Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
Abstract
We present a novel semi-supervised semantic segmentation method which jointly achieves two desiderata of segmentation model regularities: the label-space consistency property between image augmentations and the feature-space contrastive property among different pixels. We leverage the pixel-level loss and the pixel contrastive loss for the two purposes respectively. To address the computational efficiency issue and the false negative noise issue involved in the pixel contrastive loss, we further introduce and investigate several negative sampling techniques. Extensive experiments demonstrate the state-of-the-art performance of our method (PC2Seg) with the DeepLab-v3+ architecture, in several challenging semi-supervised settings derived from the VOC, Cityscapes, and COCO datasets.
1 Introduction
Modern deep learning based solutions [3, 4, 46] to semantic segmentation typically require large-scale pixel-wise annotated datasets [15, 11, 32] (i.e., the high-data regime). When the deep models are trained with limited labeled data (i.e., the low-data regime), however, their performance drops drastically due to over-fitting. The performance drop in the low-data regime and the high annotation cost associated with dense pixel labeling have motivated the community to study semi-supervised segmentation methods [17, 37, 58, 26, 57]. In the semi-supervised setting, a model is trained with the help of an additional large-scale unlabeled dataset. A successful semi-supervised method is useful in practice – only a portion of the production data needs to be densely annotated to deliver a satisfactory model.
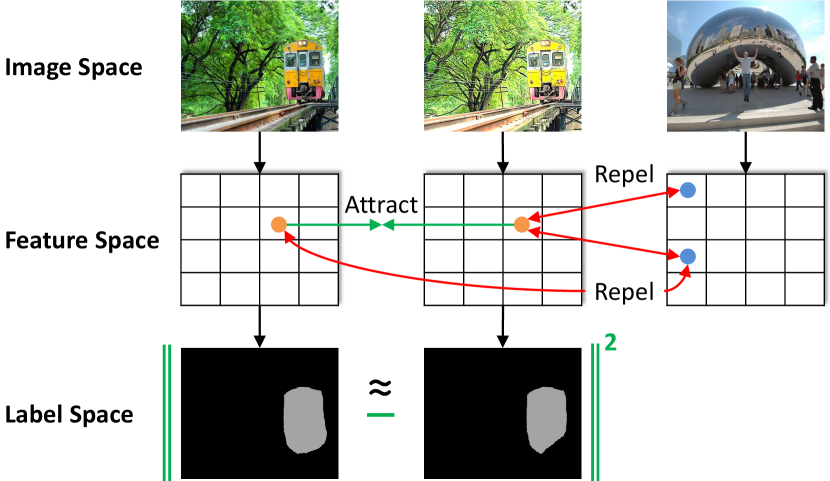
As shown in Fig. 1, our key insight is that there are two desired regularity properties which a semi-supervised segmentation model should possess. The first one is the consistency property in the label space. The output segmentation mask of the model should be invariant (or equivariant) to the transformations of the input. When an input image goes through two different color augmentations, the segmentation mask should stay the same, since the object semantics and locations are unchanged. The second property is the contrastive property in the feature space. By “contrastive,” we mean that the intermediate features of the model should have the discriminative power to group visually similar pixels together while distinguishing them from visually dissimilar pixels. Such a contrastive property will enable the model to classify pixels into correct semantic categories.
State-of-the-art semi-supervised segmentation methods, in fact, benefit from using the aforementioned label-space consistency property on the unlabeled images, in the forms of invariance under data augmentations [58, 17], invariance under feature perturbations [37], consistency of different network branches [26], and model self-consistency [57]. However, the explicit application of the feature-space contrastive property and the possibility of the joint label-consistent and feature-contrastive regularization have been largely under-explored.
Based on our insight, this paper explores how to leverage and simultaneously enforce the consistency property in the label space and the contrastive property in the feature space, leading to a novel pixel contrastive-consistent semi-supervised segmentation (PC2Seg) method. For the label consistency property, we introduce a simple pixel-wise consistency loss between the outputs of weakly and strongly augmented views of the same image. For the feature contrastive property, we extend the popular InfoNCE-based contrastive loss [19, 5] and make significant modifications for its use at the pixel level on an intermediate feature map.
More concretely, the pixel contrastive loss in semantic segmentation faces the unique technical challenges of high computational cost and harmful false negative examples, compared with the standard image-level contrastive learning. The potentially high computation is due to the need of contrasting a large number of pixels. The harm of false negative examples (i.e., when examples of the same class as the anchor are mistakenly chosen as the contrasting examples) has been noted in image-level contrastive learning [10, 23]. This problem becomes particularly severe in segmentation, where accurate per-pixel predictions are required compared with image classification. To overcome these issues, we develop simple-yet-effective negative sampling strategies. For each positive pair of pixels, we sample only a moderate number of negative pixels from the mini-batch for efficiency and avoid false negative pixels by a simple cross-image and pseudo-label weighting heuristic.
Our contributions are three-fold:
-
1.
We propose the first framework that leverages both pixel-consistency (in the label space) and pixel-contrastive (in the feature space) properties for semi-supervised semantic segmentation. We show that these two properties are complementary and their synergy is important.
-
2.
We generalize the existing image-level contrastive learning to pixel-level. To overcome the computational cost and false negative difficulties inherent in segmentation tasks, we propose a novel negative sampling technique and investigate its four variants.
-
3.
We demonstrate state-of-the-art performance on multiple widely-used benchmarks. This is achieved relatively easily by leveraging the proposed framework together with standard loss functions and data augmentations, without sacrificing efficiency compared to other semi-supervised methods.
2 Related Work
Contrastive Learning.
Self-supervised or unsupervised visual representation learning has been gaining momentum [19, 8, 5, 6, 18]. At the center of the recent progress is the contrastive learning based pretext tasks [19, 5, 6], which learn representations that discriminate similar image pairs (constructed from different augmentations of the same images) from dissimilar, negative image pairs. A variety of strategies have been investigated to choose appropriate negative pairs. In MoCo [19, 7], a memory buffer and a momentum encoder are maintained to provide negative samples. In SimCLR [5, 6], the negative samples are the large training mini-batches. Improper negative pairs might hurt learning performance: Particularly related to our negative pixel sampling strategies, [10, 23, 50] have proposed ways to alleviate the bias issue caused by incorrect (false) negative images by modifying the contrastive loss function. PC2Seg does not change the loss function but rather samples the negative examples strategically. SimSiam [8] and BYOL [18] find that simple consistency training without negatives can also be effective with carefully designed architectures and training procedures. However, our ablation study shows that PC2Seg still benefits from negative samples compared with feature-space consistency training alone.
Pixel-level contrastive learning has not been well-explored until very recently. [38, 48, 52, 45] explore dense pixel-level self-supervised pretraining. They show that pixel-level pretext tasks can transfer better to segmentation than image-level self-supervised learning. In this paper, we attempt to benefit from pixel-level contrastive learning in the semi-supervised rather than the unsupervised setting. We present a strong semi-supervised approach that jointly optimizes a contrastive loss on the intermediate features and a consistent loss on the output masks.
Contrastive learning can be used in the supervised setting [27] to improve generalization. Researchers have attempted to apply supervised contrastive learning for semantic segmentation [47, 55]. [47] directly leverages pixel contrasting in supervised segmentation training, while [55] adopts it during the first supervised stage in a multi-stage semi-supervised setting. Compared with these attempts, we focus on the single-stage semi-supervised setting, where self-supervised contrastive loss is jointly applied on the unlabeled images branch without using any ground-truth labels.
Semi-Supervised Learning.
Semi-supervised learning aims at leveraging labeled data and a large amount of unlabeled data. The idea of consistency regularization is inherent in many successful semi-supervised approaches. Iterative pseudo-labeling and re-training [30, 42, 57] implicitly enforces consistent predictions between the current model (student) and its past versions (teacher), leading to smaller entropy and larger class separation of the predicted label distribution. FixMatch [39], VAT [35], and UDA [51] leverage consistency regularization between weak and strong (or local adversarial [35]) augmented views of the same unlabeled image in a single-stage training pipeline. S4L [53] explores a self-supervised auxiliary task (e.g., predicting rotations) on unlabeled images jointly with a supervised task.
Semantic Segmentation.
Semantic segmentation is the task of predicting pixel-level category labels from images. High segmentation accuracy can be reached by deep fully convolutional neural networks (FCNs) trained on large datasets [3, 4, 46]. In these models, the convolutional nature of FCNs is exploited to generate dense prediction masks. Following [58, 17], our work builds upon the widely-used DeepLab-v3+ segmentation model [4].
Semi-Supervised Semantic Segmentation.
It is compelling to study semi-supervised segmentation approaches to reduce the mask labeling cost. [40] synthesizes additional training data with generative adversarial networks (GANs). [22, 34] couple an adversarial loss on the predicted masks with the standard supervised loss. In the line of consistency training, the output predictions of the unlabeled images are encouraged to be consistent across different augmented views [17, 28, 36, 58], feature embedding perturbations [37], and different networks as in co-training [26, 49]. When the consistency loss is set up explicitly as using one branch’s prediction as the target to train the other branch, the former predictions are often called pseudo labels [17, 58]. Self-training, which retrains the model with pseudo labels on the unlabeled data given by the previous iteration of the model, has also shown promising results for semantic segmentation [2, 57, 56]. While consistency training is extensively studied, the use of (pixel) contrastive leaning has largely eluded discussion in the semi-supervised segmentation setting.
Finally, alternative ways to reduce the annotation cost includes leveraging various forms of weak labels such as image labels [1, 33, 41, 58, 49], bounding boxes [12], and scribbles [31], or even purely unlabeled data as in unsupervised segmentation by clustering [25] and self-supervised tasks [54]. We refer interested readers to these works as the problem settings are different.
3 Method
3.1 Overview
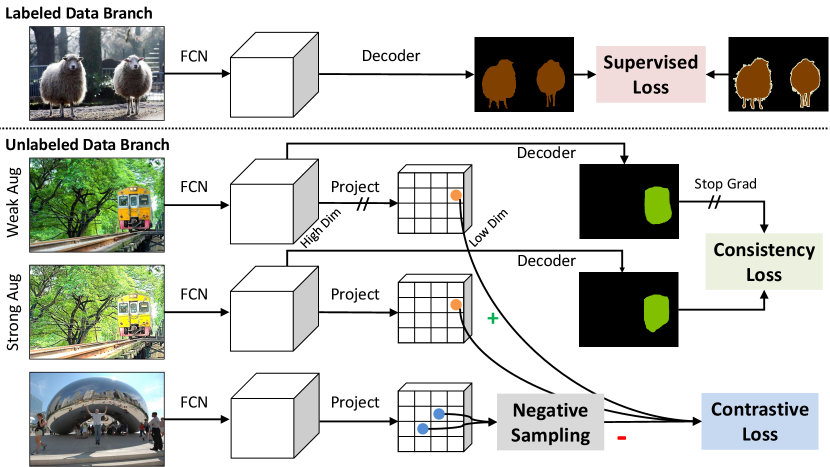
Fig. 2 summarizes the overall architecture and training procedure of our pixel contrastive-consistent semi-supervised segmentation (PC2Seg) approach. The entire pipeline consists of two data streams, with one stream for labeled images and the other for unlabeled images. The complete loss function is the sum of the labeled and unlabeled stream losses:
| (1) |
where we denote an image as , and its ground-truth segmentation mask as .
For the labeled images, the typical supervised cross-entropy loss between the predictions and the segmentation masks is applied at per-pixel locations. For the unlabeled images, in line with existing semi-supervised [39, 58] and self-supervised [5, 19, 8, 23] methods, we build a siamese network architecture with shared weights that operates on two augmented views (weak and strong) of a single unlabeled image. The weak augmentations consist of the usual crop, flip, and resize transformations, while the strong augmentations add color (brightness, contrast, and hue) and Cutout [14] transformations on top of the weak augmentations following [58]. We then jointly apply the label consistency loss on the output masks and the unlabeled pixel constrastive loss on the intermediate features:
| (2) |
Here we use to index the pixels, use , , and to represent the anchor pixel from one augmented view, the positive pixel from the other augmented view, and the negative pixels, respectively. and are the predicted pixel class softmax probabilities of the two views. and are trade-off hyper-parameters. Exactly which intermediate feature map to apply is a design choice.
Consistency Loss.
We adopt the normalized pixel consistency loss (equivalently, ) between the corresponding predicted softmax probabilities of the weak and strong views:
| (3) |
The cosine similarity is . In practice, we sharpen the softmax for the weak branch output by dividing the logits by temperature . We also put a stop-gradient operation on the weak output as in [5, 18, 8, 58], so that the gradients only back-propagate into the strong branch but not the weak branch. This effectively makes the weak branch predictions act as the pseudo labels to train the strong branch. Empirically we found that our consistency loss outperforms the cross-entropy loss in [58].
3.2 Pixel Contrastive Loss
Suppose the feature map, of either the weak branch or the strong branch, has shape , where is the batch size, and are the height and width, and is the feature dimension. We denote as the index of one pixel location on this feature map. Given the feature vector of the anchor pixel, the goal of contrastive learning is to increase its similarity to a positive pixel and reduce its similarity to negative pixels . A popular choice of the loss function to achieve such goal is the InfoNCE [21] loss, which is relevant to the noise contrastive mutual information estimator. When combining the InfoNCE loss with the cosine similarity, we arrive at the pixel contrastive loss in the form of
| (4) |
Here is a temperature hyper-parameter to control the scale of terms inside exponential, which is set to throughout our experiments following prior work [5, 6]. The use of cosine similarity is shown to be effective in existing contrastive learning work [5, 19, 43, 47, 18, 5].
Directly optimizing Eq. 4, however, is challenging. The first difficulty is that the raw feature vectors can be quite high-dimensional, e.g., the last ResNet backbone feature map has shape in DeepLab [4], leading to high memory and computational cost. We therefore utilize a linear projection layer to reduce the feature dimension from to , consistent with [23, 47]. The projection head parameters of the weak and strong branches can be separated or tied together. We found that separated projection heads work slightly better in our experiments. In the weak branch, similar to the consistency loss, a stop gradient operation is inserted before the projection.
The next major difficulty lies in deciding the positive and negative pairs. In the ideal supervised learning setting, i.e., when the ground-truth pixel labels are known, we can simply select the positive pixel from the pixels of the true category of the anchor pixel, and choose the negative pixels as the pixels from different categories [27]. By contrast, the issue becomes complicated when the labels are unknown as in our setting. Existing work on image-level contrastive learning circumvents the problem by forcing the positive example to come from another augmented view of the same image, while using both views of a large mini-batch [5] or a memory bank [19] as the source of negative examples.
However, these techniques are not easily generalizable to our task. For contrastive learning at pixel level, we still choose the positive pixel as the corresponding pixel under a random color augmentation. For example, if belongs to the weak view, can be the corresponding pixel in the strong view. As for the negative pixels, two issues occur if we directly borrow existing approaches in image-level contrastive learning: (1) Due to the huge number of pixels, we cannot afford to use all the pixels in the mini-batch as negative examples, because the memory and computational cost scale with ; (2) Since the task is at pixel-level, the segmentation model can be sensitive to noise from incorrect negative pixels, if we adopt a simple mini-batch or memory bank approach. A pixel of the same category as the anchor pixel might be wrongly chosen as a negative pixel, leading to ineffective or even misleading learning signal. To resolve these issues, we propose to sub-sample a fixed number of negative pixels for each anchor pixel, and develop several effective sub-sampling strategies as below.
3.2.1 Negative Sampling Strategies
Consider the -th anchor pixel. Assume the negative pixels are sampled without replacement according to a discrete distribution , which is defined on a total of candidate pixels. More formally,
| (5) |
Different sampling strategies essentially define different sampling distributions . We investigate and compare four of them in this paper, with illustration in Fig. 3:
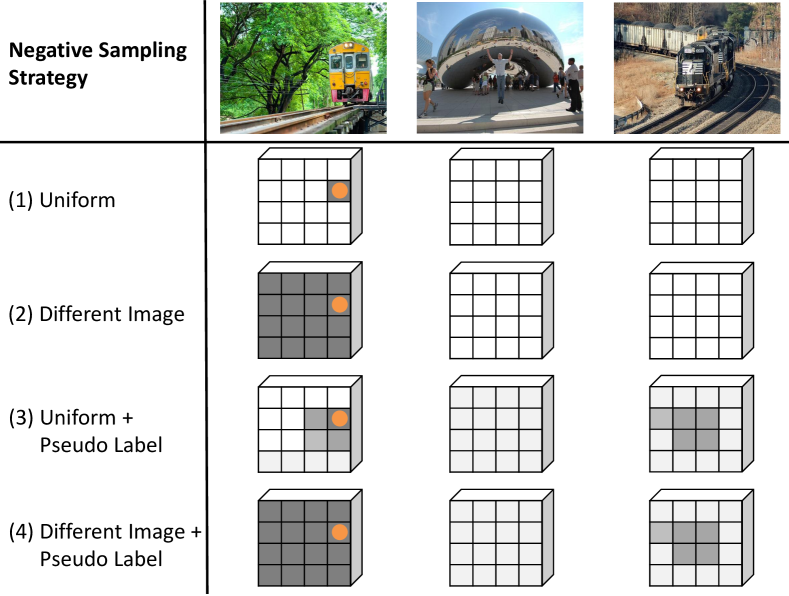
Uniform.
The most straightforward way is to sample negative pixels uniformly from the mini-batch. Suppose there are valid pixels in the current mini-batch; each pixel gets a uniformly distributed density,
As one can imagine, since many pixels on the same image may belong to the same category, the uniform strategy can produce a large number of false negative pixels, which may hurt performance. This issue motivates us to study alternative sampling distribution.
Different Image.
One idea to fix the false negative issue is to force the negative pixels to come from a different image, such that the chance of sampling an incorrect negative is reduced. Formally, we denote and as the image IDs of the anchor pixel and a candidate negative pixel , and as the indicator function. Pixel gets a non-zero density only if it belongs to a different image from pixel .
| (6) |
Pseudo-Label Debiased.
Another idea to fix the issue is to leverage the model predictions to filter out possible pixels of the same class. This strategy is similar in spirit to [10, 23]. Suppose and () are the predicted pseudo labels of pixels and , respectively (through a bilinear image resizing if necessary). The probability of sampling pixel as negative pixel can be weighted by , which biases the sampling process towards pixels that the model believes are from different categories. After a simple derivation, can be rewritten as one minus the dot product of the predicted label probability vectors and .
| (7) |
The derivation is quite straight-forward. Ideally, we want to sample from the discrete measure: . Since the ground-truth is unknown, we may approximate with the pseudo-labels and . Let the predicted probability of pixel belonging to category be and the vector , and then we have
Different Image + Pseudo-Label Debiased.
The above two strategies can be combined to further reduce the chance of sampling false negative pixels. In another word, we ensure that the negative pixels are coming from different images and at the same time reweight them by the pseudo labels.
| (8) |
4 Experiment
4.1 Datasets and Settings
VOC 2012.
The PASCAL VOC 2012 segmentation dataset [15] comes with a finely labeled train split of 1,464 images, a val split of 1,449 images, and a coarsely labeled aug split of 9,118 images. We use the public 1/2, 1/4, 1/8, and 1/16 subsets of train in [58] as the labeled data. The train and aug sets are combined as the unlabeled dataset. We also compare with existing semi-supervised semantic segmentation methods under the 1.5k/9k split setting [40, 22, 37, 58], which treats train as the labeled set and train+aug as the unlabeled set. VOC contains 20 object categories (excluding the background class). The performance is evaluated by the mean intersection-over-union (mIoU) metric on the val set.
Cityscapes.
Cityscapes [11] contains images of urban driving scenes. The train_fine split has 2,975 training images, and val_fine has 5,000 images. We employ the public 1/4, 1/8, and 1/30 subsets of the train_fine images in recent literature [22, 34, 16, 17, 58, 36] as the labeled data, while all images of the original train_fine are used as the unlabeled data. We report the mIoU over the 18 foreground categories in the Cityscapes val_fine set.
COCO.
COCO [32] is a challenging detection and segmentation dataset of 80 categories. It is significantly larger (118,287 images in the official train set) and more diverse than VOC or Cityscapes. We reuse the same 1/32, 1/64, 1/128, 1/256, and 1/512 splits of the train set from [58] as the labeled data, and further enrich the benchmark by constructing the uniformly downsampled 1/8 and 1/16 labeled variants. We again evaluate the performance by the mIoU metric on the official val set (5,000 images).
| Method | Net | 1/2 (732) | 1/4 (366) | 1/8 (183) | 1/16 (92) |
|---|---|---|---|---|---|
| AdvSemSeg [22] | R101 | 65.27 | 59.97 | 47.58 | 39.69 |
| CCT [37] | R50 | 62.10 | 58.80 | 47.60 | 33.10 |
| MT [42] | R101 | 69.16 | 63.01 | 55.81 | 48.70 |
| GCT [26] | R101 | 70.67 | 64.71 | 54.98 | 46.04 |
| VAT [35] | R101 | 63.34 | 56.88 | 49.35 | 36.92 |
| CutMix [17] | R101 | 69.84 | 68.36 | 63.20 | 55.58 |
| PseudoSeg [58] | R50 | 70.42 | 64.85 | 61.88 | 54.89 |
| PseudoSeg [58] | R101 | 72.41 | 69.14 | 65.50 | 57.60 |
| Sup. baseline | R50 | 65.73 | 57.76 | 49.57 | 43.97 |
| Sup. baseline | R101 | 66.28 | 60.02 | 49.83 | 40.02 |
| PC2Seg (Ours) | R50 | 70.90 | 67.62 | 64.63 | 56.90 1.30 |
| PC2Seg (Ours) | R101 | 73.05 | 69.78 | 66.28 | 57.00 1.32 |
| Method | Network | mIoU (%) |
| GANSeg [40] | VGG-16 | 64.10 |
| AdvSemSeg [22] | ResNet-101 | 68.40 |
| CCT [37] | ResNet-50 | 69.40 |
| PseudoSeg [58] | ResNet-50 | 71.00 |
| PseudoSeg [58] | ResNet-101 | 73.23 |
| Sup. baseline | ResNet-50 | 68.81 |
| Sup. baseline | ResNet-101 | 72.00 |
| PC2Seg (Ours) | ResNet-50 | 72.26 |
| PC2Seg (Ours) | ResNet-101 | 74.15 |
Implementation Details.
We adopt the DeepLab-v3+ architecture [4] as the test bed, which consists of a fully convolutional backbone, an atrous spatial pyramid pooling (ASPP) based encoder, and a shallow decoder. We study different backbones including ResNet-50 (the DeepLab modified beta variant [4]), ResNet-101 [20], and Xception-65 [9], to test the robustness of our approach to backbone variations. The backbones are initialized from their ImageNet [13] pretrained weights.
The hyper-parameters of our approach mainly include the loss coefficients, the negative sampling strategies, and other design choices of the pixel contrastive loss. They are tuned with the VOC 1/8 split and ResNet-50. Please refer to the ablation study in Sec. 4.3 for details. These hyper-parameters are used for other benchmarks without further tuning. The performance could be further improved by dataset-specific hyper-parameter selection. In the main results, we set the loss coefficients as and . The contrastive loss is computed for each anchor pixel in the last backbone feature maps right before the encoder network (i.e., Conv5 of ResNets and ExitFlow2 of Xception) of both the weak and strong views. The number of negative pixels is 200. They are sampled from both views with the “Different Image + Pseudo Label” strategy. Additional training details and DeepLab-related hyper-parameters are presented in the supplementary material.
| Method | Net | 1 (2,975) | 1/4 (744) | 1/8 (377) | 1/30 (100) |
|---|---|---|---|---|---|
| AdvSemSeg [22] | R101 | - | 62.3 | 58.8 | - |
| s4GAN [34] | R101 | 65.8 | 61.9 | 59.3 | - |
| DMT [16] | R101 | 68.16 | - | 63.03 | 54.80 |
| ClassMix [36] | R101 | - | 63.63 | 61.35 | - |
| CutMix [17] | R101 | - | 68.33 | 65.82 | 55.71 |
| PseudoSeg [58] | R101 | - | 72.36 | 69.81 | 60.96 |
| Sup. baseline | R50 | 73.64 | 72.86 | 68.06 | 55.25 |
| Sup. baseline | R101 | 74.88 | 73.31 | 68.72 | 56.09 |
| PC2Seg (Ours) | R50 | 75.39 | 73.80 | 72.11 | 60.37 |
| PC2Seg (Ours) | R101 | 75.99 | 75.15 | 72.29 | 62.89 |
| Method | Network | Full (118k) | 1/8 (14786) | 1/16 (7393) | 1/32 (3697) | 1/64 (1849) | 1/128 (925) | 1/256 (463) | 1/512 (232) |
|---|---|---|---|---|---|---|---|---|---|
| Sup. baseline | Xception-65 | 50.10 | 47.91 | 45.12 | 42.24 | 37.80 | 33.60 | 27.96 | 22.94 |
| PseudoSeg [58] | Xception-65 | - | - | - | 43.64 | 41.75 | 39.11 | 37.11 | 29.78 |
| PC2Seg | Xception-65 | 50.67 | 49.91 | 48.07 | 46.05 | 43.67 | 40.12 | 37.53 | 29.94 |
4.2 Main Results
VOC 2012.
We report the results on the 1/2-1/16 labeled splits in Tab. 1. Our method (PC2Seg) outperforms the prior state-of-the-art (PseudoSeg [58]) and other consistency-based approaches in almost all data splits with the ResNet-50 and ResNet-101 backbones. Note that the ratio of labeled data is small in this setting, since we use the entire train+aug 10,575 images as the unlabeled data. We observe that the gain of our approach is particularly noteworthy for moderately low-data regimes such as the 1/2 and 1/4 splits. The more extreme case of 1/16 labeled split (92 labeled images) is quite challenging, as there is very little supervision signal for the semi-supervised model to learn in the first place. We thus augment the weak branch with the momentum averaging technique as in MoCo (momentum 0.99) and report the mean and standard deviation (std) of 3 runs of the 3 randomly generated 1/16 splits and observe that our method is comparable to [58].
We also compare the results of the 1.4k/9k split in Tab. 2. We find that our method outperforms the prior arts under this setting, achieving mIoU with ResNet-101.
Cityscapes.
The Cityscapes results are shown in Tab. 3. Across all semi-superivsed settings, PC2Seg outperforms the supervised baseline by a large margin. Notably, with ResNet-101, the mIoU gap between the full set result () and the 1/4 labeled setting result () is only . The performance of our method with ResNet-50 is surprisingly good in the 1/8 and 1/30 settings, suggesting that the deeper ResNet-101 backbone might be over-fitting in such settings due to the limited amount of labeled data.
COCO.
For the COCO experiments, we mainly compare with the recent state-of-the-art PseudoSeg method [58] following their experiment protocols. Xception-65 [9], a stronger backbone than ResNet-101, is used. The results are shown in Tab. 4. We observe that our method performs better in all data splits. We even see gains in the full data setting, possibly because of the stronger data augmentation and regularization in our method. The val mIoU of the 1/8 labeled setting is quite promising, almost catching the supervised learning result of the fully labeled data.
4.3 Analyses
We report the ablation studies and diagnosis experiments in this section. Without special mentioning, all experiments are conducted with the ResNet-50 backbone and VOC 1/8 labeled split. The mIoUs are evaluated on the VOC val set.
Negative Sampling Strategy.
One key technical contribution of our method is the negative sampling strategy. We measure the average False Negative Rates (FNR) during training with different negative sampling strategies in Tab. 5. We notice that FNR reduces with more complex sampling distributions. As expected, the Uniform strategy delivers the worst performance, suggesting that the noise introduced by false negative pixels may indeed hurt performance. The ideal case (marked as Oracle) pretends that the algorithm knows the actual ground-truth masks during contrastive learning and can be seen as an upper bound. Our best sampling strategy, Different Image + Pseudo Label, achieves an mIoU almost as good as the Oracle version.
| Strategy | Unif | Diff | Unif+Pseu | Diff+Pseu | Oracle |
|---|---|---|---|---|---|
| mIoU (%) | 62.70 | 63.33 | 64.38 | 64.63 | 64.78 |
| FNR (%) | 14.77 | 3.42 | 2.83 | 2.80 | 0 |
| None | 50 | 100 | 200 | 400 | 800 | 1600 | |
|---|---|---|---|---|---|---|---|
| mIoU (%) | 63.75 | 64.08 | 64.24 | 64.63 | 64.84 | 65.03 | OOM |
Number of Negative Pixels.
Another importance factor in our pixel contrastive loss is the number of sampled negative pixels . Previous work suggests that a large number of negatives may be beneficial to image-level contrastive learning [5, 19]. While we generally agree with this argument, using a large number of negative pixels can be costly in semantic segmentation. We believe that there should be a trade-off between efficiency and accuracy. In Tab. 6, we study the effect of the number of negative pixels. With the help of the negative sampling strategy to reduce false negative rates, our approach can already obtain competitive performance with only negative pixels per anchor.
Loss Coefficients.
We show the impact of the coefficients on the label consistency loss (Eq. 3) and the feature contrastive loss (Eq. 4) in Tab. 7. We found that and achieve the best result, therefore adopting these values in all other data splits and architectures. The coefficients transfer well to other settings. Another important observation with this hyper-parameter study is the complementary nature of the label consistency and the feature contrastive properties. We notice that the joint contrastive-consistent learning ( when ) outperforms either the purely consistent version ( when ) or the best purely contrastive version ( when ), supporting our insight.
| 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | ||
|---|---|---|---|---|---|---|
| 49.57 | 51.92 | 52.29 | 52.28 | 52.74 | 53.53 | |
| 62.31 | 61.62 | 62.47 | 63.83 | 63.07 | 63.64 | |
| 63.46 | 63.26 | 63.71 | 63.79 | 63.35 | 63.43 | |
| 63.75 | 63.60 | 64.63 | 64.48 | 62.55 | 63.15 | |
| 61.33 | 64.48 | 64.30 | 64.16 | 63.08 | 63.03 |
Computational Cost.
We report the training time comparison in Tab. 8. While achieving higher performance, the training time of PC2Seg is comparable to the previous state-of-the-art semi-supervised method PseudoSeg [58]. If we remove the contrastive component of PC2Seg, the time is reduced by less than 5min, suggesting that the extra cost of our pixel contrastive learning is low. We further show the cost reduced by our negative sampling strategy through a simple calculation in the supplementary material.
| Supervised | PseudoSeg | PC2Seg consist-only | PC2Seg | |
|---|---|---|---|---|
| Time (min) | 38 | 80 | 7580 | 80 |
| val mIoU (%) | 49.57 | 61.88 | 63.21 | 64.63 |
Comparison to Other Label-Space and Feature-Space Losses.
In the label space, we compare two variants: the normalized loss (Sec. 3) and the cross-entropy (CE) loss. In the feature space, we compare four variants: (1) no feature-space loss (None), (2) image contrastive loss [5], (3) pixel consistency loss, which is the normalized distance between pixel features, and (4) pixel contrastive loss. Tab. 9 shows that the combination of the label loss and the feature pixel contrastive loss achieves the best result.
| mIoU (%) | None | Img Contrast | Pix Consist | Pix Contrast |
|---|---|---|---|---|
| Output CE | 63.54 | 60.41 | 59.33 | 58.47 |
| Output | 63.75 | 62.49 | 63.21 | 64.63 |
Choice of Contrastive Learning Layer.
In the main results, we choose to apply pixel contrastive learning on the last feature map of the backbone networks (Conv5 block of ResNet and ExitFlow2 block of Xception). We show results of applying it on other ResNet layers in Tab. 10. Earlier stage feature maps are larger in size and contain more low-level details, while later stage feature maps lose resolutions but contain more semantics. A mid-level intermediate layer yields the best performance.
| Layer | Conv3 | Conv4 | Conv5 | Encoder | Decoder | Conv5+Enc |
|---|---|---|---|---|---|---|
| mIoU (%) | 60.70 | 63.90 | 64.63 | 64.25 | 63.74 | 64.59 |
Projection Layer.
The projection layer performs dimensionality reduction on the feature vectors before contrasive learning. We find that using separate projections for the weak and strong branches yields higher mIoU than using a shared projection head ( vs. ).
Delayed-Start of Semi-Supervised Learning.
We mimic the two-stage variant that delays the start of semi-supervised learning until certain steps in Tab. 11. We notice that breaking the training into two stages in fact decreases the performance. Applying all losses jointly throughout the training () achieves a better result in our experiments.
| Delayed Steps | 0 | 2,000 | 4,000 | 8,000 | 12,000 |
|---|---|---|---|---|---|
| mIoU (%) | 64.63 | 63.30 | 62.67 | 62.56 | 62.50 |
5 Conclusion
We propose a novel semi-supervised semantic segmentation approach based on feature-space contrastive learning and label-space consistency training. We also present the negative sampling techniques to improve the efficiency and effectiveness of pixel contrastive learning. Our approach outperforms existing methods on several semi-supervised segmentation benchmarks, suggesting that pixel contrastive-consistent learning is a promising research direction to improve semi-supervised semantic segmentation.
Acknowledgment:
This work was supported in part by NSF Grant 2106825.
Appendix A Additional Implementation Details
In Tab. A.1, we list the DeepLab-related hyper-parameters. They take either the recommended default values by [4] or the values from the public code of [58]. The learning rate is linearly annealed from to as training proceeds. The weight decay is 1e-4 for ResNets [20] and 4e-5 for Xception [9]. The input train crop size is set to for all datasets. The eval crop size is set to for VOC [15], for COCO [32], and for Cityscapes [11]. The DeepLab encoder output stride is chosen as . In the VOC experiments, the model is trained for 30,000 gradient steps that are distributed on 4 asynchronous replica workers. Each worker has 2 GPUs. The Cityscapes and COCO experiments require longer training duration, which takes a total of 130,000 and 200,000 steps, respectively, on 8 asynchronous workers of 2 GPUs. For both the labeled data and unlabeled data branches, the training batch size per GPU is 4, or equivalently 8 images per worker.
| Hyper-parameter | VOC | Cityscapes | COCO |
|---|---|---|---|
| Network | ResNet50/101 | ResNet50/101 | Xception65 |
| Weight decay | 1e-4 | 1e-4 | 4e-5 |
| Train crop size | |||
| Eval crop size | |||
| Output stride | 16 | 16 | 16 |
| Atrous rates | [6, 12, 18] | [6, 12, 18] | [6, 12, 18] |
| Train steps | 30,000 | 130,000 | 200,000 |
| Learning rate | |||
| Dist. workers | 4 | 8 | 8 |
| GPUs/worker | 2 V100(16G) | 2 V100(16G) | 2 V100(16G) |
| Batch size/GPU | 4 | 4 | 4 |
Appendix B Additional Ablation Results
| Dimension | 64 | 128 | 256 | 512 |
|---|---|---|---|---|
| val mIoU (%) | 64.12 | 64.63 | 64.07 | 63.74 |
Dimension of Projection Layer.
The impact of the dimension of the projection layer in our PC2Seg method is studied in Tab. B.1 under the VOC 1/8 ResNet-50 setting. For the results reported in the main paper, we chose the dimension as 128. We found that alternative values do not bring gains over the chosen value if other hyper-parameters are fixed. Alternative dimension values may require re-tuning some hyper-parameters to achieve better results.
| Method/Split | 1 (1464) | 1/2 (732) | 1/4 (366) | 1/8 (183) | 1/16 (92) |
|---|---|---|---|---|---|
| Supervised | 68.81 | 65.73 | 57.76 | 49.57 | 43.97 |
| PC2Seg w/ LC (Ours) | 71.95 | 70.88 | 66.71 | 63.75 | 56.32 |
| PC2Seg (Ours) | 72.26 | 70.90 | 67.62 | 64.63 | 56.90 |
| Method | Supervised | PC2Seg w/ LC (Ours) | PC2Seg (Ours) |
|---|---|---|---|
| val_fine mIoU (%) | 68.06 | 71.79 | 72.11 |
Label Consistent Only.
In Tab. 9 and Paragraph “Comparison to Other Label-Space and Feature-Space Losses” of Sec. 4.3 in the main paper, we have compared PC2Seg with its label-consistent-only version in the VOC 1/8 split setting. Here, we provide additional results with other data splits, which support the claim that the joint label-consistent and feature-contrastive regularization performs better than the label-consistent regularization alone. The label-consistent version essentially removes the pixel contrastive loss and keeps everything else unchanged. The VOC results are shown in Tab. B.2. We have a similar observation with the Cityscapes 1/8 split in Tab. B.3, where the label-consistent-only version achieves 71.79% validation mIoU in comparison to 72.11% mIoU of full PC2Seg with the joint contrastive-consistent regularization.
Appendix C Training Time and Computational Cost
Since there is an additional unlabeled data branch in our semi-supervised method, the training inevitably takes longer time than the purely supervised baseline. As stated in the main paper, we measure the training time in the VOC ResNet-50 experiments. Our implementation of the supervised baseline took 38 minutes, while our PC2Seg with label consistency and feature contrastive learning took roughly 80 minutes, and the label-consistent-only version of PC2Seg took around 75 to 80 minutes. Such training time is comparable to existing approaches within the semi-supervised setting – e.g., state-of-the-art PseudoSeg [58] also took about 80 minutes.
We further show the cost reduced by our negative sampling strategy through a simple calculation. The feature tensor shape in practice is for a batch of 4 images (512-by-512 pixels). If using all pixels as negatives, we need to compute a inner-product matrix ( elements) with MulAdd operations. But, if we only draw negative pixels, it is reduced to computing a matrix ( elements) with operations. Considering the negative sampling itself requires operations to compare the pseudo labels (20 is the number of VOC classes), the overall floating point operations are about 5 times fewer.
Appendix D Visualization
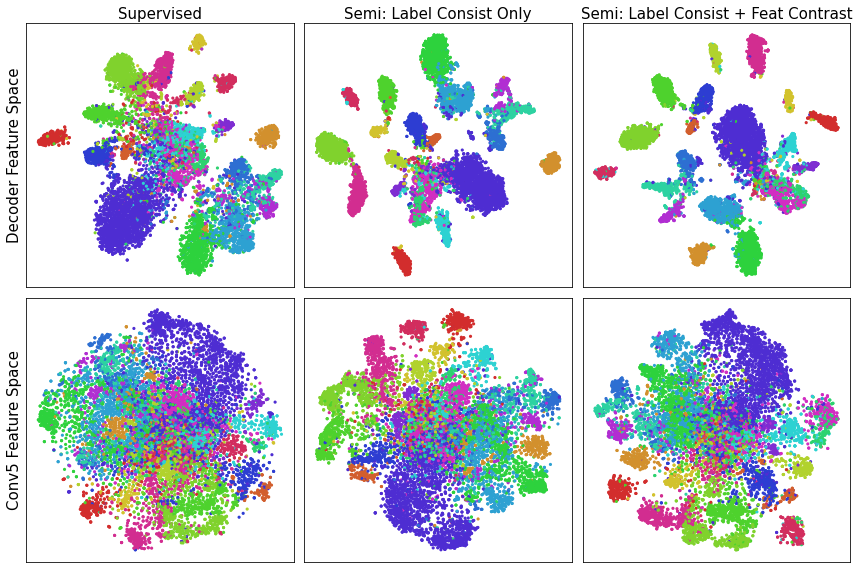
To have a better understanding of PC2Seg, we use two complementary approaches to visualize the results: (1) the t-SNE plot [44] of the feature spaces in Fig. D.1, and (2) the predicted segmentation masks in Fig. D.2 and Fig. D.3.
From the t-SNE plot, we observe that both the label-consistent-only and the joint contrastive-consistent variants of our method generate feature spaces that are more separable than the supervised baseline. In the decoder feature space, joint contrastive-consistent variant seems to increase slightly the margins between a few categories, compared with the label-consistent-only variant. From the predicted masks, we can see some success and failure cases of PC2Seg. Please refer to the figure captions for detailed descriptions.


References
- [1] Jiwoon Ahn and Suha Kwak. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In CVPR, 2018.
- [2] Liang-Chieh Chen, Raphael Gontijo Lopes, Bowen Cheng, Maxwell D Collins, Ekin D Cubuk, Barret Zoph, Hartwig Adam, and Jonathon Shlens. Naive-student: Leveraging semi-supervised learning in video sequences for urban scene segmentation. In ECCV, 2020.
- [3] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. TPAMI, 40(4):834–848, 2017.
- [4] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018.
- [5] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In ICML, 2020.
- [6] Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. Big self-supervised models are strong semi-supervised learners. In NeurIPS, 2020.
- [7] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
- [8] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In CVPR, 2021.
- [9] François Chollet. Xception: Deep learning with depthwise separable convolutions. In CVPR, 2017.
- [10] Ching-Yao Chuang, Joshua Robinson, Lin Yen-Chen, Antonio Torralba, and Stefanie Jegelka. Debiased contrastive learning. In NeurIPS, 2020.
- [11] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The Cityscapes dataset for semantic urban scene understanding. In CVPR, 2016.
- [12] Jifeng Dai, Kaiming He, and Jian Sun. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In ICCV, 2015.
- [13] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In CVPR, 2009.
- [14] Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- [15] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The PASCAL visual object classes (VOC) challenge. IJCV, 88(2):303–338, 2010.
- [16] Zhengyang Feng, Qianyu Zhou, Qiqi Gu, Xin Tan, Guangliang Cheng, Xuequan Lu, Jianping Shi, and Lizhuang Ma. DMT: Dynamic mutual training for semi-supervised learning. arXiv preprint arXiv:2004.08514, 2020.
- [17] Geoffrey French, Samuli Laine, Timo Aila, Michal Mackiewicz, and Graham Finlayson. Semi-supervised semantic segmentation needs strong, varied perturbations. In BMVC, 2020.
- [18] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. In NeurIPS, 2020.
- [19] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
- [20] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [21] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In ICLR, 2019.
- [22] Wei Chih Hung, Yi Hsuan Tsai, Yan Ting Liou, Yen-Yu Lin, and Ming Hsuan Yang. Adversarial learning for semi-supervised semantic segmentation. In BMVC, 2018.
- [23] Tri Huynh, Simon Kornblith, Matthew R Walter, Michael Maire, and Maryam Khademi. Boosting contrastive self-supervised learning with false negative cancellation. arXiv preprint arXiv:2011.11765, 2020.
- [24] Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with Gumbel-softmax. In ICLR, 2017.
- [25] Xu Ji, João F Henriques, and Andrea Vedaldi. Invariant information clustering for unsupervised image classification and segmentation. In ICCV, 2019.
- [26] Zhanghan Ke, Kaican Li Di Qiu, Qiong Yan, and Rynson WH Lau. Guided collaborative training for pixel-wise semi-supervised learning. In ECCV, 2020.
- [27] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. In NeurIPS, 2020.
- [28] Jongmok Kim, Jooyoung Jang, and Hyunwoo Park. Structured consistency loss for semi-supervised semantic segmentation. arXiv preprint arXiv:2001.04647, 2020.
- [29] Wouter Kool, Herke Van Hoof, and Max Welling. Stochastic beams and where to find them: The Gumbel-top-k trick for sampling sequences without replacement. In ICML, 2019.
- [30] Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In ICML Workshop on Challenges in Representation Learning, 2013.
- [31] Di Lin, Jifeng Dai, Jiaya Jia, Kaiming He, and Jian Sun. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In CVPR, 2016.
- [32] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
- [33] Wenfeng Luo and Meng Yang. Semi-supervised semantic segmentation via strong-weak dual-branch network. In ECCV, 2020.
- [34] Sudhanshu Mittal, Maxim Tatarchenko, and Thomas Brox. Semi-supervised semantic segmentation with high-and low-level consistency. TPAMI, 43(4):1369–1379, 2021.
- [35] Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. TPAMI, 41(8):1979–1993, 2018.
- [36] Viktor Olsson, Wilhelm Tranheden, Juliano Pinto, and Lennart Svensson. Classmix: Segmentation-based data augmentation for semi-supervised learning. In WACV, 2021.
- [37] Yassine Ouali, Céline Hudelot, and Myriam Tami. Semi-supervised semantic segmentation with cross-consistency training. In CVPR, 2020.
- [38] Pedro O Pinheiro, Amjad Almahairi, Ryan Y Benmaleck, Florian Golemo, and Aaron Courville. Unsupervised learning of dense visual representations. In NeurIPS, 2020.
- [39] Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In NeurIPS, 2020.
- [40] Nasim Souly, Concetto Spampinato, and Mubarak Shah. Semi supervised semantic segmentation using generative adversarial network. In ICCV, 2017.
- [41] Guolei Sun, Wenguan Wang, Jifeng Dai, and Luc Van Gool. Mining cross-image semantics for weakly supervised semantic segmentation. In ECCV, 2020.
- [42] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In NeurIPS, 2017.
- [43] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. In ECCV, 2020.
- [44] Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE. JMLR, 9(11):2579–2605, 2008.
- [45] Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, and Luc Van Gool. Unsupervised semantic segmentation by contrasting object mask proposals. In ICCV, 2021.
- [46] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deep high-resolution representation learning for visual recognition. TPAMI, 2020.
- [47] Wenguan Wang, Tianfei Zhou, Fisher Yu, Jifeng Dai, Ender Konukoglu, and Luc Van Gool. Exploring cross-image pixel contrast for semantic segmentation. In ICCV, 2021.
- [48] Xinlong Wang, Rufeng Zhang, Chunhua Shen, Tao Kong, and Lei Li. Dense contrastive learning for self-supervised visual pre-training. In CVPR, 2021.
- [49] Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In CVPR, 2020.
- [50] Mike Wu, Milan Mosse, Chengxu Zhuang, Daniel Yamins, and Noah Goodman. Conditional negative sampling for contrastive learning of visual representations. In ICLR, 2021.
- [51] Qizhe Xie, Zihang Dai, Eduard Hovy, Thang Luong, and Quoc Le. Unsupervised data augmentation for consistency training. In NeurIPS, 2020.
- [52] Zhenda Xie, Yutong Lin, Zheng Zhang, Yue Cao, Stephen Lin, and Han Hu. Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning. In CVPR, 2021.
- [53] Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S4L: Self-supervised semi-supervised learning. In ICCV, 2019.
- [54] Xiaohang Zhan, Ziwei Liu, Ping Luo, Xiaoou Tang, and Chen Loy. Mix-and-match tuning for self-supervised semantic segmentation. In AAAI, 2018.
- [55] Xiangyun Zhao, Raviteja Vemulapalli, Philip Mansfield, Boqing Gong, Bradley Green, Lior Shapira, and Ying Wu. Contrastive learning for label-efficient semantic segmentation. arXiv preprint arXiv:2012.06985, 2020.
- [56] Yi Zhu, Zhongyue Zhang, Chongruo Wu, Zhi Zhang, Tong He, Hang Zhang, R Manmatha, Mu Li, and Alexander Smola. Improving semantic segmentation via self-training. arXiv preprint arXiv:2004.14960, 2020.
- [57] Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin Dogus Cubuk, and Quoc Le. Rethinking pre-training and self-training. In NeurIPS, 2020.
- [58] Yuliang Zou, Zizhao Zhang, Han Zhang, Chun-Liang Li, Xiao Bian, Jia-Bin Huang, and Tomas Pfister. PseudoSeg: Designing pseudo labels for semantic segmentation. In ICLR, 2021.