Proximal Implicit ODE Solvers for Accelerating Learning Neural ODEs
Abstract
Learning neural ODEs often requires solving very stiff ODE systems, primarily using explicit adaptive step size ODE solvers. These solvers are computationally expensive, requiring the use of tiny step sizes for numerical stability and accuracy guarantees. This paper considers learning neural ODEs using implicit ODE solvers of different orders leveraging proximal operators. The proximal implicit solver consists of inner-outer iterations: the inner iterations approximate each implicit update step using a fast optimization algorithm, and the outer iterations solve the ODE system over time. The proximal implicit ODE solver guarantees superiority over explicit solvers in numerical stability and computational efficiency. We validate the advantages of proximal implicit solvers over existing popular neural ODE solvers on various challenging benchmark tasks, including learning continuous-depth graph neural networks and continuous normalizing flows.
1 Introduction
Neural ODEs [11] are a class of continuous-depth neural networks [44, 12] that are particularly suitable for learning complex dynamics from irregularly-sampled sequential data, see, e.g., [11, 46, 17, 32, 36]. Neural ODEs are used in many applications, including image classification and image generation [11], learning dynamical systems [46], modeling probabilistic distributions of complex data by a change of variables [23, 59, 25], and scientific computing [18, 4]. Recently, neural ODEs have also been employed for building continuous-depth graph neural networks (GNNs), achieving remarkable results for deep graph learning [40, 55, 8, 50]. Mathematically, a neural ODE can be formulated by the following first-order ODE:
| (1) |
where is specified by a neural network parameterized by , e.g., a two-layer feed-forward neural network. Starting from the input , neural ODEs learn the representation of the input and perform prediction by solving (1) from the initial time to the terminal time using a numerical ODE solver with a given error tolerance, often with adaptive step size solver or adaptive solver for short [15]. Solving (1) from to in a single pass with an adaptive solver requires evaluating at various timestamps, with the computational complexity counted by the number of forward function evaluations (forward NFEs), which is nearly proportional to the computational time, see [11] for details.
The adjoint sensitivity method, or the adjoint method [7], is a memory-efficient algorithm for training neural ODEs. If we regard the output as the prediction and denote the loss between and the ground truth as . Let be the adjoint state, then we have (see e.g., [11, 7] for details)
| (2) |
with satisfying the following adjoint ODE
| (3) |
which is solved numerically from to and also requires the evaluation of the right-hand side of (3) at various timestamps, with the computational complexity, or number of evaluation of the function , measured by the backward NFEs.
1.1 Computational bottlenecks of Neural ODEs
 |
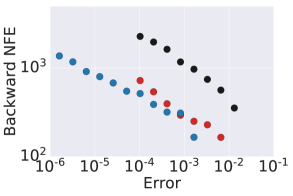 |
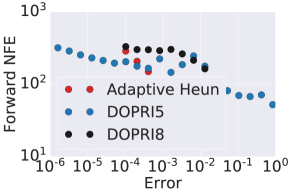
The computational bottlenecks of solving the neural ODE (1) and its adjoint ODE (3) come from the numerical stability and numerical accuracy guarantees. Since is usually high dimensional; direct application of implicit ODE solvers requires solving a system of high dimensional nonlinear equations, which is computationally inefficient, see Section 4.1 for an illustration. As such, explicit solvers — especially the explicit adaptive solvers, e.g., the Dormand-Prince method [15] — are the current default numerical solvers for neural ODE training, test, and inference; see Appendix A for a brief review of explicit adaptive neural ODE solvers. On the one hand, to guarantee numerical accuracy, we have to employ very small step sizes to discretize the neural ODE and its adjoint ODE. On the other hand, both ODEs involved in learning neural ODEs are usually very stiff, which further constrains the step size. Intuitively, a stiff ODE system has very different eigenvalues that reveal dramatically different scales of dynamics. To resolve these dynamics accurately, we have to accommodate for dynamics at significantly different scales, resulting in the use of very small step sizes. To demonstrate this issue, we consider training a recently proposed neural ODE-based GNN, named graph neural diffusion (GRAND) [8], for the benchmark CoauthorCS graph node classification; the detailed experimental settings can be found in Section 4.3. GRAND parametrizes the right-hand side of (1) with the Laplacian operator, resulting in a class of diffusion models. The diffusion model is very stiff from the numerical ODE viewpoint since the ratio between the magnitude of the largest and smallest eigenvalues is infinite. Figure 1 plots the error tolerance of the adaptive solver vs. forward and backward NFEs of different adaptive solvers — including adaptive Heun [49] and two Dormand-Prince methods [15] (DOPRI5 and DOPRI8) — for training GRAND for CoauthorCS node classification. We see that 1) all three adaptive solvers require significant NFEs in solving both neural ODE and its adjoint ODE; as the error tolerance reduces both forward and backward NFEs increase very rapidly. And 2) the higher-order scheme, e.g., DOPRI8 requires more NFEs than the lower-order scheme, indicating that the stability is a dominating factor in choosing the step size. Moreover, it is worth mentioning that both DOPRI5 and DOPRI8 often fail to solve the adjoint ODE when a large error tolerance is used, based on our experiments.
The fundamental issues of learning stiff neural ODEs using explicit solvers due to stability concerns and the high computational cost of direct application of implicit solvers motivate us to study the following question:
Can we modify or relax the implicit solvers to make them suitable for learning neural ODEs with significantly reduced computational costs than existing benchmark solvers?
1.2 Our contribution
We answer the above question affirmatively by considering learning neural ODE-style models using the proxy of a few celebrated implicit ODE solvers — including backward Euler, backward differentiation formulas (BDFs), and Crank-Nicolson — leveraging the proximal operator [38]. These proximal solvers reformulate implicit ODE solvers as variational problems. Each solver contains inner-outer iterations, where the inner iterations approximate a one-step update of the implicit solver, and the outer iterations solve the ODE over time. Leveraging fast optimization algorithms for solving the inner optimization problem, these proximal solvers are remarkably faster than explicit adaptive ODE solvers in learning stiff neural ODEs. We summarize the major benefits of proximal solvers below:
-
•
Due to the implicit nature of proximal algorithms, they are much less encumbered by the numerical stability issue than explicit solvers. Therefore, the proximal algorithms allow the use of very large step sizes for neural ODEs training, test, and inference.
-
•
To achieve the same numerical accuracy in solving stiff neural ODEs, proximal algorithms can save significant NFEs in both forward and backward propagation.
-
•
Training neural ODE-style models using proximal algorithms maintains the generalization accuracy of the model compared to using benchmark adaptive solvers.
1.3 More related works
In this part, we discuss several related works in three directions: reducing NFEs in learning neural ODEs, advances of proximal algorithms, and the development of algorithms for learning neural ODEs.
Reducing NFEs in learning neural ODEs by model design and regularization.
Several algorithms have been developed to reduce the NFEs for learning neural ODEs. They can be classified into three categories: 1. Improving the ODE model and neural network architecture, and notable works in this direction include augmented neural ODEs [17], higher-order neural ODEs [36], heavy-ball neural ODEs [56], and neural ODEs with depth variance [32]. These models can reduce the forward NFEs significantly, and heavy-ball neural ODEs can also reduce the backward NFEs remarkably. 2. Learning neural ODEs with regularization, including weight decay [23], regularizing ODE solvers and learning dynamics [19, 26, 41, 22, 37]. And 3. Input augmentation [17] and data control [32]. Our work focuses on accelerating learning neural ODEs using the proximal form of implicit solvers.
Advances of proximal algorithms.
Proximal algorithms have been the workhorse for solving nonsmooth, large-scale, or distributed optimization problems [38]. The core matter is the evaluation of proximal operators [5]. The proximal algorithms are widely used in statistical computing and machine learning [42], channel pruning of neural networks [58, 14], image processing [6], matrix completion [31, 61], computational optimal transport [47, 39], game theory and optimal control [3], etc. Proximal operators can be viewed as backward Euler method, see Section 2 for a brief mathematical introduction. From an implicit solver viewpoint, a proximal formulation of the backward Euler method has been applied to the stochastic gradient descent training of neural networks [9, 10].
Developments of efficient neural ODE learning algorithms.
Solving an ODE is required in both forward and backward propagation of learning neural ODEs. The default numerical solvers are explicit adaptive Runge-Kutta schemes [43, 11], especially the Dormand-Prince method [15]. To solve both forward and backward ODEs accurately, the adaptive solvers will evaluate the right-hand side of ODEs at many intermediate timestamps, causing tremendous computational burden. Checkpoint schemes have been proposed to reduce the computational cost [21, 62], often reducing computational cost by compromising memory efficiency. Recently, the symplectic adjoint method has been proposed [33], which solves neural ODEs using a symplectic integrator and obtains the exact gradient (up to rounding error) with memory efficiency. Approximate gradients using interpolation instead of adjoint method [13] has also been used to accelerate learning neural ODEs. Our proposed proximal solvers can be integrated with these new adjoint methods for training neural ODEs.
1.4 Notation
We denote scalars by lower or upper case letters; vectors and matrices by lower and upper case boldface letters, respectively. We denote the magnitude of a complex number as . For a vector , we use to denote its -norm. We denote the vector whose entries are all 0s as . For two vectors and , we denote their inner product as . For a matrix , we use and to denote its transpose and inverse, respectively. We denote the identity matrix as . For a function , we denote and as its gradient and Hessian, respectively. We denote , if there is a constant such that .
1.5 Organization
We organize the paper as follows: In Section 2, we present the proximal form of a few celebrated implicit ODE solvers for learning neural ODEs. We analyze the numerical stability and convergence of proximal solvers and contrast them with explicit solvers in Section 3. We verify the efficacy of proximal solvers in Section 4, followed by concluding remarks. Technical proofs and more experimental details are provided in the appendix.
2 Proximal Algorithms for Neural ODEs
In this section, we formulate the proximal version of several celebrated implicit ODE solvers, including backward Euler, Crank-Nicolson, BDFs, and a class of single-step multi-stage schemes.
2.1 A proximal viewpoint of the backward Euler solver
We first consider solving a neural ODE (1) using the proximal backward Euler solver. Directly discretizing (1) using the backward Euler scheme with a constant step size gives
| (4) |
Equation (4) is a system of nonlinear equations, which can be solved efficiently by Newton’s method. But when the dimension of is very high, solving (4) can be computationally infeasible. Nevertheless, if is the gradient of a function , we can reformulate the update in (4) using the proximal operator as follows
| (5) |
where , and is the admissible domain of , which is considered to be the whole space in this work; we omit in the following discussion. To see why (5) is equivalent to (4), we note that is a stationary point of , resulting in
replacing with in the above equation, we get the backward Euler solver (4) (note ). Based on the proximal formulation of the backward Euler method (4), we can solve the neural ODE (1) using an inner-outer iteration scheme. The outer iterations perform backward Euler iterations over time, and the inner iterations solve the optimization problem formulated in (5). We summarize the inner-outer iteration scheme for the proximal backward Euler solver in Algorithm 1.
2.1.1 Solving the inner minimization problem
Another piece of the recipe is how to effectively solve the inner minimization problem of proximal backward Euler (5), i.e., the following optimization problem
| (6) |
One of the simple yet efficient algorithms for solving (6) is gradient descent (GD), which updates as follows: for , perform
| (7) |
where is the step size and . Here, notice that we do not need to know the exact form of , and the GD update becomes
| (8) |
There are various off-the-shelf acceleration schemes that exist to accelerate the convergence of (8), e.g., Nesterov accelerated gradient (NAG) [35], NAG with adaptive restart (Restart) [45], and GD with nonlinear conjugate gradient style momentum, e.g., Fletcher–Reeves momentum (FR) [20, 53]. In particular, FR, which will be used in our experiments, updates as follows:
| (9) | ||||
where and the scalar is given below
| (10) |
With the access to the gradient we can also employ L-BFGS [29] to solve the inner minimization problem (6). Based on our testing, GD with FR momentum usually outperforms the other methods listed above, see Section 4.1 for a comparison of different optimization algorithms for solving the one-dimensional diffusion problem.
Remark 2.1.
The above discussion of gradient-based optimization algorithms assumes the existence of whose gradient is . When such a function does not exist, we can still use the iteration (8) to solve the inner minimization problem, which we can regard as a fixed point iteration. Moreover, we can accelerate the convergence of (8) using the Anderson acceleration [1, 52], and we leave it as future work. Based on our numerical tests, gradient-based optimization algorithms work quite well in solving the inner optimization problem (6) across all studied benchmark tasks.
Stopping criterion of inner solvers.
Given an error tolerance of the inner optimization solver, we stop the inner iteration if .
2.1.2 Explicit vs. proximal solvers
 |
 |
| (a) | (b) |
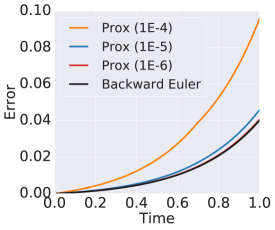
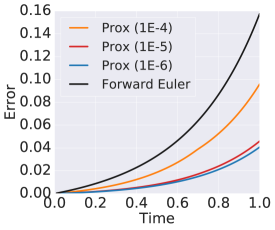
Before presenting more proximal implicit solvers, we compare forward Euler, backward Euler, and the proximal backward Euler for solving the following benchmark one-dimensional ODE, which comes from [2]
| (11) |
with initial condition . We use the integration time step size for all the above ODE solvers. Figure 2 (a) plots the error between numerical and analytic solutions of proximal backward Euler with different inner solver tolerances and the backward Euler solver. It is evident that the proximal backward Euler approximates backward Euler quite well, and the approximation becomes more accurate as the accuracy of the inner solver enhances. Figure 2 (b) contrasts the proximal backward Euler with the forward Euler solver. We see that with an appropriate tolerance of the inner solver, proximal backward Euler accumulates error slower than the forward Euler solver as the time increases. These advantages of the proximal backward Euler solver shed light on improving learning stiff neural ODEs and alleviating error accumulation.
2.2 High-order implicit schemes via proximal operators
A natural extension of the backward Euler scheme is the single-step, multi-stage schemes whose proximal form are proposed in [60], and we formulated those schemes in Algorithm 2.
Clearly, the 1-stage scheme is the backward Euler scheme. The authors of [60] give conditions on the coefficient . However, it is quite tedious to get those coefficients. For example, a second-order unconditionally stable scheme can be constructed by taking the matrix — whose entries are that appeared in Algorithm 2 — as follows
Furthermore, the matrix of a third-order scheme is
The main drawback of these multi-stage algorithms for training neural ODEs lies in the computational inefficiency. Note that for an -stage scheme, one need to solve optimization problems in each iteration.
2.3 Proximal form of Crank-Nicolson
Another single-step, second-order extension for the backward Euler is the Crank-Nicolson scheme, given by
The Crank-Nicolson scheme is also known as an implicit Runge–Kutta method or trapezoidal rule, which can be formulated in the following proximal form [16]
| (12) |
2.4 The proximal viewpoint of BDF methods
The backward Euler scheme has first-order accuracy, i.e., discretizing the ODE (1) using (4) with step size has error . Backward differentiation formulas (BDFs) are higher-order multi-step methods that can be formulated as follows
where is a constant, and is an operator acts on . The backward Euler method corresponds to the case when , and and . The second-order BDF2 scheme can be constructed by taking and . Furthermore, the BDF2 scheme can be written in the following proximal form [34, 16]
if there exists such that .
We can further construct high-order BDFs, for instance the third- and fourth-order BDFs are given below
-
•
BDF3:
-
•
BDF4:
The corresponding proximal form of BDF3 and BDF4 are given as follows
-
•
BDF3:
-
•
BDF4:
Only one optimization problem needs to be solved in BDFs, which is the advantage of BDF methods over many other high-order implicit schemes.
3 Stability and Convergence Analysis
In this section, we will 1) compare the linear stability of different explicit and implicit solvers, 2) show that the error of the inner solver will not affect the stability of proximal solvers, and 3) analyze the convergence of proximal solvers.
3.1 Linear stability: Implicit vs. explicit solvers
It is well known that explicit solvers often require a small step size for numerical stability and convergence guarantees, especially for solving stiff ODEs. Consider the linear ODE
| (13) |
Assume has spectrum and for , one can define the stiffness ratio as
We say the ODE is stiff if . The linear stability domain of the underlying numerical method is the set of all numbers for , such that , where is the numerical solution of (13) at the -th step. Table. 1 lists the linear stability domain of some single-step numerical schemes described above.
| Numerical methods | Linear stability domain |
|---|---|
| Forward Euler | |
| Backward Euler | |
| Crank-Nicolson | |
| DOPRI5 |
We call an ODE solver -stable if , where is the linear stability domain of the solver. From Table 1, it is clear that the backward Euler and Crank-Nicolson methods are both -stable. For multi-step methods, e.g., BDFs, there is no closed-form expression for the linear stability domain; see [24] for a detailed discussion. Among all BDFs, only BDF2 is -stable. The -stability of ODE solvers is related to the acceleration of the first-order optimization method [30].
3.2 The effect of the error of the inner solver
Compared to the forward methods, backward methods obtain their next step by solving an implicit equation. Dense linear equations can be solved efficiently using exact methods like QR decomposition. In general, nonlinear equations, or even sparse linear equations, do not have the luxury. At best, an approximation to a solution bounded by a specific error tolerance is attained. Fortunately, a bound of linear growth can be established on the total effect caused by the inner solver error against per step tolerance. For example, we consider a one-dimensional equation , and the backward Euler scheme with error can be written as
where is the error for the inner loop with being the tolerance. Let be the exact backward Euler scheme solution, Then we have
Where , and denote the interval . Hence
which provides a linear upper bound on the error. Similar arguments can be generalized to other solvers and for high-dimensional ODEs.
3.3 Energy stability and convergence
Besides the linear stability, there is another notion of stability, known as energy stability. We say a numerical method is energy stable if for all [48]. As an advantage of the proximal formulation, one can show that the backward Euler is unconditionally energy stable [57] for arbitrary even for non-convex (here we assume that there exists such that ). The energy stability guarantees that the numerical solver takes each step toward minimizing , which further lead to the convergence of the numerical scheme [54]. More precisely, we have the following result (see Appendix C for the detailed proof).
Proposition 3.1.
If is continuous, coercive and bounded from below, for any choice of , there exists solves (4), such that
| (14) |
Moreover, for non-convex , is unique provided , where is the smallest eigenvalue of .
Similar energy stability analysis holds for other type of proximal solvers. For instance, for BDF2, one can show there exists such that
For Crank-Nicolson, the proximal formulation (12) leads to
These energy stability result can further lead to the convergence of these scheme in the discrete level [34].
4 Experimental Results
In this section, we validate the efficacy of proximal solvers and contrast their performances with benchmark adaptive neural ODE solvers in solving the one-dimensional diffusion problem and learning continuous normalizing flows (CNFs) [23] and GRAND [8].
4.1 Solving one-dimensional diffusion equation
We consider solving the following 1D diffusion equation
for and with a periodic boundary condition. We initialize with the standard Gaussian. To solve the diffusion equation, we first partition into uniform grids and discretize using the central finite difference scheme, resulting in the following coupled ODEs
| (15) |
where is the Laplacian matrix of a cyclic graph scaled by with being the spatial resolution, and . Then we apply different ODE solvers to solve (15). It is worth noting that the diffusion equation has an infinite domain of dependence, thus in method of lines discretization, the time step to be taken for explicit methods has to be much finer compared to the spatial discretization to guarantee numerical stability.
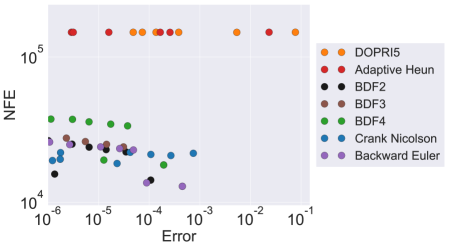
We compare our proximal methods against the predominantly used Adaptive Heun and DOPRI5 in solving (15). As the matrix is circulant, we can compute the exact solution of (15) using the discrete Fourier transform for comparison. Figure 3 compares the NFEs of proximal methods and two benchmark adaptive solvers with different errors at the final time. For each final error, we use a fixed step size for each proximal solver with FR for solving the inner minimization problem. A list of the configuration of each ODE solver can be found in Table 2 in the appendix. Figure 3 shows that adaptive solvers require many more NFEs than proximal solvers. NFEs required by explicit solvers are almost independent of the error, revealing that the step sizes are constrained by numerical stability. Each iteration of higher-order BDF schemes requires more NFEs than lower-order BDF schemes, showing a tradeoff between controlling numerical error and using high-order schemes.
 |
Convergence of inner solvers.
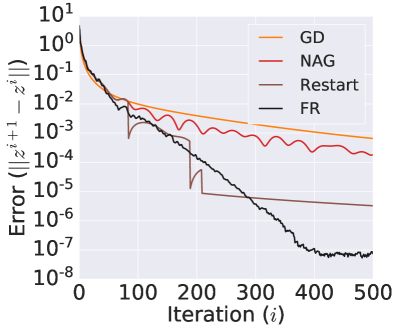
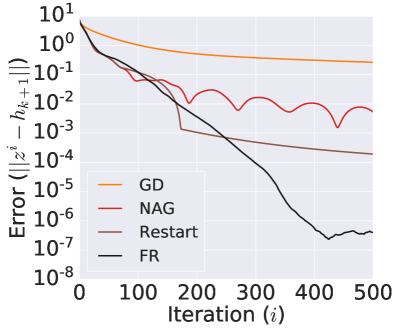
An inner optimization algorithm is required for the proximal solver. We compare the efficiency of a few gradient-based optimization algorithms, including GD, NAG, Restart, and FR, for one pass of the proximal backward Euler solver. The comparison of different optimizers using the same step size (Figure 4) shows that different solvers perform similarly to each other at the beginning of iterations, while as the iteration goes, FR performs best among the five considered solvers. The performance of different optimization algorithms further shows the rationale for solving the inner problem using gradient-based optimization algorithms since the convergence is consistent with the desired performance of each optimizer. We will use FR as the default inner solver for all experiments below.
 |
 |
| (a) | (b) |
Proximal vs. nonlinear solvers.
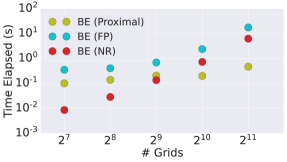
We further verify the computational advantages of proximal solvers over other nonlinear root-finding algorithms for directly solving the implicit ODE solvers. In particular, we consider solving the 1D diffusion equation mentioned before using backward Euler solver given by (4), where we use proximal backward Euler and directly solve (4) using either fixed point (FP) iteration or the Newton-Raphson method (NR). Figure 5 (a) below shows the time required by different solvers when the spatial interval is discretized into different number of grids, controlling the scale of the problem. Also, the computational time of proximal solver is almost linear w.r.t. NFE (Fig. 5 (b)). Proximal solver beats FP and NR. NR is not scalable to high-dimension since it requires evaluating Jacobian, which is very expensive in computational time and memory costs.
 |
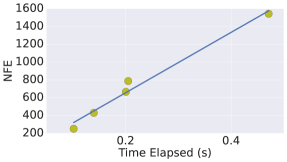 |
| (a) Number of grids vs. time | (b) NFE vs. time |
2) NFE is the number of function calls during integration; each optimization step takes one call, the reported NFEs of the proximal solvers in Sec. 4 equals the product of inner and outer iterations. We solve inner problem using Fletcher-Reeves (see Sec. 4.1), which is much faster than GD.
3) First, the -stable domain determines the largest step size that the algorithm can take. The linear stability analysis shows that the implicit solver can use much larger step sizes than explicit solvers with numerical stability guarantee. Second, regarding why our theory shows implicit solver is “faster” than explicit solver: Notice that the step size used for solving ODEs in a given time interval is constrained by local truncation error and numerical stability, and the later is often the dominating factor, as illustrated in Fig. 1 and Sec. 1.1 in our paper. Since the implicit solver uses a much larger step size than explicit solvers with stability guarantee, the implicit solver takes fewer NFEs than explicit solvers.
4.2 Learning CNFs
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
 |
| (a) | (b) | (c) |
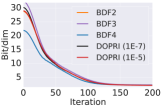
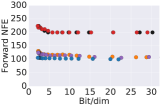
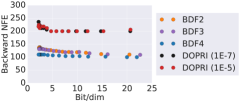
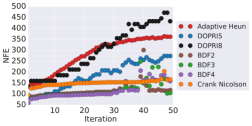
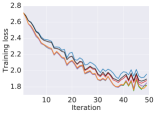
We train CNFs for MNIST [28] generation using proximal solvers and contrast them to adaptive solvers. In particular, we use the FFJORD approach outlined in [23]. We use an architecture of a multi-scale encoder and two CNF blocks, containing convolutional layers of dimension with a uniform stride length of 1 and a softplus activation function. We use two scale blocks and train for 10 epochs using Adam optimizer [27] with an initial learning rate of . We run the model using the proximal BDFs with FR and DOPRI5 with relative tolerance of and , respectively. All the other experimental settings are adapted from [23]. The proximal BDFs are tuned to have an error profile which was consistent with the DOPRI5 as shown in Figure 6 (a). We choose and and the step sizes for numerical integration and the inner optimizer are 0.2 and 0.3, respectively. We terminate the inner optimization solver once . A comparison of the forward and backward NFEs are depicted in Figure 6 (b) and (c), respectively. We see that proximal BDF2, BDF3, and BDF4 require approximately half of the NFEs as DOPRI5 to reach similar training curves.
4.3 Training GRAND
GRAND is a continuous-depth graph neural network proposed in [8]. It consists of a dense embedding layer, a diffusion layer, and a dense output layer, with ReLU activation function in between. The diffusion layer takes as input and solves (16) below to time
| (16) |
where is the graph attention function [51] with learnable parameter set . This ODE to be solved in GRAND is nonlinear and diffusive, which is particularly challenging to solve numerically.
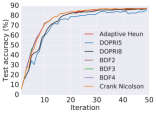
We compare the performance of proximal solvers with three major adaptive ODE solver options (DOPRI5, DOPRI8, Adaptive Heun) on training the GRAND model for CoauthorCS node classification. The CoauthorCS graph contains 18333 nodes and 81894 edges, and each node is represented by a 6805 dimensional vector. The graph nodes contains 15 classes, and we aim to classify the unlabelled nodes. We choose and as our starting and ending times of the ODE (16). For each solver, we run the experiment for 50 epochs and record the average NFEs per epoch and accuracy of trained models. For adaptive solvers we choose tolerance , and for proximal solvers we choose the integration step size 1.25 (8 steps in total) so that for the first iteration with same input admits output with error within . For optimization method we use Fletcher-Reeves with learning rate 0.3, and stop when error is below tolerance. All the other experimental settings are adapted from [8]. Figure 7 shows the advantage of proximal methods over adaptive solvers in training efficiency and maintaining the convergence of the training.
5 Concluding Remarks
We propose accelerating learning neural ODEs using proximal solvers, including proximal BDFs and proximal Crank-Nicolson. These proximal schemes approach the corresponding implicit schemes as the accuracy of the inner solver enhances. Compared to the existing adaptive explicit ODE solvers, the proximal solvers are better suited for solving stiff ODEs for numerical stability guarantees. We validate the efficiency of proximal solvers on learning benchmark graph neural diffusion and continuous normalizing flows. There are several interesting future directions. In particular, 1) accelerating the inner solver from the fixed point iteration viewpoint, e.g., leveraging Anderson acceleration, and 2) developing adaptive step size proximal solvers by integrating proximal solvers of different orders.
Appendix A Dormand-Prince Method: A Review
In this section, we briefly review the scheme, error control, and step size rule of the Dormand-Prince method, which is an explicit adaptive numerical ODE solver. The one step calculation, from to with step size , in the Dormand-Prince method for solving (1) is summarized below: First, we update to using Runge-Kutta method of order 4.
And the is calculated as
Second, we update to by Runge-Kutta method of order 5 as
We consider as the error in , and given error tolerance we select the adaptive step size at this step to be
Many other adaptive ODE solvers exist, and some are also used to learn neural ODEs, e.g., the adaptive Heun’s method, which is a second-order ODE solver. More adaptive step solvers can be found at [2].
Appendix B Derivation of Proximal ODE Solvers
In this section, we show the equivalence of the implicit solvers with their proximal formulation.
-
•
Crank-Nicolson
-
•
BDF2:
-
•
BDF3:
-
•
BDF4:
Appendix C Missing Proofs
Proof of Proposition 3.1.
For any given , recall the definition of in (6).
If is a convex function, clearly, admits a unique minimizer. If is not convex, denote be the smallest eigenvalue of . Direct computation shows that
| (17) |
which indicates that is a convex function if . Notice that , admits a unique minimizer in .
If is not convex, we define . By the coerciveness and continuity of , is a non-empty, bounded, and closed set. Hence, admits a minimizer (not unique) in . We can take , then
which gives us Equation (14). Hence, the scheme is unconditionally energy stable.
For the sequence , since
we have
for some constant that is independent with . Hence
which indicates the convergence of . Moreover, since
we have
so converges to a stationary point of . ∎
Appendix D Some More Experimental Details
D.1 Configurations of solvers for solving the one-dimensional diffusion equation
We list the numerical integration step size and the corresponding final step error of each ODE solver in Table 2. Here, we use FR optimizer to solve the inner optimization problem with step size . We stop the inner solver when .
| Proximal algorithm | Numerical integration step size | Optimization step size | Final step error |
|---|---|---|---|
| Backward Euler | e | ||
| Crank Nicolson | e | ||
| BDF2 | e | ||
| BDF3 | e | ||
| BDF4 | e |
References
- [1] Donald G Anderson. Iterative procedures for nonlinear integral equations. Journal of the ACM (JACM), 12(4):547–560, 1965.
- [2] Kendall Atkinson, Weimin Han, and David E Stewart. Numerical solution of ordinary differential equations, volume 108. John Wiley & Sons, 2011.
- [3] Hédy Attouch, Jérôme Bolte, Patrick Redont, and Antoine Soubeyran. Alternating proximal algorithms for weakly coupled convex minimization problems. applications to dynamical games and pde’s. Journal of Convex Analysis, 15(3):485, 2008.
- [4] Justin Baker, Elena Cherkaev, Akil Narayan, and Bao Wang. Learning pod of complex dynamics using heavy-ball neural odes. arXiv preprint arXiv:2202.12373, 2022.
- [5] Heinz H Bauschke, Patrick L Combettes, et al. Convex analysis and monotone operator theory in Hilbert spaces, volume 408. Springer, 2011.
- [6] Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences, 2(1):183–202, 2009.
- [7] L. Bittner. L. S. Pontryagin, V. G. Boltyanskii, R. V. Gamkrelidze, E. F. Mishechenko, the mathematical theory of optimal processes. VIII + 360 S. New York/London 1962. John Wiley & Sons. Preis 90/–. ZAMM - Journal of Applied Mathematics and Mechanics / Zeitschrift für Angewandte Mathematik und Mechanik, 43(10-11):514–515, 1963.
- [8] Ben Chamberlain, James Rowbottom, Maria I Gorinova, Michael Bronstein, Stefan Webb, and Emanuele Rossi. GRAND: Graph neural diffusion. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 1407–1418. PMLR, 18–24 Jul 2021.
- [9] Pratik Chaudhari, Anna Choromanska, Stefano Soatto, Yann LeCun, Carlo Baldassi, Christian Borgs, Jennifer Chayes, Levent Sagun, and Riccardo Zecchina. Entropy-sgd: Biasing gradient descent into wide valleys. Journal of Statistical Mechanics: Theory and Experiment, 2019(12):124018, 2019.
- [10] Pratik Chaudhari, Adam Oberman, Stanley Osher, Stefano Soatto, and Guillaume Carlier. Deep relaxation: partial differential equations for optimizing deep neural networks. Research in the Mathematical Sciences, 5(3):1–30, 2018.
- [11] Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018.
- [12] Michael A. Cohen and Stephen Grossberg. Absolute stability of global pattern formation and parallel memory storage by competitive neural networks. IEEE Transactions on Systems, Man, and Cybernetics, SMC-13(5):815–826, 1983.
- [13] Talgat Daulbaev, Alexandr Katrutsa, Larisa Markeeva, Julia Gusak, Andrzej Cichocki, and Ivan Oseledets. Interpolation technique to speed up gradients propagation in neural odes. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 16689–16700. Curran Associates, Inc., 2020.
- [14] Thu Dinh, Bao Wang, Andrea Bertozzi, Stanley Osher, and Jack Xin. Sparsity meets robustness: channel pruning for the Feynman-Kac formalism principled robust deep neural nets. In International Conference on Machine Learning, Optimization, and Data Science, pages 362–381. Springer, 2020.
- [15] J.R. Dormand and P.J. Prince. A family of embedded Runge-Kutta formulae. Journal of Computational and Applied Mathematics, 6(1):19–26, 1980.
- [16] Qiang Du and Xiaobing Feng. The phase field method for geometric moving interfaces and their numerical approximations. Handbook of Numerical Analysis, 21:425–508, 2020.
- [17] Emilien Dupont, Arnaud Doucet, and Yee Whye Teh. Augmented neural odes. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [18] Sourav Dutta, Peter Rivera-Casillas, and Matthew W Farthing. Neural ordinary differential equations for data-driven reduced order modeling of environmental hydrodynamics. arXiv preprint arXiv:2104.13962, 2021.
- [19] Chris Finlay, Joern-Henrik Jacobsen, Levon Nurbekyan, and Adam Oberman. How to train your neural ODE: the world of Jacobian and kinetic regularization. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3154–3164. PMLR, 13–18 Jul 2020.
- [20] Reeves Fletcher and Colin M Reeves. Function minimization by conjugate gradients. The computer journal, 7(2):149–154, 1964.
- [21] Amir Gholami, Kurt Keutzer, and George Biros. Anode: Unconditionally accurate memory-efficient gradients for neural odes. arXiv preprint arXiv:1902.10298, 2019.
- [22] Arnab Ghosh, Harkirat Behl, Emilien Dupont, Philip Torr, and Vinay Namboodiri. Steer : Simple temporal regularization for neural ode. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 14831–14843. Curran Associates, Inc., 2020.
- [23] Will Grathwohl, Ricky T. Q. Chen, Jesse Bettencourt, and David Duvenaud. Scalable reversible generative models with free-form continuous dynamics. In International Conference on Learning Representations, 2019.
- [24] Arieh Iserles. A first course in the numerical analysis of differential equations. Number 44. Cambridge university press, 2009.
- [25] Chiyu Jiang, Jingwei Huang, Andrea Tagliasacchi, and Leonidas Guibas. Shapeflow: Learnable deformations among 3d shapes. In Advances in Neural Information Processing Systems, 2020.
- [26] Jacob Kelly, Jesse Bettencourt, Matthew J Johnson, and David K Duvenaud. Learning differential equations that are easy to solve. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 4370–4380. Curran Associates, Inc., 2020.
- [27] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, 2015.
- [28] Yann LeCun and Corinna Cortes. MNIST handwritten digit database. ATT Labs [Online], 2010.
- [29] Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45(1):503–528, 1989.
- [30] Hao Luo and Long Chen. From differential equation solvers to accelerated first-order methods for convex optimization. Mathematical Programming, pages 1–47, 2021.
- [31] Goran Marjanovic and Victor Solo. On optimization and matrix completion. IEEE Transactions on signal processing, 60(11):5714–5724, 2012.
- [32] Stefano Massaroli, Michael Poli, Jinkyoo Park, Atsushi Yamashita, and Hajime Asama. Dissecting neural odes. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 3952–3963. Curran Associates, Inc., 2020.
- [33] Takashi Matsubara, Yuto Miyatake, and Takaharu Yaguchi. Symplectic adjoint method for exact gradient of neural ODE with minimal memory. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, 2021.
- [34] Daniel Matthes and Simon Plazotta. A variational formulation of the bdf2 method for metric gradient flows. ESAIM: Mathematical Modelling and Numerical Analysis, 53(1):145–172, 2019.
- [35] Yurii E Nesterov. A method for solving the convex programming problem with convergence rate . Proceedings of the Russian Academy of Sciences, 269:543–547, 1983.
- [36] Alexander Norcliffe, Cristian Bodnar, Ben Day, Nikola Simidjievski, and Pietro Lió. On second order behaviour in augmented neural odes. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 5911–5921. Curran Associates, Inc., 2020.
- [37] Avik Pal, Yingbo Ma, Viral Shah, and Christopher V Rackauckas. Opening the blackbox: Accelerating neural differential equations by regularizing internal solver heuristics. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8325–8335. PMLR, 18–24 Jul 2021.
- [38] Neal Parikh and Stephen Boyd. Proximal algorithms. Foundations and Trends in optimization, 1(3):127–239, 2014.
- [39] Gabriel Peyré, Marco Cuturi, et al. Computational optimal transport: With applications to data science. Foundations and Trends® in Machine Learning, 11(5-6):355–607, 2019.
- [40] Michael Poli, Stefano Massaroli, Junyoung Park, Atsushi Yamashita, Hajime Asama, and Jinkyoo Park. Graph neural ordinary differential equations. arXiv preprint arXiv:1911.07532, 2019.
- [41] Michael Poli, Stefano Massaroli, Atsushi Yamashita, Hajime Asama, and Jinkyoo Park. Hypersolvers: Toward fast continuous-depth models. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 21105–21117. Curran Associates, Inc., 2020.
- [42] Nicholas G Polson, James G Scott, and Brandon T Willard. Proximal algorithms in statistics and machine learning. Statistical Science, 30(4):559–581, 2015.
- [43] William H Press and Saul A Teukolsky. Adaptive stepsize runge-kutta integration. Computers in Physics, 6(2):188–191, 1992.
- [44] Frank Rosenblatt. Principles of neurodynamics. perceptrons and the theory of brain mechanisms. Technical report, Cornell Aeronautical Lab Inc Buffalo NY, 1961.
- [45] Vincent Roulet and Alexandre d’Aspremont. Sharpness, restart and acceleration. In Advances in Neural Information Processing Systems, pages 1119–1129, 2017.
- [46] Yulia Rubanova, Ricky T. Q. Chen, and David K Duvenaud. Latent ordinary differential equations for irregularly-sampled time series. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- [47] Adil Salim, Anna Korba, and Giulia Luise. The wasserstein proximal gradient algorithm. arXiv preprint arXiv:2002.03035, 2020.
- [48] Jie Shen, Jie Xu, and Jiang Yang. A new class of efficient and robust energy stable schemes for gradient flows. SIAM Review, 61(3):474–506, 2019.
- [49] Endre Süli and David F Mayers. An introduction to numerical analysis. Cambridge university press, 2003.
- [50] Matthew Thorpe, Tan Minh Nguyen, Hedi Xia, Thomas Strohmer, Andrea Bertozzi, Stanley Osher, and Bao Wang. GRAND++: Graph neural diffusion with a source term. In International Conference on Learning Representations, 2022.
- [51] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. In International Conference on Learning Representations, 2018.
- [52] Homer F Walker and Peng Ni. Anderson acceleration for fixed-point iterations. SIAM Journal on Numerical Analysis, 49(4):1715–1735, 2011.
- [53] Bao Wang and Qiang Ye. Stochastic gradient descent with nonlinear conjugate gradient-style adaptive momentum. arXiv preprint arXiv:2012.02188, 2020.
- [54] Yiwei Wang, Jiuhai Chen, Chun Liu, and Lulu Kang. Particle-based energetic variational inference. Statistics and Computing, 31(3):1–17, 2021.
- [55] Louis-Pascal Xhonneux, Meng Qu, and Jian Tang. Continuous graph neural networks. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 10432–10441. PMLR, 13–18 Jul 2020.
- [56] Hedi Xia, Vai Suliafu, Hangjie Ji, Tan Nguyen, Andrea Bertozzi, Stanley Osher, and Bao Wang. Heavy ball neural ordinary differential equations. Advances in Neural Information Processing Systems, 34, 2021.
- [57] Jinchao Xu, Yukun Li, Shuonan Wu, and Arthur Bousquet. On the stability and accuracy of partially and fully implicit schemes for phase field modeling. Computer Methods in Applied Mechanics and Engineering, 345:826–853, 2019.
- [58] Biao Yang, Jiancheng Lyu, Shuai Zhang, Yingyong Qi, and Jack Xin. Channel pruning for deep neural networks via a relaxed groupwise splitting method. In IEEE International Conference on Artificial Intelligence for Industries, pages 97–98, 2019.
- [59] Guandao Yang, Xun Huang, Zekun Hao, Ming-Yu Liu, Serge Belongie, and Bharath Hariharan. Pointflow: 3d point cloud generation with continuous normalizing flows. arXiv, 2019.
- [60] Alexander Zaitzeff, Selim Esedoglu, and Krishna Garikipati. Variational extrapolation of implicit schemes for general gradient flows. SIAM Journal on Numerical Analysis, 58(5):2799–2817, 2020.
- [61] S. Zhang, P. Yin, and J. Xin. Transformed Schatten-1 iterative thresholding algorithms for low rank matrix completion. Comm. Math Sci, 15(3):839–862, 2017.
- [62] Juntang Zhuang, Nicha Dvornek, Xiaoxiao Li, Sekhar Tatikonda, Xenophon Papademetris, and James Duncan. Adaptive checkpoint adjoint method for gradient estimation in neural ODE. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 11639–11649. PMLR, 13–18 Jul 2020.