ruledlabelfont=normalfont,labelsep=colon,strut=off
Predicting and Enhancing the Fairness of DNNs with the Curvature of Perceptual Manifolds
Abstract
To address the challenges of long-tailed classification, researchers have proposed several approaches to reduce model bias, most of which assume that classes with few samples are weak classes. However, recent studies have shown that tail classes are not always hard to learn, and model bias has been observed on sample-balanced datasets, suggesting the existence of other factors that affect model bias. In this work, we first establish a geometric perspective for analyzing model fairness and then systematically propose a series of geometric measurements for perceptual manifolds in deep neural networks. Subsequently, we comprehensively explore the effect of the geometric characteristics of perceptual manifolds on classification difficulty and how learning shapes the geometric characteristics of perceptual manifolds. An unanticipated finding is that the correlation between the class accuracy and the separation degree of perceptual manifolds gradually decreases during training, while the negative correlation with the curvature gradually increases, implying that curvature imbalance leads to model bias. We thoroughly validate this finding across multiple networks and datasets, providing a solid experimental foundation for future research. We also investigate the convergence consistency between the loss function and curvature imbalance, demonstrating the lack of curvature constraints in existing optimization objectives. Building upon these observations, we propose curvature regularization to facilitate the model to learn curvature-balanced and flatter perceptual manifolds. Evaluations on multiple long-tailed and non-long-tailed datasets show the excellent performance and exciting generality of our approach, especially in achieving significant performance improvements based on current state-of-the-art techniques. Our work opens up a geometric analysis perspective on model bias and reminds researchers to pay attention to model bias on non-long-tailed and even sample-balanced datasets.
Index Terms:
Fairness of DNNs, Representational learning, Long-Tailed Recognition, Image classification, Data-Centirc AI.1 Introduction
The imbalance of sample numbers in the dataset gives rise to the challenge of long-tailed visual recognition. Most previous works assume that head classes are always easier to be learned than tail classes, e.g., class re-balancing [1, 2, 3, 4, 5, 6, 7], information augmentation [8, 9, 10, 11, 12, 13, 14, 15, 16], decoupled training [17, 18, 19, 20, 21, 22], and ensemble learning [23, 24, 25, 26, 27, 28, 29] have been proposed to improve the performance of tail classes. However, recent studies [30, 31] have shown that classification difficulty is not always correlated with the number of samples, e.g., the performance of some tail classes is even higher than that of the head classes. Also, [32] observes differences in model performance across classes on non-long-tailed data, and even on balanced data. Therefore, it is necessary to explore the impact of other inherent characteristics of the data on the classification difficulty, and then improve the overall performance by mitigating the model bias under multiple sample number distribution scenarios.
Focal loss [4] utilizes the DNN’s prediction confidence on instances to evaluate the instance-level difficulty. [30] argues that for long-tailed problems, determining class-level difficulty is more important than determining instance-level difficulty, and therefore defines classification difficulty by evaluating the accuracy of each class in real-time. However, both methods rely on the model output and still cannot explain why the model performs well in some classes and poorly in others. Similar to the number of samples, we would like to propose a measure that relies solely on the data itself to model class-level difficulty, which helps to understand how deep neural networks learn from the data. The effective number of samples [1] tries to characterize the diversity of features in each class, but it introduces hyperparameters and would not work in balanced dataset.
Natural images usually obey the manifold distribution law [33, 34], i.e., samples of each class are distributed near a low-dimensional manifold in the high-dimensional space. The manifold consisting of features in the embedding space is called a perceptual manifold [35]. As shown in Fig.2, the classification task is equivalent to distinguishing each perceptual manifold, which has a series of geometric characteristics. A well-trained deep neural network achieves classification by untangling the perceptual manifolds and separating them. We speculate that some geometric characteristics may affect the classification difficulty, and therefore conduct an in-depth study.
The main contributions of our work are:

-
(1)
We introduce a novel geometric perspective to assess the fairness of models. Under this perspective, we systematically propose a series of metrics for measuring the geometric characteristics of point cloud perceptual manifolds in deep neural networks, including the volume, separability, and curvature of perceptual manifolds (Sec 3). These metrics provide tools for quantitative analysis.
-
(2)
We found that even on balanced datasets, there exists a significant negative correlation between the curvature of the perceptual manifold corresponding to each class and the model’s class accuracy (Sec 4). This discovery provides a new mechanism for explaining and evaluating the fairness of the model.
-
(3)
We comprehensively investigated the dynamics of the geometric characteristics of perceptual manifolds. In particular, we explored the effects of learning on the separability (Sec 5.1) and curvature (Sec 5.2) of perceptual manifolds. We find that the correlation between separation degree and class accuracy decreases with training, while the negative correlation between curvature and class accuracy increases with training (Sec 5.3), implying that existing methods can only mitigate the effect of separation degree among perceptual manifolds on model bias, while ignoring the effect of perceptual manifold complexity on model bias.
-
(4)
Curvature regularization is proposed to facilitate the model to learn curvature-balanced and flatter perceptual manifolds, thus mitigating model bias (Fig.1 and Fig.15) while improving its overall performance (Sec 6). Our approach shows excellent performance on multiple long-tailed and non-long-tailed datasets (Sec 7).
This work is an extension of the CVPR 2023 paper. Compared to the initial version, Section 3 has been expanded to include proofs of the properties of the proposed perceptual manifold separability. More simulation examples are provided to elucidate the measure of perceptual manifold separability that we propose. We added Section 4, where we comprehensively unveil the correlation between the curvature of perceptual manifolds generated by different layers of deep neural networks and model fairness. The experimental results of models across three datasets strongly validate our viewpoint that the curvature of perceptual manifolds can predict model fairness. This provides a solid experimental foundation for improving model fairness. We rewrote Section 5, adding more experimental results and analysis. More importantly, we included an exploration of the convergence consistency between the loss function and curvature, as well as curvature imbalance, revealing the lack of curvature constraints in existing optimization objectives. In Section 7, we added detailed steps for deriving curvature regularization and enhanced the motivation. In the experimental section, we added a subsection to introduce the role of curvature regularization in reducing model bias and curvature imbalance. Code published at: https://github.com/mayanbiao1234/Geometric-metrics-for-perceptual-manifolds.
2 Related Work
In practice, the dataset usually tends to follow a long-tailed distribution, which leads to models with very large variances in performance on each class. It should be noted that most researchers default to the main motivation for long-tail visual recognition is that classes with few samples are always weak classes. Therefore, numerous methods have been proposed to improve the performance of the model on tail classes. [36] divides these methods into three fields, namely class rebalancing [6, 32, 5, 30, 1, 4, 37, 38, 39, 40, 41, 25, 42, 43, 19], information augmentation [44, 45, 8, 9, 12, 20, 11, 46, 47, 48, 49, 50, 14], and module improvement [51, 52, 22, 53, 54, 23, 25, 55, 28, 29]. Unlike the above, [30] and [31] observe that the number of samples in the class does not exactly show a positive correlation with the accuracy, and the accuracy of some tail classes is even higher than the accuracy of the head class. Therefore, they propose to use other measures to gauge the learning difficulty of the classes rather than relying on the sample number alone. In the following, we first present past research up to [30][31] and lead to our work.
Class-Difficulty Based Methods
The study of class difficulty is most relevant to our work. The methods in the three domains presented above almost all assume that classes with few samples are the most difficult classes to be learned, and therefore more attention is given to these classes. However, recent studies [30, 31] have observed that the performance of some tail classes is even higher than that of the head classes, and that the performance of different classes varies on datasets with perfectly balanced samples. These phenomena suggest that the sample number is not the only factor that affects the performance of classes. The imbalance in class performance is referred to as the “bias” of the model, and [30] defines the model bias as
where denotes the accuracy of the -th class. When the accuracy of each class is identical, bias = 0. [30] computes the difficulty of class c using and calculates the weights of the loss function using a nonlinear function of class difficulty. Unlike [30], [31] proposes a model-independent measure of classification difficulty, which directly utilizes the data matrix to calculate the semantic scale of each class to represent the classification difficulty. As with the sample number, model-independent measures can help us understand how deep neural networks learn from data. When we get data from any domain, if we can measure the difficulty of each class directly from the data, we can guide the researchers to collect the difficult classes in a targeted manner instead of blindly, greatly facilitating the efficiency of applying AI in practice.
In this work, we propose to consider the classification task as the classification of perceptual manifolds. The influence of the geometric characteristics of the perceptual manifold on the classification difficulty is further analyzed, and feature learning with curvature balanced is proposed.
3 The Geometry of Perceptual Manifold
In this section, we systematically propose a series of geometric measures for perceptual manifolds in deep neural networks, and conduct simulation tests and analyses.
3.1 Perceptual Manifold
A perceptual manifold is generated when neurons are stimulated by objects with different physical characteristics from the same class. Sampling along the different dimensions of the manifold corresponds to changes in specific physical characteristics. It has been shown [33, 34] that the features extracted by deep neural networks obey the manifold distribution law. That is, features from the same class are distributed near a low-dimensional manifold in the high-dimensional feature space. Given data from the same class and a deep neural network , where represents a feature sub-network with parameters and represents a classifier with parameters . Extract the p-dimensional features of with the trained model, where . Assuming that the features belong to class , the features form a -dimensional point cloud manifold , which is called a class perceptual manifold [56].
Input: Training set with the total number of classes. A CNN , where and denote the feature sub-network and classifier, respectively.
Output: The volume of all perceptual manifolds.
3.2 The Volume of Perceptual Manifold
We measure the volume of the perceptual manifold by calculating the size of the subspace spanned by the features . First, the sample covariance matrix of can be estimated as Diagonalize the covariance matrix as , where and . and denote the -th eigenvalue of and its corresponding eigenvector, respectively. Let the singular value of matrix be . According to the geometric meaning of singular value [57], the volume of the space spanned by vectors is proportional to the product of the singular values of matrix , i.e., . Considering , the volume of the perceptual manifold is therefore denoted as .
However, when is a non-full rank matrix, its determinant is . For example, the determinant of a planar point set located in three-dimensional space is 0 because its covariance matrix has zero eigenvalues, but obviously the volume of the subspace tensed by the point set in the plane is non-zero. We want to obtain the “area” of the planar point set, which is a generalized volume. We avoid the non-full rank case by adding the unit matrix to the covariance matrix . is a positive definite matrix with eigenvalues . The above operation enables us to calculate the volume of a low-dimensional manifold embedded in high-dimensional space. The volume of the perceptual manifold is proportional to . Considering the numerical stability, we further perform a logarithmic transformation on and define the volume of the perceptual manifold as
where is the mean of . When , . Since is a positive definite matrix, its determinant is greater than 0. In the following, the degree of separation between perceptual manifolds will be proposed based on the volume of perceptual manifolds.
3.3 The Separation Degree of Perceptual Manifold
Euclidean or cosine distances between class centers are often applied to measure inter-class distances, and these two distances are also commonly used as loss functions when constructing sample pairs. However, maximizing the distance between proxy points or samples cannot keep a class away from all the remaining classes at the same time, and the distance between class centers does not reflect the degree of overlap of the distribution. In this section, we propose a measure of the separation degree between perceptual manifolds.
Given the perceptual manifolds and , they consist of point sets and , respectively. The volumes of and are calculated as and . Consider the following case, assuming that and have partially overlapped, when , it is obvious that the overlapped volume accounts for a larger proportion of the volume of , when the class corresponding to is more likely to be confused. Therefore, it is necessary to construct an asymmetric measure for the degree of separation between multiple perceptual manifolds, and we expect this measure to accurately reflect the relative magnitude of the degree of separation.
Input: Training set with the total number of classes. A CNN , where and denote the feature sub-network and classifier, respectively.
Output: The volume of all data manifolds.
Suppose there are perceptual manifolds , which consist of point sets . Let , , we define the degree of separation between the perceptual manifold and the rest of the perceptual manifolds as
The following analysis is performed for the case when and . According to our motivation, the measure of the degree of separation between perceptual manifolds should satisfy .
If holds, then we can get
We prove that holds when , and the details are as follows.
Proof.
Since the function is strictly concave, the real symmetric positive definite matrices and satisfy [58]
Also because
and
We can get
i.e., holds. ∎
The above analysis shows that the proposed measure meets our requirements and motivation. The formula for calculating the degree of separation between perceptual manifolds can be further reduced to
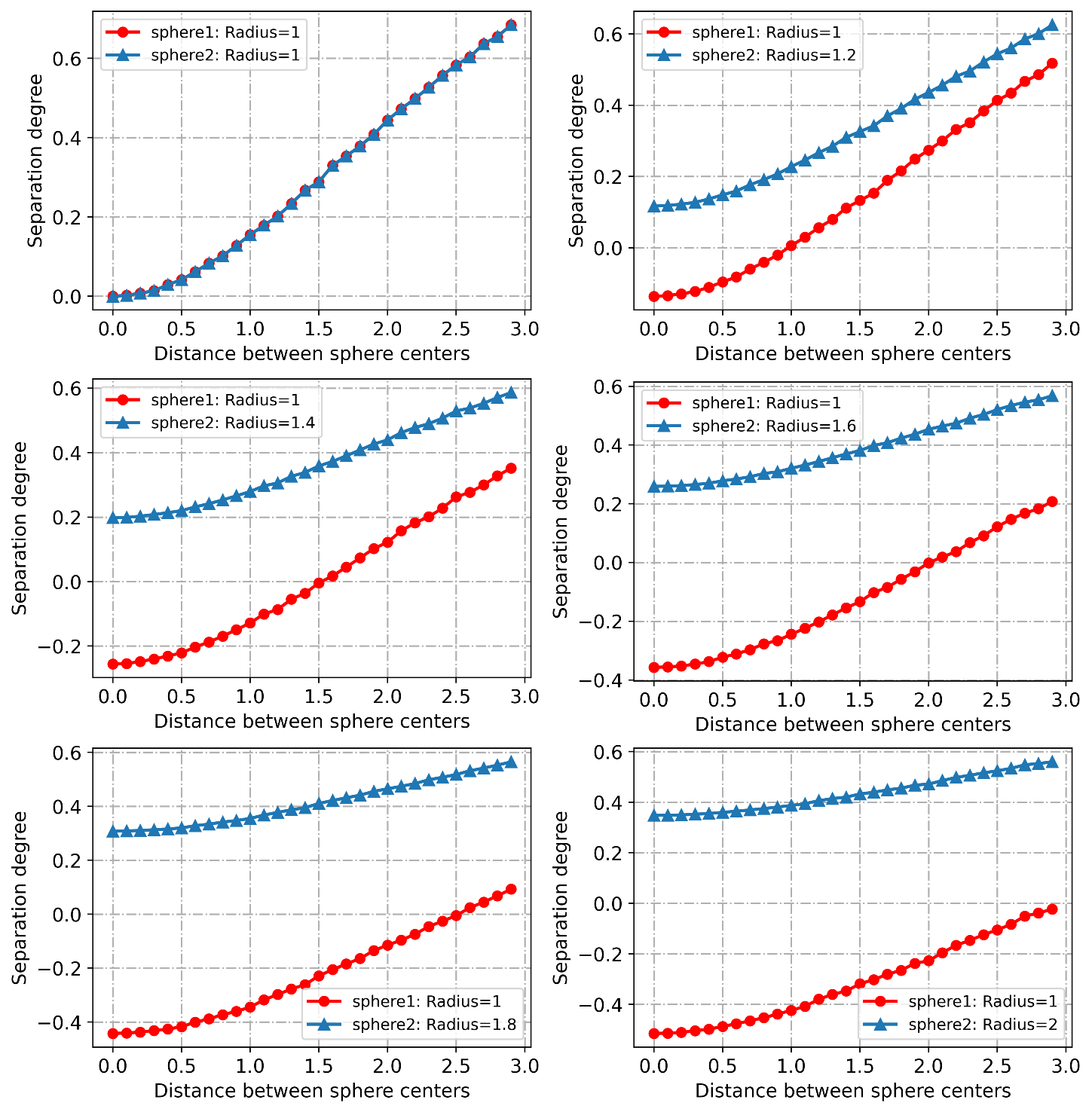
Next, we validate the proposed measure of the separation degree between perceptual manifolds in a 3D spherical point cloud scene. Specifically, we conducted the experiments in three cases:
-
(1)
Construct two 3D spherical point clouds of radius , and then increase the distance between their spherical centers. Since the volumes of the two spherical point clouds are equal, their separation degrees should be symmetric. The variation curves of the separation degrees are plotted in Fig.3, and it can be seen that the experimental results satisfy our theoretical predictions.
-
(2)
Change the distance between the centers of two spherical point clouds. Observe their separation degrees, the separation degrees of these two spherical point clouds should be asymmetric. Fig.3 shows that their separation degrees increase as the distance between their centers increases. Also, the manifold with a larger radius has a greater separation degree, and this experimental result conforms to our analysis and motivation.
-
(3)
As shown in Fig.3, as the volume difference between the two spherical point cloud manifolds becomes larger, the difference in separation between the two increases, a result that is entirely consistent with our motivation.
The separation degree between perceptual manifolds may affect the model’s bias towards classes. In addition, it can also be used as the regularization term of the loss function or applied in contrast learning to keep the different perceptual manifolds away from each other.
3.4 The Curvature of Perceptual Manifold
Given a point cloud perceptual manifold , which consists of a -dimensional point set , our goal is to calculate the Gauss curvature at each point. First, the normal vector at each point on is estimated by the neighbor points. Denote by the -th neighbor point of and the normal vector at . We solve for the normal vector by minimizing the inner product of and [59], i.e.,
where and is the number of neighbor points. Let , then the optimization objective is converted to
is the covariance matrix of neighbors of . Therefore, let and . The optimization objective is further equated to
Construct the Lagrangian function for the above optimization objective, where is a parameter. The first-order partial derivatives of with respect to and are
Let and be , we can get . It is obvious that solving for is equivalent to calculating the eigenvectors of the covariance matrix , but the eigenvectors are not unique. From we can get , so the optimization problem is equated to . Performing the eigenvalue decomposition on the matrix yields eigenvalues and the corresponding -dimensional eigenvectors , where , , . The eigenvector corresponding to the smallest non-zero eigenvalue of the matrix is taken as the normal vector of at .
Input: Given a point cloud perceptual manifold , which consists of a -dimensional point set . Denote by the -th neighbor point of and the normal vector at .
Output: The mean Gaussian curvature of the perceptual manifold .
Consider an -dimensional affine space with center , which is spanned by . This affine space approximates the tangent space at on . We estimate the curvature of at by fitting a quadratic hypersurface in the tangent space utilizing the neighbor points of . The neighbors of are projected into the affine space and denoted as
Denote by the -th component of . We use and neighbor points to fit a quadratic hypersurface with parameter . The hypersurface equation is denoted as
further, minimize the squared error
Let yield a nonlinear system of equations, but it needs to be solved iteratively. Here, we propose an ingenious method to fit the hypersurface and give the analytic solution of the parameter directly. Expand the parameter of the hypersurface into the column vector
Organize the neighbor points of according to the following form:
The target value is
We minimize the squared error
and find the partial derivative of for :
Let , we can get
Thus, the Gauss curvature of the perceptual manifold at can be calculated as
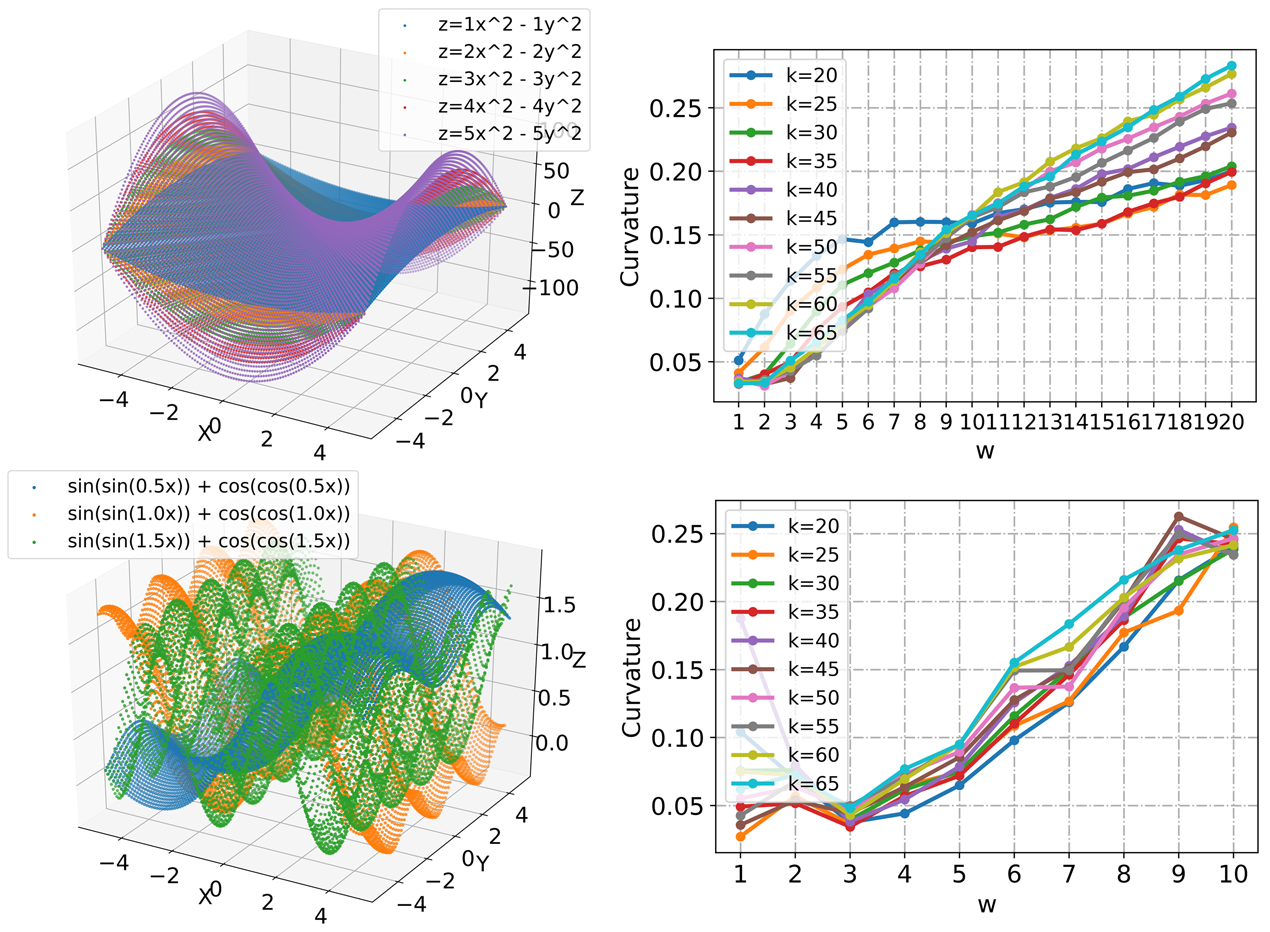
Up to this point, we provide an approximate solution of the Gauss curvature at any point on the point cloud perceptual manifold . [60] shows that on a high-dimensional dataset, almost all samples lie on convex locations, and thus the complexity of the perceptual manifold is defined as the average of the Gauss curvatures at all points on . Our approach does not require iterative optimization and can be quickly deployed in a deep neural network to calculate the Gauss curvature of the perceptual manifold. Taking the two-dimensional surface in Fig.5 as an example, the surface complexity increases as the surface curvature is artificially increased. This indicates that our proposed complexity measure of perceptual manifold can accurately reflect the changing trend of the curvature degree of the manifold. In addition, Fig.5 shows that the selection of the number of neighboring points hardly affects the monotonicity of the complexity of the perceptual manifold. In our work, we select the number of neighboring points to be .
4 The curvature of class perceptual manifolds can predict model bias
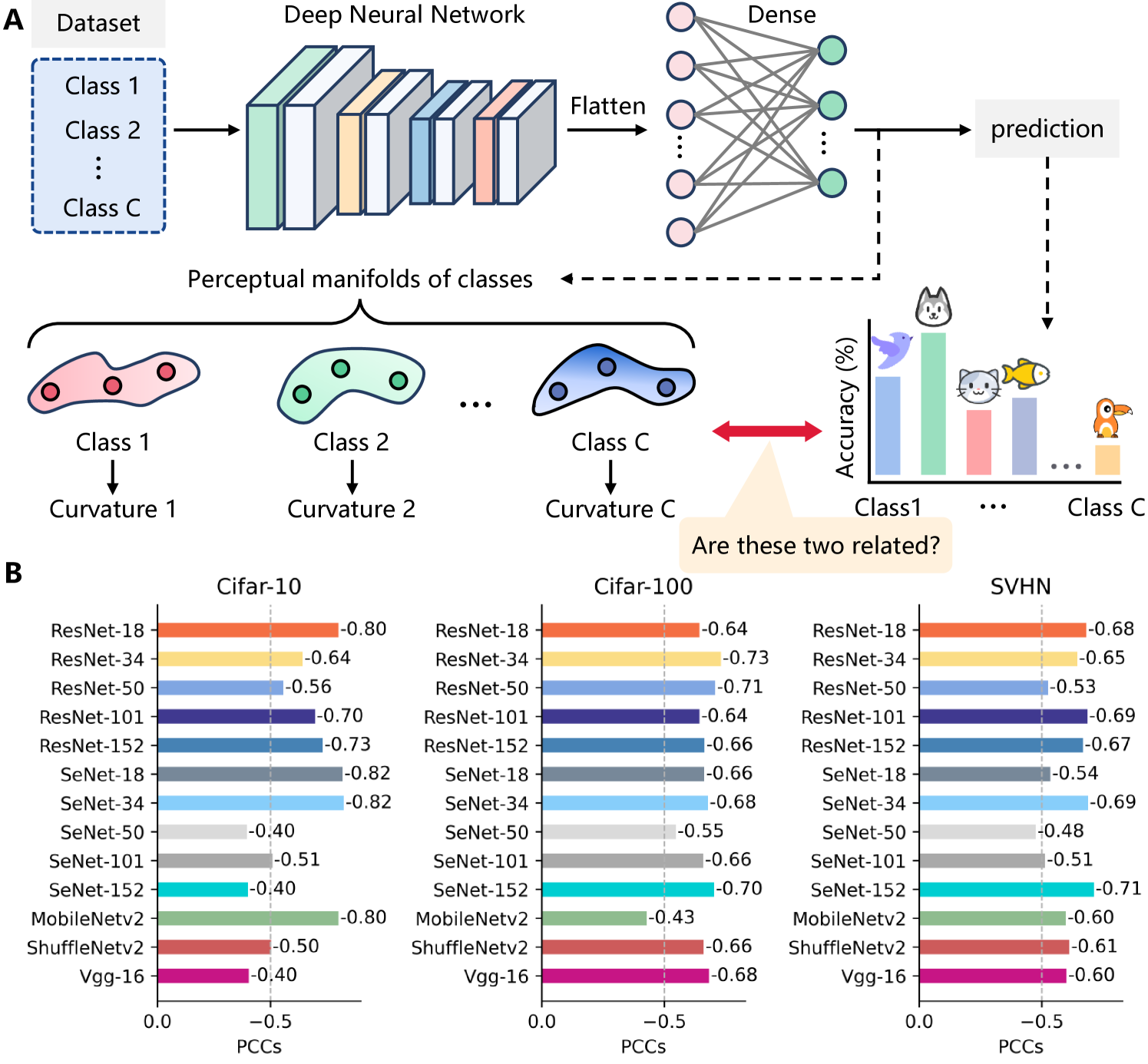
The data manifold is gradually reduced and compressed along the layers of deep neural networks for ease of classification. Intuitively, we speculate that if the curvature of the perceptual manifold of a certain class generated at the last hidden layers of a deep neural network is larger, the difficulty of classifying that class will also increase. When a model exhibits inconsistency across classes, it is typically considered biased. In this section, we comprehensively explore the relationship between class perception manifold curvature and model bias.
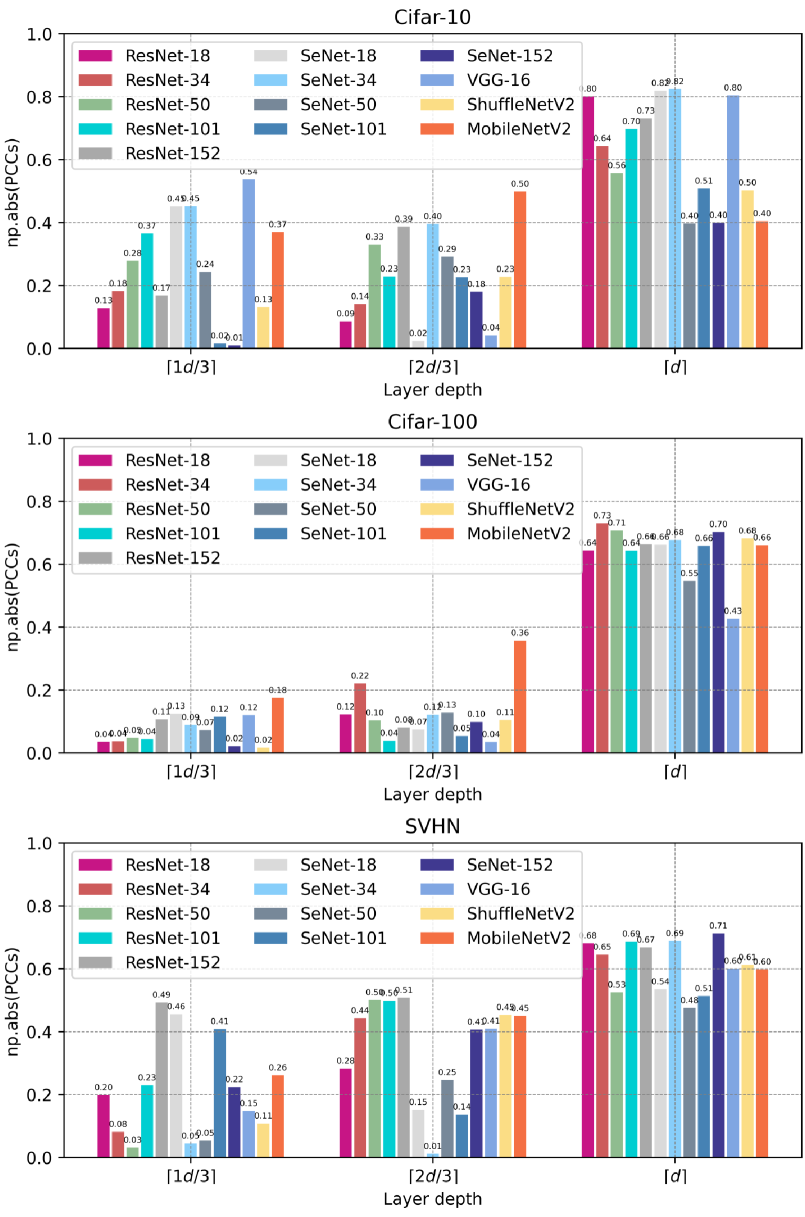
As shown in Fig.4, we first extract image embeddings corresponding to each class generated by the last hidden layer of a well-trained DNN, forming class perceptual manifolds. Subsequently, we estimate the curvature of each perceptual manifold and compute the Pearson correlation coefficient between curvature and class accuracy. Experimental results are presented in Fig.4, revealing a significant negative correlation between the curvature of class perceptual manifolds and class accuracy across three datasets with balanced sample sizes. Particularly on CIFAR-100, models consistently demonstrate a pronounced negative correlation, suggesting the universality of our findings. Given the low probability of such results occurring by chance on a dataset with classes, this discovery not only offers a new tool for investigating model fairness but also underscores the vast potential in analyzing the behavior of deep neural networks from a geometric perspective.
Furthermore, we were curious whether the curvature of class perceptual manifolds generated by other layers in deep neural networks could predict model bias. Assuming the number of layers in the model is , in addition to extracting image embeddings at the last hidden layer, we also extract image embeddings at the and layers. Similar to Fig.4, we compute the Pearson correlation coefficient between the curvature of class perceptual manifolds and class accuracy and present the results in Fig.6. We found that only the curvature of perceptual manifolds generated at the last hidden layer can reliably predict model bias. This phenomenon is particularly pronounced on datasets with a large number of classes, such as CIFAR-100. In summary, we have discovered a new mechanism for explaining model fairness and it is possible that it could serve as a geometric constraint to make models fairer.
5 How Learning Shapes the Geometric Characteristics of Perceptual Manifolds
Our experiments have demonstrated that, when a deep neural network is well-trained, the curvature of class perceptual manifolds generated by its last hidden layer can predict its bias toward classes. This finding suggests that existing models may struggle to handle biases introduced by curvature imbalances during the learning process. In contrast, we presume that existing models may effectively reduce the correlation between the separability of perceptual manifolds and model bias, as intuitively separability is a fundamental goal in classification tasks. In the following, we systematically explore how learning affects the geometric properties of perceptual manifolds.
5.1 Learning Facilitates the Separation
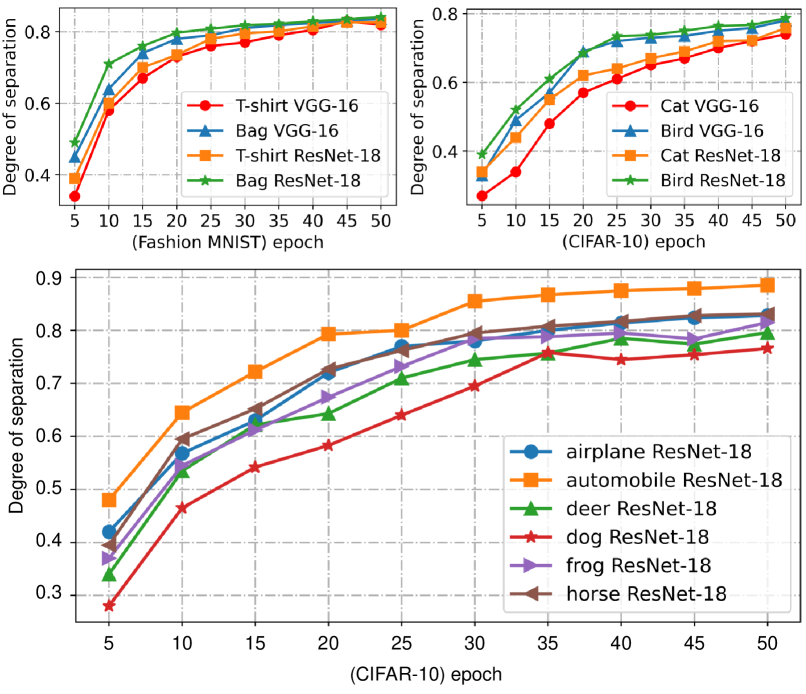
Learning typically leads to greater inter-class distance, which equates to greater separation between perceptual manifolds. We trained VGG-16 [61] and ResNet-18 [62] on F-MNIST [63] and CIFAR-10 [64] to explore the effect of the learning process on the separation degree between perceptual manifolds and observed the following phenomenon.
As shown in Fig.7, each perceptual manifold is gradually separated from the other manifolds during training. It is noteworthy that the separation is faster in the early stage of training, and the increment of separation degree gradually decreases in the later stage.
5.2 Learning Reduces Curvature and Its Imbalance
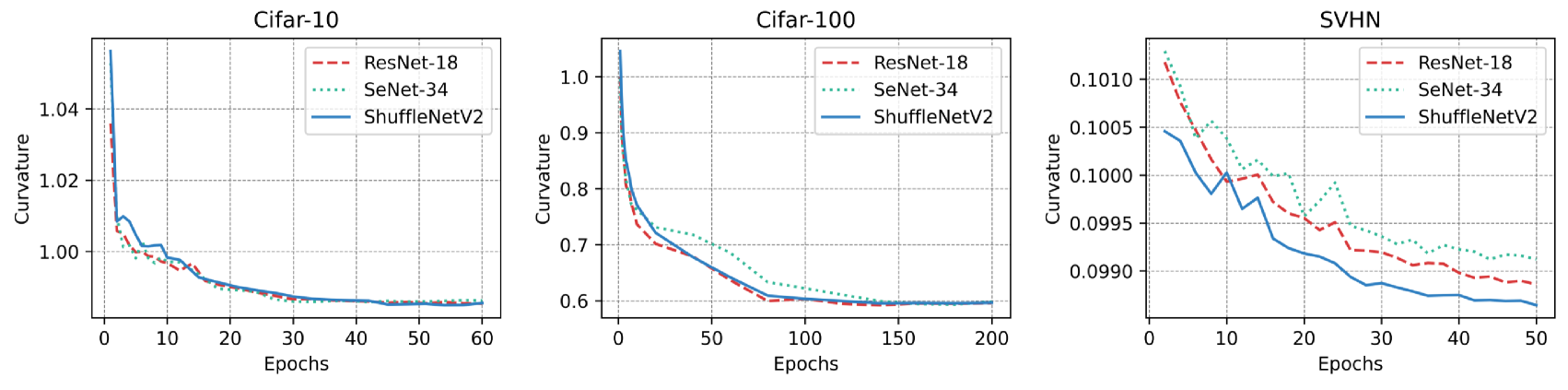
We conducted experiments on CIFAR-10, CIFAR-100, and SVHN by training ResNet-18, SeNet-34, and ShuffleNetV2 models. We extracted embeddings for each class of images at different training stages of the models. For visualization purposes, we averaged the curvature of perceptual manifolds corresponding to each class and plotted them in Fig.8. It can be observed that the curvature of perceptual manifolds decreases rapidly in the early stages of training, but as training progresses, the rate of decrease gradually slows down. Compared to the initial curvature, the degree of decrease appears less pronounced, for example, the curvature of perceptual manifolds decreased by less than on CIFAR-10. We speculate that this is due to the lack of curvature constraints in the optimization objective, leading to the rapid initial decrease because of the widespread information compression ability in deep neural networks. To confirm this hypothesis, we plotted the curves of loss decrease and curvature imbalance as a function of epochs in Fig.9. It can be observed that on all three datasets, as the loss gradually converges, the rate of decrease in curvature and imbalance also gradually decreases.
The above experiments indicate that deep neural networks, driven by optimization objectives lacking curvature constraints, are still capable of reducing the curvature of perceptual manifolds through information compression. This is understandable, as without information compression, achieving classification would be challenging. However, we must consider whether optimization objectives without curvature constraints are sufficient to address model bias caused by curvature imbalance. In the next subsection, we visualize the curve of the correlation between the curvature of the class perceptual manifold and the class accuracy with epoch to answer this question.
5.3 Curvature Imbalance and Model Bias
Although existing models separate class perceptual manifolds from each other during the learning process and also flatten the perceptual manifolds, do existing models have enough power to adequately mitigate the model bias caused by these two factors? We trained VGG-16 and ResNet-18 on Fashion MNIST and CIFAR-10 and plotted the correlation between the separation and curvature of class perceptual manifolds and class accuracy as a function of epoch.
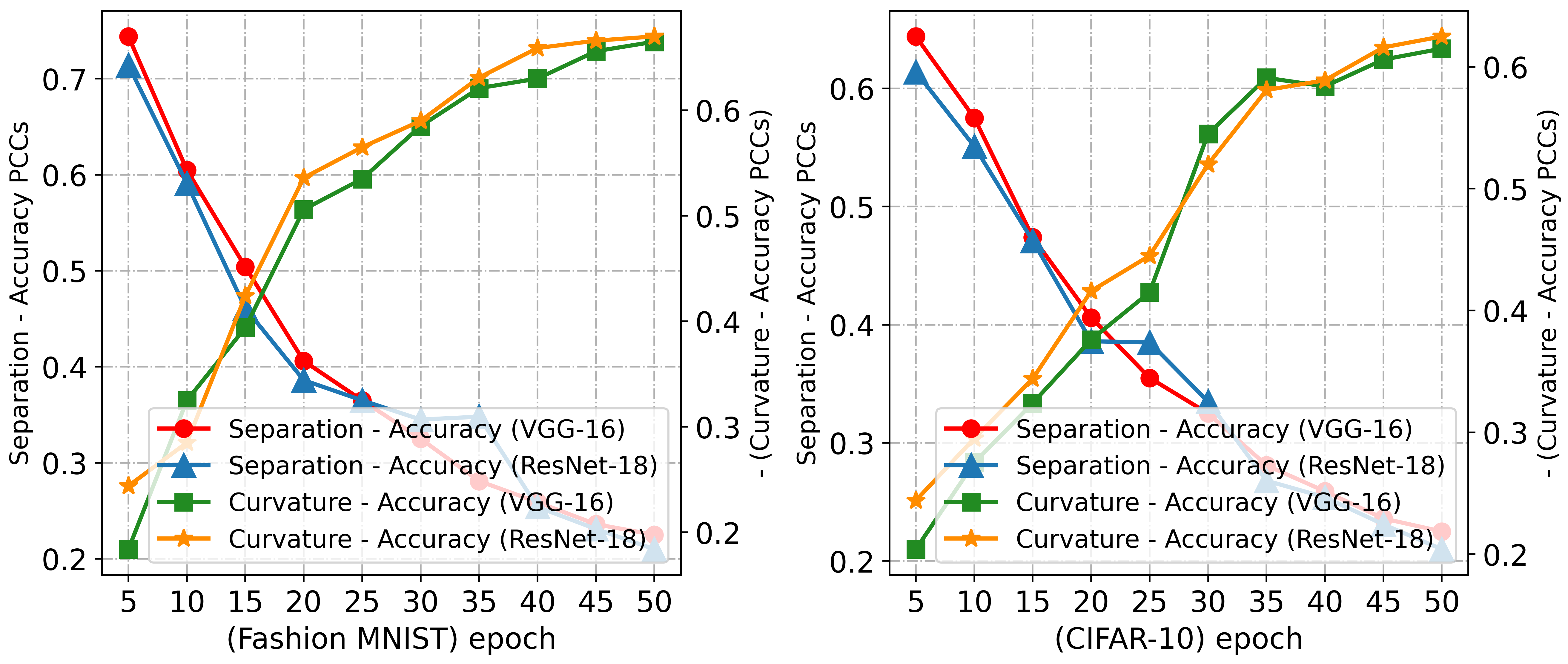
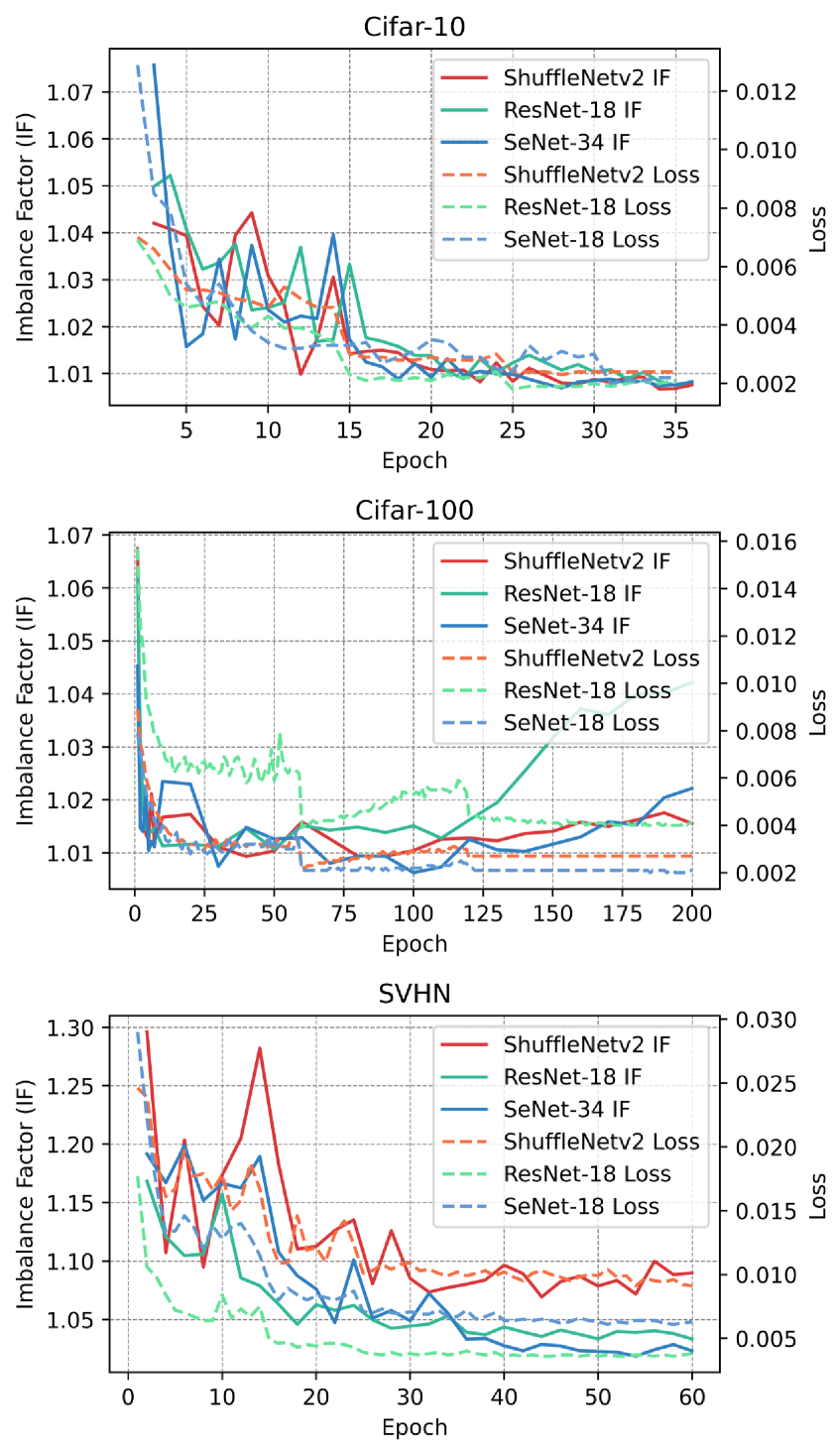
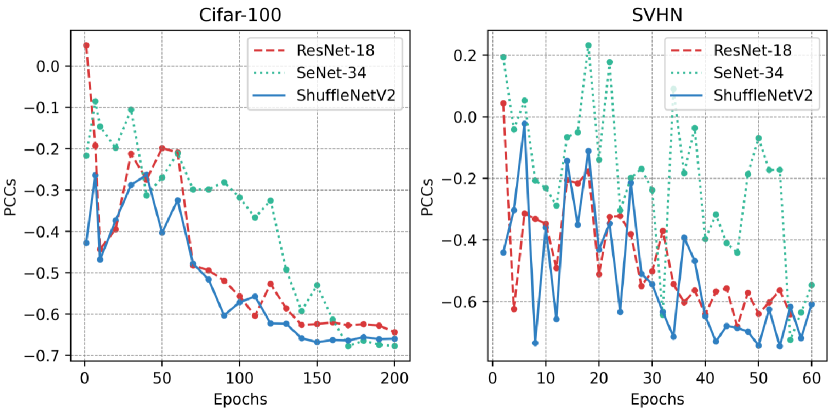
The experimental results, as shown in Fig.10, reveal a decrease in the correlation between the separability of perceptual manifolds and the accuracy of corresponding classes as training progresses, while the negative correlation between curvature and accuracy increases. This suggests that existing methods can only alleviate the impact of the separability between perceptual manifolds on model bias while overlooking the influence of the complexity of perceptual manifolds on model bias. Additionally, we further trained ResNet-18, SeNet-34, and ShuffleNetV2 on CIFAR-100 and SVHN to thoroughly observe the trends of curvature and class accuracy of class-aware manifolds as a function of epochs (see Fig.11). The experimental results demonstrate that existing models lack constraints on curvature during the training process, resulting in a highly negative correlation between curvature and class accuracy after model convergence.
6 Curvature-Balanced Feature Learning
The above study shows that it is necessary to focus on the model bias caused by the curvature imbalance among perceptual manifolds. In this section, we propose curvature regularization, which can reduce the model bias and further improve the performance of existing methods.
6.1 Design Principles of The Proposed Approach
The proposed curvature regularization needs to satisfy the following three principles to learn curvature-balanced and flat perceptual manifolds.
(1) The greater the curvature of a perceptual manifold, the stronger the penalty for it. Our experiments show that learning reduces the curvature, so it is reasonable to assume that flatter perceptual manifolds are easier to decode. (2) When the curvature is balanced, the penalty strength is the same for each perceptual manifold. (3) The sum of the curvatures of all perceptual manifolds tends to decrease.
6.2 Curvature Regularization (CR)
In order to propose curvature regularization in a reasonable way, we start from softmax cross-entropy loss to inspire our method. Given a classification task, suppose a sample is labeled as and it is predicted as each class with probabilities , respectively. The cross-entropy loss generated by sample is calculated as , where . The goal of is to make converge to , i.e., converges to , at which point converges to . Unlike cross-entropy loss, which can pull apart the difference between and other probabilities, we expect the mean Gaussian curvature of the perceptual manifolds to converge to equilibrium.
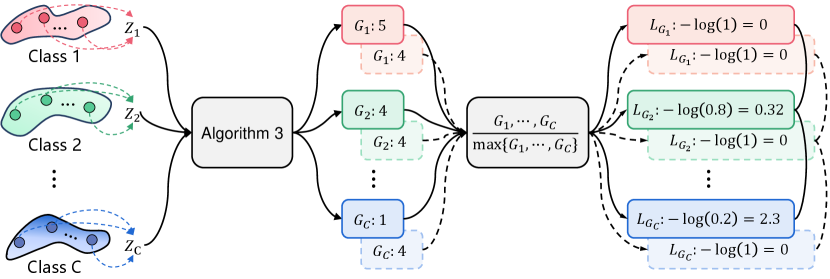
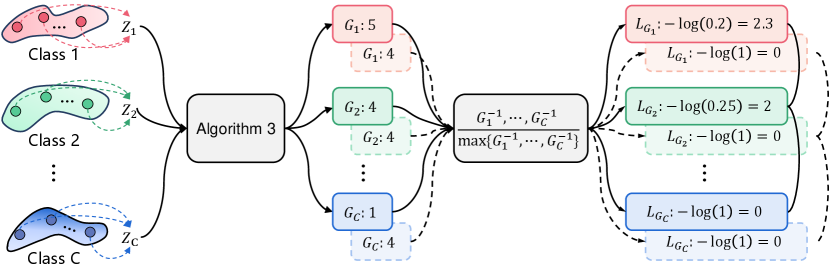
Assume that the mean Gaussian curvatures of the perceptual manifolds are (Algorithm 3), and perform the maximum normalization on them. The loss can make converge to . Therefore, perform a negative logarithmic transformation on the curvature of all perceptual manifolds and use it as loss, which can make each curvature converge to and thus achieve curvature balance. However, the above operation violates the third design principle of curvature regularization, which is that the sum of curvatures of all perceptual manifolds tends to decrease. As shown in Fig.12, all curvatures smaller than gradually increase driven by the loss function, and the smaller the curvature, the greater the resulting loss. To solve this problem, we update each curvature to the inverse of itself before performing the maximum normalization of the curvature. Eventually, the curvature penalty term of the perceptual manifold is denoted as . Considering the differentiability of the loss function, we use a smoothed form of the function, resulting in the final form of the curvature regularization:
As shown in Fig.13, the perceptual manifold with the smallest curvature produces no loss, and the larger the curvature, the larger the loss. causes the curvature of all the perceptual manifolds to converge to the value with the smallest curvature while achieving equilibrium.
In the following, we verify whether satisfies the three principles one by one.
-
(1)
When the curvature of the perceptual manifold is larger, is smaller. Since is monotonically decreasing, increases with increases. is consistent with Principle 1.
-
(2)
When , , so . follows Principle 2.
-
(3)
The curvature penalty term of the perceptual manifold is when . Since the greater the curvature, the greater the penalty, our method aims to bring the curvature of all perceptual manifolds down to . Obviously, , so our approach promotes curvature balance while also making all perceptual manifolds flatter, which satisfies Principle 3.
The curvature regularization can be combined with any loss function. Since the correlation between curvature and accuracy increases with training, we balance the curvature regularization with other losses using a logarithmic function with a hyperparameter , and the overall loss is denoted as
The term aims to make the curvature regularization loss of the same magnitude as the original loss. The term serves to gradually increase the weight of the curvature regularization term in the overall loss as training progresses, thereby amplifying its impact. Specifically, is an increasing function, where epoch represents the training cycle. Clearly, when , , which means that at this point, the curvature regularization term and have the same influence on the overall loss. Therefore, the hyperparameter controls when the influence of curvature regularization surpasses . Assuming the total number of training epochs is 200, setting to 100 indicates that after epoch 100, the impact of curvature regularization will exceed that of . We investigate reasonable values of in experiments (Sec 7.3). The design principle of curvature regularization is compatible with the learning objective of the model, and our experiments show that the effect of curvature imbalance on model bias has been neglected in the past. Thus curvature regularization is not in conflict with , as evidenced by our outstanding performance on multiple datasets.
6.3 Dynamic Curvature Regularization (DCR)
The curvature of perceptual manifolds varies with the model parameters during training, so it is necessary to update the curvature of each perceptual manifold in real-time. However, there is a challenge: only one batch of features is available at each iteration, and it is not possible to obtain all the features to calculate the curvature of the perceptual manifolds. If the features of all images from the training set are extracted using the current network at each iteration, it will greatly increase the time cost of training.
Require: Training set . A CNN , where and denote the feature sub-network and classifier, respectively. The training epoch is .
Inspired by [65, 31], we design a first-in-first-out storage pool to store the latest historical features of all images. The slow drift phenomenon of features found by [66] ensures the reliability of using historical features to approximate the current features. We show the training process in Algorithm 4. Specifically, the features of all batches are stored in the storage pool at the first epoch. To ensure that the drift of the features is small enough, it is necessary to train another epochs to update the historical features. Experiments of [31] on large-scale datasets show that taken as is sufficient, so is set to in this work. When , the oldest batch of features in the storage pool is replaced with new features at each iteration, and the curvature of each perceptual manifold is calculated using all features in the storage pool. The curvature regularization term is updated based on the latest curvature. It should be noted that for decoupled training, CR is applied in the feature learning stage. Our method is employed in training only and does not affect the inference speed of the model.
7 Experiments
We comprehensively evaluate the effectiveness and generality of curvature regularization on both long-tailed and non-long-tailed datasets. The experiment is divided into two parts, the first part tests curvature regularization on four long-tailed datasets, namely CIFAR-10-LT, CIFAR-100-LT [1], ImageNet-LT [1, 67], and iNaturalist2018 [68]. The second part validates the curvature regularization on two non-long tail datasets, namely CIFAR-100 [64] and ImageNet [67]. In addition, we train models on CIFAR-100, CIFAR-10/100-LT with a single NVIDIA 2080Ti GPU and ImageNet, ImageNet-LT, and iNaturalist2018 with eight NVIDIA 2080Ti GPUs.
7.1 Datasets and Evaluation Metrics
We conducted experiments on artificially created CIFAR-10-LT, CIFAR-100-LT [1], ImageNet-LT [1, 67], and real-world long-tailed iNaturalist2018 [68] to validate the effectiveness and generalizability of our method. For a fair comparison, the training and test images of all datasets are officially split, and the Top-1 accuracy on the test set is utilized as a performance metric.
-
•
CIFAR-10-LT and CIFAR-100-LT are long-tailed datasets including five imbalance factors (IF = ) generated based on CIFAR-10 and CIFAR-100, respectively. The imbalance factor (IF) is defined as the value of the number of the most frequent class training samples divided by the number of the least frequent class training samples.
-
•
ImageNet-LT is a long-tailed subset of ILSVRC 2012 with an imbalance factor of , which contains classes totaling images, with a maximum of images and a minimum of images per class. The balanced k images were used for testing.
-
•
The iNaturalist species classification dataset is a large-scale real-world dataset that suffers from an extremely unbalanced label distribution. The version we selected consists of images from classes. The maximum class is images and the minimum class is images (IF = ).
-
•
We use the ILSVRC2012 split contains training and validation images. Each class of CIFAR-100 contains images for training and images for testing.
7.2 Implementation Details
CIFAR-10/100-LT. To set up a fair comparison, we used the same random seed to make CIFAR-10/100-LT, and followed the implementation of [2]. Consistent with previous studies [1, 31, 36], we trained ResNet-32 by SGD optimizer with a momentum of , and a weight decay of .
ImageNet-LT and iNaturalist2018. We use ResNext-50 [69] on ImageNet-LT and ResNet-50 [62] on iNaturalist2018 as the network backbone for all methods. Following previous studies [1, 31, 36], we conduct model training with the SGD optimizer based on batch size (for ImageNet-LT) / (for iNaturalist), momentum , weight decay factor , and learning rate (linear LR decay).
ImageNet and CIFAR-100. Following widely used settings [67, 62, 70, 31], on ImageNet, we use random clipping, mixup [71], and cutmix [70] to augment the training data, and all models are optimized by Adam with batch size of , learning rate of , momentum of , and weight decay factor of . On CIFAR-100, we set the batch size to and augment the training data using random clipping, mixup, and cutmix. An Adam optimizer with learning rate of (linear decay), momentum of , and weight decay factor of is used to train all networks.
7.3 Effect of
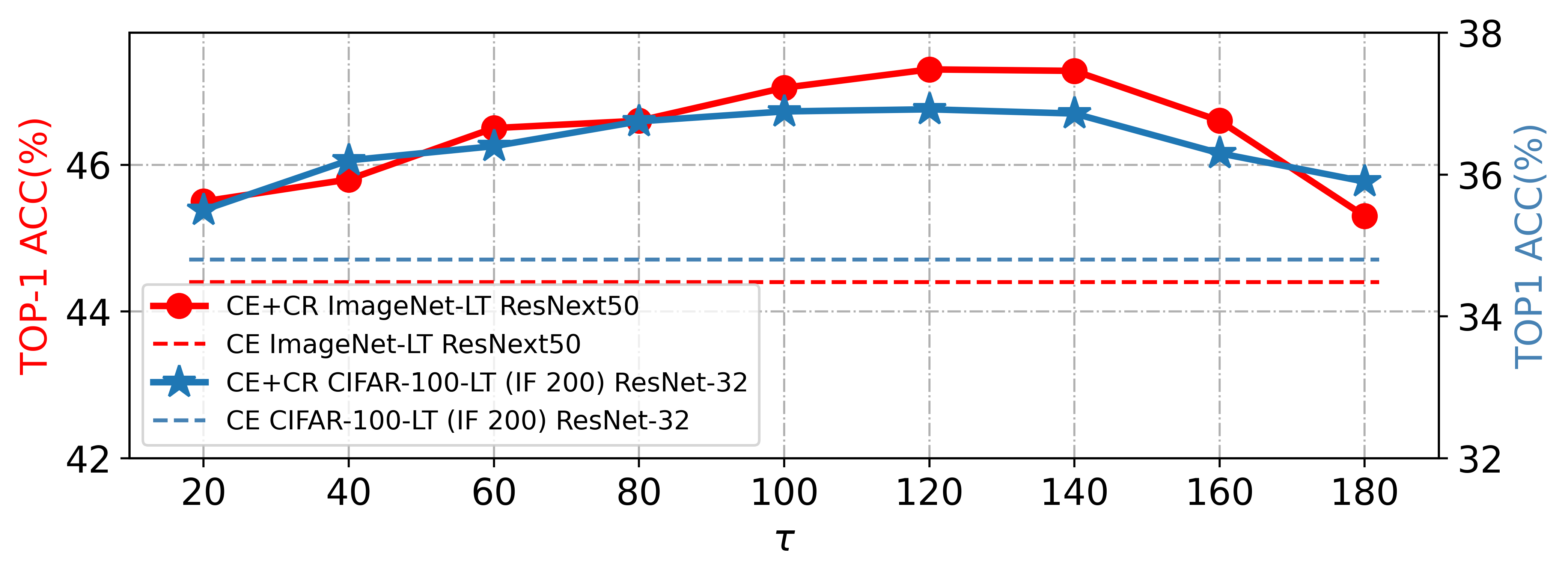
When , , so the selection of is related to the number of epochs. When the correlation between curvature and accuracy exceeds the correlation between the separation degree and accuracy, we expect , which means that the curvature regularization loss is greater than the original loss. Following the [46] setting, all models are trained for epochs, so is less than . To search for the proper value of , experiments are conducted for CE + CR with a range of , and the results are shown in Fig.14. Large-scale datasets require more training epochs to keep the perceptual manifolds away from each other, while small-scale datasets can achieve this faster, so we set on CIFAR-10/100-LT and CIFAR-100, and on ImageNet, ImageNet-LT, and iNaturalist2018.
7.4 Experiments on Long-Tailed Datasets
7.4.1 Evaluation on CIFAR-10/100-LT
| Dataset | CIFAR-10-LT | |||
|---|---|---|---|---|
| Backbone Net | ResNet-32 | |||
| imbalance factor | 200 | 100 | 50 | 10 |
| MiSLAS [19] | 77.3 | 82.1 | 85.7 | 90.0 |
| LDAM-DRW [2] | - | 77.0 | 81.0 | 88.2 |
| Cross Entropy | 65.6 | 70.3 | 74.8 | 86.3 |
| + CR | 67.9 | 72.6 | 76.2 | 89.5 |
| Focal Loss [4] | 65.2 | 70.3 | 76.7 | 86.6 |
| + CR | 67.3 | 71.8 | 79.1 | 88.4 |
| CB Loss [1] | 68.8 | 74.5 | 79.2 | 87.4 |
| + CR | 70.3 | 75.8 | 79.8 | 89.1 |
| BBN [23] | - | 79.8 | 82.1 | 88.3 |
| + CR [7] | - | 81.2 | 83.5 | 89.4 |
| De-c-TDE [72] | - | 80.6 | 83.6 | 88.5 |
| + CR | - | 81.8 | 84.5 | 89.9 |
| GCL [7] | 79.0 | 82.7 | 85.5 | - |
| + CR | 79.9 | 83.5 | 86.8 | - |
| Dataset | CIFAR-100-LT | |||
|---|---|---|---|---|
| Backbone Net | ResNet-32 | |||
| imbalance factor | 200 | 100 | 50 | 10 |
| MiSLAS [19] | 42.3 | 47.0 | 52.3 | 63.2 |
| LDAM-DRW [2] | - | 42.0 | 46.6 | 58.7 |
| Cross Entropy | 34.8 | 38.2 | 43.8 | 55.7 |
| + CR | 36.9 | 40.5 | 45.1 | 57.4 |
| Focal Loss [4] | 35.6 | 38.4 | 44.3 | 55.7 |
| + CR | 37.5 | 40.2 | 45.2 | 58.3 |
| CB Loss [1] | 36.2 | 39.6 | 45.3 | 57.9 |
| + CR | 38.5 | 40.7 | 46.8 | 59.2 |
| BBN [23] | - | 42.5 | 47.0 | 59.1 |
| + CR [7] | - | 43.7 | 48.1 | 60.0 |
| De-c-TDE [72] | - | 44.1 | 50.3 | 59.6 |
| + CR | - | 45.7 | 51.4 | 60.3 |
| RIDE (4*) [28] | - | 48.7 | 59.0 | 58.4 |
| + CR | - | 49.8 | 59.8 | 59.5 |
| RIDE + CMO [46] | - | 50.0 | 53.0 | 60.2 |
| + CR | - | 50.7 | 54.3 | 61.4 |
| GCL [7] | 44.9 | 48.7 | 53.6 | - |
| + CR | 45.6 | 49.8 | 55.1 | - |
Tables I and II summarizes the improvements of CR for several state-of-the-art methods on long-tailed CIFAR-10 and CIFAR-100, and we observe that CR significantly improves all methods. For example, in the setting of IF , CR results in performance gains of , , and for CE, Focal loss [4], and CB loss [1], respectively. When CR is applied to feature training, the performance of BBN [23] is improved by more than on each dataset, which again validates that curvature imbalance negatively affects the learning of classifiers. When CR is applied to several state-of-the-art methods (e.g., RIDE + CMO [46] (2022) and GCL [7] (2022)), CR achieved higher classification accuracy with all IF settings of CIFAR-100-LT (Table II).
| Methods | ImageNet-LT | |||
|---|---|---|---|---|
| ResNext-50 | ||||
| Head | Middle | Tail | Overall | |
| OFA [20] | 47.3 | 31.6 | 14.7 | 35.2 |
| DisAlign [21] | 59.9 | 49.9 | 31.8 | 52.9 |
| MiSLAS [19] | 65.3 | 50.6 | 33.0 | 53.4 |
| DiVE [13] | 64.0 | 50.4 | 31.4 | 53.1 |
| PaCo [53] | 63.2 | 51.6 | 39.2 | 54.4 |
| GCL [7] | - | - | - | 54.9 |
| CE | 65.9 | 37.5 | 7.70 | 44.4 |
| + CR | 65.1 | 40.7 | 19.5 | 47.3 |
| Focal Loss [4] | 67.0 | 41.0 | 13.1 | 47.2 |
| + CR | 67.3 | 43.2 | 22.5 | 49.6 |
| BBN [23] | 43.3 | 45.9 | 43.7 | 44.7 |
| + CR | 45.2 | 46.8 | 44.5 | 46.2 |
| LDAM [2] | 60.0 | 49.2 | 31.9 | 51.1 |
| + CR | 60.8 | 50.3 | 33.6 | 52.4 |
| LADE [3] | 62.3 | 49.3 | 31.2 | 51.9 |
| + CR | 62.5 | 50.1 | 33.7 | 53.0 |
| MBJ [65] | 61.6 | 48.4 | 39.0 | 52.1 |
| + CR | 62.8 | 49.2 | 40.4 | 53.4 |
| RIDE (4*) [28] | 67.8 | 53.4 | 36.2 | 56.6 |
| + CR | 68.5 | 54.2 | 38.8 | 57.8 |
| RIDE + CMO [46] | 66.4 | 54.9 | 35.8 | 56.2 |
| + CR | 67.3 | 54.6 | 38.4 | 57.4 |
| Methods | iNaturalist 2018 | |||
|---|---|---|---|---|
| ResNet-50 | ||||
| Head | Middle | Tail | Overall | |
| OFA [20] | - | - | - | 65.9 |
| DisAlign [21] | 68.0 | 71.3 | 69.4 | 70.2 |
| MiSLAS [19] | 73.2 | 72.4 | 70.4 | 71.6 |
| DiVE [13] | 70.6 | 70.0 | 67.5 | 69.1 |
| PaCo [53] | 69.5 | 72.3 | 73.1 | 72.3 |
| GCL [7] | - | - | - | 72.0 |
| CE | 67.2 | 63.0 | 56.2 | 61.7 |
| + CR | 67.3 | 62.6 | 61.7 | 63.4 |
| Focal Loss [4] | - | - | - | 61.1 |
| + CR | 69.4 | 61.7 | 57.2 | 62.3 |
| BBN [23] | 49.4 | 70.8 | 65.3 | 66.3 |
| + CR | 50.6 | 71.5 | 66.8 | 67.6 |
| LDAM [2] | - | - | - | 64.6 |
| + CR | 69.3 | 66.7 | 61.9 | 65.7 |
| LADE [3] | - | - | - | 69.7 |
| + CR | 72.5 | 70.4 | 65.7 | 70.6 |
| MBJ [65] | - | - | - | 70.0 |
| + CR | 73.1 | 70.3 | 66.0 | 70.8 |
| RIDE (4*) [28] | 70.9 | 72.4 | 73.1 | 72.6 |
| + CR | 71.0 | 73.8 | 74.3 | 73.5 |
| RIDE + CMO [46] | 70.7 | 72.6 | 73.4 | 72.8 |
| + CR | 71.6 | 73.7 | 74.9 | 73.8 |
7.4.2 Evaluation on ImageNet-LT and iNaturalist2018
The results on ImageNet-LT and iNaturalist2018 are shown in Tables III and IV. We not only report the overall performance of CR, but also additionally add the performance on three subsets of Head (more than 100 images), Middle (20-100 images), and Tail (less than 20 images). From Tables III and IV, we observe the following three conclusions: first, CR results in significant overall performance improvements for all methods, including and improvements on ImageNet-LT for CE and Focal loss, respectively. Second, when CR is combined with feature training, the overall performance of BBN [23] is improved by and on the two datasets, respectively, indicating that curvature-balanced feature learning facilitates classifier learning. Third, our approach still boosts model performance when combined with advanced techniques (RIDE [28] (2021), RIDE + CMO [46] (2022)), suggesting that curvature-balanced feature learning has not yet been considered by other methods.
| ImageNet | CIFAR-100 | |||||
|---|---|---|---|---|---|---|
| Methods | CE | CE + CR | CE | CE + CR | ||
| VGG16 [61] | 71.6 | 72.7 | +1.1 | 71.9 | 73.2 | +1.3 |
| BN-Inception [73] | 73.5 | 74.3 | +0.8 | 74.1 | 75.0 | +0.9 |
| ResNet-18 [62] | 70.1 | 71.3 | +1.2 | 75.6 | 77.1 | +1.5 |
| ResNet-34 [62] | 73.5 | 74.6 | +1.1 | 76.8 | 78.0 | +1.2 |
| ResNet-50 [62] | 76.0 | 76.8 | +0.8 | 77.4 | 78.3 | +0.9 |
| DenseNet-201 [74] | 77.2 | 78.0 | +0.8 | 78.5 | 79.7 | +1.2 |
| SE-ResNet-50 [75] | 77.6 | 78.3 | +0.7 | 78.6 | 79.5 | +0.9 |
| ResNeXt-101 [69] | 78.8 | 79.7 | +0.9 | 77.8 | 78.9 | +1.1 |
7.5 Experiments on Non-Long-Tailed Datasets
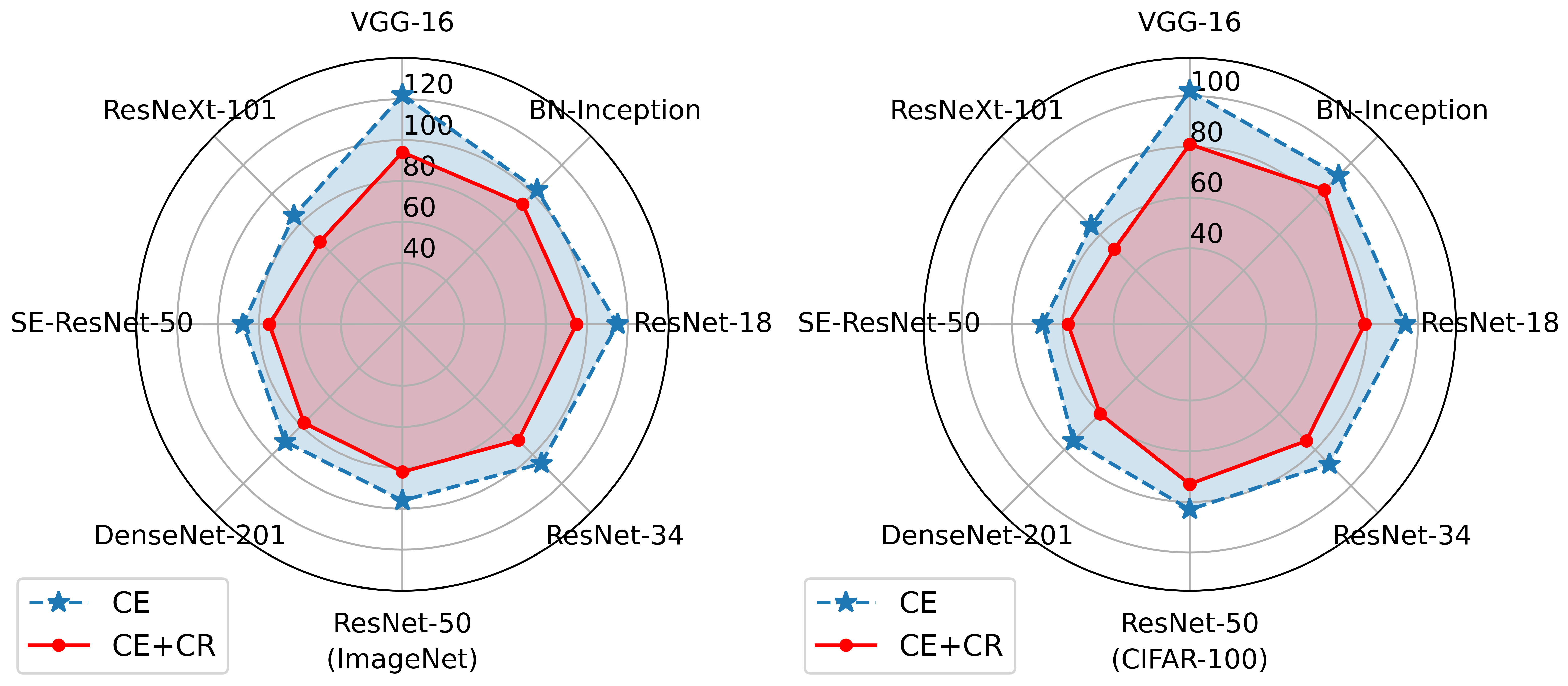
Curvature imbalance may still exist on sample-balanced datasets, so we evaluate CR on non-long-tailed datasets. Table V summarizes the improvements of CR on CIFAR-100 and ImageNet for various backbone networks, and we observe that CR results in approximately performance improvement for all backbone networks. In particular, the accuracy of CE + CR exceeds CE by on CIFAR-100 when using ResNet-18 [62] as the backbone network. The experimental results show that our proposed curvature regularization is applicable to non-long-tailed datasets and compatible with existing backbone networks and methods.
7.6 Curvature Regularization Reduces Model Bias
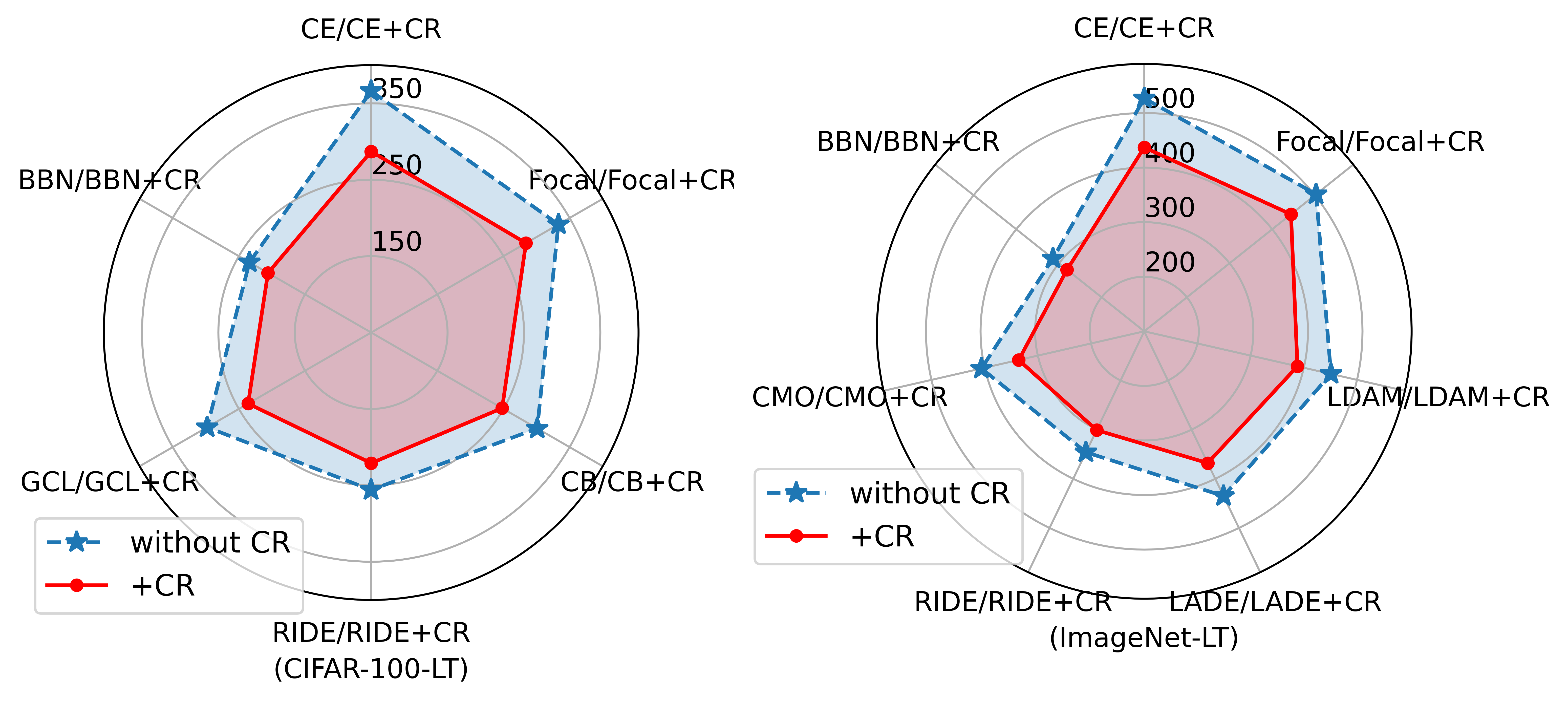
Here we explore how curvature regularization improves the model performance. Measuring the model bias with the variance of the accuracy of all classes [30]. Fig.1 presents a comparison of the model bias before and after applying our proposed curvature regularization to existing long-tailed recognition methods (GCL, BBN, Focal Loss, CB Loss, and CE Loss) on long-tailed datasets CIFAR-100-LT and ImageNet-LT. Fig.15 demonstrates the model bias on relatively balanced datasets CIFAR-100 and ImageNet, using multiple backbone networks, comparing cross-entropy loss (CE) with and without our proposed curvature regularization. The results show that curvature regularization consistently reduces model bias.
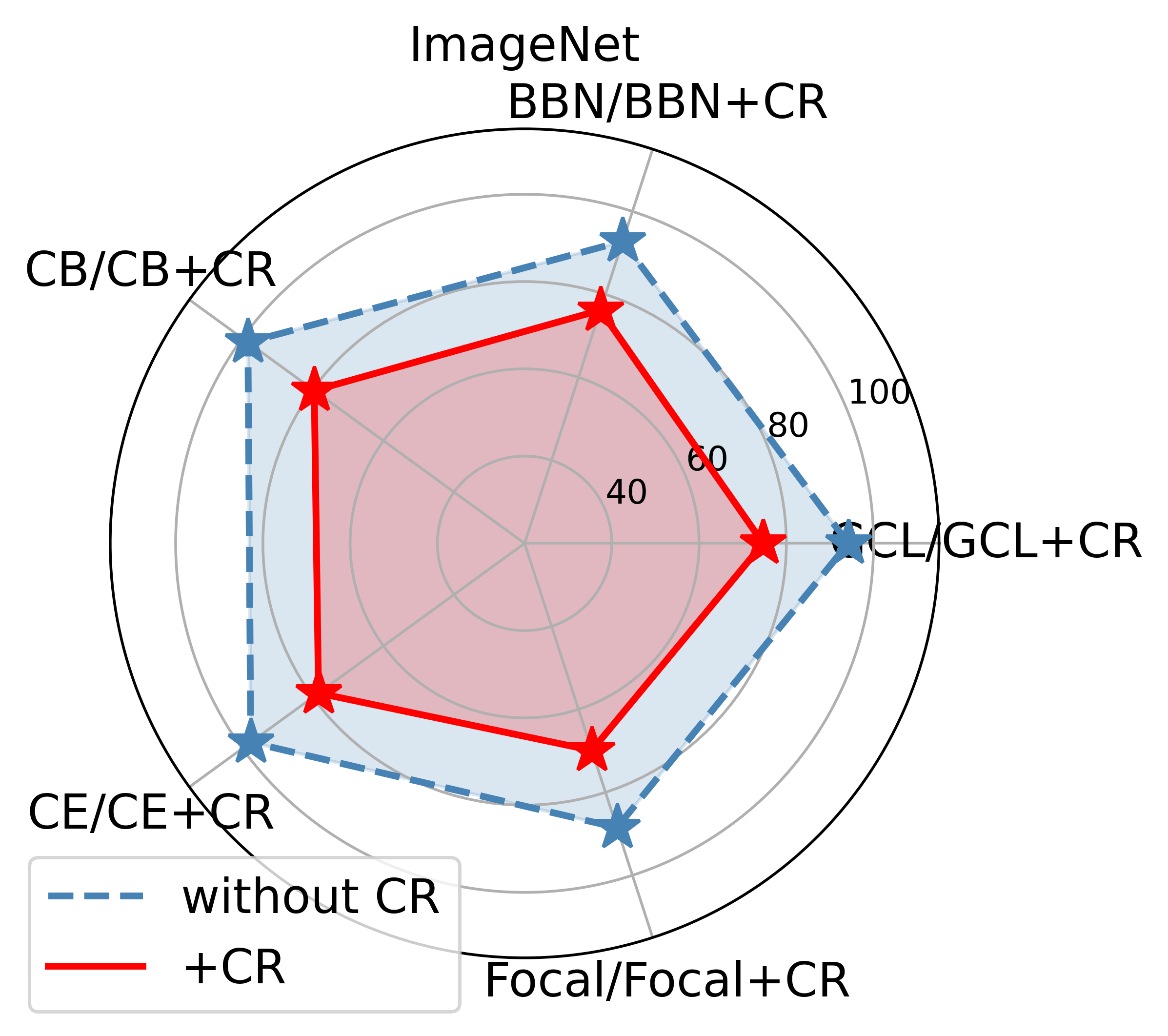
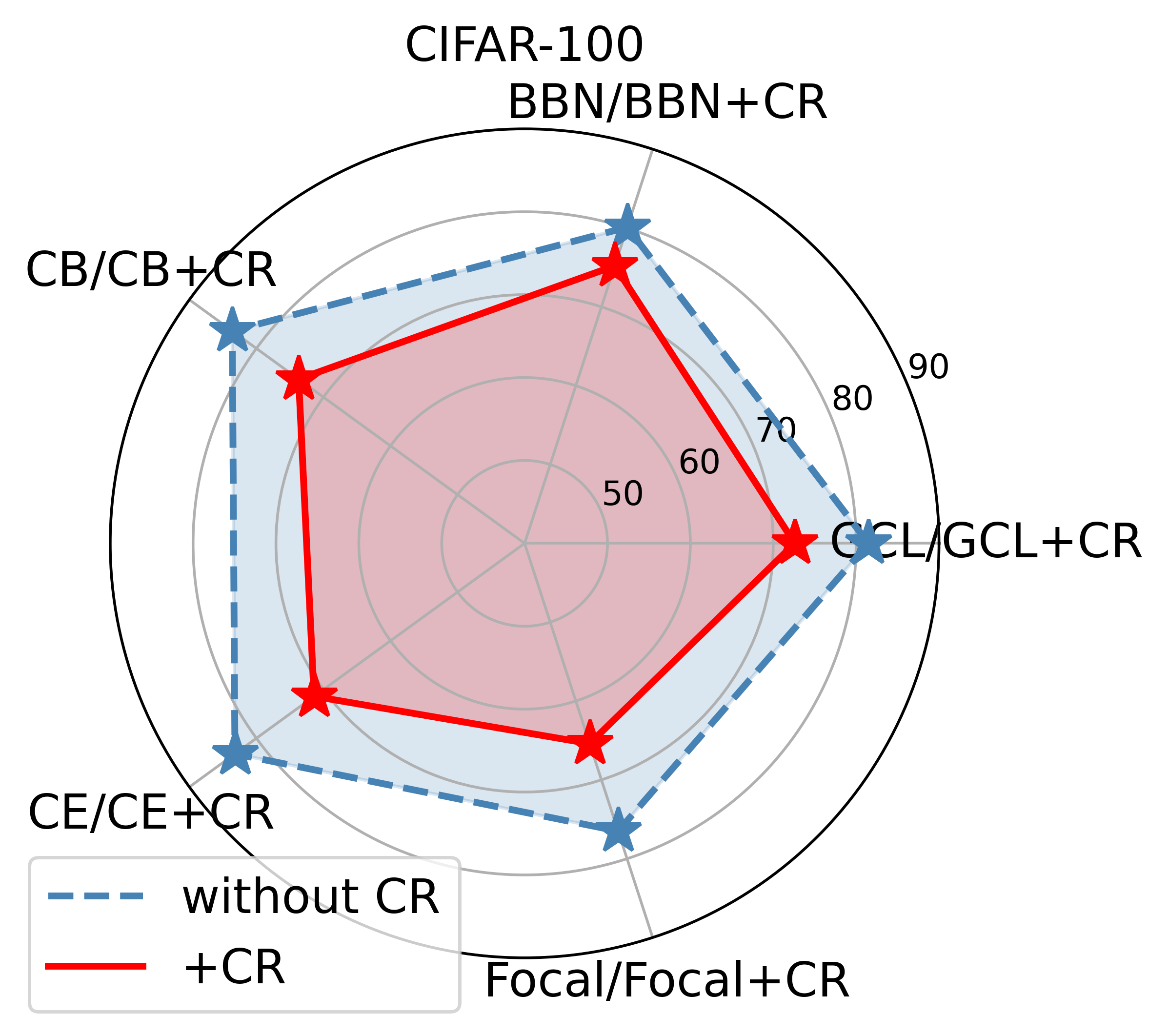
Furthermore, we employed ResNet-50 as the backbone network on the perfectly balanced CIFAR-100 and the relatively balanced ImageNet datasets. We initially trained models using existing long-tailed recognition methods such as GCL, BBN, CB Loss, and Focal Loss, followed by retraining the models with added curvature regularization on top of these methods. The experimental results, as shown in Fig.16, reveal that without curvature regularization, the bias of models trained with GCL, BBN, CB Loss, and Focal Loss was almost identical to or only slightly lower than that of models trained with standard CE Loss. This supports our viewpoint that long-tailed recognition methods designed based on sample numbers are less effective in non-long-tailed scenarios. However, after applying curvature regularization, the model bias was significantly reduced, further validating the generality and effectiveness of curvature regularization. By combining Tables I and III, it can be found that curvature regularization reduces the model bias mainly by improving the performance of the tail class and does not compromise the performance of the head class, thus improving the overall performance.
7.7 Curvature Regularization Promotes Convergence
In Fig.17, we present the classification loss curves of the long-tailed recognition methods GCL and CB Loss on the CIFAR-100 dataset with an imbalance factor of 50, both before and after applying CR. It is important to note that GCL, as a method for enhancing image embeddings, still adopts cross-entropy as its classification loss. It can be observed that CR facilitates faster convergence of the classification loss and achieves a lower final loss value. This observation supports our hypothesis that flatter and simpler perceptual manifolds are more conducive to classification, thereby accelerating the convergence of the classification loss.
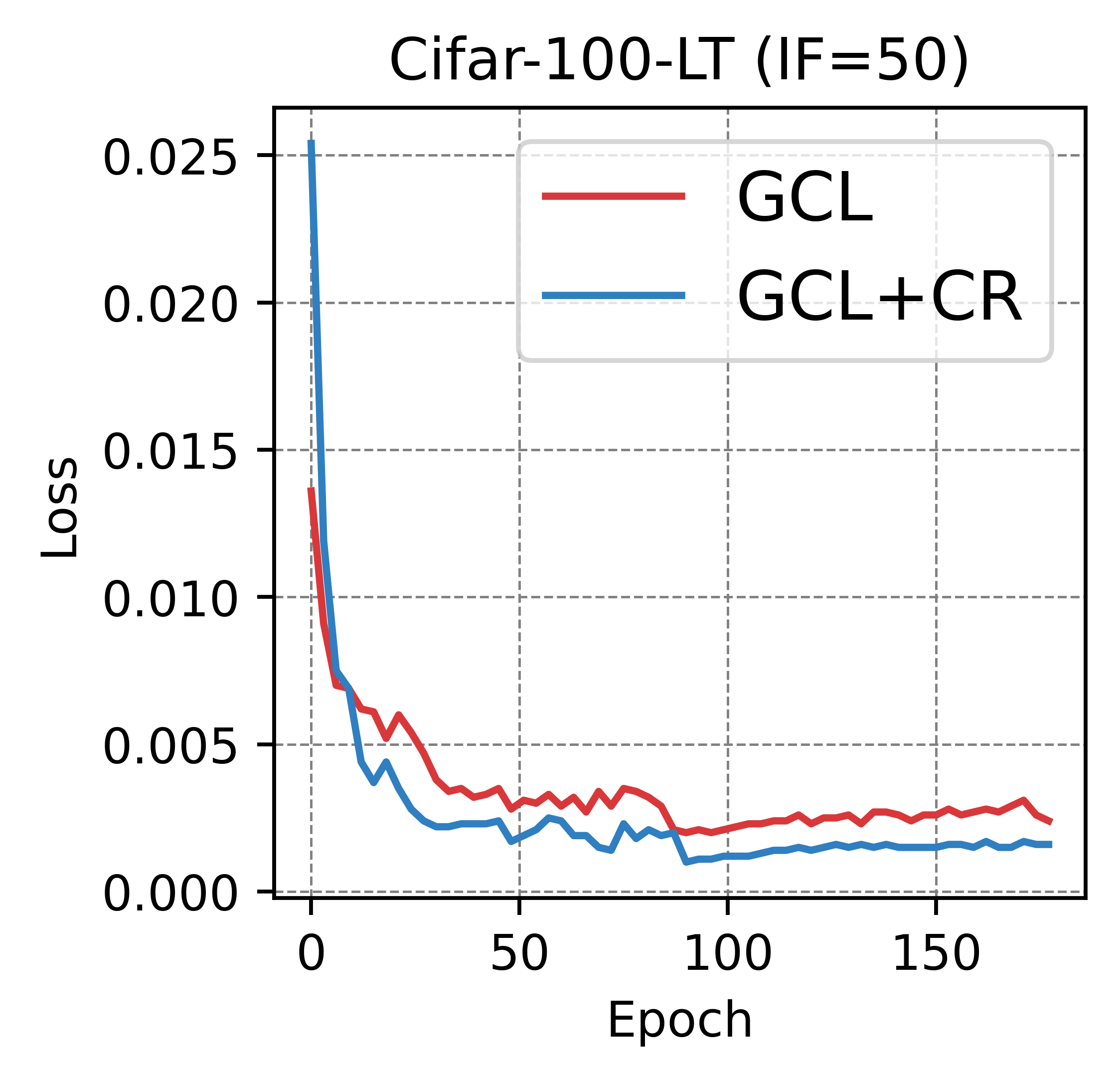
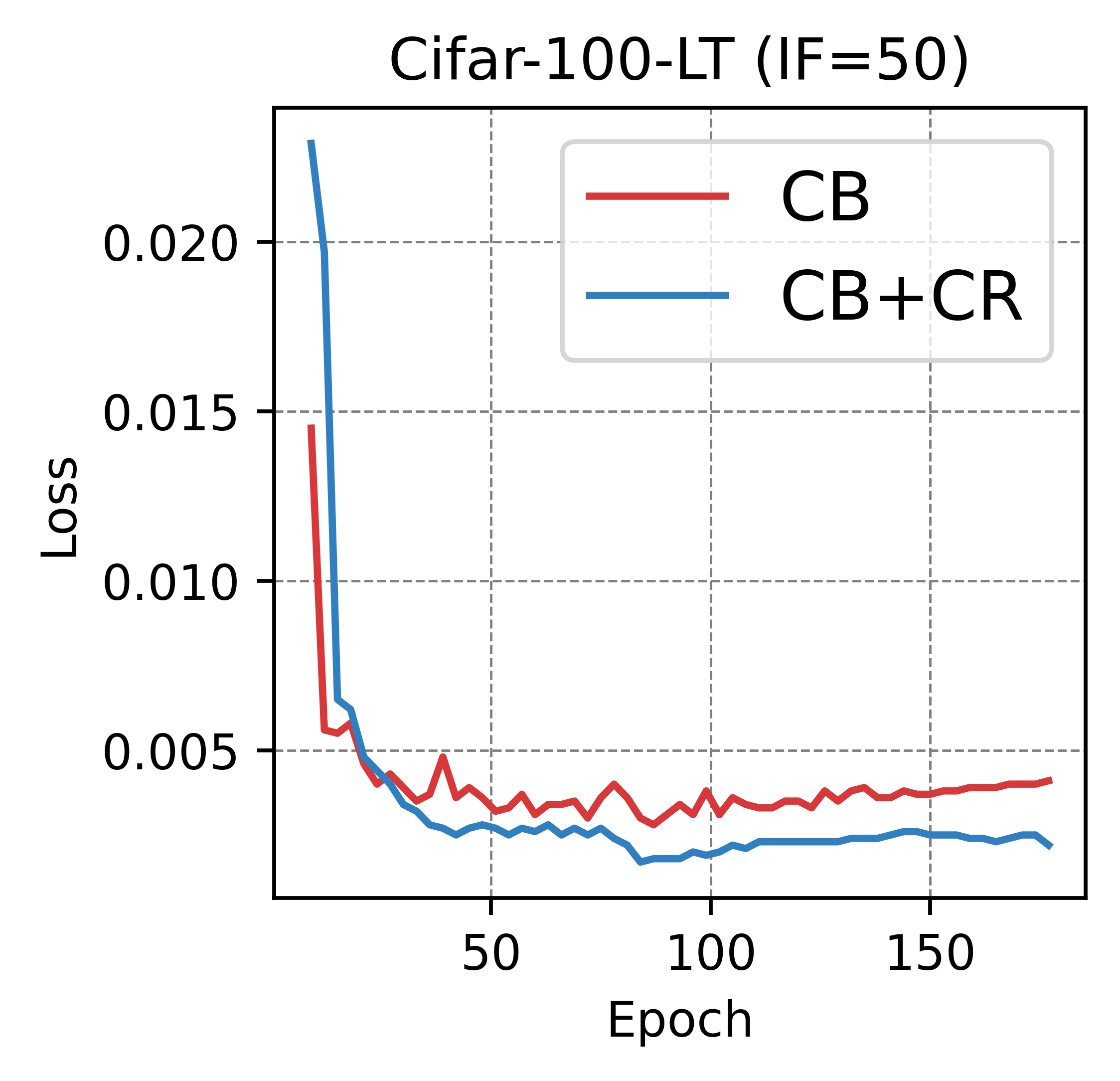
7.8 More Analysis of Curvature Regularization
Here, we explored the following two questions:
-
(1)
Is the curvature more balanced after training with CR?
-
(2)
Did the correlation between curvature imbalance and class accuracy decrease after training with CR?
Recall that in Section 7.5, we trained multiple backbone networks on ImageNet and CIFAR-100. The features of all samples were extracted using ResNet-18 and VGG-16 which was trained on ImageNet and CIFAR-100 with CE and with CE + CR, respectively, and the curvature of each perceptual manifold was calculated. The degree of imbalance is measured by the variance of the curvature of all perceptual manifolds; the larger the variance, the more imbalanced the curvature. The experimental results are shown in Table VI, where the curvature of the perceptual manifolds represented by the ResNet-18 trained with curvature regularization is more balanced.
| ImageNet | CIFAR-100 | |
|---|---|---|
| ResNet-18 | ||
| CE | 25.7 | 20.4 |
| CE + CR | 14.2 (-11.5) | 11.8 (-8.6) |
| VGG-16 | ||
| CE | 27.4 | 23.5 |
| CE + CR | 13.8 (-13.6) | 13.3 (-10.2) |
| ImageNet | CIFAR-100 | |
|---|---|---|
| ResNet-18 | ||
| CE | -0.583 | -0.648 |
| CE + CR | -0.257 (+0.326) | -0.285 (+0.363) |
| VGG-16 | ||
| CE | -0.569 | -0.635 |
| CE + CR | -0.226 (+0.343) | -0.251 (+0.384) |
We still use CE and CE + CR to train ResNet-18 on ImageNet and CIFAR-100, respectively, and then test the accuracy of two ResNet-18 on each class. The features of all samples were extracted using two ResNet-18 and the mean Gaussian curvature of each perceptual manifold was calculated. We calculated the Pearson correlation coefficients between the class accuracy and the curvature of the corresponding perceptual manifold for ResNet-18 trained with CE and with CE + CR, respectively. For VGG-16, the same experiments as for ResNet-18 were performed. The experimental results are presented in Table VII, where it can be seen that the negative correlation between the mean Gaussian curvature of the perceptual manifold and the class accuracy decreases significantly after using curvature regularization.
Reflecting on the design principles of Curvature Regularization presented in Section 6.1, we intended for the CR term to impose stronger penalties on perceptual manifolds with higher curvature, driving the curvature of all manifolds toward balance and flatness. Table 6 illustrates that after applying CR, the curvature of perceptual manifolds becomes more balanced, confirming that our proposed CR term meets its intended goals.
Why then does the negative correlation between class accuracy and perceptual manifold curvature diminish? This is because after applying CR, the curvature of the perceptual manifolds becomes more balanced. However, as shown in Figs 1, 15, and 16, while CR significantly reduces model bias, some degree of bias persists. This suggests that multiple factors influence model bias, with perceptual manifold curvature being just one of them. From the geometric perspective we have developed for analyzing model fairness, other geometric properties of perceptual manifolds—such as intrinsic dimensionality and topological complexity—are also potential factors affecting model fairness.
8 Conclusion and Discussion
This work mines and explains the impact of data on the model bias from a geometric perspective, introducing the imbalance problem to non-long-tailed data and providing a geometric analysis perspective to drive toward fairer AI.
In the field of object detection, it is often encountered that although a class does not appear frequently, the model can always detect such instances efficiently. It is easy to observe that classes with simple patterns are usually easier to learn, even if the frequency of such classes is low. Therefore, classes with low frequency in object detection are not necessarily always harder to learn. We believe that it is a valuable research direction to analyze the richness of the instances contained in each class, and then pay more attention to the hard classes. The dimensionality of all images or feature embeddings in the image classification task is the same, which facilitates the application of the semantic scale proposed in this paper. However, the non-fixed dimensionality of each instance in the field of object detection brings new challenges, so we have to consider the effect of dimensionality on the semantic scale, which is a direction worthy of further study.
References
- [1] Y. Cui, M. Jia, T.-Y. Lin, Y. Song, and S. Belongie, “Class-balanced loss based on effective number of samples,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9268–9277.
- [2] K. Cao, C. Wei, A. Gaidon, N. Arechiga, and T. Ma, “Learning imbalanced datasets with label-distribution-aware margin loss,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [3] Y. Hong, S. Han, K. Choi, S. Seo, B. Kim, and B. Chang, “Disentangling label distribution for long-tailed visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6626–6636.
- [4] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2980–2988.
- [5] J. Ren, C. Yu, X. Ma, H. Zhao, S. Yi et al., “Balanced meta-softmax for long-tailed visual recognition,” Advances in Neural Information Processing Systems, vol. 33, pp. 4175–4186, 2020.
- [6] J. Tan, C. Wang, B. Li, Q. Li, W. Ouyang, C. Yin, and J. Yan, “Equalization loss for long-tailed object recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 662–11 671.
- [7] M. Li, Y.-m. Cheung, and Y. Lu, “Long-tailed visual recognition via gaussian clouded logit adjustment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6929–6938.
- [8] X. Yin, X. Yu, K. Sohn, X. Liu, and M. Chandraker, “Feature transfer learning for face recognition with under-represented data,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5704–5713.
- [9] J. Liu, Y. Sun, C. Han, Z. Dou, and W. Li, “Deep representation learning on long-tailed data: A learnable embedding augmentation perspective,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2970–2979.
- [10] J. Wang, T. Lukasiewicz, X. Hu, J. Cai, and Z. Xu, “Rsg: A simple but effective module for learning imbalanced datasets,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 3784–3793.
- [11] B. Liu, H. Li, H. Kang, G. Hua, and N. Vasconcelos, “Gistnet: a geometric structure transfer network for long-tailed recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 8209–8218.
- [12] J. Kim, J. Jeong, and J. Shin, “M2m: Imbalanced classification via major-to-minor translation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 896–13 905.
- [13] Y.-Y. He, J. Wu, and X.-S. Wei, “Distilling virtual examples for long-tailed recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 235–244.
- [14] S. Li, K. Gong, C. H. Liu, Y. Wang, F. Qiao, and X. Cheng, “Metasaug: Meta semantic augmentation for long-tailed visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 5212–5221.
- [15] Z. Xu, Z. Chai, and C. Yuan, “Towards calibrated model for long-tailed visual recognition from prior perspective,” Advances in Neural Information Processing Systems, vol. 34, pp. 7139–7152, 2021.
- [16] S. Parisot, P. M. Esperança, S. McDonagh, T. J. Madarasz, Y. Yang, and Z. Li, “Long-tail recognition via compositional knowledge transfer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6939–6948.
- [17] A. Desai, T.-Y. Wu, S. Tripathi, and N. Vasconcelos, “Learning of visual relations: The devil is in the tails,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 404–15 413.
- [18] B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y. Kalantidis, “Decoupling representation and classifier for long-tailed recognition,” arXiv preprint arXiv:1910.09217, 2019.
- [19] Z. Zhong, J. Cui, S. Liu, and J. Jia, “Improving calibration for long-tailed recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 489–16 498.
- [20] P. Chu, X. Bian, S. Liu, and H. Ling, “Feature space augmentation for long-tailed data,” in European Conference on Computer Vision. Springer, 2020, pp. 694–710.
- [21] S. Zhang, Z. Li, S. Yan, X. He, and J. Sun, “Distribution alignment: A unified framework for long-tail visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2361–2370.
- [22] B. Kang, Y. Li, S. Xie, Z. Yuan, and J. Feng, “Exploring balanced feature spaces for representation learning,” in International Conference on Learning Representations, 2020.
- [23] B. Zhou, Q. Cui, X.-S. Wei, and Z.-M. Chen, “Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9719–9728.
- [24] H. Guo and S. Wang, “Long-tailed multi-label visual recognition by collaborative training on uniform and re-balanced samplings,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 089–15 098.
- [25] T. Wang, Y. Li, B. Kang, J. Li, J. Liew, S. Tang, S. Hoi, and J. Feng, “The devil is in classification: A simple framework for long-tail instance segmentation,” in European Conference on Computer Vision. Springer, 2020, pp. 728–744.
- [26] Y. Li, T. Wang, B. Kang, S. Tang, C. Wang, J. Li, and J. Feng, “Overcoming classifier imbalance for long-tail object detection with balanced group softmax,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 991–11 000.
- [27] L. Xiang, G. Ding, and J. Han, “Learning from multiple experts: Self-paced knowledge distillation for long-tailed classification,” in European Conference on Computer Vision. Springer, 2020, pp. 247–263.
- [28] X. Wang, L. Lian, Z. Miao, Z. Liu, and S. X. Yu, “Long-tailed recognition by routing diverse distribution-aware experts,” arXiv preprint arXiv:2010.01809, 2020.
- [29] Y. Zhang, B. Hooi, L. Hong, and J. Feng, “Test-agnostic long-tailed recognition by test-time aggregating diverse experts with self-supervision,” arXiv preprint arXiv:2107.09249, 2021.
- [30] S. Sinha, H. Ohashi, and K. Nakamura, “Class-difficulty based methods for long-tailed visual recognition,” International Journal of Computer Vision, vol. 130, no. 10, pp. 2517–2531, 2022.
- [31] Y. Ma, L. Jiao, F. Liu, Y. Li, S. Yang, and X. Liu, “Delving into semantic scale imbalance,” in The Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=07tc5kKRIo
- [32] S. Sinha, H. Ohashi, and K. Nakamura, “Class-wise difficulty-balanced loss for solving class-imbalance,” in Proceedings of the Asian Conference on Computer Vision, 2020.
- [33] J. B. Tenenbaum, V. d. Silva, and J. C. Langford, “A global geometric framework for nonlinear dimensionality reduction,” science, vol. 290, no. 5500, pp. 2319–2323, 2000.
- [34] N. Lei, D. An, Y. Guo, K. Su, S. Liu, Z. Luo, S.-T. Yau, and X. Gu, “A geometric understanding of deep learning,” Engineering, vol. 6, no. 3, pp. 361–374, 2020.
- [35] S. Chung, D. D. Lee, and H. Sompolinsky, “Linear readout of object manifolds,” Physical Review E, vol. 93, no. 6, p. 060301, 2016.
- [36] Y. Zhang, B. Kang, B. Hooi, S. Yan, and J. Feng, “Deep long-tailed learning: A survey,” arXiv preprint arXiv:2110.04596, 2021.
- [37] C. Elkan, “The foundations of cost-sensitive learning,” in International joint conference on artificial intelligence, vol. 17, no. 1. Lawrence Erlbaum Associates Ltd, 2001, pp. 973–978.
- [38] Z.-H. Zhou and X.-Y. Liu, “Training cost-sensitive neural networks with methods addressing the class imbalance problem,” IEEE Transactions on Knowledge and Data Engineering, vol. 18, no. 1, pp. 63–77, 2005.
- [39] P. Zhao, Y. Zhang, M. Wu, S. C. Hoi, M. Tan, and J. Huang, “Adaptive cost-sensitive online classification,” IEEE Transactions on Knowledge and Data Engineering, vol. 31, no. 2, pp. 214–228, 2018.
- [40] H.-J. Ye, H.-Y. Chen, D.-C. Zhan, and W.-L. Chao, “Identifying and compensating for feature deviation in imbalanced deep learning,” arXiv preprint arXiv:2001.01385, 2020.
- [41] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,” Journal of Artificial Intelligence Research, vol. 16, pp. 321–357, 2002.
- [42] A. Estabrooks, T. Jo, and N. Japkowicz, “A multiple resampling method for learning from imbalanced data sets,” Computational intelligence, vol. 20, no. 1, pp. 18–36, 2004.
- [43] Z. Zhang and T. Pfister, “Learning fast sample re-weighting without reward data,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 725–734.
- [44] Y. Ma, L. Jiao, F. Liu, S. Yang, X. Liu, and P. Chen, “Geometric prior guided feature representation learning for long-tailed classification,” International Journal of Computer Vision, pp. 1–18, 2024.
- [45] ——, “Feature distribution representation learning based on knowledge transfer for long-tailed classification,” IEEE Transactions on Multimedia, vol. 26, pp. 2772–2784, 2024.
- [46] S. Park, Y. Hong, B. Heo, S. Yun, and J. Y. Choi, “The majority can help the minority: Context-rich minority oversampling for long-tailed classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6887–6896.
- [47] Y. Cui, Y. Song, C. Sun, A. Howard, and S. Belongie, “Large scale fine-grained categorization and domain-specific transfer learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4109–4118.
- [48] Y. Yang and Z. Xu, “Rethinking the value of labels for improving class-imbalanced learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 19 290–19 301, 2020.
- [49] X. Hu, Y. Jiang, K. Tang, J. Chen, C. Miao, and H. Zhang, “Learning to segment the tail,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 14 045–14 054.
- [50] Y. Zang, C. Huang, and C. C. Loy, “Fasa: Feature augmentation and sampling adaptation for long-tailed instance segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3457–3466.
- [51] C. Huang, Y. Li, C. C. Loy, and X. Tang, “Learning deep representation for imbalanced classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 5375–5384.
- [52] Q. Dong, S. Gong, and X. Zhu, “Class rectification hard mining for imbalanced deep learning,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1851–1860.
- [53] J. Cui, Z. Zhong, S. Liu, B. Yu, and J. Jia, “Parametric contrastive learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 715–724.
- [54] W. Ouyang, X. Wang, C. Zhang, and X. Yang, “Factors in finetuning deep model for object detection with long-tail distribution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 864–873.
- [55] J. Cai, Y. Wang, and J.-N. Hwang, “Ace: Ally complementary experts for solving long-tailed recognition in one-shot,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 112–121.
- [56] U. Cohen, S. Chung, D. D. Lee, and H. Sompolinsky, “Separability and geometry of object manifolds in deep neural networks,” Nature communications, vol. 11, no. 1, pp. 1–13, 2020.
- [57] C. C. Aggarwal, L.-F. Aggarwal, and Lagerstrom-Fife, Linear algebra and optimization for machine learning. Springer, 2020, vol. 156.
- [58] S. Boyd, S. P. Boyd, and L. Vandenberghe, Convex optimization. Cambridge University Press, 2004.
- [59] Y. Asao and Y. Ike, “Curvature of point clouds through principal component analysis,” arXiv preprint arXiv:2106.09972, 2021.
- [60] R. Balestriero, J. Pesenti, and Y. LeCun, “Learning in high dimension always amounts to extrapolation,” arXiv preprint arXiv:2110.09485, 2021.
- [61] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [62] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [63] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,” arXiv preprint arXiv:1708.07747, 2017.
- [64] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” 2009.
- [65] J. Liu, J. Zhang, W. Li, C. Zhang, Y. Sun et al., “Memory-based jitter: Improving visual recognition on long-tailed data with diversity in memory,” arXiv preprint arXiv:2008.09809, 2020.
- [66] X. Wang, H. Zhang, W. Huang, and M. R. Scott, “Cross-batch memory for embedding learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 6388–6397.
- [67] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015.
- [68] G. Van Horn, O. Mac Aodha, Y. Song, Y. Cui, C. Sun, A. Shepard, H. Adam, P. Perona, and S. Belongie, “The inaturalist species classification and detection dataset,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 8769–8778.
- [69] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 1492–1500.
- [70] S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y. Yoo, “Cutmix: Regularization strategy to train strong classifiers with localizable features,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6023–6032.
- [71] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,” arXiv preprint arXiv:1710.09412, 2017.
- [72] K. Tang, J. Huang, and H. Zhang, “Long-tailed classification by keeping the good and removing the bad momentum causal effect,” Advances in Neural Information Processing Systems, vol. 33, pp. 1513–1524, 2020.
- [73] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2015, pp. 1–9.
- [74] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017, pp. 4700–4708.
- [75] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 7132–7141.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Yanbiao.jpg) |
Yanbiao Ma received the B.S. degree in Intelligent Science and Technology from Xidian University, China, in 2020. He is currently pursuing the Ph.D. degree with the Key Laboratory of Intelligent Perception and Image Understanding of the Ministry of Education, School of Artificial Intelligence Xidian University, China. He has been dedicated to research in the field of imbalanced learning and fairness in deep neural networks. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/x9.png) |
Licheng Jiao (Fellow, IEEE) received the B.S. degree from Shanghai Jiaotong University, Shanghai, China, in 1982 and the M.S. and PhD degree from Xi’an Jiaotong University, Xi’an, China, in 1984 and 1990, respectively. Since 1992, he has been a distinguished professor with the school of Electronic Engineering, Xidian University, Xi’an, where he is currently the Director of Key Laboratory of Intelligent Perception and Image Understanding of the Ministry of Education of China. He has been a foreign member of the academia European and the Russian academy of natural sciences. His research interests include machine learning, deep learning, natural computation, remote sensing, image processing, and intelligent information processing. Prof. Jiao is the Chairman of the Awards and Recognition Committee, the Vice Board Chairperson of the Chinese Association of Artificial Intelligence, the fellow of IEEE/IET/CAAI/CIE/CCF/CAA, a Councilor of the Chinese Institute of Electronics, a committee member of the Chinese Committee of Neural Networks, and an expert of the Academic Degrees Committee of the State Council. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Fang_Liu.png) |
Fang Liu (Senior Member, IEEE) received a B.S. degree in computer science and technology from Xi’an Jiaotong University, Xi’an, China, in 1984 and the M.S. degree in computer science and technology from Xidian University, Xi’an, in 1995. She is currently a Professor at the School of Computer Science, Xidian University. Her research interests include signal and image processing, synthetic aperture radar image processing, multi-scale geometry analysis, learning theory and algorithms, optimization problems, and data mining. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Maoji_Wen.jpg) |
Maoji Wen entered the major of Computer Science and Technology at Xidian University in 2020, pursuing a Bachelor of Science degree. His research interests lie in computer vision. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Lingling_Li.png) |
Lingling Li (Senior Member, IEEE) received the B.S. degree in electronic and information engineering and the Ph.D. degree in intelligent information processing from Xidian University, Xi’an, China, in 2011 and 2017, respectively. She is currently an Associate Professor with the School of Artificial Intelligence, Xidian University. From 2013 to 2014, she was an Exchange Ph.D. Student with the Intelligent Systems Group, Department of Computer Science and Artificial Intelligence, University of the Basque Country UPV/EHU, Leioa, Spain. Her research interests include quantum evolutionary optimization, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Wenping_Ma.png) |
Wenping Ma (Senior Member, IEEE) received the B.S. degree in computer science and technology and the Ph.D. degree in pattern recognition and intelligent systems from Xidian University, Xi’an, China, in 2003 and 2008, respectively. She is currently an Associate Professor with the School of Artificial Intelligence, Xidian University. Her research interests include natural computing and intelligent image processing. Dr. Ma is a member of CIE. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Shuyuan_Yang.png) |
Shuyuan Yang (Senior Member, IEEE) received the B.A. degree in electrical engineering and the M.S. and Ph.D. degrees in circuit and system from Xidian University, Xian, China, in 2000, 2003, and 2005, respectively. She has been a Professor with the School of Artificial Intelligence, Xidian University. Her research interests include machine learning and multiscale geometric analysis. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Xu_Liu.jpg) |
Xu Liu Senior Member, IEEE) received the B.S. degree in mathematics and applied mathematics from the North University of China, Taiyuan, China, in 2013, and the Ph.D. degree from Xidian University, Xian, China, in 2019. He is currently an Associate Professor of Huashan elite and a Post-Doctoral Researcher with the Key Laboratory of Intelligent Perception and Image Understanding of Ministry of Education, School of Artificial Intelligence, Xidian University, Xi’an. He is the Chair of IEEE Xidian University Student Branch from 2015 to 2019. His research interests include machine learning and image processing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76fa9450-7d93-4db9-9357-09bcb765c4bd/Puhua.jpg) |
Puhua Chen (Senior Member, IEEE) received the B.S. degree in environmental engineering from the University of Electronic Science and Technology of China, Chengdu, China, in 2009, and the Ph.D. degree in circuit and system from Xidian University, Xi’an, China, in 2016. She is currently an associate professor with the School of Artificial Intelligence, Xidian University. Her current research interests include machine learning, pattern recognition and remote sensing image interpretation. |