Progressive Knowledge Transfer Based on Human Visual Perception Mechanism for Perceptual Quality Assessment of Point Clouds
Abstract
With the wide applications of colored point cloud in many fields, point cloud perceptual quality assessment plays a vital role in the visual communication systems owing to the existence of quality degradations introduced in various stages. However, the existing point cloud quality assessments ignore the mechanism of human visual system (HVS) which has an important impact on the accuracy of the perceptual quality assessment. In this paper, a progressive knowledge transfer based on human visual perception mechanism for perceptual quality assessment of point clouds (PKT-PCQA) is proposed. The PKT-PCQA merges local features from neighboring regions and global features extracted from graph spectrum. Taking into account the HVS properties, the spatial and channel attention mechanism is also considered in PKT-PCQA. Besides, inspired by the hierarchical perception system of human brains, PKT-PCQA adopts a progressive knowledge transfer to convert the coarse-grained quality classification knowledge to the fine-grained quality prediction task. Experiments on three large and independent point cloud assessment datasets show that the proposed no reference PKT-PCQA network achieves better of equivalent performance comparing with the state-of-the-art full reference quality assessment methods, outperforming the existed no reference quality assessment network.
Index Terms:
point cloud quality assessment, no-reference, attention mechanism, visual perception.I Introduction
Thanks to the rapid development of three-dimensional (3D) data acquisition technologies, colored point clouds are now readily available and popular. As an effective representation of 3D visual contents, a point cloud consists of a set of points, each of which contains geometric coordinates and other attributes such as color [1]. Point clouds have been widely used in automatic driving [2] [3], immersive telepresence [4] and so on. However, since point clouds record the omnidirectional detail of objects and scenes, they usually need large storage space and very high transmission bandwidth in practical applications. Hence, various 3D processing algorithms were proposed to adapt to specific needs using processing operations such as simplification and compression, which inevitably cause damage to the visual quality of 3D models [5] [6]. The Moving Picture Experts Group (MPEG) has been developing two point cloud compression standards: geometry-based point cloud compression (G-PCC) [7] and video-based point cloud compression (V-PCC) [8]. Therefore, developing point cloud quality assessment (PCQA) techniques can help to understand the distortion and carry out the quality optimization for point cloud.
Since the human visual system (HVS) is the ultimate receiver of 3D point clouds in most applications, the only reliable method to assess the point cloud quality perceived by a human observer is to ask human subjects for their opinion [9]. Subjective PCQA is impractical for most applications due to the human involvement in the process. Alexiou et al. [10] focused on the evaluation of test conditions defined by MPEG for core experiments including 99 distorted point clouds. Javaheri et al. [11] encoded six original voxelized point clouds from MPEG by three codecs with different quality generating 54 distorted point clouds. Yang et al. [12] produced a point cloud subjective evaluation dataset, denoted as SJTU-PCQA, with 420 samples at different distortion levels. Additionally, Su et al. [13] carried out a subjective quality assessment experiment covering 740 distorted point clouds. However, subjective PCQA studies provide valuable data to assess the performance of objective or automatic methods of quality assessment [13]. Subjective studies also enable improvements in the performance of objective PCQA algorithms toward attaining the ultimate goal of matching human perception. Like image/video quality assessment methods, objective PCQA methods can be classified into three categories: full reference (FR), reduced reference (RR), and no reference (NR) methods [14]. To evaluate the quality of a distorted point cloud, FR methods use the pristine uncompressed point cloud as a reference, while RR methods only require statistical features that are extracted from the reference point cloud. On the other hand, NR methods evaluate the quality of the distorted point cloud in the absence of the reference. Although substantial efforts have been made to develop objective PCQA models, the proposed solutions often fail to draw a connection to the HVS or struggle in handling the irregular representation of point clouds [5].
In this paper, we propose a progressive knowledge transfer based on a human visual perception mechanism for perceptual quality assessment of point clouds (PKT-PCQA). PKT-PCQA designs an intelligent network model to simulate the process of human visual processing of point cloud information, including the global and local quality mergence, attention mechanism and functional hierarchical architecture of human vision. The main contributions of this paper are as follows:
-
1.
We develop a perceptual quality assessment model of point clouds. Inspired by the hierarchical architecture for human vision, we exploit the coarse-to-fine learning strategy to transfer the information from a coarse quality classification to fine quality prediction task. Extensive experimental results show that our model is more accurate than existing FR and RR point cloud quality models.
-
2.
We introduce a hierarchical attention mechanism in the 3D domain. The proposed mechanism is a dynamic weight adjustment process based on features of the input point cloud. Since the attention mechanism is very similar to the human selective visual attention mechanism, our model can make a more accurate prediction of the human subjective opinion score than previous models.
-
3.
Inspired by multiple scales of receptive fields of human vision, we propose a novel feature extraction framework to consider the impact of the global and local features on the point cloud quality. The global geometry feature is for key clusters extraction, reducing the complexity of the network computation and increasing the similarity between the network quality score and human perceived quality.
The remainder of this paper is organized as follows. In Section II, we discuss related work. In Section III, we propose a quality assessment network that considers the visual perception for point clouds. We conduct experimental results in Section IV and draw conclusions in Section V.
II Related Work
FR objective quality assessment techniques for colored point clouds can be classified into two categories: point-based metrics and projection-based metrics. Point-based metric identifies the mean squared error between the color information of the points in the original point cloud and the distorted point cloud [15]. The most representative point-based FR point cloud quality metric is point-to-point PSNR only for geometry or color [16] [17] , namely , and , respectively. In addition, statistics of a variant of the Local Binary Pattern [18] [19], Perceptual Color Distance Pattern [20] and Local Luminance Pattern [21] descriptors were introduced to assess the quality of the point clouds. Based on the above pioneer studies, Yang et al. [22] constructed local graphs for both reference and distorted point clouds to compute three moments of color gradients, which are used to obtain similarity index by pooling the local graph significance across all channels, namely . Excepted that, the features of every point are commonly used to assess the point cloud quality in the point-based categories. Viola, Subramanyam, and Cesar [23] only exploited color histograms and correlograms to estimate the impairment of a distorted point cloud with respect to its reference. However, in [24] and [25], both geometry-based and color-based features were extracted to predict the point cloud quality. Considering the visual masking effect of the geometric information of point cloud and the color perception of human eyes, Hua et al. [26] used geometric segmentation and color transformation respectively to construct geometric and color features and then to estimate the point cloud quality. Inspired by the point cloud generation process, Xu et al. [27]introduced elastic forces to record the shaping of the point set and used the elastic potential energy difference to quantify the point cloud distortion. Inspired by the research of elastic potential energy, Yang et al. [28] split the source and target point clouds into multiple neighborhoods and measure the discrepancy between the two points clouds as a multiscale point potential energy discrepancy. The potential energy is defined around the centers of the neighborhoods in a way that reflects the geometry, colour, and contextual information in the point cloud. Lu et al. [29] designed a dual-scale 3D-DOG filters to explore the 3D edge information inherent in the PCs, and the corresponding 3D edge similarity of the reference and distorted point clouds is calculated to measure the quality loss of the distorted PCs. Additionally, the projection-based metrics project the 3D point cloud onto a 2D surface generating multiple 2D images of the point cloud. Then the existing image quality assessment methods SSIM [30], MS-SSIM [31], [32] and VIFP [33] are used to predict the quality of the point cloud from the average quality of the projection images and the other one is a layered projection-based [34] metric and use local and global statistics of the points to assess the perceived quality from both geometry and color. He et al. [35] obtained texture and geometry projection maps from different perspectives for evaluating the colored point cloud. Freitas et al. [36] mapped attributes from the point clouds onto the folded 2D grid, generating a pure-texture 2D image that contains point cloud texture information. Then, they extracted statistical features from these texture maps using a multi-scale rotation-invariant texture descriptor. Next, they computed the geometrical similarities using geometry-only distances. Finally, they fused the texture and geometrical similarities using a stacked regressor to model the point cloud visual quality.
RR objective quality assessment models commonly extract a small amount of information from the reference and distorted point clouds, and then compare and analyze the extracted feature data to predict the point cloud quality. Viola and Cesar proposed a RR quality metric [37], and they extracted 21 geometry, normal, and luminance features from the reference and distorted point clouds and built an RR quality metric as a weighted sum of their absolute differences. In the previous work [38], we proposed an RR linear model that accurately predicts the perceptual quality of compressed point clouds from the geometry and color quantization step sizes. Besides, we also used the information extracted from a bitstream for real-time and nonintrusive quality monitoring [39], and then the geometry quantization parameter, texture quantization parameter, texture bitrate per pixel are used to estimate the point cloud distortion.
However, often the reference point cloud is not available. Therefore, developing NR objective quality assessments can further facilitate the application of point cloud in practice. Hua et al. [40] proposed a metric dedicated to characterize the distortion of the distorted point cloud from geometric, color and joint perspectives. Since deep learning has achieved great success in various fields, deep learning-based metrics have also been proposed. Chetouani et al. [41] used a two-step procedure to divide the complex point cloud quality assessment task into feature extraction and quality prediction. In the previous work, we proposed a deep learning network using multiview 3D point cloud projection images to predict the quality of the point cloud [42]. The network applies feature extraction, distortion type identification, and quality vector prediction modules. Liu et al. [43] proposed a end-to-end sparse convolutional neural network to estimate the subjective quality of point cloud, which exploited a stack of sparse convolutional layers and residual blocks to extract hierarchical features. Tu et al. [44] designed a dual-stream convolutional network from the perspective of global and local feature description to extract texture and geometry features of the distorted point cloud. Regrettably, the most of the existed NR learning-based quality prediction networks ignore the Visual attention mechanism of HVS. Tao et al. [45] took into account the attention mechanism of HVS in the spatial pooling module and realized the weighted summation of local regional quality to obtain the final global quality score of colored point clouds. However, Tao he weighted summation of the visual quality scores of all local patches from the color and geometric projection maps. On the one hand, the visual perception of the projected 2D image is still different from the 3D visual perception. On the other hand, the 2D projection image in [45] is composed of fragmented projections in multiple areas, which is also very different from the overall perceptual image received by the human eye.
Based on the above analysis, it still requires substantial efforts to develop objective metrics to accurately predict the subjective 3D point cloud quality. On the one hand, it comprehensively extracts point cloud features based on the 3D visual characteristics of HVS; on the other hand, inspired by the processing mechanism of visual information, a reasonable network structure should be designed to exploit the extracted features to predict the point cloud quality.
III Proposed Method
The overall network architecture is presented in Section III-A. Then, key clusters extraction (KCE), deep feature extraction (DFE), and the progressive prediction mechanism are introduced in the successive sections, respectively.
III-A Overview of the Proposed Method
In our proposed network, we use PointNet[46] as the backbone, which is well known for its elegance, simplicity, and excellent generalization. For effective use of key information in point clouds, we propose to extract the key clusters from the input point cloud first. Moreover, to simulate the human perception mechanism of point cloud quality, we add an attention mechanism to the network and introduce a coarse-to-fine progressive perception mechanism. In the key clusters extraction stage, we consider global geometry characteristics of the point clouds. During the deep feature extraction stage, we draw on the global and local information of the point cloud and add an attention mechanism to the last two feature extraction steps. The coarse-to-fine perception mechanism runs through the whole point cloud quality prediction network, and the overall architecture of our network is illustrated in Fig. 1
III-B Key Clusters Extraction
Due to its large size, it is difficult to use the point cloud object directly as the input to the no-reference network. We use key points and local clusters to represent the key clusters from the original point cloud and then feed these key clusters into the no-reference network, which solves the network process limitation without sacrificing the effective information of the original point cloud.
(1) Key Points Extraction
According to research in the field of neuroscience, the structure characteristics of objects are very important for human eye perception. For 2D image quality assessment, structural features have been widely used [47] [48] [49] [50] [51]. The full-reference point cloud quality evaluation model employing object structural features [22] has also shown promising results. For a 3D object, the general architecture can be described by key point roughly, which can create edges, contours, and skeletons, are usually found in the high spatial-frequency range. In this paper, we use a high-pass graph filtering method [52] to extract the key points from the input point cloud.
Suppose a point cloud has points with three-dimensional coordinates and three-dimensional color attributes, we first construct a general graph of a point cloud by encoding the local geometry information. Suppose a point cloud has points with three-dimensional coordinates and three-dimensional color attributes. Then, each point corresponds to the vertex of graph, and each effective connection between two points having positive weight is referred to as edge. The edge weight is defined through an adjacency matrix as (1), where represents the edge weight between two points and using the geometric distance as
| (1) |
Here are 3D coordinates of points , is the variance of graph nodes, and is a Euclidean distance threshold in clustering neighbor points into the same graph. Given this graph, the location and color information of point clouds are called . Then, we take the graph signal as input and produce another graph signal as an output by graph filter. Let represent the original point cloud, we get a geometric key point , after applying a high-pass filter ,
| (2) |
where is the length of filter , and is to intercept the first points as the number of key point, which is sorted from large to small by the calculation result of . Typically, the number of key points is less than the total number, this is to say that is less than . The operation of filter can be expressed as
| (3) |
| (4) |
where is -th coefficient, and is the length of graph filter. is the most elementary nontrivial graph filter, and here we set , where with . From a graph filtering perspective, we can also refer to as the input graph signal, and denote the probability value of this point becoming an edge. This probability is then used as the measurement to decide whether associated point can be selected as the key points.
(2) Key Clusters Formation
The capacity of the model to detect subtle features can be improved by capturing local information. This is achieved by a simple clustering algorithm, using the k-nearest neighbors (k-NN) algorithm within a variable radius centered on key points. Here we refer to it collectively as the center-neighbor-segmentation (CNS) algorithm. In the k-NN algorithm, the radius is continuously expanded by a growth factor until neighbors are searched. For each local region, the same feature extraction module is for local pattern learning.
III-C Deep Feature Extraction
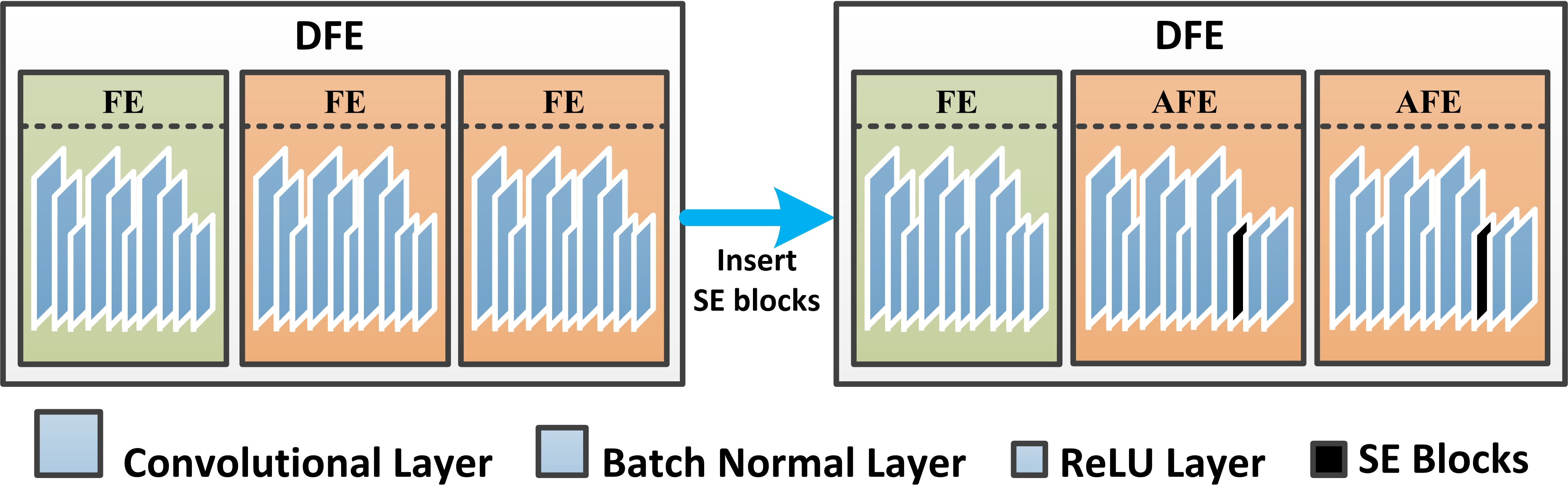
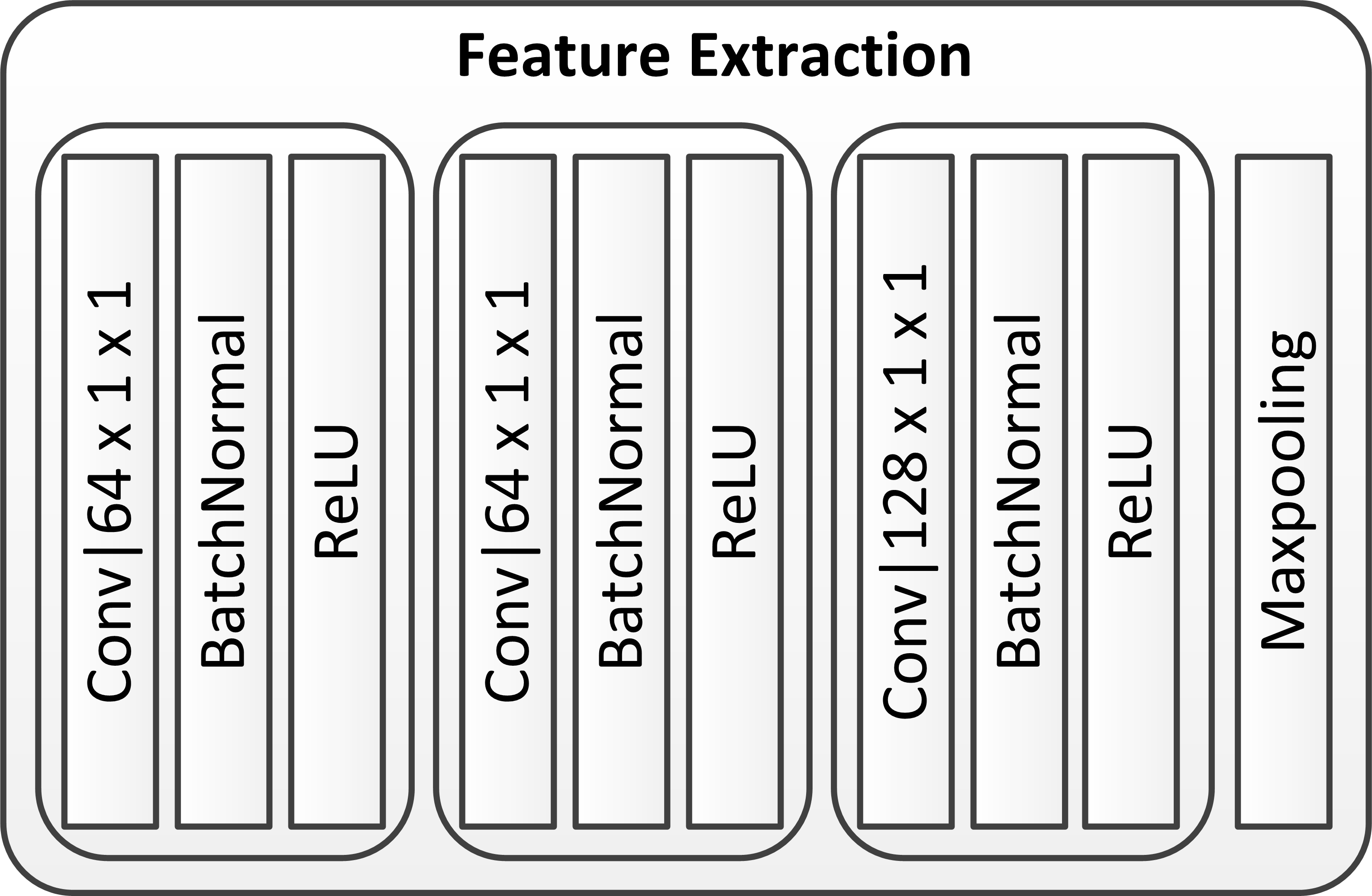
In this section, we carry out three feature extraction stages to create a higher dimensional point cloud feature representation. The first feature extraction stage is named FE, and the remaining feature extraction stages are named AFE. The FE is an ordinary convolutional structure while the AFE uses spatial and channel ’squeeze and excitation’ attention module (scSE) to implement the attention mechanism.
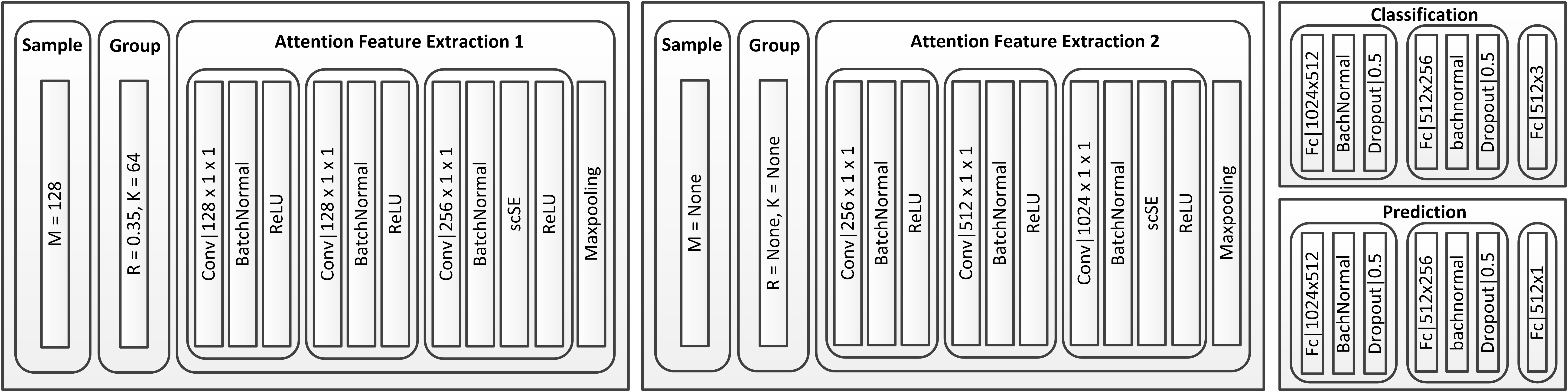
As shown in Fig. 1, we assume that the input of the AFE is point set obtained after the FE stage, and we first obtain the cluster centers with farthest point sampling (FPS). Given the same number of centroids, FPS provides better coverage of the complete point set than random sampling. Then we use the ball query approach to obtain the elements of each cluster for feature extraction. Then the constituents of each cluster are obtained by using the Ball Query Method (BQM). The ball query returns points within a radius of the query point. If the number of points in the radius is less than , the points in the radius are repeatedly sampled until points are obtained. Here the point with the smallest index in the radius is used as the supplementary point.
The reason for using different clustering algorithms is that the KNN algorithm has the advantage of ensuring each region contains the same number of points, while the ball-query algorithm ensures that each region has the same size. In the KCE module, we need to capture as much information as possible about the original point cloud (i.e., retain more original points) so KNN algorithm is better than ball-query. However, in the DFE module, we prefer to ensure that each local region has the same perceptual field (i.e., the same region size). It is worth noting that the parameter of the ball-query algorithm is particularly important in the DFE module.
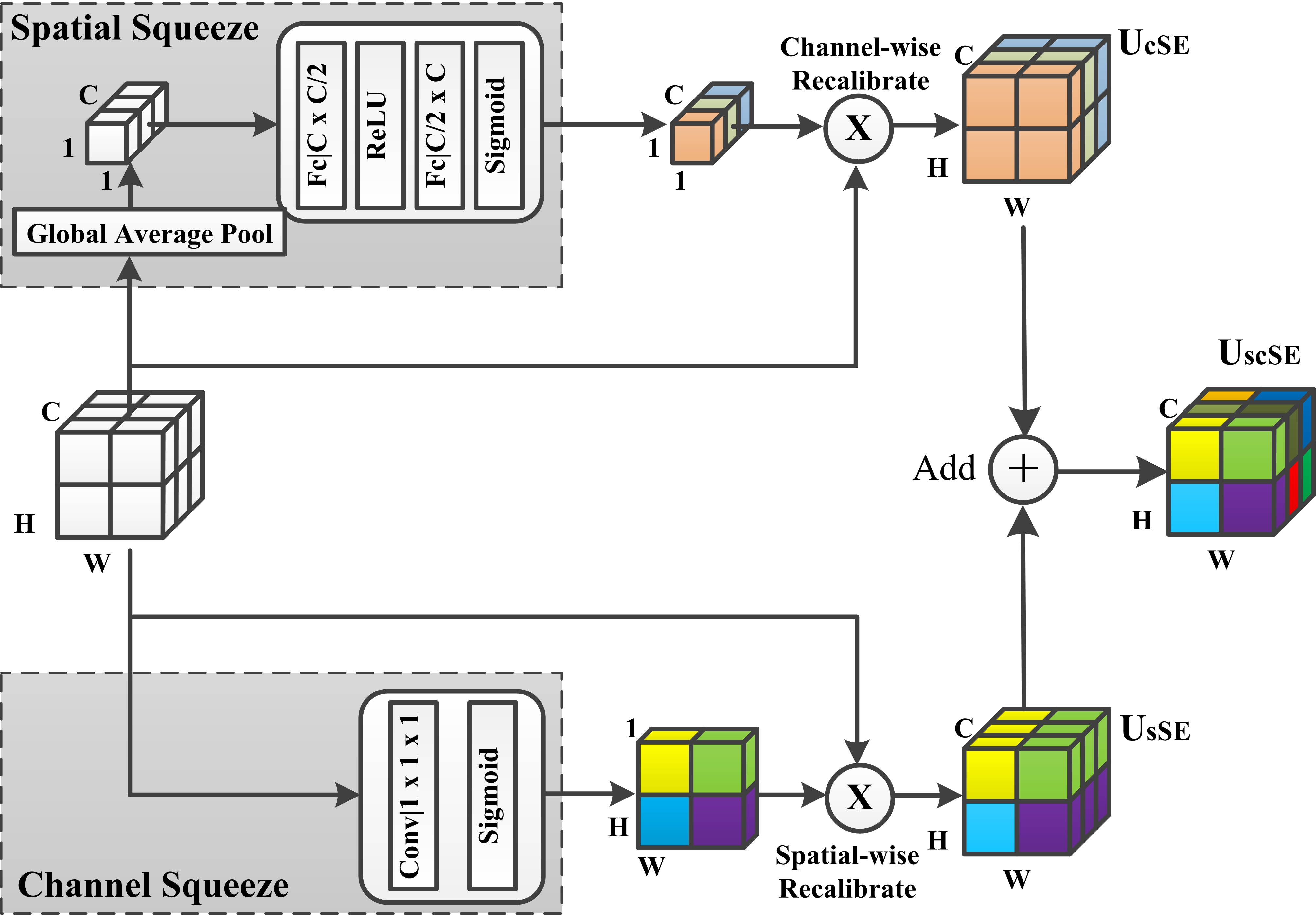
Importantly, we integrate the attention mechanism into the feature extraction module of the PointNet backbone network, termed AFE, for feature extraction of cluster2. The internal structure of the AFE is depicted in Fig. 1. To ensure that deeper features of the original point cloud are extracted, this module is repeated twice in the overall structure. According to cognitive science [22], humans selectively focus on a portion of all information while ignoring other apparent information due to bottlenecks in information processing. With limited attention resources, this is an excellent way to swiftly filter out high-value information from a vast volume of data. Neural networks incorporating attention mechanisms have made great breakthroughs in various fields, such as image classification [53], machine translation [54] [55], and image caption [56]. Hu [57] proposed the Squeezeand-Excitation (SE) block as part of a convolutional neural network (CNN). This block adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels, achieving excellent results on image classification tasks. Subsequently, Roy, Navab, and Wachinger renamed this SE module spatial squeeze and channel excitation (cSE) module [58], and developed a new channel squeeze and spatial excitation (sSE) module, squeezing channel-wise and exciting spatially. Importantly, they proposed a module termed scSE that merge the two features. We use the scSE module in the proposed network. The location of SE blocks in PKT-PC are shown in Fig. 2.
The scSE model consists of the cSE and sSE models, . The architectural flow is shown in Fig. 3. The upper part is cSE, while the lower represents sSE. We first introduced the cSE part. Consider the input feature map , where . Spatial squeeze first realized by a global average pooling layer, producing vector ,
| (5) |
Then, encoding the channel-wise dependencies through two fully-connected layers , with weights , , and ReLU operator . Finally, mapping into using sigmoid layer . The result can be expressed as
| (6) |
As the network learns, the channel weight are dynamically adjusted, turning that the less important channels are ignored and the important ones are emphasized. Unlike the cSE module, the sSE module cares more about spacial relationships. Thus, the input tensor can be described as , where , and (, ) represents its corresponding spatial location. The channel squeeze operation is achieved through a convolution layer, with . This operation generates a projection tensor , where is the linear combination of all channels in spatial location . Same as cSE, needs to be re-scaled into with a sigmoid layer to be a spatial weight. Finally, the spatial recalibration of input is
| (7) |
where activation indicates the relative importance of location for a given feature map, enabling more attention to some relevant spatial locations while ignoring less important space. By combining cSE and sSE, scSE provides more importance of the point which are relevent both spatially and channel-wise, that encourages the network to learn more meaningful feature maps.
III-D Progressive Prediction Mechanism
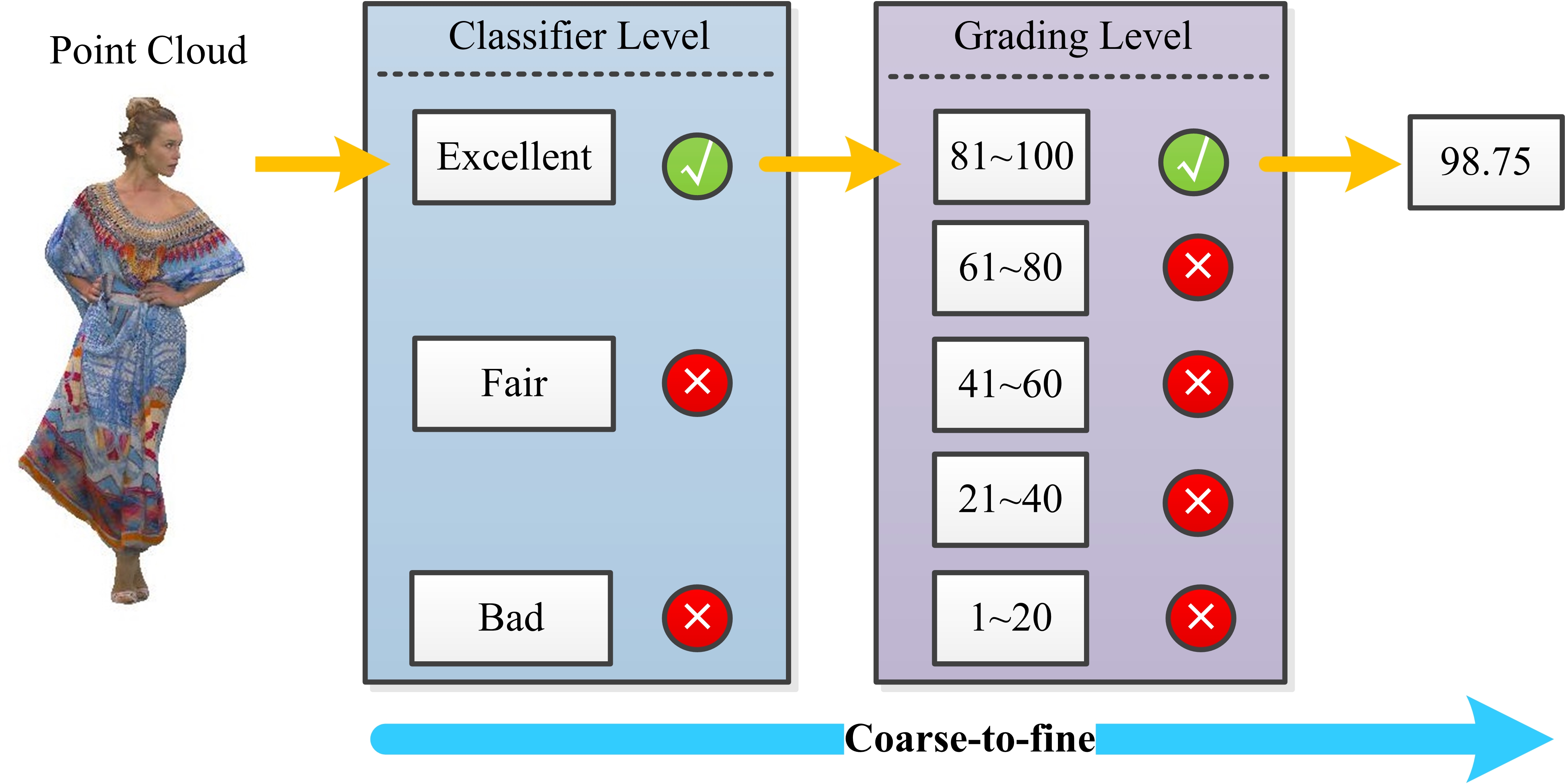
Referring to the process of evaluating the quality of point clouds by human perceptual system, we can find that there exists a native hierarchical dependency. That means that humans always first determine a point cloud coarse-grained quality, i.e., excellent, fair, or bad, and then, under the branch of the quality type, give a specific quality score by relying on subtle visual cues. Fig. 4 illustrates the coarse-to-fine principle.
In the proposed network, we adopt a two-step strategy to train the PKT-PCQA model: 1) quality level classification; 2) quality score prediction. In step 2), the feature extraction part of the PKT-PCQA model is initialized with related part in step 1), then fine-tune the quality prediction network on the first quality classification basis. In the process from coarse to fine, there are two key parts, namely, the classification of quality level and the training of the network.
(1) Quality Level Classification
The classification of quality levels is based on the statistical properties of quality scores in the dataset. That is, within a certain range, the number of point clouds at each level is guaranteed to be approximately equal in each dataset. The specific classification will be discussed in the experimental settings section. In this paper, we only use three labels: excellent, fair and bad, in order to maximize the distinction of different labels.
(2) Model Training
In the classification task, the parameters of the feature extraction part and of the classification part are determined by minimizing the loss function
| (8) |
| (9) |
where represents a specific prediction value vector for point cloud , is the label value used as an index, and is the number of types of labels.
For MOS prediction network, the model parameters of the feature extraction part are initialized as , while the prediction unit is randomly initialized, represented as . In prediction task, we care more about how well the prediction curve fits the original score curve, rather than the difference between individual scores [59]. Therefore, the related model parameters are fine-tuned through minimizing the loss function measures the difference in fit. The parameters of the model are determined by (10) after training the k-th batch.
| (10) | ||||
| (11) | ||||
| (12) |
where is pearson linear correlation coefficient (PLCC) with the range is [-1,1], and ”1” means positive correlation, ”-1” means negative correlation, ”0” means uncorrelated. In the quality prediction task, our goal is to maximize . Therefore, we can obtain the parameters of the quality prediction network after mining the loss function (i.e., L2).
IV Experimental Results and Discussion
In this section, we describe the point cloud datasets and assess the performance of the proposed method.
IV-A Experimental Settings
PKT-PCQA was implemented by using PyTorch on a computer with a 3.5 GHz CPU and GTX 1080Ti GPU.
(1) Dataset
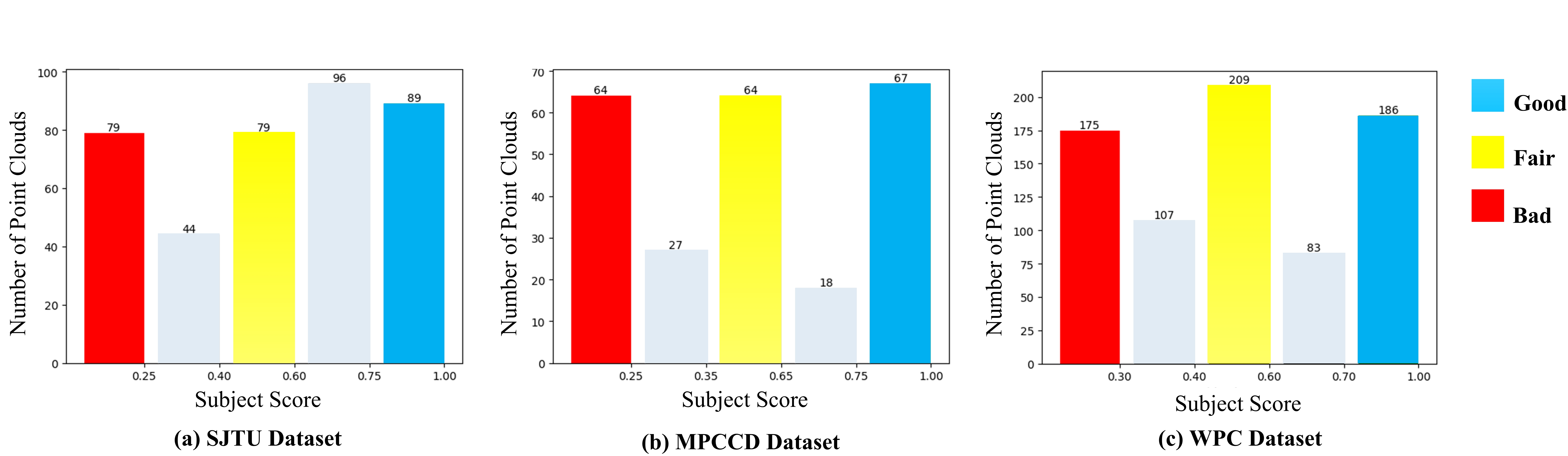
The proposed method was evaluated on three 3D point cloud: SJTU-PCQA [12], M-PCCD [10], and the Waterloo Point Cloud (WPC) [13] [32]. The quality level division on each dataset is shown in Fig. 5.
-
•
SJTU consists of 9 reference point clouds (redandblack, loot, longdress, hhi, soldier, ricardo, ULB Unicorn, Romanoillamp, statue, shiva) and 378 distorted versions (42 distorted items per reference item through 6 degradation types: OT: Octree-based compression, CN: Color Noise, DS: Downscaling, D+C: Downscaling and Color noise, D+G: Down-scaling and Geometry Gaussian noise, GGN: Geometry Gaussian noise and, C+G: Color noise and Geometry Gaussian noise).
-
•
M-PCCD consists of 8 reference point clouds (loot, longdress, soldier, Romanoillamp, amphoriskos, biplane, head, the20smaria) and 232 distorted versions (29 distorted items per reference item through 5 types of compression G-PCC with Octree coding and Lifting coding, G-PCC with Octree coding and RAHT coding, G-PCC with Triangle soup coding and Lifting coding, G-PCC with Triangle soup coding and RAHT coding, V-PCC).
-
•
WPC consists of 20 reference point clouds (bag, banana, biscuits, cake, cauliflower, flowerpot, glasses case, honeydew melon, house, litchi, mushroom, pen container, pineapple, ping-pong bat, puer tea, pumpkin, ship, statue, stone, tool box) and 740 distorted versions 37 distorted items per reference item through five degradation types TMC1: G-PCC with Triangle soup coding, TMC2: G-PCC with Octree coding, TMC3:V-PCC, Noise: White Gaussian noise, Downsample: Octree-Based Downsampling).
(2) Parameter Setting
The following parameter values were used
- •
-
•
in Deep Feature Extraction
DFE includes sampling, grouping and attention feature extraction twice, and the specific structure and parameters are shown in Fig.7, where scSE implements the attention function of the model. The parameter determines the size of the perceptual field. It is set to in the classification task and in the prediction task. -
•
Progressive Prediction Mechanism
The Classification and Prediction branches have a similar architecture; the only difference between them is the last layer. In the classification task, the out-channel of last layer in classification task is the number of quality level, while that of prediction task is one.In the classification task, the evaluation criterion is loss function, while in the prediction quality branch, we considered the PLCC (12) and Spearman’s rank-order correlation coefficient (SROCC) computed as
(13) where is the number of the tested point clouds and is the rank difference between the ground truth and the predicted of the -th point cloud.
-
•
Parameters in Multistep Training Mechanism
We used the Adam optimization technique with default parameters to train both the classification and prediction tasks. The batch size was set to 16 in training processing and 32 in testing processing, with a total epoch number of 200. In the classification task, the learning rate was initialized to 0.001 and subsequently reduced using , a strategy for adjusting the learning rate at equal intervals, with a step size of 20, and the learning rate adjustment multiplier . In the prediction task, the learning rate was set to 0.0001, using was used as a reduction strategy with step size 30, and learning rate adjustment multiplier .
IV-B Ablation Test
To fully evaluate our proposed model, we conduct the following experiments.
(1) Key Clusters Extraction
The Key Clusters Extraction (KCE) aims at simplifying the point cloud without losing critical information . Common reduction strategies include point cloud sampling and point cloud segmentation, which correspond to the global feature and local feature of a point cloud. However, in point cloud quality prediction task, neither of them is enough to represent the original point cloud. Extracting key clusters of point cloud needs to take into account global and local information. To validate this hypothesis, we evaluate point cloud extraction strategies using only global information, only local information, and both global and local information. Before making the above comparison, we need to choose a representative algorithm for each strategy.
We first compared several global information extraction strategies, including random sampling, farthest point sampling, and key-point extraction. The result of using them separately to complete the prediction of point cloud quality is shown in Fig.8. Using key points to represent the global feature gives the best result. Therefore, extracting key points method is used as a proxy for global information extraction strategy to participate in the comparison with the other two feature extraction strategies.
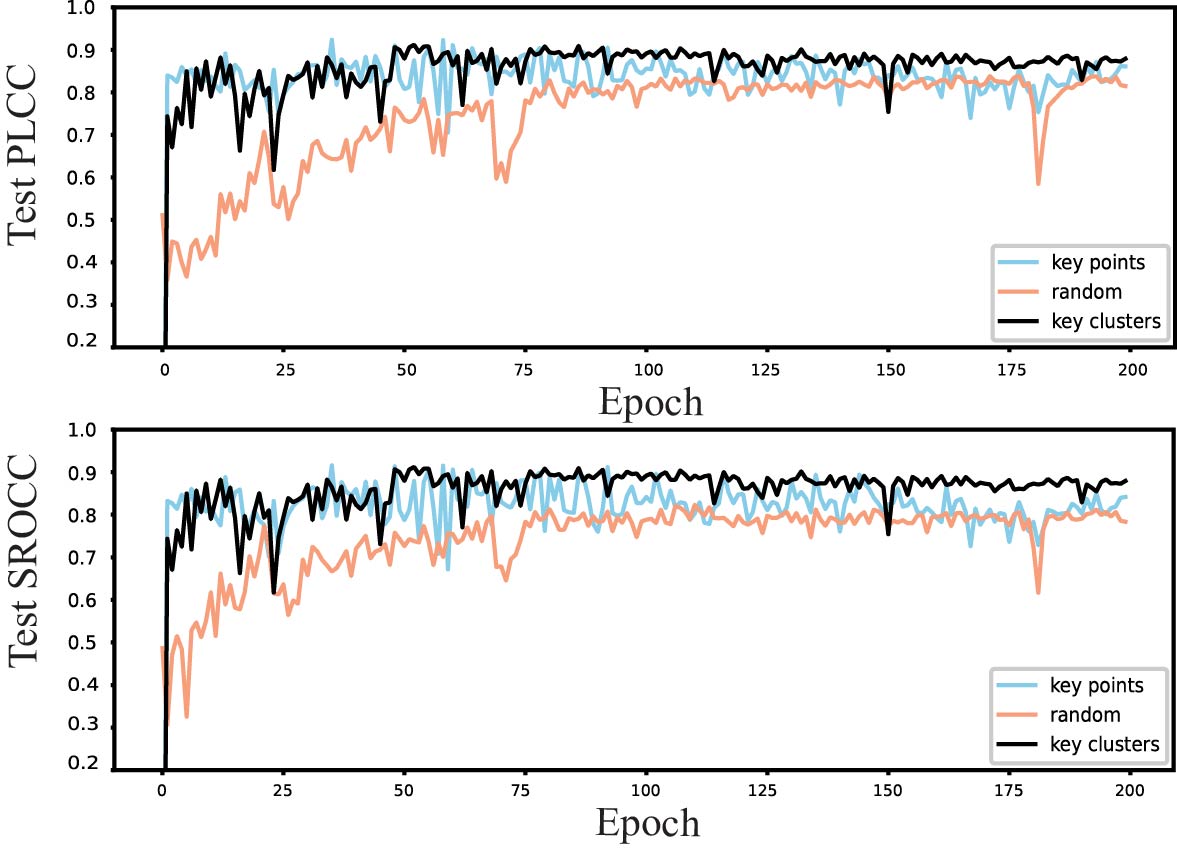
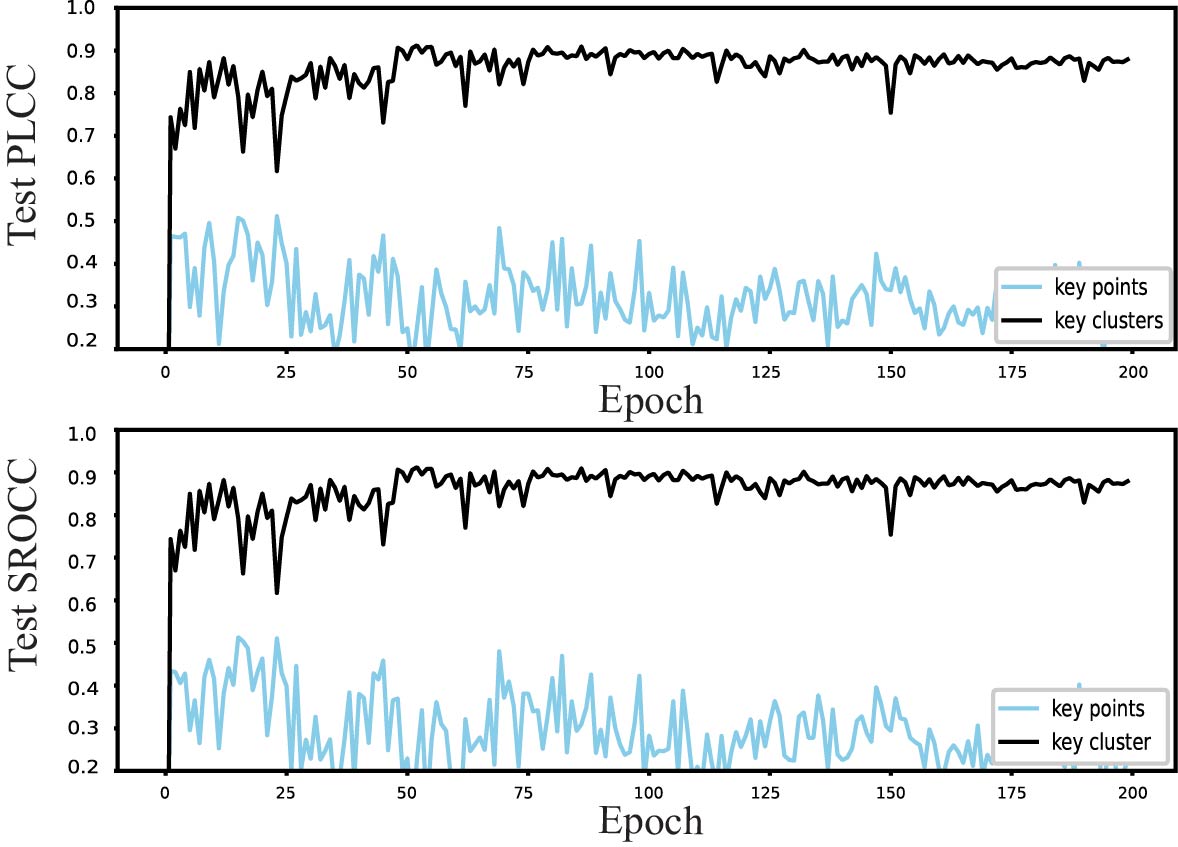
A popular technique for representing point clouds using local information is to partition them into chunks. However, in the task of predicting the quality score of a point cloud, it is challenging to determine the score of the entire point cloud using this method because each chunk receives a score, and it is inappropriate to choose one of them to represent the whole or determine the average of all chunks. Here, we only contrast the effects of the two strategies on the outcomes that is key points and key clusters. We can see that using key clusters gives better result than just using key points.
Comparing the influence of these three reconstruction methods in point cloud prediction task, as shown in Fig.9, the proposed method that considers both global and local features is a better strategy to extract the key clusters of point cloud. The results in Fig.9 also proved that strategy can provide more efficient information to subsequent network in point cloud quality evaluation task.
To find the most suitable number of the new point cloud, we also test several combinations of keypoints and local points (i.e. ).
The network structure is shown in Fig.6 and Fig.8 with the same training strategies. The experimental results are shown in Table I. We can see that the best combination of the number of key point and local point number is . The reason is that too many key points may cause information redundancy in the original point cloud, affecting the information provided by valid points, while too few key points cannot provide enough information, so the number of key points needs to be apposite.
| K | PLCC | SROCC | |
|---|---|---|---|
| 512 | 16 | 0.8803 | 0.8718 |
| 1024 | 16 | 0.9122 | 0.9316 |
| 2048 | 16 | 0.8448 | 0.8485 |
| 1024 | 32 | 0.8773 | 0.8991 |
| R | PLCC | SROCC |
|---|---|---|
| 0.4 | 0.8892 | 0.9049 |
| 0.35 | 0.9122 | 0.9316 |
| 0.3 | 0.8865 | 0.8993 |
(2) Deep Feature Extraction
The radius , which represents the perceptual field size of the depth extraction network is a critical parameter. If is too large, the tightness of neighbors and clustering centers cannot be guaranteed because the range of random sampling is too large. On the other hand, if is too small, not enough neighbor points can be collected, leading to the reduction of effective information obtained in the local area. We used point cloud key clusters to test the network with radius 0.4, 0.35, and 0.30. The results in Table II show that provides the maximum prediction accuracy.
(3) Attention Mechanism
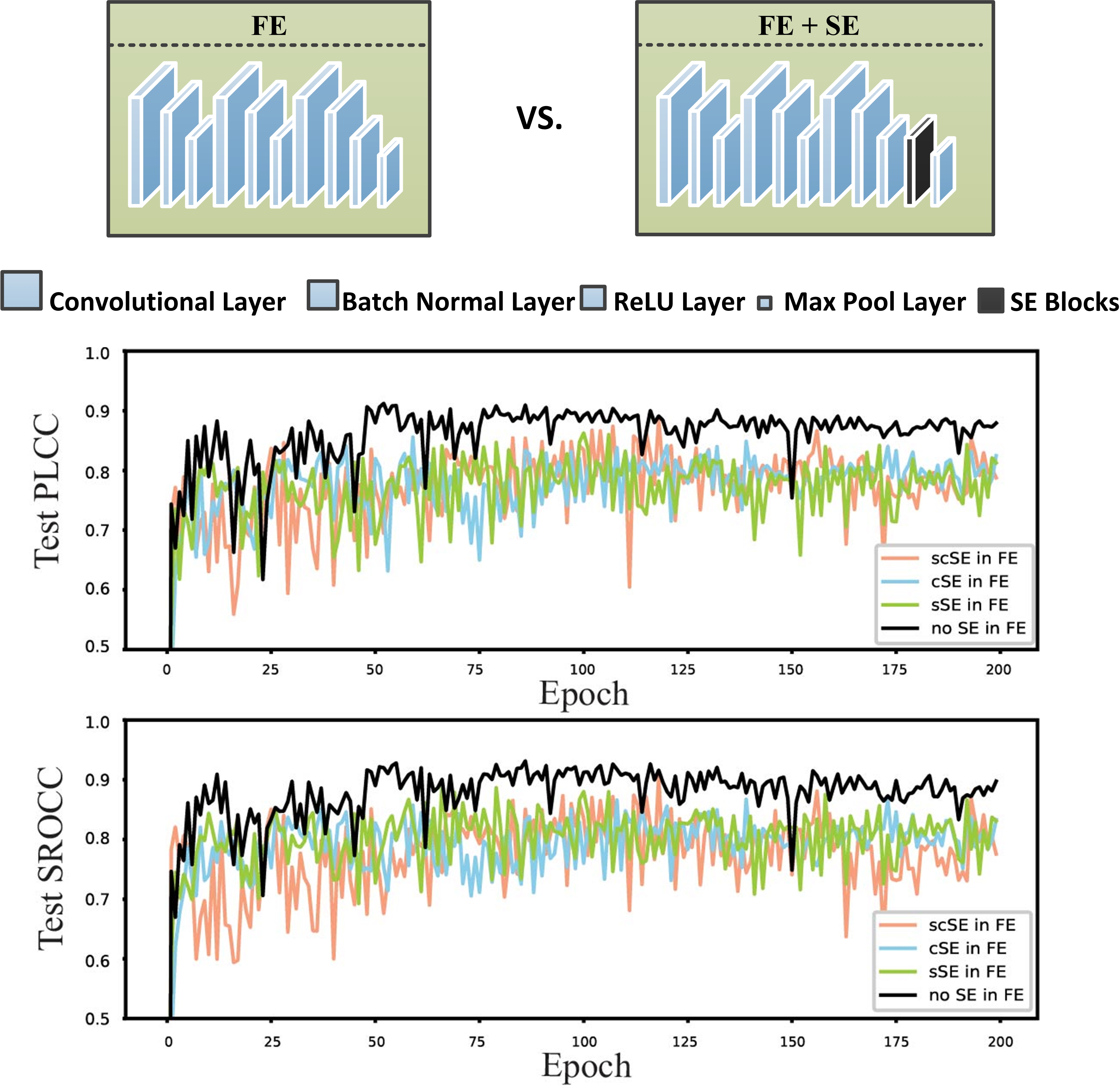
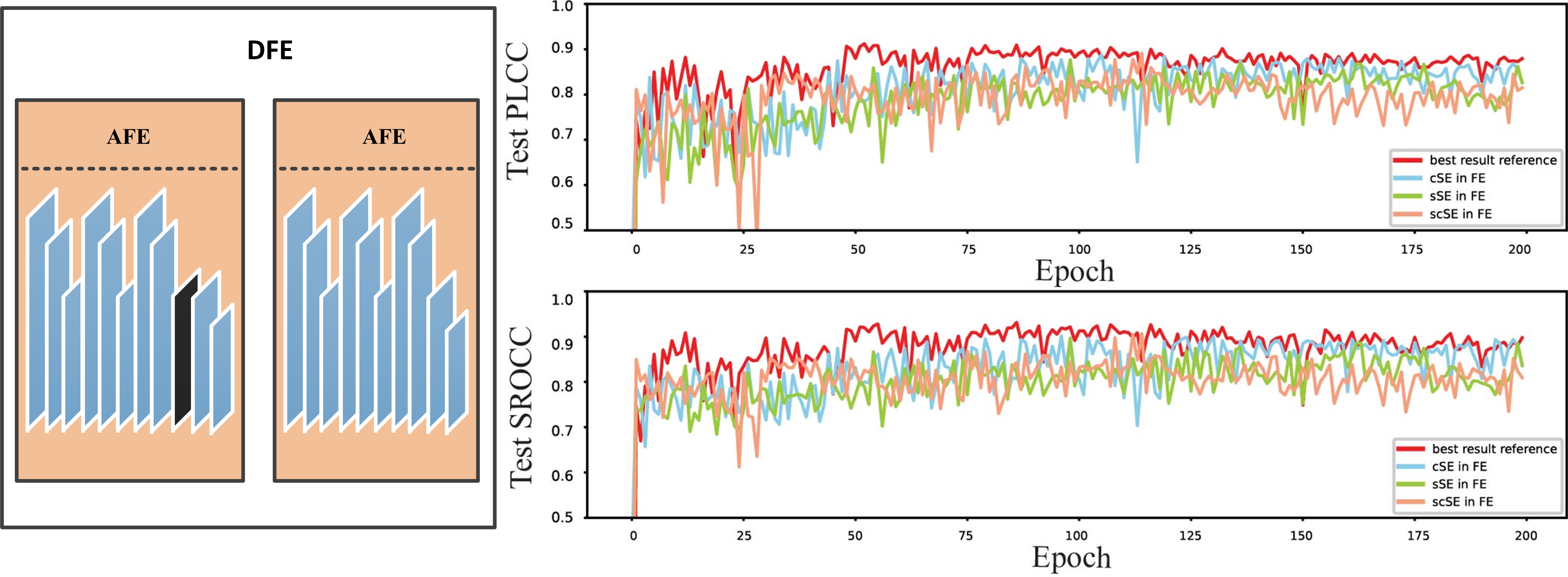
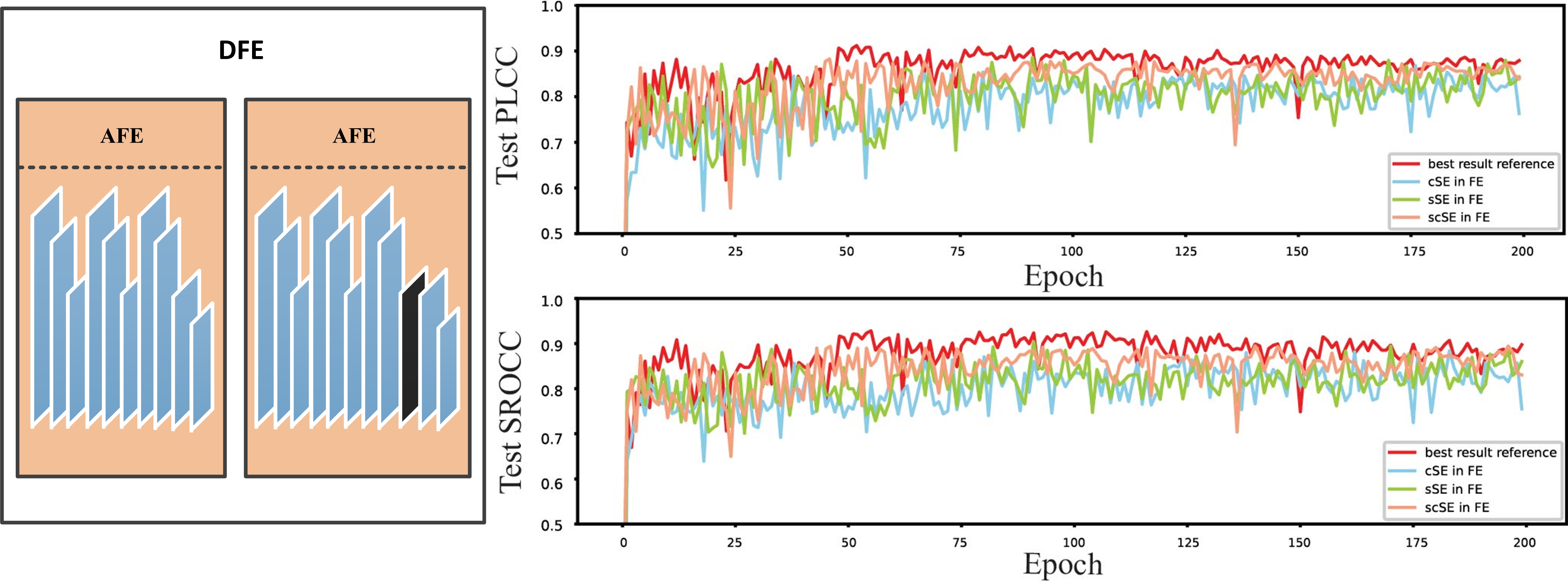
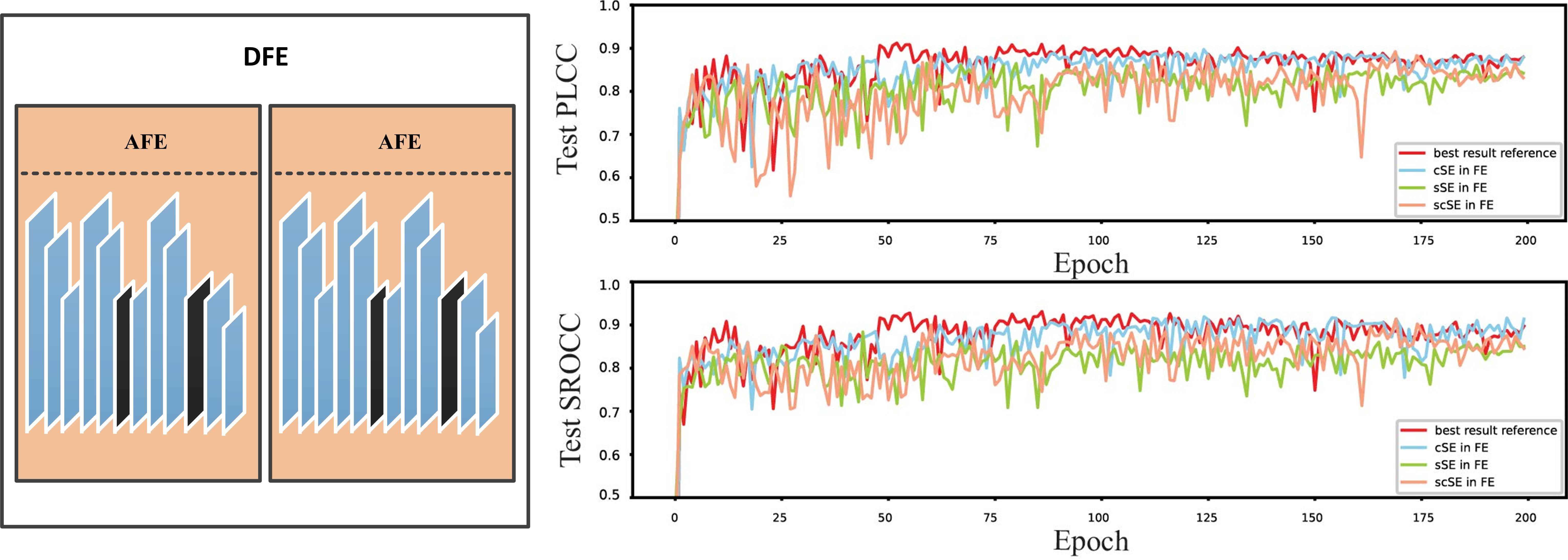
The impact of the attention mechanism on the model depends on the type of SE block and its location. To fully explore it, we compare the effects of the three type SE blocks at different locations in the model. As for the location, we discuss the different locations of SE in KCE and DFE modules separately.

| PLCC | SROCC | |||||
| cSE | sSE | scSE | cSE | sSE | scSE | |
| (a) Optimal Model | 0.8946 | 0.8742 | 0.9122 | 0.9227 | 0.8944 | 0.9316 |
| (b) SE block after ReLU | 0.8827 | 0.8797 | 0.8915 | 0.9065 | 0.9083 | 0.9032 |
| (c) Only First AFE has SE Block | 0.8880 | 0.8768 | 0.8916 | 0.9020 | 0.8969 | 0.9065 |
| (d) Only Second AFE has SE Block | 0.8683 | 0.8869 | 0.8830 | 0.8845 | 0.9044 | 0.8952 |
| (e) Two SE Blocks in One AFE | 0.8976 | 0.8926 | 0.8808 | 0.9197 | 0.8839 | 0.9136 |
-
•
Attention Mechanism for Initial Feature Map Generation Generally speaking, adding the attention mechanism can improve the performance of the proposed network. However, in our proposed network, we extract key points in KCE module, which may lead to the failure of the spatial attention mechanism in initial feature map generation. Also, since there are only six channels for each point in this step which represents their three-dimensional coordinates and color information, it is difficult to say which channel is more important. Therefore, the channel attention mechanism may not have much effect in initial feature map.
To check this assumption, we conducted comparative experiments on a key clusters () . SE Blocks in the DFE part are set as scSE. The result is shown in Fig.10. It is obviously that without any SE module in initial feature map generation can get better prediction result.TABLE IV: Overall Comparative Experiment on Attention Mechanism KCE DFE PLCC SROCC 1024 16 - - 0.8827 0.9077 - scSE 0.9122 0.9316 scSE scSE 0.8869 0.9047 -
•
Attention Mechanism in Deep Feature Extraction
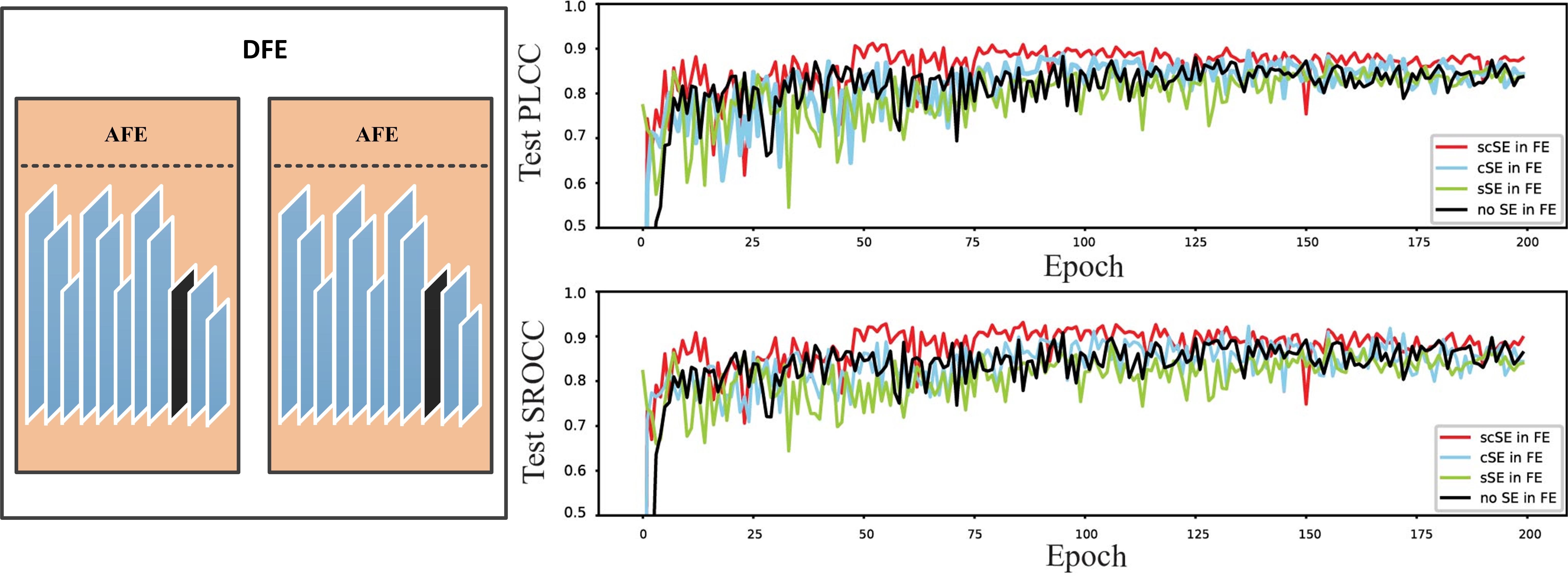
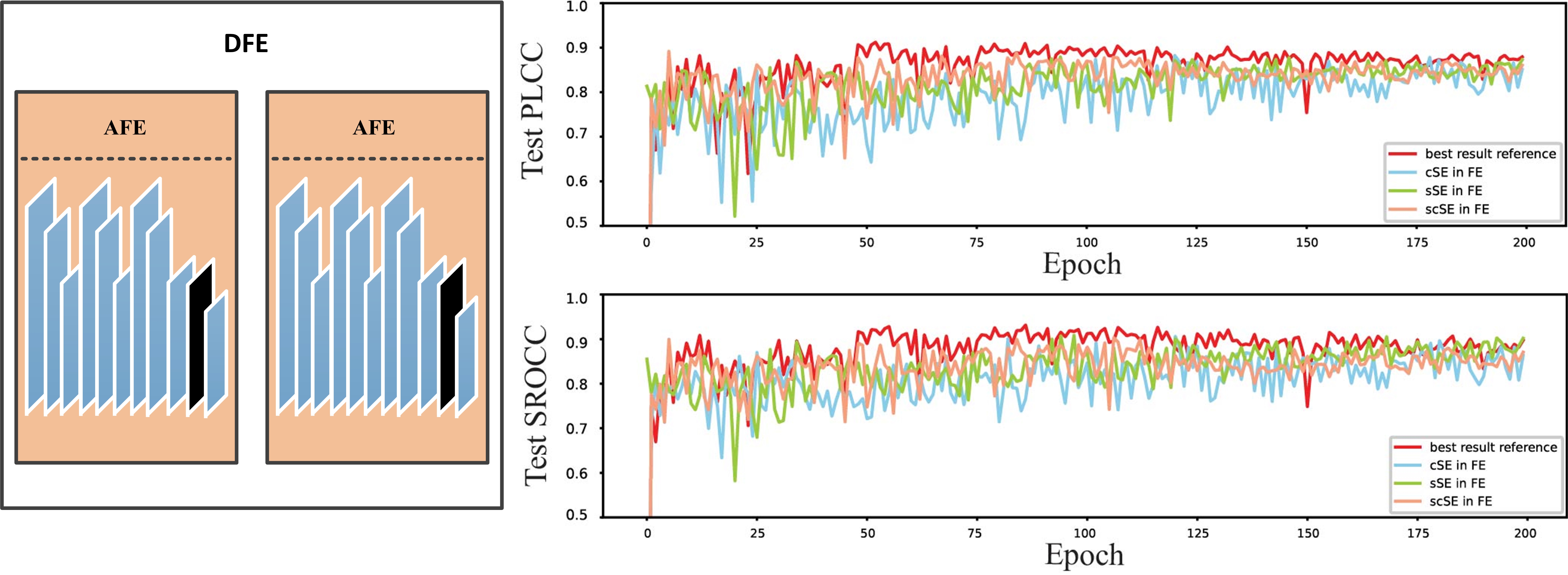
Different with the initial feature map, the deep feature of point cloud is much more abstract, that is why attention mechanism can greatly improve the performance of the original model. The degree of improvement depends not only on the type of the attention unit, but also on its location.Fig.11 shows the effect of different attention mechanism types at different locations of the AFE module. In the experiments, initial feature extraction did not include an adopt SE block. The best prediction accuracy of each model presented in Table III.
Fig. 11.11(a) shows the performance of different SE modules at the ideal position, and the black line result means that no any SE module is added, and the red, blue and green line results represent the performance of adding scSE, cSE, and sSE, respectively. We can see that the scSE module provides the best performance. We also tested the performance of different SE modules in various locations, as shown in Fig. 11.11(b) to Fig. 11.11(e). Fig. 11.11(b) allows us to evaluate whether the SE block should be before or after the ReLU layer. Fig. 11.11(c) and Fig. 11.11(d) can determine if the SE block is appropriate in only one feature extraction step of the DFE module. Besides, Fig. 11.11(e) helps to decide whether more than one SE block should be added to an AFE module. We can see that adding scSE to the last convolutional layer of each AFE module gives the best results.
Finally, we used key clusters of the point cloud to examine several combinations of the attention module in the KCE and DFE modules (Table IV). The attention module is set as scSE module since prior experiments have shown that this module can significantly improve model performance. We can observe that using the scSE module only in the DFE part leads to the highest score prediction accuracy.
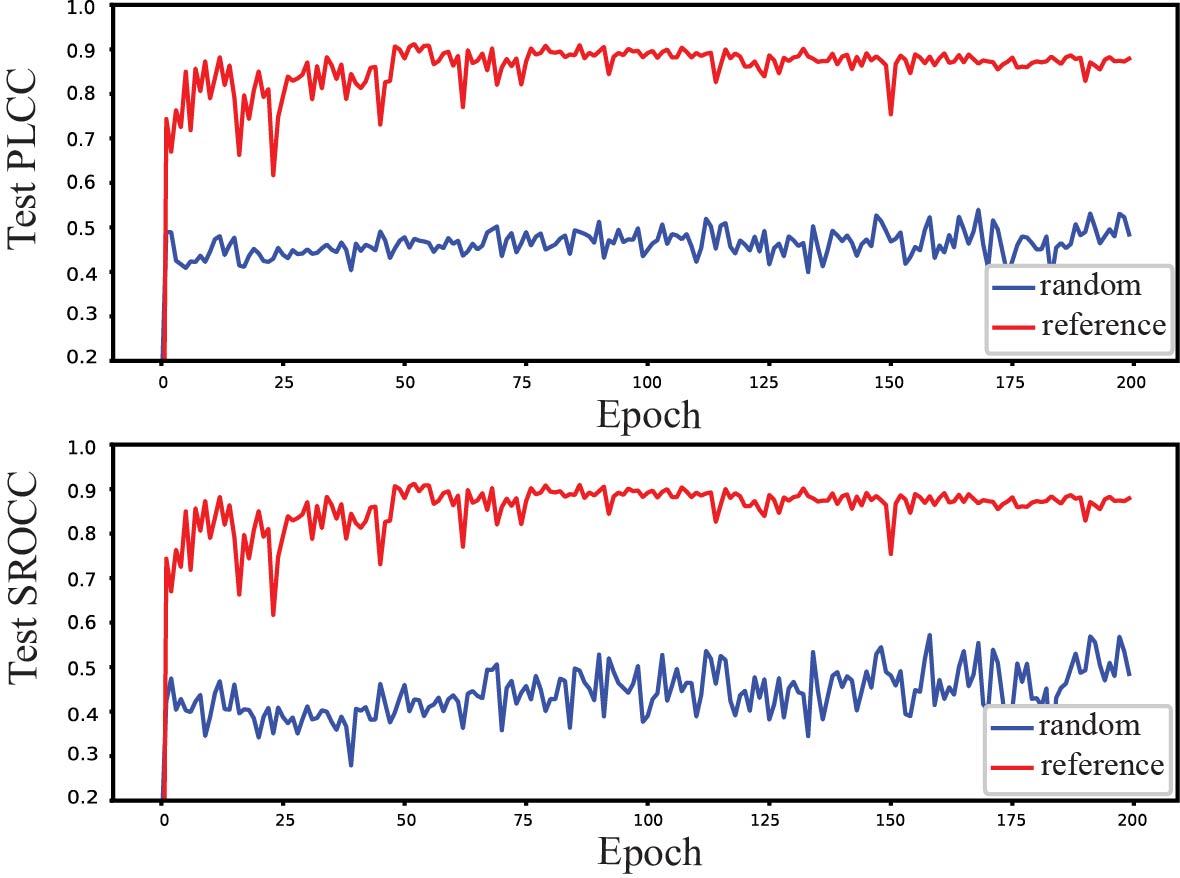
(4) Progressive Prediction Mechanism
The proposed network predicts the quality of the tested point cloud using a coarse-to-fine progressive mechanism from quality classification to quality prediction. To verify the importance of quality classification information initialization for the quality prediction task, we compared with random initialization. To make a fair comparison, all the parameters of the prediction task were identical. The results are shown in Fig.12. It can be seen that the PLCC and SROCC of the progressive method from coarse to fine are both higher than 0.9, while those of the random initialization method used are only about 0.5. The above results fully demonstrate the effectiveness of the progressive prediction mechanism.
IV-C Overall Assessment Performance
To test the performance of PKT-PCQA, we conducted experiments on the SJTU-PCQA, M-PCCD, and WPC datasets. We randomly selected about 80% of the point clouds for training and the remaining 20% for testing. There were no overlapping samples between the training and the testing sets. The performance results of the proposed network on different datasets are shown in Table V. We should note that the PLCC and SROCC can be positive or negative, and the closer the absolute value of these to 1, the better the performance.
| Datasets | PLCC | SROCC |
|---|---|---|
| SJTU-PCQA [12] | 0.9122 | 0.9316 |
| M-PCCD [10] | 0.8849 | 0.9134 |
| WPC [13] [32] | 0.5603 | 0.5571 |
The result in Table V shows that our network achieved excellent results on SJTU-PCQA and M-PCCD. Its performance was lower on WPC. One possible reason is that for WPC, the texture content of the point clouds is richer, and the content of the point clouds at each quality level is also richer, so the demand of data is also larger, and the amount of point cloud data in the WPC dataset can provide is very limited. For the proposed network, the task of predicting quality on WPC dataset is more difficult, therefore, the performance on WPC dataset degrades slightly.
| SJTU-PCQA[12] | M-PCCD[10] | WPC[13] [32] | |||||
| Method Type | Method | ||||||
| FR | [60] | 0.87 | 0.82 | 0.84 | 0.91 | 0.37 | 0.34 |
| [60] | 0.69 | 0.70 | 0.24 | 0.53 | 0.20 | 0.20 | |
| [17] | 0.83 | 0.82 | 0.99 | 0.99 | 0.48 | 0.46 | |
| [25] | 0.85 | 0.91 | 0.76 | 0.99 | 0.68 | 0.73 | |
| [22] | 0.72 | 0.63 | 0.98 | 0.98 | 0.47 | 0.46 | |
| [61] | 0.96 | 0.95 | 0.85 | 0.96 | 0.83 | 0.82 | |
| [24] | 0.89 | 0.88 | 0.95 | 0.94 | 0.36 | 0.23 | |
| [34] | 0.93 | 0.92 | 0.99 | 0.97 | 0.50 | 0.48 | |
| RR | [37] | 0.60 | 0.63 | 0.87 | 0.91 | 0.36 | 0.35 |
| NR | [42] | 0.77 | 0.71 | 0.86 | 0.85 | 0.30 | 0.20 |
| PKT-PCQA | 0.91 | 0.93 | 0.88 | 0.91 | 0.56 | 0.56 | |
IV-D Performance Comparison with other Methods
We alse compared PKT-PCQA with standard and state-of-the-art FR and RR point cloud quality metrics on different datatsets. The compared metrics were chosen to cover a diversity of design philosophies, including point-based, feature-based, projection-based and deep learning-based. The FR quality metrics include , , , , , , , and . The RR quality metrics include . More importantly, the sophisticated advanced [42] method is selected as the compared NR point cloud quality metric to prove the effectiveness of the proposed method. To map the dynamic range of the scores from objective quality assessment models into a common scale, the logistic regression recommended by VQEG is used [62]. These results are shown in Table. VI and they provide some useful insights with respect to the approaches for point cloud quality assessment. First of all, the performance of RR and NR point cloud quality metrics are generally lower than that of the FR point cloud quality metrics. Obviously, the RR and NR metrics can only use part or no original information, while, the FR metric can take advantage of all the original information. Limited by the unfair usage of the original information, the performance of RR and NR methods are reasonably worse than the FR methods. From the results,we can see that the performance of the proposed PKT-PCQA is the best in the RR and NR quality metrics and only slightly lower than the best FR methods, indicating the advantage of the proposed PKT-PCQA. In the WPC dataset, which provides the largest number of samples in the three datasets, both PLCC and SROCC of the PKT-PCQA are 0.56 which is the best in the NR point cloud quality metrics. More surprisingly, the performance of PKT-PCQA was better than the RR quality metric , and is only slightly lower than the best FR quality metric . The performance of PKT-PCQA was also impressive on SJTU-PCQA and M-PCCD datasets. Similarly, PKT-PCQA performed better than the other NR point cloud quality metric and even better than the RR point cloud quality metric. The PLCC and SROCC of PKT-PCQA were even larger than 0.91 on SJTU-PCQA. On the M-PCCD dataset, the SROCC reached 0.91. The SROCC and PLCC of the best FR point quality metric were 0.95 and 0.96, which are only 0.02 and 0.05 larger than that of PKT-PCQA. It is worth indicating that the NR point cloud quality metric PKT-PCQA does not need to refer to the original point cloud information, so its application scenarios are far more than the FR point cloud quality metrics.
V Conclusion
We proposed a novel no-reference quality assessment PKT-PCQA is proposed using coarse-to-fine progressive transfer based on human visual perception mechanism. First, the key clusters are extracted based on the global and local information. Then, to improve the similarity between prediction quality and subjective quality of the point cloud, an attention mechanism is incorporated into the network design. Next, a progressive quality assessment algorithm is designed to transfer the quality classification coarse-grained information to the quality prediction fined-grained information. Finally, multiple datasets are exploited to analyze the performance of the proposed algorithm. The experimental results show the effectiveness and superiority of the proposed method.
In the future work, we will develop an accuracy adaptive quality classification algorithm to accurately distinguish good, fair, and bad point cloud quality, so that more point cloud data without MOS can be used.
VI Acknowledgement
This work was supported in part by Natural Sciences and Engineering Research Council of Canada, in part by the National Science Foundation of China under Grant (62222110, and 62172259), in part by the Taishan Scholar Project of Shandong Province (tsqn202103001), in part by Shandong Provincial Natural Science Foundation of China under Grants (ZR2022MF275, ZR2022QF076, ZR202206060017, ZR2018PF002, and ZR2021MF025), and in part by the Joint funding for smart computing of Shandong Natural Science Foundation of China under Grant ZR2019LZH002, and jointly completed by the State Key Laboratory of High Performance Server and Storage Technology, Inspur Group, Jinan.
References
- [1] Q. Liu, H. Yuan, J. Hou, R. Hamzaoui, and H. Su, “Model-based joint bit allocation between geometry and color for video-based 3Dpoint cloud compression,” IEEE Transactions on Multimedia, vol. 23, pp. 3278–3291, 2020.
- [2] A. Javaheri, C. Brites, F. Pereira, and J. Ascenso, “Point cloud rendering after coding: Impacts on subjective and objective quality,” IEEE Transactions on Multimedia, vol. 23, pp. 4049–4064, 2021.
- [3] S. Gu, J. Hou, H. Zeng, H. Yuan, and K.-K. Ma, “3Dpoint cloud attribute compression using geometry-guided sparse representation,” IEEE Trans. Image Processing, vol. 29, pp. 796–808, 2019.
- [4] Y. Qian, J. Hou, S. Kwong, and Y. He, “Deep magnification-flexible upsampling over 3Dpoint clouds,” IEEE Transactions on Image Processing, vol. 30, pp. 8354–8367, 2021.
- [5] Z. Zhang, W. Sun, X. Min, T. Wang, W. Lu, and G. Zhai, “No-reference quality assessment for 3Dcolored point cloud and mesh models,” IEEE Transactions on Circuits and Systems for Video Technology, 2022.
- [6] H. Liu, H. Yuan, Q. Liu, J. Hou, and J. Liu, “A comprehensive study and comparison of core technologies for mpeg 3-d point cloud compression,” IEEE Transactions on Broadcasting, vol. 66, no. 3, pp. 701–717, 2019.
- [7] 3DG, “Text of ISO/IEC CD 23090-9 geometry-based point cloud compression,” Doc. ISO/IEC JTC1/SC29/WG11 MPEG N18478, Geneeve, Switzerland, Mar. 2019.
- [8] 3DG, “Text of ISO/IEC CD 23090-5: Video-based point cloud compression,” ISO/IEC JTC1/SC29/WG11 MPEG N18030, Macau, China, Oct. 2018.
- [9] X. Wu, Y. Zhang, C. Fan, J. Hou, and S. Kwong, “Subjective quality database and objective study of compressed point clouds with 6dof head-mounted display,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 12, pp. 4630–4644, 2021.
- [10] E. Alexiou, I. Viola, T. M. Borges, T. A. Fonseca, R. L. de Queiroz, and T. Ebrahimi, “A comprehensive study of the rate-distortion performance in MPEG point cloud compression,” APSIPA Trans. on Signal and Information Processing, vol. 8, 2019.
- [11] A. Javaheri, C. Brites, F. Pereira, and J. Ascenso, “Point cloud rendering after coding: Impacts on subjective and objective quality,” IEEE Transactions on Multimedia, vol. 23, pp. 4049–4064, 2020.
- [12] Q. Yang, H. Chen, Z. Ma, Y. Xu, R. Tang, and J. Sun, “Predicting the perceptual quality of point cloud: A 3D-to-2D projection-based exploration,” IEEE Trans. Multimedia, 2020.
- [13] H. Su, Z. Duanmu, W. Liu, Q. Liu, and Z. Wang, “Perceptual quality assessment of 3Dpoint clouds,” in 2019 IEEE International Conference on Image Processing (ICIP). IEEE, 2019, pp. 3182–3186.
- [14] E. Alexiou, “Perceptual quality of point clouds with application to compression,” EPFL, Tech. Rep., 2021.
- [15] R. Mekuria, K. Blom, and P. Cesar, “Design, implementation, and evaluation of a point cloud codec for tele-immersive video,” IEEE Trans. Circuits and Systems for Video Technology, vol. 27, no. 4, pp. 828–842, April 2017.
- [16] D. Tian, H. Ochimizu, C. Feng, R. Cohen, and A. Vetro, “Geometric distortion metrics for point cloud compression,” in Proc. IEEE Int. Conf. Image Processing, 2017, pp. 3460–3464.
- [17] R. Mekuria, S. Laserre, and C. Tulvan, “Performance assessment of point cloud compression,” in 2017 IEEE Visual Communications and Image Processing (VCIP). IEEE, 2017, pp. 1–4.
- [18] R. Diniz, P. G. Freitas, and M. C. Farias, “Multi-distance point cloud quality assessment,” in 2020 IEEE International Conference on Image Processing (ICIP), 2020, pp. 3443–3447.
- [19] R. Diniz, P. G. Freitas, and M. C. Farias, “Point cloud quality assessment based on geometry-aware texture descriptors,” Computers & Graphics, 2022.
- [20] R. Diniz, P. G. Freitas, and M. Farias, “A novel point cloud quality assessment metric based on perceptual color distance patterns,” Electronic Imaging, vol. 2021, no. 9, pp. 256–1, 2021.
- [21] R. Diniz, P. G. Freitas, and M. C. Farias, “Local luminance patterns for point cloud quality assessment,” in 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), 2020, pp. 1–6.
- [22] Q. Yang, Z. Ma, Y. Xu, Z. Li, and J. Sun, “Inferring point cloud quality via graph similarity,” IEEE Trans. Pattern Analysis and Machine Intelligence, 2020.
- [23] I. Viola, S. Subramanyam, and P. César, “A color-based objective quality metric for point cloud contents,” in Proc. IEEE Int. Conf. Quality of Multimedia Experience, 2020, pp. 1–6.
- [24] E. Alexiou and T. Ebrahimi, “Towards a point cloud structural similarity metric,” in 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). IEEE, 2020, pp. 1–6.
- [25] G. Meynet, Y. Nehmé, J. Digne, and G. Lavoué, “PCQM: A full-reference quality metric for colored 3D point clouds,” in Proc. IEEE Int. Conf. Quality of Multimedia Experience, 2020, pp. 1–6.
- [26] L. Hua, M. Yu, Z. He, R. Tu, and G. Jiang, “CPC-GSCT: visual quality assessment for coloured point cloud based on geometric segmentation and colour transformation,” IET Image Processing, vol. 16, no. 4, pp. 1083–1095, 2022.
- [27] Y. Xu, Q. Yang, L. Yang, and J.-N. Hwang, “EPES: point cloud quality modeling using elastic potential energy similarity,” IEEE Transactions on Broadcasting, vol. 68, no. 1, pp. 33–42, 2022.
- [28] Q. Yang, Y. Zhang, S. Chen, Y. Xu, J. Sun, and Z. Ma, “MPED: quantifying point cloud distortion based on multiscale potential energy discrepancy,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, DOI:10.1109/TPAMI.2022.3213831.
- [29] Z. Lu, H. Huang, H. Zeng, J. Hou, and K.-K. Ma, “Point cloud quality assessment via 3D edge similarity measurement,” IEEE Signal Processing Letters, vol. 29, pp. 1804–1808, 2022.
- [30] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Trans. Image Processing, vol. 13, no. 4, pp. 600–612, April 2004.
- [31] Z. Wang, E. Simoncelli, and A. Bovik, “Multiscale structural similarity for image quality assessment,” in Proc. IEEE Asilomar Conf. on Signals, Systems, and Computers. IEEE, 2003, pp. 1398–1402.
- [32] Q. Liu, H. Su, Z. Duanmu, W. Liu, and Z. Wang, “Perceptual quality assessment of colored 3D point clouds,” IEEE Transactions on Visualization and Computer Graphics, 2022, DOI:10.1109/TVCG.2022.3167151.
- [33] H. Sheikh and A. Bovik, “Image information and visual quality,” IEEE Trans. Image Processing, vol. 15, no. 2, pp. 430–444, February 2006.
- [34] T. Chen, C. Long, H. Su, L. Chen, J. Chi, Z. Pan, H. Yang, and Y. Liu, “Layered projection-based quality assessment of 3Dpoint clouds,” IEEE Access, vol. 9, pp. 88 108–88 120, 2021.
- [35] Z. He, G. Jiang, M. Yu, Z. Jiang, Z. Peng, and F. Chen, “TGP-PCQA: texture and geometry projection based quality assessment for colored point clouds,” Journal of Visual Communication and Image Representation, vol. 83, p. 103449, 2022.
- [36] X. G. Freitas, R. Diniz, and M. C. Farias, “Point cloud quality assessment: unifying projection, geometry, and texture similarity,” The Visual Computer, pp. 1–8, 2022.
- [37] I. Viola and P. Cesar, “A reduced reference metric for visual quality evaluation of point cloud contents,” IEEE Signal Processing Letters, vol. 27, pp. 1660–1664, 2020.
- [38] Q. Liu, H. Yuan, R. Hamzaoui, H. Su, J. Hou, and H. Yang, “Reduced reference perceptual quality model with application to rate control for video-based point cloud compression,” IEEE Transactions on Image Processing, vol. 30, pp. 6623–6636, 2021.
- [39] Q. Liu, H. Su, T. Chen, H. Yuan, and R. Hamzaoui, “No-reference bitstream-layer model for perceptual quality assessment of v-pcc encoded point clouds,” IEEE Transactions on Multimedia, 2022.
- [40] L. Hua, G. Jiang, M. Yu, and Z. He, “Bqe-cvp: Blind quality evaluator for colored point cloud based on visual perception,” in 2021 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), 2021, pp. 1–6.
- [41] A. Chetouani, M. Quach, G. Valenzise, and F. Dufaux, “Deep learning-based quality assessment of 3Dpoint clouds without reference,” in 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW). IEEE, 2021, pp. 1–6.
- [42] Q. Liu, H. Yuan, H. Su, H. Liu, Y. Wang, H. Yang, and J. Hou, “PQA-Net: Deep no reference point cloud quality assessment via multi-view projection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 12, pp. 4645–4660, 2021.
- [43] Y. Liu, Q. Yang, Y. Xu, and L. Yang, “Point cloud quality assessment: Dataset construction and learning-based no-reference metric,” ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 2022.
- [44] R. Tu, G. Jiang, M. Yu, T. Luo, Z. Peng, and F. Chen, “V-PCC projection based blind point cloud quality assessment for compression distortion,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2022.
- [45] W.-x. Tao, G.-y. Jiang, Z.-d. Jiang, and M. Yu, “Point cloud projection and multi-scale feature fusion network based blind quality assessment for colored point clouds,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 5266–5272.
- [46] C. R. Qi, L. Yi, H. Su, and L. J. Guibas, “Pointnet++: Deep hierarchical feature learning on point sets in a metric space,” Advances in neural information processing systems, vol. 30, 2017.
- [47] W. Xue, L. Zhang, X. Mou, and A. C. Bovik, “Gradient magnitude similarity deviation: A highly efficient perceptual image quality index,” IEEE transactions on image processing, vol. 23, no. 2, pp. 684–695, 2013.
- [48] Z. Ni, L. Ma, H. Zeng, J. Chen, C. Cai, and K.-K. Ma, “Esim: Edge similarity for screen content image quality assessment,” IEEE Transactions on Image Processing, vol. 26, no. 10, pp. 4818–4831, 2017.
- [49] Y. Fu, H. Zeng, L. Ma, Z. Ni, J. Zhu, and K.-K. Ma, “Screen content image quality assessment using multi-scale difference of gaussian,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 9, pp. 2428–2432, 2018.
- [50] Z. Ni, H. Zeng, L. Ma, J. Hou, J. Chen, and K.-K. Ma, “A gabor feature-based quality assessment model for the screen content images,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4516–4528, 2018.
- [51] Q. Yang, Z. Ma, Y. Xu, L. Yang, W. Zhang, and J. Sun, “Modeling the screen content image quality via multiscale edge attention similarity,” IEEE Transactions on Broadcasting, vol. 66, no. 2, pp. 310–321, 2019.
- [52] S. Chen, D. Tian, C. Feng, A. Vetro, and J. Kovačević, “Fast resampling of three-dimensional point clouds via graphs,” IEEE Transactions on Signal Processing, vol. 66, no. 3, pp. 666–681, 2017.
- [53] V. Mnih, N. Heess, A. Graves, and K. Kavukcuoglu, “Recurrent models of visual attention,” in Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2, 2014, pp. 2204–2212.
- [54] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014.
- [55] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [56] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in International conference on machine learning. PMLR, 2015, pp. 2048–2057.
- [57] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141.
- [58] A. G. Roy, N. Navab, and C. Wachinger, “Concurrent spatial and channel ‘squeeze & excitation’in fully convolutional networks,” in International conference on medical image computing and computer-assisted intervention. Springer, 2018, pp. 421–429.
- [59] R. K. Mantiuk, A. Tomaszewska, and R. Mantiuk, “Comparison of four subjective methods for image quality assessment,” in Computer graphics forum, vol. 31, no. 8. Wiley Online Library, 2012, pp. 2478–2491.
- [60] R. Mekuria, Z. Li, C. Tulvan, and P. Chou, “Evaluation criteria for PCC (point cloud compression),” ISO/IEC JTC1/SC29/WG11 MPEG, N16332, 2016.
- [61] Z. Wang and Q. Li, “Information content weighting for perceptual image quality assessment,” IEEE Transactions on image processing, vol. 20, no. 5, pp. 1185–1198, 2010.
- [62] VQEG. (2000) Final report from the video quality experts group on the validation of objective models of video quality assessment. [Online]. Available: https://vqeg.org/vqeg-home.aspx