Pseudo-supervised Deep Subspace Clustering
Abstract
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the -nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems. The source code of our method is available: https://github.com/sckangz/SelfsupervisedSC.
I Introduction
Clustering is one of the fundamental tasks in computer vision, pattern recognition, and machine learning. Several clustering methods have been developed over the last several decades. Some classical methods such as -means [1], agglomerative clustering [2], and spectral clustering [3] have gained a lot of popularity. In recent years, subspace clustering [4] has attracted much attention in handling high-dimensional data.
In particular, graph-based subspace clustering methods are being investigated by many researchers [5, 6, 7, 8, 9, 10, 11, 12]. These methods comprise two individual steps. First, the self-expression property, i.e., each data point is expressed as a linear combination of other points, is used to learn an affinity matrix. Then, spectral clustering is applied to the obtained graph matrix. We can see that the performance of subspace clustering depends heavily on the affinity matrix. Thus, different types of regularizer are used for the affinity matrix, such as the nuclear norm [13, 14], -norm [15], -norm[16], and Frobenius norm [17, 18]. Some recent methods unify graph learning and spectral clustering to benefit from joint learning [19, 20]. Some methods learn graphs in a latent space to enhance their robustness [21, 22]. Kernel subspace clustering is also investigated to explore the nonlinearity of data [23, 24, 25]. Although much progress has been made, shallow methods fall short of reliable discriminative abilities [26].
The tremendous success garnered by deep neural networks (DNNs) has spurred the development of deep clustering. An auto-encoder (AE) is a common building block of many existing deep clustering [27, 28, 29, 30, 31]. In essence, an AE harnesses a self-reconstruction loss to find a latent representation, which captures prominent features of raw data. Inappropriate representation might be detrimental to downstream clustering. For example, [32], first, uses an AE to project data into a lower-dimensional space, then apply -means to partition the embedded data. [28, 27, 29, 33, 34, 35] perform embedding learning and clustering jointly and alternatively, so that the obtained clustering assignment can supervise the encoding transformation and leads to a clustering-friendly representation. [36, 35] design some new objective functions by making some strong assumptions that are not sufficient for any data set. Improved deep embedding for clustering (IDEC) [28] requires a pretraining phase before clustering data and balances the clustering loss with a reconstruction cost. The deep clustering network (DCN) assigns hard labels to samples inducing a discrete optimization process. Deep embedded regularized clustering (DEPICT) [35] uses a relative cross-entropy and a regularization term that imposes the size of each cluster relying on some prior knowledge. Unfortunately, the size of clusters is usually unknown for real unsupervised problems. Based on variational AE, variational deep embedding (VaDE) [34] allows coupling clustering with data generation. However, its latent space could be negatively affected since the mean-field approximation causes information loss. Generative adversarial network (GAN)-based deep adversarial clustering [37] and information maximizing GANs [38] may conversely affect the true intrinsic structure of data since they change the latent space for clustering. Adversarial deep embedded clustering (ADEC) [39] is proposed to balance the tradeoff between feature randomness and drift; however, it lacks stability because of adversarial training. [40] uses a clear continuous objective and integrates cluster number learning and clustering.
Although AE architecture has achieved far-reaching success for representation learning, it has some drawbacks, along with the sole use of reconstruction loss. For instance, the current AE setting enforces the reconstruction of its input regardless of other data points [41, 42]. In another word, the quality of latent representation could be degraded because of the overlook of rich relation information between neighboring points. Ideally, all points should have different importance in the reconstruction cost to reflect their discriminative roles. Therefore, it is problematic to directly combine clustering and reconstruction since the former aims to destroy non-discriminative details, while the latter loses discriminative information [43].
Leaning on the recent development of subspace clustering, deep subspace clustering is drawing attention from researchers. Peng et al. [44] propose a structured AE for subspace clustering by inputting a prior similarity graph from conventional subspace clustering methods. In essence, their approach belongs to a deep clustering method since it implements -means on latent representation and does not learn any graph. Li et al. [45] use an encoder to approximate a low-rank graph. A deep subspace clustering (DSC) network [46] is the most straightforward implementation of a subspace clustering model in DNN. DSC adds a self-expression layer between the encoder and decoder to learn the similarity graph. Based on DSC, adversarial training is further introduced to boost performance [47]. Recently, multiple fully-connected linear layers have been used to capture low-level and high-level information [48]. Applications of DSC to multi-view and multimodal data are also considered [49, 50]. Deep clustering is still a challenging task due to the absence of concrete supervision despite the above progress.
Furthermore, we can observe that the performance of DSC and its variants heavily depends on the quality of latent representations. In addition, self-reconstruction tends to distort relationships between points, which will deteriorate the downstream clustering. Another ignored shortcoming of DSC is that it has a huge memory cost due to the self-expression layer structure, which hinders its applications on large-scale datasets. This explains why all DSC papers use small datasets.
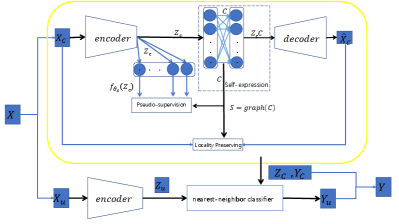
To tackle the above-mentioned issues, in this paper, we develop a pseudo-supervised deep subspace clustering (PSSC) method. The PSSC method aims to learn high-level similarities by feeding pseudo-labels. Specifically, our approach builds upon the general idea of self-training, where a model goes through multiple training iterations. At each iteration, the model uses predictions from the last iteration to relabel unlabeled samples. To achieve this, we introduce a classification module attached to a feature extraction module (encoder) that can use latent representation and similarity graph to construct pseudo-label to supervise the training of feature learning and graph learning [51]. Furthermore, to preserve the local structure and obtain a more informative representation, we adopt a weighted reconstruction loss instead of the widely used self-reconstruction loss in AE. Specifically, each instance is reconstructed by a set of instances weighted by the corresponding relation between them. We adaptively learn them from the self-expression module instead of using fixed relations.
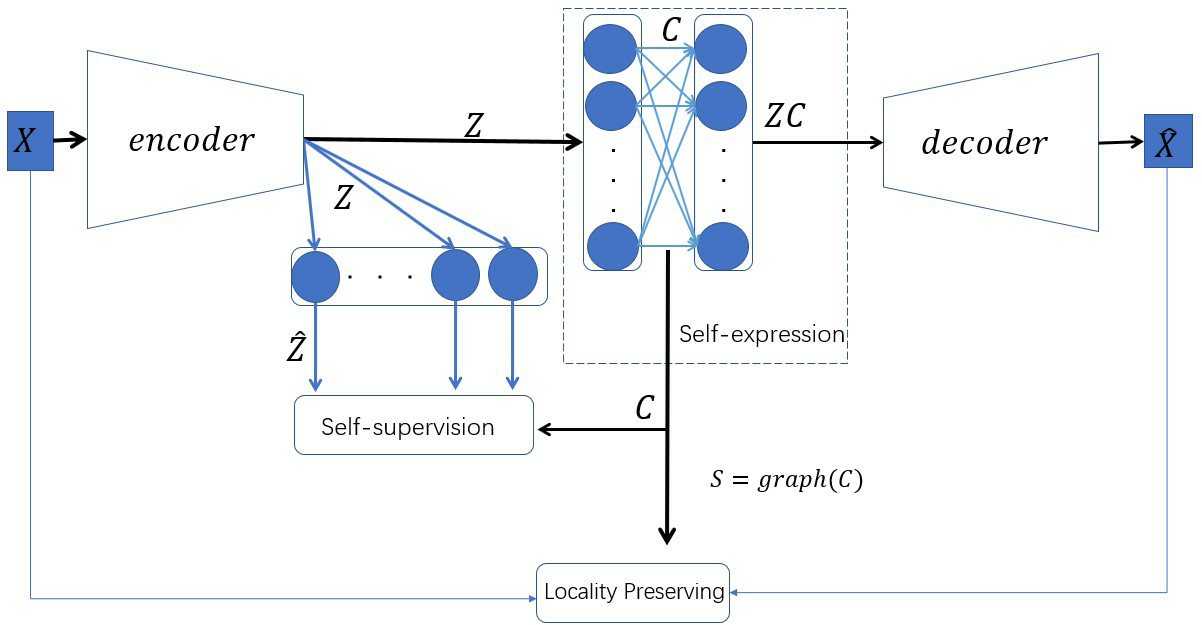
The architecture of our method is shown in Fig.1. The weights of the self-expression layer correspond to the coefficient , i.e., the relations between data samples. Locality preserving ensures the reconstruction of data with less information loss, while the pseudo-supervision guides the training of the entire network. In summary, our contributions can be summarized as follows:
-
•
We propose an efficient training framework that integrates DSC and pseudo-supervision. At the same time, it preserves the local neighborhood structure on the data manifold. Feature extraction and similarity learning benefit from such pseudo-supervision since some data with correct labels will propagate useful information, achieving better pseudo-information for supervision.
-
•
An approach to address the large-scale data challenge is demonstrated, which is the first to handle 100,000 data points for DSC.
-
•
Extensive experiments verify the superiority of our method compared to numerous state-of-the-art subspace models.
II Related Work
In this section, we review some works related to the proposed method.
II-A Deep Clustering
Existing deep clustering methods [27, 52, 53] mainly aim to combine deep feature learning with traditional clustering methods. AE [54] is a popular feature learning architecture for unsupervised tasks. It compresses data into a low-dimensional representation where , reconstructing the original data. It is often composed of an encoder and a decoder with a mirror construction. Their parameters are denoted as and , respectively. Specifically, an AE can be optimized by the following objective function:
| (1) |
For the convenience of notation, we let . Although this basic model has led to far-reaching success for data representation, it forces the reconstruction of its input without considering other data points in data, resulting in information loss and consequently degrades clustering performance [41]. Many methods are proposed to minimize the loss caused by traditional clustering methods to regularize the learning of the latent representation of an AE. In deep manifold clustering [55], the authors interpret the locality of a manifold as similar inputs that should have similar representations and minimize the reconstruction error of itself and its local neighborhood. However, they define reconstruction weights either in a supervised or pre-defined way, and the relations between samples are not flexible for modeling. To get effective representations, other authors manage to keep locality property on the latent space. The deep embedding network [32] combines AE and -means while maintaining locality-preserving and group sparsity constraints on latent representations. Two representations are enforced to be similar if their corresponding raw samples are similar, i.e., the graph manifold assumption. The deep embedded clustering (DEC) [27] method fine-tunes the encoder by minimizing KL divergence between soft assignment and target distribution.
To take advantage of the effective self-expression property in traditional subspace clustering, DSC [46] implements the subspace clustering method in DNNs by adding a novel self-expressive layer between the encoder and decoder, achieving promising results. More recently, based on the framework of [46], a deep adversarial network with a subspace-specific generator and a subspace-specific discriminator are adopted for subspace clustering in [47]. However, the discriminator needs to use the dimension of each subspace, which is usually unknown in practice. By introducing multiple AEs, DSC can be used on multi-view data [50]. Self-paced learning mechanism is also introduced into DSC to boost its generalization ability in [56]. All these methods use the self-reconstruction loss and ignore the local structure information.
II-B Pseudo-supervised Learning
The main challenge for clustering is the lack of labels. Some recent efforts manage to boost clustering performance from two concepts: self-supervision and pseudo-supervision. Self-supervised learning [57, 58] generally needs to design a pretext task, where a target objective can be computed without supervision. It assumes that the learned representations of the pretext task contain high-level semantic information that is useful for solving downstream tasks of interest, such as image classification. Therefore, the success of self-supervision highly depends on the selected pretext. Some popular pretexts examples include predicting the colorization, predicting unpainted patches, and predicting the spatial relationship of different patches and adversarial objective [58, 59].
Pseudo-supervision trains a model using pseudo-labels rather than ground truth labels [51]. In contrast to self-supervision, it does not use any proxy. Pseudo-labeling is a more recent self-training algorithm focusing on image classification [60]. Pseudo-labeling trains a model using labeled data simultaneously with unlabeled data. The corresponding predictions on unlabeled samples are referred to as pseudo-labels [51]. Recent research shows that it is possible to conduct clustering with the help of pseudo-labels. Deep Cluster [33] uses the pseudo-label computed by -means on output features as supervision to guide the training of DNNs. The deep comprehensive correlation mining (DCCM) [61] uses the local robustness assumption and uses pseudo-graphs and pseudo-labels to learn better representations. The self-supervised convolutional subspace clustering [62] introduces a spectral clustering module and a classification module into DSC, i.e., using the clustering results to supervise the training of a network. In practice, the main challenge of pseudo-supervision stems from the fact that some self-acquired labels are unreliable and mismatch the real labels. This can mislead data grouping by learning non-representative features, decreasing the discriminative ability of a model. This observation is verified in prior publications [51, 33].
In this paper, we propose a joint optimization framework by combining DSC and pseudo-supervised learning. In this way, useful pseudo-supervision information from latent representation and self-expression can be used to guide feature and similarity learning, refining pseudo-information.
III Proposed method
In this section, we will formally present our proposed PSSC method, a novel pseudo-supervised deep AE network to learn latent representations and sample relations of data. Our network is composed of a locality preserving module, a self-expression module, and a pseudo-supervision module. These three components are seamlessly interconnected and mutually enhance each other.
III-A Base Model
We will introduce the first two modules. In the next subsection, we focus on the pseudo-supervision module.
Locality Preserving Module. To preserve the local structure, we use a weighted reconstruction for an AE instead of Eq.(1). More specifically, is reconstructed by with weight , where is the similarity between samples and . Samples with larger distances between them should have a lower similarity. Then, we obtain the loss function of our weighted reconstruction as follows:
| (2) |
Since is a symmetric matrix, Eq.(2) can be further transformed as
| (3) |
where diagonal matrix , and is the Laplacian matrix. We can see that the similarity matrix would be crucial to the performance of our network. Unlike many existing work using pre-defined values, which often fail to characterize the true relations between samples [63], we propose to automatically learn from data based on the self-expression concept.
Self-Expression Module. State-of-the-art subspace clustering methods are based on the self-expression property of data, Its basic idea is that each data point can be represented by a linear combination of other data points in the same subspace [5, 6]. The combination coefficient represents the relation between samples. To learn feature representations that are suitable for subspace clustering, the loss function of our self-expression module is
| (4) |
where the first term is a certain regularization function on , and the second term minimizes the reconstruction error in the latent space , and is a tradeoff parameter. Matrix can represent the subspace structure of data, i.e., , if the -th sample and -th sample do not lie in the same subspace. The constraint is optionally used to eliminate a trivial solution of . Same as [46], we add a fully-connected layer without a bias between the encoder and decoder, whose weights represent the coefficient matrix , the so-called self-expression layer, as shown in Fig.1.
Once the self-expression coefficient matrix is obtained, the similarity is usually computed based on . Since the scale of each row and column of the similarity matrix might be different, we use the symmetric normalized Laplacian for scale normalization while maintaining the symmetry of the similarity matrix [3]. Specifically, the normalized degree matrix and normalized Laplacian matrix . Then, we have = . So the loss function of our weighted reconstruction is finally transformed as follows
| (5) |
As the second term of has a constraint for , we can remove the first term of .
III-B Pseudo-Supervision Module
As previously mentioned, learning clustering-friendly representations without leveraging any supervisory signal is an open and challenging problem. In fact, besides feature information, correlations are also helpful for deep image feature learning [61]. Inspired by this, we go one step further and fully exploit the above-learned similarity information. Specifically, we introduce pseudo-graph supervision and pseudo-label supervision to guide the network training by constructing pseudo-graphs and pseudo-labels.
Pseudo-graph Supervision. We introduce a classification layer parameterized by on top of the feature extraction module to produce pseudo-labels. More specifically, we add a fully-connected layer with a softmax function after the encoder, which transforms to , where represents the prediction feature of and is the number of clusters. It has the following properties:
| (6) |
In addition, the distribution of should be consistent with our previously learned similarity graph . Since is learned in the training process, it is a pseudo-graph by default.
The loss induced by pseudo-graph supervision can be defined by
| (7) |
There are many choices for the loss function in the literature. For example, we can use the contrastive Siamese net loss [64, 65] to regularize the distance between two samples and the binary cross-entropy loss [52] to evaluate the similarity. It is worth pointing out that our pseudo-graph is different from that in DAC [52] and DCCM [61]: Unlike previous research that uses a fixed function to calculate pseudo-graphs, we directly learn it from latent representation. This dynamic approach can reveal complex structures hidden in data. In addition, both DAC and DCCM use a threshold, which is hard to select, to find positive pairs. This could involve noisy false positive pairs. By contrast, our assigns a probability to each pair of points.
Pseudo-label Supervision. The correlation explored in previous sections is not transitive, i.e., is not deterministic given and and limited to pairwise samples, which could lead to instability in training. Ideally, a pseudo-graph should have -connected components or partitions, which could be regarded as pseudo-labels [19, 61]. This partition would make the optimal solution in the Eq. (7) lead to one-hot prediction, formulating the pseudo-label as
| (8) |
where represents the -th element of the prediction vector, and its corresponding probability of the predicted pseudo-label is .
In practice, it is difficult to achieve optimal because of non-convexity. Consequently, the prediction would not follow the one-hot property. To address this problem, we set a large threshold for probability to select highly confident pseudo-labels for supervision:
| (9) |
By doing so, only samples with highly confident pseudo-labels contribute to network training. Thus, the pseudo-label supervision loss can be formulated as:
| (10) |
where the loss function is often defined by the cross-entropy loss.
III-C The Unified Formulation
To obtain a unified framework and jointly train the network, we combine loss (4), (5), (7), and (10) and reach the final objective function of PSSC:
| (11) |
where denotes the network parameters, which include encoder parameters , self-expression layer parameters , classification layer parameter and decoder parameters . Note that, the output of the decoder is a function of , , and . All the unknowns in Eq.(11) are functions of the network parameters. This network can be implemented using neural network frameworks and trained by back-propagation. Once the network architecture is optimized, we obtain the lower-dimensional representation and relation matrix .
| Dataset | Samples | Classes | Dimensions |
|---|---|---|---|
| ORL | 400 | 40 | 3232 |
| MNIST | 1,000 | 10 | 2828 |
| Umist | 480 | 20 | 3232 |
| COIL20 | 1,440 | 20 | 3232 |
| COIL40 | 2,880 | 40 | 3232 |
IV Subspace Clustering Experiments
In this section, we evaluate the effectiveness of the proposed PSSC method.
| ORL | MNIST | Umist | COIL20 | COIL40 | |
|---|---|---|---|---|---|
| encoder | 55@5 | 55@15 | 55@20 | 33@15 | 33@20 |
| 33@3 | 33@10 | 33@10 | - | - | |
| 33@3 | 33@5 | 33@5 | - | - | |
| C | 400400 | 10001000 | 480480 | 14401440 | 28802880 |
| decoder | 33@3 | 33@5 | 33@5 | 33@15 | 33@20 |
| 33@3 | 33@10 | 33@10 | - | - | |
| 55@5 | 55@15 | 55@20 | - | - |
IV-A Datasets
We conduct experiments on five benchmark datasets that are commonly used in subspace clustering evaluation because of their relatively high dimensionality. There are two face datasets: ORL, Umist; three object datasets: MNIST, COIL20, and COIL100. Following is the detailed information of these datasets.
-
•
ORL: This dataset comprises 40 subjects, and each subject has 10 images taken with varying poses and expressions.
-
•
MNIST: This dataset contains 10 clusters, including handwritten digits 0-9. Each cluster contains 6,000 images for training and 1,000 images for testing, with a size of 2828 pixels in each image. We use the first 100 images of each digit.
-
•
Umist: This dataset contains 480 images of 20 persons, and each image is taken under very different poses. Each image of the dataset is down-sampled to 3232.
-
•
COIL20: This dataset contains 1,440 gray-scale images of 20 different toys, and the pixels in each image are 3232.
-
•
COIL40: This dataset is composed of 40 classes of 2,880 data points.
The statistics of the datasets are summarized in Table I.
| Dataset | MNIST | ORL | COIL20 | COIL40 | Umist | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MethodsMetrices | ACC | NMI | PUR | ACC | NMI | PUR | ACC | NMI | PUR | ACC | NMI | PUR | ACC | NMI | PUR |
| SSC | 0.4530 | 0.4709 | 0.4940 | 0.7425 | 0.8459 | 0.7875 | 0.8631 | 0.8892 | 0.8747 | 0.7191 | 0.8212 | 0.7716 | 0.6904 | 0.7489 | 0.6554 |
| ENSC | 0.4983 | 0.5495 | 0.5483 | 0.7525 | 0.8540 | 0.7950 | 0.8760 | 0.8952 | 0.8892 | 0.7426 | 0.8380 | 0.7924 | 0.6931 | 0.7569 | 0.6628 |
| KSSC | 0.5220 | 0.5623 | 0.5810 | 0.7143 | 0.8070 | 0.7513 | 0.7087 | 0.8243 | 0.7497 | 0.6549 | 0.7888 | 0.7284 | 0.6531 | 0.7377 | 0.6256 |
| SSC-OMP | 0.3400 | 0.3272 | 0.3560 | 0.7100 | 0.7952 | 0.7463 | 0.6410 | 0.7412 | 0.6667 | 0.4431 | 0.6545 | 0.5250 | 0.6438 | 0.7068 | 0.6171 |
| EDSC | 0.5650 | 0.5752 | 0.6120 | 0.7038 | 0.7799 | 0.7138 | 0.8371 | 0.8828 | 0.8585 | 0.6870 | 0.8139 | 0.7469 | 0.6937 | 0.7522 | 0.6683 |
| LRR | 0.5386 | 0.5632 | 0.5684 | 0.8100 | 0.8603 | 0.8225 | 0.8118 | 0.8747 | 0.8361 | 0.6493 | 0.7828 | 0.7109 | 0.6979 | 0.7630 | 0.6670 |
| LRSC | 0.5140 | 0.5576 | 0.5550 | 0.7200 | 0.8156 | 0.7542 | 0.7416 | 0.8452 | 0.7937 | 0.6327 | 0.7737 | 0.6981 | 0.6729 | 0.7498 | 0.6562 |
| AE+SSC | 0.4840 | 0.5337 | 0.5290 | 0.7563 | 0.8555 | 0.7950 | 0.8711 | 0.8990 | 0.8901 | 0.7391 | 0.8318 | 0.7840 | 0.7042 | 0.7515 | 0.6785 |
| DSC-L1 | 0.7280 | 0.7217 | 0.7890 | 0.8550 | 0.9023 | 0.8585 | 0.9314 | 0.9353 | 0.9306 | 0.8003 | 0.8852 | 0.8646 | 0.7242 | 0.7556 | 0.7204 |
| DSC-L2 | 0.7500 | 0.7319 | 0.7991 | 0.8600 | 0.9034 | 0.8625 | 0.9368 | 0.9408 | 0.9397 | 0.8075 | 0.8941 | 0.8740 | 0.7312 | 0.7662 | 0.7276 |
| DEC | 0.6120 | 0.5743 | 0.6320 | 0.5175 | 0.7449 | 0.5400 | 0.7215 | 0.8007 | 0.6931 | 0.4872 | 0.7417 | 0.4163 | 0.5521 | 0.7125 | 0.5917 |
| DKM | 0.5332 | 0.5002 | 0.5647 | 0.4682 | 0.7332 | 0.4752 | 0.6651 | 0.7971 | 0.6964 | 0.5812 | 0.7840 | 0.6367 | 0.5106 | 0.7249 | 0.5685 |
| DCCM | 0.4020 | 0.3468 | 0.4370 | 0.6250 | 0.7906 | 0.5975 | 0.8021 | 0.8639 | 0.7889 | 0.7691 | 0.8890 | 0.7663 | 0.5458 | 0.7440 | 0.5854 |
| DEPICT | 0.4240 | 0.4236 | 0.3560 | 0.2800 | 0.5764 | 0.1450 | 0.8618 | 0.9266 | 0.8319 | 0.8073 | 0.9291 | 0.8191 | 0.4521 | 0.6329 | 0.4167 |
| DSCDAN | 0.7450 | 0.7110 | 0.7480 | 0.7950 | 0.9135 | 0.8025 | 0.7868 | 0.9131 | 0.7819 | 0.7385 | 0.8940 | 0.7726 | 0.6937 | 0.8816 | 0.7167 |
| PSSCl | 0.7850 | 0.7276 | 0.7860 | 0.8525 | 0.9258 | 0.8775 | 0.9583 | 0.9667 | 0.9853 | 0.8153 | 0.9240 | 0.8538 | 0.7271 | 0.8525 | 0.7750 |
| PSSC | 0.8430 | 0.7676 | 0.8430 | 0.8675 | 0.9349 | 0.8925 | 0.9722 | 0.9779 | 0.9722 | 0.8358 | 0.9258 | 0.8642 | 0.7917 | 0.8670 | 0.8146 |
IV-B Comparison Methods
We compare our methods with both shallow and deep clustering techniques, including low-rank representation (LRR) [66], low-rank subspace clustering (LRSC) [13], sparse subspace clustering (SSC) [5], kernel SSC (KSSC) [67], SSC by orthogonal matching pursuit (SSC-OMP) [68], efficient dense subspace clustering (EDSC) [69], SSC with pre-trained convolutional AE features (AE+SSC), DSC network with -norm (DSC-L1) [46], DSC network with -norm (DSC-L2), deep embedding clustering (DEC) [27], deep -means (DKM) [70], deep comprehensive correlation mining (DCCM) [61], deep embedded regularized clustering (DEPICT) [35], and deep spectral clustering using dual AE network (DSCDAN) [71].
To show the impact of pseudo-supervision, we make an ablation study by removing and in Eq. (11) and term the left model as PSSCl.
IV-C Setup
In our experiments, we use a one-layer convolutional network for the encoder and decoder in COIL20 and COIL40, a three-layer convolutional network for others. The architecture details of the networks are shown in Table II. We choose ReLU as the non-linear activation function and implement our method with TensorFlow.
First, we pre-train the encoder and decoder without the self-expression layer and softmax layer. Then, we fine-tune the entire network and grid searching for . The learning rate is set as 1e-3 in pre-training and 1e-4 in the fine-tuning stage. The contrastive Siamese net loss and cross-entropy loss are adopted for and respectively. For pseudo-labels, threshold is empirically set to 0.8. We use Adam optimizer [72] as the optimizer. The training process is summarized in Algorithm 10.
Similar to DSC [46], after we obtain the relation , we use it to construct an affinity matrix for spectral clustering [3]. To enhance the block-structure and improve clustering accuracy, a typical method employed by various subspace clustering methods is summarized in Algorithm 2, where is empirically selected according to the level of noise and is the maximal intrinsic dimension of subspaces [69]. Specifically, can be determined by the number of nonzero singular values of data points [5]. For these parameters, we use the same setting as our main competitor DSC [46]. To quantitatively assess clustering performance, we adopt three popular evaluation metrics: accuracy (ACC), normalized mutual information (NMI), and purity (PUR).
IV-D Results




Table III shows the clustering results on the benchmark datasets. For each measure, the best methods are highlighted in boldface. We can observe that our method achieves the best performance among all comparison methods. In some cases, PSSC outperforms others by a significant margin. Specifically, we have the following observations.
-
•
PSSC outperforms shallow subspace clustering methods considerably. This is consistent with our expectation and mainly attributes to the powerful representation ability of neural networks.
-
•
PSSC and PSSCl outperform the DSC and other deep clustering methods. In particular, the improvement of PSSCl over DSC verifies the importance of locality preserving since the only difference between these two models stems from AE loss. PSSC enhances DSC by 4.48%, 4.74%, and 3.73% on average in terms of ACC, NMI, and purity, respectively.
-
•
Compared with PSSCl, PSSC always achieves better results, indicating that pseudo-supervision guides feature and relation learning. For instance, with respect to PSSCl, supervision boosts ACC by 5.8% and 6.46% on MNIST and Umist. This demonstrates that pseudo-graphs and pseudo-labels are promising methods for unsupervised tasks.
-
•
In some cases, DEC, DKM, and DCCM perform even worse than shallow approaches. This is because that they use Euclidean distance or cosine distance to evaluate the pairwise relation, which fails to capture the complex manifold structure. In general, the subspace learning approach works much better in this situation because it is originally designed to handle high-dimensional data. In general, the subspace learning approach works much better in this situation.
- •
Furthermore, self-supervised convolutional subspace clustering network (ConvSCN-) [62] and deep subspace clustering (DeepSC) [73] are two recent DSC methods. Since their authors have not published the source code, we directly cite their results on the datasets we used. For example, on COIL20, our proposed method’s ACC (NMI) is 0.9722 (0.9779), while DeepSC achieves 0.9801 (0.9791) and ConvSCN- reaches 0.9767. We can see that the performance of these methods is close. On ORL, our proposed method’s ACC is 0.8675, while ConvSCN- achieves 0.8875. Hence, our method is comparable to ConvSCN- and DeepSC. In fact, both ConvSCN- and DeepSC are not suitable for practical applications since the former involves spectral clustering and the latter needs to solve problem in each epoch, which results in high time complexity. By contrast, our pseudo-supervision is simple yet effective.
Furthermore, to intuitively show the similarity learning merit of our approach, we visualize the affinity matrix of PSSC and DSC in Fig.2, where indicates the similarity between and and brighter pixel means higher similarity. As observed, most of the energy is perfectly located at the block-diagonal pixels. Compared to PSSC, more points of DSC appear in non-diagonal area, which means that they are inaccurately calculated or noisy. This partially explain the good performance of our method.
Fig.3 shows some reconstructed images on MNIST by our method and DSC. The first row is the original images, the second row is the images reconstructed by our PSSC, and third is DSC. We can find out that PSSC recovers the edges pretty well, while the images of DSC are blurred. This is also validated by PSNR value, PSSC achieves 15.54 while DSC gives 15.04. This verifies the drawback of existing self-reconstruction loss commonly used in AE.

IV-E Parameter Analysis
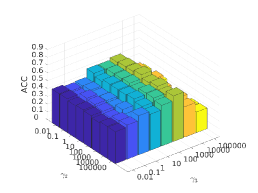
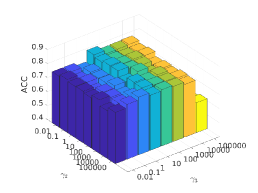
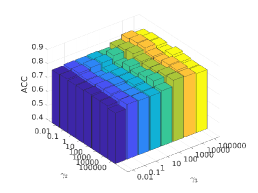
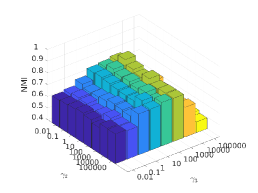
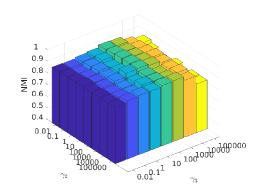
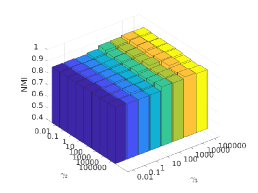
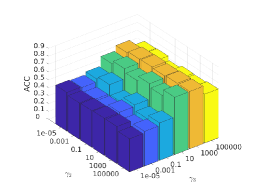
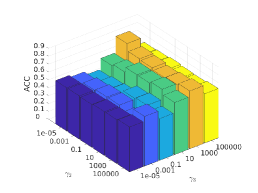
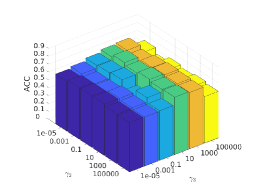
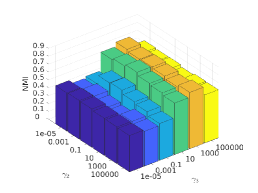
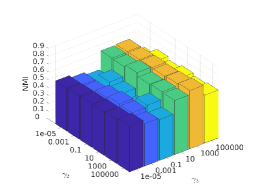
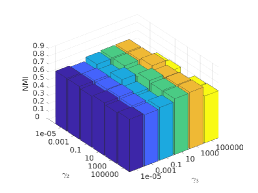
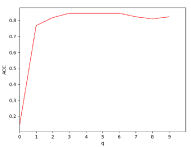
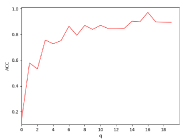
There are three hyper-parameters in PSSC. Generally, they are data-specific, thus, we perform a grid search to find the best parameter values for each dataset. To demonstrate their impacts on clustering performance, we fix value and show the ACC and NMI variations induced by different values in Figs.4-7. Although our method’s performance is influenced by the parameters, our method performs well for a wide range of values.
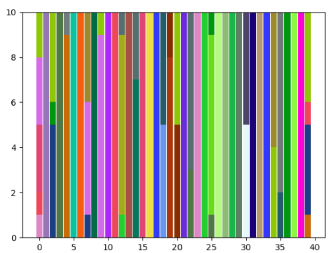
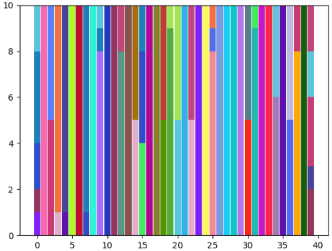
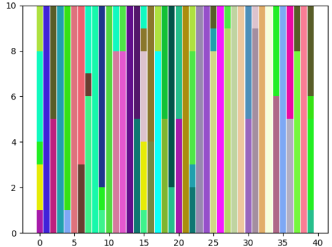
In above analysis, we follow the strategy in clustering community and treat the cluster number as a priori knowledge. In this part, we change to find out its impact on performance of ORL dataset. Since ORL has 40 classes, we set to 45 and 50 to see if no samples get assigned to the additional clusters or different variations within a class. As shown in Fig.8, all clusters are assigned with data points even goes to 50. When , there are more bars that only have a single color than other situations, which indicates correct clustering. When , more bars are with multiple colors, which indicates that the data samples from one class are split into different clusters.
As mentioned before, the intrinsic dimension of subspaces is determined by the data. For example, 3 and 16 are used in DSC for ORL and COIL20 respectively. In Fig.9, we plot the ACC values when varies. It can be seen that the best performance is achieved when is the number of nonzero singular values of data points.
!htbp Dataset Samples Classes Dimensions MNIST 70,000 10 2828 USPS 9,298 10 1616 RCV1 10,000 4 2,000
V Large-scale Experiments
As mention earlier, the self-expression layer has a size of , which hinders the applications of deep subspace clustering in practice. In this section, we show an approach to mitigate this problem and conduct experiments on large-scale datasets.
V-A Datasets
We perform experiments on two object datasets: MNIST and USPS; a text dataset: RCV1. We use the complete MNIST dataset that has 70,000 handwritten digit images in 10 classes. USPS contains 9,298 handwritten digit images in 10 classes. RCV1 contains approximately 810,000 English news stories labeled with a category tree. Following DKM [70], we randomly sample 10,000 documents from the four largest categories: corporate/industrial, government/social, markets and economics of RCV1, each sample only belongs to one of these four categories. Note that, in contrast to experiments in DEC [27] and IDEC [28], we remain samples with multiple labels only if they do not belong to any two of the selected four categories. For text datasets, we select 2,000 words with the highest tf-idf values to represent each document. The statistics of datasets in this experiment are summarized in Table IV.
| Dataset | MNIST | USPS | RCV1 | |||
|---|---|---|---|---|---|---|
| MethodsMetrices | ACC | NMI | ACC | NMI | ACC | NMI |
| KM | 0.535 | 0.498 | 0.673 | 0.614 | 0.508 | 0.313 |
| AE+KM | 0.808 | 0.752 | 0.729 | 0.717 | 0.567 | 0.315 |
| DCN | 0.811 | 0.757 | 0.730 | 0.719 | 0.567 | 0.316 |
| IDEC | 0.867 | 0.864 | 0.752 | 0.749 | 0.595 | 0.347 |
| DKM | 0.840 | 0.796 | 0.757 | 0.776 | 0.583 | 0.331 |
| DCCM | 0.655 | 0.679 | 0.686 | 0.675 | - | - |
| DEPICT | 0.929 | 0.879 | 0.856 | 0.865 | - | - |
| DSCDAN | 0.818 | 0.872 | 0.806 | 0.850 | - | - |
| SCN | 0.871 | 0.781 | 0.875 | 0.797 | - | - |
| PSSC | 0.890 | 0.790 | 0.935 | 0.856 | 0.780 | 0.463 |
V-B Setup
Different from the subspace clustering experiments in the last section, we use latent representations for the clustering task. On the one hand, it can directly demonstrate the quality of our latent representation. On the other hand, it can address out-of-sample and large-scale problems. In particular, we train the network with a reasonable small batch of samples (5,000 samples for each dataset in our experiments); then, we use the similarity matrix to predict the labels of selected samples following the above approach. Finally, we encode all data into latent space and use a nearest-neighbor classifier to predict the labels for the rest of the data. Following this approach, our method can address the out-of-sample problem, which is a long-standing challenge for subspace clustering. The architecture of our method for large-scale experiment is shown in Fig.10. The training process is summarized in Algorithm 3.
For a fair comparison, we use the same encoder/decoder architecture as DEC [27], IDEC [28], and DKM [70]. The encoder is a fully-connected network with dimensions of -500-500-2000- for all datasets, where is the dimension of input features and is the number of clusters. Correspondingly, the decoder is a mirror of the encoder, a fully-connected network with dimensions of -2000-500-500-. A ReLU activation function is used for each layer except the input, output, and self-expression layers. We pre-train the AE in 50 epochs and fine-tune the whole network with an objective function (11) in 30 epochs.
We compare PSSC with -means clustering (KM), an AE with KM applied to latent representation (AE+KM), and recent deep clustering approaches: DCN [29], IDEC [28], DKM [70], DCCM [61], DEPICT [35], DSCDAN [71], and SCN [74]. Note that we did not use DCCM, DEPICT, SCN, and DSCDAN on the text data because they are designed for image datasets. We use the SVD version of it because it gets the best performance in [74].
V-C Results
Table V summarizes the clustering performance of the above methods on three datasets. For each measure, the best result is highlighted in boldface. It can be observed that our method still outperforms recent deep clustering methods. In particular, compared to recent DKM, PSSC improves ACC by 5%, 17.8%, and 19.7% on the three datasets, respectively. With regard to DCCM, ACC improvement is more than 23%. Although the ACC of DEPICT on MNIST is approximately 3.9% higher than our method, our method achieves 7.9% higher on USPS. This performance benefits from embedding samples into subspaces and pseudo-supervising the learning process. SCN is designed for deep subspace clustering on large image datasets. Compared to it, our method improves ACC by 2% and 6% on MNIST and USPS, respectively. Our method shows a convincing ability to address large-scale and out-of-sample problems.
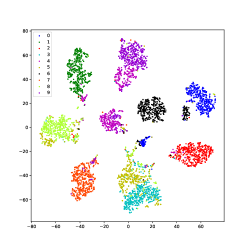
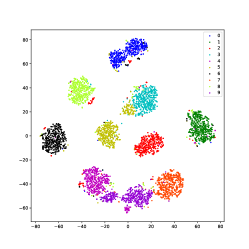
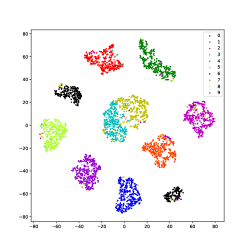
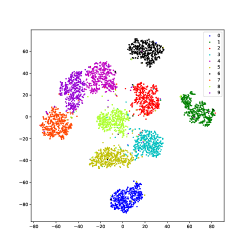
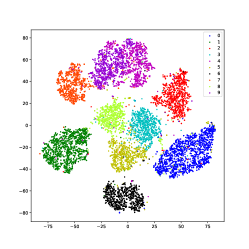
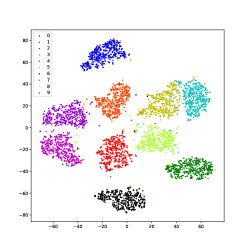
Using USPS data as an example, we use the t-SNE [75] method to visualize the learned latent representations of several methods that produce good performance. As shown in Fig.11, samples of different classes merge in IDEC and DKM, which is because they force samples to move to cluster centers. In DEPICT, the black class is separated into a different place, which could degrade the performance. DSCDSN performs a little better but still has a problem that several clusters are close to each other. The same problem bothers SCN, the pink and the purple classes blend with each other. Our method can precisely project samples of each class into a subspace, thus, samples can be well separated.
VI Conclusion
In this paper, we propose a novel clustering method, named PSSC, by combining DSC and the self-supervised learning approach. The method uses pseudo-labels as supervision and makes full use of relation information to learn discriminative features. To the best of our knowledge, it is the first effort that integrates locality preserving, self-expression, and self-supervision into a unified framework. Extensive experimental results on both small-scale and large-scale datasets have shown the superiority of the proposed method on similarity and representation learning over state-of-the-art methods, including the latest deep learning based techniques. In particular, we demonstrate how to address the large-scale and out-of-sample problem facing subspace clustering. In future work, it is interesting to explore different self-supervision approaches and further investigate the cluster structure of complex sample distributions.
References
- [1] A. K. Jain, “Data clustering: 50 years beyond k-means,” Pattern recognition letters, vol. 31, no. 8, pp. 651–666, 2010.
- [2] S. C. Johnson, “Hierarchical clustering schemes,” Psychometrika, vol. 32, no. 3, pp. 241–254, 1967.
- [3] A. Y. Ng, M. I. Jordan, and Y. Weiss, “On spectral clustering: Analysis and an algorithm,” in Advances in neural information processing systems, 2002, pp. 849–856.
- [4] R. Agrawal, J. Gehrke, D. Gunopulos, and P. Raghavan, “Automatic subspace clustering of high dimensional data for data mining applications,” in Proceedings of the 1998 ACM SIGMOD international conference on Management of data, 1998, pp. 94–105.
- [5] E. Elhamifar and R. Vidal, “Sparse subspace clustering: Algorithm, theory, and applications,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 11, pp. 2765–2781, 2013.
- [6] G. Liu, Z. Lin, S. Yan, J. Sun, Y. Yu, and Y. Ma, “Robust recovery of subspace structures by low-rank representation,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 1, pp. 171–184, 2012.
- [7] C. Tang, X. Liu, X. Zhu, E. Zhu, Z. Luo, L. Wang, and W. Gao, “Cgd: Multi-view clustering via cross-view graph diffusion.” in AAAI Conference on Artificial Intelligence, 2020, pp. 5924–5931.
- [8] J. Lv, Z. Kang, B. Wang, L. Ji, and Z. Xu, “Multi-view subspace clustering via partition fusion,” Information Sciences, vol. 560, pp. 410–423, 2021.
- [9] X. Peng, Z. Yu, Z. Yi, and H. Tang, “Constructing the l2-graph for robust subspace learning and subspace clustering,” IEEE transactions on cybernetics, vol. 47, no. 4, pp. 1053–1066, 2016.
- [10] C. Tang, X. Zhu, X. Liu, M. Li, P. Wang, C. Zhang, and L. Wang, “Learning a joint affinity graph for multiview subspace clustering,” IEEE Transactions on Multimedia, vol. 21, no. 7, pp. 1724–1736, 2019.
- [11] X. Cao, C. Zhang, C. Zhou, H. Fu, and H. Foroosh, “Constrained multi-view video face clustering,” IEEE Transactions on Image Processing, vol. 24, no. 11, pp. 4381–4393, 2015.
- [12] M. Yin, S. Xie, Z. Wu, Y. Zhang, and J. Gao, “Subspace clustering via learning an adaptive low-rank graph,” IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, pp. 1–1, 2018.
- [13] R. Vidal and P. Favaro, “Low rank subspace clustering (lrsc),” Pattern Recognition Letters, vol. 43, pp. 47–61, 2014.
- [14] C. Tang, X. Liu, X. Zhu, J. Xiong, M. Li, J. Xia, X. Wang, and L. Wang, “Feature selective projection with low-rank embedding and dual laplacian regularization,” IEEE Transactions on Knowledge and Data Engineering, pp. 1–1, 2019.
- [15] C.-G. Li and R. Vidal, “Structured sparse subspace clustering: A unified optimization framework,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 277–286.
- [16] Z. Ren, Q. Sun, B. Wu, X. Zhang, and W. Yan, “Learning latent low-rank and sparse embedding for robust image feature extraction,” IEEE Transactions on Image Processing, vol. PP, no. 99, pp. 1–1, 2019.
- [17] C.-Y. Lu, H. Min, Z.-Q. Zhao, L. Zhu, D.-S. Huang, and S. Yan, “Robust and efficient subspace segmentation via least squares regression,” in European conference on computer vision. Springer, 2012, pp. 347–360.
- [18] X. Peng, Z. Yi, and H. Tang, “Robust subspace clustering via thresholding ridge regression,” in Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015.
- [19] Z. Kang, Z. Lin, X. Zhu, and W. Xu, “Structured graph learning for scalable subspace clustering: From single-view to multi-view,” IEEE Transactions on Cybernetics, 2021.
- [20] K. Zhan, C. Zhang, J. Guan, and J. Wang, “Graph learning for multiview clustering,” IEEE transactions on cybernetics, vol. 48, no. 10, pp. 2887–2895, 2017.
- [21] V. M. Patel, H. Van Nguyen, and R. Vidal, “Latent space sparse and low-rank subspace clustering,” IEEE Journal of Selected Topics in Signal Processing, vol. 9, no. 4, pp. 691–701, 2015.
- [22] C. Zhang, H. Fu, Q. Hu, X. Cao, Y. Xie, D. Tao, and D. Xu, “Generalized latent multi-view subspace clustering,” IEEE transactions on pattern analysis and machine intelligence, vol. 42, no. 1, pp. 86–99, 2018.
- [23] M. Yin, Y. Guo, J. Gao, Z. He, and S. Xie, “Kernel sparse subspace clustering on symmetric positive definite manifolds,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 5157–5164.
- [24] Z. Kang, C. Peng, Q. Cheng, X. Liu, X. Peng, Z. Xu, and L. Tian, “Structured graph learning for clustering and semi-supervised classification,” Pattern Recognition, vol. 110, p. 107627, 2021.
- [25] S. Xiao, M. Tan, D. Xu, and Z. Y. Dong, “Robust kernel low-rank representation,” IEEE transactions on neural networks and learning systems, vol. 27, no. 11, pp. 2268–2281, 2015.
- [26] Z. Ma, Z. Kang, G. Luo, L. Tian, and W. Chen, “Towards clustering-friendly representations: Subspace clustering via graph filtering,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 3081–3089.
- [27] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised deep embedding for clustering analysis,” in International conference on machine learning, 2016, pp. 478–487.
- [28] X. Guo, L. Gao, X. Liu, and J. Yin, “Improved deep embedded clustering with local structure preservation.” in IJCAI, 2017, pp. 1753–1759.
- [29] B. Yang, X. Fu, N. D. Sidiropoulos, and M. Hong, “Towards k-means-friendly spaces: Simultaneous deep learning and clustering,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 3861–3870.
- [30] C. Zhang, Y. Liu, and H. Fu, “Ae2-nets: Autoencoder in autoencoder networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 2577–2585.
- [31] Z. Kang, X. Lu, Y. Lu, c. Peng, W. Chen, and Z. Xu, “Structure learning with similarity preserving,” Neural Networks, vol. 129, pp. 138–148, 2020.
- [32] P. Huang, Y. Huang, W. Wang, and L. Wang, “Deep embedding network for clustering,” in 2014 22nd International Conference on Pattern Recognition. IEEE, 2014, pp. 1532–1537.
- [33] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 132–149.
- [34] Z. Jiang, Y. Zheng, H. Tan, B. Tang, and H. Zhou, “Variational deep embedding: an unsupervised and generative approach to clustering,” in Proceedings of the 26th International Joint Conference on Artificial Intelligence, 2017, pp. 1965–1972.
- [35] K. Ghasedi Dizaji, A. Herandi, C. Deng, W. Cai, and H. Huang, “Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 5736–5745.
- [36] M. Jabi, M. Pedersoli, A. Mitiche, and I. B. Ayed, “Deep clustering: On the link between discriminative models and k-means,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019.
- [37] W. Harchaoui, P.-A. Mattei, and C. Bouveyron, “Deep adversarial gaussian mixture auto-encoder for clustering,” in Workshop of the 5th International Conference on Learning Representations (ICLR)., 2017.
- [38] X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel, “Infogan: Interpretable representation learning by information maximizing generative adversarial nets,” in Advances in neural information processing systems, 2016, pp. 2172–2180.
- [39] N. Mrabah, M. Bouguessa, and R. Ksantini, “Adversarial deep embedded clustering: on a better trade-off between feature randomness and feature drift,” arXiv preprint arXiv:1909.11832, 2019.
- [40] S. A. Shah and V. Koltun, “Robust continuous clustering,” Proceedings of the National Academy of Sciences, vol. 114, no. 37, pp. 9814–9819, 2017.
- [41] S. Wang, Z. Ding, and Y. Fu, “Feature selection guided auto-encoder,” in Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [42] Z. Kang, X. Lu, J. Liang, K. Bai, and Z. Xu, “Relation-guided representation learning,” Neural Networks, vol. 131, pp. 93–102, 2020.
- [43] N. Mrabah, N. M. Khan, R. Ksantini, and Z. Lachiri, “Deep clustering with a dynamic autoencoder: From reconstruction towards centroids construction,” arXiv preprint arXiv:1901.07752, 2019.
- [44] X. Peng, J. Feng, S. Xiao, W.-Y. Yau, J. T. Zhou, and S. Yang, “Structured autoencoders for subspace clustering,” IEEE Transactions on Image Processing, vol. 27, no. 10, pp. 5076–5086, 2018.
- [45] J. Li and H. Liu, “Projective low-rank subspace clustering via learning deep encoder,” in IJCAI, 2017.
- [46] P. Ji, T. Zhang, H. Li, M. Salzmann, and I. Reid, “Deep subspace clustering networks,” in Advances in Neural Information Processing Systems, 2017, pp. 24–33.
- [47] P. Zhou, Y. Hou, and J. Feng, “Deep adversarial subspace clustering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 1596–1604.
- [48] M. Kheirandishfard, F. Zohrizadeh, and F. Kamangar, “Multi-level representation learning for deep subspace clustering,” in The IEEE Winter Conference on Applications of Computer Vision, 2020, pp. 2039–2048.
- [49] M. Abavisani and V. M. Patel, “Deep multimodal subspace clustering networks,” IEEE Journal of Selected Topics in Signal Processing, vol. 12, no. 6, pp. 1601–1614, 2018.
- [50] P. Zhu, B. Hui, C. Zhang, D. Du, L. Wen, and Q. Hu, “Multi-view deep subspace clustering networks,” arXiv preprint arXiv:1908.01978, 2019.
- [51] D.-H. Lee, “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks,” in Workshop on challenges in representation learning, ICML, vol. 3, 2013, p. 2.
- [52] J. Chang, L. Wang, G. Meng, S. Xiang, and C. Pan, “Deep adaptive image clustering,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 5879–5887.
- [53] J. Yang, D. Parikh, and D. Batra, “Joint unsupervised learning of deep representations and image clusters,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 5147–5156.
- [54] Y. Bengio, P. Lamblin, D. Popovici, and H. Larochelle, “Greedy layer-wise training of deep networks,” in Advances in neural information processing systems, 2007, pp. 153–160.
- [55] D. Chen, J. Lv, and Y. Zhang, “Unsupervised multi-manifold clustering by learning deep representation,” in Workshops at the Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [56] Y. Jiang, Z. Yang, Q. Xu, X. Cao, and Q. Huang, “When to learn what: Deep cognitive subspace clustering,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 718–726.
- [57] L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” arXiv preprint arXiv:1902.06162, 2019.
- [58] A. Kolesnikov, X. Zhai, and L. Beyer, “Revisiting self-supervised visual representation learning,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2019, pp. 1920–1929.
- [59] O. Kilinc and I. Uysal, “Learning latent representations in neural networks for clustering through pseudo supervision and graph-based activity regularization,” in ICLR, 2018.
- [60] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
- [61] J. Wu, K. Long, F. Wang, C. Qian, C. Li, Z. Lin, and H. Zha, “Deep comprehensive correlation mining for image clustering,” in The IEEE International Conference on Computer Vision (ICCV), October 2019.
- [62] J. Zhang, C.-G. Li, C. You, X. Qi, H. Zhang, J. Guo, and Z. Lin, “Self-supervised convolutional subspace clustering network,” in Proceedings of the International Conference on Computer Vision, 2019, pp. 5473–5482.
- [63] Z. Kang, H. Pan, S. C. H. Hoi, and Z. Xu, “Robust graph learning from noisy data,” IEEE Transactions on Cybernetics, vol. 50, no. 5, pp. 1833–1843, 2020.
- [64] J. Bromley, I. Guyon, Y. LeCun, E. Säckinger, and R. Shah, “Signature verification using a” siamese” time delay neural network,” in Advances in neural information processing systems, 1994, pp. 737–744.
- [65] Y. Luo, J. Zhu, M. Li, Y. Ren, and B. Zhang, “Smooth neighbors on teacher graphs for semi-supervised learning,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8896–8905.
- [66] G. Liu, Z. Lin, S. Yan, J. Sun, Y. Yu, and Y. Ma, “Robust recovery of subspace structures by low-rank representation,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 1, pp. 171–184, 2013.
- [67] V. M. Patel and R. Vidal, “Kernel sparse subspace clustering,” in Image Processing (ICIP), 2014 IEEE International Conference on. IEEE, 2014, pp. 2849–2853.
- [68] C. You, D. Robinson, and R. Vidal, “Scalable sparse subspace clustering by orthogonal matching pursuit,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3918–3927.
- [69] P. Ji, M. Salzmann, and H. Li, “Efficient dense subspace clustering,” in Applications of Computer Vision (WACV), 2014 IEEE Winter Conference on. IEEE, 2014, pp. 461–468.
- [70] M. M. Fard, T. Thonet, and E. Gaussier, “Deep -means: Jointly clustering with -means and learning representations,” arXiv preprint arXiv:1806.10069, 2018.
- [71] X. Yang, C. Deng, F. Zheng, J. Yan, and W. Liu, “Deep spectral clustering using dual autoencoder network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4066–4075.
- [72] D. P. Kingma and J. L. Ba, “Adam: Amethod for stochastic optimization,” in Proc. 3rd Int. Conf. Learn. Representations, 2014.
- [73] X. Peng, J. Feng, J. T. Zhou, Y. Lei, and S. Yan, “Deep subspace clustering,” IEEE transactions on neural networks and learning systems, vol. 31, no. 12, pp. 5509–5521, 2020.
- [74] T. Zhang, P. Ji, M. Harandi, R. Hartley, and I. Reid, “Scalable deep k-subspace clustering,” in Asian Conference on Computer Vision. Springer, 2018, pp. 466–481.
- [75] L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008.