Privacy-Preserving Redaction of Diagnosis Data through Source Code Analysis
Abstract.
Protecting sensitive information in diagnostic data such as logs, is a critical concern in the industrial software diagnosis and debugging process. While there are many tools developed to automatically redact the logs for identifying and removing sensitive information, they have severe limitations which can cause either over redaction and loss of critical diagnostic information (false positives), or disclosure of sensitive information (false negatives), or both. To address the problem, in this paper, we argue for a source code analysis approach for log redaction. To identify a log message containing sensitive information, our method locates the corresponding log statement in the source code with logger code augmentation, and checks if the log statement outputs data from sensitive sources by using the data flow graph built from the source code. Appropriate redaction rules are further applied depending on the sensitiveness of the data sources to preserve the privacy information in the logs. We conducted experimental evaluation and comparison with other popular baselines. The results demonstrate that our approach can significantly improve the detection precision of the sensitive information and reduce both false positives and negatives.
1. Introduction
Diagnostics data (e.g., logs and traces) is generated by a wide variety of systems and devices, including operating systems, applications, devices, and vehicles. It is incredibly valuable for improving system performance, troubleshooting, and reducing maintenance cost(Sánchez and Batet, 2016). For example, error logs and crash reports can help developers and technicians identify software bugs and fix system issues, and network diagnostic data can reveal the issues with connectivity or bandwidth. Therefore, it is often shared between different parties, such as software developers, device manufacturers, cloud service providers, etc., for those purposes.
However, diagnostics data can raise serious privacy concerns since it may contain personally identifiable information (PII) or sensitive data. PII is any information that can be used to identify an individual, such as name, social security number and bank account number. Sensitive data could be personal health information (PHI), financial information and credential data. On the other hand, today’s regulatory compliances such as Health Insurance Portability and Accountability Act (HIPAA) (Annas, 2003), Payment Card Industry Data Security Standard (PCI-DSS) (Virtue, 2009) and General Data Protection Regulation (GDPR) (Regulation, 2018), place strict limitations on how this information can be collected and shared. Thus, diagnostics data privacy has become a severe obstacle in industrial collaborative software diagnosis and debugging processes, and it is critical for organizations to take steps to protect sensitive information in diagnostics data and prevent inadvertent disclosure.
A common approach to protecting diagnostics data privacy is log redaction. This technique involves removing or obfuscating sensitive information from diagnostic logs before they are shared. Existing log redaction mechanisms typically use two strategies: (1) Rule-based approach (Mouza et al., 2010; Park et al., 2011; Chow et al., 2008; ama, 2023; goo, 2023) that detects private information based on a set of pre-defined string patterns matching or regular expressions; (2) Machine learning-based approach (Kaul et al., 2021; Cumby and Ghani, 2011; Jones et al., 2007; mic, 2023) that trains a model to automatically identify and redact sensitive information from logs. However, there are several limitations to these strategies that hinder their effectiveness:
-
•
Rule-based approach relies on predefined rules and thus is not effective and flexible for identifying unseen or modified types or patterns of sensitive information.
-
•
Machine learning based approach requires a large amount of training data to be effective and the labeling is labor-intensive and time-consuming (He et al., 2020).
-
•
Both approaches can produce false positives when non-sensitive information is mistakenly identified as sensitive, and false negatives when sensitive information is not identified. This can cause either over redaction and loss of important diagnostic information, or disclosure of sensitive information.
To address these limitations, in this work, we argue for a novel source code based approach to log redaction by analyzing and tracking the data flow for each logging/tracing statement. It has been observed that open source software constitutes 70-90% of any given piece of modern software solutions (ope, 2023), but the source code is highly underutilized for diagnostics data processing. Our proposed methodology leverages it to identify the data sources of a log message and apply the corresponding redaction rule based on its sensitiveness. Our approach extracts the structured data flow information from the source code and matches such information with the logging/tracing output, which leads to higher precision and recall compared to existing rule-based or learning-based approaches. If the information shares a similar pattern, it is very likely that the non-sensitive information will be redacted, which is considered a false positive match. For example, not all email addresses should be redacted, and those email addresses (e.g., belong to suspect adversaries) which are related to the diagnosis/auditing purposes should not be redacted. The source code analysis can help to classify the sensitiveness of the data source and that information can be leveraged to reduce the false positives and false negatives.
1.1. Challenges
Despite the opportunities, our source code analysis approach needs to address two challenging problems.
Link log statements to sensitive data sources. A log statement usually prints program variables in a formatted string. Those variables may contain results directly or derived from sensitive sources at run-time. It is not practical and efficient to dynamically track information flow at run-time. Since log redaction post-processes logs, it is necessary to pre-build and store the linkage information between log statement variables and data sources and support efficient on-demand queries during post-processing. To address this problem, we apply static analysis techniques and build a data flow graph (DFG) from the source code. Although data flow graph has been already widely used for sensitive information tracking (Wang et al., 2023), our approach aims to build a succinct data flow graph tailored for diagnostics data to facilitate efficient redaction.
Map log message to log statement. To use the linkage between log statements and sensitive data sources for log redaction, our approach requires efficiently mapping a log message to its corresponding log statement in the source code. A general approach is to mine the log templates that consist of constant keywords in the print statements from log messages and match a log message’s template to the log statement code. However, this approach incurs additional post-processing overhead for template mining. Given that much open-source software uses standard logger packages, in this work we explore an alternative approach for simplicity that exploits logger configuration to directly output the location of log statement for a log message.
1.2. Our Contributions: A Novel Redaction Framework based on Source Code Analysis
To address these challenges, we proposed a novel log redaction framework based on source code analysis to effectively identify and redact the sensitive information from the diagnostics data, which is illustrated in Figure 1. The framework consists of three modules: Scanner/Parser, Data Flow Graph Repository, and Log Analyzer/Redactor.

(1) Scanner and Parser This module builds a data flow graph from the source code to track the data source for each log message. It takes users’ application source code, and the source codes of the linked third party libraries as input and then parse the source codes at the function level to build the data flow graph. This process consists of two steps:
Step 1. Extracting Function Information This step parses each source file into a collection of the function definitions. At the same time, the function name, arguments list, arguments datatypes, and return variables, return variable tables will be collected as metadata for each function definition. To facilitate the execution of queries over the data flow graph at the later stages, the module further creates a unique identifier for each function, which is used for fast indexing.
Step 2. Building Data Flow Graph (DFG). This step takes the source code of each function definition, which is the output of the first step, as the input to build an abstract syntax tree (AST). Then a data flow graph is built on top of the AST. Each node represents a variable or statement, and each directed edge represents the actual data that is produced by the source node and consumed by the destination node. For each data flow graph, the flow will start with the arguments that are passed to this function and end with the return value node or the last statement node if there is no return value for the given function.
(2) Data Flow Graph Repository which is proposed to effectively store and manage the data flow graphs, which are built by the first module. It stores the data flow graph (DFG) for each function as a key-value pair format, where key is its unique identifier, and the value is a pointer to the DFG. Before the DFG is stored in the repository, optimization techniques such as pruning will be applied to the data flow graph to reduce the complexity of the DFG to further save the storage overhead and improve the performance of back-tracing at the log redaction stage.
(3) Log Analyzer and Redactor takes the metadata of the data sources, the data flow graph, and the original logs as inputs; and outputs redacted logs. We assume the data sources are structured and sensitive attributes are identified and labeled by domain experts. To effectively apply appropriate reduction rules to each log message, it is important to identify the sensitiveness (or privacy level) of its data source. This is accomplished by analyzing each log message and locating its related log statement in the source file. Then, a full data flow path is identified by back-tracing the DFG from the log statement to its source nodes. While traversing the DFG for each log message, each subgraph in the DFG is retrieved based on the unique identifier and connected via the metadata, argument lists, and return value, which are collected from the source code parsing module. Once the data source is located, the corresponding redaction rules will be applied to the log message based on the sensitiveness of its data source. This process will be conducted for each log message iteratively. In the end, the module outputs the final redacted log.
2. Implementation Details
2.1. Target Scenario and System Overview
In our target scenario, software or a pipeline to be diagnosed will consume/access a collection of data sources, with each data source being structured and private/sensitive attributes being identified and annotated by domain experts. Then the software will generate diagnosis data such as logs and traces, which may contain private/sensitive information from the data sources. The goal of the proposed framework is to detect and redact log messages that contain private information.
Using a source code analysis approach, we are able to identify the data sources (e.g., attributes) that are linked to each log message and then we redact the log message, if the data sources contain sensitive information.
As aforementioned, we propose a novel diagnostic data redaction framework based on source code analysis. The framework will detect sensitive information from the diagnostic data by linking each log message to its data sources using a data flow graph extracted from the source code. To achieve this, each source file of the users’ application (i.e., the software/pipeline that generates the diagnostic data) will be scanned and parsed into a collection of data flow subgraphs at the function level. Each subgraph can be used to track how the data is transferred within a function.
Once a data flow subgraph is built, it will be stored in the data flow graph repository. An indexing that maps each function’s unique identifier to its data flow subgraph is also constructed.
Then, the log redactor takes the original diagnostic data, the user annotated sensitive data source information, the source code, and the data flow graph repository as input. It first analyzes each log message to locate the position of the log statement that produces the message, in the source code.
At the redaction time, it needs to query the data flow graphs to identify all invoked functions from the data flow graph repository. Afterwards, a complete data flow graph is assembled and the data source nodes of the current log message are also located by traversing the full data flow graph. The detected data sources are cross-checked with users’ sensitiveness annotation of the data sources to determine whether the redaction is needed and which redaction rule should be applied.
2.2. Building Data Flow Graph
Data flow graph (DFG) is used to track the movement of the data across functions and variables, as illustrated in Figure 2. Given a log message that is produced by a logging statement, by traversing the data flow graph, the system can locate the attributes of the data sources that flow to the logging statement in question. Then, based on the sensitiveness annotated for each data source attribute, the system obtains the sensitiveness of the log message.
However, building a large-scale DFG for each complicated application may suffer from several pain points: (1) building a single DFG for the entire code base could be time-consuming, and it is hard to maintain the DFG, if the source codes get frequently updated. (2) The time complexity required for traversing the DFG increases with the size of the DFG, which slows down the detection and redaction process. (3) The graphs associated with the shared libraries and the frequently invoked functions will be duplicated multiple times, which brings additional storage overhead.
To address these issues, we decided to parse each source code file into a collection of function definitions and build a relatively small DFG for each function, and store it in the data flow graph repository for being queried at the redaction time.
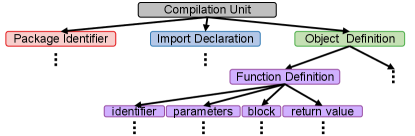
To achieve this, we track the data flow by analyzing the source code and parsing it into an abstract syntax tree (AST) 111We use the tree-sitter as the parser to parse the source code into AST. https://tree-sitter.github.io/tree-sitter. For each function, we extract the metadata from the corresponding source file, which includes the unique identifier of the function, import libraries, object/class name, input arguments, and output arguments, as shown in Figure 3(a). Then we traverse the AST from the root node to the children nodes corresponding to package-identifier, import-declaration, object-definition, and function-definition nodes, as illustrated in Figure 3(b). The functions defined in each source file are located under the children nodes corresponding to the function definitions. We traverse each function-definition node and build a data flow graph for each function based on its variable assignment statements.


2.3. Connecting DFG and Diagnostic Data
Once the log is generated, to detect the senstiveness of each log message, we need to link the message to the data flow graph by identifying the message’s producing log statement. To do so, we use a lightly augmented log message by configuring the logger to output the location of the log statement in the source code. Then, our log analyzer directly query the data flow graph that is corresponding to the function that invoked the log statement and backtrack the ancestors of the function in the graph until it reaches the data source nodes, as illustrated in Figure 4.


3. Evaluation
In this section, we evaluate the effectiveness of our novel redaction framework. Since there are no public benchmark datasets for privacy information redaction. We decided to choose three open-sourced machine learning applications: a telco customer churn prediction (tel, 2023), customer segmentation (cus, 2023), fraud detection (fra, 2023). Sensitive information such as customer profiles and financial information is involved in all three scenarios as well as the diagnostics data (i.e., logs) generated from the three applications. We compare the precision and recall of our approach to three widely-used baseline redaction tools: Google Cloud Data Loss Prevention (goo, 2023), Amazon Macie (ama, 2023), and Microsoft Presidio (mic, 2023). We run these three applications on Spark and collect logs during the running stage then apply the privacy-preserving log redaction tools. Our framework is implemented in Python with the latest numpy, pandas, and tree_sitter libraries. As illustrated in Tab. 1, our approach achieves significantly better precision and recall compared to baselines for all three scenarios.
| Method | Telcom Churn Prediction | Customer Segmentation | Fraud Detection | |||
| Precision | Recall | Precision | Recall | Precision | Recall | |
| Google Cloud Data Loss Prevention | 84.73% | 47.52% | 91.96% | 10.11% | 98.14% | 22.13% |
| Amazon Macie | 74.12% | 100% | 99.86% | 98.66% | 99.66% | 98.81% |
| Microsoft Presidio | 12.88% | 100% | 31.15% | 98.65% | 6.30% | 98.80% |
| Our Approach | 100.00% | 100% | 100.00% | 98.66% | 100.00% | 98.81% |
4. Acknowledgment
This material is based upon work supported by the U.S. Department of Homeland Security under Grant Award Number 17STQAC00001-07-00.
5. Disclaimer
The views and conclusions contained in this document are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the U.S. Department of Homeland Security.
References
- (1)
- ama (2023) 2023. Amazon Macie - Sensitive Data Discovery. https://aws.amazon.com/macie.
- cus (2023) 2023. Customer Segmentation Workloads. https://www.tpc.org/tpcx-ai.
- fra (2023) 2023. Fraud Detection Workloads. https://www.tpc.org/tpcx-ai.
- goo (2023) 2023. Google Cloud Data Loss Prevention. https://cloud.google.com/dlp.
- mic (2023) 2023. Microsoft Presidio. https://github.com/microsoft/presidio.
- ope (2023) 2023. A Summary of Census II. https://www.linuxfoundation.org/blog/blog/a-summary-of-census-ii-open-source-software-application-libraries-the-world-depends-on.
- tel (2023) 2023. Telco Customer Churn. https://www.kaggle.com/datasets/blastchar/telco-customer-churn.
- Annas (2003) George J Annas. 2003. HIPAA regulations: a new era of medical-record privacy? New England Journal of Medicine 348 (2003), 1486.
- Chow et al. (2008) Richard Chow, Philippe Golle, and Jessica Staddon. 2008. Detecting privacy leaks using corpus-based association rules. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. 893–901.
- Cumby and Ghani (2011) Chad Cumby and Rayid Ghani. 2011. A machine learning based system for semi-automatically redacting documents. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 25. 1628–1635.
- He et al. (2020) Shilin He, Jieming Zhu, Pinjia He, and Michael R Lyu. 2020. Loghub: a large collection of system log datasets towards automated log analytics. arXiv preprint arXiv:2008.06448 (2020).
- Jones et al. (2007) Rosie Jones, Ravi Kumar, Bo Pang, and Andrew Tomkins. 2007. ” I know what you did last summer” query logs and user privacy. In Proceedings of the sixteenth ACM conference on Conference on information and knowledge management. 909–914.
- Kaul et al. (2021) Akshar Kaul, Manish Kesarwani, Hong Min, and Qi Zhang. 2021. Knowledge & learning-based adaptable system for sensitive information identification and handling. In 2021 IEEE 14th International Conference on Cloud Computing (CLOUD). IEEE, 261–271.
- Mouza et al. (2010) Cédric Mouza, Elisabeth Métais, Nadira Lammari, Jacky Akoka, Tatiana Aubonnet, Isabelle Comyn-Wattiau, Hammou Fadili, and Samira Si-Saïd Cherfi. 2010. Towards an automatic detection of sensitive information in a database. In 2010 Second International Conference on Advances in Databases, Knowledge, and Data Applications. IEEE, 247–252.
- Park et al. (2011) Youngja Park, Stephen C Gates, Wilfried Teiken, and Pau-Chen Cheng. 2011. An experimental study on the measurement of data sensitivity. In Proceedings of the first workshop on building analysis datasets and gathering experience returns for security. 70–77.
- Regulation (2018) Protection Regulation. 2018. General data protection regulation. Intouch 25 (2018), 1–5.
- Sánchez and Batet (2016) David Sánchez and Montserrat Batet. 2016. C-sanitized: A privacy model for document redaction and sanitization. Journal of the Association for Information Science and Technology 67, 1 (2016), 148–163.
- Virtue (2009) Timothy M Virtue. 2009. Payment card industry data security standard handbook. Wiley Online Library.
- Wang et al. (2023) Chao Wang, Ronny Ko, Yue Zhang, Yuqing Yang, and Zhiqiang Lin. 2023. TAINTMINI: Detecting Flow of Sensitive Data in Mini-Programs with Static Taint Analysis. In ICSE.