Planning-Assisted Context-Sensitive Autonomous Shepherding of Dispersed Robotic Swarms in Obstacle-Cluttered Environments
Abstract
Robotic shepherding is a bio-inspired approach to autonomously guiding a swarm of agents towards a desired location. The research area has earned increasing research interest recently due to the efficacy of controlling a large number of agents in a swarm (sheep) using a smaller number of actuators (sheepdogs). However, shepherding a highly dispersed swarm in an obstacle-cluttered environment remains challenging for existing methods. To improve the efficacy of shepherding in complex environments with obstacles and dispersed sheep, this paper proposes a planning-assisted context-sensitive autonomous shepherding framework with collision avoidance abilities. The proposed approach models the swarm shepherding problem as a single Travelling Salesperson Problem (TSP), with two sheepdogs’ modes: no-interaction and interaction. An adaptive switching approach is integrated into the framework to guide real-time path planning for avoiding collisions with static and dynamic obstacles; the latter representing moving sheep swarms. We then propose an overarching hierarchical mission planning system, which is made of three sub-systems: a clustering approach to group and distinguish sheep sub-swarms, an Ant Colony Optimisation algorithm as a TSP solver for determining the optimal herding sequence of the sub-swarms, and an online path planner for calculating optimal paths for both sheepdogs and sheep. The experiments on various environments, both with and without obstacles, objectively demonstrate the effectiveness of the proposed shepherding framework and planning approaches.
keywords:
swarm shepherding , path planning , travelling saleperson problem , ant colony optimisation1 Introduction
As a bio-inspired swarm guidance approach, robotic shepherding seeks to guide a swarm of agents (e.g., sheep flock, crowd) to a goal area by controlling the movement of one or more outside robots (known as sheepdogs or shepherds) [1]. Simulating the shepherding behaviour has attracted increasing attention of scholars due to the ability to map the level of abstraction in the shepherding problem to many real-world applications such as crowd control [2], precision agriculture [3], objects collection [4], robotic manipulation [5], and preventing birds from entering an airspace in airports [6].
One of the most challenging issues in shepherding is how to increase success rate while reducing mission’s completion time when herding a large number of sheep that are highly dispersed in an environment with obstacles (more on this challenge in Section 2.1).
Existing swarm shepherding methods can be roughly classified as rule-based methods [7] [8], learning-based methods [9] [10], and planning-based methods [11] [12]. Rule-based algorithms lack the flexibility and adaptability required to manage a wide range of environments [13]. While learning-based methods have the potential to address adaptability, they rely heavily on training and require a large amount of data and/or significant computational time for training [14]. Planning-based methods integrate planning approaches (e.g., optimisation techniques) into rule-based methods to guide sheepdog behaviour. However, current literature is limited to motion (e.g., path) planning algorithms, mostly for a single agent or multi-agents exhibiting self-control only (i.e. they do not need to exercise indirect control over groups). Therefore, existing methods face difficulty addressing the shepherding problem. The problem is compoinded when sheepdogs have limited influence ranges and need to herd a large dispersed flock into several sub-swarms in environments containing obstacles.
Planning is an important research field in robotics and artificial intelligence [15] [16] [17]. The field promises to improve the shepherding performance in terms of success rate and completion time [18]. Aiming to address the multiple sub-swarm, obstacle-cluttered environment, and effective shepherding, this paper focuses on planning-based methods. We capitalise on the similarity between multiple sub-swarm shepherding and the Travelling Salesperson Problem (TSP) to realise the benefits of path planning in obstacle-cluttered environments. TSP is a well-known route planning problem for determining the optimal visiting sequence of a list of cities [19] and has been extensively studied as described in Section 2.2. However, the similarities and application of TSP to shepherding problems has not been studied. Path planning using metaheuristics such as Evolutionary Computation Algorithms (EC) [20] and Rapidly Exploring Random Tree algorithm [12] have shown their promising early results in facilitating swarm shepherding.
This paper proposes a planning-assisted swarm shepherding framework by integrating the TSP with path planning to improve the effectiveness of shepherding, especially for a highly dispersed sheep swarm in an obstacle-cluttered environment. In the proposed shepherding framework, the sheep swarm is firstly divided into sub-swarms to identify the set of virtual ‘cities’ and then the shepherding problem is transformed into a single TSP to determine the optimal push sequence of sheep sub-swarms. Path planning is integrated with TSP for finding the optimal path for the sheep sub-swarm to be herded towards the next ‘city’ sequentially without collision with obstacles, and for the sheepdog to move towards the driving point of the sheep sub-swarm in real time. A primary difference between a classic TSP and the way it is adopted for shepherding is that the travelling salesperson actuates on itself, while in shepherding, it actuates on a group with unpredictable responses from the members of the groups. To handle this challenge effectively, we needed to combine the offline TSP with on-line heuristics to manage the emerging dynamics from these indirect interactions.
We consider two modes for a sheepdog to respond to context-sensitive information. First, a context-sensitive interaction mode where the sheepdog is forcing the sheep sub-swarm to move. Second, a no-interaction mode where the influence of sheepdogs on the sheep swarm is minimal to avoid undesired movements of sheep. An adaptive switching approach is proposed to assist sheepdogs in switching between the two interaction and no-interaction modes based on context during real-time opertions. Subsequently, we present a hierarchical mission planning algorithm, which combines the offline grouping and TSP solver, as well as the online path planner, to solve the optimisation problems involved in the framework. The grouping method divides the sheep swarm by evaluating if there is cohesion forces among the sheep and a well-known optimisation approach, Max-Min Ant System (MMAS) [21], is introduced for addressing the TSP. Besides, a two-layer path planner, A*-Post Processing (A*-PP), is presented to optimise the path for both sheepdogs and sheep swarm.
The contributions of this paper include the following:
-
1.
A planning-assisted swarm shepherding model is proposed to effectively herd the highly dispersed sheep swarm to the goal in obstacle-cluttered environments.
-
2.
The formulation of the swarm shepherding problem as a single TSP to determine the optimal herding sequence of sub-swarms.
-
3.
A context-sensitive response model where the sheepdog adaptively switches between two modes of operation during real-time path planning.
-
4.
A hierarchical mission planning system, consisting of offline grouping and MMAS-based sequencing as well as online path planning, are designed.
The remainder of the paper is organised as follows. Section 2 provides a review of the works related to swarm shepherding and mission planning. Section 3 presents the basic shepherding model while Section 4 describes the proposed planning-assisted shepherding model. The planning algorithms used in the proposed shepherding model are presented in Section 5, followed by the experimental results and analysis Section 6. Last is the conclusion in Section 7.
2 Related works
This section covers an overview of related work to swarm shepherding.
2.1 Swarm shepherding
The success of robotic swarm shepherding relies on the modelling of sheep flocking behaviour and the design of sheepdog control strategies. The rules of BOIDS [22] [23] [24] are the most common sheep modelling method, where separation, cohesion and alignment of sheep are considered. To improve robustness when herding larger flocks, Harrison et al.[25] viewed the flock as an abstracted deformable shape, while Hu et al. [26] used adaptive protocols and artificial potential filed methods to model the sheep flocking behaviour.
The shepherding field of research has focused more on the design of sheepdog control strategies. As a representative work of rule-based shepherding methods, Strömbom et al’s shepherding algorithm [7] laid the foundations for many other shepherding methods, such as the modulation model in [8] and the Reinforcement Learning (RL) approach in [27]. Strömbom et al. [7] (described in section 3) simulated two typical sheepdog behaviours (collecting the dispersed sheep, and driving the aggregated sheep swarm to a specific location). They found that the mission completion time increases and the success rate decreases as the number of agents in the swarm increases.
A coordination algorithm was designed in [26] to employ multiple robotic sheepdogs to herd two flocks of sheep, which consists of 20 and 30 sheep, respectively. It was observed that the proposed algorithm could not handle the shepherding of a large flock. El-Fiqi et al. [13] investigated the influence of some key factors (e.g., the density of obstacles and the initial spatial distribution of sheep) on the complexity of shepherding and identified the limitations of reactive shepherding. It was suggested that an increase in the density of obstacles and the sheep’s initial level of dispersion in the environment escalate problem complexity and reduce mission success rate.
Learning-based methods have also been studied [10] [9] [28]. Go et al. [27] extended Strömbom et al.’s model by applying RL for learning the sheepdog’s behaviour policy. Hussein et al. [14] decomposed the shepherding problem into two sub-problems: learning to push an agent from a location to the destination and selecting whether to collect scattered agents or drive the largest flock to the destination. They aimed to reduce the problem’s complexity and proposed a curriculum-based RL to accelerate the learning process. However, the investigation of the swarm shepherding problem with multiple sub-swarms randomly dispersed in the obstacle-cluttered environment is still limited, and an efficient way to address this problem is lacking.
2.2 Planning approaches
Mission planning approaches such as path planning algorithms have been well investigated and applied for mobile robots. The planning sub-problems (e.g., path planning, route planning, task assignment) involved in mission planning are defined, and the promising applications for swarm shepherding are discussed in [18]. Long et al. [1] also suggested that the sheepdog should take charge of high-level planning, such as path planning and task allocation for completing complex shepherding tasks. Some research on the applications of planning approaches for swarm shepherding exist [11] [12]. For instance, Lien and Pratt [2] presented a computer-human interactive motion planning method to address the shepherding problem. They observed that the planner lacks efficiency when the flock separates into several sub-groups. To modify the shepherding model in environments with obstacles, Elsayed et al. [20] presented a 2-stage differential evolution-based path planning algorithm that optimises the path for the sheepdog and sheep. They demonstrated that the path planning algorithm could reduce the time to complete the shepherding task.
TSP is a well-known NP-hard route planning problem that aims to find the route with the optimal cost for a salesperson to visit each city exactly once and returns to the initial city, given a set of cities and the travelling cost between each pair of cities [19]. TSP is a generalisation of or can be applied to many real-world problems, such as vehicle routing problem (VRP) [29], multi-robot task allocation [30], multi-regional coverage path planning [31], transportation and delivery [32]. Significant research has been conducted on TSP [33] [34]. Some effective approaches for solving the TSP include EC [35] [36] and swarm-intelligence algorithm such as Ant Colony Optimisation (ACO) [37], which has demonstrated its ability to solve TSP in multiple studies [21] [38] [39]. Many variants of TSP, such as Multiple TSP (MTSP) and Dynamic TSP (DTSP) [35], exist. For example, when there are multiple salespersons, the problem is called MTSP and can be further classified as single-depot and multi-depot based on where salespersons depart from [40]. Transformation methods have been used to convert a complex TSP problem to a classic single TSP where general and efficient TSP solvers exist [41]. Shepherding problems, especially with multiple sub-swarms, share some similarities with TSP. For example, there are some swarm locations (‘cities’) required to be visited by some agents (sheepdogs/salespersons) in both problems. However, to the best of our knowledge, TSP has not been applied to the robotic shepherding problem before.
3 Strömbom model
Before moving to the proposed approach, we briefly describe the model proposed by Strömbom et al. to introduce the terminology associated with shepherding that will be used subsequently. Let the sheep swarm be where denotes a sheep agent and is the number of sheep agents in the swarm. is the set of sheepdog agents (UGVs) with sheepdogs denoted as . The goal position which sheepdogs herd the sheep swarm towards is denoted as . The position of / at time step is denoted as /. As per [8] [20] [13], sheep total force and sheepdog total force are calculated as Equation (1) and Equation (2) respectively.
| (1) |
| (2) |
where each is the weight of the corresponding force vector. Each force vector is described as follows:
For sheep :
-
1.
is the previous total force vector;
-
2.
represents the attraction force to its neighbours within the cohesion range ;
-
3.
represents the repulsion force from sheepdog if is within the influence range of the sheepdog ;
-
4.
is the repulsion force from other sheep within the sheep avoidance radius ;
-
5.
is the repulsion force from the obstacles within the obstacles avoidance radius ;
-
6.
is the random forces added to sheep .
For sheepdog :
-
1.
represents the normalised force vector that makes the sheepdog move to the driving point or collection point ;
-
2.
is the random forces added to Sheepdog to help avoid deadlocks.
To complete the shepherding mission, sheepdog agents switch between driving behaviour and collecting behaviour by evaluating if any sheep is further away from the sheep flock as shown in Algorithm 1. Specifically, if the distance between any sheep and the Global Centre of Mass (GCM) of flock is further than the neighbourhood range , the sheepdog moves to the collecting point , which is located behind the furthest sheep in the direction of the GCM; otherwise, the sheep are clustered in the flock and the sheepdog needs to execute a driving behaviour by moving to the driving point , which is located behind the GCM relative to the final goal . and are calculated as following:
| (3) |
| (4) |
| (5) |
where is the safe operation distance between a sheepdog and a sheep.
Then sheepdog position and sheep position are updated according to Equation (6) and Equation (7), respectively.
| (6) |
| (7) |
where and represent the moving speed of sheepdog and sheep .
4 Planning-assisted swarm shepherding framework
As discussed in Section 2, existing shepherding models are inefficient when the sheep agents are too dispersed and the density of obstacles is high. To address this issue, this section proposes a planning-assisted swarm shepherding framework to improve shepherding efficacy by integrating a grouping/clustering approach, a TSP solver, and a localised path planning and navigation into a planning-assisted shepherding framework.
4.1 Grouping of dispersed sheep in the environment
Given a highly dispersed sheep swarm in an environment, the first step in the planning-assisted shepherding framework is to group the dispersed sheep into some sub-swarms and locate the Local Centre of Mass (LCM) of each sub-swarm. The set of sheep sub-swarms is denoted as
| (8) |
where is the number of sub-swarms and the sub-swarm subjects to , and . A sheep is assigned to a sub-swarm if it is within the cohesion range from any sheep of this sub-swarm. The LCM of at time step is calculated as
| (9) |
where is the number of sheep in the sub-swarm and is the position of the sheep grouped in at . The LCM of each is regarded as a target location, which the sheepdog should visit.
4.2 Transforming the swarm shepherding problem to the TSP for task sequencing
After obtaining LCMs of sub-swarms, the swarm shepherding problem can be transformed into a variant of TSP. This section discusses how to transform the single-sheepdog shepherding and bi-sheepdog shepherding problems to a single TSP and presents the mathematical formulation of the shepherding-transformed single TSP. Subsequently, the general TSP solver (presented in Section 5.1) can be employed to find the optimal push sequence of sheep sub-swarms to guide the sheepdog(s)’ behaviours.
4.2.1 Transforming the single-sheepdog shepherding problem
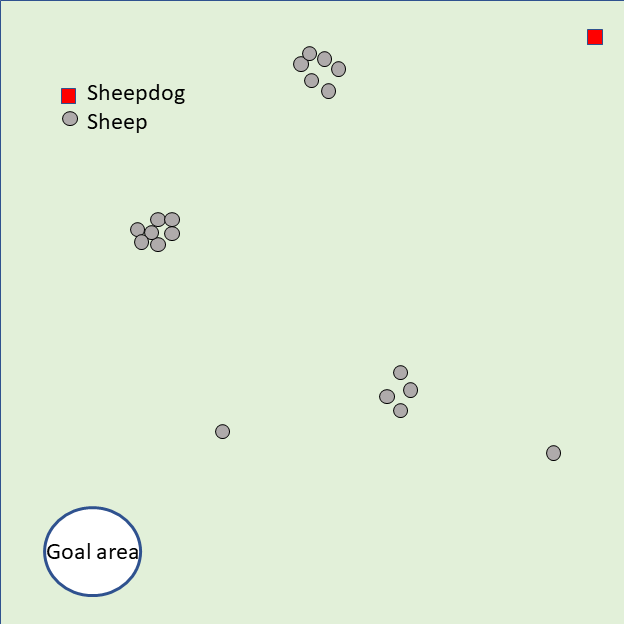
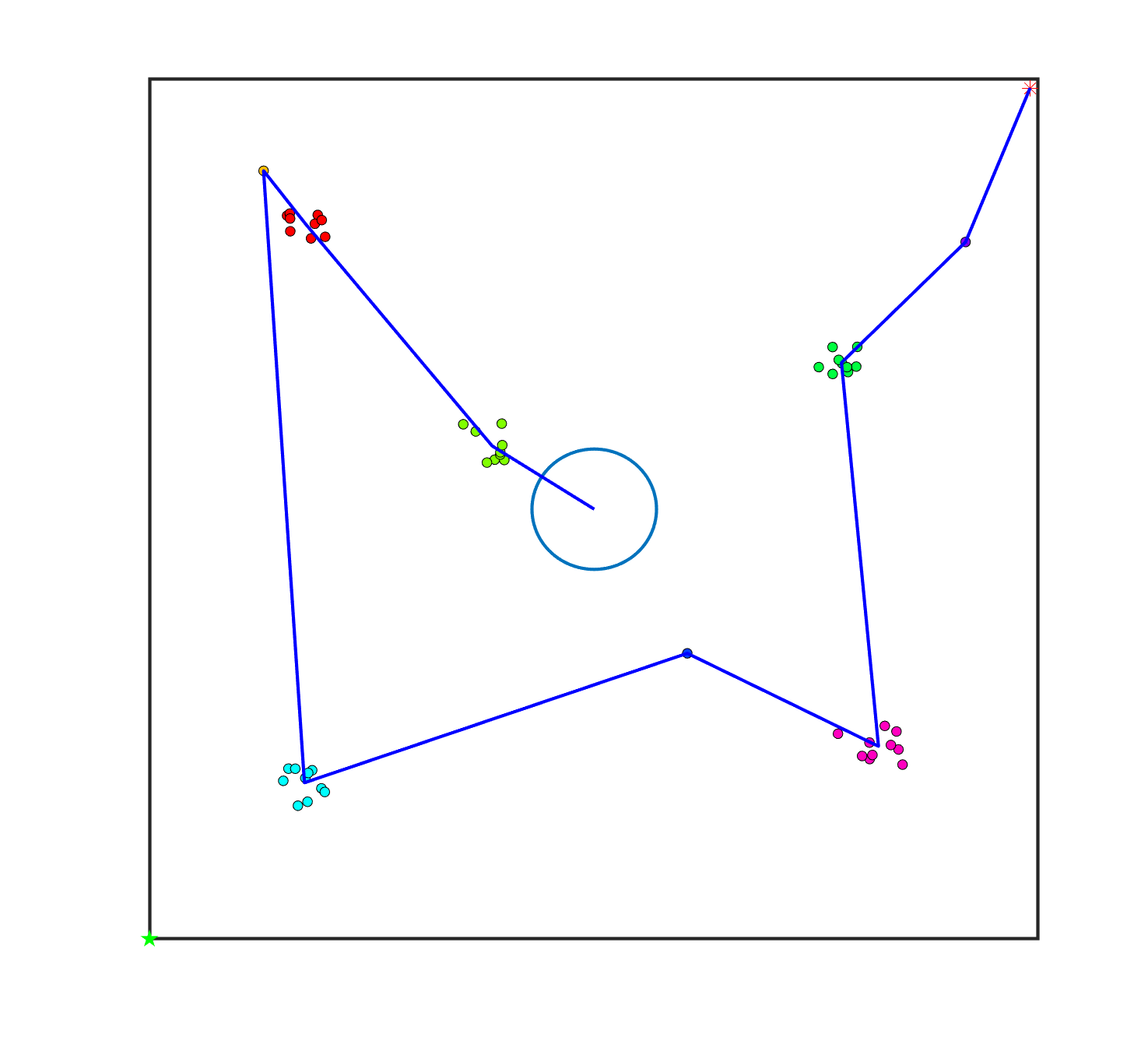
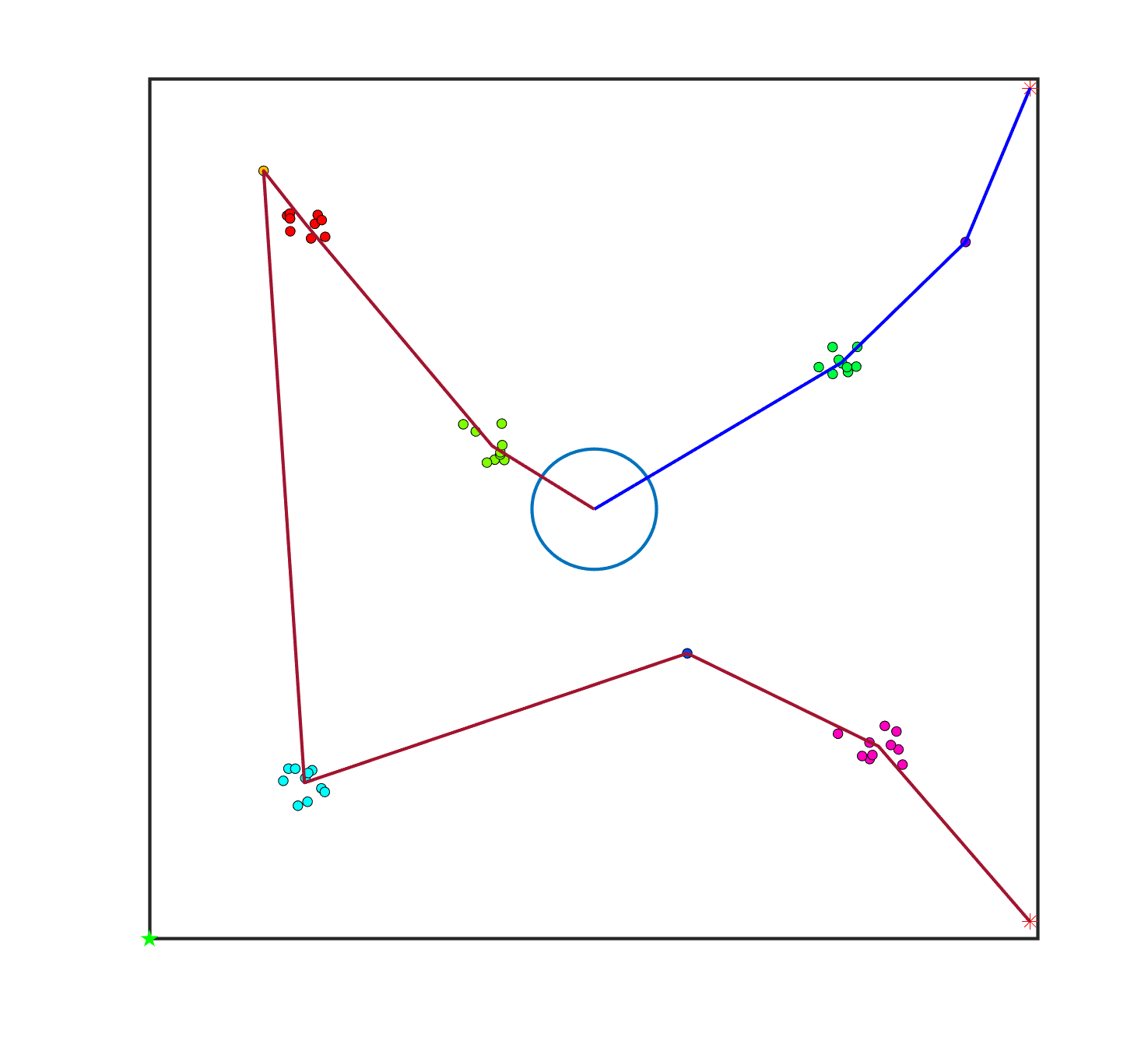
To transform the single-sheepdog shepherding problem, we first describe how the shepherding mission is expected to be completed in our proposed model. For illustrative purposes, Fig. 1(a) presents a single-sheepdog swarm shepherding problem with sheep dispersed randomly in the obstacle-free environment and a sheepdog located in the top-right corner. The grouping result is indicated in Fig. 1(b) with 5 sub-swarms in different colours and the LCMs are represented as black crosses. Assuming the optimal push sequence of sub-swarms is , Fig. 1(b) illustrates how the sheepdog is going to drive the sequenced sheep sub-swarms to reach the goal area.
Similar to the description in Section 3, the driving point of each sub-swarm is located behind the sub-swarm in the direction of the next target location, maintaining the distance of from the LCM of the sub-swarm. The driving point for each sub-swarm is represented as a yellow square in Fig. 1(b). To control the sheep sub-swarms to move as indicated by the grey thick directed line segments in Fig. 1(b), the sheepdog should follow the route represented by the red directed line segments and curves. To assist the sheepdog in switching to drive another sub-swarm, switch points are introduced in the proposed model and are represented as blue triangles in Fig. 1(b). Specifically, the sheepdog departs from its initial position for , pushes to by travelling to , then switches to for pushing , and repeats this process until all the sub-swarms reach .
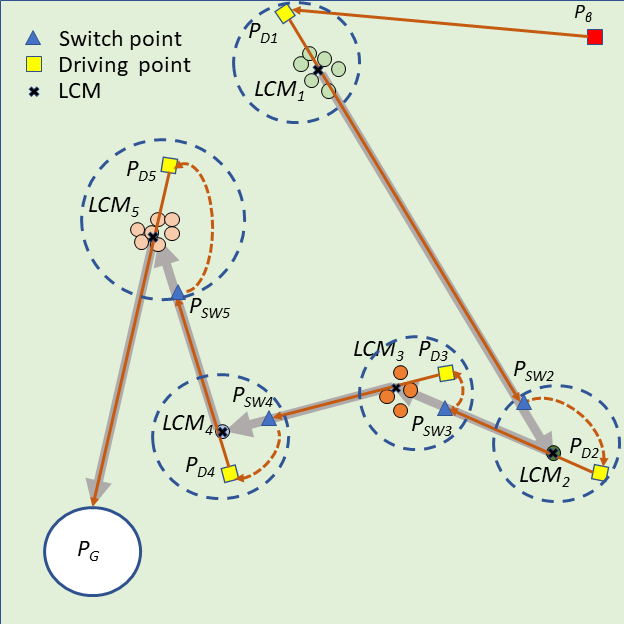
To define a TSP, two vital issues need to be addressed. These are 1) identifying the list of cities and 2) evaluating the travelling cost between each pair of cities. In the single-sheepdog swarm shepherding problem, , and the areas where the sub-swarms are located in (blue dashed circles in Fig. 1(b)) constitute the set of cities. For convenience, let the sheepdog’s initial position be , and the final goal be . The route’s start and end city are fixed to be and to ensure that the sheepdog departs from and pushes all the sheep to . The travelling cost between each pair of cities should be evaluated by the cost for pushing from to . However, it is challenging to precisely evaluate as shepherding is a complex, interactive, dynamic process involving some uncontrollable factors. In this study, we simplify the evaluation of by calculating it as the distance between and for the obstacle-free environment, and the cost of generated path between and ( as calculated in Equa (17)) for the obstacle-laden environment.
4.2.2 Transforming the bi-sheepdog shepherding problem
Similarly, the bi-sheepdog shepherding problem can be regarded as a multiple TSP where multiple sheepdogs depart from their corresponding initial locations (depots) to visit each LCM (city) exactly once for collecting the dispersed sub-swarms and finally drive them to reach the goal location (terminal). The sheepdogs are not required to return to their initial locations. In this section, we further convert the shepherding-transformed multiple TSP to a single TSP so that the general single TSP solver can be employed to address the problem.
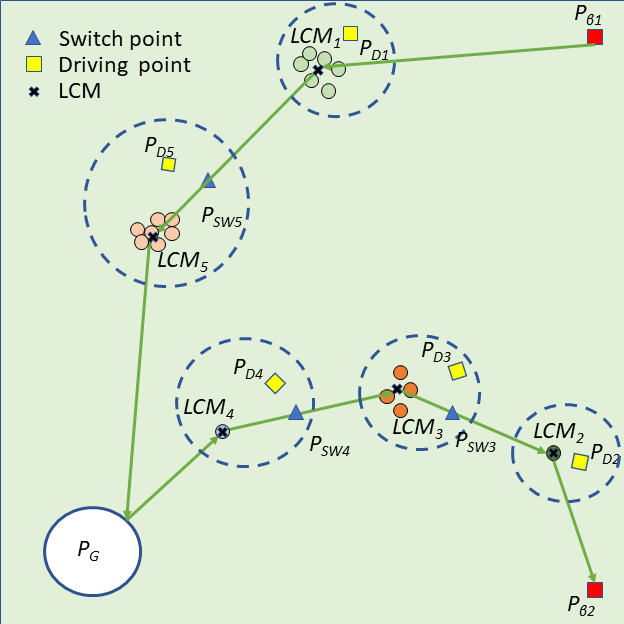
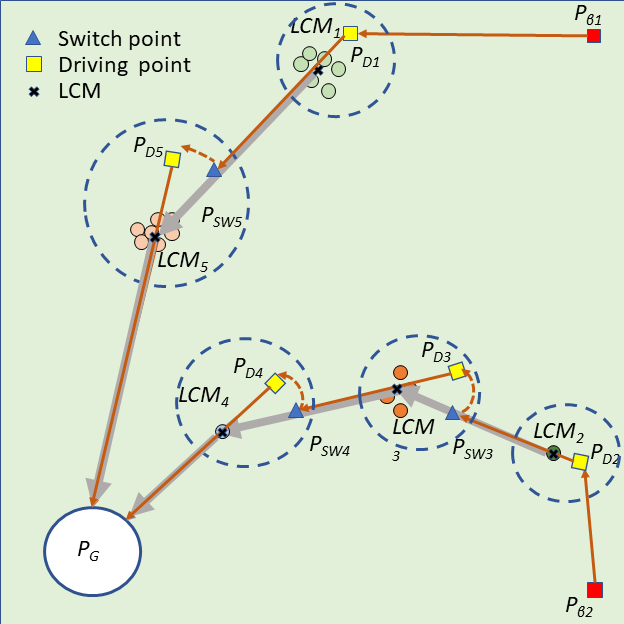
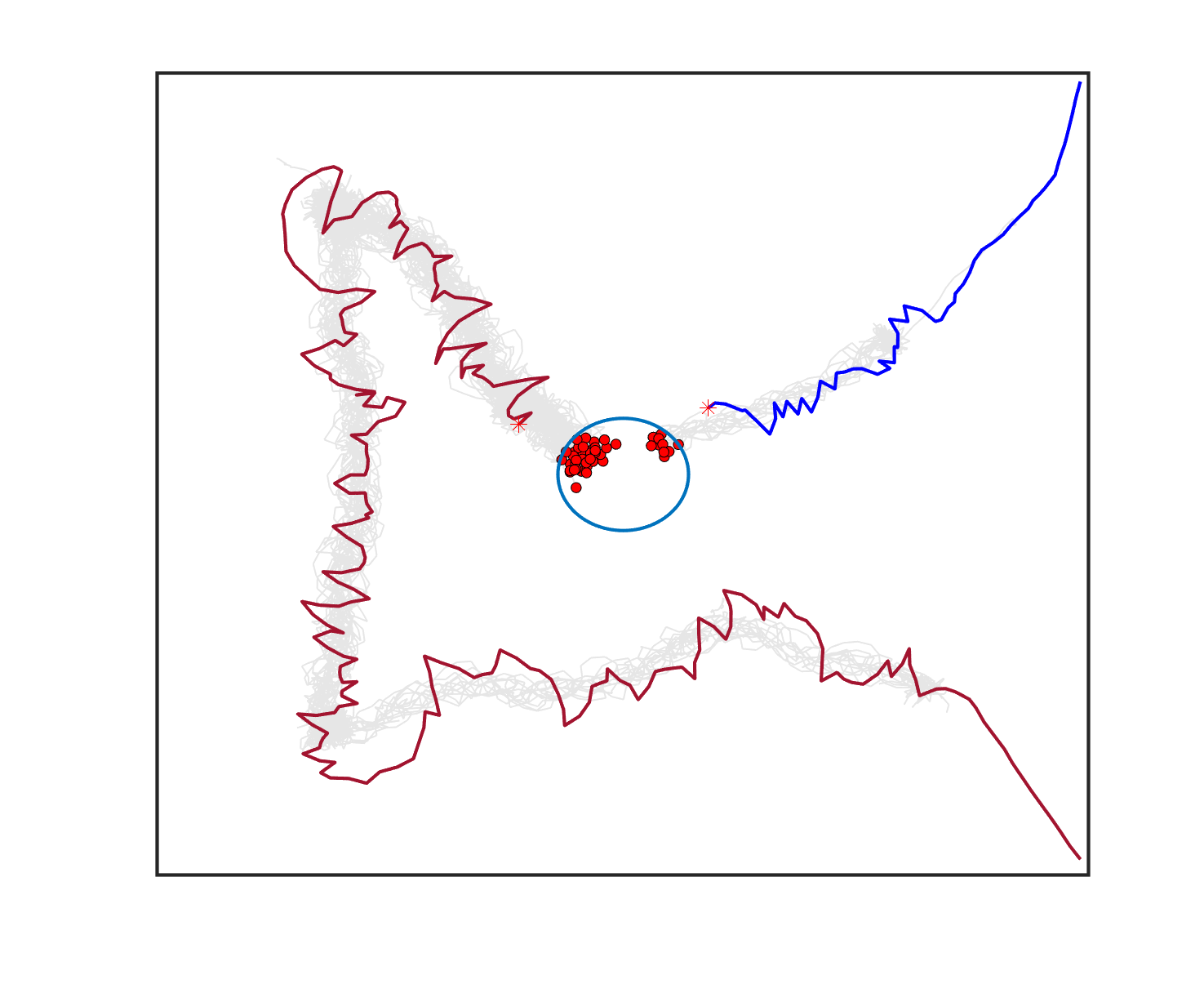
To solve the bi-sheepdog shepherding problem as a single TSP (STSP), we regard the initial position of a sheepdog as , the goal location as and another sheepdog’s initial position as . are the set of the cities’ locations. The start and the end city of the route are fixed to be and . Then a solution of the STSP can be converted to the solution of MTSP by splitting it into two lists at and reversing the order of the latter list. In this way, the first city of each list is the initial position of a sheepdog ( or ) and the end city is the goal (). Other cities on the list are the sub-swarms to be driven by the corresponding sheepdog located at the start of the list. Fig. 2(a) shows a solution of the STSP, and Fig. 2(b) illustrates the transformed solution of MTSP and the shepherding process guided by the MTSP solution.
4.2.3 Mathematical formulation of the TSP
Based on the abovementioned discussion, the solution of the shepherding-transformed TSP is formulated as follows:
| (10) |
where are the indexes of LCMs. If the sheepdog pushes from to , ; otherwise, . is the number of sheepdogs. is limited to here.
The optimisation objective of the TSP is:
Minimize:
| (11) |
4.3 Path planning for sheepdog(s) and sheep swarm
Given the sequenced sub-swarms and the corresponding LCMs , the mission of the sheepdog can be regarded as a set of sequential sub-tasks, i.e., pushing from to , . Path planning is crucial for both sheepdog(s) and sheep swarm to reduce detours and mission completion time. Next we present the mathematical formulation of path planning and discuss how to integrate the path planning algorithm into shepherding based on a proposed classification of sheepdog moving mode.
4.3.1 Mathematical formulation of path planning
In this paper, the path is defined as a sequence of way-points that can be connected as a set of path segments. Denoting the start and goal points as and , respectively, the solution of path planning between the two points could be represented as:
| (16) |
In the obstacle-cluttered environment, collision avoidance is a hard constraint which means that a path is infeasible once it intersects, i.e. collides, with any obstacle in the environment.
Referring to [42] [43], the cost evaluation function of a feasible path, which is also the optimisation objective of path planning, is defined as:
| (17) |
where and are the weights of costs.
is the path length cost and is calculated as:
| (18) |
is the threat cost evaluating the unwanted disturbance of sheepdogs on sheep and is calculated as:
| (19) |
if the path segment from to collides with the threat area which is defined as a set of circles with the centre points and the radius . is the threat range, representing the distance that the sheepdog should keep from the sheep to avoid the unwanted influence. A large will increase the path length cost of the sheepdog to reach the target point while a small might disturb the sheep and cause unexpected movements.
4.3.2 Path planning for shepherding
To integrate path planning into context-sensitive shepherding, we design a two-mode sheepdog operations, a no-interaction and an interaction modes based on whether the influence of sheepdogs on sheep swarm should be minimised or not.
No-interaction mode: The no-interaction mode is usually triggered when the sheepdog departs from its initial location for the driving point of the sub-swarm , or when the sheepdog just finished a sub-task of pushing and switches to the next sub-task by moving towards the driving point of the next sub-swarm . During the no-interaction mode, the influence of sheepdogs on the sheep swarm should be minimised to avoid unwanted movements of the sheep swarm. Sheep are considered obstacles that should be avoided to avoid disturbing the flocks while the sheepdog is positioning itself for a driving position. The path planning algorithm, A*-PP (presented in Section 5.2), is used to find the optimal path , which is obstacle-free and has the lowest cost, for the sheepdog to follow from its current location to the driving point of the target sub-swarm. The path cost is evaluated according to Equation (17) by setting as positive numbers.
Interaction mode: The interaction mode is activated when the sheepdog is driving the sheep sub-swarm from towards a sub-goal . During this phase, the sheepdog continues to influence the sheep sub-swarm by witching between collecting and driving behaviours as it evaluates the furthest distance of the sheep to . The path from the sheepdog’s current position to the driving/collecting point / of the target sub-swarm is also optimised using A*-PP. Different from the no-interaction mode, only the path length is considered for the path cost evaluation in the interaction mode. Therefore, in Equation (17) should be set to 0.
The driving point is calculated as follows:
| (20) |
where is the LCM of the sheep sub-swarm that the sheepdog will be driving or is currently driving; is the sub-goal that the sheepdog is driving towards. is set as the waypoint in the optimised path of from to , which is obtained by A*-PP as well. In this way, the sheepdog will push to move towards the optimal path so as to reduce the detours of both sheepdogs and sheep sub-swarms.
4.4 Planning-assisted shepherding framework
Based on the discussion above, the overall planning-assisted shepherding framework is presented in Algorithm 2, where represents the no-interaction mode while represents the interaction mode. Before the real-time shepherding, the offline planner obtains the grouping and sequencing results (lines 2 and 3). Then the sheepdog starts with the no-interaction mode for reaching the driving point of .
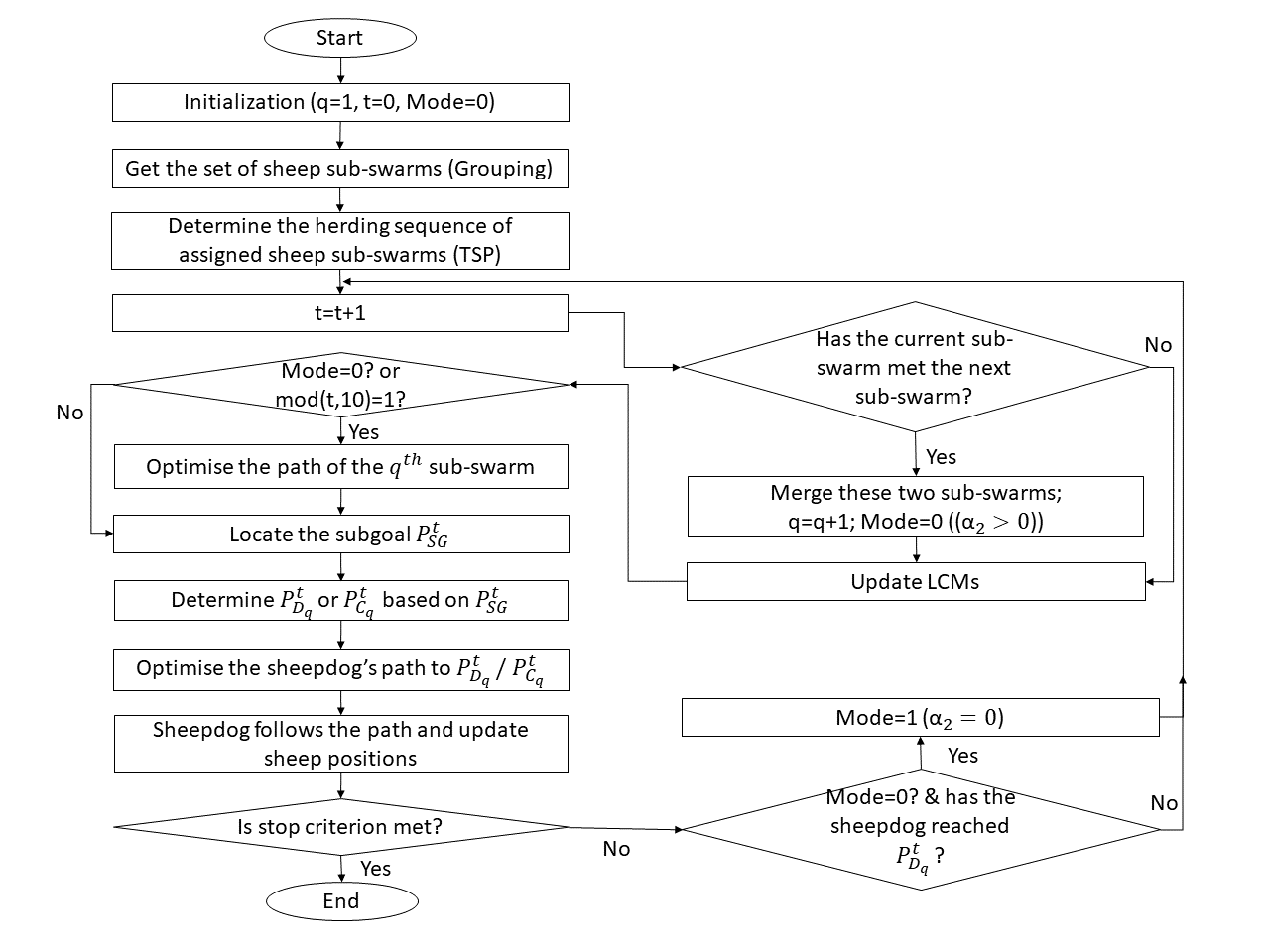
During the shepherding process, the sheepdog switches between the no-interaction and the interaction mode based on context and to complete the set of sequenced sub-tasks, i.e., pushing the sheep sub-swarms to , . An adaptive switching approach is designed based on the real-time evaluation of the shepherding progress and is integrated into the shepherding framework. As presented in line 5-9 of Algorithm 2, the switching from the interaction mode to the no-interaction mode happens when encounters , indicating that the sheepdog just successfully pushed to to merge with and is in preparation for the next sub-task by moving to the driving point of . Then once the driving point of is reached in the no-interaction mode, the sheepdog switches to the interaction mode (line 27-29), which means that the sheepdog starts pushing the sub-swarm . This process continues until all the sheep reach the goal area or the pre-defined maximum time steps is reached. Figure 3 shows the corresponding flowchart.
5 Hierarchical mission planning for shepherding
To assist the proposed swarm shepherding framework, a hierarchical mission planning system is proposed in this section by combining the approach for grouping, MMAS for TSP, and A*-PP for online path planning.
5.1 Grouping and MMAS: offline task planner
Given the sheep swarm , a cohesion range-based grouping method as presented in Algorithm 3 is used to obtain the set of sheep sub-swarms and calculate the LCMs. Then MMAS [21], a well-known ACO algorithm, is introduced to address the shepherding-transformed TSP for getting the optimal push sequence of sub-swarms due to its outstanding performance in addressing TSP. ACO is inspired from the real ant colonies’ foraging behaviour. During the foraging process, ants deposited pheromone trails on the return routes if they find food sources. It enables other ants to find optimal paths to food sources by getting information from pheromone trails.
The core components of MMAS are solution construction and pheromone update. To find the optimal visiting sequence of sheep sub-swarms, the solution in MMAS is constructed by selecting sub-goals (regarded as a solution component ) one by one based on pheromone values and the values of edges to form the complete solution, which indicates the visiting sequencing. Pheromone values are updated every generation based on the quality of constructed solutions and the evaporation of existing pheromones. The values of are defined as where is the travelling cost from to . In MMAS, only the best ant is used to update the pheromone and the pheromone values are limited in the predefined ranges . The implementation of MMAS for finding the optimal push sequence of sub-swarms is described as follows:
Step 1: Initialise the parameters of MMAS, including the ant colony size , two parameters and , evaporation rate , pheromone values of each edge , the values of each edge , the best solution NULL;
Step 2: Construct new ant solutions:
Step 2.1: Start with a partial solution ;
Step 2.2: For each , calculate the probability of moving from the current location to based on the following Equation;
| (21) |
where is a set of available solution components for the current partial solution ;
Step 2.3: Select the next solution component based on the probability and add the selected to the current partial solution ;
Step 2.4: If all are visited, add to and go to Step 2.5; otherwise, go to Step 2.2;
Step 2.5: If new solutions are constructed, go to Step 3; otherwise, go to Step 2.1;
Step 3: Calculate the cost and record the best solution found with the lowest cost;
Step 4: Update the pheromone values according to:
| (22) | ||||
| (23) |
where ;
Step 5: If the termination condition is met, output the best solution which represents the optimal travelling sequence; otherwise, go to Step 2.
5.2 A*-PP: online path planner
As discussed in Sections 4.3 and 4.4, path planning is crucial for reducing detours of both sheepdogs and sheep swarm, and is invoked during the online shepherding process. This section presents a two-layer path planning algorithm A*-PP, where the first layer, A*, finds the path with optimal cost, and the second layer, post-processing, eliminates the redundant waypoints in the path.
A* [44] is a well-known node-based path search algorithm that searches in a landscape represented by graphs. A* starts from the specific start node of the search graph and expands the nodes on candidate paths by adding one node at a time until it reaches the goal node in the graph. To decide which node on the candidate paths to be extended next, A* employs an evaluation function which can be calculated as Equation (24) to estimate the cost of the path going through node .
| (24) |
where is the cost of the optimal path from the start node to the current node and is the heuristic function for estimating the cost from the current node to the goal node. In this paper, is calculated as following:
| (25) |
where and are the length cost and threat cost. is calculated as the straight line distance from the current node to the goal node, which is permissible to guarantee A* returns the optimal path.
The pseudo-code of A* is given in Algorithm 4. is the set of nodes that can be considered for expansion. is the set of nodes that have been expanded, which makes sure that each node can be travelled at most once. is the cost from the node to node . is to record the path with the lowest cost. A* starts the search from the initial point . At each iteration of the main loop, A* selects the node with the lowest from and removes it from to . Then A* checks the neighbours of to insert feasible neighbour nodes into if is not in , or update if is already in and is better than the old . The loop continues until the node with the lowest is the goal point or is empty, meaning no feasible path exists.
However, the original path obtained by A* usually contains many waypoints and the sub-path between two waypoints might be taking an unnecessary detour in some cases where a straight line can connect these two waypoints with no obstacle collision. Therefore, a path post-processing method, line of sight path pruning [45], is introduced to remove some redundant waypoints on the path to further reduce the path cost. The pseudo-code of the path post-processing is presented in Algorithm 5. The core of this process is to replace the original sub-path between two waypoints with a straight line if the straight line does not collide with any obstacles, meaning that the waypoints on the original sub-path, except the start point and end point, will be removed.
6 Numerical Experiments
6.1 Experimental setting
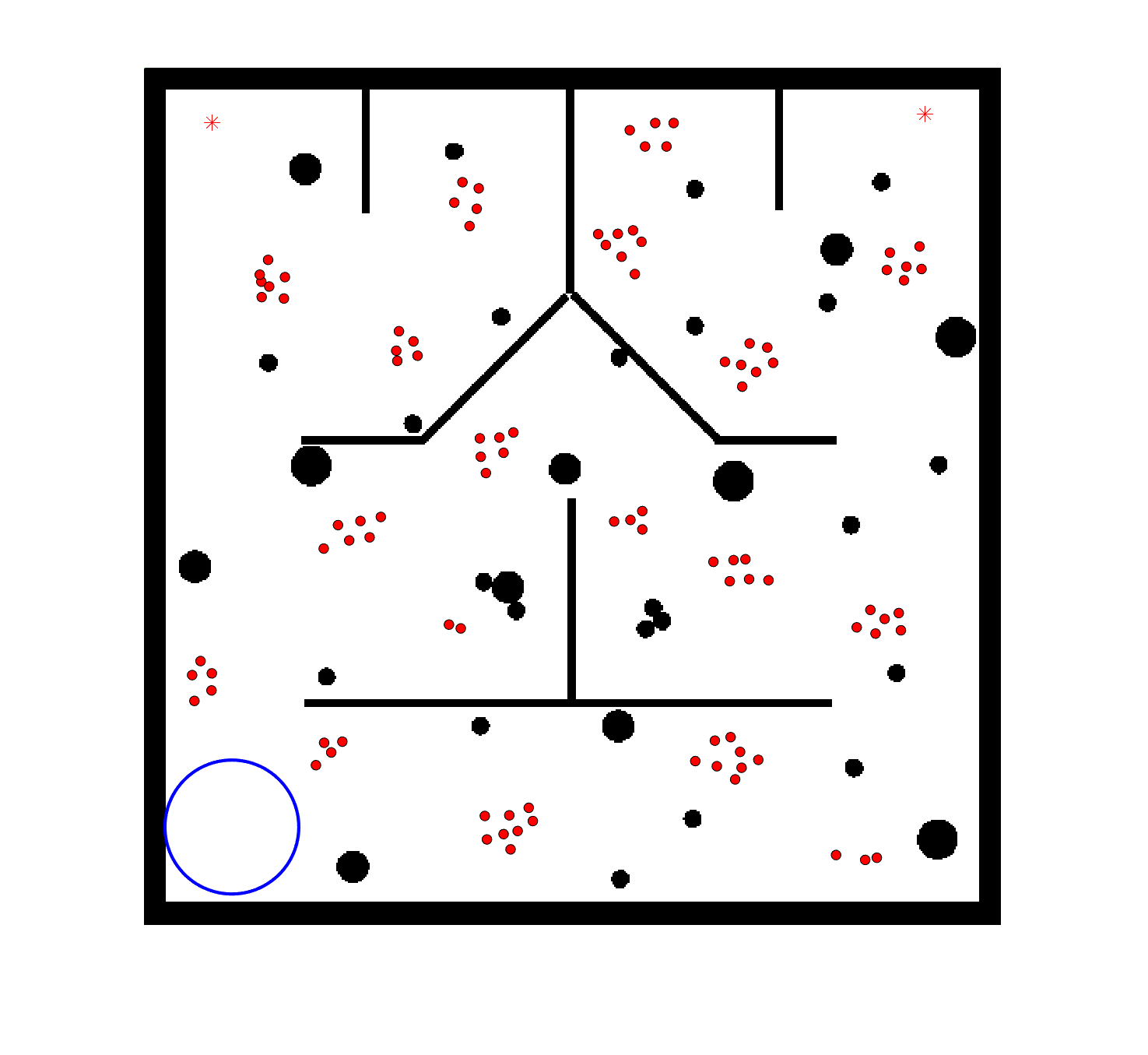
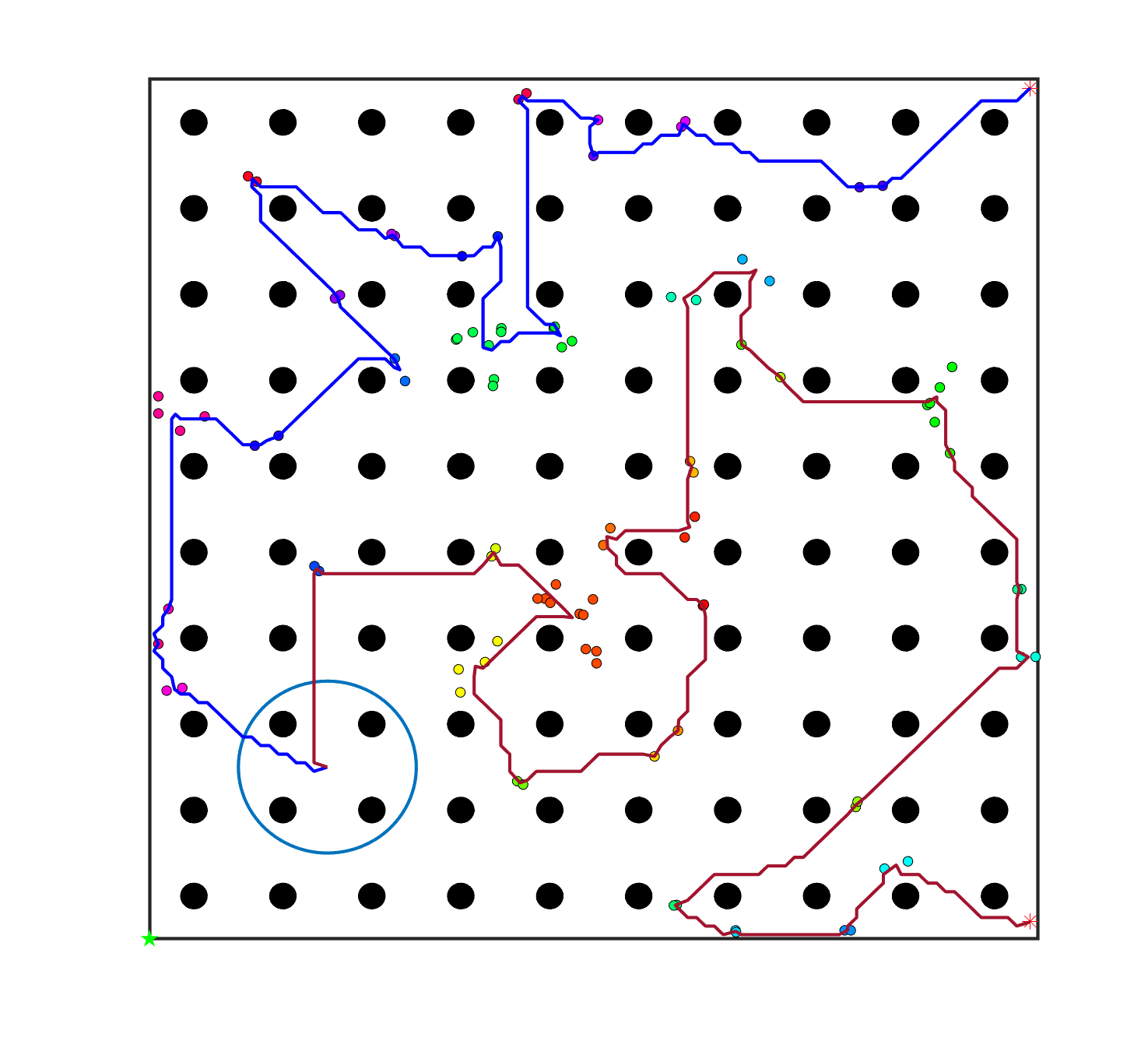
To evaluate the planning-assisted shepherding model and the hierarchical mission planning algorithm, experiments are conducted on a set of synthetic shepherding problems with different levels of complexity. Table 1 presents the details of the 20 benchmark problems, showing the environment size (mostly ), the number of sheep (20, 50, 100) and if obstacles are contained in each case. The benchmark set consists of three groups, the obstacle-free group, the obstacle-contained group with small swarms and the obstacle-contained group with large swarms. The cases in each group have an increasing level of complexity. Fig. 4 shows the visualised initialisation of each case with red dots representing the sheep, red asterisks representing sheepdogs, black areas denoting obstacles and a blue circle representing the goal area. Cases 1-6 are obstacle-free environments with an increasing level of complexity by varying the environment size, , the goal location and the swarm initialisation. Cases 7-20 are obstacle-contained environments where the density of obstacles further impacts the problem’s complexity. The initialisation in cases 11 and 18 is based on randomly distributed sheep individuals, while the initialisation in other cases is based on randomly distributed sub-swarms.
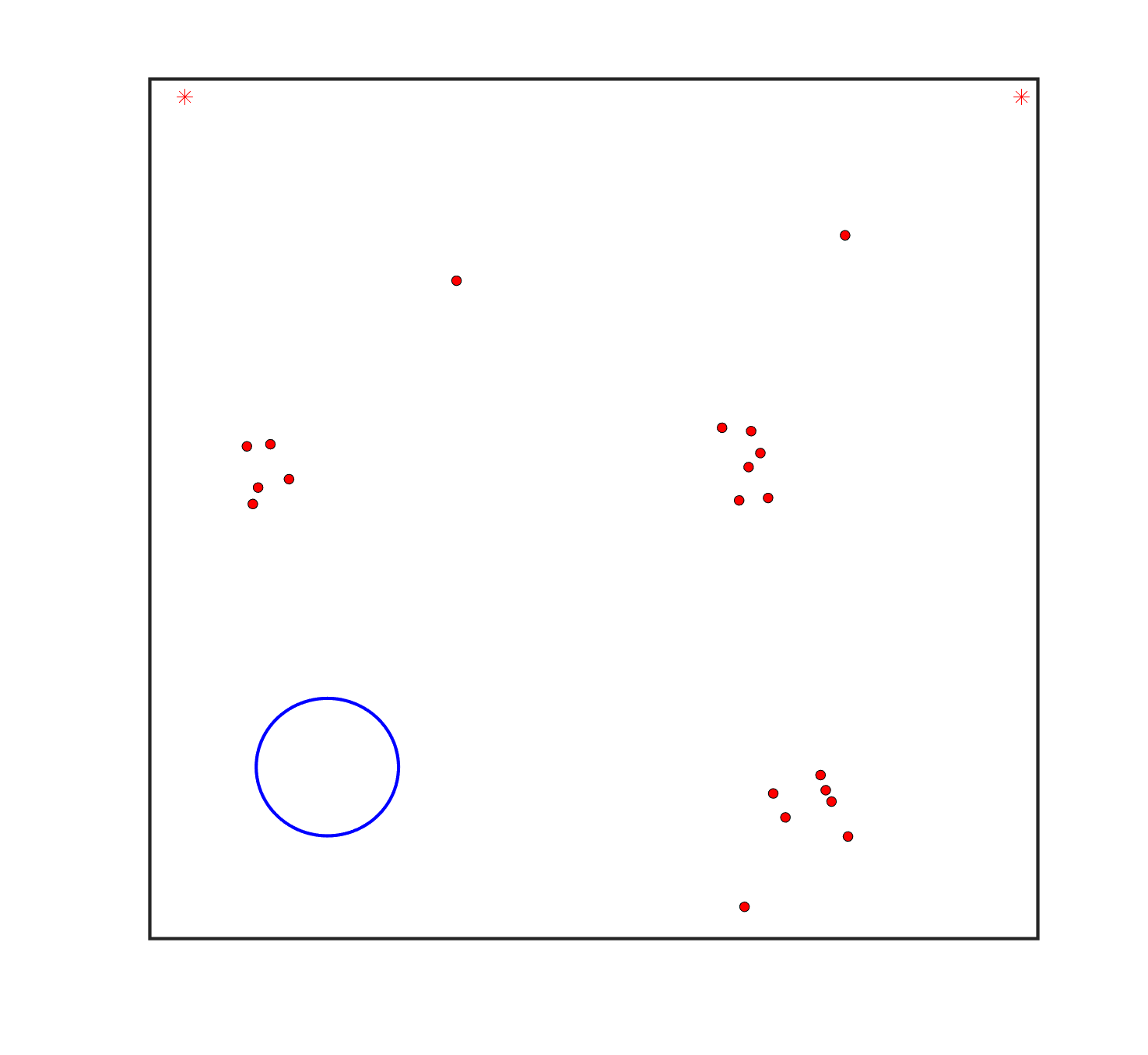
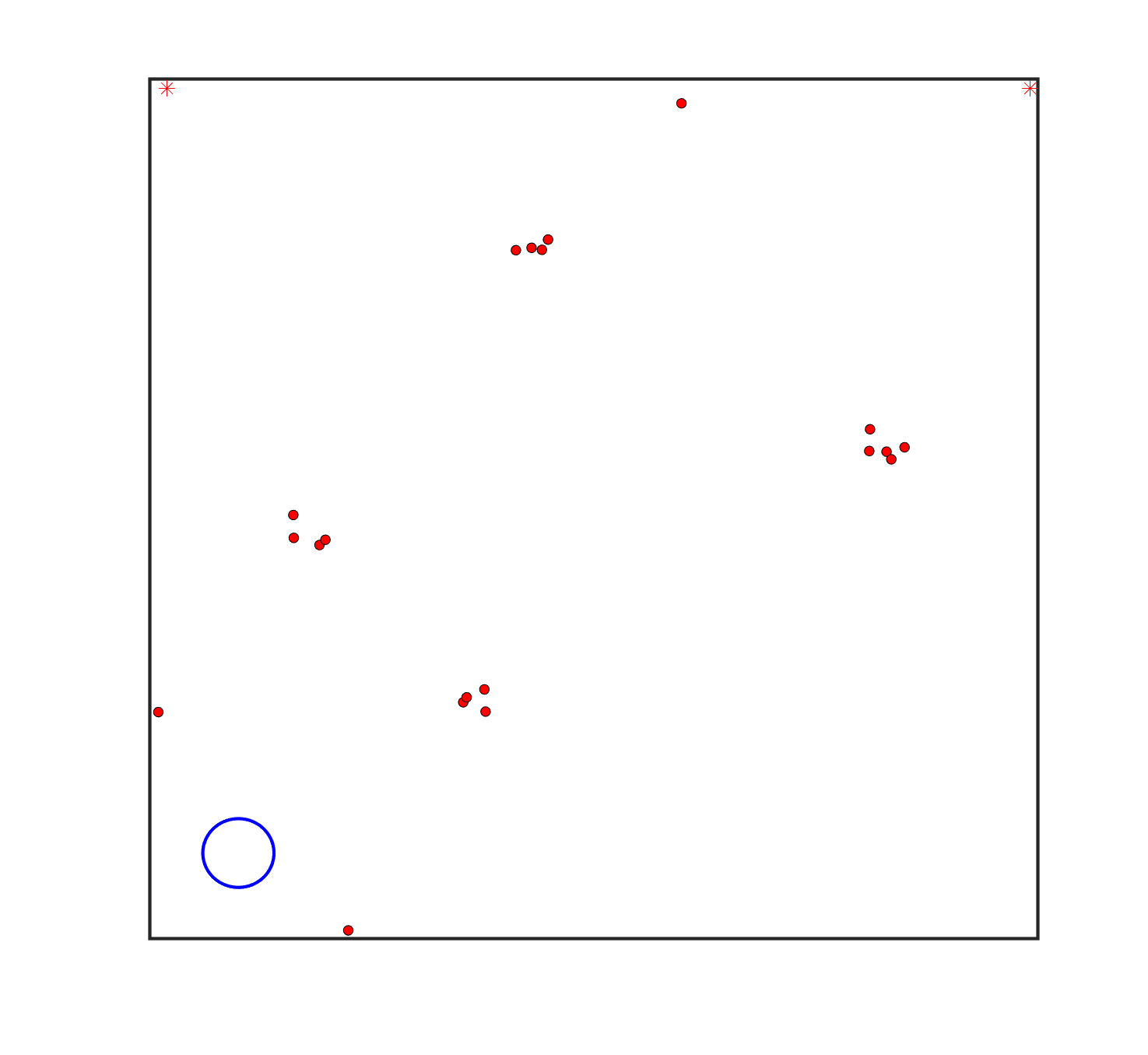
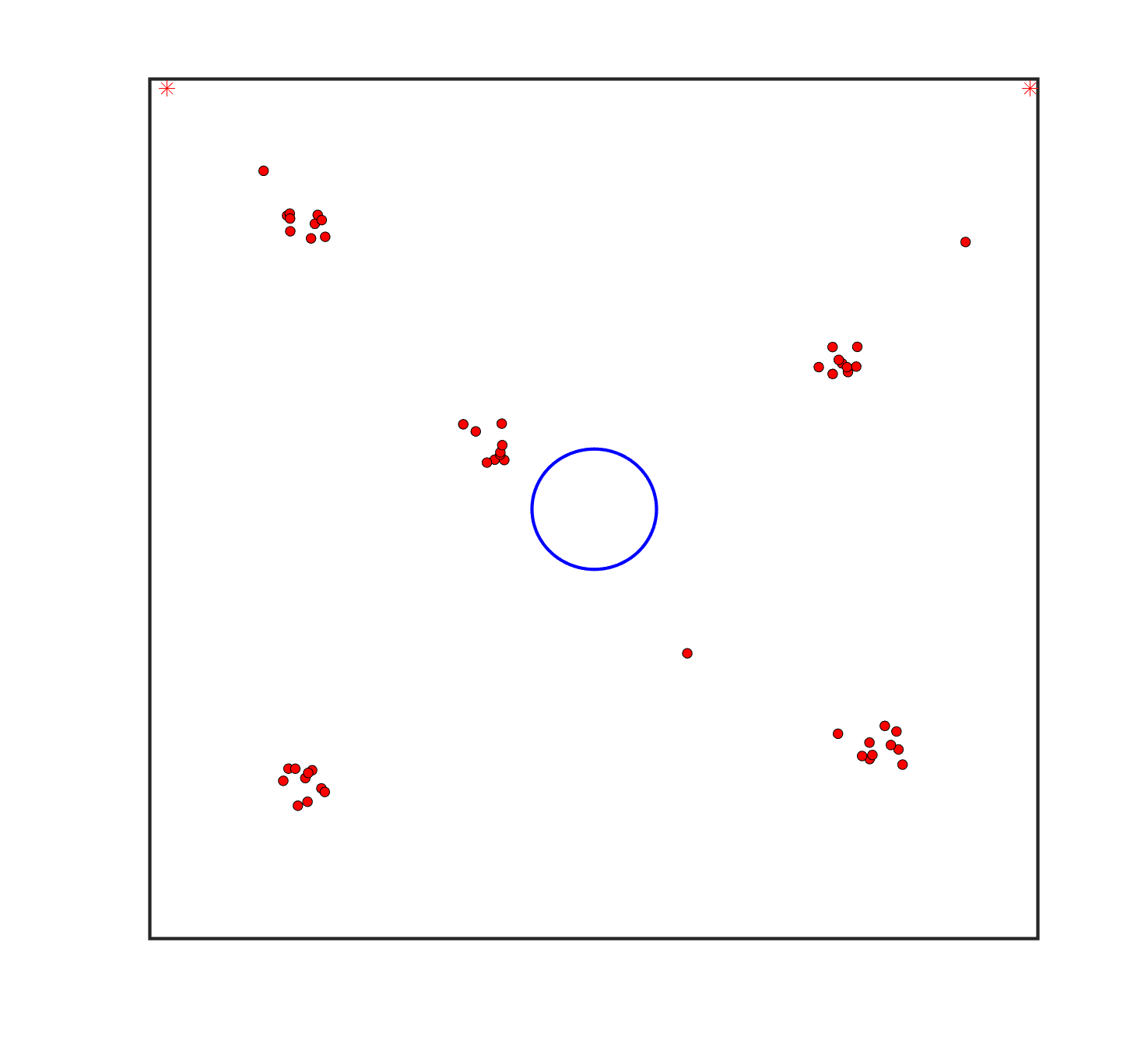
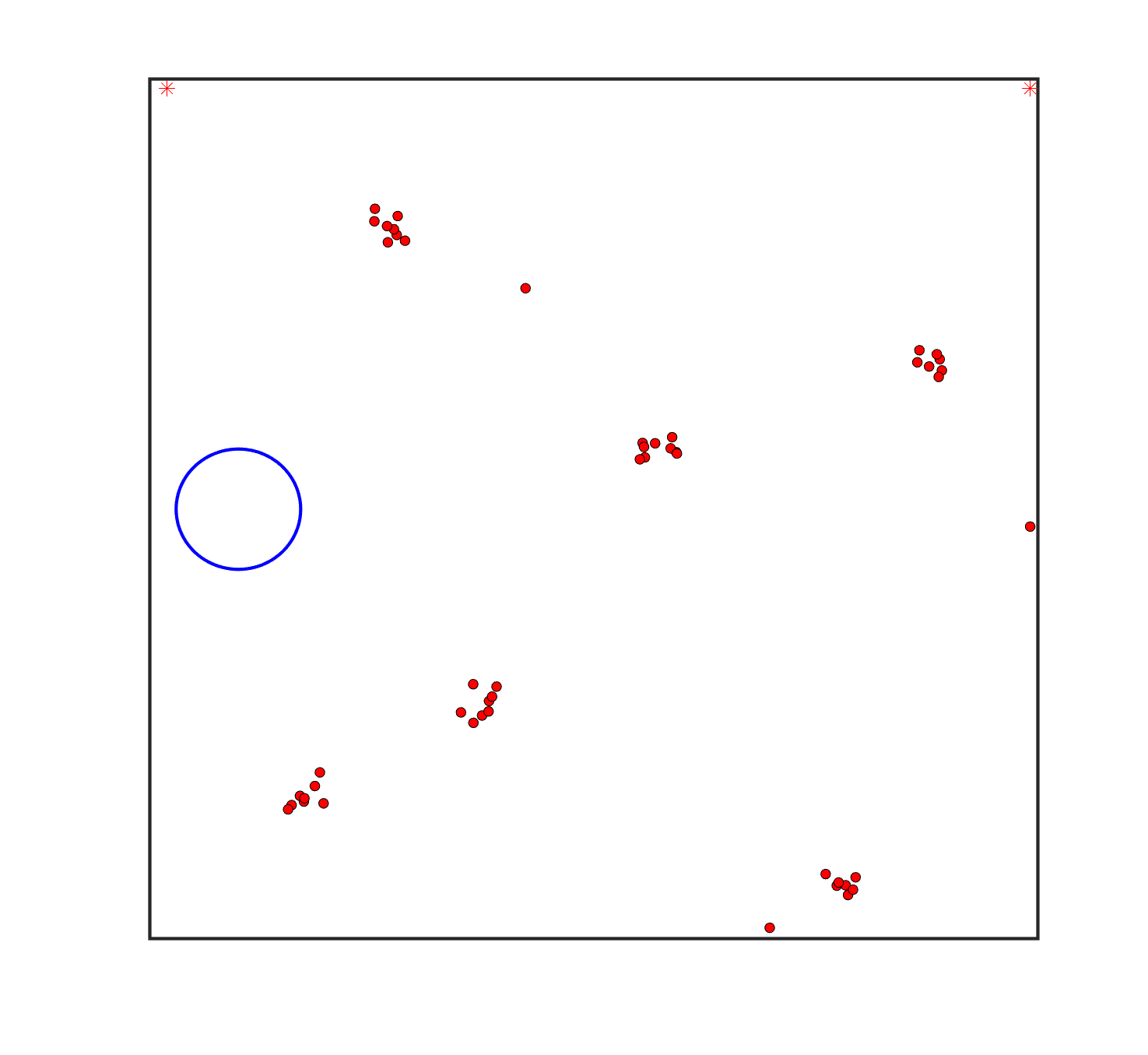
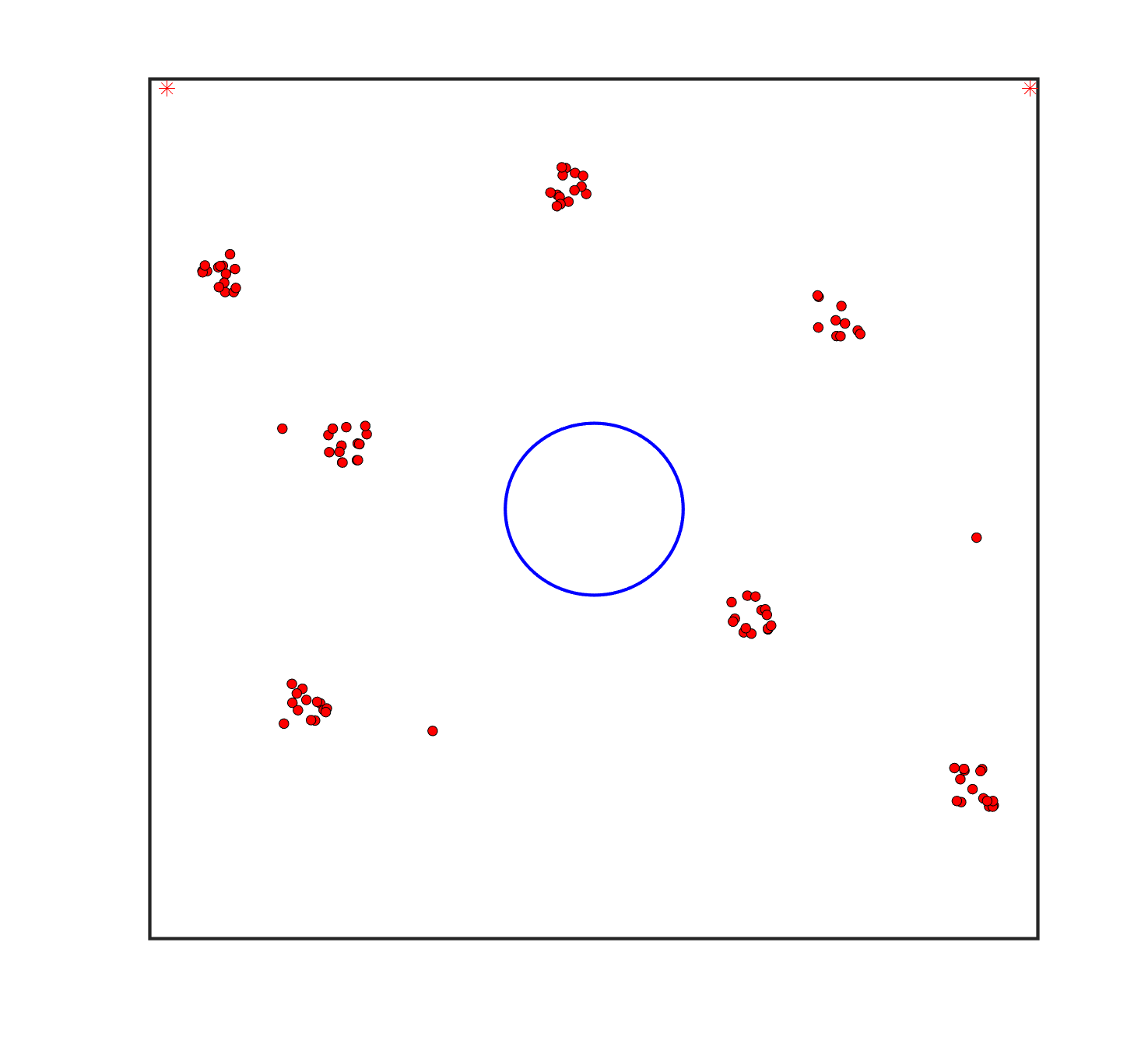
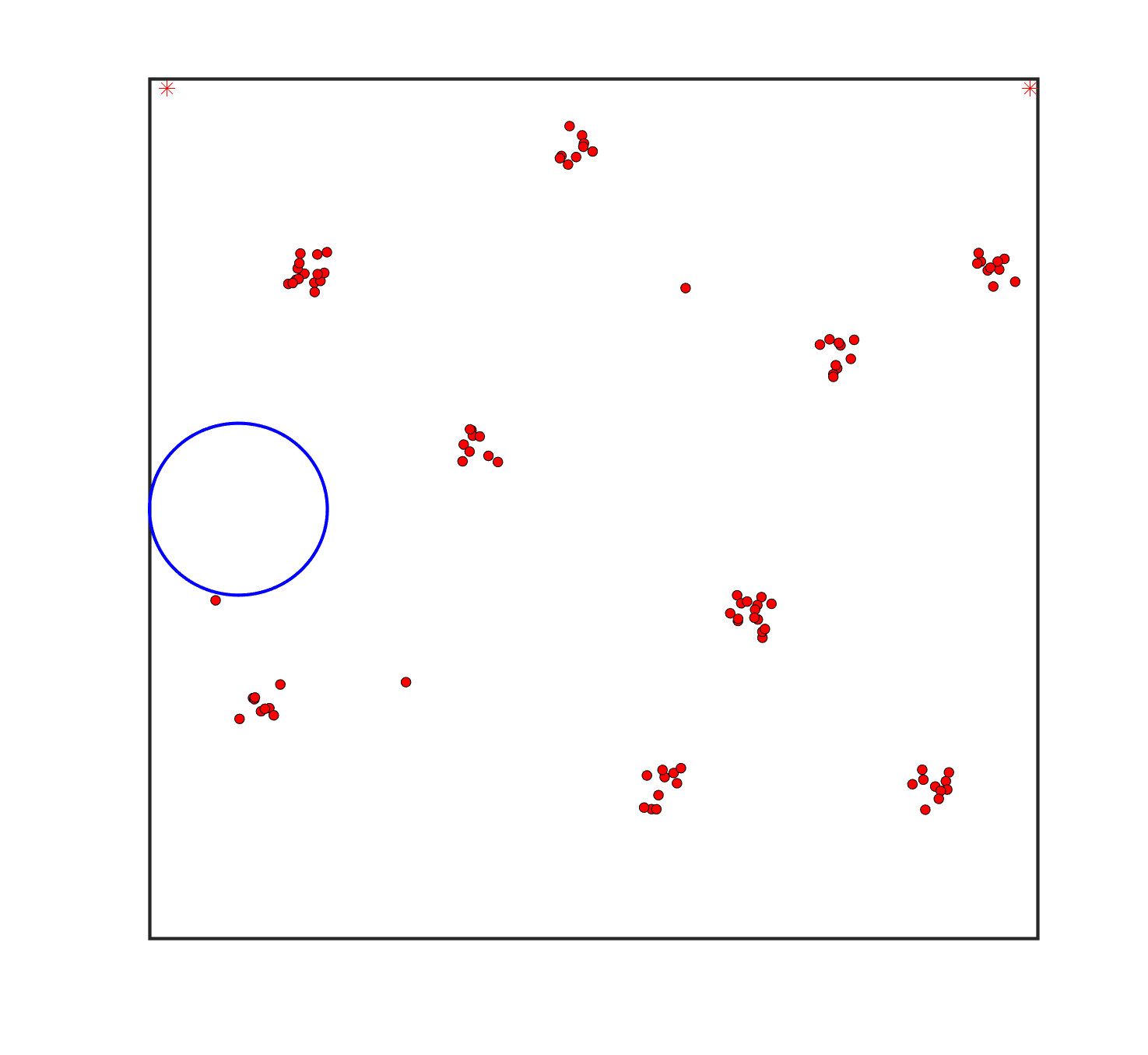
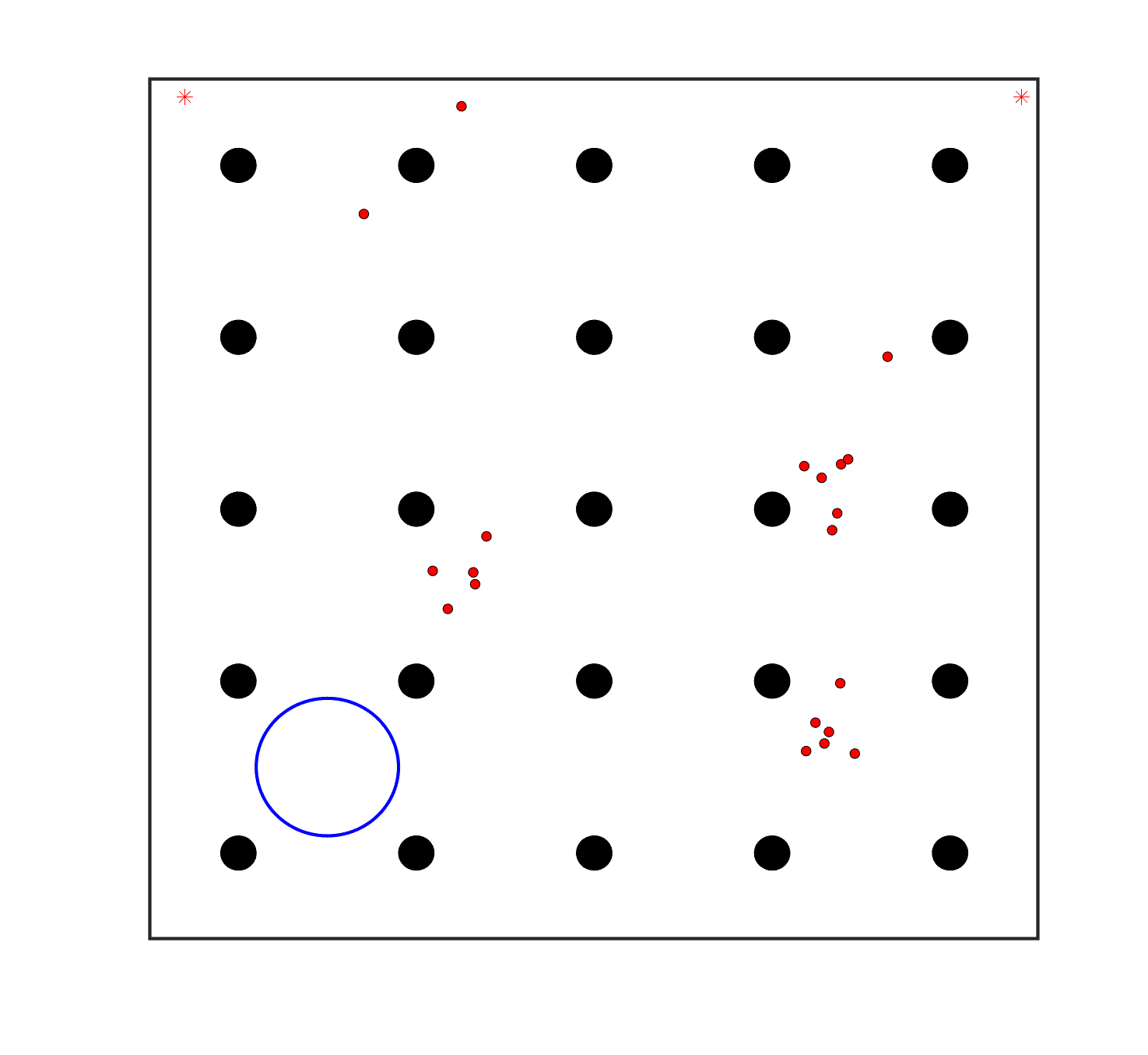
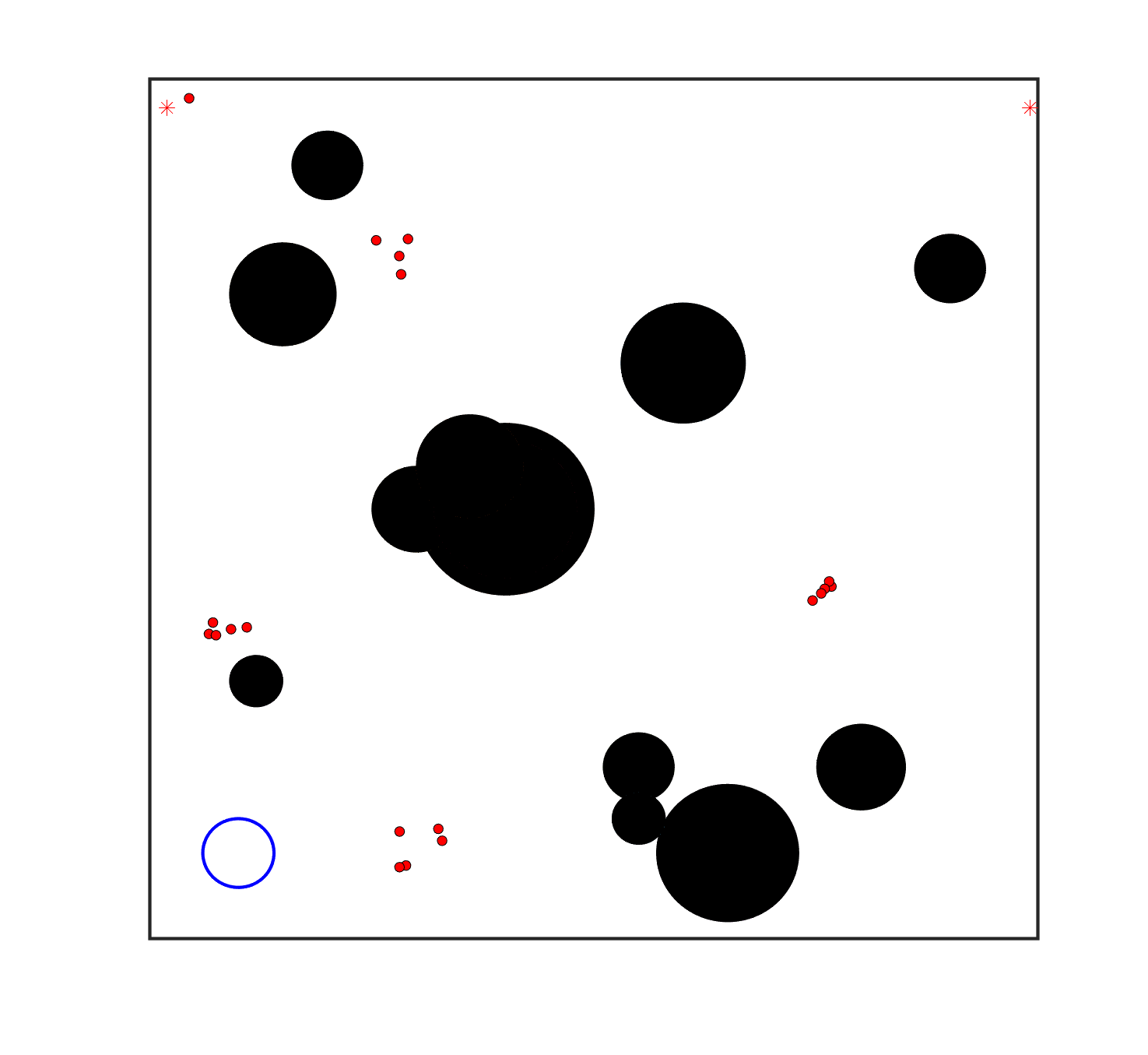
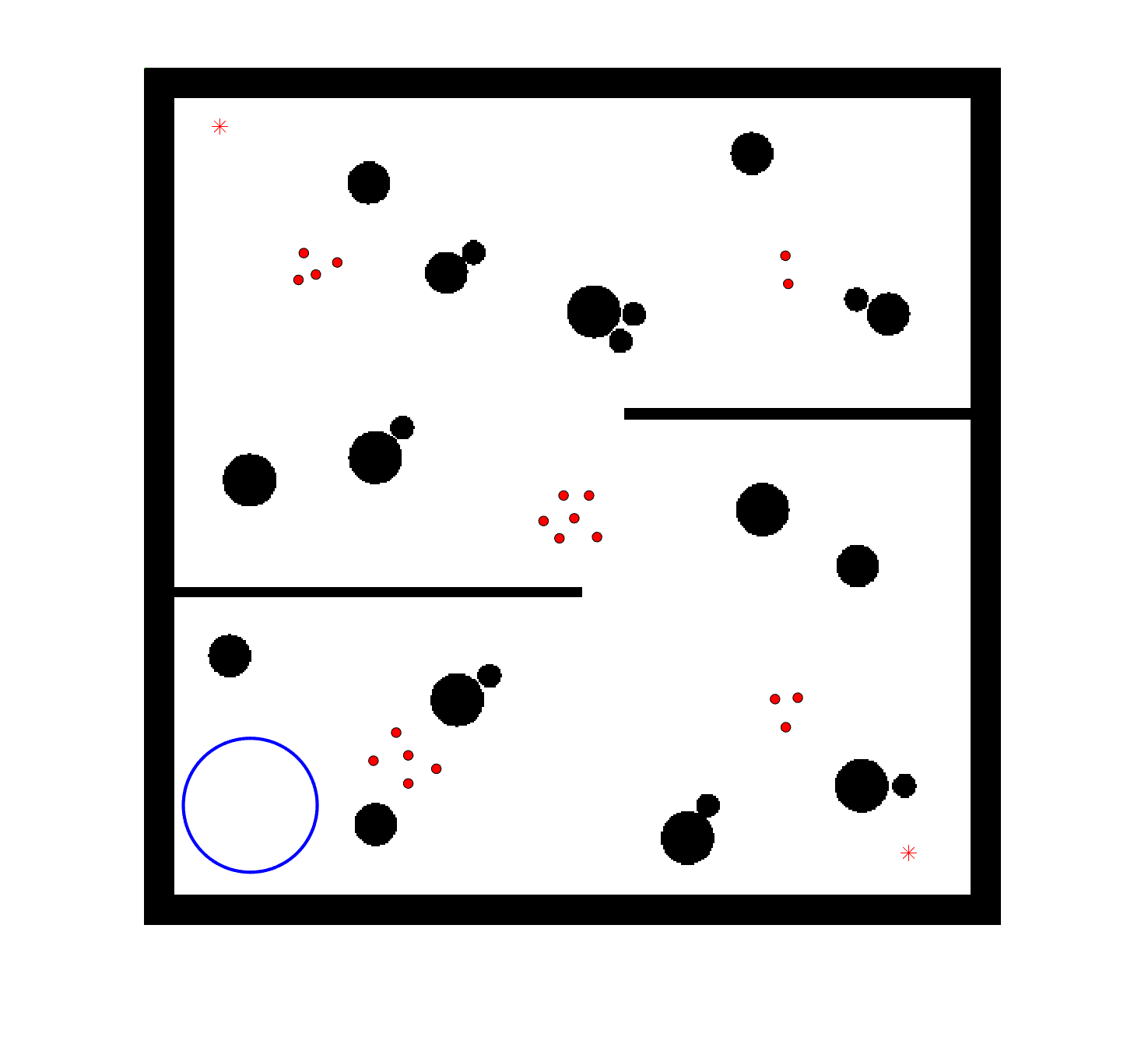
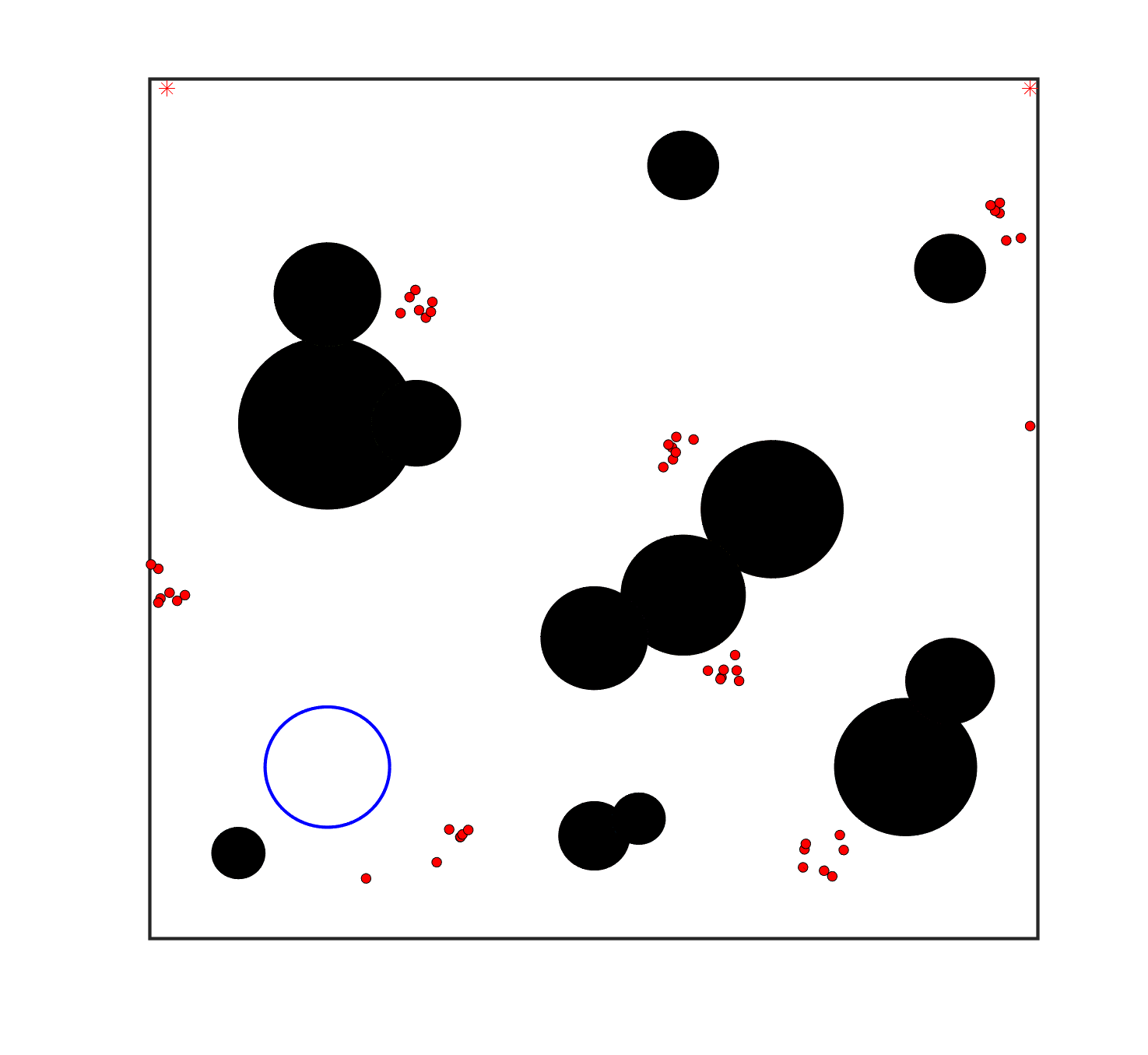
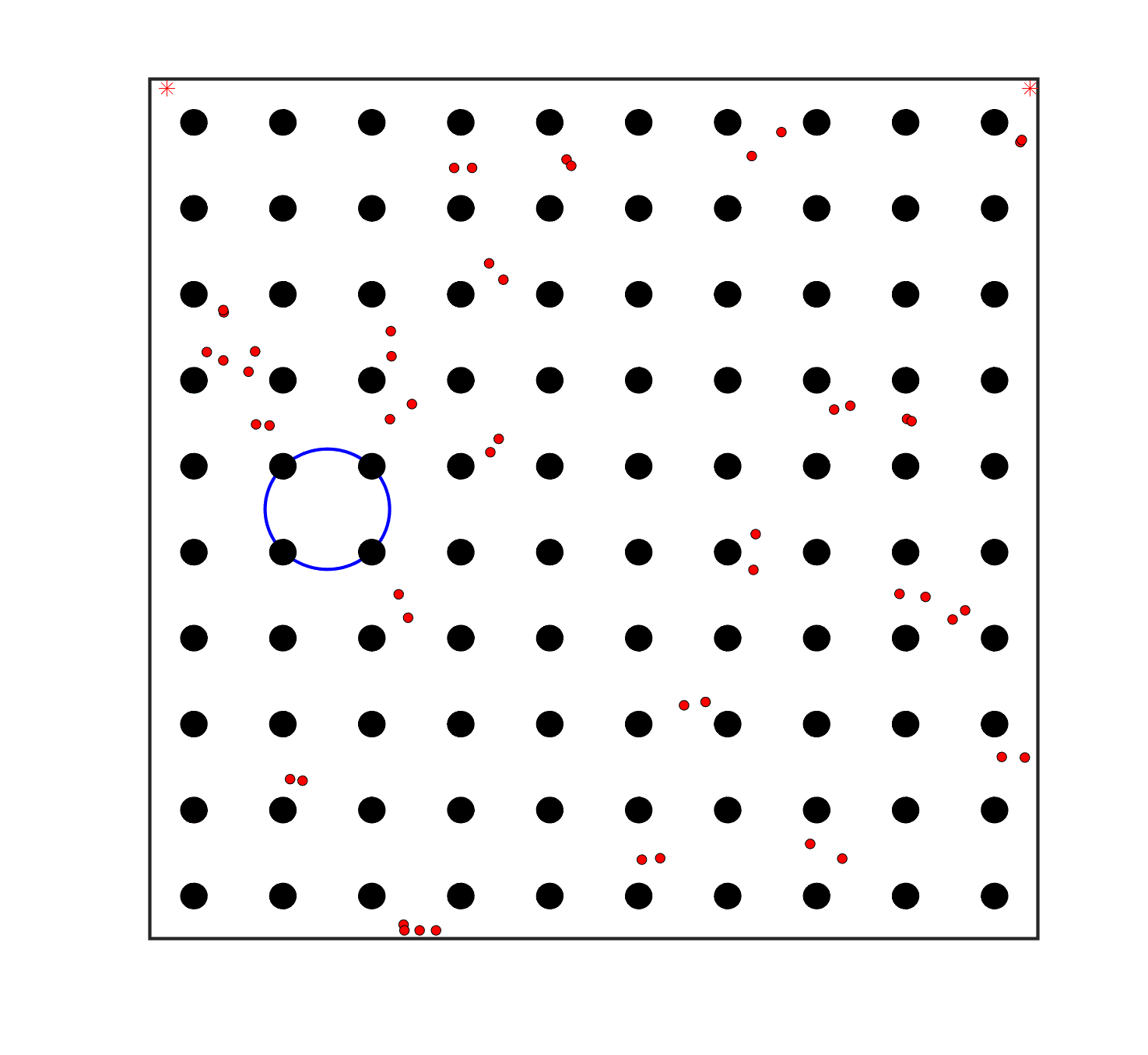
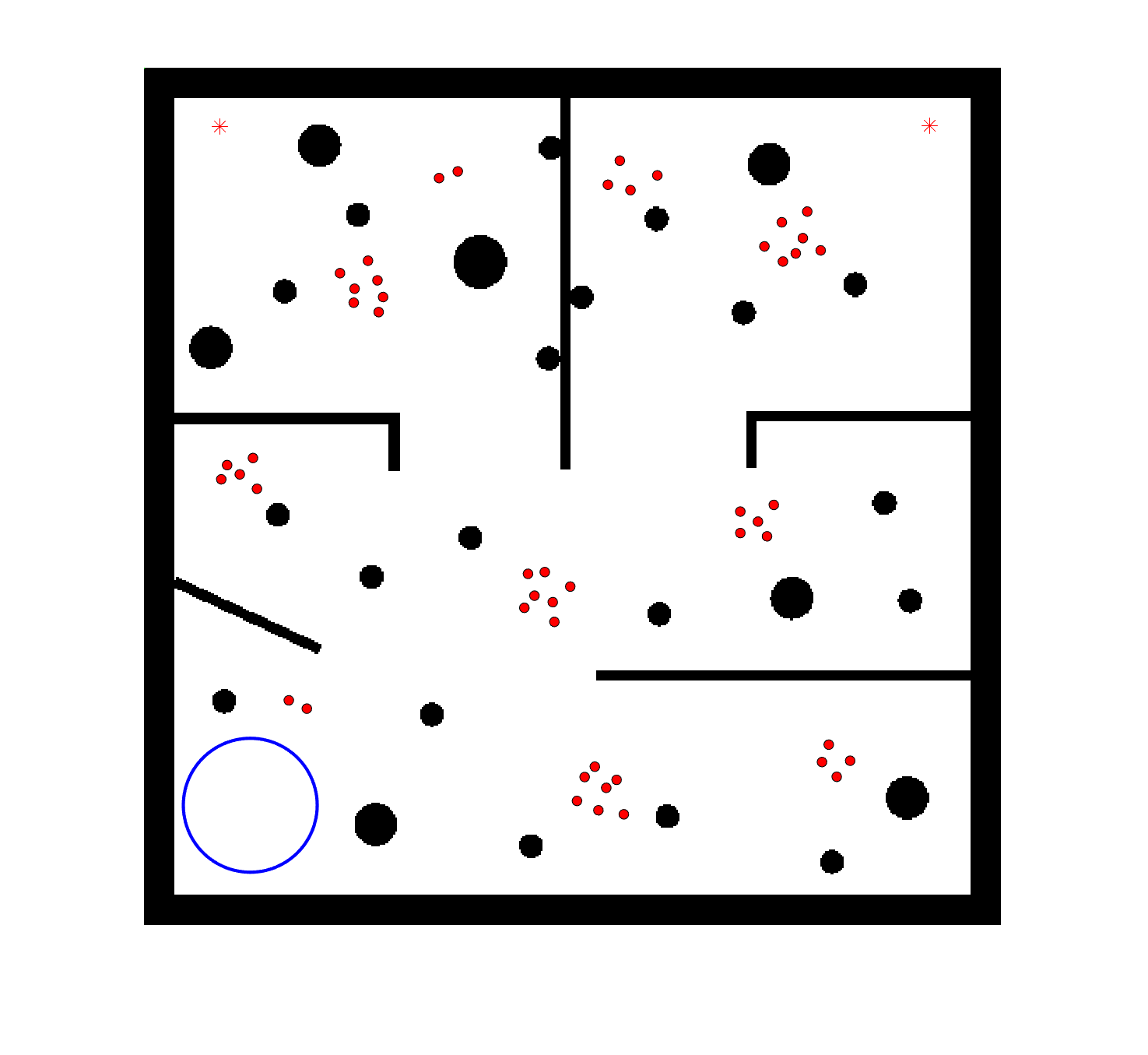
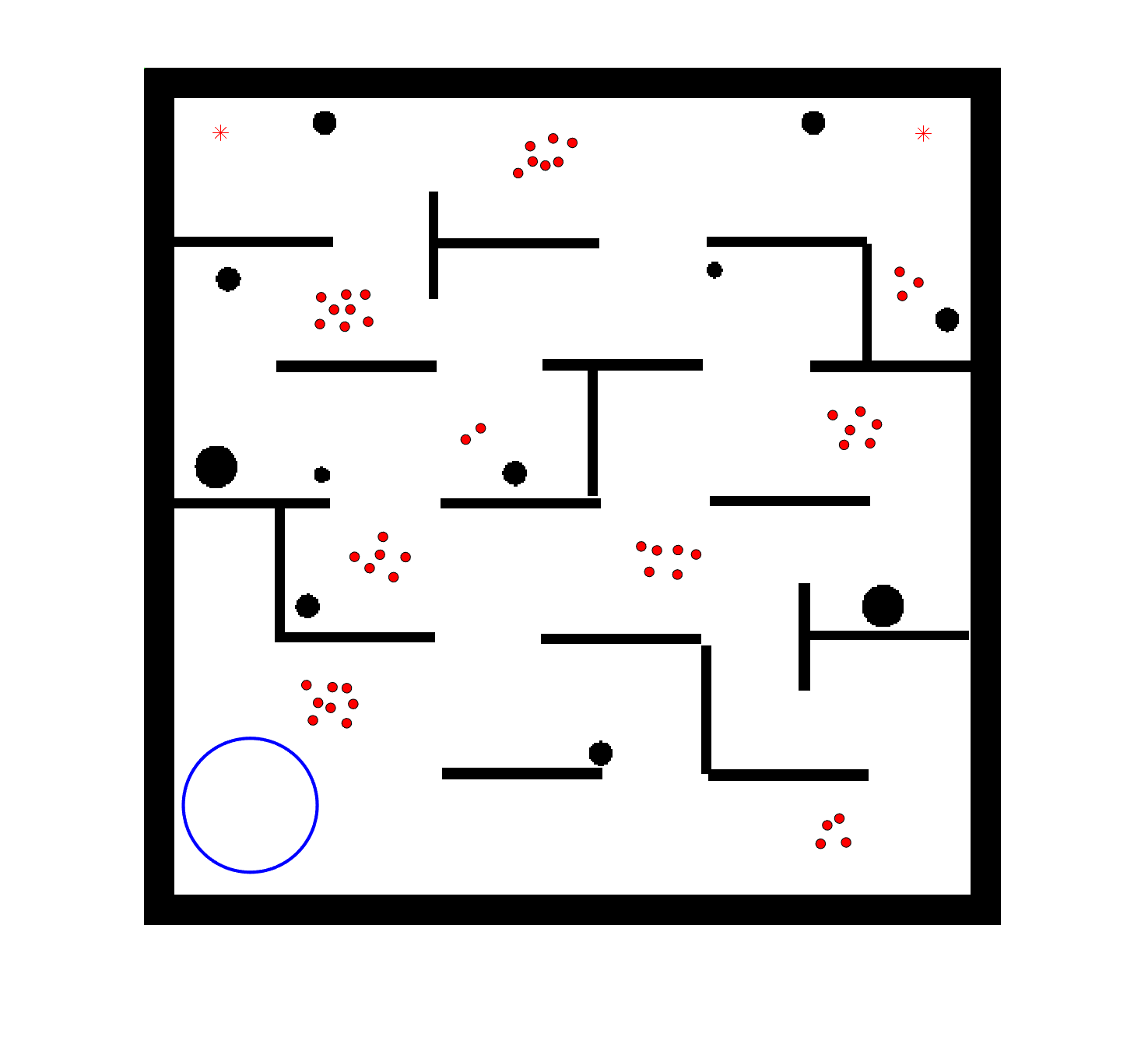
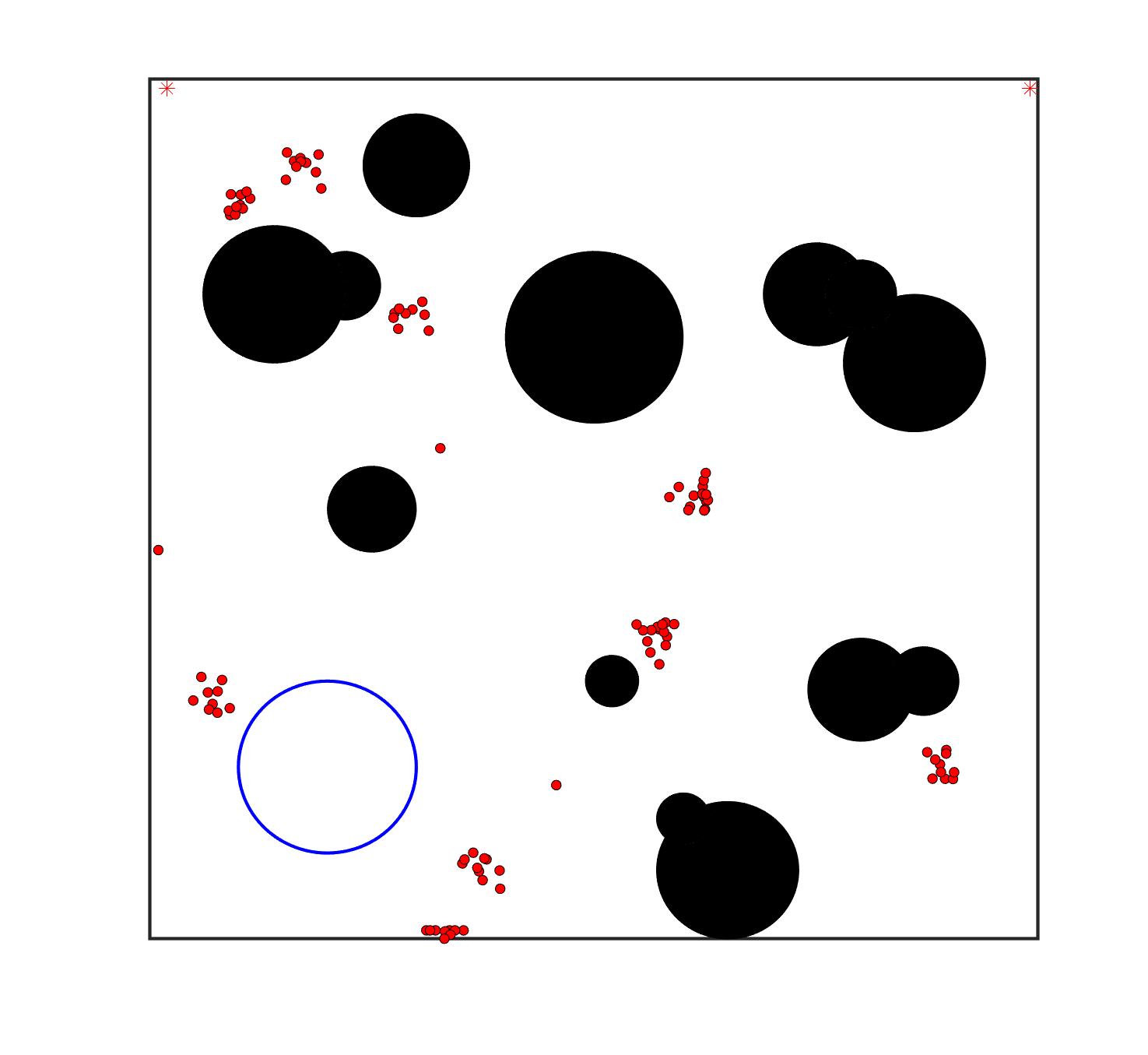
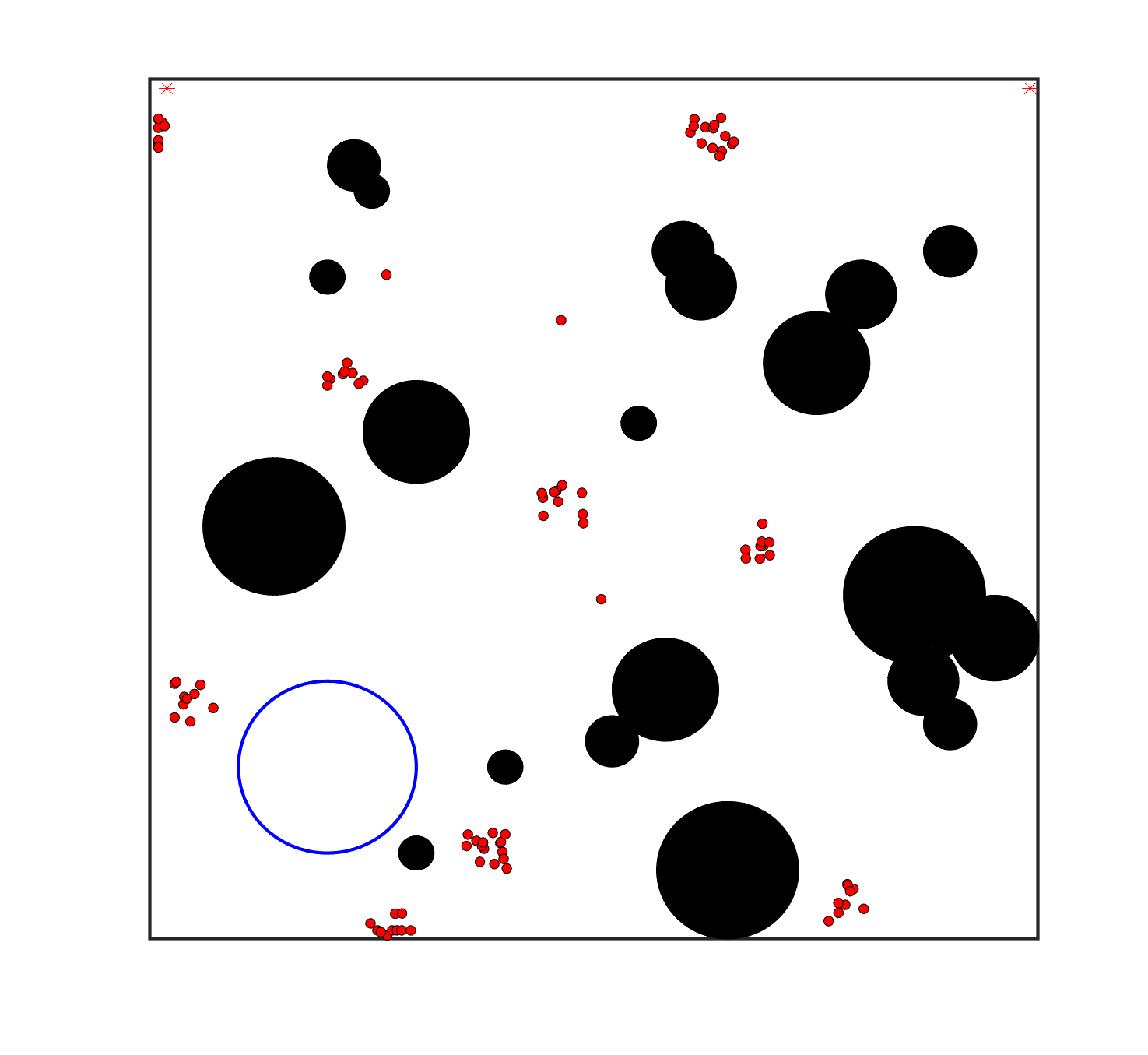
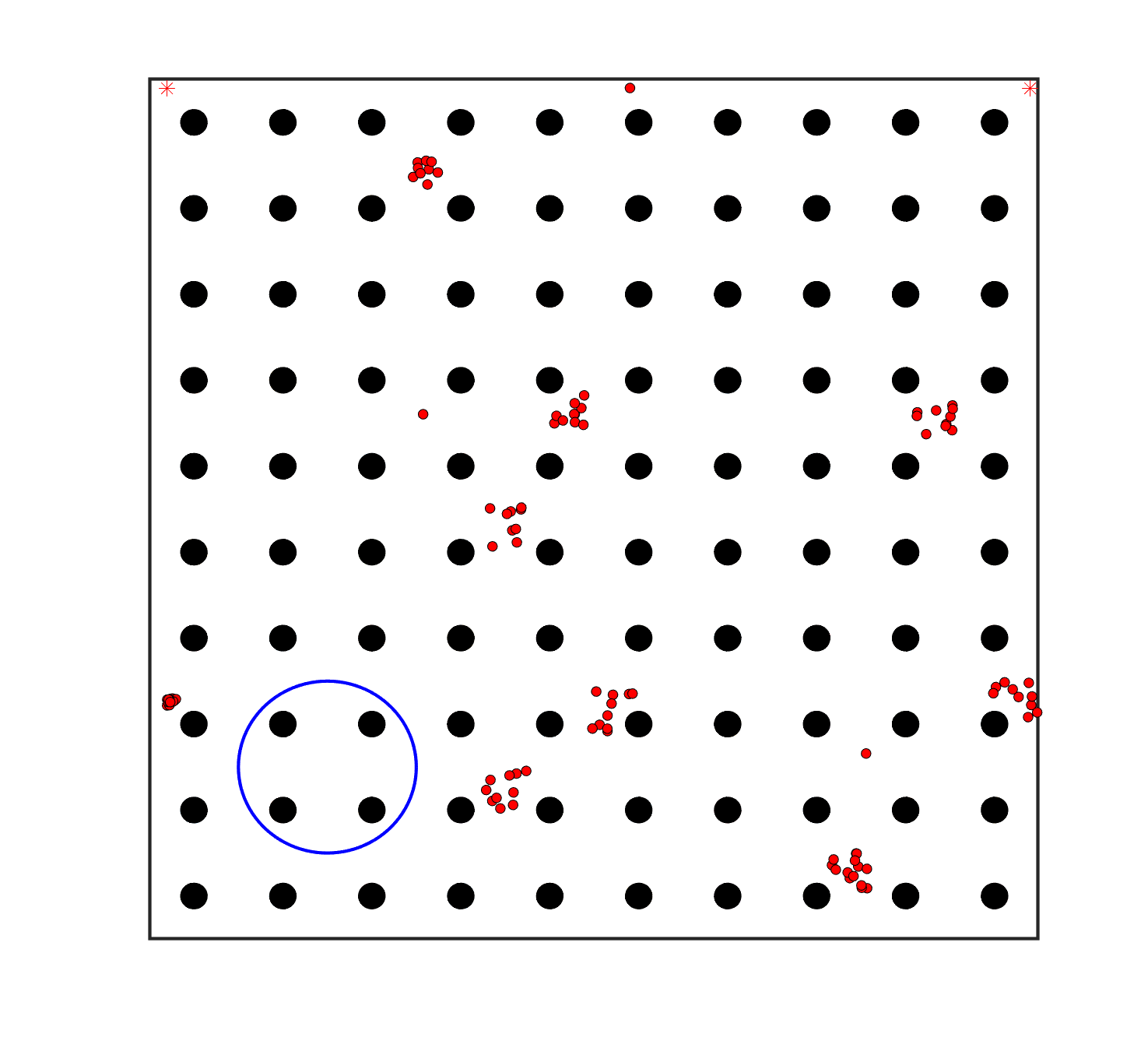
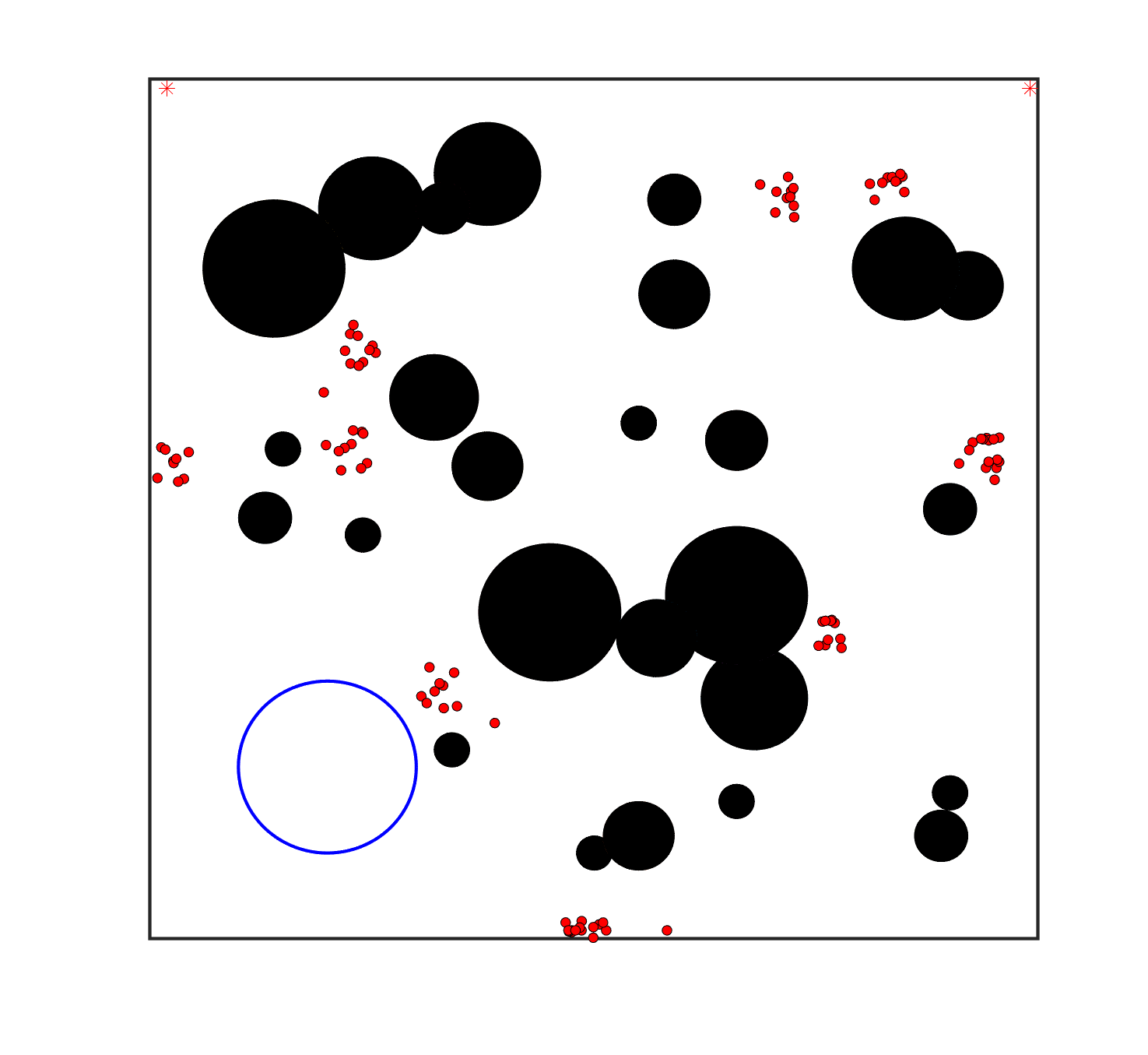
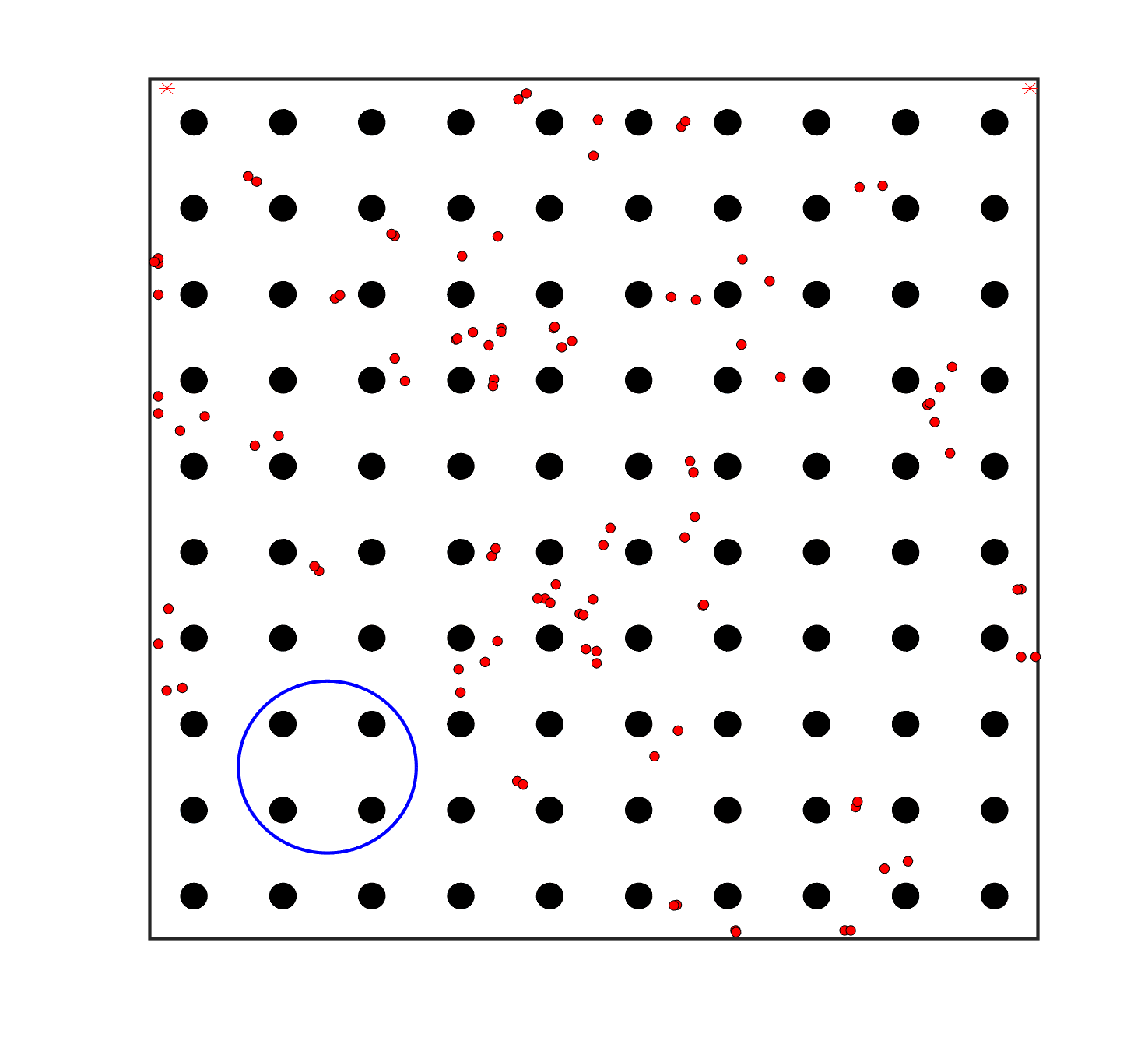
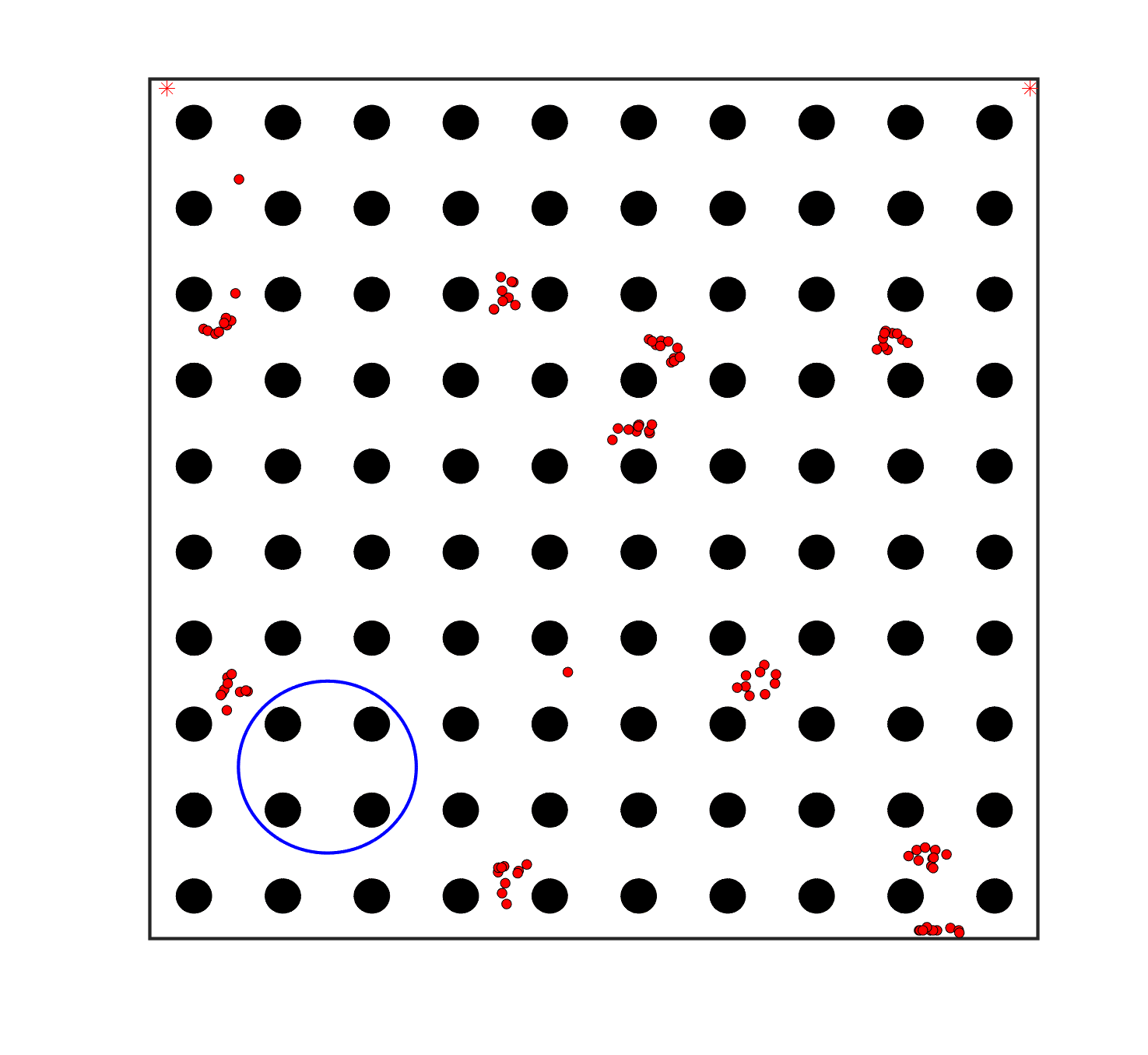
For each problem instance, the experiments are conducted 20 times to capture the statistical behaviour. The number of the maximum time steps for each run is set to . Three metrics are recorded to evaluate shepherding performance, including 1) SR: the success rate, i.e., number of times the shepherding mission was completed out of 20 runs; 2) No. of steps: the number of time steps consumed to complete the shepherding mission, and 3) path length: the total moving distance of the sheepdog. The mean and standard deviation of only the successful runs are presented for the no. of steps and path length.
| Group | Group 1: Obstacle-free cases | Group 2: Obstacle-contained cases… | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Case | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Environment size | 50*50 | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 | 50*50 | 100*100 | 100*100 | 100*100 |
| Number of sheep | 20 | 20 | 50 | 50 | 100 | 100 | 20 | 20 | 20 | 50 |
| Obstacles | N | N | N | N | N | N | Y | Y | Y | Y |
| Group | …with small sheep swarms | Group 3: Obstacle-contained cases with large sheep swarms | ||||||||
| Case | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Environment size | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 | 100*100 |
| Number of sheep | 50 | 50 | 50 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Obstacles | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| 0.5 | 1.05 | 1 | 2 | 3 | 0.3 | 0.3 | 4 | 8 | 0.4 | 2 | 4 |
6.2 Parameters values and the effects of the adaptively-switch
The parameters in MMAS are set according to [21]. To be specific, the maximum number of iteration is set to 600; the population size is set to the problem dimension; , , , , . The number of neighbours in the A* search algorithm is set to 8, and the scaling factor is 1. Table 2 presents the setting of most parameters involved in the shepherding model by referring to [7]. The newly introduced parameter and the cost weights are analysed in the following.
determines the threat area size that the sheepdog should try to avoid in the no-interaction mode. It should be no less than to keep the safe operating distance from the sheep and no more than the sheepdog’s influence range . Therefore, we tested the effects of on shepherding performance of 6 representative cases by setting to 4, 5, 6, 7 and 8. Table 3 presents the experimental results. Without the explicit declaration, the best results are shown in bold in all the following tables, and Wilcoxon rank-sum tests are conducted between the best results and other results for each case to test if their performances are statistically different, with a significance level of 0.05. ‘*’ indicates the significant difference.
| Case | SR | No. of steps | Path length |
| Case1 | 1.00 | 131.0012.14 | 214.7020.69 |
| Case3 | 1.00 | 396.0518.85 | 510.1738.77 |
| Case7 | 1.00 | 232.5047.04 | 409.3694.24 |
| Case11 | 0.95 | 996.2189.63 | 1401.94166.63 |
| Case16 | 1.00 | 1191.75137.19 | 955.65143.42 |
| Case18 | 0.60 | 2071.17156.11 | 1858.70235.51 |
| Case1 | 1.00 | 133.8513.57 | 220.7724.12 |
| Case3 | 1.00 | 432.2533.11* | 567.7653.05* |
| Case7 | 0.95 | 249.0570.08 | 439.90130.25 |
| Case11 | 0.80 | 991.00113.56 | 1391.99238.58 |
| Case16 | 1.00 | 1304.50136.34* | 1152.18257.64* |
| Case18 | 0.25 | 2088.00108.46 | 1892.80293.40 |
| Case1 | 1.00 | 146.0515.13* | 239.7029.18* |
| Case3 | 1.00 | 433.8025.89* | 577.5846.55* |
| Case7 | 1.00 | 258.85110.51 | 451.99212.87 |
| Case11 | 0.90 | 1091.8978.26 | 1560.16194.04 |
| Case16 | 1.00 | 1345.30155.60* | 1156.08250.54* |
| Case18 | 0.35 | 2038.29172.45 | 1875.59215.09 |
| Case1 | 1.00 | 156.7014.75* | 262.8030.15* |
| Case3 | 1.00 | 449.5525.79* | 595.3249.50* |
| Case7 | 1.00 | 254.6574.52 | 442.00140.60 |
| Case11 | 0.85 | 1023.06132.27 | 1442.46245.77 |
| Case16 | 0.95 | 1337.58167.01* | 1127.46242.16* |
| Case18 | 0.25 | 2052.00129.39 | 1806.3971.94 |
| Case1 | 1.00 | 156.5016.94* | 257.2828.99* |
| Case3 | 1.00 | 453.1045.54* | 605.75110.63* |
| Case7 | 1.00 | 274.60123.49 | 485.03232.67 |
| Case11 | 0.95 | 1109.37104.44 | 1605.64173.35 |
| Case16 | 1.00 | 1326.00131.83* | 1146.23247.51* |
| Case18 | 0.40 | 1999.12225.17 | 1717.57234.66 |
| * represents the statistical significance | |||
We can observe from Table 3 that performs better than other values, achieving the highest SR on 6 cases and minimum time steps and path length on 4 cases. It should also be noted that the differences in the results by setting different values are not always significant. This is due to the high randomness of sheep behaviours which are impacted by many factors such as the obstacles and the neighbourhood. But only is not significantly worse than other values in these cases. This is probably because although can not minimise the influence of sheepdogs on some sheep on the edge of the swarm, it can avoid most of the poor disturbance behaviours, e.g., crossing the swarm. On the contrary, a large might cause unnecessary detours for sheepdogs. Therefore, is set to 4 in the following experiments.
The parameters and are parameters for determining the weights of the path length cost and the threat cost. We examined the effects of the ratio of to on shepherding performance of some representative cases by fixing to 1 and varying to 0, 20, 40, 60, 80 and 100. In particular, means that the no-interaction mode turns into the interaction mode, and the adaptively switch between these two modes is disabled. Table 4 shows that, similar to the effects of , the influence of different values is not significant in some cases. Particularly, the shepherding performance is not very sensitive to the change of if it is non-zero. This is because the change of non-zero values only slightly impacts the path planning results in no-interaction mode, which does not cause a significant difference in the shepherding. However, when , which disables the adaptively switch, the shepherding performance of more cases is impacted. Therefore, are set in the following experiments.
| Case | SR | No. of steps | Path length | SR | No. of steps | Path length | SR | No. of steps | Path length |
| C1 | 1.00 | 140.9514.53* | 232.3323.90* | 1.00 | 131.4514.80 | 218.6226.35 | 1.00 | 128.8513.18 | 213.0123.70 |
| C3 | 1.00 | 425.3536.43* | 565.5372.38* | 1.00 | 410.2025.86 | 530.7041.55 | 1.00 | 405.3525.48 | 521.8538.94 |
| C7 | 1.00 | 234.9573.25 | 413.66135.80 | 1.00 | 208.2553.61 | 364.71104.67 | 1.00 | 225.5050.62 | 399.2195.84 |
| C11 | 1.00 | 976.25130.14 | 1396.81247.64 | 1.00 | 978.00120.45 | 1380.84228.90 | 0.95 | 978.00130.36 | 1376.36254.97 |
| C16 | 1.00 | 1249.50124.46 | 1002.57170.85 | 1.00 | 1202.60184.64 | 1009.26233.03 | 1.00 | 1282.00136.54 | 1091.85245.40 |
| C18 | 0.20 | 2171.25138.81* | 1768.19398.51 | 0.20 | 2095.25189.02* | 1594.14271.94 | 0.50 | 2198.4033.07* | 1606.22145.12 |
| Case | SR | No. of steps | Path length | SR | No. of steps | Path length | SR | No. of steps | Path length |
| C1 | 1.00 | 134.2511.57 | 214.3918.91 | 1.00 | 133.9011.24 | 221.5920.24 | 1.00 | 131.0012.14 | 214.7020.69 |
| C3 | 1.00 | 407.4515.67* | 523.7631.46 | 1.00 | 406.8528.58 | 521.0344.73 | 1.00 | 396.0518.85 | 510.1738.77 |
| C7 | 1.00 | 239.9074.86 | 421.64144.35 | 1.00 | 238.3559.09 | 424.55111.83 | 1.00 | 232.5047.04 | 409.3694.24 |
| C11 | 1.00 | 1004.20140.56 | 1420.79232.61 | 0.90 | 950.06139.47 | 1336.35265.27 | 0.95 | 996.2189.63 | 1401.94166.63 |
| C16 | 1.00 | 1245.05147.89 | 1012.75206.21 | 1.00 | 1225.45135.50 | 969.26132.54 | 1.00 | 1191.75137.19 | 955.65143.42 |
| C18 | 0.20 | 2104.25127.41* | 1572.75263.46 | 0.30 | 2201.33106.89* | 1594.05213.48 | 0.60 | 2071.17156.11 | 1858.70235.51* |
| * represents the statistical significance | |||||||||
6.3 Performance of the planning-assisted shepherding
The proposed method is compared to the reactive shepherding from Strömbom et al. [7], referred to as Method 1 for convenience, to validate the effectiveness of the proposed shepherding model. As the proposed model consists of offline task planning (grouping and TSP-based sequencing) and online path planning, we further add the shepherding method with only task planning assisted, referred to as Method 2 as a comparative method to evaluate the impact of task planning and path planning separately. The proposed planning-assisted shepherding method is referred to as Method 3 in the comparisons.
6.3.1 Planning-assisted shepherding with single-sheepdog
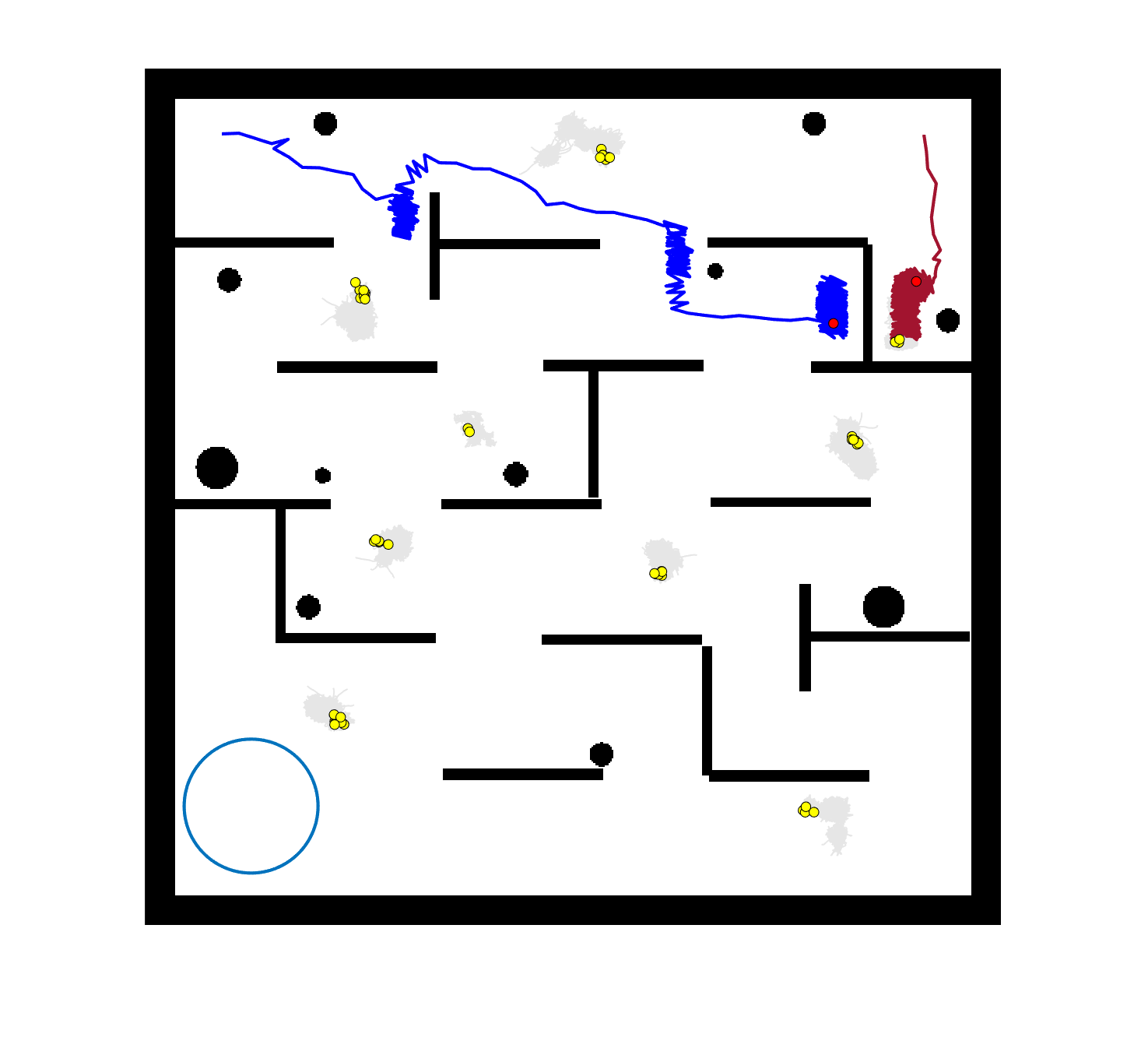
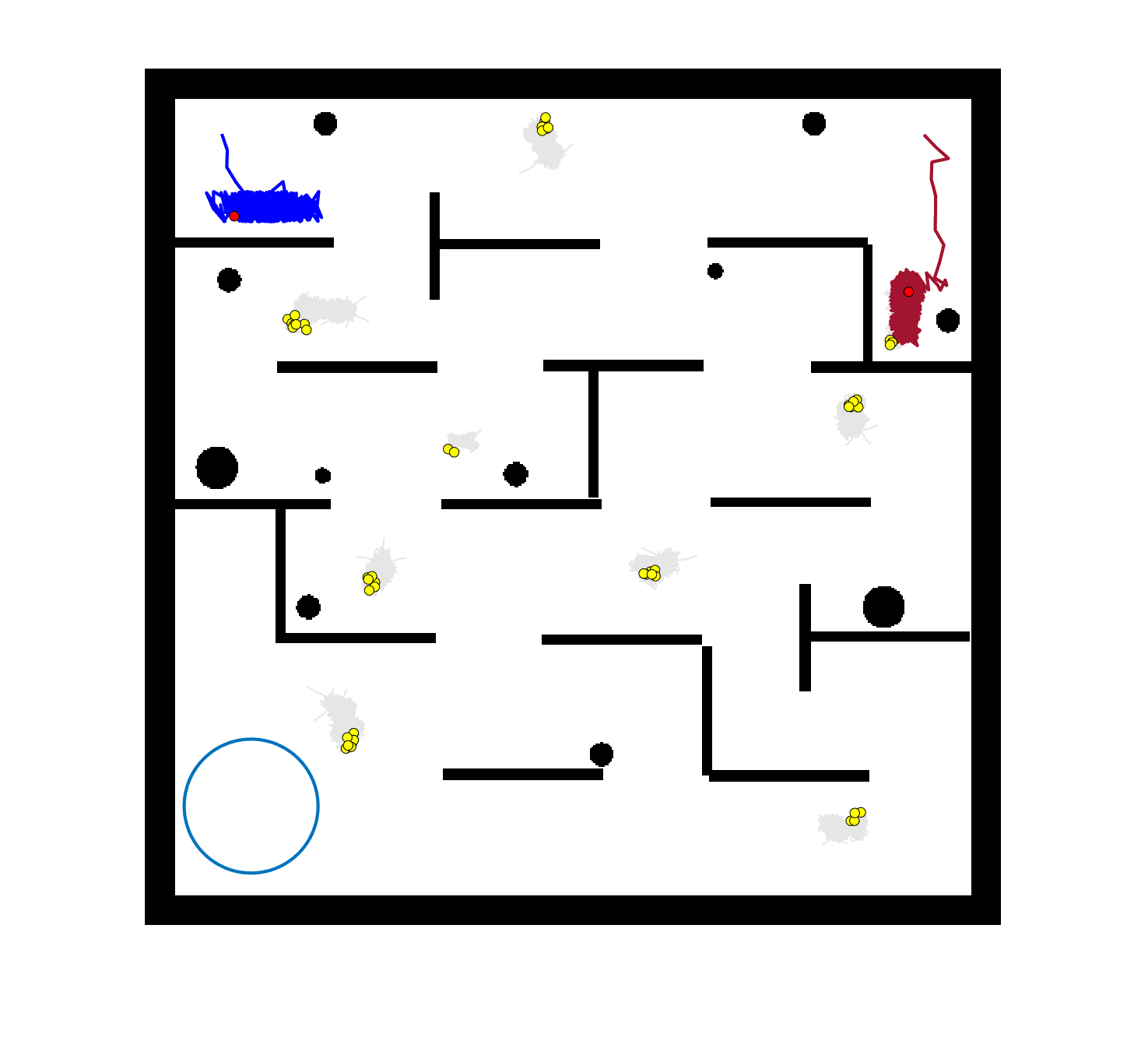
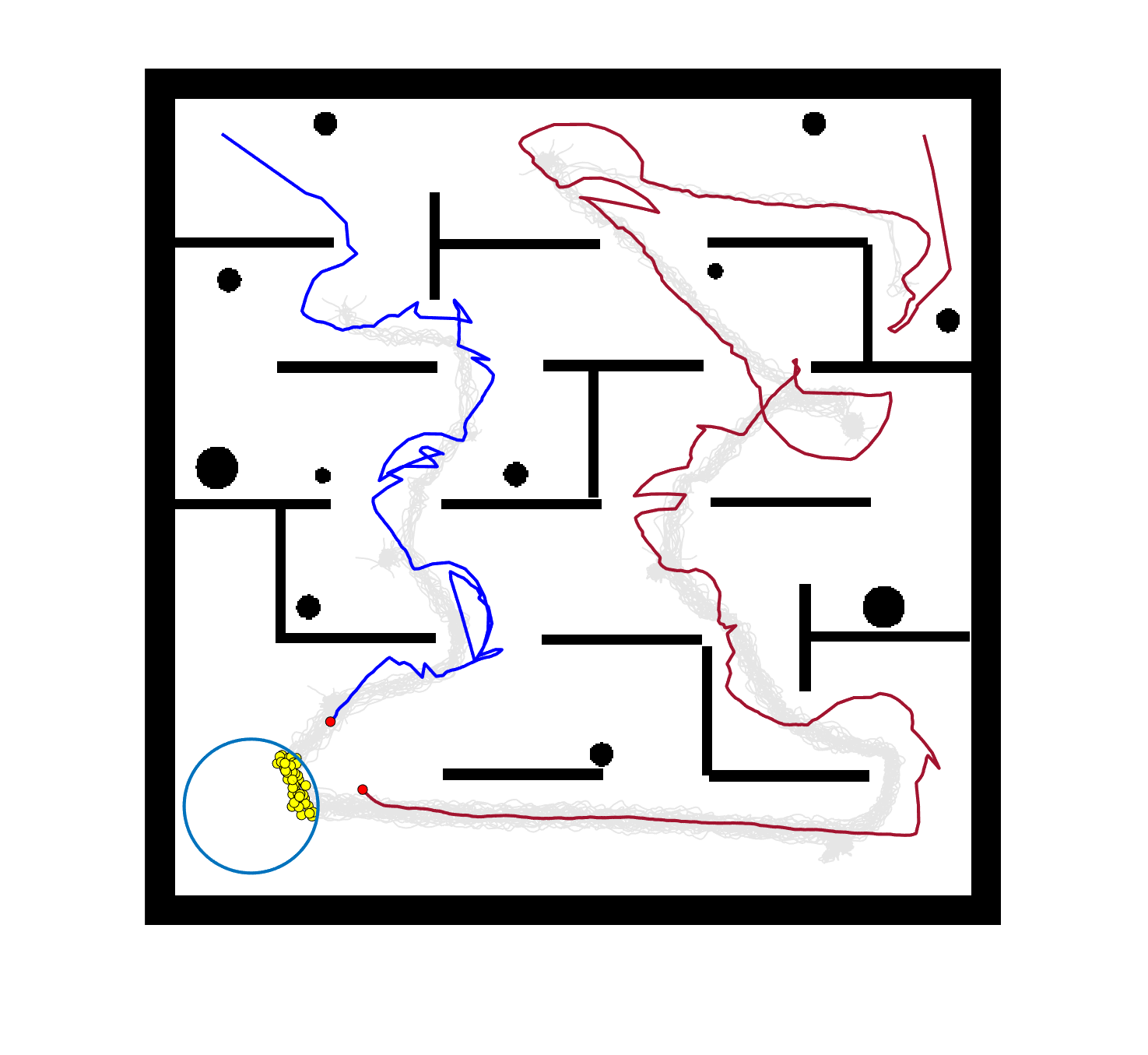
The comparative results of shepherding methods using single-sheepdog are presented in Table 5. The planning results and generated trajectories by each method during shepherding for three representative cases (one for a group) are visualised in Fig. 5. The blue lines in Fig. 5(a), 5(e), 5(i) represent the planning results. In other figures, the grey lines represent the sheep trajectories, and the blue lines represent the sheepdog trajectories.
As we can see from Table 5, the proposed planning-assisted swarm shepherding method performed the best overall among the three methods in almost all cases. In terms of the SR, with the increase of shepherding complexity, it becomes increasingly untenable for reactive shepherding to successfully complete the mission within the limited number of time steps, and the SR drops from 1 to 0. While reactive shepherding only obtained 100% SR on 3 cases of Group 1 (Cases 1, 5 and 6) and failed in 10 cases, task planning-assisted shepherding achieved 100% SR on 6 cases (Cases 1-5 of Group 1 and 7 of Group 2 ), which include most obstacle-free cases and a few obstacle-contained cases. But task planning-assisted shepherding failed in 7 cases (Cases 10, 12-13, 17-20) and had low SR (less than 50%) on 4 cases (Cases 8, 11, 15-16). This indicated that task planning, which divides the sheep swarm and determines the optimal pushing sequence of sub-swarms, could significantly increase the SR of shepherding in the environment without obstacles. It could also address some relatively simple shepherding missions in the environment with obstacles, but is unable to deal with the complex situations with cluttered obstacles and a large sheep swarm size. On the contrary, the proposed planning-assisted shepherding with both task planning and path planning integrated succeeded in all cases of Group 1 and more than half of Group 2 and 3, and achieved higher SR of Cases 8-13, 14-18 compared to Method 2. This demonstrates the effectiveness of path planning in improving the shepherding SR in obstacle-cluttered environments. Fig. 5(f)- 5(h) also validate that the sheepdog easily reached a deadlock without path planning (Methods 1 and 2), while Method 3 was able to effectively avoid this situation.
| Case | Method 1: Reactive shepherding | Method 2: Task planning-assisted shepherding | Method 3: Planning-assisted shepherding | ||||||
| SR | No. of steps | Path length | SR | No. of steps | Path length | SR | No. of steps | Path length | |
| C1 | 1.00 | 219.4546.38* | 427.4387.90* | 1.00 | 143.3512.09* | 257.3124.19* | 1.00 | 131.0012.14 | 214.7020.69 |
| C2 | 0.80 | 540.9495.78* | 1058.34184.48* | 1.00 | 281.5535.88 | 494.5567.65* | 1.00 | 272.8024.27 | 457.7543.86 |
| C3 | 0.95 | 898.53186.88* | 1801.14363.64* | 1.00 | 410.7032.80 | 604.5541.13* | 1.00 | 396.0518.85 | 510.1738.77 |
| C4 | 0.75 | 968.07145.03* | 1898.39279.91* | 1.00 | 464.1036.62 | 633.3637.50* | 1.00 | 456.7524.57 | 563.0635.75 |
| C5 | 1.00 | 1082.45192.37 | 2132.50362.61* | 1.00 | 1098.1073.27 | 645.0726.22* | 1.00 | 1118.3095.97 | 560.1230.96 |
| C6 | 1.00 | 1584.65182.53* | 3083.65373.67* | 0.95 | 1410.84210.77 | 677.3856.06* | 1.00 | 1434.05255.51 | 616.9056.48 |
| C7 | 0.85 | 438.5380.00* | 807.11154.04* | 1.00 | 251.8552.26 | 455.44100.63 | 1.00 | 232.5047.04 | 409.3694.24 |
| C8 | 0.05 | 685.000.00* | 1082.910.00* | 0.05 | 695.000.00* | 614.870.00* | 1.00 | 293.7022.20 | 490.4737.76 |
| C9 | 0.00 | —- | —- | 0.80 | 544.7537.62* | 2292.09129.15* | 1.00 | 484.3013.09 | 283.2018.14 |
| C10 | 0.00 | —- | —- | 0.00 | —- | —- | 1.00 | 567.4556.21 | 725.9788.96 |
| C11 | 0.00 | —- | —- | 0.20 | 1212.0068.00* | 1653.71259.48* | 0.95 | 996.2189.63 | 1401.94166.63 |
| C12 | 0.00 | —- | —- | 0.00 | —- | —- | 0.75 | 1230.6031.84 | 749.7157.93 |
| C13 | 0.00 | —- | —- | 0.00 | —- | —- | 0.75 | 1216.4043.09 | 773.6645.49 |
| C14 | 0.10 | 1808.0048.08* | 2652.0563.06* | 0.80 | 1528.75145.03* | 804.0492.00* | 1.00 | 1441.85109.28 | 714.7658.81 |
| C15 | 0.10 | 1763.00206.48* | 2701.55285.92* | 0.50 | 1223.30203.73* | 794.8294.96* | 1.00 | 1129.4096.65 | 722.4864.41 |
| C16 | 0.00 | —- | —- | 0.30 | 1837.83311.60* | 1652.02285.06* | 1.00 | 1191.75137.19 | 955.65143.42 |
| C17 | 0.00 | —- | —- | 0.00 | —- | —- | 0.15 | 1984.0052.12 | 967.57138.94 |
| C18 | 0.00 | —- | —- | 0.00 | —- | —- | 0.45 | 2071.17156.11 | 1858.70235.51* |
| C19 | 0.00 | —- | —- | 0.00 | —- | —- | 0.00 | —- | —- |
| C20 | 0.00 | —- | —- | 0.00 | —- | —- | 0.00 | —- | —- |
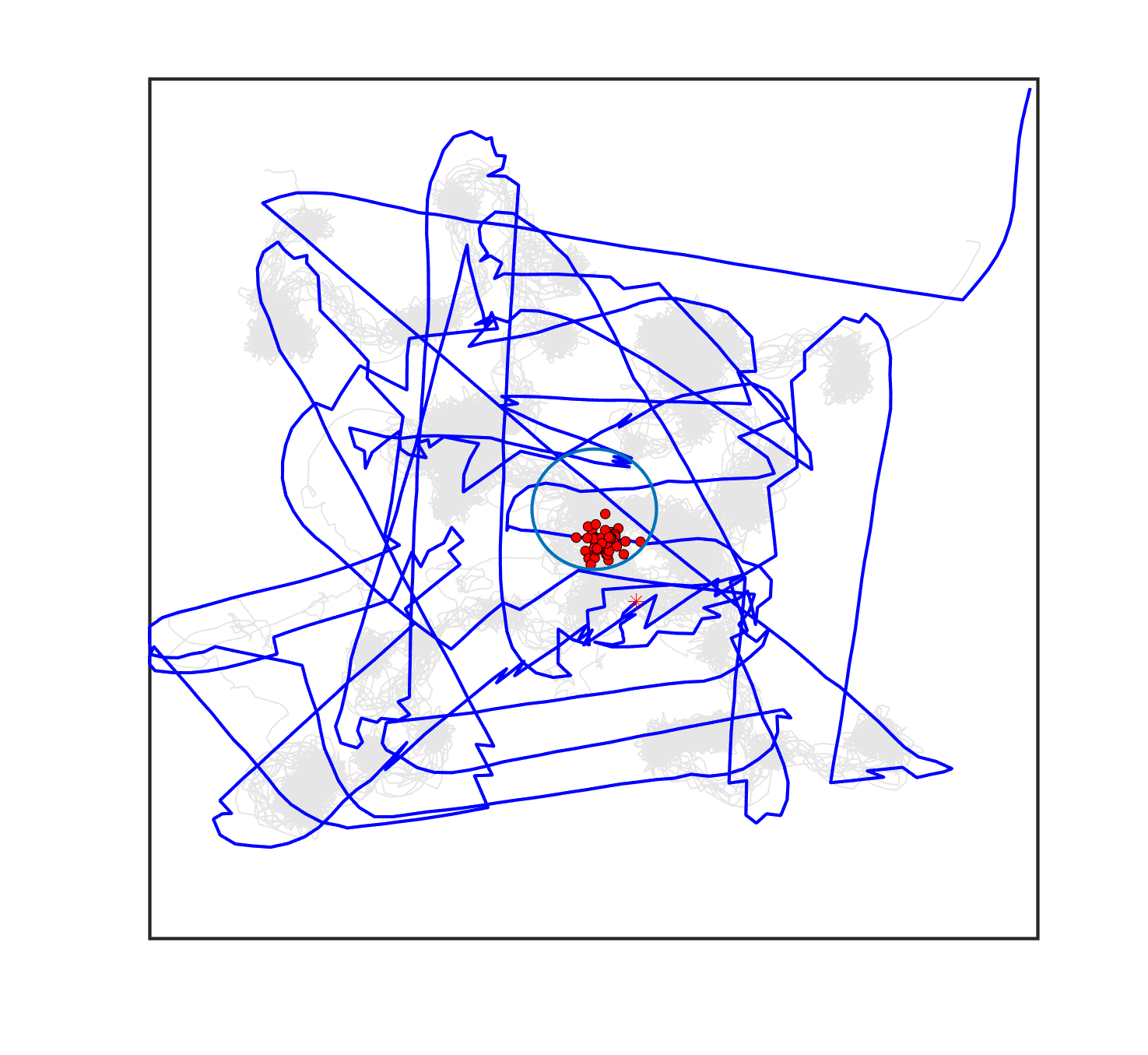
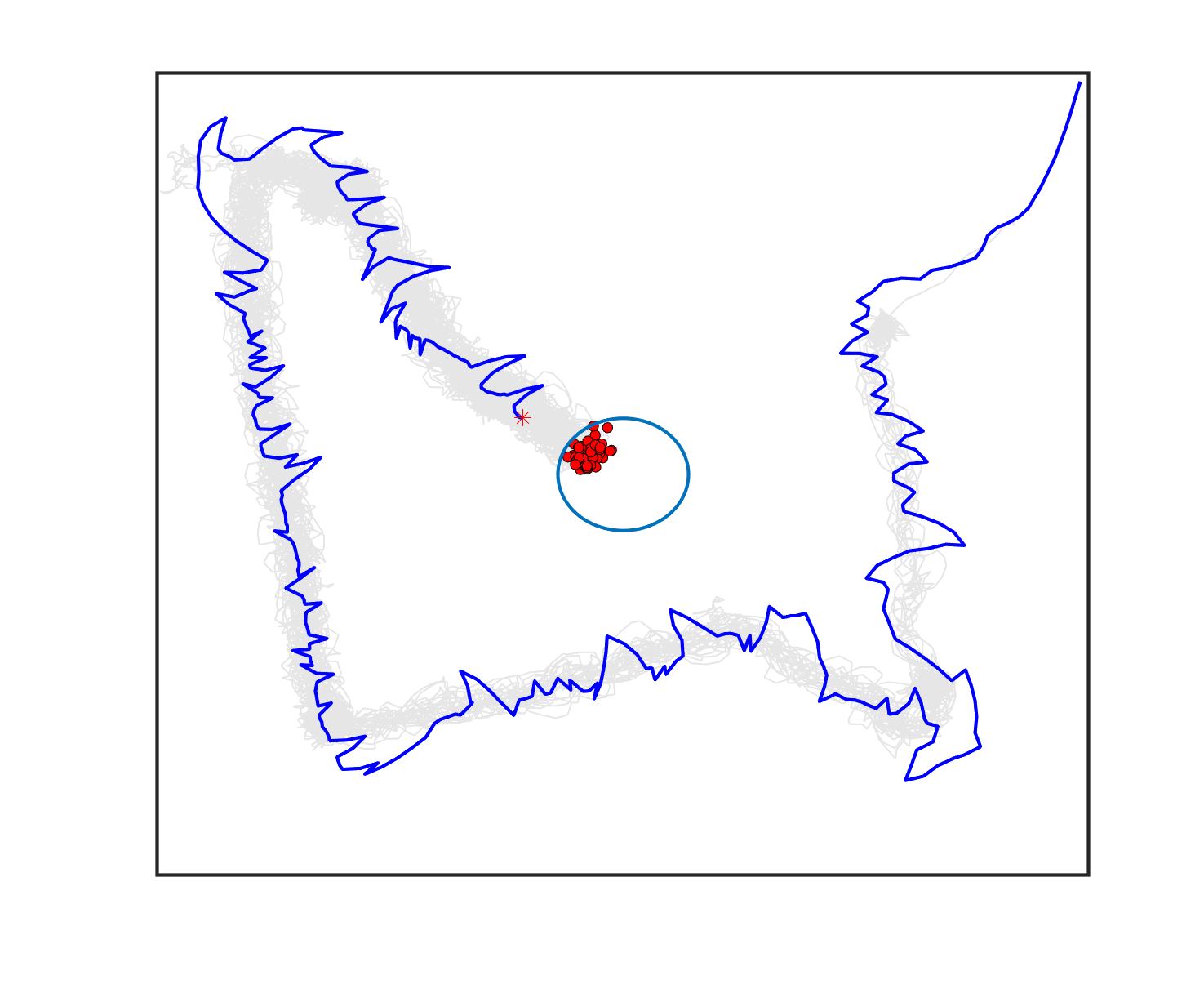
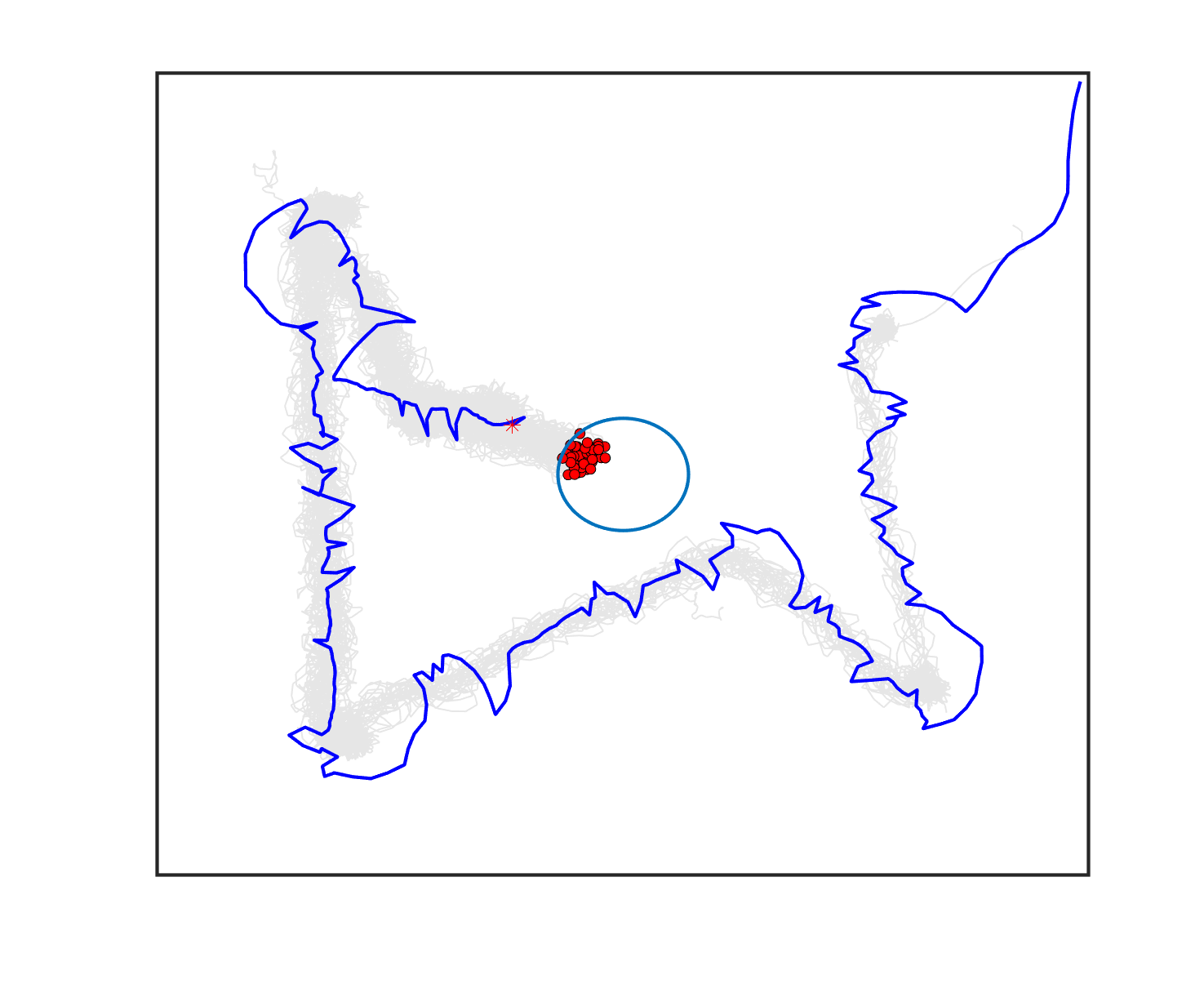
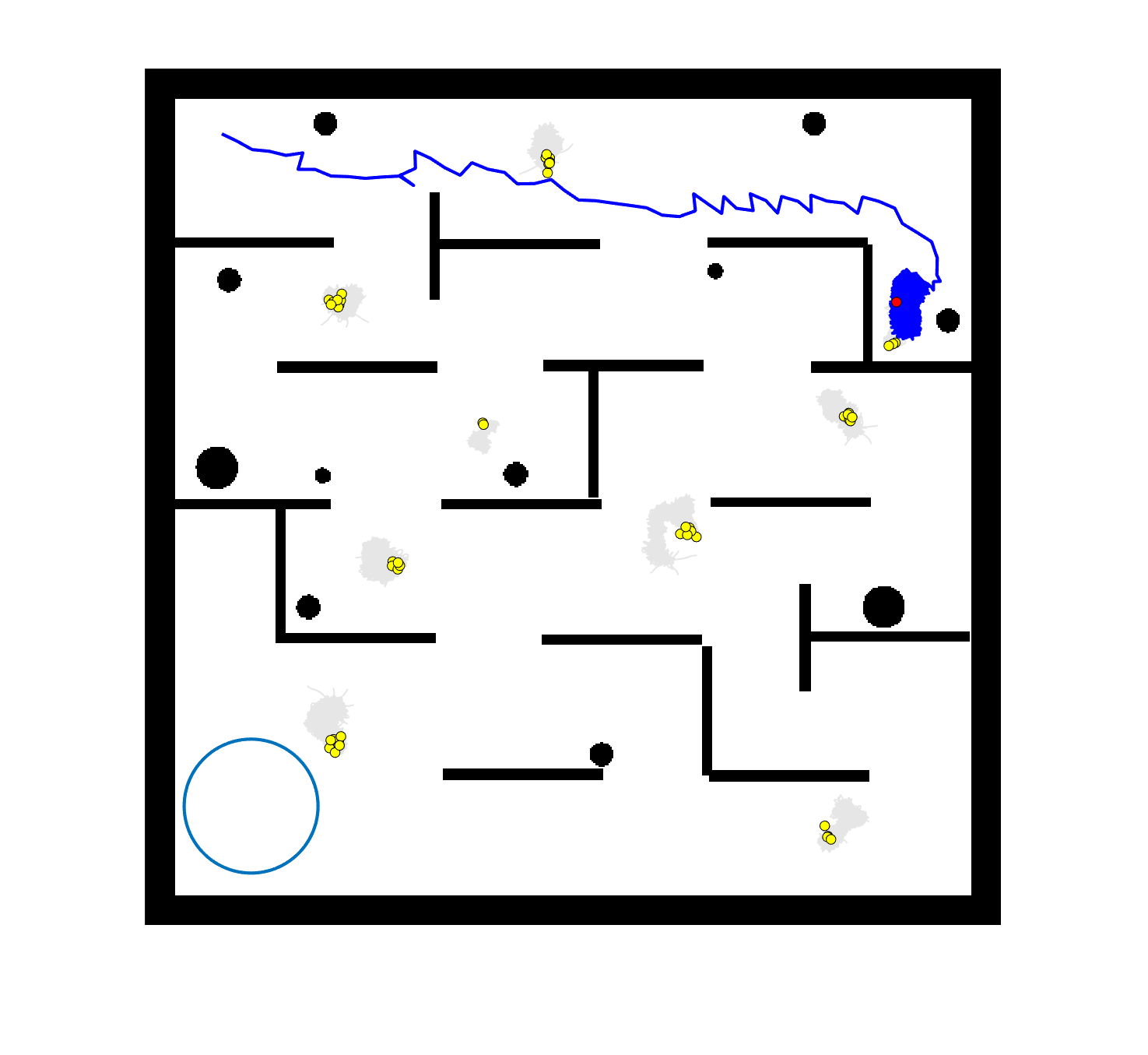
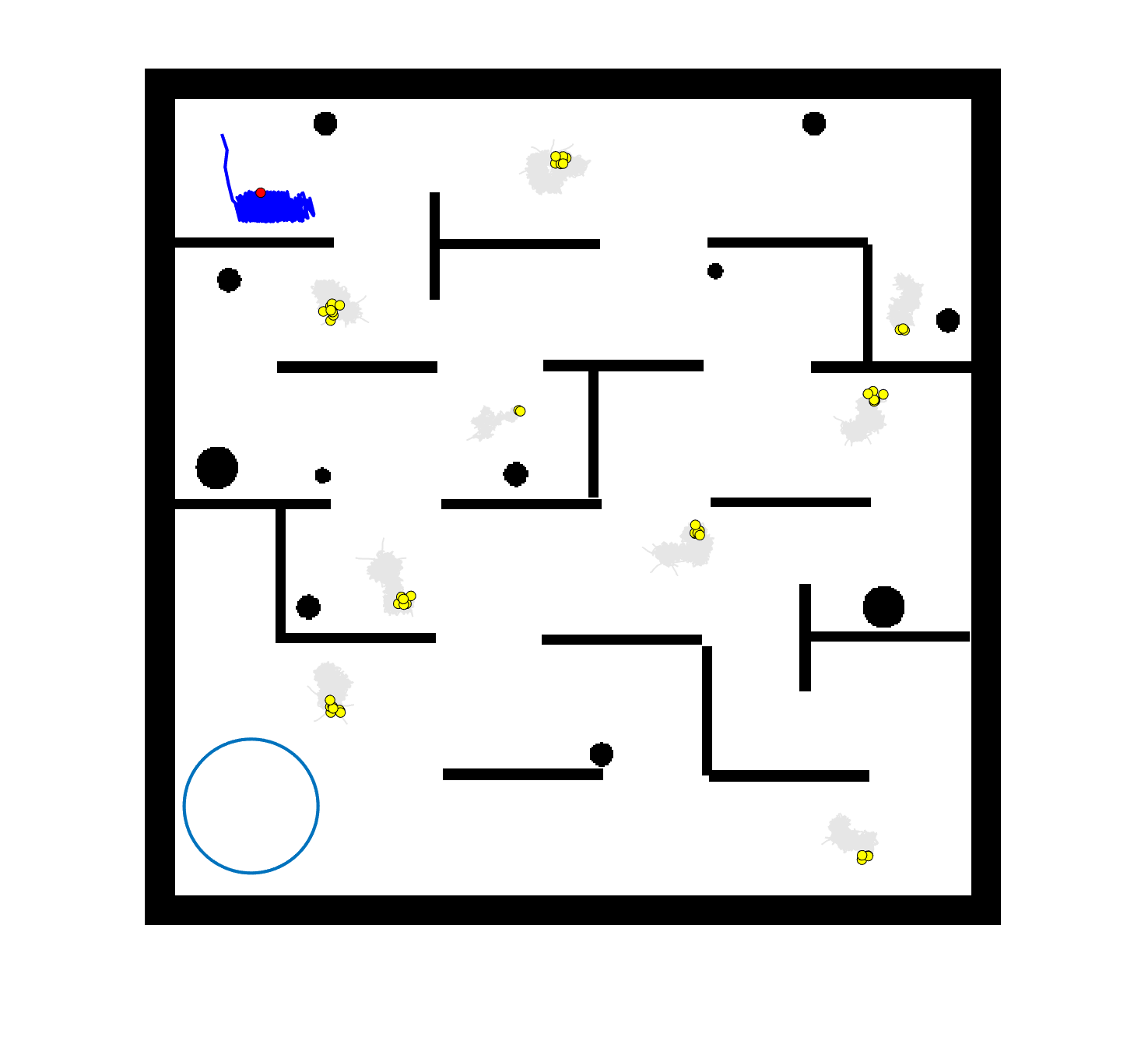
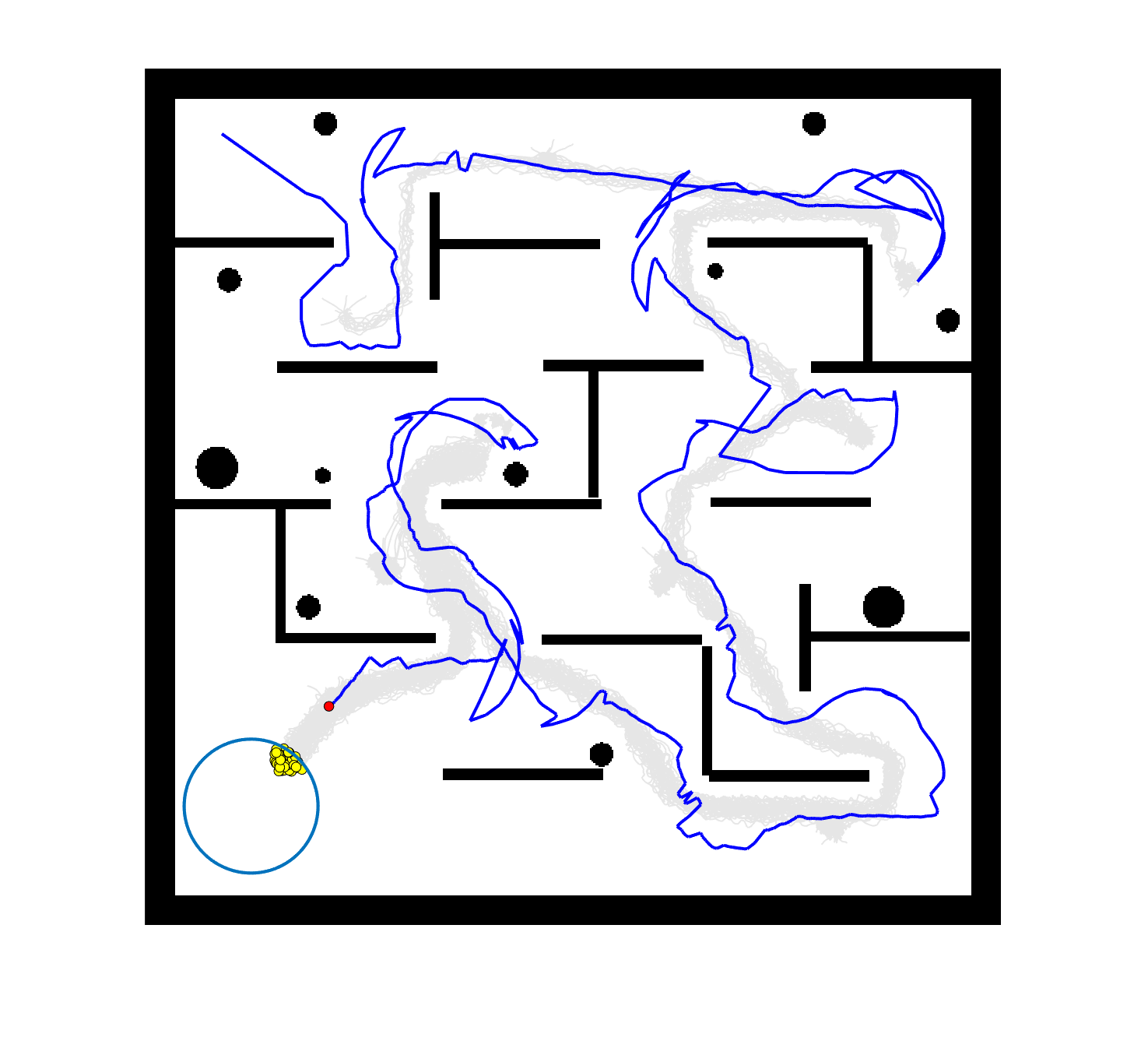
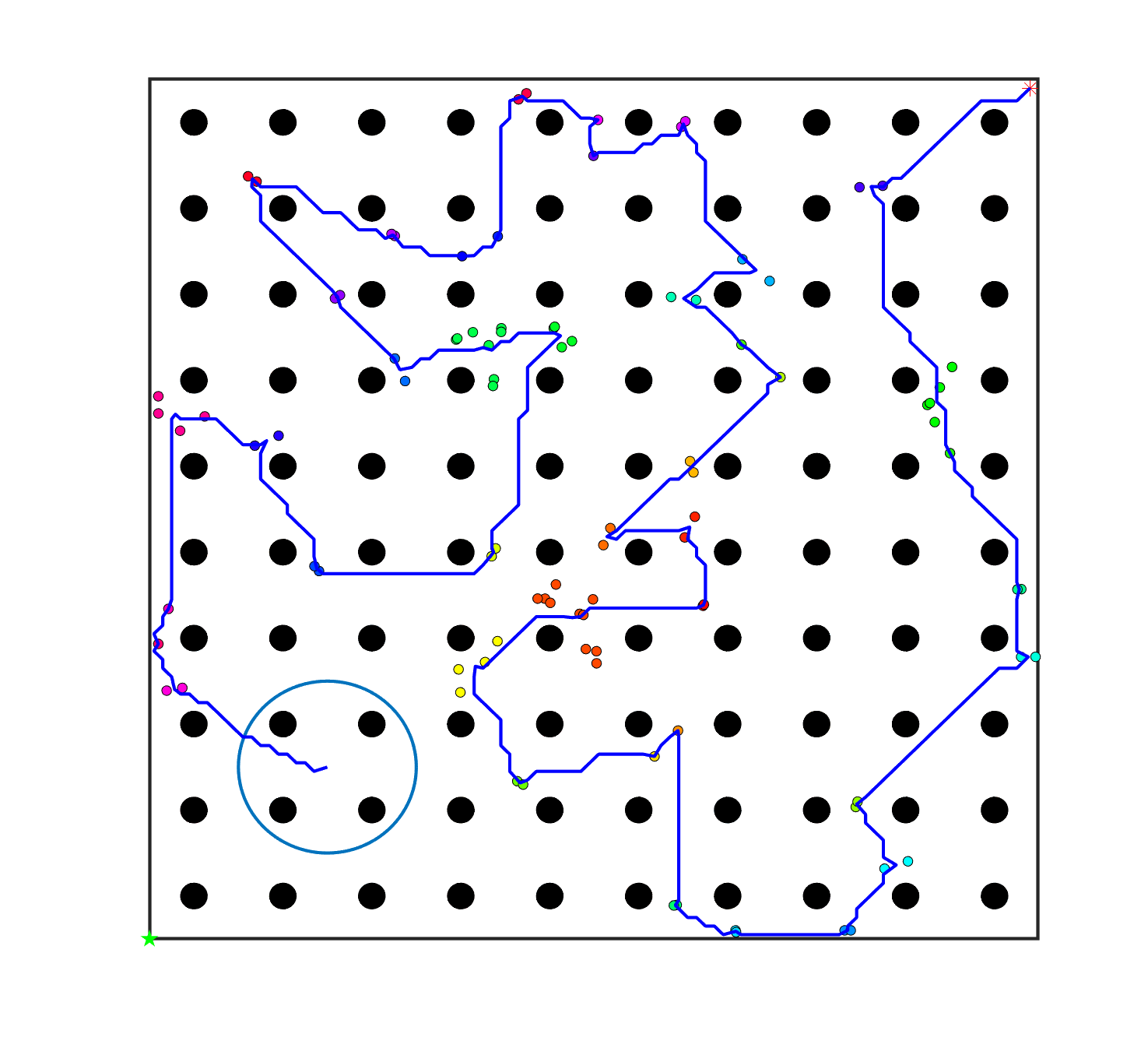
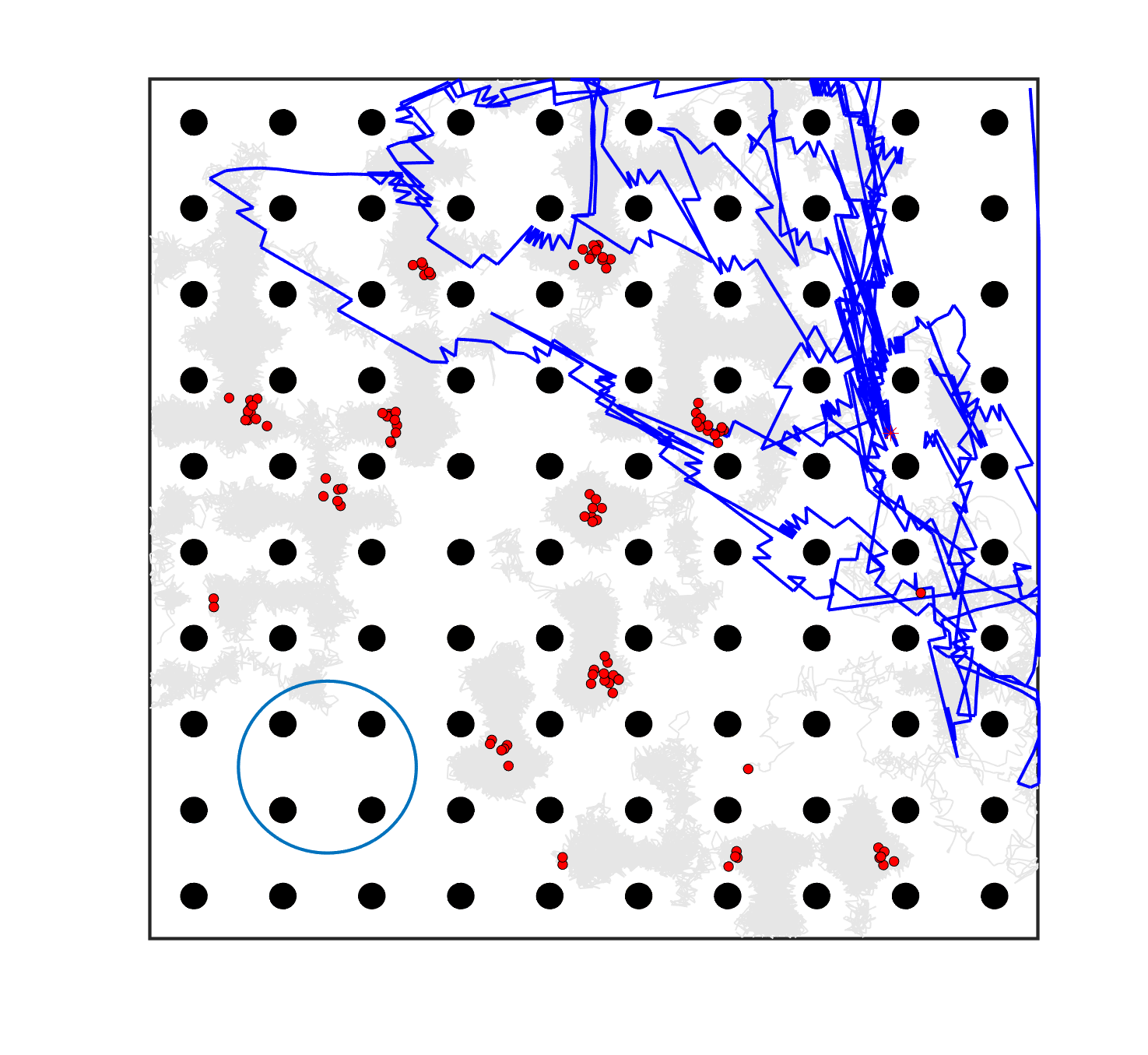
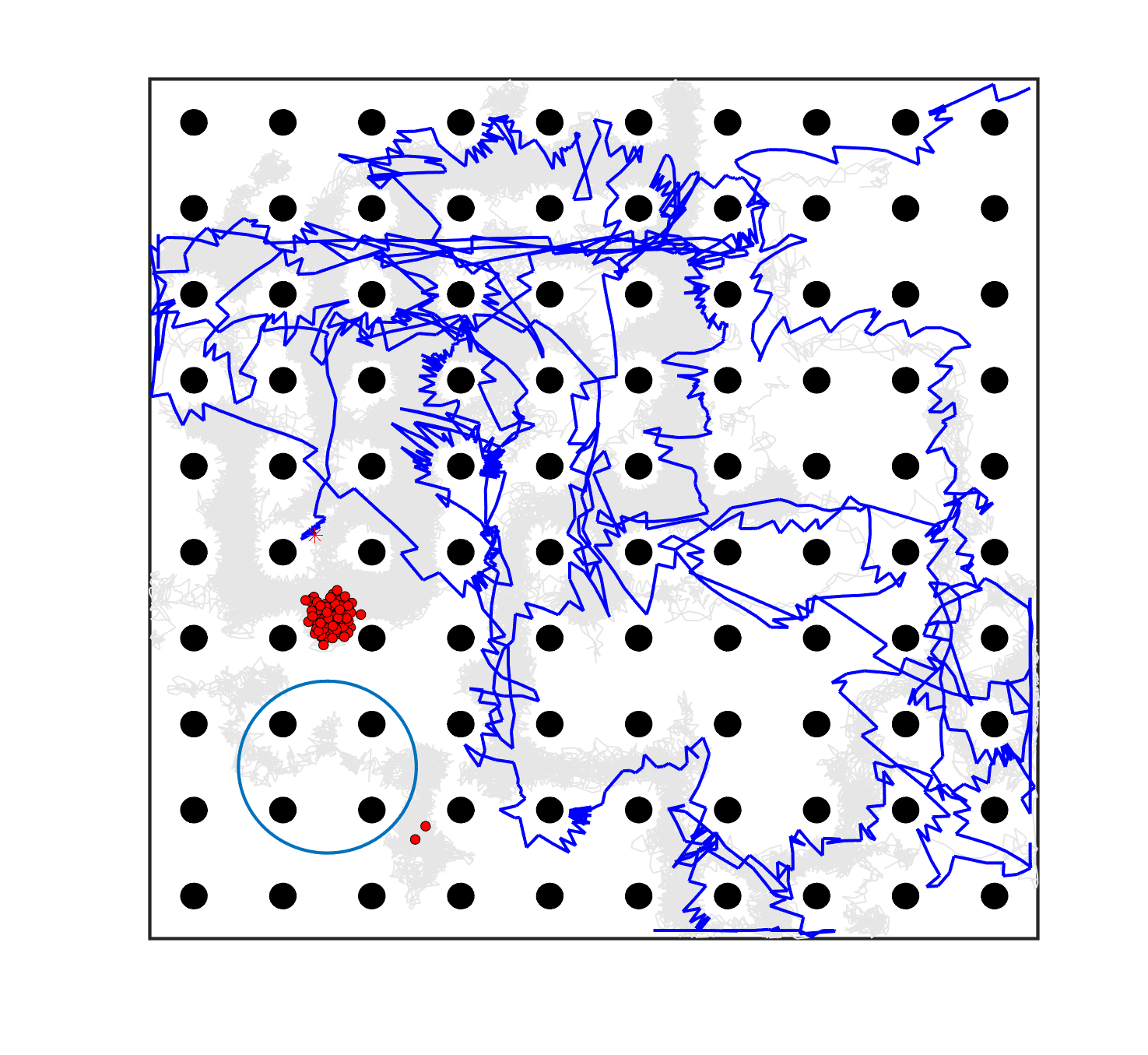
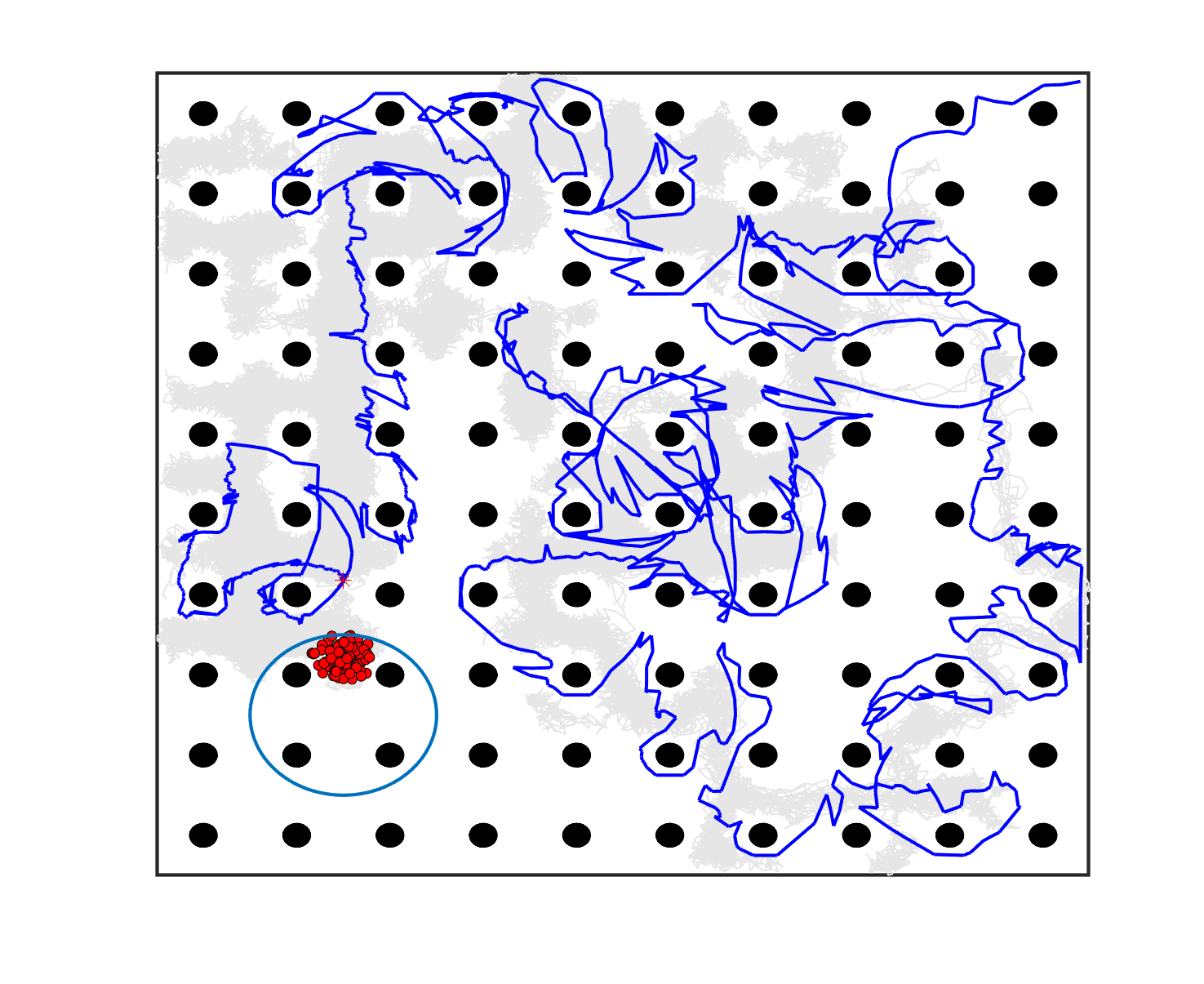
The integration of task planning and path planning also significantly reduces the number of steps and the path length required to herd the sheep swarm to the goal in almost all cases. This proves that the planning-assisted shepherding method can save time and reduce the energy consumption of robots to complete the shepherding mission, which results in significant benefit in the real-world shepherding applications. In detail, we can observe from Table 5 that, in most of the obstacle-free environments (Cases 2-6) and the relatively simple obstacle-cluttered environments (Case 7), the reduction of the number of steps is mainly caused by the employment of task planning as the difference between the number of steps obtained by task planning-assisted shepherding and planning assisted shepherding are not significant. However, when the shepherding complexity increases in Cases 8-18, path planning plays an important role in further reducing the number of time steps so that the planning-assisted shepherding achieves the minimum number of steps. In terms of the path length, the task planning-assisted shepherding performed better than the reactive shepherding on all data-applicable cases, while the planning-assisted shepherding obtained the best performance as presented in Table 5 and Fig. 5. This demonstrates that both tasking planning and path planning are very effective in reducing the detours of the sheepdog. However, the single-sheepdog planning-assisted shepherding still has difficulty in addressing the most complex Cases 19 and 20 within the limited time and cannot guarantee 100% SR for a few cases.
6.3.2 Planning-assisted shepherding with bi-sheepdog shepherding
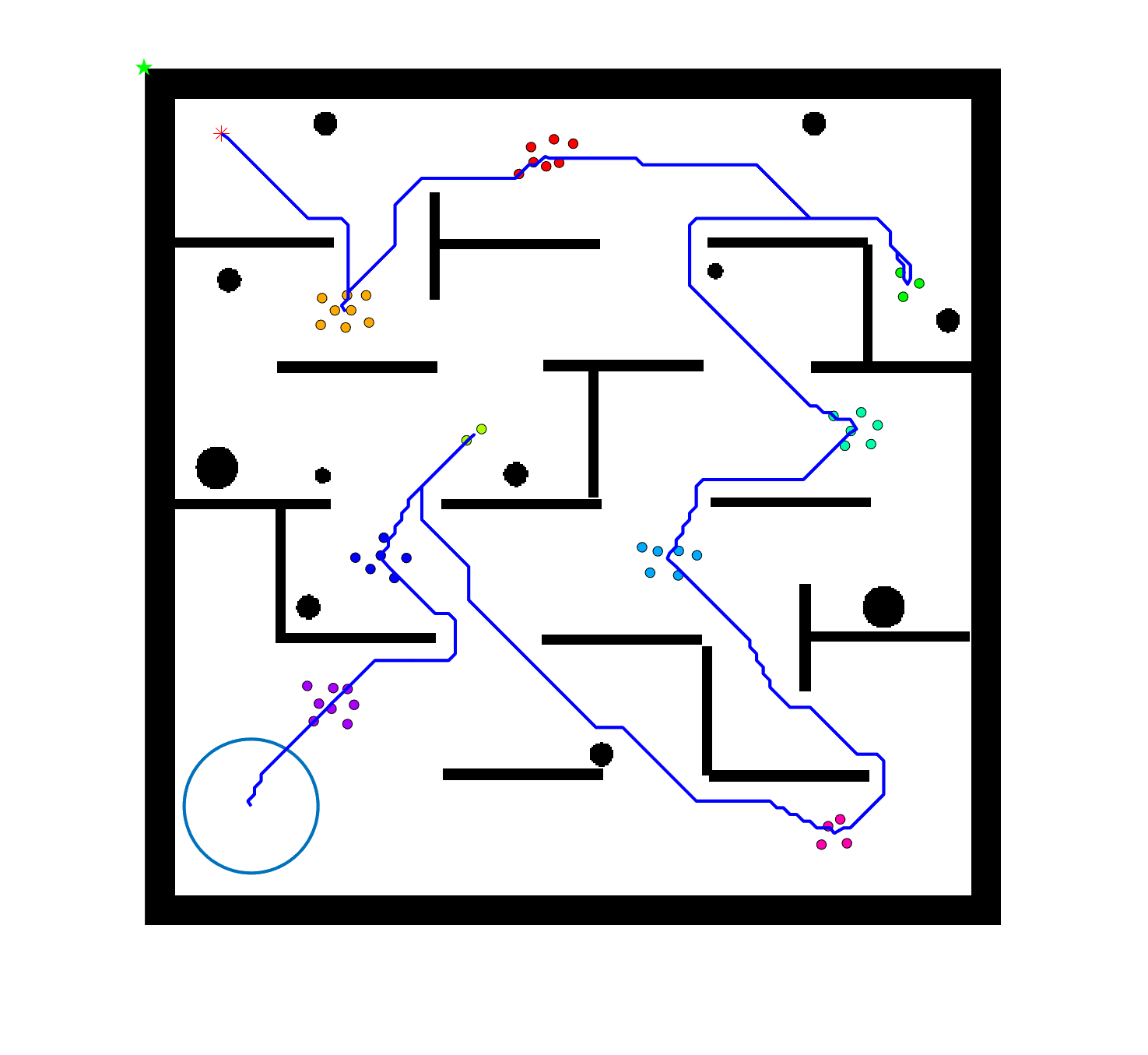
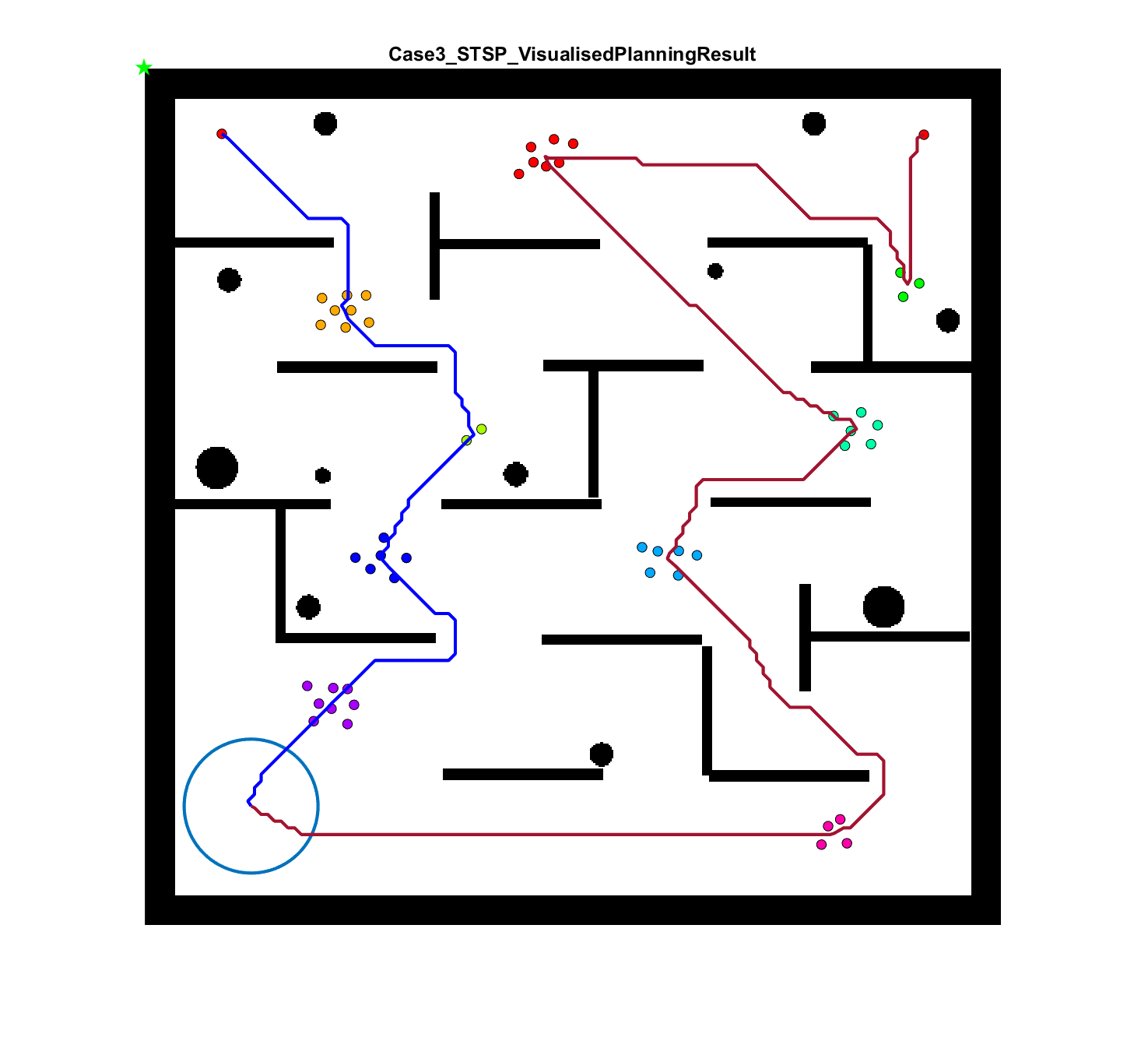
The failure of the planning-assisted shepherding with single-sheepdog in Cases 19 and 20 encourages the employment of multi-sheepdog in shepherding. We evaluated the performance of the three methods with two sheepdogs on the benchmark set, and Table 6 presents the results. When employing multiple agents, the mission completion time and the minimum cruising ability requirement are determined by the agent which consumes the most time and travels the longest distance, respectively. Therefore, the No. of steps and Path length presented in Table 6 are calculated based on the larger one between the values of the two sheepdogs. The visualised planning results for the 3 representative cases are presented in Fig. 6(a), 6(e), 6(i) where the lines in different colours represent the optimal routes for sheepdogs. The trajectories of sheep (represented as lines in grey) and sheepdogs (represented as lines in blue and red) generated during the bio-sheepdog shepherding process based on different methods for these cases are visualised as other figures in Fig. 6.
| Case | Method 1: Reactive shepherding | Method 2: Task planning-assisted shepherding | Method 3: Planning-assisted shepherding | ||||||
| SR | No. of steps | Path length | SR | No. of steps | Path length | SR | No. of steps | Path length | |
| C1 | 1.00 | 192.0560.30* | 378.07113.59* | 1.00 | 77.508.29 | 153.0013.99* | 1.00 | 76.857.94 | 132.4915.92 |
| C2 | 0.95 | 412.84136.45* | 811.45264.00* | 1.00 | 132.457.34 | 250.0113.10* | 1.00 | 133.107.37 | 232.4313.68 |
| C3 | 1.00 | 688.05124.54* | 1392.42242.39* | 1.00 | 289.4020.38 | 494.0037.71* | 1.00 | 284.4519.16 | 414.4331.54 |
| C4 | 0.95 | 662.53122.04* | 1322.85243.08* | 1.00 | 195.6510.52 | 374.6620.84* | 1.00 | 198.308.89 | 317.2920.73 |
| C5 | 1.00 | 768.90158.46* | 1543.09317.80* | 1.00 | 433.3528.25 | 424.5922.60* | 1.00 | 431.9049.90 | 365.2228.34 |
| C6 | 1.00 | 1077.00208.75* | 2128.58420.37* | 1.00 | 263.6515.46 | 366.7419.44* | 1.00 | 261.3520.29 | 298.2025.56 |
| C7 | 0.90 | 349.72118.35* | 647.45209.27* | 0.95 | 204.89113.89 | 357.89146.12* | 1.00 | 157.4036.19 | 282.7967.60 |
| C8 | 0.85 | 463.94113.64* | 854.12194.77* | 1.00 | 174.3015.00 | 323.1729.17* | 1.00 | 168.259.63 | 293.4219.03 |
| C9 | 0.00 | —- | —- | 0.00 | —- | —- | 1.00 | 407.2511.39 | 281.3323.32 |
| C10 | 0.40 | 906.50177.10* | 1556.23267.23* | 0.00 | —- | —- | 1.00 | 249.6511.50 | 383.2524.44 |
| C11 | 0.00 | —- | —- | 0.70 | 755.50267.97* | 1149.11288.59* | 1.00 | 468.95190.20 | 765.19244.20 |
| C12 | 0.00 | —- | —- | 0.00 | —- | —- | 1.00 | 568.9012.33 | 350.8717.13 |
| C13 | 0.00 | —- | —- | 0.00 | —- | —- | 1.00 | 668.9514.39 | 419.0623.33 |
| C14 | 0.85 | 1138.35336.01* | 1907.98477.13* | 0.00 | —- | —- | 1.00 | 352.5014.99 | 359.9826.04 |
| C15 | 0.60 | 1656.17394.33* | 2690.52491.41* | 1.00 | 423.20312.16* | 555.73208.74* | 1.00 | 296.9518.88 | 395.8147.19 |
| C16 | 0.10 | 1807.50245.37* | 2469.1334.49* | 0.75 | 1234.27459.81* | 1111.22453.89* | 1.00 | 605.45209.93 | 564.11116.75 |
| C17 | 0.00 | —- | —- | 0.00 | —- | —- | 1.00 | 720.95168.93 | 558.6487.80 |
| C18 | 0.05 | 2077.000.00* | 2770.340.00* | 0.30 | 1421.00600.48* | 1673.98613.43* | 0.85 | 689.29134.12 | 1028.32195.86 |
| C19 | 0.10 | 1765.5077.07* | 2892.3771.84* | 0.80 | 1030.62351.46* | 1436.14471.77* | 1.00 | 527.2548.09 | 618.39156.38 |
| C20 | 0.00 | —- | —- | 0.00 | —- | —- | 1.00 | 1162.4527.88 | 559.2136.11 |
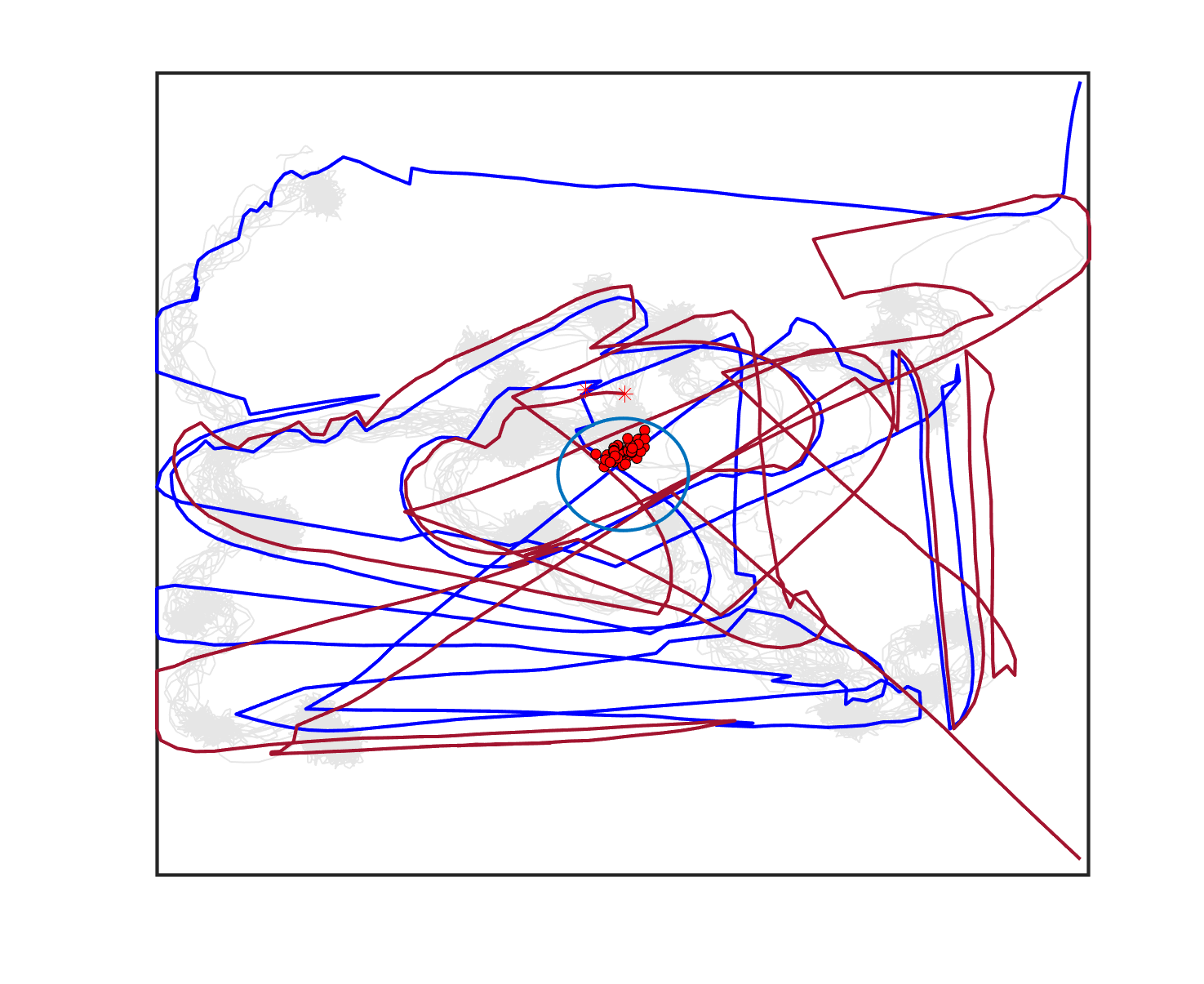
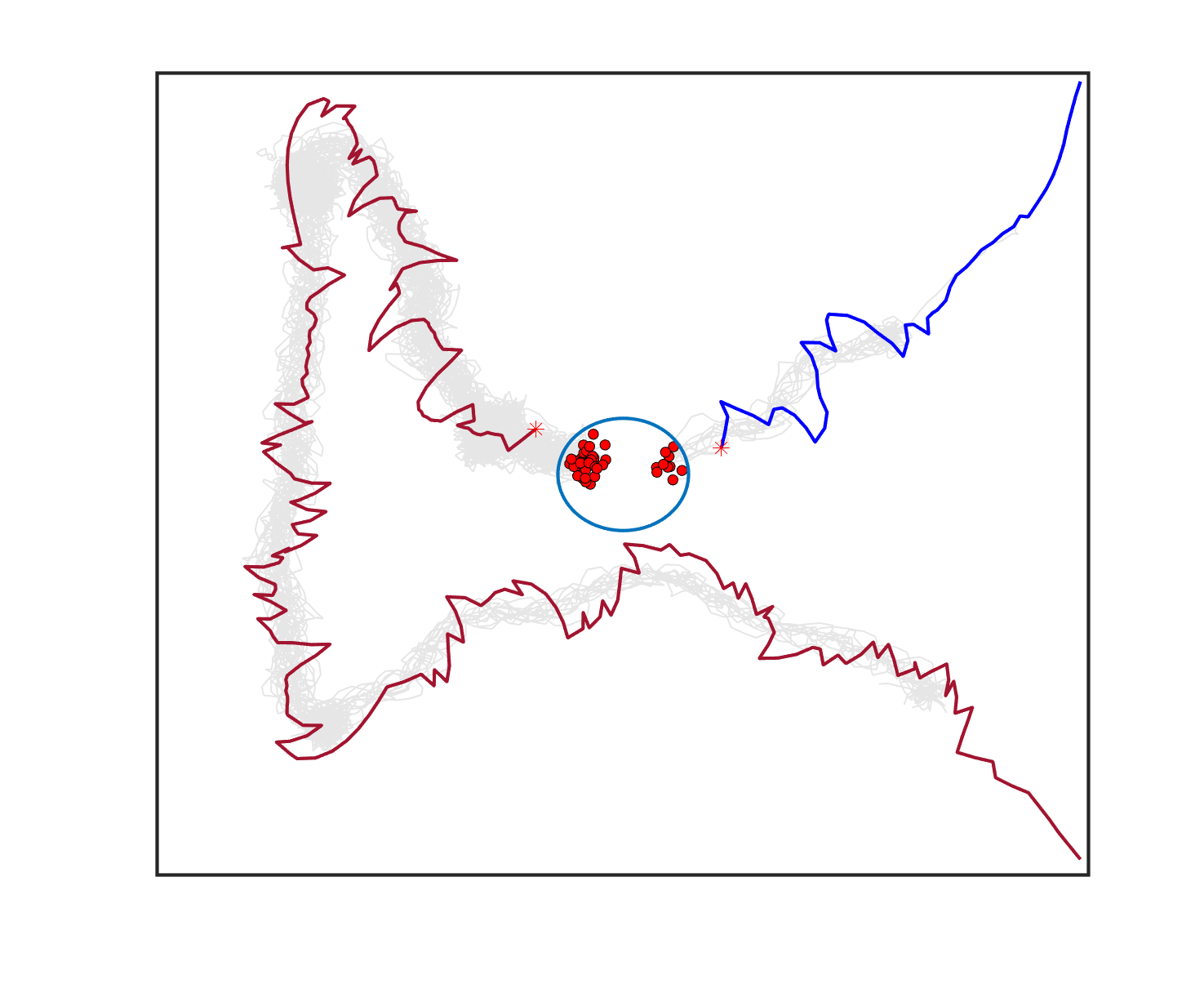
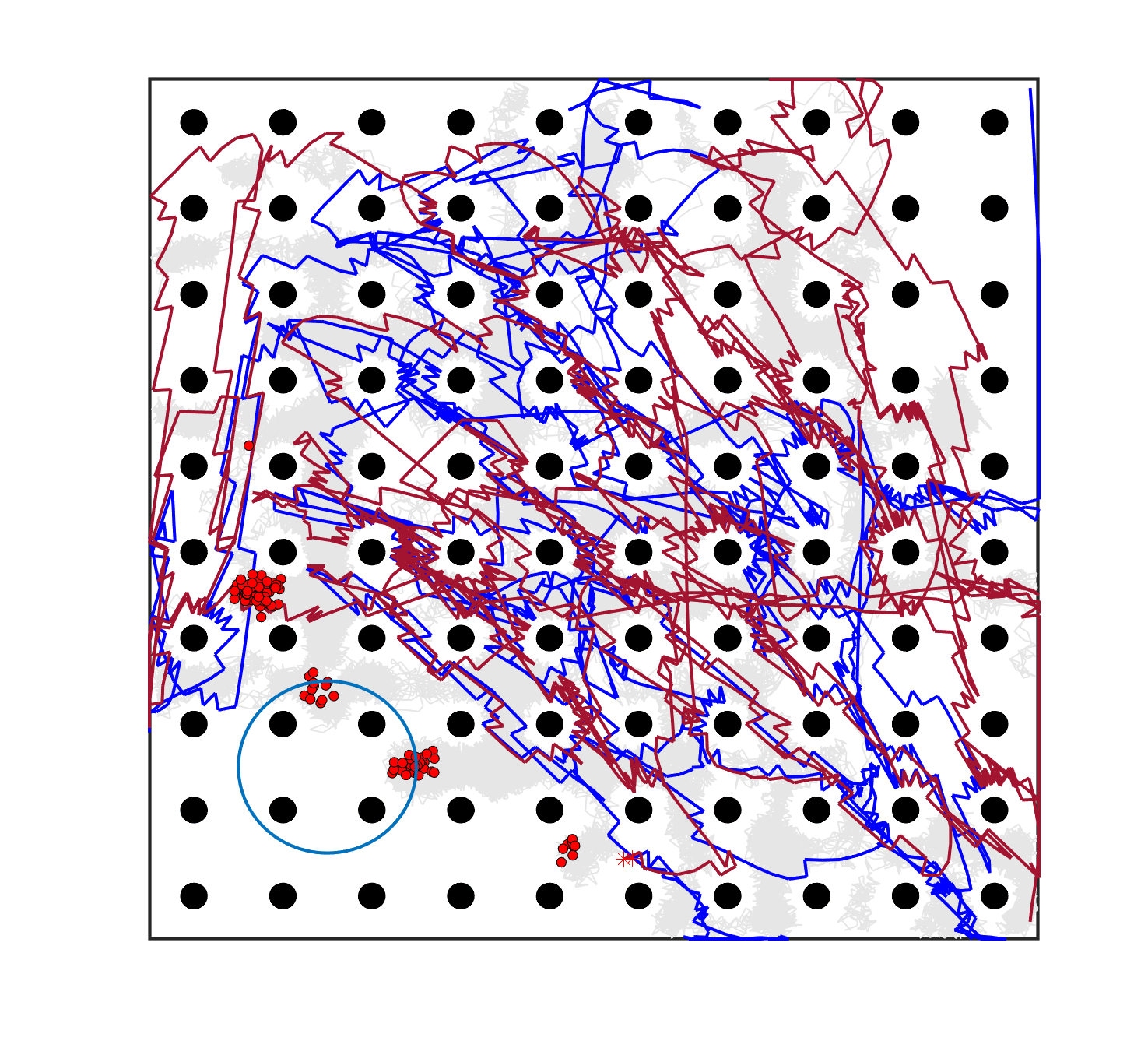
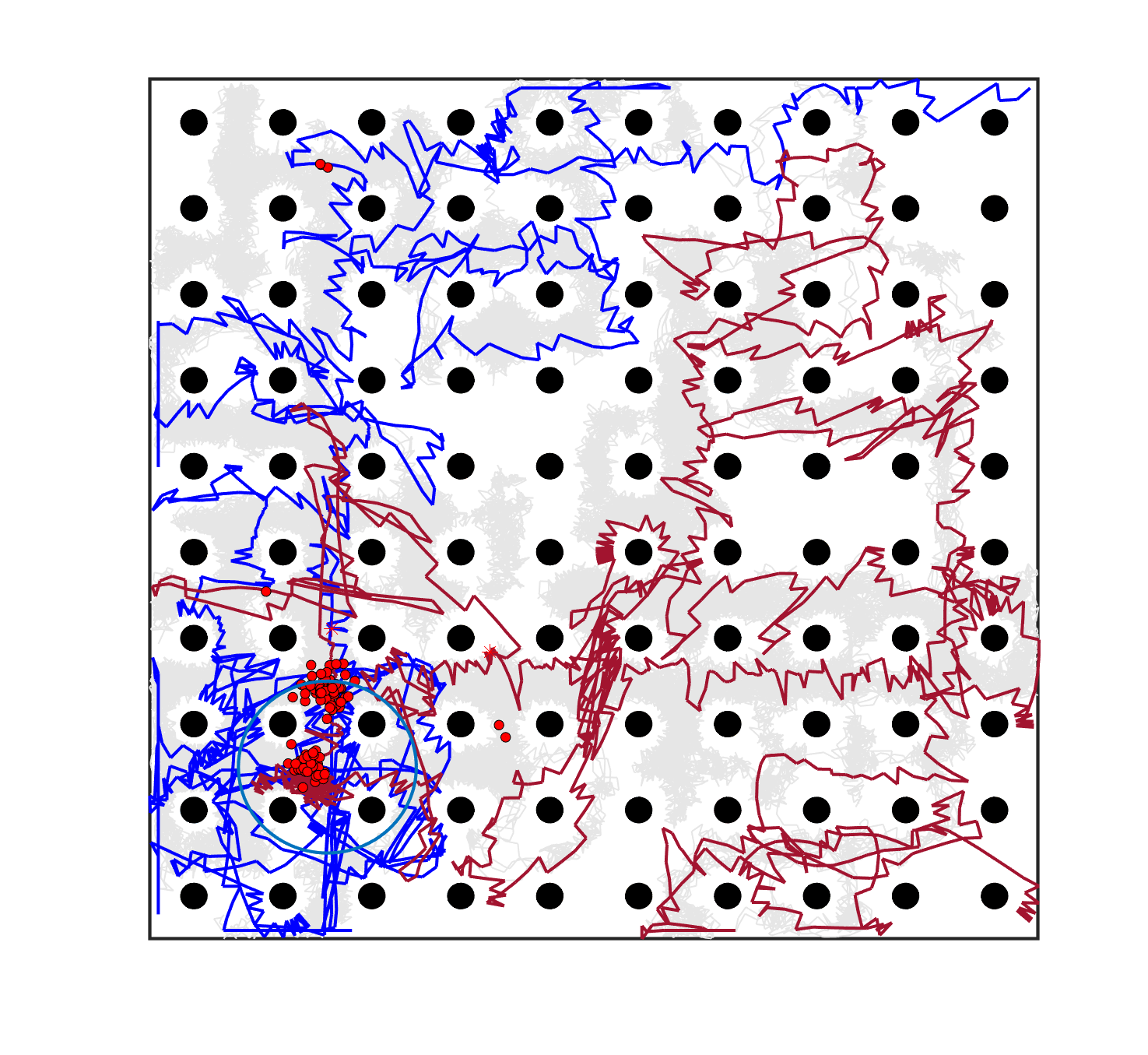
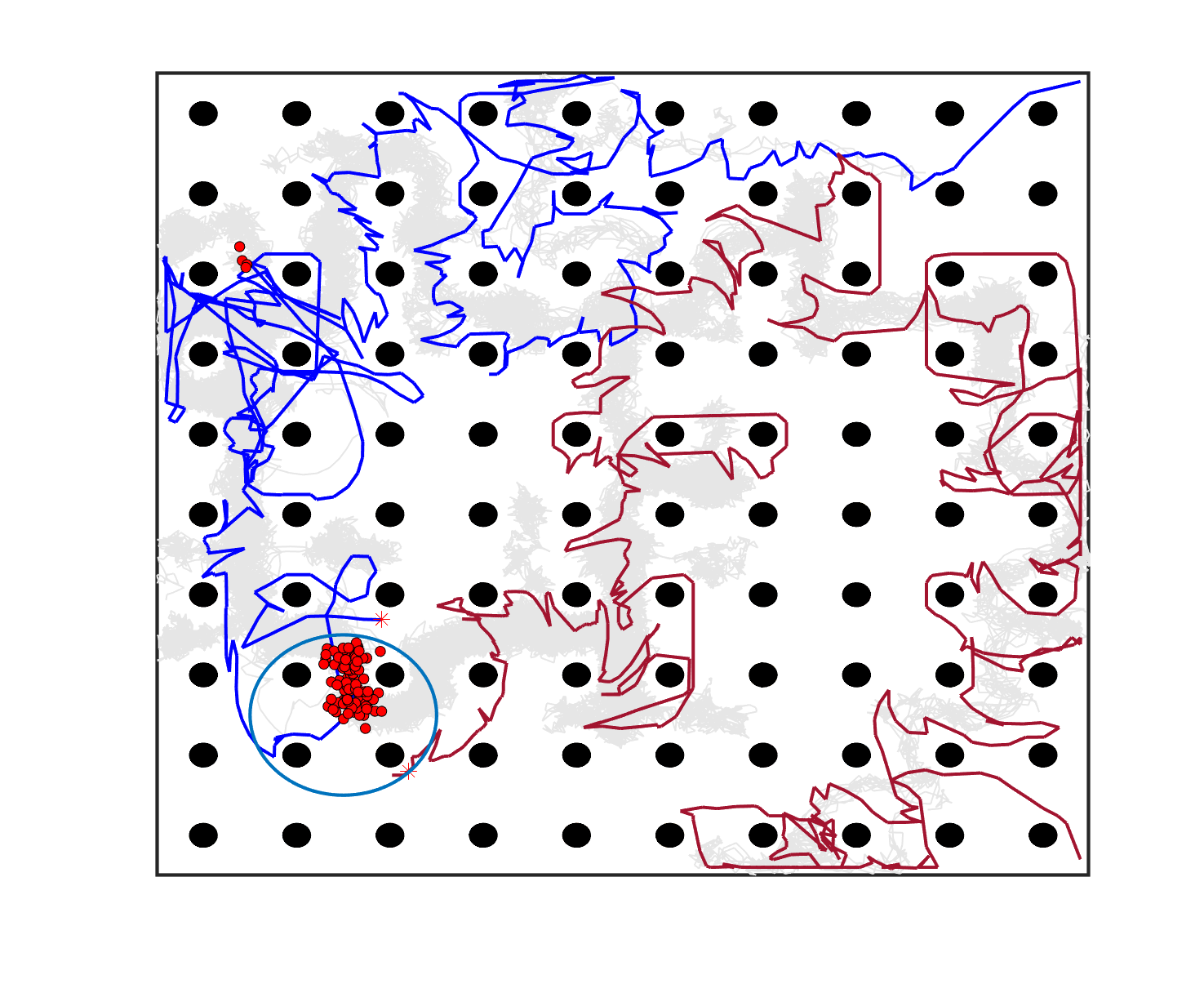
We can observe from Table 6 and Fig. 6 that the planning-assisted bi-sheepdog shepherding performed the best among these 3 methods and Method 2 performed better than Method 1, indicating the same findings from the above single-sheepdog shepherding: task planning and path planning can significantly improve the shepherding performance, especially for complex shepherding missions. Specifically, bi-sheepdog planning-assisted shepherding achieved 100% SR on all cases except Case 18, while Method 1 and Method 2 with bi-sheepdog still completely failed in some cases. Furthermore, compared to single-sheepdog shepherding, it is easy to find that the deployment of 2 sheepdogs, no matter based on which method, significantly improved the SR of addressing the complex shepherding tasks and reduced the number of time steps and the path length to complete the mission as shown in Table 6. For example, bi-sheepdog planning-assisted shepherding increased the SR from 0 to 100% on Cases 19 and 20 and obtained lower time steps and shorter path length compared to single-sheepdog planning-assisted shepherding in all cases. We can conclude that the deployment of multiple sheepdogs is an efficient way to reduce the completion time of the shepherding mission and the cruising ability requirement of the sheepdog.
To further validate the effectiveness of bi-sheepdog shepherding, we also compare the total number of steps and the total path length of 2 sheepdogs obtained by planning-assisted shepherding to the best results of single-sheepdog shepherding. The results are presented in Table 7, where the boldface denotes that the bi-sheepdog shepherding achieves better results than the single-sheepdog shepherding and ‘*’ indicates the significant difference. It can be found that the planning-assisted bi-sheepdog shepherding still significantly outperformed the single-sheepdog shepherding in most of the cases in terms of the total values. This further demonstrates the efficiency of bi-sheepdog planning-assisted shepherding in terms of reducing the total time and energy consumption to complete the mission.
| Case | The total | ||
|---|---|---|---|
| SR | No. of steps | Path length | |
| C1 | 1.00 | 112.757.99* | 195.6215.68* |
| C2 | 1.00 | 257.509.74 | 444.7419.52 |
| C3 | 1.00 | 338.7018.77 | 503.2728.82 |
| C4 | 1.00 | 332.6510.80* | 531.9722.48* |
| C5 | 1.00 | 547.7049.69 | 541.1038.67 |
| C6 | 1.00 | 467.9026.30* | 548.4435.06* |
| C7 | 1.00 | 196.4536.49* | 347.0667.72* |
| C8 | 1.00 | 307.2546.74* | 537.1785.49* |
| C9 | 1.00 | 562.0512.17* | 378.0623.17* |
| C10 | 1.00 | 518.15153.67* | 840.70283.54* |
| C11 | 1.00 | 704.45220.95* | 1183.11267.44* |
| C12 | 1.00 | 866.6515.21* | 601.4029.48* |
| C13 | 1.00 | 897.1016.47* | 606.2025.21* |
| C14 | 1.00 | 572.3069.50 | 704.61178.78 |
| C15 | 1.00 | 503.5538.45* | 612.1262.65* |
| C16 | 1.00 | 687.7085.22 | 900.81161.92 |
| C16 | 1.00 | 827.45242.41 | 947.27209.32 |
| C17 | 0.85 | 1137.29221.63 | 1728.28234.88 |
| C19 | 1.00 | 836.45122.29* | 1039.61218.38* |
| C20 | 1.00 | 1628.6539.02* | 908.1458.52* |
| * represents the statistical significance | |||
7 Conclusion
This paper presents a planning-assisted context-sensitive swarm shepherding model and a hierarchical mission planning system for effectively herding a large flock of highly dispersed sheep to the destination in an environment with obstacles. In the proposed shepherding model, the sheep swarm is first grouped into some sheep sub-swarms, based on which the shepherding problem is transformed into a TSP to determine the optimal pushing sequence of sub-swarms by regarding each sub-swarm as a ‘city’ to visit. Then the online path planning is integrated with a context-sensitive response model to find the optimal paths for the sheep sub-swarms to be pushed to the next ‘city’ and the optimal paths for the sheepdogs to push the sheep sub-swarms. The hierarchical mission planning system is designed to solve the planning problems in the proposed shepherding model by combining a cohesion range-based method for grouping, ACO for TSP, and A*-PP for path planning.
Experiments conducted on 20 shepherding cases consisting of three groups with different levels of complexity demonstrated the effectiveness of the planning-assisted swarm shepherding model in terms of increasing the success rate and reducing the time and energy consumption to complete the mission. The planning-assisted swarm shepherding model can also be extended for employing multiple sheepdogs, and experiments have also validated the performance improvements for bi-sheepdog shepherding. However, there remains more opportunities for extending this research. The employment of more than 2 sheepdogs for shepherding has not been studied in this work. Besides, when transforming the swarm shepherding problem into a TSP, the dynamics in shepherding are not considered. The travelling cost between each pair of cities does not consider the influence of the swarm size on the cost. Our future research will focus on how to model the multi-sheepdog swarm shepherding problem as a multiple dynamic TSP with a more accurate cost evaluation.
8 Funding
This work is supported by a U.S. Office of Naval Research-Global (ONR-G) Grant and a Defence Science and Technology Group grant.
Declaration of Competing Interest
None.
References
- [1] N. K. Long, K. Sammut, D. Sgarioto, M. Garratt, H. A. Abbass, A comprehensive review of shepherding as a bio-inspired swarm-robotics guidance approach, IEEE Transactions on Emerging Topics in Computational Intelligence 4 (4) (2020) 523–537.
- [2] J.-M. Lien, E. Pratt, Interactive planning for shepherd motion., in: AAAI Spring Symposium: Agents that Learn from Human Teachers, 2009, pp. 95–102.
- [3] M. Evered, P. Burling, M. Trotter, et al., An investigation of predator response in robotic herding of sheep, International Proceedings of Chemical, Biological and Environmental Engineering 63 (2014) 49–54.
- [4] D. Strömbom, A. J. King, Robot collection and transport of objects: A biomimetic process, Frontiers in Robotics and AI (2018) 48.
- [5] B. Bat-Erdene, O.-E. Mandakh, Shepherding algorithm of multi-mobile robot system, in: 2017 First IEEE International Conference on Robotic Computing (IRC), IEEE, 2017, pp. 358–361.
- [6] A. A. Paranjape, S.-J. Chung, K. Kim, D. H. Shim, Robotic herding of a flock of birds using an unmanned aerial vehicle, IEEE Transactions on Robotics 34 (4) (2018) 901–915.
- [7] D. Strömbom, R. P. Mann, A. M. Wilson, S. Hailes, A. J. Morton, D. J. Sumpter, A. J. King, Solving the shepherding problem: heuristics for herding autonomous, interacting agents, Journal of the royal society interface 11 (100) (2014) 20140719.
- [8] H. Singh, B. Campbell, S. Elsayed, A. Perry, R. Hunjet, H. Abbass, Modulation of force vectors for effective shepherding of a swarm: A bi-objective approach, in: 2019 IEEE Congress on Evolutionary Computation (CEC), IEEE, 2019, pp. 2941–2948.
- [9] T. Nguyen, J. Liu, H. Nguyen, K. Kasmarik, S. Anavatti, M. Garratt, H. Abbass, Perceptron-learning for scalable and transparent dynamic formation in swarm-on-swarm shepherding, in: 2020 International Joint Conference on Neural Networks (IJCNN), IEEE, 2020, pp. 1–8.
- [10] J. Zhi, J.-M. Lien, Learning to herd agents amongst obstacles: Training robust shepherding behaviors using deep reinforcement learning, IEEE Robotics and Automation Letters 6 (2) (2021) 4163–4168.
- [11] V. S. Chipade, D. Panagou, Multiagent planning and control for swarm herding in 2-d obstacle environments under bounded inputs, IEEE Transactions on Robotics 37 (6) (2021) 1956–1972.
- [12] H. Song, A. Varava, O. Kravchenko, D. Kragic, M. Y. Wang, F. T. Pokorny, K. Hang, Herding by caging: a formation-based motion planning framework for guiding mobile agents, Autonomous Robots 45 (5) (2021) 613–631.
- [13] H. El-Fiqi, B. Campbell, S. Elsayed, A. Perry, H. K. Singh, R. Hunjet, H. A. Abbass, The limits of reactive shepherding approaches for swarm guidance, IEEE Access 8 (2020) 214658–214671.
- [14] A. Hussein, E. Petraki, S. Elsawah, H. A. Abbass, Autonomous swarm shepherding using curriculum-based reinforcement learning., in: AAMAS, 2022, pp. 633–641.
- [15] S. M. LaValle, Planning algorithms, Cambridge university press, 2006.
- [16] Z. Zhao, M. Jin, E. Lu, S. X. Yang, Path planning of arbitrary shaped mobile robots with safety consideration, IEEE Transactions on Intelligent Transportation Systems (2021).
- [17] J. Müller, J. Strohbeck, M. Herrmann, M. Buchholz, Motion planning for connected automated vehicles at occluded intersections with infrastructure sensors, IEEE Transactions on Intelligent Transportation Systems (2022).
- [18] J. Liu, S. Anavatti, M. Garratt, H. A. Abbass, Mission planning for shepherding a swarm of uninhabited aerial vehicles, Shepherding UxVs for Human-Swarm Teaming: An Artificial Intelligence Approach to Unmanned X Vehicles (2021) 87–114.
- [19] J. K. Lenstra, A. R. Kan, Some simple applications of the travelling salesman problem, Journal of the Operational Research Society 26 (4) (1975) 717–733.
- [20] S. Elsayed, H. Singh, E. Debie, A. Perry, B. Campbell, R. Hunjel, H. Abbass, Path planning for shepherding a swarm in a cluttered environment using differential evolution, in: 2020 IEEE Symposium Series on Computational Intelligence (SSCI), IEEE, 2020, pp. 2194–2201.
- [21] T. Stützle, H. H. Hoos, Max–min ant system, Future generation computer systems 16 (8) (2000) 889–914.
- [22] C. W. Reynolds, Flocks, herds and schools: A distributed behavioral model, in: Proceedings of the 14th annual conference on Computer graphics and interactive techniques, 1987, pp. 25–34.
- [23] T. Miki, T. Nakamura, An effective rule based shepherding algorithm by using reactive forces between individuals, International Journal of InnovativeComputing, Information and Control 3 (4) (2007) 813–823.
- [24] K. Fujioka, Effective herding in shepherding problem in V-formation control, Transactions of the Institute of Systems, Control and Information Engineers 31 (1) (2018) 21–27.
- [25] J. F. Harrison, C. Vo, J.-M. Lien, Scalable and robust shepherding via deformable shapes, in: International Conference on Motion in Games, Springer, 2010, pp. 218–229.
- [26] J. Hu, A. E. Turgut, T. Krajník, B. Lennox, F. Arvin, Occlusion-based coordination protocol design for autonomous robotic shepherding tasks, IEEE Transactions on Cognitive and Developmental Systems (2020).
- [27] C. K. Go, B. Lao, J. Yoshimoto, K. Ikeda, A reinforcement learning approach to the shepherding task using sarsa, in: 2016 International Joint Conference on Neural Networks (IJCNN), IEEE, 2016, pp. 3833–3836.
- [28] H. T. Nguyen, T. D. Nguyen, V. P. Tran, M. Garratt, K. Kasmarik, S. Anavatti, M. Barlow, H. A. Abbass, Continuous deep hierarchical reinforcement learning for ground-air swarm shepherding, arXiv preprint arXiv:2004.11543 (2020).
- [29] K. Bérczi, M. Mnich, R. Vincze, Efficient approximations for many-visits multiple traveling salesman problems, arXiv preprint arXiv:2201.02054 (2022).
- [30] A. Ayari, S. Bouamama, Acd3gpso: automatic clustering-based algorithm for multi-robot task allocation using dynamic distributed double-guided particle swarm optimization, Assembly Automation 40 (2) (2019) 235–247.
- [31] J. Xie, J. Chen, Multiregional coverage path planning for multiple energy constrained uavs, IEEE Transactions on Intelligent Transportation Systems (2022).
- [32] P. Baniasadi, M. Foumani, K. Smith-Miles, V. Ejov, A transformation technique for the clustered generalized traveling salesman problem with applications to logistics, European Journal of Operational Research 285 (2) (2020) 444–457.
- [33] I. Khoufi, A. Laouiti, C. Adjih, A survey of recent extended variants of the traveling salesman and vehicle routing problems for unmanned aerial vehicles, Drones 3 (3) (2019) 66.
- [34] X. Xu, J. Li, M. Zhou, X. Yu, Precedence-constrained colored traveling salesman problem: An augmented variable neighborhood search approach, IEEE Transactions on Cybernetics (2021).
- [35] M. Mavrovouniotis, F. M. Müller, S. Yang, Ant colony optimization with local search for dynamic traveling salesman problems, IEEE transactions on cybernetics 47 (7) (2016) 1743–1756.
- [36] I. M. Ali, D. Essam, K. Kasmarik, A novel design of differential evolution for solving discrete traveling salesman problems, Swarm and Evolutionary Computation 52 (2020) 100607.
- [37] M. Dorigo, Optimization, learning and natural algorithms, PhD Thesis, Politecnico di Milano (1992).
- [38] M. Dorigo, L. M. Gambardella, Ant colony system: a cooperative learning approach to the traveling salesman problem, IEEE Transactions on evolutionary computation 1 (1) (1997) 53–66.
- [39] X. Xiang, Y. Tian, X. Zhang, J. Xiao, Y. Jin, A pairwise proximity learning-based ant colony algorithm for dynamic vehicle routing problems, IEEE Transactions on Intelligent Transportation Systems 23 (6) (2021) 5275–5286.
- [40] O. Cheikhrouhou, I. Khoufi, A comprehensive survey on the multiple traveling salesman problem: Applications, approaches and taxonomy, Computer Science Review 40 (2021) 100369.
- [41] P. Oberlin, S. Rathinam, S. Darbha, Today’s traveling salesman problem, IEEE robotics & automation magazine 17 (4) (2010) 70–77.
- [42] V. Roberge, M. Tarbouchi, G. Labonté, Comparison of parallel genetic algorithm and particle swarm optimization for real-time UAV path planning, IEEE Transactions on Industrial Informatics 9 (1) (2012) 132–141.
- [43] X. Yu, W.-N. Chen, T. Gu, H. Yuan, H. Zhang, J. Zhang, ACO-A*: Ant colony optimization plus A* for 3-D traveling in environments with dense obstacles, IEEE Transactions on Evolutionary Computation 23 (4) (2018) 617–631.
- [44] P. E. Hart, N. J. Nilsson, B. Raphael, A formal basis for the heuristic determination of minimum cost paths, IEEE transactions on Systems Science and Cybernetics 4 (2) (1968) 100–107.
- [45] K. Yang, Anytime synchronized-biased-greedy rapidly-exploring random tree path planning in two dimensional complex environments, International Journal of Control, Automation and Systems 9 (4) (2011) 750–758.