Platoon Leader Selection, User Association and Resource Allocation on a C-V2X based highway: A Reinforcement Learning Approach
Abstract
We consider the problem of dynamic platoon leader selection, user association, channel assignment, and power allocation on a cellular vehicle-to-everything (C-V2X) based highway, where multiple vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) links share the frequency resources. There are multiple roadside units (RSUs) on a highway, and vehicles can form platoons, which has been identified as an advanced use-case to increase road efficiency. The traditional optimization methods, requiring global channel information at a central controller, are not viable for high-mobility vehicular networks. To deal with this challenge, we propose a distributed multi-agent reinforcement learning (MARL) for resource allocation (RA). Each platoon leader, acting as an agent, can collaborate with other agents for joint sub-band selection and power allocation for its V2V links, and joint user association and power control for its V2I links. Moreover, each platoon can dynamically select the vehicle most suitable to be the platoon leader. We aim to maximize the V2V and V2I packet delivery probability in the desired latency using the deep Q-learning algorithm. Simulation results indicate that our proposed MARL outperforms the centralized hill-climbing algorithm, and platoon leader selection helps to improve both V2V and V2I performance. ††This work was supported in part by the Natural Sciences and Engineering Research Council of Canada and in part by Huawei Technologies Canada.
Index Terms:
New radio, cellular vehicle-to-everything, reinforcement learning, resource allocationI Introduction
Cellular vehicle-to-everything (C-V2X) is a vehicular standard that enables communication between vehicles and other entities on the road, such as pedestrians and infrastructure, to increase road safety and efficiency [1]. The C-V2X system consists of communication between different entities, such as vehicle-to-vehicle (V2V), vehicle-to-infrastructure (V2I), vehicle-to-network (V2N), and vehicle-to-pedestrian (V2P) communications. The C-V2X is envisioned to support high throughput, ultra-reliable, and low latency communications.
3GPP has provided the 5G new radio (NR) standards for vehicular communications concerning advanced use-cases in TS 22.886 [2], and evaluation methodology in TR 37.885 [3]. One component of infrastructure will be the roadside units (RSUs). RSU is a stationary wireless C-V2X device that can exchange messages with vehicles and other C-V2X entities. It uses the PC5 side-link interface to communicate with the vehicles and transmit information about road signs and traffic lights [2]. It can also receive information from the vehicles to make a dynamic map of the surroundings and share it with other vehicles/pedestrians. Furthermore, we consider the use-case of platooning, where multiple vehicles form a train-like structure and travel closely together in a line. The platoon leader (PL) organizes communications between vehicles. Vehicle platooning has been identified as an advanced use-case in [2] and has gained significant interest since it reduces fuel consumption and traffic congestion. The RSU and platoon will need to exchange a maximum of 1200 bytes in 500 ms for real-time traffic updates and 600 bytes in 10 ms for conditional automated driving [2]. We grouped these two requirements for an aggregate of 624 bytes in 10 ms. Moreover, the PL and members need to exchange 50-1200 bytes in 10 ms for cooperative driving and up to 2000 bytes in 10 ms for collision avoidance [2]. We aggregate these service requirements and keep the exchange of 1200-2800 bytes in 10 ms for our simulations. An intelligent resource allocation (RA) design is necessary for these stringent requirements.
The 5G new radio (NR) C-V2X supports two RA modes for sidelink PC5 communications: mode 1, the under-coverage mode, and mode 2, the out-of-coverage mode [4]. In mode 1, the gNB allocates the communication resources to vehicles. Meanwhile, in mode 2, the vehicles autonomously select the resources. For mode 2, the current RA technique used in standards is the sensing-based Semi-Persistent Scheduling (SPS) algorithm, which periodically selects random resources. However, the probability of resource selection collision can be high, and many works have considered either improving the SPS algorithm or alternate techniques to increase reliability. [5] proposes a novel sensing-based SPS algorithm in an urban scenario to reduce the collision probability. The authors in [6] considered a highway scenario and suggested a stochastic reservation scheme for aperiodic traffic. For the platooning use-case, [7] shows that the SPS algorithm can not achieve the required performance.
Due to the fast channel variations in vehicular networks, centralized optimization schemes that require global channel state information (CSI) will no longer be feasible. The high CSI overhead and the corresponding increase in latency make such methods impractical. To deal with this issue, distributed RA algorithms have been suggested in the literature, e.g., [8, 9]. Furthermore, traditional optimization techniques have limitations, requiring complete information about the environment and needing to be retrained for rapidly varying environments [10]. Recently, distributed multi-agent reinforcement learning (MARL) has been proposed as an alternative approach to resolving such issues. The authors in [11] used Deep Q Networks (DQN) for joint channel assignment and power allocation to maximize the V2V delivery probability and V2N sum-rate in an urban setting, where the V2V links share the time-frequency resources with V2N links. Inspired by these results, [12] used double DQN for a platoon-based scenario for the same objectives. [13] uses the actor-critic method for mode selection, subchannel selection, and power control in an urban platoon scenario to increase the transmission probability of cooperative awareness messages. The authors in [14] used the Monte-Carlo algorithm to select resource blocks to reduce the packet collision probability in a platooning scenario.
This paper considers a highway C-V2X system consisting of multiple platoons. We consider the periodic payload delivery from PLs to RSUs, termed V2I links. Furthermore, we consider the periodic transmission of messages from PLs to members, termed V2V links. We assume a limited spectrum is available for the V2V and V2I transmission, and they share the frequency resources for efficient spectrum usage. Given this system, this paper formulates a dynamic PL selection, user association, channel assignment, and power level control to maximize the packet delivery probability for both V2V and V2I links. Reliability is defined as the successful transmission of the packet within a time constraint [11, 12].
We utilize MARL in a distributed manner. The RL works on a trial-and-error strategy, and each agent slowly improves the action taken based on the feedback from the vehicular environment. We use the Deep Q-learning algorithm, which DeepMind developed for Atari video games [15]. Deep Q-Learning has been used for joint channel assignment and power allocation in C-V2X systems [11, 12]. However, we also use Deep Q-learning for user association and PL selection. As per our knowledge, dynamic PL selection has not been investigated in the literature. In our work, there are multiple collaborative agents for PL selection, V2V joint channel assignment and power allocation, and V2I joint user association and power allocation. The objective is to increase reliability for both V2V and V2I links. Simulation results indicate that the proposed MARL algorithm can outperform other benchmarks, such as the hill-climbing algorithm, which requires global CSI at the central controller. Moreover, the dynamic PL selection offers a gain in V2V and V2I reliability.
II System Model and Problem Formulation
As illustrated in Fig. 1, we consider a highway-based C-V2X System, outlined in [3]. The highway consists of 3 lanes on both sides. The roadside units (RSUs) are placed in the middle of the highway, with 100 m between them. We consider there are RSUs on the highway. Furthermore, we consider there are platoons, with vehicles in each platoon. The PL is required to share the real-time data with the RSU, referred to as V2I communications.
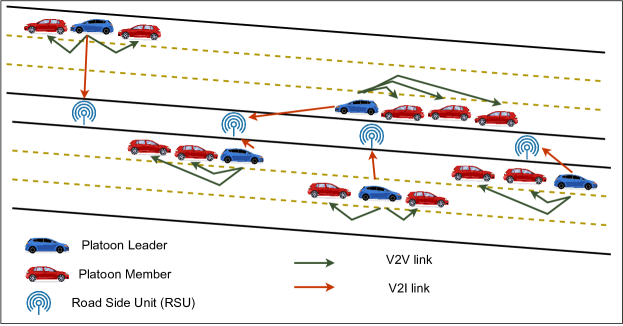
Moreover, the PLs need to periodically transmit the cooperative awareness messages and the traffic data received from RSUs to the platoon members, referred to as V2V communications. Each platoon is denoted as , and the platoon leader is denoted as . In our simulations, the PL selection is dynamic, and all vehicles in a platoon are candidates for becoming the PL. The vehicles in a platoon are in the same lane, each with a single PL at a given time. It is considered that the vehicles are separated by a fixed distance of meters and are traveling with a velocity of m/s. It is considered that the vehicles and RSUs use a single antenna to transmit/receive the signal.
We consider that a fixed and limited number of sub-bands are available for both V2V and V2I links, denoted as . Each sub-band has a bandwidth of . The PL needs to transmit a payload of size to the RSUs, and a payload of to the platoon members, within a time constraint of . We assume that both V2V and V2I links use the same spectrum for efficient spectrum utilization. However, all the V2V and V2I links can interfere, making an intelligent design for interference management necessary. The set of RSUs, platoons, and sub-bands are denoted as , and , respectively. Meanwhile, the set of members in each platoon is denoted as . In the paper, refers to the large-scale fading power from transmitter to receiver . The small-scale fading power from to in the sub-band is given by . The is used as an indicator function set to 1 if the link reuses the sub-band and 0 otherwise.
The V2I links consist of communication from the PL to the RSU. Each PL is required to transmit a fixed payload of to the RSUs within a time constraint of . We assume each RSU has a sub-band preassigned to it. Each RSU will experience interference from other V2V and V2I links using the same sub-band . Thus, the typical signal-to-interference (SINR) for a V2I link can be written as:
| (1) |
Here, the interference at the RSU receiver is denoted by
| (2) |
In (1), the is the noise power at the RSU. For simplicity, we assume that the noise power at all RSUs is equal.
Given the SINR, the achievable rate for the V2I link from can be written as:
| (3) |
Meanwhile, the V2V link consists of communications between the PL and the members. Each PL is required to transmit a fixed payload of size to each of its members in the time constraint . The platoon member will experience interference from the other V2V and V2I links using the same sub-band . The SINR for a platoon member in platoon can be written as:
| (4) |
Here, the interference at member is denoted by
| (5) |
where denotes the platoon members in platoon .
Given the SINR, the achievable rate for the platoon member in platoon can be written as:
| (6) |
where we divide the bandwidth equally among the platoon members.
II-A Problem Formulation
We consider a multi-objective optimization problem, where we simultaneously maximize the payload delivery probability for the V2V and V2I links. For the V2I link, the objective for each PL is to transmit the payload to the RSUs within a time limit of . This is given by , where is the channel coherence time. Meanwhile, for the V2V links, the objective is to maximize the delivery of payload within a time limit of . This is given by .
Due to the spectrum sharing between the V2V and V2I links, we need to optimize two competing objectives of simultaneously maximizing the V2V and the V2I payload delivery probability. To achieve this, we use MARL for multiple objectives:
-
1.
Platoon Leader selection: For each platoon , the PL will be selected dynamically and periodically. The platoon will decide which vehicle is the most suitable for being the leader so that both objectives can be met.
-
2.
Joint User Association and power allocation for V2I links: Each PL will need to decide which RSU it needs to be served by, along with its transmit power level
-
3.
Joint channel assignment and power allocation for V2V links: Each PL needs to decide the channel and transmit power to transmit to its platoon members.
III Action Selection using Deep Reinforcement Learning
III-A Reinforcement Learning and Deep Q Learning
Reinforcement Learning (RL) is a discipline of Machine Learning (ML) where an agent can make a sequence of decisions by interacting with an environment. Based on the reward received by taking action, the agent learns to become intelligent. The agent aims to take actions that maximize the long-term cumulative reward. Markov Decision Process (MDP) is used to model an RL problem. According to the Markov property, the current state captures all relevant information from history. At each time-step , the agent observes the environment through the state and takes an action . The agent receives a reward and transitions into a new state . In RL, the goal of the agents is to maximize the cumulative reward it receives in the long run, given by where represents the discount factor which reduces the present value of the future rewards.
The action-value function is defined as the expected return by taking an action in state by following a policy : where the expectation is taken over all possible transitions following the distribution . The goal of RL is to find the optimal policy that maximizes the Q-function over all the policies.
Q-learning is an off-policy RL algorithm that learns the value of an action in a state . It repetitively updates the action-value function for each state-action pair until they converge to the optimal action-value function . The update equation is given by: where represents the learning rate. If the Q-function is estimated accurately, the optimal policy at a given state would be to select the action that yields the highest value. The Deep Q-Learning [15] uses a Deep Neural Network (DNN) as a function approximator to learn the Q-function. The state space is input to the DNN, and it learns to predict the Q-value for each output action. The state-action space is explored with a soft policy such as -greedy, where the agent takes random action at a given state at time with a probability of . Otherwise, greedy action is selected. The tuple is stored in the replay memory at each time instance. At each time-step, a mini-batch is sampled from the replay memory to update the DNN parameters , and the gradient descent algorithms are used to update the parameters .
III-B Multi-Agent Reinforcement Learning for optimization
In this section, we formulate the multi-agent RL algorithm for optimization. There will be three different types of agents, all based within the vehicles in the platoon. The first agent type will be the PL selection, which will dynamically decide the PL every 100 ms. The second type of agent will be the V2V platoon, which needs to determine the joint channel assignment and power allocation. Meanwhile, the third type of agent will be the V2I agent, which will need to optimize joint user association and power allocation. All the agents will interact with the environment and learn to take appropriate actions by trial and error. Furthermore, we use a common reward for all the agents to ensure collaboration. Moreover, each agent has a separate DQN and only uses its own experience to train the DNN.
We develop two phases for the MARL problem: training and testing. During the training phase, each agent can access the common reward to train the DQN. Meanwhile, during the testing phase, each agent uses the trained DQN to select the action.
III-B1 State and Action Space for Platoon Leader Selection
For the platoon leader selection agent, the state space consist of the measurements at time-step . The state space consists of the following measurements: The large-scale fading information between all members within a platoon , i.e., ; The large-scale fading information between all vehicles in platoon to all RSUs, i.e., . Meanwhile, the action space consists of the PL selection. The action is updated every 100 ms.
III-B2 State and Action Space for V2V agent
The state space of the V2V agent, denoted by , consists of the measurements from the last time-step and consists of the following groups: Direct channel measurements from the PL to the members, i.e., The interfering channels from other PLs sharing the same sub-band with the V2V agent , which occupies the sub-band , i.e., The interfering channels from the V2I links to the RSU, i.e., The remaining payload and time limitation after the current time-step.
Meanwhile, the action space consists of the combination of sub-band selection and power allocation. The sub-band consists of disjoint sub-bands, and the power levels are broken down into multiple discrete levels in the range , where denotes the maximum power.
III-B3 State and Action Space for V2I agent
The state space of the V2I agent, denoted by , for the PL , consists of the measurements from the last time-step and consists of the following groups: Direct channel measurements from the PL to all the RSUs, i.e., The remaining payload and time remaining after current time-step. The training iteration number and the agent’s probability of random action selection .
The action space consists of the RSU selected and the power level. We assume that each RSU uses a fixed sub-band. There are RSUs to select from and transmit at a power divided into multiple discrete levels in the range .
III-B4 Reward function design
We use a common reward for all the agents in our proposed MARL design to ensure collaboration. We have a multi-objective problem, which is to maximize the payload delivery probability for the PL to RSU V2I links, and maximize the payload delivery probability for the PL to platoon members V2V links, within the time constraint . The V2V and V2I agents need to select actions to minimize interference between each other. To achieve this purpose, we define the reward at time-step , denoted as , as:
| (7) |
where is the contribution towards the reward of the V2V link and is the contribution of the V2I link from PL to RSU. Furthermore, are weights to balance the two objectives.
is the achievable rate of the PL to platoon member link , defined as:
| (10) |
where is the remaining payload for the V2V link at time-step . Furthermore, if the payload intended for link has been delivered, the agent is given an award , which needs to be greater than the maximum rate achievable, to indicate to the agent the successful transmission of the payload. is a hyperparameter that needs to be adjusted empirically [11].
Similarly, is the achievable rate of the PL to RSU link, defined as:
| (13) |
where is the payload that PL needs to transmit to the RSUs. is a hyperparameter, which needs to be greater than the maximum achievable rate of the V2I link.
III-C Training Algorithm and Testing Strategy
We devise the problem as an episodic setting, where each episode corresponds to the time limit for the V2V and V2I links to complete their transmission. Each episode consists of multiple time-steps . The vehicle location and large-scale fading are updated every 100 ms [3]. Meanwhile, the small-scale fading is updated at each time-step , changing the state space for the V2V and V2I agents and prompting the agents to adjust their actions. Each agent stops its transmission once its payload has been delivered. The training is centralized, where each agent has access to the common reward . Deep Q-Learning is used to train the agent. The algorithm is outlined in Algorithm 1.
During the testing phase, each agent observes the state. The state is input to the trained DQN, which is used to select the action. The testing is implemented in a distributed manner, where each agent takes action based on their local state observation only.
IV Illustrative Results
This section presents the simulation results to illustrate the performance of our algorithm. We consider a highway setting as described in TR 37.885 [3], with the carrier frequency of 6 GHz. The technical report provides all details, such as evaluation scenarios, vehicle drop and mobility modeling, RSU deployment, and channel models for V2V and V2I links. The small-scale fading is modeled as Rayleigh fading. We consider a highway with a length of 1 km, with 3 lanes for traffic on both sides. The RSUs are placed in the middle of the highway, with a distance of 100 m between them. We use option A in UE drop options in Section 6.1.2 of TR 37.885 [3]. The type 3 vehicles (bus/tracks) are used, with a length of 13 m and 2 m distance between each in a platoon. All vehicles travel with a velocity of 140 km/h. Each V2V platoon consists of 3 vehicles. Moreover, the antenna on vehicles is placed in the middle of each vehicle. As per TS 22.185 [2], the V2V and V2I links need to complete their transmission in 10 ms. However, we set as 5 ms, assuming the other 5 ms will be used for communication in other directions, i.e., platoon member to platoon leader. The main simulation parameters are listed in Table I.
| Carrier frequency | GHz |
|---|---|
| Bandwidth of each sub-band | MHz |
| Number of sub-bands | 2 |
| Number of RSUs | 11 |
| Number of platoons | [4,6] |
| Number of vehicles in each platoon | 3 |
| Vehicle velocity | 140 km/h |
| Tx power for V2V links | [23, 15, 5, -100] dBm |
| Tx power for V2I links | [23, -100] dBm |
| Vehicle Antenna gain | 3 dBi |
| Vehicle receiver noise figure | 9 dB |
| Noise PSD | -169 dBm/Hz |
| Time constraint | 5 ms |
| Platoon Leader update interval | 100 ms |
| V2V payload | [1200,…..,2800] bytes |
| V2I payload | 624 bytes |
The DQN was implemented in Python using the Tensorflow package. The DNN for all 3 types of agents consisted of 3 hidden layers. The DNN of PL selection agents had 71, 35, and 17 neurons, the DNN of V2V agents had 100, 50, and 24 neurons; and the DNN of V2I agents had 166, 83, and 40 neurons in their hidden layers, respectively. The rectified linear unit (ReLU) was us as the activation function for all 3 types of agents. RMSProp was used for optimization for all agents, and learning rates of 0.0001, 0.0001, and 0.001 were used for PL selection agents, V2V agents, and V2I agents, respectively. The and in (7) were set as 0.3 and 0.7, respectively. Meanwhile, the hyperparameters in (10) and in (13) were selected as 25 and 15, respectively. The training phase consisted of 2000 episodes, and the testing was performed for 100 episodes. The -greedy policy was used during the training, and the value of was reduced linearly from 1 to 0.02 for 1600 episodes. The training was performed setting as 2400 bytes and was varied between 1200-2800 bytes during testing. Meanwhile, was set to 624 bytes during the training and testing phases.
We developed three benchmarks for comparison: Hill-climbing algorithm [16]: Hill-climbing algorithm is a local search optimization method, guaranteed to reach a local optimum. It is a centralized iterative algorithm, which starts with a random solution, and then iteratively keeps improving it until it reaches an optimum. The algorithm is used as an upper benchmark in our paper. Greedy Algorithm: Each agent uses the best link available to transmit at maximum power. RL algorithm without PL selection: We run the RL algorithm, fixing the leading vehicle in each platoon as the platoon leader. This is to show the effectiveness of PL selection agents.
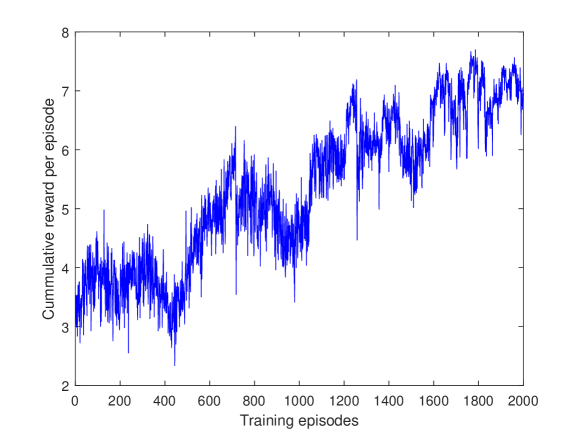
Fig. 2 shows the cumulative reward for each episode for the case of 4 platoons. The reward increases during training, indicating that the agents can collaborate.
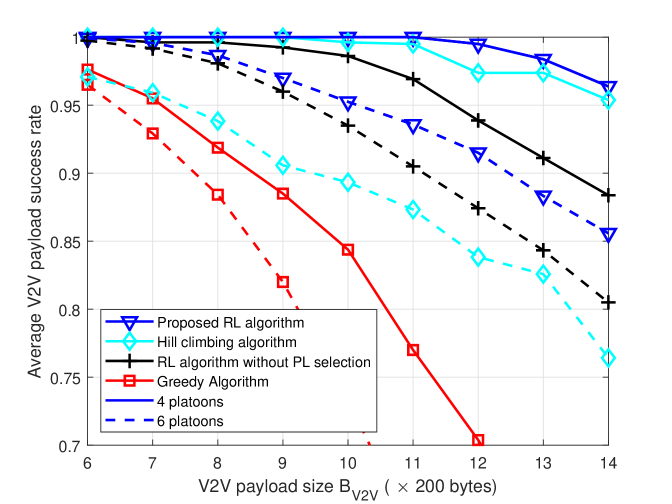
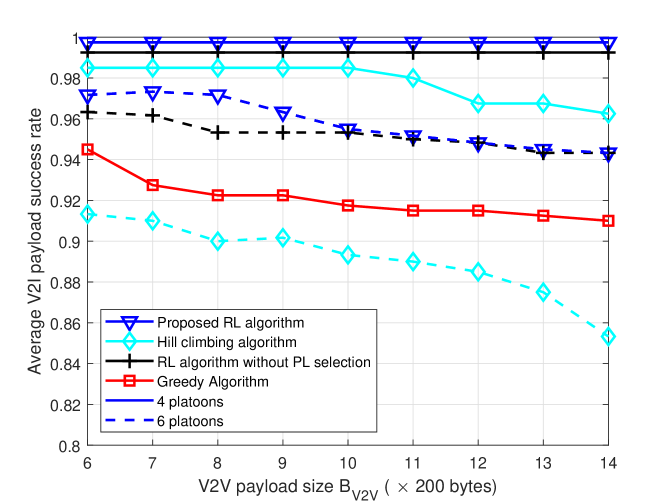
Fig. 3 shows the reliability of V2V and V2I links as we increase for the cases of 4 and 6 platoons. Fig. 3a shows that the V2V performance decreases as we increase the packet size. This is because a larger payload size requires a longer time to transmit. For 4 platoons, we achieve a reliability of 1 for up to 2200 bytes, outperforming all the other benchmarks. Fig. 3b shows that for 4 platoons, the payload success rate for V2I links is 0.9975 for all cases. However, the hill-climbing and greedy algorithm performance decrease, indicating more significant interference as we increase V2V payload size. When we increase the number of platoons to 6, the performance gap between the proposed algorithm and the hill-climbing algorithm increases, which shows the superiority of our algorithm for a higher number of agents. Furthermore, it can be seen that dynamic platoon leader selection improves performance for both V2V and V2I links.
V Conclusion
In this work, we proposed a distributed multi-agent reinforcement learning algorithm to optimize the performance of the V2V and the V2I links. The V2V and V2I links used the same spectrum, making an intelligent resource allocation design necessary to manage interference. Each platoon leader had an agent for joint channel assignment and power allocation for V2V links, and another agent for joint user association and power allocation for V2I links. Further, another agent was able to select the platoon leader, to maximize the reliability of both V2V and V2I links. Based on RL, the agents could collaborate to take suitable actions. The proposed approach is decentralized, and the agents were able to make decisions based on their local state observations only. Simulation results indicate that the proposed algorithm could perform well for variable V2V packet size and different numbers of platoons, outperforming the centralized hill-climbing algorithm. Moreover, the PL selection improved reliability for both V2V and V2I links. In the future, we plan to investigate if our approach generalizes well for different channel conditions and topologies.
References
- [1] H. Abou-Zeid, F. Pervez, A. Adinoyi, M. Aljlayl, and H. Yanikomeroglu, “Cellular V2X transmission for connected and autonomous vehicles standardization, applications, and enabling technologies,” IEEE Consumer Electronics Magazine, vol. 8, no. 6, pp. 91–98, 2019.
- [2] “3rd Generation Partnership Project; Technical Specification Group Services and System Aspects; Study on enhancement of 3GPP Support for 5G V2X Services (Release 16) ,” TR 22.886 V16.2.0, Dec. 2018.
- [3] “3rd Generation Partnership Project; Technical Specification Group Radio Access Network; Study on evaluation methodology of new Vehicle-to-Everything (V2X) use cases for LTE and NR; (Release 15) ,” TR 37.885 V15.3.0, Jun. 2019.
- [4] K. Sehla, T. M. T. Nguyen, G. Pujolle, and P. B. Velloso, “Resource Allocation Modes in C-V2X: From LTE-V2X to 5G-V2X,” IEEE Internet of Things Journal, vol. 9, no. 11, pp. 8291–8314, 2022.
- [5] S. Yi, G. Sun, and X. Wang, “Enhanced resource allocation for 5G V2X in congested smart intersection,” in 2020 IEEE 92nd Veh. Tech. Conf.
- [6] Y. Yoon and H. Kim, “A stochastic reservation scheme for aperiodic traffic in NR V2X communication,” in 2021 IEEE Wireless Commun. Networking Conf. (WCNC).
- [7] M. Segata, P. Arvani, and R. L. Cigno, “A critical assessment of C-V2X resource allocation scheme for platooning applications,” in ”2021 IEEE Wireless On-demand Network Systems and Services Conf. (WONS)”.
- [8] A. Masmoudi, K. Mnif, and F. Zarai, “A survey on radio resource allocation for V2X communication,” Wireless Communications and Mobile Computing, vol. 2019.
- [9] M. Allouch, S. Kallel, A. Soua, O. Shagdar, and S. Tohme, “Survey on radio resource allocation in long-term evolution-vehicle,” Concurrency and Computation: Practice and Experience, vol. 34, no. 7, 2022.
- [10] A. Alwarafy, M. Abdallah, B. S. Ciftler, A. Al-Fuqaha, and M. Hamdi, “Deep reinforcement learning for radio resource allocation and management in next generation heterogeneous wireless networks: A survey,” arXiv preprint arXiv:2106.00574, 2021.
- [11] L. Liang, H. Ye, and G. Y. Li, “Spectrum sharing in vehicular networks based on multi-agent reinforcement learning,” IEEE J. Sel. Areas Commun., vol. 37, no. 10, pp. 2282–2292, 2019.
- [12] H. V. Vu, M. Farzanullah, Z. Liu, D. H. Nguyen, R. Morawski, and T. Le-Ngoc, “Multi-Agent Reinforcement Learning for Channel Assignment and Power Allocation in Platoon-Based C-V2X Systems,” in 2022 IEEE 95th Veh. Tech. Conf.
- [13] M. Parvini et al., “AoI-aware resource allocation for platoon-based C-V2X networks via multi-agent multi-task reinforcement learning,” arXiv preprint arXiv:2105.04196, 2021.
- [14] L. Cao and H. Yin, “Resource allocation for vehicle platooning in 5G NR-V2X via deep reinforcement learning,” in 2021 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom). IEEE, 2021, pp. 1–7.
- [15] Mnih et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [16] S. J. Russell, Artificial intelligence a modern approach. Pearson Education, Inc., 2010.