Quantification of Risk in Classical Models of Finance
Abstract
This paper enhances the pricing of derivatives as well as optimal control problems to a level comprising risk. We employ nested risk measures to quantify risk, investigate the limiting behavior of nested risk measures within the classical models in finance and characterize existence of the risk-averse limit. As a result we demonstrate that the nested limit is unique, irrespective of the initially chosen risk measure. Within the classical models risk aversion gives rise to a stream of risk premiums, comparable to dividend payments. In this context we connect coherent risk measures with the Sharpe ratio from modern portfolio theory and extract the Z-spread—a widely accepted quantity in economics to hedge risk.
The results for European option pricing are then extended to risk-averse American options, where we study the impact of risk on the price as well as the optimal time to exercise the option.
We also extend Merton’s optimal consumption problem to the risk-averse setting.
Keywords: Risk measures, Optimal control, Black–Scholes
Classification: 90C15, 60B05, 62P05
1 Introduction
This paper studies discrete classical models in finance under risk aversion and their behavior in a high-frequency setting. Using nested risk measures we first study risk aversion in the multiperiod model.
We develop risk aversion in a discrete time and discrete space setting and find an important consistency property of nested risk measures. This consistency property, termed divisibility, is crucial in high-frequency trading environments. For this, our study of risk-averse models extends to continuous time processes as well. This very property allows consistent decision making, i.e., decisions, which are independent of individually chosen discretizations or trading frequencies. Our results also give rise to a generalized Black–Scholes framework, which incorporates risk aversion in addition.
Riedel (2004) has introduced risk measures in a dynamic setting. Later, Cheridito et al. (2004) study risk measures for bounded càdlàg processes and Cheridito et al. (2006) also discuss risk measures in a discrete time setting. Ruszczyński and Shapiro (2006) introduce nested risk measures, for which Philpott et al. (2013) provide an economic interpretation as an insurance premium on a rolling horizon basis. For a recent discussion on risk measures and dynamic optimization we refer to De Lara and Leclère (2016). Applications can be found in Philpott and de Matos (2012) or Maggioni et al. (2012), e.g., where stochastic dual dynamic programming methods are addressed, see also Guigues and Römisch (2012).
Divisibility is an indispensable prerequisite in defining an infinitesimal generator based on discretizations. This generator, called risk generator, constitutes the risk-averse assessment of the dynamics of the underlying stochastic process. Using the risk generator we characterize the existence of the risk-averse limit of discrete pricing models. For coherent risk measures and Itô diffusion processes the risk generator constitutes a nonlinear operator, comparable to the classical infinitesimal generator but with an additional term, accounting for risk, which takes the form
Here, is a scalar expressing the degree of risk aversion and is the volatility of the diffusion process describing the asset price. It turns out that the risk generator only depends on the risk measure through the coefficient of risk aversion . This surprising feature has important conceptual implications, as evaluating a risk measure is often an optimization problem itself. As well we derive that the scaling quantity allows the economic interpretation of a Sharpe ratio and is the Z-spread.
Using the risk generator we derive a nonlinear Black–Scholes equation, which we relate to the Black–Scholes formula for dividend paying stocks proposed by Merton (1973). Moreover we relate risk-averse pricing models to foreign exchange options models as in Garman and Kohlhagen (1983). Nonlinear Black–Scholes equations have been discussed previously in Barles and Soner (1998) and Ševčovič and Žitňanská (2016) in the context of modeling transaction costs. There, the nonlinearity is in the second derivative. In contrast, risk aversion leads to drift uncertainty and causes nonlinearity in the first derivative.
Very different to our approach, Stadje (2010) studies the convergence properties of discretizations of dynamic risk measures based on backwards stochastic differential equations introduced in Pardoux and Peng (1990) (see also Delong (2013) for an overview). Ruszczyński and Yao (2015) then derive risk-averse Hamilton–Jacobi–Bellmann equations based on these backwards stochastic differential equations.
For coherent risk measures we derive an explicit solution for the European option pricing problem. We show that risk aversion expressed via coherent risk measures can be interpreted either as an extra dividend payment or capital injection. Furthermore we relate risk-aversion to a change of currency as in the foreign exchange option model. The amount of the dividend payment or, equivalently, the interest rate in the risk-averse currency, is given by a multiple of the Sharpe ratio and the volatility of the underlying stock. This ratio, which expresses risk aversion, arises for any coherent risk measure and does not depend on a specific market model such as the Black–Scholes model. However, as our focus is on classical models, we restrict ourselves to Itô diffusion processes.
Using a free boundary formulation we extend the analysis from European to American option pricing. For the Black–Scholes option pricing of European and American options, risk-aversion naturally leads to a bid-ask spread, which we quantify explicitly.
Similarly we extend the Merton optimal consumption problem to a risk-averse setting. We elaborate on the optimal controls and show that risk-aversion reduces the investment in risky assets and increases consumption. We observe the same pattern as for European and American options, that is, risk-aversion corrects the drift of the underlying market model. For all classical models discussed here, the risk-averse assessment still allows explicit pricing and control formulae.
2 Preliminaries on risk measures
Recall the definition of law invariant, coherent risk measures defined on some vector space of -valued random variables first. They satisfy the following axioms introduced by Artzner et al. (1999).
-
A1.
Monotonicity: , provided that almost surely;
-
A2.
Translation equivariance: for ;
-
A3.
Subadditivity: ;
-
A4.
Positive homogeneity: for ;
-
A5.
Law invariance: , whenever and have the same law, i.e., for all .
The expectation () is also a law invariant coherent risk measure, expressing risk-neutral behavior. In contrast to the risk-neutral setting, the risk-averse setting distinguishes between and . As a result of111The inequality implies that .
we will later identify with the seller’s ask price and with the buyer’s bid price in the option pricing problems discussed below.
2.1 Nested risk measures
We consider a filtered probability space and associate with stage or time. For the discussion of risk in a dynamic setting we introduce nested risk measures corresponding to the evolution of risk over time. Nested risk measures are compositions of conditional risk measures (cf. Pflug and Römisch (2007)).
Recall that a coherent risk measures can be represented by
| (1) |
where is a convex set of probability measures absolutely continuous with respect to (cf. also Delbaen (2002)). We assume throughout that for some fixed . Following Ruszczyński and Shapiro (2006), we then introduce conditional versions of the risk measure conditioned on the sigma algebra . Note that the conditional risk measures satisfy conditional versions of the Axioms A1–A5 above. For the construction of and further details we refer the interested reader also to Shapiro et al. (2014, Section 6.8.2).
We now introduce nested risk measures in discrete time.
Definition 1 (Nested risk measures).
The nested risk measure for the partition at times is
| (2) |
where is a family of conditional risk measures.
Similar as above, we distinguish the buyer’s and seller’s perspective and consider the bid price
as well as the ask price in (2).
2.2 Nested risk measures for discrete processes
To elaborate key properties of nested risk measures as defined in (2) we discuss the binomial model, well-known from finance, by employing the mean semi-deviation, a coherent risk measure satisfying all Axioms A1–A5 above. Particularly, we expose that only specific choices of parameters can lead to consistent models.
Definition 2 (Semi-deviation).
The mean semi-deviation risk measure of order and at level is
The binomial model.
Consider the stochastic process with initial state and Markovian transitions with
| (3) |
where
It holds that . In stochastic finance, the process models the evolution of a stock over time with respect to the risk-neutral risk measure, where is the risk free interest rate.
We can evaluate various classical coherent risk measures for this binomial model explicitly. The following remark addresses the mean semi-deviation for the one-period binomial model (cf. Figure 1a) as well as the nested mean semi-deviation for the -period model in (Figure 1b).
Remark 3 (The mean semi-deviation for the binomial model).
Consider the single stage setting in Figure 1a first. The risk-averse bid price for the stock employing the mean semi-deviation of order with risk level in the binomial model is
Involving the new probability weights
| (4) |
we find
We now repeat this observation in stages and consider an -period binomial model with step size , i.e., , cf. Figure 1b. The nested mean semi-deviation for the vector of constant risk levels satisfies
where the last expectation is with respect to the probability measure
The limit
| (5) |
is non-degenerate for , provided that . Based on the central limit theorem, the limit (5) then follows a standard normal distribution.
3 The risk-averse limit of discrete option pricing models
Most well-known coherent risk measures in the literature as the Average Value-at-Risk, the Entropic Value-at-Risk as well as the mean semi-deviation involve a parameter which accounts for the degree of risk aversion. As Remark 3 elaborates, the nested risk-averse binomial model does not necessarily lead to a well-defined limit. It is essential to relate the coefficient of risk aversion of the conditional risk measures to its time period. We therefore introduce the notion of divisible coherent risk measures. The divisibility property is central in discussing the limiting behavior of risk-averse economic models.
Definition 4 (Divisible families of risk measures).
Let be fixed. A family of coherent measures of risk is called divisible, if the following two conditions are satisfied:
-
1.
For normally distributed,
(6) for some .
-
2.
Moreover there is a constant (independent of and ) such that
for all with .
We call a nested risk measure divisible if every conditional risk measure is divisible, i.e., the limit in (6) holds for random variables which are conditionally normally distributed and
for some constant .
Remark 5.
The (conditional) expectation is divisible with . For many other risk measures, the parameters can be adjusted. Candidates for risk measures satisfying this condition are spectral risk measures for which the spectral density is bounded in the norm for . The mean semi-deviation risk measure satisfies the divisibility property as well.
Lemma 6.
For and , the family
of mean semi-deviations is divisible with limit
Proof.
The second part of Definition 4 is satisfied as for such that we have
Let , then
Employing the Gamma function, the latter integral is
Taking the -th root and multiplying by we obtain
the assertion. ∎
We now extend nested risk measures to continuous time and demonstrate that the extension is well-defined for divisible families of risk measures. As a result, we show that the risk-averse binomial option pricing model converges exactly for divisible families of risk measures.
Definition 7 (Nested risk measures).
Let , and let be divisible for every partition , cf. Definition 1. The nested risk measure in continuous time for a random variable is
| (7) |
where the almost sure limit is among all partitions with mesh size tending to zero for those random variables , for which the limit exists.
The following proposition evaluates the nested mean-semideviation for the Wiener process, the basic building block of diffusion processes and thus illustrates the main purpose of the divisibility condition.
Proposition 8 (Nested mean semi-deviation for the Wiener process).
Let be a Wiener process and a partition of with . For the family of conditional risk measures , the nested mean semi-deviation is
| (8) |
where is a vector of risk levels.
Proof.
Remark 9.
For constant risk levels we obtain
the accumulated risk grows linearly in time.
3.1 The risk generator
This section addresses nested risk measures for Itô processes. Furthermore, we characterize convergence under risk using a natural condition involving normal random variables and introduce a nonlinear operator, the risk generator, which also allows discussing risk-averse optimal control problems.
It is well-known that the binomial model in Figure 1b converges to the geometric Brownian motion. We therefore discuss Itô processes solving the stochastic differential equation
| (9) | ||||
for . We assume that following (9) is well-defined and satisfy the so-called usual conditions of Øksendal (2003, Theorem 5.2.1).
We introduce the risk generator for divisible families of coherent risk measures. The risk generator describes the momentary evolution of the risk of the stochastic process.
Definition 10 (Risk generator).
Let be a continuous time process and be a family of divisible risk measures. The risk generator based on is
| (10) |
for those functions , for which the limit exists.
Using the ideas from Proposition 8 we obtain explicit expressions for the risk generator for Itô diffusion processes.
Proposition 11 (Risk generator).
Let the family be divisible for some fixed. Let be the solution of (9) and such that is Hölder continuous for in -th mean, i.e., there exists such that and
| (11) |
Then the risk generator based on is given by the nonlinear differential operator
| (12) |
Remark 12.
In the appendix we provide a sufficient condition for the Assumption (11).
Proof.
By assumption, and hence we may apply Itô’s formula. For convenience and ease of notation we set and . In this setting, Eq. (10) rewrites as
To show (12) for each fixed it is enough to show that
| (13) |
Using the properties A2–A4 of coherent risk measures together with the triangle inequality we bound the left side of (13) by
| (14) |
We continue by looking at each term separately. Note that is continuous almost surely and hence the mean value theorem for definite integrals implies that there exists a such that
From continuity of in the norm we may conclude
Note that the stochastic integral term in (14) can be bounded by
where converges to and hence
Furthermore, the stochastic integral is a continuous martingale with and by divisibility there exists a constant independent of and such that
Applying the Burkholder–Davis–Gundy inequality implies the upper bound
for some constant depending on . By assumption there exists a random such that
Therefore,
such that vanishes for , which concludes the proof. ∎
Remark 13 (Relation to -expectation).
The risk generator can be decomposed as the sum of the classical generator plus the nonlinear term . The additional risk term is a directed drift term, where the uncertain drift scales with volatility and the coefficient , which expresses risk aversion. We want to emphasize that the nonlinear term is exactly the driver of a backwards stochastic differential equation describing a coherent risk measure, also known as -expectation. Our approach is thus a constructive interpretation of the dynamic risk measures discussed in Peng (2004); Delong (2013).
For absent risk, , we obtain the classical – risk-neutral – infinitesimal generator. Furthermore, if , i.e., no randomness occurs in the model, the generator reduces to a first order differential operator describing the dynamics of a deterministic system, where risk does not apply.
3.2 Dynamic programming
This section introduces risk-averse dynamic equations using nested risk measures. In what follows we consider the value function involving nested risk measures defined by
| (15) |
Here, is a discount factor and a terminal payoff function. The structure of nested risk measures allows extending the dynamic programming principle to the risk-averse setting.
Lemma 14 (Dynamic programming principle).
Let and , then it holds that
| (16) |
Proof.
By definition of the risk-averse value function (15) it holds that
and hence the construction of the nested risk measure gives
which shows the assertion. ∎
To derive the dynamic equations for we rearrange (16) in the form
| (17) |
and let . The following theorem employs the risk generator to obtain dynamic equations for the risk-averse value function (15).
Theorem 15.
Proof.
Let be fixed. Similarly to the risk-neutral case we define
By the Itô formula, the process satisfies
As is normally distributed it follows from divisibility that
and thus following the lines of the proof of Proposition 11 shows
demonstrating the assertion. ∎
Remark 16 (Optimal controls).
The dynamic programming principle and Theorem 15 are usually considered in an environment involving adapted controls . This extends to the risk-averse setting as well. Here, we consider the value function
where is a controlled diffusion process (see Fleming and Soner (2006)). Following the ideas in Fleming and Soner (2006) and using the structure of nested risk measures as in the proof of Lemma 14 we may derive dynamic programming equations as
Moreover, following standard arguments, the Hamilton–Jacobi–Bellman equation
characterizes the value function . We resume this discussion in Section 5 below.
4 Pricing of options under risk
The previous section discusses a discrete, risk-averse binomial option pricing problem and studies the divisibility property of families of risk measures. In this section we study the risk-averse value functions of the limiting process of the binomial tree process, i.e., the geometric Brownian motion. In the risk-averse setting we find again explicit formulae. The resulting explicit pricing formulae lead us to interpret risk aversion as dividend payments and to relate the risk level to the Sharpe ratio. Moreover, we establish the relationship between divisibility and the convergence of binomial models under risk.
Consider a market with one riskless asset (a bond, e.g.) and a risky asset, usually a stock. The return of the riskless asset is constant and denoted by . As usual in the classical Black–Scholes framework, the underlying stock is modeled by a geometric Brownian motion following the stochastic differential equation
| (19) |
with initial value .
4.1 The risk-averse Black–Scholes model for European options
Similarly as above we distinguish the risk-averse value function
| (20) |
for the bid price and the corresponding value function for the ask price given by
| (21) |
Notice that the discount rate is the same as in the dynamics (19) of the stock . In the risk-neutral setting the bid and ask prices coincide.
Theorem 15 shows that the risk-averse value function (20) of the bid price satisfies the PDE
| (22) | ||||
the terminal value is the payoff function for either the European put or call option. Similarly, the following PDE describes the ask price ,
| (23) | ||||
Notice that (22) and (23) differ only in the sign of the nonlinear term, showing again that in the risk-neutral setting (i.e., the bid and ask prices coincide. We have the following explicit solution of (22) and (23) for the price of the call option.
Proposition 17 (Call option).
Let , define the auxiliary functions (cf. Delbaen and Schachermayer (2006, Section 4.4))
| (24) |
and the value functions
| (25) |
where denotes the cumulative distribution function of the standard normal distribution. Then solves the risk-averse Black–Scholes PDE (23) for the ask price, while solves (22), the corresponding PDE for the bid price; further, we have that .
We can solve the problem for the European put option similarly.
Proposition 18 (European Put option).
4.2 Rationale of risk aversion in the new formulae
4.2.1 On the nature of the risk level
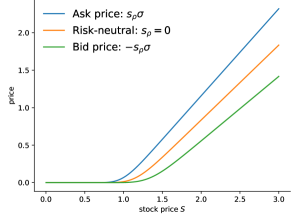
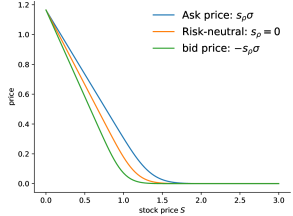
The Propositions 17 and 18 show that the value function for the risk-averse European option pricing problem can be identified with the risk-neutral problem, where the stock pays dividends. In case of the bid price of a European call option the risk dividend is . Similarly, the dividend for the bid price for a European put option is , thus negative. For an increasing risk aversion coefficients , the bid price for the put and the call price decrease. This monotonicity reverses for the ask price. It is important to note that stocks do not pay negative dividends and thus negative risk dividends may be interpreted as a premium for holding the option rather than a dividend payment from the underlying stock.
The value functions (25) and (26) can also be interpreted within the framework of the Garman–Kohlhagen model on foreign exchange options. In this sense corresponds to the interest rate in the foreign currency. We illustrate this for the bid price of a European call option. Recall that the value of a call option into a foreign currency with interest rate satisfies
where is the interest in the domestic currency and
Comparing with Equation (25) we notice that can be identified with the domestic interest rate () and with the foreign interest rate (), which bears the risk. The option price represents the value in domestic currency of a call option. Risk aversion is encoded in the underlying, which is the foreign currency.
A risk-averse investor assumes a return for the underlying asset. Subsection 4.2.2 below then identifies with . Comparing with the Garman–Kohlhagen model we observe that the foreign currency encodes the spread between the risk-neutral and the risk-averse setting.
4.2.2 Illustration of the risk level
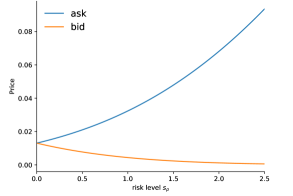
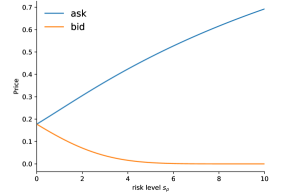
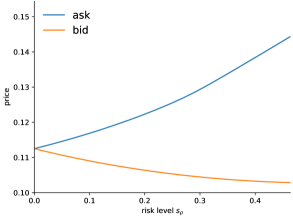
Figure 2 displays risk-averse prices for put and call options from buyer’s and seller’s perspectives. As a reference we include the risk-neutral Black–Scholes price as well. For this illustration we choose with strike , the interest rate is and the volatility is . Figure 3 exhibits the bid-ask spread, which is present in the risk-averse situation.
4.2.3 Discussion of the risk level
The Sharpe ratio is
where is the mean return of an asset with volatility and is the risk free interest rate. Comparing units in (24) we see that is an interest rate and hence has unit
the same unit as the Sharpe ratio.
To explore that the risk-aversion coefficient has the structure of a Sharpe ratio denote by the mean return a risk-averse investor expects. Depending on the sign we may equate
| (27) |
with as in (6) above. The parallel shift
over the risk free interest derived from (27) is known as Z-spread in economics.
Remark 19.
Figure 3 (as well as Figure 6 below) reveals opposite slopes of the bid and ask price at , the Black–Scholes price. This reflects the opposing risk assessment of the buying and selling investor at comparable risk aversion coefficients. The value function (25) is indeed differentiable at and the sensitivity with respect to the risk dividend relates to the classical Greek (or ) for dividend paying models.
4.3 Consistency with discrete models
We return to the binomial model with risk-averse probabilities from Remark 3. The preceding discussions on divisibility and the risk generator show that the risk level for the mean semi-deviation risk measure needs to be proportional to
Further recall the risk-neutral probabilities
and hence the risk-averse probabilities in (4) satisfy
Thus replacing the interest rate by shows that under the nested mean semi-deviation the distribution for the stock is
Recall from Lemma 6 that for the mean semi-deviation of order . However, the binomial model converges to a process with dividends . The deviating scaling factors are in line with the discontinuity of coherent risk measures with respect to convergence in distribution, described in Bäuerle and Müller (2006, Theorem 4.1). The discussion shows that adapting the risk level of the nested mean semi-deviation leads to a well-defined limit in continuous time.
In general, one may not expect that nesting conditional risk measures leads to a well-defined risk measure in continuous time. Xin and Shapiro (2011) first observed that naively nesting the conditional Average Value-at-Risk leads to an exponentially increasing upper bound and Pichler and Schlotter (2019) extend this result to more general risk measures (see also Pichler (2017) for a collection of related inequalities).
The following proposition extends the discussion of the nested mean semi-deviation to more general risk measures and provides the theoretical connection between divisibility and convergence of risk-averse option pricing models.
Proposition 20.
Proof.
Let be a divisible family of risk measures and denote by the geometric Brownian motion. As for all we have the following inequality,
Because is a divisible family of risk measures Proposition 11 shows that
For the first term notice that tends to zero in distribution and hence also converges in probability. Moreover, is uniformly bounded in and hence with divisibility and dominated convergence
It follows that
which implies the existence of the limit of risk-averse binomial models as in Remark 3. ∎
4.4 Pricing of American options under risk
The Black–Scholes model allows explicit formulae for European option prices in in the risk-averse setting. This is surprising given the initial nonlinear PDE formulation in (22) and (23). Similarly we may reformulate the risk-averse American option pricing problem and in what follows we introduce the risk-averse optimal stopping problem for American put options and introduce the value functions.
Again we assume that the stock follows the geometric Brownian motion (19). Here, the risk-averse bid price of an American option is given by , where is the payoff function and the supremum is among all stopping times with . The ask price is given by . We can further define the value functions
for the bid price and
for the ask price. For brevity we only discuss the bid price for American put options, the arguments for the ask price are analogous. By informally extending the arguments from the risk-neutral setting to the risk-averse setting we obtain the free boundary problem
| (28) | |||||
| (29) | |||||
| (30) | |||||
| (31) |
for the optimal exercise boundary . For an overview on American options and free boundary problems in general we refer to Peskir and Shiryaev (2006). The following result follows with standard arguments for American options.
Similarly to European options, risk-aversion reduces to a modification of the drift term and the standard American put option model applies for an underlying stock with risk dividends. To this end notice that
provided that . The American option is not exercised and the same arguments as for the European options show that the infimum over all constraints is attained at . The equation (28) is thus equal to
Consequently we deduce that the value function
solves the free boundary problem (28)–(31), where the state process is given by
for a risk-loaded interest interest rate.
Numerical illustration
Consider the geometric Brownian motion
The strike price in the next Figure 4 is . We consider the optimal stopping region for different risk levels . A risk-averse option buyer (bid price) would generally exercise earlier, he accepts less profits due to his risk aversion. Compared with the risk-neutral investor, the risk aware option buyer prefers exercising prematurely rather than delayed exercise.
The reverse is true for the option holder (ask price), where the investor waits longer.
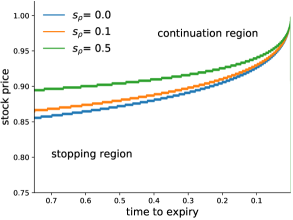
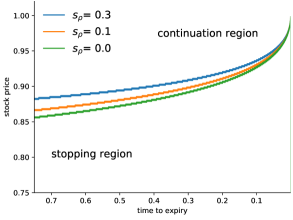
In the risk-neutral case it is never optimal to exercise an American call option before expiry. However, this is only the case if the interest rate exceeds the dividends of the underlying asset (see, for instance, Shreve (2010, Chapter 8.5) for details). As nested risk measures modify the interest rate it may be optimal to exercise the call option early. Figure 5 shows the optimal exercise boundary for the risk-averse call option with strike and initial value .
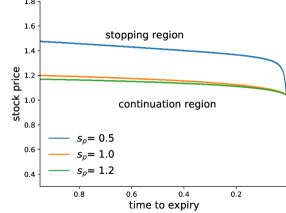
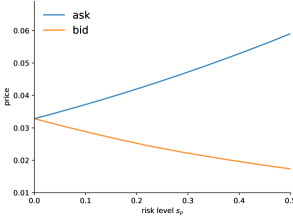
Below we show the bid-ask spread for American options.
5 The Merton problem
The preceding sections demonstrate that classical option pricing models generalize naturally to a risk-averse setting by employing nested risk measures. In what follows we demonstrate that the classical Merton problem, which allows an explicit solution in specific situations, as well allows extending to the risk-averse situation.
Consider a risk-less bond satisfying the ordinary differential equation and a risky asset driven by the stochastic differential equation
We are interested in the optimal fraction of the total wealth one should invest in the risky asset. The wealth process is
where is the rate of consumption. Following Merton we employ the power utility function with parameter and and consider the risk-averse objective function
| (33) |
where parameterizes the desired payout at terminal time. Surprisingly, has a closed form solution and the optimal portfolio allocation of the risk averse investor is
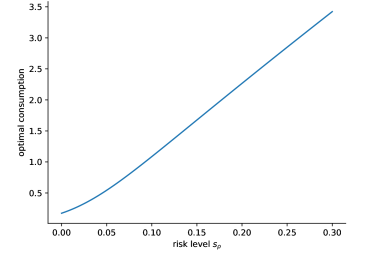
We observe again that risk aversion leads to a modified drift term in place of . The optimal portfolio allocation is a decreasing function of . This is in line with the usual economic perception, as increasing risk-aversion corresponds to less investments into the risky asset. The optimal consumption is given by
where is a constant depending on the model parameters. Consumption generally increases with risk aversion as the value of immediate consumption offsets the present value of uncertain wealth in the future.
In Remark 16 we formally extended the results of Proposition 11 to objective functions of the form (33). Based on this we now consider the Hamilton–Jacobi–Bellman equation
| (34) |
with terminal condition . In what follows we derive the optimal value function and verify the optimal portfolio allocation and optimal consumption given above.
The Hamilton–Jacobi–Bellman equation (34) allows for explicit optimal controls outlined in the following proposition.
Proposition 22.
In the risk-averse setting, the optimal controls are given by
The Hamilton-Jacobi-Bellman equation (34) rewrites as
| (35) | ||||
The preceding proposition derives first order conditions for the fraction and consumption rate . Employing the Hamilton–Jacobi–Bellman equations we obtain nonlinear second order partial differential equations for the optimally controlled value function.
Theorem 23 (Solution of the risk-averse Merton problem).
Proof.
We recall the PDE (35),
and choose the ansatz . In this case the partial derivatives are given by
The terminal condition for our Merton problem is hence . Setting and for ease of notation we substitute the derivatives in the PDE (35) and obtain the following ordinary differential equation for ;
| (36) |
For as defined in Theorem 23, the general solution of the ordinary differential equation (36) is
which is positive. The optimal value function thus is
It follows that the the optimal control is , where the optimal consumption process is which concludes the proof. ∎
The following Figure 7 illustrates the optimal consumption as a function of the risk level for , , , and . The time horizon is and we consider the wealth . Note that can take only values smaller than as otherwise .
6 Summary
This paper introduces risk aversion in classical models of finance by introducing nested risk measures. We demonstrate that classical formulae, which are of outstanding importance in economics, are explicitly available in the risk-averse setting as well. This includes the binomial option pricing model, the Black–Scholes model as well as Merton’s optimal consumption problem.
We give an explicit Z-spread, which reflects the degree of risk aversion. The Z-spread involves the volatility of the risky asset and a constant, which indicates risk aversion. The results thus provide an economic interpretation of the Z-spread by thorough risk management by iterating risk measures.
We extend nested risk measures from a discrete time to a continuous time setting. This allows deriving a non-linear risk generator expressing the momentary dynamics of the classical model under risk aversion. We demonstrate that the risk generator has a unique structure for all coherent risk measures up to the constant, the coefficient of risk aversion. The risk aversion constant is also naturally associated with the Sharpe ratio.
Acknowledgment
We thank two anonymous referees for many insightful comments and helpful discussions on this topic.
References
- Artzner et al. (1999) P. Artzner, F. Delbaen, J.-M. Eber, and D. Heath. Coherent Measures of Risk. Mathematical Finance, 9:203–228, 1999. doi:10.1111/1467-9965.00068.
- Barles and Soner (1998) G. Barles and H. Soner. Option pricing with transaction costs and a nonlinear black-scholes equation. Finance and Stochastics, 2, 1998. doi:10.1007/s007800050046.
- Bäuerle and Müller (2006) N. Bäuerle and A. Müller. Stochastic orders and risk measures: Consistency and bounds. Insurance: Mathematics and Economics, 38(1):132–148, 2006. doi:10.1016/j.insmatheco.2005.08.003.
- Cheridito et al. (2004) P. Cheridito, F. Delbaen, and M. Kupper. Coherent and convex monetary risk measures for bounded càdlàg processes. Stochastic Processes and their Applications, 112(1):1–22, jul 2004. doi:10.1016/j.spa.2004.01.009.
- Cheridito et al. (2006) P. Cheridito, F. Delbaen, and M. Kupper. Dynamic monetary risk measures for bounded discrete-time processes. Electronic Journal of Probability, (3):57–106, 2006. ISSN 1083-6489. doi:10.1214/EJP.v11-302.
- De Lara and Leclère (2016) M. De Lara and V. Leclère. Building up time-consistency for risk measures and dynamic optimization. European Journal of Operational Research, 249:177–187, 2016. doi:10.1016/j.ejor.2015.03.046.
- Delbaen (2002) F. Delbaen. Coherent risk measures on general probability spaces. In Essays in Honour of Dieter Sondermann, pages 1–37. Springer-Verlag, Berlin, 2002.
- Delbaen and Schachermayer (2006) F. Delbaen and W. Schachermayer. The Mathematics of Arbitrage. Springer, 2006.
- Delong (2013) L. Delong. Backwards Stochastic Differential Equations with Jumps and Their Actuarial and Financial Applications. 2013. ISBN 978-1-4471-5330-6. doi:10.1007/978-1-4471-5331-3.
- Fleming and Soner (2006) W. H. Fleming and H. Soner. Controlled Markov Processes and Viscosity Solutions. 2006. ISBN 0-387-26045-5.
- Garman and Kohlhagen (1983) M. B. Garman and S. W. Kohlhagen. Foreign currency option values. Journal of International Money and Finance, 2:231–237, 1983. doi:10.1016/s0261-5606(83)80001-1.
- Guigues and Römisch (2012) V. Guigues and W. Römisch. Sampling-based decomposition methods for multistage stochastic programs based on extended polyhedral risk measures. SIAM Journal on Optimization, 22(2):286–312, jan 2012. doi:10.1137/100811696.
- Karatzas and Shreve (1998) I. Karatzas and S. E. Shreve. Methods of Mathematical Finance. Springer New York, 1998. doi:10.1007/978-1-4939-6845-9.
- Klenke (2014) A. Klenke. Probability Theory. Springer London, 2014. doi:10.1007/978-1-4471-5361-0.
- Maggioni et al. (2012) F. Maggioni, E. Allevi, and M. Bertocchi. Bounds in multistage linear stochastic programming. Journal of Optimization Theory and Applications, 163(1):200–229, 2012. doi:10.1007/s10957-013-0450-1.
- Merton (1973) R. C. Merton. Theory of rational option pricing. The Bell Journal of Economics and Management Science, 4(1):141–183, 1973.
- Øksendal (2003) B. Øksendal. Stochastic Differential Equations. Springer Berlin Heidelberg, 2003. doi:10.1007/978-3-642-14394-6.
- Pardoux and Peng (1990) E. Pardoux and S. Peng. Adapted solution of a backward stochastic differential equation. Systems & Control Letters, 14(1):55–61, 1990. doi:10.1016/0167-6911(90)90082-6.
- Peng (2004) S. Peng. Nonlinear Expectations, Nonlinear Evaluations and Risk Measures. Springer, Berlin, Heidelberg, 2004. doi:10.1007/978-3-540-44644-6_4.
- Peskir and Shiryaev (2006) G. Peskir and A. Shiryaev. Optimal Stopping and Free-Boundary Problems. Birkhäuser Basel, 2006. doi:10.1007/978-3-7643-7390-0.
- Pflug and Römisch (2007) G. Ch. Pflug and W. Römisch. Modeling, Measuring and Managing Risk. World Scientific, 2007. doi:10.1142/9789812708724.
- Philpott et al. (2013) A. Philpott, V. de Matos, and E. Finardi. On solving multistage stochastic programs with coherent risk measures. Operations Research, 61(4):957–970, aug 2013. doi:10.1287/opre.2013.1175.
- Philpott and de Matos (2012) A. B. Philpott and V. L. de Matos. Dynamic sampling algorithms for multi-stage stochastic programs with risk aversion. European Journal of Operational Research, 218(2):470–483, 2012. doi:10.1016/j.ejor.2011.10.056.
- Pichler (2017) A. Pichler. A quantitative comparison of risk measures. Annals of Operations Research, 2017. doi:10.1007/s10479-017-2397-3.
- Pichler and Schlotter (2019) A. Pichler and R. Schlotter. Martingale characterizations of risk-averse stochastic optimization problems. Mathematical Programming, 181(2):377–403, 2019. doi:10.1007/s10107-019-01391-2.
- Riedel (2004) F. Riedel. Dynamic coherent risk measures. Stochastic Processes and their Applications, 112(2):185–200, 2004. doi:10.1016/j.spa.2004.03.004.
- Ruszczyński and Shapiro (2006) A. Ruszczyński and A. Shapiro. Conditional risk mappings. Mathematics of Operations Research, 31(3):544–561, 2006. doi:10.1287/moor.1060.0204.
- Ruszczyński and Yao (2015) A. Ruszczyński and J. Yao. A risk-averse analogue of the Hamilton–Jacobi–Bellman equation. In Proceedings of the Conference on Control and its Applications, chapter 62, pages 462–468. Society for Industrial and Applied Mathematics (SIAM), 2015. doi:10.1137/1.9781611974072.63.
- Ševčovič and Žitňanská (2016) D. Ševčovič and M. Žitňanská. Analysis of the nonlinear option pricing model under variable transaction costs. Asia-Pacific Financial Markets, 23(2):153–174, mar 2016. doi:10.1007/s10690-016-9213-y.
- Shapiro et al. (2014) A. Shapiro, D. Dentcheva, and A. Ruszczyński. Lectures on Stochastic Programming: Modeling and Theory. 2nd edition, 2014. doi:10.1137/1.9780898718751.
- Shreve (2010) S. E. Shreve. Stochastic Calculus for Finance II. Springer New York, 2010. ISBN 0387401016. URL https://www.ebook.de/de/product/2835534/steven_e_shreve_stochastic_calculus_for_finance_ii.html.
- Stadje (2010) M. Stadje. Extending dynamic convex risk measures from discrete time to continuous time: A convergence approach. Insurance: Mathematics and Economics, 47(3):391–404, dec 2010. doi:10.1016/j.insmatheco.2010.08.005.
- Xin and Shapiro (2011) L. Xin and A. Shapiro. Bounds for nested law invariant coherent risk measures. Operation Research Letters, 2011. doi:10.1016/j.orl.2012.09.002.
Appendix A A sufficient condition for Hölder continuity
Proposition 24.
Let be a solution of the stochastic differential equation (9) where the drift and the diffusion satisfy the usual conditions of Øksendal (2003, Theorem 5.2.1). Furthermore suppose that for a fixed the moments are finite for every and that the diffusion coefficient satisfies
for some . Then the Assumption (11) is satisfied, i.e., and in particular there exists a constant such that
Proof.
First observe that the usual conditions of Øksendal (2003, Theorem 5.2.1) as well as the assumption in Proposition 24 ensures that there exist such that
Therefore consider Hölder bounds on, let and recall the estimate
which implies
Estimate the terms separately and consider the first term. Jensen’s inequality applied to the probability measure shows
To estimate the second term use the Burkholder-Davis-Gundy inequality
An application of Gronwall’s lemma for both terms provides upper bounds
and
It follows by adding up and choosing an appropriate constant that for
As we can identify for some which shows that the assumptions of Kolmogorovs continuity theorem (cf. Theorem 21.6 in Klenke (2014)) are satisfied and implying that there exists a random such that
| (37) |
for .
It remains to show that the -norm of in (37) can be bounded. To show this, recall the Garsia–Rodemich–Rumsey inequality. For any and , there is a constant such that for any and
It suffices to consider , the Hölder norm of defined by
For any take to get
Here the second inequality follows from the first step. We conclude the assertion by observing that
where the constant is -integrable. ∎