\pkgrobumeta: An \proglangR-package for robust variance estimation in meta-analysis
Zachary Fisher, Elizabeth Tipton \Plaintitlerobumeta: an R package for robust variance estimation in meta-analysis \ShorttitleRobust variance estimation in meta-analysis \Abstract Meta-regression models are commonly used to synthesize and compare effect sizes. Unfortunately, traditional meta-regression methods are ill-equipped to handle the complex and often unknown correlations among non-independent effect sizes. Robust variance estimation (RVE) is a recently proposed meta-analytic method for dealing with dependent effect sizes. The \pkgrobumeta package provides functions for performing robust variance meta-regression using both large and small sample RVE estimators under various weighting schemes. These methods are distribution free and provide valid point estimates, standard errors and hypothesis tests even when the degree and structure of dependence between effect sizes is unknown. \Keywordsmeta-analysis, meta-regression, robust variance estimation, small-samples \Plainkeywordsmeta-analysis, meta-regression, robust variance estimation, small-samples
1 Introduction
Meta-analysis refers to a collection of quantitative methods for combining evidence across studies (Hedges and Olkin, 1985). Often this evidence is defined in terms of effect sizes, which are standardized so as to be comparable across studies. It is reasonable to treat these effect sizes as independent when estimators are derived from independent experiments or non-overlapping subject pools. However, non-independent effect sizes and effect size estimates are ubiquitous in published research (Van den Noortgate et al., 2013) and ignoring or misspecifying their covariance structure can result in estimates that are not valid (Matt and Cook, 2009).
Two common forms of dependence that arise in meta-analysis are correlated estimation errors and correlated effect size parameters. Consider the simple model
| (1) |
where is an estimate of the effect size, is the true effect size, and is the error resulting from our estimate of with . When is fixed (or varies only as a function of known characteristics), dependence can occur through the estimation errors (). In practice, this form of dependence is common to studies where multiple estimates are obtained from the same units (e.g., multiple outcomes on the same individuals, multiple time points), or where a common control group is used for multiple experimental contrasts.
When the are considered random, the dependence can occur through the . Dependence among effect size parameters is commonly encountered when a hierarchical relationship exists among studies, such as reports published by the same laboratory, different groups using the same equipment, or multiple experiments reported in a single study. In this case, it is the studies which are nested within a larger category. For a more detailed treatment of effect size dependency in meta-analysis see Gleser and Olkin (2009) or Becker (2000).
The problem with dependence is that traditional meta-analysis models assume independent effect sizes. When studies report multiple effect sizes, two approaches are common. One is to the use study average effect sizes, which result in a loss of information. A second approach is full multivariate meta-analysis (Hedges and Olkin, 1985; Raudenbush et al., 1988; Kalaian and Raudenbush, 1996). This is the optimal method for handling correlated data when the within-study covariance structure is known. Unfortunately, this information is rarely reported in published research. Without knowledge of the within-study correlations a number of factors should be considered before multivariate methods are used in practice. Those interested in a more detailed discussion of this topic should see Jackson et al. (2011).
Recently, Hedges et al. (2010) provided a new approach for handling non-independent effect sizes that does not require knowledge of the within-study covariance. The RVE method extends work on heteroskedasticity-robust (Eicker, 1967; Huber, 1967; White, 1980) and clustered (Liang and Zeger, 1986) standard errors in the general linear model, to the forms of dependence and weighting most often encountered in meta-analysis. The RVE approach has a number of desirable qualities. In meta-regression, the coefficients obtained from RVE are consistent estimates of the underlying population parameters under a broad set of conditions including non-normality. The results do not require the predictor variables to be fixed, as is the case in traditional regression methods used in meta-analysis(Hedges, 1982). Additionally, RVE produces valid standard errors, point estimates, confidence intervals, and significance tests when effect sizes are non-independent without needing to model the exact nature of this dependence. The RVE approach is increasingly being used in psychology, intervention research, medicine and ecology (see Tipton, in press). An overview of RVE methods geared towards practitioners, including a software tutorial for the \proglangStata program (Hedberg, 2011) and \proglangSPSS, can be found in Tanner-Smith and Tipton (2013).
A previous limitation of RVE is that its application was limited to situations where the number of studies is large; this is because the results described in Hedges et al. (2010) depend on asymptotic convergence. Simulation studies on the rates of convergence for regression coefficients (Williams, 2012), the standardized mean difference (Hedges et al., 2010), as well as the log odds ratio, log risk ratio, and risk difference effect sizes (Tipton, 2013), suggested that while confidence interval coverage for intercepts was adequate with as few as 10 studies, the coverage rates for slope intervals were only nominal when the number of studies was greater than 40. This is problematic since work by Ahn et al. (2012) and Polanin (2013) suggests that more than 50% of meta-analyses in psychology and education have fewer than 40 studies.
More recently, Tipton (in press) provided adjustments to the RVE estimators and degrees of freedom that greatly improve its performance in small samples. These are particularly important when the number of studies is less than 40, but also when the covariates are unbalanced or highly skewed. Tipton (in press) shows that it is hard to know a priori when these corrections are needed and suggest implementing them in all RVE analyses. The \pkgrobumeta package provides users with the ability to perform meta-regression with robust standard errors using both the original large-sample (Hedges et al., 2010) and small-sample adjusted (Tipton, in press) procedures. We briefly review these developments in RVE before proceeding to an example of RVE meta-regression using \pkgrobumeta.
2 RVE
Suppose we have studies, each with with effect size estimates, . Let study also have a vector of residuals , a design matrix , and weight matrix . The linear model relating the components can be written as
| (2) |
where the vectors and each contain stacked vectors corresponding to our studies, design matrix contains stacked matrices, and is a vector of unknown regression coefficients. For a given block diagonal matrix of weights , the weighted least squares estimates of are
| (3) |
When the covariance of the in study is , the exact covariance matrix for is
| (4) |
The problem that arises in estimating stems from difficulties in estimating the within-study covariance matrix . Although the individual variances are known, calculating the covariances of in depend on correlations that are often unreported. In RVE, the cross products of residuals for study , , are used as a rough estimate of the unknown . In doing so the estimate of becomes
| (5) |
Although the are rather poor estimates of the individual ’s, the estimator converges to the correct value, , as the number of studies in the meta-analysis (see Hedges et al., 2010, Appendix). Inferences made on the regression coefficients are based on these robust standard errors.
2.1 Weights
In traditional meta-analysis, inverse variance weights play two roles, First, they produce the most efficient estimate of . Second, the statistical estimator of the variance requires the weights to be inverse; when they are not, the estimate of the variance can be severely biased. In RVE, inverse variance weights are also used, but here they are only important for efficiency.
Weighting improves statistical efficiency by allocating more weight to studies that are more precise (i.e., have a smaller variance). Importantly, RVE provides asymptotically accurate estimates of the standard errors and valid inferential methods for any set of weights. This means the question of weights in RVE is only about efficiency. The most efficient weights would be . Clearly this is problematic since RVE is used when is unknown. For this reason, in RVE weights are developed based on a working model of the unknown covariance structure so that . Two working models (hierarchical and correlated effects) have been proposed to model the types of dependency most commonly encountered in meta-analytic research. Both of these weighting methods are only approximately efficient and in practice, researchers are urged to choose the weighting method based on the most common source of dependence in their data.
2.1.1 Correlated effects
For study , a working model based on the correlated effects dependence structure can be written as
| (6) |
where is a all-ones matrix, is a identity matrix, is the estimation error variances for the effect sizes, and is a common correlation between the effect sizes. Since the correlated effects model assumes dependence arises from measurements made on the same number of subjects (), it is assumed the error variances would be roughly constant within studies . Therefore, the simplified working model assumes a common correlation between within-study effect sizes. Approximate inverse variance weights are calculated by first partitioning the total study effect size variance equally among the effect sizes, and then taking the inverse. More generally, we do not assume the error variances are constant within studies , and approximate inverse variance weights are calculated using
| (7) |
where all the effect sizes in study are assigned the same weight , is the average study variance, and is an estimate of the between-study variance in study-average effect sizes.
To estimate , we compute an initial meta-regression where all the effect sizes within study are given equal weights (). Thus, the weighted residual sum of squares is
| (8) |
and the method of moments estimate of between studies variance is given by
| (9) |
Note that this depends on an unknown value for the common correlation . In practice, these results do not vary much for ; later we will introduce a sensitivity approach that can be implemented in practice.
2.1.2 Hierarchical effects
For study , a working model based on the hierarchical dependence structure can be written as
| (10) |
where is a all-ones matrix, is a identity matrix, is a is a diagonal matrix of error variances for study , is a measure of effect size variation within study , and is a measure of effect size variation between studies. Approximate inverse variance weights for study j are retrieved from
| (11) |
where . The weights are only constant in study if the error variances for each effect size are equal.
To estimate the parameters and , we first obtain the weighted residual sum of squares using (8). We also calculate an additional sum of squares using the results from our preliminary meta-regression
| (12) |
Hedges et al. (2010) provide the following method of moments estimators for and
| (13) |
| (14) |
Details on these equations can be found in Hedges et al. (2010).
3 Small-sample adjustments
As previously mentioned, while is a crude estimator of for individual studies, converges in probability to asymptotically (Hedges et al., 2010). The properties, and limitations, of linearization estimators like in small samples are well documented, and a number of solutions have been proposed to address these limitations. Interested readers can see Imbens and Kolesar (2012) for a discussion of these solutions.
In this section, we review two types of small sample adjustments proposed by Hedges et al. (2010) and extended by Tipton (in press). The first of these corrections is to the RVE estimator itself, while the second is to the degrees of freedom used for making inferences regarding the meta-regression coefficients .
3.1 Covariance structure adjustments
The first adjustment is to the estimator which can be written more generally as
| (15) |
where in general , , , and is a vector of true residuals. Hedges et al. (2010) proposed that this estimator could be improved by using
| (16) |
where is a by identity matrix. Simulations indicate that this adjustment is inadequate except in very specific cases and Tipton (in press) develop a new solution based on extensions to the Bias Reduced Linearization (BRL) method proposed by McCaffrey et al. (2001). Here since also depends on and working covariance matrices , the by adjustment matrix is specified separately for the hierarchical
| (17) |
and correlated effects weighting model
| (18) |
where . Additionally, if non-efficient weights are required (in \pkgrobumeta non-efficient weights can be specified using the \codeuserweights option) the adjustment matrix is specified as follows
| (19) |
where includes the rows of associated with study and the average variance of the study ’s effect sizes, .
In the above, for a general matrix note that , and where is the eigen decomposition. See the Appendix of Tipton (in press) for a detailed account of the development of these adjustments and their use with non-inverse variance weighting schemes.
3.2 Degrees of freedom adjustment
The second adjustment proposed by Hedges et al. (2010) was to use the t-distribution with when making statistical inferences using . Building off of Bell and McCaffrey (2002), however, Tipton (in press) suggests using the Satterthwaite approximation (Satterthwaite, 1946) to estimate the distribution of with , where the degrees of freedom is equal , and is the coefficient of variation.
These degrees of freedom are calculated separately for each regression coefficient under studying using
| (20) |
where are the eigenvalues of where . Here is a vector of ’s and ’s that indicates the regression coefficient, and are defined as before. Further details can be found in Tipton (in press). Simulations by Tipton (in press) show that the Satterthwaite approximation is valid so long as the . This means that RVE can be effectively used to make inferences even with a very small number of studies.
4 Testing and confidence intervals
Robust tests of the null hypothesis are conducted using the test statistic
| (21) |
where is the estimate of , is the diagonal of the matrix, and where we reject when . Additionally, a 95% confidence interval for the th regression coefficients is given by
| (22) |
Under the original Hedges et al. (2010) approach, is calculated using equation 5 and . When the small sample corrections from Tipton (in press) are used, is calculated using , , for the correlated effects, hierarchical effects and non-efficient weighting models, respectively. Here the degrees of freedom , as specified in equation 20, vary from covariate to covariate.
5 The \pkgrobumeta package
The \coderobu() function is the main fitting function for \pkgrobumeta and implements meta-regression using the large and small-sample RVE estimators described in Hedges et al. (2010) and Tipton (in press), respectively. The arguments available in \coderobu() are
robu(formula, data, studynum, var.eff.size, userweights, modelweights = c("CORR", "HIER"), rho = 0.8, small = TRUE,…)
The \codeformula object is similar to that found in other linear model specification routines (e.g., \codelm(), \codeglm()). A typical formula will look similar to \codey x1 + x2…, where \codey is a vector of effect sizes and \codex1 + x2… are the user-specified covariates. An intercept only model can be specified with \codey 1 and alternatively, the intercept can be omitted by specifying \codey -1 and multiplicative interaction terms can be specified with \codex1*x2…. The \codedata argument indicates the user-specified data frame which contains the following 3 columns
-
1.
Effect sizes (\codeeffect.size): User-specified column of effect sizes calculated from original research reports.
-
2.
Effect size variances (\codevar.eff.size): User-specified column of within-study variances for each effect size.
-
3.
Study identification (\codestudynum): User-specified column of study unique values used to identify studies.
-
4.
User-specified weights (\codeuserweights): User-specified weights if non-efficient weights are of interest (optional).
modelweights is the user-specified option for selecting either the hierarchical (\codeHIER) or correlated (\codeCORR) effects model. By default the correlated effects model is used. \coderho is the user-specified within-study effect size correlation, which must be specified when using the correlated effects model. The default value for \coderho is \code0.8 and user-specified values must be between 0 and 1. \codesmall = TRUE or \codesmall = FALSE allow the user to specify whether or not the Tipton (in press) adjusted estimation procedures will be used to fit the model, \codesmall = TRUE is the default. The \coderobu() function returns a fitted object of class \coderobu which contains a list of summary information calculated during the model fitting procedure. The \codeprint() method provides a formatted output containing this summary information.
6 Examples
6.1 Example 1
In the first example we use data from a meta-analysis conducted by Oswald et al. (2013) examining the predictive validity of the Implicit Association Test (IAT) and various explicit measures of bias for a variety of criterion measures of discrimination. The \codeoswald2013 dataset provided in \pkgrobumeta contains effect sizes collected from individual studies.
For this example, we will look at a subset of the \codeoswald2013.ex1 dataset which contains only the studies where the criterion measure of discrimination used was either neurological activity or response latency. The (\codeoswald2013.ex1) dataset contains effect sizes collected from individual studies. Additionally, the reported correlations have been transformed to Fisher’s (Gleser and Olkin, 2009). As the majority of effect-sizes in our dataset result from each study including multiple measures taken on the same individuals, we will use correlated effects weights to fit our model.
6.2 Intercept-only model
When performing a meta-regression it is standard practice to first calculate an average effect size without conditioning on the study covariates. In RVE this can be followed with a sensitivity analysis which will be discussed in more detail in the following section. The fitting function for the intercept-only model is specified with the \coderobu() function
oswald_intercept <- robu(formula = effect.size 1, data = oswald2013.ex1, studynum = Study, var.eff.size = var.eff.size, rho = .8, small = TRUE)
and the results displayed with \codeprint() as follows
print(oswald_intercept)
RVE: Correlated Effects Model with Small-Sample Corrections
Model: effect.size 1
Number of studies = 9 Number of outcomes = 32 (min = 1 , mean = 3.56 , median = 2 , max = 11 ) Rho = 0.8 I.sq = 82.05272 Tau.Sq = 0.1849812
Estimate StdErr t-value df P(|t|>) 951 intercept 0.277 0.181 1.53 7.84 0.164 -0.141 0.695 — Signif. codes: < .01 *** < .05 ** < .10 * — Note: If df < 4, do not trust the results
In addition to the coefficient table, the output from \codeprint() contains the formula call used to fit the model, summary information for the total number of studies and outcomes included in the analysis, and a coefficient table. In addition, output for the correlated effects model contains the user-specified value, the estimate of between-study variance in study-average effect sizes , and a descriptive statistic for the ratio of true heterogeneity to total variance across the observed effect sizes, (Higgins et al., 2003). is calculated using
| (23) |
where is defined as the weighted residual sum of squares as in equation 8. Unlike , is not on the same scale as the effect size index used in the analysis and is better suited to anwsering questions regarding the proportion of observed variance resulting from real effect size differences.
6.3 Sensitivity analysis
As mentioned previously, an estimate of is required to develop approximately efficient weights for the meta-regression model. The method of moments estimator for requires a value is specified for . For this reason Hedges et al. (2010) suggests conducting a sensitivity analysis to determine the effect of on . Generally, results from simulation studies suggest that and the meta-regression coefficients are relatively insensitive to changes in (Ishak et al., 2008; Williams, 2012; Tipton, 2013); however, if between-study covariances were to be considerably smaller than within-study covariances, these results might not hold. It should also be noted that a conservative approach and an external information approach have also been advocated for estimating in terms of developing efficient weights. The conservative approach involves setting to , which ensures studies don’t receive additional weight due to having more effect sizes. Additional information on these strategies can be found in Hedges et al. (2010).
The \codesensitivty() function in \pkgrobumeta computes , the average effect size and associated standard error for different values of in the interval .
R > sensitivity(oswald_intercept)
Type Variable rho=0 rho=0.2 rho=0.4 rho=0.6 rho=0.8 rho=1 1 Estimate intercept 0.277 0.277 0.277 0.277 0.277 0.277 2 Std. Err. intercept 0.181 0.181 0.181 0.181 0.181 0.181 3 Tau.Sq 0.184 0.184 0.184 0.185 0.185 0.185
From the sensitivity analysis it seems and subsequently the average effect size are relatively robust to different values of .
6.4 Forest plot
In meta-analysis, forest plots provide a graphical depiction of effect size estimates and their corresponding confidence intervals. The \codeforest.robu() function in \pkgrobumeta can be used to produce forest plots for RVE meta-analyses. The function requires the \pkggrid (R Core Team, 2013) package and is based on examples provided in Murrell (2011). As is the case in traditional forest plots, point estimates of individual effect sizes are plotted as boxes with areas proportional to the weight assigned to that effect size. Importantly, here the weight is not necessarily proportional to the effect size variance or confidence intervals, since the combined study weight is divided evenly across the study effect sizes. Two-sided 95% confidence intervals are calculated for each effect size using a standard normal distribution and plotted along with each block. The overall effect is included at the bottom of the plot as a diamond with width equivalent to the confidence interval for the estimated effect.
The RVE forest function is designed to provide users with forest plots which display each individual effect size used in the meta-analysis, while taking into account the study- or cluster-level properties inherent to the RVE analysis. As such, the user must specify columns from their original dataset that contain labels for the study or cluster and for the individual effect sizes. For instance, labels for the study column might be author names with corresponding publication years, and would be specified in the \codeforest.robu function using the \codestudy.lab argument. Labels for individual effect sizes might be “Math Score” or “Reading Score” for a meta-analysis that included such measures or as simple as “Effect Size 1” and “Effect Size 2,” and can be specified with the \codees.lab argument. Any number of additional columns can be specified to be plotted along side the confidence interval column and can be specified with the following syntax \code"arg1" = "arg2" where \code"arg1" is the title of the column on the forest plot, and \code"arg2" is the name of the column from the original \codedata.frame that contains the information to be displayed. An RVE forest plot with study labels corresponding to the author name and publication year, and effect size labels corresponding to the criterion for the Oswald data (see Figure 1 on page 1) is specified using the syntax below. In addition, a column of the RVE weights titled “Weight” and a column of effect sizes titled “Effect Sizes” is also included to illustrate the syntax for adding additional columns.
forest.robu(oswald_intercept, es.lab = "Crit.Cat", study.lab = "Study", "Effect Size" = effect.size, # optional column "Weight" = r.weights) # optional column
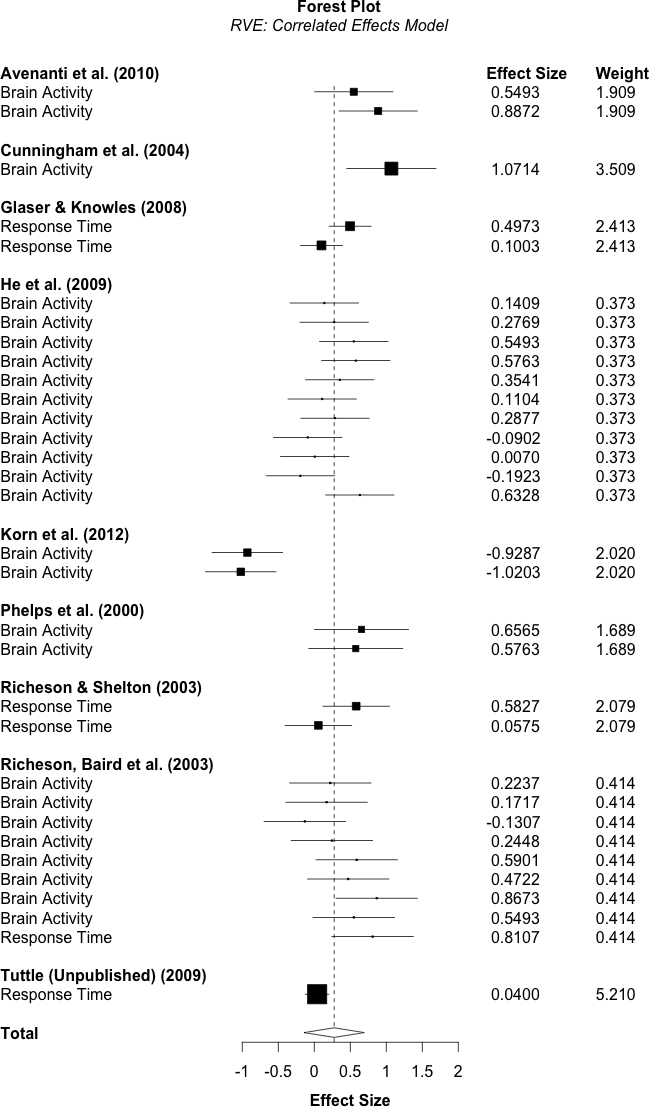
6.5 Example 2
In the following section we walk through an example where \pkgrobumeta is used to fit simulated data described in Tanner-Smith and Tipton (2013). The dataset in question resulted from a fictional meta-analysis that examined the effectiveness of a brief alcohol intervention on alcohol intake. Intervention effectiveness was determined by differences in alcohol consumption between treatment and controls following the intervention. In this example standardized mean difference effect sizes are provided using Hedges’ g, however, any effect size can be used with the \coderobu() function. The \codehierdat dataset contains unique treatment centers with effect sizes. The covariates of interest in this example are \codefollowup, which indicates the length of the follow-up period before alcohol consumption was measured, in months and \codebinge which indicates whether or not the alcohol consumption measure targeted binge drinking specifically. As the majority of dependency in this meta-analysis resulted from studies nested within treatment centers, we use the hierarchical effects weights to fit our model.
6.6 Covariate levels
In RVE dependencies result from hierarchically structured data. Borrowing terminology from the multilevel and hierarchical linear modeling literature, this hierarchical structure takes the form of lower-level observations nested within higher-level groupings. Within the RVE framework we are generally concerned with two-level structures where level-1 (the lowest level) represents effect sizes in the correlated effects case and studies in the hierarchical effects case, while level-2 represents the study-level in the correlated effects case and a higher-order grouping level such as research lab in the hierarchical effects case.
Since covariates can vary both between-level-2 and within-level-2 it is an important pre-processing step in any RVE analysis to identify the nature of this variation prior to model fitting. For example, at first glance the \codefollowup variable appears to vary both within- and between-level-2. This indicates the length of follow-up periods varies both across studies conducted by the same treatment center, and then between the treatment centers themselves. Failure to distinguish between these effects can complicate interpretation later on as the regression coefficient actually represents a weighted combination of both between- and within-level-2 effects, which can be problematic when the effects differ in direction or magnitude. For instance, if treatment centers which produce higher quality studies also tend to employ longer follow-up periods the effect of follow-up length on treatment effect sizes might differ when examined within a given treatment center’s studies, compared to the effect of follow-up length across treatment centers.
To partition these two types of effect we can create group mean and group centered versions of \codefollowup using the convenience functions \codegroup.mean() and \codegroup.center() provided in \pkgrobumeta.
R > hierdatfollowup, hierdatfollowup_c <- group.center(hierdatstudyid)
Subsequently, including both \codefollowup_m and \codefollowup_c in our meta-regression model as follows
| (24) |
allows us to decompose the effects of follow-up length into two independent estimates where and represent the effect of a 1-month increase in and a 1-month increase in on , respectively. Another important feature of centering is that it often indicates that a variable only varies at the study level, not effect size level. We therefore encourage researchers to examine these variables before proceeding with their analysis.
6.7 Meta-regression model
Now that we have completed the necessary data pre-processing we can fit our meta-regression model using hierarchical effects weighting with the following command
R > model_hier <- robu(effectsize followup_c + followup_m + binge, data = hierdat, modelweights = "HIER", studynum = studyid, var.eff.size = var, small = TRUE)
The \codeprint() method can be used to present the results
R > print(model_hier)
RVE: Hierarchical Effects Model with Small-Sample Corrections
Model: effectsize followup_c + followup_m + binge
Number of clusters = 15 Number of outcomes = 68 (min = 1 , mean = 4.53 , median = 2 , max = 29 ) Omega.sq = 0.1650524 Tau.Sq = 0.02479249
Estimate StdErr t-value df P(|t|>) 951 intercept -0.154226 0.147671 -1.044 6.07 0.3361 -0.51461 0.20615 2 followup_c -0.000162 0.000695 -0.233 1.30 0.8470 -0.00534 0.00502 3 followup_m 0.003467 0.002320 1.495 3.28 0.2243 -0.00357 0.01050 4 binge 0.666645 0.115623 5.766 4.33 0.0035 0.35514 0.97815 *** — Signif. codes: < .01 *** < .05 ** < .10 * — Note: If df < 4, do not trust the results
The results of the meta-regression suggest the p-value for \codefollowup_c and \codefollowup_m are not reliable, as the Satterthwaite degrees of freedom are less than 4. This may result from the fact that center is contributing more than half of the effect sizes included in our meta-analysis did not actually vary the followup interval across studies, resulting in an unbalanced covariate. This is in line with results from simulation studies which suggest the Satterthwaite degrees of freedom are typically smaller for unbalanced covariates (Tipton, in press). The effect of whether or not the study used a binge drinking measure (\codebinge), however, was found to be positive and significant at . This suggests that studies which used binge drinking as their criterion measure were associated with increased treatment effect sizes compared to those studies that used some other measure of alcohol consumption.
7 Conclusions
Robust variance estimation (RVE) is a user friendly procedure grounded in work on
heteroskedasticity-robust (Eicker, 1967; Huber, 1967; White, 1980) and clustered standard errors (Liang and Zeger, 1986). RVE holds promise for alleviating the problems introduced by unknown within-study correlations in meta-analysis(Jackson et al., 2011). This potential utility of RVE methods has been further expanded recently through the small- sample adjustments developed by (Tipton, in press) which greatly improve the finite-sample properties of RVE. The \pkgrobumeta package provides functions for conducting meta-regression with both the large-sample (Hedges et al., 2010) and adjusted (Tipton, in press) RVE estimators and provides functions for producing forest plots consistent with the RVE methodology.
References
- Ahn et al. (2012) Ahn S, Ames AJ, Myers ND (2012). “A Review of Meta-Analyses in Education Methodological Strengths and Weaknesses.” Review of Educational Research, 82(4).
- Becker (2000) Becker BJ (2000). “Multivariate Meta-Analysis.” In HEA Tinsley, SD Brown (eds.), Handbook of Applied Multivariate Statistics and Mathematical Modeling, pp. 499–525. Academic Press, San Diego, CA, US.
- Bell and McCaffrey (2002) Bell RM, McCaffrey DF (2002). “Bias Reduction in Standard Errors for Linear Regression with Multi-Stage Samples.” Survey Methodology, 28(2), 169–181.
- Eicker (1967) Eicker F (1967). “Limit Theorems for Regressions with Unequal and Dependent Errors.” In LM Le Cam, J Neyman (eds.), Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, volume 1, pp. 59–82. University of California Press, Berkeley.
- Gleser and Olkin (2009) Gleser LJ, Olkin I (2009). “Stochastically Dependent Effect Sizes.” In HM Cooper, LV Hedges, JC Valentine (eds.), The Handbook of Research Synthesis and Meta-Analysis, 2nd edition. Russell Sage Foundation.
- Hedberg (2011) Hedberg EC (2011). ROBUMETA: Stata module to perform robust variance estimation in meta-regression with dependent effect size estimates. BC Dept. of Economics.
- Hedges (1982) Hedges LV (1982). “Fitting Continuous Models to Effect Size Data.” Journal of Educational Statistics, 7(4), 245–270.
- Hedges and Olkin (1985) Hedges LV, Olkin I (1985). Statistical Methods for Meta-Analysis. Academic Press.
- Hedges et al. (2010) Hedges LV, Tipton E, Johnson MC (2010). “Robust Variance Estimation in Meta-Regression With Dependent Effect Size Estimates.” Research Synthesis Methods, 1(1), 39–65.
- Higgins et al. (2003) Higgins JPT, Thompson SG, Deeks JJ, Altman DG (2003). “Measuring inconsistency in meta-analyses.” BMJ : British Medical Journal, 327(7414), 557–560.
- Huber (1967) Huber P (1967). “The Behavior of the Maximum Likelihood Estimates Under Nonstandard Conditions.” In J Neyman Lucien Marie Le Cam (ed.), Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, pp. 221–233. University of California Press, Berkeley.
- Imbens and Kolesar (2012) Imbens GW, Kolesar M (2012). “Robust Standard Errors in Small Samples: Some Practical Advice.” Working Paper 18478, National Bureau of Economic Research.
- Ishak et al. (2008) Ishak KJ, Platt RW, Joseph L, Hanley JA (2008). “Impact of approximating or ignoring within-study covariances in multivariate meta-analyses.” Statistics in Medicine, 27(5), 670–686.
- Jackson et al. (2011) Jackson D, Riley R, White IR (2011). “Multivariate meta-analysis: Potential and promise.” Statistics in Medicine, 30(20), 2481–2498.
- Kalaian and Raudenbush (1996) Kalaian HA, Raudenbush SW (1996). “A Multivariate Mixed Linear Model for Meta-Analysis.” Psychological Methods, 1(3), 227–235.
- Liang and Zeger (1986) Liang KY, Zeger SL (1986). “Longitudinal Data Analysis Using Generalized Linear Models.” Biometrika, 73(1), 13–22.
- Matt and Cook (2009) Matt GE, Cook TD (2009). “Threats to the Validity of Generalized Inferences.” In HM Cooper, LV Hedges, JC Valentine (eds.), The Handbook of Research Synthesis and Meta-Analysis, 2nd edition. Russell Sage Foundation.
- McCaffrey et al. (2001) McCaffrey DF, Robert M Bell, Botts CH (2001). “Generalizations of Biased Reduced Linearization.” In Proceedings of the Annual Meeting of the American Statistical Association.
- Murrell (2011) Murrell P (2011). R Graphics. CRC/Taylor & Francis. ISBN 9781439831762.
- Oswald et al. (2013) Oswald FL, Mitchell G, Blanton H, Jaccard J, Tetlock PE (2013). “Predicting ethnic and racial discrimination: a meta-analysis of IAT criterion studies.” Journal of personality and social psychology, 105(2), 171–192.
- Polanin (2013) Polanin JR (2013). “Addressing the Issue of Meta-Analysis Multiplicity in Education and Psychology.” Doctoral Dissertation.
- R Core Team (2013) R Core Team (2013). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria.
- Raudenbush et al. (1988) Raudenbush SW, Becker BJ, Kalaian H (1988). “Modeling Multivariate Effect Sizes.” Psychological Bulletin, 103(1), 111–120.
- Satterthwaite (1946) Satterthwaite FE (1946). “An Approximate Distribution of Estimates of Variance Components.” Biometrics, 2(6), 110–114.
- Tanner-Smith and Tipton (2013) Tanner-Smith EE, Tipton E (2013). “Robust Variance Estimation with Dependent Effect Sizes: Practical Considerations Including a Software Tutorial in Stata and Spss.” Research Synthesis Methods.
- Tipton (2013) Tipton E (2013). “Robust Variance Estimation in Meta-Regression with Binary Dependent Effects.” Research Synthesis Methods, 4(2).
- Tipton (in press) Tipton E (in press). “Small Sample Adjustments for Robust Variance Estimation with Meta-Regression.” Psychological Methods.
- Van den Noortgate et al. (2013) Van den Noortgate W, López-López J, Marín-Martínez F, Sánchez-Meca J (2013). “Three-Level Meta-Analysis of Dependent Effect Sizes.” Behavior Research Methods, 45(2), 576–594.
- White (1980) White H (1980). “A Heteroskedasticity-Consistent Covariance Matrix Estimator and a Direct Test for Heteroskedasticity.” Econometrica, 48(4), 817–38.
- Williams (2012) Williams RT (2012). “Using Robust Standard Errors to Combine Multiple Regression Estimates with Meta-Analysis.” Doctoral Dissertation.