PMP: Learning to Physically Interact with Environments using Part-wise Motion Priors
Abstract.
We present a method to animate a character incorporating multiple part-wise motion priors (PMP). While previous works allow creating realistic articulated motions from reference data, the range of motion is largely limited by the available samples. Especially for the interaction-rich scenarios, it is impractical to attempt acquiring every possible interacting motion, as the combination of physical parameters increases exponentially. The proposed PMP allows us to assemble multiple part skills to animate a character, creating a diverse set of motions with different combinations of existing data. In our pipeline, we can train an agent with a wide range of part-wise priors. Therefore, each body part can obtain a kinematic insight of the style from the motion captures, or at the same time extract dynamics-related information from the additional part-specific simulation. For example, we can first train a general interaction skill, e.g. grasping, only for the dexterous part, and then combine the expert trajectories from the pre-trained agent with the kinematic priors of other limbs. Eventually, our whole-body agent learns a novel physical interaction skill even with the absence of the object trajectories in the reference motion sequence.

figure description
1. Introduction
Motions for a virtual character are often created manually by an animator, or transferred from motion capture devices. Both approaches are labor-intensive and it is not trivial to directly transfer the naturalness of novel characters or environments. As a result, most consumer VR applications merely overlay isolated objects or people in the scene, unless the allowed motion sets are carefully designed beforehand. Such a lack of direct interaction fundamentally limits the extent of the immersive experience.
The physics-based animation utilizes a physics simulator to animate virtual characters in the environment with real-world dynamics. However, the data-driven approaches are confined to creating motions that closely follow the joint states in the reference motion captures. For example, when you only have normal locomotion and a staring idle motion separately in the database, the existing techniques cannot animate a character to run to the target while simultaneously staring at a specific location. Similarly, the range of human-object interactions cannot be fully covered by the samples available in the publicly available datasets. Especially, the motion of hand joints is subtle with high degrees of freedom (DoFs) and suffers from frequent self-collision and severe occlusions, which makes it difficult to capture the hand motions. A few prior works devised methods(Park et al., 2022; Zhang et al., 2021) to concurrently obtain the hand motion with the interacting object, but still the accurate capturing is challenging. Nonetheless, the hand is crucial to accurately represent daily interaction. Furthermore, the hand configuration can affect the overall balance and is tightly correlated to body movements, for example, in gymnastics and parkour.
In this work, we present a method to animate hand-equipped characters performing complex interactions with the environment. We propose learning part-wise motion prior (PMP), and train an agent to combine a small number of expert motion sequences to perform a novel motion task. The physics simulator effectively balances the parts and deduces the unified policy of the entire body with rich repertoires compared to naïvely mimicking the reference full-body motion. By dissecting the problem into different parts, our pipeline can stably handle the imbalance prevalent in data, DoFs, and the range of motions among part segments.
Most importantly, our agent can obtain complex motor skill in a scalable way without requiring a large number of motion trajectories. Strong prior on physical interaction can also come from another simulation for a part, and our method eventually assembles the demonstrations with the motion captures on the other side of the body. Therefore with our approach, it is possible to convey an additional interaction prior to the virtual character’s dexterous parts, i.e. hands, from a single pre-training of the general interaction skill with a standalone training environment. We showcase the generalizability of the proposed pipeline with various challenging scenarios with a humanoid exhibiting different part assignments.
2. Related Work
We review recent studies that are closely related to our work such as data-driven methods for generating human-environment interaction, physics-based character controllers, and full-body character control including manipulation.
In computer animation research, data-driven approaches have been popularly used for generating motions with interaction. Researchers have tried to create complex interactions by combining several short pre-recorded motion clips including human-human or human-object interactions (Lee et al., 2006; Shum et al., 2008, 2010; Won et al., 2014). Recently, approaches based on deep learning have shown promising results as large datasets which include human-scene interaction have become publicly available. Locomotion adapting to surrounding environments (e.g. uneven terrains) has been demonstrated, where the system gets either future trajectories (Holden et al., 2017; Zhang et al., 2018) or pose conditioning frames (Harvey et al., 2020; Tang et al., 2022) as inputs. Deep neural networks that produce more general human-scene interactions (e.g. sitting on chairs or passing through doorways) can also be learned by using larger datasets that include those interactions (Starke et al., 2019; Hassan et al., 2021; Wang et al., 2021, 2022). A few works have attempted to generate limited range of interaction motions along with the hands using whole-body motion captures (Taheri et al., 2022; Wu et al., 2022; Ghosh et al., 2022; Tendulkar et al., 2022). Although these methods produce plausible motions with interaction, they could suffer from artifacts such as foot sliding or penetration especially when the datasets are not well-prepared in advance.
Physics-based methods have been investigated as an alternative to generating natural-looking motions because physical constraints ensure that the generated motions are physically plausible and they often generalize better to unseen scenarios. Especially for the motion tracking task given reference motions, a number of works showed that deep reinforcement learning (DRL) can provide near-perfect results (Peng et al., 2018; Bergamin et al., 2019; Park et al., 2019; Won et al., 2020; Peng et al., 2021; Fussell et al., 2021). On the other hand, developing physics-based controllers for reproducing complex physical interactions still has been considered as a challenging problem, and only a few studies have been demonstrated for human-human (Won et al., 2021; Bansal et al., 2017), human-object (Liu and Hodgins, 2018; Merel et al., 2020; Yang et al., 2022) interaction. The most closely relevant studies to our method are (Liu and Hodgins, 2018; Merel et al., 2020), which developed controllers of full-body characters with dexterous hands. Merel et al. (2020) proposed a vision-based controller that can catch and carry objects with hands. Although the framework is general enough to be applied to many other tasks, the motion quality is less comparable to the examples demonstrated in other motion tracking controllers, more importantly, it requires paired input motions where human actors and objects are recorded simultaneously, which are often unavailable. Liu et al. (2018) used two separate controllers for the body and arms, which are trained in the different pipelines, and the movement of the target object are reconstructed via trajectory optimization. This framework, however, does not assume the existence of paired motions, and requires curating a large amount of task-specific heuristics. Our method combines the benefits of both frameworks, where it can be easily applied for various applications and it uses actor motions only.
The key idea of our method is providing extra freedom for controllers to reassemble given reference motions, for which we develop part-wise motion priors. A few studies have also exhibited similar idea on part-wise motion assembly. Hecker et al. (2008) proposed a retargeting algorithm for highly varied user-created characters, where morphology-agnostic semantics of animations recorded during animation authoring are transferred to unknown target characters via inverse kinematics. Jang et al. (2022) developed a method called Motion Puzzle that performs part-wise style transfer of a source motion to a target motion by learning part-wise style networks and a graph convolutional network to extract motion features. These are kinematic methods, so the output motions could have similar artifacts mentioned above. Lee et al. (2022) developed physics-based controllers for new characters created by reassembling body parts of various characters, where the controllers are jointly optimized via supervised (part assembly) and reinforcement learning (dynamic control). Similarly, our method also provides a physically plausible way for part-wise assembly but our formulation is more flexible in a sense that it allows assembly of non-periodic motions with finer control rate.
3. Kinematic Motion Prior
The kinematic motion prior comes from the expert trajectories that are provided by motion capture data. We first revisit the core idea of AMP (Peng et al., 2021) (Sec. 3.1), which successfully utilizes the kinematic prior of motion in combination with RL to perform natural motion within a physics simulator. Then we explain our proposed part-wise assembly which efficiently excavates meaningful motion skills from multiple sources of motion capture data (Sec. 3.2).
3.1. Adversarial Motion Prior (AMP)
Instead of the tedious process of the reward design for naturalness, AMP (Peng et al., 2021) utilizes the reference data to infer the reward signal for natural motion. The total reward is a weighted sum of the task reward and the style reward , which is
| (1) |
The task reward is a typical reward of RL, representing how well the agent has achieved a given goal. The style reward adapts the idea of Generative Adversarial Imitation Learning (GAIL) (Ho and Ermon, 2016) and performs inverse RL to match the kinematic style of the reference motions in the dataset. Specifically, the style reward is calculated from the output of the discriminator as follows:
| (2) |
where the tuple of , and corresponds to the observations in the neighboring timesteps, and is a scaling coefficient. The discriminator is trained to mainly minimize the label prediction error between the generated motion and the demo trajectory:
| (3) |
where is a set of demonstrations, and is a policy of the agent.
The success of AMP is confined within the extent of available observations . The observations should account for the underlying DoFs of the agent performing the task. DoFs excluded in the observation are merely optimized for the task reward, and cannot be guided for natural motion. Consequently, the agent is less likely to achieve good performance in the task unless the dataset contains the motion directly related to the scenario. However, it is intractable for the off-the-shelf motion clips to cover the numerous real-world interaction scenarios.
3.2. Part-wise Motion Priors (PMP)
We propose obtaining strong part-wise motion priors that can be mixed into sophisticated skills for a wide range of interactions. A naïve strategy to avoid data insufficiency is generating an augmented motion database in advance via kinematics approach (Zhao et al., 2020; Petrovich et al., 2021) and using it as a source to train the discriminator. However, the possible combinations of motion mixtures are infinite and they are not guaranteed to be physically plausible. We instead leverage the existing motion capture data for different parts and assemble them efficiently. Our method guides each part to refer the part-specialized prior, then allows the agent to explore and dynamically select the holistic skill that best fits the scenario during the training phase. This combinatorial approach is also a practical choice when the movements of all the joints are not stored in the given reference motion.
Our method partitions the full list of joint into sets
| (4) |
For example, if we segment the body into the upper body (without hands), lower body, and two hands, then . Note that there is no restriction on the choice of sets, and the joints in the same set are not required to be spatially connected to each other in the skeleton tree. The core idea is to assign dedicated discriminators for the different sets of joints, instead of training a single discriminator for the whole body motion. The optimization objective in Eq. (3) is modified as
| (5) |
where denotes the motion dataset for the -th body part , and denotes the prediction probability of the -th discriminator given the tuples of the partial observation from either or .
Although the discriminators are independently optimized, all the DoFs of the agents are simultaneously controlled with a unified policy as in Eq (5). The style reward aggregates the terms as
| (6) |
where . We empirically found that the agent can coordinate different parts with the assistance of the physics simulation, and generate natural whole-body motion for a wide variety of scenarios. However, an extremely small reward signal in one of the parts can diminish the entire style reward after the multiplication, especially when is large. We prevent the reward from vanishing with a demo blend technique (Sec. 5), which serves a critical role to stabilize training.
4. Interaction Prior
Although the kinematic states in the motion capture provide essential information for the control, they don’t transfer the knowledge on the human-object interaction unless the trajectories of paired objects are included in the data. Our method can wisely bypass the addressed problem by incorporating an interaction prior obtained from a training of hand-only agent in a minimal environment. Recall that our PMP framework allows each motion prior to have a different feature set, which means the dexterous hand can be benefited from completely different types of data other than mocaps such as trajectories from the simulation. Interaction prior enhances the training efficiency, similar to the pre-training strategy for reusable effective skills in (Hasenclever et al., 2020; Won et al., 2022; Peng et al., 2022). Section 4.1 introduces a training environment for a hand to obtain the interaction prior, the grasping skill, and Section 4.2 contains the state definition to represent general grasping. Then Sec. 4.3 describes how we can combine the interaction prior with the part-wise kinematic priors from Sec. 3.2.
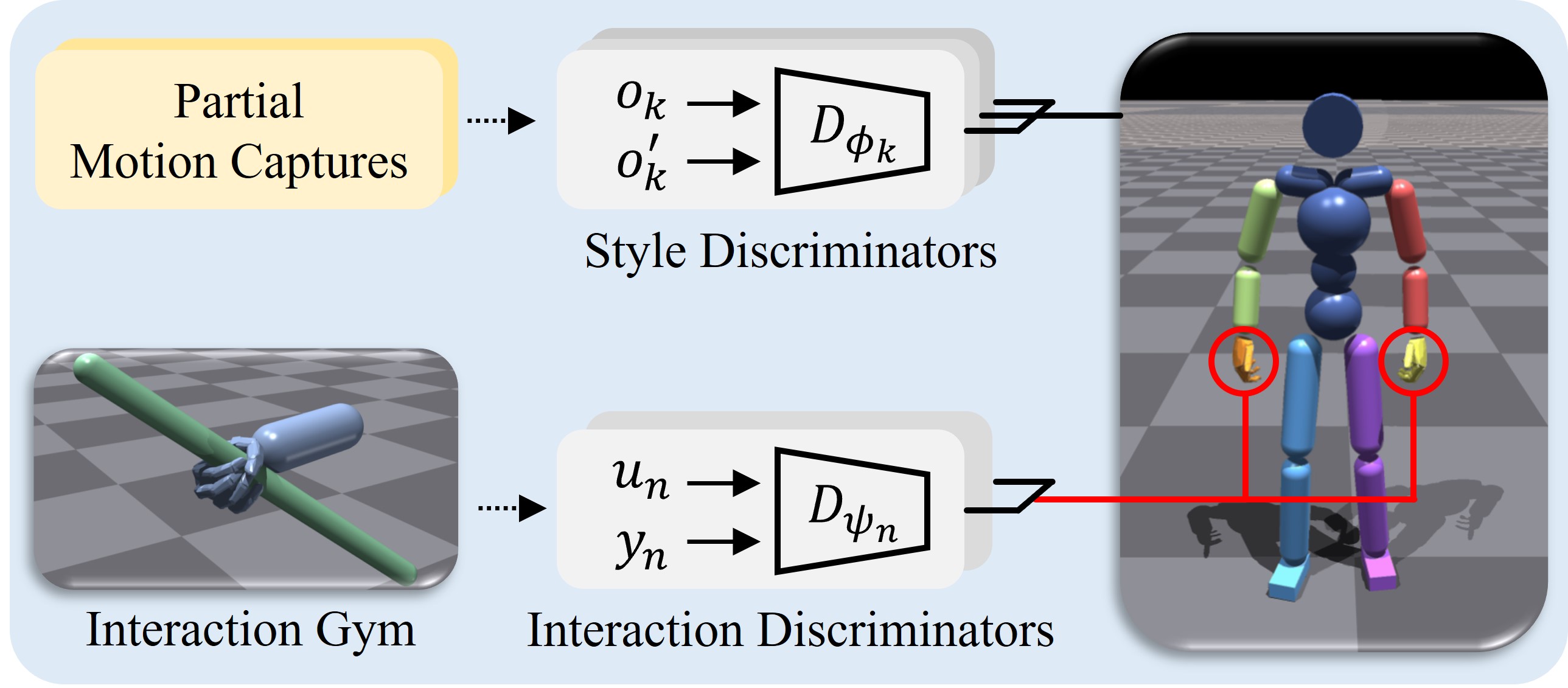
4.1. Interaction Gym
The interaction gym collects the state-action pairs of hand joints in a simulator, which can provide hand-specific supervision signals for various interaction-rich tasks. The simulator set-up is composed of a hand model and a representative target object, as shown in Fig. 2. We use a cylindrical rod for the grasping target, and the grasping skill is utilizable to more general objects as we discuss in the results. Since the controllable DoF of the hand is significantly smaller than that of the whole-body agent, we apply an RL algorithm with manually designed rewards to train natural and physically stable grasping. Out of many possible grasping styles, we enforce the hand to hold a target object with even contact to it. We further encourage stable grasping by applying an arbitrary force and torque to the target object throughout the episode.
4.2. Interaction State
The state is the input to the policy to output action , and it is crucial to have a proper part representation to learn a powerful and general interaction skill. The interaction state of the hand contains both the proprioceptive information of the actuators and the physical relationship to the target rod
| (7) |
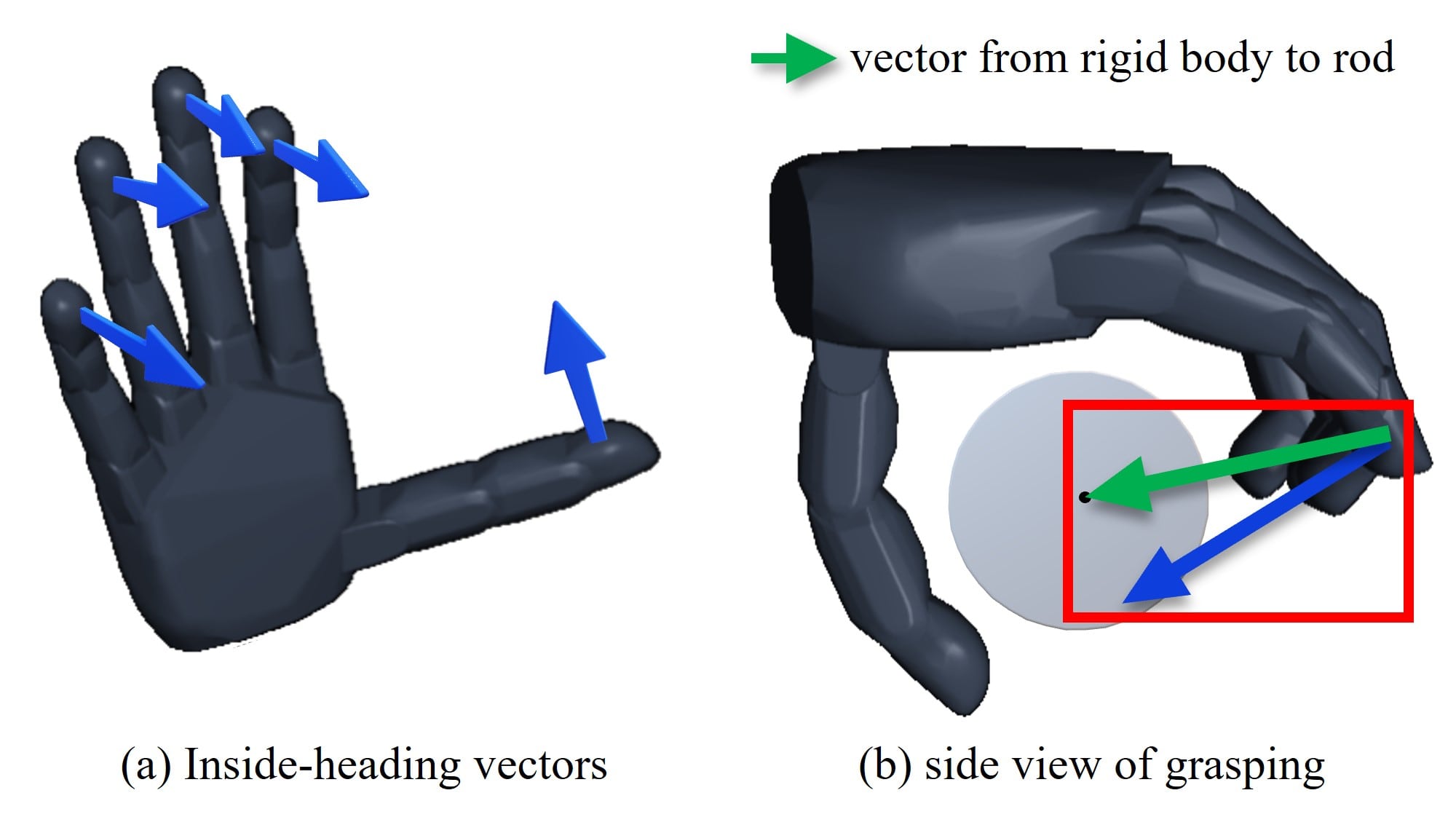
The first three terms contain the status of the hand. We use the position and velocity of the hand joints, and additionally provide 3D Cartesian positions of the end-effector for the index, middle, ring and pinky fingers in the local coordinate of the wrist. Then, we represent the pose of the target rod as a 6-dimensional vector, composed of the two end points of the rod in the wrist’s local coordinate, similar to . The last two terms sense the current state of the interaction. denotes the binary contact markers for individual fingertips. Finally, we find the cosine similarity between the vector pointing the inside of the hand from the fingers and the direction of the generated contact forces for every rigid body comprising each hand.
4.3. Integration with Kinematic Prior
After pre-training in a minimal gym, we need to transfer the learned grasping skill to the whole-body agent to successfully perform an interaction-rich task. However, the pretrained policy is not yet generalized by itself as it is trained only on the specific cylindrical rod. We utilize the adversarial imitation learning such that the agent can adapt the acquired skill to downstream tasks. Our part-wise motion priors in Sec. 3 nicely fits to the integration purpose. The expert state-action pairs () from the gym serve as another set of partial demonstrations, and we can easily blend the interaction prior for the two hands with the corresponding discriminators , where as shown in Fig. 2.
The kinematic hand prior is also necessary to generate natural preceding motions before the actual grasping. While the interaction prior serves a critical role for the grasping, the demo sequences of the gym only contains motion that is directly related to the grasping action. To make the hands naturally approach the object and initiate the grasp, we embed the interaction reward within the style reward term in Eq. 6 as
| (8) |
| (9) |
Here, and are subset of and , respectively. is a coefficient from the Gaussian kernel based on the Euclidean distance such that the likelihood of the interaction is normalized into the scale of . In this way, an agent receives more feedback from when its hand approaches to the target. The reward formulation faithfully reflects both the style prior and interaction prior. Further details including the implementation of are explained in the supplementary material.
5. Training Techniques
We use reinforcement learning to train both the unified policy of the whole-body integration (Sec. 3.2 and Sec. 4.3) and the hand-only policy in the interaction gym (Sec. 4.1). While most of the training settings are inspired by the previous works on physics-based animation (Peng et al., 2018, 2021), we make two important modifications to adapt to our part-wise setting.
5.1. State Initialization
The state initialization within a reference motion is an effective technique to allow a character to imitate a motion clip under a RL framework (Peng et al., 2018). However, our agent refers to different sets of motion clips for individual part segments, and does not have an access to a reliable whole-body pose for the initialization. We independently sample reference poses for parts without attempting to seek an optimal alignment. We empirically found that the agent eventually coordinates between parts and discovers a natural whole-body motion for various tasks.
5.2. Demo Blend Technique
Our style reward is the product of part-wise rewards from multiple parts. Intention of using multiplication rather than summation is to ensure that priors from all segmented parts contribute to the global motion. However, the reward signal may vanish if at least one of the parts fails to imitate the reference motion. It happens more frequently as the number of part segments increases, and halts the training process. To address this issue, our demo blend technique randomly mixes experienced trajectories for individual parts. Each substitution for a part happens independently in a Bernoulli distribution with a parameter . The demo blend technique is especially useful in training an agent with a large number of decomposed parts. In our experiment, we apply demo blending with the probability of for the scenario where the number of segmented parts is higher than two. The efficacy is demonstrated with the empirical results in Sec. 6.
6. Experiments
The policy of our agent outputs an action with the frequency of 30 Hz as a proportional-derivative (PD) target. We apply Proximal Policy Optimization (PPO) (Schulman et al., 2017), similar to other works on the physics-based animation. For the style reward, we collect the reference motions for each scenario from Mixamo (Adobe, 2020) and retarget them to our whole-body agent. We set weights for the task reward and style reward as and .
Our whole-body agent is modified from the humanoid of Deepmimic (Peng et al., 2018). We replace the sphere-shaped hands of the original humanoid with the hand from Modular Prosthetic Limb (MPL) (Kumar and Todorov, 2015). The total actuated DoF is 54, where each hand has 3 DoF for its wrist and 10 DoF for its fingers.
Our agents are trained with the physics simulation of the Isaac Gym (Makoviychuk et al., 2021) framework. Its GPU acceleration can simultaneously train the agents under 4096 environments. However, the efficiency of the highly parallel environment comes at the cost of losing detailed contact information, which is crucial in most of the contact-rich tasks. We observed that our pre-traing handles the nuances of subtle contacts for the whole-body agents such that the agent can interact with dexterous hands without additional information such as mesh-level contact positions.
6.1. Tasks
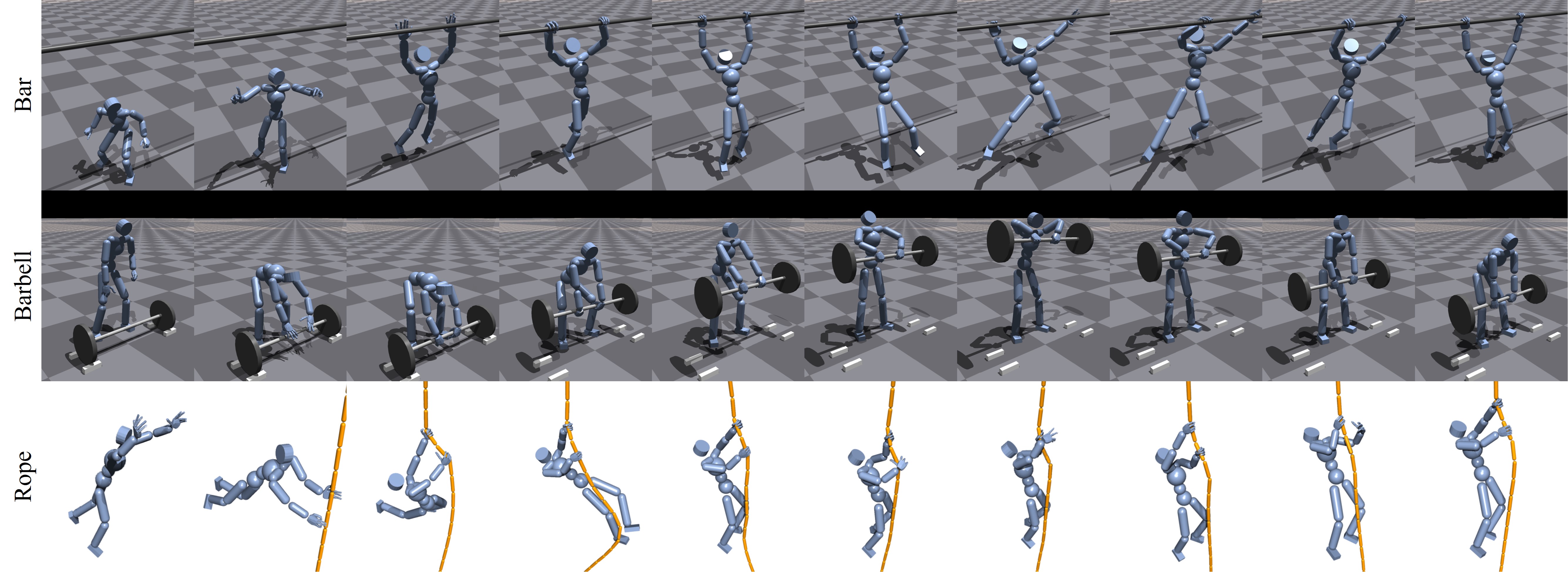
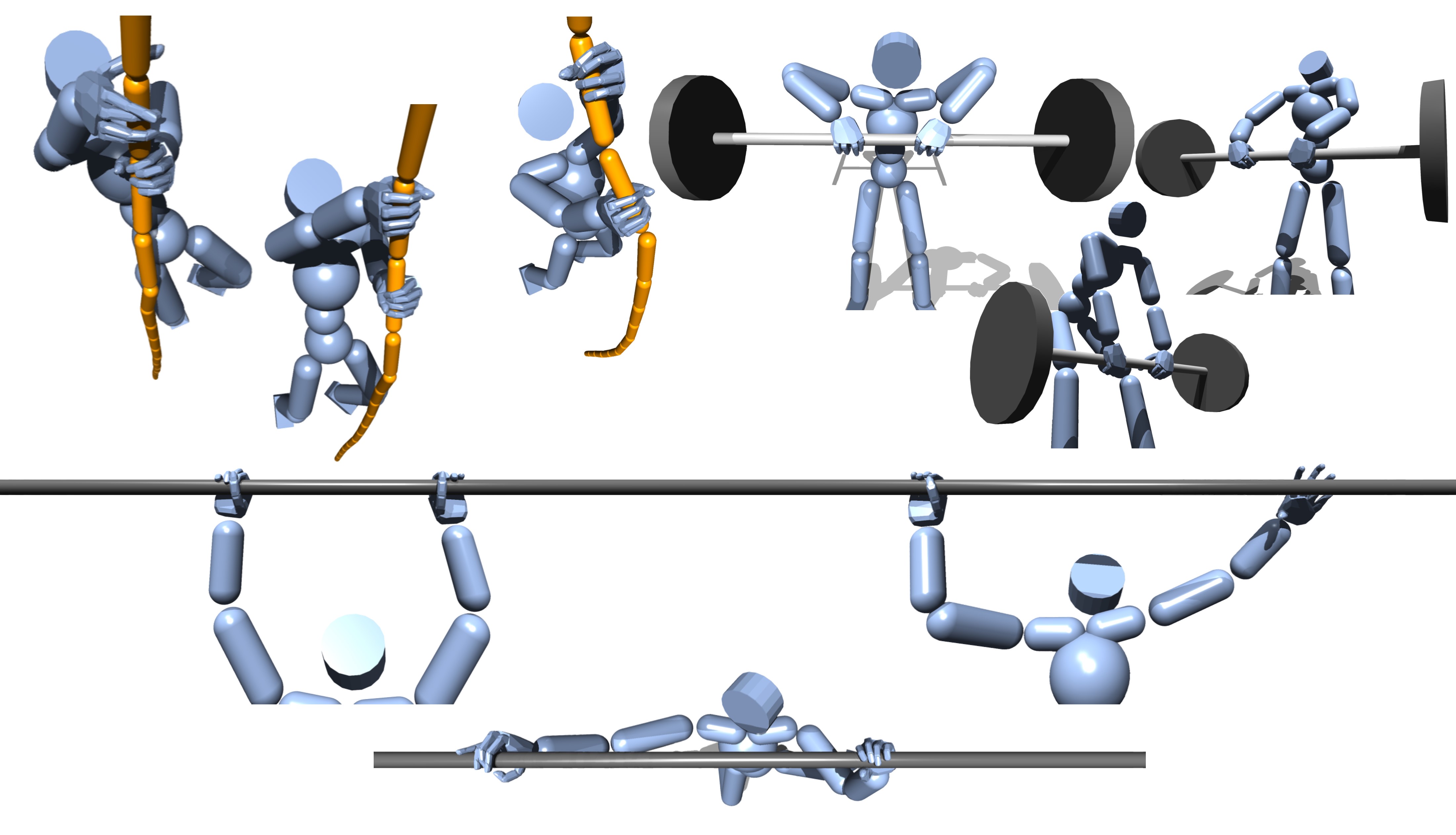
To demonstrate the general advantage of our part-wise motion prior, we show the motion quality on seven different tasks as shown in Table 1. The first three examples, Upstair Carrying, Sight Locomotion, and Walking Styles, demonstrate that PMP can efficiently assemble the part-wise motions and generate a plausible new motion to solve a novel task. The four other scenarios, Cart Pulling, Bar Hanging, Barbell Lifting, Rope Climbing, utilize the interaction prior to solve the complex interaction-rich tasks. When we incorporate the pre-trained interaction prior, we expand the state vector with the interaction state (Sec. 4.2) calculated from both hands.
Table 1 also contains the different part segments used for the presented scenarios. Upper includes abdomen, neck, shoulders, elbows, and wrists whereas Lower includes hips, knees, and ankles. Additionally, Trunk denotes only abdomen and neck joints, while Limbs represents shoulders, elbows, hips, knees, and ankles. For interaction scenarios, we group wrists with hands such that the motion of wrists can refer to the interaction prior. We briefly describe the individual tasks in the following. The full rewards and states are available in the supplementary material.
| Experiments | Part Segments () |
|---|---|
| Upstair Carrying | Upper - Lower (2) |
| Sight Locomotion | Trunk - Limbs (2) |
| Walking Styles | Trunk - R/L Arms - R/L Legs - R/L Hands (7) |
| Cart Pulling | Body - Hands (2) |
| Bar Hanging | Upper - Lower - Hands (3) |
| Barbell Lifting | Upper - Lower - Hands (3) |
| Rope Climbing | Upper - R/L Hands (3) |
| Scenario | PMP | PMP (no IP) | no PMP |
|---|---|---|---|
| Upstair Carrying | - | 0.51 (0.047) | 0.50 (0.022) |
| Sight Locomotion | - | 0.45 (0.072) | 0.39 (0.055) |
| Cart Pulling (Plain) | 0.65 (0.019) | 0.63 (0.021) | 0.59 (0.012) |
| Cart Pulling (Random) | 0.65 (0.041) | 9.2e-5 (5.9e-5) | 0.0066 (0.0035) |
| Cart Pulling (Curved) | 0.69 (0.010) | 0.63 (0.0060) | 0.59 (0.020) |
| Bar Hanging | 0.63 (0.25) | 0.33 (0.16) | 0.27 (0.19) |
| Barbell Lifting | 0.55 (0.27) | 0.052 (0.014) | 0.022 (0.019) |
| Rope Climbing | 0.63 (0.062) | 0.38 (0.13) | 0.31 (0.17) |
| Rope Climbing (Low ) | 0.26 (0.21) | 0.22 (0.20) | 0.063 (0.074) |
Upstair Carrying
The task is to walk down the ground plane to reach a stairway and then walk up to the highest stair, while carrying a ball in arms throughout the sequence. Our pipeline can fulfill the task by referring to motions from the locomotion, walking up the stair for the lower body, and carrying idle (carrying a ball while standing) for the upper body. The states and task rewards are similar to the setting in target location task in (Peng et al., 2021), but we augment the state vector with the height map to observe the stair. We penalize the agent dropping the ball by early termination (Peng et al., 2018) as an indirect reward for carrying.
Sight Locomotion
In this task, the agent tries to reach the target location (root goal) while looking at a sight goal. The root goal and sight goal are independently respawned. Available motion captures are the locomotion and looking around, which we imitate with the style reward for the limbs and the trunk, respectively. The state and rewards are again the same as the target location task, with an additional reward for the sight tracking. The sight tracking reward measures the deviation of the current sight from the sight goal.
Walking Styles
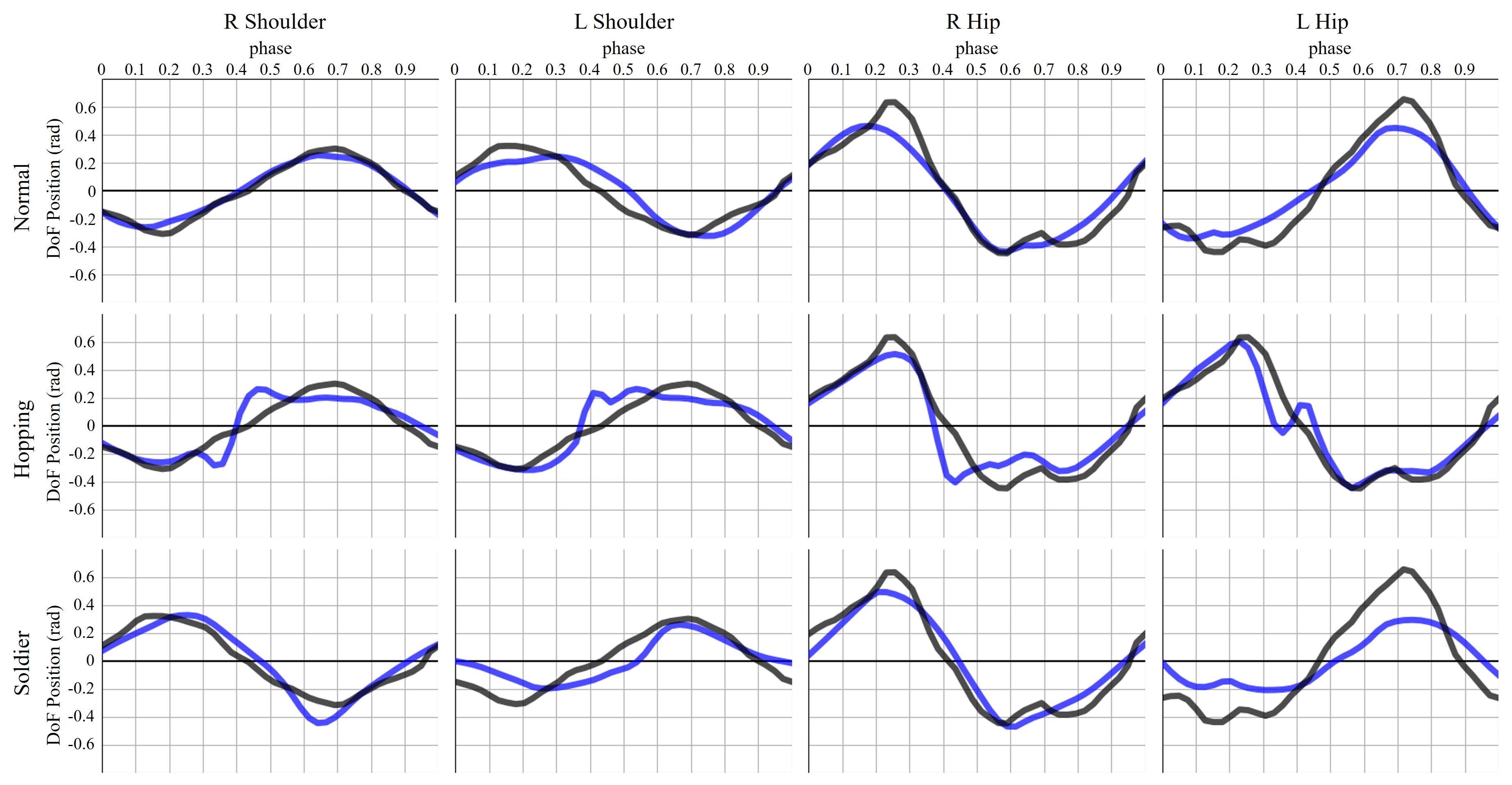
This scenario is designed to demonstrate that the part-wise prior can augment the motion trajectories in novel styles. We deliberately used a large number of part segments - seven parts. In addition to the dedicated discriminators for individual parts, we allocate one more discriminator, which enforces a set of specified joints to follow the demo trajectories. We choose the joints of the shoulders and hips to receive signal from the additional discriminator, as those joints are critical for the temporal correlations of the limb movements. We train the agent with three different styles of walking separately, namely normal, soldier, and hopping. The task reward is similar to the target heading task in (Peng et al., 2021).
Cart Pulling
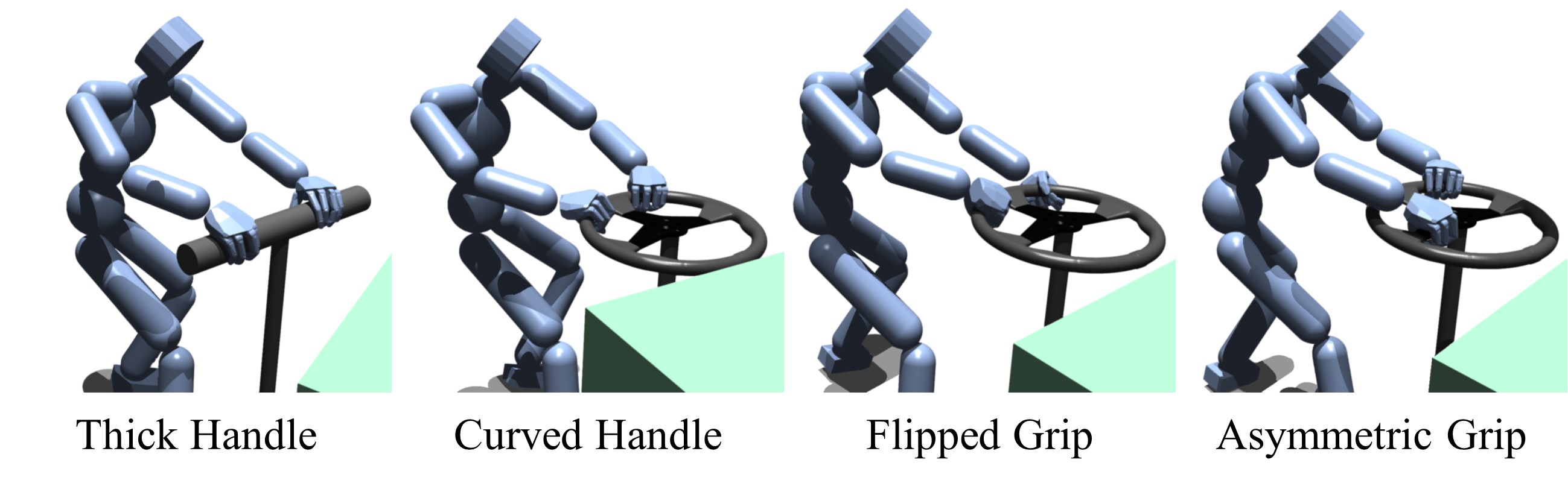
The task is to bring a 30 kg wagon cart to the goal location by pulling its handle. There are four different handles, namely a plain bar, a randomly-oriented plain bar, a thick bar, and a curved handle, where all four assets are unseen during the pre-training procedure. To highlight the applicability, we additionally train the agent to pull the cart in two different grip orientations on the curved handle. Here, we use pulling motions as a reference motion. In addition to the conventional state vector, we concatenate the cart states and the target position. The rewards encourage the hands to approach the grip, and the cart to reach the goal location.
Bar Hanging
The agent first jumps from the ground to hang on the 2 m-high bar with two hands, then horizontally shifts for 60 cm to the right or left direction along the bar according to the target grasping sites. The reference motions are jumping to hanging and horizontal hopping. The reward enforces the hands to reach their target grasping sites. To accelerate the training, we terminate an episode if the feet of the agent is still in contact with the ground after a few seconds from the start.

Barbell Lifting
This example performs an exercise of ‘sumo pull’ with a 10 kg barbell. An agent first pulls up the barbell, then brings it at the target height. The target height starts at 1.25 m, then alternates between 0.25 m and 1.25 m throughout the episode. The reference motion is sumo pulling for both the upper and lower body segments. The state and rewards are similar to the Cart Pulling.
Rope Climbing
The agent first approaches a rope from the air and grasps it. The agent then climbs up the rope, which is induced by changing the target grip positions with the input command. We intentionally ignore the lower body control, and solely rely on hands to climb the rope. The reference motion for the upper body is rope climbing motion. Because the pre-grasp period is extremely short, only idle motion is utilized for each hand. The state vector is augmented with the rope state and the distances between fingers to the target grasping site.

6.2. Results
We first show the quantitative results of our experiments. To measure the task performance, we evaluate a normalized average returns (NR) of the task reward as in (Peng et al., 2018). Similar to the previous work, we also enable the early termination and reference state initialization (Peng et al., 2018) during the measurements, and expand the maximum length of an episode for some scenarios to show the stability in a long-term performance. We average the values throughout 1000 episodes per experiment. Although the maximum value of NR is inherently unreachable for some scenarios, extremely low NR () implies complete failure in the training. For Rope Climbing, we additionally test agents climbing a rope with a lower frictional coefficient to show the effect of PMP.
As shown in Table 3, our approach outperforms the agents without PMP for all the scenarios. This implies that in the perspective of task efficiency, our method can extract motion priors more effectively from the same amount of motion captures compared to the baseline. Moreover, PMP not only enhances task performance but also generates natural motions that resembles human-object interaction in the real world. We additionally exhibit qualitative results of agents performing in the scenarios as shown in Figure 3 and 10. We further provide results on the other examples including comparisons with the baselines in the supplementary video.
7. Discussion
Skill Assembly
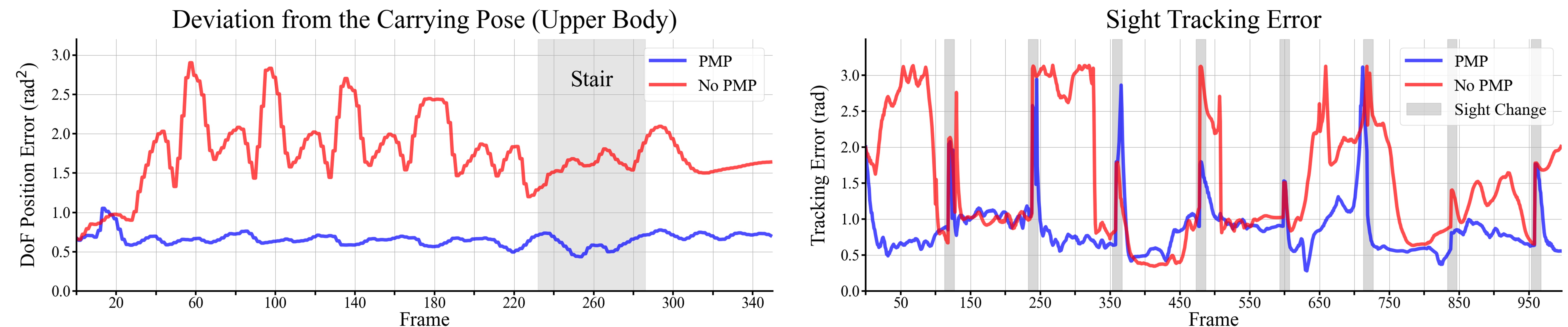
We first describe the strength of our method when the number of available motion captures is limited using the results of Upstair Carrying and Sight Locomotion. In Figure 6, we evaluate two task-related measurements: the joint position error in Upstair Carrying compares the distance of the upper body poses compared to the carrying idle pose, and the sight tracking error measures the angle difference between the actual sight direction and the goal direction for Sight Locomotion. In both scenarios, our method synthesizes meaningful skills through the combinations of existing part-wise motion data. However in Upstair Carrying, the agent without PMP treats locomotion as a more important skill to reach the goal, and thus it fails to imitate carrying motion. Similarly in Sight Locomotion, our approach shows agile sight transitions whenever the sight goal changes while the baseline results in larger errors. These results are the direct consequences of the design of the algorithm, where the policy without PMP refers to a particular full-body motion among the reference sequences, while our approach explores more rich set of skills to find the best combination for the task. We find that even with a higher weight for task reward, the agent trained with PMP maintains natural motion whereas the non-PMP agent sacrifices the quality of motions. Further visualizations of the qualitative results of the two scenarios are shown in Figure 7 and 8.

Motion Augmentation
In Walking Styles, we experiment on the capacity of PMP on the motion style augmentation. By controlling the temporal phases for the shoulders and hips only as an additional motion prior, our agent performs different styles of natural walking in a physically plausible manner. The overall results on the tracking quality of each style are shown in Figure 9. Among the experiments, we find the demo blend technique (Sec. 5.2) is critical in imitating the hopping-style motion. Since we train 8 discriminators in total for this example, an agent is highly susceptible to the reward vanishing problem. Figure 4 qualitatively compares the effect of demo blend technique. The demo blending maintains the style rewards in effect such that all the parts observable while training.
Generalization of Interaction Prior
Even though the agent in the interaction gym (Sec. 4.1) only experiences grasping of a simple cylindrical rod, target objects in the
actual interactions can have more diverse shapes. In the sub-scenarios of Cart Pulling, we test whether interaction prior can be generalized to different types of handles or various grips. In Figure 5, we find that the interaction prior can be generalized to a thicker handle (3.5 cm radius) as well as a completely different shape like curved target. Furthermore, we motivate the agent to use various grasping styles by simply changing the interaction target to different parts of the handle. We find that the simple modification results in different grips, and consequently affects the whole-body motion. This shows that users can diversify the details of the targeting scenario using an interaction prior obtained from a single training.
Whole-body Naturalness
Our pipeline effectively balances part-wise motions without explicit module for global coordination. We attribute this to the physics simulator and the reward term. The simulator only allows physically valid whole-body motion and filters out combinations that result in awkward postures. Additionally, the task reward encourages the agent to efficiently achieve the goal and suppresses irrelevant movements. The reward in some examples also contain torque minimizing rewards, which contribute to the smoother overall trajectories.
Limitation
PMP can provide a great option when motion captures are limited or interaction prior for a specific part is required. Also, proposed interaction prior reduces repetitive policy optimization for the grasping-related reward terms in multiple downstream tasks. However still, proposed method does not completely relieve all the efforts on inventing an effective task reward function to induce agent to properly behave in the challenging scenarios. As a future work, PMP may include additional demo features, such as visual inputs of the interaction scenes which may enable the agent to automatically explore the optimal combination of the part-wise skills with comparably simpler task reward terms. In addition, an automated process of exploring the optimal part segment combination can be addressed in the succeeding work.
8. Conclusion
In this work, we present a framework to incorporate part-wise motion priors to assemble multiple motion skills for a whole-body agent. We segment the body joints into parts and encourage each part to refer to different demonstrations. In our framework, an agent can benefit from both motion captures and simulated trajectories for a specific subpart of the body, which is demonstrated with the pre-trained grasping skill learned from a minimal hand-only gym. Our approach composes a complete skill of physical interaction by a novel combination of motions that is not available in the motion capture, and enables agent to perform in the various challenging tasks. A range of scenarios can be broadened with another choice of the dexterous part and interaction skill, e.g. toes with the sophisticated control of a soccer ball. We believe that the our method can be further expanded to animations with scene-level interaction or robotic whole-body manipulators in contact-rich environments.
Acknowledgements.
This work was supported by the National Research Foundation of Korea(NRF) grant funded by the Korea government(MSIT) (No. RS-2023-00208197) and Creative-Pioneering Researchers Program through Seoul National University. Jungdam Won was partially supported by the MSIT(Ministry of Science and ICT), Korea, under the ITRC(Information Technology Research Center) support program(IITP-2023-2020-0-01460) supervised by the IITP(Institute for Information & Communications Technology Planning & Evaluation), and by ICT (Institute of Computer Technology) at Seoul National University.References
- (1)
- Adobe (2020) Adobe. 2020. Adobe’s Mixamo. Adobe. http://www.mixamo.com
- Bansal et al. (2017) Trapit Bansal, Jakub Pachocki, Szymon Sidor, Ilya Sutskever, and Igor Mordatch. 2017. Emergent complexity via multi-agent competition. arXiv preprint arXiv:1710.03748 (2017).
- Bergamin et al. (2019) Kevin Bergamin, Simon Clavet, Daniel Holden, and James Richard Forbes. 2019. DReCon: data-driven responsive control of physics-based characters. ACM Transactions On Graphics (TOG) 38, 6 (2019), 1–11.
- Fussell et al. (2021) Levi Fussell, Kevin Bergamin, and Daniel Holden. 2021. Supertrack: Motion tracking for physically simulated characters using supervised learning. ACM Transactions on Graphics (TOG) 40, 6 (2021), 1–13.
- Ghosh et al. (2022) Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Christian Theobalt, and Philipp Slusallek. 2022. IMoS: Intent-Driven Full-Body Motion Synthesis for Human-Object Interactions. arXiv preprint arXiv:2212.07555 (2022).
- Harvey et al. (2020) Félix G Harvey, Mike Yurick, Derek Nowrouzezahrai, and Christopher Pal. 2020. Robust motion in-betweening. ACM Transactions on Graphics (TOG) 39, 4 (2020), 60–1.
- Hasenclever et al. (2020) Leonard Hasenclever, Fabio Pardo, Raia Hadsell, Nicolas Heess, and Josh Merel. 2020. Comic: Complementary task learning & mimicry for reusable skills. In International Conference on Machine Learning. PMLR, 4105–4115.
- Hassan et al. (2021) Mohamed Hassan, Partha Ghosh, Joachim Tesch, Dimitrios Tzionas, and Michael J Black. 2021. Populating 3D scenes by learning human-scene interaction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14708–14718.
- Hecker et al. (2008) Chris Hecker, Bernd Raabe, Ryan W Enslow, John DeWeese, Jordan Maynard, and Kees van Prooijen. 2008. Real-time motion retargeting to highly varied user-created morphologies. ACM Transactions on Graphics (TOG) 27, 3 (2008), 1–11.
- Ho and Ermon (2016) Jonathan Ho and Stefano Ermon. 2016. Generative adversarial imitation learning. Advances in neural information processing systems 29 (2016).
- Holden et al. (2017) Daniel Holden, Taku Komura, and Jun Saito. 2017. Phase-functioned neural networks for character control. ACM Transactions on Graphics (TOG) 36, 4 (2017), 1–13.
- Jang et al. (2022) Deok-Kyeong Jang, Soomin Park, and Sung-Hee Lee. 2022. Motion Puzzle: Arbitrary Motion Style Transfer by Body Part. ACM Transactions on Graphics (TOG) (2022).
- Kumar and Todorov (2015) Vikash Kumar and Emanuel Todorov. 2015. Mujoco haptix: A virtual reality system for hand manipulation. In 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids). IEEE, 657–663.
- Lee et al. (2006) Kang Hoon Lee, Myung Geol Choi, and Jehee Lee. 2006. Motion patches: building blocks for virtual environments annotated with motion data. In ACM SIGGRAPH 2006 Papers. 898–906.
- Lee et al. (2022) Seyoung Lee, Jiye Lee, and Jehee Lee. 2022. Learning Virtual Chimeras by Dynamic Motion Reassembly. ACM Transactions on Graphics (TOG) 41, 6 (2022), 1–13.
- Liu and Hodgins (2018) Libin Liu and Jessica Hodgins. 2018. Learning basketball dribbling skills using trajectory optimization and deep reinforcement learning. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–14.
- Makoviychuk et al. (2021) Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. 2021. Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning.
- Merel et al. (2020) Josh Merel, Saran Tunyasuvunakool, Arun Ahuja, Yuval Tassa, Leonard Hasenclever, Vu Pham, Tom Erez, Greg Wayne, and Nicolas Heess. 2020. Catch & Carry: reusable neural controllers for vision-guided whole-body tasks. ACM Transactions on Graphics (TOG) 39, 4 (2020), 39–1.
- Park et al. (2022) JoonKyu Park, Yeonguk Oh, Gyeongsik Moon, Hongsuk Choi, and Kyoung Mu Lee. 2022. HandOccNet: Occlusion-Robust 3D Hand Mesh Estimation Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1496–1505.
- Park et al. (2019) Soohwan Park, Hoseok Ryu, Seyoung Lee, Sunmin Lee, and Jehee Lee. 2019. Learning predict-and-simulate policies from unorganized human motion data. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–11.
- Peng et al. (2018) Xue Bin Peng, Pieter Abbeel, Sergey Levine, and Michiel van de Panne. 2018. DeepMimic: Example-guided Deep Reinforcement Learning of Physics-based Character Skills. ACM Trans. Graph. 37, 4, Article 143 (July 2018), 14 pages. https://doi.org/10.1145/3197517.3201311
- Peng et al. (2022) Xue Bin Peng, Yunrong Guo, Lina Halper, Sergey Levine, and Sanja Fidler. 2022. Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters. ACM Transactions On Graphics (TOG) 41, 4 (2022), 1–17.
- Peng et al. (2021) Xue Bin Peng, Ze Ma, Pieter Abbeel, Sergey Levine, and Angjoo Kanazawa. 2021. Amp: Adversarial motion priors for stylized physics-based character control. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–20.
- Petrovich et al. (2021) Mathis Petrovich, Michael J Black, and Gül Varol. 2021. Action-conditioned 3d human motion synthesis with transformer vae. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 10985–10995.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017).
- Shum et al. (2008) Hubert PH Shum, Taku Komura, and Shuntaro Yamazaki. 2008. Simulating interactions of avatars in high dimensional state space. In Proceedings of the 2008 Symposium on interactive 3D Graphics and Games. 131–138.
- Shum et al. (2010) Hubert PH Shum, Taku Komura, and Shuntaro Yamazaki. 2010. Simulating multiple character interactions with collaborative and adversarial goals. IEEE Transactions on Visualization and Computer Graphics 18, 5 (2010), 741–752.
- Starke et al. (2019) Sebastian Starke, He Zhang, Taku Komura, and Jun Saito. 2019. Neural state machine for character-scene interactions. ACM Trans. Graph. 38, 6 (2019), 209–1.
- Taheri et al. (2022) Omid Taheri, Vasileios Choutas, Michael J Black, and Dimitrios Tzionas. 2022. Goal: Generating 4d whole-body motion for hand-object grasping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13263–13273.
- Tang et al. (2022) Xiangjun Tang, He Wang, Bo Hu, Xu Gong, Ruifan Yi, Qilong Kou, and Xiaogang Jin. 2022. Real-time Controllable Motion Transition for Characters. arXiv preprint arXiv:2205.02540 (2022).
- Tendulkar et al. (2022) Purva Tendulkar, Dídac Surís, and Carl Vondrick. 2022. FLEX: Full-Body Grasping Without Full-Body Grasps. arXiv preprint arXiv:2211.11903 (2022).
- Wang et al. (2022) Jingbo Wang, Yu Rong, Jingyuan Liu, Sijie Yan, Dahua Lin, and Bo Dai. 2022. Towards Diverse and Natural Scene-aware 3D Human Motion Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20460–20469.
- Wang et al. (2021) Jiashun Wang, Huazhe Xu, Jingwei Xu, Sifei Liu, and Xiaolong Wang. 2021. Synthesizing long-term 3d human motion and interaction in 3d scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9401–9411.
- Won et al. (2020) Jungdam Won, Deepak Gopinath, and Jessica Hodgins. 2020. A scalable approach to control diverse behaviors for physically simulated characters. ACM Transactions on Graphics (TOG) 39, 4 (2020), 33–1.
- Won et al. (2021) Jungdam Won, Deepak Gopinath, and Jessica Hodgins. 2021. Control strategies for physically simulated characters performing two-player competitive sports. ACM Transactions on Graphics (TOG) 40, 4 (2021), 1–11.
- Won et al. (2022) Jungdam Won, Deepak Gopinath, and Jessica Hodgins. 2022. Physics-based character controllers using conditional vaes. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–12.
- Won et al. (2014) Jungdam Won, Kyungho Lee, Carol O’Sullivan, Jessica K Hodgins, and Jehee Lee. 2014. Generating and ranking diverse multi-character interactions. ACM Transactions on Graphics (TOG) 33, 6 (2014), 1–12.
- Wu et al. (2022) Yan Wu, Jiahao Wang, Yan Zhang, Siwei Zhang, Otmar Hilliges, Fisher Yu, and Siyu Tang. 2022. Saga: Stochastic whole-body grasping with contact. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part VI. Springer, 257–274.
- Yang et al. (2022) Zeshi Yang, Kangkang Yin, and Libin Liu. 2022. Learning to use chopsticks in diverse gripping styles. ACM Transactions on Graphics (TOG) 41, 4 (2022), 1–17.
- Zhang et al. (2018) He Zhang, Sebastian Starke, Taku Komura, and Jun Saito. 2018. Mode-adaptive neural networks for quadruped motion control. ACM Transactions on Graphics (TOG) 37, 4 (2018), 1–11.
- Zhang et al. (2021) He Zhang, Yuting Ye, Takaaki Shiratori, and Taku Komura. 2021. ManipNet: Neural manipulation synthesis with a hand-object spatial representation. ACM Transactions on Graphics (ToG) 40, 4 (2021), 1–14.
- Zhao et al. (2020) Rui Zhao, Hui Su, and Qiang Ji. 2020. Bayesian adversarial human motion synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6225–6234.
Appendix A Adversarial Training
In this section, we further explain the details of the adversarial training for the part-wise motion priors (PMP). Though the style discriminators and the interaction discriminators are mainly trained to minimize the discriminator loss , a few regularization terms are also involved to mitigate the unstable nature of the adversarial training. For simplification, we denote to refer to all the discriminators in our pipeline, which allows us to rewrite the discriminator loss as
| (10) |
One of the additional regularization terms is the gradient penalty introduced in the previous work (Peng et al., 2021), which is to prevent the discriminator to be deviated from the distribution of the original demonstrations. We modify the original formula to incorporate a set of discriminators, which results in
| (11) |
In the other regularization term, we use weight decay to avoid the overfitting of the discriminators to the limited reference data with the squared norm regularization as
| (12) |
In summary, the total loss function to train the discriminators can be summarized as a weighted sum of the aforementioned terms
| (13) |
where .
Appendix B Training Details
In this section, we describe the detailed settings of the training including states and rewards used for each conducted task.
B.1. General Settings
As addressed in the main paper, our character is a humanoid equipped with two MPL (Kumar and Todorov, 2015) hands. To train a whole-body agent for all the tasks, we include the proprioceptive information as well as the root states in the state vector. The basic state configuration is largely adopted from the previous work (Peng et al., 2018), where state vector can be represented as
| (14) |
Here, each of represents the height, velocity, orientation, and angular velocity of the root, while stand for the position and the velocity of the character joint respectively. Further, is the relative positions of the palms and feet with respect to the root in Cartesian space. Note that the orientation of the root and the spherical body joints are encoded as a 6D representation of rotation composed of the tangent and normal vectors. In the scenarios highlighting interactions (Cart Pulling, Bar Hanging, Barbell Lifting, Rope Climbing), we augment the state vector with the interaction state of each hand that describes the state of the hand-only agent introduced in the Interaction Gym (Sec. 4.1).
We append additional task-specific information to each task. For the scenario of Upstair Carrying, Sight Locomotion, Cart Pulling, where the task contains the mission of target location (Peng et al., 2021), we add an extra feature of the relative position of root respect to the goal position. Similarly, the relative Cartesian position of the barbell from its goal is included in the state vector for the Barbell Lifting scenario. However in Bar Hanging and Rope Climbing, an additional feature to indicate input hand goal is unnecessary as changes in the grasping target positions are already observable by an interaction state.
For the interaction scenario where two hands are guided to simultaneously grasp the object, we slightly modify the original style reward formulation of Eq. (9) into
| (15) |
In this way, both hands are trained to utilize interaction prior in a synchronized manner, making interaction much more visually natural. Empirically, we find that adding a small amount of offset, e.g. 0.3, to the interaction reward can prevent the policy from converging to utilize only the kinematic priors.
As explained in the main paper, we use Euclidean distance-based Gaussian kernel to measure the interaction coefficient given the observation of interaction state . We assume a hand is ready to interact with the target if the distance between the wrist and the object is lower than . By reflecting the assumption, the formula of is written as follows:
| (16) |
where is the distance between the wrist and the object from the observation , and the constant .
B.2. Task-related Settings
Interaction Gym
In this environment, only the orientation of the rod is sampled randomly while its position is centered around the palm. This setting makes grasping always feasible without the translation of the root of the hand. The force of and torque of in random directions are applied to the gravity-disabled rod with the frequency of .
To learn a stable yet natural grasping policy of a cylindrical rod against external disturbances, we introduce a set of reward terms in the interaction gym. Along with the rod reward motivating the firm grasping of the rod, we additionally devise several reward functions to reflect the grasping style of a real human hand. First, finger reward is designed to keep the rigid bodies comprising the hand close to the surface of the rod, and the MCP reward is applied to enforce MCP joints to exert maximal torques during grasping. Here, a hand is guided from the tip reward which minimizes the angle between heading direction toward the inside of the hand and the directional vector connecting each fingertip to the closest point on the surface of the target rod. We visualize the and in Figure 11. Next, to facilitate grasping in the various wrist pose, wrist reward is designed to track randomly set target pose while penalizing unnecessary wrist movements. Lastly, actuated torque minimizing reward for DoFs except MCP joints is used to regularize hand motions. The exact formulas for the aforementioned reward terms are written as follows:
| (17) |
| (18) |
| (19) |
| (20) |
| (21) |
| (22) |
In the equations, and refer to the linear and angular velocity of the rod, respectively. Further, indicates a mean value of the normalized target action for the MCP joints which shapes hand at hard fist when . In addition, each of represents DoF position and velocity for the spherical wrist joint, and means actuated PD force of j-th joint. Note that are a set of total hand, and fingertip rigid bodies respectively, and refer to the MCP joints set. Consequently, the total task reward is calculated as
| (23) |
Upstair Carrying
In this example, we build six stairs where each stair has a height of and width of . The task goal is to reach the goal position located at the highest stair, where the task reward is designed in a similar way to the target location (Peng et al., 2021) task
| (24) |
| (25) |
| (26) |
Here, denotes the displacement from the root to the goal, and indicates the root velocity projected onto the heading direction. Additionally, we set the target minimum speed , and use , .
Sight Locomotion
Similar to the Upstair Carrying scenario, the task goal in this example also contains a target location where the goal is respawned far from the character root in the initial state. Noteworthily, in this scenario, we have an additional goal for sight tracking, which is located on the surface of a cylinder with radius centered around the character. We reuse the reward functions in Eq. (24, 25, 26) for root tracking reward with the same coefficients in Upstair Carrying. Additionally, we design a sight tracking reward, which is written as
| (27) |
where each of and represents the orientation of goal sight and current sight respectively, and the coefficient is . The total task reward is a weighted sum of and with a ratio of 7:3.
Walking Styles
This scenario is designed to show the style augmentation of a simple walking motion, where the task reward is adapted from the target heading (Peng et al., 2021) task. The reward function can be formulated similarly to the Eq. (25) with the coefficients , and for normal, soldier styles while for hopping style. To further generate smoother motions, we use torque minimizing reward similar to Eq. (22) for training normal and soldier style walking examples.
Cart Pulling
In this scenario, the task is to pull a cart to the target position in the distance of . Therefore, we switch character root to the cart base in the formulation of Eq. (24, 25, 26) to shape cart tracking reward where coefficients are . To properly guide both hands to play a key role in pulling the cart, we introduce hand reaching reward to place hands on the proper area for the firm grasps. not only induces hand approaching to targets but also serves as a constraint. Specifically, by minimizing the search space of the positions of both hands, we can better coordinate the learned grasping and the reference mimicking body motions. To this end, we multiply a binary indicator for valid reaching, which in this example, examines whether a hand is located above the handle or not. Accordingly, the reward functions can be represented as
| (28) |
| (29) |
where indicates right and left hand, is the displacement from a hand to the target hand position, and .
Bar Hanging
In this example, the agent jumps to hang on the high horizontal bar, and subsequently hops to the left or right along the bar for every 2 seconds. To enable the transition to the hopping from the stable hanging pose, we use curriculum learning where the hand targets are fixed in the position so that no hopping is induced in the earlier phase of the training. We terminate an episode if one of two feet remains in contact with the ground after from the state initialization. Task reward is designed in a similar way to Eq. (31) with the parameter . In this example, the reaching indicator checks if each palm is sufficiently aligned with the front direction of a character. In the absence of the reaching indicator, the agent easily gets stuck in the local minima that yields unnatural poses of both hands as learning the transition between jumping and hanging motions is challenging.
Barbell Lifting
Similar to Cart Pulling, the objective in this task is to move a physical object to a desired pose. Therefore, we modify task reward function in Eq. (29) by replacing a cart tracking reward with barbell tracking reward while maintaining the other values. In contrast to previous interaction scenarios, we rather use real-numbered indicator , which corresponds to the cosine value of the angle between the vector that heads the inner side of the palm and the vector that heads the barbell. Two vectors here are alike the and respectively, in Figure 11. Note indicator is scaled in to maintain the task reward in a normalized scale. Also, in order to enhance stability of the barbell lifting motions, we incorporate the barbell balance reward described in the previous work (lee2022deep). As a result, the total reward is as follows:
| (30) |
where and .
Rope Climbing
In this example, each episode starts by throwing the agent toward the vertical rope composed with 30 units of -lengthed capsules. Each of the left or right hand is set to grasp an upper unit capsule to procedurally generate the rope climbing motion. We find that initializing the agent only with the right-hand up hanging leads to biased training and hampers the agent from learning hand alternation. To alleviate this problem, we randomize the initial target poses of both hands for each episode. We formulate the task reward in a similar way to Bar Hanging which can be represented as Eq. (31), but we slightly modify the formula as the movement of both hands occur in alternating manner. Specifically, we add a small offset to the reward of each hand so that the reward emitted by the other hand can be maintained when the target of one hand has just changed. In summary, the finalized task reward is
| (31) |
where is 128 for the first hang, 16 for the rest of the climbing phase, and the offset is 0.05. Note the hand pose indicator is calculated as a normalized cosine form similarly in Babell Lifting.
B.3. Hyperparameters
| Parameters | value |
| learning rate | 5e-5 |
| for GAE | 0.99 |
| for GAE | 0.95 |
| clip range for PPO | 0.2 |
| KL threshold for PPO | 0.008 |
| batch size for PPO | 32768 |
| batch size for PMP | 4096 |
| demo buffer size for PMP | 2e5 |
| replay buffer size for PMP | 1e6 |
| number of environments | 4096 |
| horizon length | 16 |