Physics-informed active learning with simultaneous weak-form latent space dynamics identification
Abstract
The parametric greedy latent space dynamics identification (gLaSDI) framework has demonstrated promising potential for accurate and efficient modeling of high-dimensional nonlinear physical systems. However, it remains challenging to handle noisy data. To enhance robustness against noise, we incorporate the weak-form estimation of nonlinear dynamics (WENDy) into gLaSDI. In the proposed weak-form gLaSDI (WgLaSDI) framework, an autoencoder and WENDy are trained simultaneously to discover intrinsic nonlinear latent-space dynamics of high-dimensional data. Compared to the standard sparse identification of nonlinear dynamics (SINDy) employed in gLaSDI, WENDy enables variance reduction and robust latent space discovery, therefore leading to more accurate and efficient reduced-order modeling. Furthermore, the greedy physics-informed active learning in WgLaSDI enables adaptive sampling of optimal training data on the fly for enhanced modeling accuracy. The effectiveness of the proposed framework is demonstrated by modeling various nonlinear dynamical problems, including viscous and inviscid Burgers’ equations, time-dependent radial advection, and the Vlasov equation for plasma physics. With data that contains 5-10 Gaussian white noise, WgLaSDI outperforms gLaSDI by orders of magnitude, achieving 1-7 relative errors. Compared with the high-fidelity models, WgLaSDI achieves 121 to 1,779 speed-up.
keywords:
Data-driven modeling, reduced-order modeling, weak form, latent space dynamics learning, physics-informed active learning, autoencoder1 Introduction
Physical simulations have played an increasingly significant role in the development of various scientific and engineering domains, including physics, biology, electronics, automotive, aerospace, and digital twin [1, 2, 3, 4, 5, 6, 7]. Reduced-order modeling has been developed to accelerate simulations while maintaining high accuracy to address computational challenges arising from limited computational resources and complex physical phenomena. One classical method is the projection-based reduced-order model (ROM), which can be categorized into linear and nonlinear projections. Linear projection techniques, such as the proper orthogonal decomposition [8], the reduced basis method [9], and the balanced truncation method [10], have been successfully applied to a wide range of applications, including fluid dynamics [11, 12, 13, 14, 15], fracture mechanics [16, 17], topology optimization [18, 19], structural design optimization [20, 21], etc. However, the linear projection-based ROM falls short when dealing with problems whose Kolmogorov width decays slow, e.g., advection-dominated systems. In contrast, nonlinear projection techniques based on autoencoders have demonstrated better performance for these systems [22, 23, 24, 25, 26, 27, 28].
While most projection-based ROMs (pROMs) are intrusive, maintaining extrapolation robustness and high accuracy with less training data, they necessitate access to the numerical solver and a detailed understanding of specific implementation. On the other hand, non-intrusive ROMs [29, 30, 31, 32, 33, 34, 35, 36, 37] are purely data-driven, independent of governing equations of physics and the high-fidelity physical solver. However, many non-intrusive ROMs lack interpretability, leading to unstable generalization performance.
To address these issues, equation learning algorithms [38, 39, 40] have been integrated into ROMs to identify the underlying equations governing the latent-space dynamics [41, 42, 43, 44]. Champion, et al. [45] applied an autoencoder for dimensionality reduction and the Sparse Identification of Nonlinear Dynamics (SINDy) method to identify ordinary differential equations (ODEs) that govern the latent-space dynamics, where the autoencoder and the SINDy model were trained simultaneously to achieve simple latent-space dynamics. However, the method is not parameterized and generalizable. Recently, Fries, et al. [23] proposed a parametric Latent Space Dynamics Identification (LaSDI) framework in which an autoencoder was applied for nonlinear projection and a set of SINDy models were employed to identify ODEs governing the latent-space dynamics of the training data. During inference, the ODE coefficients of the testing case are obtained by interpolating those of training data, allowing for estimating the latent space dynamics of any new parameter in the parameter space. Recent developments [28] have extended LaSDI to achieve simultaneous training and active learning based on the residual error (gLaSDI [24]), active learning based on Gaussian processes [27], and to follow the thermodynamics principles [46].
The LaSDI class of algorithms relies on SINDy for learning the ODEs governing the latent space dynamics.111excluding tLaSDI [46] SINDy [39], however, is widely acknowledged to be sensitive to noise in the data, due to the pointwise derivative approximation. To address this sensitivity, weak form methods such as weak SINDy (WSINDy) for equation learning (of ODEs [47, 48, 49], PDEs [50], SDEs [51], and hybrid systems [52]) and WENDy for parameter estimation [53] have been developed with strong theoretical convergence performance [54]. When the data is noisy, the latent variables constructed in LaSDI (autoencoder or POD) could still retain that noise. Accordingly, Tran et al., [26] proposed the WLaSDI method, extending LaSDI to use WENDy for system identification of the latent dynamics. This results in a ROM creation method that is robust to large amounts of noise while maintaining the ability to create an accurate ROM that can be simulated hundreds of times faster than the full-order model.
In WLaSDI, however, a two-step sequential procedure was adopted, first training the autoencoder and then using WENDy to estimate parameters in the ODE models for the latent dynamics. The lack of interaction between them could result in complex latent space representation discovered by the autoencoder, which could further pose challenges to the subsequent equation learning by WENDy and thus affect the model performances.
To overcome this limitation, we propose a weak-form greedy latent space dynamics identification (WgLaSDI) framework (Fig. 1). WgLaSDI is directly built upon gLaSDI, which includes simultaneous autoencoder training and dynamics identification, -NN convex interpolation of latent space dynamics for inference, and greedy physics-informed active learning for selecting optimal training samples. In WgLaSDI, WENDy is employed for robust latent space dynamics identification and trained simultaneously with the autoencoder to discover intrinsic latent representations. Each training sample has its own set of WENDy coefficients. During inference, the WENDy coefficient of the testing case is estimated by interpolating the WENDy coefficients of nearest neighbor (-NN) training samples. The greedy active learning based on the residual error maximizes the diversity of training samples in the parameter space and minimizes prediction errors. The effectiveness and enhanced performance of the proposed WgLaSDI framework in the presence of noisy data is demonstrated by modeling various nonlinear dynamical problems with a comparison with the gLaSDI and WLaSDI frameworks [24, 26].
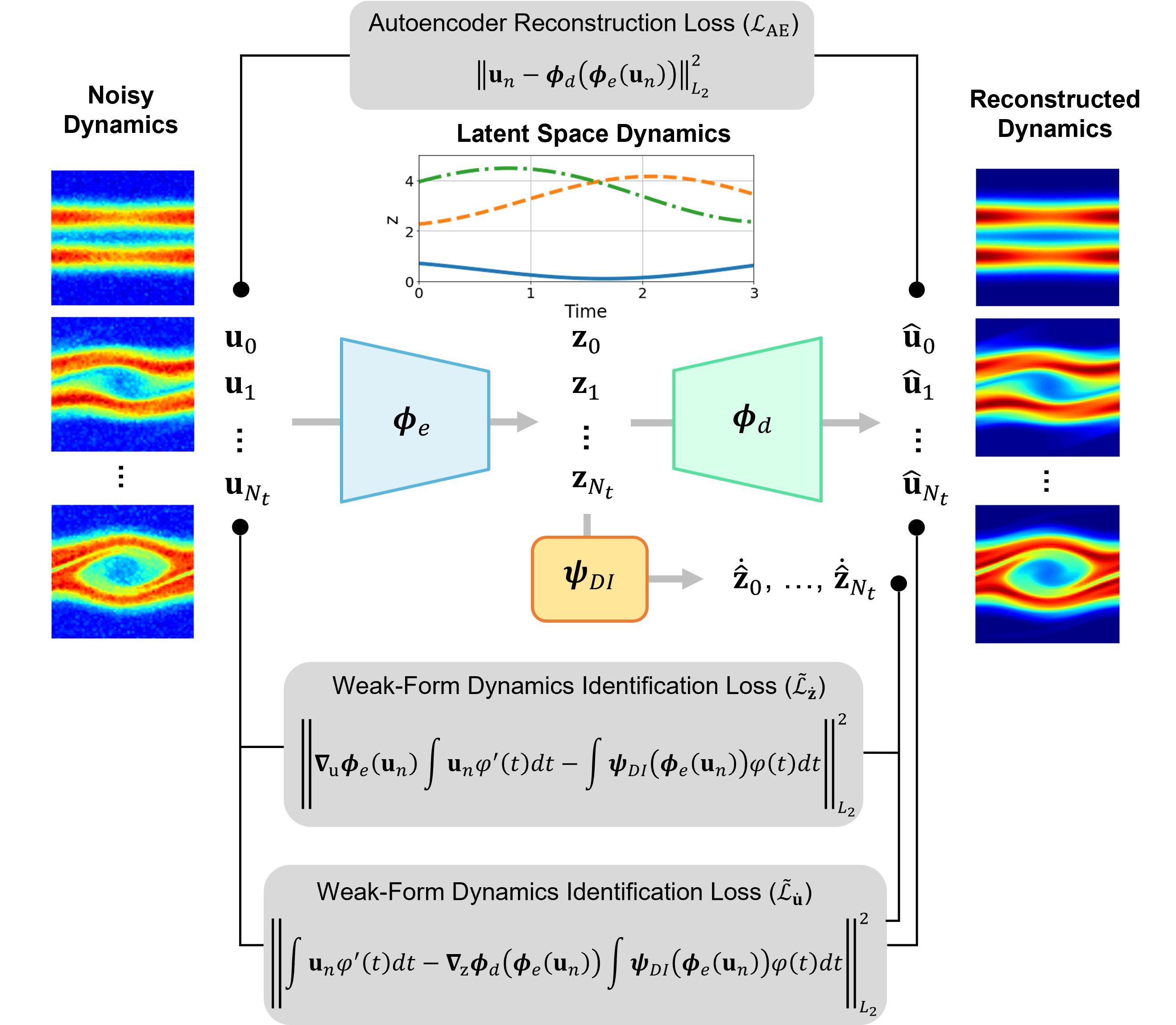
The remainder of this paper is structured as follows. The governing equations of physical systems are introduced in Section 2. In Section 3, we introduce the building blocks of gLaSDI and the proposed WgLaSDI framework, including autoencoders, strong-form and weak-form latent space dynamics identification, -NN interpolation, and greedy physics-informed active learning based on a residual error indicator. We then demonstrate the effectiveness and capability of the proposed WgLaSDI framework in Section 4 by modeling various nonlinear dynamical problems, including Burgers’ equations, time-dependent radial advection, and a two-stream plasma instability problem. The effects of the weak form, simultaneous training, and greedy physics-informed active learning are discussed with a comparison with gLaSDI and WLaSDI. Concluding remarks and discussions are summarized in Section 5.
2 Governing Equations of Physical Systems
We consider physical systems characterized by a system of partial differential equations (PDEs),
| (1) |
where represents the solution field (either scalar or vector) over the spatiotemporal domain of the physical problem; is the final time of the physical problem; is a spatial domain; denotes a differential operator that could include linear or nonlinear spatial derivatives of as well as source terms; is the initial state of , parameterized by that can have any dimension. The parameter space is denoted by . We consider a two-dimensional parameter space in this study, i.e., , although our method can be applied to problems with any positive integer value of .
The numerical solution to Eq. (1) can be obtained by numerical methods, such as the finite element method. We can obtain a residual function from the discrete system of equations. For example, let represent the semi-discretized full-order model (FOM) solution at time and is the degrees of freedom. With the implicit backward Euler time integrator, the approximate solution to Eq. (1) can be obtained by solving the following nonlinear discrete system of equations
| (2) |
where is the FOM solution at the -th time step and ; denotes the time step size and for where and is the number of time steps. The residual function of Eq. (2) is expressed as
| (3) |
Given a parameter , , we denote as the solution at the -th time step of the physical system defined in Eq. (1). The solutions at all time steps are arranged in a snapshot matrix denoted as . Compiling snapshot matrices corresponding to all parameters gives a complete FOM dataset .
In practical applications with complex physical phenomena, it is computationally expensive to solve the system of equation (Eq. (1)), especially when the degrees of freedom () is large and the computational domain () is geometrically complex. In this work, we aim to develop an accurate, efficient, and robust reduced-order modeling framework based on latent space dynamics identification, which will be discussed in detail in the following sections.
3 Weak-Form Greedy Latent Space Dynamics Identification (WgLaSDI)
In this section, we introduce the building blocks of the proposed WgLaSDI framework, including autoencoders, strong-form and weak-form latent space dynamics identification, -NN interpolation, greedy physics-informed active learning based on a residual error indicator, and generalization.
3.1 Autoencoders for Nonlinear Dimensionality Reduction
An autoencoder [55, 56] is a type of neural network designed for dimensionality reduction or representation (manifold) learning. It contains an encoder function and a decoder function , such that
| (4a) | |||
| (4b) | |||
where and are network parameters of the encoder and the decoder, respectively. The encoder transforms the high-dimensional input data to a low-dimensional latent representation , where is the latent dimension. Typically, is chosen to achieve dimensionality reduction. The decoder transforms the compressed data to a reconstructed version of , denoted as .
Given a FOM dataset , we can obtain the latent and reconstructed representations through the encoder and the decoder, denoted as and , respectively. The optimal network parameters of the autoencoder ( and from Eq. (4)) can be obtained by minimizing the loss function:
| (5) | ||||
3.2 Identification of Latent Space Dynamics
3.2.1 Strong Form
The low-dimensional latent variable () discovered by the autoencoder inherits the time dependency from the high-dimensional FOM variable (). The dynamics of the latent variable in the latent space can be described by an equation of the following form,
| (6) |
where and represents a Dynamics Identification (DI) function governing the latent space dynamics. can be approximated by a system of ODEs and identified by the sparse identification of nonlinear dynamics (SINDy) method [39].
| (7) |
where is a user-defined library that contains linear and nonlinear terms [39, 23, 24]; is a coefficient matrix associated with the parameter . The time derivative can be obtained by using the chain rule:
| (8) |
The coefficients of all parameters can be obtained by minimizing the following function:
| (9) | ||||
This loss function provides constraints to the encoder-predicted latent space dynamics () such that it is consistent with that from the DI model (), which is critical for discovery of simple and smooth latent dynamics and therefore model performance [24].
To further enhance the accuracy of the physical dynamics predicted by the decoder, the following loss function is constructed to ensure the consistency between the predicted dynamics gradients () and the gradients of the solution data ():
| (10) | ||||
where can be obtained by applying the chain rule:
| (11) |
Therefore, the loss function of gLaSDI is defined as
| (12) |
where and denote the regularization parameters to balance the scale and contributions from the loss terms.
3.2.2 Weak Form
The latent space dynamics identification described in Section 3.2.1 is based on the strong-form ODE. If the high-dimensional input data contains noise and errors, the latent representation could be nonlinear and oscillatory, which poses challenges to the strong-form dynamics identification. To enhance the robustness against noise, we leverage the variance-reduction nature of the weak form and integrate it into gLaSDI.
We begin by multiplying Eqs. (7) and (8) with a continuous and compactly supported test function and integrating them over a time domain:
| (13) |
| (14) |
When a piece-wise linear activation function, such as ReLU, is employed in the encoder network, is piece-wise constant, which is independent of time and can be taken out of the time integral in Eq. (14):
| (15) |
Due to the compact support of , we know that , and applying integration by parts yields:
| (16) |
We apply the trapezoidal rule to discretize the time integrals. Thus, the weak-form transformation allows to be computed without using the time derivative of the data (), which is challenging to obtain in the presence of noise. It contributes to the enhanced accuracy and stability of latent space dynamics identification, as will be demonstrated in Section 4. We note that alternatively, can be computed by directly applying integration by parts:
| (17) |
The weak-form loss function corresponding to the strong-form counterpart that enforces , as defined in Eq. (9), becomes
| (18) |
where is obtained by Eq. (13) and can be computed by either Eq. (16) or (17). We will compare the effects of these two approaches on the model performance in Section 4.
Similarly, we can derive the weak-form loss function corresponding to the strong-form counterpart defined in Eq. (10) that enforces
| (19) |
Multiplying Eq. (19) with the test function and integrating it over a time domain gives:
| (20) |
The right-hand side can be obtained from multiplying Eq. (11) with the test function and integrating it over a time domain:
| (21) | ||||
where can be taken out of the time integral when a piece-wise linear activation function is employed in the decoder network. Alternatively, can be obtained by directly applying integration by parts:
| (22) |
The weak-form loss function is defined as:
| (23) |
where and can be obtained by either Eq. (21) or (22). We will compare the effects of these two approaches on the model performance in Section 4.
The loss function of weak-form gLaSDI is defined as
| (24) | ||||
where the last term is a sparsity constraint of the ODE coefficients to achieve better-conditioned ODEs for the latent space. Fig. 1 depicts the interactive training of the autoencoder and WENDy in the proposed WgLaSDI framework to counteract noisy data. In this study, piece-wise polynomials are employed for the test function. For further details about the selection of test functions, please refer to [53, 50, 47].
3.3 Interpolation of Latent Space Dynamics
Each training parameter point in the parameter space is attached to a local DI model with its own ODE coefficients. The DI model for a testing parameter point can be obtained by interpolating the local DI model of training parameters. In gLaSDI, a -NN convexity-preserving partition-of-unity interpolation scheme is employed.
Given a testing parameter , the ODE coefficient matrix is obtained by a convex interpolation of coefficient matrices of its -nearest neighbors (existing training parameter points), expressed as
| (25) |
where is a set of indices of the -nearest neighbors (training parameter points) of . The selection of the -nearest neighbors is based on the Mahalanobis distance between the testing parameter and the training parameters, . The interpolation functions are defined as
| (26) |
which satisfy a partition of unity, , for transformation objectivity and convexity preservation. For more details and discussion, please refer to [24].
3.4 Greedy Physics-Informed Active Learning
To maximally explore the parameter space and achieve optimal model performance, gLaSDI employs a greedy physics-informed active learning strategy to sample training data on the fly. Given a testing parameter, the ROM prediction error is evaluated by an error indicator based on the residual of the governing equation:
| (27) |
where the residual function is defined in Eq. (3) and denotes the number of time steps used for the evaluation. Typically, is adopted to enhance evaluation efficiency.
The gLaSDI training is initiated with limited training samples (parameter points). In the examples of this study, the initial training parameter points are located at the corners of the parameter space. Greedy sampling is performed at every epochs, at which the current gLaSDI model is evaluated by a finite number of testing parameters based on the error indicator (Eq. (27)). The testing parameter associated with the largest error is added to the list of training parameter points. The corresponding FOM data is added to the training dataset before the training resumes. This physics-informed active learning process continues until a prescribed number of training samples is reached or the model prediction accuracy is satisfied. Please refer to [24] for more details about the greedy physics-informed active learning algorithms and procedures.
3.5 Generalization
Given a testing parameter , we first estimate its DI coefficient by interpolating the DI coefficients of its nearest neighboring training parameters using Eq. (25)) as introduced in Section 3.3. After that, we compute the initial condition of the latent variables and predict the latent space dynamics () by solving the set of ODE corresponding to (Eq. (7)) using a numerical integrator. Finally, the prediction of the full-order dynamics can be obtained by the decoder, .
4 Numerical results
The performance of WgLaSDI is demonstrated by solving four numerical problems: a one-dimensional (1D) inviscid Burgers’ equation, a two-dimensional (2D) viscous Burgers’ equation, time-dependent radial advection, and a two-stream plasma instability problem. In each of the numerical examples, WgLaSDI’s performance is compared with that of gLaSDI [24] and WLaSDI [26] using the maximum relative error defined as:
| (28) |
The training is performed on an NVIDIA V100 (Volta) GPU from the Livermore Computing Lassen system at the Lawrence Livermore National Laboratory, with 3,168 NVIDIA CUDA Cores and 64 GB GDDR5 GPU Memory. The open-source TensorFlow library [57] and the Adam optimizer [58] are employed. WgLaSDI testing and high-fidelity simulations are performed on an IBM Power9 CPU with 128 cores and 3.5 GHz.
4.1 1D Burgers’ equation
We first consider a 1D inviscid Burgers’ equation with a periodic boundary condition and an initial condition parameterized by :
| (29) |
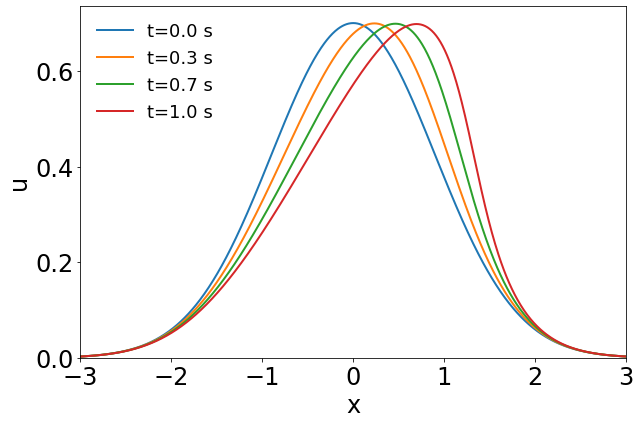
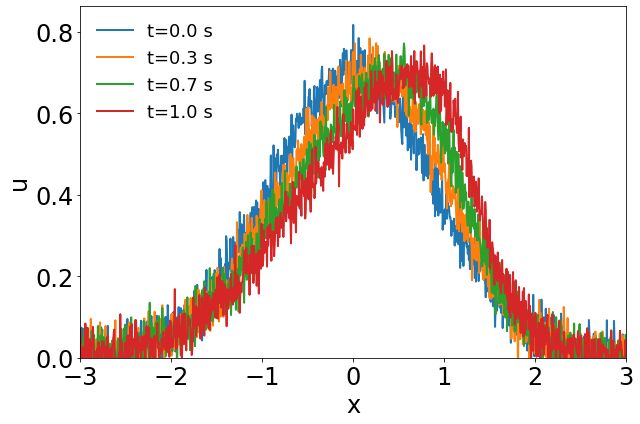
The parameter space in this example is defined as , which is discretized by , leading to a grid of parameters. High-fidelity simulations adopt a uniform spatial discretization with a nodal spacing of and Backward Euler time integration with . A Gaussian white noise component () is added to the high-fidelity simulation data. The solution at several time steps of the parameter case and the corresponding noisy data used for training are shown in Fig. 2.
4.1.1 Effects of Weak-Form Dynamics Identification
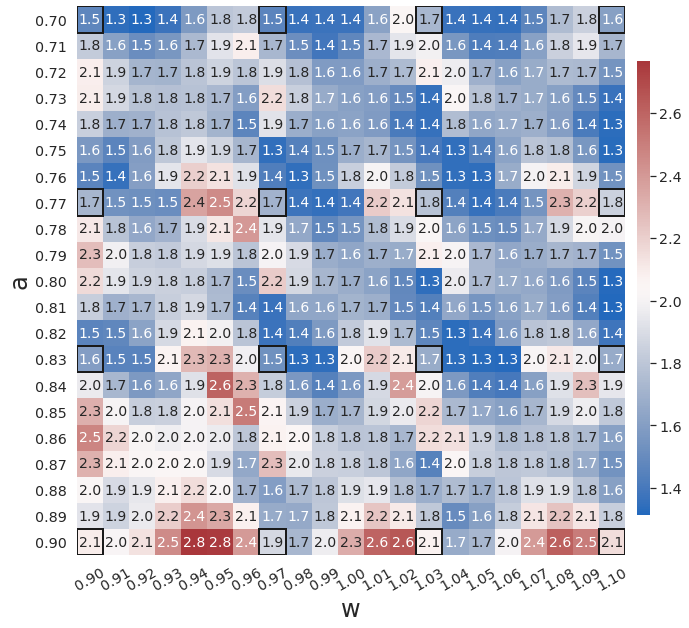
In the first test, we demonstrate the effects of the weak form on prediction accuracy when dealing with noisy training data. Both gLaSDI and WgLaSDI are trained by 16 predefined training samples uniformly distributed on the parameter space . We employ an architecture of 1,001-100-5 () with ReLU activation for the encoder and a symmetric architecture for the decoder. Linear polynomials are adopted as basis functions for latent space dynamics identification. The hyperparameters in the WgLaSDI loss function (Eq. (24)) are defined as , and , while those in the gLaSDI loss function (Eq. (12)) are defined as and . We investigated two WgLaSDI loss functions, i.e., Type I based on Eqs. (16) and (21) and Type II based on Eqs. (17) and (22). The training is performed for 20,000 epochs. For -NN interpolation of latent space dynamics, is employed for both gLaSDI and WgLaSDI.
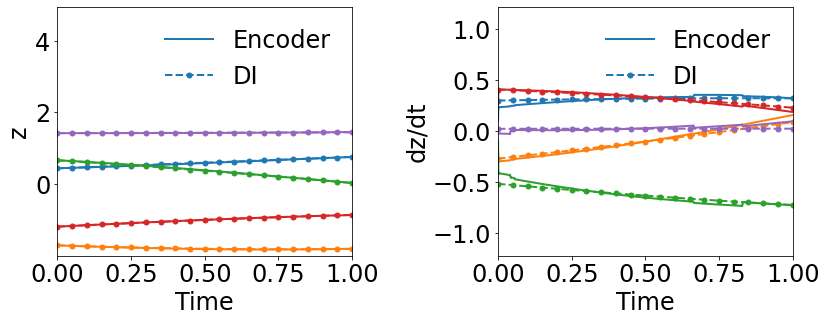
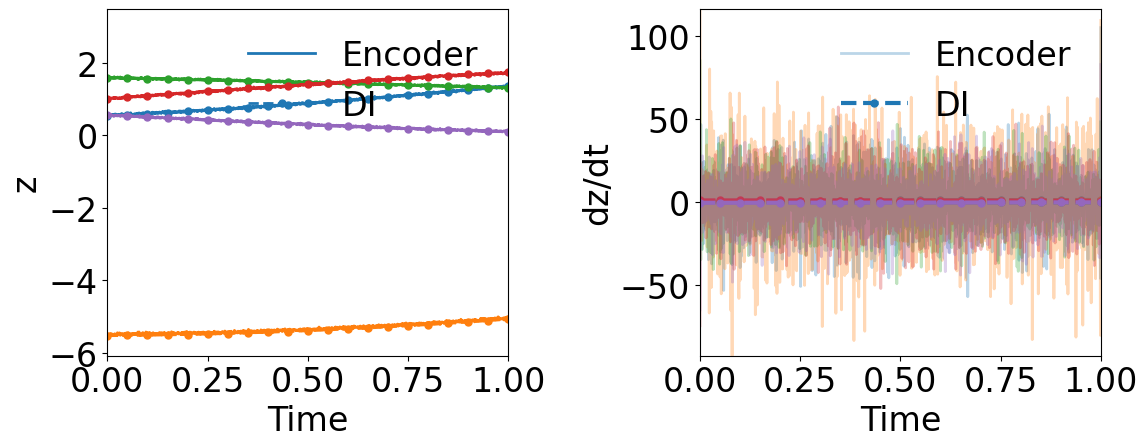
Fig. 3 compares the latent space dynamics and maximum relative errors from gLaSDI and WgLaSDI (based on the Type-I loss function) over the parameter space. Fig. 3(a-b) shows that the DI model (SINDy) in gLaSDI struggles to learn the latent space dynamics predicted by the encoder, while the DI model (WENDy) in WgLaSDI successfully identifies the latent space dynamics. The consistency between the encoder-predicted and the DI-predicted latent space dynamics is critical to the prediction accuracy of the physical dynamics as reflected in Fig. 3(c-d). WgLaSDI outperforms gLaSDI in the whole parameter space, achieving at most 1.5 error vs. 285 of gLaSDI. It is worth mentioning that the loss function of gLaSDI, as defined in Eq. (10) and (12), requires the gradient of the dynamics data, which is very oscillatory when the data contains noise, as shown in Fig. 4, leading to difficulties in training. In contrast, the weak-form loss function of WgLaSDI, as defined in Eq. (18), (23), and (24), avoids the need for the data gradient and takes advantage of the gradient of the test function, which is noise invariant, leading to significantly improved learning performance. The results of this test demonstrate that the weak form enhances the accuracy and robustness of latent space dynamics identification in the presence of noise.
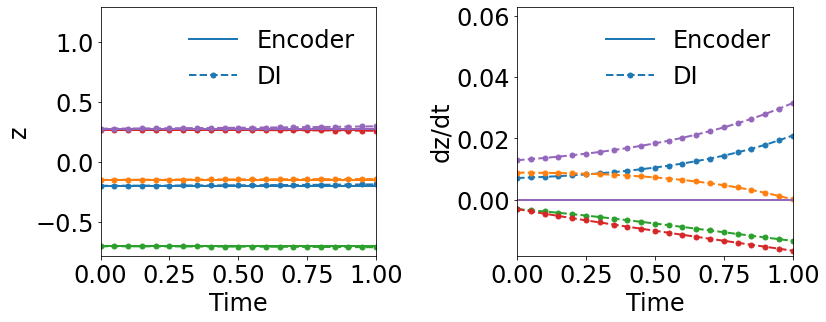
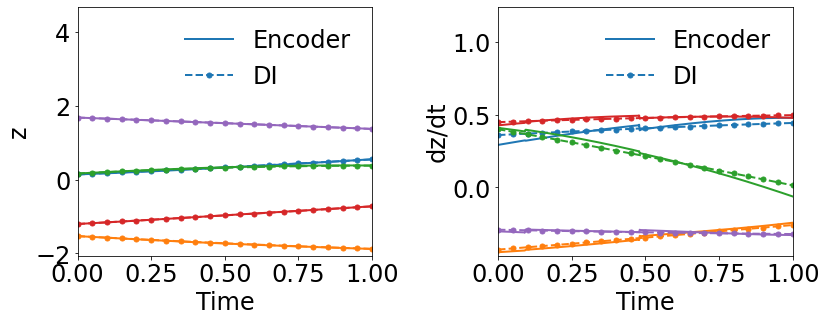
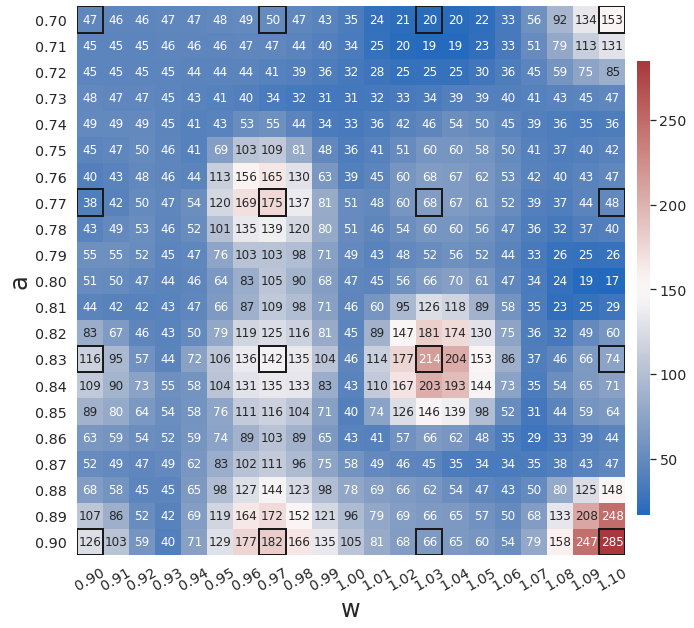
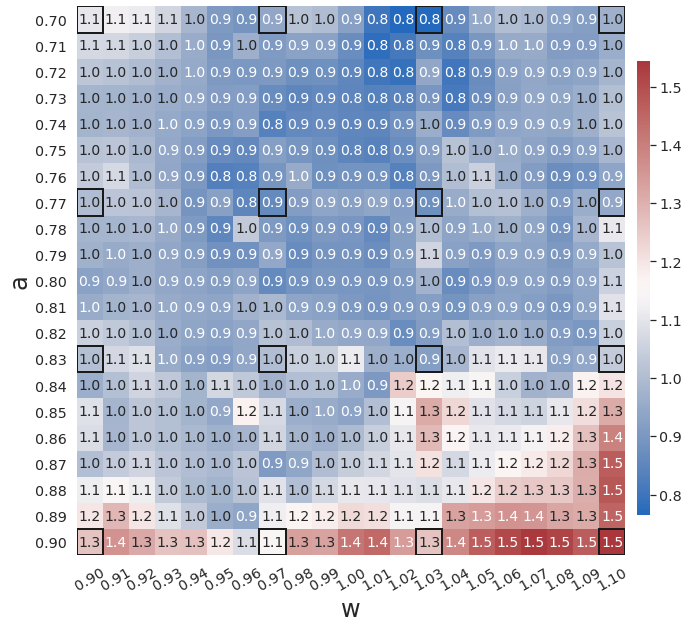
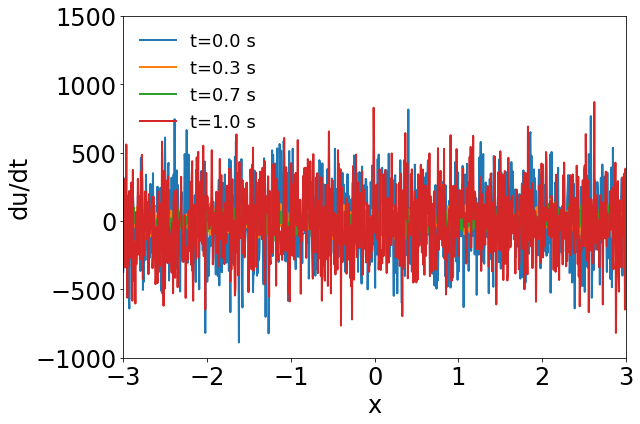
Fig. 5(a) and (c) show that WgLaSDI trained by the Type-II loss function also successfully identifies simple latent space dynamics and achieved a maximum error of 2.8, slightly higher than that (1.5) of WgLaSDI based on the Type-I loss function (Fig. 3(d)). The enhanced prediction accuracy achieved by the Type-I loss function is contributed by the involvement of the gradients of the encoder and the decoder networks, leading to stronger constraints on the autoencoder.
4.1.2 Effects of Simultaneous Training
In the second test, we compare the effects of fitting the surrogate DI model simultaneously while training the autoencoder versus a sequential training approach. Specifically, we compare the weak-form gLaSDI with the weak-form LaSDI [26]. For a fair comparison, hyperparameters such as the autoencoder architecture and the DI basis function, as well as the data are kept the same between the two methods. Fig. 5(b) and (d) show the results of WLaSDI, with a maximum error of across the entire parameter space, slightly larger than those from WgLaSDI for both types of losses. The error from WLaSDI includes both the projection error introduced by the autoencoder and the DI error from WENDy, with the projection error being the predominant factor. As discussed in Section 4.1.1, it is critical to ensure the consistency between the encoder-predicted and the DI-predicted latent space dynamics for satisfactory prediction accuracy of the physical dynamics. Due to the lack of interaction between the autoencoder and WENDy of WLaSDI, there is no constraint and regularization from the DI model on the autoencoder, leading to oscillatory latent dynamics from the encoder, as shown in the latent dynamics gradient () in Fig. 5(b). Although WENDy’s variance reduction capability enables it to learn the oscillatory latent dynamics from the encoder, the inconsistency between their predicted latent dynamics still leads to large projection errors of the physical dynamics. This highlights the impact of using simultaneous training versus the sequential approach.
4.1.3 Effects of Greedy Physics-Informed Active Learning
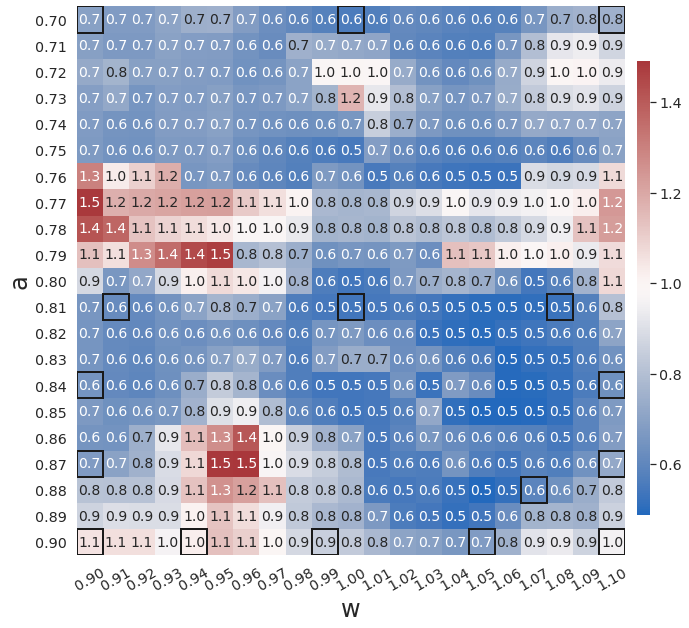
In the previous tests, the training samples are predefined on a uniform grid in the parameter space, which may not be optimal, especially for highly nonlinear physical systems. The greedy physics-informed active learning strategy in WgLaSDI allows maximum exploration of the parameter space and optimal samples to be selected on the fly during the training process. To demonstrate that, we train WgLaSDI using the same autoencoder and DI basis functions as defined in Section 4.1.1 together with active learning.
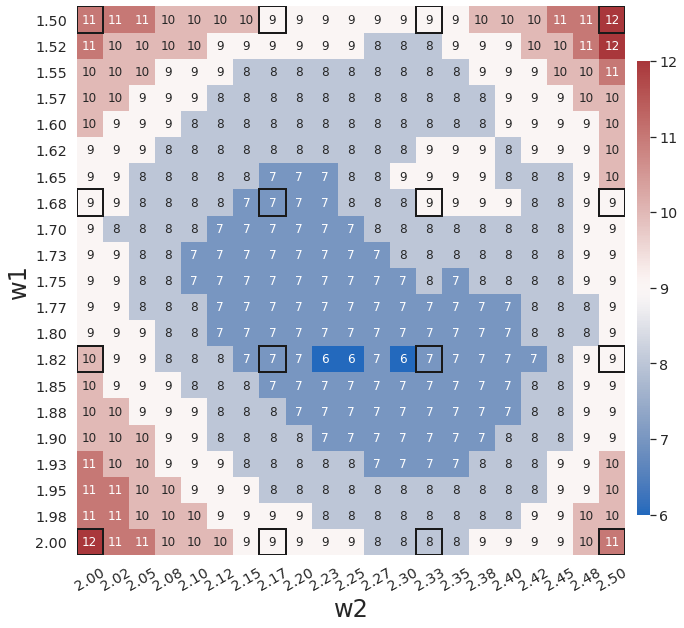
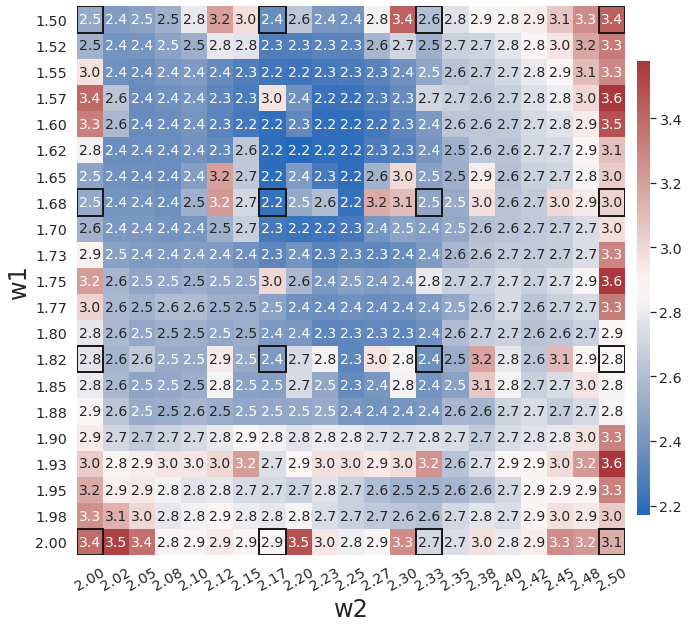
WgLaSDI without active learning already achieves excellent performance, with at most 1.5 maximum relative error over the parameter space, as shown in Fig. 3(d). WgLaSDI with active learning achieves the same maximum error (1.5) over the parameter space, as shown in Fig. 6, with an average error of 0.75, slightly lower than that (1.0) of WgLaSDI without active learning. It is observed that active learning tends to guide WgLaSDI to select more samples in the higher range of . The test results show that physics-informed active learning could potentially guide WgLaSDI to select samples for enhanced prediction accuracy over the parameter space. Compared with the high-fidelity simulation (in-house Python code) that has an around maximum relative error with respect to the high-fidelity data used for WgLaSDI training, WgLaSDI achieves 121 speed-up.
4.2 2D Burgers’ equation
In the second example, we consider a 2D viscous Burgers’ equation with an essential boundary condition and an initial condition parameterized by :
| (30) |
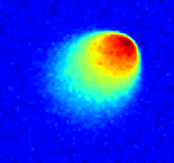
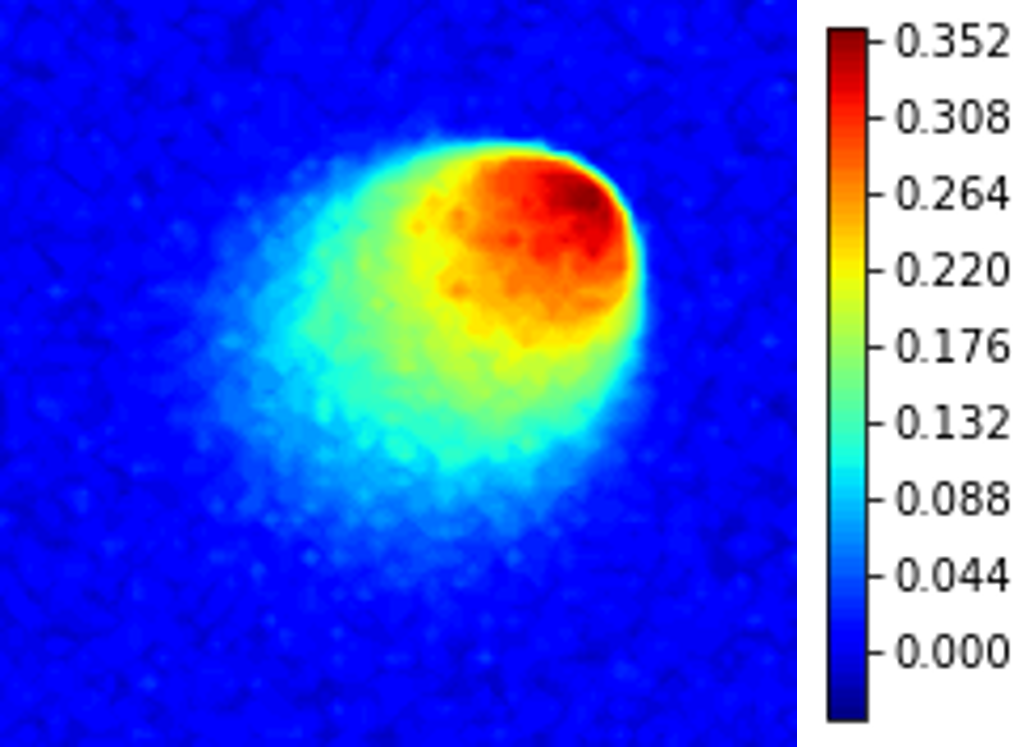
where a Reynolds number of is considered. The parameter space in this example is defined as , which is discretized by , leading to a grid of parameters. The first-order spatial derivative and the diffusion term are approximated by the backward difference and the central difference schemes, respectively. High-fidelity simulations adopt a uniform spatial discretization with nodal spacing of and Backward Euler time integration with . A Gaussian white noise component is added to the high-fidelity simulation data. The noisy dynamics data of the first velocity component of the parameter case are shown in Fig. 7.


4.2.1 Effects of Weak-Form Dynamics Identification
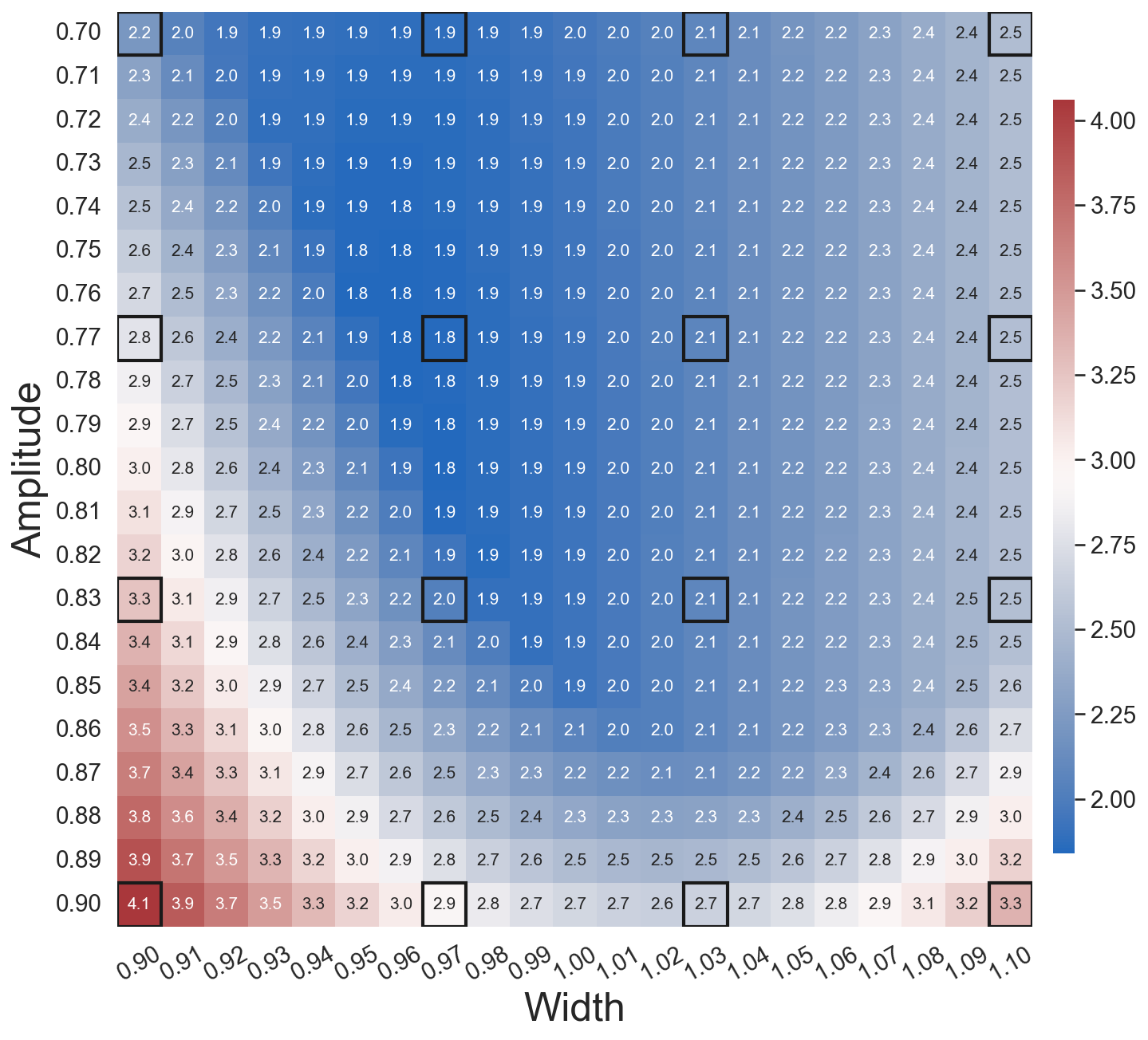
In the first test, we demonstrate the effects of the weak form on prediction accuracy when dealing with noisy training data. Both gLaSDI and WgLaSDI are trained by 25 predefined training samples uniformly distributed on the parameter space . We employ an architecture of 7200-100-5 () with ReLU activation for the encoder and a symmetric architecture for the decoder. Quadratic polynomials are adopted as basis functions for latent space dynamics identification. The hyperparameters in the loss functions (Eq. (24)) are defined as , and , while those in the gLaSDI loss function (Eq. (12)) are defined as and . We investigated two WgLaSDI loss functions, i.e., Type-I based on Eqs. (16) and (21) and Type-II based on Eqs. (17) and (22). The training is performed for 100,000 epochs. For -NN interpolation of latent space dynamics, is employed for both gLaSDI and WgLaSDI.
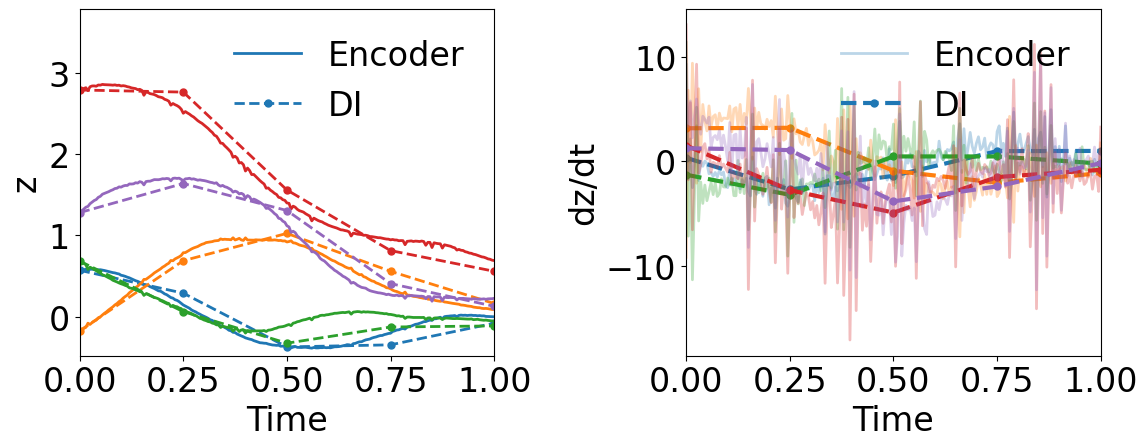
Fig. 8 shows that WgLaSDI (based on the Type-I loss function) outperforms gLaSDI in learning latent space dynamics in the presence of noise, achieving at most 7.2 error vs. 3,051 of gLaSDI across the parameter space. It further demonstrates the enhanced robustness and performance against noise due to the weak-form latent space dynamics identification.
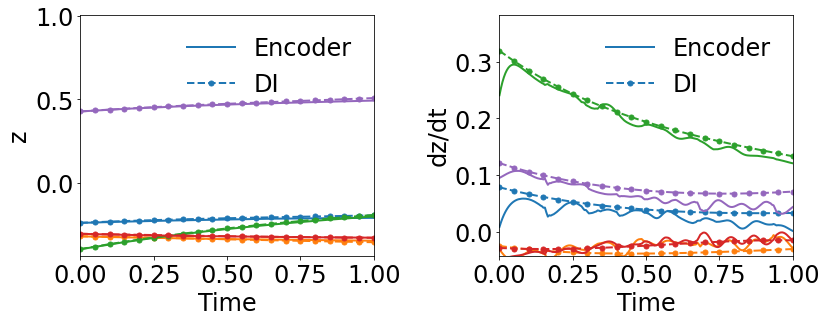
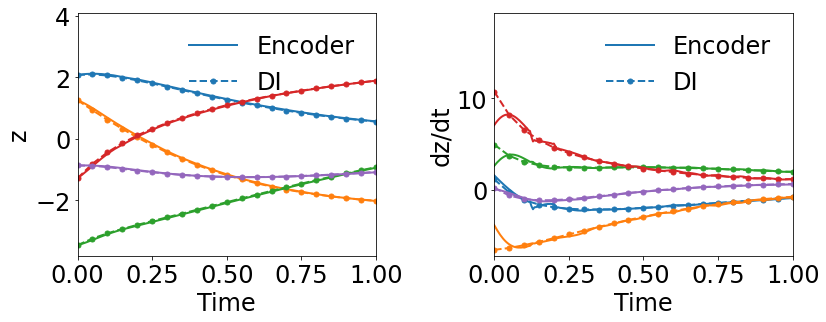
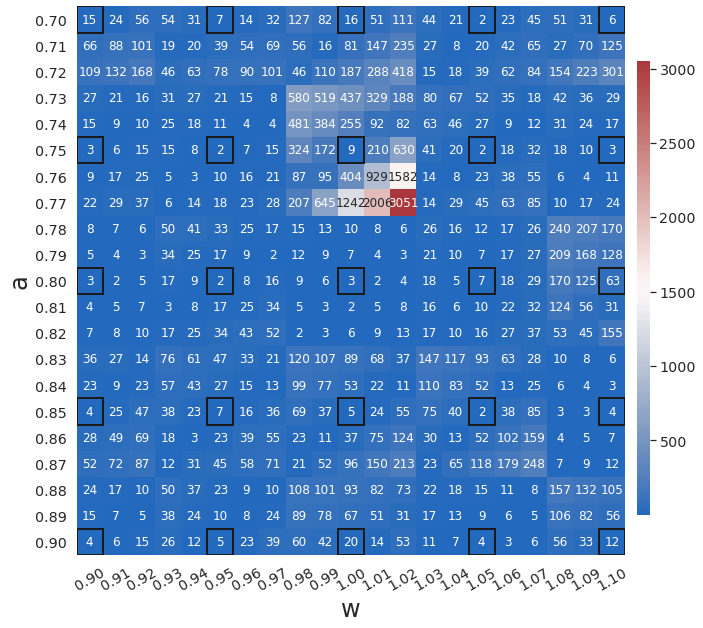
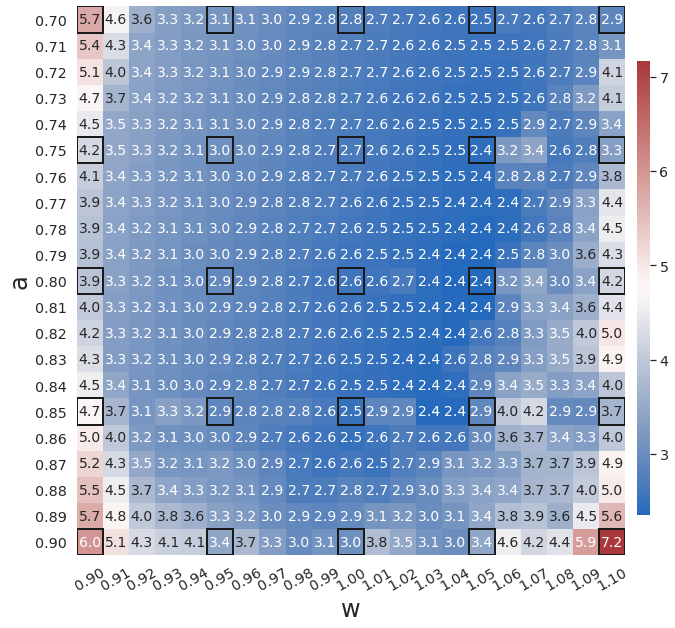
Fig. 9(a) shows the latent space dynamics identified by WgLaSDI based on the Type-II loss function, which is more oscillatory than that from the Type-I loss (Fig. 8(b)). Fig. 9(c) shows that WgLaSDI based on the Type-II loss achieves a maximum error of 10, higher than that (7.2) from the Type-I loss (Fig. 8(d)). It further demonstrates the enhanced performance achieved by the Type-I loss function. We will adopt the Type-I loss function for WgLaSDI in the following examples.
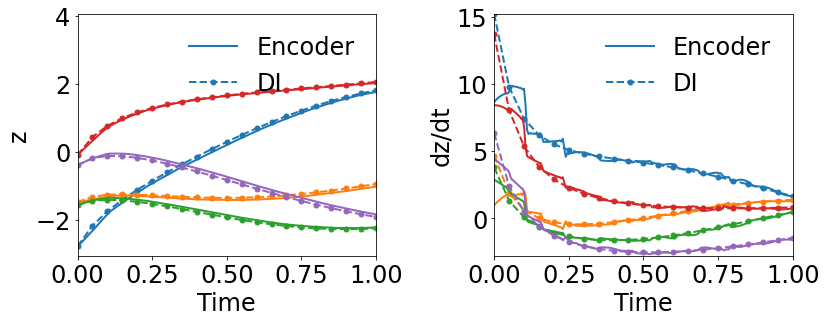
4.2.2 Effects of Simultaneous Training
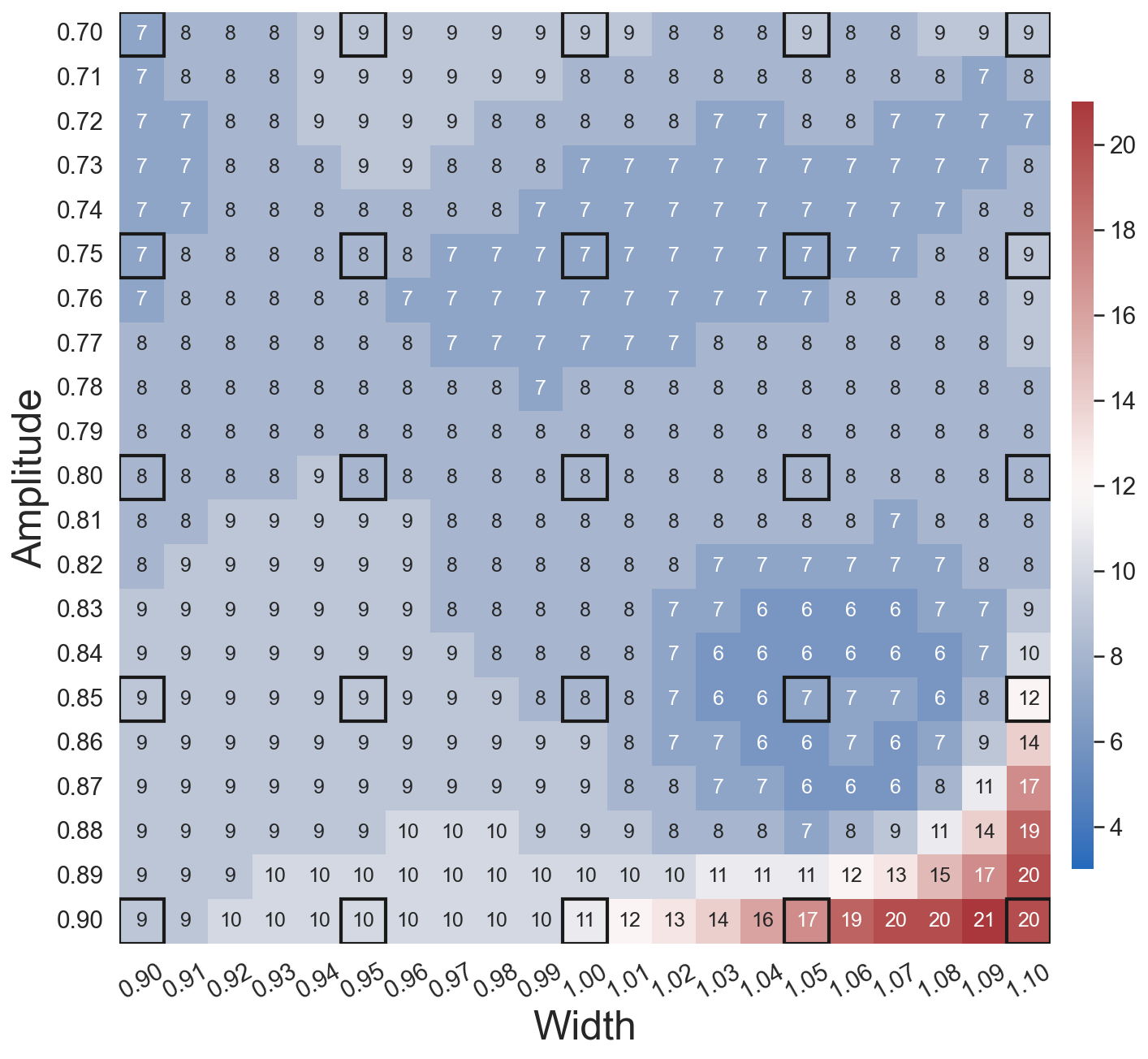
In the second test, we further demonstrate the effects of simultaneous training of the autoencoder and the DI model by comparing WgLaSDI with WLaSDI. WLaSDI is trained using the same autoencoder, DI basis functions, and data as those employed for WgLaSDI in Section 4.2.1. As shown in Fig. 9(d), the WLaSDI error ranges from 6 to 20, significantly larger than that of WgLaSDI for both types of losses (Fig. 8(d) and Fig. 9(c)). Comparing Fig. 8(b) and Fig. 9(a) with Fig. 9(b) shows that simultaneous training enforces constraints on the latent space dynamics discovered by the autoencoder through the interaction with the DI model, enabling simpler latent space dynamics, reduced projection and DI errors, and therefore better generalization performance.
4.2.3 Effects of Greedy Physics-Informed Active Learning
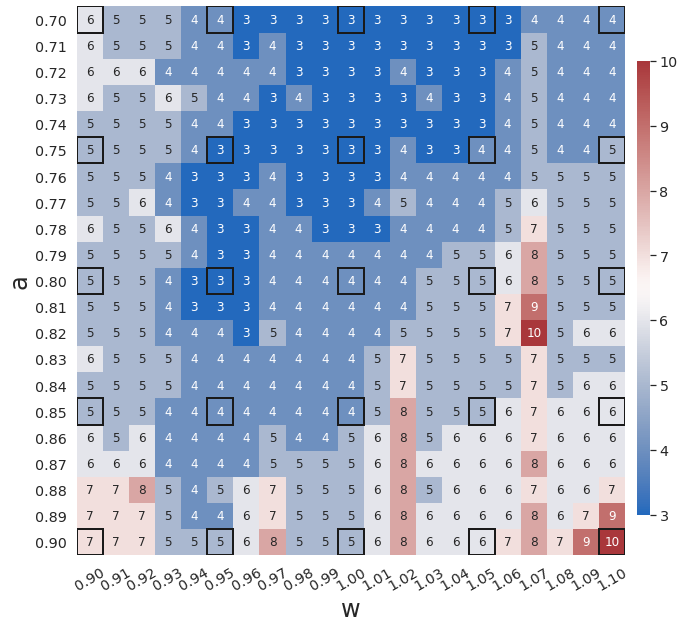
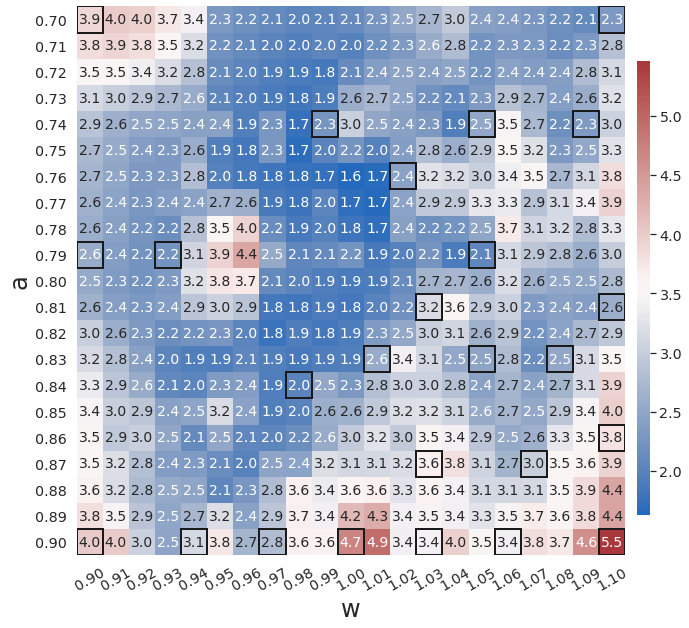
To demonstrate the effects of the greedy physics-informed active learning strategy in WgLaSDI on the model performance, we train WgLaSDI using the same autoencoder and DI basis functions defined in Section 4.2.1 together with active learning. Fig. 10 shows that WgLaSDI with active learning achieves at most 5.5 error over the parameter space, lower than that (7.2) of WgLaSDI without active learning, as shown in Fig. 8(d). Interestingly, active learning tends to guide WgLaSDI to select more samples in the higher range of to achieve better performance in the parameter space. Compared with the high-fidelity simulation (in-house Python code) that has an around maximum relative error with respect to the high-fidelity data used for WgLaSDI training, WgLaSDI achieves 1,374 speed-up.
4.3 Time-dependent radial advection
In the third example, we consider a 2D time-dependent radial advection problem with an initial condition parameterized by :
| (31) |
where denotes the fluid velocity and . The parameter space in this example is defined as , which is discretized by , leading to a grid of parameters. In high-fidelity simulations, the spatial domain is discretized by first-order periodic square finite elements constructed on a uniform grid of discrete points. The fourth-order Runge-Kutta explicit time integrator with a uniform time step of is employed. A Gaussian white noise component is added to the high-fidelity simulation data. The noisy dynamics data of the parameter case are shown in Fig. 11.
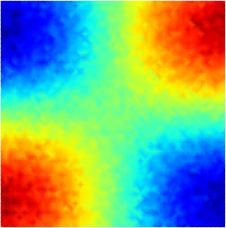
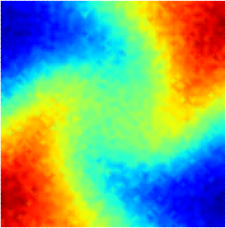
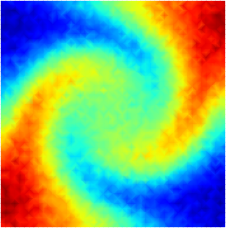
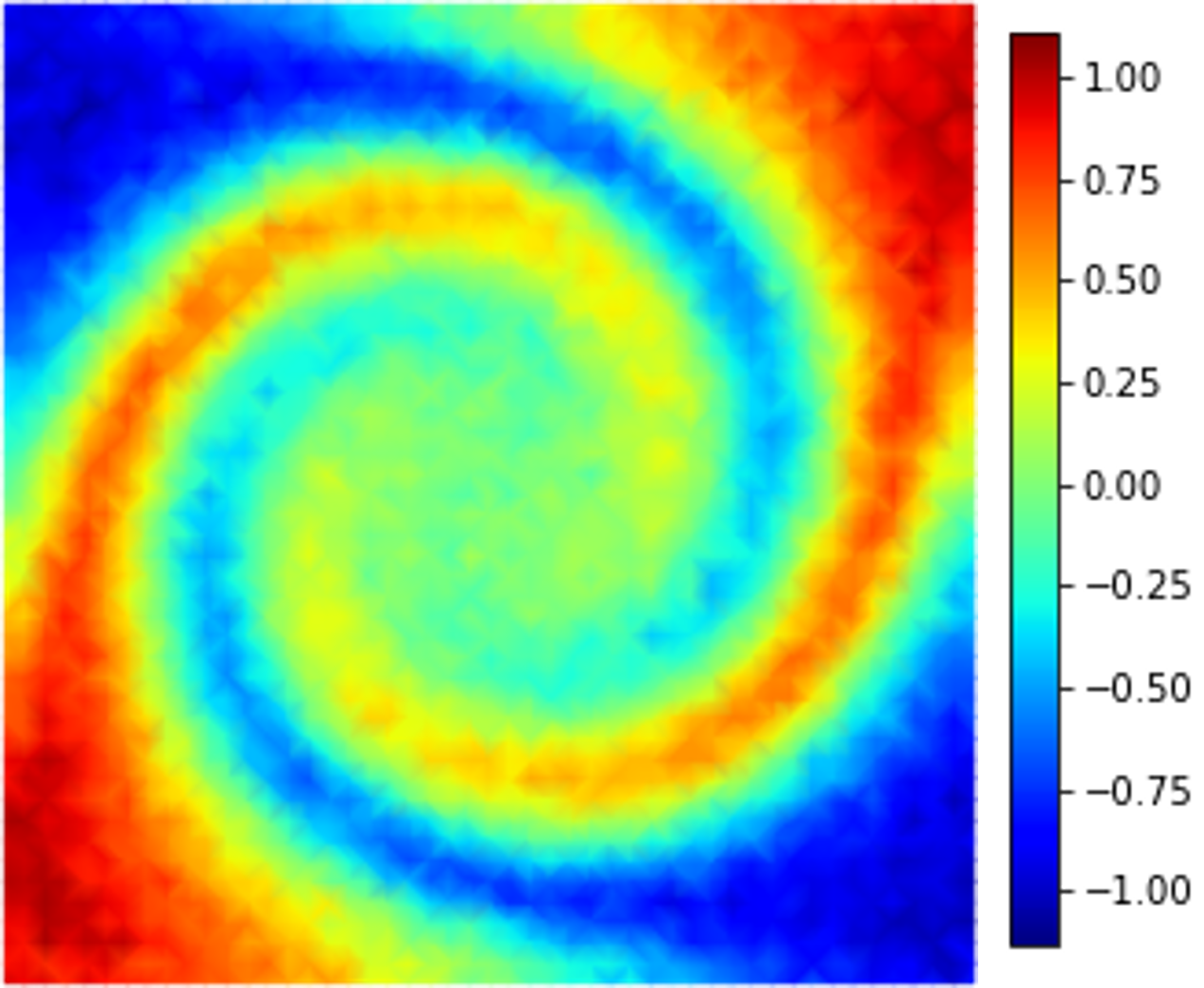
4.3.1 Effects of Weak-Form Dynamics Identification
To examine the effects of the weak form on model performance when dealing with noisy data, we train gLaSDI and WgLaSDI using 16 predefined samples uniformly distributed on the parameter space . Both models adopt an architecture of 9,216-100-3 () with ReLU activation for the encoder and a symmetric architecture for the decoder, with linear polynomials as basis functions for latent space dynamics identification. The hyperparameters in the WgLaSDI loss function (Eq. (24)) are defined as , and , while those in the gLaSDI loss function (Eq. (12)) are defined as and . The training is performed for 100,000 epochs. For -NN interpolation of latent space dynamics, is employed for both gLaSDI and WgLaSDI.
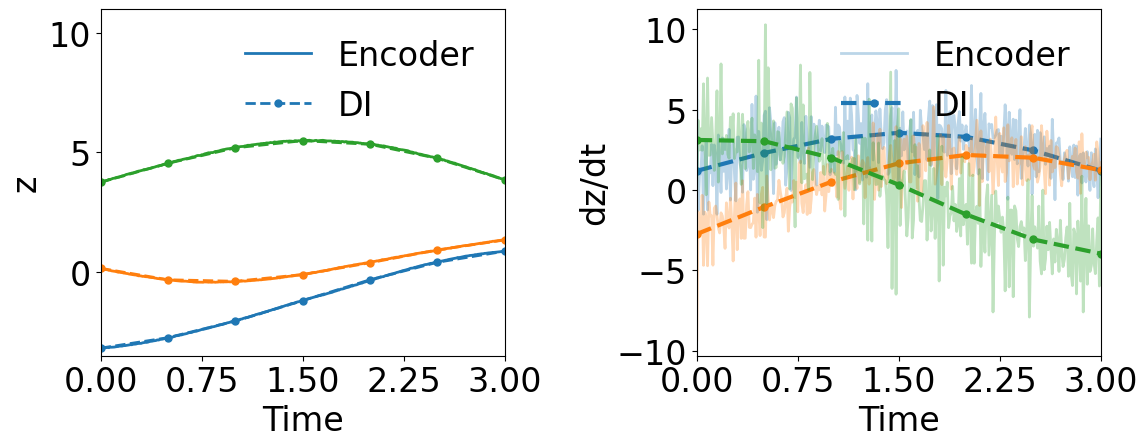
Fig. 12 shows that WgLaSDI outperforms gLaSDI in learning latent space dynamics in the presence of noise, achieving at most 3.6 error vs. 12.6 of gLaSDI across the parameter space. WgLaSDI demonstrates enhanced robustness and performance against noise due to the weak-form dynamics identification.
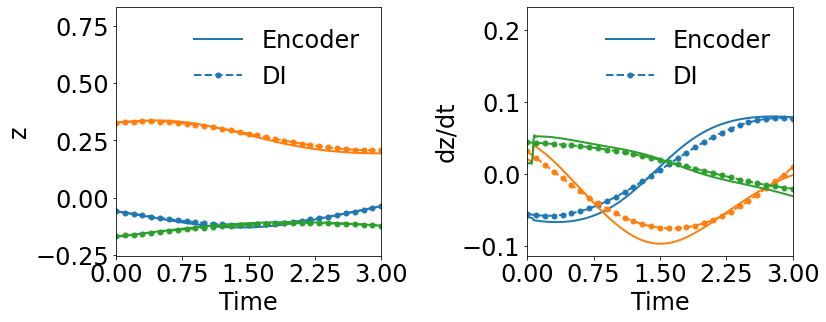
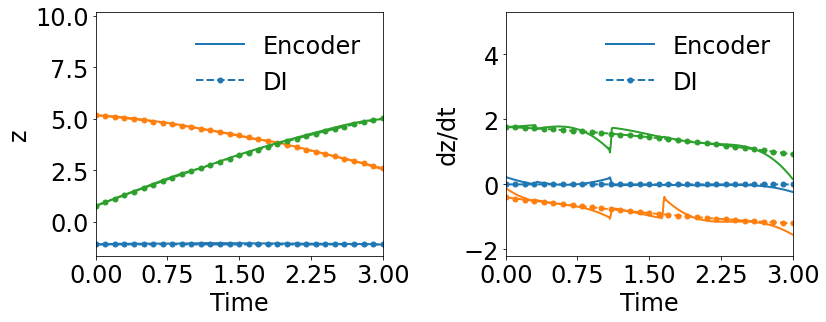
4.3.2 Effects of Simultaneous Training
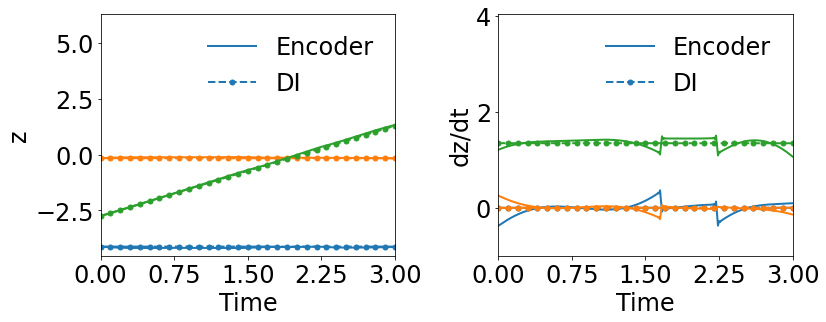
The effect of simultaneous training is further illustrated in this example of radial advection. Both WgLaSDI and WLaSDI employ the same autoencoder, DI basis functions, and data described in Section 4.3.1. According to Fig. 13(c), WLaSDI achieves a maximum error of 3.8 across the entire parameter space, slightly higher than that (3.6) of WgLaSDI (Fig. 12(d)). It further demonstrates the effectiveness and advantages of simultaneous training.
4.3.3 Effects of Greedy Physics-Informed Active Learning
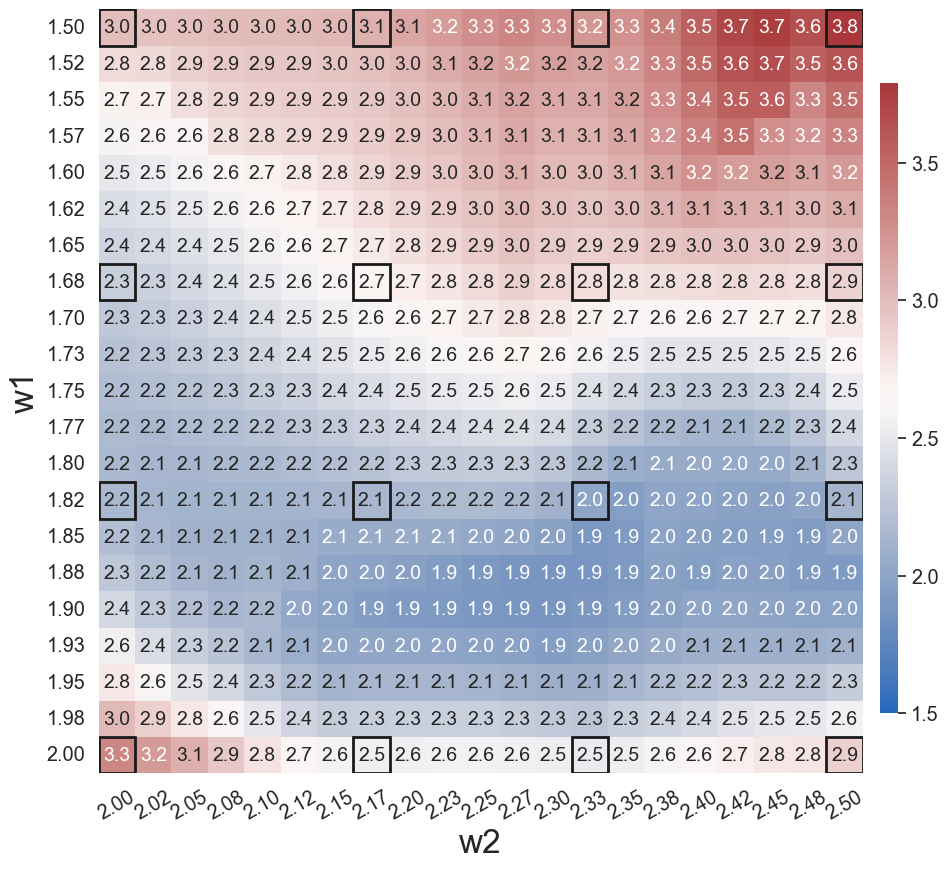
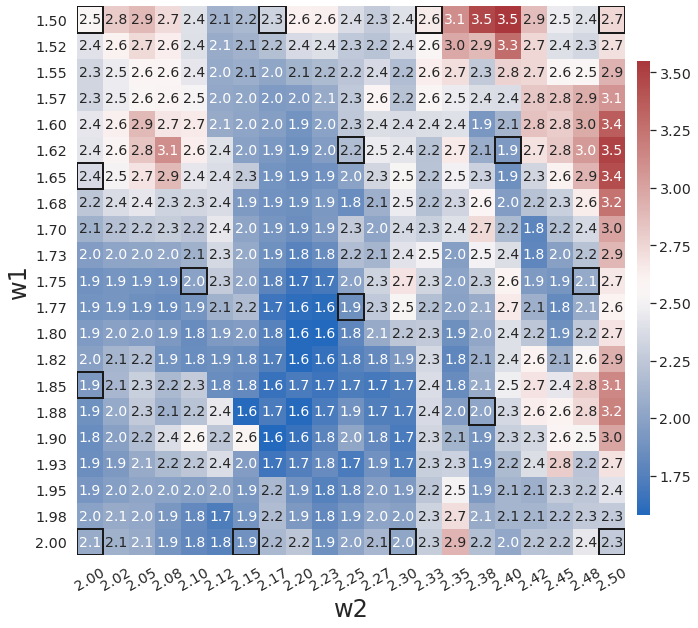
To further demonstrate the effects of the greedy physics-informed active learning on model performance, we train WgLaSDI using the same autoencoder and DI basis functions defined in Section 4.2.1 together with active learning. Fig. 13 shows that physics-informed active learning helps WgLaSDI to further reduce the maximum error from 3.6 to 3.5 and the average error from 2.7 to 2.2 in the parameter space. Compared with the high-fidelity simulation (MFEM [59]) that has an around maximum relative error with respect to the high-fidelity data used for WgLaSDI training, the WgLaSDI model achieves 178 speed-up.
4.4 1D-1V Vlasov Equation
In the last example, we consider a simplified 1D-1V Vlasov-Poisson equation with an initial condition parameterized by :
| (32) |
where is the plasma distribution function, dependent on a spatial coordinate and a velocity coordinate and is the electrostatic potential. This simplified model describes 1D collisionless electrostatic plasma dynamics, which is representative of complex models for plasma behaviors occurring in nuclear fusion reactors. This is a 2D PDE due to the velocity variable. The parameter space in this example is defined as , which is discretized by , leading to a grid of parameters. High-fidelity simulations are performed using the HyPar solver [60] with a WENO spatial discretization [61] and the fourth-order Runge-Kutta explicit time integration scheme (). A Gaussian white noise component is added to the high-fidelity simulation data. The noisy dynamics data of the parameter case are shown in Fig. 14.
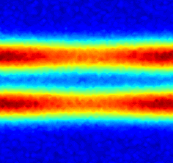
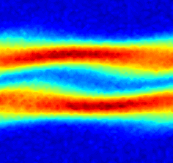

4.4.1 Effects of Weak-Form Dynamics Identification
To examine the effects of the weak form on model performance when dealing with noisy training data, we train gLaSDI and WgLaSDI using 16 predefined samples uniformly distributed on the parameter space . Both models adopt an architecture of 4,096-1000-100-50-50-50-3 () with ReLU activation for the encoder and a symmetric architecture for the decoder, with linear polynomials as basis functions for latent space dynamics identification. The hyperparameters in the WgLaSDI loss function (Eq. (24)) are defined as , and , while those in the gLaSDI loss function (Eq. (12)) are defined as and . The training is performed for 400,000 epochs. For -NN interpolation of latent space dynamics, is employed for both gLaSDI and WgLaSDI.
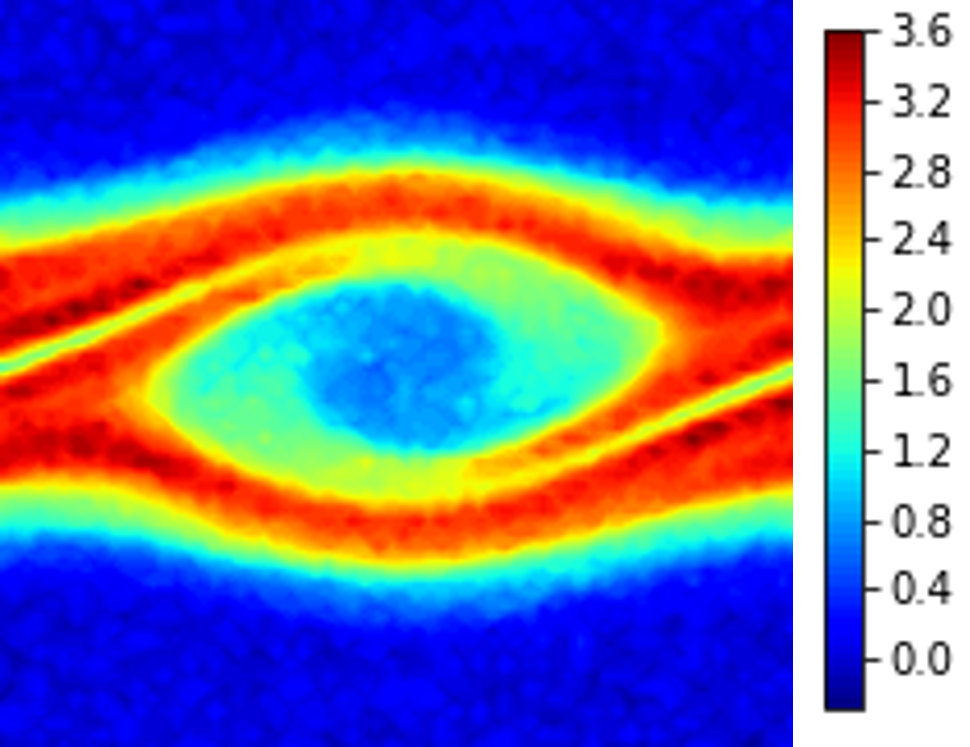
Fig. 15 shows that WgLaSDI achieves at most 7.1 error in the parameter space, significantly lower than 953 of gLaSDI. WgLaSDI again demonstrates enhanced robustness and performance against noise. Compared with the high-fidelity simulation (HyPar [60]), the WgLaSDI model achieves 1,779 speed-up.
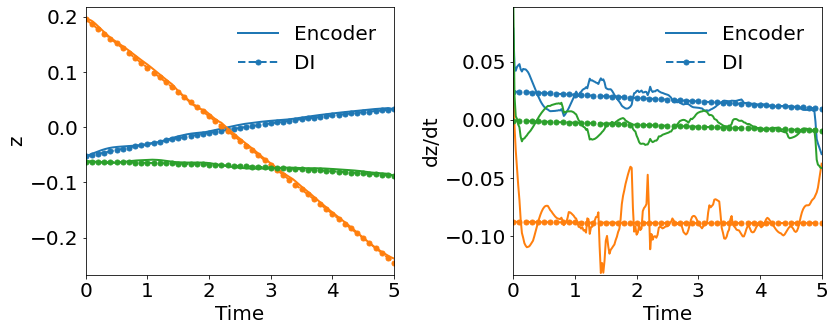
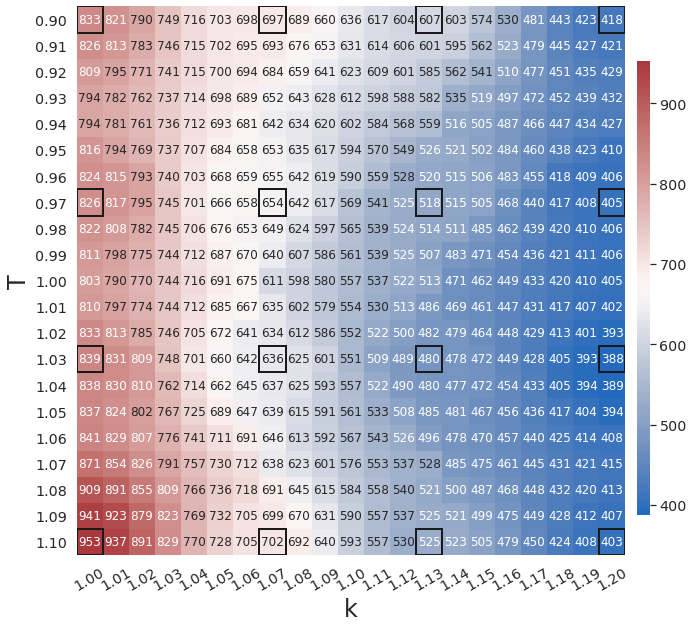
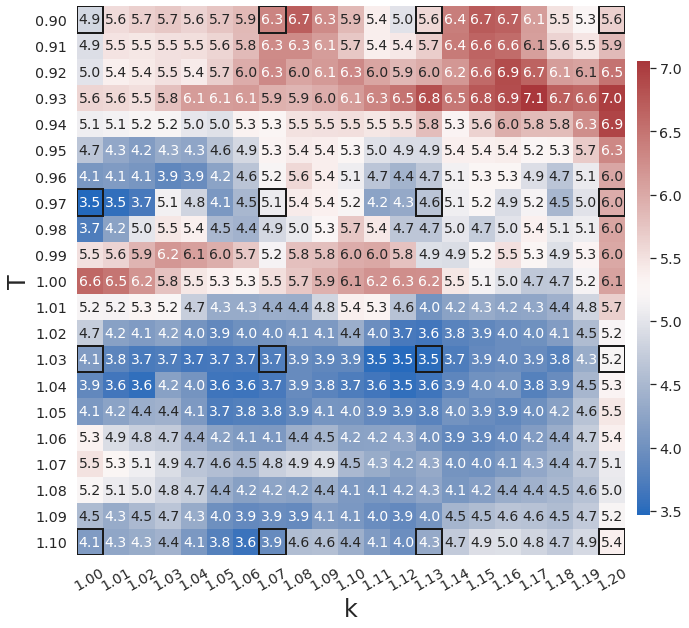
4.4.2 Effects of Simultaneous Training
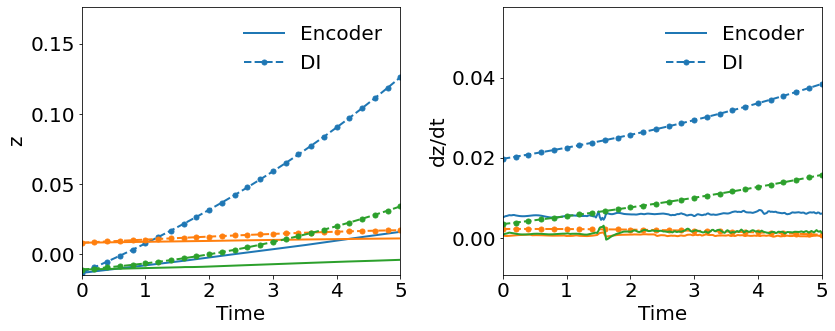
We trained a WLaSDI with the same autoencoder, DI basis functions, and data described in Section 4.4.1. The large discrepancy between the encoder-predicted and the DI-predicted latent space dynamics from WLaSDI, as shown in Fig. 16(a), leads to larger errors (20 to 26) across the parameter space (Fig. 16(b)) than those (3.5 - 7.1) of WgLaSDI (Fig. 15(d)). It again highlights that simultaneous training enhances latent space dynamics learning and contributes to simpler latent space dynamics with a stronger connection and consistency between the autoencoder and the DI model, leading to better performance.
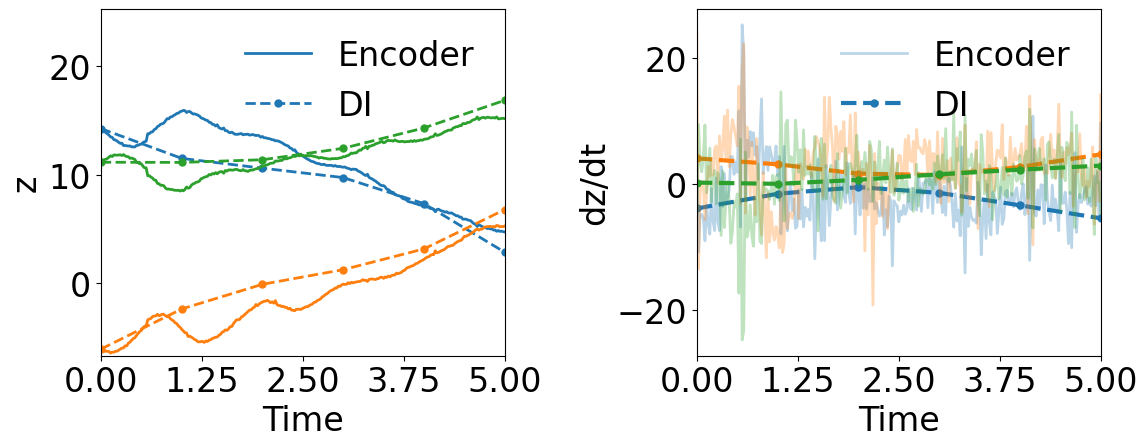
5 Conclusions
In this study, we introduced a weak-form greedy latent-space dynamics identification (WgLaSDI) framework to enhance the accuracy and robustness of data-driven ROM against noisy data. Built upon gLaSDI, the proposed WgLaSDI framework consists of an autoencoder for nonlinear dimensionality reduction and WENDy for latent-space dynamics identification. The autoencoder and WENDy models are trained interactively and simultaneously through minimizing a weak-form loss function defined in Eq. (24), enabling identification of simple latent-space dynamics for improved accuracy, efficiency, and robustness of data-driven computing. The greedy physics-informed active learning based on a residual-based error indicator facilitates parameter space exploration and searches for the optimal training samples on the fly.
We demonstrated that the proposed WgLaSDI framework is applicable to a wide range of physical phenomena, including viscous and inviscid Burgers’ equations, time-dependent radial advection, and two-stream plasma instability. We investigated the effects of various key ingredients of the WgLaSDI framework, including the weak-form latent space dynamics identification, simultaneous training of the autoencoder and DI models, and greedy physics-informed active learning, by comparing WgLaSDI with gLaSDI and WLaSDI in terms of their performance against noisy data. WgLaSDI demonstrated superior performance, with enhanced accuracy and robustness, achieving 1-7 relative errors and 121 to 1,779 speed-up (to the high-fidelity models).
Although the parametrization in this study considers only the parameters from the initial conditions, the parameterization can be easily extended to account for other parameterization types, such as governing equations and material properties, as demonstrated in [24], which could be useful for inverse problems. To further improve the proposed framework, automatic neural architecture search [62] could be leveraged to optimize the autoencoder architecture automatically and maximize generalization performance. Although the greedy physics-informed active learning in WgLaSDI offers great advantages for optimal performance with minimal data, it cannot be applied to noisy data when the physics is unknown. Extension with data-driven active learning based on uncertainty quantification, such as GPLaSDI [27], could be a promising solution.
Acknowledgements
This work was supported in part by a Rudy Horne Fellowship to AT. This work also received partial support from the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, as part of the CHaRMNET Mathematical Multifaceted Integrated Capability Center (MMICC) program, under Award Number DE-SC0023164 to YC at Lawrence Livermore National Laboratory, and under Award Number DE-SC0023346 to DMB at the University of Colorado Boulder. Lawrence Livermore National Laboratory is operated by Lawrence Livermore National Security, LLC, for the U.S. Department of Energy, National Nuclear Security Administration under Contract DE-AC52-07NA27344. IM release number: LLNL-JRNL-865859. This work also utilized the Blanca condo computing resource at the University of Colorado Boulder. Blanca is jointly funded by computing users and the University of Colorado Boulder, United States.
Data Availability
The dataset of the 1D Burgers’ equation and 2D Burgers’ equation can be generated using the open-source gLaSDI code available at https://github.com/LLNL/gLaSDI. The dataset of the time-dependent radial advection problem can generated using the open-source MFEM code (example 9) available at https://github.com/mfem/mfem/tree/master. The dataset of the Vlasov equation for plasma physics can be generated using the open-source HyPar solver available at https://github.com/debog/hypar.
Conflict of interest
The authors declare that they have no conflict of interest.
References
- [1] Jos Thijssen “Computational physics” Cambridge university press, 2007
- [2] Denis Noble “The rise of computational biology” In Nature Reviews Molecular Cell Biology 3.6 Nature Publishing Group UK London, 2002, pp. 459–463
- [3] Dragica Vasileska, Stephen M Goodnick and Gerhard Klimeck “Computational Electronics: semiclassical and quantum device modeling and simulation” CRC press, 2017
- [4] Anders Bondeson, Thomas Rylander and Pär Ingelström “Computational electromagnetics” Springer, 2012
- [5] Aisha Muhammad and Ibrahim Haruna Shanono “Simulation of a Car crash using ANSYS” In 2019 15th International Conference on Electronics, Computer and Computation (ICECCO), 2019, pp. 1–5 IEEE
- [6] Krzysztof Kurec et al. “Advanced modeling and simulation of vehicle active aerodynamic safety” In Journal of advanced transportation 2019 Hindawi, 2019
- [7] Russell M Cummings, William H Mason, Scott A Morton and David R McDaniel “Applied computational aerodynamics: A modern engineering approach” Cambridge University Press, 2015
- [8] Gal Berkooz, Philip Holmes and John L Lumley “The proper orthogonal decomposition in the analysis of turbulent flows” In Annual review of fluid mechanics 25.1 Annual Reviews 4139 El Camino Way, PO Box 10139, Palo Alto, CA 94303-0139, USA, 1993, pp. 539–575
- [9] Anthony T Patera and Gianluigi Rozza “Reduced basis approximation and a posteriori error estimation for parametrized partial differential equations” MIT Cambridge, 2007
- [10] Michael G Safonov and RY1000665 Chiang “A Schur method for balanced-truncation model reduction” In IEEE Transactions on Automatic Control 34.7 IEEE, 1989, pp. 729–733
- [11] Traian Iliescu and Zhu Wang “Variational multiscale proper orthogonal decomposition: Navier-stokes equations” In Numerical Methods for Partial Differential Equations 30.2 Wiley Online Library, 2014, pp. 641–663
- [12] Giovanni Stabile and Gianluigi Rozza “Finite volume POD-Galerkin stabilised reduced order methods for the parametrised incompressible Navier–Stokes equations” In Computers & Fluids 173 Elsevier, 2018, pp. 273–284
- [13] Dylan Matthew Copeland, Siu Wun Cheung, Kevin Huynh and Youngsoo Choi “Reduced order models for Lagrangian hydrodynamics” In Computer Methods in Applied Mechanics and Engineering 388 Elsevier, 2022, pp. 114259
- [14] Siu Wun Cheung, Youngsoo Choi, Dylan Matthew Copeland and Kevin Huynh “Local Lagrangian reduced-order modeling for the Rayleigh-Taylor instability by solution manifold decomposition” In Journal of Computational Physics 472 Elsevier, 2023, pp. 111655
- [15] Jessica Lauzon et al. “S-OPT: A points selection algorithm for hyper-reduction in reduced order models” In arXiv preprint arXiv:2203.16494, 2022
- [16] Jiun-Shyan Chen, Camille Marodon and Hsin-Yun Hu “Model order reduction for meshfree solution of Poisson singularity problems” In International Journal for Numerical Methods in Engineering 102.5 Wiley Online Library, 2015, pp. 1211–1237
- [17] Qizhi He, Jiun-Shyan Chen and Camille Marodon “A decomposed subspace reduction for fracture mechanics based on the meshfree integrated singular basis function method” In Computational Mechanics 63.3 Springer, 2019, pp. 593–614
- [18] Christian Gogu “Improving the efficiency of large scale topology optimization through on-the-fly reduced order model construction” In International Journal for Numerical Methods in Engineering 101.4 Wiley Online Library, 2015, pp. 281–304
- [19] Youngsoo Choi, Geoffrey Oxberry, Daniel White and Trenton Kirchdoerfer “Accelerating design optimization using reduced order models” In arXiv preprint arXiv:1909.11320, 2019
- [20] Sean McBane and Youngsoo Choi “Component-wise reduced order model lattice-type structure design” In Computer Methods in Applied Mechanics and Engineering 381 Elsevier, 2021, pp. 113813
- [21] Youngsoo Choi et al. “Gradient-based constrained optimization using a database of linear reduced-order models” In Journal of Computational Physics 423 Elsevier, 2020, pp. 109787
- [22] Youngkyu Kim, Youngsoo Choi, David Widemann and Tarek Zohdi “A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder” In Journal of Computational Physics 451 Elsevier, 2022, pp. 110841
- [23] William D Fries, Xiaolong He and Youngsoo Choi “LaSDI: Parametric latent space dynamics identification” In Computer Methods in Applied Mechanics and Engineering 399 Elsevier, 2022, pp. 115436
- [24] Xiaolong He et al. “gLaSDI: Parametric physics-informed greedy latent space dynamics identification” In Journal of Computational Physics 489 Elsevier, 2023, pp. 112267
- [25] Alejandro N Diaz, Youngsoo Choi and Matthias Heinkenschloss “A fast and accurate domain decomposition nonlinear manifold reduced order model” In Computer Methods in Applied Mechanics and Engineering 425 Elsevier, 2024, pp. 116943
- [26] April Tran et al. “Weak-Form Latent Space Dynamics Identification” In Computer Methods in Applied Mechanics and Engineering 427, 2024, pp. 116998
- [27] Christophe Bonneville, Youngsoo Choi, Debojyoti Ghosh and Jonathan L Belof “GPLaSDI: Gaussian process-based interpretable latent space dynamics identification through deep autoencoder” In Computer Methods in Applied Mechanics and Engineering 418 Elsevier, 2024, pp. 116535
- [28] Christophe Bonneville et al. “A Comprehensive Review of Latent Space Dynamics Identification Algorithms for Intrusive and Non-Intrusive Reduced-Order-Modeling” In arXiv preprint arXiv:2403.10748, 2024
- [29] J Nathan Kutz “Deep learning in fluid dynamics” In Journal of Fluid Mechanics 814 Cambridge University Press, 2017, pp. 1–4
- [30] Seonwoo Min, Byunghan Lee and Sungroh Yoon “Deep learning in bioinformatics” In Briefings in bioinformatics 18.5 Oxford University Press, 2017, pp. 851–869
- [31] Michela Paganini, Luke Oliveira and Benjamin Nachman “CaloGAN: Simulating 3D high energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks” In Physical Review D 97.1 APS, 2018, pp. 014021
- [32] Jeremy Morton, Antony Jameson, Mykel J Kochenderfer and Freddie Witherden “Deep dynamical modeling and control of unsteady fluid flows” In Advances in Neural Information Processing Systems 31, 2018
- [33] Teeratorn Kadeethum et al. “A framework for data-driven solution and parameter estimation of PDEs using conditional generative adversarial networks” In Nature Computational Science 1.12 Nature Publishing Group, 2021, pp. 819–829
- [34] Teeratorn Kadeethum et al. “Continuous conditional generative adversarial networks for data-driven solutions of poroelasticity with heterogeneous material properties” In Computers & Geosciences 167 Elsevier, 2022, pp. 105212
- [35] Teeratorn Kadeethum et al. “Non-intrusive reduced order modeling of natural convection in porous media using convolutional autoencoders: comparison with linear subspace techniques” In Advances in Water Resources Elsevier, 2022, pp. 104098
- [36] Teeratorn Kadeethum et al. “Reduced order modeling for flow and transport problems with Barlow Twins self-supervised learning” In Scientific Reports 12.1 Nature Publishing Group UK London, 2022, pp. 20654
- [37] Byungsoo Kim et al. “Deep fluids: A generative network for parameterized fluid simulations” In Computer Graphics Forum 38.2, 2019, pp. 59–70 Wiley Online Library
- [38] Michael Schmidt and Hod Lipson “Distilling free-form natural laws from experimental data” In science 324.5923 American Association for the Advancement of Science, 2009, pp. 81–85
- [39] Steven L Brunton, Joshua L Proctor and J Nathan Kutz “Discovering governing equations from data by sparse identification of nonlinear dynamical systems” In Proceedings of the national academy of sciences 113.15 National Acad Sciences, 2016, pp. 3932–3937
- [40] Benjamin Peherstorfer and Karen Willcox “Data-driven operator inference for nonintrusive projection-based model reduction” In Computer Methods in Applied Mechanics and Engineering 306 Elsevier, 2016, pp. 196–215
- [41] Elizabeth Qian, Boris Kramer, Benjamin Peherstorfer and Karen Willcox “Lift & learn: Physics-informed machine learning for large-scale nonlinear dynamical systems” In Physica D: Nonlinear Phenomena 406 Elsevier, 2020, pp. 132401
- [42] Peter Benner et al. “Operator inference for non-intrusive model reduction of systems with non-polynomial nonlinear terms” In Computer Methods in Applied Mechanics and Engineering 372 Elsevier, 2020, pp. 113433
- [43] Miles Cranmer et al. “Discovering symbolic models from deep learning with inductive biases” In Advances in Neural Information Processing Systems 33, 2020, pp. 17429–17442
- [44] Opal Issan and Boris Kramer “Predicting Solar Wind Streams from the Inner-Heliosphere to Earth via Shifted Operator Inference” In arXiv preprint arXiv:2203.13372, 2022
- [45] Kathleen Champion, Bethany Lusch, J Nathan Kutz and Steven L Brunton “Data-driven discovery of coordinates and governing equations” In Proceedings of the National Academy of Sciences 116.45 National Acad Sciences, 2019, pp. 22445–22451
- [46] Jun Sur Richard Park, Siu Wun Cheung, Youngsoo Choi and Yeonjong Shin “tLaSDI: Thermodynamics-informed latent space dynamics identification” In arXiv preprint arXiv:2403.05848, 2024
- [47] Daniel A Messenger and David M Bortz “Weak SINDy: Galerkin-based data-driven model selection” In Multiscale Modeling & Simulation 19.3 SIAM, 2021, pp. 1474–1497
- [48] Daniel A. Messenger, Graycen E. Wheeler, Xuedong Liu and David M. Bortz “Learning Anisotropic Interaction Rules from Individual Trajectories in a Heterogeneous Cellular Population” In J. R. Soc. Interface 19.195, 2022, pp. 20220412 DOI: 10.1098/rsif.2022.0412
- [49] Daniel A. Messenger, Joshua W. Burby and David M. Bortz “Coarse-Graining Hamiltonian Systems Using WSINDy” In Sci. Rep. 14.14457, 2024, pp. 1–24 eprint: 2310.05879
- [50] Daniel A Messenger and David M Bortz “Weak SINDy for partial differential equations” In Journal of Computational Physics 443 Elsevier, 2021, pp. 110525
- [51] Daniel A. Messenger and David M. Bortz “Learning Mean-Field Equations from Particle Data Using WSINDy” In Physica D 439, 2022, pp. 133406 DOI: 10.1016/j.physd.2022.133406
- [52] Daniel Messenger, Greg Dwyer and Vanja Dukic “Weak-Form Inference for Hybrid Dynamical Systems in Ecology” arXiv, 2024 arXiv:2405.20591 [cs, math, q-bio]
- [53] David M Bortz, Daniel A Messenger and Vanja Dukic “Direct estimation of parameters in ODE models using WENDy: weak-form estimation of nonlinear dynamics” In Bulletin of Mathematical Biology 85.11 Springer, 2023, pp. 110
- [54] Daniel A. Messenger and David M. Bortz “Asymptotic Consistency of the WSINDy Algorithm in the Limit of Continuum Data” In IMA J. Numer. Anal., 2024 (accepted) eprint: 2211.16000
- [55] David DeMers and Garrison W Cottrell “Non-linear dimensionality reduction” In Advances in neural information processing systems, 1993, pp. 580–587
- [56] Geoffrey E Hinton and Ruslan R Salakhutdinov “Reducing the dimensionality of data with neural networks” In science 313.5786 American Association for the Advancement of Science, 2006, pp. 504–507
- [57] Martín Abadi et al. “TensorFlow: A System for Large-Scale Machine Learning” In 12th USENIX symposium on operating systems design and implementation (OSDI 16), 2016, pp. 265–283
- [58] Diederik P Kingma and Jimmy Ba “Adam: A method for stochastic optimization” In arXiv preprint arXiv:1412.6980, 2014
- [59] Robert Anderson et al. “MFEM: A modular finite element methods library” In Computers & Mathematics with Applications 81 Elsevier, 2021, pp. 42–74
- [60] “HyPar Repository” https://bitbucket.org/deboghosh/hypar
- [61] G.-S. Jiang and C.-W. Shu “Efficient Implementation of Weighted ENO Schemes” In Journal of Computational Physics 126.1, 1996, pp. 202–228 DOI: 10.1006/jcph.1996.0130
- [62] Thomas Elsken, Jan Hendrik Metzen and Frank Hutter “Neural architecture search: A survey” In The Journal of Machine Learning Research 20.1 JMLR. org, 2019, pp. 1997–2017