black
Quantile Regression with Multiple Proxy Variables
Abstract
Data integration has become increasingly popular owing to the availability of multiple data sources. This study considered quantile regression estimation when a key covariate had multiple proxies across several datasets. In a unified estimation procedure, the proposed method incorporates multiple proxies that have various relationships with the unobserved covariates. The proposed approach allows the inference of both the quantile function and unobserved covariates. Moreover, it does not require the quantile function’s linearity and, simultaneously, accommodates both the linear and nonlinear proxies. Simulation studies have demonstrated that this methodology successfully integrates multiple proxies and revealed quantile relationships for a wide range of nonlinear data. The proposed method is applied to administrative data obtained from the Survey of Household Finances and Living Conditions provided by Statistics Korea, to specify the relationship between assets and salary income in the presence of multiple income records.
Keywords: data integration, measurement error model, natural cubic spline, record linkage
1 Introduction
With the emergence of multiple data sources, such as administrative, web-collected, and big data, data integration has become popular. For example, the integration of administrative and statistical data has been widely used in official statistics to improve data quality, data analyses, and data collection costs (Berg et al., 2021). As the demand for data integration increases, two kinds of statistical methodologies have been proposed—namely, record linkage and statistical matching. Record linkage assumes overlapped units, which allow the linkage of the same units between data sources, while statistical matching frequently links similar units between non-overlapped datasets (Leulescu and Agafitei, 2013). In practice, record linkage and statistical matching are often applied separately depending on whether the same unit is matched. In this study, we are interested in combining multiple values observed for the same attribute, a common issue in record linkage.
When multiple data sources are available, it is easy to have multiple observations on the same attribute due to nonresponse or measurement errors, different observation times, and mode effects. To handle these multiple observations in statistical models, we treat them as multiple proxies of the unobserved true value. These proxies include various domains, from the case in which covariates are measured with errors (Carroll et al., 2006; Fuller, 1987) when the true covariate is simply unobserved (Filmer and Pritchett, 2001), to when the variable of interest is a conceptual variable that is difficult to examine precisely (Solon, 1992; Zimmerman, 1992; Mazumder, 2001). Specifically, we consider the problem of estimating the quantile function in the presence of multiple proxies for true covariates. As in conventional linear regression, the quantile regression estimator’s inconsistency in the absence of a true covariate is a commonly discussed issue in the literature (Brown, 1982; He and Liang, 2000; Carroll et al., 2006; Wei and Carroll, 2009; Montes-Rojas et al., 2011; Hausman et al., 2021).
Several studies have incorporated proxy variables in quantile regression estimation. He and Liang (2000)—considering the problem of estimating quantile regression coefficients in errors-in-variables models with a proxy variable—proposed an estimator in the context of linear and partially linear models. Wei and Carroll (2009) presented a nonparametric method for correcting bias caused by measurement error in the linear quantile regression model by constructing joint estimating equations that simultaneously hold for all quantile levels. Further, Firpo et al. (2017) proposed a semiparametric two-step estimator when repeated measures for the proxy are available. Schennach (2007, 2008) discussed identifying a nonparametric quantile function under various settings when an instrumental variable is measured on all sampling units. Wang et al. (2012) modified the standard quantile regression objective function, tailoring it to the Gaussian measurement error model.
However, these studies are limited to combining multiple proxies in a non-unified framework and frequently require repeated observations of proxy variables. To address these issues, we propose a novel Bayesian measurement error model by specifying how the proxies are generated from unobserved covariates. Motivated by the measurement error model approach (Clayton, 1992; Richardson and Gilks, 1993; Lubotsky and Wittenberg, 2006; Fuller, 1987), we demonstrate a Bayesian flexible combining method that can (i) integrate information from multiple proxies related to unobserved covariates in a wide range of different formulas and (ii) simultaneously deal with the flexible quantile regression model with an estimation of the unobserved covariate and the unobserved relationship to the proxy. Specifically, we first consider a generalized additive model for the proxies such that these are decomposed as a smoothing function of the true covariate and unobserved additive error; by contrast, most studies have employed a classical measurement error model wherein a zero-mean error is simply added to the unobserved covariate. Moreover, we employ a factor analysis-based measurement error model introduced in Fuller (1987) to combine multiple proxies in a unified framework. We treat the true covariate as a common factor in the factor analysis and, thereafter, construct a set of additive models that include a smoothing function of the same true covariate. This approach allows the generation of synthetic values using a Bayesian approach (Clayton, 1992; Richardson and Gilks, 1993). However, following Berry et al. (2002), we use the Bayesian nonparametric quantile regression function as the outcome model with a natural cubic spline (Thompson et al., 2010) and penalized spline (Lang and Brezger, 2004), rather than linear parametric models that might be sensitive to model misspecification.
The proposed method has several advantages. First, we incorporate a more flexible form of proxy variables, previously limited to additive measurement error, thereby enabling us to account for proxies with both linear and nonlinear relationships with a true covariate. Second, the proposed method incorporates an arbitrary number of multiple proxies and infers true covariate and quantile regression functions. Third, the proposed framework does not assume the linearity of the quantile regression function, which restricts the model’s flexibility.
The remainder of the paper is organized as follows: In section 2, we describe the basic setup of the investigation. In section 3, we introduce a method of combining multiple proxies and making inferences regarding nonparametric quantile regression likelihood. Further, the related prior and detailed Gibbs sampling steps are described. In section 4, we present the simulation results for various simulation data. Extensive simulation studies on various datasets reveal the approach’s effectiveness in incorporating multiple proxies simultaneously, compared with the method of using one proxy variable directly and the previously proposed structural model. In section 5, we apply the proposed method to the public administrative dataset, which includes various economic features of 18,064 families, such as salary and property income. We apply this methodology to administrative data to study the quantile relationship between assets and actual salary income. In section 6, we provide concluding remarks .
2 Basic Setup
Let be a random sample of size , where is the outcome variable and is the explanatory covariate. Let be the -th quantile of the conditional distribution of considering such that
| (1) |
Suppose that covariate is not directly observed, but multiple proxies related to the covariate are observed from multiple data sources. These proxies are denoted as , . We employ popular methods (e.g., Li and Vuong, 1998; Carroll et al., 2006; Delaigle et al., 2008) to estimate the quantile function when proxies are replicates of mismeasured variables, wherein only the mean zero measurement error is added to the covariate. However, these methods cannot be directly extended when multiple proxies exist in a different relationship to the unobserved .
To simultaneously account for different proxies, first, we write a set of regression models such that
| (2) | ||||
| (3) | ||||
| (4) |
where the residual in (2) follows an unspecified distribution that satisfies (1). The measurement errors in (3) and (4) are assumed to have a zero mean and a constant variance , and are further assumed to be independent of each other and distributed independently of and . Equation (3) implicitly assumes a reference variable that is only exposed to sampling or additive measurement errors. This assumption is natural and popular when survey datasets exist (Fuller, 2009; Berg et al., 2021) and can be generalized to other deterministic functions of proxy and unobserved covariates, such as logarithms (Berry et al., 2002). We leave the other proxies in (4) with an arbitrary function , denoted by .
Lubotsky and Wittenberg (2006) used similar assumptions with (2) to (4) to estimate the regression coefficient for the linear regression of on , with multiple proxies for . They allowed nonzero covariance between the measurement errors; however, they assumed a linear relationship with all proxy variables for in (4) and offered a lower bound on the regression coefficient of on . Variable with additive error is the benchmark variable. The assumption of the existence of a benchmark variable is prevalent and necessary because it amounts to fixing the scale of unobserved .
Intuitively, the proxy variables are not required to be independent of each other or . However, because measurement errors are independent of each other and and , the proxies are conditionally independent considering the true covariate . This model setup makes the conditional distribution between observed proxies independent of each other; this suggests that the likelihood of multiple proxy variables can be separately specified with a mixture representation based on conditional distribution given and their prior probability distribution. This makes Bayesian Gibbs sampling reasonable for the estimation method when is treated as an auxiliary variable and contributes to the generation of the observed data .
3 Bayesian Estimation
This section briefly introduces the natural cubic spline and P-spline to be used for the quantile function in (2). The proposed methodology for combining multiple proxies in Bayesian quantile regression is followed by explicit sampling steps.
3.1 Splines for Quantile Regression
Although the proposed framework is applicable to other quantile regression functions, such as the polynomial function of covariate (Koenker and Bassett, 1978; Yu and Moyeed, 2001; Yu et al., 2003), polynomial quantile regression is frequently restricted because the degree of the polynomial must be chosen in advance, and data might have a limited local effect on the shape of the polynomial regression curve, especially for high quantiles (Thompson et al., 2010). To alleviate the parametric assumption and secure the model’s flexibility, we consider two popular spline methods for : nonparametric cubic spline and the P-spline function. For details regarding the regression spline, refer to Green and Silverman (1993); Eliers and Marx (1996); Carroll et al. (1999); Brezger and Lang (2006).
3.1.1 Natural Cubic Spline
The natural cubic spline is a piecewise cubic polynomial function with continuous first and second derivatives at each knot, and is linear beyond the boundary knots (Green and Silverman, 1993). Suppose that are fixed knots covering a range of and denote the values of the natural cubic spline at knots , . As a desirable property of the natural cubic spline, there is a unique natural cubic spline function with knots satisfying for any given value . Therefore, we can handle function using its finite-length surrogate . In terms of Bayesian inference, we can model by giving the prior to and not . Following Green and Silverman (1993), the prior for is defined by a multivariate normal distribution as follows:
| (5) |
where is the matrix with rank, a function of the difference between the knots defined by (Eubank, 1999). contributes to the smoothness of curve and has a standard conjugate gamma prior:
The quadratic term in the exponential kernel is equivalent to the roughness penalty, (Green and Silverman, 1993). This type of quadratic prior, , which measures the complexity of the parameter, is a natural choice because it corresponds to the penalty term in the penalized maximum likelihood. With this prior, the posterior log density of the function is equal to the loss function in the regression context, with the roughness penalty added to the kernel of the log-likelihood function (Hoerl and Kennard, 1970; Green and Silverman, 1993; Tibshirani, 1996).
The final step in the Bayesian approach is defining the natural cubic spline function’s likelihood by changing the conventional polynomial part of the standard quantile regression likelihood to the natural cubic spline form (Yu and Moyeed, 2001; Thompson et al., 2010). The resulting likelihood takes the following form:
| (6) |
Notably, we explicitly specify in likelihood for generalization, where is also an unknown variable.
3.1.2 Regression P-Spline
Another general approach to spline fitting is a penalized spline or simply a P-spline. For a P-spline of degree with fixed knots, is defined by where is vector composed of B-spline basis functions evaluated at observation , and is the coefficient of the basis functions (Eliers and Marx, 1996). A conventional basis is . Then, are the sizes of the jumps in the th derivative of at the knots.
Eliers and Marx (1996) suggested a roughness penalty based on differences of adjacent spline coefficient to guarantee sufficient smoothness. In Bayesian analysis, the prior of replaces the roughness penalty term of the penalized likelihood as their stochastic analogs (Lang and Brezger, 2004). Assuming a first-order random walk for , that is,
the joint conditional distribution of is
where is penalty matrix with rank and is a first-order difference matrix (Lang and Brezger, 2004; Waldmann et al., 2013). This prior on induces a prior on owing to the deterministic relationship between and , . The precision parameter , again, contributes to the smoothness of curve and has a standard gamma prior:
The P-spline function’s likelihood can be defined by changing the conventional polynomial part of the standard quantile regression likelihood. The same result is obtained in (6). However, unlike the natural cubic spline, Waldmann et al. (2013) suggested exploiting the stochastic representation of the likelihood for more efficient sampling (Kozumi and Kobayashi, 2011).
3.2 Nonparametric Quantile Regression with Multiple Proxy Variables
In this section, we describe the fully Bayesian approach to the problem setup in (2)–(4). The unknown parameters to be estimated , where and is a parameter related to . Without the loss of generality, the posterior density is
where . For the variance parameter, we use the conjugate independent inverse gamma prior . For the prior distribution of , the reasonable prior distribution and appropriate prior varies depending on the application (Berry et al., 2002). For the exemplary prior, we use a widely used hierarchical normal distribution, that is,
From these prior settings, we derive the complete conditional distributions for up to the normalizing constant
where denotes all other parameters except . Other conditional distributions are derived from the conjugacy of their prior as follows:
For the parameters related to the relationship between and , can only contribute to its expectation of the conditional distribution, and the distribution’s family remains the same because is independent of . Therefore, the generalization of to an arbitrary functional form, such as a linear regression or natural cubic spline with a pre-existing Bayesian method for , is possible. We provide specific examples in the subsequent subsection.
The priors for spline-related parameters and differ depending on the regression spline function, as specified in 3.1 and the detailed Gibbs sampling procedure for each spline function is specified in the subsequent subsection.
A key benefit of this Bayesian approach is that the smoothing spline’s observations are generated from the posterior; thus, we can estimate the entire posterior distribution of , which was difficult in Lubotsky and Wittenberg (2006). Furthermore, an additional assumption is required to combine proxies and identify the unobserved covariate (Aigner et al., 1984; Lubotsky and Wittenberg, 2006). However, in the Bayesian framework, treating unobserved as a latent variable and placing its prior probability distribution, which corresponds to the structural approach in the literature (Fuller, 1987), is natural. Although the regression function is the primary focus of interest, the joint posterior distribution is a powerful tool that enables the inference of the unobserved covariate and its unobserved relationship with proxies .
3.3 Gibbs Sampling Step
The proposed framework for combining multiple proxies can be completed by defining the formula of and the distribution of the measurement error , which can be defined by the researcher. We formulate the entire problem in the Bayesian framework using specific examples and present the Metropolis-Hastings steps (Gamerman and Lopes, 2006).
3.3.1 Natural Cubic Spline with Quadratic Proxy
Suppose we have two proxies: one with an additive error and another with a quadratic relationship.
| (7) |
where . Here, parameter for is . We use normal prior for . Following Thompson et al. (2010), we model a quantile function of covariate using the natural cubic spline, with evenly spaced fixed knots covering a range of .
A Gibbs sampling algorithm for the quantile regression model is constructed by sampling each component of from the full conditional distributions. Following Thompson et al. (2010)’s initialization, is set as the posterior mean value of the quantile regression curve (Yu and Moyeed, 2001) at , and is obtained by applying generalized cross-validation of the usual smoothing spline (Green and Silverman, 1993). Additionally, is set as a multiple proxies because it is a more reliable proxy in the initialization step with no information regarding .
One iteration of the Gibbs sampling algorithm at iteration is as follows:
-
1.
Generate candidate from the multivariate normal distributions,
and accept with probability,
where represents the proposal density function.
-
2.
Generate candidate from the log-normal distribution,
where , and accept with probability,
-
3.
Generate from the multivariate normal distribution,
and accept with probability,
From the independent assumption, this step can be separated as generating from the normal with acceptance probability reduced to the term of the -th data.
-
4.
Sample , where indicates the inverse gamma with shape parameter and scale parameter , and and are the corresponding parameters for the prior of .
-
5.
Sample with and be the parameters for the prior of .
-
6.
Sample with and be parameters for the prior of .
-
7.
Sample , where
with and the prior mean and variance for .
-
8.
Sample , where
with and as the prior mean vector and covariance matrix for and as the vector of s, .
Steps 1–3 require the Metropolis-Hastings algorithm, and the other steps can be sampled from the conjugate distribution. The inference regarding the unobserved regressor, quantile spline function, or regression coefficient is based on these posterior samples.
3.3.2 P-Spline with arbitrary nonlinear Proxy
For most observed data in applications, prespecifying the relationship between the observed proxy and unobserved covariates in advance is challenging . Usually, a polynomial parametric relationship is applied with a certain purpose, such as interpretability. However, one might want a more flexible model with few prior assumptions regarding the relationship between the proxy and unobserved covariates. Provided that a benchmark variable is available for fixing the scale of unobserved , the proposed method can adopt a nonlinear relationship for the other .
Suppose we have two proxies—one with an additive error and another with a nonlinear relationship.
| (8) |
where .
Following Waldmann et al. (2013), we used a stochastic representation of the likelihood , that is, , where and with the conjugate gamma prior on . This hierarchical representation of the likelihood in (6) enables efficient Gibbs sampling. For additional details, refer to Kozumi and Kobayashi (2011); Waldmann et al. (2013).
As we have two nonlinear functions and to be fitted, we use two P-splines. To discriminate the coefficients of the basis function for and , we use subscripts and . For a P-spline with fixed knots, is defined by , and for any realization of , there exists a corresponding realization . As both splines and share covariate , they share the same knots and penalty matrix , which reduces the computation. Thereafter, the prior is as specified in Section 3.1.2; , , and .
One iteration of the Gibbs sampling algorithm at iteration is as follows:
-
1.
Generate from the normal distribution, and accept with probability,
-
2.
Sample , where
with and represents the design matrix with .
-
3.
Sample , where is gamma distribution with shape parameter and rate parameter , and and are the corresponding parameters for the prior of .
-
4.
Sample , where is an inverse gaussian distribution with mean parameter and shape parameter .
-
5.
Sample , where and are the corresponding parameters for the prior of .
-
6.
Sample , where
with and the prior mean and variance for .
-
7.
Sample with and as the parameters for the prior of
-
8.
Sample with and as the parameters for the prior of .
-
9.
Sample , where
-
10.
Sample , where and are the corresponding parameters for the prior of .
-
11.
Sample with and as the parameters for the prior of .
The inference regarding the unobserved regressor, quantile spline function, or regression coefficient is based on these posterior samples.
4 Simulation
We conduct a simulation study to empirically evaluate the proposed method using various datasets. This simulation has the following three purposes: to evaluate the flexibility of the proposed method in various datasets by considering several different error types, to compare the proposed method with an alternative approach, and to evaluate the effect of different types of proxies and effect of the number of proxies on the proposed method.
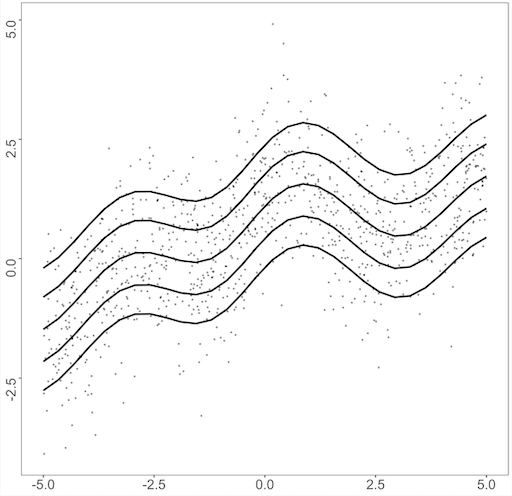
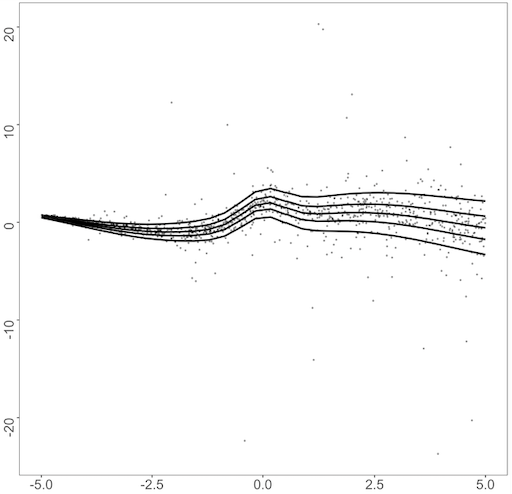
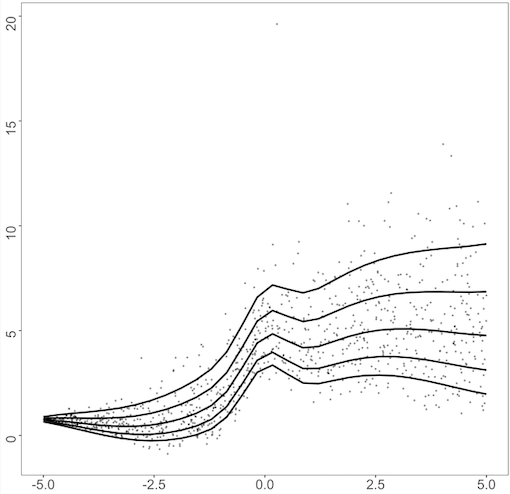
We use the dataset studied by Yue and Rue (2011); Waldmann et al. (2013). To match the scale between each dataset, we scale the range of to for each simulation using the appropriate affine transformation. We simulate the datasets using the following formulae:
-
•
Dataset1 : ;
-
•
Dataset2 : ,
and the quantile functions for each dataset are given by
-
•
Dataset1 :
-
•
Dataset2 :
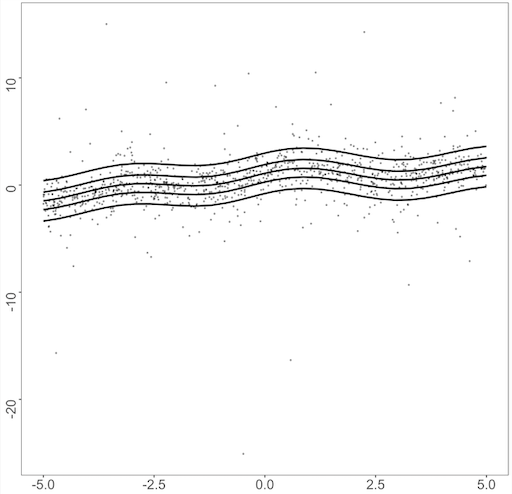
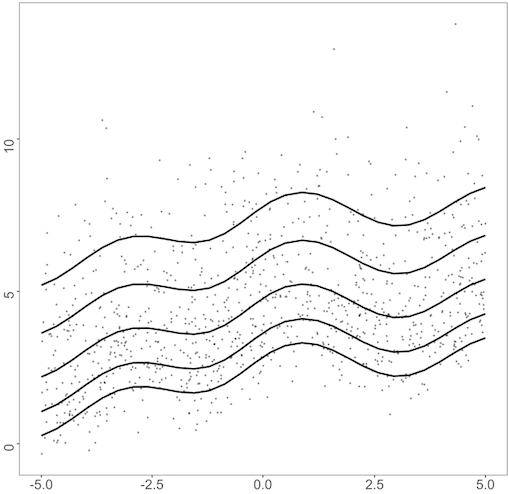
where is the cumulative distribution function of the distribution from where the error is sampled. For the error distribution , we consider three different error distributions as follows: standard normal distribution, Student’s distribution with two degrees of freedom, and gamma distribution with shape 4 and rate 1. Figure 1 displays a data structure of both datasets with each error term, on . Dataset2 follows the heteroscedastic structure, as the error generated from the error distribution is multiplied by , and the resulting quantile curves are no longer parallel to each other as in Dataset1. For the error distribution, is a heavy-tailed distribution, which may cause the dataset to include extreme outliers. The gamma distribution with shape 4 and rate 1 has a nonzero expectation skewed to the right. This causes the resulting quantile function to shift to positive values for higher quantiles. Similar examples were analyzed in Kottas and Krnjajić (2009); Taddy and Kottas (2010); Fenske et al. (2011); Yue and Rue (2011); Waldmann et al. (2013).
| (a) | (b) | (c) |
 |
 |
 |
| (d) | (e) | (f) |
 |
 |
 |
The proposed method can adapt multiple proxies with arbitrary relationships to the covariates. To assess a proxy’s effect, further, we suppose that the actual covariates are not directly observed, and that proxies are observed. For the relationship between proxy and unobserved covariate , we consider three different types as follows: identity, polynomial, and smooth nonlinear functions. That is, we have
with and . The nonlinear example is based on Friedman et al. (2001) and is generated from smoothing splines. The parameter for the quadratic coefficient is determined such that the ratio of variance in the error components to the total variance in the proxy variables in is roughly matched to that in .
Most studies that have considered the regression problem in the presence of a proxy variable with an additive error assumed the existence of replicates of the benchmark variable, which is a stricter assumption than the case considered here (Carroll et al., 2006; Wei and Carroll, 2009). Most studies have focused on mean regression; few have studies have considered estimating the quantile function in the case of proxies. Instead, we adjust Carroll et al. (1999)’s approach to be suitable for quantile regression problems. The method uses a partially Bayesian approach, which estimates the moment function of unknown using and estimates the spline function by minimizing the conventional penalized likelihood with the given estimated moments. This method uses a two-step estimation procedure that uses the information of to estimate , and the relationship between and is estimated thereafter.
| (a) | (b) |
|---|---|
 |
 |
Consequently, five estimators were considered for comparison in each simulation.
-
1.
Model without measurement error (woME): the benchmark estimator with true covariate directly observed without error.
-
2.
Structural estimator (Structural): the estimator calculated using Carroll et al. (1999)’s model, with all related prior settings equal to Bayesian estimator with multiple proxies (BEMP).
-
3.
Bayesian estimator with polynomial proxies (BEMP-poly): the proposed Bayesian estimator that incorporates two proxies and , but not .
-
4.
Bayesian estimator with nonlinear proxies (BEMP-nonlinear): the proposed Bayesian estimator that incorporates two proxies and , but not .
-
5.
Bayesian estimator with all proxies (BEMP-all): the proposed Bayesian estimator that incorporates all proxies , , and .
For the woME model, we used the natural cubic spline method applied in quantile regression using Thompson et al. (2010)’s model. For conciseness and unity, we present only the performance of the BEMP with a natural cubic spline. The performance of a BEMP with a P-spline is similar to that of a BEMP with a natural cubic spline, and is presented in the Appendix. The computation of the generation of depends on the size of knots . However, Eliers and Marx (1996) and Ruppert (2002) reported that computation can be reduced by using fewer knots with no loss of precision, and generally, between 20 and 40 ensures sufficient flexibility. We used the same 30 knots as those in Thompson et al. (2010).
For each of the generated datasets, the number of observations is fixed at and the quantile functions on a fixed grid are estimated. We assume identical MCMC sampling settings for all the five models. We set the number of iterations to 300,000 and took every 50th sample after discarding the first 50,000 steps as the burn-in period. The convergence is satisfactory, and an average of 5,000 posterior samples are used for the point estimation. After running 100 Monte Carlo (MC) simulations, we report their average and standard deviation.
We use two popular metrics to compare the estimators (Härdle, 1986; Fan, 1992; Gelfand and Ghosh, 1998):
-
•
Mean squared error (MSE):
where is the estimate of .
-
•
Posterior predictive loss (PPL):
where is the posterior predictive distribution’s variance for .
The first component in the PPL is a penalty term for model complexity, and the second is a term for goodness-of-fit. For the weight term , we use .
4.1 Simulation Result
Table 1 summarizes the simulation results for Dataset1 with normal errors: All the models that we test exhibit superior performance to the naive model, which directly treats the proxy with error as a true covariate (see Appendix). The proposed BEMP outperforms the comparative method across all metrics. For the models using two proxies, BEMP-poly outperforms BEMP-nonlinear, though we matched the ratio of variance in the error components to the total variance in the proxy variables. This is a predictable result because BEMP-nonlinear uses two sets of spline parameters, and the number of parameters to be estimated may adversely affect the resulting performance (Friedman et al., 2001). However, notably, BEMP-all exhibits the most optimal performance, even better than BEMP-poly. The superior performance of BEMP-all is interesting because the number of parameters in BEMP-all is larger than that in BEMP-nonlinear. We believe that this is because when the amount of proxy used increases, the increased amount of information aids the estimation of each other and provides a more precise estimation. In other words, a more precise estimation of makes it easier to estimate the spline parameter and vice versa. A similar discussion can be found in Berry et al. (2002); Lubotsky and Wittenberg (2006), which argued for the effect of using multiple types of information. We conduct additional simulations to validate this assumption.
| Quantile | woME | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all | |
|---|---|---|---|---|---|---|
| MSE | 0.029 (0.013) | 0.163 (0.038) | 0.09 (0.031) | 0.146 (0.06) | 0.063 (0.027) | |
| 0.08 (0.009) | 0.204 (0.041) | 0.115 (0.019) | 0.137 (0.034) | 0.1 (0.017) | ||
| 0.094 (0.015) | 0.287 (0.053) | 0.161 (0.033) | 0.214 (0.062) | 0.132 (0.028) | ||
| MSE | 0.019 (0.008) | 0.129 (0.03) | 0.053 (0.018) | 0.097 (0.035) | 0.035 (0.015) | |
| 0.05 (0.005) | 0.15 (0.024) | 0.069 (0.009) | 0.089 (0.019) | 0.061 (0.009) | ||
| 0.059 (0.009) | 0.216 (0.034) | 0.097 (0.017) | 0.134 (0.035) | 0.079 (0.016) | ||
| MSE | 0.016 (0.007) | 0.113 (0.029) | 0.04 (0.017) | 0.087 (0.04) | 0.03 (0.014) | |
| 0.038 (0.005) | 0.124 (0.021) | 0.053 (0.008) | 0.071 (0.015) | 0.045 (0.007) | ||
| 0.046 (0.008) | 0.186 (0.032) | 0.074 (0.016) | 0.113 (0.034) | 0.06 (0.013) | ||
| MSE | 0.016 (0.01) | 0.126 (0.032) | 0.071 (0.027) | 0.155 (0.035) | 0.058 (0.038) | |
| 0.04 (0.005) | 0.143 (0.019) | 0.063 (0.011) | 0.088 (0.015) | 0.055 (0.015) | ||
| 0.049 (0.009) | 0.209 (0.03) | 0.096 (0.025) | 0.165 (0.032) | 0.083 (0.033) | ||
| MSE | 0.03 (0.026) | 0.167 (0.044) | 0.129 (0.025) | 0.159 (0.034) | 0.128 (0.036) | |
| 0.059 (0.012) | 0.203 (0.028) | 0.084 (0.011) | 0.094 (0.016) | 0.08 (0.013) | ||
| 0.075 (0.024) | 0.293 (0.043) | 0.146 (0.021) | 0.175 (0.032) | 0.143 (0.03) |
The results are presented in Table 2, which summarizes the simulation results for Dataset1 with the Student distribution error. With distribution, the performance of BEMP-nonlinear exhibits a sensitive result to the outliers induced from heavy-tailed error, and the relative performance compared to BEMP-poly worsens. Consequently, in some cases, BEMP-all exhibits inferior performance to BEMP-poly, which uses true polynomial structures for . However, it still demonstrates the effect of using multiple proxies, with BEMP-all outperforming BEMP-nonlinear significantly.
| Quantile | woME | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all | |
|---|---|---|---|---|---|---|
| MSE | 0.123 (0.076) | 0.319 (0.147) | 0.161 (0.271) | 0.311 (0.202) | 0.181 (0.11) | |
| 0.192 (0.051) | 0.719 (0.19) | 0.232 (0.174) | 0.259 (0.108) | 0.197 (0.062) | ||
| 0.253 (0.087) | 0.884 (0.218) | 0.304 (0.307) | 0.414 (0.208) | 0.296 (0.114) | ||
| MSE | 0.031 (0.017) | 0.164 (0.042) | 0.064 (0.027) | 0.118 (0.057) | 0.053 (0.023) | |
| 0.072 (0.01) | 0.23 (0.047) | 0.089 (0.023) | 0.117 (0.031) | 0.083 (0.017) | ||
| 0.086 (0.018) | 0.313 (0.059) | 0.121 (0.035) | 0.175 (0.058) | 0.112 (0.027) | ||
| MSE | 0.019 (0.009) | 0.128 (0.029) | 0.039 (0.014) | 0.083 (0.036) | 0.033 (0.016) | |
| 0.042 (0.005) | 0.152 (0.026) | 0.058 (0.008) | 0.077 (0.016) | 0.052 (0.008) | ||
| 0.051 (0.009) | 0.222 (0.033) | 0.077 (0.014) | 0.12 (0.033) | 0.07 (0.015) | ||
| MSE | 0.035 (0.023) | 0.172 (0.048) | 0.089 (0.037) | 0.159 (0.035) | 0.098 (0.051) | |
| 0.056 (0.012) | 0.215 (0.036) | 0.077 (0.017) | 0.093 (0.014) | 0.076 (0.019) | ||
| 0.074 (0.023) | 0.299 (0.052) | 0.124 (0.033) | 0.174 (0.03) | 0.123 (0.044) | ||
| MSE | 0.118 (0.08) | 0.321 (0.229) | 0.17 (0.117) | 0.213 (0.176) | 0.164 (0.092) | |
| 0.12 (0.045) | 0.752 (0.237) | 0.12 (0.116) | 0.139 (0.103) | 0.108 (0.056) | ||
| 0.178 (0.082) | 0.917 (0.311) | 0.207 (0.172) | 0.246 (0.19) | 0.189 (0.101) |
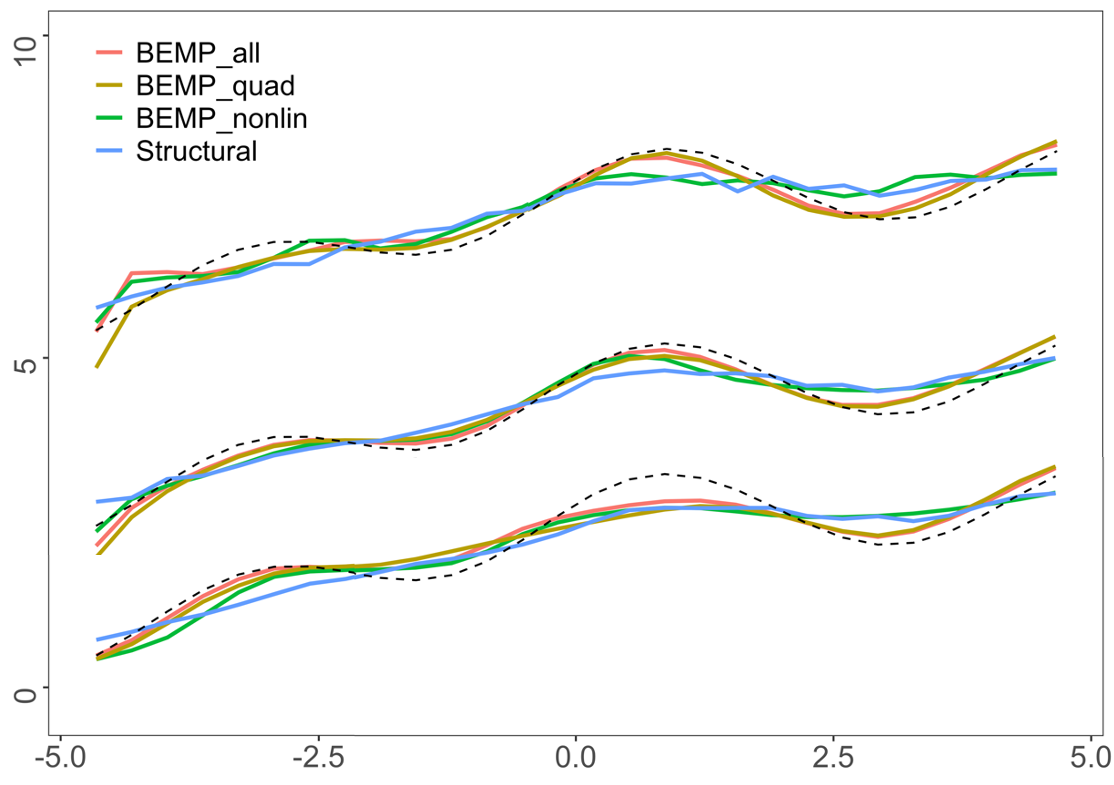
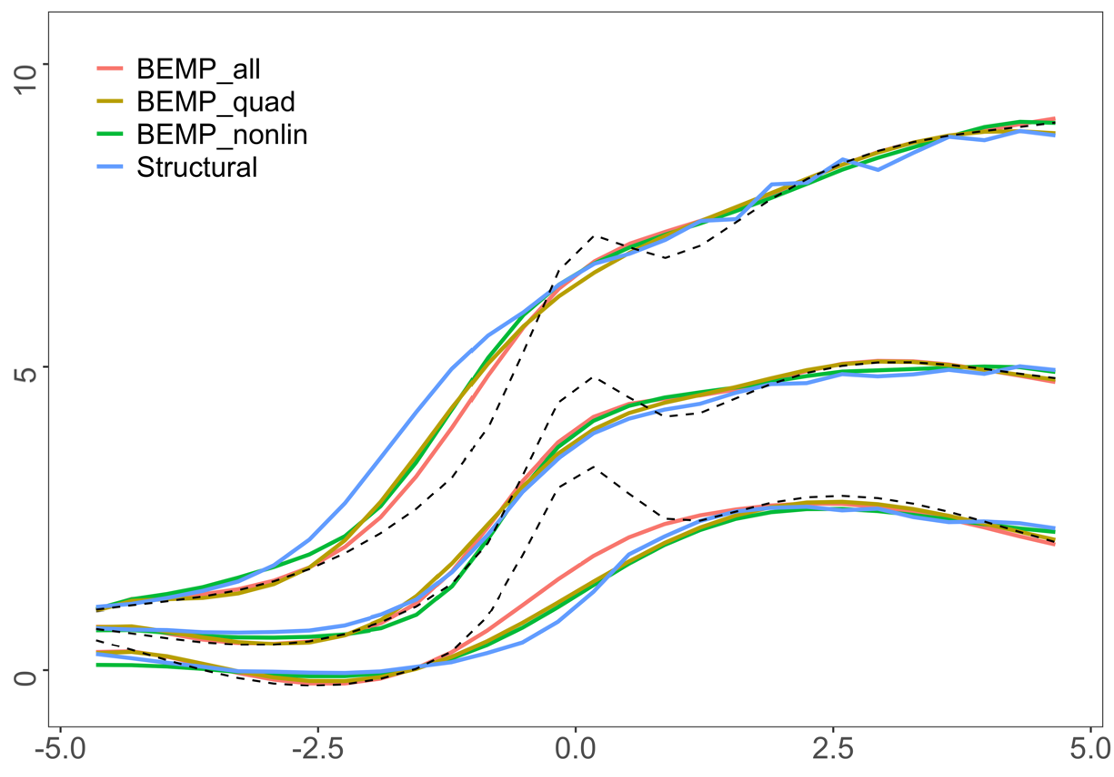
The results with the gamma-distributed error in Table 3 also present a similar trend. BEMP-all, using all available proxies, exhibits the most optimal performance, revealing that the proposed method has an efficient estimator with more information gained from combining proxy variables. However, when some information from the proxies is difficult to estimate, performance deteriorates moderately. We present the visualization of the gamma distribution error in Figure 2, where the proposed method exhibits the largest performance gap between the woMEs. Figure 2 (a) reveals that the BEMP-nonlinear approach fails to capture the true relationship’s overall shape compared with BEMP-quad and worsens BEMP-all’s performance. However, BEMP-nonlinear still works better than the structural method, and the performance drop in BEMP-all is moderate, revealing a fitted line like that of BEMP-quad. For the extreme quantiles, BEMP-all and BEMP-quad fail to capture the curvature on the right side of the domain in , whereas the methods in fail to capture the curvature on the left side of the domain.
| Quantile | woME | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all | |
|---|---|---|---|---|---|---|
| MSE | 0.038 (0.024) | 0.167 (0.047) | 0.126 (0.032) | 0.144 (0.04) | 0.125 (0.038) | |
| 0.064 (0.011) | 0.247 (0.047) | 0.085 (0.014) | 0.088 (0.017) | 0.078 (0.013) | ||
| 0.083 (0.022) | 0.323 (0.059) | 0.148 (0.028) | 0.162 (0.036) | 0.141 (0.03) | ||
| MSE | 0.032 (0.015) | 0.159 (0.045) | 0.065 (0.028) | 0.103 (0.036) | 0.061 (0.026) | |
| 0.053 (0.008) | 0.224 (0.037) | 0.068 (0.011) | 0.082 (0.023) | 0.062 (0.012) | ||
| 0.068 (0.015) | 0.3 (0.048) | 0.099 (0.025) | 0.136 (0.04) | 0.093 (0.024) | ||
| MSE | 0.045 (0.02) | 0.176 (0.054) | 0.058 (0.027) | 0.152 (0.082) | 0.056 (0.035) | |
| 0.069 (0.013) | 0.273 (0.044) | 0.084 (0.017) | 0.136 (0.048) | 0.079 (0.029) | ||
| 0.092 (0.022) | 0.368 (0.054) | 0.114 (0.029) | 0.206 (0.087) | 0.108 (0.045) | ||
| MSE | 0.093 (0.04) | 0.252 (0.088) | 0.119 (0.079) | 0.327 (0.142) | 0.148 (0.082) | |
| 0.126 (0.029) | 0.463 (0.072) | 0.177 (0.068) | 0.274 (0.076) | 0.176 (0.06) | ||
| 0.174 (0.047) | 0.597 (0.089) | 0.238 (0.105) | 0.438 (0.145) | 0.251 (0.098) | ||
| MSE | 0.205 (0.101) | 0.428 (0.177) | 0.256 (0.182) | 0.472 (0.178) | 0.344 (0.176) | |
| 0.254 (0.068) | 0.951 (0.171) | 0.318 (0.13) | 0.401 (0.102) | 0.327 (0.102) | ||
| 0.361 (0.116) | 1.176 (0.2) | 0.454 (0.217) | 0.633 (0.189) | 0.501 (0.188) |
For Dataset2, the simulation results are summarized in Tables 4, 5, and 6. While for Dataset2, the heteroscedasticity and fluctuating function with large higher derivatives make the estimation difficult (Figure 2 (b)), and the overall result remains the same. In this dataset, the performance of BEMP-all outperforms that of all error distributions. Generalizing this limited simulation and suggesting that BEMP-all outperforms in all cases is difficult, but in practice, we rarely have information regarding the true polynomial structure of the proxy or the quality of each proxy; remarkably, the result is sufficiently encouraging to generally use the BEMP-all method.
| Standard Normal Error | ||||||
|---|---|---|---|---|---|---|
| Quantile | woME | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all | |
| MSE | 0.048 (0.018) | 0.481 (0.06) | 0.333 (0.041) | 0.429 (0.066) | 0.225 (0.049) | |
| 0.067 (0.008) | 0.371 (0.054) | 0.192 (0.02) | 0.233 (0.032) | 0.138 (0.023) | ||
| 0.089 (0.016) | 0.616 (0.076) | 0.359 (0.04) | 0.449 (0.064) | 0.252 (0.047) | ||
| MSE | 0.022 (0.01) | 0.32 (0.057) | 0.204 (0.037) | 0.296 (0.053) | 0.112 (0.029) | |
| 0.04 (0.006) | 0.248 (0.046) | 0.125 (0.018) | 0.16 (0.026) | 0.078 (0.014) | ||
| 0.05 (0.011) | 0.412 (0.07) | 0.227 (0.036) | 0.308 (0.053) | 0.135 (0.028) | ||
| MSE | 0.018 (0.009) | 0.158 (0.032) | 0.094 (0.02) | 0.166 (0.036) | 0.063 (0.016) | |
| 0.035 (0.005) | 0.156 (0.033) | 0.072 (0.009) | 0.096 (0.018) | 0.054 (0.008) | ||
| 0.043 (0.009) | 0.233 (0.046) | 0.119 (0.019) | 0.18 (0.035) | 0.085 (0.015) | ||
| MSE | 0.021 (0.008) | 0.221 (0.042) | 0.112 (0.023) | 0.2 (0.048) | 0.07 (0.015) | |
| 0.041 (0.005) | 0.198 (0.038) | 0.088 (0.012) | 0.119 (0.023) | 0.063 (0.008) | ||
| 0.051 (0.008) | 0.303 (0.056) | 0.144 (0.023) | 0.22 (0.047) | 0.098 (0.015) | ||
| MSE | 0.033 (0.012) | 0.488 (0.1) | 0.282 (0.05) | 0.437 (0.145) | 0.155 (0.06) | |
| 0.064 (0.009) | 0.356 (0.071) | 0.191 (0.027) | 0.251 (0.07) | 0.125 (0.032) | ||
| 0.082 (0.014) | 0.608 (0.116) | 0.331 (0.052) | 0.466 (0.143) | 0.205 (0.062) | ||
| Student Error | ||||||
|---|---|---|---|---|---|---|
| Quantile | woME | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all | |
| MSE | 0.116 (0.06) | 0.553 (0.146) | 0.323 (0.117) | 0.39 (0.149) | 0.285 (0.145) | |
| 0.131 (0.035) | 0.62 (0.188) | 0.198 (0.057) | 0.222 (0.072) | 0.182 (0.071) | ||
| 0.194 (0.063) | 0.887 (0.241) | 0.358 (0.116) | 0.418 (0.146) | 0.326 (0.143) | ||
| MSE | 0.035 (0.016) | 0.339 (0.064) | 0.222 (0.048) | 0.296 (0.075) | 0.137 (0.043) | |
| 0.055 (0.008) | 0.308 (0.052) | 0.14 (0.024) | 0.167 (0.036) | 0.095 (0.023) | ||
| 0.071 (0.015) | 0.492 (0.072) | 0.252 (0.047) | 0.312 (0.073) | 0.162 (0.044) | ||
| MSE | 0.022 (0.01) | 0.161 (0.042) | 0.096 (0.021) | 0.167 (0.037) | 0.066 (0.019) | |
| 0.039 (0.006) | 0.18 (0.039) | 0.076 (0.01) | 0.102 (0.018) | 0.058 (0.009) | ||
| 0.05 (0.01) | 0.263 (0.056) | 0.125 (0.02) | 0.187 (0.036) | 0.09 (0.019) | ||
| MSE | 0.036 (0.026) | 0.251 (0.06) | 0.132 (0.024) | 0.183 (0.081) | 0.086 (0.024) | |
| 0.056 (0.013) | 0.26 (0.05) | 0.107 (0.013) | 0.123 (0.038) | 0.077 (0.014) | ||
| 0.075 (0.026) | 0.377 (0.074) | 0.174 (0.024) | 0.214 (0.078) | 0.12 (0.025) | ||
| MSE | 0.097 (0.091) | 0.544 (0.166) | 0.308 (0.101) | 0.341 (0.146) | 0.22 (0.106) | |
| 0.123 (0.051) | 0.64 (0.163) | 0.236 (0.06) | 0.227 (0.073) | 0.173 (0.058) | ||
| 0.167 (0.095) | 0.938 (0.217) | 0.386 (0.109) | 0.394 (0.145) | 0.28 (0.11) | ||
| Gamma Error | ||||||
|---|---|---|---|---|---|---|
| Quantile | woME | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all | |
| MSE | 0.053 (0.022) | 0.497 (0.11) | 0.362 (0.059) | 0.414 (0.106) | 0.217 (0.051) | |
| 0.071 (0.012) | 0.446 (0.1) | 0.215 (0.03) | 0.226 (0.053) | 0.138 (0.024) | ||
| 0.096 (0.022) | 0.69 (0.14) | 0.396 (0.059) | 0.432 (0.106) | 0.245 (0.049) | ||
| MSE | 0.036 (0.017) | 0.265 (0.075) | 0.163 (0.036) | 0.202 (0.072) | 0.101 (0.03) | |
| 0.056 (0.009) | 0.29 (0.076) | 0.114 (0.018) | 0.122 (0.034) | 0.08 (0.015) | ||
| 0.072 (0.016) | 0.429 (0.103) | 0.197 (0.036) | 0.221 (0.07) | 0.131 (0.029) | ||
| MSE | 0.046 (0.023) | 0.163 (0.056) | 0.109 (0.03) | 0.117 (0.056) | 0.088 (0.033) | |
| 0.062 (0.013) | 0.268 (0.058) | 0.093 (0.017) | 0.093 (0.031) | 0.077 (0.018) | ||
| 0.084 (0.024) | 0.356 (0.068) | 0.148 (0.031) | 0.151 (0.059) | 0.119 (0.034) | ||
| MSE | 0.076 (0.042) | 0.317 (0.091) | 0.161 (0.06) | 0.177 (0.085) | 0.131 (0.059) | |
| 0.092 (0.022) | 0.465 (0.093) | 0.14 (0.035) | 0.141 (0.046) | 0.114 (0.031) | ||
| 0.129 (0.042) | 0.643 (0.113) | 0.218 (0.065) | 0.229 (0.087) | 0.178 (0.06) | ||
| MSE | 0.153 (0.062) | 0.824 (0.209) | 0.31 (0.108) | 0.4 (0.171) | 0.26 (0.096) | |
| 0.157 (0.038) | 1.12 (0.261) | 0.247 (0.063) | 0.26 (0.088) | 0.188 (0.053) | ||
| 0.227 (0.067) | 1.522 (0.318) | 0.399 (0.116) | 0.459 (0.173) | 0.318 (0.1) | ||
4.2 Estimation of Nonlinear Proxy
To empirically examine the proposed model’s performance in estimating the proxy relationship and further validate the assumption regarding the effect of multiple proxies, we assess the model estimation of , the nonlinear relationship between the unobserved covariate and proxy. We evaluate the same metrics used in Section 4.1 for the posterior result of .
| Normal | Student | Gamma | |||||
| Dataset1 | |||||||
| Quantile | BEMP-nonlinear | BEMP-all | BEMP-nonlinear | BEMP-all | BEMP-nonlinear | BEMP-all | |
| MSE | 0.68 (0.375) | 0.122 (0.081) | 0.498 (0.173) | 0.138 (0.08) | 0.941 (0.323) | 0.122 (0.076) | |
| 0.43 (0.201) | 0.17 (0.043) | 0.322 (0.086) | 0.175 (0.041) | 0.539 (0.156) | 0.168 (0.04) | ||
| 0.771 (0.387) | 0.231 (0.082) | 0.565 (0.172) | 0.243 (0.08) | 1 (0.316) | 0.223 (0.076) | ||
| MSE | 0.904 (0.489) | 0.118 (0.074) | 0.498 (0.217) | 0.12 (0.084) | 0.557 (0.249) | 0.127 (0.07) | |
| 0.534 (0.263) | 0.156 (0.039) | 0.332 (0.115) | 0.163 (0.045) | 0.372 (0.132) | 0.16 (0.039) | ||
| 0.975 (0.505) | 0.216 (0.075) | 0.586 (0.222) | 0.221 (0.086) | 0.642 (0.255) | 0.222 (0.072) | ||
| MSE | 0.866 (0.364) | 0.106 (0.06) | 0.649 (0.489) | 0.116 (0.075) | 0.466 (0.178) | 0.111 (0.084) | |
| 0.514 (0.187) | 0.157 (0.037) | 0.409 (0.259) | 0.155 (0.039) | 0.306 (0.092) | 0.157 (0.043) | ||
| 0.952 (0.368) | 0.215 (0.065) | 0.718 (0.503) | 0.213 (0.075) | 0.532 (0.18) | 0.209 (0.083) | ||
| MSE | 1.082 (0.308) | 0.137 (0.102) | 0.7 (0.298) | 0.15 (0.095) | 0.492 (0.166) | 0.117 (0.067) | |
| 0.611 (0.151) | 0.168 (0.052) | 0.417 (0.15) | 0.176 (0.049) | 0.323 (0.087) | 0.157 (0.036) | ||
| 1.156 (0.303) | 0.24 (0.102) | 0.757 (0.298) | 0.251 (0.096) | 0.57 (0.169) | 0.214 (0.069) | ||
| MSE | 1.022 (0.308) | 0.133 (0.099) | 0.543 (0.191) | 0.136 (0.092) | 0.484 (0.25) | 0.134 (0.08) | |
| 0.576 (0.147) | 0.163 (0.051) | 0.349 (0.103) | 0.167 (0.047) | 0.318 (0.133) | 0.173 (0.043) | ||
| 1.081 (0.3) | 0.234 (0.099) | 0.621 (0.198) | 0.236 (0.091) | 0.56 (0.257) | 0.236 (0.081) | ||
| Dataset2 | |||||||
| Quantile | BEMP-nonlinear | BEMP-all | BEMP-nonlinear | BEMP-all | BEMP-nonlinear | BEMP-all | |
| MSE | 1.143 (0.218) | 0.14 (0.08) | 0.878 (0.319) | 0.135 (0.078) | 1.168 (0.23) | 0.117 (0.058) | |
| 0.629 (0.109) | 0.166 (0.042) | 0.519 (0.154) | 0.168 (0.042) | 0.653 (0.113) | 0.156 (0.03) | ||
| 1.203 (0.218) | 0.236 (0.082) | 0.948 (0.312) | 0.235 (0.079) | 1.23 (0.226) | 0.213 (0.058) | ||
| MSE | 1.153 (0.219) | 0.111 (0.073) | 1.111 (0.28) | 0.132 (0.073) | 1.066 (0.447) | 0.126 (0.083) | |
| 0.64 (0.115) | 0.151 (0.042) | 0.622 (0.142) | 0.158 (0.038) | 0.634 (0.243) | 0.157 (0.042) | ||
| 1.214 (0.224) | 0.206 (0.077) | 1.185 (0.279) | 0.221 (0.073) | 1.162 (0.464) | 0.221 (0.082) | ||
| MSE | 1.149 (0.209) | 0.124 (0.074) | 1.119 (0.433) | 0.123 (0.082) | 0.916 (0.511) | 0.119 (0.072) | |
| 0.654 (0.105) | 0.159 (0.038) | 0.634 (0.25) | 0.155 (0.042) | 0.53 (0.277) | 0.159 (0.037) | ||
| 1.212 (0.207) | 0.221 (0.074) | 1.198 (0.464) | 0.218 (0.081) | 0.977 (0.53) | 0.211 (0.071) | ||
| MSE | 1.123 (0.286) | 0.125 (0.088) | 1.05 (0.424) | 0.124 (0.095) | 0.71 (0.337) | 0.116 (0.078) | |
| 0.629 (0.165) | 0.16 (0.047) | 0.632 (0.212) | 0.16 (0.053) | 0.453 (0.188) | 0.156 (0.043) | ||
| 1.181 (0.303) | 0.219 (0.089) | 1.153 (0.421) | 0.215 (0.099) | 0.8 (0.355) | 0.218 (0.081) | ||
| MSE | 1.12 (0.231) | 0.146 (0.094) | 0.824 (0.336) | 0.129 (0.08) | 0.722 (0.24) | 0.127 (0.093) | |
| 0.631 (0.122) | 0.173 (0.047) | 0.509 (0.176) | 0.166 (0.042) | 0.447 (0.124) | 0.165 (0.048) | ||
| 1.19 (0.23) | 0.243 (0.093) | 0.904 (0.342) | 0.23 (0.081) | 0.812 (0.242) | 0.226 (0.093) | ||
Table 7 summarizes the result for Dataset1 and Dataset2 for all types of error distribution. We verify that the proposed method successfully estimates the nonlinear relationship between the proxy and true covariate with moderate performance across all metrics. Additionally, BEMP-all exhibits superior performance to BEMP-nonlinear in estimating the proxy’s nonlinear relationship. This result supports our assumption that information from other proxies improves the estimation of the proxy’s current relationship. The improved estimation of the relationship between the proxy and covariate directly affects the unobserved covariate’s estimation, which might be important for the estimated quantile function’s performance.
4.3 Estimation of Unobserved Covariate
Although the estimation of the regression function is the primary focus in most cases, the inference of the mismeasured covariate can be another important interest. To further investigate the proposed method, we examine the posterior samples to estimate the unobserved covariate . Table 8 presents the MSE between the posterior samples of the unobserved covariate and their true value in Dataset1 with a normal error. Notably, with the naive approach using instead of , the MSE is in expectation, which is in our simulation. The MSE of the estimation of exhibits patterns consistent with the other parameters. For all the models that we test, the MSE is smaller than that of the naive approach . BEMP-nonlinear and structural methods exhibit similar performances, whereas adding a nonlinear proxy still boosts the estimation of . This is evident in that BEMP-all generally outperforms BEMP-quad in all the quantiles, which, again, demonstrates multiple proxies’ effectiveness. The results from the other cases exhibit similar patterns (Appendix).
| Quantile | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all |
|---|---|---|---|---|
| 0.914 (0.043) | 0.259 (0.037) | 0.756 (0.087) | 0.229 (0.051) | |
| 0.915 (0.043) | 0.25 (0.038) | 0.78 (0.095) | 0.221 (0.052) | |
| 0.913 (0.045) | 0.248 (0.035) | 0.787 (0.1) | 0.219 (0.05) | |
| 0.908 (0.046) | 0.254 (0.036) | 0.899 (0.121) | 0.219 (0.052) | |
| 0.902 (0.046) | 0.261 (0.038) | 0.947 (0.128) | 0.215 (0.054) |
5 Application to Administrative Data
We apply the proposed method to a real dataset that includes asset and income variables. Statistics Korea released microdata from the Survey of Household Finances and Living Conditions (SFLC), incorporating administrative data obtained from other government institutions. The released dataset includes basic demographic variables for 18,064 families and various economic features, such as salary income, property income, assets, asset management plans, debt, and debt repayment capacity for each family unit collected in 2020.
This application aims to determine the quantile relationship between assets and true salary income. Income data provide critical information for a wide range of policies. However, administrative salary income is prone to measurement error, so the direct use of this information can precipitate misleading inferences (Moore et al., 2000; Davern et al., 2005). We consider using administrative salary income and property income as two types of proxies: one is exposed to additive error, and the other is a correlated proxy. These values are suitable for use as proxies because it is reasonable to assume that property income and salary income have a high correlation (Lerman and Yitzhaki, 1985). Consequently, the model is described as follows:
Notably, we assume that we do not observe but instead observe multiple proxies, and . To model the correlated proxy property income, we utilize a linear regression for the relationship between the proxy and covariate with parameter . As a preprocessing step, we eliminate the extreme quantiles (i.e., and percentiles in terms of each variable). After preprocessing, the data comprises 11,317 family units. Further, we attempt a log transform for asset variables to alleviate data skewness and improve model convergence. Following Thompson et al. (2010)’s suggestion, we take knots equally spaced over the range of variables, which is log-transformed administrative salary income.
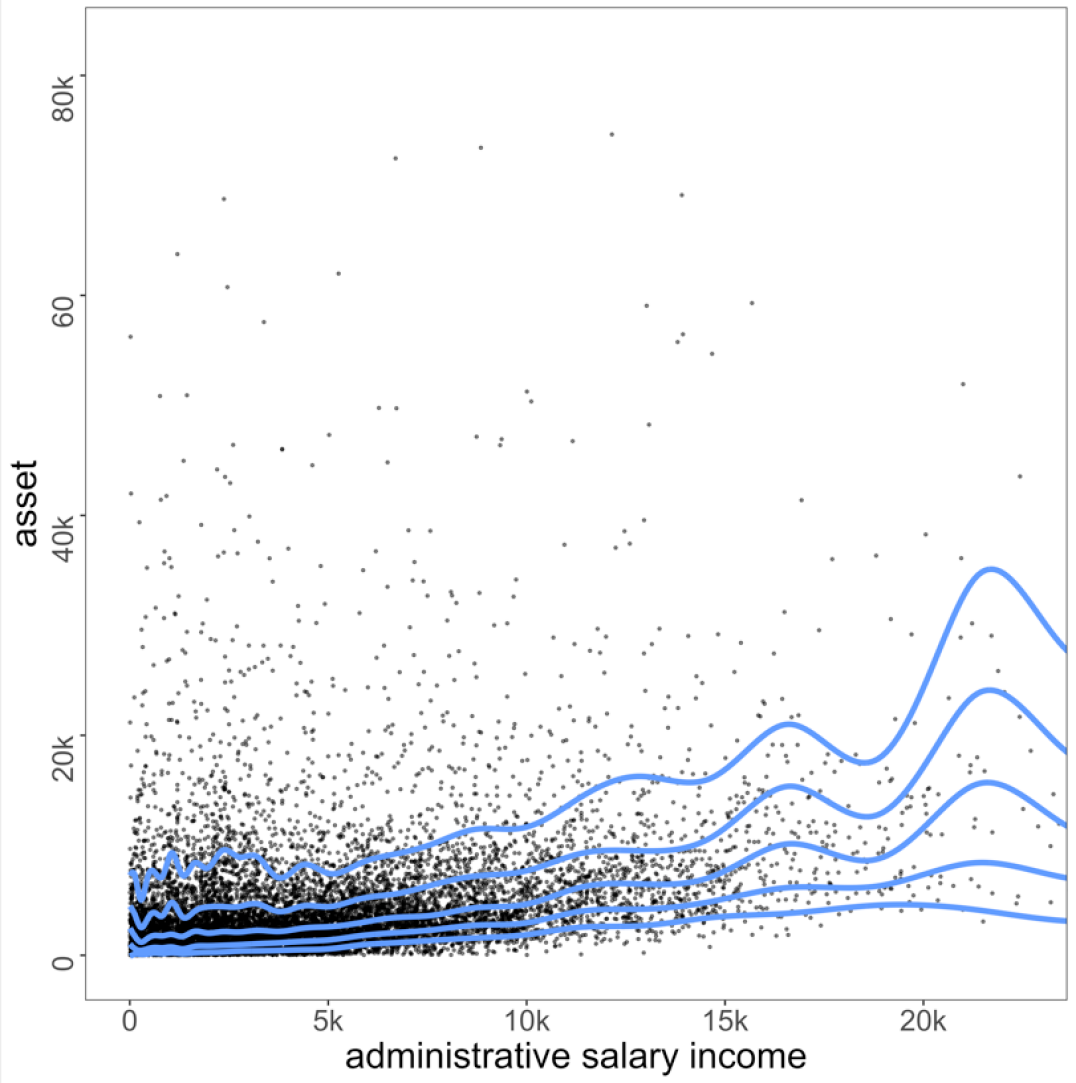
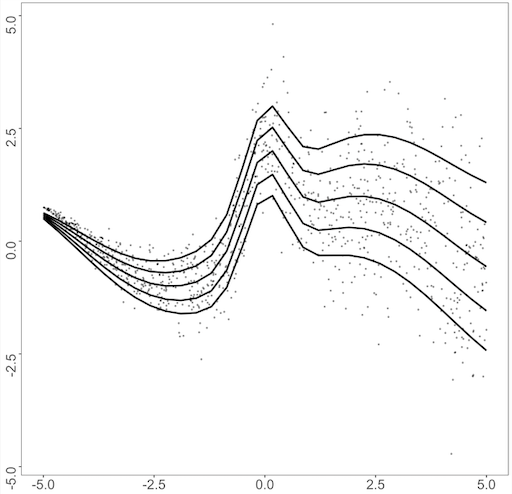
We investigate the effect of true salary income on asset in different quantile . Figure 3 presents the resulting quantile lines. In Figure 3, the fitted relation’s spread is not parallel, implying that a heterogeneous effect exists. The fitted quantile function of presents a larger gap between the other fitted quantile functions, which indicates that the conditional distribution of asset is not symmetrical and right-skewed. More interestingly, for higher quantiles, such as and , the fitted line in the lower level of administrative salary income () generally curved upward, with its highest point in .
This outcome might be attributable to various reasons. For example, people with their assets not structurally proportional to salary income or those with the upper end of asset value might structurally misreport their salary income, which is in line with the literature (Moore et al., 2000; Stocké, 2006; Valet et al., 2019). In either case, nonparametric quantile regression can derive a novel insight that was impossible through parametric regression and is more informative in combining proxies than the naïve approach.
6 Conclusion
This study proposes a Bayesian quantile regression estimation method that integrates multiple proxies obtained from multiple datasets. The proposed method has two notable advantages compared to previous methods. First, the proposed approach handles multiple data sources with different relationships to the same covariate, whereas previous methods were developed for handling a single proxy with only an additive error or limited structure. Another strength is that the proposed method is not restricted to linear regression functions and alleviates parametric assumptions regarding the regression function of interest such that the conditional distribution’s dispersion can be investigated more precisely.
A simulation study on various datasets demonstrates that the proposed method can accommodate multiple proxies with linear and nonlinear relationships with the true covariate. We demonstrate that the proposed method is promising for capturing the underlying relationship, effective in incorporating multiple proxies simultaneously, and making reliable estimations of unobserved covariates and their relationships with proxies. Further, we presented an application of this methodology using a public SFLC dataset and provided the underlying relationship between assets and salary income in the presence of multiple income records.
This study has some limitations. We adopted a spline function for quantile regression; thus, the fitted regression line’s behavior tends to be erratic near the boundaries, which is a well-known characteristic of the spline approach (Friedman et al., 2001). Further, noteworthily, both natural cubic spline quantile regression (Thompson et al., 2010) and P-spline quantile regression (Lang and Brezger, 2004) use the asymmetric Laplace distribution (ALD) for errors because Bayesian quantile regression has been widely studied by specifying the ALD (Yu and Moyeed, 2001). We chose ALD in this study because it facilitates Bayesian inference and computation in the complicated additive models considered here; the result was reasonably flexible, as presented in Section 4. With a similar framework, alternative approaches such as Dunson and Taylor (2005); Kottas and Krnjajić (2009); Taddy and Kottas (2010)’s can also be applied to settings with multiple proxies. We leave the extension of this parametric assumption for future research. Finally, the current study relies on a benchmark variable’s presence, which is necessary for estimating the unobserved covariate’s scale. The alleviation of this assumption and its subsequent analysis, such as robustness, remain a topic for future research.
Acknowledgements
Ick Hoon Jin is partially supported by the Yonsei University Research Fund of 2019-22-0210 and by the National Research Foundation (NRF) Korea (NRF 2020R1A2C1A01009881). Jongho Im’s research is also supported by the NRF Korea (NRF-2021R1C1C1014407).
References
- Aigner et al. (1984) Aigner, D. J., C. Hsiao, A. Kapteyn, and T. Wansbeek (1984). Latent variable models in econometrics. Handbook of econometrics 2, 1321–1393.
- Berg et al. (2021) Berg, E., J. Im, Z. Zhu, L.-B. Colin, and J. Li (2021). Integration of statistical and administrative agricultural data from namibia. Statistical Journal of the IAOS 37, 557–578.
- Berry et al. (2002) Berry, S. M., R. J. Carroll, and D. Ruppert (2002). Bayesian smoothing and regression splines for measurement error problems. Journal of the American Statistical Association 97(457), 160–169.
- Brezger and Lang (2006) Brezger, A. and S. Lang (2006). Generalized structured additive regression based on bayesian p-splines. Computational Statistics & Data Analysis 50(4), 967–991.
- Brown (1982) Brown, M. L. (1982). Robust line estimation with errors in both variables. Journal of the American Statistical Association 77(377), 71–79.
- Carroll et al. (1999) Carroll, R. J., J. D. Maca, and D. Ruppert (1999). Nonparametric regression in the presence of measurement error. Biometrika 86(3), 541–554.
- Carroll et al. (2006) Carroll, R. J., D. Ruppert, L. A. Stefanski, and C. M. Crainiceanu (2006). Measurement error in nonlinear models: a modern perspective. CRC press.
- Clayton (1992) Clayton, D. G. (1992). Models for the Analysis of Cohort and Case-Control Studies with Inaccurately Measured Exposures. In Statistical Models for Longitudinal Studies of Exposure and Health, edited by James H. Dwyer, Manning Feinleib, Peter Lippert, and Hans Hoffmeister, 301–31. New York: Oxford University Press.
- Davern et al. (2005) Davern, M., H. Rodin, T. J. Beebe, and K. T. Call (2005). The effect of income question design in health surveys on family income, poverty and eligibility estimates. Health services research 40(5p1), 1534–1552.
- Delaigle et al. (2008) Delaigle, A., P. Hall, and A. Meister (2008). On deconvolution with repeated measurements. The Annals of Statistics 36(2), 665–685.
- Dunson and Taylor (2005) Dunson, D. B. and J. A. Taylor (2005). Approximate bayesian inference for quantiles. Journal of Nonparametric Statistics 17(3), 385–400.
- Eliers and Marx (1996) Eliers, P. and B. Marx (1996). Flexible smoothing using b-splines and penalized likelihood (with comments and rejoinder). Statistical Science 11, 1200–1224.
- Eubank (1999) Eubank, R. L. (1999). Nonparametric regression and spline smoothing. CRC press.
- Fan (1992) Fan, J. (1992). Design-adaptive nonparametric regression. Journal of the American statistical Association 87(420), 998–1004.
- Fenske et al. (2011) Fenske, N., T. Kneib, and T. Hothorn (2011). Identifying risk factors for severe childhood malnutrition by boosting additive quantile regression. Journal of the American Statistical Association 106(494), 494–510.
- Filmer and Pritchett (2001) Filmer, D. and L. H. Pritchett (2001). Estimating wealth effects without expenditure data—or tears: an application to educational enrollments in states of india. Demography 38(1), 115–132.
- Firpo et al. (2017) Firpo, S., A. F. Galvao, and S. Song (2017). Measurement errors in quantile regression models. Journal of econometrics 198(1), 146–164.
- Friedman et al. (2001) Friedman, J., T. Hastie, R. Tibshirani, et al. (2001). The elements of statistical learning, Volume 1. Springer series in statistics New York.
- Fuller (1987) Fuller, W. A. (1987). Measurement error models. John Wiley & Sons.
- Fuller (2009) Fuller, W. A. (2009). Sampling Statistics. John Wiley & Sons.
- Gamerman and Lopes (2006) Gamerman, D. and H. F. Lopes (2006). Markov chain Monte Carlo: stochastic simulation for Bayesian inference. CRC Press.
- Gelfand and Ghosh (1998) Gelfand, A. E. and S. K. Ghosh (1998). Model choice: a minimum posterior predictive loss approach. Biometrika 85(1), 1–11.
- Green and Silverman (1993) Green, P. J. and B. W. Silverman (1993). Nonparametric regression and generalized linear models: a roughness penalty approach. Crc Press.
- Härdle (1986) Härdle, W. (1986). Approximations to the mean integrated squared error with applications to optimal bandwidth selection for nonparametric regression function estimators. Journal of multivariate analysis 18(1), 150–168.
- Hausman et al. (2021) Hausman, J., H. Liu, Y. Luo, and C. Palmer (2021). Errors in the dependent variable of quantile regression models. Econometrica 89(2), 849–873.
- He and Liang (2000) He, X. and H. Liang (2000). Quantile regression estimates for a class of linear and partially linear errors-in-variables models. Statistica Sinica 10(1), 129–140.
- Hoerl and Kennard (1970) Hoerl, A. E. and R. W. Kennard (1970). Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12(1), 55–67.
- Koenker and Bassett (1978) Koenker, R. and J. G. Bassett (1978). Regression quantiles. Econometrica: journal of the Econometric Society 46(1), 33–50.
- Kottas and Krnjajić (2009) Kottas, A. and M. Krnjajić (2009). Bayesian semiparametric modelling in quantile regression. Scandinavian Journal of Statistics 36(2), 297–319.
- Kozumi and Kobayashi (2011) Kozumi, H. and G. Kobayashi (2011). Gibbs sampling methods for bayesian quantile regression. Journal of statistical computation and simulation 81(11), 1565–1578.
- Lang and Brezger (2004) Lang, S. and A. Brezger (2004). Bayesian p-splines. Journal of computational and graphical statistics 13(1), 183–212.
- Lerman and Yitzhaki (1985) Lerman, R. I. and S. Yitzhaki (1985). Income inequality effects by income source: A new approach and applications to the united states. The review of economics and statistics 67, 151–156.
- Leulescu and Agafitei (2013) Leulescu, A. and M. Agafitei (2013). Statistical matching: a model based approach for data integration. Eurostat methodologies and working paper.
- Li and Vuong (1998) Li, T. and Q. Vuong (1998). Nonparametric estimation of the measurement error model using multiple indicators. Journal of Multivariate Analysis 65(2), 139–165.
- Lubotsky and Wittenberg (2006) Lubotsky, D. and M. Wittenberg (2006). Interpretation of regressions with multiple proxies. The Review of Economics and Statistics 88(3), 549–562.
- Mazumder (2001) Mazumder, B. (2001). Earnings mobility in the us: A new look at intergenerational inequality. Technical report, Federal Reserve Bank of Chicago.
- Montes-Rojas et al. (2011) Montes-Rojas, G. et al. (2011). Quantile regression with classical additive measurement errors. Economics Bulletin 31(4), 2863–2868.
- Moore et al. (2000) Moore, J. C., L. L. Stinson, and E. J. Welniak (2000). Income measurement error in surveys: A review. Journal of Official Statistics-Stockholm- 16(4), 331–362.
- Richardson and Gilks (1993) Richardson, S. and W. R. Gilks (1993). A bayesian approach to measurement error problems in epidemiology using conditional independence models. American Journal of Epidemiology 138(6), 430–442.
- Ruppert (2002) Ruppert, D. (2002). Selecting the number of knots for penalized splines. Journal of computational and graphical statistics 11(4), 735–757.
- Schennach (2007) Schennach, S. M. (2007). Instrumental variable estimation of nonlinear errors-in-variables models. Econometrica 75(1), 201–239.
- Schennach (2008) Schennach, S. M. (2008). Quantile regression with mismeasured covariates. Econometric Theory 24(4), 1010–1043.
- Solon (1992) Solon, G. (1992). Intergenerational income mobility in the united states. The American Economic Review 82(3), 393–408.
- Stocké (2006) Stocké, V. (2006). Attitudes toward surveys, attitude accessibility and the effect on respondents’ susceptibility to nonresponse. Quality and Quantity 40(2), 259–288.
- Taddy and Kottas (2010) Taddy, M. A. and A. Kottas (2010). A bayesian nonparametric approach to inference for quantile regression. Journal of Business & Economic Statistics 28(3), 357–369.
- Thompson et al. (2010) Thompson, P., Y. Cai, R. Moyeed, D. Reeve, and J. Stander (2010). Bayesian nonparametric quantile regression using splines. Computational Statistics & Data Analysis 54(4), 1138–1150.
- Tibshirani (1996) Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58(1), 267–288.
- Valet et al. (2019) Valet, P., J. Adriaans, and S. Liebig (2019). Comparing survey data and administrative records on gross earnings: nonreporting, misreporting, interviewer presence and earnings inequality. Quality & Quantity 53(1), 471–491.
- Waldmann et al. (2013) Waldmann, E., T. Kneib, Y. R. Yue, S. Lang, and C. Flexeder (2013). Bayesian semiparametric additive quantile regression. Statistical Modelling 13(3), 223–252.
- Wang et al. (2012) Wang, H. J., L. A. Stefanski, and Z. Zhu (2012). Corrected-loss estimation for quantile regression with covariate measurement errors. Biometrika 99(2), 405–421.
- Wei and Carroll (2009) Wei, Y. and R. J. Carroll (2009). Quantile regression with measurement error. Journal of the American Statistical Association 104(487), 1129–1143.
- Yu et al. (2003) Yu, K., Z. Lu, and J. Stander (2003). Quantile regression: applications and current research areas. Journal of the Royal Statistical Society: Series D (The Statistician) 52(3), 331–350.
- Yu and Moyeed (2001) Yu, K. and R. A. Moyeed (2001). Bayesian quantile regression. Statistics & Probability Letters 54(4), 437–447.
- Yue and Rue (2011) Yue, Y. R. and H. Rue (2011). Bayesian inference for additive mixed quantile regression models. Computational Statistics & Data Analysis 55(1), 84–96.
- Zimmerman (1992) Zimmerman, D. J. (1992). Regression toward mediocrity in economic stature. The American Economic Review 82(3), 409–429.
Appendix: Additional Simulation Results
| Dataset1 | |||||
| Quantile | Naive | BEMP-poly | BEMP-nonlinear | BEMP-all | |
| Normal | 0.622 (0.09) | 0.309 (0.035) | 0.226 (0.05) | 0.175 (0.044) | |
| Student | 0.614 (0.117) | 0.302 (0.071) | 0.257 (0.076) | 0.21 (0.066) | |
| Gamma | 0.622 (0.124) | 0.385 (0.065) | 0.233 (0.069) | 0.143 (0.042) | |
| Normal | 0.401 (0.058) | 0.209 (0.036) | 0.155 (0.036) | 0.11 (0.03) | |
| Student | 0.444 (0.077) | 0.246 (0.043) | 0.195 (0.039) | 0.135 (0.034) | |
| Gamma | 0.375 (0.082) | 0.208 (0.042) | 0.11 (0.04) | 0.095 (0.025) | |
| Normal | 0.257 (0.08) | 0.114 (0.021) | 0.101 (0.027) | 0.069 (0.023) | |
| Student | 0.287 (0.081) | 0.134 (0.02) | 0.11 (0.025) | 0.078 (0.02) | |
| Gamma | 0.262 (0.068) | 0.174 (0.035) | 0.072 (0.026) | 0.099 (0.033) | |
| Normal | 0.316 (0.094) | 0.152 (0.022) | 0.092 (0.029) | 0.074 (0.018) | |
| Student | 0.37 (0.08) | 0.184 (0.024) | 0.111 (0.029) | 0.1 (0.023) | |
| Gamma | 0.403 (0.091) | 0.293 (0.056) | 0.101 (0.039) | 0.167 (0.052) | |
| Normal | 0.715 (0.162) | 0.258 (0.039) | 0.125 (0.034) | 0.11 (0.026) | |
| Student | 0.727 (0.156) | 0.347 (0.077) | 0.165 (0.044) | 0.174 (0.068) | |
| Gamma | 0.94 (0.212) | 0.486 (0.093) | 0.199 (0.086) | 0.266 (0.085) | |
| Dataset2 | |||||
| Quantile | Naive | BEMP-poly | BEMP-nonlinear | BEMP-all | |
| Normal | 0.231 (0.062) | 0.083 (0.021) | 0.096 (0.027) | 0.06 (0.022) | |
| Student | 0.292 (0.099) | 0.135 (0.047) | 0.134 (0.046) | 0.127 (0.04) | |
| Gamma | 0.176 (0.045) | 0.084 (0.023) | 0.095 (0.024) | 0.072 (0.026) | |
| Normal | 0.154 (0.044) | 0.068 (0.015) | 0.079 (0.024) | 0.048 (0.016) | |
| Student | 0.195 (0.057) | 0.084 (0.02) | 0.097 (0.023) | 0.06 (0.019) | |
| Gamma | 0.144 (0.05) | 0.082 (0.02) | 0.089 (0.024) | 0.069 (0.02) | |
| Normal | 0.147 (0.037) | 0.056 (0.014) | 0.071 (0.029) | 0.043 (0.014) | |
| Student | 0.161 (0.038) | 0.06 (0.011) | 0.075 (0.023) | 0.046 (0.013) | |
| Gamma | 0.183 (0.05) | 0.088 (0.027) | 0.093 (0.028) | 0.075 (0.029) | |
| Normal | 0.213 (0.028) | 0.063 (0.014) | 0.078 (0.019) | 0.048 (0.015) | |
| Student | 0.206 (0.027) | 0.08 (0.019) | 0.087 (0.027) | 0.062 (0.021) | |
| Gamma | 0.234 (0.092) | 0.124 (0.037) | 0.113 (0.037) | 0.115 (0.04) | |
| Normal | 0.171 (0.04) | 0.076 (0.018) | 0.085 (0.025) | 0.056 (0.02) | |
| Student | 0.211 (0.084) | 0.127 (0.051) | 0.127 (0.043) | 0.127 (0.053) | |
| Gamma | 0.349 (0.116) | 0.175 (0.074) | 0.171 (0.067) | 0.18 (0.081) | |
| Student Error | ||||
| Quantile | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all |
| 0.913 (0.043) | 0.266 (0.035) | 0.722 (0.067) | 0.219 (0.053) | |
| 0.902 (0.043) | 0.258 (0.037) | 0.722 (0.069) | 0.223 (0.049) | |
| 0.902 (0.044) | 0.253 (0.039) | 0.723 (0.086) | 0.218 (0.05) | |
| 0.9 (0.043) | 0.255 (0.037) | 0.726 (0.093) | 0.217 (0.047) | |
| 0.9 (0.044) | 0.262 (0.034) | 0.721 (0.072) | 0.224 (0.058) | |
| Gamma Error | ||||
| Quantile | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all |
| 0.914 (0.044) | 0.262 (0.035) | 0.781 (0.122) | 0.225 (0.053) | |
| 0.904 (0.043) | 0.254 (0.038) | 0.714 (0.072) | 0.211 (0.051) | |
| 0.902 (0.044) | 0.258 (0.04) | 0.697 (0.061) | 0.211 (0.052) | |
| 0.901 (0.044) | 0.26 (0.038) | 0.721 (0.069) | 0.219 (0.05) | |
| 0.901 (0.044) | 0.269 (0.039) | 0.716 (0.056) | 0.229 (0.054) | |
| Standard Normal Error | ||||
| Quantile | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all |
| 0.913 (0.045) | 0.25 (0.036) | 0.969 (0.053) | 0.22 (0.057) | |
| 0.913 (0.044) | 0.224 (0.034) | 0.97 (0.039) | 0.215 (0.048) | |
| 0.914 (0.044) | 0.213 (0.031) | 0.969 (0.046) | 0.201 (0.046) | |
| 0.913 (0.043) | 0.23 (0.032) | 0.957 (0.088) | 0.204 (0.046) | |
| 0.913 (0.043) | 0.242 (0.034) | 0.936 (0.097) | 0.219 (0.046) | |
| Student Error | ||||
| Quantile | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all |
| 0.913 (0.044) | 0.258 (0.039) | 0.793 (0.11) | 0.231 (0.051) | |
| 0.913 (0.044) | 0.238 (0.032) | 0.931 (0.108) | 0.217 (0.055) | |
| 0.913 (0.043) | 0.226 (0.033) | 0.949 (0.085) | 0.207 (0.045) | |
| 0.913 (0.043) | 0.235 (0.03) | 0.856 (0.102) | 0.204 (0.047) | |
| 0.913 (0.044) | 0.241 (0.032) | 0.764 (0.091) | 0.219 (0.051) | |
| Gamma Error | ||||
| Quantile | Structural | BEMP-poly | BEMP-nonlinear | BEMP-all |
| 0.913 (0.041) | 0.22 (0.035) | 0.968 (0.077) | 0.184 (0.049) | |
| 0.913 (0.044) | 0.194 (0.029) | 0.823 (0.12) | 0.171 (0.041) | |
| 0.908 (0.046) | 0.187 (0.027) | 0.727 (0.097) | 0.167 (0.041) | |
| 0.908 (0.046) | 0.196 (0.027) | 0.687 (0.085) | 0.174 (0.041) | |
| 0.901 (0.044) | 0.218 (0.03) | 0.72 (0.088) | 0.188 (0.047) | |