for GCN (blue), a message-passing architecture, and GraphGPS (orange), a transformer-based architecture.
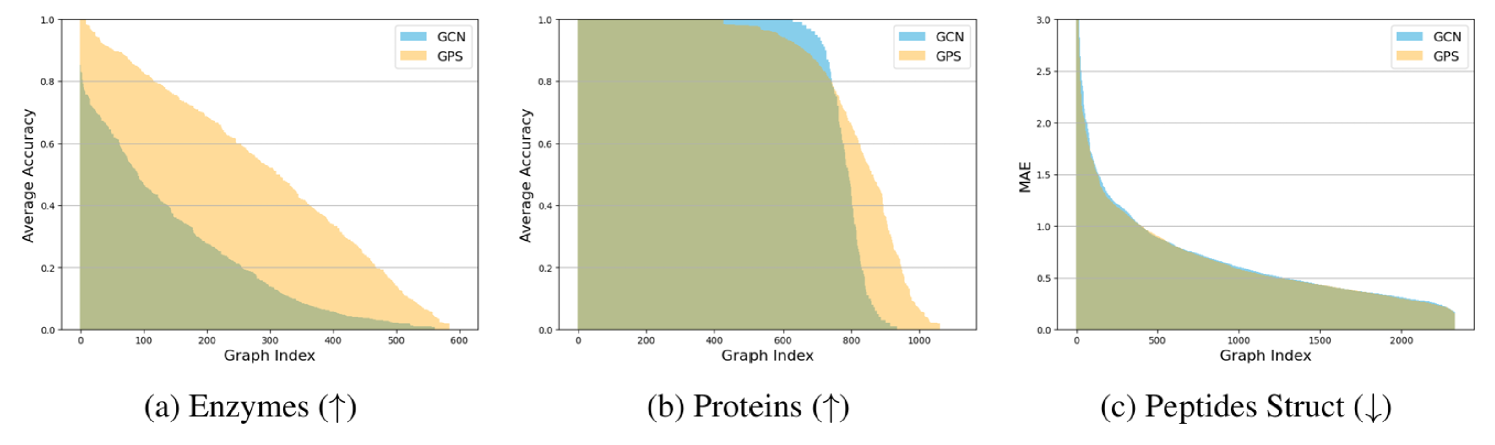
For the classification tasks we observe a large number of graphs with an average GCN accuracy of 1, and a large number of graphs with an average accuracy of 0, especially in Proteins. This indicates that within the same dataset there exist some graphs, which GCN and GraphGPS always classify correctly, and others which they never classify correctly. Enzymes shows a similar overall trend: Some graphs have high average accuracies (), while some are at or around zero. A comparable trend can be observed for GraphGPS, although the average accuracy here is visibly higher. Additional experiments on other graph classification benchmarks and using other MPGNN architectures confirm this observation (see Appendix B.1.2 and B.1.3). We refer to this phenomenon of large differences in graph-level accuracy within the same dataset as performance heterogeneity.
Furthermore, our results for Peptides Struct, a regression benchmark, indicate that heterogeneity is not limited to classification. The graph-level MAE of both GCN and GraphGPS varies widely between individual graphs in the Peptides-struct dataset. Appendix B.1.1 presents further experiments using Zinc, a regression dataset, with similar results. In general, we find heterogeneity to appear with various widths, depths, and learning rates.
3.3 Explaining performance heterogeneity
As mentioned earlier, performance heterogeneity can also be found between individual nodes in node classification tasks (Li et al., 2023; Liang et al., 2023). They find that node-level heterogeneity can be explained well based on topological features alone: Nodes with higher degrees are provably easier to classify correctly than nodes with lower degrees Li et al. (2023). A natural question is whether this extends to graph-level tasks.
Topology alone does not explain heterogeneity We test this using the same sparse multivariate regression employed by Li et al. (2023) to analyze node-level heterogeneity. For each dataset considered, we record the graph-level GCN accuracy averaged over 100 runs as above and compute several classical topological graph characteristics, such as assortativity, the clustering coefficient, and the spectral gap (see Appendix B.3 for details). We then fit a linear model to predict the accuracy of a GCN on a given graph based on its topological features. Following Li et al. (2023), we use a lasso penalty term to encourage sparsity in the regression coefficients. Unlike in the node-level case, the resulting regression model is not able to explain the variation in the data well. With the exception of Mutag, we are left with on all datasets. Furthermore, there are no obvious commonalities between the regression coefficients. For example, while a smaller spectral gap seems to make graphs in Proteins easier to classify correctly, the opposite seems to be true for Enzymes. We take this as evidence that unlike in the node-level setting, topological features alone are insufficient to explain performance heterogeneity in the graph-level setting.
Class-distance ratios are drivers of heterogeneity Next we evaluate potential drivers of heterogeneity using the Tree Mover’s Distance (TMD) (Chuang and Jegelka, 2022), introduced above. Importantly, the TMD jointly evaluates topological and feature information, i.e., provides a richer data characterization.
Definition 1 (Class-distance ratio).
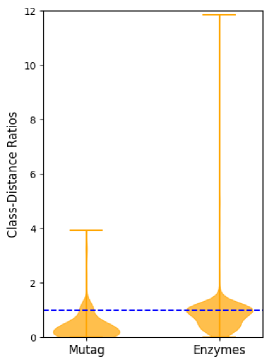
Let denote a graph dataset and the correct label of the graph . Using the TMD, we define the class-distance ratio of a graph as
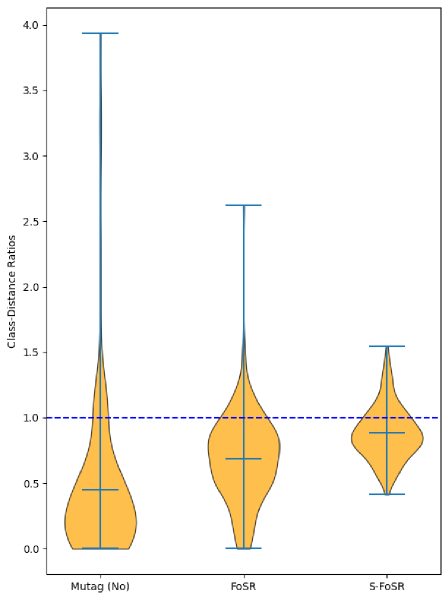
In other words, we compute the TMD to the closest graph with the same label and divide it by the distance to the closest graph with a different label. If this ratio is less than one, we are closer to a graph of the correct label than to a graph of a wrong label. Figure 3 plots the class-distance ratios for all graphs in the Mutag and Enzymes datasets. (Due to the computational complexity of the TMD, we are unfortunately limited to analyzing rather small datasets). For both datasets, we can see that there exist graphs whose class-distance ratio is far larger than one, i.e., graphs which are several times closer to graphs of a wrong label than to graphs of their own label. Computing the Pearson correlation coefficient between a graph’s class-distance ratio and its average GNN performance, we find a highly significant negative correlation for both datasets ( for Mutag and for Enzymes). Graphs with a higher class-distance ratio have much lower average accuracies, i.e. are much harder to classify correctly. The following result on the TMD provides a possible explanation for this observation:
Theorem 3.1 (Chuang and Jegelka (2022), Theorem 8).
Given an -layer GNN and two graphs , we have , where for all and is the -th number at level of Pascal’s triangle.
This result indicates that a GNN’s prediction on a graph cannot diverge too far from its prediction on a similar (in the sense of TMD) graph . A value of therefore indicates that the GNN prediction cannot be too far from a prediction made on a graph with a different label, so graphs with are hard to classify correctly.
3.4 Heterogeneity appears during GNN training
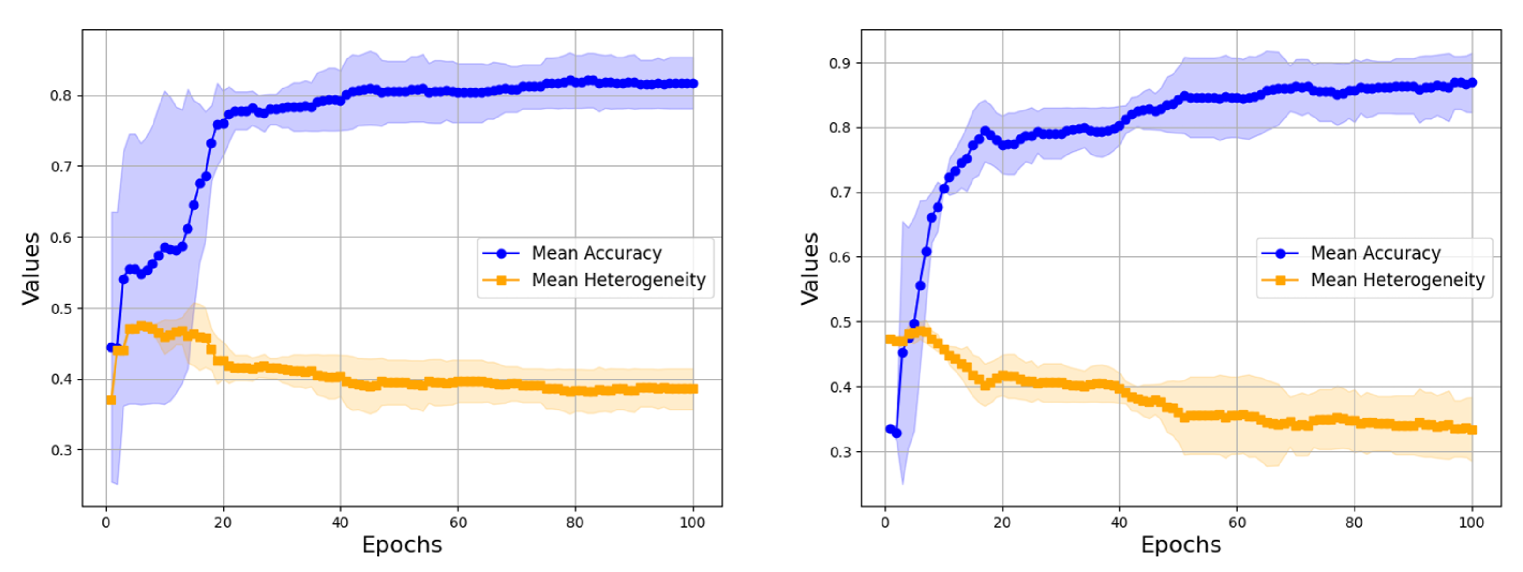
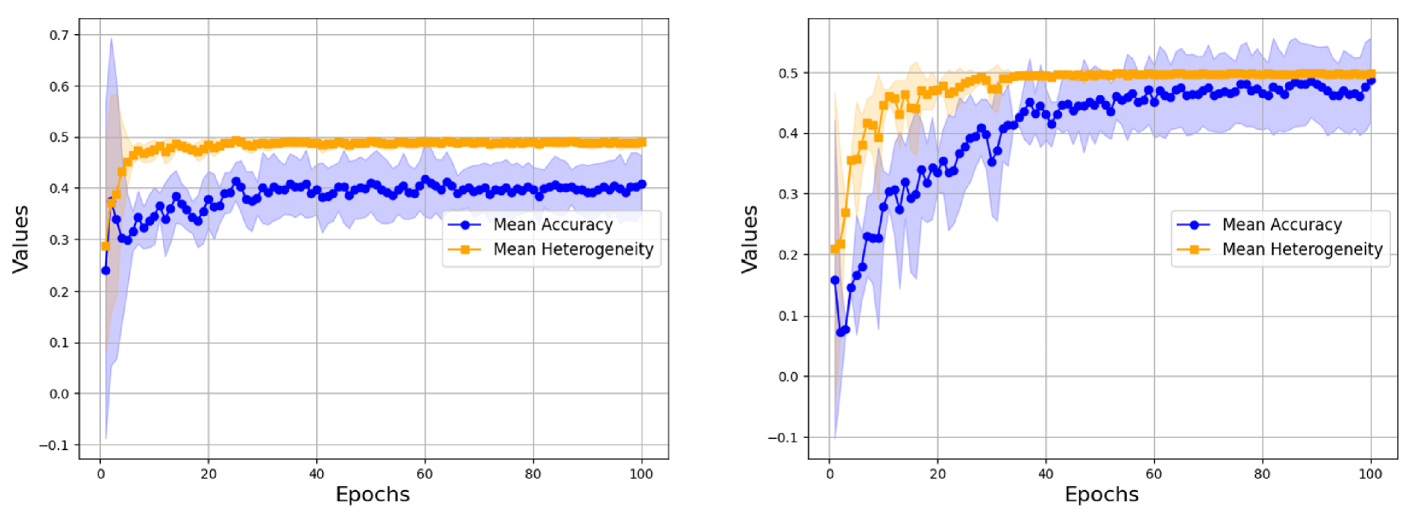
To better understand how performance heterogeneity arises during training, we analyze the predictions on individual graphs in the test dataset after each epoch. Figure 4 shows the mean accuracy and variance for GCN (message-passing) and GraphGPS (transformer-based) on Mutag. As we can see, both models have an initial increase in heterogeneity, followed by a steady decline over the rest of the training duration. Both models learn to correctly classify some graphs almost immediately, while others are only classified correctly much later. We should point out that these “difficult” graphs, i.e. graphs that are either learned during later epochs or never learned at all, are nearly identical for GCN and GraphGPS. GraphGPS, being a much more powerful model, learns to correctly classify more of these “difficult” graphs during later epochs. The (few) graphs which it cannot learn are also graphs on which GCN fails. Additional experiments on other datasets can be found in Appendix C.2. Across datasets and models, we witness this “learning in stages”, where learning easy examples leads to an initial increase in heterogeneity, followed by a steady decrease.
4 Heterogeneity-informed Preprocessing
In this section, we use heterogeneity profiles to show that preprocessing techniques can reinforce heterogeneity in graph-level learning. We focus primarily on rewiring techniques, but we also provide some experimental results with encodings in Appendix C.3. We find that while preprocessing methods such as rewiring are usually beneficial when averaged over all graphs, GNN performance on individual graphs can in fact drop by as much as 90 percent after rewiring. Deciding which graphs to preprocess is therefore crucial. We take a first step in this direction and propose a topology-aware selective rewiring method. As for encodings, our results indicate that investigating a similar, selective approach is a potentially fruitful direction (though unfortunately beyond the scope of this paper). We further note that existing theoretical results on improved expressivity when using encodings cannot explain the oftentimes detrimental effects observed in the heterogeneity analysis.
4.1 Rewiring hurts (almost) as much as it helps
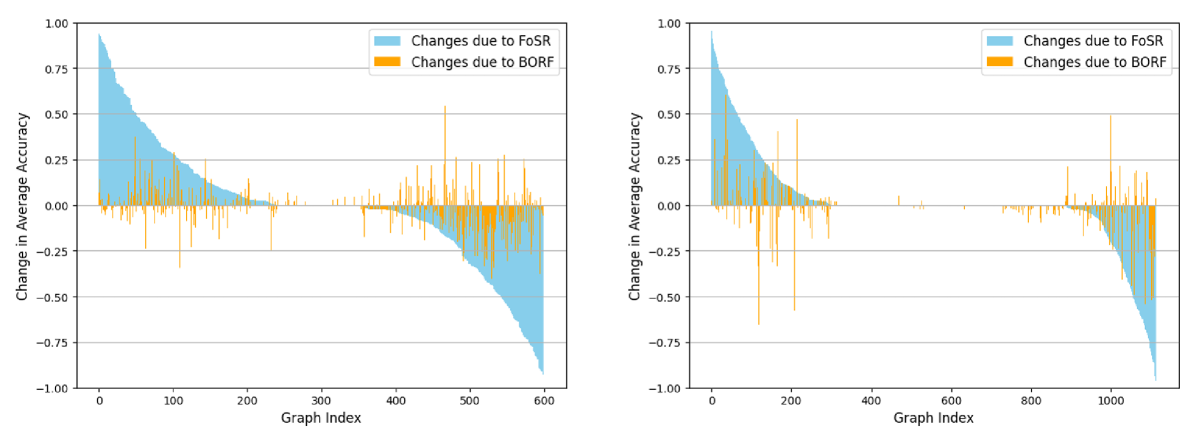
For each dataset we compute heterogeneity profiles (based on graph-level accuracy over 100 runs) with and without rewiring, with a focus on two common rewiring techniques: BORF (Nguyen et al., 2023), a curvature-based rewiring method, and FoSR (Karhadkar et al., 2023), a spectral rewiring method. Figure 5 shows the results on the Enzymes and Proteins datasets with GCN. We find that while both rewiring approaches improve the average accuracy in each data set, the accuracy for individual graphs can drop by as much as 95 percent. The graph-level changes in accuracy are particularly heterogeneous when using FoSR on both Enzymes and Proteins. BORF, while being less beneficial overall, also has less heterogeneity when considering individual graphs. This observation may indicate that not all graphs suffer from over-squashing or that over-squashing is not always harmful, providing additional evidence for arguments previously made by Tori et al. (2024).
4.2 Topology-aware selective rewiring
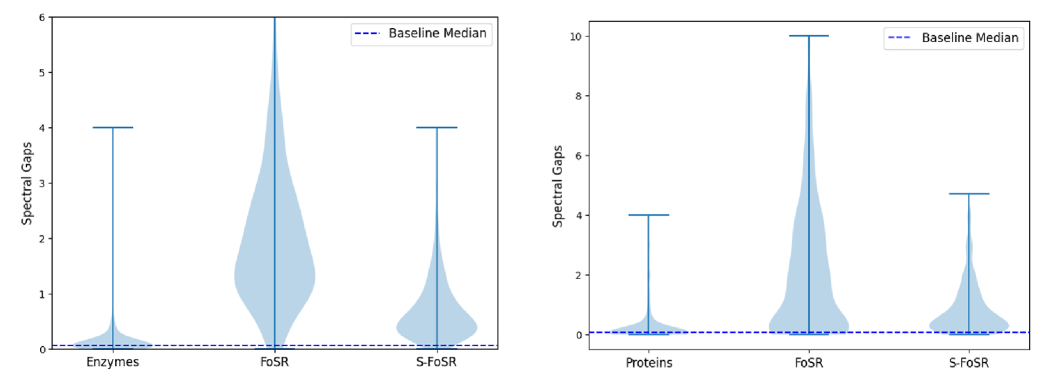
The large differences in performance benefits from FoSR on individual graphs reveal a fundamental shortcoming of almost all existing (spectral) rewiring methods: They rewire all graphs in a dataset, irrespective of whether individual graphs actually benefit. To overcome this limitation, we propose to rewire selectively, where a topological criterion is used to decide whether an individual graph’s performance will benefit from rewiring. The resulting topology-aware selective rewiring chooses a threshold spectral gap from the initial distribution of Fiedler values in a given dataset. Empirically, we find the median to work well. Using standard FoSR, we then add edges to all graphs whose spectral gap is below this threshold. The resulting approach, which we term Selective-FOSR, leaves graphs with an already large spectral gap unchanged. This “alignment” results in a larger degree of (spectral) similarity between the graphs in a dataset.
The effect on the spectral gaps of graphs in Enzymes and Proteins is plotted in Figure 6. Both datasets originally have a large number of graphs whose spectral gap is close to zero, i.e. which are almost disconnected and hence likely to suffer from over-squashing. Standard FoSR mitigates this, but simultaneously creates graphs with much larger spectral gaps than in the original dataset while more than doubling the spread of the distribution. Our selective rewiring approach avoids both of these undesirable effects. This also shows in significantly increased performance on all datasets considered when compared to standard FoSR, as can be seen in Table 1.
| Model | Dataset | None | FoSR | S-FoSR |
| GCN | Peptides-struct () | 0.28 0.02 | 0.27 0.01 | 0.25 0.01 |
| Peptides-func | 0.50 0.02 | 0.47 0.03 | 0.48 0.02 | |
| Enzymes | 23.8 1.3 | 27.2 1.1 | 30.1 1.0 | |
| Imdb | 49.7 1.0 | 50.6 0.8 | 51.2 1.1 | |
| Mutag | 72.4 2.1 | 79.7 1.7 | 81.5 1.4 | |
| Proteins | 69.9 1.0 | 71.1 0.9 | 72.6 1.1 | |
| GIN | Peptides-struct () | 0.34 0.02 | 0.27 0.02 | 0.24 0.01 |
| Peptides-func | 0.49 0.01 | 0.46 0.02 | 0.49 0.02 | |
| Enzymes | 27.1 1.6 | 26.3 1.2 | 28.6 1.3 | |
| Imdb | 68.1 0.9 | 68.5 1.1 | 69.0 0.9 | |
| Mutag | 81.9 1.4 | 81.3 1.5 | 84.9 1.0 | |
| Proteins | 71.3 0.7 | 72.3 0.9 | 72.6 0.8 | |
| GAT | Peptides-struct () | 0.28 1.2 | 0.29 0.01 | 0.27 0.01 |
| Peptides-func | 0.51 0.01 | 0.49 0.01 | 0.52 0.02 | |
| Enzymes | 23.8 1.2 | 26.0 2.0 | 31.5 1.8 | |
| Imdb | 50.1 0.9 | 50.3 1.0 | 51.6 1.0 | |
| Mutag | 70.2 1.3 | 73.5 2.0 | 78.5 1.7 | |
| Proteins | 71.3 0.9 | 70.9 1.5 | 72.5 0.8 |
5 Heterogeneity-informed Model Selection
So far, we have compared the heterogeneity profiles of different architectures, such as GCN and GraphGPS, on the same datasets, or compared profiles of datasets with and without rewiring. In this section, we now fix the preprocessing technique and base layer and focus on heterogeneity profiles at different GNN depths. This allows us to define a graph-level optimal depth. We show that the optimal depth varies widely within datasets, an observation that, we argue, is related to the graphs’ spectral gap. We show that decreasing the variation in spectral gaps within a dataset via selective rewiring makes it easier to find a depth that works well on all graphs. At the same time, those insights motivate a heuristic for choosing the GNN depth in practise, which reduces the need for (potentially expensive) tuning of this crucial hyperparameter.
5.1 Optimal GNN depth varies between graphs
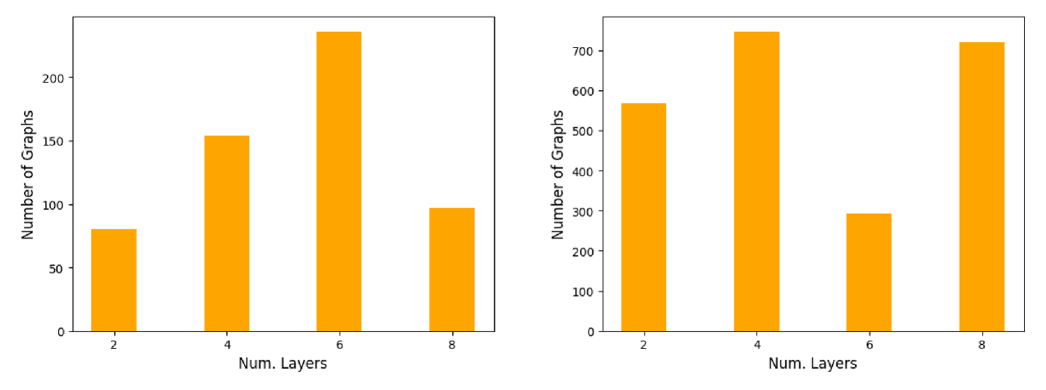
Using the experimental setup for the heterogeneity profiles (see Section 3), we record the graph-level accuracy of GCNs with 2, 4, 6, and 8 layers respectively. We then record for each graph in the dataset the number of layers that resulted in the best performance on that graph and refer to this as the optimal depth.
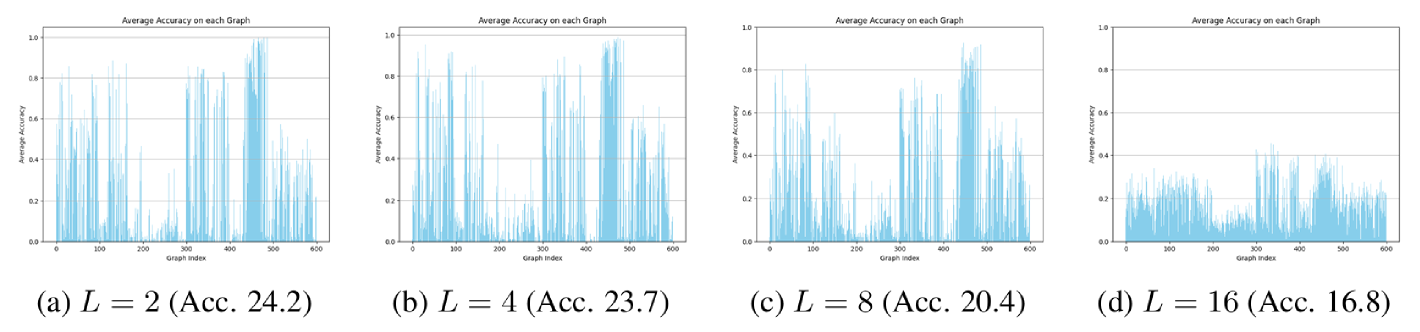
Optimal depth varies. Results on Enzymes and Peptides-struct are shown in Figure 7; additional results on other datasets and for other MPGNNs can be found in Appendix C.1. We observe a large degree of heterogeneity in the optimal depth of individual graphs. This is most striking in Peptides-Struct, where more than a quarter of all graphs attain their lowest MAE at only 2 layers, although there is also a substantial number of graphs that benefit from a much deeper network. The differences in average accuracy on a given graph between a 2-layer and an 8-layer GCN can be large: On Enzymes, we found differences of as much as 0.3. We provide the heterogeneity profiles for the 2, 4, 8 and 16-layer GCN trained on Enzymes in Appendix C.1. We observe that heterogeneity decreases with depth at the cost of accuracy. In particular, the 16-layer GCN trained on Enzymes does not classify any graphs correctly all the time, but it also consistently misclassifies only a small number of graphs. We believe that this is due to the model being much harder to train than the shallower GCNs, possibly due to exploding/ vanishing gradients. Overall, our results indicate that choosing an optimal number of layers for a given dataset - usually done via grid-search - involves a trade-off between performance increases and decreases on individual graphs.
Analysis via Consensus Dynamics We believe that the heterogeneity in optimal depth can be explained using insights from average consensus dynamics, a classical tool from network science that has been used to study epidemics and opinion dynamics in social networks.
To define average consensus dynamics, we consider a connected graph with nodes and adjacency matrix . For simplicity, we assume that each node has a scalar-valued feature , which is a function of time . We denote these time-dependent node features as . The average consensus dynamics on such a graph are characterized by the autonomous differential equation , which in coordinate form simply amounts to
In other words, at each time step a node’s features adapt to become more similar to those of its neighbours. For any given initialization , the differential equation will push the nodes’ features towards a global “consensus” in which the features of all nodes are equal. Let denote the vector of all ones. Since , is an eigenvector of with zero eigenvalue, i.e.,
Mathematically, this means that for all , as , where is the arithmetic average of the initial node features. Intuitively, these dynamics may be interpreted as an opinion formation process on a network of agents, who will in the absence of further inputs eventually agree on the same value, namely, the average opinion of their initial states. The rate of convergence is limited by the second smallest eigenvalue of , the Fiedler value , with
We can think of the number of layers in a GNN as discrete time steps. Since graphs with a smaller Fiedler value take longer to converge to a global consensus, we expect these networks to benefit from more GNN layers.
5.2 Spectral alignment allows for principled depth choices
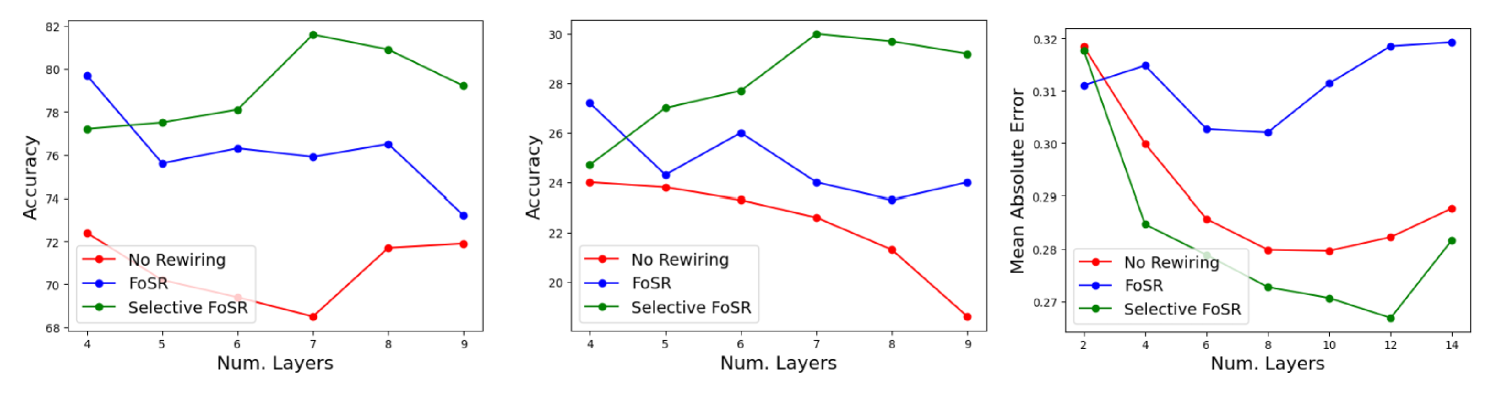
Our discussion on average consensus dynamics suggests that individual graphs might require different GNN depths because approaching a global consensus takes about time steps – in our case layers – where is the graph’s spectral gap. We also saw in the previous section that selective (spectral) rewiring lifts the spectral gaps of (almost) all graphs in a dataset above a predetermined threshold without creating graphs with very large spectral gaps. Motivated by these insights, we propose to use as a heuristic for the GNN depth.
As Fig. 8 shows, we empirically find that this approach works very well. On all three datasets depicted here (Mutag, Enzymes and Peptides-Struct), the ideal GCN depth turned out to be the integer closest to : 7 layers for both Mutag and Enzymes, and 12 layers for Peptides-struct. Using grid-search, we previously determined 4 layers to be optimal on both datasets after applying standard FoSR or no rewiring at all. We now find that the accuracy obtained with a 7-layer GCN after applying selective FoSR is 3 percent higher than the accuracy obtained with selective FoSR and 4 layers on Mutag (5 percent on Enzymes). We also note that using 7 layers after applying FoSR or no rewiring is far from optimal on both datasets, highlighting the fact that the optimal depth changes with rewiring. Our observations on Peptides-struct are similar: Computing suggests that we should use 12 layers on the selectively rewired dataset, which indeed turns out to be the ideal depth. This is far deeper than the 8 layers that are optimal with standard FoSR or no rewiring at all. Overall, we find that deeper networks generally perform better than shallow ones after selective rewiring. This might be surprising given that spectral rewiring methods are meant to improve the connectivity of the graph and hence allow for shallower models. We note that there is no such clear trend on the original datasets. For example, 8 layers perform almost as well on Mutag as 4. This further supports the notion that selective rewiring results in a spectral alignment between the graphs in a dataset.
6 Discussion
In this paper we analyzed performance heterogeneity in graph-level learning in both message-passing and transformer-based GNN architectures. Our results showed that unlike in the node-level setting, topological properties alone cannot explain graph-level heterogeneity. Instead, we identify large class-distance ratios as the main driver of heterogeneity within data sets. Our analysis suggests several lessons for architecture choice and data preprocessing, including a selective rewiring approach that optimizes the benefits of rewiring and a heuristic for choosing the optimal GNN depths. We corroborate our findings with computational experiments.
Limitations One limitation of this study is its focus on small-scale data sets for evaluating class-distance ratios using the TMD. This limitation, shared by related works, stems from the high computational complexity of the TMD, which prevents scalability to larger and denser graphs. Nevertheless, the observed effectiveness of our proposed design choices across a broader range of large-scale data sets suggests that similar effects can be expected. Furthermore, although our selection of architectures and data sets was informed by choices in comparable studies, expanding the scope of our heterogeneity analysis by including additional transformer-based architectures could have further strengthened the validity of our observations.
Future Work Our study of data preprocessing routines has focused on rewiring. However, recent literature has shown that encodings too can lead to significant performance gains in downstream tasks. While we include a preliminary study of heterogeneity in the context of encodings in Appendix C.3, a more detailed analysis is left for future work. We believe that a principled approach for selective encodings is a promising direction for extending the present work. Similarly, our theoretical understanding of common encodings such as LAPE and RWPE needs to be reassessed: Recent results argue that adding encodings makes GNNs more expressive, which does not explain the substantial detrimental effects on some graphs observed in our preliminary experiments. While our results suggest connections between performance heterogeneity and generalization, a detailed theoretical analysis of this link is beyond the scope of the present paper. We believe that in particular a detailed study of similarity measures in the style of the Tree Mover’s Distance could provide valuable insights into transformer-based architectures. Lastly, this study aimed to work towards automating model choices in GNNs. We believe that the heterogeneity perspective could provide insights beyond GNN depth and preprocessing routines.
Acknowledgments
LF was supported by a Kempner Graduate Fellowship. MW was supported by NSF award CBET-2112085 and a Sloan Research Fellowship in Mathematics. Some of the computations in this paper were run on the FASRC Cannon cluster supported by the FAS Division of Science Research Computing Group at Harvard University.
References
- Alon and Yahav (2021) Uri Alon and Eran Yahav. On the bottleneck of graph neural networks and its practical implications. In International Conference on Learning Representations, 2021.
- Arnaiz-Rodr´ıguez et al. (2022) Adrián Arnaiz-Rodríguez, Ahmed Begga, Francisco Escolano, and Nuria Oliver. Diffwire: Inductive graph rewiring via the Lovasz bound. arXiv preprint arXiv:2206.07369, 2022.
- Barbero et al. (2023) Federico Barbero, Ameya Velingker, Amin Saberi, Michael Bronstein, and Francesco Di Giovanni. Locality-aware graph-rewiring in gnns. arXiv preprint arXiv:2310.01668, 2023.
- Barceló et al. (2020) Pablo Barceló, Egor V. Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan Pablo Silva. The logical expressiveness of graph neural networks. In International Conference on Learning Representations, 2020.
- Black et al. (2023) Mitchell Black, Zhengchao Wan, Amir Nayyeri, and Yusu Wang. Understanding oversquashing in gnns through the lens of effective resistance. In International Conference on Machine Learning, pages 2528–2547. PMLR, 2023.
- Bouritsas et al. (2022) Giorgos Bouritsas, Fabrizio Frasca, Stefanos Zafeiriou, and Michael M Bronstein. Improving graph neural network expressivity via subgraph isomorphism counting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):657–668, 2022.
- Cai and Wang (2018) Chen Cai and Yusu Wang. A simple yet effective baseline for non-attributed graph classification. ICRL Representation Learning on Graphs and Manifolds, 2018.
- Chuang and Jegelka (2022) Ching-Yao Chuang and Stefanie Jegelka. Tree mover’s distance: Bridging graph metrics and stability of graph neural networks. Advances in Neural Information Processing Systems, 35:2944–2957, 2022.
- Coley et al. (2019) Connor W Coley, Wengong Jin, Luke Rogers, Timothy F Jamison, Tommi S Jaakkola, William H Green, Regina Barzilay, and Klavs F Jensen. A graph-convolutional neural network model for the prediction of chemical reactivity. Chemical science, 10(2):370–377, 2019.
- Dwivedi et al. (2022) Vijay Prakash Dwivedi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. Graph neural networks with learnable structural and positional representations. In International Conference on Learning Representations, 2022.
- Dwivedi et al. (2023) Vijay Prakash Dwivedi, Chaitanya K. Joshi, Anh Tuan Luu, Thomas Laurent, Yoshua Bengio, and Xavier Bresson. Benchmarking graph neural networks. Journal of Machine Learning Research, 24(43):1–48, 2023.
- Fesser and Weber (2024a) Lukas Fesser and Melanie Weber. Mitigating over-smoothing and over-squashing using augmentations of forman-ricci curvature. In Learning on Graphs Conference, pages 19–1. PMLR, 2024a.
- Fesser and Weber (2024b) Lukas Fesser and Melanie Weber. Effective structural encodings via local curvature profiles. In International Conference on Learning Representations, 2024b.
- Franks et al. (2024) Billy J Franks, Christopher Morris, Ameya Velingker, and Floris Geerts. Weisfeiler-leman at the margin: When more expressivity matters. arXiv preprint arXiv:2402.07568, 2024.
- Garg et al. (2020) Vikas Garg, Stefanie Jegelka, and Tommi Jaakkola. Generalization and representational limits of graph neural networks. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3419–3430. PMLR, 13–18 Jul 2020.
- Gligorijević et al. (2021) Vladimir Gligorijević, P Douglas Renfrew, Tomasz Kosciolek, Julia Koehler Leman, Daniel Berenberg, Tommi Vatanen, Chris Chandler, Bryn C Taylor, Ian M Fisk, Hera Vlamakis, et al. Structure-based protein function prediction using graph convolutional networks. Nature communications, 12(1):3168, 2021.
- Gori et al. (2005) Marco Gori, Gabriele Monfardini, and Franco Scarselli. A new model for learning in graph domains. In Proceedings. 2005 IEEE international joint conference on neural networks, volume 2, pages 729–734, 2005.
- Gosztolai and Arnaudon (2021) Adam Gosztolai and Alexis Arnaudon. Unfolding the multiscale structure of networks with dynamical Ollivier-Ricci curvature. Nature Communications, 12(1):4561, December 2021. ISSN 2041-1723.
- Hamilton et al. (2017) William L. Hamilton, Zhitao Ying, and Jure Leskovec. Inductive Representation Learning on Large Graphs. In NIPS, pages 1024–1034, 2017.
- Jain et al. (2024) Mika Sarkin Jain, Stefanie Jegelka, Ishani Karmarkar, Luana Ruiz, and Ellen Vitercik. Model-agnostic graph dataset compression with the tree mover’s distance. In 2nd Workshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Resource Optimization (WANT@ICML 2024), 2024.
- Jegelka (2022) Stefanie Jegelka. Theory of graph neural networks: Representation and learning. In The International Congress of Mathematicians, 2022.
- Jin et al. (2017) Wengong Jin, Connor Coley, Regina Barzilay, and Tommi Jaakkola. Predicting organic reaction outcomes with weisfeiler-lehman network. Advances in neural information processing systems, 30, 2017.
- (23) Gal Kaplun, Nikhil Ghosh, Saurabh Garg, Boaz Barak, and Preetum Nakkiran. Deconstructing distributions: A pointwise framework of learning. In The Eleventh International Conference on Learning Representations.
- Karhadkar et al. (2023) Kedar Karhadkar, Pradeep Kr. Banerjee, and Guido Montufar. FoSR: First-order spectral rewiring for addressing oversquashing in GNNs. In The Eleventh International Conference on Learning Representations, 2023.
- Kiani et al. (2024) Bobak T Kiani, Thien Le, Hannah Lawrence, Stefanie Jegelka, and Melanie Weber. On the hardness of learning under symmetries. In International Conference on Learning Representations, 2024.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR, 2017.
- Le and Jegelka (2024) Thien Le and Stefanie Jegelka. Limits, approximation and size transferability for gnns on sparse graphs via graphops. Advances in Neural Information Processing Systems, 36, 2024.
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Li et al. (2023) Ting Wei Li, Qiaozhu Mei, and Jiaqi Ma. A metadata-driven approach to understand graph neural networks. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Liang et al. (2023) Langzhang Liang, Zenglin Xu, Zixing Song, Irwin King, Yuan Qi, and Jieping Ye. Tackling long-tailed distribution issue in graph neural networks via normalization. IEEE Transactions on Knowledge and Data Engineering, 2023.
- Loukas (2019) Andreas Loukas. What graph neural networks cannot learn: depth vs width. In International Conference on Learning Representations, 2019.
- Maskey et al. (2022) Sohir Maskey, Ron Levie, Yunseok Lee, and Gitta Kutyniok. Generalization analysis of message passing neural networks on large random graphs. Advances in neural information processing systems, 35:4805–4817, 2022.
- Müller et al. (2023) Luis Müller, Mikhail Galkin, Christopher Morris, and Ladislav Rampášek. Attending to graph transformers. arXiv preprint arXiv:2302.04181, 2023.
- Nguyen et al. (2023) Khang Nguyen, Nong Minh Hieu, Vinh Duc Nguyen, Nhat Ho, Stanley Osher, and Tan Minh Nguyen. Revisiting over-smoothing and over-squashing using Ollivier-Ricci curvature. In International Conference on Machine Learning, pages 25956–25979. PMLR, 2023.
- Rampášek et al. (2022) Ladislav Rampášek, Michael Galkin, Vijay Prakash Dwivedi, Anh Tuan Luu, Guy Wolf, and Dominique Beaini. Recipe for a general, powerful, scalable graph transformer. Advances in Neural Information Processing Systems, 35:14501–14515, 2022.
- Rong et al. (2019) Yu Rong, Wenbing Huang, Tingyang Xu, and Junzhou Huang. Dropedge: Towards deep graph convolutional networks on node classification. arXiv preprint arXiv:1907.10903, 2019.
- Shlomi et al. (2020) Jonathan Shlomi, Peter Battaglia, and Jean-Roch Vlimant. Graph neural networks in particle physics. Machine Learning: Science and Technology, 2(2):021001, 2020.
- Topping et al. (2022) Jake Topping, Francesco Di Giovanni, Benjamin Paul Chamberlain, Xiaowen Dong, and Michael M. Bronstein. Understanding over-squashing and bottlenecks on graphs via curvature. In International Conference on Learning Representations, 2022.
- Tori et al. (2024) Floriano Tori, Vincent Holst, and Vincent Ginis. The effectiveness of curvature-based rewiring and the role of hyperparameters in gnns revisited. arXiv preprint arXiv:2407.09381, 2024.
- Tortorella and Micheli (2022) Domenico Tortorella and Alessio Micheli. Leave graphs alone: Addressing over-squashing without rewiring. arXiv preprint arXiv:2212.06538, 2022.
- Veličković et al. (2018) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph Attention Networks. In ICLR, 2018.
- Wu et al. (2022) Shiwen Wu, Fei Sun, Wentao Zhang, Xu Xie, and Bin Cui. Graph neural networks in recommender systems: a survey. ACM Computing Surveys, 55(5):1–37, 2022.
- Xu et al. (2018) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? arXiv preprint arXiv:1810.00826, 2018.
- Yehudai et al. (2021) Gilad Yehudai, Ethan Fetaya, Eli Meirom, Gal Chechik, and Haggai Maron. From local structures to size generalization in graph neural networks. In International Conference on Machine Learning, pages 11975–11986. PMLR, 2021.
- Ying et al. (2021) Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, and Tie-Yan Liu. Do transformers really perform badly for graph representation? Advances in neural information processing systems, 34:28877–28888, 2021.
- Zhao et al. (2022) Lingxiao Zhao, Wei Jin, Leman Akoglu, and Neil Shah. From stars to subgraphs: Uplifting any GNN with local structure awareness. In International Conference on Learning Representations, 2022.
- Zitnik et al. (2018) Marinka Zitnik, Monica Agrawal, and Jure Leskovec. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics, 34(13):i457–i466, 2018.
Appendix A Extended Background
A.1 More details on GNN architectures
We provide a more detailed description of the GNN architectures considered in this paper.
GCN is a generalization of convolutional neural networks to graph-structured data. It learns a joint representation of information encoded in the features and the connectivity of the graph via message-passing. Formally, a GCN layer is defined as
where denotes the node feature matrix at layer , the learnable weight matrix at layer ,
the normalized adjacency matrix, denoting the degree matrix and the adjacency matrix. Common choices for the activation function include ReLU or sigmoid functions.
GIN is an MPGNN designed to be as expressive as possible, in the sense that it can learn a larger class of structural functions compared to other MPGNNs such as GCN. GIN is based on the Weisfeiler-Lehman (WL) test for graph isomorphism, which is a heuristic for graph isomorphism testing, i.e., the task of determining if two graphs are topological identical. Formally, the GIN layer is defined as
where is the feature of a node at layer , is the set of neighbors of the node , and is a learnable parameter. Here, the update function is implemented as a multi-layer perceptron , i.e., a fully-connected neural network.
GINE is a variant of GIN that can take edge features into account. It is defined as
where is a neural network, usually an MLP.
GAT
implements an attention mechanism in the graph learning setting, which allows the network to assign different importance (or weights) to different neighbors when aggregating information. This is inspired by attention mechanisms in transformer models and can enhance the representational power of GNNs by learning to focus on more important neighbors. The GAT layer is formally defined as
Here, denotes the attention coefficient between node and neighbor , given by
where is a learnable attention vector and denotes vector concatenation.
GraphGPS is a hybrid GT architecture that combines MPGNNs with transformer layers to capture both local and global information in graph learning. It enhances traditional GNNs by incorporating positional encodings (to provide a notion of node position) and structural encodings (to capture node-specific graph-theoretic properties). By alternating between GNN layers (for local neighborhood aggregation) and transformer layers (for global attention), GraphGPS can effectively learn both short-range and long-range dependencies within a graph. It uses multi-head attention, residual connections, and layer normalization to ensure stable and effective learning.
A.2 Graph Rewiring
In this study we focus on two approaches that are representatives of the two most frequently considered classes of rewiring techniques.
FOSR
Introduced by Karhadkar et al. (2023), this rewiring approach leverages a characterization of over-squashing effects using the spectrum of the Graph Laplacian. It adds synthetic edges to a given graph to expand its spectral gap which can mitigate over-squashing.
BORF
Introduced by (Nguyen et al., 2023), BORF leverages a connection between discrete Ricci curvature and over-smoothing and over-squashing effects. Regions in the graph that suffer from over-smoothing have high curvature, where as edges that induce over-squashing have low curvature. BORF adds and removes edges to mitigate extremal curvature values. Fesser and Weber (2024a) show that the optimal number of edges relates to the curvature gap, a global curvature-based graph characteristic, providing a heuristic for choosing this hyperparameter.
A.3 Positional and structural encodings
Structural (SE) and Positional (PE) encodings endow GNNs with structural information that they cannot learn on their own, but which is crucial for downstream performance. Encodings are often based on classical topological graph characteristics. Typical examples of positional encodings include spectral information, such as the eigenvectors of the Graph Laplacian (Dwivedi et al., 2023) or random-walk based node similarities (Dwivedi et al., 2022). Structural encodings include substructure counts (Bouritsas et al., 2022; Zhao et al., 2022), as well as graph characteristics or summary statistics that GNNs cannot learn on their own, e.g., its diameter, girth, the number of connected components (Loukas, 2019), or summary statistics of node degrees (Cai and Wang, 2018) or the Ricci curvature of its edges (Fesser and Weber, 2024b). The effectiveness of encodings has been demonstrated on numerous graph benchmarks and across message-passing and transformer-based architectures.
A.4 More Details on the Tree Mover’s Distance
For completeness, we recall the formal definition of the Tree Mover’s Distance (TMD). We first define the previously mentioned notion of computation trees:
Definition 2 (Computation Trees ((Chuang and Jegelka, 2022), Def. 1)).
For a graph G we recursively define trees () as the depth- computation tree of node . The depth- tree is constructed by adding the neighbors of the depth- leaf nodes to the tree.
We further need the following definition:
Definition 3 (Blank Tree ((Chuang and Jegelka, 2022), Def. 2)).
A blank tree is a tree with only one node whose features are given by the zero vector and with an empty edge set.
Let denote two multisets of trees. If the multisets are not of the same size, it can be challenging to define optimal transport based similarity measures. To avoid this, we balance the data sets via augmentation with blank trees:
Definition 4 (Blank Tree Augmentation ((Chuang and Jegelka, 2022), Def. 3)).
The function
augments a pair of trees with blank trees.
We can now define a principled similarity measure on computation trees:
Definition 5 (Tree Distance ((Chuang and Jegelka, 2022), Def. 4)).
Let denote two trees with roots . We set
where and is a depth-dependent weighting function.
Finally, we define a distance on graphs based on the hierarchical optimal transport encoded in the above defined tree distance:
Definition 6 (TMD ((Chuang and Jegelka, 2022), Def. 5)).
Let denote two graphs and as above. We set
where and are multisets of the graph’s depth- computation trees.
Appendix B Heterogeneity and Data Characteristics
B.1 Additional Heterogeneity Profiles
B.1.1 GCN
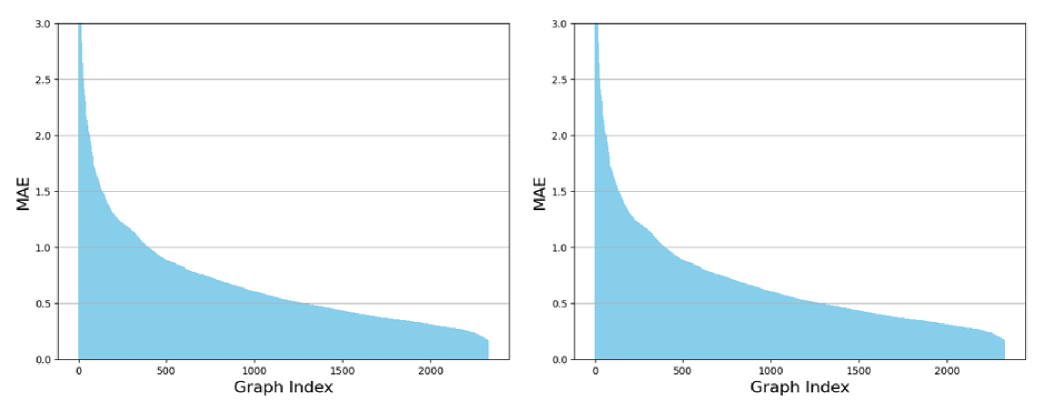
B.1.2 GIN
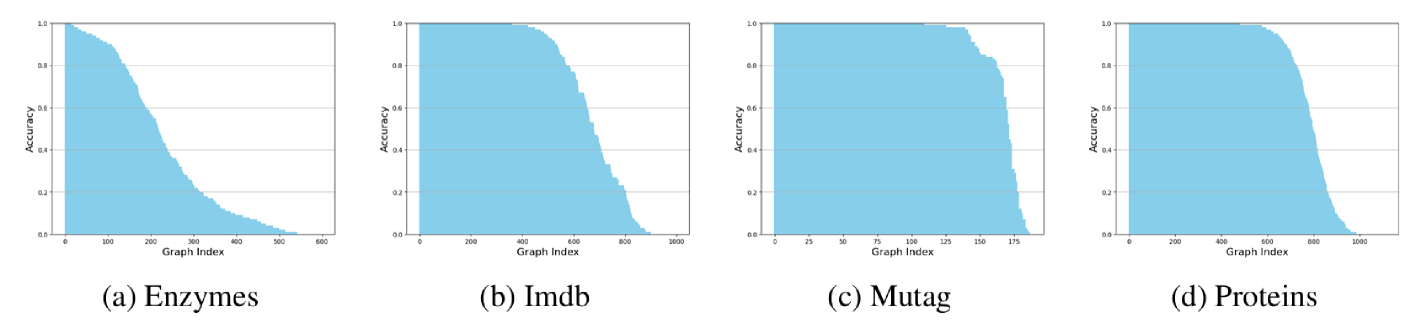
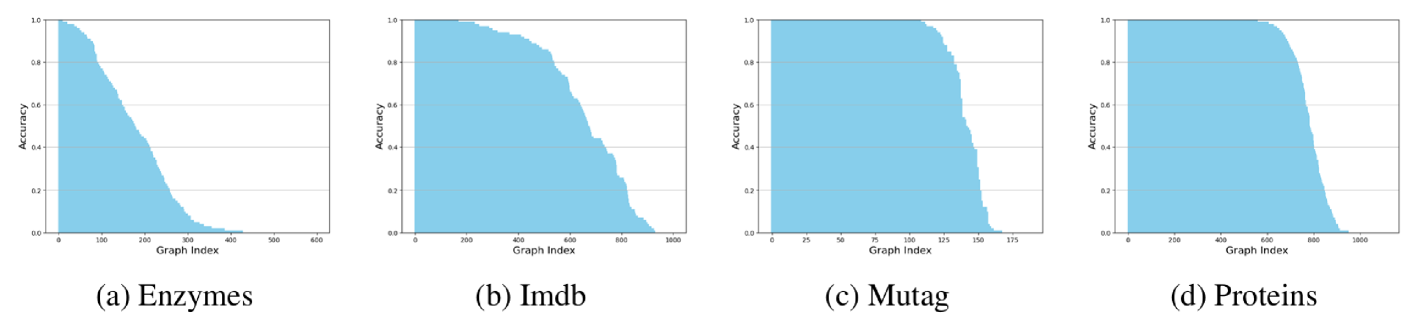
B.1.3 GAT
B.2 Class-Distance Ratios after Rewiring
B.3 Topological Properties
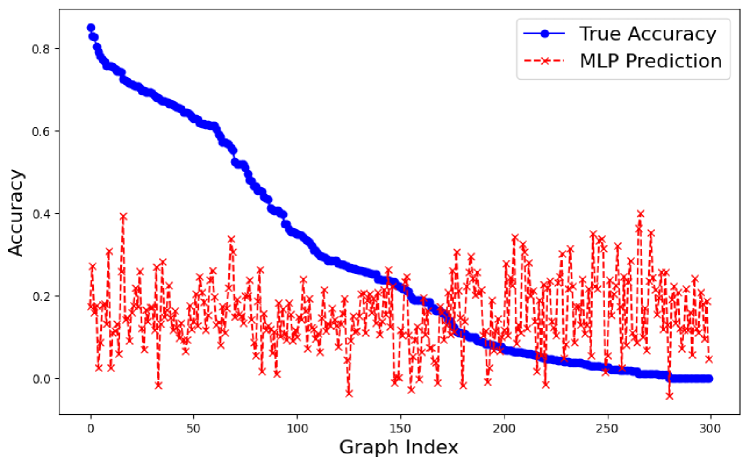
Our MLP experiments in section 3.3 and sparse multivariate regression experiments in the appendix use the following topological properties of a graph with to predict average GNN accuracy on that graph.
-
•
Edge Density. The edge density for an undirected graph is calculated as , while for a directed graph, it is computed as .
-
•
Average Degree. The average degree for an undirected graph is defined as , while for a directed graph, it is defined as .
-
•
Degree Assortativity. The degree assortativity is the average Pearson correlation coefficient of all pairs of connected nodes. It quantifies the tendency of nodes in a network to be connected to nodes with similar or dissimilar degrees and ranges between and .
-
•
Diameter. In an undirected or directed graph, the diameter is the length of the longest shortest path between any two vertices.
-
•
Average Clustering Coefficient. First define as the number of triangles including node , then the local clustering coefficient for node is calculated as for an undirected graph, where is the degree of node . The average clustering coefficient is then defined as the average local clustering coefficient of all the nodes in the graph.
-
•
Transitivity. The transitivity is defined as the fraction of all possible triangles present in the graph. Formally, it can be written as , where a triad is a pair of two edges with a shared vertex.
-
•
Spectral Gap/ Algebraic Connectivity. The Laplacian matrix of the graph is defined as: where is the degree matrix and is the adjacency matrix of the graph. The eigenvalues of the Laplacian matrix are real and non-negative, and can be ordered as follows:
The spectral gap of the graph is defined as the second-smallest eigenvalue of the Laplacian matrix, i.e. . This value is also known as the algebraic connectivity of the graph, and it reflects the overall connectivity of the graph.
-
•
Curvature Gap. Using Ollivier-Ricci curvature of an edge , we consider an edge to be intra-community if and inter-community if . Following Gosztolai and Arnaudon (2021), we define the curvature gap as
where . The curvature gap can be interpreted as a geometric measure of how much community structure is present in a graph (Fesser and Weber, 2024a).
-
•
Relative Size of the Largest Clique. The relative size of the largest clique is determined by calculating the ratio between the size of the largest clique in and .
B.4 MLP
B.5 Sparse Multivariate Regression Results
| Features | Enzymes | Imdb | Mutag | Proteins |
| Edge Density | ||||
| Average Degree | ||||
| Degree Assortativity | ||||
| Diameter | ||||
| Average Clustering Coefficient | ||||
| Transitivity | ||||
| Algebraic Connectivity | ||||
| Curvature Gap | ||||
| Rel. Size largest Clique | ||||
B.6 Pearson Correlation Coefficients
| Property | Mutag | Enzymes |
| Average Degree | 0.12423 (0.00229) | 0.02403 (0.42316) |
| Degree Assortativity | -0.01695 (0.67862) | 0.04393 (0.14307) |
| Pseudo-diameter | 0.01769 (0.66527) | 0.08380 (0.00145) |
| Average clustering Coefficient | 0.04105 (0.31536) | 0.06259 (0.03681) |
| Transitivity | 0.03575 (0.38199) | -0.06216 (0.03811) |
| Algebraic Connectivity | -0.03241 (0.42795) | -0.02461 (0.41192) |
Appendix C Heterogeneity and Model Characteristics
C.1 Additional Results on Model Depth
C.2 Additional Training Dynamics
C.3 Heterogeneity Profiles with Encodings
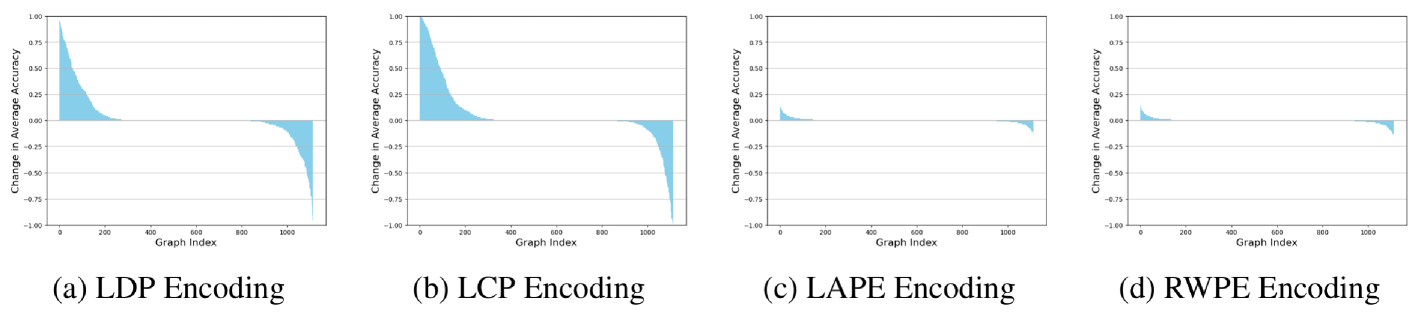
For each dataset, we repeat the experimental setup described in section 4 without any encodings and with one common structural or positional encoding. Here, we consider the Local Degree Profile (LDP) (Cai and Wang, 2018), the Local Curvature Profile (LCP) (Fesser and Weber, 2024b), Laplacian-eigenvector positional encodings (LAPE) (Dwivedi et al., 2023), and Random-Walk positional encodings (RWPE) (Dwivedi et al., 2022). For each graph in a dataset, we compare the average graph-level accuracy over 100 runs with and without a given encoding. The results on the Proteins dataset with GCN are presented in Figure C.3. Note that values larger than one indicate that graph benefiting from a particular encoding, while values smaller than one indicate a drop in accuracy due to the encoding.
We can see that the structural encodings considered here, i.e., LDP and LCP, have especially large graph-level effects for GCN. Positional encodings such as LAPE or RWPE have much smaller effects on individual graphs. However, even for positional encodings, we find that there are always graphs on which GCN accuracy decreases once we add encodings. We note that 1) these detrimental effects have, to the best of our knowledge, not been reported in the literature, and that 2) they cannot be explained by existing theory. Encodings such as LCP, LAPE, and RWPE can be shown to increase the expressivity of MPNNs such as GCN and make them more powerful than the 1-Weisfeiler Lehman test. Drastic decreases in accuracy on individual graphs are therefore perhaps surprising.
Appendix D Hyperparameter Configurations
| Features | Enzymes | Imdb | Mutag | Proteins | Peptides-f | Peptides-s | Zinc |
| Layer Type | GCN | GCN | GCN | GCN | GCN | GCN | GINE |
| Num. Layers | 7 | 7 | 7 | 7 | 12 | 12 | 4 |
| Hidden Dim. | 64 | 64 | 64 | 64 | 235 | 235 | 64 |
| Learning Rate | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| Dropout | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| Batch Size | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| Epochs | 300 | 300 | 300 | 300 | 300 | 300 | 300 |
| Edges Added | 40 | 5 | 10 | 30 | 10 | 10 | 10 |
| Features | Enzymes | Imdb | Mutag | Proteins | Peptides-f | Peptides-s | Zinc |
| Layer Type | GCN | GCN | GCN | GCN | GCN | GCN | GINE |
| Num. Layers | 4 | 4 | 4 | 4 | 8 | 8 | 4 |
| Hidden Dim. | 64 | 64 | 64 | 64 | 235 | 235 | 64 |
| Learning Rate | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| Dropout | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| Batch Size | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| Epochs | 300 | 300 | 300 | 300 | 300 | 300 | 300 |
| Edges Added | 40 | 5 | 10 | 30 | 10 | 10 | 10 |
| Features | Enzymes | Imdb | Mutag | Proteins | Peptides-f | Peptides-s | Zinc |
| Layer Type | GCN | GCN | GCN | GCN | GCN | GCN | GINE |
| Num. Layers | 4 | 4 | 4 | 4 | 8 | 8 | 4 |
| Hidden Dim. | 64 | 64 | 64 | 64 | 235 | 235 | 64 |
| Learning Rate | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| Dropout | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| Batch Size | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
| Epochs | 300 | 300 | 300 | 300 | 300 | 300 | 300 |