on behalf of the DeepLearnPhysics Collaboration
Point Proposal Network for Reconstructing 3D Particle Endpoints with Sub-Pixel Precision in Liquid Argon Time Projection Chambers
Abstract
Liquid Argon Time Projection Chambers (LArTPC) are particle imaging detectors recording 2D or 3D images of trajectories of charged particles. Identifying points of interest in these images, namely the initial and terminal points of track-like particle trajectories such as muons and protons, and the initial points of electromagnetic shower-like particle trajectories such as electrons and gamma rays, is a crucial step of identifying and analyzing these particles and impacts the inference of physics signals such as neutrino interaction. The Point Proposal Network is designed to discover these specific points of interest. The algorithm predicts with a sub-voxel precision their spatial location, and also determines the category of the identified points of interest. Using as a benchmark the PILArNet public LArTPC data sample in which the voxel resolution is 3mm/voxel, our algorithm successfully predicted 96.8 % and 97.8 % of 3D points within a distance of 3 and 10 voxels from the provided true point locations respectively. For the predicted 3D points within 3 voxels of the closest true point locations, the median distance is found to be 0.25 voxels, achieving the sub-voxel level precision. In addition, we report our analysis of the mistakes where our algorithm prediction differs from the provided true point positions by more than 10 voxels. Among 50 mistakes visually scanned, 25 were due to the definition of true position location, 15 were legitimate mistakes where a physicist cannot visually disagree with the algorithm’s prediction, and 10 were genuine mistakes that we wish to improve in the future. Further, using these predicted points, we demonstrate a simple algorithm to cluster 3D voxels into individual track-like particle trajectories with a clustering efficiency, purity, and Adjusted Rand Index of 96 %, 93 %, and 91 % respectively.
I Introduction
Accelerator based neutrino oscillation experiments have successfully deployed deep convolutional neural networks (CNN) in their data analysis pipeline Acciarri et al. (2017a); Adams et al. (2019); Radovic et al. (2018). Many of the present and future experiments utilize a liquid argon time projection chamber (LArTPC), a class of particle imaging detectors which produces 2D or 3D images over many meters of detected charged particle trajectories, with a resolution of the order of mm/pixel. Examples of such experiments along with their respective active volumes include MicroBooNE (90 tons) Acciarri et al. (2017b), the Short Baseline Near Detector (SBND, 112 tons) Antonello et al. (2015), ICARUS (600 tons) Amerio et al. (2004) and the Deep Underground Neutrino Experiment (DUNE, 40,000 tons) Acciarri et al. (2016).
The particle trajectories recorded in LArTPC images often appear as 1D lines in a 2D or 3D space. Their topological features can be diverse, ranging from straight line-like tracks to branching tree-like electromagnetic showers. In the process of analyzing an image from the pixel-level energy deposits to build a larger picture of particle trajectories with their respective kinematic properties, detecting points of interest such as the initial and terminal points of particle trajectories in the early stage of a data reconstruction chain is critical. For example, in clustering tasks on electromagnetic (EM) showers, the initial point can help to define a general direction for the whole shower that includes dozens to hundreds of EM secondaries. This is especially useful for separating neutral pions, a source of major background to signal for neutrino oscillation analysis as well as an important sample for detector energy calibration, from cosmic rays and neutrino-nucleus interactions. Finding these points can also be a crucial step in determining a neutrino interaction vertex. If each particle trajectory is associated with these points of interests, the predicted points naturally include candidates for the neutrino interaction vertex.
Localizing an arbitrary number of such points in an image is analogous to a task called object detection in the field of Computer Vision. Many object detection algorithms based on CNNs have been proposed He et al. (2017); Girshick (2015); Ren et al. (2015); Liu et al. (2016) including Faster Region Convolutional Neural Network (Faster R-CNN) which has been one of the most popular choices for object detection applications and also successfully applied in LArTPC image data Acciarri et al. (2017a). Faster R-CNN consists of a feature extractor CNN and an attention mechanism called Region Proposal Network (RPN). The feature extractor consists of convolution layers and pooling layers, and generates a data tensor with low spatial resolution compared to the input. The RPN takes this data tensor and generates region proposals, typically rectangular shaped bounding boxes, that are likely to contain a target object in the original image resolution. The insight of RPN is to act on a spatially contracted data tensor which contains fewer pixels compared to the original input, thus addressing the challenge of long compute time. R-CNN is a family of algorithms that employ the RPN concept. One of the most recent of these is Mask R-CNN, He et al. (2017) which is undeniably the most popular object instance detection algorithm to date.
Inspired by the concept behind RPN, we have designed a Point Proposal Network (PPN) to identify points of interest in a LArTPC image, namely the initial point of EM particles, referred to as shower-like particles in this paper, as well as the initial and terminal points, collectively referred to as endpoints, of track-like particles, which include all but shower-like particles. While RPN is responsible for predicting both the location and size of a bounding box for an object detection, PPN is simplified to propose only the location as the target is a point, not an object. Our goal is to integrate PPN into a generic, full 3D data reconstruction chain for LArTPCs, which consists of multi-task deep neural networks, such that the whole chain can be optimized end-to-end. Building on the previous effort, we use U-ResNet Dominé and Terao (2020) as the feature extractor and implement PPN to predict the position and semantic type of an arbitrary number of points in an image with voxel-level precision.
The contributions of this paper are two-fold:
-
•
Introduce PPN for reconstructing the 3D endpoints of track-like particles and the initial point of shower-like particle with sub-voxel precision.
-
•
Provide a performance benchmark on a public LArTPC simulation dataset (PILArNet) for future reference and comparison against other methods.
While, in this paper, our target is 3D LArTPC images, the concept of PPN is applicable to both 2D and 3D images Dominé and Terao (2018). Section II introduces the architecture of the UResNet network that we use as the backbone for PPN, as well as the details on PPN architecture, the loss definitions and post-processing methods. Section III outlines our experiments setup, including details on the public LArTPC data sample that we use. Section IV shows a first benchmark of the PPN performance on this sample.
The study presented in this paper is fully reproducible using a Singularity Sochat VV (2017) software container 111https://singularity-hub.org/containers/11757, implementations available in the lartpc_mlreco3d222https://github.com/DeepLearnPhysics/lartpc_mlreco3d repository and public simulation samples Adams et al. (2020) made available by the DeepLearnPhysics collaboration.
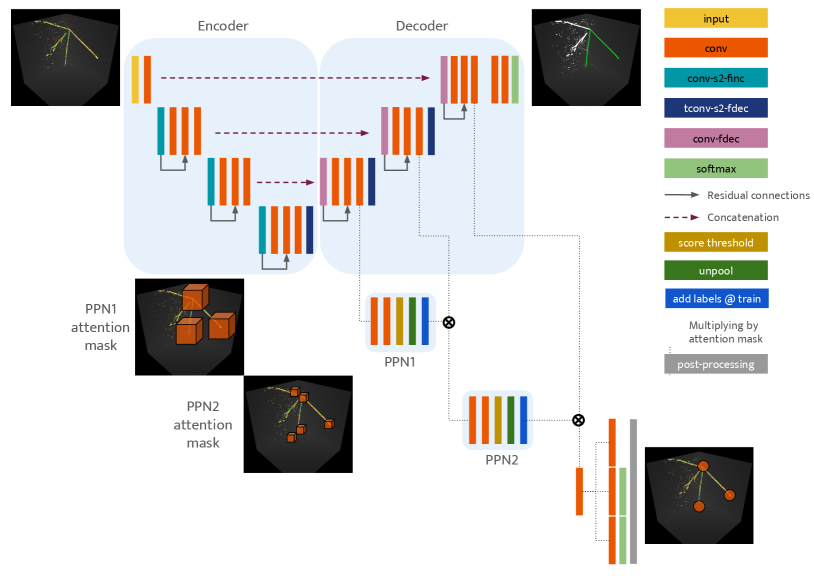
II Network Architecture
The network architecture consists of two parts: U-ResNet Dominé and Terao (2020) and PPN. Both blocks include many CNN layers. In order to make our algorithm scalable to a large-scale LArTPC detector analysis, we designed the whole chain using Sparse Submanifold Convolutional Network (SSCN) Graham and van der Maaten (2017); Graham et al. (2018).
II.1 UResNet: feature extractor
U-ResNet is designed for a voxel-level classification task, called semantic segmentation, for 3D LArTPC images Dominé and Terao (2020). The architecture of U-ResNet can be divided into two parts, namely encoder and decoder. The encoder consists of repeated blocks of convolution and strided convolution layers which down-samples the image resolution while increasing the features dimension, thus learning from key features in an image at different scales. We refer to the number of down-sampling operations as depth. The decoder takes the low-spatial size, highly compressed data tensor from the encoder and up-samples them back to the original image resolution. After each up-sampling operation, the data tensor of matching spatial size is taken from the encoder output and concatenated to the up-sampled tensor before the combined tensor is further processed by convolution layers in the decoder. The key concept behind the concatenation operation, introduced by the original U-Net Ronneberger et al. (2015) authors, is to recover the lost spatial resolution information in the encoder block due to strided convolution layers and effectively combine with the abstract features contained in the up-sampled tensor. Convolution layers in the decoder block are trained to best combine high spatial resolution information and abstract feature information. As a result, they learn how to best spatially interpolate abstract features extracted by the encoder back to the original image resolution. Figure 1 shows the architecture of U-ResNet. For the study carried out in this paper, we set the depth of UResNet to 6 and used 16 filters at the first convolution layer. The number of filters increases linearly with the depth, and is 96 at the deepest layer.
II.2 PPN layers
Within the U-shaped network architecture (see Figure 1), we implement PPN by introducing additional convolution layers at different spatial resolutions, starting with the most contracted data tensor at the lowest spatial resolution. While these PPN layers could be attached to either the encoder or the decoder of U-ResNet, it is more powerful to attach them to the decoder block as data tensors generated by the decoder should be more information rich. At the deepest level and coarsest spatial resolution, the so-called PPN1 produces a softmax score of a value between 0 and 1 for each voxel, which indicates whether or not the voxel contains the location coordinate of any of the true points, i.e. the target 3D points to be detected. We call this detection score in the following. We call the voxels positive if the detection score is above the set threshold value. We call other voxels negative. Positive voxels yield an attention mask that we can use at the next step. At an intermediate level and medium spatial resolution, we up-sample the mask predicted by PPN1 and use it as an attention mask to pre-select candidate positive voxels. The so-called PPN2 layer then similarly predicts a subset of positive voxels among these pre-selected voxels in the attention mask at this spatial resolution. Finally, we up-sample the result of PPN2 to the original image resolution and use it as another attention mask. The final layer, so-called PPN3, is made of 3x3 convolutions which predict the following quantities for each voxel that has been selected through these successive attention masks:
-
•
a detection score (of being a voxel within some neighborhood of a ground truth point, for which we choose a distance threshold of 5 voxels),
-
•
a 3D position (offset with respect to the voxel center),
-
•
and a type score (for the point to belong to a semantic type).
We note that the 3D position prediction made from a particular voxel may be located in its neighbor voxel. This implies that multiple neighbor voxels of a target voxel, which contains one or more of true points, can all propose positions that are within the target voxel, which gives more information to identify 3D points and can improve the performance.
II.3 Loss definitions
Among all voxels we define true voxels as voxels within a certain distance threshold from the true points , and all other voxels as negative:
where is the number of voxels in the input data tensor at a certain PPN layer.
We define several losses. First, for all input voxels, we compute a cross-entropy loss for positive/negative classification task at each PPN- layer and then average over all voxels. For , if indicates whether the voxel is positive or negative in the labels and is the predicted softmax score for this voxel to be positive,
Secondly, only on true voxels, we define a linear distance loss on the predicted positions. We consider the distance to the closest ground truth point . The raw predictions of the network are actually shifts with respect to the center of the subject voxels ():
Thirdly, only on true voxels, we compute a cross-entropy loss for a point type prediction. The predicted point type is compared with the semantic type of the closest true point. If is the total number of semantic types for a point, is a one-hot encoded vector indicating to which type the point belongs, and is the predicted probability that the point belongs to a semantic type , then
Finally, the sum of all losses is minimized:
II.4 Post-processing
The architecture that we proposed so far will yield a prediction of a position, detection score, and semantic type score for each voxel that has been selected in the last layer at the original image resolution. The number of such positive voxels whose predictions are considered, is related to the attention mask predicted by PPN2 and the spatial size ratio between PPN2 layer and the original image size. This will dictate for each voxel predicted as positive at PPN2 level how many voxels are selected at the last layer. Hence we might have many proposals whose positions are clustered near a true point, with different scores and type predictions. We need a strategy to combine overlapping proposals to deduce the candidate of distinct 3D points, and we want this strategy to value both accurate positions and type predictions. In this paper, we adopt the following simple post-processing scheme.
-
1.
Thresholding on the detection scores, for example we require a score value of 0.5 or higher to be considered positive.
-
2.
We then run the DBSCAN Ester et al. (1996) clustering algorithm on the positive point positions. The hyper-parameters of DBSCAN are set to 1.99 in voxel unit for the maximum Cartesian distance between two points to be clustered together, and min_samples. must be small enough to avoid merging together predicted endpoints of short tracks.
-
3.
Pooling operation on the points that belong to the same cluster in order to deduce a single score, type predictions, and 3D position. We use average-pooling for the 3D coordinate locations, and maximum-pooling for the scores including the positiveness prediction and individual semantic type.
-
4.
Finally, we enforce that a point detected by PPN as a type among (set of types, with type score for each type ) needs to be within 2 voxels of a voxel predicted by U-ResNet to have one of the types.
III Experiments
III.1 Dataset
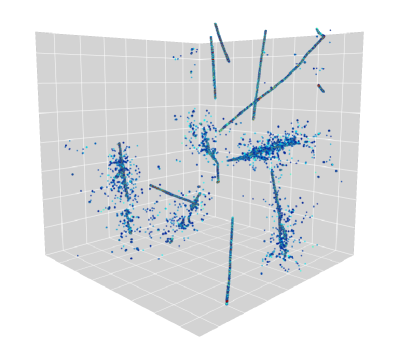
We use 3D LArTPC particle images from the PILArNet dataset Adams et al. (2020), an open dataset made available by the DeepLearnPhysics collaboration333https://dx.doi.org/10.17605/OSF.IO/VRUZP. We use the largest 3D image in the dataset, a cubic volume with each side 768 voxels (453 million voxels) at 3 mm/voxel spatial resolution. Figure 2 shows an example image from this dataset. The dataset contains 80,000 images for the training set and 20,000 images for the test set where each image contains several particles traversing the LAr volume. The PILArNet provides five types for the voxel-level semantic category. These include heavily ionizing particles (HIP, e.g. protons), minimum ionizing particles (MIP, e.g. muons and pions), electromagnetic (EM) showers, delta rays, and Michel electrons from muon decays. Further, the dataset provides particle-level metadata including endpoints of HIP and MIP particles as well as the initial point of other particle types including EM showers, delta rays and Michel electrons. These 3D points are provided with a floating-point precision in the unit of voxels, and used as true points for training PPN. More details can be found in the PILArNet reference Adams et al. (2020).
III.2 Training details
We drop the point labels for particles with less than 10 MeV in total energy deposit or a total voxel count of less than 7 voxels, which corresponds to a trajectory of a few voxels in length as a typical trajectory width is a few voxels or more. The PPN1 and PPN2 layers have a spatial size of 24 voxels and 96 voxels respectively. During training, we add true voxels to the attention masks generated by the PPN1 and PPN2 layers so that the subsequent layers, namely PPN2 and PPN3, can be trained with some mixtures of true and false voxels. This allows all PPN layers to train simultaneously from the beginning.
The batch size is 64 and we used an Adam optimizer with learning rate 0.001 to train the network. Training the U-ResNet alone first for 20k iterations, then U-ResNet+PPN for another 20k iterations, took 184 hours on a Nvidia V-100 GPU for the total of 32 epochs. The whole network (i.e. U-ResNet+PPN) can be trained from scratch without having to separate into two stages, in which case 40k iterations took 231 hours. Unless stipulated otherwise, the default configuration for the rest of this paper is the two-stage training.
IV Results
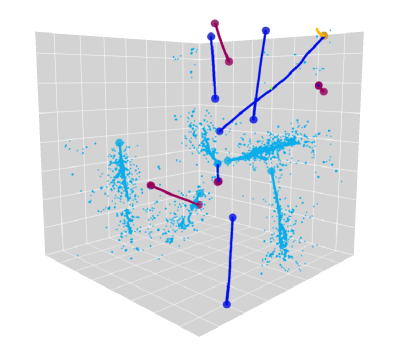
IV.1 Position Precision
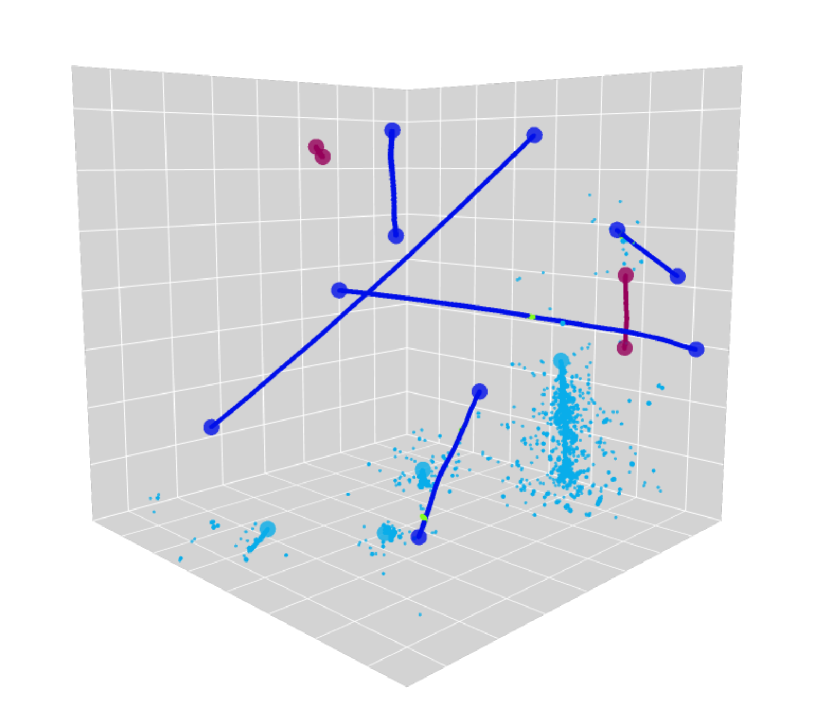
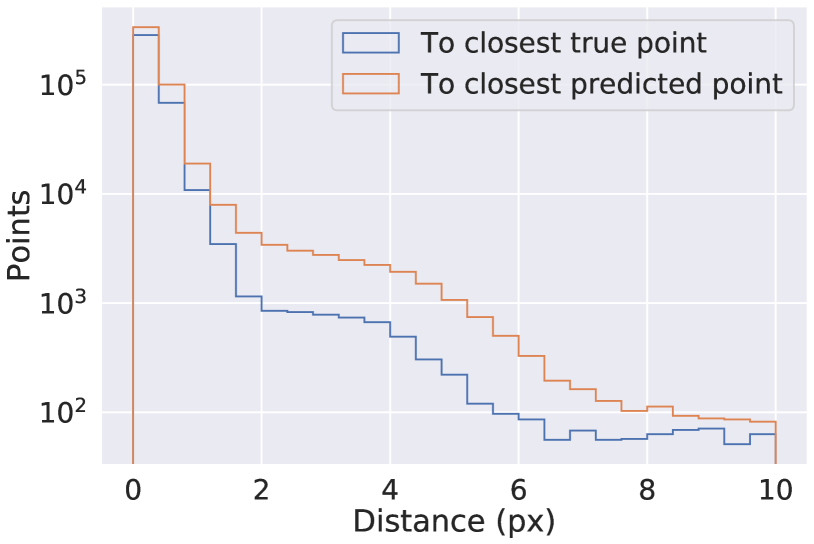
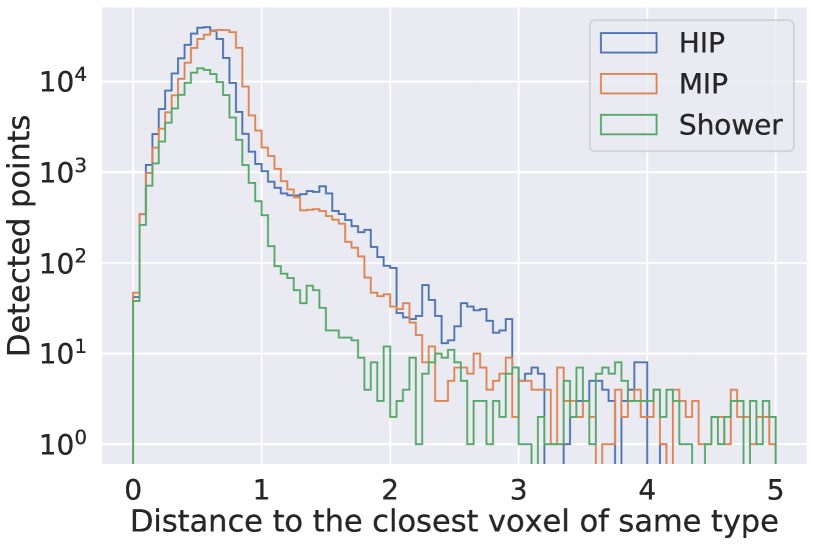
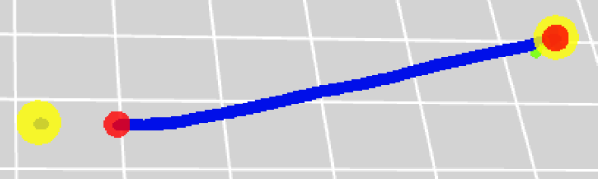
Figure 3 is a visual example of predictions made by UResNet+PPN. Figure 4 shows the distribution of distance from a true point to the closest predicted point. For all true points, 95.1 % and 97.8 % of them are within the voxel distance of 3 and 10 from a predicted point. The figure also shows the distribution of distances from a predicted point to the closest true point, and we find that our algorithm successfully predicts 96.8 % and 97.8 % of 3D points within the voxel distance of 3 and 10 from the true points respectively. If we look at semantic type-wise results, we find that the fraction of true points which are more than 3 voxels away from any predicted point is 7 %, 2.1 %, 8.2 % and 1.6 % for the HIP, MIP, EM shower and Michel electron types respectively. For this analysis and Figure 4, we excluded delta ray type true and predicted points since the true point coordinates for delta rays provided in PILArNet are less precise than those of MIP, HIP, EM shower and Michel electron types. This is likely because the initial points of delta rays often overlap with a muon trajectory, which typically has a width of a few voxels or more. We considered the predicted points to be delta ray type if the point has the delta ray type score of 0.5 or higher.
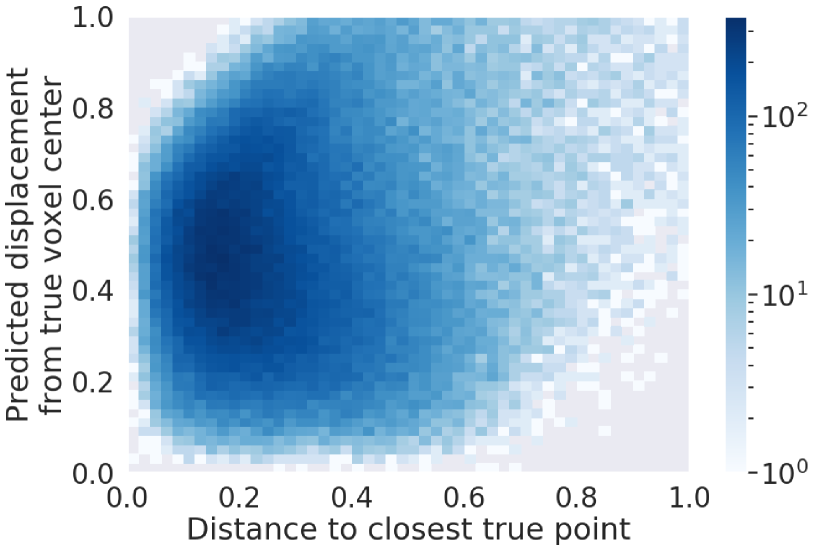
For those predicted points within 3 voxels of the closest true point, the median distance between the positions of a predicted point and the closest true point is measured to be 0.25 voxels. If PPN is only sensitive to identify a true voxel in which a true point is present, and if it is not capable of regressing the position at the sub-pixel level, we expect this resolution to be 0.66, which is the median distance between two random point positions in a voxel. We note that 17 % of the true points provided by the PILArNet are located exactly at the center of a voxel, which is typically observed as a result of an endpoint approximation within the recorded volume when a particle is exiting or entering the volume. For other true points whose position is not fixed exactly at the voxel center, the correlation of the distance between a predicted point to the closest true point and the displacement of that predicted point from the true voxel center is shown in Figure 5. When PPN predicts a point within the correct true voxel, geometrically the distance from the voxel center to the predicted point must be between 0 and 0.866. The two distances show almost no correlation in this range, which shows that PPN position resolution is uniform and independent of a true point location within the true voxel. This demonstrates that our algorithm achieved a sub-voxel level precision for this reconstruction task.
IV.2 Type Prediction Accuracy
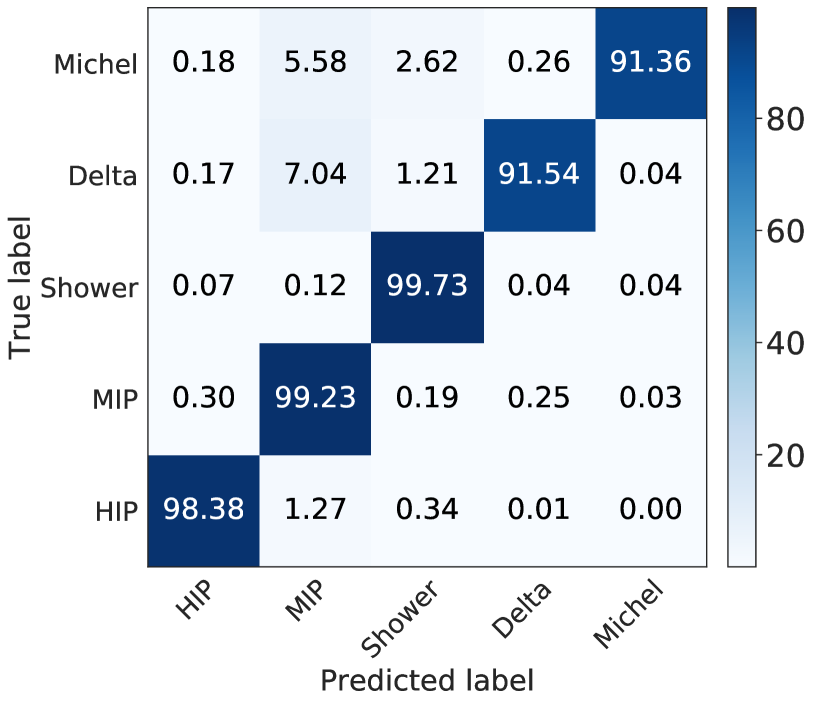
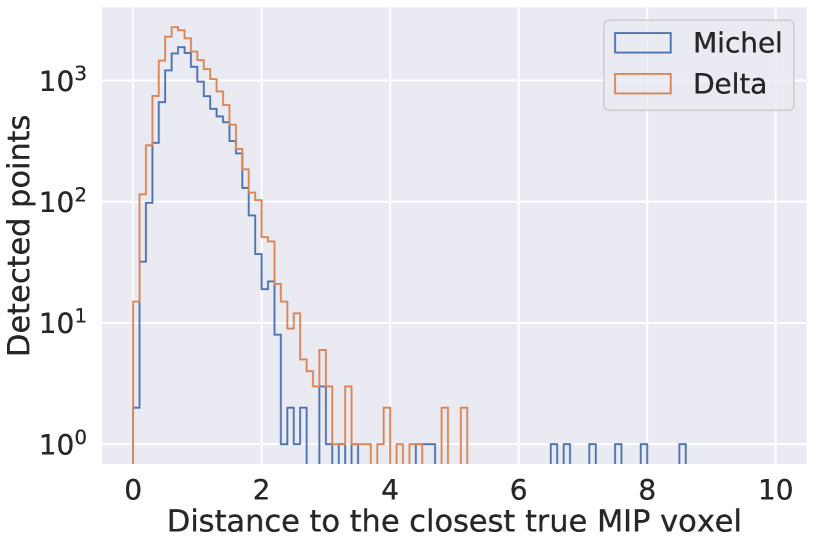
Before evaluating the point type prediction performance, it is useful to remind ourselves of the performance of the U-ResNet. In this particular training, the confusion matrix that we obtain is shown in Figure 6. We can then look at the distance from predicted points to true voxels of a certain semantic type. For example we expect predicted points with high Michel or Delta type score to be close to MIP voxels in the labels, and Figure 7 confirms this. Figure 8 shows that imposing the maximal distance threshold of 2 voxels between a predicted point with a high type score for a set of types and a voxel whose predicted type matches one of them is reasonable.
We define purity and efficiency metrics for the point type prediction as follows: for a given predicted point, we consider all semantic types for which it has a score and we refer to them as predicted types. We count a predicted type as matched if there exist a true point of the same type within 5 voxels. We note that one point may be associated with multiple types, and one point may contribute as many times as its associated type counts under this scheme. The fraction of matched predicted types is our purity metric. Similarly, for a given true label type, we say that it is matched if there is a predicted point within 5 voxels which has a score for the same semantic type. The fraction of matched true types is our efficiency metric. Under these definitions, we find a purity of 96.3 % and an efficiency of 89.2 %. The Table 1 breaks down these purity and efficiency metrics for each semantic class. The purity is significantly higher than the efficiency, which indicates that while currently predicted types are highly accurate, there is a space for PPN to improve to predict all possible types associated with a predicted point. This may be related to the architecture where PPN is coupled to U-ResNet which ultimately predicts a single type per voxel.
| Class | HIP | MIP | Shower | Michel |
|---|---|---|---|---|
| Purity | 97 % | 98 % | 92.2 % | 99.3 % |
| Efficiency | 85.3 % | 93.4 % | 90.7 % | 89.7 % |
IV.3 Mistakes analysis
About 2.2 % of predicted points, excluding points predicted as delta ray type, are more than 10 voxels away from any true point. Let us call them far mistakes. Among them, 25.8 % have a high () type score of being HIP, 21.9 % for MIP and 53.8 % for shower. We have visually scanned event displays of these mistakes and report their nature in this section. In summary, we found that a large fraction of far mistakes were due to issues with true points or legitimate mistakes where authors cannot visually distinguish from correct predictions.
IV.3.1 Fragmented EM Showers
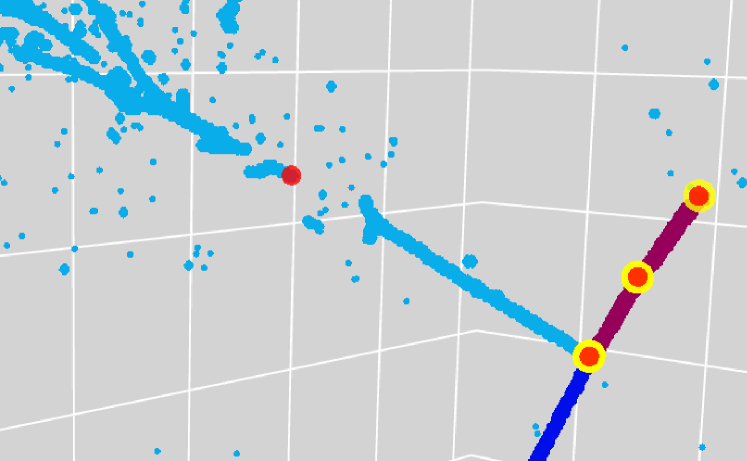
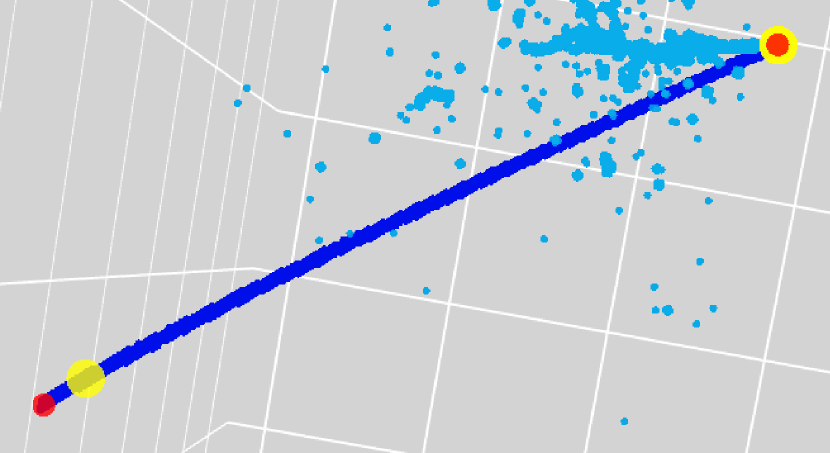
An EM shower is initiated by an EM particle including an electron, a positron, or a gamma ray, and develops a cascade of them through radiations of gamma rays. In physics analysis, typically a whole cascade is conveniently treated as one EM shower instance instead of identifying dozens to hundreds of secondaries. This is shared in the PILArNet dataset where EM shower information, such as the initial point, is provided for the whole cascade. In LArTPC, however, given the average radiation length of 14 cm rad (2017), which corresponds to 47 voxels, we expect that some radiated gamma rays in the cascade may be separated by significant gaps. This results in cases where a single EM shower may appear indistinguishable from two or more separate, overlapping EM showers.
In those cases, PPN may place multiple initial points within a single shower, as shown for example in Figure 9. While this may visually appear reasonable, they can be the cause of far mistakes as the PILArNet provides only one initial point for the whole shower. Among the far mistakes, more than half (53.2 %) have a high () type score for being EM shower and are within 2 voxels distance from voxels of true shower type in semantic segmentation labels.
IV.3.2 Mistakes due to tracks (HIP/MIP)
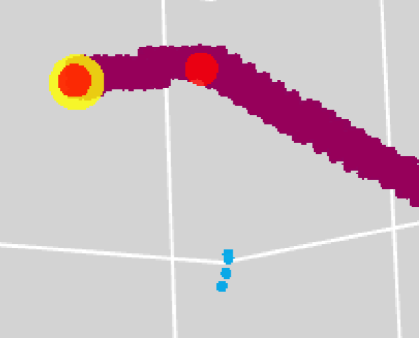
49.4 % of the far mistakes have a HIP or MIP point type score . We randomly sampled 20 cases with one far mistake with high HIP score. 15 of them (75 %) were due to very small HIP trajectories for which PPN made good predictions but true points were missing. This is caused by the fact that these trajectories fall below the threshold that we impose to define true points ( voxels, MeV total energy deposit), leading to missing true points as shown in Figure 10. 2 out of the remaining 5 cases were found to be “legitimate mistakes” due to a kink in a trajectory as shown in Figure 11. The last 3 cases were genuine mistakes (e.g. a point predicted in the middle of a trajectory without any obvious kink).

On the other hand we also sampled 20 events with far mistakes with high MIP score. One case was due to a short trajectory missing true points, and one was a rare case where PPN made an extra, faulty prediction at the crossing point of two MIP trajectories that accidentally overlapped in the 3D space. The majority (12 cases) were legitimate mistakes due to a kink in a trajectory. The rest (6 cases) were genuinely bad mistakes.
IV.3.3 Trajectories affected by the boundaries
10.1 % of far mistakes are within 5 voxels of an image boundary, indicating they may come from a particle trajectory crossing the image volume boundary. MIP trajectories are more likely to cross a volume boundary due to their length. Hence they are more affected by boundaries. Among the far mistakes that are more than 5 voxels away from the boundary, only 18 % have a high MIP type score. This fraction increases to 54 % in the region within 5 voxels from the boundary while negligible statistical change was observed for predicted points of other types.
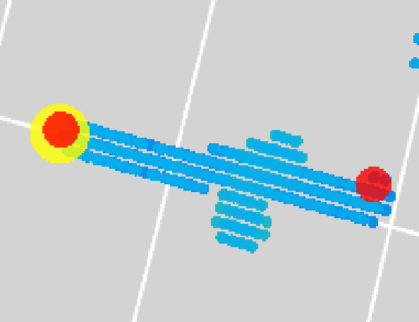
We have visually scanned randomly selected 10 far mistakes of a high MIP type score in this region next to the boundary. One of them was a legitimate mistake due to a kink in a trajectory, similar to the dominant case of MIP far mistakes found and described previously. The rest (9) of the MIP mistakes near the boundary were all due to issues related to true points. These issues include: exiting shower trajectory which gets classified as MIP by UResNet (Figure 12), and results in a too short trajectory and loss of true points as previously described for HIP cases, a MIP trajectory that exited and re-entered the image volume (Figure 13), for which the true points provided in PILArNet appear unreasonable, and also what appears as a genuine mistake of true point location on the boundary provided by PILArNet dataset (Figure 14). We conclude therefore that the majority of far mistakes made by PPN are due to either issues related to true points or legitimate mistakes that visually appear reasonable.
IV.4 Others
| Duration (s) | Memory (GB) | |||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| UResNet only | 14.3 | 4.9 | 9.9 | 2.2 |
| UResNet + PPN | 20.5 | 7.6 | 10.8 | 2.2 |
We also compared the PPN performance in two training scenarios: a single-stage training, where we start training from scratch both U-ResNet and PPN at the same time for 40k iterations, and a two-stage training where we train U-ResNet for 20k iterations first, before adding the PPN layer and continue training of U-ResNet+PPN for 20k more iterations. Everything else is identical between the two schemes. The fraction of true points that are within 10 voxels of a predicted point is 98.2 % and 97.8 % respectively. The fraction of predicted points that are within 10 voxels of a true point is 97.8 % in both cases. The fraction of true points which are more than 3 voxels away from any predicted point is 5.2 % and 5.4 % respectively. There is no significant difference between the two training schemes, which confirms that the PPN learning is conditioned by the UResNet performance.
Table 2 shows that PPN layers have a very little impact on the memory usage (about 1GB at train time, negligible at inference time). However they are responsible for about 30 % of the total computation time, if compared with the UResNet-only resources usage.
IV.5 Track clustering
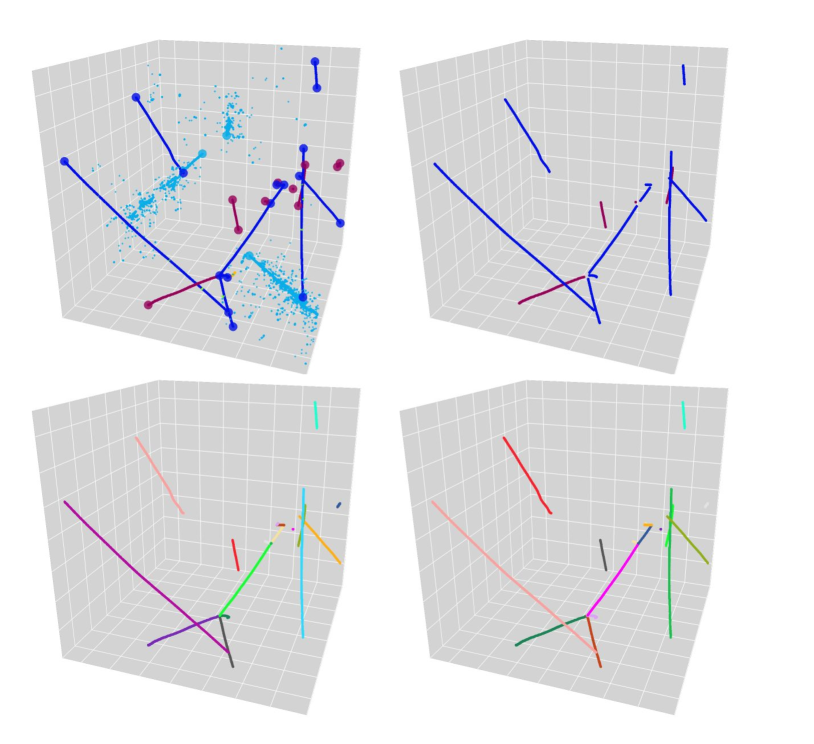
Lastly we report a simple application of U-ResNet and PPN for clustering voxels to identify individual track-like particles. This clustering task belongs to the next important step in the LArTPC data reconstruction pipeline. Using the output of UResNet and PPN, a very simple clustering algorithm can be designed: first, for each predicted semantic type, run a density-based clustering algorithm such as DBSCAN Ester et al. (1996) on the voxels predicted to belong to track-like particles (i.e. HIP and MIP types). We use here the parameters of and min_samples for DBSCAN. This will cluster together particle trajectories that are spatially adjacent, such as tracks coming out of the same interaction vertex. To mitigate this issue we can use the points predicted by PPN to “break” the predicted clusters: for each predicted cluster from the first step and associated closest predicted points, we mask a sphere of 7 voxels around each predicted point, run DBSCAN again to reconstruct the main trunk of individual track-like particles, and assign the remaining voxels in the masked regions to the closest track-like cluster to complete individual trajectories. Figure 15 illustrates this simple algorithm.
We define metrics of purity and efficiency per cluster, as fraction of the predicted cluster voxels overlapping with the true cluster and fraction of the true cluster voxels overlapping with the predicted cluster respectively. We also look at the Adjusted Rand Index (ARI) metric Hubert and Arabie (1985) per true semantic type (HIP and MIP), averaged over events, to get a sense for the overall clustering performance. We find for efficiency/purity/ARI metrics the values of 0.96/0.93/0.91 for track-like clusters.
V Conclusion
We have introduced the Point Proposal Network. Building on the previous development of U-ResNet Dominé and Terao (2020), we showed that PPN is capable detecting the endpoints of track-like particles as well as the initial point of shower-like particles. PPN successfully predict 96.8 % and 97.8 % of 3D points within the voxel distance of 3 and 10 from the true points respectively. For the predicted points and true points that reside within 3 voxels within each other, PPN achieves the sub-voxel level precision with a median distance of 0.25 voxels. PPN is also the first benchmark algorithm for PILArNet for reconstructing particle positions. Using the output of U-ResNet and PPN, we demonstrated a simple set of algorithms to cluster 3D voxels into individual track-like particles. We reported that our algorithms achieved a voxel clustering efficiency/purity/ARI of 0.96/0.93/0.91. U-ResNet and PPN are part of a scalable, deep-learning based data reconstruction chain for LArTPC detectors.
VI Acknowledgement
This work is supported by the U.S. Department of Energy, Office of Science, Office of High Energy Physics, and Early Career Research Program under Contract DE-AC02-76SF00515.
References
- Acciarri et al. (2017a) R. Acciarri et al. (MicroBooNE Collaboration), Journal of instrumentation 12, P03011 (2017a).
- Adams et al. (2019) C. Adams et al. (MicroBooNE Collaboration), Phys. Rev. D 99, 092001 (2019).
- Radovic et al. (2018) A. Radovic, M. Williams, D. Rousseau, M. Kagan, D. Bonacorsi, A. Himmel, A. Aurisano, K. Terao, and T. Wongjirad, Nature 560, 41 (2018).
- Acciarri et al. (2017b) R. Acciarri et al. (MicroBooNE), Journal of Instrumentation 12, P02017 (2017b).
- Antonello et al. (2015) M. Antonello et al. (MicroBooNE, LAr1-ND, ICARUS-WA104), (2015), arXiv:1503.01520 [physics.ins-det] .
- Amerio et al. (2004) S. Amerio et al. (ICARUS), Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment 527, 329 (2004).
- Acciarri et al. (2016) R. Acciarri et al. (DUNE), (2016), arXiv:1601.02984 [physics.ins-det] .
- He et al. (2017) K. He, G. Gkioxari, P. Dollár, and R. Girshick, in Proceedings of the IEEE international conference on computer vision (2017) pp. 2961–2969.
- Girshick (2015) R. Girshick, in Proceedings of the IEEE international conference on computer vision (2015) pp. 1440–1448.
- Ren et al. (2015) S. Ren, K. He, R. Girshick, and J. Sun, in Advances in neural information processing systems (2015) pp. 91–99.
- Liu et al. (2016) W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, Lecture Notes in Computer Science , 21–37 (2016).
- Dominé and Terao (2020) L. Dominé and K. Terao (DeepLearnPhysics Collaboration), Phys. Rev. D 102, 012005 (2020).
- Dominé and Terao (2018) L. Dominé and K. Terao, “Applying Deep Neural Network Techniques for LArTPC Data Reconstruction,” (2018).
- Sochat VV (2017) K. G. Sochat VV, Prybol CJ, PLoS ONE 12 (2017).
- Adams et al. (2020) C. Adams, K. Terao, and T. Wongjirad, “Pilarnet: Public dataset for particle imaging liquid argon detectors in high energy physics,” (2020), arXiv:2006.01993 [physics.ins-det] .
- Graham and van der Maaten (2017) B. Graham and L. van der Maaten, arXiv preprint arXiv:1706.01307 (2017).
- Graham et al. (2018) B. Graham, M. Engelcke, and L. van der Maaten, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018) pp. 9224–9232.
- Ronneberger et al. (2015) O. Ronneberger, P. Fischer, and T. Brox, in International Conference on Medical image computing and computer-assisted intervention, Vol. 9351 (Springer, 2015) pp. 234–241.
- Ester et al. (1996) M. Ester, H.-P. Kriegel, J. Sander, and X. Xu, in Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96 (AAAI Press, 1996) pp. 226–231.
- rad (2017) “Particle data group, atomic and nuclear properties of liquid argon (ar),” (retrieved Feb. 20, 2017).
- Hubert and Arabie (1985) L. Hubert and P. Arabie, , 193 (1985).