Pose-guided Feature Disentangling for Occluded Person
Re-identification Based on Transformer
Abstract
Occluded person re-identification is a challenging task as human body parts could be occluded by some obstacles (e.g. trees, cars, and pedestrians) in certain scenes. Some existing pose-guided methods solve this problem by aligning body parts according to graph matching, but these graph-based methods are not intuitive and complicated. Therefore, we propose a transformer-based Pose-guided Feature Disentangling (PFD) method by utilizing pose information to clearly disentangle semantic components (e.g. human body or joint parts) and selectively match non-occluded parts correspondingly. First, Vision Transformer (ViT) is used to extract the patch features with its strong capability. Second, to preliminarily disentangle the pose information from patch information, the matching and distributing mechanism is leveraged in Pose-guided Feature Aggregation (PFA) module. Third, a set of learnable semantic views are introduced in transformer decoder to implicitly enhance the disentangled body part features. However, those semantic views are not guaranteed to be related to the body without additional supervision. Therefore, Pose-View Matching (PVM) module is proposed to explicitly match visible body parts and automatically separate occlusion features. Fourth, to better prevent the interference of occlusions, we design a Pose-guided Push Loss to emphasize the features of visible body parts. Extensive experiments over five challenging datasets for two tasks (occluded and holistic Re-ID) demonstrate that our proposed PFD is superior promising, which performs favorably against state-of-the-art methods. Code is available at https://github.com/WangTaoAs/PFD˙Net
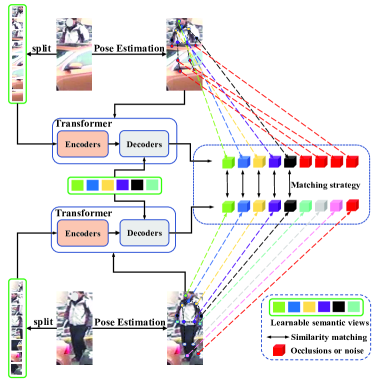
1 Introduction
Person Re-Identification (Re-ID) aims to identify a specific person across multiple non-overlapping cameras (Zheng, Yang, and Hauptmann 2016). It is an important subject in the field of computer vision and has a wide range of application backgrounds, such as video surveillance, activity analysis, security, and smart city. In recent years, holistic person Re-ID achieves great progress, and various of methods (Sun et al. 2018; Shi, Liu, and Liu 2020; Zhang, Zhang, and Liu 2021) have been proposed. However, in real scenes, such as stations, airports, shopping malls, person can be easily occluded by some obstacles (e.g., trees, cars, pedestrians), it is difficult to match people with incomplete and invisible body parts. Therefore, the occluded person re-identification task (Zhuo et al. 2018; Miao et al. 2019; Jia et al. 2021a) is of important practical significance.
Compared with holistic person Re-ID, there are two major challenges for occluded person Re-ID task: (1) Due to the existence of occlusion, various noises have been introduced that result in mismatching. (2) The occlusion may have features similar to human body parts, leading to the failure of feature learning. Some early methods (Miao et al. 2019) utilize pose information to indicate non-occluded body parts on the spatial feature map and directly divide global features into partial features. These methods are intuitive but requires strict spatial feature alignment. Some recent pose-guided methods (Gao et al. 2020; Wang et al. 2020) use graph-based approaches to model topology information by learning node-to-node or edge-to-edge correspondence to further mine the visible parts. However, these methods still suffer the problem mentioned in the challenge (2). Therefore, in this paper, to solve the above problems we explore the possibility of combining additional pose clues with transformers without spatial alignment. As the Figure 1 shows, we propose PFD, a Pose-guided Feature Disentangling transformer network that utilizes pose information to clearly disentangle semantic components (e.g. human body or joint parts), and force the similarities between the occluded features and the non-occluded features to be as inconsistent as possible, which could strengthen the learning of discriminative features while reducing background noise to solve the problem of challenge (1), and effectively alleviates the failure of feature learning mentioned in challenge (2).
Specifically, the proposed PFD includes a visual context transformer encoder, a pose estimator, a Pose-guided Feature Aggregation (PFA) module, a part view based transformer decoder, and a Pose-View Matching (PVM) module. In the visual context transformer encoder, we adopt a transformer based image classification model (i.e., ViT (Dosovitskiy et al. 2020)) and the camera perspective information to capture the robust global context information. PFA is developed to embed the pose information into the global context features and part features. The features obtained from PFA could preliminarily indicate visible body parts. In part view based transformer decoder, a set of learnable semantic views are introduced to implicitly enhance the disentangled body part features. Each part view feature corresponds to the discriminative part of the occlusion image. However, without additional supervision, we can only learn features implicitly and cannot constrain the learnable semantic views to capture accurate parts of the human body. Therefore, we propose a Pose-View Matching (PVM) module, which implicitly learns discriminative features and explicitly matches visible body parts, thereby separating the human body features from the occluded features and reducing the interference of noise mentioned in challenge (1). In addition, to avoid the failure of feature learning mentioned in challenge (2), we design a Pose-guided Push Loss to reduce the similarity between human body features and occlusion features.
The main contributions of this paper can be summarized as the following:
-
(1)
We propose a novel pose-guided feature disentangling transformer for occluded person Re-ID by using pose information to clearly disentangle semantic components (e.g. human body or joint parts) and selectively match non-occluded parts correspondingly.
-
(2)
We design a Pose-guided Push Loss to help focus on human body parts and alleviate the interference of occlusion and noise, which avoids the failure of feature learning.
-
(3)
To prove the effectiveness of our method, we perform experiments on occluded, holistic Re-ID datasets. Extensive experimental results demonstrate the proposed method performs favorably against SOTA methods.
2 Related Work
2.1 Occluded Person Re-Identification
Occluded person Re-ID is more challenging compared with holistic Re-ID due to body information incompleteness. Existing methods can be basically divided into three categories, hand-craft splitting based methods, methods using additional clues, and methods based on the transformer.
Methods based on hand-craft splitting handle the occlusion problem by measuring the similarity relationship of the aligned patches. Sun et al. (Sun et al. 2018) propose a network named Part-based Convolution Baseline (PCB) which uniformly partition the feature map and learn local features directly. Sun et al. (Sun et al. 2019c) propose a region based method VPM which perceives the visible region through self-supervision. Jia et al. (Jia et al. 2021b) propose MoS which formulates the occluded person Re-ID as a set matching problem by using Jaccard similarity coefficient between the corresponding partten set.
Some methods leverage external cues to locate the human body part such as segmentation, pose estimation or body parsing. Song et al.(Song et al. 2018) propose a mask-guided contrastive attention model to learn features separately from the body. Miao et al. (Miao et al. 2019) introduce Pose-Guided Feature Alignment (PGFA) that utilizes pose information to mine discriminative parts. Gao et al. (Gao et al. 2020) propose a Pose-guided Visible Part Matching (PVPM) model to learn discriminative part features with pose-guided attentions. Wang et al. (Wang et al. 2020) propose HOReID that introduces the high-order relation and human-topology information to learn robust features.
Recently, methods based on transformer are emerging, and the transformer has two major capalities. First, transformer has been proven to have powerful feature extraction capabilities. He et al. (He et al. 2021) investigate a pure transformer framework named TransReID that combines the camera perspective information and achieves good performance on both person Re-ID and Vehicle Re-ID. Second, transformer has the ability to learn the disentangled features. Li et al. (Li et al. 2021) is the first one to propose Part Aware Transformer (PAT) for occluded person Re-ID, which could disentangle robust human part discovery.
Different from above methods, our method combines the pose information and transformer architecture to clearly disentangle more discriminative features and effectively alleviate the failure of feature learning caused by the occlusion.
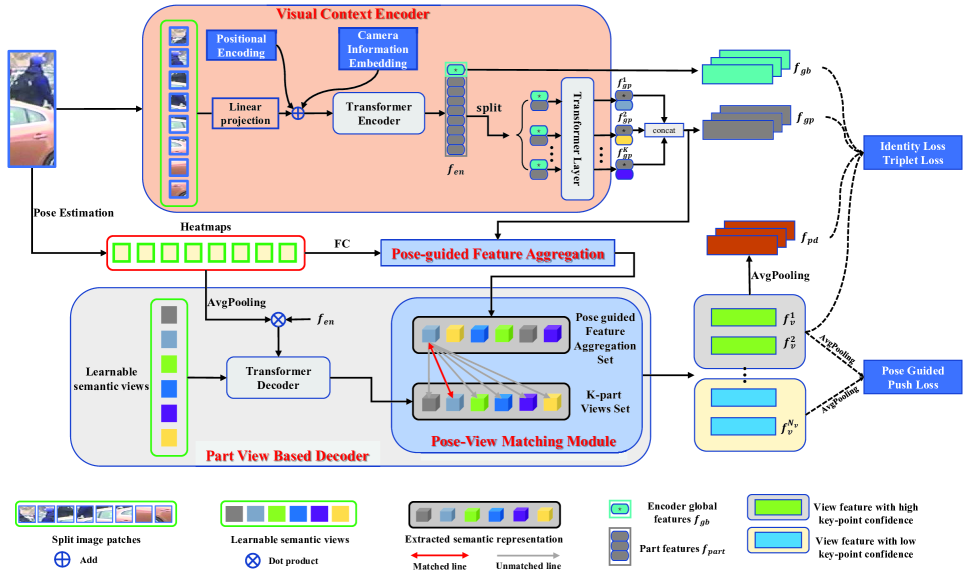
2.2 Visual Transformer
Transformer (Vaswani et al. 2017) has made great achievements in the field of natural language processing. Inspired by the self-attention mechanism, many researchers apply transformers in computer vision. For example, ViT (Dosovitskiy et al. 2020) processes images directly as sequences and achieves state-of-the-art performance in image recognition. DETR (Carion et al. 2020) performs cross-attention between object query and feature map to transform detection problem into a one-to-one matching problem, which eliminates the need for hand-crafted components in object detection.
3 Proposed Method
In this section, we introduce the proposed Pose-Guided Feature Disentangling (PFD) transformer in detail. An overview of our method is shown in Figure 2.
3.1 Visual Context Transformer Encoder
We build our encoder based on transformer-based image classification model (ViT(Dosovitskiy et al. 2020)). Given a person image , where ,, denote the height, width, and channel dimension respectively. We first split the into fixed-sized patches by using a sliding window. The step size can be denoted as , the size of each image patch as , and the number of patches can be described as:
| (1) |
where is the floor function. When is equal to patch size , The divided patches are non-overlapping. When is smaller than , the generated patches are overlapping, which can alleviate the loss of the spatial neighborhood information of the image. The transformer encoder only requires sequence as input, so a trainable linear projection function () is performed on flatten patches to map the patches to dimensions, and finally obtain the patch embeddings , (). A learnable [class] token is prepended to the patch embeddings, and the output [class] token serves as encoder global feature representation . In order to retain the position information, we apply learnable positional encodings. However, the features are very susceptible to the variation of the camera, so we follow the method in (He et al. 2021) to learn camera perspective information. Then the final input sequence can be described as:
| (2) |
where is positional embeddings, is camera embeddings, and the is same for the same images. is a hyper-parameter to balance the weight of camera embeddings. Next, the input embeddings will be processed by transformer layers. The final output of encoder can be divided into two parts (encoder global features and part features): and . In order to learn more discriminative features on human parts, the part features are split into groups in order, and the size of each group is . Then, each group that concatenates the encoder global feature will be fed into a shared transformer layer to learn group part local feature .
Encoder Supervision Loss. We adopt cross-entropy loss as identity loss and triplet loss for encoder global features and group features. The encoder loss function can be formulated as:
| (3) |
where denotes the probability prediction function.
3.2 Pose-guided Feature Aggregation
Occluded person images suffer from less body information, and non-body part information can be ambiguous, which causes performance degradation. Thus, we employ a human pose estimator to extract keypoint information from images.
Pose Estimation. Given a person image , the estimator extract landmarks from input image. Then the landmarks are utilized to generate heatmaps . Each heatmap is downsampled to the size of . The maximum response point of each heatmap corresponds to a joint point. We set a threshold to filter out high confidence landmarks and low confidence landmarks. But unlike (Miao et al. 2019), we do not set the heatmap whose landmark is smaller than to 0. Instead, a label will be assigned for each heatmap. Formally, heatmap label can be illustrated as:
| (4) |
where denotes the confidence score of i-th landmark.
Pose-guided Feature Aggregation. In order to integrate the the pose information, we set , which is exactly equal to the number of keypoints. Then, a fully connected layer is applied to heatmaps H to obtain the heatmaps , whose dimension is same as the group part local feature . Next, the heatmaps mutiply element-wisely and obtain the pose-guided feature . Although P has explicitly encoded the information of different parts of the human body, we hope to find the part of the information from that contributes the most to a certain body part. Thus, we develop a matching and distributing mechanism, which regards the part local feature and pose-guided feature as a set similarity measurement problem. Finally, we can obtain the pose-guided feature aggregation set . For each , we can find the most similar feature in , and then two features are added to form the . Formally,
| (5) |
| (6) |
where , denotes the inner product, denotes the most similar one to in .
3.3 Part View Based Transformer Decoder
In this section, we define a set of learnable semantic part views to learn the discriminative body parts. The learnable semantic part views can be denoted as , and will be added to each cross-attention layer as queries. As shown in Figure 2, the keys and values are from the combination of pose heatmap H and the output of encoder . An average pooling layer is applied to heatmap H and then multiply the , finally output the . Formally, queries, keys and values can be formulated as:
| (7) |
where , linear projections , , and are applied to semantic part views and feature , respectively. Next, we can obtain the part views set by implementing the multi-head attention mechanism and two fully-connected layer, which is the same as (Vaswani et al. 2017).
Pose-View Matching Module. In the cross-attention mechanism, the part semantic views can learn some discriminative features. However, it is unknown which part or what kind of the information has been learned. Therefore, in order to obtain features related to the human skeleton, we propose a pose-view matching module. Since each feature of the pose-guided feature aggregation set S is related to a certain keypoint information of the human body, we can find the part view related to the certain keypoint of the human body by calculating the similarity between the part view and . The matched semantic part view and the pose-guided feature aggregation feature are added to produce the final view feature set . Formally,
| (8) |
| (9) |
since the confidence score of the landmarks can indicate which part of feature contains human body information, the heatmap label can guide us to split the view feature set into two parts. Features with heatmap label in view set feature form a high-confidence keypoint view feature set , and the rest form the low-confidence keypoint view feature set , where denotes the number of features in whose heatmap label is equal to 1.
Decoder Supervision Loss. In order to focus on more non-occluded body features, we propose a Pose-guided Push Loss:
| (10) |
| (11) |
| (12) |
where denotes the training batch size. The motivation of this loss is obvious. Human body parts and non-human body parts should not have strong similarities. If and are similar, then will be large and the learnable sematic part views will adjust themselves adaptively. In order to guide the decoder view feature representation learning, an average-pooling layer is applied to high-confidence keypoints view feature set to obtain the pose-guided decoder global feature , then identity loss and triplet loss are employed to guide pose-guided decoder global feature and high-confidence feature learning as in Eq.13.
| (13) |
3.4 Training and Inference
In the training stage, the pose estimation uses a pre-trained model, and the rest of components (such as encoder, decoder and so on) are trained together with the overall objective loss, which is formulated as Eq.14.
| (14) |
where and are the scale factor of encoder loss and decoder loss respectively, and both are set to 0.5.
In the test stage, we concatenate the encoder global feature , pose-guided decoder global feature , group local part feature and high-confidence keypoint view feature as representation , ingnoring the low-confidence keypoint view feature . However, high-confidence keypoint view feature has variable length, and the network is difficult to implement. Thus, we fix the length of it to by padding zeros.
| (15) |
4 Experiments
4.1 Datasets and Evaluation Metrics
To illustrate the effectiveness of our method, We evaluate our method on five Re-ID datasets for two tasks including occluded person Re-ID and holistic person Re-ID.
Occluded-Duke (Miao et al. 2019) consists of 15,618 training images, 2,210 occluded query images and 17,661 gallery images. It is a subdataset of DukeMTMC-reID (Zheng, Zheng, and Yang 2017), whichtians occluded images and remove some overlapping images.
Occluded-REID (Zhuo et al. 2018) is captured by the mobile phone, which consist of 2,000 images of 200 occluded persons.Each identity has five full-body person images and five occluded person images with different types of severe occlusions.
Market-1501 (Zheng et al. 2015) contains 1,501 identities observed from 6 camera viewpoints, 12,936 training images of 751 identities, 19,732 gallery images, and 2,228 queries.
DukeMTMC-reID (Zheng, Zheng, and Yang 2017) contains 36,411 images of 1,404 identities captured from 8 camera viewpoints. It contains 16,522 training images, 17,661 gallery images and 2,228 queries.
MSMT17 (Wei et al. 2018) contains 125,441 images of 4101 identities captured from 15 camera viewpoints. It contains 32,621 training images. During inference, 82,161 images are randomly selected as gallery and other 11,659 images are considered as query.
Evaluation Metrics. We adopt Cumulative Matching Characteristic (CMC) curves and Mean average precision (mAP) to evaluate the quality of different Re-ID models.
4.2 Implementation Details
Both training and testing images are resized to 256 128. The training images are augmented with random horizontal flipping, padding, random cropping and random erasing (Zhong et al. 2020). The initial weights of encoder are pre-trained on ImageNet-21K and then finetuned on ImageNet-1K. In this paper, the number of the split group and the number of the estimated human landmarks are both set to 17. The number of decoder layer is set to 2 on Occluded-Duke and 6 on the other datasets. The hidden dimension is set to 768. The transformer decoder is same with (Vaswani et al. 2017). The batch size is set to 64 with 4 images per ID. The learing rate is initialized at 0.008 with cosine learning rate decay. To detect landmarks from images, we adopt HRNet (Sun et al. 2019b) pre-trained on the COCO dataset. The threshold is set to 0.2.
4.3 Comparison with the State-of-the-Art
We compare our method with the state-of-the-art methods on five benchmarks including occluded person ReID and holistic person ReID.
| Methods | Occluded-Duke | Occluded-REID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| Part-Aligned (ICCV ) | 28.8 | 44.6 | - | - |
| PCB (ECCV ) | 42.6 | 33.7 | 41.3 | 38.9 |
| Part Bilinear (ECCV ) | 36.9 | - | - | - |
| FD-GAN (NIPS ) | 40.8 | - | - | - |
| Ad-Occluded (CVPR ) | 44.5 | 32.2 | - | - |
| FPR (ICCV ) | - | - | 78.3 | 68.0 |
| PGFA (ICCV ) | 51.4 | 37.3 | - | - |
| PVPM (CVPR ) | 47.0 | 37.7 | 66.8 | 59.5 |
| GASM (ECCV ) | - | - | 74.5 | 65.6 |
| ISP (ECCV ) | 62.8 | 52.3 | - | - |
| HOReID (CVPR ) | 55.1 | 43.8 | 80.3 | 70.2 |
| MoS (AAAI ) | 61.0 | 49.2 | - | - |
| TransReID (ICCV ) | 64.2 | 55.7 | - | - |
| PAT (CVPR ) | 64.5 | 53.6 | 81.6 | 72.1 |
| PFD | 67.7 | 60.1 | 79.8 | 81.3 |
| TransReID∗ (ICCV ) | 66.4 | 59.2 | - | - |
| 69.5 | 61.8 | 81.5 | 83.0 | |
| Methods | Market-1501 | DukeMTMC | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| PCB (ECCV ) | 92.3 | 77.4 | 81.8 | 66.1 |
| DSR (CVPR ) | 83.6 | 64.3 | - | - |
| BOT (CVPRW ) | 94.1 | 85.7 | 86.4 | 76.4 |
| VPM (CVPR ) | 93.0 | 80.8 | 83.6 | 72.6 |
| MVPM (ICCV ) | 91.4 | 80.5 | 83.4 | 70.0 |
| SFT (ICCV ) | 93.4 | 82.7 | 86.9 | 73.2 |
| CAMA (CVPR ) | 94.7 | 84.5 | 85.8 | 72.9 |
| IANet (CVPR ) | 94.4 | 83.1 | 87.1 | 73.4 |
| Circle (CVPR ) | 94.2 | 84.9 | - | - |
| SPReID (CVPR ) | 92.5 | 81.3 | 84.4 | 70.1 |
| P2Net (ICCV ) | 95.2 | 85.6 | 86.5 | 73.1 |
| PGFA (CVPR ) | 91.2 | 76.8 | 82.6 | 65.5 |
| AANet (CVPR ) | 93.9 | 82.5 | 86.4 | 72.6 |
| HOReID (CVPR ) | 94.2 | 84.9 | 86.9 | 75.6 |
| TransReID (ICCV ) | 95.0 | 88.2 | 89.6 | 80.6 |
| PAT (CVPR ) | 95.4 | 88.0 | 88.8 | 78.2 |
| PFD () | 95.5 | 89.6 | 90.6 | 82.2 |
| TransReID∗ (ICCV ) | 95.2 | 88.9 | 90.7 | 82.0 |
| PFD∗ () | 95.5 | 89.7 | 91.2 | 83.2 |
Results on Occluded-Duke and Occluded-REID. Table 1 shows the results on two occluded datasets. As table shows, three kinds of methods are compared: (1) hand-crafted splitting based methods including Part-Aligned (Zhao et al. 2017) and PCB (Sun et al. 2018). (2) occluded ReID methods including Part Bilinear (Suh et al. 2018), PD-GAN (Ge et al. 2018), Ad-Occluded (Huang et al. 2018), FPR (He et al. 2019), PGFA (Miao et al. 2019), PVPM (Gao et al. 2020), GASM (He and Liu 2020), HOReID (Wang et al. 2020), ISP (Zhu et al. 2020) and MoS (Jia et al. 2021b). (3) Transformer based occluded ReID methods including PAT (Li et al. 2021) and TransReID (He et al. 2021). From the table, we can observe that our proposed method PFD achieves 67.7%/79.8% Rank-1 accuracy and 60.1%/81.3% mAP on Occluded-Duke and Occluded-REID datasets, respectively, and outperforms all kinds of methods in Occluded-Duke. Futher PFD∗ achieves higher Rank-1 and mAP with a small step sliding-window setting. Compared with PGFA, PVPM and HOReID, which are SOTA methods with keypoints information, our method surpasses them by at least +12.6% Rank-1 accuracy and +16.3% mAP on Occluded-Duke dataset. Compared to the competing transformer based methods PAT, our method surpasses it by at least +3.2% Rank-1 accuracy and +6.5% mAP on Occluded-Duke and +9.2% mAP on Occluded-REID.
The reasons for the superior performance of PFD can be attributed to the following points. First, compared with CNN, the transformer has better feature representation ability and can pay better attention to discriminative features. Second, the disentangled features obtained from our method can indicate the body part information in cluttered scenes, leading to clear semantic guidance when matching, which is more effective than spatial alignment. Third, the proposed pose-guided push loss efficiently weakens the interference of occlusions and background clutters.
Results on Holistic ReID datasets. To verify the effectiveness of our model on the holistic ReID task, we conduct experiments on three holistic ReID datasets including Market-1501, DukeMTMC-reID and MSMT17. Table 2 shows the results on Market-1501 and DukeMTMC-reID datasets. There are four types of methods in the comparison: (1) part feature based methods including PCB (Sun et al. 2018), DSR (He et al. 2018), BOT (Luo et al. 2019b) and VPM (Sun et al. 2019c). (2) global feature based methods including MVPM (Sun et al. 2019a), SFT (Luo et al. 2019a), CAMA (Yang et al. 2019), IANet (Hou et al. 2019) and Circle (Sun et al. 2020). (3) extra cue based methods including SPReID (Kalayeh et al. 2018), P2Net (Guo et al. 2019), PGFA (Miao et al. 2019), AANet (Tay, Roy, and Yap 2019) and HOReID (Wang et al. 2020). (4) transformer based methods including TransReID (He et al. 2021) and PAT (Li et al. 2021). From the table, we can observe that our proposed method achieve competitive results. Specifically, our method achieves SOTA performance (95.5%/90.6% Rank-1 accuracy and 89.5%/82.2% mAP, respectively) on Market-1501 and DukeMTMC-reID datasets. Compared with transformer based method PAT, our method surpasses it by +1.6% mAP on Market-1501 and +1.8%/+4% Rank-1 accruacy/mAP on DukeMTMC. We also conduct experiments on the proposed method on the MSMT17 dataset. Several methods are compared, including MVPM (Sun et al. 2019a), SFT (Luo et al. 2019a), OSNet (Zhou et al. 2019), IANet (Hou et al. 2019), DG-Net (Zheng et al. 2019), CBN (Zhuang et al. 2020), Cirecle (Sun et al. 2020), RGA-SC (Zhang et al. 2020), and SAN (Jin et al. 2020). From the table 3 we can see that proposed PFD achieves competitive performance. Specifically, our method achieves 82.7% Rank-1 accuracy and 65.1% mAP on MSMT17. It can be seen that although our method is not designed for holistic reid tasks, it can still achieve competitive results, which reflects the robustness of our proposed method.
| Methods | Rank-1 | mAP |
|---|---|---|
| MVPM (ICCV ) | 71.3 | 46.3 |
| SFT (ICCV ) | 73.6 | 47.6 |
| OSNet (ICCV ) | 78.7 | 52.9 |
| IANet (CVPR ) | 75.5 | 46.8 |
| DG-Net (CVPR ) | 77.2 | 52.3 |
| CBN (ECCV ) | 72.8 | 42.9 |
| Circle (CVPR ) | 76.3 | - |
| RGA-SC (CVPR ) | 80.3 | 57.5 |
| SAN (AAAI ) | 79.2 | 55.7 |
| PFD () | 82.7 | 65.1 |
| PFD∗ () | 83.8 | 64.4 |
| Index | PFA | PVM | R-1 | R-5 | R-10 | mAP | |
|---|---|---|---|---|---|---|---|
| 1 | 58.2 | 74.5 | 80.1 | 48.3 | |||
| 2 | ✓ | 63.7 | 77.8 | 82.3 | 56.2 | ||
| 3 | ✓ | 62.4 | 76.7 | 81.0 | 54.6 | ||
| 4 | ✓ | ✓ | 64.3 | 77.6 | 82.1 | 56.7 | |
| 5 | ✓ | ✓ | 67.0 | 80.0 | 84.4 | 59.5 | |
| 6 | ✓ | ✓ | ✓ | 67.7 | 80.1 | 85.0 | 60.1 |
| R-1 | R-5 | R-10 | mAP | |
|---|---|---|---|---|
| 1 | 65.5 | 79.1 | 84.0 | 57.1 |
| 5 | 66.7 | 79.9 | 83.7 | 58.4 |
| 10 | 66.9 | 79.5 | 83.9 | 58.9 |
| 15 | 67.4 | 80.0 | 84.0 | 59.1 |
| 17 | 67.7 | 80.1 | 85.0 | 60.1 |
| 20 | 66.9 | 79.4 | 84.3 | 59.0 |
4.4 Ablation Study
In this part, we conduct ablation studies on Occluded-Duke dataset to analyze the effectiveness of each component.
Effectiveness of proposed Modules. Table 4 shows the experimental results. Index-1 denotes that the pure transformer encoder-decoder architecture. We can see that the performance can reach 58.2% rank-1 accuracy and 48.3% mAP, which even shows better performance than pose-guided SOTA method HOReID. This is because the self-attention mechanism can focus on more discriminative features than CNN. From index-2, when pose-guided feature aggregation is added, the performance is greatly improved by +5.5% rank-1 accuracy and +7.9% mAP. This shows that the introduction of pose information and correct aggregation can bring good performance improvements. From index-3, we can see that our proposed PVM is also effective. And by comparing index-3 and index-5, we discover that combination of PFA and PVM can increase performance by +8.8% rank-1 accuracy and +11.2% mAP, which indicates that pose information and correct matching is very important. From index-5 and index-6, we can see that our overall model can achieve optimal performance, which shows the effectiveness of the Pose-guided Push Loss.
Analysis of the number of Semantic views. The number of semantic views determines the granularity of view features. As shown in Table 5, the performance of our proposed PFD is robust to . With increases, the performance keeps improving before arrives 17, which is exactly equal to the number of keypoints. So, we conclude that 17 semantic views may be able to capture the corresponding 17 key point features.
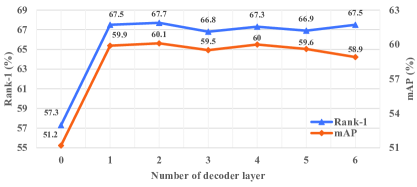
Analysis of the number of Transformer Layers. We perform quantitative experiments to find the most suitable number of decoder layer. As shown in Figure 3(a), when the decoder is removed, the performance of the model is greatly reduced. It can be seen that only the features obtained by the encoder are not robust enough, and the learnable semantic view in the decoder can implicitly learn more important features, which enhances the features from the encoder. we observe that when the number of decoder layer is set to 2, the best performance can be achieved. And with the increase of the number of layers, there is almost no improvement in performance. This is because the resolution of the images in the data set is small, and the content is relatively simple.
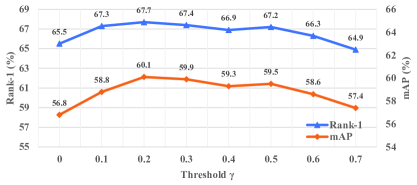
The Impact of the Threshold . The threshold is defined in Eq 4 to indicate the high confidence landmarks, which could help PVM explicitly match visible body parts. We conduct ablation study on threshold by changing it from 0 to 0.7. From the Figure 3(b), when is set to 0.2, we can get the best performance. When the value of is too small, PVM may consider all landmarks as human body areas, thereby introducing noise. Conversely, when the is too large, a certain body area information may be lost. It is worth noting that when gamma is set to 0, a lot of noise is introduced, but our method can still achieve 65.5% Rank-1 accuracy, which is still SOTA performance on Occluded-Duke. This shows that our method is robust to pose noise, and further indicates why it could achieve good results on the holistic datasets.
| Methods | R-1 | R-5 | R-10 | mAP |
|---|---|---|---|---|
| HR-Net(CVPR 19) | 67.7 | 80.1 | 85.0 | 60.1 |
| AlphaPose(ICCV 17) | 65.9 | 78.9 | 82.6 | 57.8 |
| OpenPose(CVPR 17) | 64.1 | 77.8 | 81.2 | 55.6 |
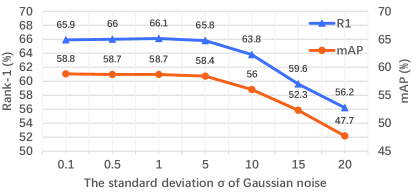
The Impact of Pose Estimation. We adopt three different pose estimation algorithms, HRNet (Sun et al. 2019b), AlphaPose (Fang et al. 2017), and OpenPose (Cao et al. 2017) in PFD. From the Table 6, the results shows that the PFD still could achieve state-of-the-art performance by using less reliable landmark estimators. Besides, we add Gaussian noise to the estimated heatmap by changing from 0.1 to 20. From Fig 4, we find that the model is robust to pose noise when is less than 10.
4.5 Visualization
We visualize decoder cross-attention for the different learnable semantic views and fuse them together to form attention heatmap. As Figure 5 shows, the fused learnable semantic views can almost accurately localize the unobstructed part of the human body, which proves the effectiveness of our proposed method.
















5 Conclusion
In this paper, we propose a transformer based Pose-guided Feature Disentangling (PFD) method for the occluded Re-ID task that utilizes pose information to clearly disentangle semantic components. PFD contains a transformer based encoder-decoder architecture, two matching modules (PFA and PVM), and a Pose-guided Push Loss. The ViT based encoder extracts the patch features with its strong capability. Then the PFA module preliminarily indicates visible body parts by matching estimated pose heatmaps and patch features. In decoder, we define a set of learnable semantic views to learn the discriminative body parts, and then the PVM module is proposed to enhance the encoder features by matching the most similar features between view set and pose guided feature aggregation set. Besides, PVM cloud automatically separate the occlusion features with the guidance of pose estimation. At last, a Pose-guided Push Loss is proposed to better eliminate the interference of occlusion noises by pushing the distance between visible parts and occluded parts in the embedded space. Finally, we conduct experiments on five popular datasets including Occluded-Duke, Occluded-REID, Market-1501, DukeMTMC-reID and MSMT17, and the competitive results demonstrate the effectiveness of the proposed method.
6 Acknowledgment
This research was supported by National Key R&D Program of China (No. 2020AAA0108904), Science and Technology Plan of Shenzhen (No.JCYJ20190808182209321).
References
- Cao et al. (2017) Cao, Z.; Simon, T.; Wei, S.-E.; and Sheikh, Y. 2017. Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Carion et al. (2020) Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), 213–229.
- Dosovitskiy et al. (2020) Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Fang et al. (2017) Fang, H.-S.; Xie, S.; Tai, Y.-W.; and Lu, C. 2017. RMPE: Regional Multi-person Pose Estimation. In ICCV.
- Gao et al. (2020) Gao, S.; Wang, J.; Lu, H.; and Liu, Z. 2020. Pose-guided visible part matching for occluded person ReID. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 11744–11752.
- Ge et al. (2018) Ge, Y.; Li, Z.; Zhao, H.; Yin, G.; Yi, S.; Wang, X.; and Li, H. 2018. Fd-gan: Pose-guided feature distilling gan for robust person re-identification. arXiv preprint arXiv:1810.02936.
- Guo et al. (2019) Guo, J.; Yuan, Y.; Huang, L.; Zhang, C.; Yao, J.-G.; and Han, K. 2019. Beyond human parts: Dual part-aligned representations for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 3642–3651.
- He et al. (2018) He, L.; Liang, J.; Li, H.; and Sun, Z. 2018. Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 7073–7082.
- He and Liu (2020) He, L.; and Liu, W. 2020. Guided saliency feature learning for person re-identification in crowded scenes. In European Conference on Computer Vision (ECCV), 357–373.
- He et al. (2019) He, L.; Wang, Y.; Liu, W.; Zhao, H.; Sun, Z.; and Feng, J. 2019. Foreground-aware pyramid reconstruction for alignment-free occluded person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 8450–8459.
- He et al. (2021) He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; and Jiang, W. 2021. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Hou et al. (2019) Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; and Chen, X. 2019. Interaction-and-aggregation network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 9317–9326.
- Huang et al. (2018) Huang, H.; Li, D.; Zhang, Z.; Chen, X.; and Huang, K. 2018. Adversarially occluded samples for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5098–5107.
- Jia et al. (2021a) Jia, M.; Cheng, X.; Lu, S.; and Zhang, J. 2021a. Learning Disentangled Representation Implicitly via Transformer for Occluded Person Re-Identification. arXiv preprint arXiv:2107.02380.
- Jia et al. (2021b) Jia, M.; Cheng, X.; Zhai, Y.; Lu, S.; Ma, S.; Tian, Y.; and Zhang, J. 2021b. Matching on sets: Conquer occluded person re-identification without alignment. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 35, 1673–1681.
- Jin et al. (2020) Jin, X.; Lan, C.; Zeng, W.; Wei, G.; and Chen, Z. 2020. Semantics-aligned representation learning for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 34, 11173–11180.
- Kalayeh et al. (2018) Kalayeh, M. M.; Basaran, E.; Gökmen, M.; Kamasak, M. E.; and Shah, M. 2018. Human semantic parsing for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1062–1071.
- Li et al. (2021) Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; and Wu, F. 2021. Diverse Part Discovery: Occluded Person Re-Identification With Part-Aware Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2898–2907.
- Luo et al. (2019a) Luo, C.; Chen, Y.; Wang, N.; and Zhang, Z. 2019a. Spectral feature transformation for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 4976–4985.
- Luo et al. (2019b) Luo, H.; Gu, Y.; Liao, X.; Lai, S.; and Jiang, W. 2019b. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).
- Miao et al. (2019) Miao, J.; Wu, Y.; Liu, P.; Ding, Y.; and Yang, Y. 2019. Pose-guided feature alignment for occluded person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 542–551.
- Shi, Liu, and Liu (2020) Shi, W.; Liu, H.; and Liu, M. 2020. Identity-sensitive loss guided and instance feature boosted deep embedding for person search. Neurocomputing, 415: 1–14.
- Song et al. (2018) Song, C.; Huang, Y.; Ouyang, W.; and Wang, L. 2018. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1179–1188.
- Suh et al. (2018) Suh, Y.; Wang, J.; Tang, S.; Mei, T.; and Lee, K. M. 2018. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), 402–419.
- Sun et al. (2019a) Sun, H.; Chen, Z.; Yan, S.; and Xu, L. 2019a. Mvp matching: A maximum-value perfect matching for mining hard samples, with application to person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 6737–6747.
- Sun et al. (2019b) Sun, K.; Xiao, B.; Liu, D.; and Wang, J. 2019b. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5693–5703.
- Sun et al. (2020) Sun, Y.; Cheng, C.; Zhang, Y.; Zhang, C.; Zheng, L.; Wang, Z.; and Wei, Y. 2020. Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 6398–6407.
- Sun et al. (2019c) Sun, Y.; Xu, Q.; Li, Y.; Zhang, C.; Li, Y.; Wang, S.; and Sun, J. 2019c. Perceive where to focus: Learning visibility-aware part-level features for partial person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 393–402.
- Sun et al. (2018) Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; and Wang, S. 2018. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), 480–496.
- Tay, Roy, and Yap (2019) Tay, C.-P.; Roy, S.; and Yap, K.-H. 2019. Aanet: Attribute attention network for person re-identifications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7134–7143.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), 5998–6008.
- Wang et al. (2020) Wang, G.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Yu, G.; Zhou, E.; and Sun, J. 2020. High-order information matters: Learning relation and topology for occluded person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 6449–6458.
- Wei et al. (2018) Wei, L.; Zhang, S.; Gao, W.; and Tian, Q. 2018. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 79–88.
- Yang et al. (2019) Yang, W.; Huang, H.; Zhang, Z.; Chen, X.; Huang, K.; and Zhang, S. 2019. Towards rich feature discovery with class activation maps augmentation for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1389–1398.
- Zhang et al. (2020) Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; and Chen, Z. 2020. Relation-aware global attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3186–3195.
- Zhang, Zhang, and Liu (2021) Zhang, Z.; Zhang, H.; and Liu, S. 2021. Person Re-Identification Using Heterogeneous Local Graph Attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12136–12145.
- Zhao et al. (2017) Zhao, L.; Li, X.; Zhuang, Y.; and Wang, J. 2017. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 3219–3228.
- Zheng et al. (2015) Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; and Tian, Q. 2015. Scalable person re-identification: A benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 1116–1124.
- Zheng, Yang, and Hauptmann (2016) Zheng, L.; Yang, Y.; and Hauptmann, A. G. 2016. Person re-identification: Past, present and future. arXiv preprint arXiv:1610.02984.
- Zheng et al. (2019) Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; and Kautz, J. 2019. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2138–2147.
- Zheng, Zheng, and Yang (2017) Zheng, Z.; Zheng, L.; and Yang, Y. 2017. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 3754–3762.
- Zhong et al. (2020) Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; and Yang, Y. 2020. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 34, 13001–13008.
- Zhou et al. (2019) Zhou, K.; Yang, Y.; Cavallaro, A.; and Xiang, T. 2019. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 3702–3712.
- Zhu et al. (2020) Zhu, K.; Guo, H.; Liu, Z.; Tang, M.; and Wang, J. 2020. Identity-guided human semantic parsing for person re-identification. In European Conference on Computer Vision (ECCV), 346–363.
- Zhuang et al. (2020) Zhuang, Z.; Wei, L.; Xie, L.; Zhang, T.; Zhang, H.; Wu, H.; Ai, H.; and Tian, Q. 2020. Rethinking the distribution gap of person re-identification with camera-based batch normalization. In European Conference on Computer Vision (ECCV), 140–157.
- Zhuo et al. (2018) Zhuo, J.; Chen, Z.; Lai, J.; and Wang, G. 2018. Occluded person re-identification. In 2018 IEEE International Conference on Multimedia and Expo (ICME), 1–6.