Playing Divide-and-Choose Given Uncertain Preferences111This is a pre-print of our publication in Management Science. The published version is available here:
https://pubsonline.informs.org/doi/10.1287/mnsc.2023.00350
Abstract
We study the classic divide-and-choose method for equitably allocating divisible goods between two players who are rational, self-interested Bayesian agents. The players have additive values for the goods. The prior distributions on those values are common knowledge. We consider both the cases of independent values and values that are correlated across players (as occurs when there is a common-value component).
We describe the structure of optimal divisions in the divide-and-choose game and identify several cases where it is possible to efficiently compute equilibria. An approximation algorithm is presented for the case when the distribution over the chooser’s value for each good follows a normal distribution, along with a randomized approximation algorithm for the case of uniform distributions over intervals.
A mixture of analytic results and computational simulations illuminates several striking differences between optimal strategies in the cases of known versus unknown preferences. Most notably, given unknown preferences, the divider has a compelling “diversification” incentive in creating the chooser’s two options. This incentive leads to multiple goods being divided at equilibrium, quite contrary to the divider’s optimal strategy when preferences are known.
In many contexts, such as buy-and-sell provisions between partners, or in judging fairness, it is important to assess the relative expected utilities of the divider and chooser. Those utilities, we show, depend on the players’ levels of knowledge about each other’s values, the correlations between the players’ values, and the number of goods being divided. Under fairly mild assumptions, we show that the chooser is strictly better off for a small number of goods, while the divider is strictly better off for a large number of goods.
1 Introduction
Ever since Abraham and Lot divided the land of Canaan, with Abraham dividing and Lot choosing, the divide-and-choose method has been employed to parcel out assets. Today the method is widely used when partners in a real estate deal invoke their buy-sell agreement, or when siblings divide up an inheritance.
The assets can be continuous, as with the classic cake-cutting problem, or separable and indivisible, for example valuables from an estate. Consider multi-dimensional cake-cutting with divisible elements vanilla filling, chocolate icing and a cherry. One player will divide the cake; the other will then choose her piece. Positing additive preferences and that fractional portions have fractional values, if the divider knows the chooser’s preferences, he arrays the assets (filling, icing, cherry) in order of the ratio of his value to her (the chooser’s) value. Just enough low-ratio assets are placed in pile 2 to assure that the chooser selects it, leaving the divider the high-ratio assets in pile 1.222Throughout this paper, we assume without loss of generality that “pile 1” is the divider’s preferred pile. Only one asset will generally need to be divided fractionally; in knife-edge situations it could be none.
Now consider a more consequential example: Partners in a real-estate company have signed a buy-sell arrangement. As is common, after a specified period of years, either partner can trigger the arrangement by creating a two-pile division. Pile 1 might consist of asset and a required payment of $1.5 million. Pile 2 would contain the remaining asset, , and receipt of $1.5 million. Partner A launches as the divider. Partner B must then choose between the two piles. The very nature of the legal agreement allows A to reject any proposals from B to adjust terms.
In real life, the players rarely know each others’ preferences. The cake divider will know his own preferences, but will only have a feel—that is, a Bayesian prior—for how the chooser values filling to icing to cherry, or asset to asset to money. While the divider can think in terms of expected ratios, he will remain uncertain of the chooser’s total value for any two piles. The divider’s optimal strategy will weigh the disadvantages of putting fewer goods (or lesser amounts of divisible goods) in pile 1 against the likelihood that the chooser picks pile 1. How that trade-off should be handled is the subject of this paper.
1.1 Our contributions
Our central contribution is to analyze the divide-and-choose game when information is asymmetric, i.e., when the players’ values are private information, but priors for those values are common knowledge. This is the typical setup for self-interested players in Bayesian games. Section 2 presents our model for divide-and-choose.
The literature on divide-and-choose games focuses overwhelmingly on the case of known preferences, though real-world situations rarely meet that standard. In the comforting land of known preferences, the divider follows the simple optimization procedure mentioned above. In sharp contrast, once uncertainty enters, a strategic Bayesian divider generally faces a complicated optimization problem, potentially with a myriad of local optima. In Section 3 we show that such complexities can arise even for extremely simple priors, such as independently and identically distributed (i.i.d.) normal distributions.
The apparent lack of structure to the divider’s optimization problem suggests that it may be computationally intractable in general. One of our main contributions is an algorithmic framework for optimizing over divisions that yields polynomial-time approximation algorithms when the distributions over the chooser’s values for each good satisfy certain properties. Specifically, when each distribution is symmetric about its mean and log-concave, we show that there exists a sequence of convex programs computing divisions that yield expected utility arbitrarily close to the maximum possible expected utility (Theorem 3.9). As special cases, we obtain a fully polynomial-time approximation scheme (FPTAS) when the distributions are Gaussian (Theorem 3.6) and a fully polynomial-time randomized approximation scheme (FPRAS) when the distributions are uniform over real intervals (Theorem 3.10). We also present an algorithm that solves the case of discrete distributions, which is practical when the number of possible chooser types is small.
This complexity of the divider’s optimization problem arises because, in contrast to the case of known preferences, it is often beneficial to divide more than one good. To take our cake analogy, if a divider prefers filling and suspects that the chooser has a high value for both the icing and the cherry, pile 1 may optimally consist of 100% of the filling, plus 59% of the icing and 31% of the cherry. By ensuring that pile 2 contains a bit of icing and cherry, he decreases the variance in the chooser’s valuation for pile 1, hence reducing the likelihood that she will choose that pile. In Section 4 we investigate the divider’s incentive to diversify his risk by dividing several goods (or, for indivisible assets, committing to lotteries that randomly allocate some goods between the piles after the chooser picks a pile). Even for a risk-neutral divider, diversification is warranted for a wide range of prior distributions. This is still the case even when the divider’s values are strongly correlated with those of the chooser. Furthermore, we show that a risk averse divider should diversify more. These results still do not determine which goods should be split between the two piles. Simple rules, we show, can lead the divider astray.
Finally, in Section 5 we analyze the expected utilities of the divider and chooser under a range of circumstances. For example, which player is better off a priori if both players’ values are drawn from the same distribution? With known preferences, it is far preferable to be the divider. With significant uncertainties about the players’ values of the individual goods, the chooser is better off when there are few goods, but the advantage tips to the divider as the number of goods increases.
Our Conclusion, Section 6, presents a number of open questions that emerged from this analysis. It closes by stressing that although our focus has been on theory and computational methods, the analysis is widely applicable in real-world contexts. The divide-and-choose method, or close analogues, though rarely identified that way, are widely used in practice. Take-it-or-leave-it offers and buy-and-sell agreements between business partners are salient examples.
1.2 Related work
The divide-and-choose method features prominently in the literature on fair division. In the cake-cutting model [25], agents are assumed to have additive, divisible preferences over the unit interval (the “cake”) and a feasible allocation is a partitioning of between the players, where each player’s part of the allocation is a finite union of intervals. With two players, the divide-and-choose method is particularly useful in this model for the following reasons:
-
(i)
If the first player divides the cake equally, the allocation will be envy-free, meaning that the players each value their own piece of cake higher.
-
(ii)
The protocol can be implemented by asking the players simple queries.
Extensions have also been discovered for 3 or more players [8, 2]. These methods require several rounds of dividing and choosing, but ultimately satisfy the same two properties. Kuhn [19] gives abstract axioms under which a simple one-round variant of divide-and-choose with one divider and choosers will yield an acceptable outcome for all players. Another major line of work studies deterministic allocations of indivisible goods, in which case envy-freeness is sometimes not feasible. Think of three goods each valued roughly the same by both players. They can at best be divided 1 and 2, so the divider will generally be envious. Hence, various natural relaxations have been studied [10, 14]. Variant settings with more complex kinds of goods and constraints have also been studied, such as goods with unknown, random values [6].
The fair division literature has largely focused on finding mechanisms satisfying axiomatic properties such as envy-freeness, efficiency, etc., when players do not behave strategically. A handful of works consider the objective of strategy-proofness as well, both for divisible [13, 12, 4, 5, 11] and indivisible [3, 1] goods. These works largely draw on the mechanism design perspective, studying questions such as, what is the optimal worst-case utility approximation to the socially optimal outcome under the constraint of strategy-proofness?
Our work is more in the spirit of Clausewitz the strategist than Solomon the arbitrator: Our prime interest is not in finding mechanisms to implement socially desirable outcomes. Rather, we focus on how strategic players should actually behave to maximize their personal welfare. Issues of welfare and efficiency enter our analysis, particularly how those issues are affected by some simple extensions of the divide-and-choose game. However, our goal is not to modify the game to bolster its fairness or efficiency, but rather to analyze the effects from a descriptive perspective. There is a small experimental literature on strategic behavior under various cake-cutting protocols; for instance, see Kyropoulou, Ortega, and Segal-Halevi [20]. On the theoretical front, however, much less is known. We are aware of one prior work, by Delgosha and Gohari [15], that studies optimal strategies in an environment where players may learn about each other’s preferences through repeated interactions. Our interest is in the more common setting of one-shot interactions.
A key concept we discuss is the critical ratio of a good, which we define to be the ratio of the divider’s value to the expectation of the chooser’s value. This is a ubiquitous notion in contexts from hypothesis testing to cost/effectiveness analyses. (See, for example, Weinstein and Zeckhauser [26].) In the case where the divider has perfect knowledge of the chooser’s preferences, the divider places the goods with the highest critical ratio in pile 1 and those with the lowest critical ratio in pile 2. He determines the cutoff so that the chooser just picks pile 2. The optimality of this strategy in the setting of cake-cutting is noted by H. P. Young [27], as well as Brânzei, Caragiannis, Kurokawa, and Procaccia [9]. One of the key conceptual takeaways from this paper is that uncertainty over preferences notably complicates the task of computing optimal divisions in a way that is not characterized by critical ratios.
Finally, we note that our model bears a technical resemblance to a model of final-offer arbitration (FOA) by Powers [24] and Brams and Merrill [7]. Just as in our setting, there are multiple divisible goods that must be allocated among two players. However, instead of playing divide-and-choose, both players simultaneously submit divisions to an arbiter, who chooses the more “reasonable” one, where players have common knowledge of the arbiter’s sense of reasonableness. A key technical difference between FOA and divide-and-choose is that, in FOA, the uncertainty is not over the other player’s values, but over the other player’s action. Yet both models involve similar optimal strategies: give just enough away to the other player to obtain the desired binary decision with decent probability.
2 Model
There are two players: the divider () and the chooser (). There are divisible goods, which we number from 1 to , writing for the set of goods. We may also think of the goods as indivisible, in which case we allow the divider to fractionally allocate goods between the piles via lotteries that are resolved after the chooser has chosen her pile. A player’s value is simply the sum of the values of the goods received. Players are risk-neutral, except in Section 4.3 on risk aversion. For each , we denote the respective private values of good to the divider and chooser by and , which are drawn from a joint distribution over . We write and for the respective marginal distributions. More compactly, we denote the value vectors and , which are drawn according to the joint distribution . Thus, we allow for values of the two players for any individual good to be correlated, but require independence across goods. We write the respective marginal distributions and . We write and for the updated distributions over the chooser’s values after the divider observes his values. The divide-and-choose game proceeds in three steps.
-
(i)
Values are drawn . The divider observes and the chooser observes .
-
(ii)
The divider chooses a division of the goods, which is a vector . We refer to pile 1 as the allocation consisting of of each good and pile 2 as the allocation consisting of of each good .
-
(iii)
The chooser picks her higher-valued pile, namely pile 1 or pile 2, for herself. The other pile goes to the divider.
Formally, the payoffs are defined as follows. If the chooser picks pile 1, then the divider receives a payoff of and the chooser receives a payoff of On the other hand, if the chooser picks pile 2, then the divider receives a payoff of and the chooser receives a payoff of To facilitate understanding, we refer to pile 1 as the pile that the divider would prefer to have for himself, an assumption that is without loss of generality (see Lemma 3.2). Given a division , we refer to the probability that the chooser picks pile 1 as .
Thus, the game is completely parameterized by the value distribution . In this paper we mostly focus on settings where the values are independent across players, except in Sections 4.2 and 5.1. We especially focus on the following distributions:
-
•
Normal priors: The value for good each is drawn from for some mean and standard deviation .
-
•
Discrete priors: The value for each good is drawn from an arbitrary distribution over with finite support.
-
•
Uniform priors: The value for each good is drawn i.i.d. from uniform distributions over intervals , where .
Throughout this paper we often assume that each has been fixed, which makes the distribution irrelevant. Given fixed values of , we define the critical ratio of good to be
where the expectation is over , i.e., the conditional expectation of given .
Note that our model allows for goods to take potentially negative values (i.e., be “bads”). With normal priors this will happen with some nonzero probability, though in most of our examples the means are sufficiently large to render this probability negligibly small. For some of our results we also require that values be nonnegative. For instance, we only discuss critical ratios in the context where all divider values and chooser means are positive.
Our solution concept is that of a subgame-perfect, Bayes-Nash equilibrium. Without loss of generality we need only consider pure strategies for both players, since at no point can either player benefit from inferring information about the other player’s type from its actions. We make a minor additional technical assumption: indifference is always broken in favor of the other player. This is only necessary for knife-edge cases in some of our theorems. In practice, we would expect optimal divisions and optimal pile choices to be unique, rendering this assumption unnecessary.
3 Computing optimal divisions
The divider first observes his values for the goods . How should he use that information together with the updated priors333Throughout this section we use the word “prior” to refer to the distribution of chooser values conditioned on the divider’s values. on the chooser’s values to determine his optimal division? We first establish some basic, general properties of the equilibria of the divide-and-choose game. We then describe algorithms to determine the divider’s optimal division for both normal priors and discrete priors. Finally, we generalize our algorithm for normal priors to handle a wider class of distributions, one that includes uniform priors.
3.1 The general structure of optimal divisions
We begin by recording two easy facts about optimal divisions, which we will use throughout the paper. Their straightforward proofs are deferred to Appendices A and B.
The first observation, to use terminology from the fair division literature, says that all equilibria satisfy proportionality for the chooser and expected proportionality for the divider. In other words, both players can expect to take away at least half of their total values.
Lemma 3.1.
In any equilibrium of the divide-and-choose game, the following hold.
-
(i)
For any realizations of and ,
-
(ii)
For any realization of ,
We refer to the utilities as the respective proportionality guarantees utilities of the divider and chooser.
It is convenient to consider the divider’s optimization problem, not employing the variables taking values in , but instead in terms of the auxiliary variables
| (1) |
taking values in . For reference, the inverse of this correspondence is
| (2) |
We frequently refer to a division as or interchangeably.
Lemma 3.2.
A divider-optimal division with the following two properties always exists.
-
•
The divider weakly prefers pile 1:
(3) -
•
The chooser is weakly more likely to pick pile 2:
(4)
Furthermore, the divider can achieve a strictly higher interim expected utility than his proportionality guarantee if and only if both of these inequalities can be made strict.
For a wide class of priors over the chooser’s value, including normal and uniform distributions, we can characterize exactly when the inequalities from Lemma 3.2 will be strict.
Proposition 3.3.
Suppose each is a non-atomic distribution that is symmetric about its mean, and suppose all divider values and chooser means are positive. Then the optimal division yields utility equal to the proportionality guarantee if and only if all goods have the same critical ratios.
Proof.
Suppose first that all goods have the same critical ratio . First note that the division For any other division , where at least one is not zero, consider the random variable
| (5) |
Since the distribution of is a nontrivial linear combination of the , it is also non-atomic and symmetric about its mean, which implies that, for any threshold ,
| (6) |
Therefore,
In other words, the chooser is strictly more likely to pick pile 1 if and only if the divider strictly prefers pile 1. That it turn implies that it is not possible to achieve a higher-than-proportional utility by the final statement of Lemma 3.2.
Now suppose that two goods and have different critical ratios, i.e., has mean and has mean such that,
Let , let be the division such that
Note that corresponds to , so in words, this is a division where good is slightly more in pile 1, good is slightly more in pile 2, and all other goods are divided equally between the two piles (scaling by ensures ). Then
so the divider strictly prefers pile 1. Also, the random variable has mean
which implies (via (6)) that
Therefore, it follows from the final statement of Lemma 3.2 that the divider achieves a utility that is higher than his proportionality guarantee. ∎
We remark that this result does not extend to some other natural families of distributions, for instance, discrete 2-point distributions. In fact, even when all chooser priors and divider values are identical, there may exist bizarre “symmetry-breaking” divisions that yield utility higher than the divider’s proportionality guarantee; see Proposition 4.1.
3.2 Normal priors
|
We now turn to prove the first main result of this paper: an efficient algorithm to compute a near-optimal division given the divider’s values for each good and normal priors for the chooser values. The procedure is presented formally as Algorithm 1; first we give an informal explanation. With a bit of manipulation, we can rewrite the divider’s optimization problem as maximizing
over the variables . This is not a linear program. However, the only nonlinearities arise from the term, which is itself a function of the . The key idea is to try to guess the optimal by trying several different values, uniformly spread out between 0 and . For each guessed value of , we add a constraint that the chooser picks pile 1 with probability at most . For normal priors, this turns the linear program into a quadratic program, yet it is still convex, so can be readily solved in polynomial time. The only catch is that we lose exact optimality, picking up an error term from potentially missing the exact optimal value of . Fortunately, we can use the structure of the objective function to bound this error in a way that gives a very strong guarantee of approximate optimality.
In what follows, denotes the standard normal cumulative distribution function.
Lemma 3.4.
Algorithm 1 runs in polynomial time in the values of and .
Proof.
Observe that there are at most iterations of the main loop. Thus, all that remains to show is that each iteration takes polynomial time in . This follows from the observation that each is a convex program. To see this, note that the objective function is clearly linear in the variables, and all constraints except for the final one are linear as well. The final constraint is not linear, but we claim that the set of points satisfying the constraint is convex. Suppose , and let . Then, for any positive real number , the scaled vector lies in as well, since
Therefore, is a cone centered at the origin, which is a convex set. ∎
We remark that, beyond being efficient in theory, this algorithm proves to be fast in practice. We implemented this algorithm using Gurobi [18] to solve as a convex quadratic program and used it to verify many of the examples in this paper.
Lemma 3.5.
Algorithm 1 finds a division yielding divider utility within an additive of the optimal divider utility.
The proof is long and technical, so it is deferred to Appendix C.
With a bit more work, we can translate this additive approximation guarantee into a multiplicative one. Formally, we can show that Algorithm 1 is a fully polynomial-time approximation scheme (FPTAS) for maximizing divider utility, which means that, on instances where the optimal value is , for any , it can find a solution with objective value at least in time polynomial in both and .
Theorem 3.6.
When all , running Algorithm 1 with is a fully polynomial-time approximation scheme with approximation parameter .
Proof.
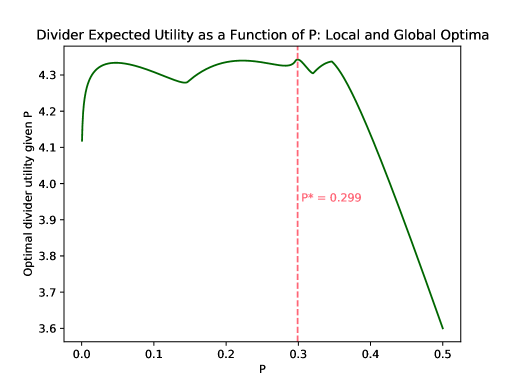
One might wonder why it is necessary to sequentially search for the optimal value of . If the optimal divider utility given were a single-peaked function of , then it would be possible to rapidly compute an optimal division through a ternary search over . However, single-peakedness is not always satisfied, as Figure 1 demonstrates. In fact, local optima can occur even in very simple scenarios:
Proposition 3.7.
Even for goods, there exist positive divider values and normal chooser priors with identical positive means such that the divider’s interim expected utility, as a function of the division , has a local maximum that is not a global maximum.
Proof.
This was discovered and verified via computational methods, so here we just explain the example at a high level. Suppose , , , and , . There are two locally-optimal strategies. Approximately, they are:
-
(i)
Divide the high-variance good 3 evenly between the two piles, so that it has no influence on the probability that the chooser picks pile 1. Then execute the optimal perfect-information strategy, putting most of good 1 in pile 1 and all of good 2 in pile 2. The risk that the chooser picks pile 1 is very low, at .
-
(ii)
Put good 3 entirely into pile 2, so that it is possible to extract a substantial amount of both goods 1 and 2 in pile 1. The risk that the chooser picks pile 1 is moderate, at .
As we verified using Algorithm 1, strategy (i) yields utility of approximately 11 (as one would expect), whereas, despite the risk in relying on the high-variance good, strategy (ii) yields utility of approximately 12. However, intermediate strategies yield utilities less than either one of these extremes. ∎
3.3 Symmetric log-concave priors
It turns out that the technique from Algorithm 1 applies to a much wider class of distributions. Specifically, we consider distributions whose density functions have two properties: symmetry about their mean and log-concavity. While we are not able to get a clean quadratic program, as we obtain in the case of normal distributions, we can still show convexity. As an application, we give a randomized approximation algorithm that handles the case where each is a uniform distribution over an interval.
Many well-studied families of continuous distributions are symmetric and log-concave, including normal distributions and uniform distributions over intervals. A product measure
is symmetric and log-concave in an -dimensional sense whenever each is. Our interest in these distributions stems from the following theorem.
Theorem 3.8 (Meyer and Reisner [22]).
Let be a symmetric, log-concave measure over and let . There exists a set such that, for any hyperplane separating into halfspaces and ,
-
(i)
if and only if is nonempty, and
-
(ii)
if and only if contains a single point, which is always the centroid of restricted to .
The sets are called “floating bodies” of . When is a uniform distribution over a compact set , a geometric interpretation lends insight. We consider all possible ways to slice off a -fraction of the volume of . After all such slices are made simultaneously, is the set that remains. Then the backward direction of statement (i) is immediate, following from the observation that every supporting hyperplane of slices off at least a -fraction of the volume of . The nontrivial forward direction is that there are no “redundant” hyperplanes: every plane slicing off at least a -fraction of the volume of is a supporting hyperplane of . This part requires the distribution to be symmetric and log-concave. It implies that each hyperplane intersects at a single point, which must be the center of mass of by a straightforward calculus exercise.
The Meyer-Reisner Theorem has received surprisingly little attention in the literature on convex optimization. However, it is intimately tied to convexity, and plays a crucial role in the proofs of our next two theorems.
Theorem 3.9.
If the chooser prior is symmetric and log-concave, then the set of divisions for which the probability the chooser prefers Pile 1 is at most is a convex set.
Proof.
Let be two divisions for which the probability the chooser picks Pile 1 is at most . Suppose, toward a contradiction, that for some , the probability the chooser picks Pile 1 under is . In other words, for ,
| (7) |
but
| (8) |
For each , consider the -dimensional plane
with positive side defined as
Then Equation (8) says that
Applying Theorem 3.8 part (i) (forward direction), we deduce that there is some specific point . Since
it follows that, for some , we have . Applying Theorem 3.8 part (i) (backward direction) to , it follows that
contradicting Inequality (7). ∎
Already, this suggests that the technique from Algorithm 1 can be extended beyond normal distributions. When each is Gaussian, the constraint that is a convex quadratic constraint. If we only require to be symmetric and log-concave, the constraint is no longer necessarily quadratic, but it is at least convex.
However, convexity alone does not immediately imply we can optimize over in polynomial time. For that we must build a separation oracle, which is an algorithm that can efficiently decide whether any given point is in , and if it is not, output a hyperplane separating from , i.e., a linear constraint that every point in satisfies but does not. It turns out that neither of these tasks is computationally tractable in general. In the case where each is a uniform distribution over an interval, determining whether a given point is in is equivalent to computing the volume of an -dimensional plane cuts out of an -dimensional cube. That well-studied problem is thought to be intractable.444In general, computing volumes of polyhedra is #P-hard [16]. The best known formula for this particular problem involves enumerating the exponentially-many vertices [17]. However, our next result shows that we can effectively solve this problem by the means of sophisticated random sampling techniques, using Theorem 3.8 part (ii) to get an (approximate) separating hyperplane. Since the algorithm uses randomness, it is not an FPTAS but rather an FPRAS (fully polynomial-time randomized approximation scheme). An FPRAS is the same as an FPTAS except that it is only required to be correct with some constant probability greater than .
Theorem 3.10.
An FPRAS exists to compute an approximately optimal division given rational divider values and chooser priors encoded by rational numbers and .
The proof is deferred to Appendix D.
3.4 Discrete priors
Using similar ideas we can also efficiently solve the case where the chooser’s prior is a discrete distribution when the number of chooser types is small.
Proposition 3.11.
There is a function such that, given a discrete joint distribution over the chooser’s values (even allowing for correlations across goods), with goods and , it is possible to compute an optimal division in time .
Algorithm 2, presented in Appendix E, solves this problem by optimizing a similar ensemble of linear programs and taking the best solution. Unlike our other algorithms, this returns an exact (rather than approximate) solution and works even when there are correlations among the chooser’s values for the various goods.
4 Diversification: Why and how
To maximize his expected utility, the divider must balance two objectives when he allocates goods to the piles: maximizing the returns from the more-desirable pile 1, and reducing the risk that the chooser picks pile 1. The divider trades off between these objectives by transferring just the right amount of value into pile 2. One might naturally expect that the divider’s strategic approach from the case of known chooser preferences would still be optimal. Namely, the divider could start with all goods in pile 1 and transfer goods into pile 2 in order of ascending critical ratios, thus creeping along the risk-return frontier to find the optimal utility. In the end, at most one good would need to be divided.
However, another strategic factor—diversification—can reduce the risk to the divider that the chooser will pick pile 1, and thus enable the divider to do better. In the investment context, investors know they can push the entire risk-return frontier outwards by investing in many assets. This analogy applies quite well to our setting: given that the chooser is more likely to pick pile 2 (which is always the case by Lemma 3.2), when the expected difference in the chooser’s values for the two piles is fixed, she is more likely to pick pile 2 if the variability of the difference is lower. Thus, the optimizing divider should not merely transfer a sufficient amount of value into pile 2. He should also reduce variance in this value by dividing multiple goods between the two piles, thereby diversifying the piles to reduce risk. In this section, we analyze how this incentive affects the divider’s optimization problem.
If goods are indivisible, diversification can still be achieved by using lotteries, whereby the divider does not merely divide the goods into two piles, but commits to random allocations of certain goods after the chooser has made her choice. Consider goods 1 and 2 (of many others), for which the chooser’s values are equally likely to be 0 or 1. If good 1 is put in pile 1 and good 2 in pile 2, then there is a 25% chance that the chooser’s value of those two assets will be greater in pile 1 than in pile 2. By contrast, if each good is put in pile 1 with a 50% chance, and pile 2 with a 50% chance, then the chooser—before the lotteries have been conducted—will always value the probabilistic assets in the piles equally. We emphasize here that the “diversification” imperative under examination is not aimed at reducing the risk in the lotteries for each good, but instead at reducing the risk that the chooser picks pile 1 before the lotteries are resolved. If the divider is risk-averse, then the incentive to diversify over risk in the chooser’s action can be at odds with an inherent aversion to using lotteries. This is a subtle issue we address briefly in Section 4.3, when we discuss risk-aversion given both divisible goods and indivisible goods that can be divided via lotteries.
4.1 Which goods get divided?
We know that the divider can find the optimal division of goods in the normal and discrete cases using Algorithm 1 and Algorithm 2 respectively. Here we provide a qualitative explanation of how goods are optimally allocated between the two piles.
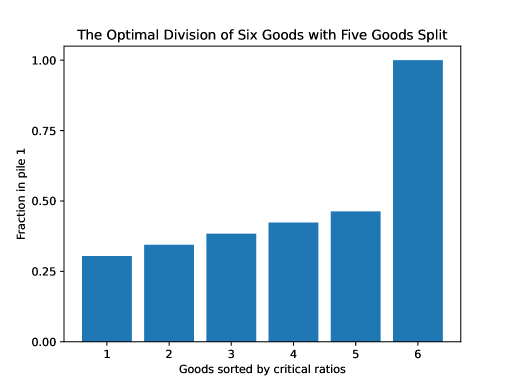
We begin by observing that it may be optimal for the divider to split all but one good, as Figure 2 illustrates. The most valuable good—worth about twice as much as any of the others—is placed entirely in pile 1, while the other goods are all placed mostly in pile 2 but split between the two piles in order to reduce variance, pushing extremely close to zero. This optimal division was computed using Algorithm 1.555Technically speaking, the division output by Algorithm 1 is not guaranteed to be “close” to the globally optimal division, even though the objective values must be similar. However, for the divisions in Figures 2, 4, and 8, we did verify that the optimal division, , must be close to the computed division shown in the figure, , in the sense that . (For Figure 8, we only obtained 0.1 instead of 0.05.) This is a close enough approximation to conclude that the properties we are claiming hold in these two examples. We computed this by re-running Algorithm 1 with an additional constraint that each be bounded away from the value in the original computed solution by 0.05. We did this separately for each good , and each direction of the deviation (bounded away from above/below). For a small enough value of the error parameter , we can conclude that, in each of these constrained optimizations, the optimal objective value decreases by more than . Thus, the globally optimal solution cannot respect any of these additional constraints, implying that .
This result starkly contrasts with the case of complete information. As we discussed in Section 1.2, a divider with perfect information never needs to split more than one good between the piles. Figure 3 interpolates between these two cases by decreasing the variance from one down to zero. One by one, the high value goods are placed entirely in pile 1 and the low value goods are placed entirely in pile 2. Eventually, as the variance approaches zero, we arrive at the certainty case, where there is no longer any diversification.
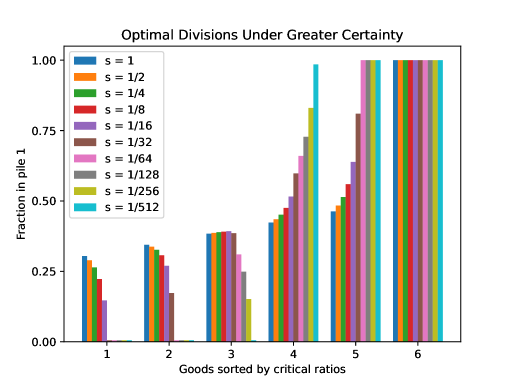
Although the first five goods are diversified in this example, the ones the divider values more tilt more toward pile 1 than do the ones the divider values less. This suggests an intuitive rule by which the divider could be guided in constructing his optimal division. Recall that, in the absence of uncertainty, the fraction of good placed in pile 1 is monotonically increasing in the critical ratio of good .666Indeed, that fraction is zero or one, except for a single good intended to keep the piles even in value to the chooser. Does this monotonicity result survive in the presence of uncertainty?
While it seems intuitive that prioritization by critical ratios would carry over to the uncertainty case, it will not if the priors have different variances. Even if a good has a very large or very small critical ratio, its variance may be so large to make it too risky to place it mostly in one pile. Thus, when variances differ among goods, monotone divisions may be suboptimal. Surprisingly, we observe that monotonicity may be lost even when goods have normal priors with identical variances.
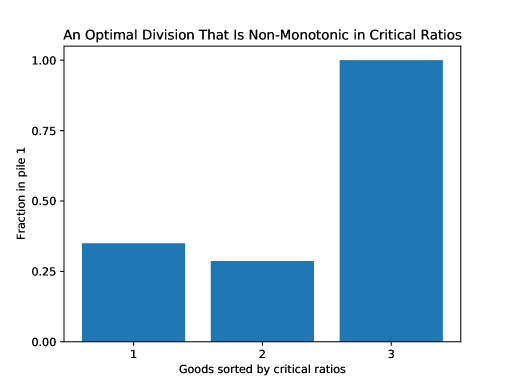
Figure 4 shows the optimal division in a simple example with three normally-distributed goods, again computed using Algorithm 1. Even though good 2 has a higher critical ratio and the same variance as good 1, the optimal division sets . The primary reason is that the value of good 2 to the chooser, in absolute terms (rather than relative to the divider’s value), is so large that, in order to ensure that the value of stays low, raising would require lowering by such a large amount that the divider would be worse off. Note that we do require a high variance of 25 for each good to see this effect. As we decrease the variance to zero, we see convergence to the case of known preferences, with the division becoming monotone in the critical ratios starting around a variance of 5.
This example is surprising given the small amount of variance relative to the mean of each good. While in the polar case of zero variance, monotonicity in the critical ratios is optimal, a sliver of uncertainty breaks this result.
A further departure from the case of certain preferences is that the divider can achieve a higher-than-proportional utility even when all critical ratios are the same—in fact, even when the chooser’s prior distributions are identical and the divider values every good identically. Clearly, such a division is not feasible with normal priors by Proposition 3.3. With two-point (or multi-point) discrete priors, despite such identical values across goods, it is feasible for the divider to beat his proportionality guarantee.
Proposition 4.1.
There exists a number of goods and a discrete distribution supported on two positive values such that, even if, for each good , and , there exists a division of goods yielding utility higher than the divider’s proportionality guarantee.
Proof.
Let and let be the following distribution: value 0.01 with probability 0.6 and value 1 with probability 0.4. Consider the division
Observe that if the chooser values the first good at 0.01 and at least one of the other goods at 1, then she prefers pile 2. This happens with probability
Since the divider values pile 1 more than pile 2, he achieves a higher utility than his proportionality guarantee; specifically, his expected utility is . ∎
Finally, we note that there is a limit to the need to diversify through lotteries. It is never strictly optimal to split all goods between the two piles. The proof is straightforward, and is included in Appendix F for completeness.
Lemma 4.2.
If the divider can achieve a utility exceeding his proportionality guarantee, he will always leave one good entirely in one of the two piles.
We also remark that, even though all examples above place an undivided good optimally in pile 1, sometimes it is optimal to place a sole undivided good in pile 2.
4.2 The effects of correlation between the players’ values
Thus far we have only considered settings where the divider’s prior over the chooser’s values is specified arbitrarily and is independent of the divider’s values. In this section we briefly study optimal divisions embedded in a larger, realistic context where there is a joint prior over both players’ values. Such a situation would arise if there were a public value component to the player’s valuations, as say for market value when jewelry pieces or real estate assets are being divided. The divider uses his own values to update his beliefs about the chooser’s values.
Specifically, consider a scenario where both players’ values follow a Gaussian marginal distribution for each good . However, the values for each good are correlated. For each good , there is a common public value that is distributed according to , for a parameter . Additionally, each player has a private value distributed independently according to . The values for good are and .
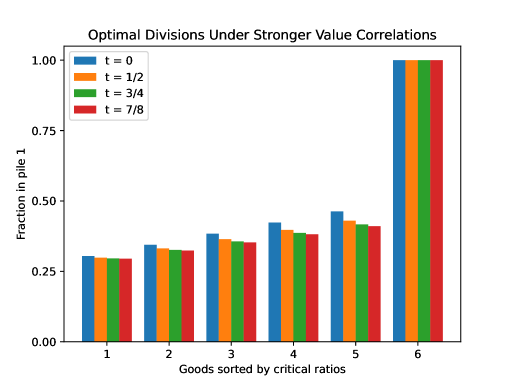
Figure 5 shows the optimal divisions for increasing values of in the same setting as before, where the divider has one good at a very high value of 15 and the other goods’ values are close to the mean of 10. As is evident, the divider’s general strategy does not change in any significant qualitative way. The high-value good is still placed entirely in pile 1, and the divider still diversifies among the other goods. Perhaps surprisingly, as increases toward 1, the divider actually diversifies more, with the gaps between the fractions in pile 1 among the first 5 goods shrinking.
One possible explanation for this trend is as follows. As increases, the divider increasingly expects the chooser to have similar values, as most of the variation can be attributed to the public value. It thus becomes more important for the divider to divide “evenly.” Otherwise, if the divider concentrates too much value in pile 1, then because the chooser has similar values, the chooser will pick pile 1. But then, as the piles start to have similar values to the divider, the consequences of the chooser picking pile 1 become less dire. So the divider will optimally choose a division with a higher value of . (Indeed, this is the case in this example. In going from to , the value of doubles, then continues to approach as approaches 1.) In this regime, diversification becomes more important, as decreasing variability in the values of the two piles can have an even greater effect on improving the chances the chooser picks pile 2.
4.3 The effects of risk aversion
It is optimal for the divider to increase his expected value by taking a risk on the value he receives; how does his strategy adjust if he is averse to risk? Suppose the divider is an expected utility maximizer with utility , where is an increasing concave function and is the total value of all goods the divider receives.
Thus far, we have not distinguished between deterministic divisions of divisible goods versus randomized divisions of indivisible goods. For example, if , then it could mean that good is literally split between the piles into two equal pieces, or that it will be randomly allocated, in whole, to one pile or the other after the chooser picks a pile. In the two cases the two players’ incentives are the same. However, if the divider is risk-averse, a lottery that is resolved after piles are selected will impose unwanted risk on him. In this section, we assume that the goods are divisible and note where results would be different if the goods were indivisible and allocated by lottery.
We identify two main effects of a divider’s risk-aversion. First, it decreases the probability that the chooser picks pile 1, as the following theorem shows.
Theorem 4.3.
Assume all values of goods are always nonnegative. Fix divider values and let be a concave utility function. The probability that the chooser picks pile 1 under any optimal division by a risk-neutral divider is weakly greater than the probability the chooser picks pile 1 under any optimal division by a divider with utility function .
Proof.
Let be the optimal division by a risk-neutral divider, and let be the optimal division by a risk-averse divider with utility function . Let be the total divider value of all goods. Let , , and , denote the divider’s value for pile 1 and the probability the chooser picks pile 1 according to and , respectively. Suppose toward a contradiction that . Then we must have , for otherwise would be a strictly better division than for the risk-averse divider, as it would simultaneously yield a higher value in pile 1 and higher probability of the chooser picking pile 2. Also, since the risk-neutral divider prefers to , it must be that
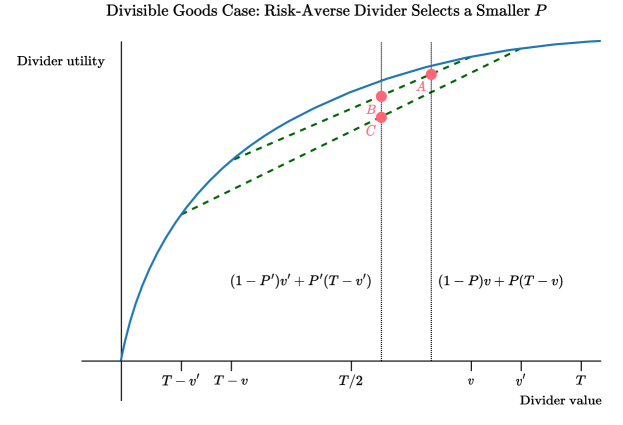
Thus, values are ordered exactly as shown in Figure 6, where the -coordinate of points and are the respective expected divider values of and . If the solid blue curve is the utility function , then the -coordinates of points and are the expected utilities of the risk-averse divider using and , respectively. It follows from monotonicity and convexity that must have a higher -coordinate than , which must have a higher -coordinate than . This contradicts our assumption that the risk-averse divider prefers . ∎
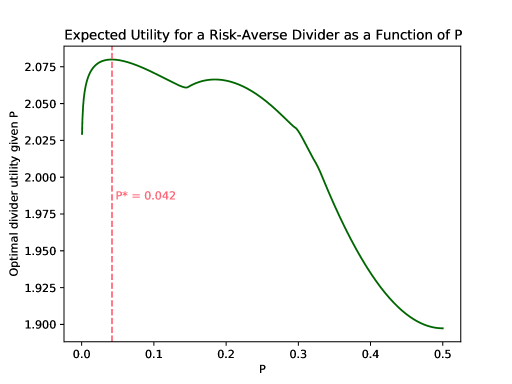
We may observe this effect empirically by assuming the utility function . This turns the convex program from Algorithm 1, which maximizes divider utility with respect to a fixed value of , into a non-convex program. However, it can be written with only two non-convex constraints, so it is still practically feasible to solve it exactly. Figure 7 plots the optimal expected divider utility given any value of for a divider with utility function . The divider’s values and chooser’s priors are the same as in Figure 1. Comparing the two figures, one can see that risk aversion reduces the optimal utility for larger values of , making smaller values of more attractive.
Theorem 4.3 does not hold when goods are indivisible and allocated randomly. Consider a scenario with only goods. Good 1 deterministically has value 4 for both players. Good 2 is worth 16 to the divider and either 1 or 12 to the chooser, each with probability . A risk-neutral divider will put of good 2 in pile 1 and everything else in pile 2, ensuring that the chooser always picks pile 2 (i.e., ). If the divider has utility function , then assuming “ of good 2” is a lottery over good 2, this strategy yields expected utility . However, by just putting the goods in separate piles and not using lotteries, the chooser will pick pile 2 with probability , yielding expected divider utility
We verified computationally that no division in which yields expected divider utility greater than .
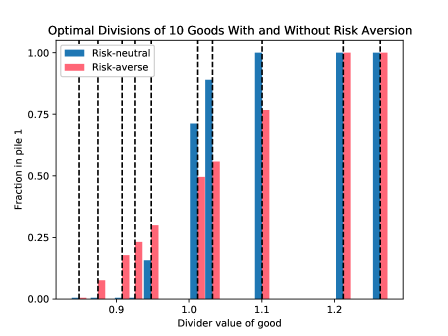
The second major effect of divider risk aversion is to increase the amount of diversification. Consider the setting with 40 goods with both divider and chooser values drawn i.i.d. from . Figure 8 compares the optimal divisions by a risk-neutral divider and a risk-averse divider using the utility function with values for the 10 goods drawn independently from . As one can see, risk-aversion leads to more goods being split between the two piles, and they are generally split more equally. Still, one good is always left undivided, as Lemma 4.2 holds with the same proof.
5 Welfare of the players
We now turn to analyze the expected welfare of the players. Knowing their expected welfare is important if our concern is some conception of fairness. It is also critical in enabling a player to decide when to try to play divider, and when chooser. The divide and choose game is explicitly asymmetric, and despite its minimal axiomatic guarantees (e.g., envy-freeness), one player might end up better off than the other merely due to this asymmetry. In this section we identify conditions under which one role is preferable to the other.
5.1 Number of goods
The cake-cutting literature suggests that the chooser is better off for the unknown-preferences case, as the divider is compelled to divide goods roughly evenly, while the chooser can get a more favorable outcome because she will typically value one pile more than the other. However, if the divider has strong knowledge of the chooser’s preferences, then the divider can exploit this knowledge [27, 9]. Indeed, as Nicoló and Yu [23] note in the context of cake-cutting, “The divide and choose rule leads to a no-envy outcome but the rule itself is not envy free: the chooser envies the role of the divider.” Thus, the best generalization one could hope to make is that the relative utilities of the two players depend on the amount of uncertainty faced by the divider. Hence, the greater one’s own and one’s counterpart’s knowledge, the greater the benefit of playing the divider. Weak knowledge, on either side, favors being the chooser.
One natural example of this phenomenon is when values for all goods are drawn i.i.d. from the same distribution. If is small, there is significant uncertainty in how the chooser will value the piles. Moreover, the divider cannot count on receiving what he places in pile 1. Consequently, when goods are few, the chooser has the advantage.
In contrast, when is large, the uncertainty in the value of a pile shrinks relative to its mean value. In this situation, the divider can cluster his high-value goods into pile 1, and expect to receive that pile with high probability. Thus, the divider is favored. These observations lead to the final major result in this paper: For plausible distributions of players’ values, the chooser is favored when is small; the divider is favored when is large. In the latter case, this is true even when values are correlated (positively or negatively) between the players.
Theorem 5.1.
Let be a probability distribution over . Suppose the values for each good are drawn from , independently across . Then, as long as the critical ratio of each good is not always the same value with probability one, the following hold in any equilibrium.
-
(i)
If the two components of are independent, then for it is strictly better to be the chooser:
-
(ii)
If, for all , for all sufficiently large ,
(9) then for all sufficiently large , it is strictly better to be the divider:
As an illustration of Theorem 5.1, take to be the uniform distribution on : every player’s value for every good is drawn uniformly from the unit interval. This easily satisfies all the assumptions of Theorem 5.1. Table 1 lists the ex-ante expected utilities for each player with two goods and with many goods. With two goods, the chooser is about 50% better off; with many goods, the divider is 50% better off.
Why does this happen? In the two-good case, the key observation is that the divider will always fractionally allocate his favorite good, mostly in pile 1, placing his less favorite good entirely in pile 2. Thus, when the chooser’s favorite good is different from the divider’s, she always does better, since she receives all of the good rather than part of it. When they prefer the same good, one can likewise see that the chooser is still better off via a simple case analysis over the relative fractions of the favorite good that each player would have kept in pile 1 had they been the divider.
For large , relying on the law of large numbers, the divider could be confident that if he placed slightly more than 50% of the goods in pile 2, the chooser would pick pile 2 with an arbitrarily high probability. For example, when , on average, the optimizing divider puts his 45 highest-valued goods in pile 1, and his 55 lowest-valued goods in pile 2. The chooser picks pile 1 with probability . In the limit as , tends to zero, so the divider’s ex-ante utility is the sum of his top-half most-valued goods. On the other hand, for very large , by the law of large numbers, the chooser can expect only her proportionality guarantee utility from each pile, i.e., the sum of a random subset of half of her values. This is essentially the whole argument of the proof, though establishing the trends in full generality, even when values are correlated, requires carefully defining and analyzing the optimal divisions.
| Equilibrium utility per good | ||
|---|---|---|
| Proportionality guarantee | 0.25 | 0.25 |
| Divider | 0.375 | |
| Chooser | 0.25 |
In Appendix G we remark on several ways in which the assumptions are necessary and conclusions as strong as possible. Below, we give a complete proof for part (i) because it is short and intuitive. The proof of part (ii), which involves tedious approximations and concentration bounds, is deferred to Appendix H.
Proof of Theorem 5.1 part (i)..
By Lemma 4.2, the divider will always leave one good undivided. Since the chooser’s values for both goods are drawn independently from the same distribution , which is supported only over positive values, the chooser is more likely to pick the pile with the undivided good. Therefore, it must be that the divider’s least-preferred good is the one that remains undivided, for otherwise he could have a higher expected utility switching the roles of the two goods. In other words, for some function (that depends on the fixed distribution ), the optimal division is always as follows: given values and , the divider places a fraction of good in pile 1, with the rest of that good and all of the other good in pile 2. Analogously, let , i.e., the amount of the chooser’s preferred good that would have gone into pile 1 had the chooser been the divider.
To compare the two players’ ex-ante expected utilities, we fix realizations of , , , and , and compare the chooser’s actual utility with the hypothetical utility had the roles been reversed. There are three possible cases to consider, depending on the realizations of , , , and .
Case 1: The two players weakly prefer different goods. In this case, the chooser will receive all of her favorite good in pile 2. Had she instead been the divider, she would have only received a -fraction of her favorite good. Since , the chooser is weakly better off.
Case 2: The two players strictly prefer the same good, and . In this case, the chooser receives a -fraction of her favorite good in pile 1. As in Case 1, had she instead been the divider, then she would have only received a -fraction of her favorite good. Since , the chooser is weakly better off.
Case 3: The two players strictly prefer the same good, and . In this case, had the chooser been the divider, the divider would have opted for the chooser’s preferred pile 1, since we know the divider would have weakly preferred a -fraction of his favorite good to everything else, so he must have strictly preferred a -fraction of his favorite good. Thus, if roles had been reversed, the chooser would have received her least-preferred pile, obtaining utility at most her proportionality guarantee. Since the chooser always can get at least this utility, the chooser is weakly better off being the chooser.
In short, we have shown that the chooser is weakly better off in all cases. Furthermore, the chooser is strictly better off in Case 1 whenever . If this never occurs, that means that the divider always puts the goods entirely into different piles, in which case the divider receives utility equal to his proportionality guarantee and the chooser exceeds her proportionality guarantee (since the assumptions on imply the chooser’s values for the two goods are not always the same), so we are done. Assuming that with nonzero probability, we further observe that, conditioning on , the players will prefer different goods (or be indifferent) at least half of the time. Thus, we see that the chooser is strictly better off with nonzero probability, so she is strictly better off overall. ∎
Theorem 5.1 appears to hold for normal priors with a positive mean as well (even though they may take unbounded and negative values). For , the chooser is better off, while for large , the divider is better off. At what value of does the crossover occur? Figure 9 plots estimated utilities per good for an empirical experiment where all values are drawn from . The crossover appears to be around 15 goods.
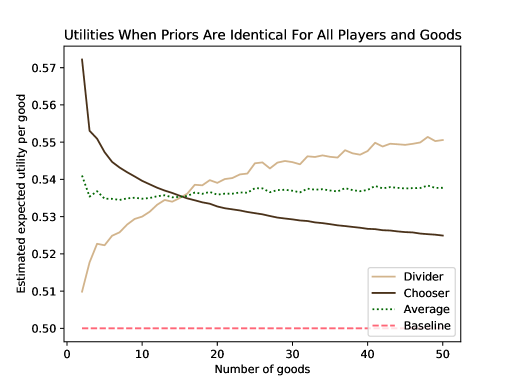
5.2 Heterogeneity of values
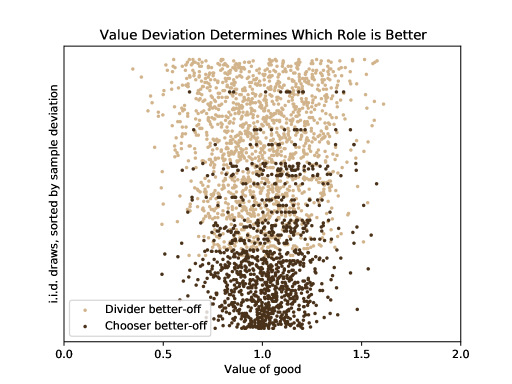
Thus far we have been measuring and comparing the utilities afforded by the two roles ex-ante. However, there is more to the story: the realizations of the values will generally affect which role is more desirable. Figure 10 plots random samples of the values of 13 goods drawn from the same distribution, , as in Figure 9. We chose the number of goods to be 13 since that is near the crossover point in Figure 9, where the two roles have similar ex-ante utilities.777Even though the expected utilities are closer at 15 goods, the probability that the chooser is better off than the divider is closer to at 13 goods than at 15 goods. As one can see, when values vary more widely it is better to be the divider. This is because the divider’s optimal strategy is to place all goods that he values highly in pile 1; he cares much less about the low-value goods. On the other hand, when values are more concentrated around the mean, it is better to be the chooser. In such a scenario, the divider’s strategy will not yield a substantially high payoff. Instead, the chooser benefits simply from the fact that she will probably be able to take a larger and more valuable pile under the divider’s optimal strategy.
6 Conclusions
Divide-and-choose methods are widely employed by business partners going separate ways, inheritors dividing assets, and divorcing couples. They also lie at the heart of an array of managerial decisions.
The divide-and-choose game is not unfamiliar to economics and computer science. However, typical formulations—such as the famed cake-cutting model—assume the players’ preferences are known, or at the very least can be elicited truthfully. In the real world, by contrast, a divider will merely have subjective beliefs about the chooser’s preferences. This analysis pioneers the study of optimal strategies in divide-and-choose when one’s counterpart’s preferences are unknown.
A major finding is that the known and unknown preference situations lead to qualitatively different strategies. Moreover, a number of the results for the unknown preferences case are surprising. For example, with known preferences, the ratio of values for the two players, what we label the critical ratio, proves critical. All the goods in one pile have a higher ratio than any of the goods in the other. In addition, at most one good is divided between the piles, with division via a lottery if that good is physically indivisible. With unknown preferences, by contrast, assignment by critical ratios may be violated. That is, fractions allocated to pile 1 may be non-monotonic in the ratios. Moreover, it might be optimal to fractionally allocate up to out of goods.
Uncertainty on preferences makes diversification a vital concern. It competes with efficient division as an objective for the divider. The analysis proceeds with a pile 1, preferred by the divider, with its complement denoted pile 2. The divider is eager to get the chooser to pick the latter. This is fostered in part by assigning greater chooser expected value to pile 2. This process is limited because the total value in pile 1 is being diminished, and that is the pile the divider hopes to get and will get most of the time. Holding the disparity in expected values fixed, the chooser is more likely to opt for pile 1 the greater is variability in actual values. Diversification—achieved by dividing multiple goods between the two piles—significantly reduces the variability in the chooser’s valuation of piles. Hence, it reduces the likelihood that the divider ends up with pile 2.
Computing the divider’s optimal division is easy in the known-preferences case. It is surprisingly difficult with preferences unknown. We already mentioned the troubling lack of monotonicity in critical ratios. Worse still, multiple local optima are commonly encountered. Despite these challenges, we are pleased to identify algorithms that compute divisions for normal and uniform priors in polynomial time, approximating the optimal utility to within arbitrary precision. We suspect that exactly computing optimal divisions in either of these settings is NP-Hard. Characterizing the precise computational complexity is an interesting open question.
We investigated some general effects of divider risk aversion. While this makes the divider’s optimization task more computationally difficult, our results do shed some light on how to actually find optimal divisions. Chooser risk aversion, not addressed here at all, merits future study. If goods are divisible, chooser risk aversion is irrelevant. With indivisible goods only divided via lotteries, it could be consequential. One intriguing question is whether correlating lotteries across multiple goods can increase the divider’s expected utility.
Many of our results have direct implications for real-world divide-and-choose situations, implying that the models from which they flow represent stylized facts. For example, a typical buy-sell arrangement allows either player to grab the yet unclaimed divider’s role. The relative attraction of the divider’s role is greater the more refined one’s assessment of the other player’s preferences, the better informed the other player about your preferences, and the greater the number of goods. Both the divider and the chooser roles gain in value the more extreme one’s preferences relative to expectation; the parameters of the specific situation will determine which role is preferred.
Insights from divide-and-choose apply in a range of contexts that are not specifically divide-and-choose. A closely related setting occurs, for example, when one party makes a take-it-or-leave-it offer, such as a job offer, to another party. The recipient can accept the offer or stick with the status quo. Such offers commonly include divisible goods. Thus, the offer of a university to a job candidate might specify a salary and a teaching load, where there is a permissible range for each attribute.
There is an indirect equivalent to our formulation. An accepted offer, the university’s preferred outcome, is the equivalent of pile 1. A rejected offer is the status quo. (No resources change hands given a rejection.) The chooser accepts when he prefers the offer to the status quo. In the traditional divide-and-choose situation, the divider is uncertain about the chooser’s valuation of the two piles. In a take-it-or-leave it offer, she is uncertain about the chooser’s valuation of the offer relative to the status quo. On a technical level, these two games are slightly different, where the latter game essentially involves the same optimization problem except that the variables must be nonnegative and can be greater than . Thus we would expect our analyses about critical ratios and diversification to still apply.
Posit that the university and the candidate have linear and additive preferences over the two attributes. However, the university has only priors on the candidate’s weights on attributes and valuation of the status quo. It would like to increase the probability of acceptance, i.e., that the offer lies above the candidate’s unknown reservation value, but also wants to increase its value from an accepted offer. An offer using interior values for some attributes—a direct analogue to fractional allocations in our model—will often be optimal. Interior values provide diversification; they increase the probability of acceptance for a given value of an accepted offer to the university.
As a final example, many bargaining contexts involve reciprocal concessions on different issues over time as a means to build confidence. Thus, a labor union might initially give up on its four-day-a-week demand in exchange for the corporation’s willingness to fund pensions more generously. When offering such preliminary trades, each party will reason about critical ratios to decide the optimal offer or counteroffer. But it will also be thinking ahead as to what it will have to give up on the big issue, say salary, to get an acceptance. While our model is formally situated as a one-shot interaction, we believe our insights extend qualitatively to these more complex negotiations: at every step on the path to a deal, the parties must think about both critical ratios and effective diversification.
There are intriguing areas for future work, only touched on in this paper, that will require a blend of analytic advances and attention to real-world features. They include player risk aversion, ex-post renegotiation of agreed-upon allocations, and mechanisms—such as alternating choices—that mix responsibilities for playing divider and chooser.
Of course, a salient feature of the real world is that players are not perfectly rational. An interesting theoretical question for future work would be to investigate an alternative equilibrium concept where players make mistakes with small probability. Also, an experimental study is currently underway to see how dividers and choosers actually play in a game closely resembling our formulation.
Allocation systems, in a range of areas from divide-and-choose to the market, involve players acting strategically to maximize their take given what they know of the other player’s valuation. This paper hopes to have shown that, in the allocation of analytic attention, the art of actually playing the divide-and-choose game has received a smaller pile than it deserves.
Acknowledgments
We are deeply grateful to Jack Stade, who suggested the proof approach for Theorem 3.9; to Pranay Gorantla, who found and alerted us to the Meyer-Reisner Theorem (Theorem 3.8); and to Yannai Gonczarowski, for his careful reading of an earlier draft with extremely helpful feedback.
We also thank Justin Chan for numerous suggestions that improved readability, as well as our anonymous reviewers at both Management Science and EC 2023. Finally, we thank Paul Gölz, Gregory Kehne, Prashanth Amireddy, Elizabeth Pratt, and Santhoshini Velusamy, who also consulted on Theorem 3.9, and David Eppstein, who consulted on Theorem 3.10.
This material is based upon work supported by the National Science Foundation Graduate Research Fellowship Program under Grant No. DGE1745303, and by the Mossavar-Rahmani Center for Business and Government, Harvard University. Any opinions, findings, and conclusions or recommendations expressed in this material reflect the views of the authors and not necessarily those of the National Science Foundation or the Mossavar-Rahmani Center.
References
- [1] Georgios Amanatidis, Georgios Birmpas, Federico Fusco, Philip Lazos, Stefano Leonardi, and Rebecca Reiffenhäuser. Allocating indivisible goods to strategic agents: Pure nash equilibria and fairness. In Web and Internet Economics - 17th International Conference, WINE 2021, Potsdam, Germany, December 14-17, 2021, Proceedings, pages 149–166, 2021.
- [2] Haris Aziz and Simon Mackenzie. A bounded and envy-free cake cutting algorithm. Communications of the ACM, 63(4):119–126, 2020.
- [3] Siddharth Barman, Ganesh Ghalme, Shweta Jain, Pooja Kulkarni, and Shivika Narang. Fair division of indivisible goods among strategic agents. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’19, Montreal, QC, Canada, May 13-17, 2019, pages 1811–1813, 2019.
- [4] Xiaohui Bei, Ning Chen, Guangda Huzhang, Biaoshuai Tao, and Jiajun Wu. Cake cutting: Envy and truth. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017, pages 3625–3631, 2017.
- [5] Xiaohui Bei, Guangda Huzhang, and Warut Suksompong. Truthful fair division without free disposal. Soc. Choice Welf., 55(3):523–545, 2020.
- [6] Anna Bogomolnaia, Hervé Moulin, and Fedor Sandomirskiy. On the fair division of a random object. Management Science, 68(2):1174–1194, 2022.
- [7] Steven J Brams and Samuel Merrill, III. Equilibrium strategies for final-offer arbitration: There is no median convergence. Management Science, 29(8):927–941, 1983.
- [8] Steven J. Brams and Alan D. Taylor. An envy-free cake division protocol. The American Mathematical Monthly, 102(1):9–18, 1995.
- [9] Simina Brânzei, Ioannis Caragiannis, David Kurokawa, and Ariel D. Procaccia. An algorithmic framework for strategic fair division. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 12-17, 2016, Phoenix, Arizona, USA, pages 418–424, 2016.
- [10] Eric Budish. The combinatorial assignment problem: Approximate competitive equilibrium from equal incomes. Journal of Political Economy, 119(6):1061–1103, 2011.
- [11] Yiling Chen, John K. Lai, David C. Parkes, and Ariel D. Procaccia. Truth, justice, and cake cutting. Games and Economic Behavior, 77(1):284–297, 2013.
- [12] Yun Kuen Cheung. Better strategyproof mechanisms without payments or prior - an analytic approach. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI 2016, New York, NY, USA, 9-15 July 2016, pages 194–200, 2016.
- [13] Richard Cole, Vasilis Gkatzelis, and Gagan Goel. Mechanism design for fair division: allocating divisible items without payments. In Proceedings of the fourteenth ACM Conference on Electronic Commerce, EC 2013, Philadelphia, PA, USA, June 16-20, 2013, pages 251–268, 2013.
- [14] Vincent Conitzer, Rupert Freeman, and Nisarg Shah. Fair public decision making. In Proceedings of the 2017 ACM Conference on Economics and Computation, EC ’17, Cambridge, MA, USA, June 26-30, 2017, pages 629–646, 2017.
- [15] Payam Delgosha and Amin Gohari. Information theoretic cutting of a cake. IEEE Transactions on Information Theory, 63(11):6950–6978, 2017.
- [16] Martin E. Dyer and Alan M. Frieze. On the complexity of computing the volume of a polyhedron. SIAM Journal on Computing, 17(5):967–974, 1988.
- [17] Rolfdieter Frank and Harald Riede. Hyperplane sections of the n-dimensional cube. The American Mathematical Monthly, 119(10):868–872, 2012.
- [18] Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2021.
- [19] Harold W Kuhn. On games of fair division, essays in mathematical economics in honor of oskar morgenstern, edited by martin shubik, 1967.
- [20] Maria Kyropoulou, Josué Ortega, and Erel Segal-Halevi. Fair cake-cutting in practice. In Proceedings of the 2019 ACM Conference on Economics and Computation, EC 2019, Phoenix, AZ, USA, June 24-28, 2019, pages 547–548, 2019.
- [21] László Lovász and Santosh S. Vempala. Hit-and-run from a corner. SIAM J. Comput., 35(4):985–1005, 2006.
- [22] M Meyer and S Reisner. Characterization of affinely-rotation-invariant log-concave measures by section-centroid location. In Geometric Aspects of Functional Analysis: Israel Seminar (GAFA) 1989–90, pages 145–152. Springer, 1991.
- [23] Antonio Nicolò and Yan Yu. Strategic divide and choose. Games and Economic Behavior, 64(1):268–289, 2008.
- [24] Brian R Powers. An analysis of dual-issue final-offer arbitration. International Journal of Game Theory, 48(1):81–108, 2019.
- [25] Ariel D. Procaccia. Cake cutting: not just child’s play. Communications of the ACM, 56(7):78–87, 2013.
- [26] Milton Weinstein and Richard Zeckhauser. Critical ratios and efficient allocation. Journal of Public Economics, 2(2):147–157, 1973.
- [27] H. Peyton Young. Equity - in theory and practice. Princeton University Press, 1995.
Appendix A Proof of Lemma 3.1
To prove (i), observe that the average utility from the chooser’s two options is
so at least one of the options must yield at least this utility. To prove (ii), observe that the division yields utility when the chooser picks pile 2 and utility when the chooser picks pile 1. As the divider always has a strategy guaranteeing utility , at equilibrium he must receive at least that utility in expectation. ∎
Appendix B Proof of Lemma 3.2
We first show that optimal divisions exist. Using Equation (2), We may express the divider’s expected utility as
| (10) |
The optimal utility is attained by maximizing Equation (10) over the variables . Let denote the supremum of this optimal utility, and consider a sequence of divisions whose expected utilities converge to . Let be the division in the limit of a convergent subsequence. We claim that yields the optimal utility . Indeed, since Equation (10) is a continuous function of and , this could only fail if there were a discontinuity in the function at . Such a discontinuity must be the result of a set of chooser types of positive probability mass where all types in pick the divider’s strictly preferred pile at and the other pile after an arbitrarily small deviation from . But this means that all chooser types in are indifferent between the two piles, which contradicts our assumption that an indifferent chooser breaks her indifference in favor of the divider. Thus, attains the optimal utility .
If a given division does not satisfy Equation (3), then sending each will satisfy it. This corresponds to sending , so it is an equivalent division up to renaming the piles. Thus, it is without loss of generality to assume (3) holds in an optimal division.
Appendix C Proof of Lemma 3.5
Observe that each division computed by Algorithm 1 is valid, since if and only if , which is enforced by the first constraint of . We claim that, on each iteration of the main loop, the division computed by Algorithm 1 achieves an interim expected utility of . (In fact, the utility will be exactly , but equality is not necessary to prove.)
The chooser weakly prefers pile 1 if and only if
Note that this is equivalent to
Since each follows a normal distribution with mean and variance , we know that follows a normal distribution with mean
and variance
Hence, the probability that is given by
Since the algorithm computes optimal on each iteration of the main loop to satisfy the third constraint, we know that this probability is at most . Therefore,
| (since the second constraint ensures the term in parentheses is nonpositive) | |||
Thus, the claim is proved.
Let denote an optimal division from Lemma 3.2, yielding interim expected utility , and let denote the respective auxiliary variables for this division (i.e., obtained from Equation (1)). Recall that, in this optimal division, the divider weakly prefers pile 1, and the probability that the chooser picks pile 1 is . Therefore, on some iteration of Algorithm 1,
Let denote the optimal solution to on this iteration, with optimal value , and let denote the corresponding division.
Observe that is feasible for . To see this, note that the first constraint is satisfied by the fact that it corresponds to a valid division with each . The second constraint is satisfied because we are assuming the divider prefers pile 1. Finally, for the third constraint, since implies , we have
Thus, is a feasible solution for .
Therefore, denoting the objective function of by , we have that the utility of the optimal solution returned by the algorithm is
as desired. ∎
Appendix D Proof of Theorem 3.10
For any and , let
This is the set of divisions for which the chooser picks Pile 1 with probability at most and Pile 1 is worth at least more to the divider than Pile 2. We will describe an algorithm, running in polynomial time in the size of the input, , and , that either finds a division or reports that is empty, and is correct with probability . It is straightforward to see that such an algorithm can be called repeatedly to give the desired FPRAS: we apply the same search over as in Algorithm 1. However, instead of solving the quadratic program, we repeatedly test feasibility of , using a binary-search to find the maximal .
Consider the following randomized separation oracle for . Given a queried point , first we test whether . If not, then we return this inequality as a violated constraint. Otherwise, we empirically estimate the probability that the chooser picks Pile 1 by repeatedly sampling many chooser values and counting the number of times . If the empirical estimate is at most , then we return true. Otherwise, we compute an estimate of the centroid of the set
and return the violated linear constraint that . Computing the approximate centroid can be accomplished by repeatedly sampling many uniformly random points from and taking the average, which can be done in polynomial time using the hit-and-run random walk [21]. We omit the tedious details concerning the sample complexity of estimating and . All we require is that, for any , we can, in polynomial time in , ensure with probability at least that is within of the true probability and is within
of the true centroid (under the norm). We say misses if one of these two conditions is false.
We run the ellipsoid algorithm using separation oracle until it returns true. This takes a number of iterations that is at most a polynomial function of the size of the input and . Letting , each call to will take polynomial time, and we know by the union bound that the probability some iteration misses is at most . Thus, to show that the algorithm is correct, we just need to show that returns a correct result whenever it does not miss. There are three cases to consider, depending on what returns when queried on division .
If returns true, then and . Assuming does not miss, we will have , in which case by the triangle inequality. Hence, the algorithm has found a division as desired.
If returns that violates the inequality , then it is always correct (in fact, there was no way for it to miss). It has determined that does not satisfy this constraint, and obviously any does satisfy it.
Finally, consider the case where returns that violates the inequality . Observe that does indeed violate this inequality because . All that remains to show is that all do satisfy it. We show the contrapositive, that an arbitrary violating the inequality is not in . So suppose . Without loss of generality, assume that has the largest magnitude out of all for all . Note that , for otherwise is the all-zero vector, so would have been violated, as we are assuming . Since is positive, we have that
Therefore, . It remains to justify the final inequality above, which follows from the following two inequalities:
| (11) | ||||
| (12) |
To prove Inequality (11), let and be the -dimensional planes
with positive sides defined as
Recall that is the true probability that , and is the estimate of . Applying Theorem 3.8 part (ii) to , we know that . Since , we have as well, so . Hence, applying Theorem 3.8 part (i) (backward direction) to , we derive that
Assuming did not miss, we additionally know that and , so Inequality (11) follows from the triangle inequality.
Finally, we prove Inequality (12) holds under any fixed values of for , letting be the only random variable. Using the assumptions that has the largest magnitude and that did not miss, we know that
Therefore, since , the probability is at most , so Inequality (12) holds.
This proves that the separation oracle is correct with probability , and thus so is the algorithm. ∎
Appendix E Proof of Lemma 3.5
Suppose is an arbitrary distribution supported on a finite set . For each , we write for the probability that . The main idea for finding an optimal division is similar to that of Algorithm 1: we try to guess the set of chooser types who pick pile 1; we then use linear programming to compute the optimal division with respect to the additional constraints that entails. (Since there are an exponential number of subsets in contention, this means the algorithm is only practical when the number of types is small.) Specifically, consider the following algorithm.
|
Let denote an optimal division from Lemma 3.2, with divider utility and probability that the chooser picks pile 1. Let denote the set of chooser types such that, when the chooser has value vector , she chooses pile 1 given the division . Note that the probability the chooser picks pile 1 given is . It is not too hard to see that finds the optimal division given the additional constraint that all types pick pile 2, assuming further that all types will pick pile 1 (which can only lower the objective value). In particular, this means that is always at least the utility from some feasible division, and on the iteration of the main loop when , Algorithm 2 will successfully find , and the optimal utility will be . The claim about running time follows from the observation that each is a linear program. ∎
Appendix F Proof of Lemma 4.2
Let be an optimal division from Lemma 3.2. If achieves a higher-than-proportional utility, then there must be some good such that . Let be a good maximizing . If , then good is put entirely into one of the two piles; otherwise, we claim that the divider can improve the division by linearly scaling , dividing each component by . Since
the chooser is just as likely to pick pile 1, but now the divider obtains a greater utility from pile 1, so he receives a higher expected utility. ∎
Appendix G Tightness of Theorem 5.1
In this section we provide counterexamples to possible ways that one might hope to strengthen/generalize Theorem 5.1.
-
•
The condition on that the critical ratios are not always identical. Otherwise the divider may not be able to beat his proportionality guarantee. For instance, in the extreme case where the values of the two goods are always identical, both roles confer the same utility, which would violate both parts of the theorem.
-
•
The assumption that values are not correlated for . Suppose is a distribution where the divider faces no uncertainty of the chooser’s value after seeing his own value. Then the divider can extract all of the surplus from having different values, leaving the chooser with utility equal to her proportionality guarantee. Hence, correlations can make the divider better off, even for only two goods.
-
•
Positivity of . If is the uniform distribution on , one can see that in any division, so the divider cannot surpass his proportionality guarantee utility for any number of goods. However, for large , the chooser will certainly reap more than her proportional utility (assuming the divider breaks his indifference between divisions in a way that benefits the chooser).
-
•
The condition in Equation (9). Roughly, this says that the values from are typically not extremely small. To see why this assumption is necessary, suppose the divider’s value for each good is 0 with probability 90% and 1 with probability 10%, while the chooser’s value is uniformly distributed on . For a large number of goods, the divider will place the roughly 10% of the goods for which he has high-value in pile 1 and the remaining roughly 90% of the goods in pile 2. By choosing pile 2, the chooser obtains an ex-ante expected utility of per good. If she were the divider, she would have to create piles of roughly even size (with the preferred pile 1 containing the best half of the goods, slightly smaller than pile 2), only receiving an ex-ante utility of per good. Thus, in this example, it is favorable for the first player to be the chooser. However, this is only because the second player sometimes draws the value zero. As we show in the proof, as long as the divider’s value is not zero, even the slightest bit greater than zero, the optimal division leaves the chooser with only her proportionality utility guarantee.
-
•
The chooser is better off with two goods but not always with three goods. Suppose each of the three goods have value 1 with 99% probability and and 300 with 1% probability. There are three cases to consider.
-
–
With probability , all six valuations will be the low value of 1. The divider will divide the goods evenly and the chooser will pick an arbitrary pile, with both players gaining the same utility.
-
–
With probability , there will be exactly one high-valued good. If it is the divider’s value, the divider will optimally place it alone, entirely in pile 1 and most of the other two goods in pile 2. The divider’s expected utility is at least and the chooser’s expected utility is at most 2. If the chooser has the high valuation, the divider will evenly divide the goods between the piles, so there is a chance the chooser’s favorite good will be fractionally allocated. Specifically, some good must be divided with at least in each pile. So the chooser’s expected utility from the high-value good is at most , for a total utility of at most 278. Thus, in this case, the expected utility of the divider is higher than that of the chooser by at least
-
–
With probability , there will be exactly two high-valued goods. We can upper bound the chooser’s utility in this case by the expected value of all goods to the chooser, which is .
-
–
With the remaining probability of , more than two goods have high value, in which case we may upper bound the chooser’s utility by the maximal value of the sum of all goods, which is 900.
In total, the expected utility of the divider minus that of the chooser is at least
-
–
Appendix H Proof of Theorem 5.1 part (ii)
Assume without loss of generality that the support of is contained in . Note that this means the maximum possible utility for either player is at most . Let
We will show that, for all sufficiently large , the player whose values are drawn according to the first component of attains an expected utility of at least as the divider for some constant , but attains utility strictly less than this as the chooser for any .
We begin with the divider’s utility. Since the critical ratio of a good is not always the same value, there must be a pair of values , such that the critical ratio of a good is at least with some nonzero probability, and at most with some nonzero probability. By similar reasoning, we can write such that, with nonzero probability, the numerator of the critical ratio is bounded below by and the denominator is bounded above by ; likewise, we can write such that, with nonzero probability, the numerator of the critical ratio is bounded above by and the denominator is bounded below by . Note that implies
| (13) |
By independence of the values of goods and , it follows that, with some probability , good will have a higher critical ratio than good as according to these bounds:
| (14) |
We let be the set of odd for which the condition in Equation 14 is satisfied. Consider the following division, which is reminiscent of the proof of Proposition 3.3:
| where |
The divider strictly prefers pile 1 by
which is a constant greater than zero. Likewise, the interim expectation of the difference between the two piles’ value for the chooser is
which is a constant less than zero. Thus, by standard concentration bounds, for large enough the probability the chooser picks pile 1 converges to zero, so the divider’s utility gains beyond the proportionality guarantee converges to
Thus, letting , the desired conclusion follows.
We now compute the utility of the first component player if they are the chooser. We need to be slightly more formal in stating the concentration bounds required for this case. Specifically, given , we choose large enough so that and
Note that this is a restatement of Equation (9) applied to . It follows from the union bound that
| (15) |
For any division , let be the random variable as defined in Equation (5), which is the chooser’s value for pile 1 minus the chooser’s value for pile 2. Write for the expectation of conditioned on the divider’s values. Assume we draw a list of divider values such that the event in Equation (15) does not occur, i.e.,
| (16) |
Then, under any division,
There are three inequalities derived from this chain that we will use shortly:
| (17) | ||||
| (18) | ||||
| (19) |
We claim that, still assuming Equation (16) holds, under any optimal division. First suppose that . By Equation (17), with probability at least , we will have , in which case the triangle inequality implies . This means the chooser will pick pile 1 with probability strictly greater than , which cannot happen in an optimal division, so we have a contradiction. Next suppose that . Note that any optimal division has some ; otherwise the chooser picks pile 1 with certainty. Take such a , and consider the alternative division where and for all . Let be the new difference in pile utilities under , with mean . Let and be the respective probabilities that the chooser picks pile 1 in and , and let and be the respective expected divider utilities. Since the value of the good has expectation at most 1, we have . Thus, implies , so
| (21) |
In the middle inequality, we have applied Equation (18) to , which is valid since the bound holds under any division. Note in particular this means that . We may thus lower bound the utility gain of the divider from switching to as follows:
| (by Equation (10)) | |||
Thus, we have shown that is a strictly better division, contradicting the assumption that was optimal. It follows that .
Therefore, we know from Equations (15) and (19) that the conditions and are each violated with probability less than . By the union bound, it follows that, with probability at least , neither condition is violated. In this case, we know that by the triangle inequality. Thus, with probability at least , we may bound by , whereas in the other case we may still bound by . Putting these bounds together, we conclude that the chooser’s expected utility is
as desired. ∎