Privacy-Preserving Multimedia Mobile Cloud Computing Using Protective Perturbation
Abstract.
Mobile cloud computing has been adopted in many multimedia applications, where the resource-constrained mobile device sends multimedia data (e.g., images) to remote cloud servers to request computation-intensive multimedia services (e.g., image recognition). While significantly improving the performance of the mobile applications, the cloud-based mechanism often causes privacy concerns as the multimedia data and services are offloaded from the trusted user device to untrusted cloud servers. Several recent studies have proposed perturbation-based privacy preserving mechanisms, which obfuscate the offloaded multimedia data to eliminate privacy exposures without affecting the functionality of the remote multimedia services. However, the existing privacy protection approaches require the deployment of computation-intensive perturbation generation on the resource-constrained mobile devices. Also, the obfuscated images are typically not compliant with the standard image compression algorithms and suffer from significant bandwidth consumption. In this paper, we develop a novel privacy-preserving multimedia mobile cloud computing framework, namely PMC2, to address the resource and bandwidth challenges. PMC2 employs secure confidential computing in the cloud to deploy the perturbation generator, which addresses the resource challenge while maintaining the privacy. Furthermore, we develop a neural compressor specifically trained to compress the perturbed images in order to address the bandwidth challenge. We implement PMC2 in an end-to-end mobile cloud computing system, based on which our evaluations demonstrate superior latency, power efficiency, and bandwidth consumption achieved by PMC2 while maintaining high accuracy in the target multimedia service.
1. Introduction
Mobile cloud computing has been adopted in many mobile multimedia applications to compensate for the limited computing resources on the mobile devices (Wang and Dey, 2013; Cerqueira et al., 2014; Xu and Mao, 2013; Khan et al., 2022; Alhilal et al., 2022; Zhao et al., 2022; Chen et al., 2017; Tian et al., 2017). In a typical mobile multimedia cloud computing system, the mobile device sends input data (e.g., images) to a remote cloud server, which provides computation-intensive services (e.g., image recognition) that cannot be deployed on the mobile device due to resource limitations or intellectual property regulations. With the rapid advancements of high-speed communication networks and high-capacity data centers, mobile cloud computing has demonstrated significant performance advantages over traditional mobile-only computing in many application domains, such as image recognition/annotation (Tian et al., 2017), object detection (Chen et al., 2017), and gaming (Alhilal et al., 2022).
Despite the performance benefits, mobile cloud computing can result in privacy concerns as the input data (e.g., images) on the mobile device often involve privacy-sensitive components, which either the users themselves do not intend to release from their private possession (Zhao et al., 2023) or disallow data sharing and dissemination due to privacy regulations (GDP, 2016; HIP, 2021). Among various privacy concerns with a diverse set of data types, visual privacy (Zhao et al., 2023; Ye et al., 2022; Padilla-López et al., 2015) is one of the most direct privacy issues faced by the end users when the multimedia data (e.g., images and videos) are offloaded to the cloud for processing. Visual privacy is concerned about the visual information contained in the disseminated data being visually perceivable by unauthorized individuals other than the owner of the data, even if there are no factual security or privacy breaches or side effects that can be attributed to the visual exposure. Given the rich visual information in the multimedia data, the visual privacy issue has raised significant public concerns and introduced challenges in the deployments of many multimedia services (Stangl et al., 2022; Akter et al., 2020; Pletcher, 2023; Chattopadhayay and Rijal, 2023).
To address the visual privacy issue, protective perturbation-based approaches have been proposed recently, which inject noises to the private images in order to prevent the visual privacy exposure to human vision while preserving the capability of machine vision to complete the machine learning services (Ren et al., 2018; Sun et al., 2018; Wu et al., 2021; Zhu et al., 2020; Ye et al., 2022). However, such perturbation injection approaches often require executing a computation-intensive perturbation generation model on the resource-constrained mobile device, posing significant challenges to the latency, power consumption, and user experience. Therefore, it is challenging to deploy such privacy protection approaches on the mobile device in an end-to-end system.
We develop a protective perturbation-based multimedia mobile computing framework, namely PMC2, to address the aforementioned privacy and resource challenges. PMC2 adopts the state-of-the-art protective perturbation approach to protect the privacy of the private images but offloads the computation-intensive perturbation generation to a secure edge server to alleviate the computation workload on the resource-constrained mobile device. The protected images generated by the secure edge server are then transferred to the remote cloud server for the desired multimedia service. To ensure the confidentiality and integrity of the perturbation generation process, PMC2 employs hardware-based confidential computing techniques to deploy and execute the perturbation generation model in a secure container on the edge server, which provides the same level of trustworthiness as the user mobile device and thus eliminate the potential visual privacy exposure. It is worth noting that the secure edge server is deployed in a local and user-trusted domain, while the cloud server is deployed in an untrusted, remote domain. A trusted domain is deployed with a series of security/privacy-preserving techniques, e.g., force HTTPS, access control, secure data storage and management, and firewalls to prevent security/privacy threats (Tru, 2023). The user trusts such a domain and has the ability to verify the integrity of the system (e.g., via attestation (SEV, 2023)). The trusted domain resides in a local area network (LAN) as small as a home LAN to deploy applications like an AI-powered photo management system (pho, 2023). In addition to the security/privacy benefits, the local trusted domain also enables faster and cheaper in-domain communications between the mobile device and the edge server. On the other hand, the untrusted domain resides in the remote cloud service, which provides powerful computation resources and proprietary machine learning models; however, it inevitably incurs bandwidth expensive cross-domain communications between the secure edge server and the cloud server.
While deploying the proposed PMC2 framework, we identify a key technical challenge that the perturbed images cannot be efficiently compressed by the standard image encoding/compression algorithms, resulting in significantly increased bandwidth consumption in the cross-domain communication when transmitting the privacy-preserving, perturbed images. To address this bandwidth challenge, we develop a neural compressor tailored to efficiently compress images with protective perturbations. The neural compressor is trained using a dataset of perturbed images and optimizes for the compression ratio while minimizing the distortion between the original and reconstructed images. Given the unique patterns of protective perturbations embedded in the images, the neural compression approach is capable of achieving a significantly higher compression ratio compared to standard image encoding methods.
We implement the proposed PMC2 framework in an end-to-end multimedia mobile cloud computing system, involving a mobile device, a protective perturbation generator deployed in a secure edge sever with confidential containers enabled by AMD SEV (AMD, 2023), and a regular cloud server running image recognition services. Our evaluations using 5000 images from the CIFAR-10 dataset show superior latency, power, and bandwidth results of the proposed PMC2 framework in comparison with the baseline systems. Note that the perturbation generation and compression models required by PMC2 can be trained with only black box access to the image recognition service model, without the knowledge of the model structure/parameters or modifying the model. Therefore, PMC2 can be seamlessly deployed in empirical and legacy multimedia mobile cloud computing systems.
To summarize, we have made the following contributions by developing PMC2:
-
•
We develop the first cloud-based protective perturbation generation system for visual privacy protection, alleviating the computation workload on the resource-constrained mobile devices to improve the latency and power efficiency;
-
•
The proposed neural compression approach tailored to perturbed images achieves significantly higher bandwidth savings than standard image encoding methods; and
-
•
We deploy the proposed PMC2 framework in an end-to-end multimedia mobile cloud computing system, which we plan to open source upon the publication of the paper to motivate further research in the community.
2. Background and Related Work
2.1. Multimedia Mobile Cloud Computing
A typical multimedia mobile cloud computing system involves a mobile client and a cloud server. The mobile client offloads input data to the cloud server to request computation-intensive services from the cloud server, which makes the mobile device achieve significantly lower resources (e.g., power) consumption and higher performance. Also, it enables the service providers to deploy the proprietary image recognition models in their trusted domains for effective maintenance and intellectual property protection.
However, as a trade-off, the empirical deployment of such a mobile cloud computing system faces the following two challenges:
-
•
Privacy/Security challenge. Since the user data, which are often of a privacy-sensitive nature, must be offloaded to the cloud server, privacy concerns are often raised due to both the user’s natural psychological needs and the legal regulations (Pri, 2020). Also, the untrusted or unsecured cloud service provider and network may enable adversaries to obtain and abuse the private user data to issue various cybersecurity attacks (Str, 2020).
-
•
Bandwidth challenge. The data offloading from the mobile client to the cloud server may consume a large amount of bandwidth in the communication network, especially when rich multimedia content is involved (e.g., high-definition images or videos).
2.2. Privacy-Preserving Protective Perturbation
We only consider visual privacy as the threat model in this work, and do not consider security threats like crossmatching attacks or other attacks that may compromise the visual privacy solutions (e.g., protective perturbations). Many research efforts have focused on privacy-preserving image delivery to address the visual privacy challenge, where the goal is to prevent the user’s private image from being exposed to others. For example, several research works propose to inject perturbations to blur and protect the privacy-sensitive information in the images (Ren et al., 2018; Sun et al., 2018; Wu et al., 2021; Zhu et al., 2020; Ye et al., 2022). Such perturbation generator can be deployed on the mobile client to blur the sensitive images before it is exposed to the untrusted network or service provider.
Without loss of generality, we adopt the state-of-the-art protective perturbation generator (Ye et al., 2022) in our mobile cloud image recognition system. This perturbation generator utilizes U-Net as the core generative model, which is trained to inject perturbations to the original images, so that they are entirely blurred to human vision for privacy protection but remain as effective inputs to the image recognition model on the cloud server to achieve highly accurate recognition results. The goal is achieved by minimizing the loss function , where are tunable weights of each term, is the Cross-Entropy Loss, is the true label of the input image , and are predicted labels of the perturbed image . Note that this work utilizes two image recognition models during the training process, a target model (outputs ) and an auxiliary model (outputs ), where the target model is the model on the cloud server, and the auxiliary model is a different image recognition model to help generate the perturbation, chosen by experiments.
| Image Type | Encoding Methods | |||
| PNG | JPEG (no subsampling) | |||
| Size (Bytes) | Accuracy | Size (Bytes) | Accuracy | |
| Regular | 2662.60 | 94.24% | 724.44 | 90.28% |
| Perturbed | 2690.56 | 91.44% | 1818.77 | 90.40% |
2.3. Limitations of Existing Protective Perturba- tion and Image Encoding Approaches
We conduct two case studies to reveal the limitations of the existing protective perturbation and image encoding approaches, which cannot effectively address the aforementioned privacy and bandwidth challenges in our target end-to-end mobile cloud image recognition system.
2.3.1. Case Study 1: Excessive on-device power consumption and latency
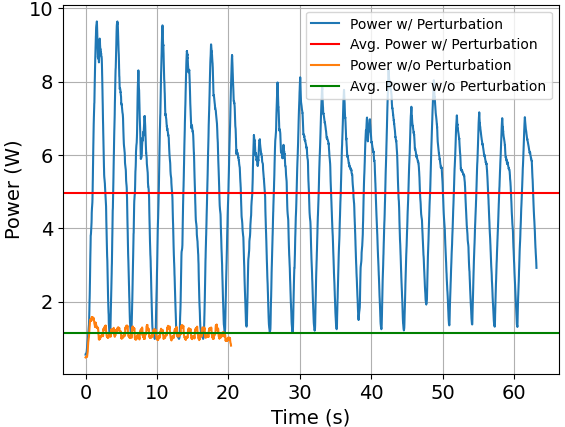
Since the perturbation generation process involves the execution of a computation-intensive neural network model, the perturbation generator is expected to consume a significant amount of battery power if deployed on the mobile device as in the state-of-the-art solutions (Ye et al., 2022). In this case study, we measure and compare the power consumption of the image recognition application (Ye et al., 2022) running on a Pixel 3 phones with and without injecting protective perturbation, as shown in Figure 1. The image recognition application involves a stream of 5000 test images from the CIFAR-10 dataset (Krizhevsky et al., 2009), with a batch size of 256 for the perturbation generator. The target image recognition model is VGG13_bn, and the image encoding method is PNG. We observe that the average power consumption in the with perturbation case (the red line) is 4.961W, which is a 4.36x of 1.139W in the without perturbation case (the green line). Figure 1 also shows the latency results of the image recognition application for 5000 test images, as indicated by the durations of the power traces. When the protective perturbation is added, the latency increases from 20.033s to 63.345s, which is a 3.16x slowdown. Furthermore, combining the power and latency results, the energy consumption of the privacy-preserving version of the application is around 13.78x of the original application without privacy protection. To summarize, the huge overhead of protective perturbation on mobile devices (i.e., 4.36x in power, 3.16x in latency, and 13.78x in energy) must be addressed to make the privacy protection approach practical.
2.3.2. Case Study 2: Ineffective compression for perturbed image
The standard image encoding mechanisms like PNG and JPEG are designed for regular images optimizing for perceivable visual qualities, instead of the perturbed images targeting machine learning services in the privacy-preserving image recognition application. To identify the potential limitations, we conduct a case study comparing the effectiveness of compressing regular and perturbed images using PNG and JPEG, with the target of achieving at least 90% of accuracy in image recognition, using as VGG13_bn as target image recognition model and 5000 test images from the CIFAR-10 dataset (Krizhevsky et al., 2009). Table 1 shows the results of the case study. JPEG achieves 3.7x of compression ratio on regular images compared to lossless PNG. However, such compression ratio would decrease to 1.5x in the case of perturbed images in order to maintain a similar image recognition accuracy. The significant reduction in compression ratio indicates the ineffective compression achieved by the standard image encoding methods, which would cause higher bandwidth consumption in the delivery of the perturbed images.
In summary, the two case studies reveal the limitations of existing perturbation generation and image encoding approaches in achieving a practical end-to-end privacy-preserving image recognition system, which we aim to address in this work.
3. PMC2 System Design
We develop a privacy-preserving multimedia mobile cloud computing framework, namely PMC2, to proactively protect the privacy of user data in mobile-cloud image recognition, while consuming low on-device resources and network bandwidth for practical deployment. In a nutshell, the PMC2 system addresses the aforementioned privacy/security challenge, as well as the associated power/latency overhead, by executing the security-sensitive and computation-intensive perturbation generation task on the trusted secure edge server, which is protected by the state-of-the-art confidential computing techniques and equipped with abundant resources for high performance computing. Also, it addresses the aforementioned bandwidth challenge by employing perturbation-aware neural compression for the perturbed images. Furthermore, the deployment of PMC2 system does not require modifications to the target image recognition model, which is assumed to be proprietary, making it immediately deployable to empirical mobile cloud systems.
3.1. System Overview
Figure 2 shows the overall architecture of PMC2. It introduces a trusted secure edge server between the mobile client and the traditional cloud server. The secure edge server accomplishes privacy-preserving perturbation generation in a confidential computing container protected by the trusted execution environment (TEE) technology. In addition, a neural encoder and decoder are deployed on the secure edge server and the cloud server, respectively, to attain the bandwidth-saving goal.
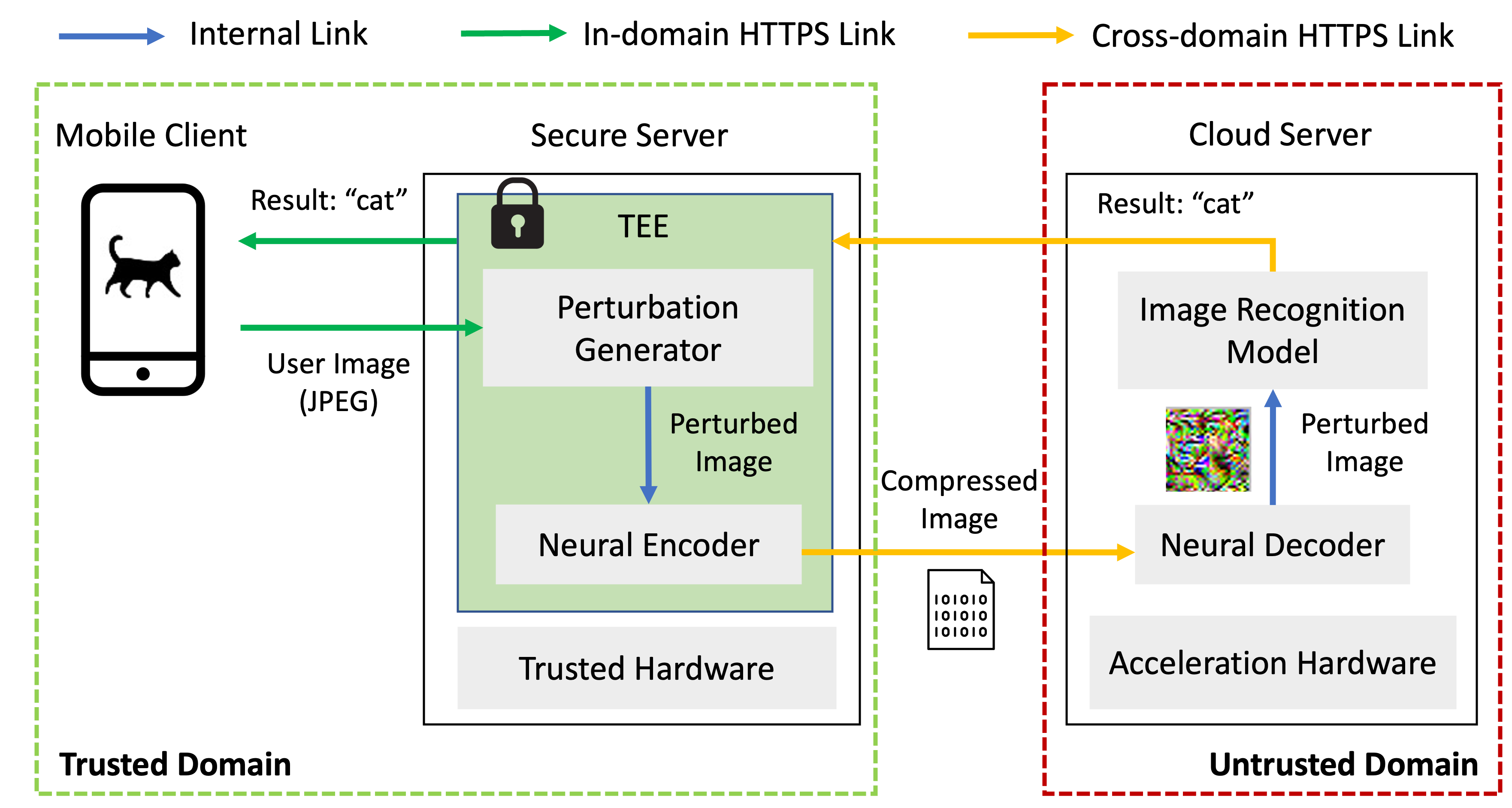
The end-to-end PMC2 system works as follows to achieve privacy-preserving mobile-cloud image recognition. First, the mobile client compresses the privacy-sensitive images using JPEG and offloads them to the trusted secure edge server via an in-domain HTTPS link. The secure edge server is deployed inside the same trusted domain as the mobile client. Second, on the secure edge server, a perturbation generator runs inside the TEE-protected confidential container to securely inject protective perturbations to the received user images in real time; Then, the perturbed images are compressed by a perturbation-aware neural encoder and transferred to the cloud server for image recognition via the cross-domain HTTPS link. The cloud server is deployed in a remote and untrusted domain. Third, the cloud server decodes the compressed images using a neural decoder, which reconstructs the perturbed images and feeds them into the machine learning-based image recognition model for the computation-intensive classifications. Finally, the image recognition results are returned to the mobile client via the secure edge server.
3.2. Secure Protective Perturbation Generation
We employ the state-of-the-art confidential computing techniques to generate the protective perturbations on the secure edge server to address the privacy/security challenge without incurring power and latency overhead on the mobile client. Confidential computing has been widely adopted in the modern cloud platforms by leveraging trusted computing environment (TEE) technology (AWS, 2023; Goo, 2023; Azu, 2023; IBM, 2023). Such technology provides secure enclaves in the system, which guarantees that the computation conducted in each enclave is encrypted and isolated from the rest of the system. Generally there are two types of TEEs, namely process-based TEEs and virtual machine (VM)-based TEEs. Process-based TEEs such as Intel SGX (sgx, 2021) can achieve minimal trusted computing base (TCB) since they only deploy the processes that must be protected into enclaves. On the other hand, such techniques require partitioning each application into secure and non-secure domains and thus introduce significant offline overhead (i.e., application partitioning) and runtime overhead (i.e., context switches between the secure and non-secure domains). Due to these limitations on process-based TEEs, there has recently been increasing demand for VM-based TEEs, such as Intel TDX (Int, 2023) and AMD SEV (AMD, 2023), which deploy the entire VM into an enclave. Although VM-based TEEs result in larger TCB than the process-based TEEs, they are more suitable for cloud-native computing and can be easily integrated into Infrastructure as a Service (IaaS) and Platform as a Service (PaaS) platforms.
To protect the confidentiality of the perturbation generation in PMC2, we deploy the perturbation generator into a TEE on the secure edge server. Note that our proposed framework is generally compatible with any TEE techniques but, in this work, we leverage confidential containers (CoCo) (CoC, 2023) with AMD SEV (AMD, 2023) (i.e., a VM-based TEE) for the following reasons. First, CoCo supports running containerized applications and can be managed by Kubernetes (K8s) (K8s, 2023) platforms, which helps us achieve a cloud-native computing environment. Second, CoCo supports multiple VM-based TEE techniques, such as AMD SEV and Intel TDX (Int, 2023), which provides flexibility for the users to choose different hardware platforms. Third, applications can be directly deployed into CoCo without any modifications, which significantly increases the diversity of supported perturbation generation models that can be applied to the PMC2 framework and does not introduce additional offline overhead to modify the models.
Kindly notice that the protective perturbation generators run with CPU only without leveraging GPU or other acceleration hardware since accelerator TEEs have not become widely available in the server/cloud environment yet. We will leverage secure accelerators in the future upon their availability.
3.3. Bandwidth-Saving Encoding
As shown in Figure 2, there are two communication links in PMC2 that consume network bandwidth: (a) in-domain, the compressed user image is transmitted from the mobile client to the secure edge server, and (b) cross-domain, the encoded perturbed image is transmitted from the secure edge server to the cloud server. Let us denote the original image as , which is encoded and stored in PNG by default. The JPEG-compressed version, , is delivered via the in-domain link. The perturbed image is equivalent to , where is the perturbation generator, and it will be encoded by the encoder function . Then, is the image transmitted via the cross-domain link.
Based on our experiments, the target model accuracy for
and have very small differences (¡ 2%) with huge bandwidth savings (about 40%); therefore, the bandwidth-saving encoding for the the in-domain link can be easily solved by adopting JPEG. To address the bandwidth challenge for the cross-domain link, i.e., ,
we consider PNG and JPEG as the baseline approaches, which are subject to the compression inefficiency issue discussed in Section 2.3.2. PNG achieves lossless compression but with low compression ratio and high bandwidth consumption. For JPEG, we observe that the default parameters would break the functionality of the target model. When is disabled, to attain the same level of the target model accuracy, the compression ratio for perturbed images is significantly lower than that of regular images, as shown in Section 2.3.2. These observations motivate us to develop a new neural compressor tailored to the perturbed images to reduce the bandwidth consumption on the cross-domain link.
3.3.1. Baseline Approach: JPEG Compression
4:2:0 chroma subsampling is widely used in video cameras, Blu-ray movies, and also used by default in libjpeg-turbo (lib, 2023), a popular JPEG library. The first number 4 specifies a 4x2 pixel block, the second number 2 means there are two chroma samples in the first row, and the last number 0 stands for the second row of chroma values being discarded. This subsampling makes chroma samples one-quarter of the luma ones. In our case study that uses JPEG to compress the protected image generated by the protective perturbation, we observe the target model accuracy reduces signifiantly with chroma subsampling enabled. For example, when the quality factor is 89, the target model accuracy decreases from 91.17% to 11.50%, and the file size decreases from 2057.36 B to 1212.33 B. Although the file size is significantly reduced, the functionality of the target model is compromised. This indicates that the image recognition model recognizes the luma and chroma channels of the protected images equally and, when a lot of information is discarded in the chroma channel, the model cannot work properly. To maintain the high accuracy of the image recognition model and reduce the file size simultaneously, we disable the chroma subsampling (i.e., the sampling factor is 4:4:4) when using the JPEG encoding. The quality factor used in the system can be found in Table 3. The PNG and JPEG compression/decompression are condcuted by the Python Pillow 8.4.0 (Clark, 2015), with the option set as .
3.3.2. Proposed Approach: Perturbation-Aware Neural Compression
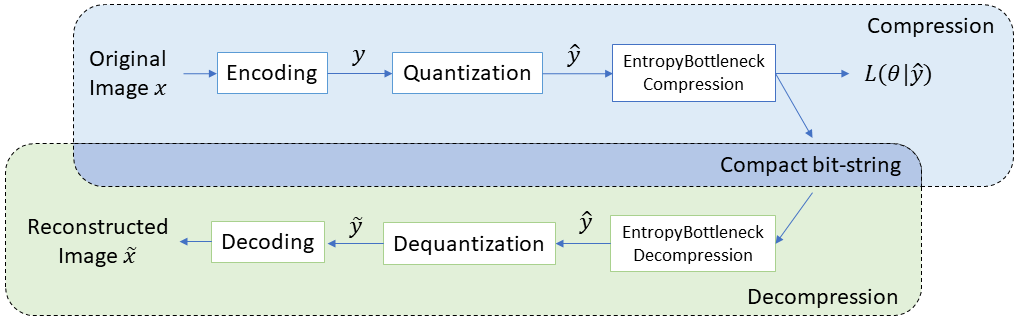
Neural image compression (Yang et al., 2023) is an emerging approach to image compression that employs neural networks to compress and decompress images. Unlike traditional image compression methods, which typically rely on heuristics and mathematical algorithms, neural image compression uses machine learning techniques to learn a compressed representation of the image. A typical lossy neural compressor works as follows. The input image is first mapped to a latent representation by an encoding transformation (i.e., a neural network). In the next step, is quantized to , and then a lossless entropy encoding model (e.g., EntropyBottleneck (Ballé et al., 2018)) encodes it to a bit-string. During decompression, the aforementioned steps are executed in the reverse order to generate the reconstructed image . Since the compression is lossy, an error between and will be introduced.
Figure 3 illustrates the workflow of the neural compression and decompression procedure in PMC2, which is based on the Factorized Prior model (Ballé et al., 2018). In compression, the input image is first encoded to latent . The encoding step consists of three convolution layers, each followed by a Generalized Divisive Normalization (GDN) layer (Ballé et al., 2015). is quantized to to reduce the entropy (or the bit-rate). The EntropyBottleneck (EB) layer (Ballé et al., 2018) utilizes the built-in probabilistic model to generate the compressed bit-string and the likelihood of under the parameters of the EB layer. In decompression, the compressed bit-string is decompressed by the EB first to recover , and the quantization and the decoding steps convert it to the reconstructed image . The decoding step is the inverse of the encoding, and it contains three deconvolution layers, each of which is followed by an inversed GDN layer.
In theory, the neural compressor used for PMC2 (i.e., high compression ratio, low impact on the target model accuracy) should be trained by a loss function comprised of rate loss and the accuracy loss. In this case, there is no need to optimize for distortion loss as it indicates the perceivable visual quality of a compressed image, which is not a concern in the context of compression for a machine learning service. The design of protective perturbation has resulted in a poor visual quality (most SSIM values between the original and the perturbed images are less than 0.02) (Ye et al., 2022), which is desired and unlikely to be restored and break the visual privacy protection by the neural compressor. In the experiments, we find that using the classical rate-distortion loss without any modification for training gives us a compressor that meets our rate-accuracy goal. In the rate-distortion loss, the loss comes from the mean square error (MSE) between and , and we use bits per pixel (bpp) as the rate loss calculated by
| (1) |
where is the total number of pixels in . To train the Factorized Prior model using the CIFAR-10 dataset (Krizhevsky et al., 2009) perturbed by the protective perturbation generator, we set the rate-distortion parameter as 0.01. Adam optimizer (Kingma and Ba, 2014) is used to optimize both the rate-distortion loss of the model and the auxiliary loss in the Entropy Bottleneck layer, with 0.0001 and 0.001 learning rates, respectively. ReduceLROnPlateau (Red, 2023) is used as the lr scheduler for the rate-distortion loss, and works in the min mode, which means that the lr will be reduced when the loss stops decreasing. Moreover, the gradient norm will be clipped when exceeding 1.0 during the training. The training batch size is set as 16, the number of workers (dataloader threads) is set as 4, and the maximum training epochs is 100. In the evaluation, the batch size is 256. The neural compressor is trained and deployed with the help of the Compress AI framework (Bégaint et al., 2020).
4. Experimental Results
4.1. Experimental Setup and Implementation
4.1.1. PMC2 System Setup
We deploy the end-to-end system as illustrated in Figure 2 to evaluate the performance of the proposed PMC2 system. The mobile client is a Google Pixel 3 smartphone running Android 12, which has four 2.5GHz CPUs, four 1.6GHz CPUs, an Adreno 630 GPU, and a 2915 mAh battery. A client APP runs on the mobile device to send the compressed JPEG images (by Android Bitmap.compress() API) and receive the recognition results. The secure edge server has an AMD EPYC 7443P Milan CPU with 24 cores and 48 threads, runs at 2.9GHz, and equips with 256 GB memory. Following the implementation of secure edge server described in Section 3.2, we adopt and deploy the opensource perturbation generator (Ye et al., 2022) to the confidential container of the secure edge server. We choose 8 target image recognition models and train their corresponding perturbation generators following the instructions provided in (Ye et al., 2022). The auxiliary model used in the training and the target model accuracy of the test images are listed in Table 2. We run all the evaluations of generators using the batch size of 256. The target image recognition model runs on a cloud server with 8 vCPUs, 1/3 NVIDIA A40 GPU, and 40 GB memory. The data flows between the client and the two servers are transmitted over HTTPS. The mobile client is deployed locally and connects to the Internet via an 802.11ac Wi-Fi, and the secure edge server and the cloud server are deployed in different cloud centers (Vul, 2023). Specifically, the secure edge server is located much closer to the mobile client than the cloud server to serve as an edge server.
4.1.2. Baseline System Setup
We adopt the opensource protective perturbation system developed in (Ye et al., 2022) as the baseline system for comparison. For fair evaluation and comparison, we upgrade the communication protocol in the baseline system to HTTPS and change the generator’s batch size from 1 to 256. The mobile client APP and the server program run on the same mobile device and the cloud server as the PMC2 system.
| Target Model | Auxiliary Model |
|
||
|---|---|---|---|---|
| VGG13_bn | ResNet18 | 91.52% | ||
| VGG16_bn | ResNet18 | 91.94% | ||
| ResNet18 | VGG13_bn | 91.62% | ||
| ResNet34 | ResNet18 | 91.54% | ||
| DenseNet121 | ResNet18 | 91.38% | ||
| MobileNet_v2 | VGG13_bn | 91.82% | ||
| GoogLeNet | ResNet18 | 91.22% | ||
| Inception_v3 | GoogLeNet | 91.86% |
4.1.3. Dataset
We use the CIFAR-10 (Krizhevsky et al., 2009) dataset to train all the models and perform all the evaluations. The images are in the size of 32x32 and the average file size is 2662.56 Bytes. We use the 50000 images in the training set of CIFAR-10 to train the 8 protective perturbation generators listed in Table 2, 5000 images in the test set for validation, and the rest 5000 images in the test set for evaluations. We split the test dataset into two 5000-image sets in the same way as described in (Ye et al., 2022). For each perturbation generator, we use the same images but with the particular perturbations added by the generator to train a dedicated Factorized Prior neural compression model (Ballé et al., 2018).
| Target Model | Encoding Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PNG | JPEG | Neural | |||||||
| (Bytes) | (Bytes) | Accuracy | (Bytes) | (Bytes) | Accuracy | (Bytes) | (Bytes) | Accuracy | |
| VGG13_bn | 1642.456.42 | 2691.386.79 | 90.30% | 1854.956.69 | 1848.421.12 | 90.22% | 1642.456.42 | 8.160.05 | 90.40% |
| VGG16_bn | 1509.065.79 | 2599.113.13 | 90.06% | 1572.236.17 | 1984.750.41 | 90.14% | 1509.065.79 | 8.010.02 | 90.06% |
| ResNet18 | 1509.065.79 | 2544.703.27 | 90.22% | 1509.065.79 | 1861.480.35 | 90.24% | 1509.065.79 | 8.120.03 | 90.20% |
| ResNet34 | 1572.236.17 | 2576.233.36 | 90.04% | 1726.206.73 | 1943.050.48 | 90.12% | 1642.456.42 | 8.190.05 | 90.42% |
| DenseNet121 | 1572.236.17 | 2794.402.14 | 90.48% | 1642.456.42 | 2042.200.65 | 90.38% | 1572.236.17 | 8.290.07 | 90.42% |
| MobileNet_v2 | 1509.065.79 | 2636.927.65 | 90.20% | 1572.236.17 | 2113.561.51 | 90.26% | 1572.236.17 | 8.350.08 | 90.58% |
| GoogLeNet | 1572.236.17 | 2796.735.53 | 90.00% | 1726.206.73 | 1891.501.06 | 90.32% | 1726.206.73 | 8.000.01 | 90.42% |
| Inception_v3 | 1509.065.79 | 3170.880.11 | 90.32% | 1509.065.79 | 2390.500.57 | 90.04% | 1572.236.17 | 8.000.00 | 90.36% |
4.2. Accuracy and Bandwidth Overhead
Table 3 presents the image recognition accuracy and the average size of the compressed image when deploying different image encoding methods between the secure edge server and the cloud server. The average size of (i.e., the images sent from the mobile client to the secure edge server) and the average size of (i.e., the images sent from the secure edge server to the cloud server) are represented by and , respectively. The standard deviation values of and are also provided after the symbols to describe the distribution of file sizes. All the standard deviation values are relatively small, indicating all the file sizes are generally close to the average values. The PNG-encoded achieves recognition accuracies between 90.00% to 90.48%, and the image sizes range from 2544.70 to 3170.88 Bytes. The accuracy values decrease by 0.90% to 1.88% compared to the numbers reported in Table 2. Since the results in Table 2 come from the cases where uncompressed user images are used to generate perturbed images, (i.e., the reduction of ) is the only factor that impacts the target model accuracy. Considering the raw size of a 32x32 RGB image is just 3096 Bytes (32x32x3), it is apparent that the protected images are not effectively compressed in the PNG format. We then take a step forward by replacing PNG with JPEG compression, which achieves significant data size reduction, ranging from 19.85% (MobileNet_v2) to 32.37% (GoogLeNet), while maintaining similar recognition accuracies (i.e., above 90%).
The neural compressor in the proposed PMC2 system shows superior accuracy and bandwidth savings. More specifically, the neural-compressed images still keep high target model accuracy, which is only reduced by 0.80% (GoogLeNet) to 1.88% (VGG16_bn) compared to the PNG encoding. On the other hand, a protected image can be compressed to a bit-string ranging from 8 to 8.35 Bytes, which is achieved by a neural compression model sized at only 12 MB. The data size is reduced by more than 99% compared to both PNG and JPEG encoding methods. In short, the proposed neural compression outperforms JPEG compression in terms of data size and thus bandwidth consumption between the secure edge server and the cloud server, without affecting the functionality of the image recognition model.
Note that the quality factors used for JPEG in both links, if applicable, are chosen experimentally to achieve similar target model accuracy (i.e., 90%) for a fair comparison. It is also worth noting that the average size of is 2662.56 Bytes and, after applying JPEG compression with proper JPEG quality factors, the size (i.e., ) decreases by 40% on average, with almost no negative impact on the target model accuracy.
4.3. Timing Performance
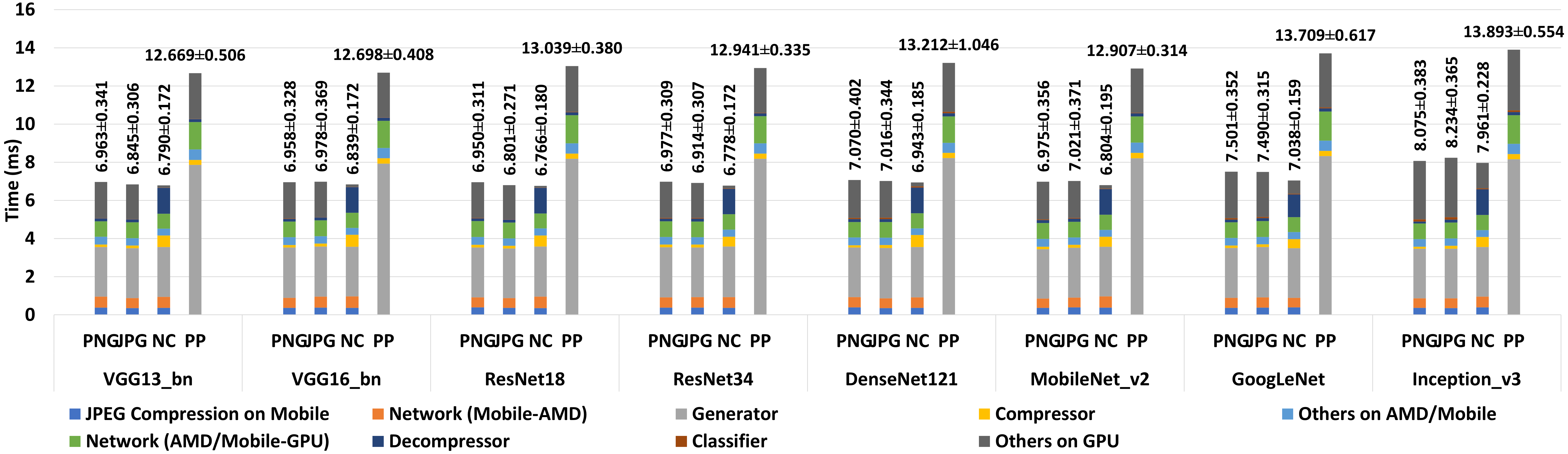
We further evaluate the end-to-end latency of the proposed PMC2 system using the 8 target image recognition models and image encoding methods. For comparison, we also conduct the same timing evaluation on the baseline protective perturbation system to uncover the gains of the proposed mechanism. Figure 4 shows the average end-to-end latency results with standard deviation values and timing breakdown analysis in 4 test cases for each target model. The first 3 test cases, namely PNG, JPG, and NC, represent using PNG, JPEG, and neural compression for the secure edge server-cloud server link in the PMC2 system; the 4th test case, namely protective perturbation (PP), represents the baseline protective perturbation system with PNG encoding. The time breakdown results include nine components, which are listed at the bottom of Figure 4. The secure edge server is named “AMD”, and the cloud server is named “GPU”. Particularly, there are no “JPEG Compression on Mobile”and “Network (Mobile-AMD)” components in the baseline case (i.e., PP).
The end-to-end latency of the PMC2 system ranges from 6.766 to 8.234 , which is significantly less than the baseline protective perturbation system ranging from 12.669 to 13.893 . Among all three cases for PMC2, the neural compression approach consistently outperforms the standard PNG by 1.40% (Inception_v3) to 6.17% (GoogLeNet), and it outperforms JPEG by 0.90% (ResNet18) to 6.42% (GoogLeNet). In general, PMC2 takes 42.69% (Inception_v3 w/ neural compressor) to 48.67% (GoogLeNet w/ neural compressor) less time than the baseline protective perturbation system for the same target model.
The “JPEG Compression on Mobile” takes about 0.37 on average, while the “Network (Mobile-AMD)” takes about 0.54 on average. Based on its design, the protective perturbation generator has an almost constant running time regardless of the target image recognition model. On average, it takes 2.615 inside an SEV-enabled CoCo container or 8.135 on a smartphone to generate a protected image. Overall, it is the most time-consuming component in all the cases, which can take up to 39.27% of the processing time spent in PMC2, and 63.60% of that in the baseline protective perturbation system.
The average PNG compression and decompression times are 0.125 and 0.142 in PMC2, 0.272 and 0.164 in the baseline system, while those for JPEG are 0.150 and 0.158 in PMC2. For both PNG and JPEG, compression and decompression take less than 4.45% of the total running time in PMC2, and at most 3.49% in the baseline system. Other operations on the secure edge server take about 0.4 for both encoding methods, and other operations on the cloud server take about 1.8 to 3.1 . On the other hand, the compression and decompression times are 0.558 and 1.325 on average for the neural compressor, which take 7.99% to 18.96% time in the entire system. The neural compressor needs 0.362 for other operations on the secure edge server and 0.099 to 1.322 on the cloud server. It turns out that PNG and JPEG encoding/decoding take approximately equal time, with PNG slightly faster. The neural compressor needs about 4x time for compression and 9x time for decompression but less time for other operations to prepare the data for compression/decompression. The network latency and the image recognition model take stable and short time in all cases.
4.4. Power Consumption
We use the Monsoon power monitor (Mon, 2023) to collect the power traces of the mobile device. The power monitor is connected to a Ubuntu workstation and controlled by Python scripts. The smartphone keeps the same network connection and screen brightness (e.g., the lowest) during the testing for a fair comparison.
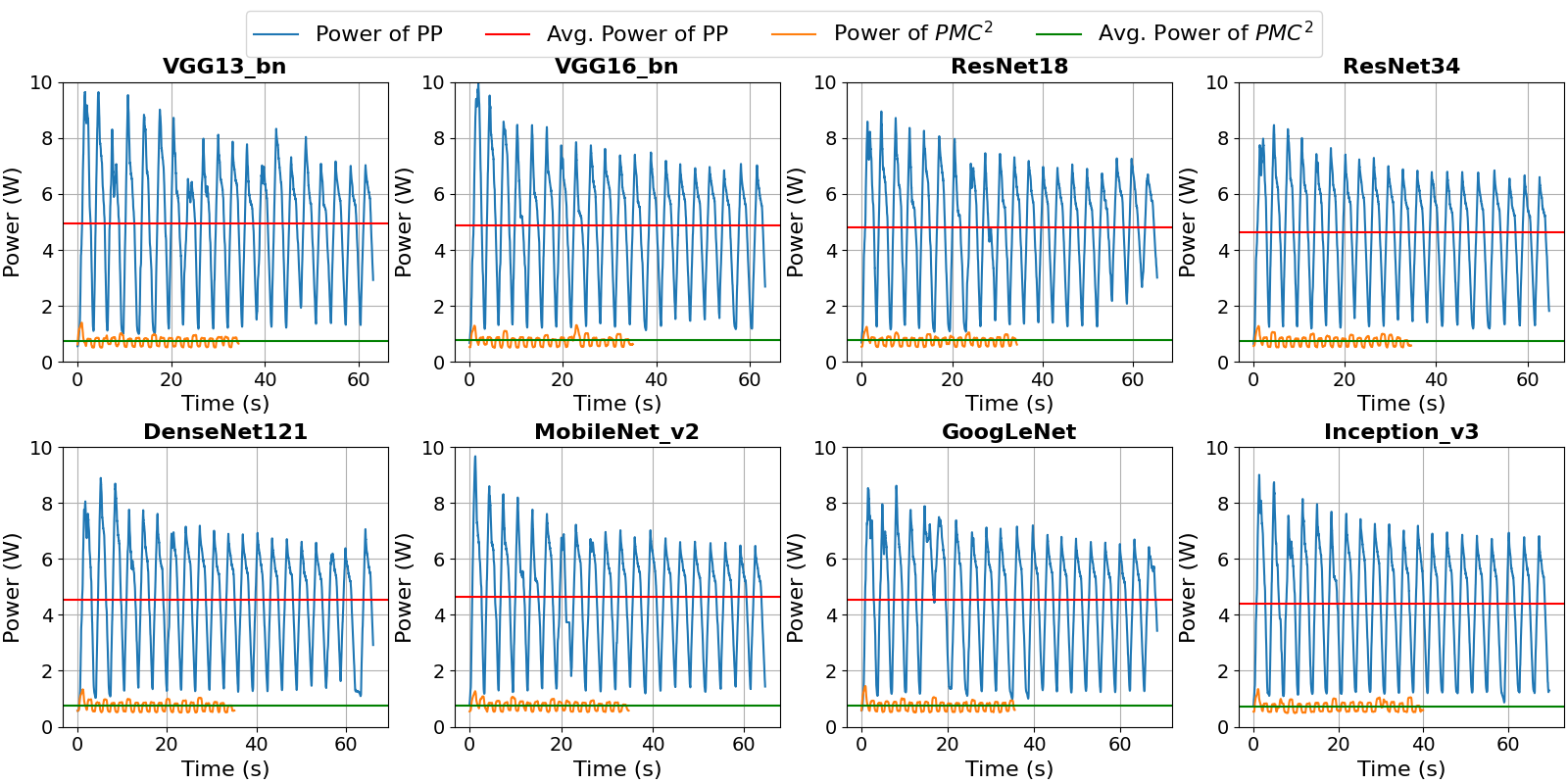
Figure 5 shows the power consumption comparison between the baseline protective perturbation system and the PMC2 system using 8 different target models. PNG is employed for the baseline system, and the neural compressor is adopted for the PMC2 system. The results for all the target models show a similar pattern that indicates significant power savings on the resource-constrained mobile device achieved by the proposed PMC2 system. For example, we can take a closer look at the two power tracing results of VGG13_bn and Densenet121 as, in the timing results of PMC2, VGG13_bn is the fastest target model among all 8 models, and DenseNet121 is the slowest. In the VGG13_bn case, the target image recognition model used in both systems is VGG13_bn. In the baseline system, most power traces fall into the 1.5 to 8.0 Watts range (blue lines), averaging 4.961 Watts (red lines). As a comparison, the PMC2 system consumes 0.751 Watts on average (green lines). Offloading the protective perturbation generation to the secure edge server makes the system much faster, as the test only lasts 33.956 seconds, almost half of the 63.345 seconds for the baseline system. Suppose we calculate the energy consumption by multiplying the average power and processing time; it turns out that the PMC2 costs only 8.11% energy of the baseline system. Similarly, when DenseNet121 is deployed as the target model, the baseline system consumes 66.065 seconds and 4.556 Watts average power to process all the 5000 images from the test dataset. Meanwhile, PMC2 only needs 34.716 seconds and 0.748 Watts average power to finish the same task, which yields a 91.37% energy reduction.
5. Conclusion
We have developed a privacy-preserving multimedia mobile cloud computing framework, namely PMC2, to address the privacy/security and bandwidth challenges in the mobile image recognition application. PMC2 offloads the computation-intensive perturbation generation operation intended for privacy protection from the resource-constrained mobile device to the trustworthy confidential container operated on a resource-rich secure server, which achieves superior power efficiency and latency compared to the state-of-the-art mobile-only system, while maintaining the privacy and security of user images. Furthermore, PMC2 employs a neural compression mechanism to effectively compress the perturbed images, which achieves significant bandwidth savings compared to the standard PNG and JPEG image encoding techniques. We implemented PMC2 in an end-to-end mobile cloud image recognition system and evaluated its accuracy, bandwidth, timing, and power consumption in comparison to the baseline, mobile-only protective perturbation system. Our evaluation results based on 5000 test images and 8 target image recognition models justify the superiority of the proposed PMC2 system. Upon the publication of this paper, we plan to open source PMC2 on GitHub to motivate further research.
References
- (1)
- GDP (2016) 2016. GDPR. Intersof Consulting. https://gdpr-info.eu.
- Str (2020) 2020. 40+ Alarming Cloud Security Statistics for 2023. https://www.strongdm.com/blog/cloud-security-statistics.
- Pri (2020) 2020. The Importance of Privacy—Both Psychological and Legal. https://www.psychologytoday.com/us/blog/emotional-nourishment/202007/the-importance-privacy-both-psychological-and-legal.
- HIP (2021) 2021. HIPAA. US Department of Health and Human Services. https://www.hhs.gov/hipaa/index.html.
- sgx (2021) 2021. Intel Software Guard Extensions (SGX). https://software.intel.com/content/www/us/en/develop/topics/software-guard-extensions.html.
- AMD (2023) 2023. AMD Secure Encrypted Virtualization. In AMD. https://www.amd.com/en/processors/amd-secure-encrypted-virtualization.
- SEV (2023) 2023. Attestation with AMD SEV-SNP. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/snp-attestation.html.
- Azu (2023) 2023. Azure confidential computing. In Microsoft. https://azure.microsoft.com/en-us/solutions/confidential-compute/.
- Goo (2023) 2023. Confidential Computing - Google Cloud. In Google. https://cloud.google.com/confidential-computing.
- AWS (2023) 2023. Confidential computing: an AWS perspective. In Amazon. https://aws.amazon.com/blogs/security/confidential-computing-an-aws-perspective/.
- IBM (2023) 2023. Confidential computing on IBM Cloud. In IBM. https://www.ibm.com/cloud/confidential-computing.
- CoC (2023) 2023. Confidential Containers. https://github.com/confidential-containers.
- Mon (2023) 2023. High Voltage Power Monitor. https://www.msoon.com/high-voltage-power-monitor.
- Int (2023) 2023. Intel Trust Domain Extensions. In Intel. https://www.intel.com/content/www/us/en/developer/articles/technical/intel-trust-domain-extensions.html.
- K8s (2023) 2023. Kubernetes. https://kubernetes.io/.
- lib (2023) 2023. libjpeg-turbo. https://libjpeg-turbo.org/.
- pho (2023) 2023. Photoprism. https://www.photoprism.app/.
-
Red (2023)
2023.
ReduceLROnPlateau.
https://pytorch.org/docs/stable/generated/
torch.optim.lr_scheduler.ReduceLROnPlateau.html. - Tru (2023) 2023. Trusted Network. https://www.sciencedirect.com/topics/computer-science/trusted-network.
- Vul (2023) 2023. Vultr. https://www.vultr.com.
- Akter et al. (2020) Taslima Akter, Bryan Dosono, Tousif Ahmed, Apu Kapadia, and Bryan Semaan. 2020. ” I am uncomfortable sharing what I can’t see”: Privacy Concerns of the Visually Impaired with Camera Based Assistive Applications. In 29th USENIX Security Symposium (USENIX Security 20). 1929–1948.
- Alhilal et al. (2022) Ahmad Alhilal, Tristan Braud, Bo Han, and Pan Hui. 2022. Nebula: Reliable low-latency video transmission for mobile cloud gaming. In ACM Web Conference 2022. 3407–3417.
- Ballé et al. (2015) Johannes Ballé, Valero Laparra, and Eero P Simoncelli. 2015. Density modeling of images using a generalized normalization transformation. arXiv (2015).
- Ballé et al. (2018) Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang, and Nick Johnston. 2018. Variational image compression with a scale hyperprior. arXiv (2018).
- Bégaint et al. (2020) Jean Bégaint, Fabien Racapé, Simon Feltman, and Akshay Pushparaja. 2020. CompressAI: a PyTorch library and evaluation platform for end-to-end compression research. arXiv preprint arXiv:2011.03029 (2020).
- Cerqueira et al. (2014) Eduardo Cerqueira, Euisin Lee, Jui-Ting Weng, Jae-Han Lim, Joshua Joy, and Mario Gerla. 2014. Recent advances and challenges in human-centric multimedia mobile cloud computing. In International Conference on Computing, Networking and Communications (ICNC). 242–246.
- Chattopadhayay and Rijal (2023) Ankur Chattopadhayay and Isha Rijal. 2023. Towards Inclusive Privacy Consenting for GDPR Compliance in Visual Surveillance: A Survey Study. In 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC). 1287–1293.
- Chen et al. (2017) Chien-Hung Chen, Che-Rung Lee, and Walter Chen-Hua Lu. 2017. Smart in-car camera system using mobile cloud computing framework for deep learning. Vehicular Communications 10 (2017), 84–90.
- Clark (2015) Alex Clark. 2015. Pillow (PIL Fork) Documentation. https://buildmedia.readthedocs.org/media/pdf/pillow/latest/pillow.pdf
- Khan et al. (2022) Muhammad Asif Khan, Emna Baccour, Zina Chkirbene, Aiman Erbad, Ridha Hamila, Mounir Hamdi, and Moncef Gabbouj. 2022. A survey on mobile edge computing for video streaming: Opportunities and challenges. IEEE Access (2022).
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv (2014).
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. (2009).
- Padilla-López et al. (2015) José Ramón Padilla-López, Alexandros Andre Chaaraoui, and Francisco Flórez-Revuelta. 2015. Visual privacy protection methods: A survey. Expert Systems with Applications 42, 9 (2015), 4177–4195.
- Pletcher (2023) Scott Pletcher. 2023. Visual Privacy: Current and Emerging Regulations Around Unconsented Video Analytics in Retail. arXiv preprint arXiv:2302.12935 (2023).
- Ren et al. (2018) Zhongzheng Ren, Yong Jae Lee, and Michael S Ryoo. 2018. Learning to anonymize faces for privacy preserving action detection. In European conference on computer vision (ECCV). 620–636.
- Stangl et al. (2022) Abigale Stangl, Kristina Shiroma, Nathan Davis, Bo Xie, Kenneth R Fleischmann, Leah Findlater, and Danna Gurari. 2022. Privacy concerns for visual assistance technologies. ACM Transactions on Accessible Computing (TACCESS) 15, 2 (2022), 1–43.
- Sun et al. (2018) Qianru Sun, Liqian Ma, Seong Joon Oh, Luc Van Gool, Bernt Schiele, and Mario Fritz. 2018. Natural and effective obfuscation by head inpainting. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 5050–5059.
- Tian et al. (2017) Yifan Tian, Yantian Hou, and Jiawei Yuan. 2017. Capia: Cloud assisted privacy-preserving image annotation. In 2017 IEEE Conference on Communications and Network Security (CNS). 1–9.
- Wang and Dey (2013) Shaoxuan Wang and Sujit Dey. 2013. Adaptive mobile cloud computing to enable rich mobile multimedia applications. IEEE Transactions on Multimedia 15, 4 (2013), 870–883.
- Wu et al. (2021) Hao Wu, Xuejin Tian, Minghao Li, Yunxin Liu, Ganesh Ananthanarayanan, Fengyuan Xu, and Sheng Zhong. 2021. PECAM: privacy-enhanced video streaming and analytics via securely-reversible transformation. In Annual International Conference on Mobile Computing and Networking. 229–241.
- Xu and Mao (2013) Yi Xu and Shiwen Mao. 2013. A survey of mobile cloud computing for rich media applications. IEEE Wireless Communications 20, 3 (2013), 46–53.
- Yang et al. (2023) Yibo Yang, Stephan Mandt, Lucas Theis, et al. 2023. An introduction to neural data compression. Foundations and Trends® in Computer Graphics and Vision 15, 2 (2023), 113–200.
- Ye et al. (2022) Mengmei Ye, Zhongze Tang, Huy Phan, Yi Xie, Bo Yuan, and Sheng Wei. 2022. Visual privacy protection in mobile image recognition using protective perturbation. In ACM Multimedia Systems Conference (MMSys). 164–176.
- Zhao et al. (2023) Ruoyu Zhao, Yushu Zhang, Tao Wang, Wenying Wen, Yong Xiang, and Xiaochun Cao. 2023. Visual Content Privacy Protection: A Survey. arXiv preprint arXiv:2303.16552 (2023).
- Zhao et al. (2022) Yi Zhao, Zheng Yang, Xiaowu He, Xinjun Cai, Xin Miao, and Qiang Ma. 2022. Trine: Cloud-edge-device cooperated real-time video analysis for household applications. IEEE Transactions on Mobile Computing (2022).
- Zhu et al. (2020) Bingquan Zhu, Hao Fang, Yanan Sui, and Luming Li. 2020. Deepfakes for Medical Video De-Identification: Privacy Protection and Diagnostic Information Preservation. In AAAI/ACM Conference on AI, Ethics, and Society (AIES). 414–420.