Prefer to Classify: Improving Text Classifiers via Auxiliary Preference Learning
Abstract
The development of largely human-annotated benchmarks has driven the success of deep neural networks in various NLP tasks. To enhance the effectiveness of existing benchmarks, collecting new additional input-output pairs is often too costly and challenging, particularly considering their marginal impact on improving the current model accuracy. Instead, additional or complementary annotations on the existing input texts in the benchmarks can be preferable as an efficient way to pay the additional human cost. In this paper, we investigate task-specific preferences between pairs of input texts as a new alternative way for such auxiliary data annotation. From ‘pair-wise’ comparisons with respect to the task, the auxiliary preference learning enables the model to learn an additional informative training signal that cannot be captured with ‘instance-wise’ task labels. To this end, we propose a novel multi-task learning framework, called prefer-to-classify (P2C), which can enjoy the cooperative effect of learning both the given classification task and the auxiliary preferences. Here, we provide three different ways to collect preference signals in practice: (a) implicitly extracting from annotation records (for free, but often unavailable), (b) collecting explicitly from crowd workers (high paid), or (c) pre-trained large language models such as GPT-3 (low paid). Given existing classification NLP benchmarks, we demonstrate that the proposed auxiliary preference learning via P2C on them is effective in improving text classifiers. Our codes are publicly available.111https://github.com/minnesotanlp/p2c
1 Introduction
The recent development of natural language processing (NLP) systems significantly boosts state-of-the-art performances on various NLP tasks (Brown et al., 2020; Ouyang et al., 2022). This success of NLP systems has been driven by, among other things, the construction of largely human-annotated benchmarks, such as GLUE (Wang et al., 2019), SQuAD (Rajpurkar et al., 2016), or BIG-bench (Srivastava et al., 2022). These benchmarks are usually constructed by (a) collecting (or writing) the relevant input texts and (b) assigning output labels by human annotators. Here, (a) is arguably more costly and cumbersome in many practical scenarios; for example, input texts with distribution mismatch or spurious patterns could make the model suffer from learning the generalized representation (Gururangan et al., 2018; Karamcheti et al., 2021), and hence the much higher cost is often paid to the collection process to keep the quality of the constructed benchmark (Kaushik et al., 2020). Therefore, it is often preferable to pay the additional human cost to annotate the existing benchmarks in a complementary way (instead of collecting new input texts), e.g., one can improve the label quality (Nie et al., 2020b; Fornaciari et al., 2021) by assigning multiple annotators to each input or obtain the finer task information with the new label space (Williams et al., 2022). In this paper, we investigate a new alternative way to better exploit the existing benchmarks (input texts and task labels), with auxiliary annotation to further improve the model performance.



Contribution. We introduce task-specific preferences between pairs of input texts as a new and auxiliary data annotation, to improve the text classification system upon the existing task annotations (Figure 1(a)). By relatively ordering a pair of two texts and better calibrating them with respect to the task through ‘pair-wise’ comparison, we expect that the auxiliary preference learning provides an additional informative training signal that cannot be captured with ‘instance-wise’ evaluation (see Figure 1(b)).
This preference signal could be obtained not only from human annotators (called subjective preference), but also from the existing annotation records (called extractive preference), if available, and even the recent strong pre-trained language models (called generative preference). To be specific, generative preference is obtained by querying the preference between two sentences to the recent language models (LMs), e.g., GPT-3 (Brown et al., 2020), with a prompting. Next, extractive preference is constructed from the existing annotation records in datasets ‘without additional cost’; if one sample has been less voted than the other, we treat the latter as a relatively higher preference between the two samples. Finally, we collect subjective preferences for 5,000 pairs of texts from (paid) crowd workers by asking them which text is more preferred to the task label.
To utilize both existing class labels and newly obtained preference labels with their cooperative effect, we propose a novel multi-task learning framework, coined prefer-to-classify (P2C), to effectively train the model from both classification and preference learning tasks. Specifically, we first introduce diverse multiple preference heads beside the classification head of the model for better learning from preference labels. Then, we introduce a new consistency regularization between classification and preference heads for imposing the model to have higher classification confidence in the preferred samples and hence enabling to detection of the inherent relationship between two tasks. Lastly, we propose two advanced sampling schemes to select more informative text pairs for improving the efficiency of training.
Through the extensive experiments on ten text classification datasets, we demonstrate the effectiveness of our new auxiliary preference learning framework via P2C; for example, P2C with generative preference from GPT-3 exhibited 11.55% relative test error reduction on average compared to the standard training method of the classifier. Next, P2C with extractive preference even outperforms the state-of-the-art methods utilizing annotation records with the 4.27% relative test error reduction. Lastly, the newly-collected subjective preference labels show the largest improvement compared to generative and extractive ones, which reveals the benefit of a more accurate preference signal; it does not only with the improvement in task performance but also with better calibration and task modeling; for example, 6.09% of expected calibration error while 9.19% from the same number of task labels. Overall, our work highlights the effectiveness of preference learning as an auxiliary method to improve the classification system, and we believe our work could inspire researchers to consider a new alternative way for data annotation.
2 Improving Text Classifiers via Auxiliary Preference Learning
In this section, we present prefer-to-classify (P2C), a novel multi-task learning framework to use the preference labels as an auxiliary data annotation for improving the text classifier. The auxiliary preference learning via P2C could provide a new informative training signal that cannot be captured with the existing ‘instance-wise’ evaluation by relatively ordering a pair of two texts and better calibrating them with respect to the task through ‘pair-wise’ comparison.

2.1 Preliminaries
Problem description. We describe the problem setup of our interest under a text classification scenario with classes. Let denote the given training dataset consisting of tuples where is the sequence of input tokens , and is the target task label. Our goal is to train a classifier , composed with Transformer-based language model backbone (e.g., BERT (Devlin et al., 2019)) and a random initialized classification head , to minimize the task-specific loss such as a cross-entropy loss where .
Preference learning. In this paper, we use a preference label between two data instances as an auxiliary learning signal to train the classifier. Specifically, the preference signals reflect the relative suitability between the two input samples with respect to the given task. We first assume that the preference labels of the given dataset are available. Then, our goal is to train a preference predictor to learn from the given human preferences, by predicting which one among the two input samples is more preferred. To this end, we formulate a preference learning as a supervised learning problem following the approaches in other domains such as reinforcement learning and generative modeling (Christiano et al., 2017; Ziegler et al., 2019; Lee et al., 2021). Given a pair of two different input tokens and task label , a preference label is additionally given; it indicates which input is preferred considering , i.e., , where 1 indicates (i.e., is preferred than ), 0 indicates , and 0.5 implies an equally preferable case. Each preference label is stored in a dataset as a quadruplet . Then, we predict a preference using the preference predictor following (Bradley & Terry, 1952):
| (1) |
where implies that input is preferable to input . The underlying assumption of this model is that the probability of preferring an input depends exponentially on its output. Then, the preference predictor is trained through supervised learning with the given human preferences, by minimizing the binary cross-entropy loss as follow222Equally preferable case is learned with the same coefficients.:
| (2) |
2.2 Prefer-to-classify (P2C)
Next, we present the specific techniques to train the classifier with given preference labels: (a) multi-task learning of classification and preference learning, (b) consistency regularization between classification and preference learning, and (c) informative pair sampling method based on the disagreement or inconsistency.
Multi-task learning with preference labels. To effectively learn from the given preference label and the task label , we train the classifier via multi-task learning (Ruder, 2017; Sener & Koltun, 2018) of both classification and preference learning. Specifically, we model the preference predictor in Eq. 1 upon the classifier similar to the case of . The preference prediction head is added on the output of Transformer backbone and task label , i.e., 333 means the concatenation between and . where .
Preference learning with diverse multi-preference heads. In addition, we introduce multiple preference heads and trained with in Eq. 2 to fully exploit the given preference labels. As obtaining preference labels requires additional cost, it is crucial to find effective ways to exploit them. By incorporating multiple preference prediction heads, we can obtain diverse learning signals from each preference label, based on their different random initialization (Ganaie et al., 2021). However, these multiple preference heads easily collapse into identical ones, as they are built on the compact representation of the pre-trained Transformer shared with the classification head. Hence, we introduced diversity regularization between during the training; we add a regularization to encourage the diverse prediction for each preference head by maximizing KL-divergence (Wang et al., 2021):
| (3) |
where is the predictive distribution of the preference predictor , i.e., . Overall, we train the classifier with the following multi-task learning objective under hyper-parameter :
| (4) |
where indicate the preference learning objective with each head and .
A: I got 3 veggies and a side of fries for over a 11 dollars if you like homecooked food B: She listened to my ideas, asked questions to get a better idea about my style, and was excellent at offering advice as if I were a total pleb. Sentiment: Positive, Generative Preference: A B, Extractive Preference: A B, Subjective Preference: B A A: We enjoyed our first and last meal in Toronto at Bombay Palace, and I can’t think of a better way to book our journey. B: So glad I finally tried this place because if confirmed my suspicions about that critic who rated it a 10. Sentiment: Positive, Generative Preference: A B, Extractive Preference: B A, Subjective Preference: No preference A: The buffalo chicken was not good, but very costly. B: There was so much stuff from all over that I had to leave to find an ATM for more cash to pay for it all. Sentiment: Negative, Generative Preference: A B, Extractive Preference: B A, Subjective Preference: B A A: The hotel offered complimentary breakfast. B: My friends had a full acrylic and the other had a fill. It looked so good. Sentiment: Positive, Generative Preference: A B, Extractive Preference: A B, Subjective Preference: A B
Consistency regularization between classification and preference learning. Even though multi-task learning is an effective way to train the model, it is still unclear whether or not the model can capture the relations between the two tasks explicitly. Accordingly, we hypothesize that a more preferred instance should have higher confidence from the classifier, i.e., if with the given task label . Hence, to impose the model explicitly follows this intuition, we further propose a consistency regularization between the two tasks as follows:
| (5) |
Additionally, when the degree of preference is explicitly provided, i.e., (see Section 4.3 of extractive preference case) rather than , we further extend this consistency regularization with margin which represents the degree of preference:
| (6) |
where . We note that the previous consistency regularization Eq. 5 becomes the special case of Eq. 6 with . Overall, our training loss of the classifier is as follows:
| (7) |
where is a hyper-parameter.
Selecting informative pairs. As the number of pairs of samples is proportional to the square of the number of training samples, it is difficult to obtain the preference label for all possible pairs, and even harder to learn from them even if we have all the preference labels. Hence, we propose the following advanced sampling scheme to maximize preference learning’s effectiveness during training: (1) Disagreement-based sampling, which selects pairs of instances with high variance across multiple preference predictors , and (2) Inconsistency-based sampling, which seeks to reduce the mismatched pairs with high consistency loss in Eq. 5. We evaluate the effects of these sampling methods in Appendix C.
3 Collection of Preference Labels
In this section, we present the descriptions of three different types of preference labels (generative, extractive, and subjective) to apply auxiliary preference learning via P2C. The detailed procedure of collecting each preference label and comparison between them is presented in Appendix B.
Generative preference from large language models. First, we propose to use the recent generative pre-trained large language models (Brown et al., 2020; Ouyang et al., 2022) to obtain the preference between pair of samples, and call the obtained preference label as generative preference. These models have recently demonstrated the strong zero/few-shot generalization performance in various NLP tasks, and our high-level intuition is that such capability could be effective to provide a useful signal between the samples. To be specific, we use GPT-3 through the officially provided API,444text-davinci-003 in https://beta.openai.com/docs/models/gpt-3 by querying the pair of sentences along with the properly designed prompts, presented in Appendix B. For the experiments of the dataset with samples, we randomly select one pair for each sample and acquire generative preference labels for P2C.
Extractive preference from data annotation records. Another way is to extract the preference signals from the existing datasets; our high-level assumption is that annotation records of each data, which are naturally gathered during the construction of the dataset, implicitly capture the preference between data samples. For example, if one sample has higher voting (9 out of 10) than the other sample (6 out of 10) as positive sentiment, one can assume that the former has a relatively higher preference. We call this implicit preference label as extractive preference; since the extractive preference is derived from existing sources of the dataset, it can be obtained for any pair of samples without additional cost. Hence, for the dataset with samples, one can obtain of extract preference labels at maximum. We randomly sample the pair of each sample and use their preference labels during training for P2C.
Subjective preference from crowd workers. Lastly, we consider directly collecting the human preference and call it as subjective preference; while it requires a high payment to hire human annotators, it is expected to be the most accurate as it is directly obtained by asking humans. Hence, to investigate the advantage of human preference, we construct the subjective preference dataset based on DynaSent-R2 dataset (Potts et al., 2021) for the sentiment classification task. Specifically, we gather the subjective preference of the sentence pairs by asking crowd workers to answer “which sentence is more positive (neutral, or negative)?” using Amazon’s Mechanical Turk crowd-sourcing platform (Crowston, 2012). Then, each worker should select one of the two sentences or answer “No Preference”. Following (Nie et al., 2020a), we hire three crowd workers for each pair of sentences at the most, and the pairs are dynamically selected across multiple rounds to maximize the obtained information. Consequently, we collect a total of 5,000 pairs’ subjective preference labels.
As described above, each type of preference has distinct characteristics as shown in Table 2; extractive preference could be freely obtained if the annotation records of the benchmark are available (i.e., lowest cost). On the other hand, generative preference may require an additional cost, but it is not expensive and provides the easiest way to access the preference labels. While subjective preference is the most expensive (e.g., 1.6$ for 10 samples, while 8.0$ for 5,000 samples with GPT-3), it has a clear advantage of providing an accurate and human-aligned preference signal. To verify the effect of those differences, we present qualitative and quantitative examples in Table 1 and Appendix B.
| Types | Cost | Accuracy | Accessibility |
|---|---|---|---|
| Generative Preference | Medium | Medium | High |
| Extractive Preference | Low | Medium | Medium |
| Subjective Preference | High | High | Low |
4 Experiments
| CoLA | SMS Spam | Hate Speech | Emotion | |||||
| Method | / wAcc | bAcc / wAcc | bAcc / wAcc | |||||
| Vanilla | 63.71.0 | 3.61.6 | 96.90.3 / 95.11.5 | 1.30.3 | 81.11.8 / 69.94.6 | 5.11.0 | 88.62.3 / 76.17.8 | 4.01.1 |
| Label Smoothing | 63.90.3 | 4.61.2 | 96.90.8 / 94.01.5 | 1.10.3 | 81.50.9 / 71.33.2 | 6.61.0 | 89.80.8 / 76.96.6 | 4.00.9 |
| Max Entropy | 64.10.3 | 4.50.4 | 96.91.1 / 94.71.6 | 1.20.3 | 81.61.8 / 70.54.2 | 4.30.7 | 89.11.1 / 73.12.5 | 3.60.9 |
| CS-KD | 64.51.4 | 4.11.1 | 96.80.9 / 94.02.4 | 1.10.2 | 81.42.6 / 69.65.1 | 5.31.8 | 89.41.6 / 74.06.8 | 4.10.2 |
| GPT-3 (0-shot) | 60.4 | - | 90.3 / 84.3 | - | 68.7 / 41.6 | - | 50.2 / 23.3 | - |
| GPT-3 (5-shot) | 58.50.4 | - | 92.20.5 / 88.50.7 | - | 78.52.0 / 70.33.6 | - | 46.60.6 / 30.32.6 | - |
| GPT-3 (20-shot) | 58.31.4 | - | 95.80.4 / 94.40.7 | - | 77.80.5 / 69.01.5 | - | 47.51.0 / 30.84.5 | - |
| P2C (Ours) | 65.41.0 | 2.81.1 | 97.40.4 / 95.21.0 | 1.10.3 | 82.41.3 / 73.64.5 | 4.00.3 | 90.70.7 / 81.74.7 | 3.60.8 |
4.1 Setups
Datasets. For the experiments, we first use the following four text classification datasets: (1) CoLA (Warstadt et al., 2019), (2) SMS Spam (Almeida et al., 2011), (3) Hate Speech (Fišer et al., 2018), and (4) Emotion (Saravia et al., 2018). In addition, to demonstrate the effectiveness of extractive preference, we investigate the publicly available datasets providing the annotation records and use the following six text classification datasets. DynaSent (Potts et al., 2021) is a dynamically constructed sentiment classification benchmark with ternary (positive/negative/neutral) sentiments; we use the dataset from the first round, (5) DynaSent-R1, and from the second round, (6) DynaSent-R2, the dataset for our experiments. Standford politeness corpus (Danescu-Niculescu-Mizil et al., 2013) is a binary classification benchmark for predicting whether the given sentence is polite or impolite. Since there are two different input domains within this benchmark, we split them into two different datasets: (7) Polite-Wiki from Wikipedia, and (8) Polite-SE from StackExchange, following the original setup. (9) Offensive agreement dataset (Leonardelli et al., 2021) is a binary classification benchmark for predicting whether the given sentence is offensive or not. (10) MultiNLI (Williams et al., 2018) is a crowd-sourced collection of sentence pairs annotated with textual entailment information; as the only validation set includes the annotation records, we split it into 8:1:1 for training, validation, and test sets. All datasets have the annotation records from 5 annotators for each sample. More details of datasets are presented in Appendix A.1.
Baselines. We first compare the proposed P2C to a naïve training with a cross-entropy loss and majority voted task label, denoted by (a) Vanilla. Then, since P2C with extractive preference can be viewed as a new way to utilize the annotation records, we compare this method with a wide range of disagreement learning methods in Section 4.3, as listed as follows; (b) Soft-labeling (Fornaciari et al., 2021): using the probabilistic distribution of annotations as soft labels for training; (c) Margin (Sharmanska et al., 2016): training the model with hinge loss by setting a margin proportional to the annotators’ agreements; (d) Filtering (Leonardelli et al., 2021): removing the training samples with a high disagreement. (e) Weighting (Uma et al., 2021): using weighted cross-entropy with smaller weights for the samples with high disagreements; (f) Multi-annotator (Davani et al., 2022): training the multiple classification heads for each annotation and using its ensemble for the evaluation. Furthermore, since we train the model with pair of samples, we also consider the baseline considering pair-wise training, (g) Class-wise Self-Knowledge Distillation (CS-KD) (Yun et al., 2020), which forces the similar predictive distribution between the same class samples to be similar. Lastly, we consider two regularization methods, (h) Label Smoothing (Müller et al., 2019) and (i) Max Entropy (Pereyra et al., 2017), as the baselines of P2C with generative preference in Section 4.2. Details are described in Appendix A.2.
Implementation details. All the experiments are conducted by fine-tuning RoBERTa-base (Liu et al., 2019) using Adam optimizer (Kingma & Ba, 2015) with a fixed learning rate 1e-5 and the default hyper-parameters of Adam. For all datasets, the model is fine-tuned using the specified training method with batch size 16 for 20 epochs. In the case of P2C, we use preference heads and 2-layer MLPs for each . We choose hyper-parameters from a fixed set of candidates based on the validation set: . We sample the pair of instances with the same task labels for efficiency. With the extractive preference, we apply the consistency loss with margin (Eq. 6) by using the difference of annotation as the margin . For other cases, we apply P2C with consistency loss without margin (Eq. 5) on the pre-defined pairs of samples. More details and experimental supports for the design choices can be found in Appendix A.3 and C, respectively.
4.2 Experiments with generative preference
In this section, we first evaluate our framework with the generative preference labels obtained from the pre-trained large language model, GPT-3 (Brown et al., 2020). To validate the effectiveness of P2C under the more challenging scenario, we use the following four datasets which have a skewed label distribution without annotation records: CoLA, SMS Spam, Hate Speech, and Emotion. Since their test datasets are also imbalanced, we measure the balanced accuracy (bAcc) (Huang et al., 2016) and the worst-group accuracy (wAcc) (Sagawa et al., 2020), to evaluate the generalization capability of the model, except CoLA since it is usually used with own metric, Matthews correlation coefficient (Mcc) (Chicco & Jurman, 2020). In addition, to measure the calibration of the trained model, we report Expected Calibration Error (ECE) (Guo et al., 2017). Here, we commonly adopt the temperature scaling to measure ECE following (Guo et al., 2017). As the annotation records are unavailable, we compare P2C with the baseline methods incurring the smoothed prediction of classifier only using the task label: Label Smoothing, Entropy Maximization, and CS-KD. In addition, we use -shot prompting predictions of GPT-3 () as an additional baseline.
As shown in Table 3, the generative preference labels with P2C are consistently effective in improving the performance of the text classifier; for example, P2C exhibited 11.55% relative test error reduction on average compared to Vanilla while also improving the predictive calibration. At the same time, we note that P2C shows better performance than the considered baseline, which indicates that the training signal from the preference label is more than smoothing the prediction of the classifier. Finally, as shown in Table 3, P2C significantly outperforms GPT-3 baselines, which means that our framework does not just distill the ‘instance-wise’ knowledge of GPT-3, but obtains complementary information through the proposed ‘pair-wise’ comparisons.
| Method | Offensive | Polite-Wiki | Polite-SE | MNLI | DynaSent-R1 | DynaSent-R2 |
|---|---|---|---|---|---|---|
| Vanilla | 75.880.72 | 89.351.53 | 70.001.49 | 81.920.70 | 80.430.30 | 71.231.05 |
| Soft-labeling | 76.081.44 | 89.571.76 | 70.351.68 | 82.670.50 | 81.100.33 | 72.151.59 |
| Margin Loss | 76.671.18 | 88.510.93 | 70.511.16 | 81.410.63 | 80.420.23 | 69.270.98 |
| Filtering | 76.131.18 | 89.500.87 | 68.282.43 | 82.130.67 | 80.380.34 | 69.860.78 |
| Weighting | 76.171.18 | 89.651.46 | 68.381.67 | 82.480.49 | 80.210.41 | 71.811.12 |
| Multi-annotator | 76.501.98 | 89.881.82 | 69.392.84 | 82.610.70 | 81.140.55 | 71.971.25 |
| CS-KD | 75.750.66 | 89.651.84 | 70.101.29 | 82.320.23 | 80.630.27 | 71.810.67 |
| P2C (Ours) | 77.810.21 | 91.060.64 | 71.210.93 | 83.150.29 | 81.500.39 | 73.060.31 |


4.3 Experiments with extractive preference
| Method | Sampling | DynaSent-R2 | Offensive | |||||
|---|---|---|---|---|---|---|---|---|
| Vanilla | - | ✓ | - | - | - | - | 71.231.05 | 75.880.72 |
| Preference | 1 | ✓ | ✓ | - | - | - | 71.840.78 | 75.901.15 |
| 3 | ✓ | ✓ | - | - | - | 71.920.66 | 76.430.32 | |
| 3 | ✓ | ✓ | ✓ | - | - | 72.051.30 | 76.671.38 | |
| 3 | ✓ | ✓ | ✓ | ✓ | - | 72.670.89 | 77.670.99 | |
| P2C (Ours) | 3 | ✓ | ✓ | ✓ | ✓ | ✓ | 73.060.31 | 77.810.21 |
| Method | / | / | ||||
|---|---|---|---|---|---|---|
| Vanilla | 7.5k | - | 69.031.29 | 59.332.57 / 80.001.22 | 9.251.39 | 0.8560.01 / 0.4050.03 |
| Task Labels | 12.5k | - | 71.171.35 | 57.862.31 / 84.211.05 | 9.191.36 | 0.8780.04 / 0.3270.02 |
| Generative Preference | 7.5k | 5k | 71.461.16 | 61.770.94 / 82.281.01 | 6.640.79 | 0.8500.02 / 0.3610.02 |
| Extractive Preference | 7.5k | 5k | 71.361.19 | 61.161.91 / 83.111.78 | 6.750.78 | 0.8470.03 / 0.3510.03 |
| Subjective Preference | 7.5k | 5k | 71.741.04 | 62.080.94 / 83.011.27 | 6.090.31 | 0.8280.02 / 0.3560.02 |
While the generative preference is an efficient way to apply auxiliary preference learning with P2C using the moderate cost, it would be much better if one could still benefit from P2C for free. In this section, we evaluate the effectiveness of P2C with the extractive preference labels, which could be freely obtained from the existing benchmarks if the annotations records are available. We compare P2C with various disagreement learning schemes to fine-tune the RoBERTa-base classifier for each dataset, as they also utilize the annotation records for better training. Table 4 summarizes the results on six text classification datasets. Remarkably, P2C consistently outperforms the baseline methods for all six datasets. To be specific, P2C exhibits 7.59% relative test error reduction compared to the vanilla method in the average. Furthermore, compared to the previous best disagreement learning method of each dataset, P2C exhibits 4.27% relative test error reduction on average. These results show that extractive preferences successfully provide complementary training signals to the classifier from the pair-wise preference, and demonstrate the effectiveness of P2C as a training method to utilize the annotation records.
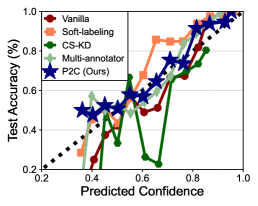
Next, on DynaSent-R2, we conduct additional experiments to verify how P2C improves the classifier. We first check whether the prediction of the trained model with P2C is similar to the annotators’ judgment, as the extractive preference labels come from annotation records. Specifically, we compare the L1 distance between the predictions of the model and the soft labels from the annotation records in Figure 3(a). We verify that P2C achieves the lowest distance to the soft labels, showing the validity of our preference learning for better modeling of the given task. Moreover, we verify that the calibration of the classifier is more improved than the baselines, as a result of pair-wise preference modeling. To be specific, we provide a reliability diagram (Yun et al., 2020), which plots the expected sample accuracy as a function of the confidence of the classifier in Figure 3(b). We remark that the plotted identity function (dashed diagonal) implies perfect calibration (Guo et al., 2017), and our method is the closest one among the baselines. This calibration effect of P2C is further verified through ECE in Figure 3(c).
To validate the effectiveness of the proposed component of P2C in Section 2.2, we perform the ablation experiments, and the results are presented in Table 5, as the extractive preference of all pairs is accessible. It is observable that diverse multi-preference heads improve the effectiveness of preference labels with better modeling compared to the single preference head (2-4th rows). In addition, consistency regularization between classification and preference heads enables the classifier to fully utilize the pair-wise training signal to solve the task, hence the performance is significantly improved (5th row). The performance is further improved by selecting the informative pairs during the training (6th row). More results are in Appendix C.
4.4 Experiments with subjective preference
Lastly, we verify the effectiveness of collected subjective preference labels compared to other types of labels. To this end, we consider the scenario that the specific types of labels are additionally obtained on top of the existing task labels. Namely, task labels could be collected more with additional training samples, or preference labels between the existing samples could be obtained. Table 6 summarizes the experimental results. Here, it is observed that subjective preference labels are the most effective for improving the test accuracy () along with a better calibration effect. Remarkably, it is noticeable that the preference labels significantly improve the accuracy on relatively hard samples () regardless of its type, while the additional task labels are effective for the relatively easy samples.555We define the difficulty based on the disagreement of annotators, i.e., more disagree indicates more difficult. Somewhat surprisingly, one can observe that the additional 5k generative preference labels by GPT-3 are more effective than the same number of task labels, although the former is much cheaper to obtain than the latter; it indicates that our framework can serve as a new effective way to evolve the existing benchmarks along with the recent development of pre-trained large language models at a considerable cost.
4.5 Applications of P2C beyond text classification
| Method / Tasks | nat.light | man-made | open | enclosed | nohorizon | Average |
|---|---|---|---|---|---|---|
| Vanilla | 78.671.05 | 62.502.65 | 79.001.43 | 85.830.61 | 76.420.62 | 76.481.25 |
| P2C (Ours) | 79.830.94 | 64.831.71 | 82.330.72 | 86.251.43 | 77.001.06 | 78.051.17 |
While we primarily demonstrate the effectiveness of P2C on the text classification datasets, our approach has the potential to be applicable beyond text classification. To empirically verify such advantages, we have conducted additional experiments on an image classification task to validate our approach’s applicability. Specifically, we used the publicly available SUN Attribute dataset (Patterson et al., 2014) and constructed multiple binary scene attribute classification tasks from it, following the setups in (Sharmanska et al., 2016). Here, we considered the largest five attributes for the experiments. As this dataset includes annotation records, we constructed extractive preference labels to apply P2C. For experiments, we commonly trained ResNet-18 (He et al., 2016) from scratch, for 100 epochs using the SGD optimizer with a weight decay of 0.01 and a learning rate of 0.1 (decreased to 0.01 and 0.001 at 50 and 75 epochs, respectively).
In Table 7, one can observe that our P2C approach effectively improves the performance of the image classifier, with an average relative test error reduction of 6.66% compared to the Vanilla method. These results indicate that the effectiveness of our approach is not only limited to text classification and can be extended to broader applications.
5 Related Works
Preference learning. Preference learning is about modeling the preference using a set of instances, associated with an order relation (Fürnkranz & Hüllermeier, 2010). Since it is much easier for humans to make relative judgments, i.e., comparing behaviors as better or worse, preference-based learning becomes an attractive alternative; hence, extensive research has been conducted to address this problem by proposing different techniques to learn from human judgments (Bıyık et al., 2020; Chu & Ghahramani, 2005). One of the most representative fields that adopt preference-based learning is Reinforcement Learning (RL), to learn RL algorithms from the preferences rather than the explicit design of reward function (Wirth et al., 2017). After the successful scale-up of preference-based learning with deep neural networks (Christiano et al., 2017; Lee et al., 2021), this research direction has been extensively explored in other domains such as NLP (Stiennon et al., 2020; Ziegler et al., 2019) and computer vision (Kazemi et al., 2020), especially focused on the generation tasks, e.g., text summarization and image generation. However, preference learning is yet under-explored for classification tasks, despite its great potential to provide complementary and informative training signals via pair-wise comparison of samples.
Learning-to-rank. Preference learning shares a close relationship with learning-to-rank (LTR), a prevalent framework for constructing models or functions to rank objects, as both seek to establish the specific order among samples (Hüllermeier et al., 2008). While preference learning focuses on developing a model to predict preferences between objects, LTR primarily aims to generate ranked lists of items based on their relevance to a given query or context (Fürnkranz & Hüllermeier, 2010). Consequently, LTR has become a key component of various information retrieval problems, such as document retrieval and web search (Burges et al., 2005; Cao et al., 2007). Simultaneously, several works have applied LTR to classification tasks; for instance, (Chang et al., 2020) illustrates the efficacy of LTR for multi-label classification. Furthermore, (Atapour-Abarghouei et al., 2021) transforms classification into LTR and demonstrates its potential for broader classification problems. Compared to these works, our work introduces a novel approach to integrating pairwise comparison for generic classification problems through a multi-task learning framework, accompanied by new methods for obtaining pairwise comparisons between samples.
Auxiliary data annotation. As the development and deployment of NLP systems are directly affected by the quality of benchmarks, various approaches have been recently explored to construct more effective and robust benchmarks. For example, one line of works propose to continuously evolve the benchmark to prevent it becomes obsolete or human-aligned by collecting the adversarial samples of the state-of-the-art models (Nie et al., 2020a; Potts et al., 2021) or incorporating human in the data construction loop (Kiela et al., 2021; Yuan et al., 2021). However, as the collection of new examples is costly, another line of work focuses on finding a better way to annotate the existing benchmarks. For example, some recent works investigate the alternative labeling method rather than a simple majority voting from the annotation records, to avoid sacrificing the valuable nuances embedded in the annotators’ assessments and their disagreement (Fornaciari et al., 2021; Leonardelli et al., 2021; Davani et al., 2022). Our work suggests a new alternative way for a better annotation of the existing benchmark via preference between pairs of samples.
6 Conclusion
In this paper, we introduce task-specific preference signals between pairs of samples as a new and auxiliary data annotation to improve the existing text classification system, which relies on instance-wise annotations. To this end, we propose a novel multi-task learning framework, called prefer-to-classify (P2C), to effectively train the classifier from both task and preference labels, and demonstrate this framework under three different types of preference labels.
Acknowledgements. We thank Jongjin Park and Jihoon Tack for providing helpful feedback. This work was supported by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No.2019-0-00075, Artificial Intelligence Graduate School Program (KAIST); No. 2022-0-00184, Development and Study of AI Technologies to Inexpensively Conform to Evolving Policy on Ethics) and the Engineering Research Center Program through the National Research Foundation of Korea (NRF) funded by the Korean Government (MSIT) (NRF-2018R1A5A1059921).
References
- Almeida et al. (2011) Almeida, T. A., Hidalgo, J. M. G., and Yamakami, A. Contributions to the study of sms spam filtering: New collection and results. In Proceedings of the 11th ACM symposium on Document engineering, pp. 259–262, 2011.
- Atapour-Abarghouei et al. (2021) Atapour-Abarghouei, A., Bonner, S., and McGough, A. S. Rank over class: The untapped potential of ranking in natural language processing. In 2021 IEEE International Conference on Big Data (Big Data), pp. 3950–3959. IEEE, 2021.
- Bıyık et al. (2020) Bıyık, E., Huynh, N., Kochenderfer, M. J., and Sadigh, D. Active preference-based gaussian process regression for reward learning. arXiv preprint arXiv:2005.02575, 2020.
- Bradley & Terry (1952) Bradley, R. A. and Terry, M. E. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- Brown et al. (2020) Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in Neural Information Processing Systems (NeurIPS), 2020.
- Burges et al. (2005) Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, N., and Hullender, G. Learning to rank using gradient descent. In Proceedings of the International Conference on Machine Learning (ICML), 2005.
- Cao et al. (2007) Cao, Z., Qin, T., Liu, T.-Y., Tsai, M.-F., and Li, H. Learning to rank: From pairwise approach to listwise approach. In Proceedings of the International Conference on Machine Learning (ICML), 2007.
- Chang et al. (2020) Chang, W.-C., Yu, H.-F., Zhong, K., Yang, Y., and Dhillon, I. S. Taming pretrained transformers for extreme multi-label text classification. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 3163–3171, 2020.
- Chicco & Jurman (2020) Chicco, D. and Jurman, G. The advantages of the matthews correlation coefficient (mcc) over f1 score and accuracy in binary classification evaluation. BMC genomics, 21:1–13, 2020.
- Christiano et al. (2017) Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems (NeurIPS), 2017.
- Chu & Ghahramani (2005) Chu, W. and Ghahramani, Z. Preference learning with gaussian processes. In Proceedings of the International Conference on Machine Learning (ICML), 2005.
- Crowston (2012) Crowston, K. Amazon mechanical turk: A research tool for organizations and information systems scholars. In Shaping the future of ict research. methods and approaches, pp. 210–221. Springer, 2012.
- Danescu-Niculescu-Mizil et al. (2013) Danescu-Niculescu-Mizil, C., Sudhof, M., Jurafsky, D., Leskovec, J., and Potts, C. A computational approach to politeness with application to social factors. In Annual Meeting of the Association for Computational Linguistics (ACL), 2013.
- Davani et al. (2022) Davani, A. M., Díaz, M., and Prabhakaran, V. Dealing with disagreements: Looking beyond the majority vote in subjective annotations. Transactions of the Association for Computational Linguistics (TACL), 10:92–110, 2022.
- Devlin et al. (2019) Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2019.
- Fišer et al. (2018) Fišer, D., Huang, R., Prabhakaran, V., Voigt, R., Waseem, Z., and Wernimont, J. Proceedings of the 2nd workshop on abusive language online (alw2). In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), 2018.
- Fornaciari et al. (2021) Fornaciari, T., Uma, A., Paun, S., Plank, B., Hovy, D., and Poesio, M. Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2021.
- Fürnkranz & Hüllermeier (2010) Fürnkranz, J. and Hüllermeier, E. Preference learning and ranking by pairwise comparison. In Preference learning, pp. 65–82. Springer, 2010.
- Ganaie et al. (2021) Ganaie, M. A., Hu, M., et al. Ensemble deep learning: A review. arXiv preprint arXiv:2104.02395, 2021.
- Guo et al. (2017) Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. On calibration of modern neural networks. In Proceedings of the International Conference on Machine Learning (ICML), 2017.
- Gururangan et al. (2018) Gururangan, S., Swayamdipta, S., Levy, O., Schwartz, R., Bowman, S. R., and Smith, N. A. Annotation artifacts in natural language inference data. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2018.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Huang et al. (2016) Huang, C., Li, Y., Loy, C. C., and Tang, X. Learning deep representation for imbalanced classification. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Hüllermeier et al. (2008) Hüllermeier, E., Fürnkranz, J., Cheng, W., and Brinker, K. Label ranking by learning pairwise preferences. Artificial Intelligence, 172(16-17):1897–1916, 2008.
- Karamcheti et al. (2021) Karamcheti, S., Krishna, R., Fei-Fei, L., and Manning, C. D. Mind your outliers! investigating the negative impact of outliers on active learning for visual question answering. In Annual Meeting of the Association for Computational Linguistics (ACL), 2021.
- Kaushik et al. (2020) Kaushik, D., Hovy, E., and Lipton, Z. C. Learning the difference that makes a difference with counterfactually-augmented data. In International Conference on Learning Representations (ICLR), 2020.
- Kazemi et al. (2020) Kazemi, H., Taherkhani, F., and Nasrabadi, N. Preference-based image generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3404–3413, 2020.
- Kiela et al. (2021) Kiela, D., Bartolo, M., Nie, Y., Kaushik, D., Geiger, A., Wu, Z., Vidgen, B., Prasad, G., Singh, A., Ringshia, P., et al. Dynabench: Rethinking benchmarking in nlp. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2021.
- Kingma & Ba (2015) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015.
- Lan et al. (2020) Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., and Soricut, R. Albert: A lite bert for self-supervised learning of language representations. In International Conference on Learning Representations (ICLR), 2020.
- Lee et al. (2021) Lee, K., Smith, L., and Abbeel, P. Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training. In Proceedings of the International Conference on Machine Learning (ICML), 2021.
- Leonardelli et al. (2021) Leonardelli, E., Menini, S., Aprosio, A. P., Guerini, M., and Tonelli, S. Agreeing to disagree: Annotating offensive language datasets with annotators’ disagreement. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021.
- Liu et al. (2019) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Müller et al. (2019) Müller, R., Kornblith, S., and Hinton, G. E. When does label smoothing help? In Advances in Neural Information Processing Systems (NeurIPS), 2019.
- Nie et al. (2020a) Nie, Y., Williams, A., Dinan, E., Bansal, M., Weston, J., and Kiela, D. Adversarial nli: A new benchmark for natural language understanding. In Annual Meeting of the Association for Computational Linguistics (ACL), 2020a.
- Nie et al. (2020b) Nie, Y., Zhou, X., and Bansal, M. What can we learn from collective human opinions on natural language inference data? In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020b.
- Ouyang et al. (2022) Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
- Patterson et al. (2014) Patterson, G., Xu, C., Su, H., and Hays, J. The sun attribute database: Beyond categories for deeper scene understanding. International Journal of Computer Vision, 108:59–81, 2014.
- Pereyra et al. (2017) Pereyra, G., Tucker, G., Chorowski, J., Kaiser, Ł., and Hinton, G. Regularizing neural networks by penalizing confident output distributions. arXiv preprint arXiv:1701.06548, 2017.
- Potts et al. (2021) Potts, C., Wu, Z., Geiger, A., and Kiela, D. Dynasent: A dynamic benchmark for sentiment analysis. In Annual Meeting of the Association for Computational Linguistics (ACL), 2021.
- Rajpurkar et al. (2016) Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. Squad: 100,000+ questions for machine comprehension of text. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2016.
- Ruder (2017) Ruder, S. An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098, 2017.
- Sagawa et al. (2020) Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. In International Conference on Learning Representations (ICLR), 2020.
- Saravia et al. (2018) Saravia, E., Liu, H.-C. T., Huang, Y.-H., Wu, J., and Chen, Y.-S. Carer: Contextualized affect representations for emotion recognition. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018.
- Sener & Koltun (2018) Sener, O. and Koltun, V. Multi-task learning as multi-objective optimization. In Advances in Neural Information Processing Systems (NeurIPS), 2018.
- Sharmanska et al. (2016) Sharmanska, V., Hernández-Lobato, D., Miguel Hernandez-Lobato, J., and Quadrianto, N. Ambiguity helps: Classification with disagreements in crowdsourced annotations. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Srivastava et al. (2022) Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., Brown, A. R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
- Stiennon et al. (2020) Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., and Christiano, P. F. Learning to summarize with human feedback. Advances in Neural Information Processing Systems (NeurIPS), 2020.
- Uma et al. (2021) Uma, A. N., Fornaciari, T., Hovy, D., Paun, S., Plank, B., and Poesio, M. Learning from disagreement: A survey. Journal of Artificial Intelligence Research, 72:1385–1470, 2021.
- Wang et al. (2019) Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. Glue: A multi-task benchmark and analysis platform for natural language understanding. In International Conference on Learning Representations (ICLR), 2019.
- Wang et al. (2021) Wang, X., Lian, L., Miao, Z., Liu, Z., and Yu, S. X. Long-tailed recognition by routing diverse distribution-aware experts. In International Conference on Learning Representations (ICLR), 2021.
- Warstadt et al. (2019) Warstadt, A., Singh, A., and Bowman, S. R. Neural network acceptability judgments. Transactions of the Association for Computational Linguistics, 7:625–641, 2019.
- Williams et al. (2018) Williams, A., Nangia, N., and Bowman, S. R. A broad-coverage challenge corpus for sentence understanding through inference. In NAACL-HLT, 2018.
- Williams et al. (2022) Williams, A., Thrush, T., and Kiela, D. Anlizing the adversarial natural language inference dataset. In Proceedings of the Society for Computation in Linguistics 2022, 2022.
- Wirth et al. (2017) Wirth, C., Akrour, R., Neumann, G., Fürnkranz, J., et al. A survey of preference-based reinforcement learning methods. Journal of Machine Learning Research, 18(136):1–46, 2017.
- Xiao et al. (2010) Xiao, J., Hays, J., Ehinger, K. A., Oliva, A., and Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2010.
- Yuan et al. (2021) Yuan, A., Ippolito, D., Nikolaev, V., Callison-Burch, C., Coenen, A., and Gehrmann, S. Synthbio: A case study in human-ai collaborative curation of text datasets. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- Yun et al. (2020) Yun, S., Park, J., Lee, K., and Shin, J. Regularizing class-wise predictions via self-knowledge distillation. In Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- Ziegler et al. (2019) Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
Appendix
Prefer to Classify: Improving Text Classifiers via Auxiliary Preference Learning
Appendix A Experimental Details
A.1 Datasets
As described in Section 4.1, we extensively demonstrate the effectiveness of P2C on the multiple classification datasets; 10 text classification datasets and 1 image classification dataset. For text data, we commonly set the maximum length as 256 for the tokenization of given data. First, we use the following four text classification datasets in Section 4.2, which do not release the annotation records; hence, the extractive preference labels are not available:
CoLA (Warstadt et al., 2019) is a binary single sentence classification task, where the goal is to predict whether the given English sentence is linguistically valid or not. It is composed of 8.5k training samples and 1k development samples. We remark that the CoLA dataset is part of the popular benchmark, GLUE (Wang et al., 2019), and the dataset is officially available at https://huggingface.co/datasets/glue.
SMS Spam (Almeida et al., 2011) is a public set of SMS-labeled messages that have been collected for mobile phone spam research. It has one collection composed of 5,574 English, real and non-encoded messages, tagged according to being legitimate (ham) or spam. We split the dataset into an 8:1:1 ratio to construct training, validation, and test datasets. SMS Spam is officially available at https://huggingface.co/datasets/sms_spam.
Hate Speech (Fišer et al., 2018) is constructed by extracting the texts from Stormfront, a white supremacist forum. A random set of forum posts have been sampled from several subforums and split into sentences. Those sentences have been manually labeled as containing hate speech or not, according to certain annotation guidelines. Overall, it is composed of 10,703 sentences. We split the dataset into an 8:1:1 ratio to construct training, validation, and test datasets. Hate Speech is officially available at https://huggingface.co/datasets/hate_speech18.
Emotion (Saravia et al., 2018) is a dataset of English Twitter messages with six basic emotions: sadness (0), joy (1), love (2), anger (3), fear (4), and surprise (5). In the given Emotion dataset, there are 16,000 training, 2,000 validation, and 2,000 test samples. We use the Emotion dataset at https://huggingface.co/datasets/dair-ai/emotion.
Next, we use the following six text classification datasets, obtained from the following three different sources, which release the annotation records during the construction of the datasets. Here, all datasets have the annotation records of 5 different annotators for each data; however, the annotators can be different among data, i.e., there are more than 5 annotators overall.
DynaSent (Potts et al., 2021) is a sentiment classification benchmark with ternary (positive/negative/neutral) sentiments. It is dynamically constructed through multiple iterations of training a classifier model and finding its adversarial samples by involving a human annotator in the loop. In our experiments, we use the dataset from the first round, DynaSent-R1, and the dataset from the second round, DynaSent-R2. DynaSent-R1 comprises 80,488 training samples, 3,600 validation samples, and 3,600 test samples, respectively. DynaSent-R2 comprises 13,065 training samples, 720 validation samples, and 720 test samples. All the validation and test samples are fully balanced between the three classes. DynaSent dataset and more details of the dataset are officially available at https://github.com/cgpotts/dynasent.
Standford politeness corpus (Danescu-Niculescu-Mizil et al., 2013) is a binary classification benchmark for predicting whether the given sentence is polite or impolite. Since there are two different input domains within this benchmark, we split them into two different datasets: Polite-Wiki from Wikipedia, and Polite-SE from Stack Exchange, following the original paper (Danescu-Niculescu-Mizil et al., 2013). Here, two classes: polite and impolite, are defined as the top and, respectively, bottom quartile of sentences when sorted by their politeness score. The classes are therefore balanced, with each class consisting of 1,089 samples for the Wikipedia domain and 1,651 samples for the Stack Exchange domain. We split each dataset into an 8:1:1 ratio to construct training, validation, and test datasets. The source data and more details of the dataset are officially available at https://www.cs.cornell.edu/~cristian/Politeness.html.
Offensive agreement dataset (Leonardelli et al., 2021) is a binary classification benchmark for predicting whether the given sentence is offensive or not. Each sentence is collected from Twitter using Twitter public APIs, based on the hashtags and keywords on three different domains: Covid-19, US Presidential elections and the Black Lives Matter (BLM) movement. Remarkably, some of the original samples are not available anymore due to the elimination of tweets from the user side; for example, 10,735 samples are collected initially (Leonardelli et al., 2021), but only 6,513 samples are now available. To address the issue of the reduced number of samples, we slightly modify the dataset to keep the setups of the original paper, e.g., balanced among the classes and domains. Specifically, we gather the given splits of the dataset into the unified one and then re-split it as much be balanced as possible. This re-constructed dataset has 2,400 training samples, 400 validation samples, and 400 test samples. Also, the ratio between Covid-19, Election, and BLM is 3:3:2. The dataset is officially available with the request to authors at https://github.com/dhfbk/annotators-agreement-dataset.
Multi-Genre Natural Language Inference (MultiNLI) (Sener & Koltun, 2018) is a crowd-sourced collection of 433k sentence pairs annotated with textual entailment information: for a given premise sentence, one should classify whether the given hypothesis sentence is entailment, neutral, or contradiction to the premise (ternary classification). Since the annotation records are only available with the validation set, we construct the datasets by splitting it into 8:1:1 for training, validation, and test sets. This re-constructed dataset has 15,717 training samples, 1,964 validation samples, and 1,966 test samples. The source data and more details of the dataset are officially available at https://cims.nyu.edu/~sbowman/multinli.
Finally, to demonstrate the applicability of P2C beyond NLP tasks, we use the SUN Attribute dataset (Patterson et al., 2014):
SUN Attribute dataset (Patterson et al., 2014) is constructed by conducting Amazon’s Mechanical Turk crowd-sourcing platform (Crowston, 2012) to annotate the presence of the target attribute in the given image. The dataset consists of 14,340 scene images from the SUN dataset (Xiao et al., 2010), which has 102 scene attributes such as sunny, natural, man-made, etc. In this dataset, the presence of the attribute is measured as an average score of three binary user responses, i.e., it contains the annotation records and hence we use it to construct the extractive preference for our framework. The source data and more details of the dataset are officially available at https://cs.brown.edu/~gmpatter/sunattributes.html.
A.2 Baselines
We first introduce some notations for a clear explanation. For each sample , there are annotation records where is the number of class and is the number of votes666All the used datasets commonly have . Then, the majority voted target label is obtained by finding the most agreed labels, i.e., , and simply denoted by . Here, our goal is to train a classifier , composed with Transformer-based language model backbone (e.g., BERT (Devlin et al., 2019)) and a random initialized classification head , where the prediction for is obtained with softmax, i.e., . For the analysis in Figure 3, we only include four baselines with high performance based on the results in Table 4.
Vanilla: as described in Section 2.1, the model is trained with the following cross-entropy loss:
Soft-labeling (Fornaciari et al., 2021): instead of using majority voted label , it use the soft-labels with a cross entropy loss:
Margin Loss (Sharmanska et al., 2016): instead of using majority voted label and cross-entropy loss, it uses the soft-labels as a margin for the multi-class hinge loss:
Filtering (Leonardelli et al., 2021): following the setups in the original paper, we exclude the ambiguous samples that have a low agreement between the annotators. Specifically, we exclude the samples with since there are 5 annotators for all considered datasets by following (Leonardelli et al., 2021), and use majority voting for the others.
Weighting (Uma et al., 2021): using weighted cross entropy that down-weigh the samples with a low agreement:
where .
Multi-annotator (Davani et al., 2022): instead of aggregating the different annotators’ annotation records, it introduces multiple classification heads for learning from each annotator’s annotation . Since each annotator does not annotate all the samples, we simply separate the annotations and train each classification head where . For the inference of test samples, the ensemble of multiple classification heads is used.
where .
CS-KD (Yun et al., 2020): for each sample , the sample within the same class, defined by a majority voted label , is also sample and the consistency regularization is additionally imposed between their prediction with a temperature . Following the original paper, we use .
where .
Label Smoothing (Müller et al., 2019): instead of directly using majority voted label , it first constructs the soft-label by subtracting for the class and equally distributing it to remaining classes, i.e., . We find the best hyper-parameter among using the validation set. Then, this soft label is used to train the model with a cross-entropy loss:
Max Entropy (Pereyra et al., 2017): in addition to the cross-entropy loss with the majority voted label , the regularization loss to increase the entropy of the prediction is used as a training loss with a hyper-parameter . is tuned among using the validation set:
A.3 Prefer-to-Classify (P2C)
In this section, we describe the details of P2C. We first note that the details are slightly different between extractive preference learning (Section 4.3) and subjective preference learning (Section 4.4) due to the difference in experimental setups between them. As described in Section 4, we commonly use preference heads and 2-layer MLPs with activation for each . We choose hyper-parameters from a fixed set of candidates based on the validation set; . Also, we only sample the pair of instances with the same majority voted labels for efficiency.
In the case of learning with extractive preference in Section 4.3, we apply the consistency regularization with margin (Eq. 6) by using the difference of annotation as the margin . Specifically, we set a margin of class between two samples and as the difference of their soft-labels , defined in Section A.2. Then, we apply the consistency regularization to all classes . In addition, we apply the inconsistency-based sampling for the experiments with extractive preference labels based on the superior experimental results, presented in Section C.
In the case of learning with subjective and generative preference labels in Section 4.4 and 4.2, we apply the consistency regularization without margin (Eq. 5) since the explicit degree of preference is not given. Also, since the number of pairs with subjective preference labels is limited, we use all of them in training without applying the sampling methods described in Section 2.2. We introduce the additional mini-batch from these pairs to optimize the model with consistency regularization. The full procedures of P2C with extractive and subjective preference are described in Algorithm 1 and 2, respectively.
Appendix B Collection of Preference Labels
B.1 More details of preference labels






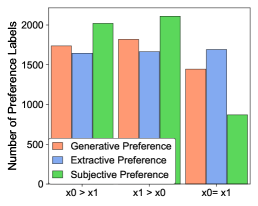
Extractive preference. For a formal description of the process of collecting extractive preference, we borrow some notations introduced in Section A.2. As described in Section 3, we obtain the extractive preference label by comparing the number of votes with the given task label : if , then we assign where it indicates . Similarly, we assign when and when , respectively. To reduce the noisy signal and focus on the effective pair, we only compare the samples that have the same majority voted labels, i.e., . The resulting distribution of extractive preference labels for each data is presented in Figure 4.




I


Generative preference. As we denote in Section 3, we collect the generative preference labels by querying the pair of samples to the recent large pre-trained language model, GPT-3 (Brown et al., 2020). Specifically, we use the officially provided API777text-davinci-003 in https://beta.openai.com/docs/models/gpt-3. To this end, we design our prompt as Figure 6; for th pair of sentences, we provide two sentences along with their task labels. The resulting distribution of generative preference labels for each data is presented in Figure 5.
Subjective preference. We collect the subjective preference labels based on paired samples from DynaSent-R2 dataset (Potts et al., 2021) for the sentiment classification task. To be specific, we gather the subjective preference of the pairs by asking crowd workers to answer “which sentence is more positive (neutral, or negative)?” using Amazon’s Mechanical Turk crowd-sourcing platform (Crowston, 2012). Then, each worker should select one of the two sentences or answer “No Preference”. Following (Nie et al., 2020a), we initially provide each pair of sentences to two crowd workers. If two workers give the same preference label, this pair is labeled with that. If they disagree, we ask a third crowd worker to break the tie. If they still fail to reach a consensus, this pair is labeled with “No Preference”.
Under this procedure, we first gather 1,000 subjective preference labels of randomly selected pairs of sentences. Then, we dynamically collect the additional subjective preference labels to maximize the information of collected pairs, motivated by the recent dynamic benchmark constructions (Kiela et al., 2021; Nie et al., 2020a). Namely, we first train the model with existing subjective preference labels. Then, we find the most informative pairs in the aspect of the trained model, using the disagreement-based sampling introduced in Section 2.2 and query their preference labels in the next stage. We select an equal number of pairs for each class to balance the label distribution. Overall, starting with 1,000 random pairs, we collect the preference of 2,000 pairs at each round and iterate this procedure for 2 rounds, i.e., a total of 5,000 pairs’ subjective preference labels are collected.
Figure 7 shows the interface used to collect subjective preference labels from crowd workers for sentiment analysis based on DynaSent-R2 (Potts et al., 2021). The top provides the instructions, and then one example is shown. The whole task has 10 items per Human Interface Task (HIT). Workers were paid US$0.8 per HIT on average, and all workers were paid for their work. To improve the quality of collected preference labels, we only hire the Master workers identified as high-performing workers from Amazon’s Mechanical Turk system.
B.2 Comparison between different types of preference labels


As generative, extractive, and subjective preferences come from different sources of knowledge, they are naturally expected to have different characteristics. To this end, we first compare the distribution of preference labels with 5,000 pair of samples on DynaSent-R2, which are exactly used to collect the subjective preference labels; as shown in Figure 8(a), they have clearly different label distributions. This discrepancy is more clearly verified when we measure the coincidence between the preference labels (Figure 8(b)); three preference labels output the same label for only 10.72 % of pairs, while outputting the mutually exclusive one for 19.78 % of pairs. To further investigate the effectiveness of each preference label, we fine-tuned RoBERTa model only using those pair of samples with the different preference labels for each method; as shown in Figure 8(c), the subjective preference shows the best performance, while the generative preference shows the worst performance. It implies the importance of the quality of preference labels and the effectiveness of generative preference could be from approximating extractive or subjective ones in a cheap way.
B.3 More examples of preference labels
In Table 8, we present more examples in our extractive, subjective, and generative preference labels on DynaSent-R2 dataset, similar to Table 1.
A: I noticed when I walked in they looked at me, the eyes of them reflecting. B: I’ve been to the restaurant a more times and I can understand why this dichotomy may exist. Sentiment: Neutral, Generative Preference: No preference, Extractive Preference: B A, Subjective Preference: B A A: The pet clinic was very unprofessional. B: Fast forward to today 2 months later and still I have not received my plates that I paid for and I am driving around on their temp paper plate. I was angry. Sentiment: Negative, Generative Preference: B A, Extractive Preference: No preference, Subjective Preference: No preference A: The fresh bread of the bagel available here. B: Since it isn’t a big restaurant, to get the attention from the waitress isn’t that hard. Sentiment: Positive, Generative Preference: A B, Extractive Preference: B A, Subjective Preference: A B A: I expect everything to turn out well. B: We tried a new place. We couldn’t recommend them more highly. Sentiment: Positive, Generative Preference: B A, Extractive Preference: A B, Subjective Preference: A B A: But his humor isn’t for everyone. I love humor. B: That may have been the norm, but they were above average. Sentiment: Positive, Generative Preference: B A, Extractive Preference: A B, Subjective Preference: No Preference A: Management is an embarrassement. B: I saw table of guys feasting on a whole pigs head and having a great time, but it made me pretty sick. Sentiment: Negative, Generative Preference: B A, Extractive Preference: No Preference, Subjective Preference: B A A: they put one inside the grocery store. B: We moved here based on reviews and selected South shores with distance of hours Sentiment: Neutral, Generative Preference: B A, Extractive Preference: No Preference, Subjective Preference: No Preference
Appendix C More Ablation Study
In this section, we provide more ablation studies on the design choices of P2C. Here, all experiments are conducted on DynaSent-R2 (Potts et al., 2021) and Offensive (Leonardelli et al., 2021) datasets with extractive preference labels, as same as we have done in Section 4.3. The values and error bars are the mean and standard deviation across five random seeds. The results with the chosen design in Section 4.3 are indicated in bold.
Multiple preference heads for preference learning. In Section 2.2, we introduce multi-preference heads with diversity regularization (Eq. 3) to effectively learn the given preference labels. To see the effect, we compare it with two different designs for preference heads: 1) single-preference head and 2) multi-preference heads without diversity regularization. Remark that the other components, consistency regularization, and inconsistency-based sampling, are still applied to separately verify the effect from different designs of the preference head. As shown in Table 9, one can verify that a single preference head is not enough to exploit the given preference labels fully; hence, the empirical gain is relatively small compared to multi-preference heads. Also, it is observable that the proposed regularization is more effective to impose diversity than only relying on random initialization.
| Single-Pref | Multi-Pref Heads | Multi-Pref Heads | |
|---|---|---|---|
| Dataset | Head | without diversity | with diversity |
| DynaSent-R2 | 72.220.55 | 72.750.42 | 73.060.31 |
| Offensive | 77.080.57 | 77.250.92 | 77.810.21 |
Auxiliary loss for preference learning. As described in Section 2.2, we use a consistency regularization (Eq. 5 and 6) between classification and preference learning as an auxiliary loss for learning preference; specifically, consistency regularization with margin (Eq. 6) is used in Section 4.3. To clarify the effectiveness of this regularization, we compare it with 1) consistency regularization without margin (Eq. 5). We also compare it to 2) soft-labeling, which also uses the annotation records to construct soft-labels instead of the preference and margin. Here, we use random sampling instead of inconsistency-based sampling since it is designed explicitly for consistency regularization while using the multi-preference heads. Table 10 shows the results of these auxiliary losses; although consistency regularization is effective in improving the performance without margin, the gain is smaller than the consistency regularization with margin since the latter utilizes the additional knowledge about the given preference label. In addition, the result with soft-labeling validates that the gain from our consistency loss is not from the use of the annotation records but from the regularization that imposes the following intuition: more preferred instance should have higher confidence from the classifier.
| Soft | Consistency | Consistency | |
|---|---|---|---|
| Dataset | -labeling | without margin | with margin |
| DynaSent-R2 | 72.290.88 | 72.400.71 | 72.670.89 |
| Offensive | 77.041.05 | 77.540.95 | 77.670.99 |
Sampling of pairs for preference learning. To improve the efficiency of preference learning by sampling the informative pairs during the training, we introduce two advanced sampling methods: (1) disagreement-based sampling and (2) inconsistency-based sampling in Section 2.2. Remark that the other components, consistency regularization with margin and multi-preference heads, are still applied to verify the effect from different sampling methods separately. In Table 11, we compare both sampling methods to random sampling. Here, one can verify that both ways are more effective than random sampling, and inconsistency-based sampling is slightly better than disagreement-based sampling. Hence, we commonly used inconsistency-based sampling in Section 4.3.
| Dataset | Random | Disagreement | Inconsistency |
|---|---|---|---|
| DynaSent-R2 | 72.670.89 | 72.730.66 | 73.060.31 |
| Offensive | 77.670.99 | 77.751.49 | 77.810.21 |
Sensitivity to . To verify the sensitivity of our method with , we conduct the experiments by introducing , a coefficient of , and varying it to investigate its effect. In Table 12, one can observe that KL divergence does not dominate the entire loss until the certain level of including the original value (=1), but it can diverge with too large value (e.g., ). Hence, we recommend using the original value or investigating with smaller than 1.
| Dataset | ||||
|---|---|---|---|---|
| DynaSent-R2 | 72.750.42 | 73.060.31 | 71.440.68 | 57.052.14 |
| Offensive | 77.250.92 | 77.810.21 | 75.351.03 | 65.056.70 |
Appendix D Additional Experimental Results
Smaller training samples. Here, we validate the effectiveness of P2C with extractive preferences for the smaller training samples. Specifically, we control the number of training samples () of the DynaSent-R2 dataset from to and compare our method with three representative baselines with high performance: Vanilla, Soft-labeling, and Multi-annotator. As shown in Table 13, P2C shows significant improvement, especially when the dataset size is smaller. We also remark that P2C shows consistent improvement for all cases while other baselines do not.
| Method | |||||
|---|---|---|---|---|---|
| Vanilla | 54.892.46 | 60.362.98 | 63.610.92 | 66.500.76 | 68.691.41 |
| Soft-labeling | 57.752.35 | 60.031.46 | 62.811.45 | 66.781.16 | 68.171.09 |
| Multi-annotator | 57.333.23 | 61.391.76 | 63.000.87 | 66.190.84 | 68.781.46 |
| P2C (Ours) | 58.941.16 | 61.831.15 | 64.131.04 | 67.720.46 | 69.830.64 |
Compatibility with other types of models. While we have previously used a model built over RoBERTa-base (Liu et al., 2019), the proposed P2C is not limited to the specific model. To verify this, we conduct additional experiments based on DynaSent-R2 with extractive preference labels from the annotation records. As shown in Table 14, the proposed P2C consistently improves the test accuracy of classifiers of other language models: BERT-base (Devlin et al., 2019), ALBERT-base (Lan et al., 2020), and RoBERTa-large.
| Method | BERT-base | ALBERT-base | RoBERTa-large |
|---|---|---|---|
| Vanilla | 67.261.15 | 62.720.73 | 75.620.60 |
| P2C (Ours) | 68.260.56 | 65.001.13 | 77.710.36 |