Primal-Dual Damping algorithms for optimization
Abstract
We propose an unconstrained optimization method based on the well-known primal-dual hybrid gradient (PDHG) algorithm. We first formulate the optimality condition of the unconstrained optimization problem as a saddle point problem. We then compute the minimizer by applying generalized primal-dual hybrid gradient algorithms. Theoretically, we demonstrate the continuous-time limit of the proposed algorithm forms a class of second-order differential equations, which contains and extends the heavy ball ODEs and Hessian-driven damping dynamics. Following the Lyapunov analysis of the ODE system, we prove the linear convergence of the algorithm for strongly convex functions. Experimentally, we showcase the advantage of algorithms on several convex and non-convex optimization problems by comparing the performance with other well-known algorithms, such as Nesterov’s accelerated gradient methods. In particular, we demonstrate that our algorithm is efficient in training two-layer and convolution neural networks in supervised learning problems.
Keywords— Optimization; Primal-dual hybrid gradient algorithms; Primal-dual damping dynamics.
1 Introduction
Optimization is one of the essential building blocks in many applications, including scientific computing and machine learning problems. One of the classical algorithms for unconstrained optimization problems is the gradient descent method, which updates the state variable in the negative gradient direction at each step [Boyd and Vandenberghe, 2004]. Nowadays, accelerated gradient descent methods have been widely studied. Typical examples include Nesterov’s accelerated gradient method [Nesterov, 1983], Polyak’s heavy ball method [Polyak, 1964], and Hessian-driven damping methods [Chen and Luo, 2019, Attouch et al., 2019, 2020, 2021].
On the other hand, some first-order methods are introduced to solve linear-constrained optimization problems. Typical examples include the primal-dual hybrid gradient (PDHG) method [Chambolle and Pock, 2011] and the alternating direction method of multipliers (ADMM) [Boyd et al., 2011, Gabay and Mercier, 1976]. They are designed to solve an inf-sup saddle point type problem, which updates the gradient descent direction for the minimization variable and applies the gradient ascent direction for the maximization variable. Both PDHG and ADMM are designed for solving optimization problems with affine constraints. Ouyang et al. [2015] proposed accelerated linearized ADMM, which incorporates a multi-step acceleration scheme into linearized ADMM. Recently, the PDHG method has been extended into solving nonlinear-constrained minimization problems [Valkonen, 2014].
In this paper, we study a general class of accelerated first-order methods for unconstrained optimization problems. We reformulate the original optimization problem into an inf-sup type saddle point problem, whose saddle point solves the optimality condition. We then apply a linearized preconditioned primal-dual hybrid gradient algorithm to compute the proposed saddle point problem.
The main description of the algorithm is as follows. Consider the following inf-sup problem for a strongly convex function over
| (1.1) |
where is a constructed “dual variable”, is a constant, is an Euclidean inner product, and is an Euclidean norm. We later prove that the solution to the saddle point problem 1.1 gives the global minimum of . We propose a linearized preconditioned PDHG algorithm for solving the above inf-sup problem:
| (1.2a) | ||||
| (1.2b) | ||||
| (1.2c) | ||||
where is the iteration step, , are stepsizes for the updates of , , respectively, and is a parameter. In the above algorithm, , where , and act as preconditioners on the updates of and , respectively. This paper will only focus on the simple case where for some constant . Although there is a second-order term in the update of (hidden in ), our algorithm is still a first-order algorithm by choosing for some that is easy to compute. For example, we test that is a very good choice in most of our numerical examples. See empirical choices of parameters in our numerical sections.
Our method forms a class of ordinary differential equation systems in terms of in the continuous limit , . We call it the primal-dual damping (PDD) dynamics. We show that the PDD dynamics form a class of second-order ODEs, which contains and extends the inertia Hessian-driven damping dynamics [Chen and Luo, 2019, Attouch et al., 2019]. Theoretically, we analyze the convergence property of PDD dynamics. If is a quadratic function of , with constant , , the PDD dynamic satisfies a linear ODE system. Under suitable choices of parameters, we obtain a similar convergence acceleration in heavy ball ODE [Siegel, 2019]. Moreover, for general nonlinear function , we have the following informal theorem characterizing the convergence speed of our algorithm:
Theorem 1.1 (Informal).
Numerically, we test the algorithms in both convex and non-convex optimization problems. In convex optimization, we demonstrate the fast convergence results of the proposed algorithm with selected preconditioners, compared with the gradient descent method, Nesterov accelerated gradient method, and Heavy ball damping method. This justifies the convergence analysis. We also test our algorithm for several well-known non-convex optimization problems. Some examples, such as the Rosenbrock and Ackley functions, demonstrate the potential advantage of our algorithms in converging to the global minimizer. In particular, we compare our algorithms with the stochastic gradient descent method, Adam, for training two-layer and convolutional neural network functions in supervised learning problems. This showcases the potential advantage of the proposed methods in terms of convergence speed and test accuracy.
PDHG has been widely used in linear-constrained optimization problems [Chambolle and Pock, 2011]. Recently, Valkonen [2014] applied the PDHG for nonlinearly constrained optimization problems. They proved the asymptotic convergence for the nonlinear coupling saddle point problems. It is different from our PDHG algorithm for computing unconstrained optimizations. And we show the linear convergence for a particular nonlinear coupling saddle point problem. Meanwhile, Nesterov accelerated gradient methods and Hessian damping algorithms can also be formulated in both discrete-time updates and continuous-time second-order ODEs. Wibisono et al. [2016] also introduced the idea of Bregman Lagrangian to study a family of accelerated methods in continuous time limit. It forms a nonlinear second-order ODE. Compared to them, the PDD algorithm induces a generalized second-order ODE system, which contains both heavy ball ODE [Siegel, 2019] and Hessian damping dynamics [Chen and Luo, 2019, Attouch et al., 2019, 2020, 2021]. For example, when , algorithm Eq. 1.2 can be viewed as the other time discretization of Hessian damping dynamics [Chen and Luo, 2019, Attouch et al., 2019]. It provides a different update in discrete time update. We only evaluate the gradient of once, whereas Attouch’s algorithm [Attouch et al., 2020] evaluates the gradient of twice. In numerical experiments, we demonstrate that the proposed algorithm outperforms Nesterov accelerated methods and Hessian-driven damping methods in some non-convex optimization problems, including supervised learning problems for training neural network functions.
Our work is also related to preconditioning, an important technique in numerical linear algebra [Trefethen and Bau, 2022] and numerical PDEs [Rees, 2010, Park et al., 2021]. In general, preconditioning aims to reduce the condition number of some operators to improve convergence speed. One famous example would be preconditioning gradient descent by the inverse of the Hessian matrix, which gives rise to Newton’s method. In recent years, preconditioning techniques have also been developed in training neural networks Osher et al. [2022], Kingma and Ba [2014]. Adam [Kingma and Ba, 2014] is arguably one of the most popular optimizers in training deep neural networks. It can also be viewed as a preconditioned algorithm using a diagonal preconditioner that approximates the diagonal of the Fisher information matrix [Pascanu and Bengio, 2013]. Shortly after Chambolle and Pock [2011] developed PDHG for constrained optimization, the same authors also studied preconditioned PDHG method [Pock and Chambolle, 2011], in which they developed a simple diagonal preconditioner that can guarantee convergence without the need to compute step sizes. Liu et al. [2021] proposed non-diagonal preconditioners for PDHG and showed close connections between preconditioned PDHG and ADMM. Park et al. [2021] studied the preconditioned Nesterov’s accelerated gradient method and proved convergence in the induced norm. Jacobs et al. [2019] introduced a preconditioned norm in the primal update of the PDHG method and improved the step size restriction of the PDHG method.
Our paper is organized as follows. In Section 2 we provide some background and derivations of our algorithm. We also provide the ODE formulations for our primal-dual damping dynamics. In Section 3, we prove our main convergence results for the algorithm. In Section 4 we showcase the advantage of our algorithm through several convex and non-convex examples. In particular, we show that our algorithm can train neural networks and is competitive with commonly used optimizers, such as SGD with Nesterov’s momentum and Adam. We conclude in Section 5 with more discussions and future directions.
2 Primal-dual damping algorithms for optimizations
In this section, we first review PDHG algorithms for constrained optimization problems. We then construct a saddle point problem for the unconstrained optimization problem and apply the preconditioned PDHG algorithm to compute the proposed saddle point problem. We last derive an ODE system, which takes the limit of stepsizes in the PDHG algorithm. It forms a second-order ODE, which generalizes the Hessian-driven damping dynamics. We analyze the convergence properties of the ODE system for quadratic optimization problems.
2.1 Review PDHG for constrained optimization
In Chambolle and Pock [2011], the following saddle point problem was considered:
| (2.1) |
where and are two finite-dimensional real vector spaces equipped with inner product and norm . The map is a continuous linear operator. and are proper, convex, lower semi-continuous (l.s.c.) functions. is the convex conjugate of a convex l.s.c. function . It is straightforward to verify that 2.1 is the primal-dual formulation of the nonlinear primal problem
Then the PDHG algorithm for saddle point problem 2.1 is given by
| (2.2a) | ||||
| (2.2b) | ||||
| (2.2c) | ||||
where is the identity operator and is the resolvent operator, which is defined the same way as the proximal operator
When , Chambolle and Pock [2011] proved convergence if , where is the induced operator norm. It is worth noting that the convergence analysis requires that is a linear operator.
2.2 Saddle point problem for unconstrained optimization
We consider the problem of minimizing a strongly convex function over . Instead of directly solving for , we consider the following saddle point problem:
| (2.3) |
due to the following proposition.
Proposition 2.1.
Let be a strongly convex function. Then the saddle point to 2.3 is the unique global minimum of .
Proof.
Directly differentiating 2.3 and setting the derivatives to 0 yields
By the strong convexity of , we obtain that is the unique global minimum and . ∎
Recall that by the optimality condition. Thus we make the following change to our saddle point formulation. We add a regularization term in 2.3:
| (2.4) |
where is a constant. This regularization term further drives to . Similar to Proposition 2.1, we have the following proposition
Proposition 2.2.
Let be a strongly convex function. Then the saddle point to 2.4 is the unique global minimum of .
Proof.
Directly differentiating 2.4 and setting derivatives to 0 yields
Since is strongly convex, we have and the second equation implies . Then the first equation implies . Since is strongly convex, we conclude that is the unique global minimum. ∎
2.3 PDHG for unconstrained optimization
We apply the scheme given by 2.2 to the saddle point problem 2.4 (set and identify in 2.1). Thus,
| (2.5a) | ||||
| (2.5b) | ||||
| (2.5c) | ||||
where we have added symmetric positive definite matrices , , as preconditioners for updates of , , respectively. We also denote the norm as , where .
As mentioned, the convergence analysis of PDHG relies on the assumption that is a linear operator. So we can not apply the same convergence analysis to 2.5 since is not necessarily linear in . By taking the optimality conditions of 2.5, we find that and solves
| (2.6a) | ||||
| (2.6b) | ||||
where we substitute the update Eq. 2.5b into update Eq. 2.6b. We use to represent the identity matrix in Eq. 2.6b.
Note that the update for in Eq. 2.6b is implicit, unless does not depend on . We also remark that the update for in Eq. 2.6b will be explicit if we perform a gradient step instead of a proximal step in Eq. 2.5c. To be more precise, when , the linearized version of Eq. 2.5c can be written as
Taking a gradient step instead of proximal step yields
| (2.7) |
For general choice of preconditioner , the linearized version of Eq. 2.5c satisfies
Here we always denote a matrix function , such that
For simplicity of presentation, we only consider the simple case where for some . We now summarize the linearized update Eq. 2.6 into the following algorithm.
2.4 PDD dynamics
An approach for analyzing optimization algorithms is by first studying the continuous limit of the algorithm using ODEs [Su et al., 2015, Siegel, 2019, Attouch et al., 2019]. The advantage of doing so is that ODEs provide insights into the convergence property of the algorithm.
We first reformulate the proposed algorithm Eq. 2.6 into a first-order ODE system.
Proposition 2.3.
As and , both updates in 2.6 and Algorithm 1 can be formulated as a discrete-time update of the following ODE system.
| (2.8a) | ||||
| (2.8b) | ||||
where and the initial condition satisfies , . Suppose that is Lispchitz continuous and each index in matrix , is continuous and bounded. Then, there exists a unique solution for the ODE system Eq. 2.8. A stationary state of ODE system Eq. 2.8 satisfies
Proof.
Proposition 2.4 (Primal-dual damping second order ODE).
The proof follows by direct calculations and can be found in Appendix C. We note that the formulation given by Eq. 2.9 includes several important special cases in the literature. In a word, we view Eq. 2.4 as a preconditioned accelerated gradient flow.
Example 2.1.
Remark 2.5.
We next provide a convergence analysis of ODE Eq. 2.8 for quadratic optimization problems. We demonstrate the importance of preconditioners in characterizing the convergence speed of ODE Eq. 2.8.
Theorem 2.6.
Suppose for some symmetric positive definite matrix . Assume , are constant matrices. In this case, equation Eq. 2.8 satisfies the linear ODE system:
Suppose that commutes with , such that . Suppose and are simultaneously diagonalizable and have positive eigenvalues. Let be the eigenvalues of and the -th eigenvalue of (not necessarily in descending order) in the same basis. Then
- (a)
-
(b)
When , the optimal convergence rate is achieved at . The corresponding rate is , where .
-
(c)
Moreover, when , the system will not converge for any initial data .
-
(d)
If , , for some , then
We defer the proof to Appendix B.
Remark 2.7.
Remark 2.8.
If is an estimate of the smallest eigenvalue , then the convergence speed for the solution of heavy ball ODE is . In Theorem 2.6 (d), if and , then which is the same as the convergence rate of the heavy ball ODE [Siegel, 2019]. However, if and , then we have , which converges faster than the heavy ball ODE.
3 Lyapunov Analysis
In this section, we present the main theoretical result of this paper. We provide the convergence analysis for general objective functions in both continuous-time ODEs Eq. 2.8 and discrete-time Algorithm 1. From now on, we make the following two assumptions for the convergence analysis.
Assumption 3.1.
There exists two constants such that for all , where , and .
Assumption 3.2.
There exists a constant such that
| (3.1) |
for all , where .
3.1 Continuous time Lyapunov analysis
In this subsection, we establish convergence results of the ODE system Eq. 2.8.
Theorem 3.3.
Proof.
It is straightforward to compute the following
| (3.4) |
We shall find such that . Then we obtain the exponential convergence by Gronwall’s inequality, i.e.,
We can compute
| (3.5) |
By Lemma A.1, we obtain the following sufficient conditions for
| (3.6a) | ||||
| (3.6b) | ||||
where is the eigenvalue of . By our assumptions, we have . Eq. 3.6 give two upper bounds on . Define , and on the interval . Then Eq. 3.6 implies that
| (3.7) |
for all and . Since each is a piece-wise linear in , it is not hard to see that
for . This proves the formula for . When , we have , and
Further, requiring yields . And we obtain
| (3.8) |
We note that is maximized when taking . We obtain .
∎
3.2 Discrete time Lyapunov analysis
In this subsection, we study the convergence criterion for the discretized linearized PDHG flow given by Eq. 1.2 and Algorithm 1.
From now on, we assume that is a strongly convex function.
We can rewrite the iterations as
| (3.9a) | ||||
| (3.9b) | ||||
where . We define the following notations which will be used later.
| (3.10) |
And
Remark 3.4.
The matrix and also depends on the , , , and .
Define the Lyapunov functional in discrete time as
Theorem 3.5.
Suppose that there exists positive constants , such that
for all . If for some , then the functional decreases geometrically, i.e.
Proof.
It follows from our definition of that
| (3.11) |
Theorem 3.6.
Let be a strongly convex function. Suppose satisfies
| (3.14) |
for some and all . Here
Suppose further that there exists positive constants such that
for all . If for some , then the functional decreases geometrically, i.e.
Remark 3.7.
Proof.
We will prove it by induction. Using the mean-value theorem, we have
| (3.15) |
where is in between and . By Eq. 3.2 and Eq. 3.11, we can bound
| (3.16) |
where the last inequality is by our assumption on . Using our assumptions on the lower bound of and the upper bound of , we obtain
| (3.17) |
where we used for some . Hence,
This proves the base case. Now suppose it holds that
for some . In particular, this implies that
which yields
Then, repeating the derivation of Eq. 3.2 and Eq. 3.2 yields
Combining with our induction hypothesis, we conclude that
The proof is complete by induction. ∎
Proof.
Corollary 3.9.
Proof.
We can decompose
Observe that
Therefore,
| (3.20) |
To get the last inequality, we consider such that . Thus
We now have
This proves part (1) of our Corollary. It follows that
| (3.21) |
where we recall .
Theorem 3.10 (Restatement of Theorem 1.1).
4 Numerical experiment
We test our PDD algorithm using several convex and non-convex functions and compare the results with other commonly used optimizers, such as gradient descent, Nesterov’s accelerated gradient (NAG), IGAHD (inertial gradient algorithm with Hessian damping) [Attouch et al., 2020], and IGAHD-SC (inertial gradient algorithm with Hessian damping for strongly convex functions) [Attouch et al., 2020].
4.1 Summary of algorithms
For reference, we write down the iterations of gradient descent, NAG, IGAHD-SC, and IGAHD for better comparison.
Gradient descent:
where is a stepsize.
NAG:
where is a stepsize, and is a parameter.
IGAHD: Suppose is -Lipschitz.
Here for some . needs to satisfy
And is a stepsize, which needs to satisfy
Remark 4.1.
As mentioned earlier, in each iteration of IGAHD, is evaluated twice: at and at . This differs from one gradient evaluation in gradient descent, NAG, and our method Eq. 1.2. Chen and Luo [2021] proposed a slightly different algorithm from IGAHD that only requires one gradient evaluation in each iteration.
IGHD-SC: Suppose is -strongly convex and is -Lipschitz.
Here and need to satisfy
| (4.1) |
4.2 regularized log-sum-exp
Consider the regularized log-sum-exp function
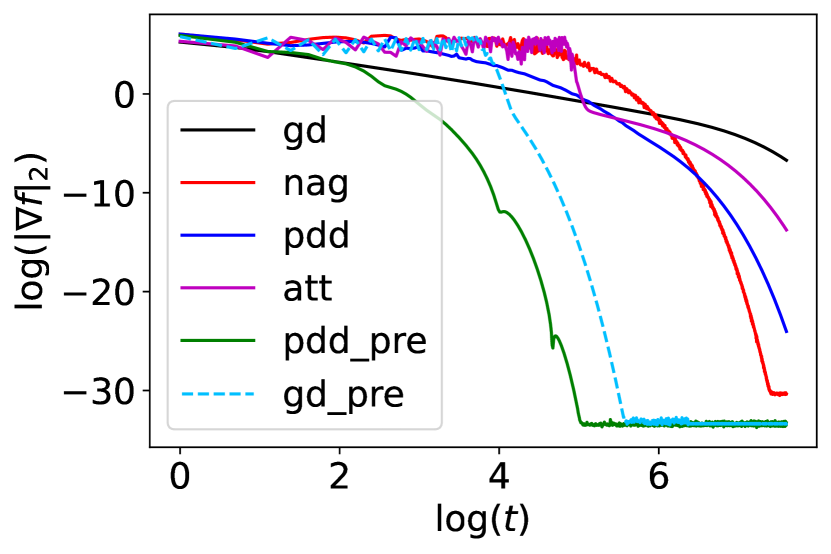
where , and is the ith row of . is chosen to be diagonally dominant, i.e. . In this case, we may choose the diagonal preconditioner . We compare the performance of gradient descent, preconditioned gradient descent, PDD with , PDD with diagonal preconditioner, NAG, and IGAHD-SC (inertial gradient algorithm with Hessian damping for strongly convex functions) by Attouch et al. [2020] methods for minimizing . The stepsize of gradient descent is determined by , where and are the maximum and minimum eigenvalues of , respectively. For a pure quadratic objective function, , the optimal stepsize of gradient descent is . However, since our objective function also contains a log-sum-exp term, we slightly change the stepsize. Otherwise, gradient descent will not converge. Similarly, when deciding the parameters for NAG, we choose and , where , which is slightly smaller than the optimal parameters of NAG for a purely quadratic function to guarantee convergence. For PDD with , we choose , , , . For PDD with diagonal preconditioner , we choose , , , . We use the same as a preconditioner for gradient descent. The stepsize for preconditioned gradient descent is chosen to be the same as . For IGAHD-SC (‘att’), we need as the smallest eigenvalue of . In this example, we may estimate as the smallest eigenvalue of . And via grid search. in IGAHD-SC is found by solving (see Theorem 11 Eq. (26) of Attouch et al. [2020])
which gives
| (4.2) |
The initial condition is . The result is presented in Fig. 1(a).
4.3 Quadratic minus cosine function
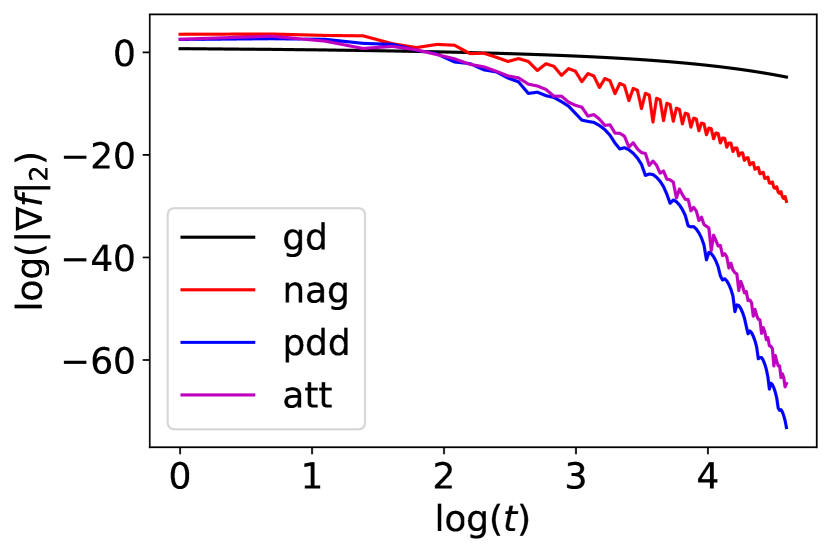
Consider the function
where is a vector in with . Then a direct calculation shows that for any . This allows us to choose the optimal stepsize for gradient descent and NAG. When minimizing using gradient descent, we can choose . Meanwhile, for NAG, we may choose , and , where . For PDD with , we choose , , , . For IGAHD-SC (‘att’), we choose , via grid search and is given by Eq. 4.2. The initial condition is . The result is presented in Fig. 1(b).
4.4 Rosenbrock function
4.4.1 2-dimension
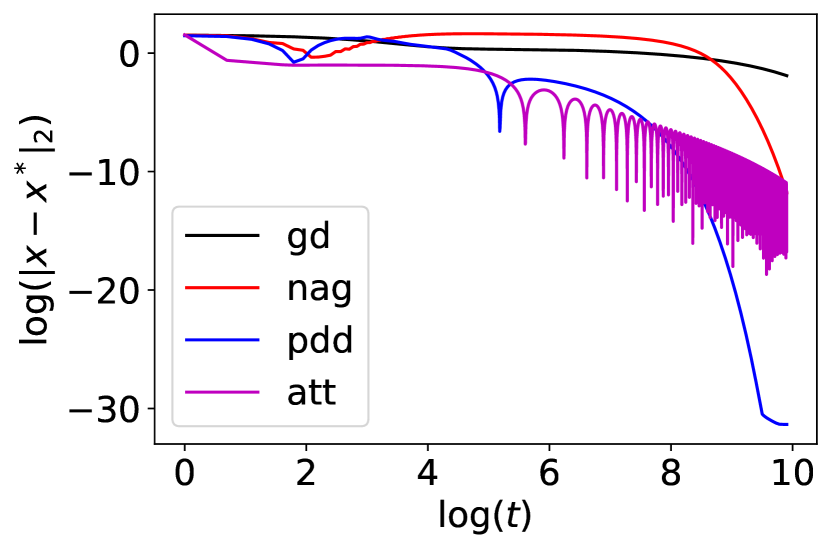
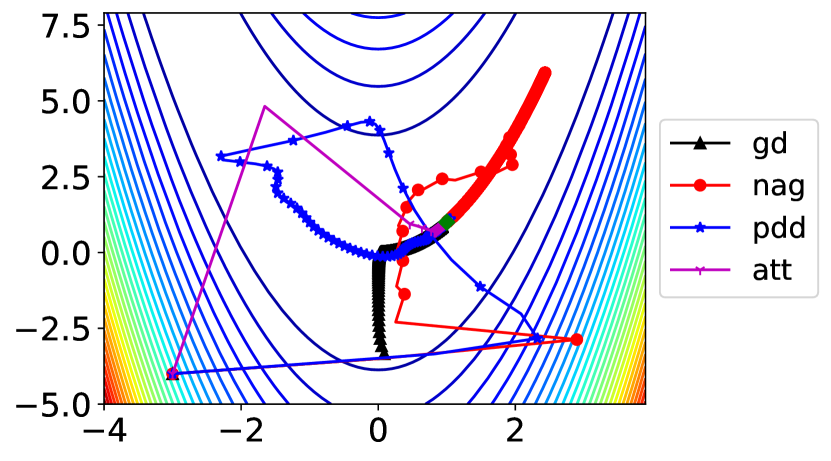
The 2-dimensional Rosenbrock function is defined as
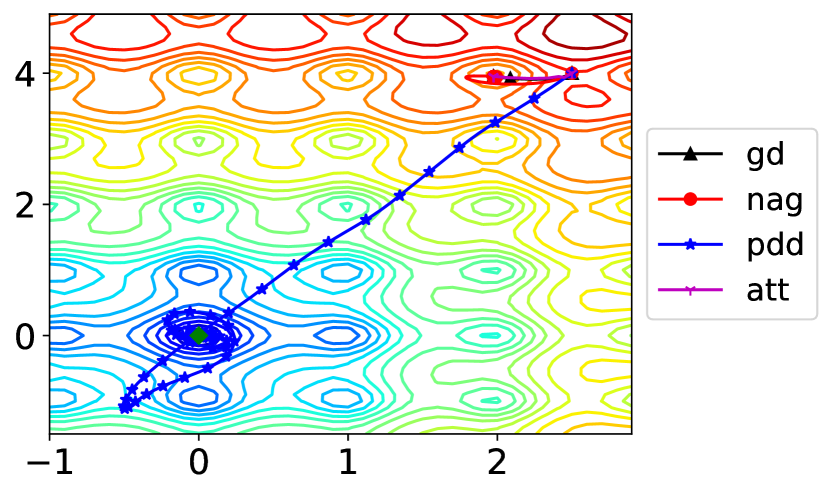
where a common choice of parameters is , . This is a non-convex function with a global minimum of . The global minimum is inside a long, narrow, parabolic-shaped flat valley. To find the valley is trivial. To converge to the global minimum, however, is difficult. We compare the performance of gradient descent, NAG, PDD with and IGAHD (inertia gradient algorithm with Hessian damping) by Attouch et al. [2020] when minimizing the Rosenbrock function starting from . The stepsize of gradient descent is . The stepsize of NAG is , . The parameters of PDD are , , , . The stepsize of the PDD method is larger than and because gradient descent and NAG do not allow larger stepsizes for convergence. For IGAHD (‘att’), we choose , , . The convergence result and the optimization trajectories are shown in Fig. 2.
4.4.2 N-dimension
The -dimensional coupled Rosenbrock function is defined as
where we choose and as in the 2-dimensioal case and we set . The global minimum is at . Using the same stepsizes as in the 2-dimensional case, we compare the performance of the three algorithms starting from . The stepsize of gradient descent is . The stepsize of NAG is , . The parameters of PDD are , , , . The stepsize of the PDD method is larger than and because gradient descent and NAG do not allow larger stepsizes for convergence. For IGAHD (‘att’), we choose , , . The result is summarized in Fig. 3
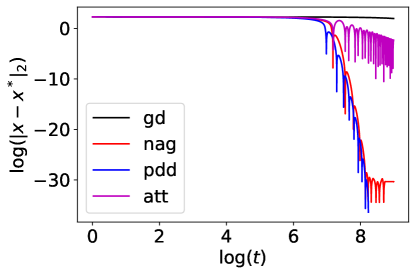
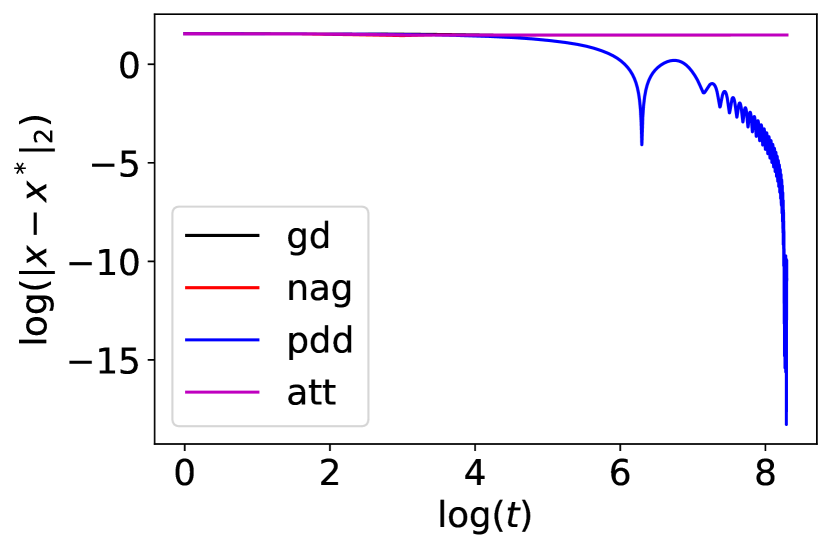
4.5 Ackley function
We consider minimizing the two-dimensional Ackley function given by
which has many local minima. The unique global minimum is located at . We compare the performance of gradient descent, NAG, PDD, and IGAHD (‘att’) for minimizing the two-dimensional Ackley function starting from . The stepsize of gradient descent is . The stepsize of NAG is , . The parameters of PDD are , , , . For IGAHD (‘att’), we choose , , . The results are summarized in Fig. 4.
Remark 4.2.
We remark that our algorithm has no stochasticity. It will not always converge to the global minimum for non-convex functions in general. For example, it will not converge for the Griewank, Drop-Wave, and Rastrigin functions.
4.6 Neural Networks training
4.6.1 MNIST with Two-layer neural network
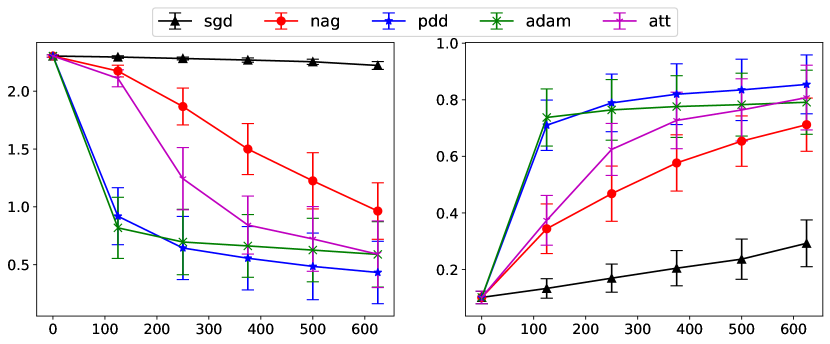
We consider the classification problem using the MNIST handwritten digit data set with a two-layer neural network. The neural network has an input layer of size , a hidden layer of size followed by another hidden layer of size , and an output layer of size . We use ReLU activation function across the layers, and the loss is evaluated using the cross-entropy loss. We use a batch size of 200 for all the algorithms. The stepsize of gradient descent is . The stepsize of NAG is , . The parameters of PDD are , , , , . For IGAHD (‘att’), we choose , , . For Adam, we choose , , .
| Algorithm | SGD | NAG | PDD | Adam | Att |
|---|---|---|---|---|---|
| train loss | 2.223 0.034 | 0.964 0.244 | 0.433 0.270 | 0.589 0.282 | 0.591 0.288 |
| test acc | 29.3 8.3 % | 71.2 9.4 % | 85.4 10.4 % | 79.1 11.3 % | 80.8 11.4 % |
4.6.2 CIFAR10 with CNN
We train a convolutional neural network using the CIFAR10 datasets with SGD, Nesterov, PDD, Adam, and IGAHD (‘Att’). The architecture of the network is described as follows. The network consists of two convolutional layers. The first convolutional layer has output channels, and the filter size is . The second convolutional layer has output channels, and the filter size is . Each convolutional layer is followed by a ReLU activation and then a max-pooling layer. Lastly, we have fully connected layers of size , , and . The loss is evaluated using the cross-entropy loss. The stepsize of gradient descent is . The stepsize of NAG is , . The parameters of PDD are , , , , . For IGAHD (‘att’), we choose , , . For Adam, we choose , , .
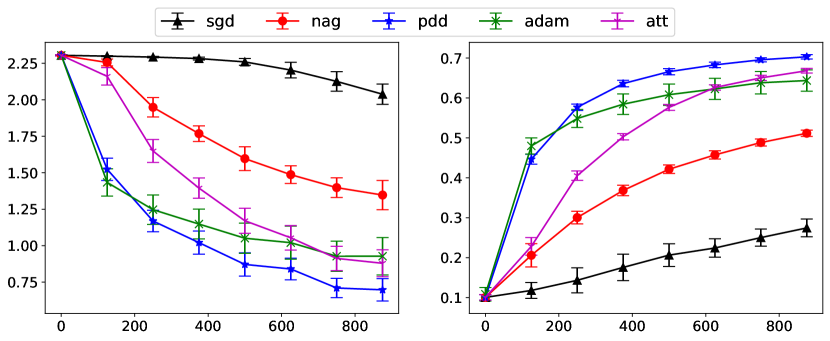
| Algorithm | SGD | NAG | PDD | Adam | Att |
|---|---|---|---|---|---|
| train loss | 2.038 0.070 | 1.347 0.100 | 0.697 0.077 | 0.927 0.128 | 0.879 0.092 |
| test acc | 27.5 2.2 % | 51.2 0.7 % | 70.3 0.5 % | 64.4 2.7 % | 66.8 0.6 % |
5 Discussion
This paper presents primal-dual hybrid gradient algorithms for solving unconstrained optimization problems. We reformulate the optimality condition of the optimization problem as a saddle-point problem and then compute the proposed saddle-point problem by a preconditioned PDHG method. We present the geometric convergence analysis for the strongly convex objective functions. In numerical experiments, we demonstrate that the proposed method works efficiently in non-convex optimization problems, at least in some examples, such as Rosenbrock and Ackley functions. In particular, it could efficiently train two-layer and convolution neural networks in supervised learning problems.
So far, our convergence study is limited to strongly convex objective functions, not convex ones. Meanwhile, the choice of preconditioners and stepsizes are independent of time. We also have not discussed the optimal choices of parameters or general proximal operators in the updates of algorithms. These generalized choices of functions, parameters, and their convergence properties have been intensively studied in Nesterov accelerated gradient methods and Attouch’s Hessian-driven damping methods. In future work, we shall explore the convergence property of PDHG methods for convex functions with time-dependent parameters. We also investigate the convergence of similar algorithms in scientific computing problems of implicit time updates of partial differential equations [Li et al., 2022, 2023, Liu et al., 2023].
Acknowledgement: X. Zuo and S. Osher’s work was partly supported by AFOSR MURI FP 9550-18-1-502 and ONR grants: N00014-20-1-2093 and N00014-20-1-2787. W. Li’s work was supported by AFOSR MURI FP 9550-18-1-502, AFOSR YIP award No. FA9550-23-1-0087, and NSF RTG: 2038080.
References
- Attouch et al. [2019] H. Attouch, Z. Chbani, and H. Riahi. Fast proximal methods via time scaling of damped inertial dynamics. SIAM Journal on Optimization, 29(3):2227–2256, 2019.
- Attouch et al. [2020] H. Attouch, Z. Chbani, J. Fadili, and H. Riahi. First-order optimization algorithms via inertial systems with Hessian driven damping. Mathematical Programming, pages 1–43, 2020.
- Attouch et al. [2021] H. Attouch, Z. Chbani, J. Fadili, and H. Riahi. Convergence of iterates for first-order optimization algorithms with inertia and Hessian driven damping. Optimization, pages 1–40, 2021.
- Boyd and Vandenberghe [2004] S. Boyd and L. Vandenberghe. Convex optimization. Cambridge university press, 2004.
- Boyd et al. [2011] S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends® in Machine learning, 3(1):1–122, 2011.
- Chambolle and Pock [2011] A. Chambolle and T. Pock. A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of mathematical imaging and vision, 40:120–145, 2011.
- Chen and Luo [2019] L. Chen and H. Luo. First order optimization methods based on Hessian-driven Nesterov accelerated gradient flow. arXiv preprint arXiv:1912.09276, 2019.
- Chen and Luo [2021] L. Chen and H. Luo. A unified convergence analysis of first order convex optimization methods via strong Lyapunov functions. arXiv preprint arXiv:2108.00132, 2021.
- Gabay and Mercier [1976] D. Gabay and B. Mercier. A dual algorithm for the solution of nonlinear variational problems via finite element approximation. Computers & Mathematics with Applications, 2(1):17–40, 1976. ISSN 0898-1221. doi: https://doi.org/10.1016/0898-1221(76)90003-1. URL https://www.sciencedirect.com/science/article/pii/0898122176900031.
- Jacobs et al. [2019] M. Jacobs, F. Léger, W. Li, and S. Osher. Solving large-scale optimization problems with a convergence rate independent of grid size. SIAM Journal on Numerical Analysis, 57(3):1100–1123, 2019.
- Kingma and Ba [2014] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Li et al. [2022] W. Li, S. Liu, and S. Osher. Controlling conservation laws II: Compressible Navier–Stokes equations. Journal of Computational Physics, 463:111264, 2022.
- Li et al. [2023] W. Li, S. Liu, and S. Osher. Controlling conservation laws I: Entropy–entropy flux. Journal of Computational Physics, 480:112019, 2023.
- Liu et al. [2023] S. Liu, S. Osher, W. Li, and C.-W. Shu. A primal-dual approach for solving conservation laws with implicit in time approximations. Journal of Computational Physics, 472:111654, 2023.
- Liu et al. [2021] Y. Liu, Y. Xu, and W. Yin. Acceleration of primal–dual methods by preconditioning and simple subproblem procedures. Journal of Scientific Computing, 86(2):21, 2021.
- Nesterov [1983] Y. E. Nesterov. A method of solving a convex programming problem with convergence rate . In Doklady Akademii Nauk, volume 269, pages 543–547. Russian Academy of Sciences, 1983.
- Osher et al. [2022] S. Osher, B. Wang, P. Yin, X. Luo, F. Barekat, M. Pham, and A. Lin. Laplacian smoothing gradient descent. Research in the Mathematical Sciences, 9(3):55, 2022.
- Ouyang et al. [2015] Y. Ouyang, Y. Chen, G. Lan, and E. Pasiliao Jr. An accelerated linearized alternating direction method of multipliers. SIAM Journal on Imaging Sciences, 8(1):644–681, 2015.
- Park et al. [2021] J.-H. Park, A. J. Salgado, and S. M. Wise. Preconditioned accelerated gradient descent methods for locally lipschitz smooth objectives with applications to the solution of nonlinear PDEs. Journal of Scientific Computing, 89(1):17, 2021.
- Pascanu and Bengio [2013] R. Pascanu and Y. Bengio. Revisiting natural gradient for deep networks. arXiv preprint arXiv:1301.3584, 2013.
- Pock and Chambolle [2011] T. Pock and A. Chambolle. Diagonal preconditioning for first order primal-dual algorithms in convex optimization. In 2011 International Conference on Computer Vision, pages 1762–1769, 2011. doi: 10.1109/ICCV.2011.6126441.
- Polyak [1964] B. T. Polyak. Some methods of speeding up the convergence of iteration methods. USSR computational mathematics and mathematical physics, 4(5):1–17, 1964.
- Rees [2010] T. Rees. Preconditioning iterative methods for PDE constrained optimization. PhD thesis, University of Oxford Oxford, UK, 2010.
- Siegel [2019] J. W. Siegel. Accelerated first-order methods: Differential equations and Lyapunov functions. arXiv preprint arXiv:1903.05671, 2019.
- Su et al. [2015] W. Su, S. Boyd, and E. J. Candes. A differential equation for modeling Nesterov’s accelerated gradient method: theory and insights. arXiv preprint arXiv:1503.01243, 2015.
- Trefethen and Bau [2022] L. N. Trefethen and D. Bau. Numerical linear algebra, volume 181. SIAM, 2022.
- Valkonen [2014] T. Valkonen. A primal–dual hybrid gradient method for nonlinear operators with applications to MRI. Inverse Problems, 30(5):055012, 2014.
- Wibisono et al. [2016] A. Wibisono, A. C. Wilson, and M. I. Jordan. A variational perspective on accelerated methods in optimization. Proceedings of the National Academy of Sciences, 113(47):E7351–E7358, 2016.
Appendix A Matrix lemma
Lemma A.1.
Let be real symmetric matrices that are simultaneously diagonalizable. Then for any , if
for all , where are the th eigenvalues of respectively in the same basis. Then
for all .
Proof.
Let . By our assumption, there exists unitary such that are simultaneously diagonalizable by . Set and . Then we can compute
where the first inequality follows from for any . ∎
Appendix B Proof of Theorem 2.6
B.1 Part (a)
We have the following system of ODE:
| (B.1) |
Let us compute the eigenvalues of the above system. Let be an eigenvalue, then satisfies
The late equality is because commutes with . We assume that and are simultaneously diagonalizable. Thus,
If and , then the real part of the eigenvalues are negative, and the system will converge. The convergence rate depends on the largest real part of the eigenvalues, which is
B.2 Part (c)
When , we see that is purely imaginary. Thus solutions to Eq. B.1 will be oscillatory and will not converge.
B.3 Part (b)
Let us define
Essentially, we would like to find . We then define
Observe that if , then for all . Thus
For and , one can check that the function is increasing in by computing the partial derivative with respect to . Then we get
where . The last approximation is valid for . This shows that . Similarly, if , then for all . Thus
This shows that . Combining with our previous observation, we get . Now let us fix some . Let . By our assumption on , we know that . Now for , we have
And for , we have
It is thus clear that for ,
It is straightforward to calculate that for , we have
So
And for we have
This implies
This shows .
B.4 Part (d)
Define . Also define . Then for , we have if and only if . Note that for if . Then for all if and . In particular, for all if for some . We have
Appendix C Proof of Proposition 2.4
We directly compute