Point-line-based RGB-D SLAM and Bundle Adjustment Uncertainty Analysis
Abstract
Most of the state-of-the-art indirect visual SLAM methods are based on the sparse point features. However, it is hard to find enough reliable point features for state estimation in the case of low-textured scenes. Line features are abundant in urban and indoor scenes. Recent studies have shown that the combination of point and line features can provide better accuracy despite the decrease in computational efficiency. In this paper, measurements of point and line features are extracted from RGB-D data to create map features, and points on a line are treated as keypoints. We propose an extended approach to make more use of line observation information. And we prove that, in the local bundle adjustment, the estimation uncertainty of keyframe poses can be reduced when considering more landmarks with independent measurements in the optimization process. Experimental results on two public RGB-D datasets demonstrate that the proposed method has better robustness and accuracy in challenging environments.
Index Terms:
Line guidance features, RGB-D SLAM, uncertainty analysis.I INTRODUCTION
Visual odometry (VO) and Simultaneous Localization and Mapping (SLAM) are popular topics in the field of robotics research. In recent years, they receive more attention due to their applications in self-driving cars, augmented reality and 3D reconstruction. Visual odometry and SLAM can be addressed with different camera sensors, such as monocular cameras [1], stereo cameras [2], and RGB-D cameras [3]. RGB-D cameras can provide depth measurements for each frame and reduce costs for indoor state estimation and mapping despite of their relatively short depth measurement range. Generally, lack of features and uneven feature distributions can pose challenges for feature-based visual SLAM methods. Therefore, in this work, we aim at developing a more robust and accurate RGB-D SLAM approach.
Current visual SLAM methods can be typically divided into two categories, indirect (or feature-based) such as PTAM [4] and ORB-SLAM [5] and direct methods such as [6, 7]. Indirect methods usually need to extract features from the image and then match them with history features for data association, so that a 3D sparse map can be built and the pose of subsequent frames can be calculated by minimizing geometric errors of the features in the image plane. Direct methods directly exploit on the pixel intensity and estimate the pose by minimizing photometric errors of a certain amount of pixels, while avoiding the processes of feature extraction and matching.
Among the indirect methods, most visual SLAM systems are based on point features because they are easy to extract with less time consumption. However, these methods rely on sufficient keypoint distributions in frames and are vulnerable to the low-textured scenes. The lack of reliable feature points often occurs in man-made environments where a certain number of lines may still exist. Methods with the combination of point and line features have been proposed in recent years [8, 9, 10]. Point-line-based methods showed better performance than point-based methods in some low-textured scenes. In addition, most of current point-line-based methods represent a 3D line by its 3D endpoints [9] or the coordinates with six degrees of freedom [11].
In order to use more measurement information of line features from the RGB-D data, we sample a set of points on the line segments to create map features, and then compute the reprojection errors based on the distance between points and lines. The line segments are used to guide the selection of points and construct reprojection errors for these points. In summary, the main contributions of this paper are:
-
•
Under the maximum likelihood estimation and Gaussian noise assumption, we prove that including more landmarks with independent measurements in the local bundle adjustment can produce less uncertainty in the estimation of local keyframe poses. The significance of our theoretical analysis is that, we provide a heuristic example to explain why the more observation information used in a SLAM system, the more accurate the pose estimation usually. The analysis is not limited to point features and RGB-D cameras.
-
•
A robust RGB-D SLAM method is presented by combining point and line guidance features. A map line is represented by multiple points on the line instead of endpoints or the coordinates. Experiments are performed on public RGB-D datasets to evaluate the good performance of our method, compared with other existing methods.
II RELATED WORK
Our algorithm focuses on how to make better use of line features in SLAM systems, which belongs to indirect methods. Thus, in this section, we divide the recent related VO or SLAM works into two categories, point-based and point-line-based methods, and briefly introduce them.
II-A Point-based Methods
Many famous visual odometry and SLAM works have been developed based on point features, for example PTAM and ORB-SLAM. In these works, keypoints are extracted and exploited for pose estimation and mapping with different descriptors. Then the keypoints in different frames are matched according to their descriptor distances. Based on the feature correspondences, a sparse 3D map is built so that the subsequent camera poses are estimated by solving the PnP problems. Methods based on monocular cameras inevitably encounter the problem of scale drift due to depth ambiguity. In contrast, RGB-D and stereo cameras can easily avoid this issue [12], but stereo camera methods cost more time due to the feature matching between left and right images. In terms of robustness, low-textured scenes are considered as a main challenge for indirect methods.
Compared with feature-based methods, direct approaches [13] directly deal with the raw pixel intensities, which can significantly save the time of feature extraction and matching. Direct methods have been performed for different sensors, such as LSD-SLAM for monocular cameras and DVO [14] for RGB-D cameras. High computational efficiency is one of the advantages of direct methods. For example, as a typical semi-dense method, SVO [1] can run with hundreds of frames per second. The core of these methods is the minimization of the photometric errors for pixels of a certain size, so they can operate well in some texture-less scenes with few point features.
II-B Point-line-based Methods
Considering that the detection of line features is less sensitive to lighting variations and the accuracy of line-based methods is usually not comparable with that of point features, combinations of point and line features have been proposed for VO/SLAM methods recently. For feature-based methods, lines are usually treated similarly to points, that is, the line features are detected first and then the corresponding descriptors are computed for feature matching [9]. The work [8] proposed a stereo point-line-based SLAM method with open source code, and lines are integrated into the process of loop closing. More recently, PL-VIO is presented in the work [15], which combines point and line features in a visual inertial system.
Besides the indirect methods, line features can also be integrated into direct methods. Based on the idea that the points on a line have large pixel gradient, DLGO [16] used a set of points in a line rather than two endpoints, which improved the performance of DSO.
In addition, the work [17] discussed the combined use of point and line features with several parameterizations for an EKF-SLAM system. Point-line-based methods have also been proposed for RGB-D cameras.
Lu et al. [18] proposed a RGB-D visual odometry and analyzed the uncertainty of motion estimation to show the benefit of fusing line features with point features. In terms of the relationship between features and the accuracy of pose estimation, the work in [19] has conducted experiments and shown that increasing the number of features leads to higher accuracy of a monocular SLAM system.
III SYSTEM OVERVIEW
We build our system upon the ORB-SLAM2 [20] framework, which is a relatively complete SLAM system including relocalization, loop closing and map reuse capabilities (see Fig. 1). The proposed SLAM approach is also based on three main threads: tracking, local mapping and loop closing. For the details of system and point feature operations, ORB-SLAM and ORB-SLAM2 are suggested for reference.
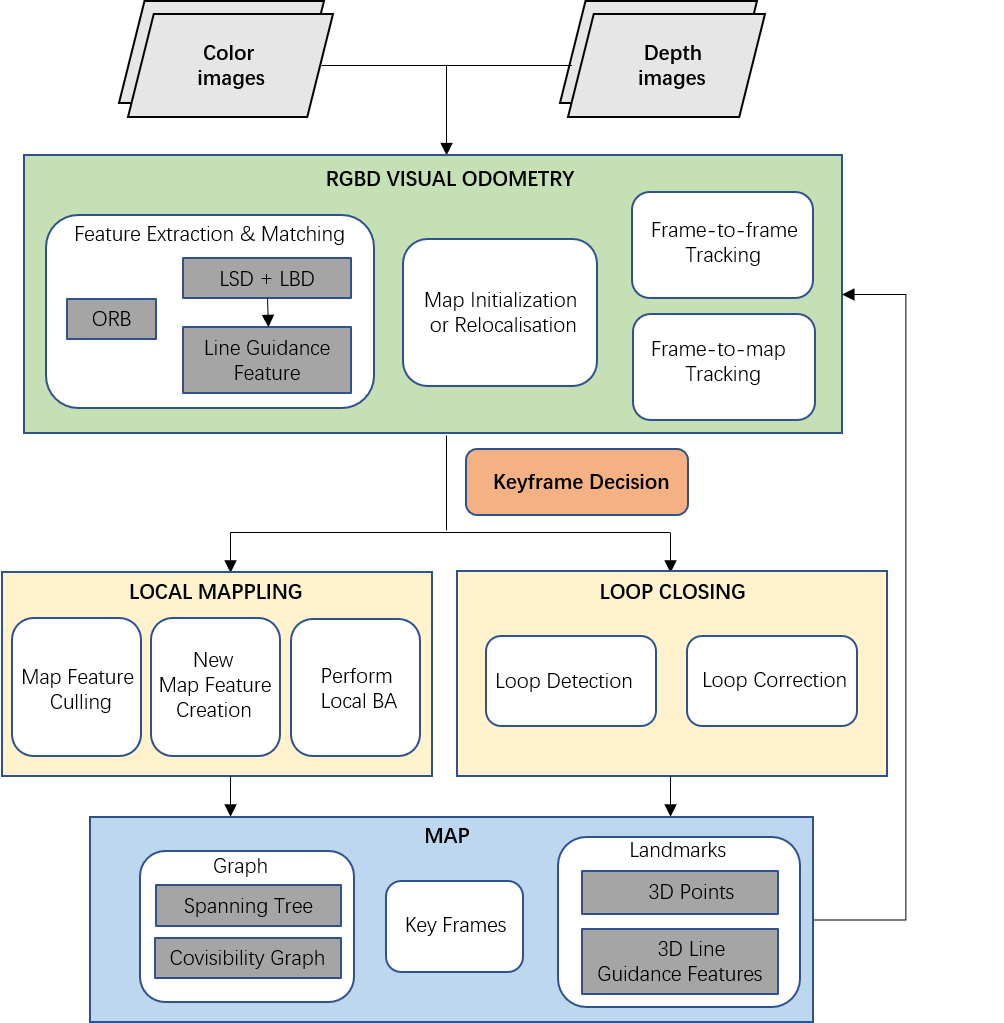
The ORB detector is employed for extracting point features, while line segments are detected with LSD [21], an O(n) line segment detector with good speed and quality. We compute the LBD descriptors [22] for each line and match them based on the distance between different descriptors. The LBD descriptor is considered to be robust against image artifacts without costing too much computational time.
For RGB-D cameras, a 3D map is constructed and updated by back-projecting the tracked point and line features. The motion estimation is solved through a probabilistic Gauss-Newton minimization of the point and line geometric reprojection errors. In the process of optimization, we adopt a Pseudo-Huber loss function to remove the outliers and reduce the negative influence of feature mismatches. In addition, we use line features for tracking and local mapping threads, preserving the original relocalization and loop closing modules of ORB-SLAM2. We review some issues related to the line features in section IV and analyze the uncertainty of state estimation in the local bundle adjustment in section V.
IV LINE-BASED ERROR
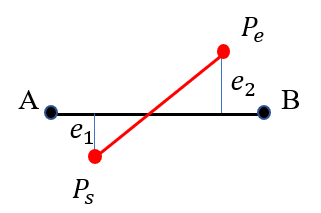
In general, two 3D endpoints are used to parameterize a spatial line [8, 9], whose corresponding matching lines (i.e. measurements) can be found in the 2D image plane. Due to the characteristics of line matching, the endpoints of pairwise lines are not often strictly aligned. But the projection of the 3D line should be collinear with the matching line under the correct estimation.
For a 3D line, let , be the homogeneous coordinates of 2D endpoints of its projection line in the image plane, , be the endpoints of the 2D matching line. According to and we can determine the corresponding 2D line equation, which has a line coefficient vector and a normalized line coefficient vector:
| (1) |
The line reprojection error is defined based on the distance between the projected endpoints and the 2D matching line:
| (2) |
with
| (3) |
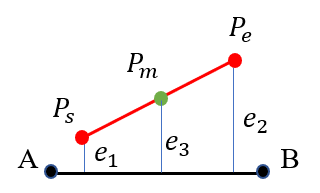
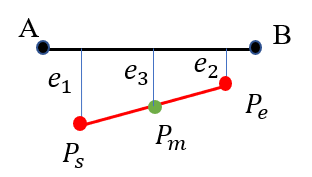
As shown in Fig. 2, we consider three different relationships between the projection of a 3D line and the 2D matching line. Suppose that the midpoint () and the endpoints ( and are not outliers, the larger the point-line distance error, the greater influence in the optimization problem. For example in the case of Fig. 2(b), the error formed by the point is larger than , and it is more reasonable to use the midpoint to construct the line reprojection error instead of the endpoint . Keeping this in mind, perhaps using more points on the same line to form the reprojection errors can provide more geometric constraints for the optimization problem and improve the system performance. In the next section we will analyze the uncertainty of pose estimation and show the benefit of combining line features and point features in a relatively complete SLAM system, which contains a local map optimization (i.e. local bundle adjustment).
V STATE ESTIMATION & UNCERTAINTY ANALYSIS
The work in [18] has proved that the combination of point and line features can reduce the uncertainty of pose estimation between two frames than just using points or lines in a RGB-D visual odometry. In this paper, we extend the uncertainty analysis to the case of local bundle adjustment (BA), which jointly optimizes multiple keyframe poses and many landmark positions and is also the core of sliding window algorithms in some other systems. This analysis can explain the relationship between data association and estimation uncertainty in a way for a relatively general SLAM system.
In the local map, the variables to be optimized include the current keyframe , the keyframes connected to in the covisibility graph and all the landmarks observed by these keyframes. The keyframes that can observe those landmarks but are not connected to (i.e. those share insufficient landmarks with ) remain fixed in the optimization.
The transformation matrix can be represented by a six-vector in the Lie algebra or by the rotation matrix and translation vector :
| (4) |
where is a 3D point in the world coordinates.
The projection function from 3D to 2D is defined as:
| (5) |
where is the principal point of camera, is the focal length, all obtained from camera calibration.
V-A Local BA with Original Landmarks
We define the variables to be optimized in the local bundle adjustment as follows:
| (6) |
which contains keyframe poses and landmark positions in the local map. Let the number of fixed keyframes in the local map be , and the current keyframe be . If the -th landmark is observed in the -th keyframe, the corresponding reprojection error can be computed from and :
| (7) |
where is the observation of the landmark on the -th keyframe. Note that the reprojection error expression is different for different types of landmarks (e.g.,line landmarks). Next, we integrate all the reprojection errors in the local BA into an error function:
| (8) |
where the form of varies with the observation relationships in the local map. In order to better illustrate the problem, we have shown a factor graph corresponding to the local BA in Fig. 3 as an example. The corresponding error function in Fig. 3 is . For a more general representation, we define the error function as (8). According to the Maximum Likelihood Estimation (MLE), the core of local bundle adjustment is to solve the following least square problem:
| (9) |
where and is the covariance of the observation . Note that (9) is derived based on the Maximum a Posteriori (MAP) problem, which is equivalent to the Maximum Likelihood Estimation (MLE) in a typical visual SLAM problem. And observations of the landmarks need to satisfy independence assumptions.
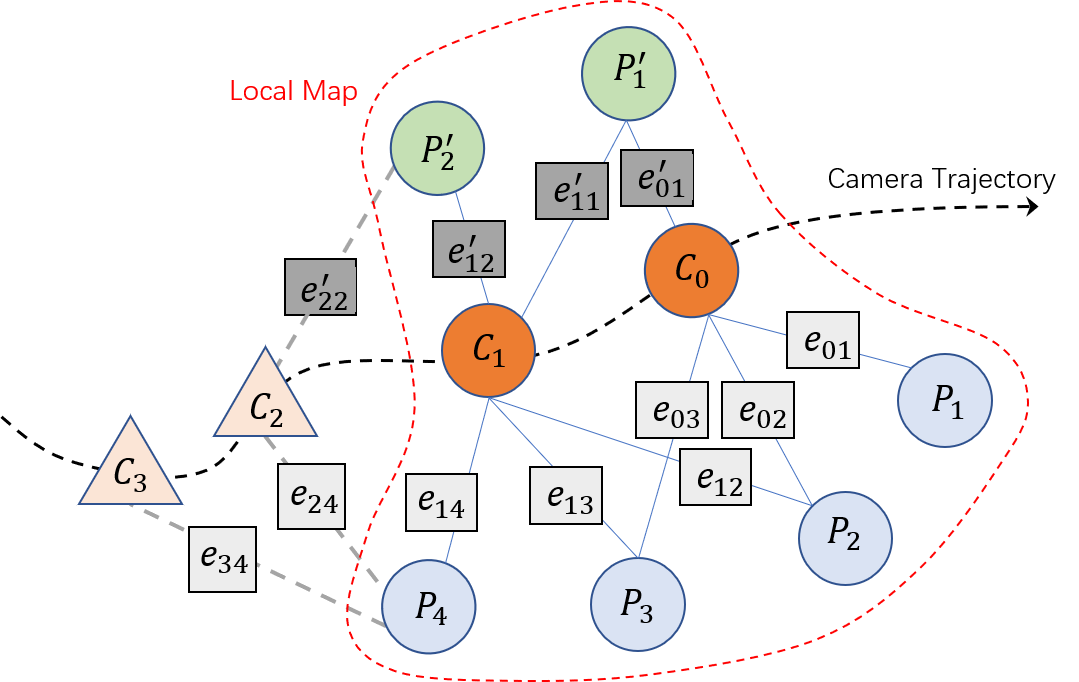
Next, we define the following notations:
| (10) |
According to first order linear approximation and the back-propagation of covariance, the MLE of has covariance [23]:
| (11) |
with . We further derive .
Generally, the accuracy of camera trajectory gets more attention than geometrical reconstruction (e.g. landmarks), especially for the indirect SLAM methods. As the first part of the state , the covariance of corresponds to the upper left submatrix of , with the size of . Therefore, under Gaussian noise assumption, the MLE of (multiple keyframe poses in the local map) has covariance:
| (12) |
V-B Local BA with New Landmarks
If we solve the problem of local BA with new landmarks and the same keyframe states as mentioned in Section V-A, we can define these new landmarks as:
| (13) |
In this case, the variables to be optimized are written as:
| (14) |
Let the number of fixed keyframes be in this case. Define the error function as:
| (15) |
where represents the reprojection error corresponding to the -th new landmark in the -th keyframe:
| (16) |
For example, the error function can be expressed as in Fig. 3.
The local BA solves the following least square problem:
| (17) |
where and is the covariance of the observation .
According to the back-propagation of covariance, the MLE of has covariance:
| (18) |
where . We further derive .
Therefore, in this case, under Gaussian noise assumption, the MLE of has covariance:
| (19) |
V-C Local BA with All the Landmarks
If considering all the landmarks as mentioned in Section V-A and Section V-B, the states to be estimated in the local map is denoted as:
| (20) |
The error function can be expressed as:
| (21) |
Local BA solves the following problem:
| (22) |
where .
The MLE of has covariance:
| (23) |
where
. Next, we derive .
Similarly, it can be deduced that, under Gaussian noise assumption, the MLE of has covariance:
| (24) |
With (12), (19) and (24), the following relationship is derived:
| (25) |
If matrices and are real symmetric and is positive definite, we can define . Hence, the covariance matrices and satisfy: , .
According to matrix theory, we have:
| (26) |
which means the -th largest eigenvalue of is smaller than the -th largest eigenvalue of and [24].
V-D Uncertainty Analysis and Line Guidance Features
According to (25), the following conclusions can be drawn: first, adding more new landmarks with their observations in the local BA leads to smaller uncertainty in the MLE of keyframe poses; second, the more accurate observations of the new landmarks, the smaller uncertainty in the MLE of keyframe poses, that is, the smaller , the smaller .
In our system, we sample points on a 2D line feature and back-project them to generate the map line landmarks. Each map line is represented by 3D points (named line guidance features). Let be the states (including local keyframe poses and landmark positions) to be estimated in the local BA. The local BA aims to minimize the reprojection errors between the projections of the 3D landmarks and their corresponding 2D observations in the local keyframes:
| (27) |
where , and respectively refer to the sets of local keyframes, local map points, local map lines and
The expression of reprojection error is similar to (7). The observation parameterization of an ORB feature is defined as based on original pixel measurement and depth measurement , where is the baseline of camera. Assuming pixel coordinates and satisfy the zero-mean Gaussian distribution with the standard deviation and , the covariance of original measurements is:
| (28) |
where is related to the extraction layer of ORB feature in the Gaussian pyramid, and is modeled by a quadratic function of [25]. The covariance of is defined as:
| (29) |
where .
The reprojection error is obtained by the distance between the projected 2D position of 3D line-guidance feature and the corresponding straight line (i.e. observation) in the image plane:
| (30) |
Compared to point-based methods, our method is based on point and line guidance features, and expands the number of landmarks to be estimated in the local BA, which will result in smaller estimation uncertainty of keyframe poses according to the uncertainty analysis in this section. Line features are often at the edges of objects, such that the corresponding depth measurements are noisy. Considering the noisy depth measurements and the mismatch of line features, oversampling points on a line will introduce too many landmarks with poor initial values and have a bad impact on the optimization problem. A good SLAM algorithm should carefully balance the quantity and quality of landmarks in the bundle adjustment.
VI Experimental Validation
In this section, we compare our algorithm with several state-of-the-art visual SLAM methods on two public RGB-D datasets:
-
•
ICL-NUIM [26] is a dataset providing RGB and depth image sequences in two synthetically generated scenes (the living room and office room). Some sequences is challenging to estimate camera poses due to low-textured characteristics of the environments.
-
•
TUM RGB-D benchmark [27] contains sequences from RGB-D sensors with different texture, structure and illumination conditions in real indoor environments.
We implement our line guidance feature-based method by sampling five points for each line. The difference in the number of sampling points can affect the performance of our algorithm, which will be discussed later. All experiments were carried out with an Intel Core i7-8550U (4 cores @4.0 GHz) and 8Gb RAM.
VI-A ICL-NUIM Dataset
We first compare the proposed method against some state-of-the-art approaches, including ORB-SLAM2, DVO-SLAM [14] and L-SLAM [28]. Artificial noise was used in the image data to simulate realistic sensor noise in this dataset, meanwhile every sequence has a version without noise.
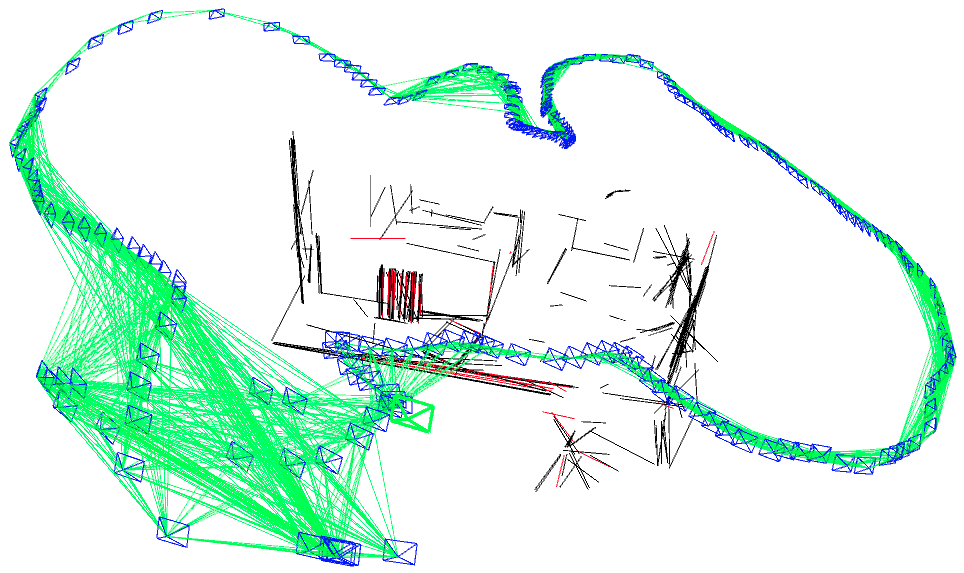
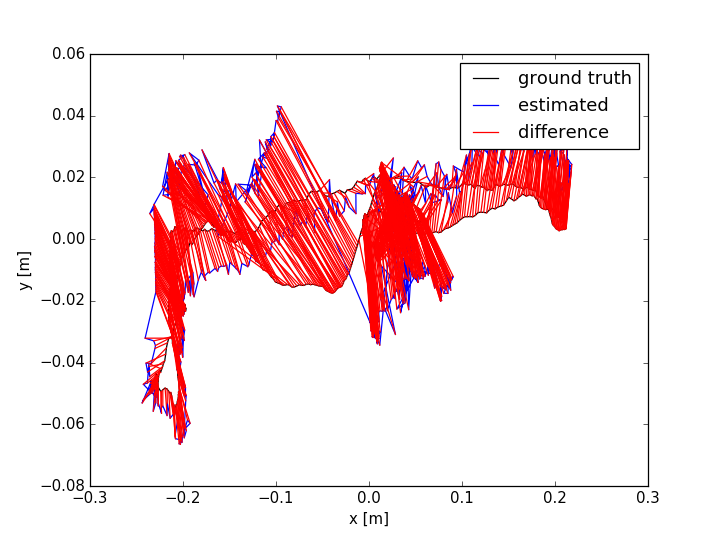
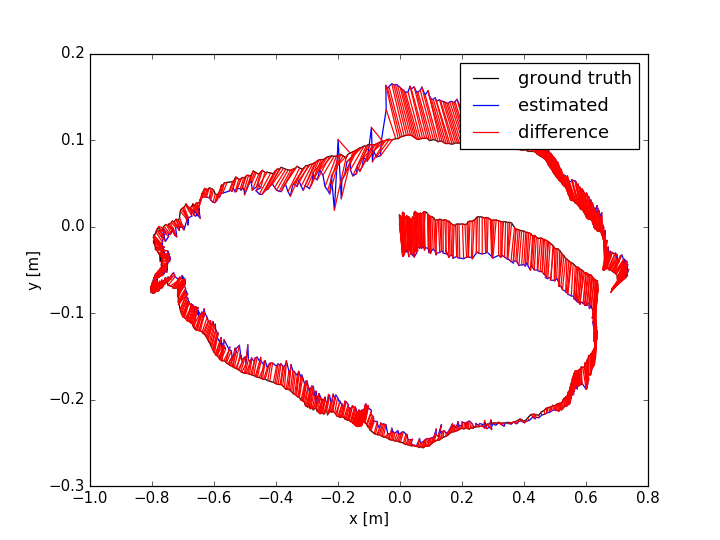
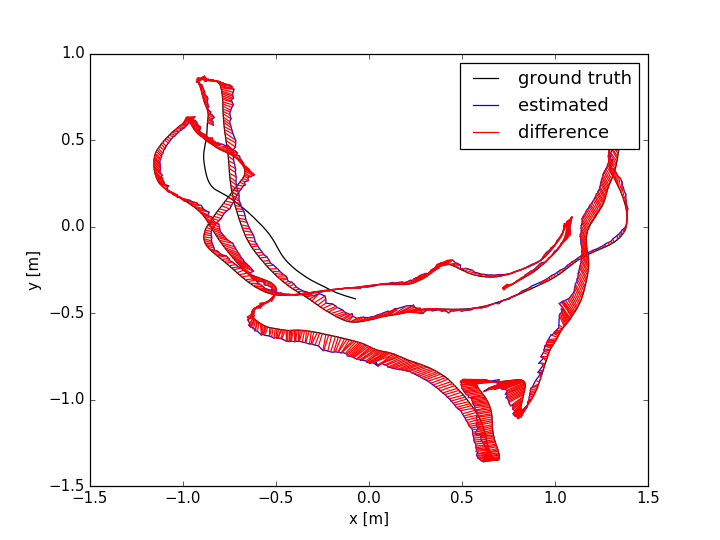
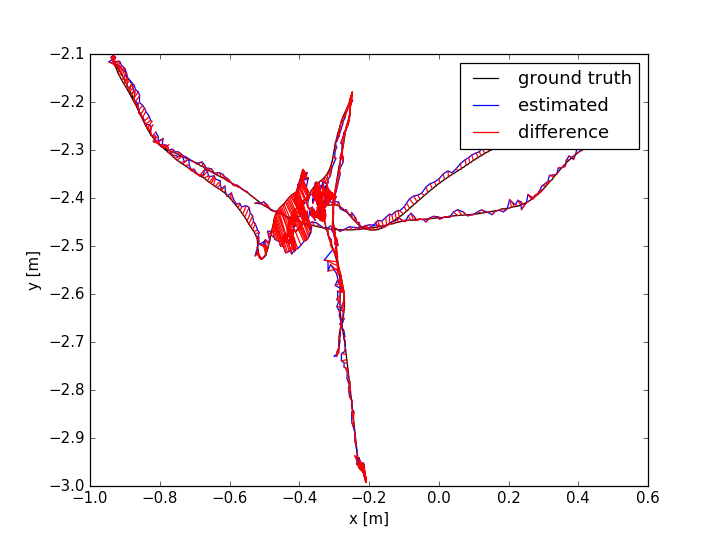
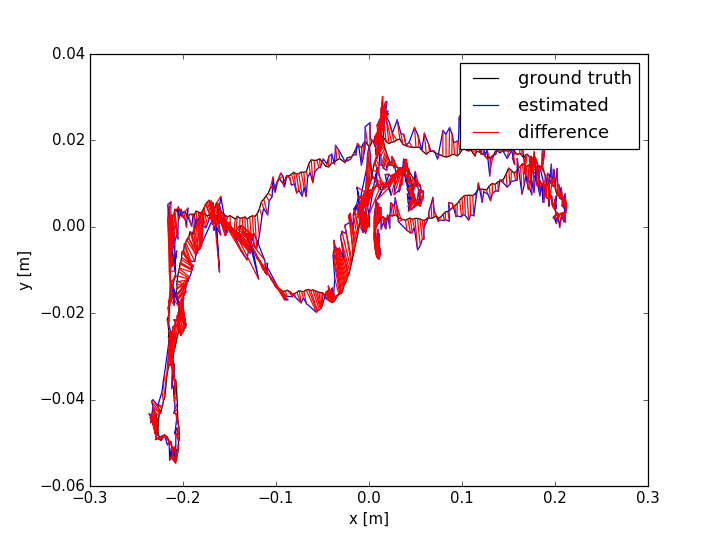
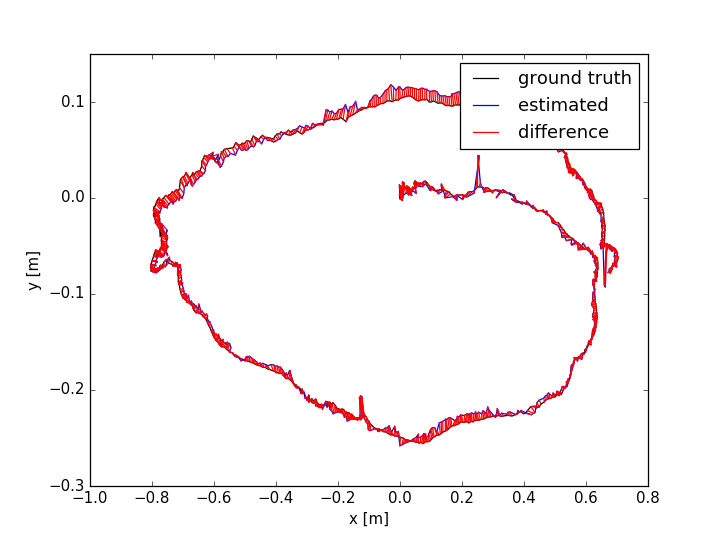
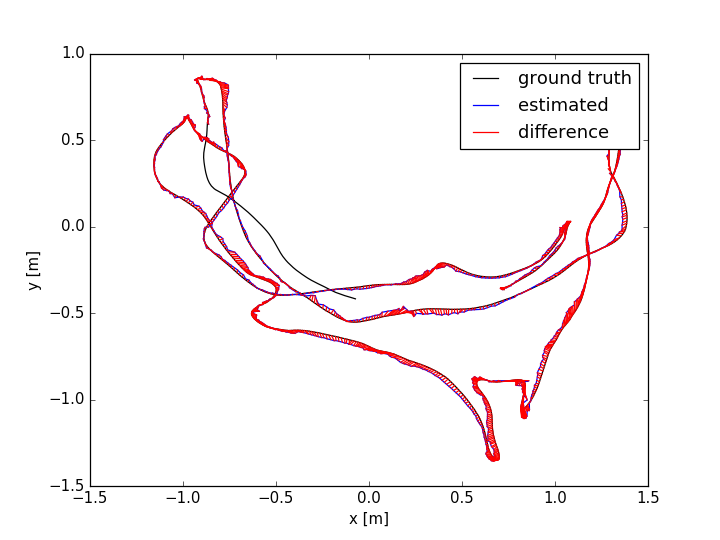
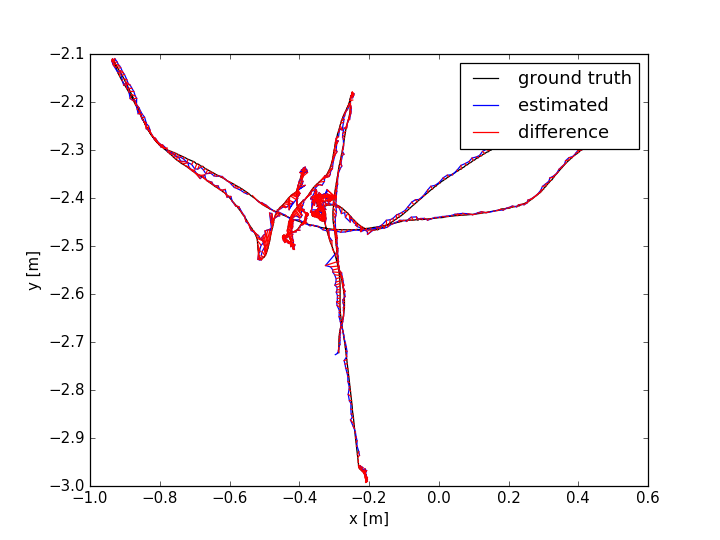
The evaluation results are shown in TABLE I for all the sequences with noise. The Absolute Trajectory Error (ATE) is used for measuring the root mean squared error (RMSE) between the estimated trajectory and ground truth. Though L-SLAM performs best in three noise sequences, it is limited to planar environments. Note that our method outperforms the other methods in half of all the noise sequences. We show the 788th frame (low-textured scene) from sequence lr-1 during the tracking process in Fig.4(a) and the estimated trajectories comparison between ORB-SLAM2 and Ours in Fig. 7. In addition, we also conduct experiments for ORB-SLAM2 and Ours in all the sequences without noise, as shown in TABLE I. According to the results of ORB-SLAM2 and Ours in TABLE I, it can be found that the higher quality of newly added landmarks with their measurements leads to more accurate pose estimation, which is basically consistent with our analysis in section V-D.

| Without noise | With noise | |||||
| Seq. | Ours | ORB- SLAM2 | Ours | ORB- SLAM2 | L- SLAM | DVO- SLAM |
| lr-0 | 0.005 | 0.008 | 0.009 | 0.008 | 0.012 | 0.108 |
| lr-1 | 0.008 | 0.126 | 0.009 | 0.134 | 0.027 | 0.059 |
| lr-2 | 0.016 | 0.023 | 0.016 | 0.032 | 0.053 | 0.375 |
| lr-3 | 0.007 | 0.017 | 0.012 | 0.014 | 0.143 | 0.433 |
| of-0 | 0.019 | 0.030 | 0.040 | 0.054 | 0.020 | 0.244 |
| of-1 | 0.017 | 0.051 | 0.025 | 0.058 | 0.015 | 0.178 |
| of-2 | 0.014 | 0.015 | 0.021 | 0.025 | 0.026 | 0.099 |
| of-3 | 0.008 | 0.070 | 0.015 | 0.050 | 0.011 | 0.079 |
VI-B TUM RGB-D Dataset
We choose fr3/office for mapping visualization, as shown in Fig. 4(b). Line features can provide more spatial structural information of the environments than point features. Fig. 5 shows the difference of sparse map between ORB-SLAM2 and Ours, which indicates that our method can construct a more accurate map structure.
In this dataset, we compare our algorithm with eight state-of-the-art SLAM methods: ORB-SLAM2, an indirect point-line-based method PL-SLAM [9], a direct point-line-based method DLGO [16], RKD-SLAM [29], Kintinuous [30], ElasticFusion [31], DVO-SLAM and RGBD SLAM [32].



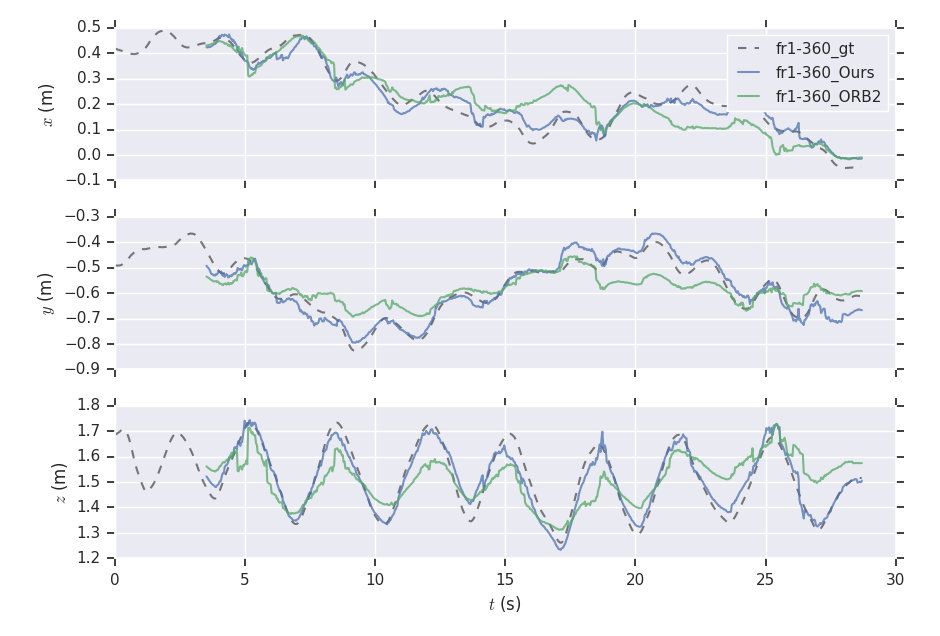
The ATE results are shown in TABLE II. From the table, we can find that: (i) the methods with combination of points and lines lead to higher accuracy than those only using points; (ii) our method achieves better performance than other methods in more than half of the sequences. In dynamic environments (fr3/sit_static, fr3/sit_half, fr3/walk_half), the performance of ORB-SLAM2 is worse than the point-line-based methods, since the line features are basically on the static objects. PL-SLAM fails in the sequence fr3/nstr_tex_far and the main reason is that the images are blurred due to the fast camera motion. Additionally, we show the estimated trajectories (ORB-SLAM2 and Ours) corresponding to the sequences fr1/room and fr3/sit_half in Fig. 7. The performance of ORB-SLAM2 drops in the low-textured (lr-1) and low dynamic (fr3/sit_half) environments. We also show the comparison of trajectory errors in different axes for sequence fr1/360 in Fig. 6.
| Sequence | Ours | ORB-SLAM2 | PL-SLAM | DLGO | RKD-SLAM | Kintinuous | ElasticFusion | DVO-SLAM | RGBD SLAM |
| fr1/xyz | 0.009 | 0.010 | 0.012 | 0.054 | 0.007 | 0.017 | 0.011 | 0.011 | - |
| fr1/desk2 | 0.022 | 0.024 | - | - | 0.024 | 0.071 | 0.048 | 0.046 | - |
| fr1/floor | 0.013 | 0.016 | 0.076 | - | 0.262 | - | - | - | - |
| fr1/room | 0.030 | 0.059 | - | - | 0.134 | 0.075 | 0.068 | 0.053 | 0.087 |
| fr1/360 | 0.068 | 0.228 | - | - | 0.109 | - | 0.108 | 0.083 | - |
| fr2/desk | 0.008 | 0.009 | - | 1.33 | 0.071 | 0.034 | 0.071 | 0.017 | 0.057 |
| fr2/desk_person | 0.007 | 0.006 | 0.020 | 0.412 | 0.045 | - | - | - | - |
| fr3/office | 0.010 | 0.010 | 0.020 | 1.168 | 0.028 | 0.030 | 0.017 | 0.035 | - |
| fr3/nstr_tex_far | 0.023 | 0.051 | X | 0.575 | 0.053 | - | 0.074 | - | - |
| fr3/nstr_tex_near | 0.013 | 0.024 | 0.021 | 0.060 | 0.027 | 0.031 | 0.016 | 0.018 | - |
| fr3/str_tex_far | 0.010 | 0.011 | 0.009 | 0.744 | 0.016 | - | 0.013 | - | - |
| fr3/str_tex_near | 0.009 | 0.011 | 0.013 | - | 0.018 | - | 0.015 | - | - |
| fr3/sit_static | 0.006 | 0.009 | - | - | 0.009 | - | - | - | - |
| fr3/sit_half | 0.011 | 0.021 | 0.013 | 0.160 | 0.019 | - | - | - | - |
| fr3/walk_half | 0.091 | 0.431 | 0.016 | 0.374 | 0.182 | - | - | - | - |
VI-C Number of Sampling Point
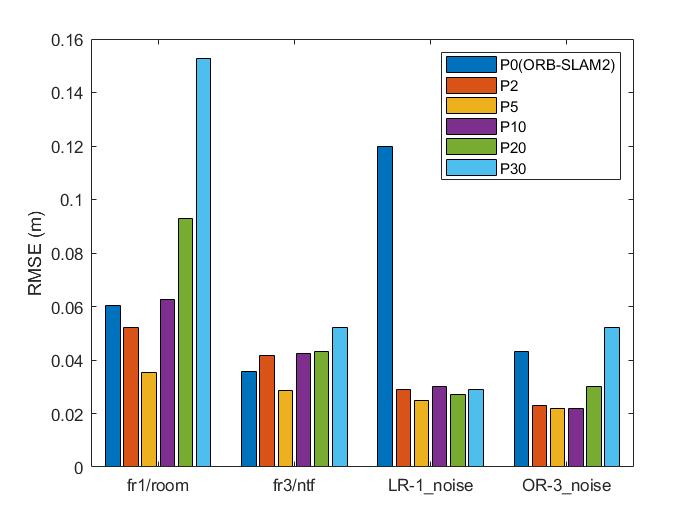
We test the ATE of our method with different number of sampling points and the same parameter setting in the sequences fr1/room, fr3/nstr_tex_far, lr-1_noise and of-3_noise, and the results are shown in Fig. 8. In our opinion, the quantity and quality of newly added landmarks need to be balanced and paid enough attention. Sampling too many points will lead to reduction of the quality of line landmarks due to the noisy depth measurements and result in an increase of the number of outliers. It would be better to sample a small number of points and we choose five sampling points in our implementation.
VI-D Computation Time
The point-line-based visual SLAM methods improve the accuracy and robustness, but at the same time lead to higher computational complexity. In particular, the extraction and matching of line features increase a lot of time consumption. We summarize the results of mean tracking time per frame for ORB-SLAM2 and Ours in TABLE III.
| Method | fr1/desk2 | fr1/360 | fr2/desk | fr3/office | fr3/ntn |
| ORB-SLAM2 | 53.0 | 44.2 | 61.5 | 58.7 | 47.3 |
| Ours | 71.7 | 63.9 | 78.5 | 83.0 | 75.3 |
VII CONCLUSIONS
In this work, we proposed a RGB-D SLAM method through combining both point and line features, which allows to improve the accuracy and robustness in some situations where point-only based methods are prone to fail due to not enough feature points. We have proved that, compared with original landmarks, adding new landmarks with corresponding independent observations can ensure smaller uncertainty in the estimation of keyframe poses in the local bundle adjustment. Compared to several state-of-the-art methods, the proposed method improves the accuracy and robustness under challenging environments, such as the scenes with low-texture, fast camera movement and low dynamic objects. In the future, we will further optimize the system to increase the time efficiency of point-line-based SLAM method.
References
- [1] C. Forster, M. Pizzoli, and D. Scaramuzza, “Svo: Fast semi-direct monocular visual odometry,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 15–22.
- [2] T. Pire, T. Fischer, J. Civera, P. De Cristóforis, and J. J. Berlles, “Stereo parallel tracking and mapping for robot localization,” in 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2015, pp. 1373–1378.
- [3] C. Kerl, J. Sturm, and D. Cremers, “Robust odometry estimation for rgb-d cameras,” in 2013 IEEE International Conference on Robotics and Automation. IEEE, 2013, pp. 3748–3754.
- [4] G. Klein and D. Murray, “Parallel tracking and mapping for small ar workspaces,” in Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality. IEEE Computer Society, 2007, pp. 1–10.
- [5] R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: a versatile and accurate monocular slam system,” IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
- [6] J. Engel, T. Schöps, and D. Cremers, “Lsd-slam: Large-scale direct monocular slam,” in European Conference on Computer Vision. Springer, 2014, pp. 834–849.
- [7] J. Engel, V. Koltun, and D. Cremers, “Direct sparse odometry,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 3, pp. 611–625, 2017.
- [8] R. Gomez-Ojeda, F.-A. Moreno, D. Zuñiga-Noël, D. Scaramuzza, and J. Gonzalez-Jimenez, “Pl-slam: a stereo slam system through the combination of points and line segments,” IEEE Transactions on Robotics, vol. 35, no. 3, pp. 734–746, 2019.
- [9] A. Pumarola, A. Vakhitov, A. Agudo, A. Sanfeliu, and F. Moreno-Noguer, “Pl-slam: Real-time monocular visual slam with points and lines,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 4503–4508.
- [10] S. Yang and S. Scherer, “Direct monocular odometry using points and lines,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 3871–3877.
- [11] X. Zuo, X. Xie, Y. Liu, and G. Huang, “Robust visual slam with point and line features,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 1775–1782.
- [12] F. Steinbrücker, J. Sturm, and D. Cremers, “Real-time visual odometry from dense rgb-d images,” in 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops). IEEE, 2011, pp. 719–722.
- [13] J. Engel, J. Sturm, and D. Cremers, “Semi-dense visual odometry for a monocular camera,” in Proceedings of the IEEE international conference on computer vision, 2013, pp. 1449–1456.
- [14] C. Kerl, J. Sturm, and D. Cremers, “Dense visual slam for rgb-d cameras,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2013, pp. 2100–2106.
- [15] Y. He, J. Zhao, Y. Guo, W. He, and K. Yuan, “Pl-vio: Tightly-coupled monocular visual–inertial odometry using point and line features,” Sensors, vol. 18, no. 4, p. 1159, 2018.
- [16] S.-J. Li, B. Ren, Y. Liu, M.-M. Cheng, D. Frost, and V. A. Prisacariu, “Direct line guidance odometry,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 1–7.
- [17] J. Sola, T. Vidal-Calleja, J. Civera, and J. M. M. Montiel, “Impact of landmark parametrization on monocular ekf-slam with points and lines,” International Journal of Computer Vision, vol. 97, no. 3, pp. 339–368, 2012.
- [18] Y. Lu and D. Song, “Robust rgb-d odometry using point and line features,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3934–3942.
- [19] H. Strasdat, J. Montiel, and A. J. Davison, “Real-time monocular slam: Why filter?” in 2010 IEEE International Conference on Robotics and Automation. IEEE, 2010, pp. 2657–2664.
- [20] R. Mur-Artal and J. D. Tardós, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017.
- [21] R. G. Von Gioi, J. Jakubowicz, J.-M. Morel, and G. Randall, “Lsd: A fast line segment detector with a false detection control,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 4, pp. 722–732, 2008.
- [22] L. Zhang and R. Koch, “An efficient and robust line segment matching approach based on lbd descriptor and pairwise geometric consistency,” Journal of Visual Communication and Image Representation, vol. 24, no. 7, pp. 794–805, 2013.
- [23] R. Hartley and A. Zisserman, Multiple view geometry in computer vision. Cambridge university press, 2003.
- [24] R. A. Horn and C. R. Johnson, Matrix analysis. Cambridge university press, 2012.
- [25] J. Smisek, M. Jancosek, and T. Pajdla, “3d with kinect,” in Consumer depth cameras for computer vision. Springer, 2013, pp. 3–25.
- [26] A. Handa, T. Whelan, J. McDonald, and A. J. Davison, “A benchmark for rgb-d visual odometry, 3d reconstruction and slam,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 1524–1531.
- [27] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 573–580.
- [28] P. Kim, B. Coltin, and H. Jin Kim, “Linear rgb-d slam for planar environments,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 333–348.
- [29] H. Liu, C. Li, G. Chen, G. Zhang, M. Kaess, and H. Bao, “Robust keyframe-based dense slam with an rgb-d camera,” arXiv preprint arXiv:1711.05166, 2017.
- [30] T. Whelan, M. Kaess, M. Fallon, H. Johannsson, J. J. Leonard, and J. McDonald, “Kintinuous: Spatially extended kinectfusion,” 2012.
- [31] T. Whelan, R. F. Salas-Moreno, B. Glocker, A. J. Davison, and S. Leutenegger, “Elasticfusion: Real-time dense slam and light source estimation,” The International Journal of Robotics Research, vol. 35, no. 14, pp. 1697–1716, 2016.
- [32] F. Endres, J. Hess, J. Sturm, D. Cremers, and W. Burgard, “3-d mapping with an rgb-d camera,” IEEE Transactions on Robotics, vol. 30, no. 1, pp. 177–187, 2013.