Quantized Neural Networks via Encoding Decomposition and Acceleration
Abstract
The training of deep neural networks (DNNs) always requires intensive resources for both computation and data storage. Thus, DNNs cannot be efficiently applied to mobile phones and embedded devices, which severely limits their applicability in industrial applications. To address this issue, we propose a novel encoding scheme using to decompose quantized neural networks (QNNs) into multi-branch binary networks, which can be efficiently implemented by bitwise operations (i.e., xnor and bitcount) to achieve model compression, computational acceleration, and resource saving. By using our method, users can achieve different encoding precisions arbitrarily according to their requirements and hardware resources. The proposed mechanism is highly suitable for the use of FPGA and ASIC in terms of data storage and computation, which provides a feasible idea for smart chips. We validate the effectiveness of our method on large-scale image classification (e.g., ImageNet), object detection, and semantic segmentation tasks. In particular, our method with low-bit encoding can still achieve almost the same performance as its high-bit counterparts.
Index Terms:
Deep neural networks, Model compression and acceleration, Multi-branch binary networks, Bitwise operations, Smart chipsI Introduction
Deep Neural Networks (DNNs) have been successfully applied in many fields, such as image classification, object detection and natural language processing. Because of a great number of parameters in multilayer networks and complex model architectures, huge storage space and considerable power consumption are needed. For instance, the VGG-16 model has a total of million parameters, and requires more than MB storage space and billion float point operations in the inference process. With the rapid development of chip (e.g., GPU and TPU) technologies, computing power has been dramatically improved. In the rapid evolution of deep learning, most researchers use multiple GPUs or computer clusters to train deeper and even more complex neural networks. Nevertheless, the energy consumption and limitation of computing resources are still significant factors in industrial applications, which are generally ignored in scientific research. In other words, breathtaking results of many DNN algorithms under the condition of applying GPUs are lagging behind the demand of the industry. DNNs can hardly be applied in mobile phones and embedded devices directly due to their limited memory and calculation resources. Therefore, the model compression and acceleration in DNNs are especially important in the future industrial and commercial applications.
In recent years, many solutions have been proposed to improve the energy efficiency of hardware and achieve model compression or computational acceleration, such as network sparsification and pruning [2, 3, 4], low-rank approximation [5, 6, 7], designing architectures [8, 9] and model quantization [10, 11, 12]. Network sparsification and pruning can dramatically decrease the number of connections in the network, and thus considerably reduce the computational load in the inference process without a pretty high loss in accuracy. Luo et al. [13] presented a unified framework, and exploited a filter level pruning method to discard some less important filters. [7] used low-rank tensor decomposition to remove the redundancy in convolution kernels, which can serve as a generic tool for speed-up. Since there is some redundant information in the networks, most straightforward approaches of cutting down those information are to optimize the structure and yield smaller networks [14, 15]. For example, [8] proposed to use bitwise separable convolutions to build light networks for mobile applications. Most of those networks still utilize floating-point representations (i.e., full-precision values). However, [16] discussed that the full-precision representations of the weights and activations in DNNs are not necessary during the training, and a nearly identical or slightly better accuracy may be obtained under lower-precision representation and calculation. Thus, many scholars are working on the topic of model quantization to achieve model compression and resource saving. Model quantization can be applied to many network architectures and applications. In particular, it can also combine with other strategies (e.g., pruning) to achieve more efficient performance.
Model quantization methods mainly include low-bit quantization approaches (e.g., BNN [17], XNOR-Net [11], TWN [18], and TBN [19]) and -bit (e.g., or ) quantization approaches (e.g., DoReFa-Net [20], INQ [21], ABC-Net [12], and LQ-Nets [22]). Those low-bit quantization methods can achieve extreme model compression, computational acceleration and resource saving. For example, XNOR-Net [17] uses bitwise operations (i.e., xnor and bitcount) to replace full-precision matrix multiplication, achieving 58 speedups and 32 memory saving in CPU [11]. As discussed in [23], FP-BNN attains a higher acceleration ratio on FPGA, which can speed up to about 705 in the peak condition compared with CPU, and is 70 faster than GPU. However, most models were proposed for a fixed precision, and cannot be extended to other precision models. The representation capability of low-bit parameters is insufficient for many practical applications, especially for large-scale image classification (e.g., ImageNet) and regression tasks. Therefore, the low-bit quantization methods suffer from significant performance degradation. In contrast, -bit quantization networks have better representation capability than low-bit quantization ones, and thus can be applied to more complex real-world applications. Some scholars use -bit quantization to improve both accuracy and compression ratio of their networks, but seldom consider their computational acceleration [16, 24, 21]. Both ABC-Net [12] and LQ-Nets [22] used the linear combination of multiple binary parameters constrained to to approximate full-precision weights and activations. Therefore, the complex full-precision matrix multiplication can be decomposed into some simpler operations. [25] and [26] used the same technique to accelerate the training of convolutional neural networks (CNNs) and recurrent neural networks (RNNs). However, those methods not only increase the number of parameters many times, but also introduce a scale factor to transform the original problem into an NP-hard problem, which makes the solution difficult and highly complex. The slow convergence rate in training process and the lack of efficient acceleration strategies in inference process are two typical issues in -bit quantization networks.
In order to extend the efficient bitwise operations (i.e., xnor and bitcount) of binary quantization to -bit quantization without excessively increasing time complexity and space complexity, we propose a novel encoding scheme using to decompose trained quantized neural networks (QNNs) into multi-branch binary networks. Our method bridges the gap between binary and full-precision quantizations, and can be applied to many cases (from -bit to -bit). Thus, our encoding mechanism can improve the utilization of hardware resources, and achieve parameter compression and computation acceleration. In our experiments, we not only validate the performance of our multi-precision quantized networks for image classification on CIFAR-10 and large-scale datasets (e.g., ImageNet), but also implement object detection and semantic segmentation tasks. The main advantages of our method are summarized as follows:
-
•
Training easier. For efficiently training our networks, we use the parameters of high-bit trained models sequentially to initialize a low-bit model, which converges faster than those straightforward approaches (e.g., DoReFa-Net, ABC-Net, and INQ). Hence, our networks can be trained within a short time, and only dozens of times fine-tuning is needed to achieve the accuracies in our experiments. Thus, our multi-branch binary networks can be easily applied to various practice engineering applications.
-
•
More options. Different from BWN, BNN, XNOR-Net and TWN, our method can provide available encoding options for different encoding precision networks. Naturally, each option with a special encoding precision has a different calculation speed, resource requirement and experimental precision. Therefore, users can choose the appropriate option for their requirements.
-
•
Suitable for hardware implementations. After the process of decomposition, instead of storing all encoding bits in data types, e.g., char, int, float or double, the parameters can be individually stored by bit vectors. Thus, the smallest unit of data in electronic equipments can be reduced to -bit from -bit, -bit, -bit or -bit, which raises the utilization rate of resources and compression ratios of the model. Then the data can be encoded, calculated and stored in various encoding precisions.
-
•
Suitable for diverse networks and applications. In our experiments, we evaluate our method on many widely used deep networks (e.g., AlexNet, ResNet-18, ResNet-50, InceptionV3, MobileNetV2 and DeepLabV3) and real-world applications (e.g., image classification, object detection and semantic segmentation). Our encoding scheme could also be applied to many other networks and applications.
II Related Work
DNN quantization has attracted a lot of attention to promote the industrial applications of deep learning, especially for mobile phones, video surveillance, unmanned aerial vehicle and unmanned driving. Many researchers use quantitative methods to get lighter and more efficient networks. All the research mainly focuses on the following three issues.
How to quantize the values of weights or activation in DNNs to achieve model compression? Quantization methods play a significant role in QNNs, and can be used to convert their floating-point weights and activations into their fixed-point (e.g., from -bit to -bit) counterparts for achieving model compression. [16] used the notation of integer and fractional bits to denote a -bit fixed-point representation, and proposed a stochastic rounding method to quantify weights and activations. [24] used -bit quantization to convert weights into signed char and activation values into unsigned char, and all the values are integer. For multi-state quantification (from -bit to -bit), linear quantization is used in [10, 27, 28]. Besides, [29] proposed logarithmic quantization to represent data and used bitshift operations in log-domain to compute dot products. For ternary weight networks [18], the weights are quantized to , where , is the model weights and is its number. In [30], the positive and negative states are trained together with other parameters. When the states are constrained to -bit, [17] applied the sign function to quantize both weights and activations to and . [11] also used to represent the binary states, where .
How to achieve computational acceleration in the inference process? After quantized training, weights and/or activation values are represented in a low-bit form (e.g., -bit and -bit), which has the potential of acceleration computation and memory saving. The most direct quantization is to convert floating-point parameters into corresponding fixed-point (e.g., -bit) ones, and we can achieve hardware acceleration for fixed-point based computation [16, 24, 31, 32]. When the weight is extremely quantized to 1-bit (i.e., binary or ) as in [33] or 2-bit (i.e., ternary or ) as in [18, 34], the matrix multiplication can be transformed into full-precision matrix addition and subtraction to accelerate computation. Especially when the weight and activation values are binarized, matrix multiplication operations can be transformed into highly efficient xnor and bitcount operations [17, 11]. Bitwise operations are based on -bit units, and thus they cannot be directly applied to multi-bit computation. [25, 12] used a series of linear combinations of to approximate the parameters of full-precision convolution models, and then converted floating point operations into multiple binary weight operations to achieve model compression and computation acceleration. Miyashita et al. [29] applied logarithmic data representation on activations and weights that transform the dot product from linear domain into log-domain. Therefore, the dot product can be computed by the bitshift operation to achieve computational acceleration.
How to train QNNs in the quantized domain? It is clear that some discrete functions, which may be non-differentiable or have zero derivatives everywhere, are required to quantize weights or activation values in QNNs. The traditional stochastic gradient descent (SGD) methods are unsuitable to train the deep networks. Therefore, many researchers are devoting themselves to addressing this issue. All the optimization methods can be divided into two categories: quantizing pre-trained models with or without retraining such as [35, 36, 18, 12] and directly training quantized networks such as [33, 17, 11, 27]. [10], [17, 37], and [26] use the strategy of straight-through estimator (STE) [38] in training process to optimize deep networks. STE uses nonzero gradient to approximate the function gradient, which is not-differentiable or whose derivative is zero, and then applies SGD to update the parameters. Zhuang et al. [28] proposed a two-stage optimization procedure, which quantizes the weights and activations in a two-step manner. [39] and [40] use high-precision teacher networks to guide low-precision student networks to improve performance, which is called knowledge distillation. [12, 22, 41], and [42] apply alternating optimization methods to train network weights and their corresponding scaling factors.
III Multi-Precision Quantized Neural Networks
In this section, we propose a novel encoding scheme using to decompose QNNs into multi-branch binary networks. In each branch binary network, we use and as the basic elements to efficiently achieve model compression and forward inference acceleration for QNNs. Different from fixed-precision neural networks (e.g., binary and ternary), our method can yield multi-precision networks and make full use of the advantage of bitwise operations to accelerate training of our network.
III-A Computational Decomposition
As the basic computation in most layers of neural networks, matrix multiplication costs lots of resources and is also the most time-consuming operation. Modern computers store and process data in binary format, thus non-negative integers can be directly encoded by . Therefore, we propose a novel decomposition scheme to accelerate matrix multiplication as follows: Let and be two vectors of non-negative integers, where for . The dot product of those two vectors is written as follows:
| (1) |
All of the above operations consist of multiplications and additions. Based on the above encoding scheme, the vector can be encoded to a binary form using bits, i.e.,
| (2) |
Then the right-hand side of the formulation (2) can be converted into the following form:
| (3) |
where
| (4) | |||||
| (5) |
In such an encoding scheme, the number of represented states is not greater than . We also encode another vector with -bit representation in the same way. Therefore, the dot product of the two vectors can be computed as follows:
| (6) |
where is the encoding element of . From the above formula, the dot product is decomposed into sub-operations, in which every element is or . Because of the restriction of encoding and without using the sign bit, the above representation can only be used to encode non-negative integers. However, it is impossible to limit the weights and the values of the activation functions to non-negative integers.

In order to extend encoding space to negative integer and reduce the computational complexity, we propose a new encoding scheme, which uses as the basic elements of our encoder rather than . Except for the difference of basic elements, the encoding scheme is similar to the rules in Eq. (4), and is formulated as follows:
| (7) |
where denotes the number of encode bits, and can represent states. And the encoding space is extended to . We can use multiple bitwise operations (i.e., xnor and bitcount) to effectively achieve the above vector multiplications. Therefore, the dot product of those two vectors can be computed as follows:
| (8) |
where denotes the bitwise operation, and its details will be defined below. Therefore, this operation mechanism is suitable for all vector/matrix multiplications.
III-B Model Decomposition
In various neural networks, matrix multiplication is one basic operation in some commonly used layers (e.g., fully connected layers and convolution layers). Based on the above computational decomposition mechanism of matrix multiplication, we can decompose the quantized networks into a more efficient architecture.
Let be the number of encoding bits, and thus the encode space can be defined as: , in which each state is an integer value. The boundaries of the values are determined by the number of encoding bits, . However, the parameters in DNNs are usually distributed within the interval . In order to apply our decomposition mechanism to network model decomposition, we use the following formulation for the computation of common layers in neural networks.
| (9) |
where is the basic operations for multiple layers (e.g., fully connected operations and convolution operations), is the number of bits to encode input , is the number of bits to encode weights , and is the encoding process. Here, can be viewed as a scaling factor, and is usually set to . If there is a batch normalization layer after the above layer, the scaling factor is not used in the computation of our decomposition scheme.
For instance, we use a -bit encoding scheme (i.e., ) for a fully connected layer to introduce the mechanism of our decomposition model, as shown in Fig. 1. We define an “Encoder” that can be used in the 2BitEncoder function (i.e., and defined below) for encoding input data. Here, is encoded by and , where is high bit data and is low bit data. Therefore, we have the following formula: . In the same way, the weight can be converted into and . After cross multiplications, we get the four intermediate variables {}. In other words, each multiplication can be considered as a binarized fully connected layer, whose elements are or . This decomposition can produce multi-branch layers, and thus we call our networks as multi-branch binary networks (MBBNs). For instance, we decompose the -bit fully connection operation into four branches binary operations, which can be accelerated by bitwise operations, and then the weighted sum of those four results by the fixed scaling factor (e.g., in Fig. 1) is the final output. Besides fully connected layers, our decomposition scheme is suitable for the convolution and deconvolution layers in various deep neural networks.
III-C M-bit Encoding Functions
As an important part of various DNNs, activation functions can enhance the nonlinear characterization of networks. In our model decomposition method, the encoding function also plays a critical role and can encode input data to multi-bits ( or ). Those numbers represent the encoding of input data. For some other QNNs, several quantization functions have been proposed. However, it is not clear what the nonlinear mapping is between quantized numbers and encode bits. In this subsection, a list of -bit encoding functions are proposed to produce the element of each bit that follows the rules for encoding data.
| | |
|---|---|
| |
Before encoding, the data should be limited to a fixed numerical range. Table 1 lists the four activation functions. is used to project input data to , and it consists of the sign function to achieve binary encoding of weights and activations [17, 23]. Since the convergence of SGD for training the networks with is faster than other activation functions, we propose a new activation function , which retains the linear characteristics in the specific range and limits the range of input data to . Different from general activation functions mentioned above, the output of our -bit encoding function defined below should be numbers, which are or . Those numbers represent the encoding of input data. Therefore, the dot product can be computed by Eq. (9). In addition, in the above described experimental condition, when we use -bit to encode the data and constrain to , there are 4 encoded states, as shown in Table 2. The nonlinear mapping between quantized real numbers and their corresponding encoded states is given in Table 2. From the table, we can see that there is a linear factor between quantized real numbers and encoded states (i.e., for Table 2). When we use Eq. (9) to compute the multiplication of two encoded vectors, the value will be expanded times. Therefore, the result can multiply its scaling factor to get the final result, e.g., as in Fig. 1.
| Number Space | ||||
|---|---|---|---|---|
| Quantized Number | ||||
| Encoded States |
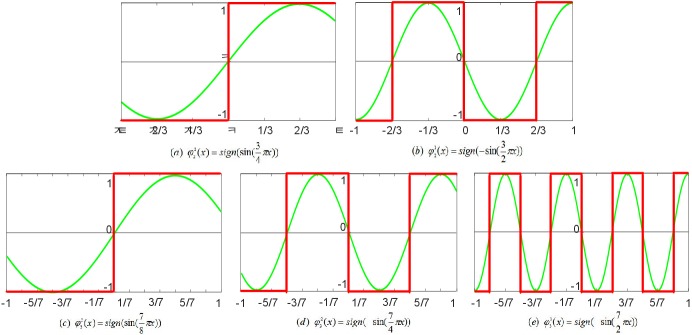
From the above results, we obviously need an activation function to achieve the transformation from the quantized number to its corresponding encoded state. The most straightforward transformation method is to determine the encoded states according to the number value through the look-up table, which is suitable for many hardware platforms (e.g., FPGA and ASIC). However, its derivative is hardly be defined, and thus this method can not be applied in training process. Therefore, we need a kind of derivable encoding function as activation functions to train the network.
This is a typical single-input multiple-output problem. The Fourier neural network (FNN) [53, 54] can be used to transform a nonlinear optimization problem into a combination of multiple linear ones [55]. It has been successfully used for stock prediction [54], aircraft engine fault diagnostics [56], harmonic analysis [57], lane departure prediction [58], and so on. In[59], it has verified that the trigonometric activation function can achieve faster and better results than those using established monotonic functions for some certain tasks. Fig. 2 shows the illustration of the -bit and -bit encoding functions. We can see that those encoding functions are required to be periodic, and they should have different periods. Inspired by FNN, we apply trigonometric functions as the basic encoding functions, whose lines are highlighted in red. Finally, we use the sign function to determine whether the value is or . Hence, we use several trigonometric functions to approximate the nonlinear mapping between quantized numbers and their encoded states, which is called as the function, and is formulated as follows:
| (10) |
when (i.e., ) is the encoding function of the highest bit of the function. For example, for the 2-bit case, the function is formulated as follows:
| (11) |
where is the encoding function of the first bit () of the function, and denotes the encoder function of the second bit () of the function. The periodicity is clearly different from the others because it needs to denote more states.
IV Training Networks
To train QNNs, we usually face the problem that the derivative is not defined, and thus traditional gradient optimization methods are not applicable. [17] presented the HTanh function to binarily quantize both weights and activations, and also defined the derivative to support the back-propagation (BP) training process. They used the loss computed by binarized parameters to update full precision parameters. Similarly, [11] also proposed to update the weights with the help of the second parameters. [38] discussed that using STE to train network models containing discrete variables can obtain faster training speed and better performance. By utilizing equivalent transformation of our method, QNNs can be decomposed to MBBNs. The goal of training networks is to get the optimum parameters, which are quantized to or . Obviously, we have two ways to train our model: The first way is to train the decomposed MBBNs directly, and the second one is that we first to train the quantized networks to get the quantized weights, and then we use our equivalent transformation method to transform the quantized weights to the bit encoded binary weights. Next, we will describe the two ways in detail.
IV-A Training Multi-Branch Binary Networks
Generated by the decomposition of QNNs, MBBNs need to use -bit encoding functions as activation functions to get the elements of each bit, which can be used by more efficient bitwise operations to replace arithmetic operations. As described in Section 3.3, -bit encoding functions are the combination of a series of trigonometric and sign functions. The sign function of the encoder makes it difficult to implement the BP process. Thus, we approximate the derivative of the encoding function with respect to as follows:
| (12) |
We take the 2-bit encoding as an example to describe the optimization method of MBBNs.
| (13) |
Besides activations, all the weights of networks also need to be quantized to binary values. Therefore, MBBN can be viewed as a special binarized neural network [17]. In this training method, we use the same mechanisms to constrain and update parameters, and use and to represent the real-valued weights and its binarized weights, respectively. is constrained between and by the HTanh() function to avoid excessive growth. Instead of -bit encoding functions that are complex, we use the sign function directly to binarize parameters. Therefore, the binarization function for transforming to can be directly formulated as follows:
| (14) |
For this function, we define the gradient function of each component to constrain the search space. In the training process, we apply to compute the loss and gradients, which are used to update . That is, the input of the sign function can be constrained to by , and it can also speed up convergence. The parameters of the whole network are updated in the condition of differentiability.
We give the detailed training algorithm of MBBN in Algorithm 1, where we describe the main computing process of the network, and some details about batch normalization, pooling and loss layers are omitted. Note that the forward() operation is the basic operation in DNNs, such as convolutional and full-connected operations. Those operations can be accelerated by binary bitwise operations. We use backward() and BackMBitEncoder() to specify how to backpropagate through forward() and MBitEncoder() operations. Update() specifies how to update the parameters with their known gradients. For example, we usually use Adam or SGD as our optimization algorithm.
Require:
A mini-batch of inputs and targets , previous weights , and learning rate .
Ensure:
Updated weights .
1. Computing the parameter gradients:
1.1 Forward propagation:
IV-B Training Quantized Networks
The above training scheme is proposed to optimize binary networks, which are transformed by our model decomposition method. However, this decomposition method can produce multiple times as many parameters as the original network. If we optimize the binary network, it may easily fall into local optimal solutions and has slow convergence speed. Based on the nonlinear mapping between quantized numbers and their encoded states, we can directly optimize the quantized network and then utilize our equivalent transformation method to decompose quantized network. The decomposed parameters can be used by MBBN in the inference process to achieve computational acceleration.
Two quantization schemes are usually applied in QNNs [17, 20, 29], and include linear quantization and logarithmic quantization. Due to the requirement of our encoding mechanism, linear quantization is used to quantize our networks. We quantize a tensor linearly into -bit, which can be formulated as follows:
| (15) |
where the clamp function is used to truncate all values into the range of , is a learned parameter, and the scaling factor is defined as: . The rounding operation can be used to quantize a real number to a certain state, we call it a hard ladder function, which can segment input space to multi-states. Table 2 lists the four states quantized by Eq. (11). However, the derivative of this function is almost zero everywhere, and thus it cannot be applied in the training process. Inspired by STE [38], we use the same technique to speed up computing process and yield better performance. We use the loss computed by quantized parameters to update full precision parameters. Note that for our encoding scheme with low-precision quantization (e.g., binary), we use Adam to train our model, otherwise SGD is used. Algorithm 2 shows the main training process of our quantized network, where () specifies how to backpropagate through the () function with -bit quantization.
Require:
A mini-batch of inputs and targets , previous weights , and learning rate .
Ensure:
Trained weights .
1. Computing the parameter gradients:
1.1 Forward propagation:
V Experiments
In this section, we compare the performance of our method with those of some typical methods for image classification tasks on CIFAR-10 and ImageNet, object detection tasks on PASCAL VOC2007/2012, and semantic segmentation tasks on PASCAL VOC2012. In recent years, many scholars are devoted to improving the performance (e.g., accuracy and compression ratio) of QNNs, while very few researchers have studied their engineering acceleration, which is an important reason for hindering industrial promotion. Therefore, we mainly focus on an acceleration method, which is especially suitable for engineering applications.
V-A Image Classification
| Models | Lenet | ResNet-18 | ResNet-50 | |||
| Methods | Compression ratio | CIFAR-10 | ImageNet (Top-1) | ImageNet (Top-5) | ImageNet (Top-1) | ImageNet (Top-5) |
| BWN [33] | 32 | 90.10% | 60.80% | 83.00% | - | - |
| BNN [17] | 32 | 88.60% | 42.20% | 67.10% | - | - |
| XNOR-Net [11] | 32 | - | 51.20% | 73.20% | - | - |
| TWN [18] | 16 | 92.56% | 61.80% | 84.20% | - | - |
| DoReFa-Net[1/4-bit] [20] | 32 | - | 59.20% | 81.50% | - | - |
| ABC-Net[5-bit] [12] | 6.4 | - | 65.00% | 85.90% | 70.10% | 89.70% |
| INQ[5-bit] [21] | 6.4 | - | 68.92% | 89.10% | 74.81% | 92.45% |
| SYQ[2/8-bit] [60] | 16 | - | 67.70% | 87.80% | 72.30% | 90.90% |
| Full-Precision | 1 | 91.40% | 70.10% | 89.81% | 76.20% | 93.21% |
| Encoded activations and weights | ||||||
| MBBN() | 32 | 90.39% | 52.33% | 79.51% | 56.65% | 80.78% |
| MBBN() | 16 | 91.06% | 66.07% | 87.28% | 73.04% | 91.33% |
| MBBN() | 10.7 | 91.27% | 69.17% | 89.24% | 75.21% | 92.54% |
| MBBN() | 8 | 91.15% | 70.31% | 89.89% | 76.22% | 93.09% |
| MBBN() | 6.4 | 90.92% | 70.98% | 90.17% | 76.53% | 93.27% |
| MBBN() | 5.3 | 91.01% | 71.42% | 90.51% | 76.61% | 93.44% |
| MBBN() | 4.6 | 90.20% | 71.46% | 90.66% | 76.65% | 93.54% |
| MBBN() | 4 | 90.43% | 71.46% | 90.54% | 76.71% | 93.40% |
CIFAR-10 is an image classification dataset, which has training and testing images. All the images are color images representing airplanes, automobiles, birds, cats, deer, dogs, frogs, horses, ships and trucks.
We validated our method with different bit encoding schemes, in which activations and weights are equally treated, that is, both of them use the same number of encoding bits. Table 3 lists the results of our method and many state-of-the-art models, including BWN [33], BNN [17], XNOR-Net [11], XNOR-Net [11], TWN [18], DoReFa-Net [20], ABC-Net [12], INQ [21], and SYQ [60]. Here we used the same network architecture as in [33] and [17], except for the encoding functions. We used as the activation function and employed Adam to optimize all the parameters of the networks. From all the results, we can see that the representation capabilities of our networks encoded by 1-bit or 2-bit are enough for small-scale datasets, e.g., CIFAR-10. Our method with low-precision encoding (e.g., -bit) achieved nearly the same classification accuracy as its high precision versions (e.g., -bit) and full-precision models, while we can attain memory saving compared with its full-precision counterpart. When both activations and weights are constrained to -bit, our network structure is similar to BNN [17], and our method yielded even better accuracy mainly because of our proposed encoding functions.
ImageNet: We further compared the performance of our method with all the other methods mentioned above on the ImageNet (ILSVRC-2012) dataset [61]. This dataset consists of 1K categories images, and has over M images in the training set and K images in the validation set. Here, we used ResNet-18 and ResNet-50 to illustrate the effectiveness of our method. and used Top-1 and Top-5 accuracies to report classification performance. For large-scale training sets (e.g., ImageNet), it usually costs plenty of time and requires sufficient computing resources for classical full-precision models. Moreover, it will be more difficult to train quantized networks, and thus the initialization of parameters is particularly important. Here, we used as the activation function to constrain activations. In particular, the full-precision model parameters activated by can be directly used as the initialization parameters for our -bit quantized network. After a little number of fine-tuning, our -bit quantized networks can be well-trained. Similarly, we used the -bit model parameters as the initialization parameters to train -bit quantized networks, and so on. There is a special case, when we use and the 1BitEncoder function to encode activations, and all the activations are constrained to . Thus, we used as the activation function for -bit encoding. Note that we used SGD to optimize parameters when the number of encoding bits is not less than , and the learning rate was set to . When the number of the encoding bits is or , the convergent speed of Adam is faster than SGD, as discussed in [17, 11].
Table 3 lists the performance (e.g., accuracies and compression ratios) of our method and many state-of-the-art models mentioned above. Experimental results show that our method performs much better than its counterparts. Similarly, our method with -bit encoding significantly outperforms ABC-Net[-bit] [12]. Moreover, our networks can be trained in a very short time to achieve the accuracies in our experiments, and only dozens of fine-tuning are needed. Different from BWN and TWN, whose weights are only quantized rather than activation values, our method quantifies both weights and activation values, simultaneously. Although BWN and TWN can obtain little higher accuracies than our -bit quantization model, we obtain significantly better speedups, and the speedup ratios of existing methods such as BWN and TWN are limited to . Due to limited and fixed expression ability, existing methods (such as BWN, TWN, BNN and XNOR-Net) cannot satisfy various quantization precision requirements. In particular, our method can provide available encoding choices, and hence our encoded networks with different encoding precisions have different speedup ratios, memory requirements and experimental accuracies.
| Layer name | ResNet-18 | Precision#1 | Precision#2 |
| Conv1 | , 64, stride 2 | , | , |
| Conv2x | , | , | |
| Conv3x | , | , | |
| Conv4x | , | , | |
| Conv5x | , | , | |
| FC | 1000 | , | , |
| Compression ratio | 5.0x | 14.1x | |
| Accuracy | Top-1=71.45% | Top-1=69.32% | |
| Top-5=90.60% | Top-5=89.37% | ||
In the above experiments, all activation values and weights are constrained to the same bit precision (e.g., ). However, our method also has an advantage that it can support mixed precisions (e.g., and ), that is, weights and activations for each layer can have different bit precisions. This makes model quantification and acceleration be more flexible, and thus meets more requirements for model design. We used ResNet-18 as an example to verify the effect of mixed precisions. Table 4 lists the network structures, bit precision of each layer, compression ratios, and classification accuracies on ImageNet. For the convenience, we set the same bit precision for each residual block of ResNet-18. The experimental results show that the mixed precisions can obtain higher classification accuracies. As shown in Table 4, the classification results of Precision#1 are higher than those of their full-precision counterparts, while obtaining a 5 compression ratio. We also set the bit precision of all the activation values to 4, and different bit precisions for each weight in Table 4, and achieve compression ratio and Top-1 accuracy.
V-B Object Detection
Besides image classification, QNNs can also be used for object detection tasks [62, 63]. Hence, we use our method to quantize some trained networks with the Single Shot MultiBox Detector (SSD) framework [64] for object detection tasks, (i.e., a coordinate regression task and a classification task). The regression task has higher demands on the encoding precision, and thus the application of object detection presents a new challenge for QNNs.
| Backbone | Precision | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| InceptionV3 | full(32-bit) | 78.8 | 80.8 | 86.8 | 81.5 | 72.1 | 53.6 | 86.9 | 87.7 | 87.4 | 62.0 | 81.4 | 75.3 | 88.0 | 87.1 | 86.0 | 79.3 | 58.7 | 81.5 | 72.9 | 87.2 | 80.2 |
| 78.0 | 79.0 | 85.8 | 79.8 | 72.4 | 49.8 | 83.5 | 86.8 | 86.5 | 60.7 | 84.2 | 75.4 | 87.5 | 86.6 | 84.4 | 78.9 | 57.5 | 81.9 | 73.3 | 86.7 | 78.8 | ||
| 77.2 | 79.1 | 85.3 | 78.9 | 67.8 | 51.4 | 85.1 | 86.4 | 87.8 | 59.3 | 82.7 | 73.3 | 87.0 | 85.5 | 83.7 | 77.7 | 56.8 | 78.8 | 70.7 | 87.9 | 78.7 | ||
| 66.6 | 71.1 | 76.2 | 62.7 | 59.2 | 36.0 | 75.0 | 80.9 | 76.2 | 40.8 | 71.6 | 67.4 | 73.8 | 78.8 | 74.6 | 71.1 | 41.9 | 64.9 | 63.2 | 79.3 | 66.9 | ||
| BWN | 44.8 | 56.5 | 57.2 | 26.8 | 34.6 | 17.4 | 51.6 | 59.6 | 51.2 | 22.3 | 41.5 | 55.3 | 42.1 | 63.4 | 54.9 | 53.3 | 15.7 | 44.0 | 40.2 | 60.2 | 50.2 | |
| ResNet-50 | full(32-bit) | 77.2 | 79.5 | 85.0 | 81.2 | 71.1 | 55.3 | 83.7 | 87.3 | 87.3 | 60.4 | 84.5 | 72.6 | 85.0 | 83.5 | 82.9 | 80.3 | 50.7 | 78.7 | 72.4 | 85.4 | 77.6 |
| 78.4 | 80.7 | 86.5 | 79.8 | 70.8 | 59.4 | 85.6 | 87.5 | 88.7 | 64.1 | 84.1 | 72.1 | 85.4 | 85.4 | 86.5 | 80.6 | 53.1 | 79.1 | 73.8 | 85.4 | 78.9 | ||
| 77.1 | 78.6 | 84.8 | 77.9 | 70.0 | 55.6 | 86.8 | 87.0 | 86.9 | 61.6 | 82.6 | 72.5 | 81.1 | 84.1 | 83.6 | 80.5 | 50.4 | 80.1 | 73.1 | 85.5 | 78.3 | ||
| 66.4 | 70.7 | 79.2 | 58.4 | 56.9 | 41.3 | 73.5 | 81.5 | 77.0 | 47.6 | 66.6 | 67.6 | 68.4 | 77.0 | 76.6 | 73.2 | 40.0 | 64.3 | 64.1 | 77.3 | 67.4 | ||
| BWN | 45.6 | 53.1 | 49.8 | 30.0 | 37.9 | 20.4 | 53.7 | 69.4 | 47.8 | 23.4 | 44.0 | 51.5 | 47.8 | 53.6 | 59.3 | 57.9 | 21.9 | 42.6 | 36.4 | 61.2 | 49.9 | |
| MobileNetV2 | full(32-bit) | 72.6 | 77.8 | 82.6 | 71.2 | 64.4 | 48.5 | 79.0 | 86.0 | 81.4 | 54.0 | 77.9 | 65.1 | 79.3 | 79.3 | 78.7 | 75.5 | 49.5 | 77.3 | 65.3 | 84.5 | 74.0 |
| 71.5 | 77.3 | 81.3 | 70.8 | 64.3 | 46.0 | 77.6 | 84.5 | 79.9 | 51.9 | 75.8 | 66.5 | 78.4 | 78.4 | 78.2 | 75.6 | 47.5 | 74.0 | 68.4 | 82.2 | 70.4 | ||
| 70.5 | 77.2 | 81.0 | 68.5 | 60.4 | 45.3 | 77.1 | 84.4 | 79.1 | 51.8 | 73.4 | 65.2 | 77.9 | 77.9 | 77.3 | 75.1 | 46.2 | 72.3 | 66.5 | 81.1 | 71.4 | ||
| 55.1 | 68.7 | 69.6 | 42.7 | 43.9 | 27.7 | 62.9 | 76.5 | 56.9 | 29.6 | 56.2 | 56.1 | 51.8 | 51.8 | 68.1 | 64.1 | 26.5 | 55.8 | 49.6 | 72.1 | 58.4 | ||
| BWN | 21.8 | 34.7 | 18.6 | 9.3 | 16.6 | 9.1 | 34.3 | 34.3 | 20.4 | 7.5 | 12.9 | 26.3 | 16.0 | 35.5 | 32.2 | 26.2 | 9.1 | 15.9 | 18.3 | 34.1 | 24.0 |

| Backbone | Precision | mAP | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| InceptionV3 | , | 69.9 | 70.4 | 78.0 | 68.5 | 59.8 | 40.7 | 79.2 | 82.1 | 83.3 | 48.7 | 72.8 | 74.6 | 77.6 | 80.0 | 81.1 | 72.3 | 41.4 | 67.0 | 68.2 | 80.3 | 71.3 |
| , | 69.4 | 74.1 | 79.3 | 67.3 | 61.3 | 41.2 | 74.7 | 82.3 | 79.6 | 48.1 | 74.7 | 67.8 | 75.2 | 80.2 | 75.4 | 73.5 | 41.8 | 72.6 | 66.6 | 81.8 | 70.4 | |
| , | 67.6 | 80.8 | 86.6 | 79.7 | 73.2 | 53.8 | 84.4 | 86.9 | 87.6 | 60.4 | 83.5 | 76.3 | 87.8 | 86.2 | 85.5 | 78.1 | 56.0 | 79.9 | 70.8 | 87.0 | 77.8 | |
| , | 64.7 | 71.1 | 74.9 | 53.8 | 55.9 | 33.7 | 72.3 | 79.4 | 77.0 | 43.2 | 66.8 | 68.8 | 69.1 | 76.1 | 74.0 | 70.3 | 37.1 | 61.7 | 67.1 | 78.4 | 64.0 |
In this experiment, all the models were trained on the PASCAL VOC2007 and VOC2012 trainval set, and tested on the VOC2007 test set. Here, we used MobileNetV2 [9], InceptionV3 [65] and ResNet-50 [66] as the basic networks to extract features in the SSD framework. Note that we quantize the basic network layers, and keep the other layers in full-precision. All the networks are trained on a large input image of size . In order to quickly achieve convergence of the network parameters, we adopted the same training strategy in the above experiments, in which the parameters of high-bit models are used to initialize low-bit models. We used the average precision (AP) to measure the performance of the detector on each category and mean average precision (mAP) to evaluate multi-target detector performance. Table IV shows the object detection results of our method and its counterparts, including its full-precision counterpart and BWN. It is clear that our method with -bit encoding scheme can yield very similar performance as its full-precision counterparts. Especially for ResNet-50, we achieve the best results of mAP in the case of -bit precision that is better than its full-precision counterpart by mAP. When we use -bit to encode both activation values and weights, the evaluation index drops slightly. If the number of encode bits is constrained to , the performance of this task has visibly deteriorated. Especially for MobileNetV2, when the number of the encoding bits is converted to from , the mAP result drops monotonically from to . For some categories (e.g., bottle, chair and plant), the AP results dramatically drop. In our experiments, we also implemented the binary weight form of different basic networks. Obviously, our method with -bit encoding has a higher accuracy advantage over BWN [33]. For object detection tasks, fixed extremely low-bit precision network seems powerless. Especially for MobileNetV2, BWN achieves the result of mAP that is not suitable for many industrial applications.
To compare the performance of different models with different precisions more conveniently, Fig. 3 shows some detection results on the examples of the VOC2007 test set. Detections are shown with scores higher than . The detection output pictures, which are tested by different precisions, are shown in the same column. From all the results, we can see that -bit and -bit encoding precisions have similar performance as their full-precision counterparts. There is almost no obvious difference between those detection examples. However, when the encoding precision is constrained to -bit, we can see that some offsets are produced on the bounding box (e.g., bike). Meanwhile, some small objects and obscured targets may be missed (e.g., cow and sheep).
In fact, it is not necessary to constrain both activation values and weights to the same bit precision. Table 5 shows the results of our method with four different bit precisions based on the InceptionV3 network. For the first case, we constrain activation values and weights to -bit and -bit, respectively. For the second case, we constrain activation values and weights to -bit and -bit, respectively. The two cases have the same computational complexity, however, they have different compression ratios and results. The results of the third case, where activation values and weights are constrained to -bit and -bit, respectively, are obviously better than the fourth case, where activation values and weights are constrained to -bit and -bit, respectively. Therefore, the diversity of activation values is more important than weights. In order to mitigate the performance degradation of QNNs, we should encode activation values with a higher precision than weights.
V-C Semantic Segmentation
As a typical task in the field of unmanned driving, image semantic segmentation has attracted many scholars and companies to invest in research. The application scenario for this task usually relies on small devices, and therefore, the model compression and computational acceleration seems particularly important for real-world applications. We evaluate the performance of our method on the PASCAL VOC2012 semantic segmentation benchmark, which is consisted of foreground object classes and one background class. We use pixel accuracy (pixAcc) and mean IoU (mIoU) as the metrics to report the performance.
We used DeepLabV3 [71] based on ResNet-101 [66] as the basic network in this experiment. Similarly, we use different encoding precisions to evaluate the semantic segmentation performance of our method. Fig. 5 shows the evaluating indicators of different encoding precisions, where the dotted line denotes the mIoU of the full-precision network, and the solid line denotes the pixAcc of the full-precision network. From the other curves, we can see that with the increase of encoding precisions, the semantic segmentation performance is becoming better. For instance, when the encoding precision is -bit, our method achieves the best performance ( mIoU and pixAcc), which is much better than its full-precision counterpart ( mIoU and pixAcc). Fig. 4 shows some visualization results on VOC2012 with different encoding precisions. Obviously, the segmentation results can become more precise with higher encoding bits. For example, from the fourth image we can see that as the increase of encoding precisions, the detail of segmentation of horse’s legs is becoming more and more clear.
In this experiment, we evaluated the performance of our method based on the DeepLabV3 framework. However, it can also be applied to FCN [72] and PSP [73]. Besides semantic segmentation tasks, our method can be applied to other real-word tasks, e.g., instance segmentation.


V-D Efficiency Analysis
Courbariaux et al. [17] used a matrix multiplication on a GTX750 NVIDIA GPU to illustrate the performance of XNOR kernel, and can achieve speedup ratio than the baseline kernel. Therefore, we will use the same matrix multiplication to validate the performance of our method by theoretical analysis and experimental study.
In this subsection, we analyze the speed-up ratios of our method with different encoding bits. Suppose there are two vectors and , which are composed by real numbers. If we use the -bit floating-point data type to represent each element of the two vectors, the element-wise vector multiplication should require multiplications. However, after each element of the two vectors is quantized to a binary state, we use -bit to represent their elements, and can use the -bit data types to represent the two vectors. Then the element-wise multiplication of the two vectors can be computed at once. This method is sometimes called SIMD (single, instuction, multiple data) within a register. The details are shown in Fig. 6. The general computing platform (i.e., CPU or GPU) can perform a -bit binary operation in one clock cycle. In addition, an Intel SSE (e.g., AVX or AVX-512) instruction can perform (or 256 and 512) bits binary operations. This mechanism is very suitable for the FPGA platform, which is designed for arithmetic and logical operations. Therefore, our method can achieve model compression, computational acceleration and resource saving in the inference process.

Suppose the length of two vectors is . We use to denote the speedup ratio of our method by constraining activation values to -bit and weights to -bit, where , and can be formulated as follows:
| (16) |
where is the speedup ratio between the multiply-accumulate operation (MAC) and bitwise operations, denotes the speedup ratio between addition compared and bitwise operations, and represents the length of register (e.g., 8, 16, 32, and 64). If we use to represent the time complexity of -bit operations, we can use to denote the time complexity of our method by constraining activation values to -bit and the values of weights to -bit. Following TBN [19], we can know that and . According to the speedup ratio achieved by BWN [33], we can safely assume . Thus, the matrix multiplication after encoded by -bit can obtain at most speedups over its full-precision counterpart.
Besides the theoretical analysis, we also implemented the multiplication of two matrices via our encoding scheme on GTX 1080 GPU. Please refer to [17] for the experimental design and analysis. In our experiments, we first get the encoding numbers of two matrices, and then store those numbers by bits. The matrix multiplication after encoded by -bit has obtained at most speedup ratio than the baseline kernel (a quite unoptimized matrix multiplication kernel). Because of the parallel architecture of GPU, the experimental result is slightly higher than its theoretical speedup ratio. Fig. 7 shows the speedup ratios of different encoding precisions (from -bit to -bit), where both and denote the number of encoding bits for weights and activations, respectively. From all the results, we can see that the computational complexity is gradually increasing with the increase of encoding bits. Thus, users can easily achieve different encoding precisions arbitrarily according to their requirements (e.g., accuracy and speed) and hardware resources (e.g., memory). The code can be available at: https://github.com/qigongsun/BMD.
VI Discussion and Conclusion
VI-A Encoding and Encoding Schemes
As described in [20], there exists a nonlinear mapping between quantized numbers and their encoded states. The quantized values are usually restricted to a closed interval . For example, the mapping is formulated as follows:
| (17) |
where denotes a quantized number, and denotes the fixed-point integer encoded by and . We use a -bit fixed-point integer to represent a quantized number . The product can be formulated as follows:
| (18) |
As shown in (VI-A), the product form is a polynomial, which has four terms. Note that each term has its own scaling factor. The computation of can be accelerated by bitwise operations. However, the polynomial and scaling factors increase the computational complexity.
For our proposed quantized binary encoding scheme, the product of and is defined as
| (19) |
where and denote the fixed-point integers encoded by and . Obviously, compared with the above encoding of , the product can be more efficiently calculated by using our proposed encoding scheme.
VI-B Linear Approximation and Quantization
As described in [12, 25, 26], the weight can be approximated by the linear combination of binary subitems {} and , which can be computed by more efficient bitwise operations. In order to obtain the combination, we need to solve the following problem
| (20) |
When this approximation is used in DNNs, can be considered as model weights. However, the scaling factors are introduced into this approximation, and such a scheme expands times the number of parameters. Therefore, this approximation can convert the original model into a complicated binary network, which leads to be hard to train [74] and easily falls into local optimal solutions.
For our method, we use the quantized parameters to approximate as follows:
| (21) |
where is a positive or negative odd number, and its absolute value is not larger than . Unlike the above linear approximation, our method can achieve the quantized weights, and directly get the corresponding encoding elements. Thus, our networks can be more efficiently trained via our quantization scheme than the linear approximation.
VI-C Conclusions
In this paper, we proposed a novel encoding scheme using to decompose QNNs into multi-branch binary networks, in which we used bitwise operations (xnor and bitcount) to achieve model compression, acceleration and resource saving. In particular, users can easily achieve different encoding precisions arbitrarily according to their requirements (e.g., accuracy and speed) and hardware resources (e.g., memory). This special data storage and calculation mechanism can yield great performance in FPGA and ASIC, and thus our mechanism is feasible for smart chips. Our future work will focus on improving the hardware implementation, and exploring some ways (e.g., neural architecture search [75, 76, 77]) to automatically select proper bits for various network architectures, e.g., VGG [78] and ResNet [79].
References
- [1] Q. Sun, F. Shang, K. Yang, X. Li, Y. Ren, and L. Jiao, “Multi-precision quantized neural networks via encoding decomposition of {-1,+1},” in Proc. 33rd AAAI Conf. Artif. Intell., 2019, pp. 5024–5032.
- [2] B. Hassibi and D. G. Stork, “Second order derivatives for network pruning: Optimal brain surgeon,” in Proc. Adv. Neural Inf. Process. Syst., 1993, pp. 164–171.
- [3] W. Wen, C. Wu, Y. Wang, Y. Chen, and H. Li, “Learning structured sparsity in deep neural networks,” in Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 2074–2082.
- [4] S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and connections for efficient neural networks,” in Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 1135–1143.
- [5] E. L. Denton, W. Zaremba, J. Bruna, Y. LeCun, and R. Fergus, “Exploiting linear structure within convolutional networks for efficient evaluation,” in Proc. Adv. Neural Inf. Process. Syst., 2014, pp. 1269–1277.
- [6] M. Jaderberg, A. Vedaldi, and A. Zisserman, “Speeding up convolutional neural networks with low rank expansions,” BMVC, 2014.
- [7] C. Tai, T. Xiao, Y. Zhang, X. Wang et al., “Convolutional neural networks with low-rank regularization,” in Proc. Int. Conf. Learn. Representations, 2016.
- [8] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [9] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4510–4520.
- [10] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, “Quantized neural networks: Training neural networks with low precision weights and activations,” Journal of Machine Learning Research, vol. 18, no. 1, pp. 6869–6898, 2017.
- [11] M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi, “XNOR-Net: Imagenet classification using binary convolutional neural networks,” in Proc. 14th Eur. Conf. Comput. Vis., 2016, pp. 525–542.
- [12] X. Lin, C. Zhao, and W. Pan, “Towards accurate binary convolutional neural network,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 345–353.
- [13] J.-H. Luo, H. Zhang, H.-Y. Zhou, C.-W. Xie, J. Wu, and W. Lin, “ThiNet: Pruning CNN filters for a thinner net,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 10, 2019.
- [14] S. Ioffe and C. Szegedy, “Batch normalization: accelerating deep network training by reducing internal covariate shift,” in Proc. Int. Conf. Mach. Learn., 2015, pp. 448–456.
- [15] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “Squeezenet: Alexnet-level accuracy with 50x fewer parameters and 0.5 mb model size,” in Proc. Int. Conf. Learn. Representations, 2017.
- [16] S. Gupta, A. Agrawal, K. Gopalakrishnan, and P. Narayanan, “Deep learning with limited numerical precision,” in Proc. Int. Conf. Mach. Learn., 2015, pp. 1737–1746.
- [17] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, and Y. Bengio, “Binarized neural networks,” in Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 4107–4115.
- [18] F. Li, B. Zhang, and B. Liu, “Ternary weight networks,” in Proc. Int. Conf. Learn. Representations, 2017.
- [19] D. Wan, F. Shen, L. Liu, F. Zhu, J. Qin, L. Shao, and H. T. Shen, “TBN: Convolutional neural network with ternary inputs and binary weights,” Proc. 15th Eur. Conf. Comput. Vis., vol. 1, no. 2, pp. 0–6, 2018.
- [20] S. Zhou, Y. Wu, Z. Ni, X. Zhou, H. Wen, and Y. Zou, “DoReFa-Net: Training low bitwidth convolutional neural networks with low bitwidth gradients,” arXiv preprint arXiv:1606.06160, 2016.
- [21] A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen, “Incremental network quantization: Towards lossless cnns with low-precision weights,” in Proc. Int. Conf. Learn. Representations, 2017.
- [22] D. Zhang, J. Yang, D. Ye, and G. Hua, “Lq-nets: Learned quantization for highly accurate and compact deep neural networks,” in Proc. 15th Eur. Conf. Comput. Vis., 2018, pp. 365–382.
- [23] S. Liang, S. Yin, L. Liu, W. Luk, and S. Wei, “FP-BNN: Binarized neural network on FPGA,” Neurocomput, vol. 275, 2017.
- [24] V. Vanhoucke, A. Senior, and M. Z. Mao, “Improving the speed of neural networks on CPUs,” in Proc. Adv. Neural Inf. Process. Syst. Workshop, vol. 1, 2011, p. 4.
- [25] Y. Guo, A. Yao, H. Zhao, and Y. Chen, “Network sketching: Exploiting binary structure in deep CNNs,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 4040–4048.
- [26] C. Xu, J. Yao, Z. Lin, W. Ou, Y. Cao, Z. Wang, and H. Zha, “Alternating multi-bit quantization for recurrent neural networks,” in Proc. Int. Conf. Learn. Representations, 2018.
- [27] P. Wang, Q. Hu, Y. Zhang, C. Zhang, Y. Liu, J. Cheng et al., “Two-step quantization for low-bit neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4376–4384.
- [28] B. Zhuang, C. Shen, M. Tan, L. Liu, and I. Reid, “Towards effective low-bitwidth convolutional neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 7920–7928.
- [29] D. Miyashita, E. H. Lee, and B. Murmann, “Convolutional neural networks using logarithmic data representation,” arXiv preprint arXiv:1603.01025, 2016.
- [30] C. Zhu, S. Han, H. Mao, and W. J. Dally, “Trained ternary quantization,” in Proc. Int. Conf. Learn. Representations, 2017.
- [31] B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang, A. Howard, H. Adam, and D. Kalenichenko, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 2704–2713.
- [32] X. Geng, J. Fu, B. Zhao, J. Lin, M. M. S. Aly, C. Pal, and V. Chandrasekhar, “Dataflow-based joint quantization of weights and activations for deep neural networks,” arXiv preprint arXiv:1901.02064, 2019.
- [33] M. Courbariaux, Y. Bengio, and J.-P. David, “Binaryconnect: Training deep neural networks with binary weights during propagations,” in Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 3123–3131.
- [34] P. Wang and J. Cheng, “Fixed-point factorized networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 4012–4020.
- [35] D. Lin, S. Talathi, and S. Annapureddy, “Fixed point quantization of deep convolutional networks,” in Proc. Int. Conf. Mach. Learn., 2016, pp. 2849–2858.
- [36] A. Zhou, A. Yao, Y. Guo, L. Xu, and Y. Chen, “Incremental network quantization: Towards lossless cnns with low-precision weights,” in Proc. Int. Conf. Learn. Representations, 2017.
- [37] J. Feng, J. Chen, Q. Sun, R. Shang, X. Cao, X. Zhang, and L. Jiao, “Convolutional neural network based on bandwise-independent convolution and hard thresholding for hyperspectral band selection,” IEEE Transactions on Cybernetics, 2020.
- [38] Y. Bengio, N. Léonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,” arXiv preprint arXiv:1308.3432, 2013.
- [39] A. Mishra and D. Marr, “Apprentice: Using knowledge distillation techniques to improve low-precision network accuracy,” in Proc. Int. Conf. Learn. Representations, 2018.
- [40] A. Polino, R. Pascanu, and D. Alistarh, “Model compression via distillation and quantization,” in Proc. Int. Conf. Learn. Representations, 2018.
- [41] Q. Hu, P. Wang, and J. Cheng, “From hashing to cnns: Training binary weight networks via hashing,” in Proc. 32rd AAAI Conf. Artif. Intell., 2018.
- [42] Q. Hu, G. Li, P. Wang, Y. Zhang, and J. Cheng, “Training binary weight networks via semi-binary decomposition,” in Proc. 15th Eur. Conf. Comput. Vis., 2018, pp. 637–653.
- [43] Z. Cai and N. Vasconcelos, “Rethinking differentiable search for mixed-precision neural networks,” 2020. [Online]. Available: http://arxiv.org/abs/2004.05795
- [44] S. Nandakumar, M. Le Gallo, I. Boybat, B. Rajendran, A. Sebastian, and E. Eleftheriou, “Mixed-precision architecture based on computational memory for training deep neural networks,” in IEEE Trans. Circuits. Syst. (ISCAS). IEEE, 2018, pp. 1–5.
- [45] S. Uhlich, L. Mauch, F. Cardinaux, K. Yoshiyama, J. A. Garcia, S. Tiedemann, T. Kemp, and A. Nakamura, “Mixed precision dnns: All you need is a good parametrization,” 2019. [Online]. Available: http://arxiv.org/abs/1905.11452
- [46] Q. Sun, L. Jiao, Y. Ren, X. Li, F. Shang, and F. Liu, “Effective and fast: A novel sequential single path search for mixed-precision quantization,” arXiv preprint arXiv:2103.02904, 2021.
- [47] J. Lin, C. Gan, and S. Han, “Defensive quantization: When efficiency meets robustness,” arXiv preprint arXiv:1904.08444, 2019.
- [48] M. Shkolnik, B. Chmiel, R. Banner, G. Shomron, Y. Nahshan, A. Bronstein, and U. Weiser, “Robust quantization: One model to rule them all,” arXiv preprint arXiv:2002.07686, 2020.
- [49] Q. Sun, X. Li, Y. Ren, Z. Huang, X. Liu, L. Jiao, and F. Liu, “One model for all quantization: A quantized network supporting hot-swap bit-width adjustment,” arXiv preprint arXiv:2105.01353, 2021.
- [50] Q. Sun, Y. Ren, L. Jiao, X. Li, F. Shang, and F. Liu, “Mwq: Multiscale wavelet quantized neural networks,” arXiv preprint arXiv:2103.05363, 2021.
- [51] M. Nagel, R. A. Amjad, M. Van Baalen, C. Louizos, and T. Blankevoort, “Up or down? adaptive rounding for post-training quantization,” in International Conference on Machine Learning. PMLR, 2020, pp. 7197–7206.
- [52] Y. Li, R. Gong, X. Tan, Y. Yang, P. Hu, Q. Zhang, F. Yu, W. Wang, and S. Gu, “Brecq: Pushing the limit of post-training quantization by block reconstruction,” arXiv preprint arXiv:2102.05426, 2021.
- [53] A. Silvescu, “Fourier neural networks,” in IJCNN’99. International Joint Conference on Neural Networks. Proceedings (Cat. No. 99CH36339), vol. 1. IEEE, 1999, pp. 488–491.
- [54] K.-i. Minami, H. Nakajima, and T. Toyoshima, “Real-time discrimination of ventricular tachyarrhythmia with fourier-transform neural network,” IEEE transactions on Biomedical Engineering, vol. 46, no. 2, pp. 179–185, 1999.
- [55] L. Mingo, L. Aslanyan, J. Castellanos, M. Diaz, and V. Riazanov, “Fourier neural networks: An approach with sinusoidal activation functions,” International Journal of Information Theories & Applications, 2004.
- [56] H. Tan, “Fourier neural networks and generalized single hidden layer networks in aircraft engine fault diagnostics,” Journal of Engineering for Gas Turbines and Power, vol. 128, no. 4, pp. 773–782, 2006.
- [57] K. E. Germec, “Fourier neural networks for real-time harmonic analysis,” in 2009 IEEE 17th Signal Processing and Communications Applications Conference, 2009, pp. 333–336.
- [58] D. Tan, W. Chen, and H. Wang, “On the use of monte-carlo simulation and deep fourier neural network in lane departure warning,” IEEE Intelligent Transportation Systems Magazine, vol. 9, no. 4, pp. 76–90, 2017.
- [59] G. Parascandolo, H. Huttunen, and T. Virtanen, “Taming the waves: sine as activation function in deep neural networks,” in Proc. Int. Conf. Learn. Representations, 2017.
- [60] J. Faraone, N. Fraser, M. Blott, and P. H. Leong, “Syq: Learning symmetric quantization for efficient deep neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4300–4309.
- [61] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, 2015.
- [62] Y. Wei, X. Pan, H. Qin, W. Ouyang, and J. Yan, “Quantization mimic: Towards very tiny cnn for object detection,” in Proc. 15th Eur. Conf. Comput. Vis., 2018, pp. 267–283.
- [63] R. Li, Y. Wang, F. Liang, H. Qin, J. Yan, and R. Fan, “Fully quantized network for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2019, pp. 2810–2819.
- [64] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Proc. 14th Eur. Conf. Comput. Vis., 2016, pp. 21–37.
- [65] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 2818–2826.
- [66] K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” in Proc. 14th Eur. Conf. Comput. Vis. Springer, 2016, pp. 630–645.
- [67] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2014, pp. 580–587.
- [68] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” in Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 91–99.
- [69] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” in Proc. 13th Eur. Conf. Comput. Vis., 2014, pp. 346–361.
- [70] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 779–788.
- [71] L. C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 4, pp. 834–848, 2018.
- [72] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 4, pp. 640–651, 2014.
- [73] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 2881–2890.
- [74] H. Li, S. De, Z. Xu, C. Studer, H. Samet, and T. Goldstein, “Training quantized nets: A deeper understanding,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 5811–5821.
- [75] B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learning,” in Proc. Int. Conf. Learn. Representations, 2017.
- [76] T. Elsken, J. H. Metzen, and F. Hutter, “Neural architecture search: A survey.” Journal of Machine Learning Research, vol. 20, no. 55, pp. 1–21, 2019.
- [77] H. Liu, K. Simonyan, and Y. Yang, “Darts: Differentiable architecture search,” in Proc. Int. Conf. Learn. Representations, 2019.
- [78] A. Z. Karen Simonyan, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [79] X. Z. S. R. He, Kaiming and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 770–778.