PersonMAE: Person Re-Identification Pre-Training with Masked AutoEncoders
Abstract
Pre-training is playing an increasingly important role in learning generic feature representation for Person Re-identification (ReID). We argue that a high-quality ReID representation should have three properties, namely, multi-level awareness, occlusion robustness, and cross-region invariance. To this end, we propose a simple yet effective pre-training framework, namely PersonMAE, which involves two core designs into masked autoencoders to better serve the task of Person Re-ID. 1) PersonMAE generates two regions from the given image with RegionA as the input and RegionB as the prediction target. RegionA is corrupted with block-wise masking to mimic common occlusion in ReID and its remaining visible parts are fed into the encoder. 2) Then PersonMAE aims to predict the whole RegionB at both pixel level and semantic feature level. It encourages its pre-trained feature representations with the three properties mentioned above. These properties make PersonMAE compatible with downstream Person ReID tasks, leading to state-of-the-art performance on four downstream ReID tasks, i.e., supervised (holistic and occluded setting), and unsupervised (UDA and USL setting). Notably, on the commonly adopted supervised setting, PersonMAE with ViT-B backbone achieves and mAP on the MSMT17 and OccDuke datasets, surpassing the previous state-of-the-art by a large margin of +8.0 mAP, and +5.3 mAP, respectively.
Index Terms:
high-quality ReID representation, masked autoencoder, pre-trainingI Introduction
Person re-identification (ReID) aims to match a specific person across different camera views, which is a challenging retrieval problem. Its challenges largely come from the presence of disturbing factors, e.g. unconstrained recording conditions, occlusion, cropping misalignment, etc. Although current ReID methods [1, 2, 3, 4, 5, 6, 7, 8] have achieved remarkable progress, they are data-hungry and usually suffer the overfitting issue due to limited annotated ReID data. To alleviate this issue, some methods [9, 10, 11] resort to self-supervised contrastive pre-training on large-scale unlabeled pedestrian data and demonstrate promising results.

However, these pre-trained feature presentations are not well-suited for person ReID. We argue that a good pre-training representation for ReID should have three main properties as shown in Figure 1. 1) Multi-Level Awareness. Pedestrians with quite similar wearing exist commonly in ReID tasks, so the visual representation should be aware of all the discriminative cues adequately, including both the semantics (a broad range of aspects, such as person clothes, belongings and their context) and low-level details (such as the color of the bag). 2) Occlusion Robustness. In real-world scenarios, the target pedestrian is often occluded by surrounding objects, such as cars, trees, non-target people, etc. So the visual representation should be robust to diverse occlusion and focus on the key cues of the target pedestrian. 3) Cross-Region Invariance. Pedestrian images are usually cropped via the off-the-shelf human detector/tracker, which leads to misalignment issues. The visual representation of the same pedestrian should be invariant, regardless of cropping misalignment.
Previous self-supervised ReID pre-training [9, 10, 11] methods are dominated by contrastive learning (CL). They generally learn semantics by pulling the global features of two augmented regions of the same image closer and pushing the features of two different images away. While their pre-trained features inherently satisfy the cross-region invariance property, they are deficient in the remaining two properties. Specifically, for occlusion robustness, although random erasing is used as one augmentation in contrastive pre-training, their used mask ratios are often relatively small, resulting in their representations that cannot handle large occlusion well. Additionally, since the contrastive loss is only applied upon the global feature of the image, and lacks supervision on each token, it yields a bottleneck in capturing low-level and local detail information.
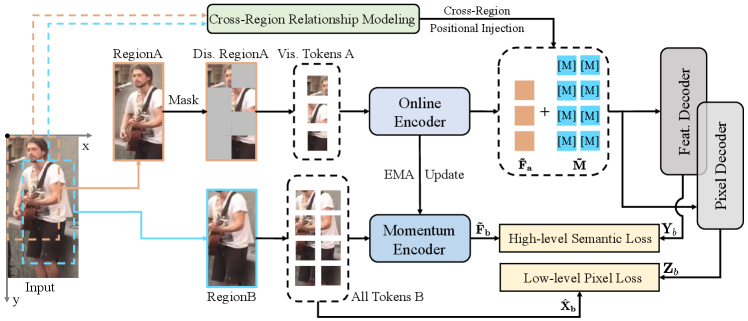
In this paper, we aim to satisfy three important properties and build a new pre-training framework, namely PersonMAE. It introduces cross-region multi-level prediction objective, in coordination with masked autoencoders [12]. Specifically, with a given pedestrian image, we first generate two regions with the cross-region generation module, i.e., the input RegionA and prediction target RegionB. Then we mask a large portion of RegionA and only feed its visible parts into the encoder. Finally, the decoder leverages the encoder output and the cross-region relationship between RegionA and RegionB to predict the whole RegionB at both low-level pixel space and high-level semantic space.
Our PersonMAE framework differs substantially from previous contrastive-based approaches in its emphasis on the reasoning capability of the whole human image to better serve the ReID task. It is achieved by: 1) incorporating per-token supervision on both low-level pixel and high-level semantics, thereby explicitly guiding the model’s learning of multi-level awareness. 2) The input region image is heavily masked and only a small visible part is passed to the encoder, compelling it to capture all relevant features, not merely the most prominent ones in the full image. This “mask and drop” operation facilitates the model’s learning of occlusion robustness. 3) The pseudo-ground-truth is provided by another region, which simulates the effects of jittering human detection. The model embeds cross-region invariance through an outer prediction approach that exploits the consistency between these two regions.
We pre-train our PersonMAE on the widely used LUPerson [9] dataset and thoroughly evaluate the performance of PersonMAE under four settings, i.e., supervised holistic and occluded ReID, unsupervised domain adaptation (UDA), and unsupervised learning (USL) setting. For the most commonly used supervised settings, we reach new SOTA results with mAP on the challenging MSMT17 and mAP on the OccDuke dataset, surpassing the previous SOTA method PASS [11] with and respectively. When it comes to the unsupervised settings, we get and mAP on MSMT17 for UDA and USL ReID, outperforming PASS by and respectively.
Our contributions are summarized as follows,
-
•
We analyze the challenges of the ReID tasks and identify three important properties that a desired ReID representation should satisfy: multi-level awareness, occlusion robustness, and cross-region invariance.
-
•
To achieve this goal, we propose a simple yet effective ReID pre-training framework called PersonMAE. PersonMAE introduces a cross-region multi-level prediction objective, in cooperation with masked autoencoders to exhibit these desired properties.
-
•
Through extensive experiments, our PersonMAE demonstrates superior performance, achieving SOTA performance in a series of downstream ReID tasks on different datasets.
II Related Work
II-A Person Re-Identification
Person re-identification aims to match a specific person across different camera views. It is a kind of retrieval problem, whose challenges come from unconstrained recording conditions, occlusion, cropping errors, etc. Generally, ReID contains supervised and unsupervised task settings, which are introduced as follows.
Supervised Person ReID. Typically, it contains two settings, i.e., holistic and occluded ReID. Holistic ReID is a general fully-supervised setting and aims to retrieve a certain person across different camera views. Current methods have achieved remarkable progress [13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25], and can be grouped into two mainstreams. One focuses on the design of novel architectures to mine fine-grained discriminative cues [26, 4, 3, 27, 28, 29, 30, 8]. MGN [3] emphasizes the fine-grained details by explicitly splitting the holistic pedestrian image into multiple granularities. TransReID [8] organizes the holistic image as multiple local tokens and first leverages the strong Vision Transformer (ViT) [31]. Another mainstream resorts to effective optimization, including the hard triplet loss [32], circle loss [33], rank fusion [34], etc.
Different from holistic ReID, the occluded counterpart is a harder task and its query set is constructed by occluded pedestrian images [35, 36, 37, 38, 39]. Zhuo et al. [36] first study this problem via the attention mechanism and occlusion simulation. The following works further disentangle discriminative cues from the occlusion with the assistance of pose landmarks [37, 40] or human parsing [38, 41].
Unsupervised Person ReID. This task directly trains a model without utilizing annotation of the target dataset [42, 43, 44, 45, 6, 46, 47, 48, 49]. There are two typical categories, i.e., unsupervised domain adaptation (UDA) and unsupervised learning (USL). SpCL [6] proposes a self-paced contrastive learning framework, which gradually fine-tunes the network with the pseudo labels generated by reliable clustering. As one of the state-of-the-art methods, C-Contrast [46] computes the contrastive loss based on the cluster-level contrastive loss to relieve the inconsistent updating progress among different clusters.
II-B Self-Supervised Pre-Training
Self-supervised pre-training aims to learn more generic feature representations from a large amount of unlabeled data, which benefits the downstream tasks. Among them, contrastive learning has been widely studied for pre-training [50, 51, 52, 53, 54], which aims to pull the representation of similar instances closer, while pushing away negative instances. In order to obtain informative negative instances, some works resort to the techniques like memory banks [50] and large batch sizes [51]. There also exist some other works [55, 56] achieving great performance without the requirement of negative instance. DINO [52] achieves overwhelming performance by emphasizing the distillation between global and local views. Recently, motivated by the success of BERT [57] in NLP, some works [12, 58, 59, 60, 61, 62, 63, 64] works with masked autoencoders (MAE) and achieve promising performance. Typically, MAE adopts the ViT backbone and aims to predict the masked patches from the remaining visible ones.
In person ReID, there exist works leveraging the success of self-supervised pre-training [9, 65, 66, 11]. Fu et al. [9] proposes a large-scale LUPerson dataset and pioneers the exploration of contrastive-based pre-training based on this dataset. Luo et al. [10] investigate contrastive-based pre-training based on ViT and improve pre-training via reducing the domain gap between pre-training and fine-tuning data. PASS [11] further proposes part-aware pre-training based on DINO. These methods demonstrate their effectiveness on the downstream ReID tasks and are all based on contrastive learning. Different from them, we aim to make the first attempt to leverage the advance of masked autoencoders into ReID pre-training.
III Methodology
III-A Overview
As we briefly introduced in Section 1, a good person-ReID model should maintain three important properties: multi-level awareness, occlusion robustness, and cross-region invariance. To maintain these properties, we propose our PersonMAE framework. As shown in Figure 2, with a given image, we first generate the input image RegionA and prediction target RegionB with a cross-region generation module. Then we mask a large portion of RegionA and use the unmasked part as the online encoder input. The decoders use both the encoder output features and mask tokens to predict the whole RegionB. As is well known, both low-level clues (such as the color of clothes and hair) and high-level semantics (such as global identity information) matter in ReID. Therefore, we utilize a pixel decoder to predict the raw pixels of RegionB for low-level reasoning, and a feature decoder to predict the feature of RegionB for high-level semantic learning.
III-B Cross-Region Generation
Previous general MAE-based pre-training methods always mask part of the input and then predict itself. It is an inner prediction manner that aims to model and understand the semantic content within the input image. However, this prediction manner may hardly handle the disturbance from unreliable cropping of pedestrian images. To help the model learn robust representation regardless of such misalignment, we propose our cross-region generation module.
In detail, with a given pedestrian image, we first perform random resizing as follows,
| (1) |
where denotes the interpolation function, whose inputs are the original image and desired output image size. represents the maximum shift size. With the resized image , we extract two regions at the same scale with the size of as follows,
| (2) |
where , and and these two tuples represent the coordinate of the upper-left corner and cropped image size, respectively. Then these two regions are separately split into non-overlapping patches, whose total number is and represents the patch size. With this step, a certain region is transformed into the visual token sequence, e.g. . is obtained via squeezing the visual token and represents the image channel dimension. The same can be obtained for .
It is an outer prediction problem that the model should not only understand the content of the input RegionA, but also the invariance between RegionA and RegionB. It is much more challenging than previous inner prediction and better improves the cropping-error robustness of the model.
III-C Semantic Extraction in Encoder
Occlusion is one of the most challenging problems in the ReID task, since the pedestrian may be occluded by some obstacles, e.g. trees, cars, walls, and other passengers. So it requires the model not only focus on the most salient feature of the input but all the reasonable features within it. To mimic various occlusions during training, we utilize the block-wise masking strategy introduced in BEiT [58] for the input RegionA and only use the unmasked part as the encoder input. Formally:
| (3) |
where is the sampling function without replacement and the number of the masked positions is . denotes the online encoders with parameters .
III-D Cross-Region Relationship Modeling
For previous inner prediction methods, the input and target images share the region, so they could use the same position information directly. On the contrary, our outer prediction design leads to a different region for input and target, the decoder needs to predict the target RegionB based on the feature of RegionA and their cross-region relationship.
In practice, we use absolute position embedding to model such a relationship. We build a coordinate system and set the upper-left corner of the RegionA as the origin. Denote and are the horizontal and vertical index of the predicted region. Formally:
| (4) |
where and . We follow common practices to convert into the fixed 2D position embedding based on and operators [12].
Then the formulated shifting relation and the output of the online encoder are jointly fed into the following two decoders for RegionB prediction, i.e., pixel regression decoder and feature prediction decoder.
III-E Low-Level Reasoning via Pixel Regression
As illustrated above, low-level clues are important for the ReID task. Therefore, a pixel decoder is adopted to conduct prediction at the low-level aspect via recovering all RegionB pixels. Specifically, we organize learnable tokens as the mask tokens . To inform the framework where the corresponding output of each mask token should predict, we further add the position embedding on , denoted as . Then the PE-informed is concatenated with the normalized as the input of the pixel decoder. The pixel decoder contains two ViT blocks, followed by an MLP layer to regress the missing pixel value. Denote the output of the pixel decoder as . During pre-training, the low-level region-consistency constraint is calculated as follows,
| (5) |
where and are the mean and standard deviation of the -th patch and we utilize the normalized patch as the target. This constraint serves as a strong regularization term during optimization and makes the framework model human statistics via reasoning about the low-level textures.
III-F High-Level Understanding via Feature Prediction
Meanwhile, high-level semantics are the core for person re-identification, so we use the feature decoder to conduct feature prediction. Similar to the pixel regression branch, we adopt a new set of learnable tokens as the mask token and associate it with the same position embedding , denoted as . It is concatenated with the normalized as the input of the feature decoder. The feature decoder contains two ViT blocks, followed by a fully-connected layer to project the features on the desired semantic space. We argue that dense local supervision forces the model to capture more fine-grained details, so the prediction target is all the local features of RegionB encoded by an EMA model. Formally,
| (6) |
where is the momentum encoder, and represent the parameters of the online encoder and momentum encoder, respectively. Compared with the online encoder , the parameters of are updated much slower and provide a more stable prediction target, which is beneficial for modeling the pedestrian statistics in the semantic space.
With the prediction target , we denote the output of feature prediction decoder as and the feature-level region consistency constraint is formulated as follows,
| (7) |
where we utilize smooth L1 loss for feature matching. represents the stop gradient function and is the smoothing factor. Overall, during pre-training, the objective function is formulated as follows,
| (8) |
where is the weighting factor. and are the low-level and semantic constraint, respectively.
IV Experiment
IV-A Evaluation Protocol
Datasets. We pre-train our PersonMAE on the large-scale pedestrian dataset LUPerson [9]. It contains 4.18M unlabeled images with 46,260 diverse scenes, which are collected from the Internet. For downstream ReID tasks, we conduct experiments on three datasets, i.e., Market1501 [2], MSMT17 [5] and OccDuke [67]. Market1501 and MSMT17 are general holistic person ReID benchmarks, which contain 32,668 images from 1,501 persons and 126,441 images from 4,101 persons, respectively. OccDuke contains 35,489 images from 1,812 persons, which is the most challenging occluded person ReID benchmark.
Evaluation metrics. Following common practices, we utilize the cumulative matching characteristics at Top-1 (Rank1) and mean average precision (mAP) for performance evaluation.
Implementation details. We introduce the specific settings during pre-training, supervised ReID and unsupervised ReID settings.
Pre-training setting. Pre-training is conducted on 8V100 GPUs for 100 epochs. Adam is adopted for optimization. The learning rate is set to 1.2e-3, with a warmup of 20 epochs, and single-cycle cosine learning rate decay. The weight decay is set as 0.05. We only utilize horizontal flipping and random cropping on the raw data to generate the global pedestrian image. The input resolution is 256128. represents momentum coefficient. It is initially set as 0.999, linearly changed to 0.9999 in the first 20 epochs, and kept as 0.9999 for the remaining epochs. represents the smoothing factor and is set to 2.
Supervised ReID setting. During fine-tuning, we feed the unmasked image into the pre-trained online encoder for further optimization. We follow the common practice in [9] and utilize the MGN [3] head for downstream ReID tasks. During supervised fine-tuning, we utilize the layer-wise lr decay strategy following [12, 58]. The batch size is set as 256, with 16 pedestrians in each batch. Adam optimizer is adopted with the learning rate and weight decay set as 5e-3 and 0.05, respectively. The layer decay is set as 0.65. The training lasts 60 epochs, and we utilize the cosine learning rate decay scheduler. We keep the same setting for supervised holistic and occluded ReID.
| Method | Backbone | Market1501 | MSMT17 | ||
|---|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | ||
| Pretraining on ImageNet1K-1.3M | |||||
| PCB [26] (2018) | Res-50 | 81.6 | 93.8 | - | - |
| MGN* [3] (2018) | Res-50 | 87.5 | 95.1 | 63.7 | 85.1 |
| BOT [68] (2019) | Res-50 | 85.9 | 94.5 | 50.2 | 74.1 |
| ABDNet* [69] (2019) | Res-50 | 88.3 | 95.6 | 60.8 | 82.3 |
| SAN [70] (2020) | Res-50 | 88.0 | 96.1 | 55.7 | 79.2 |
| GASM [40] (2020) | Res-50 | 84.7 | 95.3 | 52.5 | 79.5 |
| ISP [71] (2020) | Res-50 | 88.6 | 95.3 | - | - |
| HOReID [72] (2020) | Res-50 | 84.9 | 94.2 | - | - |
| FA-Net [73] (2021) | Res-50 | 84.6 | 95.0 | 51.0 | 76.8 |
| PAT [74] (2021) | Res-50 | 88.0 | 95.4 | - | - |
| NFormer [75] (2022) | Res-50 | 91.1 | 94.7 | 59.8 | 77.3 |
| Pretraining on ImageNet21K-14M | |||||
| TransReID [8] (2021) | ViT-B | 87.4 | 94.6 | 63.6 | 82.5 |
| AAformer* [76] (2021) | ViT-B | 87.7 | 95.4 | 63.2 | 83.6 |
| FED [39] (2022) | ViT-B | 86.3 | 95.0 | - | - |
| DCAL [77] (2022) | ViT-B | 87.5 | 94.7 | 64.0 | 83.1 |
| Pretraining on LUPerson-4.2M | |||||
| MoCov2* [78, 9] (2021) | Res-50 | 91.0 | 96.4 | 65.7 | 85.5 |
| UPReID [65] (2022) | Res-50 | 91.1 | 97.1 | 63.3 | 84.3 |
| MoCov3 [79, 10] (2021) | ViT-S | 82.2 | 92.1 | 47.4 | 70.3 |
| MoBY [80, 10] (2021) | ViT-S | 84.0 | 92.9 | 50.0 | 73.2 |
| DINO [52, 10] (2021) | ViT-S | 90.3 | 95.4 | 64.2 | 83.4 |
| DINO-CFS [10] (2021) | ViT-S | 91.0 | 96.0 | 66.1 | 84.6 |
| MAE† [12] (2022) | ViT-B | 91.1 | 96.1 | 71.2 | 88.0 |
| PASS [11] (2022) | ViT-S | 92.2 | 96.3 | 69.1 | 86.5 |
| PASS [11] (2022) | ViT-B | 93.0 | 96.8 | 71.8 | 88.2 |
| Ours | ViT-S | 92.5 | 96.7 | 75.2 | 89.1 |
| Ours | ViT-B | 93.6 | 97.1 | 79.8 | 91.4 |
Unsupervised ReID setting. For unsupervised ReID tasks, we build upon C-Contrast [46, 10] with the ViT backbone and follow most of its settings. UDA and USL ReID only differ in model initialization. UDA utilizes the pre-trained model from the source dataset, while USL directly utilizes our LUPerson pre-trained parameters. Then the training is conducted in an unsupervised manner on the target dataset. The visual features corresponding to images in the training set are first extracted, followed by clustering for pseudo labels and corresponding clustering centers. Then the framework leverages the contrastive objective between output features and clustering centers during optimization. More details can be found in [46]. SGD optimizer is adopted. The initial learning rate is set as 0.007 and is decayed with 0.1 every 20 epochs. The batch size is set as 256, with 32 pedestrians in each batch.
IV-B Comparison with State-of-the-Art Methods
We compare our method with previous state-of-the-art methods on four different downstream ReID tasks, i.e., supervised (holistic and occluded ReID), and unsupervised (UDA and USL ReID). Note that we do not adopt any post-processing method like Re-Rank [81] in our method.
| Method | Backbone | OccDuke | |
|---|---|---|---|
| mAP | Rank1 | ||
| Pretraining on ImageNet1K-1.3M | |||
| PCB [26] (2018) | Res-50 | 33.7 | 42.6 |
| DSR [82] (2018) | Res-50 | 30.4 | 40.8 |
| Ad-Occ [83] (2018) | Res-50 | 32.2 | 44.5 |
| PGFA [67] (2019) | Res-50 | 37.3 | 51.4 |
| RE [84] (2020) | Res-50 | 30.0 | 40.5 |
| PVPM [85] (2020) | Res-50 | 37.7 | 47.0 |
| ISP [71] (2020) | Res-50 | 52.3 | 62.8 |
| HOReID [72] (2020) | Res-50 | 43.8 | 55.1 |
| PAT [74] (2021) | Res-50 | 53.6 | 64.5 |
| LKWS [7] (2021) | Res-50 | 46.3 | 62.2 |
| Pretraining on ImageNet21K-14M | |||
| TransReID [8] (2021) | ViT-B | 53.1 | 60.5 |
| PFD [86] (2022) | ViT-B | 60.1 | 67.7 |
| FED [39] (2022) | ViT-B | 56.4 | 68.1 |
| Pretraining on LUPerson-4.2M | |||
| DINO-CFS* [10] (2021) | ViT-S | 58.3 | 67.7 |
| MAE† [12] (2022) | ViT-B | 60.8 | 68.1 |
| PASS† [11] (2022) | ViT-S | 59.7 | 69.0 |
| PASS† [11] (2022) | ViT-B | 64.2 | 74.5 |
| Ours | ViT-S | 65.2 | 72.0 |
| Ours | ViT-B | 69.5 | 76.0 |
Supervised ReID. As shown in Table I, we generally divide previous methods by model initialization, i.e., utilizing supervised ImageNet pre-training and self-supervised LUPerson pre-training as backbone initialization, respectively. For methods adopting ImageNet-supervised pre-trained parameters, they usually focus on designing novel architectures to capture fine-grained pedestrian details. With the popularity of Transformer, more and more current methods have turned to ViT backbone and achieved promising results. However, they need to pre-train on ImageNet-21k dataset (larger than LUPerson, 14M vs 4.2M data volume) [76, 8, 39, 77]. Compared with these works, our method pre-trains on the LUPerson dataset and achieves remarkable performance gains over the most challenging competitor, i.e., 5.9% and 15.8% mAP gain on Market1501 and MSMT17, respectively.
Methods in the bottom part conduct self-supervised pre-training on LUPerson to initialize the backbone. Regardless of the adopted backbones, their pre-training methods are dominated by the variants of contrastive learning. UPReID [65] and PASS [11] design subtle techniques to further mine the information between global image and local patches. Our method achieves new state-of-the-art performance, i.e., 93.6 and 79.8 mAP on Martket1501 and MSMT17 datasets, respectively. It is worth mentioning that a more significant performance gain is achieved on more challenging MSMT17, i.e., 6.1% and 8% mAP gain on ViT-S and ViT-B over previous SOTA, respectively.
Supervised occluded ReID is evaluated on OccDuke benchmark as shown in Table II. It is a harder setting than the holistic counterpart since the given query pedestrian contains diverse occlusion conditions. Previous methods for this setting mainly leverage external cues or design novel architectures for feature disentanglement. ISP [71] iteratively learns feature maps at the pixel level to provide identity-guided parsing cues. FED [39] builds on the ViT-B backbone and designs two modules to eliminate the disturbance from occlusion. Compared with previous works, our method demonstrates superiority without utilizing external cues, i.e., achieving 69.5% mAP on OccDuke. It can be attributed to our explicit occlusion-aware design in the pre-training strategy, which makes our framework model pedestrian identity statistics well even under severe occlusion.
| Method | Backbone | MSMar | MarMS | ||
|---|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | ||
| Pretraining on ImageNet1K-1.3M | |||||
| DG-Net++ [87] (2020) | Res-50 | 64.6 | 83.1 | 22.1 | 48.4 |
| MMT [45] (2020) | Res-50 | 75.6 | 83.9 | 24.0 | 50.1 |
| SpCL [6] (2020) | Res-50 | 77.5 | 89.7 | 26.8 | 53.7 |
| C-Con [46] (2021) | Res-50 | 82.4 | 92.5 | 33.4 | 60.5 |
| MCRN [88] (2022) | Res-50 | - | - | 32.8 | 64.4 |
| Pretraining on LUPserson-4.2M | |||||
| MoCov2 [9] (2021) | Res-50 | 85.1 | 94.4 | 28.3 | 53.8 |
| DINO [10] (2021) | ViT-S | 88.5 | 95.0 | 43.9 | 67.7 |
| DINO-CFS [10] (2021) | ViT-S | 89.4 | 95.4 | 47.4 | 70.8 |
| PASS [11] (2022) | ViT-S | 90.2 | 95.8 | 49.1 | 72.7 |
| Ours | ViT-S | 90.6 | 95.9 | 53.0 | 76.1 |
| Method | Backbone | Mar | MS | ||
|---|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | ||
| Pretraining on ImageNet1K-1.3M | |||||
| MMCL [89] (2020) | Res-50 | 45.5 | 80.3 | 11.2 | 35.4 |
| HCT [90] (2020) | Res-50 | 56.4 | 80.0 | - | - |
| IICS [91] (2021) | Res-50 | 72.9 | 89.5 | 26.9 | 52.4 |
| C-Con [46] (2021) | Res-50 | 82.6 | 93.0 | 33.1 | 63.3 |
| MCRN [88] (2022) | Res-50 | 80.8 | 92.5 | 31.2 | 63.6 |
| Pretraining on LUPserson-4.2M | |||||
| MoCov2 [9] (2021) | Res-50 | 84.0 | 93.4 | 31.4 | 58.8 |
| DINO [10] (2021) | ViT-S | 87.8 | 94.4 | 38.4 | 63.8 |
| DINO-CFS [10] (2021) | ViT-S | 88.2 | 94.2 | 40.9 | 66.4 |
| PASS [11] (2022) | ViT-S | 88.5 | 94.9 | 41.0 | 67.0 |
| Ours | ViT-S | 88.1 | 95.3 | 48.8 | 74.2 |
Unsupervised ReID. We perform comparison with previous methods on unsupervised ReID, i.e., UDA in Table III and USL in Table IV. Unsupervised ReID contains two settings, i.e., unsupervised domain adaptation (UDA) and unsupervised learning (USL). For these two settings, our method achieves new state-of-the-art performance on most metrics. Notably, our method outperforms the previous SOTA PASS with a large margin, i.e., 3.9% mAP on MarketMSMT UDA setting and 7.8% mAP on the USL setting, respectively. These results further verify the generalization of our designed pre-training.
IV-C Ablation Studies
In this section, we perform ablation studies on supervised ReID to demonstrate the effectiveness of the key components. Unless stated, we adopt ViT-B as our backbone and conduct pre-training with 50 epochs.
Ablation on the multi-level prediction. We introduce both high-level and low-level supervision during PersonMAE pre-training, and we study their impact by modifying the weighting factor in Table V. It is observed that pixel-level regularization is necessary for convergence. Thus we start by only adopting the pixel-level constraint, i.e., corresponding to the first line in Table V (). Compared with this vanilla setting, adding semantic constraint further enhances the performance on downstream ReID tasks. It can be explained that semantic constraint guides the framework to focus more on consensus on the feature space, which is in line with the ReID goal. We further study the weighted balance between these two constraints. It can be observed that both constraints are complementary and the best performance is achieved when is set as 1.
| Market1501 | MSMT17 | |||
|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | |
| 0 | 92.6 | 96.6 | 77.1 | 90.3 |
| 0.5 | 93.2 | 96.8 | 77.7 | 90.5 |
| 1.0 | 93.3 | 97.0 | 78.6 | 91.2 |
| 2.0 | 93.1 | 96.9 | 78.2 | 90.8 |
| Mask Strategy | Market1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | |
| Random | 92.7 | 96.9 | 76.1 | 89.8 |
| Block | 93.3 | 97.0 | 78.6 | 91.2 |
Ablation on the masking strategy. We study two masking strategies in Table VI, i.e., random and block-wise masking. The first one randomly selects the patches from the masked positions, while the latter chooses the masked patches in a block-wise manner. Their masking ratios are both set as 75%. It can be observed that the block-wise masking strategy brings better performance on the downstream task than the random counterpart. We assume that the block-wise strategy better mimics the real-world cases since common occlusion usually appears in form of a chunk.
Ablation on the masking ratio. We further study the effects of the masking ratio in Table VII. It can be observed that the performance reaches the peak when the masking ratio is equal to 75%. It indicates there is much information redundancy in the pedestrian image and a suitable ratio makes the framework model its statistics well.
| Mask Ratio | Market1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | |
| 20% | 91.9 | 96.4 | 75.7 | 89.1 |
| 40% | 93.0 | 96.6 | 76.4 | 89.6 |
| 60% | 93.1 | 96.4 | 78.4 | 90.5 |
| 70% | 93.1 | 97.0 | 78.4 | 91.1 |
| 75% | 93.3 | 97.0 | 78.6 | 91.2 |
| 80% | 93.1 | 96.9 | 77.8 | 90.6 |

Ablation on cross-region generation. Cross-region generation module is utilized to simulate the cropping jittering in ReID, and we realize it with a shift operation. We investigate the suitable shift size in Table VIII. The first row corresponds to the setting when two regions are the same and the method degrades to the inner prediction case. In this setting, although the framework is able to model the pedestrian statistics from heavy occlusion, its cross-region invariance capability is shrunk, which leads to inferior performance. When the shift size increases, the performance gradually increases. The best performance is achieved when the shift size is equal to 64. Further shift size increase over 64 degrades the performance. It can be explained that a too-large shift size increases the difficulty of the pretext task and makes pre-training not optimal.
| Shift Size | Market1501 | MSMT17 | ||
|---|---|---|---|---|
| mAP | Rank1 | mAP | Rank1 | |
| 0 | 92.5 | 96.8 | 76.9 | 90.1 |
| 32 | 92.9 | 96.9 | 77.8 | 90.9 |
| 64 | 93.3 | 97.0 | 78.6 | 91.2 |
| 96 | 92.5 | 96.6 | 76.7 | 90.1 |
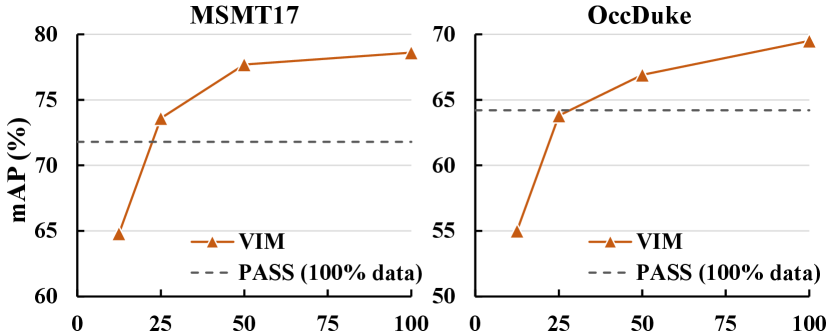

Pre-training data scale. We study the impact of the pre-training data scale on challenging MSMT17 and OccDuke datasets in Figure 4. We randomly extract a portion of the LUPerson dataset to conduct pre-training. Then we perform fine-tuning with the same setup. The performance gradually improves when the involved pre-training data scale increases. Notably, our method even outperforms previous SOTA PASS on MSMT17 by leveraging 25% of pre-training data and 50% of the pre-training epochs.
Superiority over simple integration of CL and MAE. Another alternative to achieve the three desired properties is simply combining the objectives from CL and MAE. To this end, we build a comparison method (DINO+MAE), which is built based on DINO and adds MAE in its student branch. The comparison is conducted on the ViT-S backbone. DINO+MAE achieves 64.7(83.6)/88.0(94.9) mAP(Rank1) on MSMT17/Market1501, which is significantly worse than PersonMAE with 75.2(89.1)/92.5(96.7).
IV-D Qualitative Analysis
We perform qualitative visualization of our prediction results on unseen person images in Figure 3. In each group, we show RegionA, distorted RegionA, ground-truth RegionB and our predicted RegionB in sequence. Our framework can infer the whole cloth texture or fill the whole personal belonging well (e.g. bag), even with a glance at the partial region. This strong hallucination capability may be largely attributed to the well-model pedestrian statistics during pre-training.
Furthermore, we demonstrate some retrieved pedestrian images of previous SOTA (PASS) and our method in Figure 5. We list top-5 ranking results for each query. In the upper-left part, the query pedestrian wears the white schoolbag and only shows the bag straps in the query image. However, PASS ignores this fine-grained cue and focuses on the red sweater and black coat, which leads to false retrieval. In contrast, our framework is able to identify this detail and retrieves the pedestrian correctly. For the bottom-right part, the query person is heavily occluded by a car, which is a highly challenging scenario. Our framework does not rely too much on the blue coat and retrieves correctly by capturing the cues from the bag color and hat type. These results qualitatively suggest that our method is able to satisfy the aforementioned three main properties for accurate ReID.
V Limitation & Future Work
Although our framework brings notable performance gains on the downstream ReID tasks, it still contains some failure cases. Due to inaccurate person detection or low recording conditions, the cropped person image presents in low quality. This factor may lead to final failure detection. Besides, non-target pedestrian inherently introduces ambiguity on which pedestrian to match, and may cause failure retrieval.
In future work, we will explore more suitable masking strategies, which better simulate diverse occlusion characteristics or model pedestrian statistics with awareness of human parts. We believe these directions can bring further performance improvement. Besides, it is also desirable to explore video-based ReID tasks with the inspiration of our framework.
VI Conclusion
In this paper, we propose the first pre-training framework with masked autoencoders for person ReID, namely PersonMAE. It aims to embrace three important properties, i.e., multi-level awareness, occlusion robustness and cross-region invariance, to meet the challenge of ReID. Two regions are generated from the global pedestrian image, i.e., the input RegionA and prediction target RegionB. RegionA is corrupted with the masking strategy, and its unmasked parts are fed into the encoder. Then the framework utilizes the encoder output and cross-region relationship to predict whole RegionB on both low-level clues and high-level semantics. Extensive experiments validate the effectiveness of our framework on a series of downstream tasks, i.e., supervised (holistic and occluded ReID), unsupervised (UDA and USL ReID) setting. Our method achieves new state-of-the-art performance with a notable margin.
Broader impact. Our research aims to meet the urgent demand for public safety. The capability of matching a specific person across different cameras has many applications, e.g. locating the suspect easier. On the other hand, this task involves identifying a specific person and may have potential privacy issues if it is misused. A variety of regulatory and technical measures have been proposed to address this issue.
References
- [1] D. Fu, B. Xin, J. Wang, D. Chen, J. Bao, G. Hua, and H. Li, “Improving person re-identification with iterative impression aggregation,” IEEE TIP, vol. 29, pp. 9559–9571, 2020.
- [2] L. Zheng, L. Shen, L. Tian, S. Wang, J. Wang, and Q. Tian, “Scalable person re-identification: A benchmark,” in ICCV, 2015, pp. 1116–1124.
- [3] G. Wang, Y. Yuan, X. Chen, J. Li, and X. Zhou, “Learning discriminative features with multiple granularities for person re-identification,” in ACM MM, 2018, pp. 274–282.
- [4] Y. Suh, J. Wang, S. Tang, T. Mei, and K. M. Lee, “Part-aligned bilinear representations for person re-identification,” in ECCV, 2018, pp. 402–419.
- [5] L. Wei, S. Zhang, W. Gao, and Q. Tian, “Person transfer GAN to bridge domain gap for person re-identification,” in CVPR, 2018, pp. 79–88.
- [6] Y. Ge, F. Zhu, D. Chen, R. Zhao et al., “Self-paced contrastive learning with hybrid memory for domain adaptive object Re-ID,” NeurIPS, pp. 11 309–11 321, 2020.
- [7] J. Yang, J. Zhang, F. Yu, X. Jiang, M. Zhang, X. Sun, Y.-C. Chen, and W.-S. Zheng, “Learning to know where to see: a visibility-aware approach for occluded person re-identification,” in ICCV, 2021, pp. 11 885–11 894.
- [8] S. He, H. Luo, P. Wang, F. Wang, H. Li, and W. Jiang, “TransReID: Transformer-based object re-identification,” in ICCV, 2021, pp. 15 013–15 022.
- [9] D. Fu, D. Chen, J. Bao, H. Yang, L. Yuan, L. Zhang, H. Li, and D. Chen, “Unsupervised pre-training for person re-identification,” in CVPR, 2021, pp. 14 750–14 759.
- [10] H. Luo, P. Wang, Y. Xu, F. Ding, Y. Zhou, F. Wang, H. Li, and R. Jin, “Self-supervised pre-training for transformer-based person re-identification,” arXiv, pp. 1–15, 2021.
- [11] K. Zhu, H. Guo, T. Yan, Y. Zhu, J. Wang, and M. Tang, “PASS: Part-aware self-supervised pre-training for person re-identification,” in ECCV, 2022, pp. 198–214.
- [12] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in CVPR, 2022, pp. 16 000–16 009.
- [13] M. Ye, J. Shen, G. Lin, T. Xiang, L. Shao, and S. C. Hoi, “Deep learning for person re-identification: A survey and outlook,” IEEE TPAMI, vol. 44, no. 6, pp. 2872–2893, 2021.
- [14] W. Li, R. Zhao, T. Xiao, and X. Wang, “Deepreid: Deep filter pairing neural network for person re-identification,” in CVPR, 2014, pp. 152–159.
- [15] F. Wang, W. Zuo, L. Lin, D. Zhang, and L. Zhang, “Joint learning of single-image and cross-image representations for person re-identification,” in CVPR, 2016, pp. 1288–1296.
- [16] G. Chen, C. Lin, L. Ren, J. Lu, and J. Zhou, “Self-critical attention learning for person re-identification,” in ICCV, 2019, pp. 9637–9646.
- [17] M. M. Kalayeh, E. Basaran, M. Gökmen, M. E. Kamasak, and M. Shah, “Human semantic parsing for person re-identification,” in CVPR, 2018, pp. 1062–1071.
- [18] Z. Zheng, X. Yang, Z. Yu, L. Zheng, Y. Yang, and J. Kautz, “Joint discriminative and generative learning for person re-identification,” in CVPR, 2019, pp. 2138–2147.
- [19] K. Yang and X. Tian, “Domain-class correlation decomposition for generalizable person re-identification,” IEEE TMM, pp. 1–11, 2022.
- [20] X. Chen, C. Fu, Y. Zhao, F. Zheng, J. Song, R. Ji, and Y. Yang, “Salience-guided cascaded suppression network for person re-identification,” in CVPR, 2020, pp. 3300–3310.
- [21] H. Li, G. Wu, and W.-S. Zheng, “Combined depth space based architecture search for person re-identification,” in CVPR, 2021, pp. 6729–6738.
- [22] H. Park and B. Ham, “Relation network for person re-identification,” in AAAI, 2020, pp. 11 839–11 847.
- [23] T. Yu, D. Li, Y. Yang, T. M. Hospedales, and T. Xiang, “Robust person re-identification by modelling feature uncertainty,” in ICCV, 2019, pp. 552–561.
- [24] Z. Zhang, C. Lan, W. Zeng, X. Jin, and Z. Chen, “Relation-aware global attention for person re-identification,” in CVPR, 2020, pp. 3186–3195.
- [25] C. Yan, G. Pang, X. Bai, C. Liu, X. Ning, L. Gu, and J. Zhou, “Beyond triplet loss: Person re-identification with fine-grained difference-aware pairwise loss,” IEEE TMM, vol. 24, pp. 1665–1677, 2022.
- [26] Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang, “Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline),” in ECCV, 2018, pp. 480–496.
- [27] J. Guo, Y. Yuan, L. Huang, C. Zhang, J.-G. Yao, and K. Han, “Beyond human parts: Dual part-aligned representations for person re-identification,” in ICCV, 2019, pp. 3642–3651.
- [28] K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” in ICCV, 2019, pp. 3702–3712.
- [29] X. Ren, D. Zhang, X. Bao, and Y. Zhang, “S2-net: Semantic and salient attention network for person re-identification,” IEEE TMM, pp. 1–13, 2022.
- [30] R. Hou, B. Ma, H. Chang, X. Gu, S. Shan, and X. Chen, “Interaction-and-aggregation network for person re-identification,” in CVPR, 2019, pp. 9317–9326.
- [31] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021, pp. 1–21.
- [32] A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,” arXiv, pp. 1–17, 2017.
- [33] Y. Sun, C. Cheng, Y. Zhang, C. Zhang, L. Zheng, Z. Wang, and Y. Wei, “Circle loss: A unified perspective of pair similarity optimization,” in CVPR, 2020, pp. 6398–6407.
- [34] S. Paisitkriangkrai, C. Shen, and A. Van Den Hengel, “Learning to rank in person re-identification with metric ensembles,” in CVPR, 2015, pp. 1846–1855.
- [35] Y. Peng, S. Hou, C. Cao, X. Liu, Y. Huang, and Z. He, “Deep learning-based occluded person re-identification: A survey,” arXiv, pp. 1–14, 2022.
- [36] J. Zhuo, Z. Chen, J. Lai, and G. Wang, “Occluded person re-identification,” in ICME, 2018, pp. 1–6.
- [37] L. He, Y. Wang, W. Liu, H. Zhao, Z. Sun, and J. Feng, “Foreground-aware pyramid reconstruction for alignment-free occluded person re-identification,” in ICCV, 2019, pp. 8450–8459.
- [38] H. Huang, X. Chen, and K. Huang, “Human parsing based alignment with multi-task learning for occluded person re-identification,” in ICME, 2020, pp. 1–6.
- [39] Z. Wang, F. Zhu, S. Tang, R. Zhao, L. He, and J. Song, “Feature erasing and diffusion network for occluded person re-identification,” in CVPR, 2022, pp. 4754–4763.
- [40] L. He and W. Liu, “Guided saliency feature learning for person re-identification in crowded scenes,” in ECCV, 2020, pp. 357–373.
- [41] S. Yu, D. Chen, R. Zhao, H. Chen, and Y. Qiao, “Neighbourhood-guided feature reconstruction for occluded person re-identification,” arXiv, pp. 1–8, 2021.
- [42] Y. Lin, X. Dong, L. Zheng, Y. Yan, and Y. Yang, “A bottom-up clustering approach to unsupervised person re-identification,” in AAAI, 2019, pp. 8738–8745.
- [43] H. Fan, L. Zheng, C. Yan, and Y. Yang, “Unsupervised person re-identification: Clustering and fine-tuning,” ACM TOMM, vol. 14, no. 4, pp. 1–18, 2018.
- [44] Y. Fu, Y. Wei, G. Wang, Y. Zhou, H. Shi, and T. S. Huang, “Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification,” in ICCV, 2019, pp. 6112–6121.
- [45] Y. Ge, D. Chen, and H. Li, “Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification,” in ICLR, 2020, pp. 1–15.
- [46] Z. Dai, G. Wang, W. Yuan, X. Liu, S. Zhu, and P. Tan, “Cluster contrast for unsupervised person re-identification,” arXiv, pp. 1–11, 2021.
- [47] X. Zhang, D. Li, Z. Wang, J. Wang, E. Ding, J. Q. Shi, Z. Zhang, and J. Wang, “Implicit sample extension for unsupervised person re-identification,” in CVPR, 2022, pp. 7369–7378.
- [48] F. Yang, Z. Zhong, Z. Luo, S. Lian, and S. Li, “Leveraging virtual and real person for unsupervised person re-identification,” IEEE TMM, vol. 22, no. 9, pp. 2444–2453, 2020.
- [49] Y. Cho, W. J. Kim, S. Hong, and S.-E. Yoon, “Part-based pseudo label refinement for unsupervised person re-identification,” in CVPR, 2022, pp. 7308–7318.
- [50] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in CVPR, 2020, pp. 9729–9738.
- [51] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in ICML, 2020, pp. 1597–1607.
- [52] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in ICCV, 2021, pp. 9650–9660.
- [53] S. Li, D. Chen, Y. Chen, L. Yuan, L. Zhang, Q. Chu, B. Liu, and N. Yu, “Improve unsupervised pretraining for few-label transfer,” in ICCV, 2021, pp. 10 201–10 210.
- [54] ——, “Unsupervised finetuning,” arXiv, pp. 1–10, 2021.
- [55] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” NeurIPS, pp. 21 271–21 284, 2020.
- [56] X. Chen and K. He, “Exploring simple siamese representation learning,” in CVPR, 2021, pp. 15 750–15 758.
- [57] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “”BERT: Pre-training of deep bidirectional transformers for language understanding”,” in NAACL, 2019, pp. 4171–4186.
- [58] H. Bao, L. Dong, S. Piao, and F. Wei, “BEiT: BERT pre-training of image transformers,” in ICLR, 2022, pp. 1–18.
- [59] X. Dong, J. Bao, T. Zhang, D. Chen, W. Zhang, L. Yuan, D. Chen, F. Wen, and N. Yu, “Bootstrapped masked autoencoders for vision BERT pretraining,” in ECCV, 2022, pp. 247–264.
- [60] ——, “PeCo: Perceptual codebook for BERT pre-training of vision transformers,” arXiv, pp. 1–14, 2021.
- [61] R. Wang, D. Chen, Z. Wu, Y. Chen, X. Dai, M. Liu, Y.-G. Jiang, L. Zhou, and L. Yuan, “BEVT: BERT pretraining of video transformers,” in CVPR, 2022, pp. 14 733–14 743.
- [62] Z. Huang, X. Jin, C. Lu, Q. Hou, M.-M. Cheng, D. Fu, X. Shen, and J. Feng, “Contrastive masked autoencoders are stronger vision learners,” arXiv, pp. 1–15, 2022.
- [63] C. Tao, X. Zhu, G. Huang, Y. Qiao, X. Wang, and J. Dai, “Siamese image modeling for self-supervised vision representation learning,” arXiv, pp. 1–14, 2022.
- [64] Z. Xie, Z. Zhang, Y. Cao, Y. Lin, J. Bao, Z. Yao, Q. Dai, and H. Hu, “SimMIM: A simple framework for masked image modeling,” in CVPR, 2022, pp. 9653–9663.
- [65] Z. Yang, X. Jin, K. Zheng, and F. Zhao, “Unleashing potential of unsupervised pre-training with intra-identity regularization for person re-identification,” in CVPR, 2022, pp. 14 298–14 307.
- [66] D. Fu, D. Chen, H. Yang, J. Bao, L. Yuan, L. Zhang, H. Li, F. Wen, and D. Chen, “Large-scale pre-training for person re-identification with noisy labels,” in CVPR, 2022, pp. 2476–2486.
- [67] J. Miao, Y. Wu, P. Liu, Y. Ding, and Y. Yang, “Pose-guided feature alignment for occluded person re-identification,” in ICCV, 2019, pp. 542–551.
- [68] H. Luo, W. Jiang, Y. Gu, F. Liu, X. Liao, S. Lai, and J. Gu, “A strong baseline and batch normalization neck for deep person re-identification,” IEEE TMM, vol. 22, no. 10, pp. 2597–2609, 2019.
- [69] T. Chen, S. Ding, J. Xie, Y. Yuan, W. Chen, Y. Yang, Z. Ren, and Z. Wang, “ABD-Net: Attentive but diverse person re-identification,” in ICCV, 2019, pp. 8351–8361.
- [70] X. Jin, C. Lan, W. Zeng, G. Wei, and Z. Chen, “Semantics-aligned representation learning for person re-identification,” in AAAI, 2020, pp. 11 173–11 180.
- [71] K. Zhu, H. Guo, Z. Liu, M. Tang, and J. Wang, “Identity-guided human semantic parsing for person re-identification,” in ECCV, 2020, pp. 346–363.
- [72] G. Wang, S. Yang, H. Liu, Z. Wang, Y. Yang, S. Wang, G. Yu, E. Zhou, and J. Sun, “High-order information matters: Learning relation and topology for occluded person re-identification,” in CVPR, 2020, pp. 6449–6458.
- [73] Y. Liu, W. Zhou, J. Liu, G.-J. Qi, Q. Tian, and H. Li, “An end-to-end foreground-aware network for person re-identification,” IEEE TIP, vol. 30, pp. 2060–2071, 2021.
- [74] Y. Li, J. He, T. Zhang, X. Liu, Y. Zhang, and F. Wu, “Diverse part discovery: Occluded person re-identification with part-aware transformer,” in CVPR, 2021, pp. 2898–2907.
- [75] H. Wang, J. Shen, Y. Liu, Y. Gao, and E. Gavves, “Nformer: Robust person re-identification with neighbor transformer,” in CVPR, 2022, pp. 7297–7307.
- [76] K. Zhu, H. Guo, S. Zhang, Y. Wang, G. Huang, H. Qiao, J. Liu, J. Wang, and M. Tang, “AAformer: Auto-aligned transformer for person re-identification,” arXiv, pp. 1–9, 2021.
- [77] H. Zhu, W. Ke, D. Li, J. Liu, L. Tian, and Y. Shan, “Dual cross-attention learning for fine-grained visual categorization and object re-identification,” in CVPR, 2022, pp. 4692–4702.
- [78] X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,” arXiv, pp. 1–3, 2020.
- [79] X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised vision transformers,” in ICCV, 2021, pp. 9640–9649.
- [80] Z. Xie, Y. Lin, Z. Yao, Z. Zhang, Q. Dai, Y. Cao, and H. Hu, “Self-supervised learning with swin transformers,” arXiv, pp. 1–8, 2021.
- [81] Z. Zhong, L. Zheng, D. Cao, and S. Li, “Re-ranking person re-identification with k-reciprocal encoding,” in CVPR, 2017, pp. 1318–1327.
- [82] L. He, J. Liang, H. Li, and Z. Sun, “Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach,” in CVPR, 2018, pp. 7073–7082.
- [83] H. Huang, D. Li, Z. Zhang, X. Chen, and K. Huang, “Adversarially occluded samples for person re-identification,” in CVPR, 2018, pp. 5098–5107.
- [84] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” in AAAI, 2020, pp. 13 001–13 008.
- [85] S. Gao, J. Wang, H. Lu, and Z. Liu, “Pose-guided visible part matching for occluded person ReID,” in CVPR, 2020, pp. 11 744–11 752.
- [86] T. Wang, H. Liu, P. Song, T. Guo, and W. Shi, “Pose-guided feature disentangling for occluded person re-identification based on transformer,” in AAAI, 2022, pp. 2540–2549.
- [87] Y. Zou, X. Yang, Z. Yu, B. Kumar, and J. Kautz, “Joint disentangling and adaptation for cross-domain person re-identification,” in ECCV, 2020, pp. 87–104.
- [88] Y. Wu, T. Huang, H. Yao, C. Zhang, Y. Shao, C. Han, C. Gao, and N. Sang, “Multi-centroid representation network for domain adaptive person re-id,” in AAAI, 2022, pp. 2750–2758.
- [89] D. Wang and S. Zhang, “Unsupervised person re-identification via multi-label classification,” in CVPR, 2020, pp. 10 981–10 990.
- [90] K. Zeng, M. Ning, Y. Wang, and Y. Guo, “Hierarchical clustering with hard-batch triplet loss for person re-identification,” in CVPR, 2020, pp. 13 657–13 665.
- [91] S. Xuan and S. Zhang, “Intra-inter camera similarity for unsupervised person re-identification,” in CVPR, 2021, pp. 11 926–11 935.