Provable Membership Inference Privacy
Abstract
In applications involving sensitive data, such as finance and healthcare, the necessity for preserving data privacy can be a significant barrier to machine learning model development. Differential privacy (DP) has emerged as one canonical standard for provable privacy. However, DP’s strong theoretical guarantees often come at the cost of a large drop in its utility for machine learning; and DP guarantees themselves can be difficult to interpret. In this work, we propose a novel privacy notion, membership inference privacy (MIP), to address these challenges. We give a precise characterization of the relationship between MIP and DP, and show that MIP can be achieved using less amount of randomness compared to the amount required for guaranteeing DP, leading to smaller drop in utility. MIP guarantees are also easily interpretable in terms of the success rate of membership inference attacks. Our theoretical results also give rise to a simple algorithm for guaranteeing MIP which can be used as a wrapper around any algorithm with a continuous output, including parametric model training.
1 Introduction
As the popularity and efficacy of machine learning (ML) have increased, the number of domains in which ML is applied has also expanded greatly. Some of these domains, such as finance or healthcare, have ML on sensitive data which cannot be publicly shared due to regulatory or ethical concerns (Assefa et al., 2020; Office for Civil Rights, 2002). In these instances, maintaining data privacy is of paramount importance and must be considered at every stage of the ML process, from model development to deployment. During development, even sharing data in-house while retaining the appropriate level of privacy can be a barrier to model development (Assefa et al., 2020). After deployment, the trained model itself can leak information about the training data if appropriate precautions are not taken (Shokri et al., 2017; Carlini et al., 2021a).
Differential privacy (DP) (Dwork et al., 2014) has emerged as the gold standard for provable privacy in the academic literature. Training methods for DP use randomized algorithms applied on databases of points, and DP stipulates that the algorithm’s random output cannot change much depending on the presence or absence of one individual point in the database. These guarantees in turn give information theoretic protection against the maximum amount of information that an adversary can obtain about any particular sample in the dataset, regardless of that adversary’s prior knowledge or computational power, making DP an attractive method for guaranteeing privacy. However, DP’s strong theoretical guarantees often come at the cost of a large drop in utility for many algorithms (Jayaraman and Evans, 2019). In addition, DP guarantees themselves are difficult to interpret by non-experts. There is a precise definition for what it means for an algorithm to satisfy DP with , but it is not a priori clear what this definition guarantees in terms of practical questions that a user could have, the most basic of which might be to ask whether or not an attacker can determine whether or not that user’s information was included in the algorithm’s input. These constitute challenges for adoption of DP in practice.
In this paper, we propose a novel privacy notion, membership inference privacy (MIP), to address these challenges. Membership inference measures privacy via a game played between the algorithm designer and an adversary or attacker. The adversary is presented with the algorithm’s output and a “target” sample, which may or may not have been included in the algorithm’s input set. The adversary’s goal is to determine whether or not the target sample was included in the algorithm’s input. If the adversary can succeed with probability much higher than random guessing, then the algorithm must be leaking information about its input. This measure of privacy is one of the simplest for the attacker; thus, provably protecting against it is a strong privacy guarantee. Furthermore, MIP is easily interpretable, as it is measured with respect to a simple quantity–namely, the maximum success rate of an attacker. In summary, our contributions are as follows:
-
•
We propose a novel privacy notion, which we dub membership inference privacy (MIP).
-
•
We characterize the relationship between MIP and differential privacy (DP). In particular, we show that DP is sufficient to certify MIP and quantify the correspondence.
-
•
In addition, we demonstrate that in some cases, MIP can be certified using less randomness than that required for certifying DP. (In other words, while DP is sufficient for certifying MIP, it is not necessary.) This in turn generally means that MIP algorithms can have greater utility than those which implement DP.
-
•
We introduce a “wrapper” method for turning any base algorithm with continuous output into an algorithm which satisfies MIP.
2 Related Work
Privacy Attacks in ML
The study of privacy attacks has recently gained popularity in the machine learning community as the importance of data privacy has become more apparent. In a membership inference attack (Shokri et al., 2017), an attacker is presented with a particular sample and the output of the algorithm to be attacked. The attacker’s goal is to determine whether or not the presented sample was included in the training data or not. If the attacker can determine the membership of the sample with a probability significantly greater than random guessing, this indicates that the algorithm is leaking information about its training data. Obscuring whether or not a given individual belongs to the private dataset is the core promise of private data sharing, and the main reason that we focus on membership inference as the privacy measure. Membership inference attacks against predictive models have been studied extensively (Shokri et al., 2017; Baluta et al., 2022; Hu et al., 2022; Liu et al., 2022; He et al., 2022; Carlini et al., 2021a), and recent work has also developed membership inference attacks against synthetic data (Stadler et al., 2022; Chen et al., 2020).
In a reconstruction attack, the attacker is not presented with a real sample to classify as belonging to the training set or not, but rather has to create samples belonging to the training set based only on the algorithm’s output. Reconstruction attacks have been successfully conducted against large language models (Carlini et al., 2021b). At present, these attacks require the attacker to have a great deal of auxiliary information to succeed. For our purposes, we are interested in privacy attacks to measure the privacy of an algorithm, and such a granular task may place too high burden on the attacker to accurately detect “small” amounts of privacy leakage.
In an attribute inference attack (Bun et al., 2021; Stadler et al., 2022), the attacker tries to infer a sensitive attribute from a particular sample, based on its non-sensitive attributes and the attacked algorithm output. It has been argued that attribute inference is really the entire goal of statistical learning, and therefore should not be considered a privacy violation (Bun et al., 2021; Jayaraman and Evans, 2022).
Differential Privacy (DP)
DP (Dwork et al., 2014) and its variants (Mironov, 2017; Dwork and Rothblum, 2016) offer strong, information-theoretic privacy guarantees. A DP (probabilistic) algorithm is one in which the probability law of its output does not change much if one sample in its input is changed. That is, if and are two adjacent datasets (i.e., two datasets which differ in exactly one element), then the algorithm is -DP if for any subset of the output space. DP has many desirable properties, such as the ability to compose DP methods or post-process the output without losing guarantees. Many simple “wrapper” methods are also available for certifying DP. Among the simplest, the Laplace mechanism, adds Laplace noise to the algorithm output. The noise level must generally depend on the sensitivity of the base algorithm, which measures how much a single input sample can change the algorithm’s output. The method we propose in this work is similar to the Laplace mechanism, but we show that the amount of noise needed can be reduced drastically. Abadi et al. (2016) introduced DP-SGD, a powerful tool enabling DP to be combined with deep learning, based on a small modification to the standard gradient descent training. However, enforcing DP does not come without a cost. Enforcing DP with high levels of privacy (small ) often comes with sharp decreases in algorithm utility (Tao et al., 2021; Stadler et al., 2022). DP is also difficult to audit; it must be proven mathematically for a given algorithm. Checking it empirically is generally computationally intractable (Gilbert and McMillan, 2018). The difficulty of checking DP has led to widespread implementation issues (and even errors due to finite machine precision), which invalidate the guarantees of DP (Jagielski et al., 2020).
While the basic definition of DP can be difficult to interpret, equivalent “operational” definitions have been developed (Wasserman and Zhou, 2010; Kairouz et al., 2015; Nasr et al., 2021). These works show that DP can equivalently be expressed in terms of the maximum success rate on an adversary which seeks to distinguish between two adjacent datasets and , given only the output of a DP algorithm. While similar to the setting of membership inference at face value, there are subtle differences. In particular, in the case of membership inference, one must consider all datasets which could have contained the target record, and all datasets which do not contain the target record, and distinguish between the algorithm’s output in this larger space of possibilities.
Lastly, the independent work of Thudi et al. (2022) specifically applies DP to bound membership inference rates, and our results in Sec. 3.4 complement theirs on the relationship between membership inference and DP. However, our results show that DP is not required to prevent membership inference; it is merely one option, and we give alternative methods for defending against membership inference.
3 Membership Inference Privacy
In this section, we will motivate and define membership inference privacy and derive several theoretical results pertaining to it. We will provide proof sketches for many of our results, but the complete proofs all propositions, theorems, etc., can be found in Appendix A.
3.1 Notation
We make use of the following notation. We will use to refer to our entire dataset, which consists of samples all of which must remain private. We will use or to refer to a particular sample. refers to a size- subset of . We will assume the subset is selected randomly, so is a random variable. The remaining data will be referred to as the holdout data. We denote by the set of all size- subsets of (i.e., all possible training sets), and we will use to refer to a particular realization of the random variable . Finally, given a particular sample , (resp. ) will refer to sets for which (resp. ).
3.2 Theoretical Motivation
The implicit assumption behind the public release of any statistical algorithm–be it a generative or predictive ML model, or even the release of simple population statistics–is that it is acceptable for statistical information about the modelled data to be released publicly. In the context of membership inference, this poses a potential problem: if the population we are modeling is significantly different from the “larger” population, then if our algorithm’s output contains any useful information whatsoever, it should be possible for an attacker to infer whether or not a given record could have plausibly come from our training data or not.
We illustrate this concept with an example. Suppose the goal is to publish an ML model which predicts a patient’s blood pressure from several biomarkers, specifically for patients who suffer from a particular chronic disease. To do this, we collect a dataset of individuals with confirmed cases of the disease, and use this data to train a linear regression model with coefficients . Formally, we let denote the features (e.g. biomarker values), denote the patient’s blood pressure, and . In this case, the private dataset contains only the patients with . Assume that in the general populace, patient features are drawn from a mixture model:
In the membership inference attack scenario, an adversary observes a data point and the model , and tries to determine whether or not . If and are well-separated, then an adversary can train an effective classifier to determine the corresponding label for by checking whether or not . Since only data with belong to , this provides a signal to the adversary as to whether or not could have belonged to or not. The point is that in this setting, this outcome is unavoidable if is to provide any utility whatsoever. In other words:
In order to preserve utility, membership inference privacy must be measured with respect to the distribution from which the private data are drawn.
The example above motivates the following theoretical ideal for our membership inference setting. Let be the private dataset and suppose that for some probability distribution . (Note: Here, corresponds to the complete datapoint in the example above.) Let be our (randomized) algorithm, and denote its output by . We generate a test point based on:
i.e. is a fresh draw from or a random element of the private training data with equal probability. Let denote any membership inference algorithm which takes as input and the algorithm’s output . The notion of privacy we wish to enforce is that cannot do much better to ascertain the membership of than guessing randomly:
| (1) |
where ideally .
3.3 Practical Definition
In reality, we do not have access to the underlying distribution . Instead, we propose to use a bootstrap sampling approach to approximate fresh draws from .
Definition 1 (Membership Inference Privacy (MIP)).
Given fixed , let be a size- subset chosen uniformly at random from the elements in . For , let . An algorithm is -MIP with respect to if for any identification algorithm and for every , we have
Here, the probability is taken over the uniformly random size- subset , as well as any randomness in and .
Definition 1 states that given the output of , an adversary cannot determine whether a given point was in the holdout set or training set with probability more than better than always guessing the a priori more likely outcome. In the remainder of the paper, we will set , so that is -MIP if an attacker cannot have average accuracy greater than . This gives the largest a priori entropy for the attacker’s classification task, which creates the highest ceiling on how much of an advantage an attacker can possibly gain from the algorithm’s output, and consequently the most accurate measurement of privacy leakage. The choice also keeps us as close as possible to the theoretical motivation in the previous subsection. We note that analogues of all of our results apply for general .
The definition of MIP is phrased with respect to any classifier (whose randomness is independent of the randomness in ; if the adversary knows the algorithm and the random seed, we are doomed). While this definition is compelling in that it shows a bound on what any attacker can hope to accomplish, the need to consider all possible attack algorithms makes it difficult to work with technically. The following proposition shows that MIP is equivalent to a simpler definition which does not need to simultaneously consider all identification algorithms .
Proposition 2.
Let and let denote the probability law of . Then is -MIP if and only if
Furthermore, the optimal adversary is given by
Proposition 2 makes precise the intuition that the optimal attacker should guess the more likely of or conditional on the output of . The optimal attacker’s overall accuracy is then computed by marginalizing this conditional statement.
Finally, MIP also satisfies a post-processing inequality similar to the classical result in DP (Dwork et al., 2014). This states that any local functions of a MIP algorithm’s output cannot degrade the privacy guarantee.
Theorem 3.
Suppose that is -MIP, and let be any (potentially randomized, with randomness independent of ) function. Then is also -MIP.
Proof.
Let be any membership inference algorithm for . Define . Since is -MIP, we have
Thus, is -MIP by Definition 1. ∎
For example, Theorem 3 is important for the application of MIP to generative model training – if we can guarantee that our generative model is -MIP, then any output produced by it is -MIP as well.
3.4 Relation to Differential Privacy
In this section, we make precise the relationship between MIP and the most common theoretical formulation of privacy: differential privacy (DP). We provide proof sketches for most of our results here; detailed proofs can be found in the Appendix. Our first theorem shows that DP is at least as strong as MIP.
Theorem 4.
Let be -DP. Then is -MIP with . Furthermore, this bound is tight, i.e. for any , there exists an -DP algorithm against which the optimal attacker has accuracy .
Proof sketch.
Let and and suppose without loss of generality that . We have and by Proposition 6 below, . This implies that , and applying Proposition 2 gives the desired result.
For the tightness result, there is a simple construction on subsets of size 1 of . Let and . The algorithm which outputs with probability and with probability is -DP, and the optimal attacker has exactly the accuracy given in the theorem. ∎
To help interpret this result, we remark that for , we have . Thus in the regime where strong privacy guarantees are required (), .
In fact, DP is strictly stronger than MIP, which we make precise with the following theorem.
Theorem 5.
For any , there exists an algorithm which is -MIP but not -DP for any .
Proof sketch.
The easiest example is an algorithm which publishes each sample in its input set with extremely low probability. Since the probability that any given sample is published is low, the probability that an attacker can do better than guess randomly is low marginally over the algorithm’s output. However, adding a sample to the input dataset changes the probability of that sample’s being published from 0 to a strictly positive number, so the guarantee on probability ratios required for DP is infinite. ∎
In order to better understand the difference between DP and MIP, let us again examine Proposition 2. Recall that this proposition showed that marginally over the output of , the conditional probability that given the algorithm output should not differ too much from the unconditional probability that . The following proposition shows that DP requires this condition to hold for every output of .
Proposition 6.
If is an -DP algorithm, then for any , we have
Proposition 6 can be thought of as an extension of the Bayesian interpretation of DP explained by Jordon et al. (2022). Namely, the definition of DP immediately implies that, for any two adjacent sets and ,
We remark that the proof of Proposition 6 indicates that converting between the case of distinguishing between two adjacent datasets (as in the inequality above, and as done in (Wasserman and Zhou, 2010; Kairouz et al., 2015; Nasr et al., 2021)) vs. the case of membership inference is non-trivial: both our proof and a similar one by Thudi et al. (2022) require the construction of a injective function between sets which do/do not contain .
4 Guaranteeing MIP via Noise Addition
In this section, we show that a small modification to standard training procedures can be used to guarantee MIP. Suppose that takes as input a data set and produces output . For instance, may compute a simple statistical query on , such as mean estimation, but our results apply equally well in the case that e.g. are the weights of a neural network trained on . If are the weights of a generative model, then if we can guarantee MIP for , then by the data processing inequality (Theorem 3), this guarantees privacy for any output of the generative model.
The distribution over training data (in our case, the uniform distribution over size subsets of our complete dataset ) induces a distribution over the output . The question is, what is the smallest amount of noise we can add to which will guarantee MIP? If we add noise on the order of , then we can adapt the standard proof for guaranteeing DP in terms of algorithm sensitivity to show that a restricted version of DP (only with respect subsets of ) holds in this case, which in turn guarantees MIP. However, recall that by Propositions 2 and 6, MIP is only asking for a marginal guarantee on the change in the posterior probability of given , whereas DP is asking for a conditional guarantee on the posterior. So while seems necessary for a conditional guarantee, the moments of should be sufficient for a marginal guarantee. Theorem 7 shows that this intuition is correct.
Theorem 7.
Let be any norm, and let be an upper bound on the -th central moment of with respect to this norm over the randomness in and . Let be a random variable with density proportional to with . Finally, let . Then is -MIP, i.e., for any adversary ,
Proof sketch.
The proof proceeds by bounding the posterior likelihood ratio from above and below for all in a large -ball. This in turn yields an upper bound on the max in the integrand in Proposition 2 with high probability over . The central moment allows us to apply a generalized Chebyshev inequality to establish these bounds. The full proof is computationally intensive and the complete details can be found in the Appendix. ∎
At first glance, Theorem 7 may appear to be adding noise of equal magnitude to all of the coordinates of , regardless of how much each contributes to the central moment . However, by carefully selecting the norm , we can add non-isotropic noise to such that the marginal noise level reflects the variability of each specific coordinate of . This is the content of Corollary 8. ( refers to the probability distribution with density proportional to .)
Corollary 8.
Let , , and define . Generate
and draw . Finally, set and return . Then is -MIP.
Proof sketch.
Let . It can be shown that the density of has the proper form. Furthermore, by definition of the , we have . The corollary follows directly from Theorem 7. The improvement in the numerical constant (from 7.5 to 6.16) comes from numerically optimizing some of the bounds in Theorem 7, and these optimizations are valid for . ∎
In practice, the may not be known, but they can easily be estimated from data. We implement this intuition and devise a practical method for guaranteeing MIP in Algorithm 1. We remark briefly that the estimator for used in Algorithm 1 is not unbiased, but it is consistent (i.e., the bias approaches as ). When , there is a well-known unbiased estimate for the variance which replace with , and one can make similar corrections for general (Gerlovina and Hubbard, 2019). In practice, these corrections yield very small difference and the naive estimator presented in the algorithm should suffice.
When Does MIP Improve Over DP?
By Theorem 4, any DP algorithm gives rise to a MIP algorithm, so we never need to add more noise than the amount required to guarantee DP, in order to guarantee MIP. However, Theorem 7 shows that MIP affords an advantage over DP when the variance of our algorithm’s output (over subsets of size ) is much smaller than its sensitivity , which is defined as the maximum change in the algorithm’s output when evaluated on two datasets which differ in only one element. For instance, applying the Laplace mechanism from DP requires a noise which scales like to guarantee -DP. It is easy to construct examples where the variance is much smaller than the sensitivity if the output of our “algorithm” is allowed to be completely arbitrary as a function of the input. However, it is more interesting to ask if there are any natural settings in which this occurs. Proposition 9 answers this question in the affirmative.
Proposition 9.
For any finite , define . Given a dataset of size , define and define
Here the variance is taken over . Then for all , there exists a dataset such that but .
Proof sketch.
Assume is even for simplicity. Let and . Take
When , then , and this occurs with probability . For all other subsets , . ∎
5 Simulation Results
5.1 Noise Level in Proposition 9
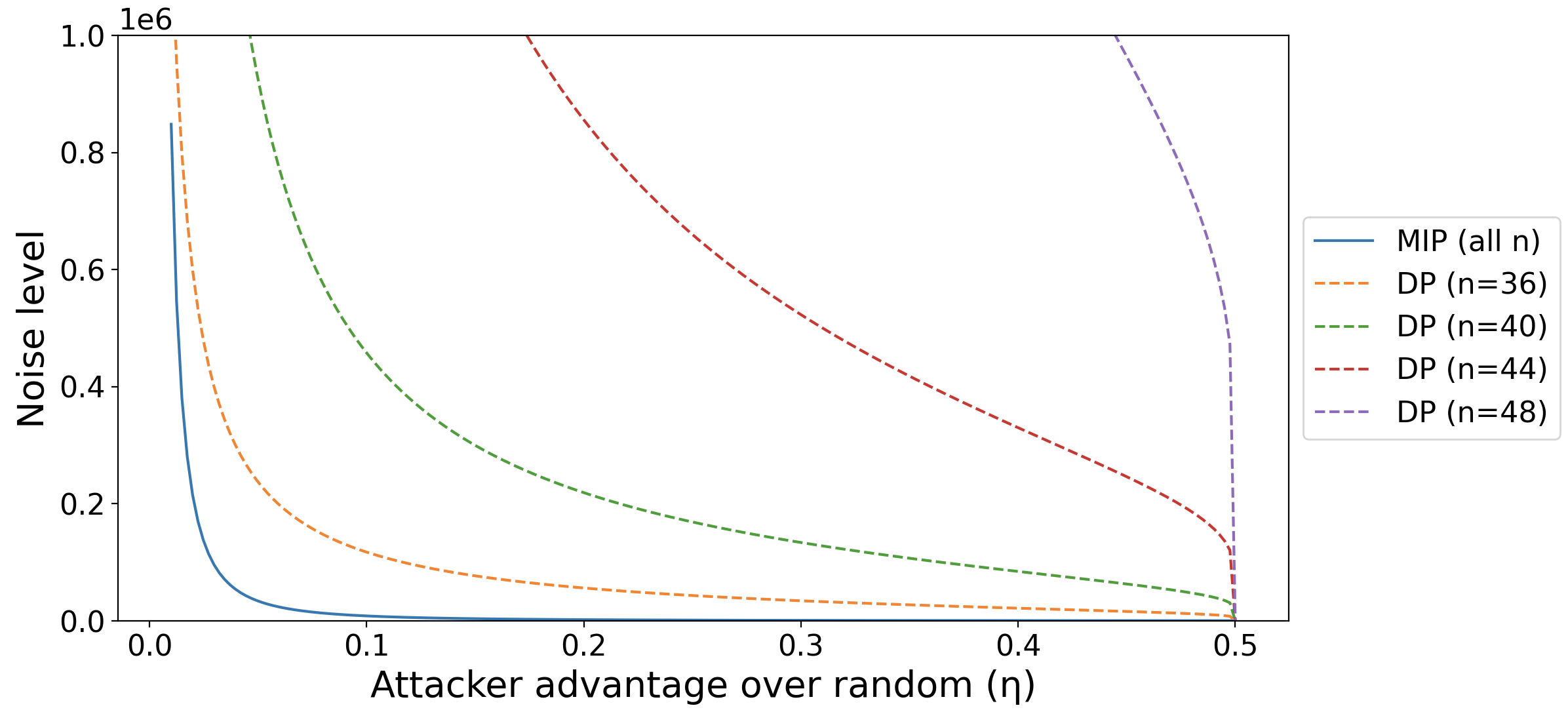
To illustrate our theoretical results, we plot the noise level needed to guarantee MIP vs. the corresponding level of DP (with the correspondence given by Theorem 4) for the example in Proposition 9.
Refer to Fig. 1. Dotted lines refer to DP, while the solid line is for MIP with . The -axis gives the best possible bound on the attacker’s improvement in accuracy over random guessing–i.e., the parameter for an -MIP method–according to that method’s guarantees. For DP, the value along the -axis is given by the (tight) correspondence in Theorem 4, namely . corresponds to perfect privacy (the attacker cannot do any better than random guessing), while corresponds to no privacy (the attacker can determine membership with perfect accuracy). The -axis denotes the amount of noise that must be added to the non-private algorithm’s output, as measured by the scale parameter of the Laplace noise that must be added (lower is better). For MIP, by Theorem 7, this is where is an upper bound on the variance of the base algorithm over random subsets, and for DP this is . (This comes from solving for , then using the fact that noise must be added to guarantee -DP.) For DP, the amount of noise necessary changes with the size of the private dataset. For MIP, the amount of noise does not change, so there is only one line.
The results show that for even small datasets () and for , direct noise accounting for MIP gives a large advantage over guaranteeing MIP via DP. In practice, such small datasets are uncommon. As increases above even this modest range, the advantage in terms of noise reduction for MIP vs. DP quickly becomes many orders of magnitude and is not visible on the plot. (Refer to Proposition 9. The noise required for DP grows exponentially in , while it remains constant in for MIP.)
5.2 Synthetic Data Generation
We conduct an experiment as a representation scenario for private synthetic data generation. We are given a dataset which consists of i.i.d. draws from a private ground truth distribution . Our goal is to learn a generative model which allows us to (approximately) sample from . That is, given a latent random variable (we will take ), we have . If is itself private and a good approximation for , then by the post-processing theorem (Theorem 3), we can use to generate synthetic draws from , without violating the privacy of any sample in the training data.
For this experiment, we will take to be a single-layer linear network with no bias, i.e. for some weight matrix . The ground truth distribution is a mean-0 normal distribution with (unknown) non-identity covariance . In this setting, would exactly reproduce .
Let be the training data. Rather than attempting to learn directly, we will instead try to learn . We can then set . If , then we will have and . We learn by minimizing the objective
via gradient descent.
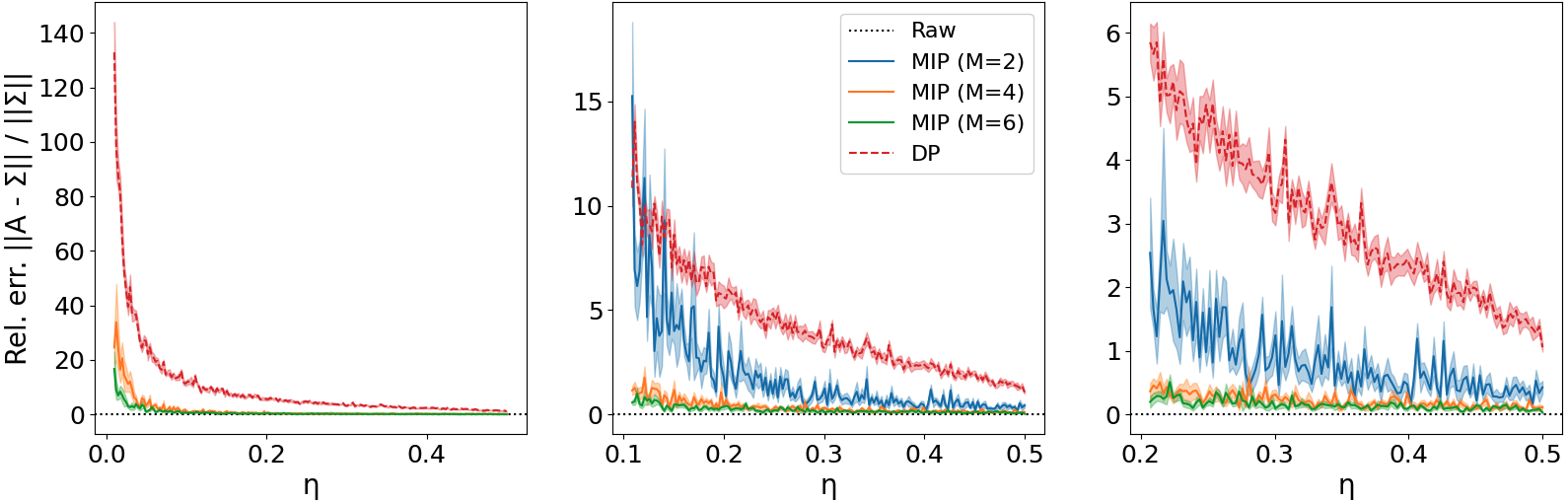
For the DP method, we implement DP-SGD (Abadi et al., 2016) with a full batch. We chose the clipping parameter according to the authors’ recommendations, i.e. the median of the unclipped gradients over the training procedure. To implement MIP, we used Corollary 8 with and the corresponding ’s computed empirically over 128 random train/holdout splits of the base dataset. The results below use and .
Refer to Figure 2. The -axes show the theoretical privacy level (again using the tight correspondence between and from Theorem 4), and the -axes show the relative error (lower is better). The three plots show the same results zoomed in on different ranges for to see greater granularity, and the shaded region shows the standard error of the mean over 10 runs. For , MIP with any of the tested values of outperforms DP in terms of accuracy. For the entire tested range (the smallest of which was ), MIP with or outperforms DP. (The first plot does not show MIP with because its error is very large when .) Finally, observe that DP is never able to obtain relative error less than (meaning the resulting output is mostly noise), while MIP obtains relative error less than for and larger.
6 Discussion
In this work, we proposed a novel privacy property, membership inference privacy (MIP) and explained its properties and relationship with differential privacy (DP). The MIP property is more readily interpretable than the guarantees offered by (DP). MIP also requires a smaller amount of noise to guarantee as compared to DP, and therefore can retain greater utility in practice. We proposed a simple “wrapper” method for guaranteeing MIP, which can be implemented with a minor modification both to simple statistical queries or more complicated tasks such as the training procedure for parametric machine learning models.
Limitations
As the example used to prove Theorem 5 shows, there are cases where apparently non-private algorithms can satisfy MIP. Thus, algorithms which satisfy MIP may require post-processing to ensure that the output is not one of the low-probability events in which data privacy is leaked. In addition, because MIP is determined with respect to a holdout set still drawn from , an adversary may be able to determine with high probability whether or not a given sample was contained in , rather than just in , if is sufficiently different from the rest of the population.
Future Work
Theorem 4 suggests that DP implies MIP in general. However, Theorem 7 shows that a finer-grained analysis of a standard DP mechanism (the Laplace mechanism) is possible, showing that we can guarantee MIP with less noise. It seems plausible that a similar analysis can be undertaken for other DP mechanisms. In addition to these “wrapper” type methods which can be applied on top of existing algorithms, bespoke algorithms for guaranteeing MIP in particular applications (such as synthetic data generation) are also of interest. Noise addition is a simple and effective way to enforce privacy, but other classes of mechanisms may also be possible. For instance, is it possible to directly regularize a probabilistic model using Proposition 2? Finally, the connections between MIP and other theoretical notions of privacy (Renyi DP (Mironov, 2017), concentrated DP (Dwork and Rothblum, 2016), etc.) are also of interest. Lastly, this paper focused on developing on the theoretical principles and guarantees of MIP, but systematic empirical evaluation is an important direction for future work.
References
- Abadi et al. (2016) Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security, pages 308–318, 2016.
- Assefa et al. (2020) Samuel A Assefa, Danial Dervovic, Mahmoud Mahfouz, Robert E Tillman, Prashant Reddy, and Manuela Veloso. Generating synthetic data in finance: opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, pages 1–8, 2020.
- Baluta et al. (2022) Teodora Baluta, Shiqi Shen, S Hitarth, Shruti Tople, and Prateek Saxena. Membership inference attacks and generalization: A causal perspective. ACM SIGSAC Conference on Computer and Communications Security, 2022.
- Bun et al. (2021) Mark Bun, Damien Desfontaines, Cynthia Dwork, Moni Naor, Kobbi Nissim, Aaron Roth, Adam Smith, Thomas Steinke, Jonathan Ullman, and Salil Vadhan. Statistical inference is not a privacy violation. DifferentialPrivacy.org, 06 2021. https://differentialprivacy.org/inference-is-not-a-privacy-violation/.
- Carlini et al. (2021a) Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. arXiv preprint arXiv:2112.03570, 2021a.
- Carlini et al. (2021b) Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650, 2021b.
- Chen et al. (2020) Dingfan Chen, Ning Yu, Yang Zhang, and Mario Fritz. Gan-leaks: A taxonomy of membership inference attacks against generative models. In Proceedings of the 2020 ACM SIGSAC conference on computer and communications security, pages 343–362, 2020.
- Dwork and Rothblum (2016) Cynthia Dwork and Guy N Rothblum. Concentrated differential privacy. arXiv preprint arXiv:1603.01887, 2016.
- Dwork et al. (2014) Cynthia Dwork, Aaron Roth, et al. The algorithmic foundations of differential privacy. Foundations and Trends® in Theoretical Computer Science, 9(3–4):211–407, 2014.
- Gerlovina and Hubbard (2019) Inna Gerlovina and Alan E Hubbard. Computer algebra and algorithms for unbiased moment estimation of arbitrary order. Cogent mathematics & statistics, 6(1):1701917, 2019.
- Gilbert and McMillan (2018) Anna C Gilbert and Audra McMillan. Property testing for differential privacy. In 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), pages 249–258. IEEE, 2018.
- He et al. (2022) Xinlei He, Zheng Li, Weilin Xu, Cory Cornelius, and Yang Zhang. Membership-doctor: Comprehensive assessment of membership inference against machine learning models. arXiv preprint arXiv:2208.10445, 2022.
- Hu et al. (2022) Pingyi Hu, Zihan Wang, Ruoxi Sun, Hu Wang, and Minhui Xue. M^ 4i: Multi-modal models membership inference. Advances in Neural Information Processing Systems, 2022.
- Jagielski et al. (2020) Matthew Jagielski, Jonathan Ullman, and Alina Oprea. Auditing differentially private machine learning: How private is private sgd? Advances in Neural Information Processing Systems, 33:22205–22216, 2020.
- Jayaraman and Evans (2019) Bargav Jayaraman and David Evans. Evaluating differentially private machine learning in practice. In 28th USENIX Security Symposium (USENIX Security 19), pages 1895–1912, 2019.
- Jayaraman and Evans (2022) Bargav Jayaraman and David Evans. Are attribute inference attacks just imputation? ACM SIGSAC Conference on Computer and Communications Security, 2022.
- Jordon et al. (2022) James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N Cohen, and Adrian Weller. Synthetic data–what, why and how? arXiv preprint arXiv:2205.03257, 2022.
- Kairouz et al. (2015) Peter Kairouz, Sewoong Oh, and Pramod Viswanath. The composition theorem for differential privacy. In International conference on machine learning, pages 1376–1385. PMLR, 2015.
- Liu et al. (2022) Yiyong Liu, Zhengyu Zhao, Michael Backes, and Yang Zhang. Membership inference attacks by exploiting loss trajectory. ACM SIGSAC Conference on Computer and Communications Security, 2022.
- Mironov (2017) Ilya Mironov. Rényi differential privacy. In 2017 IEEE 30th computer security foundations symposium (CSF), pages 263–275. IEEE, 2017.
- Nasr et al. (2021) Milad Nasr, Shuang Songi, Abhradeep Thakurta, Nicolas Papernot, and Nicholas Carlin. Adversary instantiation: Lower bounds for differentially private machine learning. In 2021 IEEE Symposium on security and privacy (SP), pages 866–882. IEEE, 2021.
- Office for Civil Rights (2002) HHS Office for Civil Rights. Standards for privacy of individually identifiable health information. final rule. Federal register, 67(157):53181–53273, 2002.
- Shokri et al. (2017) Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017.
- Stadler et al. (2022) Theresa Stadler, Bristen Oprisanu, and Carmela Troncoso. Synthetic data – anonymisation groundhog day. In 31st USENIX Security Symposium (USENIX Security 22). USENIX Association, 2022.
- Tao et al. (2021) Yuchao Tao, Ryan McKenna, Michael Hay, Ashwin Machanavajjhala, and Gerome Miklau. Benchmarking differentially private synthetic data generation algorithms. arXiv preprint arXiv:2112.09238, 2021.
- Thudi et al. (2022) Anvith Thudi, Ilia Shumailov, Franziska Boenisch, and Nicolas Papernot. Bounding membership inference. arXiv preprint arXiv:2202.12232, 2022.
- Wasserman and Zhou (2010) Larry Wasserman and Shuheng Zhou. A statistical framework for differential privacy. Journal of the American Statistical Association, 105(489):375–389, 2010.
Appendix A Deferred Proofs
For the reader’s convenience, we restate all lemmas, theorems, etc. here. See 2
Proof.
We will show that the membership inference algorithm is optimal, then compute the resulting probability of membership inference. We have
The choice of algorithm just specifies the value of for each sample and each . We see that the maximum membership inference probability is obtained when
| (2) |
which implies that
| (3) |
To conclude, observe that
| (4) |
The result follows by rearranging the expression (4) and plugging it into (2) and (3). ∎
In what follows, we will assume without loss of generality that . The proofs in the case are almost identical and can be obtained by simply swapping and .
Lemma 10.
Fix and let and . If then there is an injective function such that for all .
Proof.
We define a bipartite graph on nodes and . There is an edge between and if can be obtained from by removing from and replacing it with another element, i.e. if . To prove the lemma, it suffices to show that there is a matching on which covers . We will show this via Hall’s marriage theorem.
First, observe that is a -biregular graph. Each has neighbors which are obtained from by selecting which of the remaining elements to replace with; each has neighbors which are obtained by selecting which of the elements in to replace with .
See 4
Proof.
See 5
Proof.
Let be defined as follows. Given a training set , outputs a random subset of where each element is included independently and with probability . It is obvious that such an algorithm is not -DP for any : if , then with positive probability. But if we replace with and call this adjacent dataset (so that , then with probability 0. Thus is not differentially private for any .
We now claim that is -MIP for any , provided that is small enough. To see this, observe the following. For any identification algorithm ,
| (8) | ||||
| (9) |
Inequality (8) holds because with probability regardless of whether of not , and therefore the probability that is at most (again regardless of or not) for any . The constant simply counts the number of possible , which depends only on and but not . Thus as , . This completes the proof. ∎
The proof of Theorem 5 emphasizes that the membership inference privacy guarantee is marginal over the ouput of . Conditional on a particular output, an adversary may be able to determine whether or not with arbitrarily high precision. This is in contrast with the result of Proposition 6, which shows that even conditionally on a particular output of a DP algorithm, the adversary cannot gain too much.
See 6
Proof.
Using expression (4) (and the corresponding expression for ), we have
We now analyze this latter expression. We refer again to the biregular graph defined in Lemma 10. For , refers to the neighbors of in , and recall that for all . Note that since each has neighbors, we have
Using this equality, we have
Since and , we have This completes the proof. ∎
See 7
Proof.
We will assume that is an integer. Let , and let and . Define for and for . Let be a random variable which is uniformly distributed on . We may assume without loss of generality that . In what follows, , , , and are constants which we will choose later to optimize our bounds. We also make repeated use of the inequalities for all ; for all ; and and for . Let have density proportional to . The posterior likelihood ratio is given by
We claim that for all with , . First, suppose that . Then we have:
| (10) |
Otherwise, . We now have the following chain of inequalities:
| (11) | ||||
Combining this with (10) shows that for all .
Next, we must measure the probability of . We can lower bound this probability by first conditioning on the value of :
Note that the exact same logic (reversing the roles of the ’s and ’s) shows that with probability at least as well.
Finally, we can invoke the result of Proposition 2. Let and note that
Thus we have
| (12) | ||||
where the last inequality follows by setting and solving, yielding . Solving for , we find that suffices. This completes the proof. ∎
Corollary 11.
When , taking guarantees -MIP.
Proof.
The constant improves as increases, so it suffices to consider . Let and , and refer to the proof of Theorem 7. Equation (11) can be improved to
using the inequality for instead of , which was used to prove Theorem 7. With , (12) becomes
| (13) |
Observe that since , when we set , we always have , in which case
Thus, with , we have
This completes the proof. ∎
See 8
Proof.
We with to apply the result of Theorem 7 with . To do this, we must bound the resulting and show that the density of has the correct form. First, observe that
It remains to show that the density has the correct form, i.e. depends on only through . This will be the case if the marginal density of is uniform. Let be the density of . Observe that, for any , we have that iff for some . Thus
The last inequality holds because is constant. Thus, the density is independent of and we can directly apply Theorem 7. ∎
Lemma 12 (Chebyshev’s Inequality).
Let be any norm and be a random vector with . Then for any , we have
Proof.
This follows almost directly from Markov’s inequality:
∎