Personalized Federated Learning: A Unified Framework and Universal Optimization Techniques
Abstract
We investigate the optimization aspects of personalized Federated Learning (FL). We propose general optimizers that can be applied to numerous existing personalized FL objectives, specifically a tailored variant of Local SGD and variants of accelerated coordinate descent/accelerated SVRCD. By examining a general personalized objective capable of recovering many existing personalized FL objectives as special cases, we develop a comprehensive optimization theory applicable to a wide range of strongly convex personalized FL models in the literature. We showcase the practicality and/or optimality of our methods in terms of communication and local computation. Remarkably, our general optimization solvers and theory can recover the best-known communication and computation guarantees for addressing specific personalized FL objectives. Consequently, our proposed methods can serve as universal optimizers, rendering the design of task-specific optimizers unnecessary in many instances.
1 Introduction
Modern personal electronic devices, such as mobile phones, wearable devices, and home assistants, can collectively generate and store vast amounts of user data. This data is essential for training and improving state-of-the-art machine learning models for tasks ranging from natural language processing to computer vision. Traditionally, the training process was performed by first collecting all the data into a data center (Dean et al., 2012), raising serious concerns about user privacy and placing a considerable burden on the storage capabilities of server suppliers. To address these issues, a novel paradigm – Federated Learning (FL) (McMahan et al., 2017; Kairouz et al., 2021) – has been proposed. Informally, the main idea of FL is to train a model locally on an individual’s device, rather than revealing their data, while communicating the model updates using private and secure protocols.
While the original goal of FL was to search for a single model to be deployed on each device, this objective has been recently questioned. As the distribution of user data can vary greatly across devices, a single model might not serve all devices simultaneously (Hard et al., 2018). Consequently, data heterogeneity has become the main challenge in the search for efficient federated learning models. Recently, a range of personalized FL approaches has been proposed to address data heterogeneity (Kulkarni et al., 2020), wherein different local models are used to fit user-specific data while also capturing the common knowledge distilled from data of other devices.
Since the motivation and goals of each of these personalized approaches vary greatly, examining them separately can only provide us with an understanding of a specific model. Fortunately, many personalized FL models in the literature are trained by minimizing a specially structured optimization program. In this paper, we analyze the general properties of such an optimization program, which in turn provides us with high-level principles for training personalized FL models. We aim to solve the following optimization problem
| (1) |
where corresponds to the shared parameters, with , corresponds to the local parameters, is the number of devices, and is the objective that depends on the local data at the -th client.
By carefully designing the local loss , the objective (1) can recover many existing personalized FL approaches as special cases. The local objective does not need to correspond to the empirical loss of a given model on the -th device’s data. See Section 2 for details. Consequently, (1) serves as a unified objective that encompasses numerous existing personalized FL approaches as special cases. The primary goal of our work is to explore the problem (1) from an optimization perspective. By doing so, we develop a universal convex optimization theory that applies to many personalized FL approaches.
1.1 Contributions
We outline the main contributions of this work.
Single personalized FL objective. We propose a single objective (1) capable of recovering many existing convex personalized FL approaches by carefully constructing the local loss . Consequently, training different personalized FL models is equivalent to solving a particular instance of (1).
Recovering best-known complexity and novel guarantees. We develop algorithms for solving (1) and prove sharp convergence rates for strongly convex objectives. Specializing our rates from the general setting to the individual personalized FL objectives, we recover the best-known optimization guarantees from the literature or advance beyond the state-of-the-art with a single exception: objective (11) with . Therefore, our results often render optimization tailored to solve a specific personalized FL unnecessary in many cases.
Universal (convex) optimization methods and theory for personalized FL. To develop an optimization theory for solving (1), we impose particular assumptions on the objective: strong convexity of and convexity and -smoothness of for all (see Assumptions 1, 2). These assumptions are naturally satisfied for the vast majority of personalized FL objectives in the literature, with the exception of personalized FL approaches that are inherently nonconvex, such as MAML (Finn et al., 2017). Under these assumptions, we propose three algorithms for solving the general personalized FL objective (1): i) Local Stochastic Gradient Descent for Personalized FL (LSGD-PFL), ii) Accelerated Block Coordinate Descent for Personalized FL (ACD-PFL), and iii) Accelerated Stochastic Variance Reduced Coordinate Descent for Personalized FL (ASVRCD-PFL). The convergence rates of these methods are summarized in Table 1. We emphasize that these optimizers can be used to solve many (convex) personalized FL objectives from the literature by casting a given objective as a special case of (1), oftentimes matching or outperforming algorithms originally designed for the particular scenario.
Minimax optimal rates. We provide lower complexity bounds for solving (1). Using the construction of Hendrikx et al. (2021), we show that to solve (1), one requires at least communication rounds. Note that communication is often the bottleneck when training distributed and personalized FL models. Furthermore, one needs at least evaluations of and at least evaluations of . Given the -finite sum structure of with -smooth components, we show that one requires at least stochastic gradient evaluations with respect to -parameters and at least stochastic gradient evaluations with respect to -parameters. We show that ACD-PFL is always optimal in terms of communication and local computation when the full gradients are available, while ASVRCD-PFL can be optimal either in terms of the number of evaluations of the -stochastic gradient or the -stochastic gradient. However, note that ASVRCD-PFL cannot achieve optimal rate for both evaluations of the -stochastic gradient and the -stochastic gradient simultaneously, which we leave for future research.
Personalization and communication complexity. Given that a specific FL objective contains a parameter that determines the amount of personalization, we observe that the value of is always a non-increasing function of this parameter. Since the communication complexity of (1) is equal to up to constant and log factors, we conclude that personalization has a positive effect on the communication complexity of training an FL model.
New personalized FL objectives. The universal personalized FL objective (1) enables us to obtain a range of novel personalized FL formulations as special cases. While we study various (parametric) extensions of known models, we believe that the objective (1) can lead to easier development of brand new objectives as well. However, we stress that proposing novel personalized FL models is not the main focus of our work; the paper’s primary focus is on providing universal optimization guarantees for (convex) personalized FL.
Despite the aforementioned benefits of our proposed unified framework, we acknowledge that this is neither the only nor the universally best approach for personalized federated learning. However, providing a general framework that can include many existing methods as special cases can help us gain a clear understanding and motivate us to propose new personalized methods.
| Alg. | Communication | # | # | |||||||||
| LSGD-PFL |
|
|
|
|||||||||
| ACD-PFL | ❀ | ❀ | ❀ | |||||||||
| ASVRCD-PFL | ❀ | ❀ |
1.2 Assumptions and Notations
Complexity Notations. For two sequences and , if there exists such that for all large enough; if and simultaneously. Similarly, if for some ; if and simultaneously.
Local Objective. We assume three different ways to access the gradient of the local objective . The first, and the simplest case, corresponds to having access to the full gradient of with respect to either or for all simultaneously. The second case corresponds to a situation where is the expectation itself, i.e.,
| (2) |
while having access to stochastic gradients with respect to either or simultaneously for all , where represents the loss function on a single data point. The third case corresponds to a finite sum :
| (3) |
having access to or to for all and selected uniformly at random.
Assumptions. We argue that the objective (1) is capable of recovering virtually any (convex) personalized FL objective. Since the structure of the individual personalized FL objectives varies greatly, it is important to impose reasonable assumptions on the problem (1) in order to obtain meaningful rates in the special cases.
Assumption 1.
The function is jointly -strongly convex for , while for all , function is jointly convex, -smooth w.r.t. parameter and -smooth w.r.t. parameter . In the case when , assume additionally that (1) has a unique solution, denoted as and .
When is a finite sum (3), we require the smoothness of the finite sum components.
Assumption 2.
Suppose that for all , function is jointly convex, -smooth w.r.t. parameter and -smooth w.r.t. parameter .111It is easy to see that and .
In Section 2 we justify Assumptions 1 and 2 and characterize the constants , , , , for special cases of (1). Table 3 summarizes these parameters.
Price of generality. Since Assumption 1 is the only structural assumption we impose on (1), one cannot hope to recover the minimax optimal rates, that is, the rates that match the lower complexity bounds, for all individual personalized FL objectives as a special case of our general guarantees. Note that any given instance of (1) has a structure that is not covered by Assumption 1, but can be exploited by an optimization algorithm to improve either communication or local computation. Therefore, our convergence guarantees are optimal in light of Assumption 1 only. Despite this, our general rates specialize surprisingly well as we show in Section 2: our complexities are state-of-the-art in all scenarios with a single exception: the communication/computation complexity of (11).
Individual treatment of and . Throughout this work, we allow different smoothness of the objective with respect to global parameters and local parameters . At the same time, our algorithm is allowed to exploit the separate access to gradients with respect to and , given that these gradients can be efficiently computed separately. Without such a distinction, one might not hope for the communication complexity better than , which is suboptimal in the special cases. Similarly, the computational guarantees would be suboptimal as well. See Section 2 for more details.
Data heterogeneity. While the convergence rate of LSGD-PFL relies on data heterogeneity (See Theorem 1), we allow for an arbitrary dissimilarity among the individual clients for analyzing ACD-PFL and ASVRCD-PFL (see Theorem 7 and Theorem 8). Our experimental results also support that ASCD-PFL (ACD-PFL with stochastic gradient to reduce computation) and ASVRCD-PFL are more robust to data heterogeneity compared to the widely used Local SGD.
The rest of the paper is organized as follows. In Section 2, we show how (1) can be used to recover various personalized federated learning objectives in the literature. In Section 3, we propose a local-SGD based algorithm, LSGD-PFL, for solving (1). We further establish computational upper bounds for LSGD-PFL in strongly convex, weakly convex, and nonconvex cases. In Section 4, we discuss the minimax optimal algorithms for solving (1). We first show the minimax lower bounds in terms of the number of communication rounds, number of evaluations of the gradient of global parameters, and number of evaluations of the gradient of local parameters, respectively. We subsequently propose two coordinate-descent based algorithms, ACD-PFL and ASVRCD-PFL, which can match the lower bounds. In Section 5 and Section 6, we use experiments on synthetic and real data to illustrate the performance of the proposed algorithms and empirically validate the theorems. Finally, we conclude the paper with Section7. Technical proofs are deferred to the Appendix.
2 Personalized FL objectives
We recover a range of known personalized FL approaches as special cases of (1). In this section, we detail the optimization challenges that arise in each one of the special cases. We discuss the relation to our results, particularly focusing on how Assumptions 1, 2 and our general rates (presented in Sections 3 and 4) behave in the special cases. Table 3 presents the smoothness and strong convexity constants with respect to (1) for the special cases, while Table 3 provides the corresponding convergence rates for our methods when applied to these specific objectives. For the sake of convenience, define
in the case when functions have a finite sum structure (3).
| Rate? | ||||||
| Traditional FL ((4)) (McMahan et al., 2017) | 0 | 0 | recovered | |||
| Fully Personalized FL ((5)) | 0 | 0 | recovered | |||
| MT2 ((8)) (Li et al., 2020) | new♣ | |||||
| MX2 ((11)) (Smith et al., 2017) | recovered♠ | |||||
| APFL2 ((14)) (Deng et al., 2020) | new♣ | |||||
| WS2 ((16)) (Liang et al., 2020) | new | |||||
| Fed Residual ((18)) (Agarwal et al., 2020) | new |
2.1 Traditional FL
The traditional, non-personalized FL objective (McMahan et al., 2017) is given as
| (4) |
where corresponds to the loss on the -th client’s data. Assume that is -smooth and strongly convex for all . The minimax optimal communication to solve (4) up to -neighborhood of the optimum is (Scaman et al., 2018). When is an -finite sum with convex and smooth components, the minimax optimal local stochastic gradient complexity is (Hendrikx et al., 2021). The FL objective (4) is a special case of (1) with and our theory recovers the aforementioned rates.
2.2 Fully Personalized FL
At the other end of the spectrum lies the fully personalized FL where the -th client trains their own model without any influence from other clients:
| (5) |
The above objective is a special case of (1) with . As the objective is separable in , we do not require any communication to train it. At the same time, we need local stochastic oracle calls to solve it (Lan & Zhou, 2018) – which is what our algorithms achieve.
2.3 Multi-Task FL of Li et al. (2020)
The objective is given as
| (6) |
where is a solution of the traditional FL in (4) and . Assuming that is known (which Li et al. (2020) does), the problem (6) is a particular instance of (5); thus our approach achieves the optimal complexity.
A more challenging objective (in terms of optimization) is the following relaxed version of (6):
| (7) |
where is the relaxation parameter, recovering the original objective for . Note that, since , finding a minimax optimal method for the optimization of (6) is straightforward. First, one has to compute a minimizer of the classical FL objective (4), which can be done with a minimax optimal complexity. Next, one needs to compute the local solution , which only depends on the local data and thus can also be optimized with a minimax optimal algorithm.
A more interesting scenario is obtained when we do not set in (7), but rather consider a finite that is sufficiently large. To obtain the right smoothness/strong convexity parameter (according to Assumption 1), we scale the global parameter by a factor of and arrive at the following objective:
| (8) |
where
The next lemma determines parameters in Assumption 1. See the proof in Appendix B.1.
Lemma 1.
Let . Then, the objective (8) is jointly strongly convex, while the function is jointly convex, -smooth w.r.t. and -smooth w.r.t. . Similarly, the function is jointly convex, -smooth w.r.t. and -smooth w.r.t. .
Evaluating gradients. Note that evaluating under the objective (8) can be perfectly decoupled from evaluating . Therefore, we can make full use of our theory and take advantage of different complexities w.r.t. and . Resulting communication and computation complexities for solving (8) are presented in Table 3.
2.4 Multi-Task Personalized FL and Implicit MAML
In its simplest form, the multi-task personalized objective (Smith et al., 2017; Wang et al., 2018) is given as
| (9) |
where and (Hanzely & Richtárik, 2020). On the other hand, the goal of implicit MAML (Rajeswaran et al., 2019; Dinh et al., 2020) is to minimize
| (10) |
By reparametrizing (1), we can recover an objective that is simultaneously equivalent to both (9) and (10). In particular, by setting
the objective (1) becomes
| (11) |
It is a simple exercise to notice the equivalence of (11) to both (9) and (10).222To the best of our knowledge, we are the first to notice the equivalence of (9) and (10). Indeed, we can always minimize (11) in , arriving at , and thus recovering the solution of (9). Similarly, by minimizing (11) in we arrive at (10).
Lemma 2.
Let . Then the objective (11) is jointly -strongly convex, while is -smooth w.r.t. and -smooth w.r.t. . The function
is jointly convex, -smooth w.r.t. and -smooth w.r.t. .
The proof is given in Appendix B.2. Hanzely et al. (2020a) showed that the minimax optimal communication complexity to solve (9) (and therefore to solve (10) and (11)) is . Furthermore, they showed that the minimax optimal number of gradients w.r.t. is and proposed a method that has the complexity w.r.t. the number of -gradients. We match the aforementioned communication guarantees when and computation guarantees when . Furthermore, when , our complexity guarantees are strictly better compared to the guarantees for solving the implicit MAML objective (10) directly (Rajeswaran et al., 2019; Dinh et al., 2020).
2.5 Adaptive Personalized FL (Deng et al., 2020)
The objective is given as
| (12) |
where is a solution to (4) and . Assuming that is known, as was done in Deng et al. (2020), the problem (12) is an instance of (5); thus our approach achieves the optimal complexity.
A more interesting case (in terms of optimization) is when considering a relaxed variant of (12), given as
| (13) |
where is the relaxation parameter that allows recovering the original objective when . Such a choice, alongside with the usual rescaling of the parameter results in the following objective:
| (14) |
where
Lemma 3.
Let and . If
then the function is jointly -strongly convex, -smooth w.r.t. and -smooth w.r.t. .
The proof is given in Appendix B.3.
2.6 Personalized FL with Explicit Weight Sharing
The most typical example of the weight sharing setting is when parameters correspond to different layers of the same neural network. For example, could be the weights of first few layers of a neural network, while are the weights of the remaining layers (Liang et al., 2020). Or, alternatively, each of can correspond to the weights of last few layers, while the remaining weights are included in the global parameter (Arivazhagan et al., 2019). Overall, we can write the objective as follows:
| (15) |
where . Using an equivalent reparameterization of the space, we aim to minimize
| (16) |
which is an instance of (1) with .
Lemma 4.
The function is jointly -strongly convex, -smooth w.r.t. and -smooth w.r.t. . Similarly, the function is jointly convex, -smooth w.r.t. and -smooth w.r.t. .
The proof is straightforward and, therefore, omitted. A distinctive characteristic of the explicit weight sharing paradigm is that evaluating a gradient w.r.t. -parameters automatically grants either free or highly cost-effective access to the gradient w.r.t. -parameters (and vice versa).
2.7 Federated Residual Learning (Agarwal et al., 2020)
Agarwal et al. (2020) proposed federated residual learning:
| (17) |
where is a local feature vector (there may be an overlap between and ), represents the model prediction using global parameters/features, denotes the model prediction using local parameters/features, and is a loss function. Clearly, we can recover (17) with
| (18) |
Unlike the other objectives, here we cannot relate constants to , since we do not write as a function of . However, it seems natural to assume (or )-smoothness of (or ) as a function of (or ) for any . Let us define , analogously, given that has an -finite sum structure. Assuming, furthermore, that is -strongly convex and is convex (for each ), we can apply our theory.
2.8 MAML Based Approaches
Meta-learning has recently been employed for personalization (Chen et al., 2018; Khodak et al., 2019; Jiang et al., 2019; Fallah et al., 2020; Lin et al., 2020). Notably, the model-agnostic meta-learning (MAML) (Finn et al., 2017) based personalized FL objective is given as
| (19) |
Although we can recover (19) as a special case of (1) by setting , our (convex) convergence theory does not apply due to the inherent non-convex structure of (19). Specifically, objective is non-convex even if function is convex. In this scenario, only our non-convex rates of Local SGD apply.
3 Local SGD
The most popular optimizer to train non-personalized FL models is the local SGD/FedAvg (McMahan et al., 2016; Stich, 2019). We devise a local SGD variant tailored to solve the personalized FL objective (1) – LSGD-PFL. See the detailed description in Algorithm 1. Specifically, LSGD-PFL can be seen as a combination of local SGD applied on global parameters and SGD applied on local parameters . To mimic the non-personalized setup of local SGD, we assume access to the local objective in the form of an unbiased stochastic gradient with bounded variance.
Admittedly, LSGD-PFL was already proposed by Arivazhagan et al. (2019) and Liang et al. (2020) to solve a particular instance of (1). However, no optimization guarantees were provided. In contrast, we provide convergence guarantees for LSGD-PFL that recover the convergence rate of LSGD when and the rate of SGD when . Next, we demonstrate that LSGD-PFL works best when applied to an objective with rescaled -space, unlike what was proposed in the aforementioned papers.
We will need the following assumption on the stochastic gradients.
Assumption 3.
Assume that the stochastic gradients and satisfy the following conditions for all , , and :
Let
We are now ready to state the convergence rate of LSGD-PFL.
Theorem 1.
The iteration complexity of LSGD-PFL can be seen as a sum of two complexities: the complexity of minibatch SGD to minimize a problem with a condition number and the complexity of local SGD to minimize a problem with a condition number . Note that the key reason why we were able to obtain such a rate for LSGD-PFL is the rescaling of the -space by a constant . Arivazhagan et al. (2019) and Liang et al. (2020), where LSGD-PFL was introduced without optimization guarantees, did not consider such a reparametrization.
We also have the following result for weakly convex objectives.
Theorem 2.
The proofs of Theorem 1 and Theorem 2 can be found in Section 3.2. The reparametrization of plays a key role in proving the iteration complexity bound. Unlike the convergence guarantees for ACD-PFL and ASVRCD-PFL, which are introduced in Section 4, we do not claim any optimality properties for the rates obtained in Theorem 1 and Theorem 2. However, given the popularity of Local SGD as an optimizer for non-personalized FL models, Algorithm 1 is a natural extension of Local SGD to personalized FL models, and the corresponding convergence rate is an important contribution.
3.1 Nonconvex Theory for LSGD-PFL
To demonstrate that LSGD-PFL works in the nonconvex setting as well, we develop a non-convex theory for it. Therefore, the algorithm is also applicable, for example, for solving the explicit MAML objective. Note that we do not claim the optimality of our results.
Before stating the results, we need to make the following assumptions, which are slightly different from the rest of the paper. First, we need a smoothness assumption on local objective functions.
Assumption 4.
The local objective function is differentiable and -smooth, that is, for all and .
This condition is slightly different compared to the smoothness assumption on the objective stated in Assumption 1. Next, we need local stochastic gradients to have bounded variance.
Assumption 5.
The stochastic gradients , satisfy for all , , :
for all , where are all positive constants.
This assumption is common in the literature. See, for example, Assumption 3 in Haddadpour & Mahdavi (2019). Note that this assumption is weaker than Assumption 3. We also need an assumption on data heterogeneity.
Assumption 6 (Bounded Dissimilarity).
There is a positive constant such that for all and , , we have
This way of characterizing data heterogeneity was used in Haddadpour & Mahdavi (2019) – see Definition 1 therein. Given the above assumptions, we can establish the following convergence rate of LSGD-PFL for general non-convex objectives.
Theorem 3.
The following assumption is commonly used to characterize non-convex objectives in the literature.
Assumption 7 (-Polyak-Łojasiewicz (PL)).
There exists a positive constant , such that for all and , , we have
When the local objective functions satisfy the PL-condition, we obtain a faster convergence rate stated in the theorem below.
Theorem 4.
3.2 Proof of Theorem 1 and Theorem 2
The main idea consists of invoking the framework for analyzing local SGD methods introduced in Gorbunov et al. (2021) with several minor modifications. In particular, Algorithm 1 is an intriguing method that runs a local SGD on -parameters and SGD on -parameters. Therefore, we shall treat these parameter sets differently. Define where is defined as in Theorem 3.
The first step towards the convergence rate is to figure out the parameters of Assumption 2.3 from Gorbunov et al. (2021). The following lemma is an analog of Lemma G.1 in Gorbunov et al. (2021).
The proof is given in Appendix B.4. Using Lemma 5 we recover a set of crucial parameters of Assumption 2.3 from Gorbunov et al. (2021).
Lemma 6.
Let and . Then
| (23) |
and
| (24) |
The proof is given in Appendix B.5. Finally, the following lemma is an analog of Lemma E.1 in Gorbunov et al. (2021) and gives us the remaining parameters of Assumption 2.3 therein.
The proof is given in Appendix B.6. With these preliminary results, we are ready to state the main convergence result for Algorithm 1.
Theorem 5.
4 Minimax Optimal Methods
We discuss the complexity of solving (1) in terms of the number of communication rounds required to reach an -solution and the amount of local computation, both in terms of the number of (stochastic) gradients with respect to global -parameters and local -parameters.
4.1 Lower Complexity Bounds
We provide lower complexity bounds for solving (1) when is a finite sum (3). We show that any algorithm with access to the communication oracle and local (stochastic) gradient oracle with respect to the or parameters requires at least a certain number of oracle calls to approximately solve (1).
Oracle. The considered oracle allows us at any iteration to compute either:
-
•
on each device for a randomly selected and any ; or
-
•
on each device for a randomly selected and any ; or
-
•
the average of ’s alongside broadcasting the average back to clients (communication step).
Our lower bound is provided for iterative algorithms whose iterates lie in the span of historical oracle queries only. Let us denote such a class of algorithms as . In particular, for each we must have
and
where
with being the index of the last communication round until iteration . While such a restriction is widespread in the classical optimization literature (Nesterov, 2018; Scaman et al., 2018; Hendrikx et al., 2021; Hanzely et al., 2020a), it can be avoided by more complex arguments (Nemirovskij & Yudin, 1983; Woodworth & Srebro, 2016; Woodworth et al., 2018).
We then have the following theorem regarding the minimal calls of oracles for solving (1).
Theorem 6.
The proof is given in Appendix B.8. In the special case where , Theorem 6 provides a lower complexity bound for solving (1) with access to the full gradient locally. Specifically, it shows both the communication complexity and local gradient complexity with respect to -variables of the order , and the local gradient complexity with respect to -variables of the order .
4.2 Accelerated Coordinate Descent for PFL
We apply Accelerated Block Coordinate Descent (ACD) (Allen-Zhu et al., 2016; Nesterov & Stich, 2017; Hanzely & Richtárik, 2019) to solve (1). We separate the domain into two blocks of coordinates to sample from: the first one corresponding to parameters and the second one corresponding to . Specifically, at every iteration, we toss an unfair coin. With probability , we compute and update block . Alternatively, with probability , we compute and update block . Plugging the described sampling of coordinate blocks into ACD, we arrive at Algorithm 2. Note that ACD from Allen-Zhu et al. (2016) only allows for subsampling individual coordinates and does not allow for “blocks.” A variant of ACD that provides the right convergence guarantees for block sampling was proposed in Nesterov & Stich (2017) and Hanzely & Richtárik (2019).
We provide an optimization guarantee for Algorithm 2 in the following theorem.
Theorem 7.
The proof follows directly from Theorem 4.2 of Hanzely & Richtárik (2019). Since is evaluated on average once every iterations, ACD-PFL requires communication rounds and gradient evaluations with respect to , thus matching the lower bound. Similarly, as is evaluated on average once every iterations, we require evaluations of to reach an -solution; again matching the lower bound. Consequently, ACD-PFL is minimax optimal in terms of all three quantities of interest simultaneously.
We are not the first to propose a variant of coordinate descent (Nesterov, 2012) for personalized FL. Wu et al. (2021) introduced block coordinate descent to solve a variant of (11) formulated over a network. However, they do not argue about any form of optimality for their approach, which is also less general as it only covers a single personalized FL objective.
4.3 Accelerated SVRCD for PFL
Despite being minimax optimal, the main drawback of ACD-PFL is the necessity of having access to the full gradient of local loss with respect to either or at each iteration. Specifically, computing the full gradient with respect to might be very expensive when is a finite sum (3). Ideally, one would desire an algorithm that is i) subsampling the global/local variables and just as ACD-PFL, ii) subsampling the local finite sum, iii) employing control variates to reduce the variance of the local stochastic gradient (Johnson & Zhang, 2013; Defazio et al., 2014), and iv) accelerated in the sense of Nesterov (1983).
We propose a method – ASVRCD-PFL – that satisfies all four conditions above, by carefully designing an instance of ASVRCD (Accelerated proximal Stochastic Variance Reduced Coordinate Descent) (Hanzely et al., 2020b) applied to minimize an objective in a lifted space that is equivalent to (1). We are not aware of any other algorithm capable of satisfying i)-iv) simultaneously.
The construction of ASVRCD-PFL involves four main ingredients. First, we rewrite the original problem in a lifted space, which corresponds to the problem form discussed in Hanzely et al. (2020b). Second, we construct an unbiased stochastic gradient estimator by sampling coordinate blocks. Next, we enrich the stochastic gradient by control variates as in SVRG. Finally, we incorporate Nesterov’s momentum. We explain the construction of ASVRCD-PFL in detail below.
Lifting the problem space. ASVRCD-PFL is an instance of ASVRCD applied to an objective (1) in a lifted space. We have that
where
and
Variables correspond to for all and , while variables correspond to for all . The equivalence between the objective (1) and the objective in the lifted space is ensured with the indicator function , which forces different variables to take the same values. We apply ASVRCD with a carefully chosen non-uniform sampling of coordinate blocks to minimize .
Sampling of coordinate blocks. The key component of ASVRCD-PFL is the construction of the unbiased stochastic gradient estimator of , which we describe here. We consider two independent sources of randomness when sampling the coordinate blocks.
First, we toss an unfair coin . With probability , we have . In such a case, we ignore the local variables and update the global variables only, corresponding to or in our current notation. Alternatively, with probability . In such a case, we ignore the global variables and update local variables only, corresponding to or in our current notation.
Second, we consider local subsampling. At each iteration, the stochastic gradient is constructed using only, where and is selected uniformly at random from . For the sake of simplicity, we assume that all clients sample the same index, i.e., the randomness is synchronized. A similar rate can be obtained without shared randomness.
With these sources of randomness, we arrive at the following construction of , which is an unbiased stochastic estimator of :
Control variates and acceleration. We enrich the stochastic gradient by incorporating control variates, resulting in an SVRG-style stochastic gradient estimator. In particular, the resulting stochastic gradient will take the form of , where is another point that is updated upon a successful toss of a -coin. The last ingredient of the method is to incorporate Nesterov’s momentum.
Combining the above ingredients, we arrive at the ASVRCD-PFL procedure, which is detailed in Algorithm 3 in the lifted notation. Algorithm 4 details ASVRCD-PFL in the notation consistent with the rest of the paper.
The following theorem provides convergence guarantees for ASVRCD-PFL.
Theorem 8.
The communication complexity and the local stochastic gradient complexity with respect to -parameters of order , is obtained by setting . Analogously, setting yields the local stochastic gradient complexity with respect to -parameters of order . In contrast with Theorem 6, this result shows that ASVRCD-PFL can be optimal in terms of the local computation either with respect to -variables or in terms of the -variables. Unfortunately, these bounds are not achieved simultaneously unless are of a similar order, which we leave for future research. The proof is given in Appendix B.9. Additional discussion on how to choose the tuning parameters is given in Theorem 9.
5 Simulations
We present an extensive numerical evaluation to verify and support the theoretical claims. We perform experiments on both synthetic and real data, with a range of different objectives and methods (both ours and the baselines from the literature). The experiments are designed to shed light on various aspects of the theory. In this section, we present the results on synthetic data, while in the next section, we illustrate the performance of different methods on real data. The code to reproduce the experiments is publicly available at
https://github.com/boxinz17/PFL-Unified-Framework.
The experiments on synthetic data were conducted on a personal laptop with a CPU (Intel(R) Core(TM) i7-9750H CPU@2.60GHz). The results are summarized over 30 independent runs.
5.1 Multi-Task Personalized FL and Implicit MAML Objective
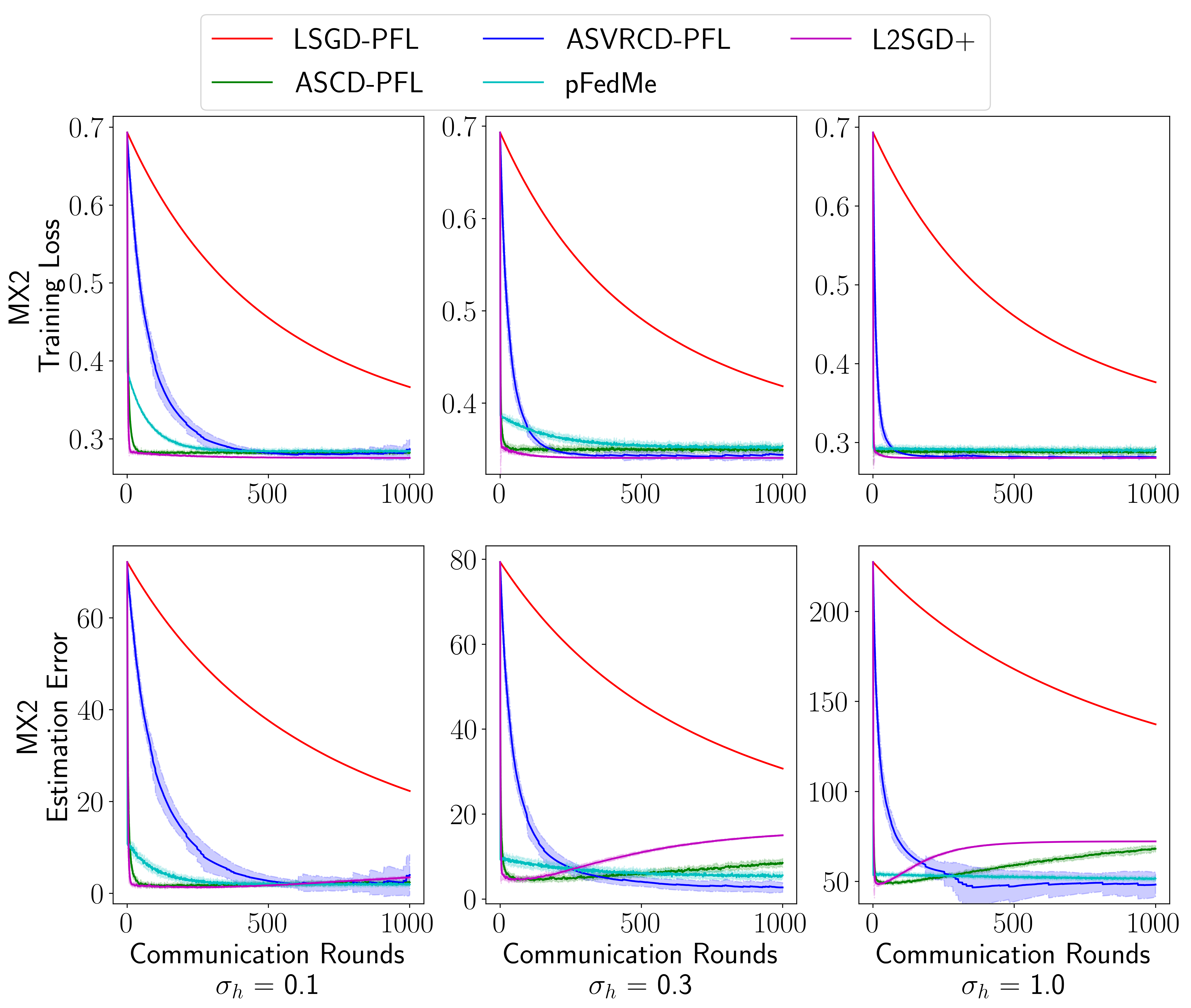
In this section, we focus on the performance of different methods when solving the objective (11). We implement three proposed algorithms – LSGD-PFL, ASCD-PFL333ASCD-PFL is ASVRCD-PFL without control variates. See the detailed description in Appendix A., and ASVRCD-PFL – and compare them with two baselines – L2SGD+ (Hanzely & Richtárik, 2020) and pFedMe (Dinh et al., 2020). As both L2SGD+ and pFedMe were designed specifically to solve (11), the aim of this experiment is to demonstrate that our universal approach is competitive with these specifically designed methods.
Data and model. We perform this experiment on synthetically generated data which allows us to properly control the data heterogeneity level. As a model, we choose logistic regression. We generate with i.i.d. entries from , and set , where entries of are generated i.i.d. from and for all . Thus, can be regarded as a measure of heterogeneity level, with a large corresponding to large heterogeneity. Finally, for each device , we generate with entries i.i.d. from for all , and , where . We set , , , and let to explore different levels of heterogeneity.
Objective function. We use objective (11) with being the cross-entropy loss function. We set , so that larger heterogeneity level will induce a larger penalty, which will further encourage parameters on each device to be closer to their geometric center. In addition to the training loss, we also record the estimation error in the training process, defined as .
Tuning parameters of proposed algorithms. For LSGD-PFL (Algorithm 1), we set the batch size to compute the stochastic gradient , the average period , and the learning rate . For and in ASCD-PFL (Algorithm 5) and ASVRCD-PFL (Algorithm 4), we set them as and , where and . We set . For and in ASVRCD-PFL, we set them according to Theorem 9, where , , and . We let be the smallest eigenvalue of . The in ASCD-PFL are the same as in ASVRCD-PFL, and we let . In addition, we initialize all iterates at zero for all algorithms.
Tuning Parameters of pFedMe. For pFedMe (Algorithm 1 in Dinh et al. (2020)), we set all parameters according to the suggestions in Section 5.2 of Dinh et al. (2020). Specifically, we set the local computation rounds to , computation complexity to , Mini-Batch size to , and . We also set . To solve the objective (7) in Dinh et al. (2020), we use gradient descent, as suggested in the paper. Additionally, we initialize all iterates at zero.
Tuning Parameters of L2SGD+. For L2SGD+ 444Algorithm 2 in Hanzely & Richtárik (2020), we set the stepsize (the parameter in Hanzely & Richtárik (2020)) and the probability of averaging to be the same as in ASRVCD-PFL and ASCD-PFL. We also initialize all iterates at zero.
Results. The results are summarized in Figure 1. We observe that our general-purpose optimizers are competitive with L2SGD+ and pFedMe. In particular, both ASVRCD-PFL and L2SGD+ consistently achieve the same training error as the other methods, which is well predicted by our theory. Although L2SGD+ is slightly faster in terms of convergence due to the specific parameter setting, it is not as general as the methods we propose. Furthermore, we note that the widely used LSGD-PFL suffers from data heterogeneity on different devices, whereas ASVRCD-PFL is not affected by this heterogeneity, as predicted by our theory. The average running time over 30 independent runs is reported in Table 4.
| 0.1 | 0.3 | 1.0 | |
| LSGD | 260.98 | 256.16 | 237.18 |
| ASCD | 28.79 | 51.71 | 142.59 |
| ASVRCD | 47.94 | 97.61 | 274.60 |
| pFedMe | 399.33 | 370.42 | 370.35 |
| L2SGDplus | 25.83 | 47.59 | 182.29 |
5.2 Explicit Weight Sharing Objective
In this section, we present another experiment on synthetic data that aims to optimize the explicit weight sharing objective (16). Since there is no good baseline algorithm for this objective, the purpose of this experiment is to compare the three proposed algorithms: LSGD-PFL, ASCD-PFL, and ASVRCD-PFL.
Data and Model. As a model, we choose logistic regression. We generate with i.i.d. entries from , and with i.i.d. entries from , where for all . Thus, can be regarded as a measure of the heterogeneity level, with a large corresponding to a high degree of heterogeneity. Finally, for each device , we generate with entries i.i.d. from for all , and , where . We set , , , , and let to explore different levels of heterogeneity.
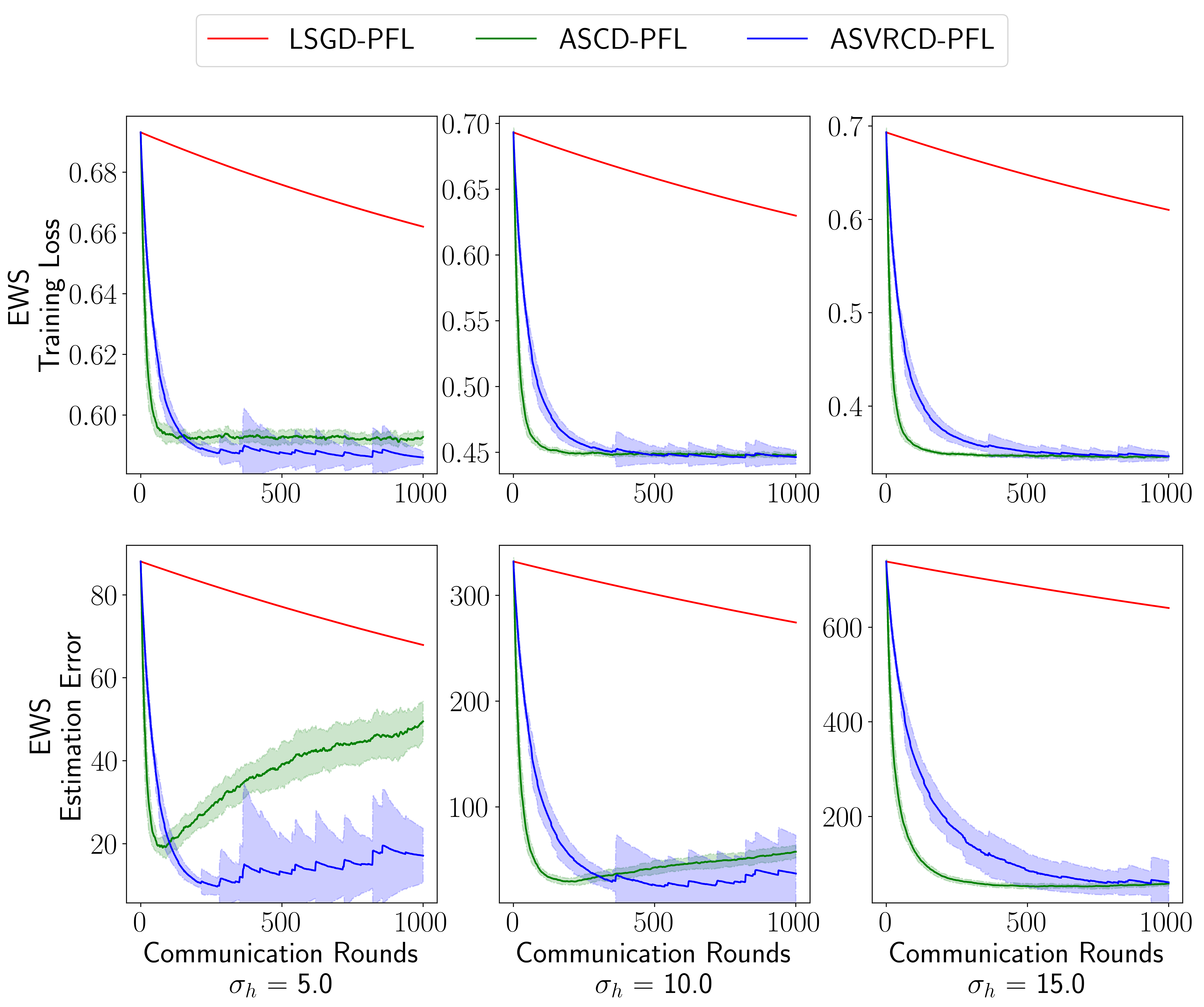
Objective function. We use objective (11) with representing the cross-entropy loss function. We set , so smaller heterogeneity levels will induce a larger penalty, encouraging parameters on each device to be closer to their geometric center. In addition to the training loss, we also record the estimation error during the training process, defined as .
| 5.0 | 10.0 | 15.0 | |
| LSGD | 238.01 | 237.67 | 234.33 |
| ASCD | 17.00 | 16.55 | 16.46 |
| ASVRCD | 23.35 | 22.12 | 23.51 |
Results. The results are summarized in Figure 2. When examining the training loss, we observe that ASCD-PFL drives the loss down quickly initially, while ASVRCD-PFL ultimately achieves a better optimum. This suggests that we can apply ASCD-PFL at the beginning of training and add control variates to reduce the variance at a later stage of training, thus combining the benefits of both algorithms. Both ASCD-PFL and ASVRCD-PFL perform much better than the widely used LSGD-PFL. When analyzing the estimation error, we observe that when the heterogeneity level is small, there is a tendency for overfitting, especially for ASCD-PFL; and when the heterogeneity level increases, there is less concern for overfitting. In general, however, ASCD-PFL and ASVRCD-PFL still achieve better estimation error than LSGD-PFL. The average running time over 30 independent runs is reported in Table 5.
6 Real Data Experiment Results
In this section, we use real data to illustrate the performance and various properties of the proposed methods. In Section 6.1, we compare the performance of the three proposed algorithms. In Section 6.2, we illustrate the effect of communication frequency of global parameters for ASCD-PFL and demonstrate that the theoretical choice based on Theorem 9 can generate the best communication complexity. Finally, in Section 6.3, we show the effect of reparametrizing for ASCD-PFL.
6.1 Performance of the Proposed Methods on Real Data
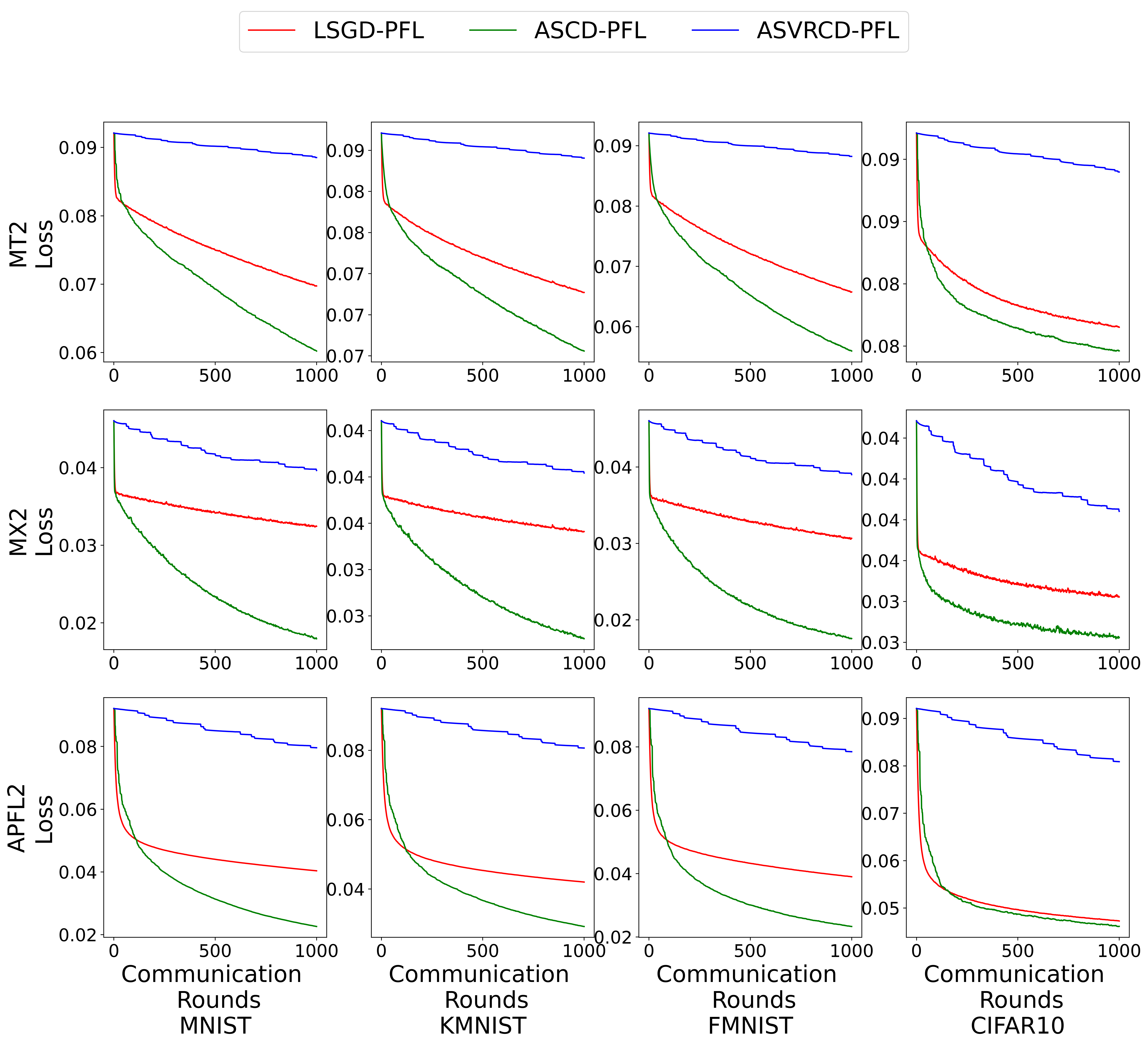
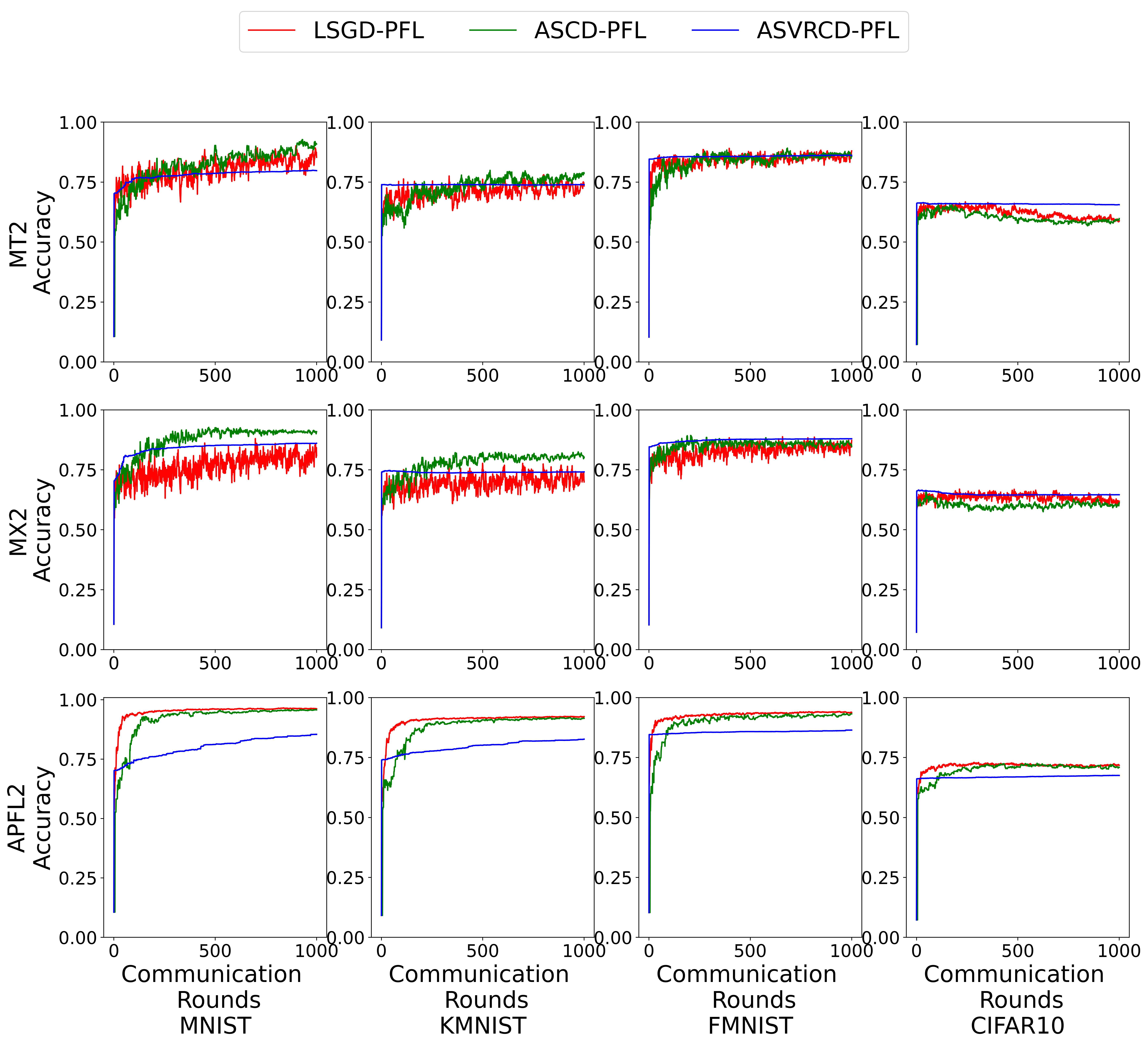
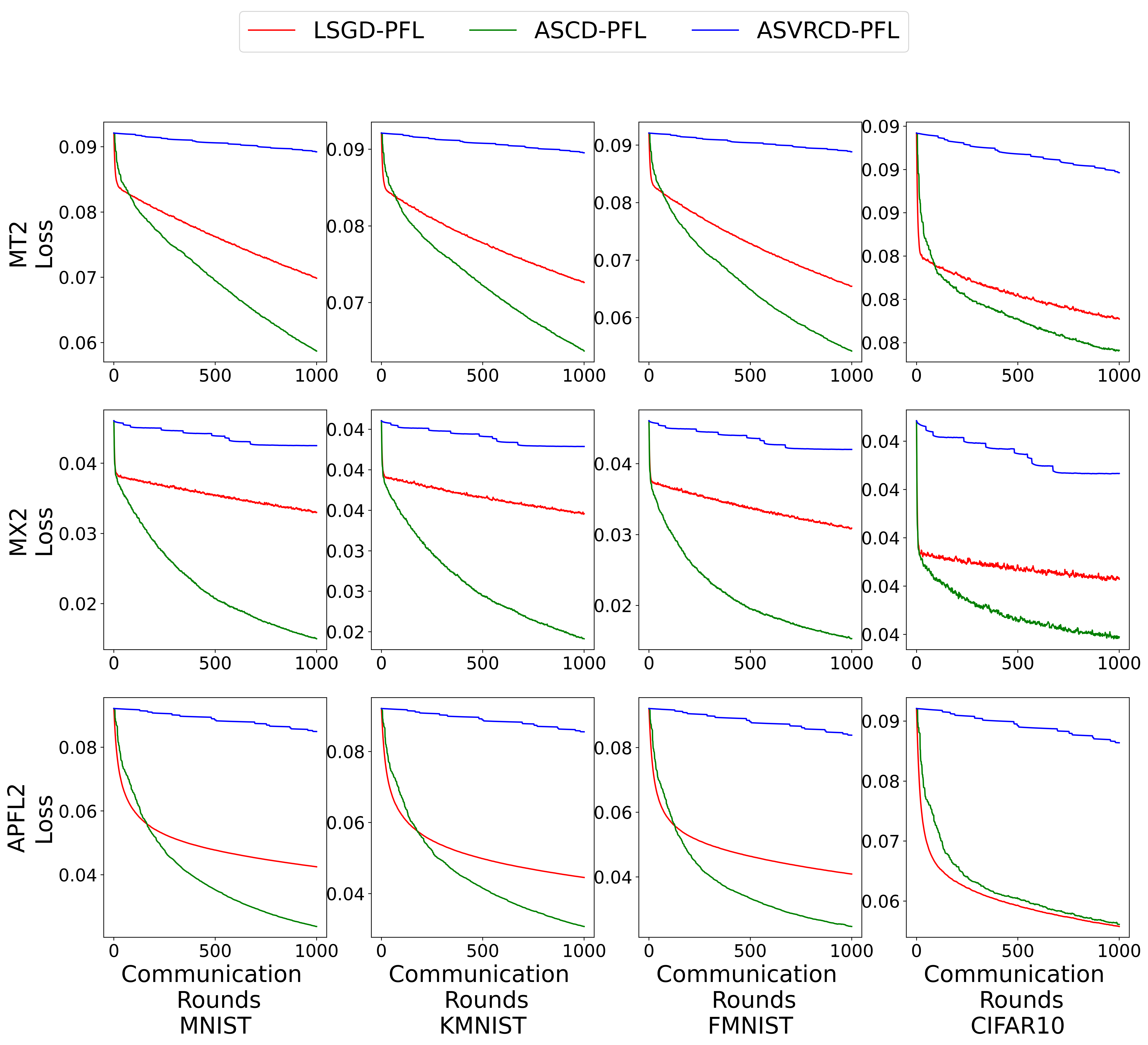
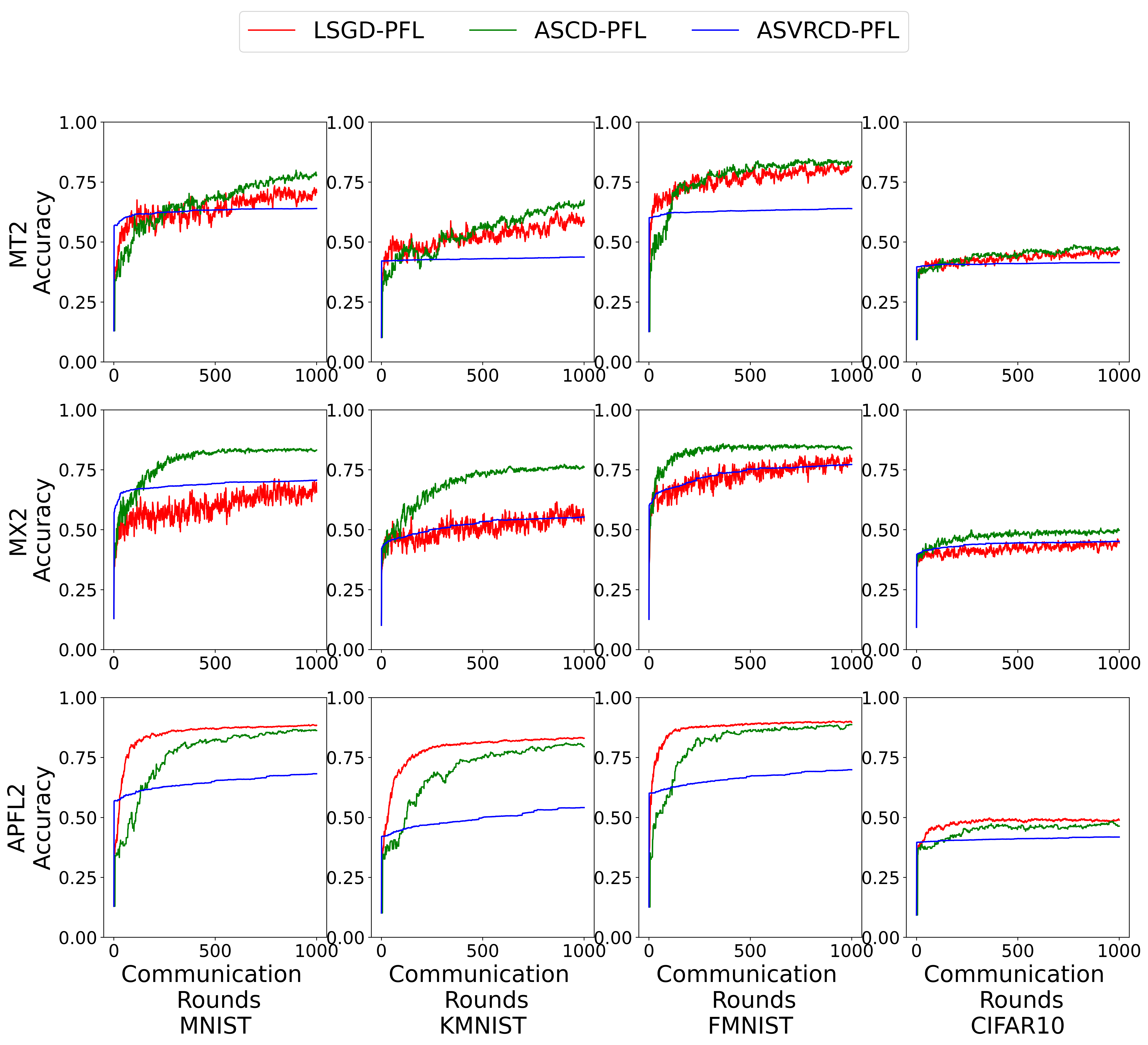
We compare the three proposed algorithms – LSGD-PFL, ASCD-PFL (ASVRCD-PFL without control variates), and ASVRCD-PFL – across four image classification datasets – MNIST (Deng, 2012), KMINIST (Clanuwat et al., 2018), FMINST (Xiao et al., 2017), and CIFAR-10 (Krizhevsky, 2009) with three objective functions (8), (11), and (14). As a model, we use a multiclass logistic regression, which is a single-layer fully connected neural network combined with a softmax function and cross-entropy loss. Experiments were conducted on a personal laptop (Intel(R) Core(TM) i7-9750H CPU@2.60GHz) with a GPU (NVIDIA GeForce RTX 2070 with Max-Q Design).
Data preparation. We set the number of devices . We focus on a non-i.i.d. setting of McMahan et al. (2017) and Liang et al. (2020) by assigning classes out of ten to each device. We let to generate different levels of heterogeneity. A larger means a more balanced data distribution and thus smaller data heterogeneity. We then randomly select samples for each device based on its class assignment for training and samples for testing. We normalize each dataset in two steps: first, we normalize the columns (features) to have mean zero and unit variance; next, we normalize the rows (samples) so that every input vector has a unit norm.
Model. Given a grayscale picture with a label , we unroll its pixel matrix into a vector . Then, given a parameter matrix , the function in (8), (11), and (14) is defined as
where is the softmax function and is the cross-entropy loss function. In this setting, the function is convex.
Personalized FL objectives. We consider three different objectives:
-
1.
the multitask FL objective (8) with and ;
-
2.
the mixture FL objective (11), with ; and
-
3.
the adaptive personalized FL objective (14), with and for all ,
where is the number of labels for each device. When computing the testing accuracy, we only use the local parameters. Note that the choices of hyperparameters in the chosen objectives are purely heuristic. Our purpose is to demonstrate the convergence properties of the proposed algorithms on the training loss. Thus, it is possible that a smaller training loss does not necessarily imply better testing accuracy (or generalization ability). How to choose hyperparameters optimally is not the focus of this paper and requires further research.
Tuning parameters of proposed algorithms. For LSGD-PFL (Algorithm 1), we set the batch size to compute the stochastic gradient and set the average period . For in ASCD-PFL (Algorithm 6) and ASVRCD-PFL (Algorithm 7), we set it as . For the objective in (8), we set and ; for the objective in (11), we set and ; for the objective in (14), we set and . We set for all objectives. We set for ASCD-PFL and ASVRCD-PFL. For and in ASVRCD-PFL, we set them according to Theorem 9, where , , and . We let . Since the dimension of the iterates is larger than the sample size, the objective is weakly convex and, thus, . Therefore, our choice of is aimed at improving the numerical behavior of algorithms. The in ASCD-PFL are the same as in ASVRCD-PFL, and we let . In addition, we initialize all iterates at zero for all algorithms.
Results. The results are summarized in Figure 3, Figure 4, and Figure 5 for respectively. We observe that ASCD-PFL outperforms the widely-used LSGD-PFL. We also observe that ASVRCD-PFL converges slowly when minimizing the training loss. As we are working in the over parametrization regimes, which makes , the assumptions of our theory are violated. As a result, it is more advisable to use ASCD-PFL during the initial phase of training and use ASVRCD-PFL when the iterates get closer to the optimum.
6.2 Subsampling of the Global and Local Parameters
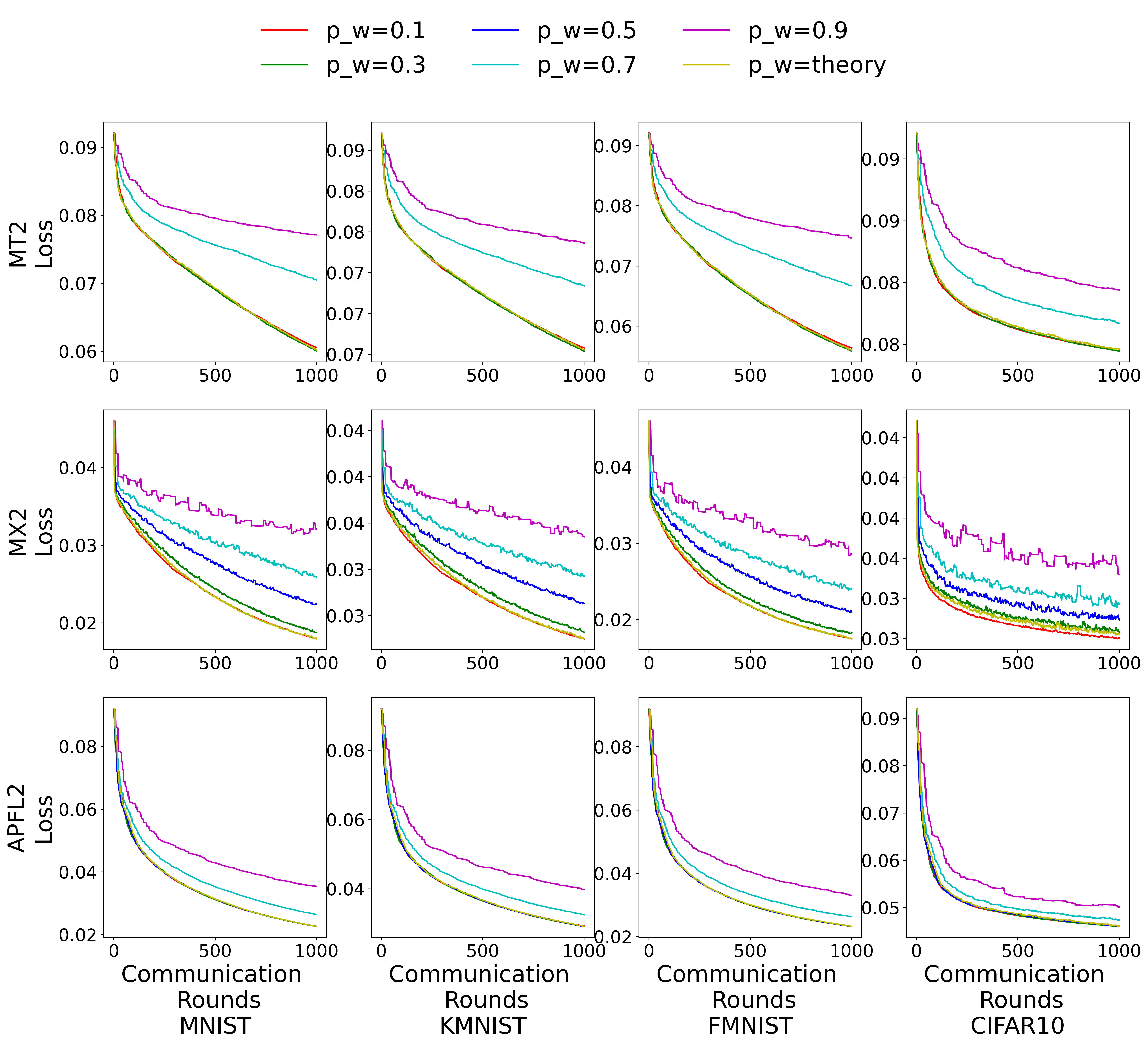
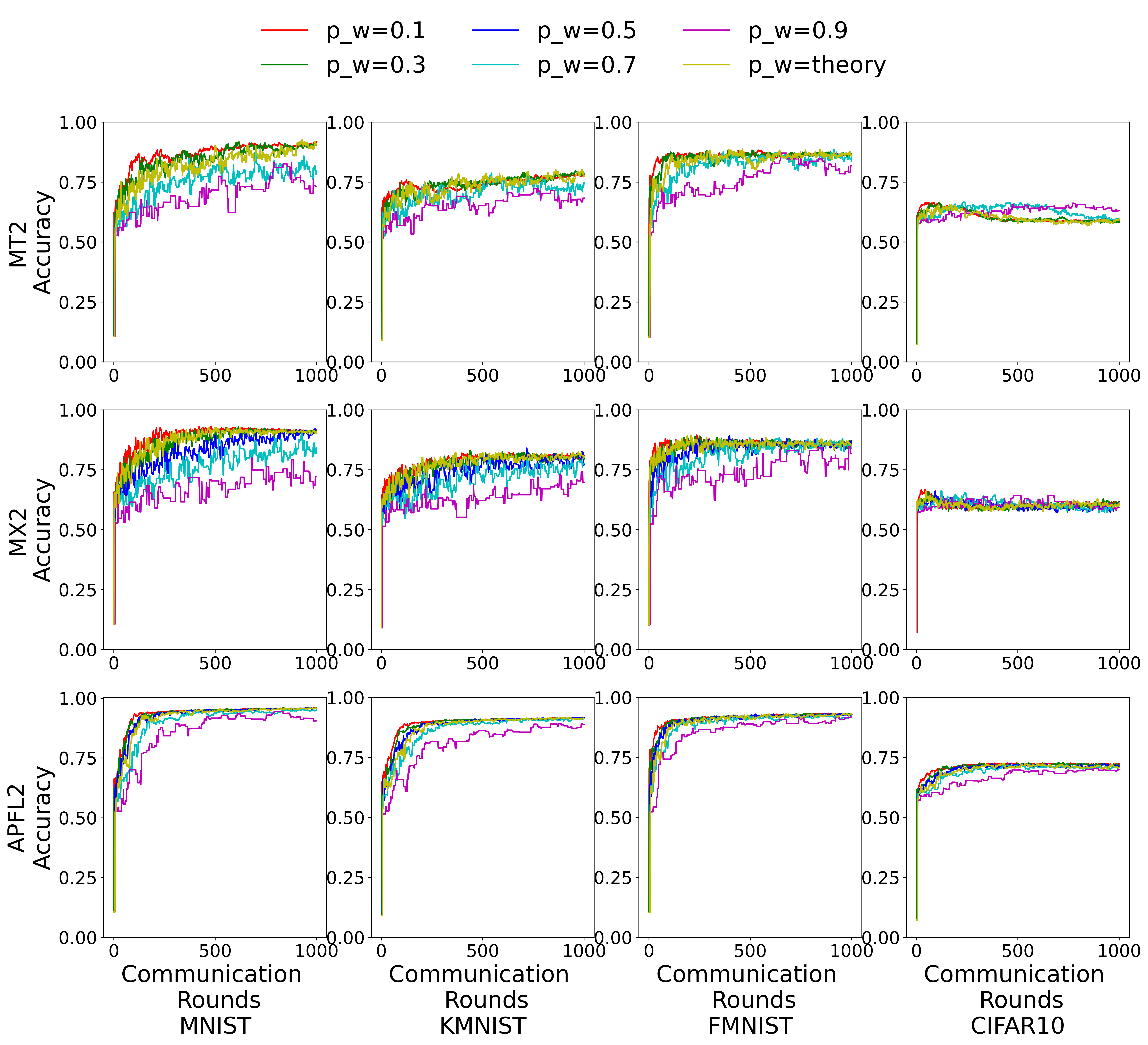
We demonstrate that the choice of based on Theorem 9, specifically setting , results in the best communication complexity of ASCD-PFL. More precisely, based on Theorem 9, we set the learning rate , where . The expressions of and for , , and are stated in Lemma 1, Lemma 2, Lemma 3, and also restated in the previous section, where is after normalization. We set . We compare the performance of ASCD-PFL using the theoretically suggested with other choices of . We fix those parameters that are independent of . See more details about the choice of tuning parameters in the previous section.
We plot the loss against the number of communication rounds, which illustrates the communication complexity. The number of classes for each device is . The results are summarized in Figure 6, which also includes the test accuracy. We observe that choosing based on theoretical considerations leads to the best communication complexity.
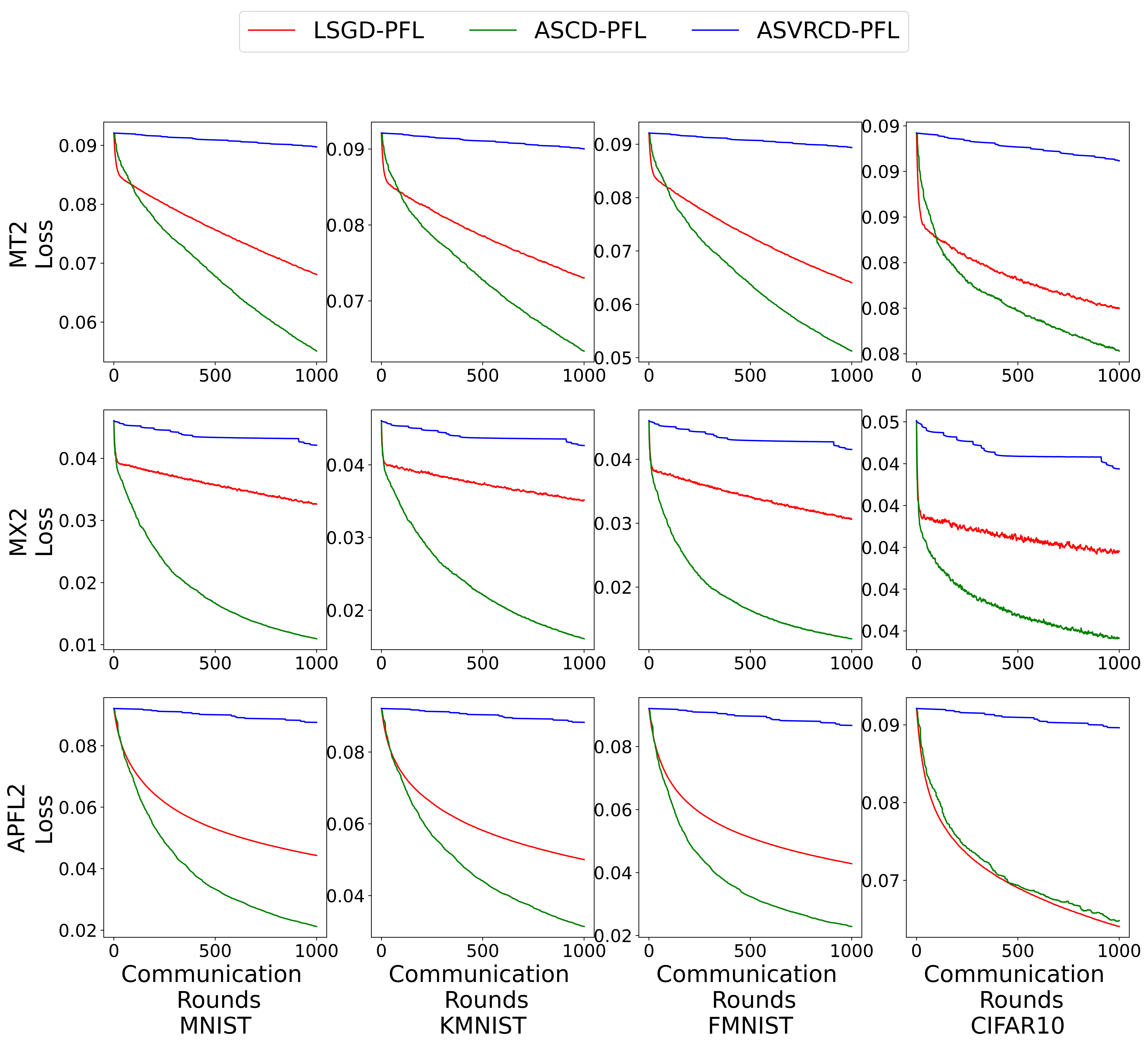
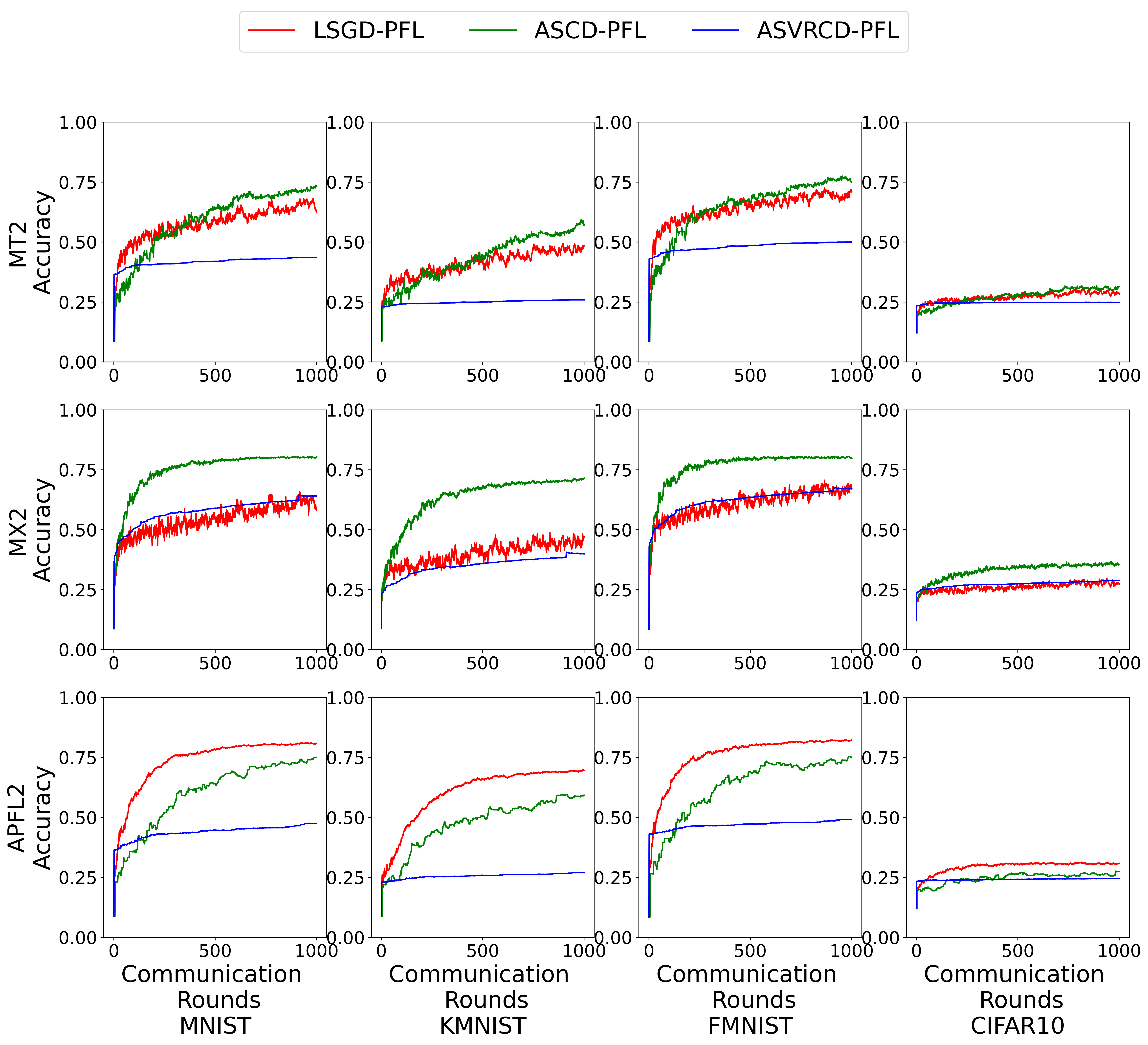
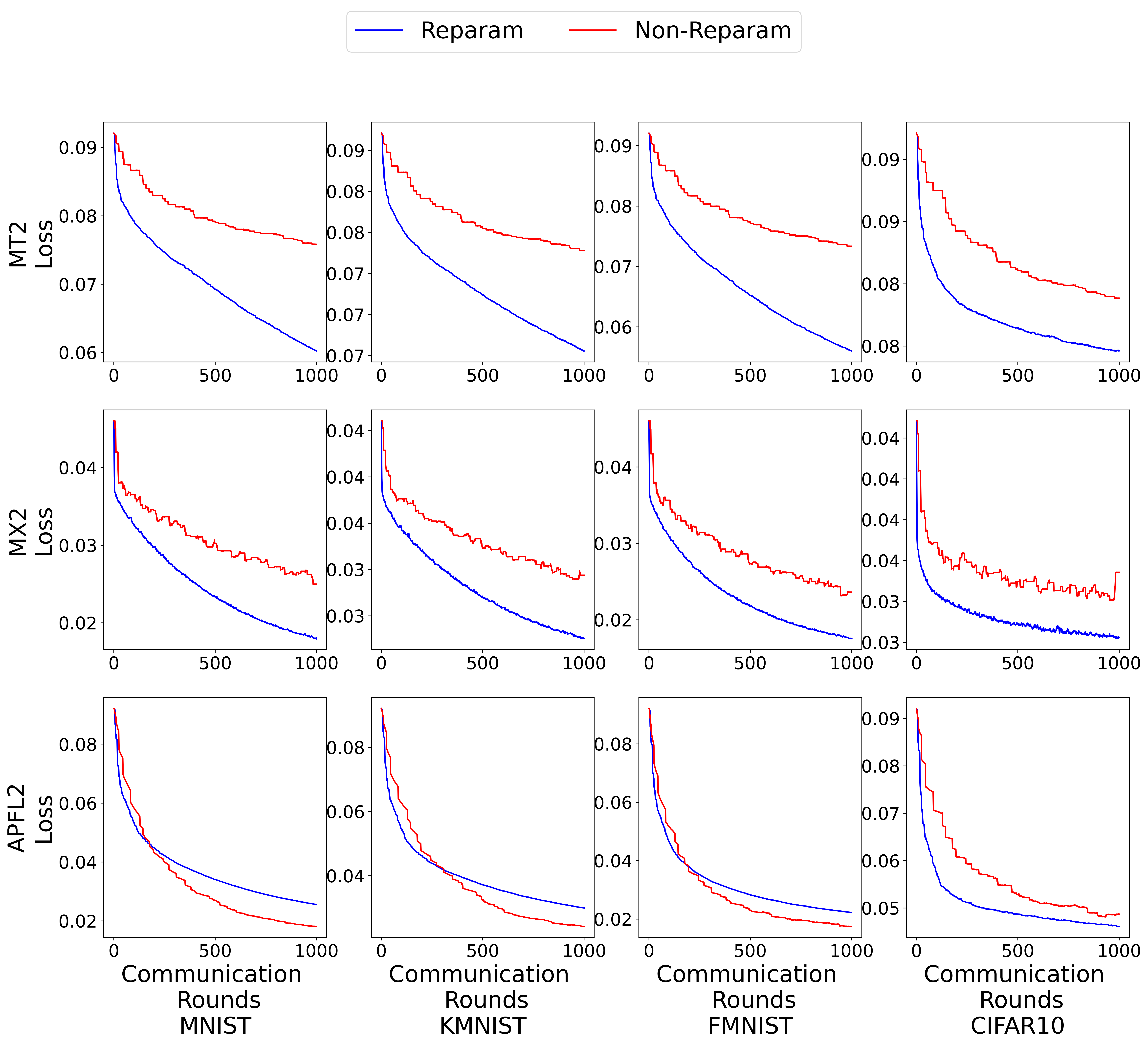
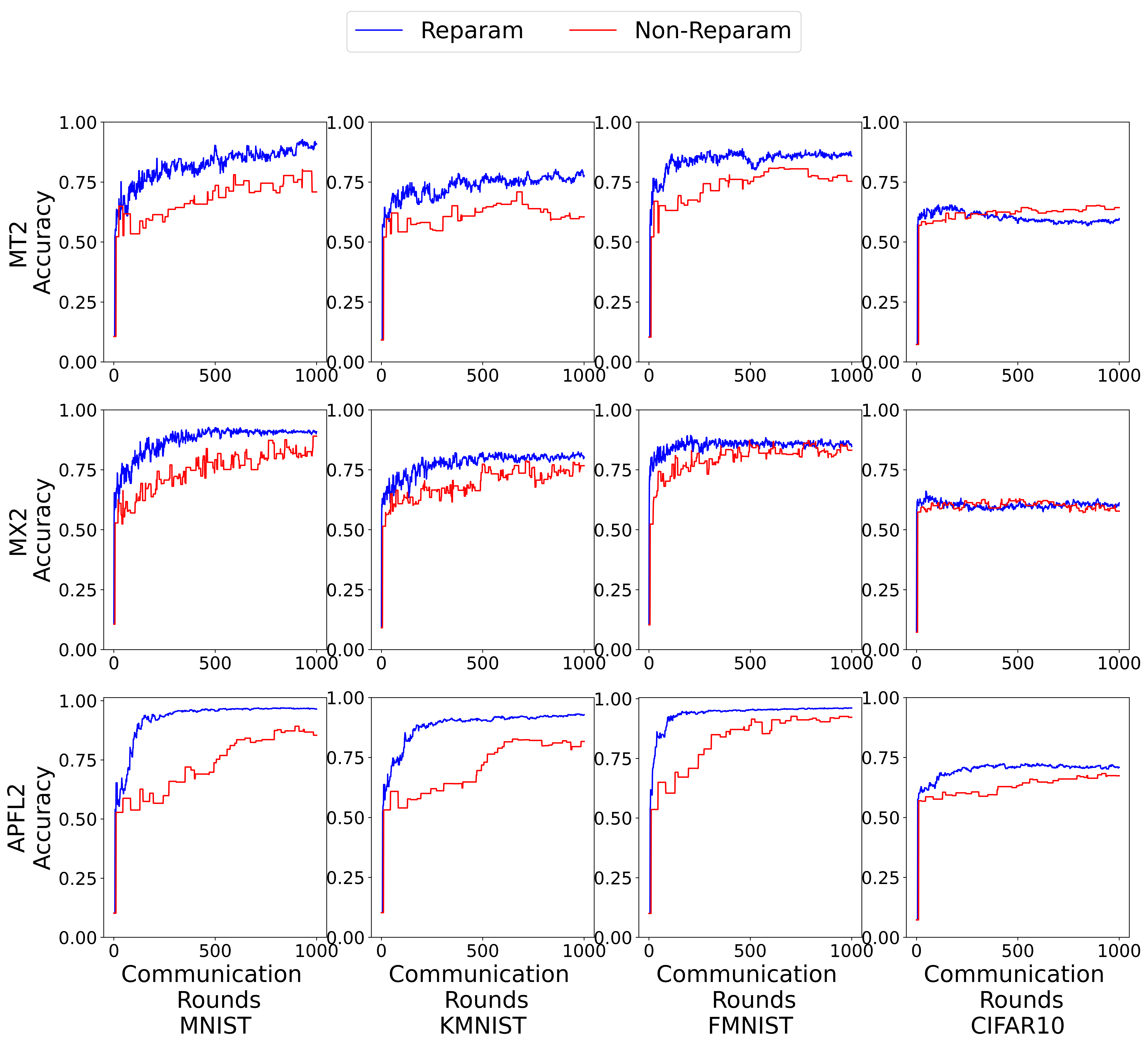
6.3 Effect of Reparametrization in ASCD-PFL.
We demonstrate the importance of reparametrization of the global parameter by rescaling by a factor of . We run reparameterized and non-reparameterized ASCD-PFL across different objectives and datasets. We set the number of classes for each device . The results are summarized in Figure 7. For the training loss, we observe that reparametrization improves the convergence of ASCD-PFL, except for the APFL2 objective (14), where the non-reparametrized variant performs slightly better in three of the four datasets. On the other hand, when considering the testing accuracy, reparametrization always helps improve the results, indicating that reparametrization can help prevent overfitting. Based on the experiment, we suggest always using reparametrization to ensure the scale of the learning rate is appropriate for both global and local parameters.
6.4 Potential Benefits of Extended Objectives
We empirically justify the potential benefits of our extended objectives. More specifically, we vary the relaxation parameter in (7) to show the change in performance. Since the multitask objective proposed by Li et al. (2020) is equivalent to setting , our main interest is to explore whether a larger always implies better performance. We set , , , , and . The remaining settings are the same as in Section 6.1. We vary over the values , and the resulting performance is shown in Figure 8. The plot shows that the performance slightly improves as increases from to , but then drops when . This result suggests that by selecting an appropriate , it is possible to achieve better empirical performance. Furthermore, although proposing new personalized FL objectives is not the main focus of this paper, the above empirical result suggests the potential benefits of a general framework.
7 Conclusions and Directions for Future Research
We proposed a general convex optimization theory for personalized FL. While our work answers a range of important questions, there are many directions in which our work can be extended in the future, such as partial participation, minimax optimal rates for specific personalized FL objectives, brand new personalized FL objectives, and non-convex theory.
Partial participation and client sampling. An essential aspect of FL that is not covered in this work is the partial participation or client sampling when one has access to only a subset of devices at each iteration. While we did not cover partial participation and focused on answering orthogonal questions, we believe that partial participation should be considered when extending our results in the future. Typically, when one chooses clients uniformly, the theorems in this paper should be extended easily; however, a more interesting question is how to sample clients with a non-uniform distribution to speed up the convergence. We leave this problem for future study.
Minimax optimal rates for specific personalized FL objectives. As outlined in Section 1.2, one cannot hope for the general optimization framework to be minimax optimal in every single special case. Consequently, there is still a need to keep exploring the optimization aspects of individual personalized FL objectives as one might come up with a more efficient optimizer that exploits the specific structure not covered by Assumption 1 or Assumption 2.
Brand new personalized FL objectives. While in this work we propose a couple of novel personalized FL objectives obtained as an extension of known objectives, we believe that seeing personalized FL as an instance of (1) might lead to the development of brand new approaches for personalized FL.
Non-convex theory. In this work, we have focused on a general convex optimization theory for personalized FL. Our convex rates are meaningful – they are minimax optimal and correspond to the empirical convergence. However, an inherent drawback of such an approach is the inability to cover non-convex FL approaches, such as MAML (see Section 2.8), or non-convex FL models. We believe that obtaining minimax optimal rates in the non-convex world would be very valuable.
References
- Agarwal et al. (2020) A. Agarwal, J. Langford, and C.-Y. Wei. Federated residual learning. arXiv preprint arXiv:2003.12880, 2020.
- Allen-Zhu et al. (2016) Z. Allen-Zhu, Z. Qu, P. Richtárik, and Y. Yuan. Even faster accelerated coordinate descent using non-uniform sampling. In International Conference on Machine Learning, 2016.
- Arivazhagan et al. (2019) M. G. Arivazhagan, V. Aggarwal, A. K. Singh, and S. Choudhary. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818, 2019.
- Chen et al. (2018) F. Chen, M. Luo, Z. Dong, Z. Li, and X. He. Federated meta-learning with fast convergence and efficient communication. arXiv preprint arXiv:1802.07876, 2018.
- Clanuwat et al. (2018) T. Clanuwat, M. Bober-Irizar, A. Kitamoto, A. Lamb, K. Yamamoto, and D. Ha. Deep learning for classical japanese literature. arXiv preprint arXiv:1812.01718, 2018.
- Dean et al. (2012) J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. V. Le, M. Z. Mao, M. Ranzato, A. W. Senior, P. A. Tucker, K. Yang, and A. Y. Ng. Large scale distributed deep networks. In Advances in Neural Information Processing Systems, 2012.
- Defazio et al. (2014) A. Defazio, F. R. Bach, and S. Lacoste-Julien. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives. In Advances in Neural Information Processing Systems, 2014.
- Deng (2012) L. Deng. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- Deng et al. (2020) Y. Deng, M. M. Kamani, and M. Mahdavi. Adaptive personalized federated learning. arXiv preprint arXiv:2003.13461, 2020.
- Dinh et al. (2020) C. T. Dinh, N. H. Tran, and T. D. Nguyen. Personalized federated learning with moreau envelopes. In Advances in Neural Information Processing Systems, 2020.
- Fallah et al. (2020) A. Fallah, A. Mokhtari, and A. Ozdaglar. Personalized federated learning: A meta-learning approach. arXiv preprint arXiv:2002.07948, 2020.
- Finn et al. (2017) C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning, 2017.
- Gorbunov et al. (2021) E. Gorbunov, F. Hanzely, and P. Richtárik. Local SGD: unified theory and new efficient methods. In International Conference on Artificial Intelligence and Statistics, 2021.
- Haddadpour & Mahdavi (2019) F. Haddadpour and M. Mahdavi. On the convergence of local descent methods in federated learning. arXiv preprint arXiv:1910.14425, 2019.
- Hanzely & Richtárik (2019) F. Hanzely and P. Richtárik. Accelerated coordinate descent with arbitrary sampling and best rates for minibatches. In International Conference on Artificial Intelligence and Statistics, 2019.
- Hanzely & Richtárik (2020) F. Hanzely and P. Richtárik. Federated learning of a mixture of global and local models. arXiv preprint arXiv:2002.05516, 2020.
- Hanzely et al. (2020a) F. Hanzely, S. Hanzely, S. Horváth, and P. Richtárik. Lower bounds and optimal algorithms for personalized federated learning. In Advances in Neural Information Processing Systems, 2020a.
- Hanzely et al. (2020b) F. Hanzely, D. Kovalev, and P. Richtárik. Variance reduced coordinate descent with acceleration: New method with a surprising application to finite-sum problems. In International Conference on Machine Learning, 2020b.
- Hard et al. (2018) A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, and D. Ramage. Federated learning for mobile keyboard prediction. arXiv preprint arXiv:1811.03604, 2018.
- Hendrikx et al. (2021) H. Hendrikx, F. Bach, and L. Massoulie. An optimal algorithm for decentralized finite-sum optimization. SIAM Journal on Optimization, 31(4):2753–2783, 2021.
- Jiang et al. (2019) Y. Jiang, J. Konečný, K. Rush, and S. Kannan. Improving federated learning personalization via model agnostic meta learning. arXiv preprint arXiv:1909.12488, 2019.
- Johnson & Zhang (2013) R. Johnson and T. Zhang. Accelerating stochastic gradient descent using predictive variance reduction. In Advances in Neural Information Processing Systems, 2013.
- Kairouz et al. (2021) P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021.
- Khodak et al. (2019) M. Khodak, M. Balcan, and A. Talwalkar. Adaptive gradient-based meta-learning methods. In Advances in Neural Information Processing Systems, 2019.
- Krizhevsky (2009) A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
- Kulkarni et al. (2020) V. Kulkarni, M. Kulkarni, and A. Pant. Survey of personalization techniques for federated learning. In 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), pp. 794–797, 2020.
- Lan & Zhou (2018) G. Lan and Y. Zhou. An optimal randomized incremental gradient method. Mathematical programming, 171(1-2):167–215, 2018.
- Li et al. (2020) T. Li, S. Hu, A. Beirami, and V. Smith. Federated multi-task learning for competing constraints. arXiv preprint arXiv:2012.04221, 2020.
- Liang et al. (2020) P. P. Liang, T. Liu, L. Ziyin, R. Salakhutdinov, and L.-P. Morency. Think locally, act globally: Federated learning with local and global representations. arXiv preprint arXiv:2001.01523, 2020.
- Lin et al. (2020) S. Lin, G. Yang, and J. Zhang. A collaborative learning framework via federated meta-learning. In International Conference on Distributed Computing Systems, 2020.
- McMahan et al. (2017) B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas. Communication-efficient learning of deep networks from decentralized data. In International Conference on Artificial Intelligence and Statistics, 2017.
- McMahan et al. (2016) H. B. McMahan, E. Moore, D. Ramage, and B. A. y Arcas. Federated learning of deep networks using model averaging. arXiv preprint arXiv:1602.05629, 2016.
- Nemirovskij & Yudin (1983) A. S. Nemirovskij and D. B. Yudin. Problem complexity and method efficiency in optimization. Wiley-Interscience, 1983.
- Nesterov (2012) Y. Nesterov. Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM Journal on Optimization, 22(2):341–362, 2012.
- Nesterov (1983) Y. Nesterov. A method for solving the convex programming problem with convergence rate . In Doklady Akademii Nauk, volume 269, pp. 543–547, 1983.
- Nesterov (2018) Y. Nesterov. Lectures on Convex Optimization. Springer, 2018.
- Nesterov & Stich (2017) Y. Nesterov and S. U. Stich. Efficiency of the accelerated coordinate descent method on structured optimization problems. SIAM Journal on Optimization, 27(1):110–123, 2017.
- Rajeswaran et al. (2019) A. Rajeswaran, C. Finn, S. M. Kakade, and S. Levine. Meta-learning with implicit gradients. In Advances in Neural Information Processing Systems, 2019.
- Scaman et al. (2018) K. Scaman, F. R. Bach, S. Bubeck, L. Massoulié, and Y. T. Lee. Optimal algorithms for non-smooth distributed optimization in networks. In Advances in Neural Information Processing Systems, 2018.
- Smith et al. (2017) V. Smith, C. Chiang, M. Sanjabi, and A. Talwalkar. Federated multi-task learning. In Advances in Neural Information Processing Systems, 2017.
- Stich (2019) S. U. Stich. Local SGD converges fast and communicates little. In International Conference on Learning Representations, 2019.
- Wang et al. (2018) W. Wang, J. Wang, M. Kolar, and N. Srebro. Distributed stochastic multi-task learning with graph regularization. arXiv preprint arXiv:1802.03830, 2018.
- Woodworth & Srebro (2016) B. E. Woodworth and N. Srebro. Tight complexity bounds for optimizing composite objectives. In Advances in Neural Information Processing Systems, 2016.
- Woodworth et al. (2018) B. E. Woodworth, J. Wang, A. D. Smith, B. McMahan, and N. Srebro. Graph oracle models, lower bounds, and gaps for parallel stochastic optimization. In Advances in Neural Information Processing Systems, 2018.
- Wu et al. (2021) R. Wu, A. Scaglione, H. Wai, N. Karakoç, K. Hreinsson, and W. Ma. Federated block coordinate descent scheme for learning global and personalized models. In AAAI Conference on Artificial Intelligence, 2021.
- Xiao et al. (2017) H. Xiao, K. Rasul, and R. Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017.
Appendix A Additional Algorithms Used in Simulations
In this section, we detail algorithms that are used in Section 5. We detail ASCD-PFL in Algorithm 5. ASCD-PFL is a simplified version of ASVRCD-PFL that does not incorporate control variates. SCD-PFL is detailed in Algorithm 6. SCD-PFL is a simplified version of ASCD-PFL that does not incorporate the control variates or Nesterov’s acceleration. SVRCD-PFL is detailed in Algorithm 7. SVRCD-PFL is a simplified version of ASVRCD-PFL that does not incorporate Nesterov’s acceleration.
Appendix B Technical Proofs
Throughout this section, we use to denote the identity matrix, to denote the zero matrix, and to denote the vector of ones.
B.1 Proof of Lemma 1
To show the strong convexity, we shall verify the positive definiteness of
Note that can be written as a sum of matrices, each of them having
as a submatrix and zeros everywhere else. To verify positive semidefiniteness of , we shall prove that the determinant is positive:
as desired. Verifying the smoothness constants is straightforward.
B.2 Proof of Lemma 2
We have
Note that can be written as a sum of matrices, each of them having at the position , at positions and at the position . Using the assumption , it is easy to see that each of these matrices is positive semidefinite, and thus so is . Consequently, is positive semidefinite and thus is jointly - strongly convex. Verifying the smoothness constants is straightforward.
B.3 Proof of Lemma 3
Let for notational simplicity. We have
Next, we show that
| (28) |
For that, it suffices to show that
which holds since
Finally, using (28) times, it is easy to see that
as desired. Verifying the smoothness constants is straightforward.
B.4 Proof of Lemma 5
B.5 Proof of Lemma 6
B.6 Proof of Lemma 7
B.7 Proof of Theorem 3 and Theorem 4
We start by introducing additional notation. We set , where is the length of the averaging period. Let . Denote the total number of iterations as and assume that for some . The final result is set to be that and for all . We assume that the solution to (1) is and that the optimal value is . Let for all . Note that this quantity will not be actually computed in practice unless for some , where we have for all . In addition, let and .
Let , , and . Let
| (29) |
where
We assume that the gradient is unbiased, that is,
Let
| (30) |
so that . We update the parameters by
In addition, we define
Then for all .
We denote the Bregman divergence associated with for and as
Finally, we define the sum of residuals as
| (31) |
and let .
The following proposition states some useful results that will be used in the proof below. The results are are standard and can be found in, for example, Nesterov (2018).
Proposition 1.
If the function is differentiable and -smooth, then
| (32) |
If is also convex, then
| (33) |
for all .
For all vectors , we have
| (34) | ||||
| (35) |
For vectors , by the Jensen’s inequality and the convexity of the map: , we have
| (36) |
Next, we establish a few technical results.
Lemma 8.
Suppose Assumption 4 holds. Given , we have
where the expectation is taken only with respect to the randomness in .
Proof.
By the -smoothness assumption on and (32), we have
Thus, we have
which further implies that
The result follows by taking the expectation with respect to the randomness in , while keeping the other quantities fixed. ∎
Lemma 9.
Proof.
Lemma 10.
Under Assumption 4, we have
Proof.
Proof.
B.7.1 Proof of Theorem 3
Under Assumptions 4-6, given , it follows from Lemmas 8-10 that
where the expectation is taken with respect to the randomness in . Thus, taking the unconditional expectation on both sides of the equation above, we have
which implies that
| (38) |
By Lemma 12, for all , we have that
Therefore, we have
Combined with (38), we have
Since we require that
the equation above implies that
Since we have assumed that for some , we further have
This implies that
and the proof is complete.
B.7.2 Proof of Theorem 4
By Lemmas 8, 9, 11 and 12, for , we have
where
| (39) | ||||
Let
and denote
Then
for all . Under the conditions on and , by Lemmas 13 and 14, we have
| (40) |
Let , where . Then
and, thus,
Note that . Plugging the above inequality into (40), we then get
Since we have assumed that , we thus have
| (41) |
Since, for , we have
we also have
| (42) |
Assume that , where . Then
as we have assumed that . Thus
and
Next, note that
| (43) |
B.7.3 Auxiliary Results
We give two technical lemmas that are used to prove Theorem 4.
Lemma 13.
Proof.
Lemma 14.
Proof.
Let and be defined as in (39). Since for all , after -th communication, for the right hand side of (46), we have
Thus, by induction, we have
| (47) | ||||
As increases, we have that decreases, increases, and decreases. Thus, for , we have . On the other hand, we can lower bound the right hand side of (46) as
| (48) | ||||
If
| (49) |
then the conditions on stepsizes in Lemma 13 are satisfied for all by combining (47)-(49). Thus, we only need to show that (49) is satisfied to complete the proof.
To that end, we need to have
To satisfy the above equation, we need
| (50) |
Note that . Thus, to satisfy the first inequality in (50), we need
Since , the condition above follows if
| (51) |
Next, to satisfy the second inequality in (50), we need
Since
we need
Let . Then the above equation is equivalent to
First, we let or equivalently
| (52) |
Then we need to be large enough such that
Since for any , the left hand side is smaller or equal to
Therefore, we need
| (53) |
The final result follows from the combination of (51)-(53). ∎
B.8 Proof of Theorem 6
Nesterov’s worst case objective. (Nesterov, 2018) Let be the Nesterov’s worst case objective (see), i.e., with tridiagonal having diagonal elements equal to (for some ) and offdiagonal elements equal to .555This is for the strongly convex case; one can do convex similarly. The proof rationale is to show that a -th iterate of any first order method must satisfy and consequently
| (54) |
where , .
Finite sum worst case objective. (Lan & Zhou, 2018) The construction of the worst case finite-sum objective666We have lifted their construction to the infinite-dimensional space for the sake of simplicity. One can get a similar finite-dimensional results. is such that corresponds only on a -th block of the coordinates; in particular if ; we set . It was shown that to reach one requires at least iterations for -smooth functions and strongly convex .
Distributed worst case objective. (Scaman et al., 2018) Define
where is an infinite block diagonal matrix with blocks and and are some constants determining the smoothness and strong convexity of the objective. The worst case objective of Scaman et al. (2018) is now .
Distributed worst case objective with local finite sum. (Hendrikx et al., 2021) The given construction is obtained from the one of Scaman et al. (2018) in the same way as the worst case finite sum objective (Lan & Zhou, 2018) was obtained from the construction of Nesterov (2018). In particular, one would set where . Next, it was shown that such a construction with properly chosen yields a lower bound on the communication complexity of order and the lower bound on the local computation of order where is a smoothness constant of , is a smoothness constant of and is the strong convexity constant of .
Our construction and sketch of the proof. Now, our construction is straightforward – we set with , scaled appropriately such that the strong convexity ratio is as per Assumption 1. Clearly, to minimize the global part , we require at least iterations and at least stochastic gradients of . Similarly, to minimize , we require at least stochastic gradients of . Therefore, Theorem 6 is established.
B.9 Proof of Theorem 8
Taking the stochastic gradient step followed by the proximal step with respect to , both with stepsize , is equivalent to (Hanzely et al., 2020b):
| (55) | |||||
Let , . The update rule (55) can be rewritten as
where corresponds to the described unbiased stochastic gradient obtained by subsampling both the space and the finite sum simultaneously. To give the rate of the aforementioned method, we shall determine the expected smoothness constant. To achieve that, we introduce the following two lemmas.
Lemma 16.
Let be a (jointly) convex function such that
Then
| (56) |
and
| (57) |
Proof.
We are now ready to state the convergence rate of ASVRCD-PFL.
Theorem 9.
Proof.
Overall, the algorithm requires
communication rounds and the same number of gradient calls w.r.t. parameter . Setting , we have
which shows that Algorithm 3 enjoys both communication complexity and the global gradient complexity of order . Analogously, setting yields personalized/local gradient complexity of order .