Probabilistic Reduced-Dimensional Vector Autoregressive Modeling with Oblique Projections
?abstractname?
In this paper, we propose a probabilistic reduced-dimensional vector autoregressive (PredVAR) model to extract low-dimensional dynamics from high-dimensional noisy data. The model utilizes an oblique projection to partition the measurement space into a subspace that accommodates the reduced-dimensional dynamics and a complementary static subspace. An optimal oblique decomposition is derived for the best predictability regarding prediction error covariance. Building on this, we develop an iterative PredVAR algorithm using maximum likelihood and the expectation-maximization (EM) framework. This algorithm alternately updates the estimates of the latent dynamics and optimal oblique projection, yielding dynamic latent variables with rank-ordered predictability and an explicit latent VAR model that is consistent with the outer projection model. The superior performance and efficiency of the proposed approach are demonstrated using data sets from a synthesized Lorenz system and an industrial process from Eastman Chemical.
keywords:
Identification and model reduction; process control; estimation; statistical learning, and
1 Introduction
With the popular deployment of the industrial internet of things, high-dimensional data with low-dimensional dynamics [35] pose new challenges to traditional time series analysis methods that assume fully excited full-dimensional dynamics. In many real industrial operations, high dimensional time series often do not exhibit full-dimensional dynamics [25]. In addition, autonomous systems deploy redundant sensors for safety and fault tolerance, resulting in high collinearity in the collected time-series data. Moreover, computationally intensive applications like digital twins produce high dimensional data to capture important dynamics for effective decision-making [13]. These popular application scenarios call for parsimonious modeling to extract reduced-dimensional dynamics in high dimensional data [30, 32].
Classic reduced-dimensional analytic tools, such as principal component analysis (PCA), partial least squares (PLS) [15, 31], and canonical correlation analysis (CCA), have been successful in many applications. While they perform dimension reduction, their statistical inference requires serial independence in the data [30].
Many efforts in the statistical field have raised the issue of reduced dimensional dynamics in multivariate time series data. An early account of this problem is given in [3], which does the dynamics modeling and dimensional reduction in two steps and thus is not optimal. Subsequently, dynamic factor models (DFMs) are developed, which rely on time-related statistics to estimate parsimonious model parameters, including [25, 18, 26, 14]. However, these DFMs do not enforce a parsimonious latent dynamic model. The linear Gaussian state-space model in [37] and the autoregressive DLV model in [41] extract the dynamic and static characteristics simultaneously. Nevertheless, they ignore the structured signal-noise relationship and are not concerned with the dimension reduction in noise.
In process data analytics, a dynamic latent variable (DLV) model was developed in [19] to extract DLVs first and characterize the dynamic relations in the DLVs and the static cross-correlations in residuals afterward. Assuming the latent dynamics is integrating or being ‘slow’, slow feature analysis has been developed [40, 33, 11] to induce dimension reduction focusing on slow dynamics only. To develop full latent dynamic features, dynamic-inner PCA (DiPCA) [10] and dynamic-inner CCA (DiCCA) [9, 8] are proposed to produce rank-ordered DLVs to maximize the prediction power in terms of covariance and canonical correlation, respectively. Furthermore, Qin developed a latent vector autoregressive modeling algorithm with a CCA objective (LaVAR-CCA) [28, 29], whose state-space generalization is developed in [38]. Casting the LaVAR model in a probabilistic setting, [12] uses the Kalman filter formulation to solve for the dynamic and static models via maximum likelihood, but fails short of solving the dynamic model parameters explicitly and resorts to genetic algorithms for the solution. A key to signal reconstruction and prediction lies in separating the serially dependent signals from serially independent noise that may have energy or variance comparable to that of the signals [30].
The prevalence of low-dimensional dynamics in high-dimensional uncertainties requires a statistical framework for simultaneous dimension reduction and latent dynamics extraction. In this paper, we propose a probabilistic reduced-dimensional vector autoregressive (PredVAR) model to extract low-dimensional dynamics from high-dimensional noisy data. Our probabilistic model partitions the measurement space into a low-dimensional DLV subspace and a static noise subspace, which are generally oblique. An oblique projection is adopted to delineate the structural signal-noise relationship, extending the widely used orthogonal projection [21]. The oblique projection for the dynamic-static decomposition in our model is found simultaneously with an explicit low-dimensional latent dynamic model. Accordingly, our model consists of two interrelated components, namely, the optimal oblique projection and the latent dynamics. An expectation-maximization (EM) procedure is used to estimate model parameters [7, 39] that satisfy the maximum likelihood optimal conditions.
The main contributions of this work are as follows.
A probabilistic reduced-dimensional vector regressive (PredVAR) model is proposed with general oblique projections. Our study of using VAR to capture latent dynamics should initiate exploring more dynamic models.
A particular oblique projection is derived for the optimal dynamic-static decomposition, which achieves the best predictability regarding prediction error covariance and has an intriguing geometric interpretation. Also, ordered DLVs are obtained based on predictability.
A PredVAR model identification algorithm is developed based on the optimal dynamic-static decomposition, the interplay between latent dynamics and projection identifications, and the EM method. The noise covariance matrices are estimated as a byproduct of the EM method and the analytical comparison with LaVAR-CCA and DiCCA naturally follows.
Extensive simulations are presented to illustrate our approach compared to conceivable benchmarks over the synthesized Lorenz data and real Eastman process data.
The rest of the paper is organized as follows. The PredVAR model is formulated in Section 2. An efficient PredVAR model identification algorithm is developed in Section 3, based on the optimal dynamic-static decomposition introduced in Section 4. Additional analysis is presented in Section 5, including the distributions of parameter estimates and the selection of model sizes. Section 6 presents simulation comparison and studies. Finally, this paper is concluded in Section 7. Table 1 summarizes the major notation.
| for a natural number | |
| order of the vector autoregressive (VAR) dynamics | |
| dimension of the measurement space | |
| dynamic latent dimension (DLD) | |
| measurement vector in | |
| Dynamic latent variables (DLVs) in | |
| one-step ahead DLVs prediction in | |
| DLV innovations vector in , | |
| outer model noise in , | |
| innovations vector in , | |
| identity/zero matrix of a compatible dimension | |
| VAR coefficient matrix in , | |
| DLV loadings matrix in | |
| static loadings matrix in | |
| DLV weight matrix in | |
| static weight matrix in | |
| covariance matrix of a random vector |
2 Model Formulation
2.1 The PredVAR Model
Consider a time series with for all . Qin [29] defines that the time series is serially correlated or dynamic if, for at least one ,
Otherwise, it is serially uncorrelated. Further, as per Qin [29], is a reduced-dimensional dynamic (RDD) series if it is serially correlated but is serially uncorrelated for some . If no exists to render serially uncorrelated, is full-dimensional dynamic (FDD). Qin [29] develops a latent VAR model to estimate the RDD dynamics of the data series. However, no statistical analysis is given since the latent VAR model does not give the distributions of noise terms.
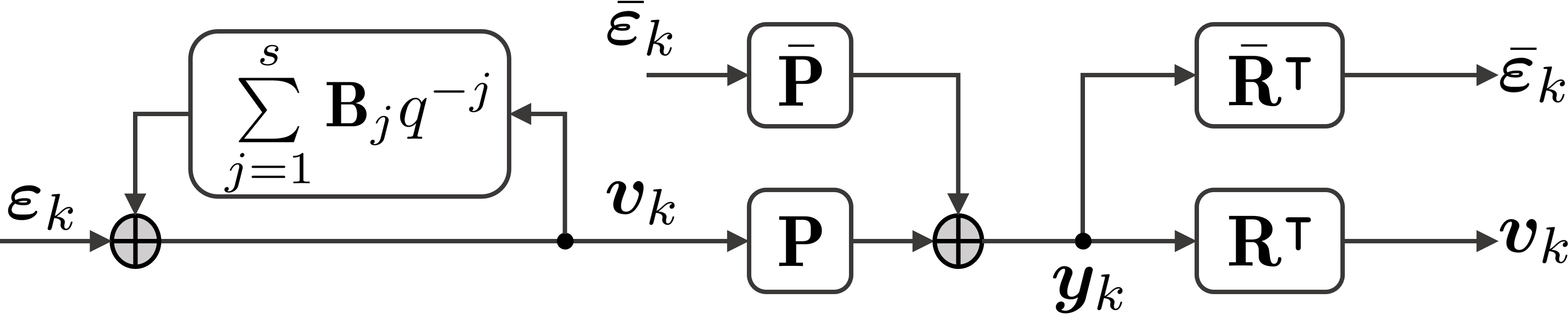
In this paper, we define a probabilistic reduced-dimensional vector autoregressive series as
| (1) | ||||
| (2) |
where and are i.i.d. Gaussian noise terms and denotes the vector of DLVs. Both and form the innovations and therefore are uncorrelated with the past for all . With , the loadings matrices , , and have full rank. Using the backward-shift operator , the latent dynamic system (2) can be converted to
Then, the transfer matrix form of (1)–(2) is given by
which clearly shows the reduced-dimensional dynamics that are commonly observed in routine operational data [29] and economics [34, 14]. Further, for weakly FDD time series, an RDD approximation is often useful to enable rapid downstream decision-making [13]. It should be noted that the latent VAR model (2) can be replaced by a state-space, an ARIMA, or a kernel-based model [8, 38, 27, 17].
2.2 Explicit Expression of DLVs
2.3 Identifiability of the PredVAR Model
Given any pair of nonsingular matrices and , (1) can be rewritten as
| (6) |
which indicates that the tuple cannot be uniquely identified since it can be exactly represented by . However, all equivalent realizations differ by similarity transformation only.
The non-uniqueness of the matrices offers the flexibility to extract desired coordinates or features of the DLVs. For example, we can enforce the following conditions to achieve identifiability.
-
1.
orthogonal or the covariance or diagonal, and independently,
-
2.
orthogonal or the covariance or diagonal if is non-singular.
-
3.
If is singular, we can represent with being full-column rank and having a lower dimension than .
In this paper, however, the DLV and static loadings matrices and need not be mutually orthogonal, requiring an oblique projection for the DLV modeling.
These options have been used in the literature to enforce diagonal and as in [2], which does not consider rank-deficient innovations, or enforce as in [29] to achieve the CCA objective. Further, the DLVs in [29] are arranged in a non-increasing order of predictability. A rank-deficient corresponds to a rank-deficient , which is studied in this paper. These freedoms allow us to obtain desirable realizations of the PredVAR model.
2.4 Equivalent Reduced-Rank VAR Models
A reduced-rank VAR (RRVAR) model is specified as follows: instead of estimating a full-rank coefficient matrix for each lag in a regular VAR model, we impose a factor structure on the coefficient matrices, such that they can be written as a product of lower-rank matrices, namely,
| (7) |
where is invertible with and is the full-dimensional innovations vector driving .
The reduced-rank VAR is analogous to the reduced-rank regression (RRR) for linear regression [16, 32]. Just as RRR requires specific solutions that differ from ordinary least squares, RRVAR also requires a specific solution differing from that of regular VAR. Theorem 1 shows that the PredVAR and RRVAR models are equivalent.
Theorem 1.
3 Optimal Model Estimation Algorithm
The RRVAR model parameters will be derived based on constrained maximum likelihood estimation. As the parameter matrices appear nonlinearly in the model, the solution algorithm will be iterative, realizing an EM procedure that alternates between the estimations of DLVs and model parameters. To simplify the derivation, we first derive the solution by assuming and are uncorrelated. The assumption implies that
| (9) |
or alternatively,
| (10) |
In the next section, we show that an optimality condition in the prediction error covariance leads to the uncorrelated noise condition, thus removing the assumption.
3.1 Necessary Condition for Optimal Solutions
Given the measured data , the following likelihood function should be maximized:
Considering the RRVAR model (8), maximizing the likelihood amounts to minimizing the following function constrained by and from (9),
| (11) | |||
Then, it follows from (3), (4), and (10) that
For each , differentiating with respect to and setting it to zero lead to
Rearranging the above equation gives
| (12) |
On the other hand, denoting the one-step prediction
it follows that (11) can be rearranged as
| (13) |
Differentiating (13) with respect to and and setting them to zero lead to
| (14) | |||
| (15) |
Substituting (14) into (15) leads to
| (16) |
3.2 The EM Solution
It is clear that the necessary condition of optimality involves nonlinear equations of the parameters . To solve them iteratively, we separate the solution into two EM steps. First, given and respectively, the E-step of the EM procedure gives
| (17) | |||
| (18) |
for .
Second, (17) and (18) can be used to estimate the model parameters in the M-step. Formulate matrices
which include the formation of and . Substituting the estimated DLV vectors (17) into (12) leads to
| (19) |
Further, denoting
| (20) |
where is a projection matrix, which shows that is the orthogonal projection of onto the range of . It follows from (14) and (16) that
| (21) | ||||
| (22) |
where is a projection matrix.
Finally, we need to update to complete the iteration loop. Based on (9), pre-multiplying and post-multiplying to (22) lead to
| (23) |
From the orthogonal projection in (20), it is straightforward to show that , which gives . The last term in (23) becomes
Further, (23) becomes
| (24) |
The best predictive DLV model is one that has the smallest prediction error covariance given in the sense that is positive semi-definite for any other . However, since can be made arbitrarily small by scaling , we need to fix the scale of one of the terms in (24). In [29], the scale is fixed by enforcing . In this paper, an equivalent scaling is implemented in the next subsection with
| (25) |
where . Then (24) becomes
Therefore, maximizing subject to (25) leads to the smallest .
3.3 An Optimal PredVAR Algorithm with Normalization
The constraint (25) can be implemented by normalizing the data based on , a technique used in [29, 14]. The constraint (25) indicates that can only be found in the eigenspace of corresponding to the non-zero eigenvalues. Thus, assuming , we must have the number of DLVs .
By performing eigenvalue decomposition (EVD) on
where , , and contains the non-zero eigenvalues in non-increasing order, we define a normalized data vector with
| (26) |
which represents with the following normalized PredVAR model
| (27) |
where , , and we make without any loss of generality. Then, it follows from (26) and (27) that
| (28) |
Forming the same way as for , it is straightforward to show that . By using the uncorrelated condition of the DLVs and static noise, we have
| (29) |
i.e., , , and . Comparing the above relation to (3), it is clear that and coincide with each other, i.e., . Therefore, we generate the DLVs with
giving . Therefore, the optimal PredVAR solution is converted to finding , and thus , to make most predictable.
To find the estimate , the constraint (25) becomes
| (30) |
which again makes an orthogonal matrix. Equation (23) becomes
| (31) |
Therefore, to minimize subject to (30) with DLVs, must contain the eigenvectors of the largest eigenvalues of . Performing EVD on
| (32) |
where contains the eigenvalues in non-increasing order, it is convenient to choose
| (33) |
as the optimal solution, making
contain the leading canonical correlation coefficients (i.e., values) of the DLVs and
| (34) |
the residual covariance. It is noted that if some diagonal elements of are zero, the noise covariance is rank-deficient, and the corresponding DLVs have perfect predictions.
To summarize, the whole EM iteration solution boils down to updating and until convergence. With the converged and , we can calculate , , from (28), and from (22).
The static part of the model can be calculated from the oblique complement of the dynamic counterpart. It is straightforward to calculate from (29). From (26) and (27), we have
Therefore, to match (1) and satisfy (3), we can choose
| (35) | ||||
| (36) |
which give the static noise
| (37) |
The pseudocode of the PredVAR algorithm is shown in Algorithm 1. The data are first normalized based on before the EM iteration. Then, the estimates are iterated with the EM-based PredVAR solution. After convergence, we obtain for the RRVAR model and for the static noise model.
3.4 Rank-deficient Covariances of Innovations
In real applications, it is possible that the covariances , , and can be rank-deficient. Algorithm 1 handles the rank deficiency of by the initial EVD step. Since is enforced in this algorithm, the null space of cannot be part of , and therefore, it must be part of . On the other hand, with the enforced , it is possible to have rank-deficient , which corresponds to DLVs perfectly predictable. Therefore, we give the following remarks.
Remark 1.
Singularities in are considered in the PredVAR model as the leading DLVs that are perfectly predictable. Let
where corresponds to all perfectly predictable DLVs. Similarly partitioning , we have the following relation from (8)
| (38) |
For the case of full rank , (38) gives a VAR model with the rank-reduced innovation with a dimension less than that of . The situation of rank-reduced innovations is a topic of active research, e.g., [36] and [5].
Remark 2.
For the case of rank-deficient , its null space is contained in , making rank-deficient. Therefore, rank-deficient and are naturally taken care of in Algorithm 1.
3.5 Initialization
We give the following effective strategy for initializing , which is consistent with the updating of in Algorithm 1. Specifically, similar to , form the augmented matrix
Replacing with in (32) and performing EVD give rise to
| (39) |
where and contains the eigenvalues in a non-increasing order, we can initialize as .
The underlying idea is to estimate the error covariance matrix from the following full-rank VAR model
which makes
Interestingly, the canonical analysis of time series in [3] estimates the VAR error covariance matrix first, and then performs EVD to select canonical components for the smallest eigenvalues of the error covariance matrix, which is equivalent to the selection of in this initialization step. Therefore, the work[3] serves as an initial step of the PredVAR iteration only.
4 Optimal RDD Decomposition
While there exists a one-to-one correspondence between the dynamic-static decomposition of and the ranges of and , the decomposition is not unique. This fact offers the flexibility to extract DLVs and static noise with desired properties. Particularly, the data series can be decomposed into a dynamic series and a static noise series to make
-
1.
the DLV series as predictable or the covariance of the error as small as possible, and
-
2.
a realization of the static noise series the least correlated with the DLV innovations series .
The latter is feasible since the realization of needs not to be orthogonal to in PredVAR, which is the benefit of using oblique projections. Interestingly, our analysis also reveals the consistency between the two goals.
4.1 Uncorrelated Noise Realization
The PredVAR solution finds to minimize the prediction error covariance of DLVs subject to . Thus, given and , we solve the following optimization problem under the Loewner order [4]
| (40) |
for the best predictability. The optimization result leads to the following theorem that gives rise to uncorrelated innovations of and .
Theorem 2.
When Problem (40) attains the optimum, the following statements hold and are equivalent.
-
1.
;
-
2.
and are uncorrelated;
-
3.
and are uncorrelated;
-
4.
;
-
5.
if is nonsingular;
-
6.
;
-
7.
if is nonsingular.
Theorem 2 is proven in Appendix B. The theorem reveals that minimizing the covariance of the DLV innovations leads to the uncorrelated realization as stated in the theorem. Thus, Algorithm 1 can be applied whenever a minimum covariance realization is desired. The uncorrelated realization is a consequence of the oblique projection stated in (40) that minimizes .
4.2 Geometric Interpretation
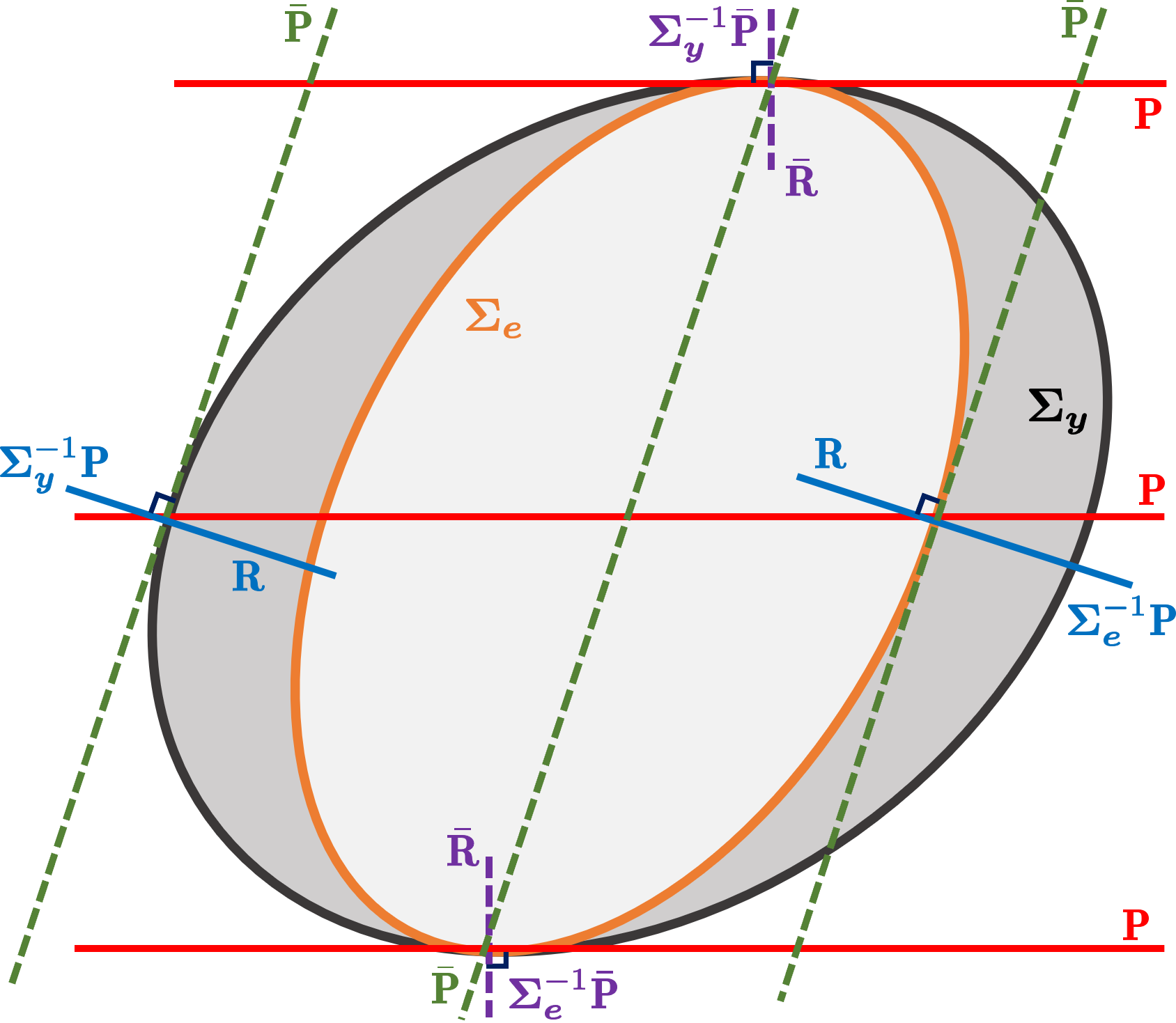
We illustrate the oblique projection necessitated by the covariance of the measurement vector in Figs. 2(a) and 2(b). Fig. 2(a) gives the oblique geometry of the optimal dynamic-static decomposition for the case of non-singular and , which are respectively represented by the ellipsoids
The two opposite tangent points of the ellipses indicate the static variance direction, which is irreducible by the RRVAR model prediction. The tangent spaces of the two ellipsoids at their intersections on surfaces are the same, agreeing with the range of . For the best predictability of DLVs in terms of , a complementary subspace is chosen such that the oblique projection of the -ellipsoid onto the dynamic subspace along the complementary subspace is as small as possible. Then, the complementary subspace should be specified by the tangent space to the -ellipsoid at the intersection of the dynamic subspace passing the center and the surface. The corresponding normal space is the range of , as shown in Fig. 2(a). Both and are orthogonal to , aligning with Statement (5) in Theorem 2. Similarly, both and are orthogonal to , agreeing with Statement (4) in Theorem 2.
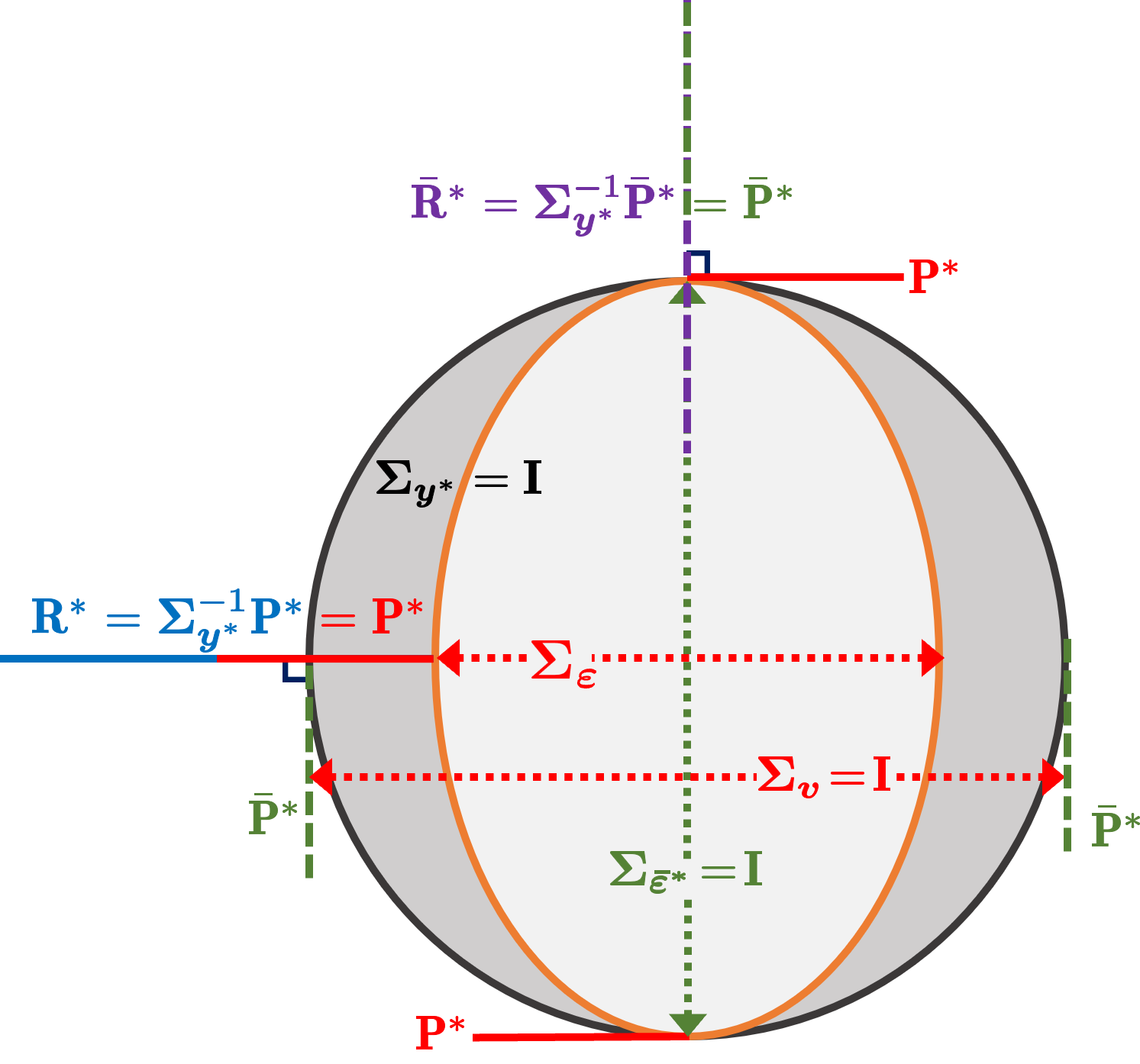
On the other hand, Fig. 2(b) illustrates the orthogonal geometry after normalization with . In this case, the optimal projection is normalized to an orthogonal one, making coincide with . The covariances for the DLVs and static noise, and , are scaled to identity matrices. Correspondingly, the predictability of the DLVs is visualized by the volume ratio of the two ellipsoids.
5 Additional Analysis
5.1 Distributions of Parameter Estimates
As in [32], we derive the statistical properties of the model estimates under the assumption that the matrix of DLVs is fixed. First, it follows that
and
Therefore, is an unbiased estimate and can be assessed by replacing with its estimate.
Similarly, since is uncorrelated to , it follows from (21) that
and
Again, can be replaced by its estimate to assess . To sum up, we conclude that the parameter estimates can be approximated with the following distributions given :
5.2 Selection of Model Sizes
For full-rank VAR models, the multiple final prediction error (MFPE) developed by Akaike [1] can be used to determine the order . Following this idea, we derive a reduced-rank MFPE (RRMFPE) to determine and for the RRVAR model. We choose to work on the normalized vector since and coincide with each other and and are orthogonal. Therefore, we can write the model explicitly conditional on as follows based on (27)
and the prediction error based on the estimates is given as follows
The covariance of the prediction error is
where and for the PredVAR algorithm. Following [1] and using the fact that from (19) is a least-square estimate with respect to , the estimate of the above covariance is
Since , taking the determinant of the above covariance estimate gives the RRMFPE of the PredVAR algorithm with the model size as follows
| (41) |
using and from (34). To handle the possible rank-deficient due to perfect prediction of some DLVs, denote and exclude the zero variance terms by replacing with . To further simplify the expression, we take logarithm to obtain
When is large enough, taking the first-order Taylor approximation gives
| (42) |
We can fit the model with a grid of -pairs, and the one that gives the minimum log-RRMFPE can be chosen as the optimal model size. The two terms in (42) give a clear trade-off between model complicity and model errors. With fixed , the first term decreases with , while the second term increases linearly with . On the other hand, with fixed , the first term decreases with , while the second term increases quadratically with .
5.3 Comparison among PredVAR, LaVAR-CCA, and DiCCA Algorithms
Since the PredVAR, LaVAR-CCA [29], and DiCCA [8] algorithms all use equivalent normalization of the data, it is convenient to compare them using the normalized data . LaVAR-CCA [29] essentially updates by solving the following optimization problem
Comparing to (31), the proposed PredVAR algorithm updates by
Therefore, the two algorithms are different in general. As per (20), the range of is contained in that of , that is, . A projection onto the former implies a more parsimonious model. Consequently, the PredVAR algorithm focuses on the portion of the past information that is relevant to predicting the current data. Therefore, the PredVAR algorithm makes better use of the latent dynamics for the optimal dimension reduction than LaVAR-CCA. The two algorithms coincide in the special case of since the range of is the same as that of .
The difference between PredVAR and DiCCA is evident since DiCCA works on univariate latent dynamics. For the special case of , DiCCA and LaVAR-CCA use the same objective. However, the difference between PredVAR and DiCCA remains since the range of is contained in that of .
5.4 Comparison to Non-iterative One-Shot Solutions
The PredVAR, LaVAR-CCA, and DiCCA algorithms are all iterative to find . In the literature, papers like [14] adopt non-iterative one-shot (OS) solutions, which do not enforce an explicit latent VAR model to obtain . The DLV sequences are calculated and used to retrofit the VAR model matrices similar to (19). However, the estimated VAR model is not used to further update . Thus, OS solutions appear to be a single iteration step of the iterative algorithms like the PredVAR.
We consider the OS algorithm developed in [14] and compare it with PredVAR. The work in [14] first normalizes the data and obtains an orthonormal from the eigenvectors corresponding to the least eigenvalues of
| (43) |
where is the same as in [14] as a pre-specified integer. Using to obtain , is found to be the eigenvectors associated with the smallest eigenvalues of . In other words, is a diagonal matrix of the smallest eigenvalues. This solution is consistent with (6) in Theorem 2, which makes zero ideally.
It is apparent that the above OS solution resembles the initialization step of PredVAR in (39), but ignores the subsequent iterations of the PredVAR algorithm. The OS solution from (43) finds the left singular vectors of , which is essentially the covariance from the two matrices. On the other hand, the initialization step of PredVAR in (39) makes use of the eigenvectors of , which are projections of onto , or the left singular vectors of . Since the covariance of is identity, contains the canonical correlations from the two matrices.
To summarize, one-shot solutions like [14] resemble the initialization step of iterative solutions such as PredVAR and do not iterate further to enforce consistency of the outer projection and inner dynamic VAR models. In addition, [14] relies on the covariance instead of the correlations to find the solution. The difference between the two is the weight matrix , whose effect has been studied in the subspace identification literature extensively [23, 20, 6]. It is noted that the weight matrix does affect the singular vector solutions.
6 Case Studies
In this section, we conduct comprehensive numerical comparisons of the proposed PredVAR algorithm with other leading algorithms, including the LaVAR-CCA (abbreviated as LaVAR) in [29], DiCCA in [8], and the one-shot algorithm in [14] (see Sec. 5.4). All simulations are conducted via MATLAB with an Apple M2 Pro.
| 2 | 12 | 22 | 32 | 42 | 52 | |
|---|---|---|---|---|---|---|
| 1 | 0.8265 | 0.8198 | 0.8198 | 0.8198 | 0.8198 | 0.8198 |
| 2 | 0.6032 | 0.5918 | 0.5918 | 0.5918 | 0.5918 | 0.5918 |
| 3 | 0.1891 | 0.1895 | 0.1895 | 0.1895 | 0.1896 | 0.1895 |
| 4 | 0.5142 | 0.5132 | 0.5129 | 0.5127 | 0.5126 | 0.5123 |
| 5 | 0.6385 | 0.6379 | 0.6381 | 0.6386 | 0.6388 | 0.6383 |
| 6 | 0.7071 | 0.7071 | 0.7071 | 0.7071 | 0.7071 | 0.7071 |
| 2 | 12 | 22 | 32 | 42 | 52 | |
|---|---|---|---|---|---|---|
| 1 | 0.3129 | 0.7641 | 0.7599 | 0.7592 | 0.7589 | 0.7586 |
| 2 | 0.6349 | 0.9166 | 0.9123 | 0.9119 | 0.9117 | 0.9117 |
| 3 | 0.9995 | 0.9995 | 0.9995 | 0.9995 | 0.9995 | 0.9995 |
| 4 | 0.7658 | 0.7543 | 0.7599 | 0.7714 | 0.7670 | 0.7716 |
| 5 | 0.6995 | 0.7086 | 0.7002 | 0.7242 | 0.7489 | 0.6853 |
| 6 | 0.6501 | 0.6501 | 0.6501 | 0.6501 | 0.6501 | 0.6501 |
| 2 | 12 | 22 | 32 | 42 | 52 | |
|---|---|---|---|---|---|---|
| 1 | 0.3112 | 0.7641 | 0.7599 | 0.7590 | 0.7583 | 0.7573 |
| 2 | 0.6332 | 0.9166 | 0.9123 | 0.9120 | 0.9120 | 0.9119 |
| 3 | 0.9974 | 0.9698 | 0.9994 | 0.9994 | 0.9995 | 0.9995 |
| 4 | 0.9987 | 0.9897 | 0.9870 | 0.9851 | 0.9827 | 0.9806 |
| 5 | 0.9981 | 0.9869 | 0.9833 | 0.9769 | 0.9781 | 0.9688 |
| 6 | 0.9977 | 0.9837 | 0.9759 | 0.9680 | 0.9616 | 0.9546 |
| 2 | 12 | 22 | 32 | 42 | 52 | |
|---|---|---|---|---|---|---|
| 1 | 0.9993 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 2 | 0.9997 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 3 | 0.9975 | 0.9680 | 0.9999 | 0.9999 | 0.9999 | 0.9999 |
| 4 | 0.7657 | 0.7517 | 0.7561 | 0.7678 | 0.7621 | 0.7673 |
| 5 | 0.6990 | 0.7037 | 0.6937 | 0.7199 | 0.7430 | 0.6718 |
| 6 | 0.6495 | 0.6436 | 0.6409 | 0.6396 | 0.6348 | 0.6324 |
| 2 | 12 | 22 | 32 | 42 | 52 | |
|---|---|---|---|---|---|---|
| 1 | 0.1633 | 0.4891 | 0.4876 | 0.4873 | 0.4872 | 0.4870 |
| 2 | 0.4127 | 0.6072 | 0.6056 | 0.6055 | 0.6054 | 0.6054 |
| 3 | 0.6505 | 0.6505 | 0.6505 | 0.6505 | 0.6505 | 0.6505 |
| 4 | 0.8634 | 0.8763 | 0.8689 | 0.8542 | 0.8583 | 0.8480 |
| 5 | 0.9424 | 0.9231 | 0.9288 | 0.9094 | 0.8725 | 0.9439 |
| 6 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 2 | 12 | 22 | 32 | 42 | 52 | |
|---|---|---|---|---|---|---|
| 1 | 0.1623 | 0.4895 | 0.4883 | 0.4888 | 0.4881 | 0.4873 |
| 2 | 0.4117 | 0.6076 | 0.6063 | 0.6070 | 0.6068 | 0.6066 |
| 3 | 0.6491 | 0.6305 | 0.6512 | 0.6515 | 0.6514 | 0.6513 |
| 4 | 0.6503 | 0.6470 | 0.6468 | 0.6474 | 0.6463 | 0.6461 |
| 5 | 0.6497 | 0.6452 | 0.6437 | 0.6452 | 0.6446 | 0.6380 |
| 6 | 0.6495 | 0.6436 | 0.6409 | 0.6396 | 0.6348 | 0.6324 |
6.1 Case Study with the Lorenz Attractor Data
As in [29], use the nonlinear Lorenz oscillator to generate samples for the DLV . The static noise is generated following a zero-mean Gaussian distribution whose variance is the same as that of the DLV series. Then, the -dimensional measurement samples is obtained by mixing the DLVs and static noise via (1), where are orthonormal and is invertible. The first measurement samples are for training, and the remaining is for testing.
| (with ) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PredVAR – LaVAR | 0.0001 | 0.0001 | 0.0000 | 0.0000 | 0.0001 | 0.0002 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0002 | 0.0000 |
| PredVAR – DiCCA | 0.0539 | 0.0297 | 0.0480 | 0.0320 | 0.0308 | 0.0392 | 0.0440 | 0.0378 | 0.0401 | 0.0486 | 0.0515 | 0.0518 |
| LaVAR – DiCCA | 0.0539 | 0.0297 | 0.0480 | 0.0320 | 0.0308 | 0.0393 | 0.0440 | 0.0378 | 0.0401 | 0.0486 | 0.0514 | 0.0518 |
| (with ) | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| PredVAR – LaVAR | 0.1494 | 0.1203 | 0.3430 | 0.3234 | 0.0078 | 0.0004 | 0.0005 | 0.0008 | 0.0000 | 0.0008 | 0.0002 | 0.0045 |
| PredVAR – DiCCA | 0.4287 | 0.4055 | 0.2977 | 0.1990 | 0.2037 | 0.0961 | 0.1283 | 0.0538 | 0.0518 | 0.1146 | 0.2427 | 0.1350 |
| LaVAR – DiCCA | 0.4104 | 0.3949 | 0.2284 | 0.3392 | 0.2009 | 0.0960 | 0.1285 | 0.0541 | 0.0518 | 0.1151 | 0.2427 | 0.1314 |
6.1.1 The DLD and the VAR order
Given the estimated model sizes , we first identify the PredVAR parameters via the proposed algorithm using the training data and then validate the performance of the estimated model using the testing data. To compare between two loadings matrices and , the D-distance between them defined in [24, 14] is adopted and extended for the case of as follows
We further define the average correlation between and by the average absolute value of the pair-wise correlations, i.e.,
With the two measures, Table 2 shows the performances of our approach under the different -pairs. Since depends on the latent coordinates from various methods, we map it to the original data space by the loadings matrix or its estimate to compare various models.
It is easily seen from Tables 2(a) – 2(d) that , which is also the truth, gives the highest average correlation between the original noise-free signal series and the signal reconstruction series (Table 2(b)) or the signal prediction series (Table 2(c)).
Since the noise-free series is unavailable in practical scenarios, Table 2(d) – 2(f) deserves particular attention. Specifically, for each , the average correlation between and significantly deceases as the overestimate of occurs. Moreover, for a proper , the average correlation between and achieves the maximum value when .
6.1.2 Comparison to other Methods
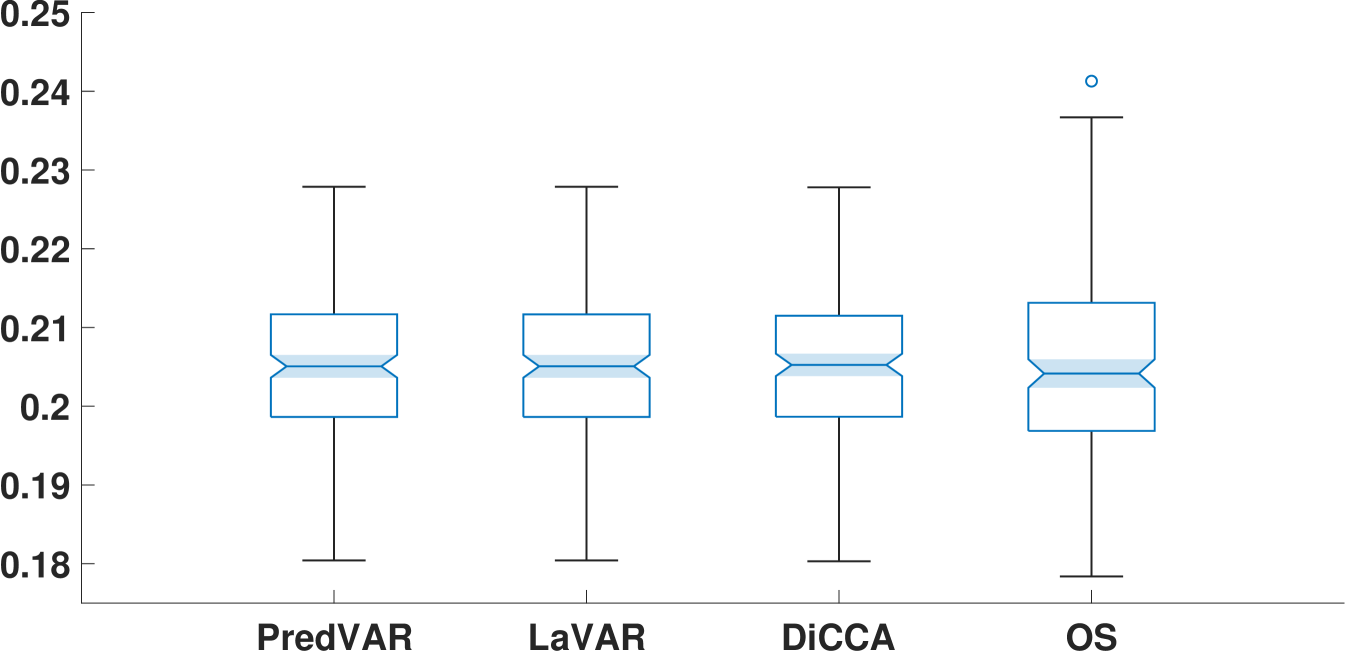
Using the same DLV series and loadings matrices, we perform a Monte-Carlo simulation of the noise from the same distribution to obtain series of points each. For each time series, the first data points are for training and the rest for testing. Uniformly set and . Fig. 3 shows the performance of the PredVAR and the benchmark algorithms on the testing data series.
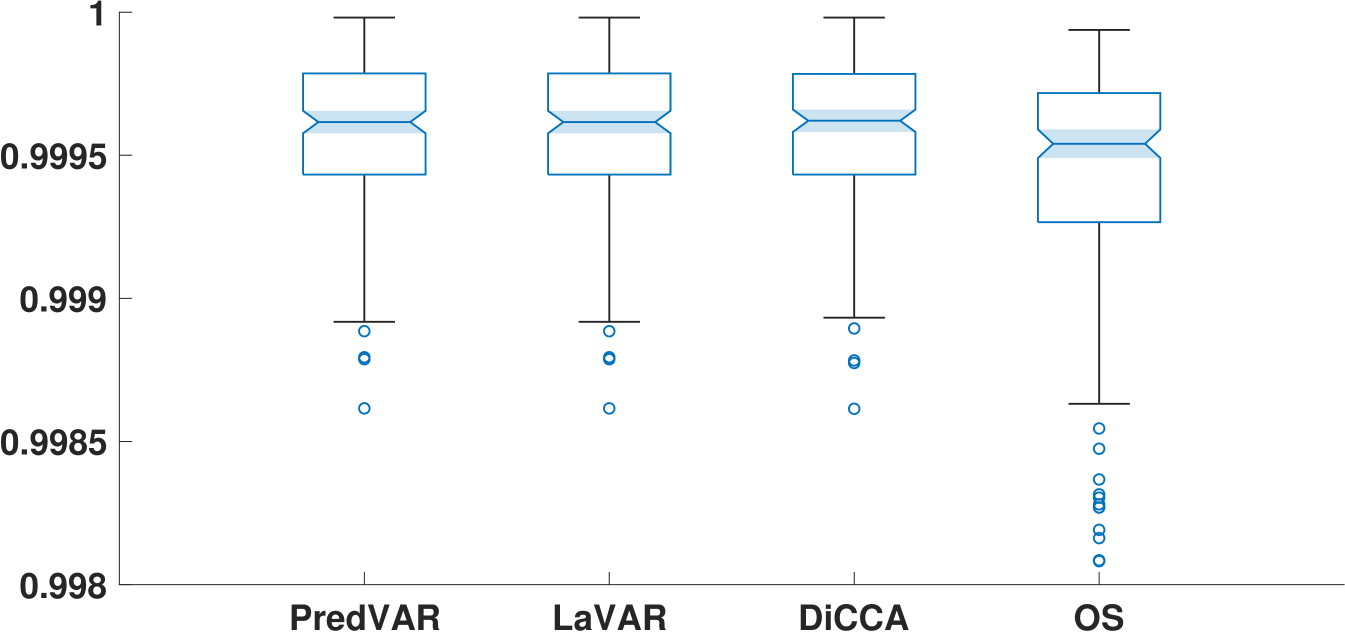
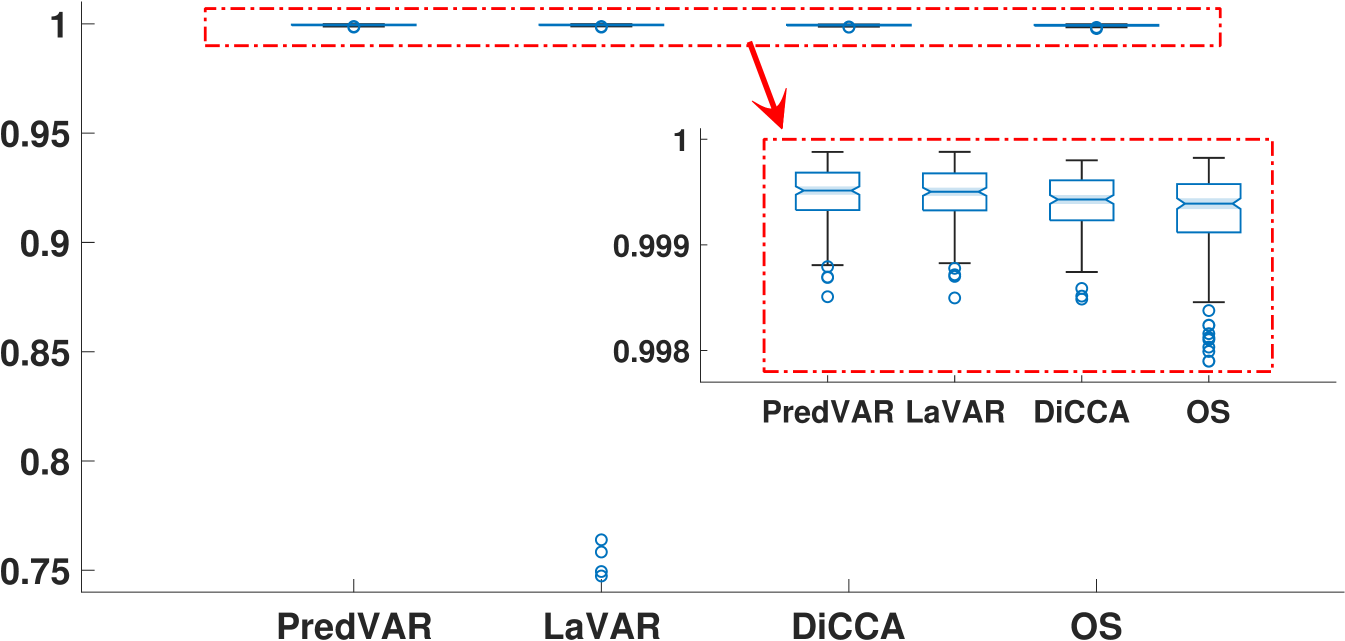
Figs. 3(a) and 3(b) show that the PredVAR, LaVAR, and DiCCA algorithms are comparable in identifying the dynamic subspace and reconstructing the uncorrupted signal. In contrast, the OS algorithm has notably inferior performance. Moreover, the OS algorithm exhibits more significant variability regarding subspace identification and signal reconstruction than the other algorithms.
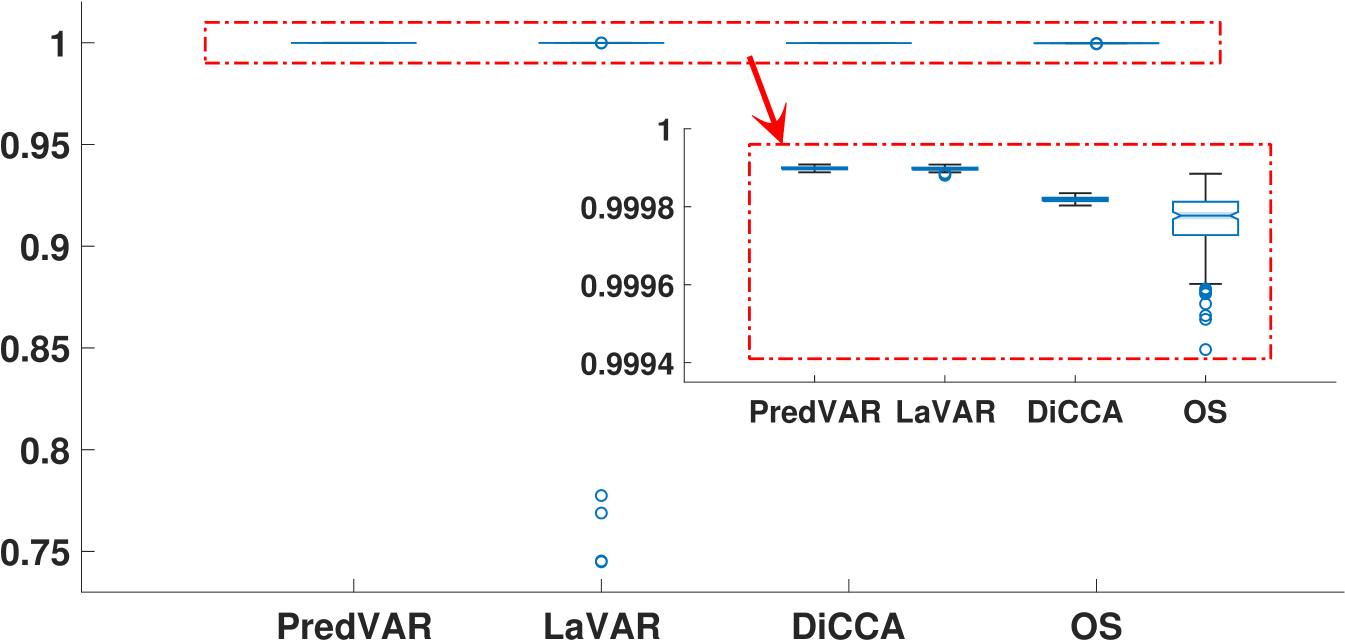
Fig. 3(c) showcases the performance of various algorithms in predicting the noise-free signal, with the PredVAR approach performing the best. In most cases, the LaVAR algorithm performs similarly to PredVAR and surpasses DiCCA and OS. However, LaVAR exhibits more significant outliers than the other three algorithms, meaning that LaVAR is numerically less reliable. A similar phenomenon is observed in Fig. 3(d), regarding the average correlation between the reconstruction and prediction time series. Furthermore, in Fig. 3(d), DiCCA and OS perform significantly worse than PredVAR and LaVAR in general. This fact strongly verifies the importance of exploring the interactions among different DLVs and the alternating updates of projection-related and dynamics-related parameters.
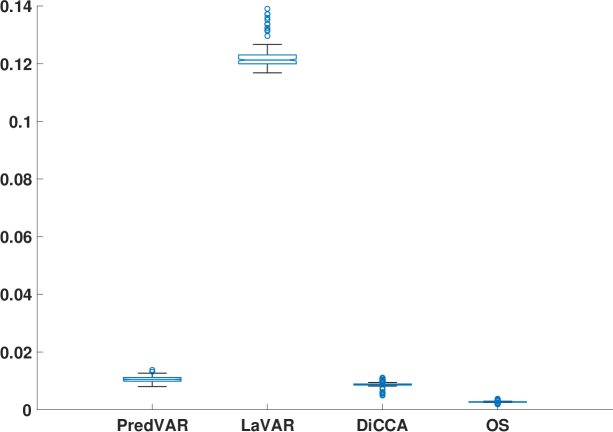
We also compare the algorithms in terms of training time. As shown in Fig. 4, OS requires the least training effort, and LaVAR demands the most. One would expect DiCCA to have less training time than PredVAR and LaVAR since DiCCA does not involve interactions among DLVs. Surprisingly, Fig. 4 suggests that PredVAR takes slightly less training time than DiCCA. However, a unique advantage of DiCCA over other interacting DLV models is that, when a DiCCA model with DLVs is obtained, it yields a suite of DiCCA models for . For algorithms with interacting DLV models, one has to build one model with each DLD from 1 to .
6.2 Case Study on Industrial Process Data
In this study, the plant-wide oscillation dataset from the Eastman Chemical Company [29] is used to demonstrate the effectiveness of the proposed PredVAR algorithm, where variables with oscillation patterns are selected for modeling over their first sequential samples.
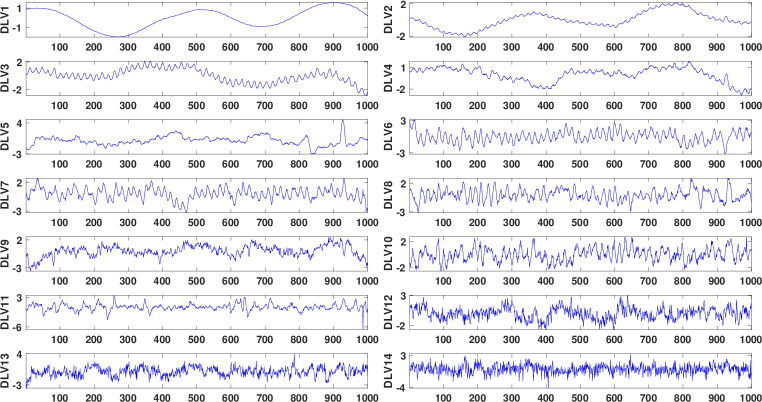
The RRMFPE criterion suggests and . With such model sizes, the DLVs extracted by the PredVAR algorithm are plotted in Fig. 5. The first three DLVs prominently display low-frequency oscillations. The last DLV seems to exhibit the highest volatility. Moreover, Table 3 depicts the D-distances between the dynamic subspaces estimated by PredVAR, LaVAR-CCA, and DiCCA as or varies. Similarly to before, the difference is more responsive to the change of than . The dynamic subspaces obtained by PredVAR and LaVAR-CCA are more similar than those estimated by DiCCA.
7 Conclusions
A probabilistic reduced dimensional VAR modeling algorithm, namely, PredVAR, is successfully developed with oblique projections, which is required for optimal low-dimensional dynamic modeling from high-dimensional data. The PredVAR model is equivalent to a reduced-rank VAR model, where the VAR coefficient matrices have reduced rank. Both model forms admit a serially independent subspace of the measurement vector. The algorithm is iterative, following the principle of expectation maximization, which alternately estimates the DLV dynamic model and the outer oblique projection. We show with a simulated case and an industrial case study that the PredVAR algorithm with the oblique projections outperforms other recently developed algorithms, including a non-iterative one for reduced-dimensional dynamic modeling. The computational cost of the EM-based PredVAR algorithm is much reduced compared to the alternating optimization based LaVAR algorithm in [29].
?refname?
- [1] H. Akaike. Autoregressive model fitting for control. Ann. Inst. Stat. Math., 23:163–180, 1971.
- [2] J. Bai and K. Li. Statistical analysis of factor models of high dimension. Ann. Stat., 40:436–465, 2012.
- [3] G. E. P. Box and G. C. Tiao. A canonical analysis of multiple time series. Biometrika, 64(2):355–365, 1977.
- [4] S. Boyd and L. Vandenberghe. Convex Optimization. Cambridge university press, 2004.
- [5] W. Cao, G. Picci, and A. Lindquist. Identification of low rank vector processes. Automatica, 151:110938, 2023.
- [6] A. Chiuso and G. Picci. Consistency analysis of some closed-loop subspace identification methods. Automatica, 41:377–391, 2005.
- [7] A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B Methodol., 39:1–22, 1977.
- [8] Y. Dong, Y. Liu, and S. J. Qin. Efficient dynamic latent variable analysis for high-dimensional time series data. IEEE Trans. Ind. Informat., 16(6):4068–4076, 2020.
- [9] Y. Dong and S. J. Qin. Dynamic latent variable analytics for process operations and control. Comput. Chem. Eng., 114:69–80, 2018.
- [10] Y. Dong and S. J. Qin. A novel dynamic PCA algorithm for dynamic data modeling and process monitoring. J. Process Control, 67:1–11, 2018.
- [11] L. Fan, H. Kodamana, and B. Huang. Semi-supervised dynamic latent variable modeling: I/o probabilistic slow feature analysis approach. AIChE J., 65(3), 2019.
- [12] W. Fan, Q. Zhu, S. Ren, L. Zhang, and F. Si. Dynamic probabilistic predictable feature analysis for multivariate temporal process monitoring. IEEE Trans. Control Syst. Technol., page e17609, 2022.
- [13] W. D. Fries, X. He, and Y. Choi. LaSDI: Parametric latent space dynamics identification. Comput. Methods Appl. Mech. Eng., 399:115436, 2022.
- [14] Z. Gao and R. S. Tsay. Modeling high-dimensional time series: A factor model with dynamically dependent factors and diverging eigenvalues. J. Am. Stat. Assoc., pages 1–17, 2021.
- [15] P. Geladi and B. R. Kowalski. Partial least-squares regression: A tutorial. Anal. Chim. Acta, 185:1–17, 1986.
- [16] A. J. Izenman. Reduced-rank regression for the multivariate linear model. J. Multivar. Anal., 5(2):248–264, 1975.
- [17] M. Khosravi and R. S. Smith. The existence and uniqueness of solutions for kernel-based system identification. Automatica, 148:110728, 2023.
- [18] C. Lam and Q. Yao. Factor modeling for high-dimensional time series: Inference for the number of factors. Ann. Stat., pages 694–726, 2012.
- [19] G. Li, S. J. Qin, and D. Zhou. A new method of dynamic latent-variable modeling for process monitoring. IEEE Trans. Ind. Electron., 61:6438–6445, 2014.
- [20] L. Ljung. System Identification: Theory for the User. Prentice-Hall, Inc., Englewood Cliffs, New Jersey, 1999. Second Edition.
- [21] Z. Lou, Y. Wang, Y. Si, and S. Lu. A novel multivariate statistical process monitoring algorithm: Orthonormal subspace analysis. Automatica, 138:110148, 2022.
- [22] Y. Mo, J. Yu, and S. J. Qin. Probabilistic reduced-dimensional vector autoregressive modeling for dynamics prediction and reconstruction with oblique projections. In IEEE Conf. Decis. Control (CDC), 2023.
- [23] P. V. Overschee and B. D. Moor. Subspace Identification for Linear Systems. Kluwer Academic Publishers, 1996.
- [24] J. Pan and Q. Yao. Modelling multiple time series via common factors. Biometrika, 95(2):365–379, 2008.
- [25] D. Peña and G. E. P. Box. Identifying a simplifying structure in time series. J. Am. Stat. Assoc., 82:836–843, 1987.
- [26] D. Peña, E. Smucler, and V. J. Yohai. Forecasting multiple time series with one-sided dynamic principal components. J. Am. Stat. Assoc., 2019.
- [27] G. Pillonetto, F. Dinuzzo, T. Chen, G. De Nicolao, and L. Ljung. Kernel methods in system identification, machine learning and function estimation: A survey. Automatica, 50:657–682, 2014.
- [28] S. J. Qin. Latent vector autoregressive modeling for reduced dimensional dynamic feature extraction and prediction. In IEEE Conf. Decis. Control (CDC), pages 3689–3694, 2021.
- [29] S. J. Qin. Latent vector autoregressive modeling and feature analysis of high dimensional and noisy data from dynamic systems. AIChE J., page e17703, 2022.
- [30] S. J. Qin, Y. Dong, Q. Zhu, J. Wang, and Q. Liu. Bridging systems theory and data science: A unifying review of dynamic latent variable analytics and process monitoring. Annu Rev Control, 50:29–48, 2020.
- [31] S. J. Qin, Y. Liu, and S. Tang. Partial least squares, steepest descent, and conjugate gradient for regularized predictive modeling. AIChE J., 69(4):e17992, 2023.
- [32] G. Reinsel and R. Velu. Multivariate Reduced-Rank Regression, volume 136 of Lecture Notes in Statistics. Springer, New York, NY, 1998.
- [33] C. Shang, F. Yang, B. Huang, and D. Huang. Recursive slow feature analysis for adaptive monitoring of industrial processes. IEEE Trans. Ind. Electron., 65(11):8895–8905, 2018.
- [34] J. H. Stock and M. W. Watson. Forecasting using principal components from a large number of predictors. J. Am. Stat. Assoc., 97:1167–1179, 2002.
- [35] M. Sznaier. Control oriented learning in the era of big data. IEEE Control Syst. Lett., 5:1855–1867, 2020.
- [36] H. H. Weerts, P. M. Van den Hof, and A. G. Dankers. Prediction error identification of linear dynamic networks with rank-reduced noise. Automatica, 98:256–268, 2018.
- [37] Q. Wen, Z. Ge, and Z. Song. Data-based linear Gaussian state-space model for dynamic process monitoring. AIChE J., 58(12):3763–3776, 2012.
- [38] J. Yu and S. J. Qin. Latent state space modeling of high-dimensional time series with a canonical correlation objective. IEEE Control Syst. Lett., 6:3469–3474, 2022.
- [39] W. Yu, M. Wu, B. Huang, and C. Lu. A generalized probabilistic monitoring model with both random and sequential data. Automatica, 144:110468, 2022.
- [40] C. Zhao and B. Huang. A full-condition monitoring method for nonstationary dynamic chemical processes with cointegration and slow feature analysis. AIChE J., 64(5):1662–1681, 2018.
- [41] L. Zhou, G. Li, Z. Song, and S. J. Qin. Autoregressive dynamic latent variable models for process monitoring. IEEE Trans. Control Syst. Technol., 25:366–373, 2016.
?appendixname? A Proof of Theorem 1
Proof of Part 1). From the PredVAR model (1) and (2) it is straightforward to have
with , where . Since and are i.i.d. Gaussian, is i.i.d. Gaussian.
From the canonical RRVAR model, pre-multiplying to (8) leads to
where and . Since is i.i.d. Gaussian, is i.i.d. Gaussian.
?appendixname? B Proof of Theorem 2
Applying the Lagrangian multiplier to (40) leads to
Differentiating with respect to and setting the derivative to zero gives
| (44) |
Since , pre-multiplying to (44) gives
| (45) |
Substituting (45) into (44) leads to 1). It follows from the Lagrangian multiplier analysis [4] that Problem (40) attains the optimum only if 1) holds. It remains to show the equivalence of the six statements.
1) 2) is due to that is of full column rank and post-multiplying to 1) leads to
2) 3) follows from (3), namely
3) 4) follows from the definitions of , , and .
4) 5) follows from the fact that the inverse of a block diagonal matrix is also block diagonal, and (10).
4) 6) follows from and
6) 7) follows from the equivalence among
if is non-singular, and