PrEF: Percolation-based Evolutionary Framework for the diffusion-source-localization problem in large networks
Abstract
We assume that the state of a number of nodes in a network could be investigated if necessary, and study what configuration of those nodes could facilitate a better solution for the diffusion-source-localization (DSL) problem. In particular, we formulate a candidate set which contains the diffusion source for sure, and propose the method, Percolation-based Evolutionary Framework (PrEF), to minimize such set. Hence one could further conduct more intensive investigation on only a few nodes to target the source. To achieve that, we first demonstrate that there are some similarities between the DSL problem and the network immunization problem. We find that the minimization of the candidate set is equivalent to the minimization of the order parameter if we view the observer set as the removal node set. Hence, PrEF is developed based on the network percolation and evolutionary algorithm. The effectiveness of the proposed method is validated on both model and empirical networks in regard to varied circumstances. Our results show that the developed approach could achieve a much smaller candidate set compared to the state of the art in almost all cases. Meanwhile, our approach is also more stable, i.e., it has similar performance irrespective of varied infection probabilities, diffusion models, and outbreak ranges. More importantly, our approach might provide a new framework to tackle the DSL problem in extreme large networks.
1 Introduction
There has recently been an enormous amount of interest focusing on the diffusion-source-localization (DSL) problem on networks, which aims to find out the real source of an undergoing or finished diffusion [1, 2, 3]. Two specific scenarios are epidemics and misinformation and both of which can be well modeled by the networks. Being one of the biggest enemies to global health, infectious diseases could cause rapid population declines or species extinction [4], from the Black Death (probably bubonic plague), which is estimated to have caused the death of as much as one third of the population of Europe between 1346 and 1350 [5], to nowadays COVID-19 pandemic, which might result in the largest global recession in history, in particular, climate change keeping exacerbating the spread of diseases and increasing the probability of global epidemics [6, 7]. In this case, the study of the DSL problem can potentially help administrations to make policies to prevent future outbreaks and hence save a lot of lives and resources. Further regarding misinformation, as one of the biggest threats to our societies, it could cause great impact on global health and economy and further weaken the public trust in governments [8], such as the ongoing COVID-19 where fake news circulates on online social networks (OSNs) and has made people believe that the virus could be killed by drinking slaty water and bleach [9], and the ‘Barack Obama was injured’ which wiped out $130 billion in stock value [10]. In this circumstance, the localization of the real source would play important role for containing the misinformation fundamentally.
The main task of the DSL problem is to find an estimator that could give us an inferred source based on the known partial information, and the most ideal estimator is the one that gives us the real source. However, due to the complexity of contact patterns and the uncertainty of diffusion models, the real source is generally almost impossible to be inferred exactly, even the underlying network is a tree [11]. Hence, as an alternative, the error distance is used, and an estimator is said to be better than another one if the corresponding inferred source is closer to the real source in hop-distance [2, 12, 13, 14, 3, 11]. And therefore, varied methods have been developed to minimize such error distance based on different-known-information assumptions, such as observers having knowledge of time stamps and infection directions [2], the diffusion information [15], and the states of all nodes [3], etc. [14, 11]. But here we argue that: what should we do next once we acquire the estimator having small error distance? Indeed, one can carry out intensive detection on the neighbor region of the inferred source to search for the real source. In this case, for regular networks, a small error distance is usually associated with a small number of nodes to be checked. However, most real-world networks are heterogeneous, which indicates that even a short error distance might correspond to a great number of nodes, especially those social networks.
Hence, in this paper, we present a method, Percolation-based Evolutionary Framework (PrEF), to tackle the DSL problem by suppressing a candidate set that the real source belongs to for sure. In particular, we assume that there are a group of nodes in the networks, whose states can be investigated if necessary. Meanwhile, those nodes are also assumed to have information of both time stamps and infection directions. Then, our goal is to use as fewer observers (nodes) as possible to achieve the containment of the candidate set. We find that such goal can be reached by the solution of the network immunization problem. Hence, we have our method based on the network percolation and evolutionary computation. Results on both model and empirical networks show that the proposed method is much better compared to the state-of-the-art approaches.
Key contributions of this paper are summarized as follows:
-
•
DSL vs. network immunization. We concretely study and derive the connection of the DSL problem and the network immunization problem, and find that the solution of the network immunization problem can be used to and could effectively cope with the DSL problem.
-
•
Percolation-based evolutionary framework. We propose a percolation-based evolutionary framework to solve the DSL problem, which takes a network percolation process and potentially works for a range of scenarios.
-
•
Extensive evaluation on synthetic and empirical networks. We evaluate the proposed method on two synthetic networks and four empirical networks drawn from different real-world scenarios, whose sizes are up to over nodes. Results show that our method is more effective, efficient, and stable than the-state-of-the-art approaches, and is also capable of handling large networks.
2 Related Work
DSL approaches. Shah and Zaman first studied the DSL problem of single diffusion source and introduced the rumor centrality method by counting the distinct diffusion configurations of each node [1, 16]. They considered the Susceptible-Infected (SI) model and concluded that a node is said to be the source with higher probability if it has a larger rumor centrality. Following that, Dong et al. also investigated the SI model and proposed a better approach based on the local rumor center generalized from the rumor centrality, given that a priori distribution is known for each node being the rumor source [17]. Similarly, Zhu and Ying investigated the problem under the Susceptible-Infected-Recovered (SIR) model and found that the Jordan center could be used to characterize such probability [12]. Wang et al. showed that the detection probability could be boosted if multiple diffusion snapshots were observed [13], which can be viewed as the case that the information of the diffusion time was integrated to some extent. Indeed, if the time-stamp or other additional information is known, the corresponding method would usually work better [2, 3, 18]. In short, almost all those exiting methods study the DSL problem on either simple networks (such a tree-type networks or model networks) or small empirical networks. Hence, their performance might be questioned in real and complex scenarios, such as networks having a lot of cycles [19, 20].
Network immunization. The network immunization problem aims to find a key group of nodes whose removal could fragment a given network to the greatest extend, which has been proved to be a NP-hard problem [21]. In general, approaches for coping with this problem can be summarized into four categories. The first one is to obtain the key group by strategies such as randomly selecting nodes from the network, which is usually called local-information-based methods [22, 23]. In this scope, since the network topology information does not have to be precisely known, these methods would be quite useful in some scenarios. Rather than that, when the network topology is known, the second category is usually much more effective. Methods of the second category draw the key group by directly classifying nodes based on measurements like degree centrality, eigenvector centrality, pagerank, and betweenness centrality [20]. More concretely, they firstly calculate the importance of each node using their centralities and choose those ranking on the top as the key group. The third category takes the same strategy but will heuristically update the importance of nodes in the remaining network after the most important node is removed, and the key group eventually consists of all removed nodes [21]. The last category obtains the key group in indirect ways [24, 25]. For instance, refs. [26, 27] achieve the goal by tackling the feedback vertex set problem.
3 Model
We assume that a diffusion occurs on a network , where and are the corresponding node set and edge set, respectively. Letting be the edge between nodes and , we define the nearest neighbor set regarding as . A connected component of is a subnetwork satisfying , , and . In particular, denoting the size of (i.e., the number of nodes in ), the largest connected component (LCC), , is then defined as the component that consists of the majority of nodes, that is, . Now assuming that is the remaining network of after the removal of fraction nodes and the incident edges, the corresponding size of the LCC, , will hence be a monotonically decreasing function of . Such function is also known as the order parameter , where is the number of nodes in . According to the percolation theory [28], when is large enough, say larger than the critical threshold , the probability that a randomly selected node belongs to the LCC would approach zero. In other words, if , then there would be no any giant connected component in .
The diffusion is generally associated with four factors: the network structure , the diffusion source , the dynamic model , and the corresponding time , say . Regarding , here we particularly consider the Susceptible-Infected-Recovered (SIR) model [29] as an example to explain the proposed method. More models will further be discussed in the result section. For nodes of governed by the SIR model, their states are either susceptible, infected or recovered. As , an infected node has an infection probability (or a time interval ) to transmit the information or virus, say , to its susceptible neighbor . Meanwhile, it recovers with a recovery probability (or duration of ). Those recovered nodes stay in the recovered state and cannot pass through a recovered node.
Now supposing that a group of nodes are particularly chosen as observers and hence their states could be investigated if necessary, we study what and how the configuration of could facilitate better solutions for the diffusion-source-localization (DSL) problem [1, 2, 3]. In particular, we assume that a node would record the relative infection time stamp once it gets infected. Besides, we also consider that part of , say , have the ability to record the infection direction, that is, a node can also show us the node if transmits to . Based on these assumptions, for a diffusion triggered by an unknown diffusion source at time , the DSL problem aims to design an estimator that gives us the inferred source satisfying , where is the probability that we observe given . Obviously, the state of a node is governed by all parameters of but with unknown and . Hence, with high probability differs from the real source in most scenarios [2, 12, 3]. And therefore, the error distance is conducted to verify the performance of an estimator, where represents the hop-distance between and . Usually, an estimator is said to be better than another one if it has smaller .
But here we argue that: what should we do next after we obtain the estimator having a small ? Or in other words, can the estimator help us find the diffusion source more easily? Indeed, after acquiring , one can further conduct more intensive search on the neighbor region of to detect . In this case, a small generally corresponds to a small search region. However, due to the heterogeneity of contact patterns in most real-world networks [30], even a small region (i.e., a small ) might be associated with a lot of nodes. Therefore, it would be more practical in real scenarios if such estimator gives us a candidate set satisfying for sure. And hence, we formulate the goal function that this paper aims to achieve as
| (1) |
where is the size of . Intuitively, Eq. (1) is developed based on the assumption that: the smaller the candidate set, the lower the cost of the intensive search. And in general, should be finite guaranteed by finite for an infinite , otherwise, the cost would be infinite since the intensive search has to be carried out on an infinite population.
4 Method
Let be the removal node set and the rest, i.e., and . For the subnetwork regarding , the boundary of a connected component , say , is defined as
| (2) |
Likewise, we write the component cover that a specific node corresponds to as
| (3) |
where represents the component that node belongs to. Denoting the time stamp that node gets infected and , where is assumed to be infinite if is still susceptible, the proposed approach is developed based on the following observation (Observation 1).
Observation 1.
Letting
| (4) |
we then have for sure.
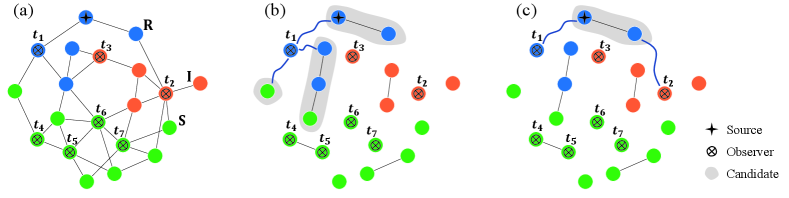
Example 1. Considering Fig. 1(a) and (b), the boundary of the connected component that the diffusion source belongs to is .
Example 2. Regarding Fig. 1(b), consists of all nodes covered by those shadows.
Example 3. With respect to Fig. 1(c), comprises of node , node , the diffusion source, and the node adjacent to the source.
We now consider the generation of the observer set (or equivalently ). For a given network constructed by the configuration model [31], letting and accordingly be the first and second moments of the corresponding degree sequence, we then have Lemma 1.
Lemma 1.
(Molloy-Reed criterion [31]) A network constructed based on the configuration model with high probability has a giant connected component (GCC) if
| (5) |
where GCC represents a connected component whose size is proportional to the network size .
Now suppose that consists of nodes randomly chosen from and let represent the fraction of removed nodes. Apparently, such removal would change the degree sequence of the remaining network (i.e., subnetwork , also see Fig. 1(b) as an example). Assuming that there is a node shared by both and , the probability that its degree (in ) decreases to a specific degree (in ) should be
where is the combinational factor (note that each node has probability of being removed). Letting denote the degree distribution of , we then have the new degree distribution of as
| (6) |
and hence the corresponding first and second moments can be further obtained as
| (7) |
and
| (8) |
respectively. Since is constructed using the configuration model, its edges are independent of each other. That is, each edge of shares the same probability of connecting to . In other words, the removal of would remove each edge with the same probability and hence can be viewed as a special network that is also constructed by the configuration model. Thus, Lemma 1 can be used to determine whether a GCC exists in and we reach
| (9) |
where is the critical threshold of , that is: i) if , with high probability there is a GCC in ; ii) if , with high probability there is no GCC in [32, 33].
For random networks (such as Erdős-Rényi (ER) networks [34]), gives us , which indicates that is usually less than and it increases as becomes denser. But for heterogeneous networks, say , diverges if (most empirical networks have [20]), which means approaches .
Remark 1.
From the above analysis, we have the following conclusions regarding the case that the observer set is randomly chosen. For random networks, indicates that one can always have a proper to achieve finite . And usually the denser the network, the larger the observer set . But for heterogeneous networks, means that such goal could only be achieved by putting almost all nodes into the observer set .
We further consider the case that consists of hubs [35], where hubs represent those nodes that have more connections in a particular network. Specifically, for a network , we first define a sequence regarding and assume that each element of is uniquely associated with a node in . Then, letting and if , satisfying , where represents the degree of node , we have . For heterogeneous networks under such removals on hubs, threshold can be achieved and obtained by numerically solving [36]
| (10) |
where is the minimum degree.
For , however, we could not obtain an explicit equation to indicate whether it is finite. But we can roughly show that there should be that gives us a finite for networks generated by the configuration model with degree distribution . Supposing that the size of the LCC of is proportional to with , then
| (11) |
gives us the possibly largest size of , where is the maximum degree of and here we assume that such degree is unique. In the mentioned case, holds and hence it approaches as if (again, this is the case that we are particularly interested in), which indicates that one can always find some proper value of satisfying for a given . Note that, same as the random removal, each edge of also shares the same probability of being removed. Hence, both the size of the LCC and the number of connections that node has with decrease as increases, where represents the node whose degree is .
But for networks having such as star-shape networks, is still infinite when is finite. In this case, the information of only infection time stamps of nodes in is apparently not enough. However, if the infection direction is also recorded, then the central node as the unique observer is fairly enough for the DSL problem in those star-shape networks. Note that most existing DSL methods would also fail in star-shape networks. Hence, we further assume that part of , say , can also show the infection direction. Obviously, is a monotonically decreasing function of for a specific . In particular, if , then the size of would be bounded by the size of the LCC.
Remark 2.
In general, finite of heterogeneous networks can be achieved by carefully choosing . Or in other words, the configuration of plays fundamental role for the suppression of . Associating with the sequence , such as random removal can be viewed as a removal over a random sequence , our goal is now to acquire a better that could give us a smaller in regard to a specific . Besides, since the number of components that connects to is usually difficult to measure especially for real-world networks, here we choose to achieve the containment of by curbing the LCC of (see also Eq. (11)), which coincides with the suppression of the order parameter .
Therefore, we reach
| (12) |
where , , and is a given parameter (such as ). Eq. (12) is also known as the network immunization problem which aims to contain epidemics by the isolation of as fewer nodes as possible [33]. And a lot of methods have been proposed to cope with such problem [21, 27, 37, 38, 39, 40, 24, 25]. Here we particularly choose and consider the approach based on the evolutionary framework (AEF) to construct since it can achieve the state of the art in most networks.
We first introduce several auxiliary variables to the ease of description of AEF. Consider a given network and the corresponding sequence . Let , where is a subsequence of . Likewise, denote a subnetwork , in which and . Based on that, of regarding is written as . Further, letting of , we define the critical subsequence as the subsequence satisfying that of and of . Note that all is scaled by , namely, the size of the studied network .
The core of AEF is the relationship-related (RR) strategy that works by repeatedly pruning the whole sequence . Specifically, per iteration , RR keeps a new sequence (i.e., ) if (or ), which is obtained through the following steps. 1) Let , , and be a subnetwork of , which consists of all nodes in and the associated edges in . 2) Construct the candidate set by randomly choosing times from , where and are randomly generated per iteration, and and are given parameters. 3) Choose the node ,
| (13) |
where or , in which is the component set that node would connect. 4) Update and , namely, , , and swap and satisfying . 5) . 6) Repeat steps 2) - 5) until , which accounts for one round (see also Algorithm 1). And RR acquires the solution by repeating steps 1) - 6) times.
Input: , , , Output: 1 Initialization: , , , , and 2 while do 3 4 Get the candidate set based on and 5 Choose node based on Eq. (13) 6 Update and 7 8if then 9 Algorithm 1 One round of RR [38]
Observation 2.
Supposing that
| (14) |
holds, then for a specific sequence regarding a given network , would be independent of if either or satisfies. That is, for such a case, the order of nodes in has no effect on .
AEF is developed based on RR and Observation 2. Specifically, at , a random integer is generated, where and are two given boundaries. Let . Then, for all subsequences , RR with the optimization of is conducted if is unknown, otherwise, is optimized by RR with minimum.
Hence, the containment of has been achieved (see also Eq. (4)), based on which existing DSL approaches can be used to further acquire the candidate set (see also Eq. (1)). Here, since our goal is to have a framework that can effectively cope with the DSL problem in large-scale networks, we choose to propose the following approach. Let be the effective periphery node set of defined as
| (15) |
where
| (16) |
Letting , we first refine the time stamp by . Then, a Reverse-Influence-Sampling (RIS) [41] like strategy is conducted to infer the source , which works in the following processes. 1) Let and be the reverse network of satisfying that and if . 2) Randomly choose a node and let , where is randomly generated from and is a given parameter. 3) View as the source and transmits to one of its randomly chosen neighbors, and then it recovers. 4) Such transmission repeats steps and denote the latest infected node by . 5) Let . 6) Repeat 2)-5) times. Using to represent the frequency that a node has regarding , then we estimate the source by
| (17) |
The candidate set (see also Eq. (1)) is finally acquired by simply considering a few layers of neighbors of .
Remark 3.
Relying on AEF a finite can be achieved by a small , especially when is large, i.e., the larger the , the better the corresponding result, where characterizes the rate of regarding . In particular, in tandem with the approach that we present to draw from , we name such framework as the Percolation-based Evolutionary Framework (PrEF) for the diffusion-source-localization problem. Note that other strategies can also be further developed or integrated into PrEF to acquire based on , such as those existing DSL methods.
5 Results
Competitors. We mainly compare the proposed approach with the Jordan-Center (JC) method [12] that generally achieves comparable results in most cases [15, 11, 18]. For JC, the corresponding candidate set is constructed based on the associated node rank since neighbor-based strategy usually results in much larger . Meanwhile, consists of hubs is also considered as a baseline, say Hubs_s. Besides, since most current DSL approaches do not work for large networks, we also verify the performance of the proposed method by comparing it with approaches from the network immunization field, including the collective influence (CI) [21], the min-sum and reverse-greedy (MSRG) strategy [27], and the FINDER (FInding key players in Networks through DEep Reinforcement learning) method [25].
Settings. JC considers all infected and recovered nodes to achieve the source localization. PrEF is conducted with , , , , , for networks of , for , for (AEF), and (RIS). Besides, we use to represent PrEF regarding a specific . In addition, for each network, is obtained at of AEF.
Diffusion models. SIR1: and , . SIR2: and , , i.e., the Susceptible-Infected (SI) model [29]. SIR3: and , , i.e., the Independent Cascade (IC) model [42, 43].
Letting and accordingly be the number of nodes in infection and recovery states at of a particular diffusion , we generate a DSL sample by the following processes. 1) A node is randomly chosen as the diffusion source to trigger . 2) is terminated at the moment when
where is the outbreak range rate. Note that might be much larger than if the infection probability is large.
Evaluation metric. We mainly consider the fraction of the candidate set (see also Eq. (1)), , to evaluate the performance of the proposed method, which is defined as
In what follows, is the mean drawn from over independent realizations if there is no special explantation. Besides, we also use to denote of a specific approach, such as represents of PrEF.
| Networks | ||
|---|---|---|
| ER | ||
| SF | ||
| PG | ||
| SCM | ||
| LOCG | ||
| WG |
Networks. We consider both model networks (including the ER network [34] and scale-free (SF) network [30]) and empirical networks (including the Power Grid (PG) network [19], the Scottish-cattle-movement (SCM) network [37], the loc-Gowalla (LOCG) network [44], and the web-Google (WG) network [45]). We choose the PG network since it is widely used to evaluate the performance of DSL approaches. Rather than that, the rest are all highly associated with the DSL problem. In particular, the SCM network is a network of Scottish cattle movements, on which the study of the DSL problem plays important role for food security [46]. Besides, the LOCG is a location-based online social network and the WG network is a network of Google web whose nodes represent web pages and edges are hyperlinks among them. The study of them can potentially contribute to the containment of misinformation. The basic information regarding those networks can be found in Table 1.
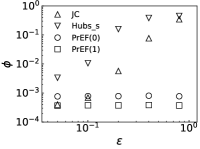
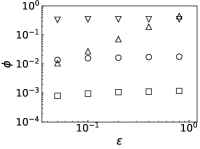
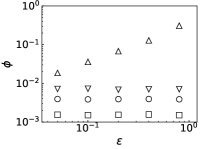
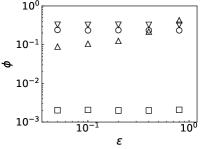
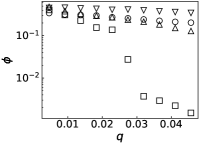
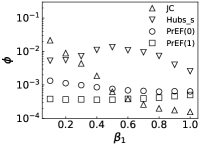
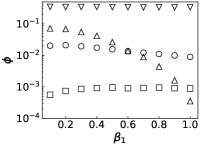
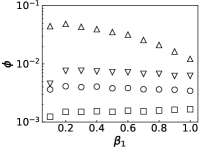
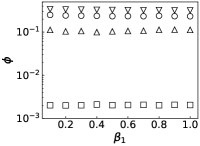
Results. We first fix to verify the performance of PrEF over varied infection probability . Indeed, if the diffusion is symmetrical, JC would be an effective estimator (see Figs. 2a and 2b when is large). But such effectiveness sharply decreases as decreases. By contrast, PrEF has steady performance for the whole range of and is much better than JC when is small, such as versus at in the SF network. Besides, apparently works better in the ER network compared to the SF network, which indicates that might have impact on the effectiveness of since the SF network has a much larger . To further demonstrate that, we also consider two empirical networks: the Power Grid network (with ) and the Scottish network (with ). As shown in Figs. 3c and 3d, even Hubs_s is more effective than JC in the Power Grid network but, JC, Hubs_s, and all fail in the Scottish network. Rather than that, works extremely well in both cases. Further considering the fraction of the candidate set as a function of the outbreak range rate (Fig. 3), and still have stable performance while rapidly increases as .
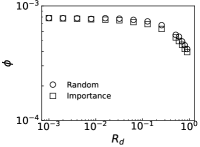
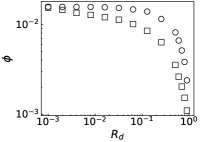
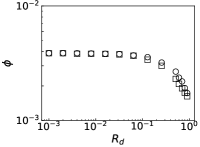
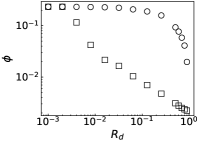
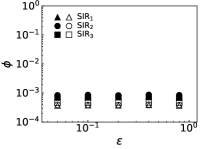
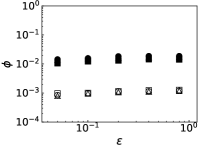
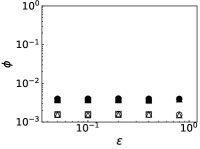
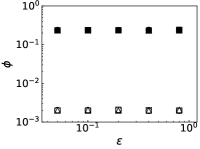
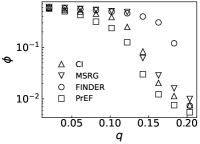
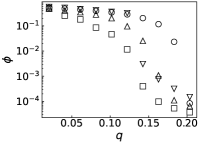
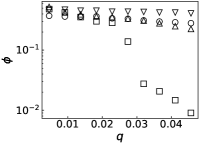
We further evaluate the performance of PrEF under different by comparing it with CI, MSRG, and FINDER on the two large networks. From those results shown in Fig. 4, we have the following conclusions: i) when , which is in accordance with our previous discussion, i.e., when ; ii) A specific method that has better performance regarding usually also works better with respect to ; iii) For a specific , PrEF always has much smaller compared to CI, MSRG, and FINDER, especially for the WG network. Indeed, the size of the observer set , the value of (see also Fig. 5), the strategy generating all play fundamental roles for minimizing . In particular, PrEF has the best performance for almost all range of . Besides, results in Fig. 6 further demonstrate that the proposed method is also stable against varied diffusion models.
6 Conclusion
Aiming at the development of the-state-of-the-art approach to cope with the DSL problem for large networks, the PrEF method has been developed based on the network percolation and evolutionary computation, which can effectively narrow our search region of the diffusion source. Specifically, We have found that the DSL problem is in a degree equivalent to the network immunization problem if viewing immune nodes as observers, and hence it can be tackled in a similar scheme. In particular, we have demonstrated that the search region would be bounded by the LCC if the direction information of the diffusion is known, regardless of the network structure. But for the case that only the time stamp is recorded, both LCC and the largest degree have impact on the search region. We have also conducted extensive experiments to evaluate the performance of the proposed method. Results show that our method is much more effective, efficient, and stable compared to existing approaches.
References
- [1] D. Shah and T. Zaman, “Detecting sources of computer viruses in networks: theory and experiment,” in Proceedings of the ACM SIGMETRICS international conference on Measurement and modeling of computer systems, 2010, pp. 203–214.
- [2] P. C. Pinto, P. Thiran, and M. Vetterli, “Locating the source of diffusion in large-scale networks,” Physical review letters, vol. 109, no. 6, p. 068702, 2012.
- [3] S. S. Ali, T. Anwar, A. Rastogi, and S. A. M. Rizvi, “Epa: Exoneration and prominence based age for infection source identification,” in Proceedings of the 28th ACM International Conference on Information and Knowledge Management, 2019, pp. 891–900.
- [4] C. D. Harvell, C. E. Mitchell, J. R. Ward, S. Altizer, A. P. Dobson, R. S. Ostfeld, and M. D. Samuel, “Climate warming and disease risks for terrestrial and marine biota,” Science, vol. 296, no. 5576, pp. 2158–2162, 2002.
- [5] F. Brauer, C. Castillo-Chavez, and C. Castillo-Chavez, Mathematical models in population biology and epidemiology. Springer, 2012, vol. 2.
- [6] A. J. McMichael, D. H. Campbell-Lendrum, C. F. Corvalán, K. L. Ebi, A. Githeko, J. D. Scheraga, and A. Woodward, Climate change and human health: risks and responses. World Health Organization, 2003.
- [7] D. T. Jamison, L. H. Summers, G. Alleyne, K. J. Arrow, S. Berkley, A. Binagwaho, F. Bustreo, D. Evans, R. G. Feachem, J. Frenk et al., “Global health 2035: a world converging within a generation,” The Lancet, vol. 382, no. 9908, pp. 1898–1955, 2013.
- [8] X. Zhou and R. Zafarani, “A survey of fake news: Fundamental theories, detection methods, and opportunities,” ACM Computing Surveys (CSUR), vol. 53, no. 5, pp. 1–40, 2020.
- [9] S. Sahoo, S. K. Padhy, J. Ipsita, A. Mehra, and S. Grover, “Demystifying the myths about covid-19 infection and its societal importance,” Asian journal of psychiatry, vol. 54, p. 102244, 2020.
- [10] K. Rapoza, “Can ’fake news’ impact the stock market?” https://www.forbes.com/sites/kenrapoza/2017/02/26/can-fake-news-impact-the-stock-market/?sh=5f820b392fac, 2017, accessed: 2021-09-15.
- [11] J. Choi, S. Moon, J. Woo, K. Son, J. Shin, and Y. Yi, “Information source finding in networks: Querying with budgets,” IEEE/ACM Transactions on Networking, vol. 28, no. 5, pp. 2271–2284, 2020.
- [12] K. Zhu and L. Ying, “Information source detection in the sir model: A sample-path-based approach,” IEEE/ACM Transactions on Networking, vol. 24, no. 1, pp. 408–421, 2014.
- [13] Z. Wang, W. Dong, W. Zhang, and C. W. Tan, “Rumor source detection with multiple observations: Fundamental limits and algorithms,” ACM SIGMETRICS Performance Evaluation Review, vol. 42, no. 1, pp. 1–13, 2014.
- [14] J. Jiang, S. Wen, S. Yu, Y. Xiang, and W. Zhou, “Identifying propagation sources in networks: State-of-the-art and comparative studies,” IEEE Communications Surveys & Tutorials, vol. 19, no. 1, pp. 465–481, 2016.
- [15] A. Y. Lokhov, M. Mézard, H. Ohta, and L. Zdeborová, “Inferring the origin of an epidemic with a dynamic message-passing algorithm,” Physical Review E, vol. 90, no. 1, p. 012801, 2014.
- [16] D. Shah and T. Zaman, “Rumor centrality: a universal source detector,” in Proceedings of the 12th ACM SIGMETRICS/PERFORMANCE joint international conference on Measurement and Modeling of Computer Systems, 2012, pp. 199–210.
- [17] W. Dong, W. Zhang, and C. W. Tan, “Rooting out the rumor culprit from suspects,” in 2013 IEEE International Symposium on Information Theory. IEEE, 2013, pp. 2671–2675.
- [18] Y. Chai, Y. Wang, and L. Zhu, “Information sources estimation in time-varying networks,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 2621–2636, 2021.
- [19] D. J. Watts and S. H. Strogatz, “Collective dynamics of ‘small-world’ networks,” Nature, vol. 393, no. 6684, pp. 440–442, 1998.
- [20] M. Newman, Networks. Oxford university press, 2018.
- [21] F. Morone and H. A. Makse, “Influence maximization in complex networks through optimal percolation,” Nature, vol. 524, no. 7563, pp. 65–68, 2015.
- [22] R. Cohen, S. Havlin, and D. Ben-Avraham, “Efficient immunization strategies for computer networks and populations,” Physical Review Letters, vol. 91, no. 24, p. 247901, 2003.
- [23] Y. Liu, Y. Deng, and B. Wei, “Local immunization strategy based on the scores of nodes,” Chaos: An Interdisciplinary Journal of Nonlinear Science, vol. 26, no. 1, p. 013106, 2016.
- [24] X.-L. Ren, N. Gleinig, D. Helbing, and N. Antulov-Fantulin, “Generalized network dismantling,” Proceedings of the national academy of sciences, vol. 116, no. 14, pp. 6554–6559, 2019.
- [25] C. Fan, L. Zeng, Y. Sun, and Y.-Y. Liu, “Finding key players in complex networks through deep reinforcement learning,” Nature Machine Intelligence, pp. 1–8, 2020.
- [26] S. Mugisha and H.-J. Zhou, “Identifying optimal targets of network attack by belief propagation,” Physical Review E, vol. 94, no. 1, p. 012305, 2016.
- [27] A. Braunstein, L. Dall’Asta, G. Semerjian, and L. Zdeborová, “Network dismantling,” Proceedings of the National Academy of Sciences, vol. 113, no. 44, pp. 12 368–12 373, 2016.
- [28] D. Stauffer and A. Aharony, Introduction to percolation theory. CRC press, 2018.
- [29] M. J. Keeling and P. Rohani, Modeling infectious diseases in humans and animals. Princeton university press, 2011.
- [30] A.-L. Barabási and R. Albert, “Emergence of scaling in random networks,” Science, vol. 286, no. 5439, pp. 509–512, 1999.
- [31] M. Molloy and B. Reed, “A critical point for random graphs with a given degree sequence,” Random structures & algorithms, vol. 6, no. 2-3, pp. 161–180, 1995.
- [32] R. Cohen, K. Erez, D. Ben-Avraham, and S. Havlin, “Resilience of the internet to random breakdowns,” Physical Review Letters, vol. 85, no. 21, p. 4626, 2000.
- [33] A.-L. Barabási et al., Network science. Cambridge university press, 2016.
- [34] P. Erdős and A. Rényi, “On random graphs I.” Publicationes Mathematicae (Debrecen), vol. 6, pp. 290–297, 1959.
- [35] R. Albert, H. Jeong, and A.-L. Barabási, “Error and attack tolerance of complex networks,” Nature, vol. 406, no. 6794, pp. 378–382, 2000.
- [36] R. Cohen, K. Erez, D. Ben-Avraham, and S. Havlin, “Breakdown of the internet under intentional attack,” Physical Review Letters, vol. 86, no. 16, p. 3682, 2001.
- [37] P. Clusella, P. Grassberger, F. J. Pérez-Reche, and A. Politi, “Immunization and targeted destruction of networks using explosive percolation,” Physical Review Letters, vol. 117, no. 20, p. 208301, 2016.
- [38] Y. Liu, X. Wang, and J. Kurths, “Optimization of targeted node set in complex networks under percolation and selection,” Physical Review E, vol. 98, no. 1, p. 012313, 2018.
- [39] ——, “Framework of evolutionary algorithm for investigation of influential nodes in complex networks,” IEEE Transactions on Evolutionary Computation, vol. 23, no. 6, pp. 1049–1063, 2019.
- [40] C. Fan, Y. Sun, Z. Li, Y.-Y. Liu, M. Chen, and Z. Liu, “Dismantle large networks through deep reinforcement learning,” in ICLR representation learning on graphs and manifolds workshop, 2019.
- [41] C. Borgs, M. Brautbar, J. Chayes, and B. Lucier, “Maximizing social influence in nearly optimal time,” in Proceedings of the twenty-fifth annual ACM-SIAM symposium on Discrete algorithms. SIAM, 2014, pp. 946–957.
- [42] J. Goldenberg, B. Libai, and E. Muller, “Talk of the network: A complex systems look at the underlying process of word-of-mouth,” Marketing letters, vol. 12, no. 3, pp. 211–223, 2001.
- [43] D. Kempe, J. Kleinberg, and É. Tardos, “Maximizing the spread of influence through a social network,” in Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, 2003, pp. 137–146.
- [44] E. Cho, S. A. Myers, and J. Leskovec, “Friendship and mobility: user movement in location-based social networks,” in Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2011, pp. 1082–1090.
- [45] J. Leskovec, K. J. Lang, A. Dasgupta, and M. W. Mahoney, “Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters,” Internet Mathematics, vol. 6, no. 1, pp. 29–123, 2009.
- [46] M. Keeling, M. Woolhouse, R. May, G. Davies, and B. T. Grenfell, “Modelling vaccination strategies against foot-and-mouth disease,” Nature, vol. 421, no. 6919, pp. 136–142, 2003.