Physical Meaning of Principal Component Analysis for Lattice Systems with Translational Invariance
Abstract
We seek for the physical implication of principal component analysis (PCA) applied to lattice systems with phase transitions, especially when the system is translationally invariant. We present a general approximate formula for a principal component as well as all other eigenvalues and argue that the approximation becomes exact if the size of data is infinite. The formula explains the connection between the principal component and the corresponding order parameter and, therefore, the reason why PCA is successful. Our result can also be used to estimate a principal component without performing matrix diagonalization.
An unprecedented achievement of machine learning has brought physics into the realm of data-driven science. Like other successful applications of machine learning in physics [1, 2], principal component analysis (PCA) [3] for systems with phase transitions has attracted attention because it operates almost as an automated machine for identifying transition points, even without detailed information about the nature of the transitions [4, 5, 6, 7, 8].
A PCA study of phase transitions typically involves two steps. In the first step, which will be referred to as the data-preparation step, independent configurations are sampled using Monte Carlo simulations. The second step, which will be called the PCA step, analyzes the singular values of a matrix constructed by concatenating the configurations obtained in the data-preparation step (in the following presentation, we will actually consider positive matrices whose eigenvalues are the singular values in question). It is the largest singular value (that is, the principal component) that pinpoints a critical point and estimates a certain critical exponent [4, 5, 6, 7, 8].
The numerical observations clearly suggest that the principal component should be associated with the order parameter of a system in one way or another. In this Letter, we attempt to explain how the principal component is related with the order parameter. To be specific, we will find approximate expressions for all the singular values of matrices constructed in the PCA step. The expressions will be given for any -dimensional lattice system with translational invariance. By the expressions, the connection between the principal component and the order parameter is immediately understood. In due course, we will argue that the more (data are collected in the data-preparation step), the better (the approximation).
We will first develop a theory for a one-dimensional lattice system with sites. A theory for higher dimensional systems will be easily come up with, once the one-dimensional theory is fully developed. Although we limit ourselves to hypercubic lattices, our theory can be easily generalized to other Bravais lattices.
Let us begin with the formal preparation for lattice systems. We assume that each site , say, has a random variable . Depending on the context, can be a binary number ( or for the Ising model, or for hard-core classical particles), a nonnegative integer (classical boson particles; see Ref. [9, 10] for a numerical method to simulate classical reaction-diffusion systems of bosons), a continuous vector (the model, the Heisenberg model), or even a complex number ( in the model, for instance). We assume periodic boundary conditions; in one dimension and a similar criterion in two or more dimensions. By , we will denote a (random) configuration of a system. Denoting a column vector with a one in the -th row and zeros in all other rows by (the subscript is intended to mean “real” space), we represent a configuration as
Obviously, ’s form an orthonomal basis. To make use of the periodic boundary conditions, we set .
By , we mean probability that the system is in configuration (in the case that takes continuous values, should be understood as probability density). Here, is not limited to stationarity; can be probability at a certain fixed time of a stochastic lattice model. For a later reference, we define “ensemble” average of a random variable as
where means a realization of in configuration and should be understood as an integral if is probability density.
When we write for a certain configuration, in will be denoted by . By translational invariance, we mean if configuration is related with configuration by for all and for a certain .
Now we are ready to develop a formal theory. Let be a fixed positive integer and let ’s be independent and identically distributed random configurations sampled from the common probability (). In practice, ’s are prepared for in the data-preparation step.
For a later reference, we define an “empirical” average of a random variable Y as
Unlike the ensemble average, the empirical average is a random variable. By the law of large numbers, converges (at least in probability) to , if exists, under the infinite limit. We define a centered configuration as
In the PCA step, main interest is in the spectral decomposition of an empirical second-moment matrix and an empirical covariance matrix , defined as
The elements of and can be written as ()
where the asterisk means complex conjugate. If is a vector as in the Heisenberg model, then the multiplications in the above would be replaced by inner products of two vectors. The periodic boundary conditions imply and similar relations for . Obviously, and are positive matrices. In what follows, we will denote the -th largest eigenvalue of and by and , respectively.
We will first find an approximate formula for . Once it is done, an approximate formula for will be obtained immediately. Let us introduce a hermitian matrix with elements
Since by definition, is translationally invariant in that for any pair of and . Also note that .
Let be a translation operator with for all . Note that
for is the eigenstate of with the corresponding eigenvalue . Since is translationally invariant, we have and, accordingly, ’s are also the eigenstates of . Due to orthonormality , the eigenvalues of are obtained by .
If ’s are real and nonnegative, which is the case if ’s are nonnegative real numbers, then we have, by the Perron-Frobenius theorem, the largest eigenvalue of as
| (1) | ||||
where
is a random variable, signifying a spatial average of ’s.
Now we move on to the eigenvalues of . Let . As increases, should become more and more translationally invariant in the sense that , for any pair of and , converges (presumably at least in probability) to zero under the infinite limit. Therefore, if is sufficiently large, is very likely to be a small perturbation in comparison with .
If is small or an atypical collection of configurations (unfortunately) happens to be sampled, however, may not be considered a perturbation. For example, if and ’s are nonnegative, is a rank one matrix with eigenstate and the only nonzero eigenvalue of is , while the largest eigenvalue of is still given in Eq. (1). In the case that only assumes zero or one and , cannot be regarded as a perturbation, because . Note, however, that if in the above example, then even for is still a perturbation.
In many cases (see below), is the order parameter. If this is indeed the case, then the principal component of for is just the order parameter, especially for large , and, therefore, can still be used to study phase transitions, although PCA for is practically unnecessary.
In the case that indeed can be treated as a perturbation, the Rayleigh-Schrödinger perturbation theory in quantum mechanics (up to the first order) gives the approximate eigenvalues of as
where
is the -th mode of Fourier transform of , with . That is, all the eigenvalues of are approximated by the empirical average of the (square of) moduli of Fourier modes when is sufficiently large. Following the same discussion as above, we can get the approximate eigenvalues of as . It is straightforward to get
Since , we have and .
Let be a permutation of such that for all , then we have . A similar rearrangement of will give . Therefore, one can find all the eigenvalues of and approximately, already in the data-preparation step. Furthermore, we would like to emphasize once again that should converge (at least in probability) to under the limit .
If the system has the translational invariance, the law of large numbers gives
for all and, accordingly,
for nonzero . Therefore, we have
for nonzero . Hence, only and may remain different as one collects more and more samples, while and become closer and closer to each other as gets larger and larger.
For a -dimensional system with sites along the -th direction, the result for the one-dimensional system can be easily generalized, to yield approximate expressions for eigenvalues of and as
| (2) | ||||
where is the lattice vector with (),
is the reciprocal lattice vector (of the -dimensional hypercubic lattice) with (), and is the total number of sites.
If happens to be an order parameter of a phase transition, is just square of the order parameter and is the fluctuation of the order parameter. Here, the subscript is a shorthand notation for the zero reciprocal lattice vector . Accordingly, under the infinite limit, or, equivalently, , should play the role of an order parameter and and, equivalently, the principal component should diverge at the critical point. For example, in the Ising model, is the magnetization and, therefore, and for sufficiently large . This obviously explains why PCA works.
To support the above theory numerically, we apply PCA to the one and two dimensional contact process (CP) [11]. The CP is a typical model of absorbing phase transitions (for a review, see, e.g., Ref [12, 13]). In the CP, each site is either occupied by a particle () or vacant (). No multiple occupancy is allowed. Each particle dies with rate and branches one offspring to randomly chosen one of its nearest neighbor sites with rate . If the target site is already occupied in the branching attempt, no configuration change occurs. Note that is the order parameter and should converge to for all under the infinite limit.
In the data-preparation step, we simulated the one dimensional CP (at ) with and the two dimensional CP (at ) with . For all cases, we use the fully occupied initial condition ( for all ), which ensures the translational invariance at all time. We collected independent configurations at . In the PCA step, we constructed ’s and ’s with different numbers of configurations, which were numerically diagonalized.
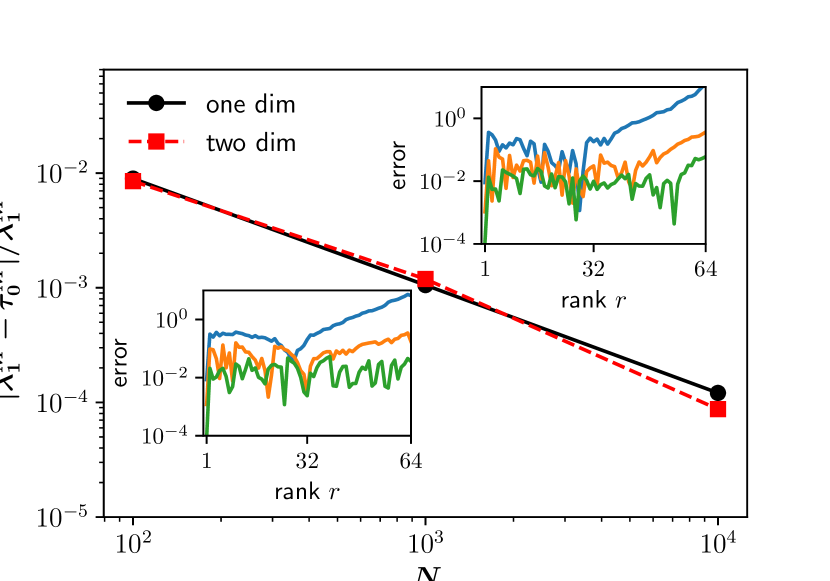
In Fig. 1, we depict the relative error of , defined as , for the one-dimensional and the two-dimensional CPs against on a double-logarithmic scale. Indeed, the error gets smaller with in any dimensions. Quantitatively, the relative error decreases as , which should be compared with due to the central limit theorem.
Since our theory is not limited to the largest eigenvalue, we also study relative errors of other eigenvalues. In the inset of Fig. 1, we depict vs ( is the rank of the values) for the one-dimensional (upper panel) and the two-dimensional (lower panel) CPs. Again, the errors indeed tend to decrease with .
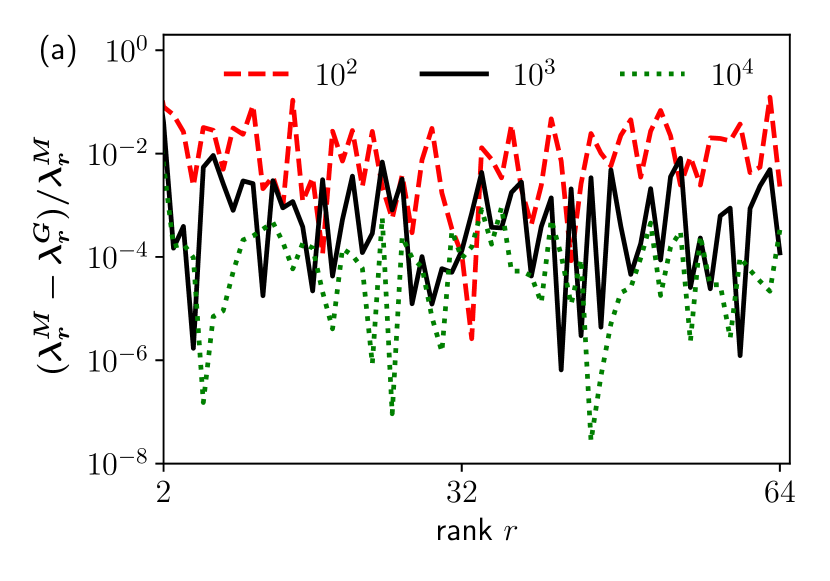
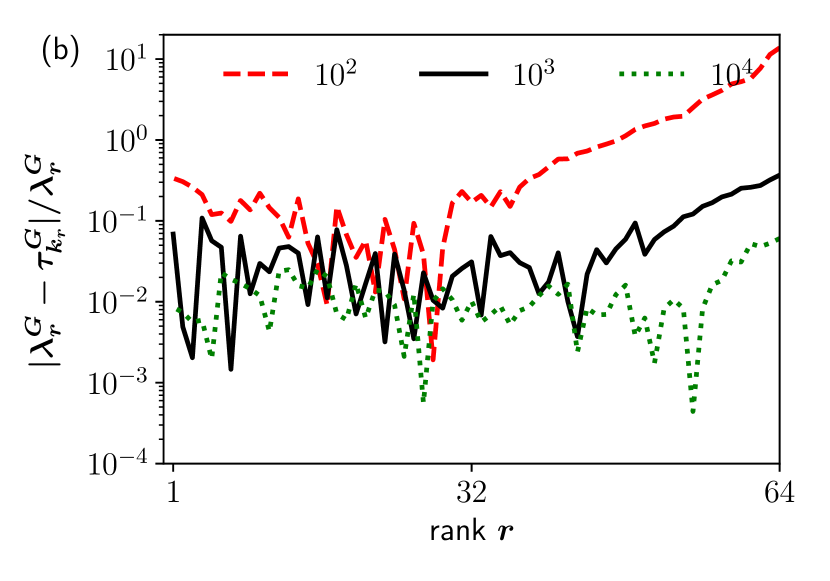
In Fig. 2(a), we compare and for . As expected, the difference of the eigenvalues except the largest one tends to approach zero as increases. In Fig. 2(b), we compare and , which also supports that ’s with appropriate ordering indeed tend to become better and better approximations for , as increases. A similar behavior is also observed in two dimensions (details not shown here). The example of the CP supports the validity of our theory.
For a sufficiently large system, a typical configuration of a translationally invariant system is expected to be homogeneous and, therefore, it is likely that for converges (presumably at least in probability) to zero under the infinite limit. Hence, except the mode, all other eigenvalues goes to zero as , which is consistent with numerical observations in the literature (see, for example, Fig. 1 of Ref. [4] that shows the decrease of non-principal components with ).
In all the examples in the above, the largest eigenvalue happens to be approximated by . However, this needs not be the case for every stochastic lattice model. For example, let us consider the Kawasaki dynamics [14] of the two dimensional Ising model with zero magnetization. In this case, both and are by definition zero, regardless of . Therefore, should be a Fourier mode with nonzero reciprocal lattice vector. Since the Ising model is also isotropic, we must have
for any integer . In case the Fourier mode with the smallest nonzero gives the in the infinite limit, there should be significant eigenvalues of for finite , which was indeed observed in Fig. 4 of Ref. [4].
To conclude, Eq. (2) for approximating all the eigenvalues of the empirical second-moment matrix and the empirical covariance matrix clearly indicates the relation between the principal component and the order parameter of the system in question and explains why PCA has to be working. Moreover, Eq. (2) can reduce computational efforts, because it can be calculated already in the data-preparation step; there is no need of the PCA step for PCA if the system has the translational invariance.
Since our theory heavily relies on the translational invariance, Eq. (2) is unlikely to be applicable to a system without the translational invariance such as a system with quenched disorder, a system on a scale-free network, and so on. It would be an interesting future research topic to check whether PCA for a system without the translational invariance still be of help and, if so, to answer why.
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (Grant No. RS-2023-00249949).
References
- Mehta et al. [2019] P. Mehta, M. Bukov, C.-H. Wang, A. G. Day, C. Richardson, C. K. Fisher, and D. J. Schwab, A high-bias, low-variance introduction to machine learning for physicists, Phys. Rep. 810, 1 (2019).
- Carleo et al. [2019] G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová, Machine learning and the physical sciences, Rev. Mod. Phys. 91, 045002 (2019).
- Jolliffe [2002] I. T. Jolliffe, Principal Component Analysis (Springer, New York, 2002).
- Wang [2016] L. Wang, Discovering phase transitions with unsupervised learning, Phys. Rev. B 94, 195105 (2016).
- Carrasquilla and Melko [2017] J. Carrasquilla and R. G. Melko, Machine learning phases of matter, Nat. Phys. 13, 431 (2017).
- Hu et al. [2017] W. Hu, R. R. P. Singh, and R. T. Scalettar, Discovering phases, phase transitions, and crossovers through unsupervised machine learning: A critical examination, Phys. Rev. E 95, 062122 (2017).
- Sale et al. [2022] N. Sale, J. Giansiracusa, and B. Lucini, Quantitative analysis of phase transitions in two-dimensional models using persistent homology, Phys. Rev. E 105, 024121 (2022).
- Muzzi et al. [2024] C. Muzzi, R. S. Cortes, D. S. Bhakuni, A. Jelić, A. Gambassi, M. Dalmonte, and R. Verdel, Principal component analysis of absorbing state phase transitions (2024), arXiv:2405.12863 [cond-mat.stat-mech] .
- Park [2005] S.-C. Park, Monte carlo simulations of bosonic reaction-diffusion systems, Phys. Rev. E 72, 036111 (2005).
- Park [2006] S.-C. Park, Monte Carlo simulations of bosonic reaction-diffusion systems and comparison to Langevin equation description, Eur. Phys. J. B 50, 327 (2006).
- Harris [1974] T. E. Harris, Contact interactions on a lattice, Ann. Prob. 2, 969 (1974).
- Hinrichsen [2000] H. Hinrichsen, Non-equilibrium critical phenomena and phase transitions into absorbing states, Adv. Phys. 49, 815 (2000).
- Ódor [2004] G. Ódor, Universality classes in nonequilibrium lattice systems, Rev. Mod. Phys. 76, 663 (2004).
- Kawasaki [1966] K. Kawasaki, Diffusion constants near the critical point for time-dependent Ising models. I, Phys. Rev. 145, 224 (1966).