∎ 11institutetext: ∗Department of Mathematical Sciences, Worcester Polytechnic Institute, 100 Institute Road, Worcester, MA 01609, USA; 11email: mbichuch@wpi.edu, ssturm@wpi.edu. Work partially supported by NSF grant DMS-0739195 while the authors were Postdoctoral Research Associates at Princeton University.
Portfolio Optimization under Convex Incentive Schemes
Abstract
We consider the terminal wealth utility maximization problem from the point of view of a portfolio manager who is paid by an incentive scheme, which is given as a convex function of the terminal wealth. The manager’s own utility function is assumed to be smooth and strictly concave, however the resulting utility function fails to be concave. As a consequence, the problem considered here does not fit into the classical portfolio optimization theory. Using duality theory, we prove wealth-independent existence and uniqueness of the optimal portfolio in general (incomplete) semimartingale markets as long as the unique optimizer of the dual problem has a continuous law. In many cases, this existence and uniqueness result is independent of the incentive scheme and depends only on the structure of the set of equivalent local martingale measures. As examples, we discuss (complete) one-dimensional models as well as (incomplete) lognormal mixture and popular stochastic volatility models. We also provide a detailed analysis of the case where the unique optimizer of the dual problem does not have a continuous law, leading to optimization problems whose solvability by duality methods depends on the initial wealth of the investor.
Keywords:
portfolio optimization, fund manager’s problem, incentive scheme, convex duality, delegated portfolio managementMSC:
91G10, 90C26JEL Subject Classification G11
1 Introduction
Whereas classical portfolio theory studies utility maximization from the point of view of an investor, whose preferences are modeled by a concave utility function, in reality, portfolio management is commonly delegated to a fund manager. To increase the efficacy of the manager, he is often paid by an incentive scheme that depends on the performance of the fund he manages. Such a scheme can be composed, for example, of a fixed fee, some percentage of the fund, plus an additional reward, which consists of one (or a combination of several) call options on the fund. As a consequence, two differences to the classical setting arise. First, the utility function, under which the optimization is carried out, does not represent the preference structure of the investor (also called the principal), but rather the manager’s (the agent’s) preference structure. Second, what is optimized under this utility function is not the terminal value of the fund itself, but rather some function of it, which depends on the specific incentive scheme.
The resulting optimization problem is, in general, no longer concave, and therefore does not fit into the classical setting first studied by Merton Merton , who used a stochastic optimal control approach. Specifically, Merton derived a Hamilton-Jacobi-Bellman (HJB) equation satisfied by the value function and found a closed form solution in the case of power utility. The drawback of this method – namely that it requires the state process to be Markov – can be overcome by using the fact that the processes dual to the portfolio processes are given via the set of equivalent local martingale measures, as pioneered by Karatzas, Lehoczky and Shreve KILS and Pliska Pliska . A thorough study of the portfolio optimization problem in a general (incomplete) semimartingale market was conducted by Kramkov and Schachermayer KramSchach1 , KramSchach2 , Bouchard, Touzi and Zeghal BTZ and others.
As pointed out, all of the above literature concentrates on the principal investor himself. The problem becomes more involved, if the investor, rather than investing himself, delegates his money to a fund manager. The agent invests on the principal’s behalf, in exchange for a fee schedule, which is based on the fund’s performance at the final time , and given by a function of the portfolio at terminal time. We assume that the agent’s utility function is smooth, strictly concave and has a domain bounded from below. These assumptions allow for the classical examples of power and logarithmic utility (but not utility functions defined on the whole real line such as the exponential). The fee schedule function is assumed to be convex and dominated by an affine function – i.e., its slope has to be bounded; without loss of generality we will assume that the maximal slope is . The financial reasoning for these assumptions on is that we expect the manager’s fees to increase as the fund’s profit increases. Therefore, should be convex. The fund manager’s utility, which results from his payoff, is hence a composition of the two functions, , and may no longer be concave. Thus, the previously mentioned results are no longer applicable.
The resulting problem is not well understood; the existing literature discusses mainly the question of whether such a compensation scheme leads the portfolio manager to take excessive risk. In Ross , Ross discusses some conditions to make the agent more or less risk averse then the principal. Carpenter shows in carp the existence of the fund manager’s optimal portfolio in case of a utility function with constant relative risk aversion and a call option like fee schedule in a Brownian stock price model. In this setting, her analysis is generalized by Larsen Lars into an agency problem, where the investor optimizes the resulting payoff over piecewise affine incentive schemes, which he might choose to offer the portfolio manager.
We want to point out that there is also a different approach to portfolio optimization under incentive schemes, in which the compensation is based on high-watermarks, i.e., the running maximum of the fund. Recent references to this compensation approach include ObGua , JanSir , PanWest . In all of these papers the authors also assume a Brownian stock price model and solve the appropriate HJB equation.
In the present paper we will investigate the more fundamental problem of existence and uniqueness of an agent’s optimal investment portfolio in a general semimartingale model. As noted above, the resulting fund manager’s utility function may not be concave. It is well-known that the solution is then to concavify , and solve the concavified problem instead. Even though this new utility is now concave, it is not necessarily strictly concave, nor does it necessarily satisfy the usual Inada condition at zero, both of which are needed in the classical utility maximization framework. Moreover, the smoothness of the concavified function is not clear a priori. Using a dynamic programming approach via HJB equation is – at least in the straightforward way – also not possible, since the concavified utility function can (and usually will) be affine in some parts, and hence finding the optimal portfolio becomes impossible. Thus, we have effectively to weaken the utility function requirement of Kramkov and Schachermayer KramSchach1 . Our approach is to use the more general framework of Bouchard, Touzi and Zeghal BTZ and, by proving additional regularity of the concavified utility function, show the uniqueness of the dual optimizer. We are thus able to utilize the abstract framework of Bouchard, Touzi and Zeghal in a concrete setting, which is a rare feat (note, however, the exception of Seifried Seifried , who discusses capital gains taxes in a complete market).
The next step is to develop sufficient conditions, broad enough to be of interest, for the solution of the concavified problem to be also the solution of the original problem. It turns out that a necessary and sufficient condition is that the corresponding unique dual optimizer has a continuous law (i.e., the distribution of the random variable has no atoms). A similar procedure can be found in a related paper by Carassus and Pham Carassus , who consider a problem of portfolio optimization in a complete market with Brownian stock price, with a utility function created by two piecewise concave functions. We show that the condition of atomlessness holds, not only true in the classical Black-Scholes model with discounted stock price having nonzero drift, but also in two example classes of markets, independent of the initial capital of the fund and independent of the concrete incentive schemes: (1) complete one-dimensional Itô-process models (such as local volatility models), and (2) incomplete lognormal mixture and stochastic volatility models (such as the popular correlated Hull-White, Scott and Heston models).
The practical consequence of this is that the agent shuns successfully away from any part of the domain where the concavified utility function is linear . However, he does this in a smooth way. The optimal terminal wealth has no atoms except possibly at zero (meaning that the fund manager jeopardizes the fund with a positive probability), and it is zero under any linear spot of the concavified utility function.
If the assumption on the non-atomic structure of the dual optimizers fails, we are still able to give an affirmative answer, albeit only for some initial capitals. In general, the fund manager’s optimal wealth does not have to agree with the one calculated from the concavified problem, and even if it does, it does not have to be unique. As a note of caution, we present easy counterexamples that show that this method should not be implemented without proper conditions. We also give simple examples for our theorems, which conceptually present how the optimal portfolio can be explicitly calculated in a complete market setting.
The rest of this paper is organized as follows. In Section 2 we introduce the mathematical model of our delegated portfolio optimization problem and state our main results. The two following sections are devoted to examples illustrating our findings. In Section 3 we discuss in detail the case of power utility in a Black-Scholes market, highlighting the central importance of the distributional properties of the dual optimizer and investigating the problem from the point of view of the managers risk aversion. Section 4 contains several complete and incomplete market models in which our assumptions hold true. The remaining sections are devoted to the more technical side of the problem. Section 5 provides the background on general results on smooth and non-smooth duality theory and discusses how they can put to work for our needs. Section 6 contains the detailed proofs on the relationship of the conacavified and the dual problem. Section refsec:7 draws the conclusions for the original problem and contains the proof of the main theorem. Finally, Section 8 discusses the limitations of the main theorem and provides partial results for an atomic dual optimizer. The conclusions of our exposition are summarized in Section 9.
After finishing a first version of the present paper, we have learnt of the work of Reichlin Rei , who studies the utility maximization problem for more general non-concave utility functions under a fixed pricing measure.
2 Setting and Main Results
We start by reviewing utility maximization in a general semimartingale framework and state our main results. Assume that , is a d-dimensional, locally bounded semimartingale on a filtered probability space , representing discounted stock price processes; without loss of generality we assume . We focus on portfolio processes with initial capital and predictable and -integrable hedging strategies . The value process of such a portfolio is then given by
Denote by the set of all nonnegative wealth processes with initial capital ,
| (1) |
We refer to as the set of all admissible wealth processes.
We want to look at the portfolio optimization problem from the perspective of a portfolio manager, who is paid with incentives that depend on the performance of the portfolio at some future time . In this article we allow the incentive scheme to be a function , nonconstant, nondecreasing, convex and with maximal slope , i.e.,
| (2) |
We note that the agent’s private capital can be absorbed into (if positive). To simplify the exposition, we will assume throughout this text that, without loss of generality, . Setting , the portfolio manager’s utility maximization problem is
| (3) |
Assumption 1
To make the problem nontrivial, we assume that there exists at least some such that
Assumption 2
To preclude the possibility of arbitrage in the sense of ‘free lunch with vanishing risk’ (for details see the work of Delbaen and Schachermayer, DS ) we assume that the set of equivalent local martingale measures is not empty,
Assumption 3
The fund manager’s preferences are represented by a utility function (without loss of generality we assume ).
-
a)
We assume that is strictly increasing, strictly concave and continuously differentiable on ; we extend continuously to , allowing the value at ;
-
b)
The utility function satisfies the Inada-conditions
(4) -
c)
Moreover, it satisfies the asymptotic elasticity condition
(5)
These three standard assumptions of utility maximization problems (see, e.g., KramSchach1 ) will be the standing assumptions for the rest of this paper.
Before introducing the dual problem, we recall some standard notions and notation of convex analysis. A function defined on some convex domain is called convex (respectively concave) if its epigraph (respectively hypograph)
is a convex set. The effective domain of a convex function is defined as
Similarly, for a concave function, we define its domain as the set of points in the pre-image not mapping to . Generalizing the usual notations from utility maximization problems in an obvious way, we define, for any function dominated by some affine function, its convex conjugate and its biconjugate by
Note that is the concavification of , i.e., the hypograph of is the closed convex hull of the hypograph of , . We note that is the convex conjugate of in the classical sense of convex analysis. We will use standard results of convex analysis (cf., e.g., HUL ) with the obvious modifications without further notice.
We note that the function is not necessarily concave, placing the problem (3) outside the standard setting of utility maximization. Instead of analyzing the non-concave problem (3) directly, we will first consider the concavified problem
| (6) |
Similar to KramSchach1 we define the set of process dual to (2) by
It turns out then that both problems share the dual problem (see Theorem 2.1 below), i.e.,
| (7) |
In general the concavified utility function will be neither strictly concave nor satisfy the Inada condition at . Hence, we will have to rely on results for nonsmooth utility maximization (see Theorem 5.2 for more details). We will see that Assumptions 1, 2, and 3 place us in a setting where we will be able to apply this theorem.
Finally let
The following are the main theorems of this paper. Theorem 2.1 establishes the duality relationship between and , and relates and , the optimizers of the problems (6) and (7), respectively. Theorem 2.2 provides conditions under which and – the optimizers of the problems (3) and (6), respectively, are the same.
Theorem 2.1
For the utility optimization problem under a convex incentive scheme it holds that
-
a)
The functions and are finite on as is on , and . Moreover, is strictly convex on the whole domain if . Otherwise, there exists some such that is convex on the interval and constant on . The function is continuously differentiable on , and concave.
-
b)
The optimizer of the dual problem (7) exists for every and is a.s. unique on .
-
c)
For there exists an optimizer of the concavified problem (6) that satisfies
for such that and is a uniformly integrable martingale.
-
d)
Additionally we have
however the infimum is in general not attained in .
Theorem 2.2
Assume that for every the terminal value of the dual optimizers has a continuous cumulative distribution function. Then
-
a)
The optimizer for the concavified problem (6) is unique for every .
- b)
At a first glance the condition that the distribution of the dual optimizer has no atoms seems quite abstract and hard to check. Therefore, we present a sufficient condition for no atoms, in terms of equivalent local martingale measures, which can be checked more easily in some concrete models.
Proposition 1
Assume that the laws of the Radon-Nikodým derivatives , , are uniformly absolutely continuous with respect to the Lebesgue measure on (i.e., the densities are uniformly integrable). Then the terminal value of the optimizer of the dual problem (7) has a continuous law.
While this assumption it is quite restrictive, it is the only one we know which works in general without having a priori knowledge of the maximizer. It is in particular satisfied in the Black-Scholes model with nonzero drift. We will show in section 4 that these assumptions are also satisfied in other incomplete market models, such as lognormal mixture models. In more general models – as stochastic volatility models, see also section 4 – one can nevertheless derive the result, if one has some a priori knowledge about the optimizer, essentially depending on the measurability properties of the Sharpe ratio.
3 Examples around the Black-Scholes model
We first present our findings for power utility maximization in the Black-Scholes model with an incentive of call option type: . This setting not only allows us to connect our results to previous work carp and provide explicit solutions, but it also allows us to illustrate the degeneracy if the Sharpe ratio vanishes – producing a purely atomic Radon-Nikodým derivative. Another benefit of studying this setting is that it allows us to analyze the situation from the point of view of the (relative) risk aversion of the manager. Specifically, we address the issue of the optimal relation between the number of options and the value of the strike among all those producing the same relative risk aversion (compare this to Ross ).
Example 1
Assume that the discounted stock price is modeled by
for some Brownian motion generating the filtration . These stock price dynamics, together with the riskless numéraire, describe a complete market. The set of all equivalent local martingale measures is hence the singleton , where the measure is given by the Radon-Nikodým density with market price of risk and is a -Brownian motion. Furthermore, let the incentive scheme be given by , , .
The portfolio manager’s utility will be given by the function be . We will now consider two cases, and . In the second case, we will assume without loss of generality that and find
where is the solution of , and . In the former case
To make our example more computationally tractable, we will focus on the power utility case with . Here , , and , and thus
| (12) | ||||
| (15) |
For the illustration in Figure 1 we assumed . Then it is easily seen that and
| (20) | ||||
| (23) |
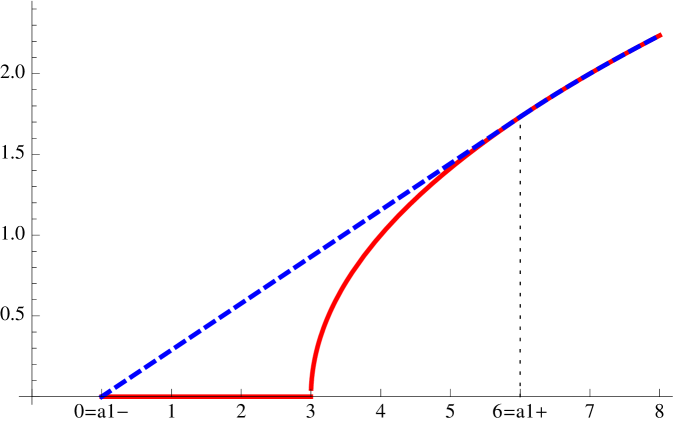
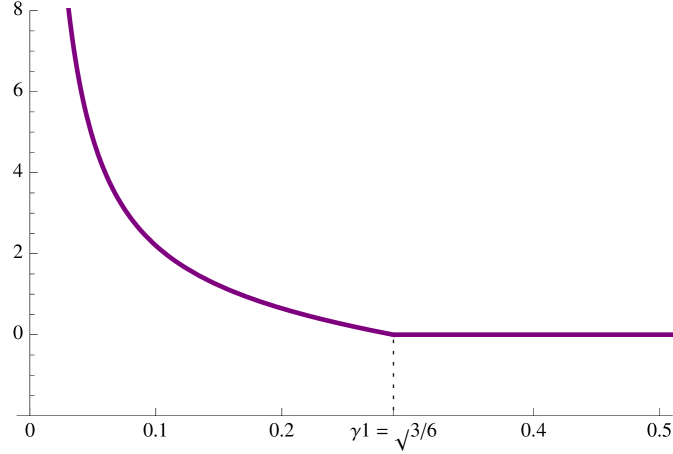
The non-atomicity condition on the dual optimizer (here just the Radon Nikodým derivative ) implies that we have to consider two distinct cases: either is positive (equivalently, we could assume negative), or . The reason for this distinction lies in the fact that with , the original measure is already the (unique) risk-neutral measure . In other words, . Hence, the random variable has an atom of mass one at . In the other case the random variable has a (smooth) density.
3.1 Case 1:
We proceed first with the case in which the random variable has a density. Tedious, but straightforward stochastic calculus reveals the following results. The dual value function is given by
where is the cumulative distribution function of the normal distribution. Thus, is continuously differentiable and strictly concave on the whole real line. Therefore, using the fact that , the function is also strictly concave and continuously differentiable on . For the terminal value of the optimizer we obtain (we can use almost everywhere defined derivatives since the law of has no atoms)
To compute the optimal strategy we simply observe that
solves the (reverse) heat equation on with terminal condition
satisfying . Then it follows from Itô’s formula that
Thus, the optimal strategy (in terms of cash invested in stock) is simply .
Explicitly, we derive
Thus, the optimal strategy in terms of money invested in stock is given by
We note that this can also be derived more generally by using (OconeKaratzas, , Theorem 6.2) and observing that their condition (6.7) is always satisfied in our case, as asymptotic elasticity implies the inequalities of (KramSchach1, , Lemma 6.3) (where we only have to replace the derivatives by suprema of subdifferentials).
On a more practical side, we would like to investigate the optimization problem conditional on the portfolio manager’s risk aversion. It turns out that the proper concept for this issue is to look on relative risk aversion (RRA) and to apply this also to the dual value function. Using the fact that , it follows that for , and we can compute the relative risk aversion
Using the fact the , and that , we obtain
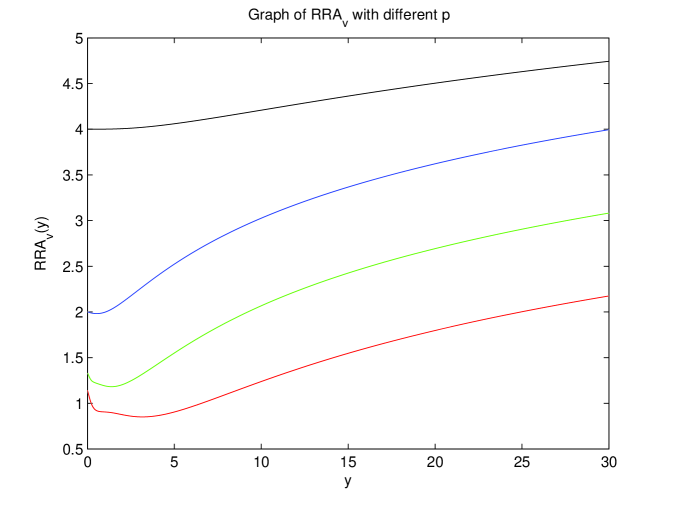
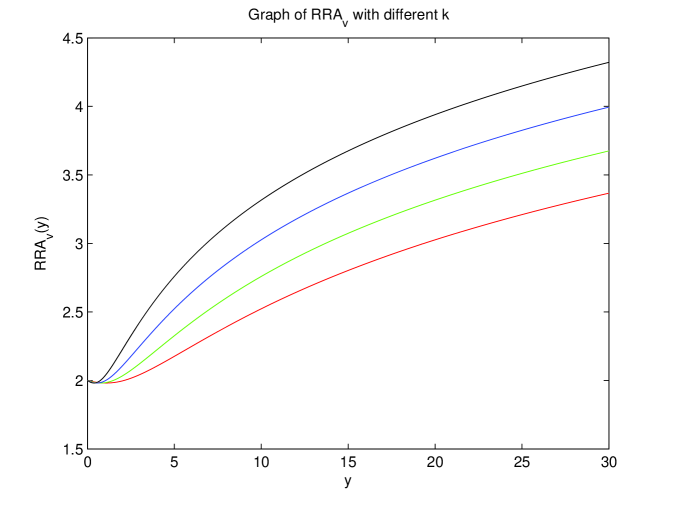
For the rest of this subsection, to highlight the dependency on and , we will write , , , for the concavified dual utility functions, the value function, its dual, and the concavified value function, respectively.
Notice that if we parametrize and by in the way that , then does not depend on . The same is true for , and it follows that . This is not surprising, since the same scaling property holds for the concavified dual utility function . Finally, we conclude that does not depend on . That is, the relative risk aversion of the fund manager is does not change when his compensation scheme is scaled in the above way. Additionally, it is easily seen that
Note that the family includes all the functions (up to an additive constant) that have the same relative risk aversion as the original dual function .
This leads finally to the following questions. Among the incentive schemes with same relative risk aversion , is there is one that is optimal from the manger’s point of view? If so, how it can be characterized? It turns out that the answer to the former question is affirmative if there is some such that the elasticity of is equal to one: . The elasticity of a utility function being defined as
| (24) |
(compare this with the definition of the asymptotic elasticity in (5)). Indeed, any solution to is precisely a solution to . Hence, an optimal solution is characterized via , and thus . Moreover, because is concave this is a maximum. In the case that on there is no optimal , as the manager’s expected utility increases as tends to infinity since .
3.2 Case 2:
We now consider the second case, in which . We remind the reader that we are still assuming that . Also, for future reference, note that
| (25) |
Indeed, this holds for , where from (15) , and for it is true, because and . As mentioned above this case is different from Case 1 as we have now with . It follows that the dual value function is given by and thus, using the fact that , we have for the concavified problem .
We first consider the case when . We have from duality that . This optimum is of course attained by the trivial strategy yielding the optimal wealth process for the concavified problem. However, plugging this into the original problem yields . Thus, is an optimizer for the concavified problem, but yields a smaller value for the original problem. Moreover, is even not an optimizer for the primal problem, as we will show that .
In this example, a way around this problem can be seen by thinking in terms of investment strategies. Not only does the trivial strategy lead to the optimum for the concavified problem, but so does every strategy with terminal value satisfying , since in the interval the concavified utility function is linear. Therefore, by the martingale property of the wealth process under , we have . However, any strategy yielding a terminal value , which has some support in is clearly not optimal by the strict concavity of the concavified utility function. Finally, a strategy that maximizes, not only the concavified problem, but also yields the same value for original problem, has to satisfy since on by (25).
The existence of this strategy follows from a simple application of martingale representation theorem. Indeed, fix such that . Then, by the martingale representation theorem, the random variable has the representation , where . Thus, . 111We thank an anonymous referee for pointing out this straightforward existence proof.
It turns out that one can easily explicitly construct the optimal strategy by using a strategy similar to the classical doubling strategy in the Black-Scholes model. However, contrary to the classical dubbling strategy our strategy will be admissible. Define the strategy , which gives rise to the value process
We note that is a local martingale with quadratic variation process
hence, it is a time changed Brownian motion . Defining now the stopping time we can see that we have for the stopped strategy ,
Thus, the process hits either or before time a.s. and the stopped process at terminal time, , is hence almost surely concentrated on . Thus, is indeed a strategy which yields the optimum.
This example, specifically the treatment of the case in section 3.2, reveals yet an other interesting fact. While the dual optimizer is purely atomic for ever , for it nevertheless follows that is reached also by the trivial strategy . However, in this case, the solution of the concavified and the original problem coincide. This means that the condition of the atomlessness of the dual optimizer is not a necessary one, at least as one does not require an existence result which is independent of the initial capital.
4 Examples of Models in the Class of Itô Process
We now want to illustrate that Theorems 2.1 and 2.2 not only hold in Black-Scholes type markets, but also in many complete and incomplete markets, where the stock price process is given by an Itô process. First we will consider complete market models given by one-dimensional Itô processes and prove a general sufficient condition in terms of Malliavin differentiability, which can be applied, e.g., to local volatility models. Then we show that some classes of incomplete market models, such as the lognormal mixture models of Brigo and Mercurio Brigo , satisfy the conditions of Proposition 1. Additionally, we show that, under certain assumptions, stochastic volatility models satisfy directly the conditions of Theorem 2.2. We also provide examples of well-known models by Hull-White, Heston and Scott satisfying those assumptions.
Example 2
(One dimensional diffusion models): Let be a one-dimensional 222Generalization to the multi-dimensional case is straightforward. However, to make the exposition more tractable, we stay in one dimension. Brownian motion, defined on some probability space . Denote by the filtration generated by the Brownian motion, augmented by all -negligible sets (as usual, we assume without loss of generality that ). Additionally, let denote the Borel--field on the interval . Let the stock price process given by
| (26) |
where and are -progressive processes satisfying
In particular, we do not assume any Markovianity of the drift or diffusion coefficient. Moreover, let the money market account be given by
for some progressive interest process satisfying . Define the market price of risk through
To preclude arbitrage in the sense of a ’free lunch with vanishing risk’, we must assume that the market price of risk satisfies
where denotes the stochastic (Doléans-Dade) exponential of the semimartingale . Additionally, for our results, we have to assume a little bit more regularity in terms of Malliavin differentiability (for a reference on Malliavin calculus see Nua , ENua ). We are in a one-dimensional stochastic volatility model. Hence, the underlying Hilbert space is given by , endowed with the canonical inner product. For we denote by
| (27) | ||||
the subspace of of random variables with -integrable Malliavin derivatives. We note that denotes the the Malliavin derivative. Moreover, denote by the class of all processes such that for almost all such that there exists a measurable version of the two-parameter process satisfying
Assumption 4
We assume that and
| (28) |
We note, in particular, that this Assumption is satisfied by local volatility models
| (29) |
as long as and are nice enough. Specifically, a sufficient condition is that , , , and are bounded functions, uniformly continuous in the first component and twice continuously differentiable in the second component with bounded derivatives and that is uniformly bounded away from zero.
Recall that denotes the set of all equivalent local martingale measures, in our current setting given by
| (30) |
Since we are in a complete market case, it is well-known that the set of all equivalent local martingale measures consists of a single measure
| (31) |
Lemma 1
If -a.e., then has continuous law.
Proof
We will show more then required – asserting that under the stated conditions the random variable has a density with respect to the Lebesgue measure. This will be done by using a Malliavin calculus-based result, which is due to Bouleau and Hirsch. For the logarithm we have
It follows that
by Assumption 4. Hence,
Following the criterium for absolute continuity (cf. (Nua, , Theorem 2.1.3)), it is therefore enough to show that
From
and from the fact that -a.s., this is equivalent to the fact that -a.s. However, for every adapted process , the domain of the Skorohod integral, we have, by the definition of
Thus, we conclude that -a.s., if only if -a.s.∎
We turn our attention now to incomplete market models:
Example 3
(Lognormal mixture models): Similar to Example 2 let be a one-dimensional Brownian motion defined on some probability space and denote by the filtration generated by it, augmented by all -negligible sets. Let and consider a random variable on such that , for some counting measure where and . Let the stock price process modeled on the space by
| (32) |
where and are deterministic functions, bounded and bounded away from zero, and satisfying for for some , and for all , for some , satisfying . We note that the filtration generated by the stock price is not right continuous at , and it agrees with the filtration generated by and only for , whereas it is strictly smaller at . Following Brigo and Mercurio (Brigo, , Section 10.4) this SDE has a unique strong solution.
Let the money market account be given by
for some bounded progressive interest process and, conditioned on , define the market price of risk through
Assume also that the are linearly independent.
Lemma 2
The the set of all equivalent local martingale measures is given by
| (33) |
where . If -a.e. for every , then the set has uniformly absolutely continuous distributions.
Proof
Note first that from (Amen, , Theorem 4.1) it follows that any integrable random variable in the filtration has the representation
| (34) |
where and an -predictable and locally integrable process. More precisely, setting and applying (Amen, , Theorem 4.1) yields and sending to zero this converges to (34) as the stochastic integrals are consistently constructed and is a backward martingale that converges by the backward martingale convergence theorem almost surely to . Moreover, using the classical martingale representation theorem this yields
with an -predictable and locally integrable process and . Applying Itô’s formula to we conclude that
The no arbitrage condition requires that the discounted stock price is a local martingale under or, equivalently, that is a local -martingale. Noting that
implies
| (35) |
we have just to check under which conditions (3) is a -martingale. Note that it is enough to check when the exponential is a local martingale (checking that for for and is straightforward, at this follows from the continuity of the exponential). Calculating the quadratic variation of the stochastic integral and comparing it with the determinist one yields
Moreover, as is only supported on and the martingale condition forces , we get that the representation (33) is a necessary condition on equivalent local martingale measures. It is straightforward to check that it is also sufficient.
Additionally, we have that all are uniformly bounded. It follows that the densities of the normally distributed random variables are also uniformly bounded. Furthermore, the Gramian matrix with elements , has non-zero Gram determinant, by our assumption that are linearly independent. It follows that the random vector
is normally distributed with mean zero, and variance . Hence, it has a bounded density. Finally, note that for the random variable
is an exponential transformation of , since the functions are deterministic. Therefore, it has a density, too. This transformation is continuous as a function of and, thus, so is the density of . It follows that the density of is uniformly bounded for any in the compact closure .∎
As the family has uniformly absolutely continuous distributions, we can then apply Proposition 1 to establish the distributional continuity of the dual optimizer.
Stochastic Volatility Examples
We now generalize the setting of Example 2 to encompass stochastic volatility models, dropping the assumption of market completeness. Namely, let and be two independent one-dimensional Brownian motions (the generalization to the multi-dimensional case is again straightforward) defined on some probability space and denote by the filtration generated by them, augmented by all -negligible sets (as usual we assume without loss of generality that ). Let the stock price process given by
where and are -progressive processes satisfying
In particular we again do not assume any Markovianity of the drift or diffusion coefficient. Moreover, we still assume that the money market account be given by
for some progressive interest process satisfying and define the market price of risk through
We readily adjust all of the remaining definitions of Example 2 to this framework. We note that, in this case, will be given by . The definition of in (27) will not change. Finally, we will adjust the definition to be the class of all processes such that for almost all such that there exists a measurable version of the two-parameter process satisfying
We, of course, still preclude arbitrage in the sense of a ’free lunch with vanishing risk’ by assuming that the market price of risk satisfies
and we still assume Assumption 4 is satisfied.
Recall that , given by (30), denotes the set of all equivalent local martingale measures. The first major change, in comparison to Example 2, is that, in our current setting, is given by
Lemma 3
The set of all equivalent local martingale measures can be characterized as
| (36) |
where
Moreover, if -a.e., then the random variable has a continuous law.
Proof
To begin, we prove the characterization of the set of equivalent local martingale measures, which follows the proof for the classical Markovian case (cf. Frey ). First, it is clear that, only under the condition , will the new measure be a probability measure. By the martingale representation theorem, we know that we can find predictable processes , such that
Since and are equivalent, the density process is strictly positive and we can define its logarithm which satisfies, by Itô’s formula
Expressing now the stock-price process under , we get, by Girsanov’s theorem
| (37) |
for some -Brownian motion independent of . Hence, the discounted stock price is a local martingale only if
for some predictable, square-integrable process . On the other hand, every expression on the right hand side of (3) defines an equivalent probability measure. By (4), the stock price is a local martingale under this measure.
The second part of the assertion – that has a continuous law – is a direct consequence of Lemma 1.∎
Next, we would like to apply Proposition 1 to conclude that has a continuous law. But, this is not easy to do, since we need to satisfy the assumption of Proposition 1 that the family is uniformly absolutely continuous with respect to the Lebesgue measure. Here, we propose an alternative approach, which requires a certain restriction, namely that the market price of risk does not depend on the Brownian motion driving the stochastic volatility. The classical example of this would be a constant market price of risk. While this is a shortcoming from a theoretical point of view, it does not matter much from a practical perspective. The straight-forward idea of using a constant drift does not work out nicely in many situations, as there may not exist an equivalent change of measure (e.g., in the Stein & Stein model or in the Heston model without Feller condition - c.f. HW ). A standard procedure (compare the discussion in (FPSS, , Section 2.4.2)) is exactly to assume a constant market price of risk to avoid these integrability issues.
Lemma 4
Assume that the market price of risk . Then the infimum over all equivalent local martingale measures in the calculation of the value function of the dual problem is reached for , i.e.,
Proof
From Jensen’s inequality it follows that for any
Since and are independent, a.s., and we note that
Since, of course, , we conclude that
∎
Theorem 4.1
Finally, we want to show that the Assumption 4 is satisfied in many standard volatility models. First we remark that if the volatility function is a smooth function in , bounded and bounded away from zero, and the volatility process satisfies , then the assumption is satisfied. This is also enough to ensure the existence of an equivalent local martingale measure. Turning to more standard models, we observe that it can be shown that many standard volatility processes, such as e.g., Ornstein-Uhlenbeck, CIR or geometric Brownian motion, satisfy the Malliavin differentiability condition (for the CIR process, at least in the nice regime when Feller’s condition holds – cf. AlosEwald ). Thus, all possible problems arise, not from the Malliavin smoothness condition, but from the requirement that , which is usually not satisfied for constant drift. As mentioned above, the standard way to circumvent this problem is to allow for a volatility-dependent excess appreciation:
Example 4
(Correlated Hull-White model): We consider a bond with constant interest rate and the stock price given by
for constants, , , , and and independent Brownian motions , . Moreover we assume that the excess appreciation rate is given via a bounded -function with bounded derivative, and that it is not identically zero. This guarantees that the market price of risk remains bounded and ensures that the integrability condition of Assumption 4 is satisfied.
Calculating the Malliavin derivative of the
We can conclude that since and are bounded. Moreover, -a.s since is continuous and not identically zero. Thus, all the conditions of Lemma 1 are satisfied.
The proofs for the additional two examples follow the proof of the previous example, and are thus omitted.
Example 5
(Correlated Scott model): The Scott (or exponential Ornstein-Uhlenbeck) model is given (besides the bond with constant interest rate ) by the stock price dynamics
for constants, , , , , and and independent Brownian motions , . Again we assume that the excess appreciation rate is given via a bounded -function with bounded derivative, and that it is not identically zero. This guarantees that the market price of risk remains bounded and ensures the integrability condition of Assumption 4.
Example 6
(Correlated Heston model under Feller condition): We consider a bond with constant interest rate and the stock price given by
for constants , , , , and and independent Brownian motions , . Moreover, we impose the Feller condition . Again, we assume that the excess appreciation rate is given via a bounded -function with bounded derivative, and that it is not identically zero. This guarantees that the market price of risk remains bounded and ensures the that integrability condition of Assumption 4 is satisfied.
Finally, we would like to remark that the same reasoning applied above to stochastic volatility models also holds true for Markovian regime switching models, as they have the same kind of representation of equivalent local martingale measures (c.f. Siu ). As long as the market price of risk is positive, sufficiently (Skorohod-) integrable and depends only on the stock-driving Brownian motion, the infimum is attained independently of the volatility risk. Therefore, we conclude that the optimizer has a density.
5 Preliminaries - The Classical Utility Optimization Problem
We will now briefly review the classical results of utility optimization. We adapt statements of BTZ and WZ (mainly Theorem 3.2 of BTZ ) on non-smooth utility maximization for the use in our setting. To keep notation concise and well-integrated with the rest of the paper, we hide our incentive scheme by setting throughout this section. To emphasize this we will talk about the classical utility optimization problems
| (38) |
and its dual
| (39) |
We will continue with our standing Assumptions 1 and 2 throughout this section. However, we will later relax Assumption 3. The central result of Kramkov and Schachermayer (KramSchach1, , Theorem 2.2.) is the following:
Theorem 5.1 (Kramkov-Schachermayer)
Asymptotic elasticity is the minimal condition to assure the duality result in general semimartingale models for smooth utility functions (cf. KramSchach1 ). (If one poses a joint condition on model and utility function, then the minimal condition is the finiteness of the dual value function, cf. KramSchach2 .) However, as previously mentioned, the concavified utility function will be, in general, neither strictly concave nor satisfy the Inada condition at . Thus, we will have to rely on results for nonsmooth utility maximization. While we will still impose Assumptions 1 and 2, we will have to relax Assumption 3. In the nonsmooth case, it turns out that the asymptotic elasticity – following Deelstra, Pham, and Touzi DPhT – has to be written on the convex conjugate of the utility function. The following general result is due to Bouchard, Touzi and Zeghal (BTZ, , Theorem 3.2.). A simplification of the proof can be found in Westray and Zheng (WZ, , Theorem 5.1.).
We relax the conditions on the utility function , assuming only that , , is nonconstant, nondecreasing and concave (we extend again continuously to , allowing the value at while still assuming that ). In particular, we no longer assume that is continuously differentiable on nor do we require that to be strictly increasing or strictly concave. Finally, we no longer impose Inada conditions, but merely that the closure of the domain of the dual function is . As mentioned above, the asymptotic elasticity condition will be written on the dual function. Hence, we substitute the following assumption for Assumption 3
Assumption 5
The investor’s preferences are represented by a utility function .
-
a)
We assume that is nonconstant, nondecreasing and concave;
-
b)
The dual function satisfies ;
-
c)
Moreover, it satisfies the dual asymptotic elasticity condition
(40) -
d)
There exists such that defined by (39) is finite.
Remark 1
We note that for smooth the classical and dual asymptotic elasticity condition are equivalent under Inada-type conditions (cf. (DPhT, , Proposition 4.1.) for a precise statement).
Theorem 5.2 (Bouchard-Touzi-Zeghal)
Note that the subdifferential-valued random variables in part b) should be understood as random variables whose range is a subset of the image of a random variable under a set-valued function. This is a much larger set then just the collection of random variables one would obtain by picking only fixed elements in the subdifferential and looking on images under these mappings. In the first case we can have a different mapping for every , whereas in the second case one fixes a single function for all .
Proof
We adapted here the statement of BTZ and WZ to better fit the framework with KramSchach1 .The fact that the formulations in [3] and [29] differ from the formulations in [16] stems from the goal of the authors of [3] and [29] to accommodate a discussion of portfolio optimization on the whole real line with random initial endowment (as opposed to [16] who consider a simple portfolio optimization problem on the positive half of real line). However, their formulations (in terms of processes or terminal random variables) are equivalent for our case (without random endowment); they are (using the terminology of Kramkov/Schachermayer) the concrete and the abstract side of the same problem. The ultimate reason for the equality of both formulations is that the set of nonnegative -measurable random variables dominated by some , , is the bipolar of the set . This is due to the bipolar theorem on the cone of nonnegative random variables proved by Brannath and Schachermayer BS . For details, see (KramSchach1, , Proposition 3.1 and Section 4).
First, without loss of generality, we may assume that , otherwise, shift everything by . Next, we can apply Theorem 3.2 of BTZ with . It is not hard to see that, by Assumption 1 and by the concavity of , the function is finite on . The fact that is finite follows directly from Lemma 5.4 of WZ and from Assumption 5. One concludes that from Theorem 3.2 part (iii) of BTZ .
The existence of optimal solutions and follows from parts (i) and (ii) of Theorem 3.2 of BTZ , respectively. The fact that is a consequence of part (i). Additionally, (41) and the fact that is a (uniformly integrable) martingale follow from part (iii). Finally, (42) is obtained from Remark 3.9 part 1. of BTZ . ∎
Finally, we note that the solutions are, in general, not unique and that the value function may not be smooth. Moreover, there may well exist a random variable satisfying , which is not dominated by the terminal value of any , as shown by Westray and Zheng in WZcounter .
6 The Dual and the Concavified Problem
Keeping in mind our standing Assumptions 1-3, we resume our discussion about the portfolio manager’s maximization problem 3, the concavified problem 6, and their common dual problem 7. Our plan now is to apply Theorem 5.2. Therefore, must first ensure that satisfies all the conditions of Theorem 5.2. We also collect some properties of this function:
Proposition 2
For the concavified utility function we have
Furthermore, , together with its conjugate , enjoys the following regularity properties. is continuously differentiable on ; is strictly convex on the whole domain if , otherwise it is strictly convex on and constant on . Finally, satisfies Assumption 1 and Assumption 5.
We divide the proof into three lemmas. The proof is elementary, but rather technical, so it can be safely skipped on the first reading.
Lemma 5
Proof
Consider first the case . Note that since is continuous, its epigraph is closed and thus is its concave hull. Thus, by Caratheodory’s theorem (cf. (HUL, , Theorem A.1.3.6.)), we know that
Since , it follows that the linear combination has to be the trivial, i.e, and . Thus, it follows that .
Similarly, if , we note first that if , we have and . Thus, we can conclude, exactly as in the previous case, that . However, if , we know by the definition of that is real valued if and only if . In this case, the assumption that leads to a contradiction by Caratheodory’s theorem. It follows that and hence . Putting the information from all three cases together we recover the statement .
Now, set and note that . We have, for
| (43) |
Hence, we have , i.e., part b) of Assumption 5 is satisfied. It is straight forward to see that part a) holds for the concavification of a nondecreasing, nonconstant function. Finally, using the above, it follows also for
We conclude by Theorem 5.1 that
is finite on . This proves Assumption 1. Moreover, from (43), we see that
| (44) |
The right hand side of (44) is finite by Theorem 5.1. Thus, is finite on , and Assumption 5 part d) is satisfied. Hence, all the requirements of Theorem 5.2 are satisfied except c) of Assumption 5, whose proof we postpone to Lemma 7. ∎
Lemma 6
The concavified utility function and its conjugate enjoy the following regularity properties:
-
a)
The concavified utility function is continuously differentiable on .
-
b)
The dual utility function is strictly convex on the whole domain if , otherwise it is strictly convex on and constant on .
Proof
To prove a), we note first that the set where and do not agree, is a countable union of pairwise disjoint open intervals. We also note that the function is continuous on since it is the composition of continuous functions ( is as convex, nondecreasing function, thus continuous). The same is true for , which is a concave function by definition. Hence, is the -sublevel set of the continuous function and is thus open. But every open set in can be written as countable union of pairwise disjoint open intervals, say , . We note explicitly that and for some are allowed. On every interval in the function is affine (the straight linear interpolation between and ) and hence we can write it as for some , , with a sequence satisfying that if indices and are such that then . Thus, clearly is differentiable in .
Now, denote by the open interior of the set where and agree, i.e., . We will prove that, on the set , the function is continuously differentiable. Pick some point . Since is convex, it holds that , where are the left- and right-hand derivatives, respectively. Thus, it follows by the differentiability of that . But, on the other hand, the concavity of implies . Thus, the left- and right-derivatives have to agree for every . We conclude, then, that the function is continuously differentiable there.
We then note that . Thus to complete our argument, it remains only to prove continuous differentiability on one of the points . Note that for such , we can find a sequence (assume without loss of generality it is , as we can handle the same way), such that . Additionally, note that by continuity of , and the fact that it follows that . Assume by contradiction that is not continuously differentiable at . It follows that
| (45) |
The first inequality stems from the fact that (since is continuously differentiable) every point of non-differentiability of is due to not having an interior derivative of . However, for the convex function we have (and ). The strict inequality is the consequence of our assumption that is not differentiable at and that it is a concave function. The second inequality follows from the fact that is the concave hull of (and both functions agree on ). Indeed, using the concavity of and the fact that we write
However, (45) leads to a contradiction, since, by a similar argument
Thus, has to be continuously differentiable in and hence, on the whole interval .
In passing we note that the differentiability of implies that cannot be differentiable at any . Assume indirectly that it would be differentiable. Then, there exists some such that . Furthermore, convex duality implies . However, the differentiability of reduces the subdifferential to a singleton. This means that can only be the slope of at the single point , which is in contradiction to the fact that it is the slope on the whole interval .
Finally to show b), we note that the strict convexity in the range of the gradient mapping is a classical consequence in convex Analysis, see e.g., (HUL, , Theorem E.4.1.2.), i.e., is strictly convex on . We claim that . Indeed, is nonincreasing, and for
with the boundary points of intervals in as above. Thus, since is convex, nonconstant and nondecreasing function, it must satisfy . It follows by the Inada condition at that . For the right hand of the domain of strict convexity of we have to consider three cases. First, if , then we have , since . We therefore obtain . Second, if is real and , then we can conclude in similar manner that . Finally, if is real and , then is strictly convex on . However, for , we can conclude that . Since , it follows that on . ∎
Finally, we have to prove the dual asymptotic ellipticity of . The following result builds on and generalizes (in the one-dimensional case) the equivalence result of dual and classical asymptotic elasticity given by Deelstra, Pham and Touzi (DPhT, , Proposition 4.1.) (their result can be seen as the linear case ).
Lemma 7
The concavified function satisfies the dual asymptotic elasticity condition (40), i.e.,
Proof
First, we note that, by the slope bound and the non-constancy of
is finite and strictly positive. Thus, we obtain on one hand that there exists for every some (which we will assume to be bigger then ) such that for all
| (46) |
and
Moreover, we note that, in the case of affine with and , we have that
Setting and , we note that
as long as . Thus, we can conclude by (46) that for it holds that
We note that from Lemma 6, it follows that for (and all in the case of concave )
| (49) | ||||
| (52) |
By convex conjugacy we have
Hence, since by concavity the gradient is nonincreasing, we see that
Thus, we can conclude that . Let be the generalized inverse of a function . Then
We discern now two cases. First, if is bounded, then we can directly conclude that , since . Second, if is unbounded, then by the Inada condition for we have that
From (46) we see that holds for all . Applying this to (note that is here a true inverse since was assumed to be bigger then ) we conclude that , for all . It follows that with we have
for satisfying . By the unboundedness of this is satisfied for all small enough. Since satisfies the dual asymptotic elasticity condition by (DPhT, , Proposition 4.1.) (cf. Remark 1) we have for some that
From
we conclude that
for chosen small enough (note that only depends on the original utility function, hence it is independent of ). ∎
We can now look more closely at how the concavified problem relates to the classical Kramkov/Schachermayer setting. The concavified utility function is indeed continuously differentiable. It will follow from (49) that it satisfies also the Inada condition . Hence, by (DPhT, , Proposition 4.1.) the primal asymptotic elasticity condition is also satisfied. However, it fails, in general, the Inada condition . Furthermore, it will not necessarily be strictly concave.
Relying heavily on Proposition 2, we can now prove Theorem 2.1, which is the result concerning existence and uniqueness of an optimal solution of the dual problem (7) as well as existence for the concavified problem (6). In the next sections we will use this central result to discuss the uniqueness of the concavified problem as well as discuss how one can use the concavified problem to solve the original problem (3).
Proof (Theorem 2.1)
It follows from Proposition 2 that the conditions of Theorem 5.2 are satisfied for the concavified utility function with . This implies the finiteness and the duality statements of a).
The existence part of b) also follows directly from Theorem 5.2. For the uniqueness part, we note Proposition 2 implies that is strictly convex on . Assume, by contradiction, that and are the terminal values of two different optimizers of the dual problem such that
That is, the random variables differ on the set with positive probability. It follows that for every and we have, by the strict convexity of , that
which contradicts the optimality of , or .
To prove the remaining statements of a) we note that we have for every and ,
Thus, we can conclude by the strict convexity of that for , and with we have that
Hence, is strictly convex on and constant on . By (HUL, , Theorem E.4.1.1.) this implies the continuous differentiability of .
Part c) follows directly from Theorem 5.2 and the differentiability of in the interior of its domain, .
Finally, d) is a direct consequence of Theorem 5.2. ∎
7 The Original Problem: Wealth-independent Solution
We are now finally ready to give the proof for Theorem 2.2 and Proposition 1. We will rely heavily on the following results from the proof of Proposition 2, specifically Lemma 6. The set where the two utility functions disagree is an open subset of . As such, is a countable union of pairwise disjoint open intervals,
On every one of these intervals the function is affine, for some , , where is a sequence satisfying that if indices and are such that then . We set
and note that on every the dual utility function has a kink, i.e., the function is not continuously differentiable. We insist that not every kink of has to lie in , nor is every region of linearity of necessarily contained in (e.g., when is itself concave and has regions of linearity). However, by the duality relationship of and , we know that, for the subdifferentials
| (53) |
holds true.
Proof (Theorem 2.2)
Given that has a continuous law and is unique where is not vanishing, it follows that for any , we have -a.s. Hence
is -a.s. uniquely defined by a strictly increasing function . Since has a continuous law, so does , proving a).
By the duality relationship (53) we can conclude that
| (54) | ||||
since the distribution of has no atoms for any . Thus, is -a.s. equal to on . Thus, we have on one hand
and on the other hand
Thus, it is clear that is also an optimizer for the original problem, , proving b). ∎
Note that we have said nothing about the optimal portfolio of the original problem per se, but only about the coincidence of its maximizer with that of the concavified problem. That is, the statement is as follows: when the law of the dual optimizer has no atoms, then there is no ’biduality gap’, and the original problem can be solved by considering the problem with the concavified utility function.
The following remark discusses the economic consequences of Theorem 2.2:
Remark 2
-
a)
The optimizer of Theorem 2.1 satisfies , -a.s. That is, the portfolio manager flees successfully all possible outcomes that underperform the concavification.
-
b)
Similar to the calculation in (54) we can show that the law of is atomless, except possibly an atom at . Indeed, by Theorem 2.2 it is enough to show that the distribution of is atomless, as it coincides with a.s. Take and , then and
(55) However, there is a possibility that an atom occurs at . The same calculation shows that if , then the distribution of cannot have an atom at . Specifically, the law has an atom at if and only if and . Moreover, in this case,
This outcome, which occurs, for example, by pure call option payoffs in Black-Scholes markets with nonzero drift, is not very satisfactory for the investor, since the incentive scheme for the portfolio manager is such that the optimal strategy jeopardizes the whole capital with positive probability. What is worse, a call option incentive scheme leads to a higher probability of the ruin as the benchmark increases.
- c)
Proof (Proposion 1)
We know by Theorem 2.1 that the value function of the dual problem can be represented as an infimum over equivalent local martingale measures,
| (56) |
Hence, we can, in particular, extract a sequence so that converges to . Note that the sequence is bounded in , since the expectations of densities are bounded by one. Hence, we can apply Komlós’ Lemma ((Bogachev, , Theorem 4.27)) to find a subsequence and a random variable such that every subsequence of converges to , -a.s. in the sense of Cesàro. We note that is a minimizer of (56) since
By the convexity of , the right hand converges as Cesàro-subsequence of a convergent sequence to . Whereas the convex combination of the random variables on the left hand is the density corresponding to some equivalent local martingale measure by the convexity of .
Next, we assert that has a distribution, which has a continuous law. Indeed, since the laws of all the approximating are uniformly absolutely continuous with respect to Lebesgue measure, so are the approximating Cesàro sums. Denote these sums by . Uniform absolute continuity with respect to the Lebesgue measure of the laws of implies that, for the respective cumulative distribution functions, it holds that for every and all there exists a such that . We have that in distribution, so at all points of continuity of the cumulative distribution function . To prove our assertion, it is enough to show that is continuous for every . Indeed, since is increasing and bounded, it has at most countable number of discontinuity points. Take for given some , , , such that , and such that is continuous at both, and . Then for all . We can also chose big enough such that , . Finally, we can conclude that, for all
Thus, is continuous at . ∎
Remark 3
The proof becomes even simpler if one switches to the more abstract level of the bipolar theorem on of BS . The set of nonnegative random variables dominated by the terminal values of the processes in is the bipolar of , i.e., the smallest solid, convex set closed in the sense of convergence in probability that contains . Thus, every element in this set is given as a limit of times a Radon-Nikodým derivative. Thus, by Riesz’s theorem, we can extract a subsequence, which converges almost surely. Moreover, in this abstract perspective we are able to give the following interpretation. The optimizer of utility maximization under a convex incentive scheme is well-behaved (i.e., atomless) if the whole set of possible optimizers is well-behaved. Furthermore, this set is (up to a multiplicative factor) simply the bipolar of the set of Radon-Nikodým derivatives of equivalent local martingale measures. Thus, if this set is nice enough (i.e., the distribution of its elements are uniformly absolute continuous with respect to the Lebesgue measure), we always obtain a unique optimizer for utility maximization under convex incentive schemes, independent of the initial capital and the concrete choice of the incentive scheme.
8 The Original Problem: Wealth-dependent Solution
Inspired by Example 1 and, specifically by the case with zero drift in section 3.2, we try now to deduce how one can extend Theorem 2.1 to get existence and/or uniqueness results for particular initial conditions. For we denote by
the at most countable set of atoms of the law of the dual optimizer . Moreover, we recall the notations
where is the slope of on . We are now able to make the following statement.
Theorem 8.1
Proof
First, note that condition (57) implies that no atom of the distribution of lies on a point in the domain of where this function is not differentiable. Thus, we can conclude, as in the proof of Theorem 2.2, that, for , , we have , -a.s. Hence
is -a.s. uniquely defined by a strictly increasing function , which proves uniqueness of . To prove the existence of an optimizer of the original problem, we note that, from (57), we know that . Thus, similar to the proof of Theorem 2.2, we can conclude that is (the unique) solution to the original problem. ∎
For the case that such that , we cannot generally recover any of our results. In particular:
-
a)
The optimizer of the concavified problem may not be unique, as discussed in the remark at the end of Example 1, Case 2.
-
b)
It can happen that the optimum of the concavified problem is not reached by the value function of the original problem, i.e., . An example therefore will be given below in Example 7.
-
c)
Even if the maximum of the concavified problem can be reached by the original value function, i.e., , it may happen that the optimizer of the original problem is not unique. To see this, we use the setting of Example 1 (with initial capital ), changing only the incentive scheme
which is a convex function with slope bounded by one. However, . Thus, all of the solutions of the concavified problem in Example 1 are also solutions to the original problem with incentive scheme .
Example 7
To see that the optimizer of the concavified problem can be strictly bigger then any admissible terminal value for the original problem, we once again use the utility function and incentive scheme of (23) from Example 1, namely and . We also take as initial capital. To describe the discounted stock price process, we fix an -measurable random variable that satisfies and consider the process
in its natural filtration. Thus, in essence, our model a disguised form of a binomial model. We note that
and , where the measure is given via the Radon-Nikodým derivative
implying and .
Our goal is to show that . To compute , we note that, for any predictable -integrable investment strategy
Since has to be nonnegative, it follows that . Hence, , and we can conclude that
For the calculation of we use the fact that, in a complete market, . Thus, the dual value function can be directly computed via the unique dual optimizer ,
Now, calculating the subdifferential,
and using by convex duality that if and only if , we conclude that for it follows that . Thus, Theorem 5.2 implies that
and we can conclude by the admissibility constraint that
This can be seen also in a simpler way. Since depends only on which, by predictability, has to be -measurable and hence constant. We have by admissibility . Hence
The maximum is achieved with , i.e., the optimal portfolio is . It follows in either case that . Thus, we conclude that .
Note, finally, that such behavior can be excluded in the case of complete markets; Reichlin (Rei, , Section 5) shows that the optimizer of the concavified problem is an optimizer of the original problem if the underlying probability space is atomless.
9 Conclusion
We have considered the non-concave utility maximization problem as seen from the point of view of a fund manager, who manages the capital for an investor and who is compensated by a convex incentive scheme. We have proved the existence and uniqueness of the dual optimizer and also proved the existence and uniqueness of the original problem for arbitrary initial capital in case in which the dual optimizer has a continuous distribution. We have shown that this is true in a large class of (possibly incomplete) market models, independent of the specific incentive scheme. When this condition fails, we have proved the existence of a unique solution for the concavified problem and shown that this solution is also a solution of the original problem under additional assumptions on the initial capital. However, there are models, where, for some initial capital, the optimal value of the concavified problem cannot be reached, as we have demonstrated through a counterexample. Moreover, we have illustrated our findings by specific examples, which in essence contain the explicit solution strategies for complete markets. Finally, we have discussed the economic implications of our findings.
Acknowledgements.
Both authors acknowledge partial financial supported by NSF grant DMS-0739195 and want to thank René Carmona for suggesting the problem under consideration and steady encouragement.They are thankful to two anonymous referees and an associate editor for thoughtful remarks and comments that have improved the quality of the article. Also thanks to Gerard Brunick, Christian Reichlin, Ronnie Sircar and Ramon van Handel for helpful discussions and comments. Thanks to Matt Lorig, who put a lot of effort to improve the readability and grammatical correctness of the text.References
- (1) Alòs, E., Ewald, C.O.: Malliavin differentiability of the Heston volatility and applications to option pricing. Adv. in Appl. Probab. 40(1), 144–162 (2008)
- (2) Amendinger, J.: Martingale representation theorems for initially enlarged filtrations. Stochastic Process. Appl. 89(1), 101–116 (2000)
- (3) Bogachev, V.I.: Measure theory. Vol. I and II. Berlin: Springer (2007)
- (4) Bouchard, B., Touzi, N., Zeghal, A.: Dual formulation of the utility maximization problem: the case of nonsmooth utility. Ann. Appl. Probab. 14(2), 678–717 (2004)
- (5) Brannath, W., Schachermayer, W.: A bipolar theorem for . In: Séminaire de Probabilités, XXXIII, Lecture Notes in Math., vol. 1709, pp. 349–354. Springer, Berlin (1999)
- (6) Brigo, D., Mercurio, F.: Interest rate models—theory and practice, second edn. Springer Finance. Springer-Verlag, Berlin (2006)
- (7) Carassus, L., Pham, H.: Portfolio optimization for piecewise concave criteria functions (the 8th workshop on stochastic numerics). RIMS Kokyuroku 1620, 81–108 (2009)
- (8) Carpenter, J.N.: Does option compensation increase managerial risk appetite? The Journal of Finance 55(5), 2311–2331 (2000)
- (9) Deelstra, G., Pham, H., Touzi, N.: Dual formulation of the utility maximization problem under transaction costs. Ann. Appl. Probab. 11(4), 1353–1383 (2001)
- (10) Delbaen, F., Schachermayer, W.: The mathematics of arbitrage. Springer Finance. Springer-Verlag, Berlin (2006)
- (11) Fouque, J., Papanicolaou, G., Sircar, R., Sølna, K.: Multiscale stochastic volatility for equity, interest rate, and credit derivatives. Cambridge University Press, Cambridge (2011)
- (12) Frey, R.: Derivative asset analysis in models with level-dependent and stochastic volatility. CWI Quarterly 10(1), 1–34 (1997). Mathematics of finance, Part II
- (13) Guasoni, P., Obłój, J.K.: The incentives of hedge fund fees and high-water marks. to appear in Math. Finance
- (14) Hiriart-Urruty, J.B., Lemaréchal, C.: Fundamentals of convex analysis. Grundlehren Text Editions. Springer-Verlag, Berlin (2001). Abridged version of Convex analysis and minimization algorithms I and II
- (15) Janeček, K., Sîrbu, M.: Optimal investment with high-watermark performance fee. SIAM J. Control Optim. 50(2), 790–819 (2012)
- (16) Karatzas, I., Lehoczky, J.P., Shreve, S.E.: Optimal portfolio and consumption decisions for a ’small investor’ on a finite horizon. SIAM J. Control Optim. 25, 1557–1586 (1987)
- (17) Kramkov, D., Schachermayer, W.: The asymptotic elasticity of utility functions and optimal investment in incomplete markets. Ann. Appl. Probab. 9(3), 904–950 (1999)
- (18) Kramkov, D., Schachermayer., W.: Necessary and sufficient conditions in the problem of optimal investment in incomplete markets. Ann. Appl. Probab. 13(4), 1504–1516 (2003)
- (19) Larsen, K.: Optimal portfolio delegation when parties have different coefficients of risk aversion. Quant. Finance 5(5), 503–512 (2005)
- (20) Merton, R.C.: Optimum consumption and portfolio rules in a continuous-time model. Journal of Economic Theory 3(4), 373–413 (1971)
- (21) Nualart, D.: Malliavin calculus and its applications, CBMS Regional Conference Series in Mathematics, vol. 110. Published for the Conference Board of the Mathematical Sciences, Washington, DC (2009)
- (22) Nualart, E.: Lectures on Malliavin calculus and its applications. Lecture Notes (2011)
- (23) Ocone, D.L., Karatzas, I.: A generalized Clark representation formula, with application to optimal portfolios. Stochastics Stochastics Rep. 34(3-4), 187–220 (1991)
- (24) Panageas, S., Westerfield, M.M.: High-water marks: High risk appetites? Convex compensation, long horizons, and portfolio choice. The Journal of Finance 64(1), 1–36 (2009)
- (25) Pliska, S.R.: A stochastic calculus model of continuous trading: optimal portfolios. Math. Oper. Res. 11(2), 370–382 (1986)
- (26) Reichlin, C.: Utility maximization with a given pricing measure when the utility is not necessarily concave. Math. Financ. Econ. 7, 531–556 (2013)
- (27) Ross, S.A.: Compensation, incentives, and the duality of risk aversion and riskiness. The Journal of Finance 59(1), 207–225 (2004)
- (28) Seifried, F.T.: Optimal investment with deferred capital gains taxes: a simple martingale method approach. Math. Methods Oper. Res. 71(1), 181–199 (2010)
- (29) Siu, T.K.: Regime-switching risk: to price or not to price? Int. J. Stoch. Anal. pp. 1–14 (2011)
- (30) Westray, N., Zheng, H.: Constrained nonsmooth utility maximization without quadratic inf convolution. Stochastic Process. Appl. 119(5), 1561–1579 (2009)
- (31) Westray, N., Zheng, H.: Minimal sufficient conditions for a primal optimizer in nonsmooth utility maximization. Finance Stoch. 15(3), 501–512 (2011)
- (32) Wong, B., Heyde, C.C.: On changes of measure in stochastic volatility models. J. Appl. Math. Stoch. Anal. (2006)