Preconditioned Stochastic Gradient Langevin Dynamics for
Deep Neural Networks
Abstract
Effective training of deep neural networks suffers from two main issues. The first is that the parameter spaces of these models exhibit pathological curvature. Recent methods address this problem by using adaptive preconditioning for Stochastic Gradient Descent (SGD). These methods improve convergence by adapting to the local geometry of parameter space. A second issue is overfitting, which is typically addressed by early stopping. However, recent work has demonstrated that Bayesian model averaging mitigates this problem. The posterior can be sampled by using Stochastic Gradient Langevin Dynamics (SGLD). However, the rapidly changing curvature renders default SGLD methods inefficient. Here, we propose combining adaptive preconditioners with SGLD. In support of this idea, we give theoretical properties on asymptotic convergence and predictive risk. We also provide empirical results for Logistic Regression, Feedforward Neural Nets, and Convolutional Neural Nets, demonstrating that our preconditioned SGLD method gives state-of-the-art performance on these models.
Introduction
Deep Neural Networks (DNNs) have recently generated significant interest, largely due to their state-of-the-art performance on a wide variety of tasks, such as image classification (?) and language modeling (?). Despite this significant empirical success, it remains a challenge to effectively train DNNs. This is due to two main problems: The function under consideration is often difficult to optimize and find a good local minima. It is believed that this is in large part due to the pathological curvature and highly non-convex nature of the function to be optimized (?). Standard optimization techniques lead to overfitting, typically addressed through early stopping (?).
A Bayesian approach for learning neural networks incorporates uncertainty into model learning, and can reduce overfitting (?). In fact, it is possible to view the standard dropout technique (?) as a form of Bayesian approximation that incorporates uncertainty (?; ?). Many other recent works (?; ?; ?) advocate incorporation of uncertainty estimates during model training to help improve robustness and performance.
While a Bayesian approach can ameliorate the overfitting issue in these complicated models, exact Bayesian inference in DNNs is generally intractable. Recently, several approaches have been proposed to approximate a Bayesian posterior for DNNs, including a stochastic variational inference (SVI) method “Bayes by Backprop” (BBB) (?) and an online expectation propogation method (OEP) “probabilistic backpropagation” (PBP) (?). These methods assume the posterior is comprised of separable Gaussian distributions. While this is a good choice for computational reasons, it can lead to unreasonable approximation errors and underestimation of model uncertainty.
A popular alternative to SVI and OEP is to use Stochastic Gradient Markov Chain Monte Carlo (SG-MCMC) methods to generate posterior samples (?; ?; ?; ?). One of the most common SG-MCMC methods is the Stochastic Gradient Langevin Dynamics (SGLD) algorithm (?). One merit of this approach is that it is highly scalable; it requires only the gradient on a small mini-batch of data, as in the optimization method Stochastic Gradient Descent (SGD). It has been shown that these MCMC approaches converge to the true posterior by using a slowly-decreasing sequence of step sizes (?; ?). Costly Metropolis-Hasting steps are not required.
Unfortunately, DNNs often exhibit pathological curvature and saddle points (?), which render existing SG-MCMC methods inefficient. In the optimization literature, numerous approaches have been proposed to overcome this problem, including methods based on adapting a preconditioning matrix in SGD to the local geometry (?; ?; ?). These approaches estimate second-order information with trivial per-iteration overhead, have improved risk bounds in convex problems compared to SGD, and demonstrate improved empirical performance in DNNs. The idea of using geometry in SG-MCMC has been explored in many contexts (?; ?; ?) and includes second-order approximations. Often, these approaches use the expected Fisher information, adding significant computational overhead. These methods lack the scalability necessary for learning DNNs, as discussed further below.
We combine adaptive preconditioners from optimization with SGLD, to improve SGLD efficacy. To note the distinction from SGLD, we refer to this as the Preconditioned SGLD method (pSGLD). This procedure is simple and adds trivial per-iteration overhead. We first show theoretical properties of this method, including bounds on risk and asymptotic convergence properties. We demonstrate improved efficiency of pSGLD by demonstrating an enhanced bias-variance tradeoff of the estimator for small problems. We further empirically demonstrate its application to several models and large datasets, including deep neural networks. In the DNN experiments, pSGLD outperforms the results based on standard SGLD from (?), both in terms of convergence speed and the test-set performance. Futher, pSGLD generates state-of-the-art performance for the examples tested.
Related Work
Various regularization schemes have been developed to prevent overfitting in neural networks, such as early stopping, weight decay, dropout (?), and dropconnect (?). Bayesian methods are appealing due to their ability to avoid overfitting by capturing uncertainty during learning (?). MCMC methods work by producing Monte Carlo approximations to the posterior, with asymptotic consistency (?). Traditional MCMC methods use the full dataset, which does not scale to large data problems. A pioneering work in combining stochastic optimization with MCMC was presented in (?), based on Langevin dynamics (?). This method was referred to as Stochastic Gradient Langevin Dynamics (SGLD), and required only the gradient on mini-batches of data. The per-iteration cost of SGLD is nearly identical to SGD. Unlike SGD, SGLD can generate samples from the posterior by injecting noise into the dynamics. This encourages the algorithm to explore the full posterior, instead of simply converging to a maximum a posterior (MAP) solution. Later, SGLD was extended by (?), (?) and (?). Furthermore, higher-order versions of the SGLD with momentum have also been proposed, including stochastic gradient Hamiltionian Monte Carlo (SGHMC) (?) and stochastic gradient Nose-Hoover Thermostats (SGNHT) (?).
It has been shown that incoporating higher-order gradient information helps train neural networks when employing optimization methods (?). However, calculations of higher-order information is often cumbersome in most models of interest. Methods such as quasi-Newton, and those approximating second-order gradient information, have shown promising results (?). An alternative to full quasi-Newton methods is to rescale parameters so that the loss function has similar curvature along all directions. This strategy has shown improved performance in Adagrad (?), Adadelta (?), Adam (?) and RMSprop (?) algorithms. Recently, RMSprop has been explained as a diagonal preconditioner in (?). While relatively mature in optimization, these techniques have not been developed in sampling methods. In this paper, we show that rescaling the parameter updates according to geometry information can also improve SG-MCMC, in terms of both training speed and predictive accuracy.
Preliminaries
Given data , the posterior of model parameters with prior and likelihood is computed as . In the optimization literature, the prior plays the role of a penalty that regularizes parameters, while the likelihood constitutes the loss function to be optimized. The task in optimization is to find the MAP estimate, . Let denote the change in the parameters at time . Stochastic optimization methods such as Stochastic Gradient Descent (SGD)111For maximization, this is Stochastic Gradient Ascent. Here, we abuse notation because SGD is a more common term. update using the following rule:
| (1) |
where is a sequence of step sizes, and a subset of data items randomly chosen from at iteration . The convergence of SGD has been established (?).
For DNNs, the gradient is calculated by backpropagation (?). One data item may consist of input and output , with being the output space (e.g., a discrete label space in classification). In the testing stage, the Bayesian predictive estimate for input , is given by . The MAP estimate simply approximates this expectation as , ignoring parameter uncertainty.
Stochastic sampling methods such as SGLD incorporate uncertainty into predictive estimates. SGLD samples from the posterior distributions via a Markov Chain with steps:
| (2) |
with denoting the identity matrix. It also uses mini-batches to take gradient descend steps at each iteration. Rates of convergence are proven rigorously in (?). Given a set of samples from the update rule (2), posterior distributions can be approximated via Monte Carlo approximations as , where is the number of samples.
Both stochastic optimization and stochastic sampling approaches have the requirement that the step sizes satisfy the the following assumption.222The requirement for SGLD can be relaxed, see (?; ?) for more details.
Assumption 1
The step sizes are decreasing, i.e., , with 1) ; and 2) .
If these step-sizes are not satisfied in stochastic optimization, there is no guarantee of convergence because the gradient estimation noise is not eliminated. Likewise, in stochastic sampling, decreasing step-sizes are necessary for asymptotic consistency with the true posterior, where the approximation error is dominated by the natural stochasticity of Langevin dynamics (?).
Preconditioned Stochastic Gradient Langevin Dynamics
As noted in the previous section, standard SGLD updates all parameters with the same step size. This could lead to slow mixing when the components of have different curvature. Unfortunately, this is generally true in DNNs due to the composition of nonlinear functions at multiple layers. A potential solution is to employ a user-chosen preconditioning matrix in SGLD (?). The intuition is to consider the family of probability distributions parameterised by lying on a Riemannian manifold. One can use the non-Euclidean geometry implied by this manifold to guide the random walk of a sampler. For any probability distribution, the expected Fisher information matrix defines a natural Riemannian metric tensor. To further scale up the method to a general online framework stochastic gradient Riemannian Langevin dynamics (SGRLD) was suggested in (?). At position , it gives the step333The update form in (?) is more complicated and seemingly different from (3); however, they can be shown to be equivalent.,
| (3) | ||||
where describes how the preconditioner changes with respect to . . This term vanishes in SGLD because the preconditioner of SGLD is a constant . Both the direction and variance in Eq.(3) depends on the geometry of . The natural gradient in the SGRLD step takes the direction of steepest descent on a manifold. Convergence to the posterior is guaranteed (?; ?) as long as step sizes satisfy Assumption 1.
Unfortunately, for many models of interest, the expected Fisher information is intractable. However, we note that any positive definite matrix defines a valid Riemannian manifold metric. Hence, we are not restricted to using the exact expected Fisher information. Preconditioning aims to constitute a local transform such that the rate of curvature is equal in all directions. Following this, we propose to use the same preconditoner as in RMSprop. This preconditioner is updated sequentially using only the current gradient information, and only estimates a diagonal matrix. It is given sequentially as,
| (4) | |||
| (5) |
where for notational simplicity, , is the sample mean of the gradient using mini-batch , and . Operators and represent element-wise matrix product and division, respectively.
RMSprop utilizes magnitudes of recent gradients to construct a preconditioner. Flatter landscapes have smaller gradients while curved landscapes have larger gradients. Gradient information is usually only locally consistent. Therefore, two equivalent interpretations for Eq. (3) can be reached intuitively: i) the preconditioner equalizes the gradient so that a constant stepsize is adequate for all dimensions. ii) the stepsizes are adaptive, in that flat directions have larger stepsizes while curved directions have smaller stepsizes.
In DNNs, saddle points are the most prevalent critical points, that can considerably slow down training (?), mostly because the parameter space tends to be flat in many directions and ill-conditioned in the neighborhood of these saddle points. Standard SGLD will slowly escape the saddle point due to the typical oscillations along the high positive curvature direction. By transforming the landscape to be more equally curved, it is possible for the sampler to move much faster.
In addition, there are two tuning parameters: controls the extremes of the curvature in the preconditioner (default ), and balances the weights of historical and current gradients. We use a default value of to construct an exponentially decaying sequence. Our Preconditioned SGLD with RMSprop is outlined in Algorithm 1.
Preconditioned SGLD Algorithms in Practice
This section first analyzes the finite-time convergence properties of pSGLD, then proposes a more efficient variant for practical use. We note that prior work gave similar theoretical results (?), and we extend the theory to consider the use of preconditioners.
Finite-time Error Analysis
For a bounded function , we are often interested in its true posterior expectation . For example, the class distribution of a data point in DNNs. In our SG-MCMC based algorithm, this intractable integration is approximated by a weighted sample average at time , with stepsizes . These samples are generated from an MCMC algorithm with a numerical integrator (e.g., our pSGLD algorithm) that discretizes the continuous-time Langevin dynamics. The precision of the true posterior average and its MCMC approximation is characterized by the expected difference between and . We analyze the pSGLD algorithm by extending the work of (?; ?) to include adaptive preconditioners. We first show the asymptotic convergence properties of our algorithm in Theorem 1 by the mean of the mean squared error (MSE)444This is different from the optimization literature where the regret is studied, which is not straightforward in the MCMC framework.. To get the convergence result, some mild assumptions on the smoothness and boundness of , the solution functional of , is needed, where is the generator of corresponding stochastic differential equation for pSGLD. We discuss these conditions and prove the Theorem in Appendix A.
Theorem 1
Define the operator . Under Assumption 1, for a test function , the MSE of the pSGLD at finite time is bounded, for some independent of , as:
| (6) | ||||
MSE is a common measure of quality of an estimator, reflecting the precision of an approximate algorithm. It can be seen from Theorem 1 that the finite-time approximation error of pSGLD is bounded by , consisting of two factors: estimation error from stochastic gradients, , and discretization error inherited from numerical integrators, . These terms asymptotically approach under Assumption 1, meaning that the decreasing-step-size pSGLD is asymptotically consistent with true posterior expectation.
Practical Techniques
Of interest when considering the practical issue of limited computation time, we now interpret the above finite-time error using the framework of risk of an estimator, which provides practical guidance in implementation. From (?), the predictive risk, , of an algorithm is defined as the MSE above, and can be decomposed as , where is the bias and is the variance. Denote as the ergodic average under the invariant measure, , of the pSGLD. After burnin, it can be shown that
| Bias | (7) | ||||
| Variance | (8) |
where is the variance of with respect to (i.e., ) , which is a constant (further details are given in Appendix D). is the effective sample size (ESS), defined as
| ESS | (9) |
where is the autocovariance function, manifesting how strong two samples with a time lag are correlated. The term is the integrated autocorrelation time (ACT), which measures the interval between independent samples.
In practice, there is always a tradeoff between bias and variance. In the case of infinite computation time, the traditional MCMC setting can reduce the bias and variance to zero. However, in practice, time is limited. Obtaining more effective samples can reduce the total risk (Eq. (6)), even if bias is introduced. In the following, we provide two model-independent practical techniques to further speed up the proposed pSGLD.
Excluding term
Though the evaluation of in our case is manageable due to its diagonal nature, we propose to remove it during sampling to reduce the computation. It is interesting that in our case ignoring produces a bias controlled by on the MSE.
Corollary 2
Omitting introduces an extra term in the bound that is controlled by the parameter . The proof is in Appendix B. Since is always set to a value that is very close to , the term , the effect of negligible. In addition, more samples per unit time are generated when is ignored, resulting in a smaller variance on the prediction. Note that the term is heuristically ignored in (?), but is only able to approximate the true posterior in the case of infinite data, which is not required in our algorithm.
Thinning samples
Making predictions using a whole ensemble of models is cumbersome and may be too computationally expensive to allow deployment for a large number of users, especially when the models are large neural nets. One practical technique is to average models using a thinned version of samples. By thinning the samples in pSGLD, the total number of samples is reduced. However, these thinned samples have a lower autocorrelation time and can have a similar ESS. We can also guarantee the MSE remains the same form under the thinning schema. The proof is in Appendix C.
Corollary 3
By thinning samples from our pSGLD algorithm, the MSE remains the same form as in Theorem 1, and asymptotically approaches 0.
Experiments
Our experiments focus on the effectiveness of preconditioners in pSGLD, and present results in four parts: a simple simulation, Bayesian Logistic Regression (BLR), and two widely used DNN models, Feedforward Neural Networks (FNN) and Convolutional Neural Networks (CNN).
The proposed algorithm that uses the discussed practical techniques is denoted as pSGLD. The prior on the parameters is set to . If not specifically mentioned, the default setting for DNN experiments is shared as follows. , minibatch size is 100, thinning interval is 100, burn-in is 300. We employ a block decay strategy for stepsize; it decreases by half after every epochs.
Simulation
We first demonstrate pSGLD on a simple 2D Gaussian example, . Given posterior samples, the goal is to estimate the covariance matrix. A diagonal covariance matrix is used to show the algorithm can adjust the stepsize at different dimension.
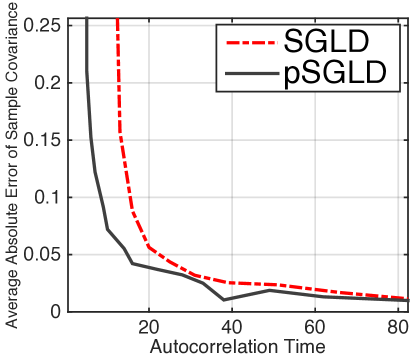
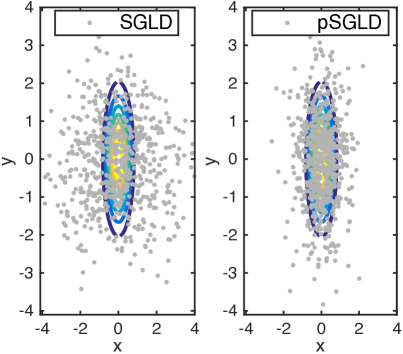
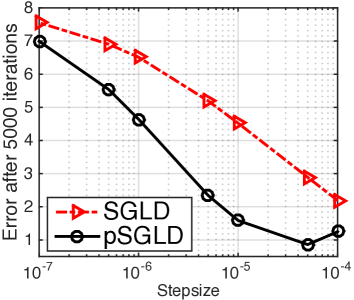
We first compare SGLD and pSGLD with a large range of different stepsizes . samples are collected for each algorithm. Reconstruction errors and autocorrelation time are shown in Fig. 1 (a). We see that pSGLD dominates the “vanilla” SGLD in that it consistently shows a lower error and autocorrelation time, particularly with larger stepsize. When the stepsize is small enough, the sampler does not move much, and the performances of the two algorithms become similar. The first samples of both methods for are shown in Fig. 1 (b). Because step sizes in pSGLD can be adaptive, it implies that even if the covariance matrix of a target distribution is mildly rescaled, a new stepsize is unnecessary for pSGLD. Meanwhile, the stepsize of the vanilla SGLD needs to be fine-tuned in order to obtain decent samples. See Appendix E for further details.
|
|
|---|---|
| (a) Error and ACT | (b) Samples |
Bayesian Logstic Regression
To demonstrate that our pSGLD is applicable to general Bayesian posterior sampling, we demonstrate results on BLR. A small Australian dataset (?) is first used with and dimension . We choose a minibatch size of . The prior variance is . iterations are used. For both pSGLD and SGLD, we test stepsize ranging from to , with 50 runs for each algorithm.
|
|
|---|---|
| (a) Variance | (b) Parameter estimation |
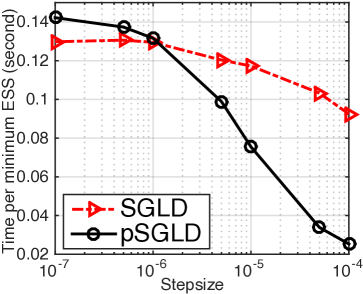
Following (?), we report the time per minimum Effective Sample () in Fig. 2 (a), which is proportional to the variance. pSGLD generates much larger ESS compared to SGLD, especially when the stepsize is large. Meanwhile, Fig. 2 (b) shows that pSGLD provides smaller error in estimating weights, where the “groundtruth” is obtained by samples from HMC with Metroplis-Hastings. Therefore, the overall risk is reduced.
We then test BLR on a large-scale Adult dataset, (?), with and . Minibatch size is set to 50, and the prior variance is . The thinning interval is 50, burn-in is 500, and iterations are used. Stepsize for pSGLD and SGLD. The test errors are compared in Table 1Bayesian Logstic Regression, and learning curves are shown in Fig. 3Bayesian Logstic Regression. Both SG-MCMC methods outperform the recently proposed doubly stochastic variational Bayes (SDVI) (?), and higher-order variational autoencoder methods (L-BFGS-SGVI, HFSGVI) (?). Furthermore, pSGLD converges in less than iterations, while SGLD at least needs double the time to reach this accuracy.
| Method | Test error |
|---|---|
| pSGLD | 14.85% |
| SGLD | 14.85% |
| DSVI | 15.20% |
| L-BFGS-SGVI | 14.91% |
| HFSGVI | 15.16% |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/09dfdfc6-512b-4c93-98b1-dbe574bc6021/x5.png)
Feedforward Neural Networks
The first DNN model we study is the Feedforward Neural Networks (FNN), or multilayer perceptron (MLP). The activation function is rectified linear unit (ReLU). A two-layer model, 784-X-X-10, is employed, where X is the number of hidden units for each layer. 100 epochs are used, with . We compare our propose method, pSGLD, with representative stochastic optimization methods: SGD, RMSprop and RMSspectral (?). After tuning, we set the optimal stepsize for each algorithm as: for pSGLD and RSMprop as follows: , while for SGLD and SGD as .
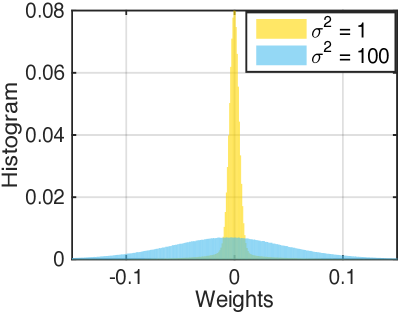
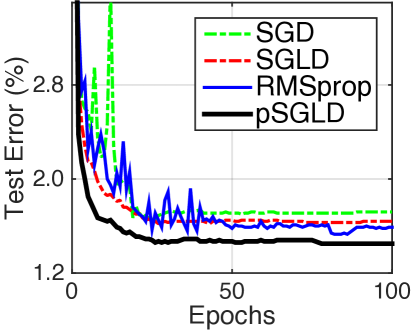
We test the algorithms on the standard MNIST dataset, consisting of images (thus the 784-dimensional input vector) from different classes ( to ) with training and test samples. The test classification errors for network (X-X) size 400-400, 800-800 and 1200-1200 are shown in Table LABEL:tab:fnn. The results of stochastic sampling methods are better than their corresponding stochastic optimization counterparts. This indicates that incorporating weight uncertainty can improve performances. By increasing the variance of pSGLD from to , more uncertainty is introduced into the model from the prior, and higher performance is obtained. Figure 4 (a) displays the distribution histograms of weights in the last training iteration of the 1200-1200 model. We observe that smaller variance in the prior imposes lower uncertainty, by making the weights concentrate to ; while larger variance in the prior leads to a wider range of weight choices, thus higher uncertainty.
 |
|
| (a) Weights distribution | (b) Learning curves |
We also compare to other techniques developed to prevent overfitting (dropout) and weight uncertainty (BPB, Gaussian and scale mixtures). pSGLD provides state-of-the-art performance for FNN on test accuracy. We further note that pSGLD is able to give increasing performance with increasing network size, whereas BPB and SGD dropout do not. This is probably because overfitting is harder to be dealt with in large neural networks with pure optimization techniques.
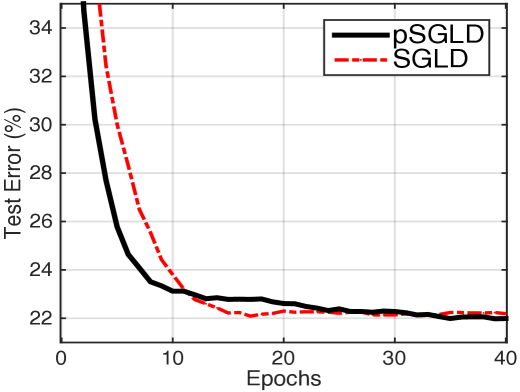
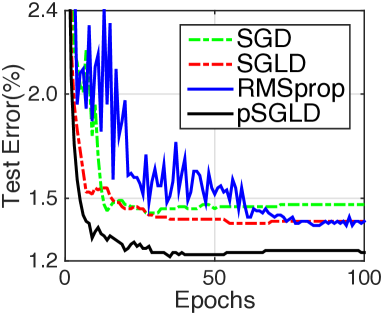
Finally, learning curves of network configuration 1200-1200 are plot in Fig. 4 (b)555RMSspectral is not shown because it uses larger batch sizes and so is difficult to compare on this scale.. We empirically find that pSGLD and SGLD take fewer iterations to converge, and the results are more stable than their optimization counterparts. Moreover, it can be seen that pSGLD consistently converges faster and to a better point than SGLD. Learning curves for other network sizes are provided in Appendix F. While the ensemble of samples requires more computation than a single FNN in testing, it shows significantly improved performance. As well, (?) showed that learning a single FNN that approximates the model average result gave nearly the same performance. We employ this idea, and suggest a fast version, distilled pSGLD. Its results for show it can maintain good performances.
Convolutional Neural Networks
Our next DNN is the popular CNN model. We use a standard network configuration with 2 convolutional layers followed by 2 fully-connected layers (?). Both convolutional layers use filter size with 32 and 64 channels, respectively; max pooling is used after each convolutional layer. The fully-connected layers have 200-200 hidden nodes with ReLU nonlinearities, 20 epochs are used, and is set to 10. The stepsizes for pSGLD and RMSprop is set to via grid search. For SGLD and SGD, this is . Additional results with CNNs are in Appendix G.
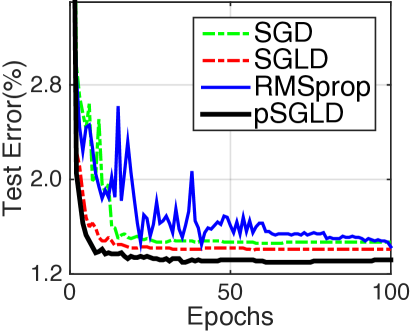
The same MNIST dataset is used. A comparison of test errors is shown in Table 3G, with the corresponding learning curves in Fig. 5G. We emphasize that the purpose of this experiment is to compare methods on the same model architecture, not to achieve overall state-of-the-art results. The CNN trained with traditional SGD gives an error of 0.82%. pSGLD shows significant improvement, with an error of 0.45%. This result is also comparable with some recent state-of-the-art CNN based systems, which have much more complex architectures. These include the stochastic pooling (?), Network in Network (NIN) (?) and Maxout Network(MN) (?).
| Method | Test error |
|---|---|
| pSGLD | 0.45% |
| SGLD | 0.71% |
| RMSprop | 0.65% |
| RMSspectral | 0.78% |
| SGD | 0.82% |
| Stochastic Pooling | 0.47% |
| NIN + Dropout | 0.47% |
| MN + Dropout | 0.45% |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/09dfdfc6-512b-4c93-98b1-dbe574bc6021/x8.png)
Conclusion
A preconditioned SGLD is developed based on the RMSprop algorithm, with controllable finite-time approximation error. We apply the algorithm to DNNs to overcome their notorious problems of overfitting and pathological curvature. Extensive experiments show that our pSGLD can adaptive to the local geometry, allowing improved effective sampling rates and performance. It provides sample-based uncertainty in DNNs, and achieves state-of-the-arts performances on FNN and CNN models. Interesting future directions include exploring applications to latent variable models or recurrent neural networks (?).
Acknowledgements
This research was supported in part by ARO, DARPA, DOE, NGA, ONR and NSF.
References
- [Ahn, Korattikara, and Welling 2012] Ahn, S.; Korattikara, A.; and Welling, M. 2012. Bayesian posterior sampling via stochastic gradient fisher scoring. In ICML.
- [Bakhturin 2001] Bakhturin, Y. A. 2001. Campbell–Hausdorff formula. Encyclopedia of Mathematics, Springer.
- [Blundell et al. 2015] Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; and Wierstra, D. 2015. Weight uncertainty in neural networks. In ICML.
- [Bottou 2004] Bottou, L. 2004. Stochastic learning. Advanced Lectures on Machine Learning 146–168.
- [Carlson et al. 2015] Carlson, D.; Collins, E.; Hsieh, Y. P.; Carin, L.; and Cevher, V. 2015. Preconditioned spectral descent for deep learning. In NIPS.
- [Chen, Ding, and Carin 2015] Chen, C.; Ding, N.; and Carin, L. 2015. On the convergence of stochastic gradient MCMC algorithms with high-order integrators. In NIPS.
- [Chen, Fox, and Guestrin 2014] Chen, T.; Fox, E. B.; and Guestrin, C. 2014. Stochastic gradient Hamiltonian Monte Carlo. In ICML.
- [Chen-Yu et al. 2015] Chen-Yu, L.; Saining, X.; Patrick, G.; Zhengyou, Z.; and Zhuowen, T. 2015. Deeply-supervised nets. AISTATS.
- [Dauphin et al. 2014] Dauphin, Y. N.; Pascanu, R.; Gulcehre, C.; Cho, K.; Ganguli, S.; and Bengio, Y. 2014. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In NIPS.
- [Dauphin, de Vries, and Bengio 2015] Dauphin, Y. N.; de Vries, H.; and Bengio, Y. 2015. Equilibrated adaptive learning rates for non-convex optimization. In NIPS.
- [Ding et al. 2014] Ding, N.; Fang, Y.; Babbush, R.; Chen, C.; Skeel, R. D.; and Neven, H. 2014. Bayesian sampling using stochastic gradient thermostats. In NIPS.
- [Duchi, Hazan, and Singer 2011] Duchi, J.; Hazan, E.; and Singer, Y. 2011. Adaptive subgradient methods for online learning and stochastic optimization. JMLR.
- [Fan et al. 2015] Fan, K.; Wang, Z.; Beck, J.; Kwok, J.; and Heller, J. 2015. Fast second-order stochastic backpropagation for variational inference. In NIPS.
- [Gal and Ghahramani 2015] Gal, Y., and Ghahramani, Z. 2015. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. arXiv:1506.02142.
- [Gamerman and Lopes 2006] Gamerman, D., and Lopes, H. F. 2006. Markov chain Monte Carlo: stochastic simulation for Bayesian inference. CRC Press.
- [Gan et al. 2015] Gan, Z.; Li, C.; Henao, R.; Carlson, D.; and Carin, L. 2015. Deep temporal sigmoid belief networks for sequence modeling. NIPS.
- [Girolami and Calderhead 2011] Girolami, M., and Calderhead, B. 2011. Riemann manifold langevin and hamiltonian monte carlo methods. In JRSS: Series B.
- [Goodfellow et al. 2013] Goodfellow, I.; Warde-farley, D.; Mirza, M.; Courville, A.; and Bengio, Y. 2013. Maxout networks. In ICML.
- [Hernández-Lobato and Adams 2015] Hernández-Lobato, J. M., and Adams, R. P. 2015. Probabilistic backpropagation for scalable learning of bayesian neural networks. In ICML.
- [Jarrett et al. 2009] Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; and LeCun, Y. 2009. What is the best multi-stage architecture for object recognition? In ICCV.
- [Kingma and Ba 2015] Kingma, D., and Ba, J. 2015. Adam: A method for stochastic optimization. ICLR.
- [Kingma, Salimans, and Welling 2015] Kingma, D. P.; Salimans, T.; and Welling, M. 2015. Variational dropout and the local reparameterization trick. NIPS.
- [Korattikara et al. 2015] Korattikara, A.; Rathod, V.; Murphy, K.; and Welling, M. 2015. Bayesian dark knowledge. NIPS.
- [Korattikara, Chen, and Welling 2014] Korattikara, A.; Chen, Y.; and Welling, M. 2014. Austerity in MCMC land: Cutting the Metropolis-Hastings budget. ICML.
- [Krizhevsky and Hinton 2009] Krizhevsky, A., and Hinton, G. 2009. Learning multiple layers of features from tiny images.
- [Krizhevsky, Sutskever, and Hinton 2012] Krizhevsky, A.; Sutskever, I.; and Hinton, G. E. 2012. Imagenet classification with deep convolutional neural networks. In NIPS.
- [Li et al. 2016] Li, C.; Chen, C.; Fan, K.; and Carin, L. 2016. High-order stochastic gradient thermostats for Bayesian learning of deep models. In AAAI.
- [Lin, Chen, and Yan 2014] Lin, M.; Chen, Q.; and Yan, S. 2014. Network in network. ICLR.
- [Lin, Weng, and Keerthi 2008] Lin, C.-J.; Weng, R. C.; and Keerthi, S. S. 2008. Trust region newton method for logistic regression. JMLR.
- [MacKay 1992] MacKay, D. J. C. 1992. A practical bayesian framework for backpropagation networks. Neural computation.
- [Mattingly, Stuart, and Tretyakov 2010] Mattingly, J. C.; Stuart, A. M.; and Tretyakov, M. V. 2010. Construction of numerical time-average and stationary measures via Poisson equations. SIAM J. NUMER. ANAL. 48(2):552–577.
- [Neal 1995] Neal, R. M. 1995. Bayesian learning for neural networks. PhD thesis, University of Toronto.
- [Neal 2011] Neal, R. M. 2011. MCMC using Hamiltonian dynamics. Handbook of Markov Chain Monte Carlo.
- [Ngiam et al. 2011] Ngiam, J.; Coates, A.; Lahiri, A.; Prochnow, B.; Le, Q. V.; and Ng, A. Y. 2011. On optimization methods for deep learning. In ICML.
- [Patterson and Teh 2013] Patterson, S., and Teh, Y. W. 2013. Stochastic gradient Riemannian Langevin dynamics on the probability simplex. In NIPS.
- [Rumelhart, Hinton, and Williams 1986] Rumelhart, D. E.; Hinton, G. E.; and Williams, R. 1986. Learning representations by back-propagating errors. Nature.
- [Srivastava et al. 2014] Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; and Salakhutdinov, R. 2014. Dropout: A simple way to prevent neural networks from overfitting. JMLR.
- [Sutskever, Vinyals, and Le 2014] Sutskever, I.; Vinyals, O.; and Le, Q. V. 2014. Sequence to sequence learning with neural networks. In NIPS.
- [Teh, Thiéry, and Vollmer 2014] Teh, Y. W.; Thiéry, A. H.; and Vollmer, S. J. 2014. Consistency and fluctuations for stochastic gradient Langevin dynamics.
- [Tieleman and Hinton 2012] Tieleman, T., and Hinton, G. E. 2012. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera: Neural Networks for Machine Learning.
- [Titsias and Lázaro-Gredilla 2014] Titsias, M., and Lázaro-Gredilla, M. 2014. Doubly stochastic variational bayes for non-conjugate inference. In ICML.
- [Wan et al. 2013] Wan, L.; Zeiler, M.; Zhang, S.; LeCun, Y.; and Fergus, R. 2013. Regularization of neural networks using dropconnect. In ICML.
- [Welling and Teh 2011] Welling, M., and Teh, Y. W. 2011. Bayesian learning via stochastic gradient Langevin dynamics. In ICML.
- [Zeiler and Fergus 2013] Zeiler, M., and Fergus, R. 2013. Stochastic pooling for regularization of deep convolutional neural networks. ICLR.
- [Zeiler 2012] Zeiler, M. D. 2012. Adadelta: An adaptive learning rate method. arXiv:1212.5701.
Supplementary Material of
Preconditioned Stochastic Gradient Langevin Dynamics for
Deep Neural Networks
Appendix A A. The proof for main theorem
In (?), the authors provide the convergence property for general SG-MCMC, here we follow their assumptions and proof techniques, with specific treatment on the 1st-order numerical integrator, and the case of preconditioner.
Details on the assumption
Before the proof, we detail the assumptions needed for Theorem 1. For pSGLD, its associated Stochastic Differential Equation (SDE) has an invariant measure , the posterior average is defined as: for some test function of interest. Given samples from pSGLD, we use the sample average to approximate . In the analysis, we define a functional that solves the following Poisson Equation:
| (10) |
The solution functional characterizes the difference between and the posterior average for every , thus would typically possess a unique solution, which is at least as smooth as under the elliptic or hypoelliptic settings (?). In the unbounded domain of , to make the presentation simple, we follow (?) and make certain assumptions on the solution functional, , of the Poisson equation (10), which are used in the detailed proofs.
The mild assumptions of smoothness and boundedness made in the main paper are detailed as follows.
Assumption 2
and its up to 3rd-order derivatives, , are bounded by a function , i.e., for , . Furthermore, the expectation of on is bounded: , and is smooth such that , for some .
Proof of Theorem 1
Based on Assumption 2, we prove the main theorem.
-
Proof
First let us denote
(11) the local generator of our proposed pSGLD with stochastic gradients, where is the vector inner product, is the matrix double dot product. Furthermore, let be the true generator of the Langevin dynamic corresponding to the pSGLD, e.g., replacing the stochastic gradient in with the true gradient. As a result, we have the relation:
(12) where , is the full gradient, is the stochatic gradient calculated from the -th minibatch.
In pSGLD, we use the Euler integrator, which is a first order integrator. As a result, according to (?), for a test function , we can decompose it as:
(13) where is the identity map, i.e., .
According to the assumptions, there exists a functional that solves the following Poisson Equation:
(14) where is defined in the main text.
Sum over in the above equation, take expectation on both sides, and use the Poisson Equation (14) and the relation to expand the first order term. We obtain
(15) Divide both sides by , we have
(16) As a result, there exists some positive constant , such that:
(17) can be bounded by assumptions, and can be easily shown to be bounded by due to the Gaussian noise. It turns out that the resulting terms have order higher than those from the other terms, thus can be ignored in the expression below. After some simplifications, (17) is bounded by:
(18) for some . It is easy to show under the assumptions, all the terms in the above bound approach zero. This completes the first part of the theorem.
Appendix B B. The proof for Corollary 2
To prove Corollary 2, we first show the following results.
Lemma 4
Assume that the 1st-order and 2nd-order gradient are bounded, then there exists some constant , for k-th component of , we have
| (19) |
- Proof
Since is a diagnal matrix, we focus on one of its elements thus omit the index in the following.
First, the iterative form of exponential moving average can be written as a function of the gradients at all the previous timesteps:
| (20) | |||
| (21) |
Based on this, for each component of , we have
| (22) | |||
| (23) | |||
| (24) |
With the assumption that the 1st-order and 2nd-order gradient are bounded, we have , where is a constant independent of . Therefore, .
Based on Lemma 4, we now proceed to the proof of Corollary 2.
-
Proof
By dropping the terms, we get a modified version of the local generator corresponding to the SDE of the pSGLD, defined as
where with defined in the proof of Theorem 1.
Appendix C C. The proof for Corollary 3
-
Proof
By thinning samples from the pSGLD, we obtain a sequence of subsamples from the original samples where and is a subsequence of . Since we use the 1st-order Euler integrator, based on the definition in (?), we have for the original samples:
(28) where denotes the Kolmogorov operator. Now for samples between and , i.e., , we have
(29) where denotes the composition of the two operators and , i.e., is evaluated on the output of B. Now substitute (28) into (29), and use the Baker-Campbell-Hausdorff formula (?) for commutators, we have
(30) where . This means by thinning the samples, going from to corresponds to a 1st-order local integrator with stepsize and a modified generator of the corresponding SDE as , which is in the same form as the original generator .
By performing the same derivation with the new generator , we obtain the same MSE as in Theorem 1 in the main text.
Appendix D D. The proof for bias-variance tradeoff
Bias-variance decomposition
| Risk | (31) |
- Proof
where
| Bias | (32) | ||||
| Variance | (33) |
Variance term in risk of estimator
| Variance | (34) |
-
Proof
(36) (37) (38) (39) (40) where the term is omitted from (37) to (38), which is usually small according to the property of autocovariance function.
We repeat some defintions from the main paper (?).
(41) is the autocovariance function, manifesting how strong two samples with a time lag are correlated. Its normalized version
ACF (42) is called the autocorrelation function (ACF).
ACT (43) is the integrated autocorrelation time (ACT), which measures the interval between independent samples.
Note that effective sample size (ESS) is defined as
ESS (44) Plugin the definition into the derivation for variance, we have
(45)
Appendix E E. More results on simulation
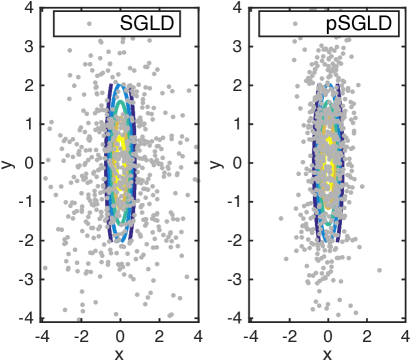
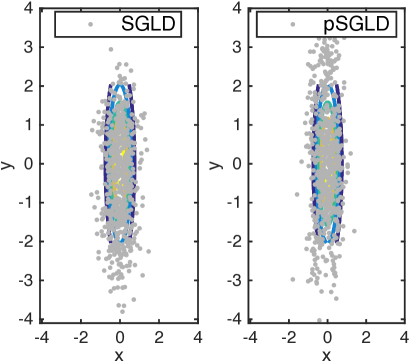
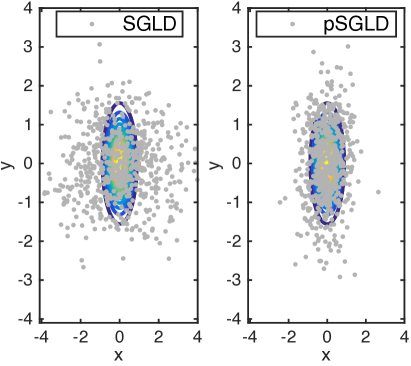
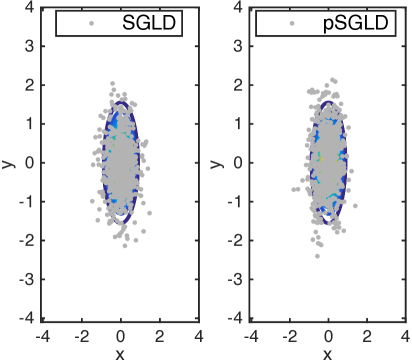
We demonstrate our pSGLD on a simple 2D gaussian example, . The first 600 samples of both methods for different and are shown in Fig. 1.
Comparing the results for different stepsize at the same , it can be seen that pSGLD can adapt stepsizes acorrding to the manifold geometry of different dimensions.
When is rescaled from to , stepsize is appropriate for SGLD at , but not a good choice at , because the space is not fully explored. This also implies that even if the covariance matrix of a target distribution is mildly rescaled, we do not have to choose a new stepsize for pSGLD. Whilst, the stepsize of the standard SGLD needs to be fine-tuned in order to obtain decent samples.
|
|
| (a) | (b) |
|
|
| (c) | (d) |
Appendix F F. More results on
Feedforward Neural Networks
Learning curves for network sizes of 400-400 and 800-800 on MNIST are provided in Fig. 7 (a) and (b), respectively. Similar with results of network size 1200-1200 in the main paper, stochastic sampling methods take less iterations to converge, and the results are more stable than their optimization counterparts. Moreover, it can be seen that pSGLD consistently converges faster and better than SGLD and others.
|
|
|---|---|
| (a) 400-400 | (b) 800-800 |
Appendix G G. More results on
Convolutional Neural Networks
We use another fairly standard network configuration containing 2 convolutional layers on MNIST dataset. It is followed by a single fully-connected layer (?), containing 500 hidden nodes that uses ReLU. Both convolutional layers use filter size with 32 and 64 channels, respectively, max pooling are used after each convolutional layer. 100 epochs are used, and is set to 20. The stepsizes for pSGLD and RSMprop are set to via grid search. For SGLD and SGD, this is .
A comparison of test errors is shown in Table 1G, with the corresponding learning curves in Fig. 3G. Again, under the same network architecture, CNN trained with traditional SGD gives an error of 0.81%, while pSGLD has a significant improvement, with an error of 0.56%.
| Method | Test error |
|---|---|
| pSGLD | 0.56% |
| SGLD | 0.76% |
| RMSprop | 0.64% |
| SGD | 0.81% |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/09dfdfc6-512b-4c93-98b1-dbe574bc6021/x15.png)
We also tested a similar 3-layer CNN with 32-32-64 channels on Cifar-10 RGB image dataset (?), which consists of samples for training and samples for testing. No data augmentation is employed for the dataset. We keep the same setting for pSGLD and SGLD from MNIST, and show the comparison on Cifar-10 in Fig. 9. pSGLD converges faster and reach a lower error.