Privacy-Preserving Distributed Online Mirror Descent for Nonconvex Optimization
Abstract
We investigate the distributed online nonconvex optimization problem with differential privacy over time-varying networks. Each node minimizes the sum of several nonconvex functions while preserving the node’s differential privacy. We propose a privacy-preserving distributed online mirror descent algorithm for nonconvex optimization, which uses the mirror descent to update decision variables and the Laplace differential privacy mechanism to protect privacy. Unlike the existing works, the proposed algorithm allows the cost functions to be nonconvex, which is more applicable. Based upon these, we prove that if the communication network is -strongly connected and the constraint set is compact, then by choosing the step size properly, the algorithm guarantees -differential privacy at each time. Furthermore, we prove that if the local cost functions are -smooth, then the regret over time horizon grows sublinearly while preserving differential privacy, with an upper bound . Finally, the effectiveness of the algorithm is demonstrated through numerical simulations.
keywords:
Nonconvex problems , differential privacy , distributed online optimization , regret analysis.1 Introduction
In distributed optimization, each node is aware of its local cost function. Nodes exchange information with their neighboring nodes through a communication network and collaborate to optimize the global cost function. This collaboration results in convergence towards the global optimal solution, where the global cost function is the sum of the local cost functions of all nodes. In numerous practical scenarios, each node’s local cost function varies over time which leads to distributed online optimization problems. Distributed online optimization problems have wide applications in signal processing ([1]), economic dispatch ([2]), and sensor networks ([3]) et al. The regret is commonly used to evaluate the performance of a distributed online optimization algorithm. If the regret grows sublinearly, then the algorithm is effective. The existing works show that if the cost function is convex, then the best regret bound achieved by an algorithm is , and if the cost function is strongly convex, then the best regret bound is , where denotes the time horizon ([4, 5]). In recent years, distributed online optimization problems have been extensively studied ([6, 7, 8, 9]). The algorithms above are designed based on the Euclidean distance. Such algorithms often face challenges in computing projections for complex cost functions and constraint sets, e.g. problems with simplex constraints. Beck et al. ([10]) proposed the mirror descent algorithm based on the Bregman distance instead of the Euclidean distance, which effectively improves the computational efficiency. The mirror descent algorithm is highly effective for handling large-scale optimization problems ([11]), and numerous studies have focused on extending this algorithm to distributed settings ([12, 13]).
In distributed algorithms, each node possesses a data set containing its private information. By collecting the information exchanged between nodes, attackers could potentially deduce the data sets of the nodes, leading to privacy leakage. To protect private information, an effective approach is the differential privacy mechanism proposed by Dwork et al. ([14]). The fundamental principle of the differential privacy mechanism is to add a certain level of noises to the communication, thereby ensuring that attackers can only obtain limited privacy information from their observations. Recently, extensive works have been proposed for distributed online convex optimization problems with differential privacy ([15, 16, 17, 18, 19, 20, 21]). Yuan et al. ([15]) proposed a privacy-preserving distributed online optimization algorithm based on the mirror descent. For a fixed graph, they proved that if the cost function is strongly convex, then the regret bound of the algorithm is the same as that without differential privacy, which is . Zhao et al. ([16]) proposed a distributed online optimization algorithm with differential privacy based on one-point residual feedback. They proved that, even if the gradient information of the cost function is unknown, the algorithm can still achieve differential privacy and the regret of the algorithm grows sublinearly. For constrained optimization problems, Lü et al. ([17]) introduced an efficient privacy-preserving distributed online dual averaging algorithm by using the gradient rescaling strategy. Li et al. ([18]) proposed a framework for differentially private distributed optimization. For time-varying communication graphs, they obtained the regrets bounds and for convex and strongly convex cost functions, respectively. Zhu et al. ([19]) proposed a differentially private distributed stochastic subgradient online convex optimization algorithm based on weight balancing over time-varying directed networks. They demonstrated that the algorithm ensures -differential privacy and provided the regret bound of the algorithm.
The aforementioned privacy-preserving distributed online optimization algorithms all address the cases of convex cost functions. However, in practical applications, many problems involve nonconvex cost functions. For example, in machine learning, the cost function may be nonconvex due to sparsity and low-rank constraints ([22]). In wireless communication, energy efficiency problems may also involve nonconvex cost functions due to constraints on node transmission power ([23]). Since the cost function is nonconvex, finding a global minimizer is challenging. Therefore, the regret for convex optimization cannot be used to measure the performance of nonconvex online algorithms. For nonconvex optimization, the goal is usually to find a point that satisfies the first-order optimality condition ([24, 25, 26, 27]). They used the regret based on the first-order optimality condition to evaluate the performance of the algorithm. Under appropriate assumptions, they proved that the regret grows sublinearly.
The privacy-preserving distributed online nonconvex optimization problems have wide applications in practical engineering fields, such as distributed target tracking. Up to now, the studies on privacy-preserving distributed nonconvex optimization have been restricted to offline settings ([28, 29]). In [28], a new algorithm for decentralized nonconvex optimization was proposed, which can enable both rigorous differential privacy and convergence. Compared with the existing works, the main challenges for privacy-preserving distributed online nonconvex optimization are as follows. The first challenge is ensuring the convergence of the algorithm with the differential privacy mechanism. Existing works on distributed online nonconvex optimization do not incorporate privacy protection, and adding noises to decision variables may lead to divergence for differential privacy in distributed online optimization algorithms. The second challenge is improving the computational efficiency of online algorithms. For online optimizations, computational resources are limited, and the immediate decision-making is required. Compared with [28], which addressed unconstrained optimization problems, we focus on optimization problems with set constraints, making the solution process more difficult and the computational cost higher. The algorithm in [28] is based on the gradient descent. For constrained optimization problems, directly incorporating Euclidean projection into the algorithm given in [28] may lead to high computational costs. Motivated by selecting Bregman projections based on different constraint conditions can improve computational efficiency, we combine the differential privacy mechanism with the distributed mirror descent method to design a privacy-preserving distributed online mirror descent algorithm for nonconvex optimization (DPDO-NC). The proposed algorithm can address distributed online nonconvex optimization problems while protecting privacy. To evaluate the algorithm’s performance, we use the regret based on the first-order optimality condition and give a thorough analysis of the algorithm’s regret. Table 1 compares our algorithm with existing privacy-preserving distributed online optimization algorithms. The main contributions of this paper are summarized as follows.
| Reference | Cost functions | Constraint | Communication graph |
|---|---|---|---|
| [15] | strongly convex | convex set | fixed undirected |
| [16], [20] | convex/strongly convex | convex set | fixed directed |
| [17] | convex | convex set | fixed directed |
| [18] | convex/strongly convex | convex set | time-varying undirected |
| [19] | convex/strongly convex | no | time-varying directed |
| [21] | convex | equality | fixed undirected |
| our work | nonconvex | convex set | time-varying directed |
In our algorithm, each node adds noises to its decision variables and then broadcasts the perturbed variables to neighboring nodes via the communication network to achieve consensus. Finally, the mirror descent method is used to update the local decision variables. We prove that the proposed algorithm maintains -differential privacy at each iteration. Compared with [27], our algorithm adds Laplace noises during communication with neighbors to protect privacy information, and the communication topology in our algorithm is a time-varying graph rather than a fixed graph. Compared with [14, 15, 16, 17, 18], we do not require the cost function to be convex. While [14, 15, 16] used fixed graphs, we consider time-varying graphs, which have broader application scenarios.
To overcome the challenges posed by constraints and online nonconvex cost functions, the proposed algorithm updates decisions by solving subproblems. The subproblems include the Bregman divergence. If the Bregman divergence satisfies appropriate conditions, then the algorithm can effectively track its stationary point. By using the mirror descent algorithm, we can choose different Bregman divergences depending on the problem, which can reduce the computational cost. By appropriately selecting the step size, we prove that the regret upper bound of the algorithm is , i.e., the algorithm converges to the stationary point sublinearly. The regret order is the same as the regret for distributed online nonconvex optimization algorithms without differential privacy.
The numerical simulations demonstrate the effectiveness of the proposed algorithm. By using the distributed localization problem, we demonstrate that the algorithm’s regret is sublinear. Additionally, the numerical simulations reveal the tradeoff between the level of privacy protection and the algorithm’s performance.
The main structure and content of this paper are arranged as follows. Section 2 introduces the preliminaries, including the graph theory and the problem description. Section 3 presents the differentially private distributed online nonconvex optimization algorithm. Section 4 includes the differential privacy analysis and the regret analysis. Section 5 gives the numerical simulations. The final section concludes the paper.
Notations: let and be the set of real numbers and integers, respectively. For a vector or matrix , and represent its 2-norm and 1-norm, respectively. Let be the transpose of , and be the -th row of the matrix. For a given function , denotes its gradient. Let 1 be a column vector of appropriate dimension with all elements equal to 1. Let be an identity matrix of appropriate dimension. For a random variable , and denote its probability distribution and expectation, respectively. For a random variable , indicates that follows a Laplace distribution with scale parameter , whose probability density function is given by .
2 Preliminaries and Problem Description
This section provides the problem description and preliminaries for the subsequent analysis.
2.1 Graph theory
The communication network is modeled by a directed graph (digraph) , where is the set of nodes and is the set of edges. Elements in are represented as pairs , where , and indicates that node can directly send information to node . Let and denote the in-neighbors and out-neighbors of node at each time , respectively. The matrix is called the weight matrix of the graph . If , then for some , and otherwise. If is symmetric, then is an undirected graph. If satisfies and , then is called a doubly stochastic matrix, and is called a balanced graph. For a fixed graph , if for any two nodes , there exist such that , then the graph is strongly connected. For the digraph , a -edge set is defined as for some integer . The digraph is -strongly connected if the digraph with the node set and the edge set is strongly connected for all ([30]).
2.2 Problem description
In this paper, we consider the time-varying system with nodes, where each node only knows its cost function and communicates with neighboring nodes through a directed time-varying network . The nodes cooperate to solve the following optimization problem
| (1) |
where is the cost function of node at time , and is the time horizon. The following basic assumptions are given for problem (1).
Assumption 1
For all , is -strongly connected, and the weight matrix is doubly stochastic.
Assumption 2
The set is a bounded closed convex set.
Assumption 3
For all , , is differentiable and -smooth with respect to , i.e., there exist such that
By Assumptions 2-3, we know that there are and such that for all , and for all , , and . Assumptions 2-3 are common in the research on distributed optimization ([18][20]). Moreover, there are no convexity requirements for the cost functions in this paper. We give the following practical example that satisfies Assumptions 1-3.
Example 1
Distributed localization problem ([25][31]). Consider sensors collaborating to locate a moving target. Let be the true position of the target at time , and be the position of sensor . Each sensor can only obtain the distance measurement between the target’s position and its position, given by
where is the measurement error at time . To estimate the target’s position, the sensors collaborate to solve the following optimization problem
where is a bounded closed convex set representing the range of the target’s position. It can be observed that is nonconvex with respect to .
In distributed online convex optimization, each node uses local information and information transmitted from neighboring nodes to make a local prediction of the optimal solution at time , where is the decision variable of node at time . Node can only observe at time , so in order to solve the global optimization task, the nodes must communicate with each other through the network .
Generally speaking, find the global optimal point is impossible for nonconvex optimization. We use the following definition of regret.
Definition 1
([32]) Let be the sequence of decisions generated by a given distributed online optimization algorithm, the regret of node is defined by
| (2) |
Different from the convex optimization, which aims at finding a global minimum, using the regret (2) aims at finding a stationary point of a nonconvex cost function. Our goal is to design an efficient online distributed optimization algorithm such that the regret (2) grows sublinearly with respect to time horizon , i.e., , while also ensuring the privacy of each node’s information.
Remark 1
Lu et al. ([27]) provides the following individual regret for distributed online nonconvex optimization
| (3) |
where . If is a stationary point of , then .
3 Algorithm Design
Without revealing the private information of individual nodes, in this paper, we propose a differentially private distributed online optimization algorithm for solving the nonconvex optimization problem (1), based on the distributed mirror descent algorithm and the differential privacy mechanism. The mirror descent algorithm is based on the Bregman divergence.
Definition 2
([12]) Given a -strongly convex function , i.e., there is such that
The Bregman divergence generated by is defined as
| (5) |
The Bregman divergence measures the distortion or loss resulting from approximating by . From Definition 2, the Bregman divergence has the following properties: (i) . (ii) is strongly convex with respect to . We give some assumptions on the Bregman divergence.
Assumption 4
(i) For any , is convex respect to , i.e., for any satisfying ,
(ii) For any , the Bregman divergence is M-smooth respect to , i.e., there is such that
Assumption 4 is a common assumption in the distributed mirror descent algorithm and is also mentioned in [12] and [15].
Suppose an attacker can eavesdrop on the communication channel and intercept messages exchanged between nodes, which may lead to privacy leakage. To protect privacy, we add noises to the communication. At time , each node adds noises to perturb the decision variables before communication. Then, each node communicates the perturbed decision variables with its neighbors for consensus. The specific iteration process is given by
| (6) |
where . Next, each node updates its local decision variable using the mirror descent based on the consensus variable . The specific iteration process is given by
| (7) |
where is the step size, and is given by (5). In (7), is strongly convex with respect to , which ensures a unique solution for . The pseudocode for the algorithm is given as follows.
Remark 2
Selecting Bregman functions based on different constraint conditions can improve computational efficiency. For example, for the optimization problem with probabilistic simplex constraint, i.e. with , if choosing the squared Euclidean distance, then in each projection step, projecting the iterates back onto the simplex constraint is computationally complex. However, if choosing the Bregman function , then one can deduce that and . The iteration points automatically remain within the set without additional projection computations and the computational cost is significantly reduced.
4 Algorithm Analyses
In this section, we provide the analyses of the differential privacy and the regret of the proposed algorithm. Denote
4.1 Differential privacy analysis
We firstly introduce the basic concepts related to the differential privacy.
Definition 3
([33]) Given two data sets and , if there exists an such that and for all , then the data sets and are adjacent. Two adjacent data sets is denoted as .
For the distributed online optimization problem , let the execution of the algorithm be . The observation sequence in the above execution of the algorithm is (the information exchanged during the algorithm’s execution). Denote the mapping from execution to observation by . Let be the observation sequence of the algorithm for any distributed online optimization problem . For any initial state , any fixed observation , and any two adjacent data sets and , we denote the algorithm’s executions for the two distributed online optimization problems and by and , , respectively. Let be the set of elements in the execution . Using the above notation, we give the definition of differential privacy.
Definition 4
([34]) For any two adjacent data sets and , any initial state , and any set of observation sequences , if the algorithm satisfies
where is the privacy parameter, then the algorithm satisfy -differential privacy.
If two data sets are adjacent, then the probability that the algorithm produces the same output for both data sets is very close. Differential privacy aims to mitigate the difference in outputs between two adjacent data sets by adding noises to the algorithm. To determine the amount of noises to add, the sensitivity plays an important role in algorithm design. We will now provide the definition of algorithm sensitivity.
Definition 5
In differential privacy, sensitivity is a crucial quantity that determines the amount of noises to be added in each iteration to achieve differential privacy. The sensitivity of an algorithm describes the extent to which a change in a single data point in adjacent data sets affects the algorithm. Therefore, we determine the noises magnitude by constraining sensitivity to ensure -differential privacy. The following lemma provides a bound for the sensitivity of Algorithm 1.
Lemma 1
Proof 1
Based on (7) and the first-order optimality condition, we have
| (9) |
By (5), we have
| (10) |
Let , by (9) and (10), we obtain
By Assumption 2 and Cauchy-Schwarz inequality, we have
Therefore, we have
| (11) |
Similarly, we have
| (12) |
At each time , by Definition 5, the attacker observes the same information from two adjacent data sets, i.e., . From (6), we know that . By (11), (12) and the triangle inequality, we have
| (13) |
From the arbitrariness of observation and adjacent data sets and , as well as (13), we obtain (8). \qed
The data set contains all the information that needs to be protected, where represents the information that the algorithm needs to protect at time . The adjacent data set of is denoted as , where . Next, we present the -differential privacy theorem.
Theorem 1
Proof 2
Remark 3
According to Theorem 1, Algorithm 1 satisfies -differential privacy in each iteration. Since the upper bound for the sensitivity includes the step size, if choosing a decaying step size, then the sensitivity will gradually decrease. The level of differential privacy depends on the step size , the bound on the gradient , the dimension of the decision variables , the strong convexity parameter , and the noise magnitude . The smaller is, the higher the level of differential privacy.
4.2 Regret analysis
This subsection analyzes the regret of Algorithm 1. By appropriately choosing parameters, for Algorithm 1, this section provides an upper bound on its regret. We present some lemmas for analyzing the regret of the algorithm.
For any , the state transition matrix is defined as
According to Property 1 in [30], we have the following lemma.
Lemma 2
In order to prove the main results, some necessary lemmas are provided.
Lemma 3
Proof 3
Firstly, denote and . By (11), we have
| (17) |
By (6), we obtain
| (18) |
By (18), we obtain
| (19) |
By Assumption 1 and (18), we have
| (20) |
Combining Lemma 2, (17), (18), and (19), we obtain
| (21) |
where the last inequality holds due to Lemma 2, (17), and . Therefore, for any , by (3) and the triangle inequality, we have (16). \qed
Lemma 4
Proof 4
By Assumption 1, Assumption 4 and (6), for any , we have
From (6) and (7), it is known that and are independent. Combining the properties of the Laplace distribution and Assumption 4, we obtain
| (23) |
By Assumptions 2 - 4, we obtain
| (24) |
where the first inequality holds due to and
and the second inequality holds due to , . By (23) and (4), we have (22). \qed
Lemma 5
Lemma 6
Proof 5
Denote , , , and . By Lemma 5, we have
From the non-negativity of Bregman divergence and the above inequality, we have
Rearranging and summing the above inequality yields
| (26) |
By Assumptions 1- 3, for any , , we have
| (27) |
where the inequality holds due to , , and . Combining (22), (5), and (5), the lemma is thus proved. \qed
Next, we present the theorem for the regret analysis of Algorithm 1.
Theorem 2
Proof 6
To prove is sublinear, it suffices to show is sublinear for any . By (6), , and , we have
| (29) |
By (6), the triangle inequality, and , we have
| (30) |
By (16), (3), and the properties of the Laplace distribution, we obtain
| (31) |
By the triangle inequality, (3), and (31), we obtain
| (32) |
Substituting (6), (6), and (6) into (6), and combining with , and (16), we obtain
Substituting and into the above inequality, and combining with , , and
we obtain
| (33) |
By the arbitrariness of and combining with (6), we obtain (28). \qed
Remark 4
From Theorem 2, we know that Algorithm 1 converges sublinearly. This is consistent with the best results in existing works on distributed online nonconvex optimization. The differential privacy mechanism we added does not affect the order of the upper bound on the regret, but only the coefficient. Furthermore, the regret of the algorithm depends on the properties of the cost function, the constraint set, the problem’s dimension, the number of nodes, the connectivity of the communication graph, and the privacy parameters. It is worth noting that from Theorem 2, we can see that the larger the privacy parameter , the tighter the bound on the regret. However, in the differential privacy analysis of Theorem 1, the smaller the privacy parameter, the higher the privacy level. Therefore, in practical applications, it is necessary to choose an appropriate privacy parameter to balance algorithm performance and privacy level.
5 Numerical Simulations
In this section, we demonstrate the theoretical results of the proposed algorithm (DPDO-NC) through the distributed localization problem (Example 1). We consider a time-varying communication topology consisting of 6 sensors. The time-varying communication topology switches between three graphs, denoted by . The weight matrices for these three graphs are denoted as , where
The evolution process of the target location is defined as
where , and initial state . The distance measurements are given by
where is the measurement error of the model, which follows a uniform distribution over . The sensors collaborate to solve the following problem
where . The initial positions of the sensors are . The initial estimates of the sensors are . Fix the number of iterations to . The distance function of the algorithm is , and the step size is .
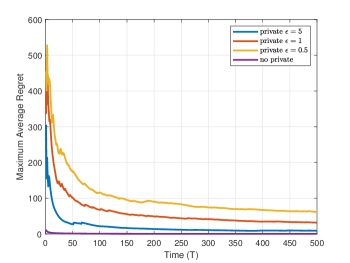
Figure 1 shows the evolution of with different privacy levels, where the privacy parameters are set to , , and , and the cases without differential privacy is also compared. From Figure 1, it can be observed that Algorithm 1 converges under different privacy levels, and the lower the privacy level, i.e., the larger , the better the convergence performance of the algorithm. The parameter reveals the trade-off between privacy protection and algorithm performance, which is consistent with the theoretical results presented in this paper.
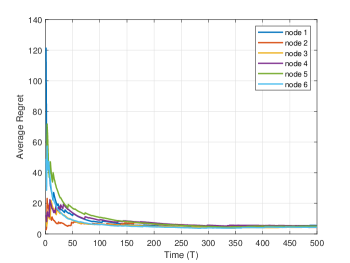
When the privacy parameter is set to , we compare the convergence of each node. Figure 2 depicts the variation in the regret of each node. As shown in Figure 2, all nodes converge, and the convergence speeds are almost identical. This indicates that through interaction with neighboring nodes, the regret of each node achieves sublinear convergence.
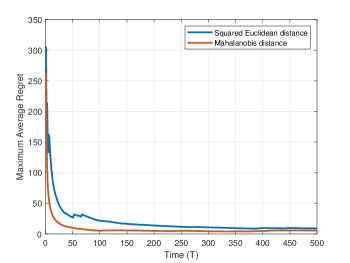
We also present the convergence of the algorithm with different Bregman divergences. We demonstrate the algorithm’s performance using the squared Euclidean distance and the Mahalanobis distance, with and , where is a positive semi-definite matrix. Both distance functions satisfy Assumption 4. Figure 3 shows the evolution of under different Bregman divergence with . As seen in Figure 3, for different Bregman divergences, as long as they satisfy Assumption 4, the proposed differential privacy distributed online nonconvex optimization algorithm can converge to the stationary point, and the regret is sublinear.
6 Conclusion
In this paper, we study the privacy-preserving distributed online optimization for nonconvex problems over time-varying graphs. Based on the Laplace differential privacy mechanism and the distributed mirror descent algorithm, we propose a privacy-preserving distributed online mirror descent algorithm for nonconvex optimization (DPDO-NC), which guarantees -differential privacy at each iteration. In addition, we establish the upper bound of the regret for the proposed algorithm and prove that the individual regret based on the first-order optimality condition grows sublinearly, with an upper bound . Finally, we demonstrate the effectiveness of the algorithm through numerical simulations and analyze the relationship between the algorithm regret and the privacy level. Future research could explore more complex communication networks and scenarios with intricate constraints, as well as focus on improving the convergence rate of algorithms for solving distributed online nonconvex optimization problems.
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant 62261136550.
References
- [1] G. Tychogiorgos, A. Gkelias, K. K. Leung, A non-convex distributed optimization framework and its application to wireless ad-hoc networks, IEEE Transactions on Wireless Communications 12 (9) (2013) 4286–4296.
- [2] W. Chen, T. Li, Distributed economic dispatch for energy internet based on multiagent consensus control, IEEE Transactions on automatic control 66 (1) (2020) 137–152.
- [3] W. Ma, J. Wang, V. Gupta, C. Chen, Distributed energy management for networked microgrids using online admm with regret, IEEE Transactions on Smart Grid 9 (2) (2016) 847–856.
- [4] P. Nazari, D. A. Tarzanagh, G. Michailidis, Dadam: A consensus-based distributed adaptive gradient method for online optimization, IEEE Transactions on Signal Processing 70 (2022) 6065–6079.
- [5] E. Hazan, A. Agarwal, S. Kale, Logarithmic regret algorithms for online convex optimization, Machine Learning 69 (2) (2007) 169–192.
- [6] M. Akbari, B. Gharesifard, T. Linder, Individual regret bounds for the distributed online alternating direction method of multipliers, IEEE Transactions on Automatic Control 64 (4) (2018) 1746–1752.
- [7] R. Dixit, A. S. Bedi, K. Rajawat, Online learning over dynamic graphs via distributed proximal gradient algorithm, IEEE Transactions on Automatic Control 66 (11) (2020) 5065–5079.
- [8] J. Li, C. Gu, Z. Wu, Online distributed stochastic learning algorithm for convex optimization in time-varying directed networks, Neurocomputing 416 (2020) 85–94.
- [9] K. Lu, G. Jing, L. Wang, Online distributed optimization with strongly pseudoconvex-sum cost functions, IEEE Transactions on Automatic Control 65 (1) (2019) 426–433.
- [10] A. Beck, M. Teboulle, Mirror descent and nonlinear projected subgradient methods for convex optimization, Operations Research Letters 31 (3) (2003) 167–175.
- [11] A. Ben-Tal, T. Margalit, A. Nemirovski, The ordered subsets mirror descent optimization method with applications to tomography, SIAM Journal on Optimization 12 (1) (2001) 79–108.
- [12] S. Shahrampour, A. Jadbabaie, Distributed online optimization in dynamic environments using mirror descent, IEEE Transactions on Automatic Control 63 (3) (2017) 714–725.
- [13] D. Yuan, Y. Hong, D. W. Ho, S. Xu, Distributed mirror descent for online composite optimization, IEEE Transactions on Automatic Control 66 (2) (2020) 714–729.
- [14] C. Dwork, F. McSherry, K. Nissim, A. Smith, Calibrating noise to sensitivity in private data analysis, in: Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006. Proceedings 3, Springer, 2006, pp. 265–284.
- [15] M. Yuan, J. Lei, Y. Hong, Differentially private distributed online mirror descent algorithm, Neurocomputing 551 (2023) 126531.
- [16] Z. Zhao, Z. Yang, M. Wei, Q. Ji, Privacy preserving distributed online projected residual feedback optimization over unbalanced directed graphs, Journal of the Franklin Institute 360 (18) (2023) 14823–14840.
- [17] Q. Lü, K. Zhang, S. Deng, Y. Li, H. Li, S. Gao, Y. Chen, Privacy-preserving decentralized dual averaging for online optimization over directed networks, IEEE Transactions on Industrial Cyber-Physical Systems 1 (2023) 79–91.
- [18] C. Li, P. Zhou, L. Xiong, Q. Wang, T. Wang, Differentially private distributed online learning, IEEE transactions on knowledge and data engineering 30 (8) (2018) 1440–1453.
- [19] J. Zhu, C. Xu, J. Guan, D. O. Wu, Differentially private distributed online algorithms over time-varying directed networks, IEEE Transactions on Signal and Information Processing over Networks 4 (1) (2018) 4–17.
- [20] Y. Xiong, J. Xu, K. You, J. Liu, L. Wu, Privacy-preserving distributed online optimization over unbalanced digraphs via subgradient rescaling, IEEE Transactions on Control of Network Systems 7 (3) (2020) 1366–1378.
- [21] H. Wang, K. Liu, D. Han, S. Chai, Y. Xia, Privacy-preserving distributed online stochastic optimization with time-varying distributions, IEEE Transactions on Control of Network Systems 10 (2) (2022) 1069–1082.
- [22] J. Zhang, S. Ge, T. Chang, Z. Luo, Decentralized non-convex learning with linearly coupled constraints: Algorithm designs and application to vertical learning problem, IEEE Transactions on Signal Processing 70 (2022) 3312–3327.
- [23] S. Hashempour, A. A. Suratgar, A. Afshar, Distributed nonconvex optimization for energy efficiency in mobile ad hoc networks, IEEE Systems Journal 15 (4) (2021) 5683–5693.
- [24] E. Hazan, K. Singh, C. Zhang, Efficient regret minimization in non-convex games, in: International Conference on Machine Learning, PMLR, 2017, pp. 1433–1441.
- [25] A. Lesage-Landry, J. A. Taylor, I. Shames, Second-order online nonconvex optimization, IEEE Transactions on Automatic Control 66 (10) (2020) 4866–4872.
- [26] J. Li, C. Li, J. Fan, T. Huang, Online distributed stochastic gradient algorithm for non-convex optimization with compressed communication, IEEE Transactions on Automatic Control 69 (2) (2024) 936–951.
- [27] K. Lu, L. Wang, Online distributed optimization with nonconvex objective functions: Sublinearity of first-order optimality condition-based regret, IEEE Transactions on Automatic Control 67 (6) (2021) 3029–3035.
- [28] Y. Wang, T. Başar, Decentralized nonconvex optimization with guaranteed privacy and accuracy, Automatica 150 (2023) 110858.
- [29] M. Khajenejad, S. Martínez, Guaranteed privacy of distributed nonconvex optimization via mixed-monotone functional perturbations, IEEE Control Systems Letters 7 (2022) 1081–1086.
- [30] A. Nedic, A. Ozdaglar, Distributed subgradient methods for multi-agent optimization, IEEE Transactions on Automatic Control 54 (1) (2009) 48–61.
- [31] M. Cao, B. D. Anderson, A. S. Morse, Sensor network localization with imprecise distances, Systems & control letters 55 (11) (2006) 887–893.
- [32] Y. Hua, S. Liu, Y. Hong, K. H. Johansson, G. Wang, Distributed online bandit nonconvex optimization with one-point residual feedback via dynamic regret, arXiv preprint arXiv:2409.15680.
- [33] C. Dwork, Differential privacy, in: International colloquium on automata, languages, and programming, Springer, 2006, pp. 1–12.
- [34] Z. Huang, S. Mitra, N. Vaidya, Differentially private distributed optimization, in: Proceedings of the 16th International Conference on Distributed Computing and Networking, 2015, pp. 1–10.
- [35] Y. Wang, A. Nedić, Tailoring gradient methods for differentially private distributed optimization, IEEE Transactions on Automatic Control 69 (2) (2023) 872–887.
- [36] A. Beck, M. Teboulle, Mirror descent and nonlinear projected subgradient methods for convex optimization, Operations Research Letters 31 (3) (2003) 167–175.