Quantifying and Attributing the Hallucination of Large Language Models via Association Analysis
Abstract
Although demonstrating superb performance on various NLP tasks, large language models (LLMs) still suffer from the hallucination problem, which threatens the reliability of LLMs. To measure the level of hallucination of LLMs, previous works first categorize the hallucination according to the phenomenon similarity, then quantify the proportion that model outputs contain hallucinatory contents. However, such hallucination rates could easily be distorted by confounders. Moreover, such hallucination rates could not reflect the reasons for the hallucination, as similar hallucinatory phenomena may originate from different sources. To address these issues, we propose to combine the hallucination level quantification and hallucination reason investigation through an association analysis, which builds the relationship between the hallucination rate of LLMs with a set of risk factors. In this way, we are able to observe the hallucination level under each value of each risk factor, examining the contribution and statistical significance of each risk factor, meanwhile excluding the confounding effect of other factors. Additionally, by recognizing the risk factors according to a taxonomy of model capability, we reveal a set of potential deficiencies in commonsense memorization, relational reasoning, and instruction following, which may further provide guidance for the pretraining and supervised fine-tuning process of LLMs to mitigate the hallucination.
Introduction
Large Language Models (LLMs) such as GPT-3 (Brown et al. 2020), PaLM (Anil et al. 2023), and GPT-4 (Bubeck et al. 2023) have demonstrated remarkable performance on various natural language tasks (Wang et al. 2019; Rajpurkar, Jia, and Liang 2018; Joshi et al. 2017). Through the pretraining process upon massive text corpora and the following finetuning process, LLMs are trained to understand natural language, generate highly fluent and realistic responses for the given context, and follow human instructions to complete the demanded tasks (Zhao et al. 2023).
Despite the impressive capabilities exhibited by LLMs, it is observed in many cases that the generations of LLMs may be untruthful to contain false (Zheng, Huang, and Chang 2023), illogical (Zhong et al. 2023), fabricated contents (Agrawal, Mackey, and Kalai 2023), or unfaithful to deviate from human instructions (Jones and Steinhardt 2022; Wang et al. 2023). Previous literature concludes this plethora of phenomenons that the LLMs fail to as hallucination (Ji et al. 2023). The hallucination of LLMs arises concerns regarding the trustworthiness of LLMs and limits their application, especially in domains demanding high credibility, such as medicine or financing.
The broad existence of hallucination calls for accurately and comprehensively quantifying the hallucination level of LLMs, to evaluate the reliability of model outputs. However, this task still remains challenging, as the hallucination is fundamentally a composition of a set of phenomena(Ji et al. 2023). Moreover, similar hallucination phenomena may originate from distinct sources (Zheng, Huang, and Chang 2023). Hence, rather than comprehensively quantify the hallucination level of LLMs, primary research makes compromises by focusing on specific subtypes of hallucination (e.g., intrinsic hallucination (Ji et al. 2023)), upon certain tasks, such as text summarization (Cao, Dong, and Cheung 2022), dialogue (Shuster et al. 2022; Bang et al. 2023), or question answering (Anil et al. 2023; Brown et al. 2020). Then upon a certain task, the hallucination level can be measured using a hallucination rate, i.e., a proportion that the model outputs deviates from the ideal situation.
However, the hallucination rates may be restricted in faithfully characterizing the hallucination level of LLMs, as it would be easily distorted by confounders, such as the sample distribution of datasets. As for two models with different hallucination rates in two subtypes of instances, by adjusting the proportion of these two types of instances in the dataset, the relative hallucination rate between the two models would change significantly. Hence, a more faithful hallucination quantification should be conducted by managing to control the effects of potential confounders. Furthermore, a more critical issue is why LLMs hallucinate, and how much the risk factors contribute to the hallucination. This is essential for guiding the training process to mitigate the hallucination. However, this issue remains largely unexplored, as most previous research focused on elucidating the origins of hallucinations in domain-specific models. Whereas the differences in training procedure and parameter scales between LLMs and domain-specific models lead to different origins for the hallucination phenomena of the two kinds of model.
To address these issues, we propose to combine the hallucination level quantification of LLMs with the attribution of hallucination through an association analysis. Specifically, we model the relationship between the probability of hallucinating with a set of potential risk factors and recognize the risk factors according to potential impairments in the model’s fundamental capabilities. This enables us to compare the hallucination level of LLMs under the same level of each risk factor, to unbiasedly quantify the hallucination level by controlling the effect of potential confounders. Moreover, by observing the sensitivity of the hallucination rate upon these risk factors, and the statistical significance of the risk factors, the contribution of each risk factor can be measured to unveil the reasons for the hallucination of LLMs, so as to facilitate the mitigation of the hallucination.
Experimental results show that: (1) The LLMs tend to make more on entities or relational knowledge that appears with lower frequency in the corpus, and with more complexity; (2) In the relational reasoning task, the number of arguments and statements significantly positively related to the hallucination rate; (3) The conflicts between human instruction and language modeling significantly related to the hallucination rate.
Related Work
Before the emergence of large language models, researchers noticed that task-specific generative models may generate nonsensical, unfaithful, or illogical content (Filippova 2020; maynez2020faithfulness,raunak2021curious). These research concluded such phenomena as hallucination, then categorized the hallucination according to phenomena similarity and tasks. For example, (Ji et al. 2023) classify all the hallucinations into intrinsic hallucinations and extrinsic hallucinations, where intrinsic hallucinations refer to the generated outputs contradicting the source content; extrinsic hallucinations mean that the generations cannot be verified from the source. Pagnoni, Balachandran, and Tsvetkov (2021), (Thomson and Reiter 2020) and Li et al. (2020) explored intrinsic and extrinsic hallucination in abstract summarization, question answering, and dialogue, respectively.
However, compared to the hallucination of task-specific models, the hallucination of large language models is a broader and more comprehensive concept. As multitask model, LLMs are not confined to a single task or specific scenario, which consequently amplifies the potential hallucinations compared to the task-specific models (Brown et al. 2020; Anil et al. 2023; Bubeck et al. 2023). For example, in the fiction writing task, we may hope the LLM generates unreal content; in counterfactual tasks, we may want the model to generate content that does not conform to facts, which is also “untruthful”. Additionally, the different training paradigms may bring in different sources of the hallucination phenomena, and further increase the complexity of the hallucination of LLMs (Brown et al. 2020; Anil et al. 2023). Considering the complexity of the hallucination of LLMs, pioneer research about the hallucination of LLMs mainly focuses on a certain type of hallucination in confined scenarios, so as to exclude the impact of potential confounding factors. For example, (Agrawal, Mackey, and Kalai 2023; Ouyang et al. 2022) test whether the model’s ability to separate fact from an adversarially-selected set of incorrect statements using benchmark TruthfulQA (Lin, Hilton, and Evans 2022). Zheng, Huang, and Chang (2023) examine whether the LLMs can memorize, recall and correctly wield commonsense knowledge for answering questions. Agrawal, Mackey, and Kalai (2023) test whether the LLMs are aware that they are fabricating non-exist contents by taking the reference generation as an example. McKenna et al. (2023) investigate the source of hallucination in the natural language inference task. However, the hallucination rate may easily be influenced by confounders such as data distribution, while in the hallucination attributing works, the specific contributions for the sources of hallucinations are not yet quantified. Moreover, the multitasking nature of LLMs would make it rather laborious to investigate the hallucination of LLMs in each task. To address these issues, in this paper, we propose to analyze the association between the hallucination level of LLMs with a set of risk factors about deficiencies in the model capability, so that the hallucination level quantification and hallucination attributing can be conducted simultaneously.
Methodology
Formalization of Hallucination
Before describing our methodology, we first formalize the hallucination of LLM to elucidate the scope of this research. Previous literature defines the model hallucination as generating content unfaithful, untruthful, illogical, or contradictory to the context (Filippova 2020; maynez2020faithfulness,raunak2021curious; Ji et al. 2023). However, in certain situations such as in novel writing or counterfactual generation tasks, the LLMs might be required to generate content that disobeys the previous hallucination definition. This makes the traditional definition of model hallucination inappropriate for LLMs.
The ultimate goal of the LLM is to follow human instructions, to complete the demanding of human beings, with respect to the historical context. From this perspective, in this paper, we define the hallucination as generations of the model that violate the human instructions:
| (1) |
where is the ideal output, is the actual model generation, is the context, e.g., dialogue history; is the demanding task, e.g., text summarization, and denotes the human instruction.
Association Analysis-Based Hallucination Level Quantification
Previous works quantify the hallucination level of an LLM using a single index , denoting the probability that the model generations contain hallucinatory content upon a certain type of task. In this paper, we propose to quantify the hallucination level through a sensitivity, which investigates how the hallucination level of varies with the value of a set of risk factors, i.e., , where is a function, is a risk factor, is the th confounder. So that using , we can: (1) Obtain model hallucination level with each value of , meanwhile control the effects other risk factors and confounders to increase the unbiasedness; (2) Explain the source of the hallucination by examining the sensitivity of over , then offer guidance for the further mitigation of hallucinations. Additionally, given a set of LLMs , corresponding sensitivity analysis models can be fitted for each LLM. Then we can compare the hallucination level of different models with the value of risk factors aligned, and the effects of confounders controlled.
Without generality, we set as a linear logistic regression function:
| (2) |
where is a 0/1 label denoting whether the generation of is hallucinatory given an input ; is an interception term, and is the th value of the th risk factor and the th confounder, respectively.
With such formalization, the regression coefficient can be explained as how much fold the risk of hallucination changes if the level of risk factor changes 1 unit, i.e, .
Model Capability Based Risk Factors Identification
A critical issue of our approach is how to identify the potential risk factors more comprehensively. Ideally, the risk factors should be related to reasons why the model fails to generate outputs satisfying human demands. Hence, we choose to find the risk factors from the perspective of potential deficiency in the model’s fundamental capabilities. To this end, a taxonomy of the model’s pivotal capability is necessary, so that under such taxonomy, we dive into the training process of LLMs to recognize the potential risk factors that lead to the deficiency of each subtype of model capabilities.
Model Capability Deficiency based Hallucination Taxonomy
Most of the previous research categorizes the hallucination into subtypes according to phenomena similarity, then assesses the level of subtypes of hallucination upon specific tasks, such as question answering, or language understanding. However, such a taxonomy fails to reveal the reasons for hallucinations. Additionally, one prominent characteristic of LLMs is that they are multitasking models that can accommodate various NLP tasks (Brown et al. 2020; Anil et al. 2023; Bubeck et al. 2023). It would be rather laborious to enumerate all possible datasets and scenarios.
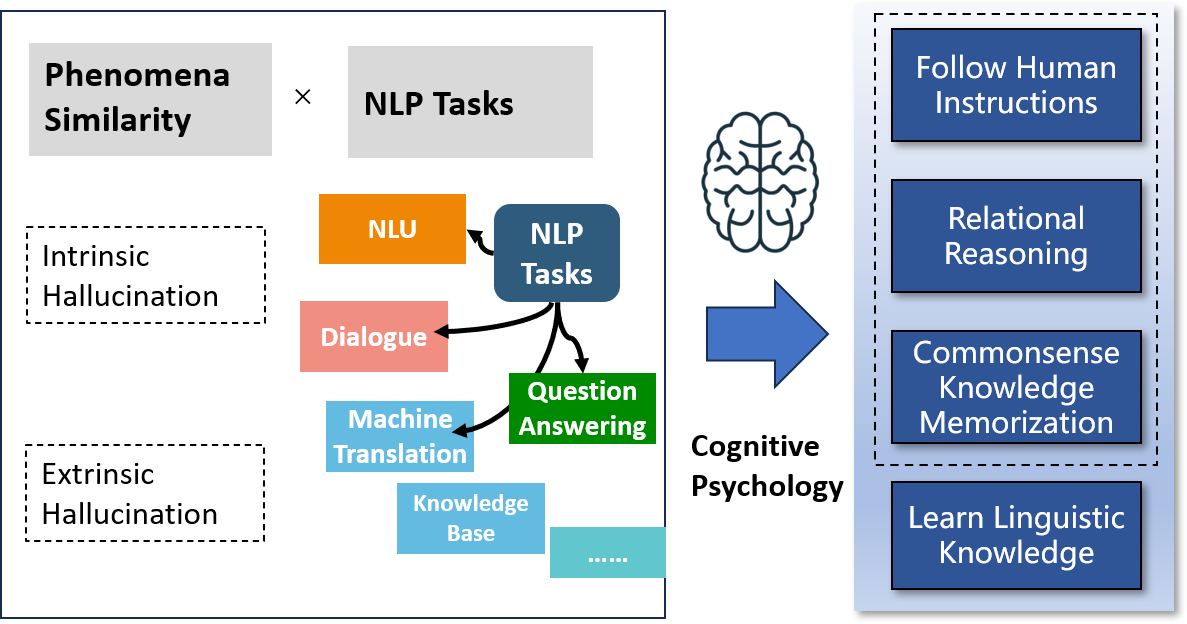
Hence, instead of categorizing the hallucination using the taxonomy of tasks, we resort to the deficiency in model capability, in other words, why the LLM fails to complete the demanded task. However, there is currently no universally accepted theory to categorize the various capabilities of large LLMs. Considering that the LLMs can achieve impressive performance on certain cognitive reasoning tasks, we categorize their capabilities into the following levels based on cognitive psychology theories (Sternberg and Stemberg 2012; Barsalou 2014), and the deficiency in each level of model capability would lead to hallucination. Figure 1 shows our categorization for the hallucination of LLMs, and the relationship between the previous works. In specific:
(1) Learn linguistic knowledge, including lexical, syntax, morphology, and pragmatics knowledge. Which is the foundation of understanding natural language;
(2) Memorize and recall commonsense knowledge (such as the definition of entities, the relationship between entities, and the relationship between events) for understanding the language. Commonsense knowledge supports the commonsense reasoning process, to allow the model to understand the material world and human society. Cognitive psychology theory concludes such ability as Crystallized Intelligence (Ziegler et al. 2012; Cattell 1963);
(3) Understand abstract relationships and make inferences. Which is the foundation of high-level cognitive processes, such as planning, problem-solving, and decision-making (Miller and Wallis 2009; Alexander 2016). Such ability is called Fluid Intelligence in cognitive psychology (Ziegler et al. 2012; Cattell 1963);
(4) Understand and follow human instructions.
Through the pretraining process on the large-scale corpus, the LLMs have demonstrated impressive performance upon various linguistic tasks, such as syntactic parsing. Hence, in this paper, we focus on testing the relationship between the model hallucination with the (2) (3), and (4) levels of ability. Based on linguistic knowledge, commonsense knowledge, and relationship modeling ability, LLMs are able to model language. On this basis, models learn to complete tasks under human instruction. The composition of these fundamental abilities can cover a wide span of NLP tasks. Hence, we design tasks and recognize risk factors to probe the deficiency of model capabilities.
Task Setting
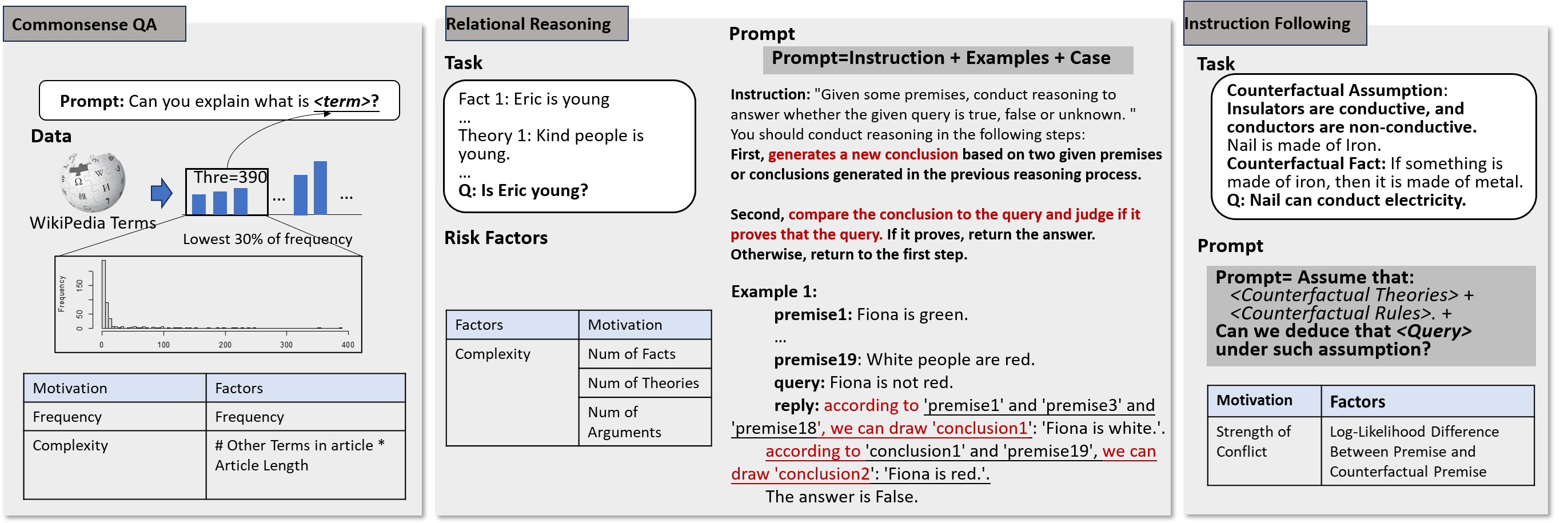
However, it would be rather challenging to construct a task that can simultaneously probe all the capabilities abovementioned. Hence, in this paper, we separately quantify the hallucination brought by different subtypes of model capability deficiency using a commonsense QA task, a relational reasoning task, and a counterfactual commonsense reasoning task. Figure 2 shows the tasks and corresponding prompts.
Commonsense QA Task
Among various kinds of commonsense knowledge, we focus on investigating the hallucination level about the definition of entities and abstract concepts. These two kinds of knowledge stand as representatives of two major kinds of commonsense knowledge, factual knowledge. As other kinds of factual knowledge and relational knowledge, such as event and event relationship knowledge share a similar learning process, the conclusion on entities/concepts and their relationships would also be applicable to other kinds of factual knowledge and relational knowledge.
To manage to avoid the influence of dataset biases in the existing selective commonsense QA benchmarks (Clark, Yatskar, and Zettlemoyer 2019; Wu et al. 2020) and facilitate further risk factor identification, we choose to construct a dataset de novo. Based on the Wikitext dataset, we obtain the concepts and entities terms by collecting the title of the articles in the Wikitext dataset. Among all terms, we mainly focus on the long-tail terms. Hence, we calculate the frequency of each term and construct samples based on the terms with the lowest 10% frequency. The frequency distribution is shown in Figure 2. Then the sampled terms are filled into the templates to form prompts and submitted to LLMs for obtaining the description or explanation of the terms. Hence, the influence of dataset biases can be managed to avoid by the generative task setting and unified prompt. Moreover, the questions are about single terms rather than complex questions such as that in the TruthfulQA dataset, which facilitates the calculating of statistical characteristics. After that, the answers of LLMs are assigned to human annotators to examine their correctness.
Relational Reasoning
Previously a set of natural language-based relational reasoning tasks have been proposed. However, model performance upon these tasks would also be influenced by confounders, such as whether the model possesses the necessary background knowledge for understanding the statement and the relationship. Hence, To get rid of the effect of confounders, we conduct experiments on the natural language satisfiability task (NLSat) (Richardson and Sabharwal 2022). Figure 2 shows an example of this task, which requires the model to perform deductive reasoning to derive a conclusion based on a set of systematically constructed short-sentence-based, explicitly stated rules and facts. The rules and facts can be regarded as logical statements expressed by natural language, without involving any additional world knowledge. Hence the potential confounding effect of language and background knowledge can be excluded. We construct the instances by controlling the number of arguments, predicates, statements, and theories, then observe the hallucination rate of LLMs upon these samples. Moreover, note that the results can be deduced by pure symbolic calculation. This enables us to examine the correctness of the LLM’s reasoning process by comparing it with the symbolic calculation process.
Instruction Following
Multiple aspects of reasons can make the model fail to follow human instructions, such as (1) the task being too complex for a model to accomplish, (2) the instructions are not clearly enough to describe the task, or (3) the model is inherently cannot accomplish certain tasks. However, (1) and (2) are not brought about by the inherent flaws of the model. Hence, in this paper, we mainly focus on why an LLM inherently cannot accomplish a certain task.
Previous analyses show that the transformer can approximate any seq2seq function (Yun et al. 2019; Edelman et al. 2022). Hence, the inductive bias of LLM would not be the restriction. We argue that an LLM inherently cannot accomplish a certain task that may originate from the conflict between the pretraining stage and the supervised finetuning (SFT) stage. Note that, in the pretraining stage, the task can be defined as Generating the subsequent sequence of . With regard to , the object in the pretraining stage may conflict with that in the tuning stage, i.e., . For example, in the pretraining stage, we hope the LLM to learn to generate the given text, while in the finetuning stage, the model may be required to generate counterfactual texts, such as fiction. This conflict may distort the outputs to make them deviate from human instructions. This implies that the training objective of LLM in the pre-training stage may not necessarily align with that in the human alignment stage. This conflict may lead to potential hallucinations. Interestingly, such phenomena are also observed in the cognitive process of human beings, which was concluded as the conflict between the subconscious and conscious, or conflict between the perception system and cognition system.
To detect the contribution of such conflict to the model hallucination level, we propose a counterfactual Natural Language Inference (c-NLI) task. Specifically, the same as the traditional NLI task, this task requires the model to predict a label with a value of “entailment” or “contradictory” for a set of given statements. While as Figure 2 shows, the statements in the c-NLI task are all counterfactual, such as “Insulator can conduct electricity”. In such a situation, the object in the SFT stage would drive the model to complete the reasoning process with the counterfactual setting, while in the pretrain stage, the LLMs are trained to model language by assigning counterfactual generations a small likelihood. Hence, the abovementioned conflict would occur in such instances.
By constructing the dataset based on commonsense knowledge largely covered by the corpus for training LLMs and controlling the length of each theory and statement, the confounders can be excluded. We provide the details of constructing the c-NLI dataset in the Appendix.
Risk Factor Recognition
Based on the categorization of the fundamental ability of LLMs, we dive into the training process of LLMs to find the risk factors that lead to the deficiency of these abilities and further lead to hallucinations.
Commonsense Memorization
With such an object, the LLM is trained to “memorize” the training data (Bang et al. 2023; Tirumala et al. 2022). Hence, intuitively, whether the model could memorize a piece of commonsense knowledge would be decided by two aspects: (1) The frequency of the commonsense knowledge appearing in the corpus; (2) The complexity of the commonsense knowledge: the more complex the commonsense knowledge is, the hard would it be for the model to completely remember the commonsense knowledge and precisely recall the commonsense knowledge.
Given the vast scale of the corpus used for training the model and the diversity of the expressions, it would be challenging to accurately count how many times a particular entity or concept is defined within the entire corpus. Hence, rather than focusing on all possible entities or concepts in the whole corpus, we focus on the terms of Wikipedia. Since the entities or concepts and their relationships are mainly described in the Wikipedia Corpus, we approximate the frequency of the terms of Wikipedia using count their frequency in the Wikipedia corpus.
Inspired by cognitive psychology, we measure the complexity of an entity/concept using descriptive complexity, i.e., the complexity of an entity or concept can be measured using the effort that is required to describe something (Immerman 2012; Wimsatt 1972; Grohe 2017). In specific, we employ: (1) The length of the corresponding article of this term in Wikipedia, (2) How many other terms appear in the article, (3) The sum of the length of the corresponding article for other terms that appear in the article of one term.
Relationship Reasoning
Formally, the relationship reasoning process can be abstracted as understanding the relationships between a set of arguments and then making an inference. Where the relationships are described by a set of theories and statements, and each statement and theory is composed of a predicate and several arguments. Hence, the main challenge for correctly conducting the reasoning process to draw a conclusion lies in the complexity of the relational reasoning process, which can be measured using: (1) The number of facts; (2) The number of theories; (3) The number of arguments.
Following Human Instructions
Given the instances of c-NLI, we measure the strength of potential conflict between the objective of two training stages of LLMs using the log-likelihood decrease by changing the statements into the corresponding counterfactual forms, for example, as shown in Figure 2, changing the assumption from “conductors are conductive, insulators are non-conductive” to “insulators are conductive, conductors are non-conductive”. As the more decrease of the log-likelihood, the more likely the model would fail to conduct inference by assuming the correctness of the counterfactual statements.
Then given the datasets, we obtain corresponding generations of LLMs and make judgments about whether a generation contains hallucinatory contents through human annotation.
Experimental Setup
Models
We examine the hallucination rate of the following OpenAI models:
(1) GPT-3 (Brown et al. 2020) is a generative language model pretrained upon text corpus with 175B parameters.
(2) text-davinci-001 is a GPT-3.5 series model, which is pretrained upon both text and code corpus, then aligned with human beings through supervised finetuning and reinforcement learning from human feedback (RLHF) to generate longer outputs with consistent instruction-following.
(2) text-davinci-003 is further optimized based on InstructGPT to deliver clearer, more engaging, and more compelling content with enhanced commonsense knowledge and relational modeling ability.
(3) GPT-3.5-Turbo is the most capable GPT-3.5 model optimized for chat.
(4) GPT-4 is a large multimodal model with broader general knowledge and advanced reasoning capabilities. Like GPT-3.5-turbo, GPT-4 is optimized for chat but works well for traditional NLP tasks.
Evaluation Dataset Construction
We build the commonsense QA dataset based on the WikiText corpus. We calculate the frequency of each term, a total of 200 terms are sampled from the lowest 30% frequency.
In the NLSat task, following (Richardson and Sabharwal 2022), we conduct experiments on the test set of the Ruletaker-depth-3ext dataset (abbreviated as Ruletaker). The experiments are conducted with the few-shot setting, for each instance, we randomly choose n=3,4,5 examples from the corresponding training set to present to the model in the prompt.
We build the counterfactual natural language inference dataset based on the eQASC dataset (Jhamtani and Clark 2020), which provides a set of human-annotated reasoning chains about commonsense knowledge, and such commonsense knowledge is largely covered by the corpus of LLMs. In practice, we obtain the counterfactual statements using the GPT4 API, then check the correctness of automated generated counterfactual statements by human annotation. More details about the data construction process are provided in the Appendix. Totally 150 instances are generated to test the model hallucination rate.
As the hidden states of Open-AI LLMs are unknown, we obtain the log-likelihood of the statements and counterfactual assumptions using RoBERTa-Large (Liu et al. 2019).
Human Annotation
In the commonsense QA and the c-NLI experiment, the outputs of LLMs are submitted to human annotators to check their correctness. We assign each generated output to two annotators simultaneously. Only both of the annotators deem that there is no factual error (for commonsense QA) or reasoning mistake (for c-NLI), then the output is taken as non-hallucinated.
Hyperparameters
In all experiments, the hyperparameters are set as default values, with Top-P=1 and temperature = 1.
Results and Discussion
Commonsense Knowledge Memorization
| Model | ||
|---|---|---|
| GPT-3 | ||
| Text-davinci-001 | ||
| Text-davinci-003 | ||
| GPT-3.5-turbo | ||
| GPT-4 |
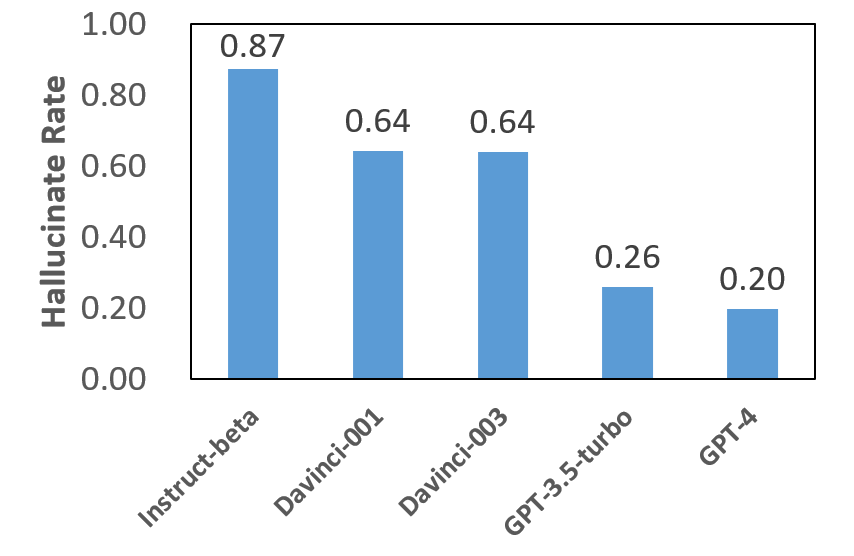
Table 1 and Figure 3 summarize the relationship between the hallucination rate and the value of risk factors in commonsense knowledge memorization. From which we observe that,
(1) State-of-the-Art LLMs are still suffering from memorizing long-tailed commonsense knowledge in the training corpus. For example, GPT-4 has a hallucination rate of 19.5% on explaining Wikipedia terms with 30% lowest frequency.
(2) The frequency and the length of the terms are statistically significantly related to the hallucination rate. This pattern shares with the four kinds of LLMs. This suggests that controlling other factors, the higher the frequency of a certain entity or concept in the corpus, the easier it is to be remembered by the LLMs. However, as the complexity of the entity or concept, the model is more likely to generate hallucinatory outputs. This indicates that, during the training process, adding the weight of the instances with lower frequency and higher complexity would decrease the hallucination rate.
(3) Comparing the average hallucination rate with the regression coefficients suggest that, in general, a model with a lower hallucination level would also be more insensitive to the change in the risk factors.
Relational Reasoning

| Model | |||
|---|---|---|---|
| GPT-3 | |||
| Davinci-001 | |||
| Davinci-003 | |||
| GPT-3.5-turbo | |||
| GPT-4 |
Figure 4 and Table 2 shows the hallucination rate of LLMs and the significance of risk factors upon the Ruletaker dataset. From that, we can observe:
(1) The number of example instances and the model performance is statistically irrelevant (P-value=0.53 for GPT-3.5-turbo). This indicates that the model already understands the task, as increasing the number of examples does not bring in performance improvement.
(2) Compared to GPT-3, text-davinci-003, GPT-3.5-turbo and GPt-4 demonstrate significantly higher accuracy. These results indicate the pretraining process on the code data can significantly enhance the model’s ability to understand complex logical relationships.
(3) There exists a discrepancy between the result accuracy and the accuracy of both the answer and reasoning process is correct. This suggests that the LLMs may utilize incorrect intermediate reasoning steps to draw the final conclusions. Hence, it may be inadequate to detect the hallucination level of LLMs only based on results, at least for the relation modeling task. This highlights that when investigating the hallucination of LLMs, especially in the related task, whether or not the generated contents are hallucinated cannot be judged only based on the correctness of results. In the following sections, only the instances with both the answer and reasoning process are correct are taken as not hallucinated.
(4) The hallucination rate of LLMs is significantly related to risk factors about the complexity of relationships, including the number of theories, number of facts, and number of arguments. Take GPT-4 as an example, with the number of theories, number of facts, and number of arguments increasing by 1, the hallucination rate would be , , and fold, respectively.
(5) State-of-the-Art LLMs may still struggle with the complex logical reasoning task. For example, GPT-4 has an accuracy of 57% to generate correct answers based on a correct reasoning process on the Ruletaker dataset. Conclusions (4) and (5) highlight the necessity for incorporating more relational reasoning data into the pretraining and supervised finetuning process of LLMs to further enhance the complex relational modeling ability of LLMs.
Instruction Following
| Model | |
|---|---|
| GPT-3 | |
| Text-davinci-001 | |
| Text-davinci-003 | |
| GPT-3.5-turbo | |
| GPT-4 |
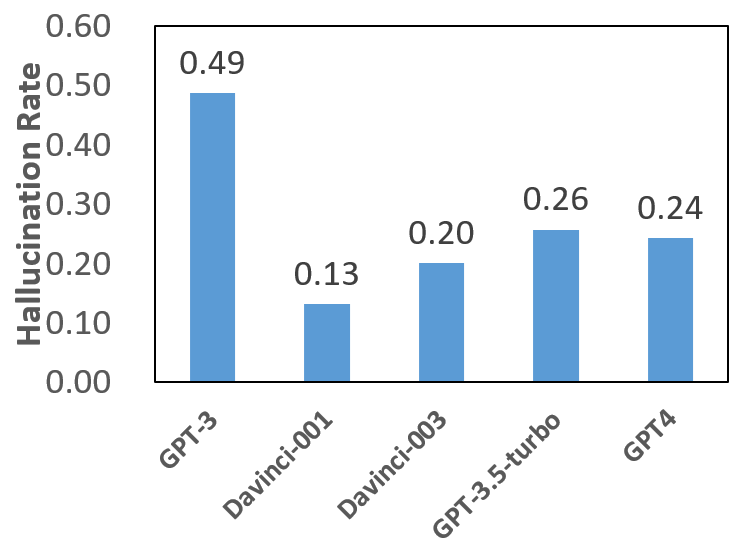
Figure 5 and Table 3 show the hallucination rate of LLMs on the c-NLI task, together with the statistical significance of the decrease of log probability upon the hallucination rate. From which we observe that:
(1) GPT-4 The model performances upon the baseline dataset show that the LLMs can largely understand the corresponding commonsense knowledge.
(2) There is a U-shaped inverse correlation between hallucination rate and model ability: GPT-3, which is not aligned with human cognition, and the state-of-the-art language model GPT-4, both display a relatively high hallucination rate on the c-NLI task. As GPT-3 is not aligned with human beings, it may fail to understand human instructions, so inferences are made only on the probability of language modeling and lead to false results. While for the SoTA LLM GPT-4, note that when the statements in c-NLI are transformed into counterfactual forms, GPT-4 shows a significantly larger likelihood decrease compared to other models. This suggests a stronger language modeling ability, as it can better separate the counterfactual statements by assigning a lower likelihood. Moreover, the decrease in likelihood is significantly positively associated with the hallucination rate. This suggests that the strong language modeling ability may conflict with human instructions, finally leading to hallucinations. Previously, McKenzie et al. (2023) stated that tasks containing an easy distractor task would lead to inverse scaling. In this paper, we demonstrate one reason for this phenomenon.
Conclusion
Different from previous works which focus only on certain tasks and quantify the hallucination level of LLMs using solely an index, we aim at providing a new methodology to simultaneously quantify the hallucination level of LLMs and attribute the source of hallucinations by analyzing the association between the probability of hallucination with a set of risk factors. This enables us to unbiasedly measure the hallucination level of LLMs by controlling the effect of potential confounders, and probing the contribution of each risk factor. By recognizing the risk factors through diving into the training process of the LLMs, a set of potential risk factors in the training process are recognized, which offer guidance for further mitigation of the hallucination. Experimental results show that the present SoTA LLMs still suffer from hallucination in key capabilities of LLMs, such as commonsense knowledge memorization, relational reasoning, and instruction following, which highlight the necessity for discovering more risk factors, to facilitate obtaining more trustworthy large language models. Although with a relatively limited number of risk factors, our work can serve as a pioneer to provide insights for future explorations.
References
- Agrawal, Mackey, and Kalai (2023) Agrawal, A.; Mackey, L.; and Kalai, A. T. 2023. Do Language Models Know When They’re Hallucinating References? arXiv preprint arXiv:2305.18248.
- Alexander (2016) Alexander, P. A. 2016. Relational thinking and relational reasoning: harnessing the power of patterning. NPJ science of learning, 1(1): 1–7.
- Anil et al. (2023) Anil, R.; Dai, A. M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Chen, Z.; et al. 2023. Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Bang et al. (2023) Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; et al. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023.
- Barsalou (2014) Barsalou, L. W. 2014. Cognitive psychology: An overview for cognitive scientists.
- Brown et al. (2020) Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. NeurIPS, 33: 1877–1901.
- Bubeck et al. (2023) Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y. T.; Li, Y.; Lundberg, S.; et al. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712.
- Cao, Dong, and Cheung (2022) Cao, M.; Dong, Y.; and Cheung, J. C. K. 2022. Hallucinated but Factual! Inspecting the Factuality of Hallucinations in Abstractive Summarization. In Proceedings of the 60thACL (Volume 1: Long Papers), 3340–3354.
- Cattell (1963) Cattell, R. B. 1963. Theory of fluid and crystallized intelligence: A critical experiment. Journal of educational psychology, 54(1): 1.
- Clark, Yatskar, and Zettlemoyer (2019) Clark, C.; Yatskar, M.; and Zettlemoyer, L. 2019. Don’t Take the Easy Way Out: Ensemble Based Methods for Avoiding Known Dataset Biases. In Proceedings of the 2019 EMNLP-IJCNLP, 4069–4082.
- Edelman et al. (2022) Edelman, B. L.; Goel, S.; Kakade, S.; and Zhang, C. 2022. Inductive biases and variable creation in self-attention mechanisms. In International Conference on Machine Learning, 5793–5831. PMLR.
- Filippova (2020) Filippova, K. 2020. Controlled Hallucinations: Learning to Generate Faithfully from Noisy Data. In Findings of the Association for Computational Linguistics: EMNLP 2020, 864–870.
- Grohe (2017) Grohe, M. 2017. Descriptive complexity, canonisation, and definable graph structure theory, volume 47. Cambridge University Press.
- Immerman (2012) Immerman, N. 2012. Descriptive complexity. Springer Science & Business Media.
- Jhamtani and Clark (2020) Jhamtani, H.; and Clark, P. 2020. Learning to explain: Datasets and models for identifying valid reasoning chains in multihop question-answering. arXiv preprint arXiv:2010.03274.
- Ji et al. (2023) Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y. J.; Madotto, A.; and Fung, P. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12): 1–38.
- Jones and Steinhardt (2022) Jones, E.; and Steinhardt, J. 2022. Capturing failures of large language models via human cognitive biases. NeurIPS, 35: 11785–11799.
- Joshi et al. (2017) Joshi, M.; Choi, E.; Weld, D. S.; and Zettlemoyer, L. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55thACL (Volume 1: Long Papers), 1601–1611.
- Li et al. (2020) Li, Y.; Yao, K.; Qin, L.; Che, W.; Li, X.; and Liu, T. 2020. Slot-consistent NLG for task-oriented dialogue systems with iterative rectification network. In Proceedings of the 58thACL, 97–106.
- Lin, Hilton, and Evans (2022) Lin, S.; Hilton, J.; and Evans, O. 2022. TruthfulQA: Measuring How Models Mimic Human Falsehoods. In Proceedings of the 60thACL (Volume 1: Long Papers), 3214–3252.
- Liu et al. (2019) Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; and Stoyanov, V. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.
- McKenna et al. (2023) McKenna, N.; Li, T.; Cheng, L.; Hosseini, M. J.; Johnson, M.; and Steedman, M. 2023. Sources of Hallucination by Large Language Models on Inference Tasks. arXiv preprint arXiv:2305.14552.
- McKenzie et al. (2023) McKenzie, I. R.; Lyzhov, A.; Pieler, M.; Parrish, A.; Mueller, A.; Prabhu, A.; McLean, E.; Kirtland, A.; Ross, A.; Liu, A.; et al. 2023. Inverse Scaling: When Bigger Isn’t Better. arXiv preprint arXiv:2306.09479.
- Miller and Wallis (2009) Miller, E.; and Wallis, J. 2009. Executive function and higher-order cognition: definition and neural substrates. Encyclopedia of neuroscience, 4(99-104).
- Ouyang et al. (2022) Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. NeurIPS, 35: 27730–27744.
- Pagnoni, Balachandran, and Tsvetkov (2021) Pagnoni, A.; Balachandran, V.; and Tsvetkov, Y. 2021. Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 4812–4829.
- Rajpurkar, Jia, and Liang (2018) Rajpurkar, P.; Jia, R.; and Liang, P. 2018. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56thACL (Volume 2: Short Papers), 784–789.
- Richardson and Sabharwal (2022) Richardson, K.; and Sabharwal, A. 2022. Pushing the limits of rule reasoning in transformers through natural language satisfiability. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 11209–11219.
- Shuster et al. (2022) Shuster, K.; Komeili, M.; Adolphs, L.; Roller, S.; Szlam, A.; and Weston, J. 2022. Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion. In Findings of the Association for Computational Linguistics: EMNLP 2022, 373–393.
- Sternberg and Stemberg (2012) Sternberg, R. J.; and Stemberg, K. 2012. Cognitive Psychologh.
- Thomson and Reiter (2020) Thomson, C.; and Reiter, E. 2020. A Gold Standard Methodology for Evaluating Accuracy in Data-To-Text Systems. In Proceedings of the 13th International Conference on Natural Language Generation, 158–168.
- Tirumala et al. (2022) Tirumala, K.; Markosyan, A.; Zettlemoyer, L.; and Aghajanyan, A. 2022. Memorization without overfitting: Analyzing the training dynamics of large language models. NeurIPS, 35: 38274–38290.
- Wang et al. (2019) Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; and Bowman, S. 2019. Superglue: A stickier benchmark for general-purpose language understanding systems. NeurIPS, 32.
- Wang et al. (2023) Wang, Y.; Zhong, W.; Li, L.; Mi, F.; Zeng, X.; Huang, W.; Shang, L.; Jiang, X.; and Liu, Q. 2023. Aligning Large Language Models with Human: A Survey. arXiv preprint arXiv:2307.12966.
- Wimsatt (1972) Wimsatt, W. C. 1972. Complexity and organization. In PSA: Proceedings of the biennial meeting of the Philosophy of Science Association, volume 1972, 67–86. Cambridge University Press.
- Wu et al. (2020) Wu, M.; Moosavi, N. S.; Rücklé, A.; and Gurevych, I. 2020. Improving QA Generalization by Concurrent Modeling of Multiple Biases. In Findings of the Association for Computational Linguistics: EMNLP 2020, 839–853.
- Yun et al. (2019) Yun, C.; Bhojanapalli, S.; Rawat, A. S.; Reddi, S.; and Kumar, S. 2019. Are Transformers universal approximators of sequence-to-sequence functions? In International Conference on Learning Representations.
- Zhao et al. (2023) Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223.
- Zheng, Huang, and Chang (2023) Zheng, S.; Huang, J.; and Chang, K. C.-C. 2023. Why does chatgpt fall short in providing truthful answers. ArXiv preprint, abs/2304.10513.
- Zhong et al. (2023) Zhong, Q.; Ding, L.; Liu, J.; Du, B.; and Tao, D. 2023. Can chatgpt understand too? a comparative study on chatgpt and fine-tuned bert. arXiv preprint arXiv:2302.10198.
- Ziegler et al. (2012) Ziegler, M.; Danay, E.; Heene, M.; Asendorpf, J.; and Bühner, M. 2012. Openness, fluid intelligence, and crystallized intelligence: Toward an integrative model. Journal of Research in Personality, 46(2): 173–183.