Quantum-Chemical Insights from Deep Tensor Neural Networks
Abstract
Learning from data has led to paradigm shifts in a multitude of disciplines, including web, text, and image search, speech recognition, as well as bioinformatics. Can machine learning spur similar breakthroughs in understanding quantum many-body systems? Here we develop an efficient deep learning approach that enables spatially and chemically resolved insights into quantum-mechanical observables of molecular systems. We unify concepts from many-body Hamiltonians with purpose-designed deep tensor neural networks (DTNN), which leads to size-extensive and uniformly accurate (1 kcal/mol) predictions in compositional and configurational chemical space for molecules of intermediate size. As an example of chemical relevance, the DTNN model reveals a classification of aromatic rings with respect to their stability – a useful property that is not contained as such in the training dataset. Further applications of DTNN for predicting atomic energies and local chemical potentials in molecules, reliable isomer energies, and molecules with peculiar electronic structure demonstrate the high potential of machine learning for revealing novel insights into complex quantum-chemical systems.
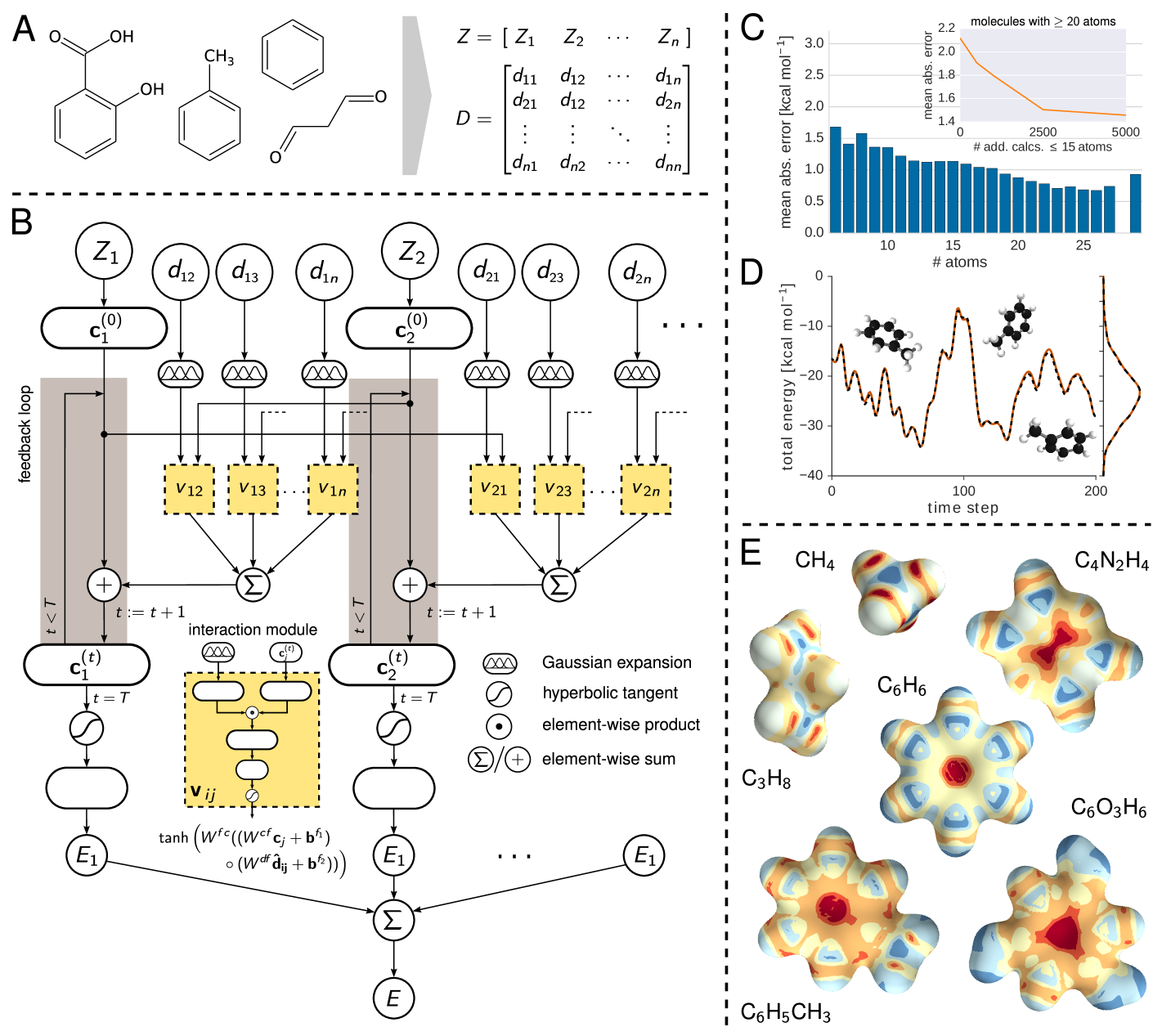
Chemistry permeates all aspects of our life, from the development of new drugs to the food that we consume and materials we use on a daily basis. Chemists rely on empirical observations based on creative and painstaking experimentation that leads to eventual discoveries of molecules and materials with desired properties and mechanisms to synthesize them. Many discoveries in chemistry can be guided by searching large databases of experimental or computational molecular structures and properties by using concepts based on chemical similarity. Because the structure and properties of molecules are determined by the laws of quantum mechanics, ultimately chemical discovery must be based on fundamental quantum principles. Indeed, electronic structure calculations and intelligent data analysis (machine learning, ML) have recently been combined aiming towards the goal of accelerated discovery of chemicals with desired properties kang2009battery; norskov2009towards; hachmann2011harvard; pyzer2015high; curtarolo2013high; snyder2012finding; rupp2012fast; ramakrishnan2015big. However, so far the majority of these pioneering efforts have focused on the construction of reduced models trained on large datasets of density-functional theory calculations. In this work, we develop an efficient deep learning approach that enables spatially and chemically resolved insights into quantum-mechanical properties of molecular systems beyond those trivially contained in the training dataset. Obviously, computational models are not predictive if they lack accuracy. In addition to being interpretable, size extensive and efficient, our deep tensor neural network (DTNN) approach is uniformly accurate (1 kcal/mol) throughout compositional and configurational chemical space. On the more fundamental side, the mathematical construction of the DTNN model provides statistically rigorous partitioning of extensive molecular properties into atomic contributions – a long-standing challenge for quantum-mechanical calculations of molecules.
I Molecular Deep Tensor Neural Networks
It is common to use a carefully chosen representation of the problem at hand as a basis for machine learning bishop2006pattern; ghiringhelli2015big; schutt2014represent. For example, molecules can be represented as Coulomb matrices rupp2012fast; montavon2013machine; hansen2013assessment, scattering transforms hirn2015quantum, bags of bonds (BoB) Hansen-JCPL, smooth overlap of atomic positions (SOAP) bartok2013representing; bartok2010gaussian, or generalized symmetry functions behler2011atom; behler2011neural. Kernel-based learning of molecular properties transforms these representations non-linearly by virtue of kernel functions. In contrast, deep neural networks lecun2015deep are able to infer the underlying regularities and learn an efficient representation in a layer-wise fashion montavon2011kernel.
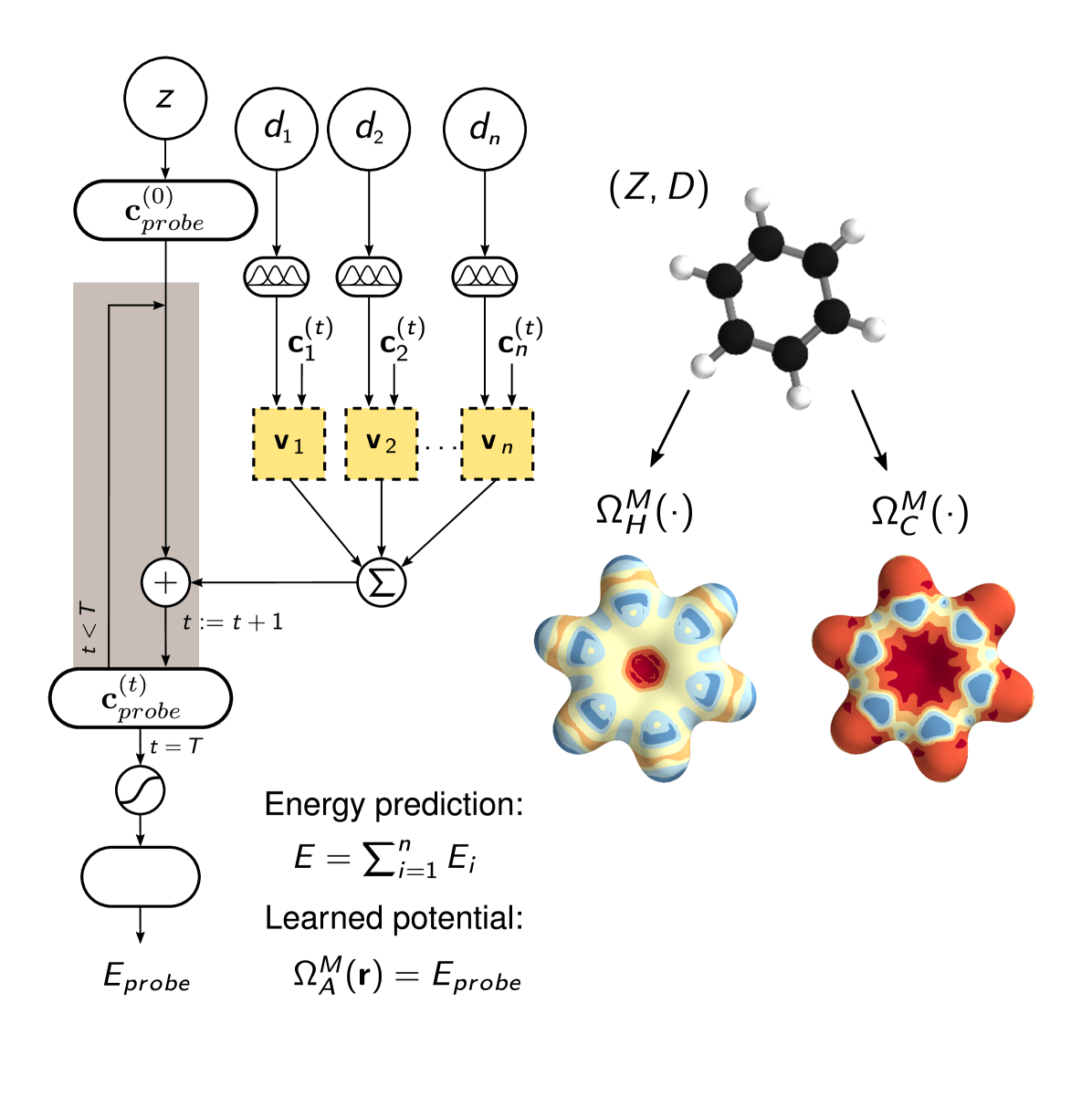
Molecular properties are governed by the laws of quantum mechanics, which yield the remarkable flexibility of chemical systems, but also impose constraints on the behavior of bonding in molecules. The approach presented here utilizes the many-body Hamiltonian concept for the construction of the DTNN architecture (see Fig. 1), embracing the principles of quantum chemistry, while maintaining the full flexibility of a complex data-driven learning machine.
DTNN receives molecular structures through a vector of nuclear charges and a matrix of atomic distances ensuring rotational and translational invariance by construction (Fig. 1A). The distances are expanded in a Gaussian basis, yielding a feature vector , which accounts for the different nature of interactions at various distance regimes.
The total energy for the molecule composed of atoms is written as a sum over atomic energy contributions , thus satisfying permutational invariance with respect to atom indexing. Each atom is represented by a coefficient vector , where is the number of basis functions, or features. Motivated by quantum-chemical atomic basis set expansions, we assign an atom type-specific descriptor vector to these coefficients . Subsequently, this atomic expansion is repeatedly refined by pairwise interactions with the surrounding atoms
| (1) |
where the interaction term reflects the influence of atom at a distance on atom . Note that this refinement step is seamlessly integrated into the architecture of the molecular DTNN, and is therefore adapted throughout the learning process. Considering a molecule as a graph, refinements of the coefficient vectors are comprised of all walks of length through the molecule ending at the corresponding atom scarselli2009graph; duvenaud2015convolutional; suppl. From the point of view of many-body interatomic interactions, subsequent refinement steps correlate atomic neighborhoods with increasing complexity.
While the initial atomic representation only considers isolated atoms, the interaction terms characterize how the basis functions of two atoms overlap with each other at a certain distance. Each refinement step aims to reduce these overlaps, thereby embedding the atoms of the molecule into their chemical environment. Following this procedure, the DTNN implicitly learns an atom-centered basis that is unique and efficient with respect to the property to be predicted.
Non-linear coupling between the atomic vector features and the interatomic distances is achieved by a tensor layer socher2013recursive; sutskever2011generating, such that the coefficient of the refinement is given by
| (2) |
where is the bias of feature and and are the weights of atom representation and distance, respectively. The slice of the parameter tensor combines the inputs multiplicatively. Since incorporates many parameters, using this kind of layer is both computationally expensive as well as prone to overfitting. Therefore, we employ a low-rank tensor factorization, as described in taylor2009factored, such that
| (3) |
where ’’ represents element-wise multiplication while , , , and are the weight matrices and corresponding biases of atom representations, distances and resulting factors, respectively. As the dimensionality of and corresponds to the number of factors, choosing only a few drastically decreases the number of parameters, thus solving both issues of the tensor layer at once.
Arriving at the final embedding after a given number of interaction refinements, two fully-connected layers predict an energy contribution from each atomic coefficient vector, such that their sum corresponds to the total molecular energy . Therefore, the DTNN architecture scales with the number of atoms in a molecule, fully capturing the extensive nature of the energy. All weights, biases as well as the atom type-specific descriptors were initialized randomly and trained using stochastic gradient descent matmeth.
II Learning molecular energies
To demonstrate the versatility of the proposed DTNN, we train models with up to three interaction passes for both compositional and configurational degrees of freedom in molecular systems. The DTNN accuracy saturates at , and leads to a strong correlation between atoms in molecules, as can be visualized by the complexity of the potential learned by the network (see Fig. 1E). For training, we employ chemically diverse datasets of equilibrium molecular structures, as well as molecular dynamics (MD) trajectories for small molecules matmeth. We employ two subsets of the GDB-13 database blum2009gdb13; reymond2015chemical referred to as GDB-7, including more than 7,000 molecules with up to 7 heavy (C, N, O, F) atoms, and GDB-9, consisting of 129,000 molecules with up to 9 heavy atoms ramakrishnan2014quantum. In both cases, the learning task is to predict the molecular total energy calculated with density-functional theory (DFT). All GDB molecules are stable and synthetically accessible according to organic chemistry rules reymond2015chemical. Molecular features such as functional groups or signatures include single, double and triple bonds; (hetero-) cycles, carboxy, cyanide, amide, amine, alcohol, epoxy, sulfide, ether, ester, chloride, aliphatic and aromatic groups. For each of the many possible stoichiometries, many constitutional isomers are considered, each being represented only by a low-energy conformational isomer.
As Table S2 demonstrates, DTNN achieves a mean absolute error (MAEs) of 1.0 kcal/mol on both GDB datasets, training on 5.8k GDB-7 (80%) and 25k (20%) GDB-9 reference calculations, respectively suppl. Fig. 1C shows the performance on GDB-9 depending on the size of the molecule. We observe that larger molecules have lower errors because of their abundance in the training data. The per-atom DTNN energy prediction and the fact that chemical interactions have a finite distance range means that the DTNN model will yield a constant error per atom upon increasing molecular size. To assess the effective range of chemical interactions we have imposed a distance cutoff to interatomic interactions of , yielding only a 0.1 kcal/mol increase in the error. However, this distance cutoff restricts only the direct interactions considered in the refinement steps. With multiple refinements, the effective cutoff increases by a factor of due to indirect interactions over multiple atoms. Given large enough molecules, so that a reasonable distance cutoff can be chosen, scaling to larger molecules will require only to have well-represented local environments. Along the same vein, we trained the network on a restricted subset of 5k molecules with more than 20 atoms. By adding smaller molecules to the training set, we are able to reduce the test error from 2.1 kcal/mol to less than 1.5 kcal/mol (see inset in Fig. 1C). This result demonstrates that our model is able to transfer knowledge learned from small molecules to larger molecules with diverse functional groups.
While only encompassing conformations of a single molecule, reproducing MD simulation trajectories poses a radically different challenge to predicting energies of purely equilibrium structures. We learned potential energies for MD trajectories of benzene, toluene, malonaldehyde and salicylic acid, carried out at a rather high temperature of 500 K to achieve exhaustive exploration of the potential-energy surface of such small molecules. The neural network yields mean absolute errors of 0.05 kcal/mol, 0.18 kcal/mol, 0.17 kcal/mol and 0.39 kcal/mol for these molecules, respectively (see Table S2). Fig. 1D shows the excellent agreement between the DFT and DTNN MD trajectory of toluene as well as the corresponding energy distributions. The DTNN errors are much smaller than the energy of thermal fluctuations at room temperature (0.6 kcal/mol), meaning that DTNN potential-energy surfaces can be utilized to calculate accurate molecular thermodynamic properties by virtue of Monte Carlo simulations.
The ability of DTNN to accurately describe equilibrium structures within the GDB-9 database and MD trajectories of selected molecules of chemical relevance demonstrates the feasibility of developing a universal machine learning architecture that can capture compositional as well as configurational degrees of freedom in the vast chemical space (see Applications section for further analysis). While the employed architecture of the DTNN is universal, the learned coefficients are different for GDB-9 and MD trajectories of single molecules.
III Applications
III.1 Quantum-chemical insights
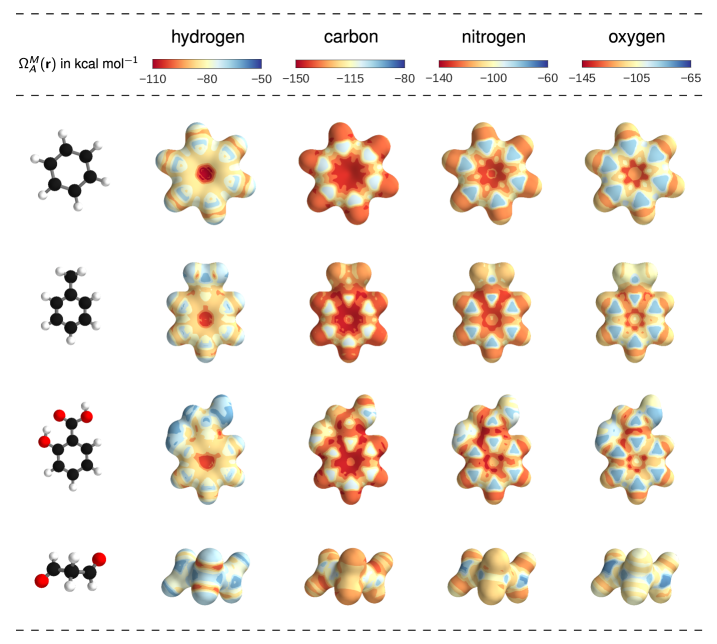
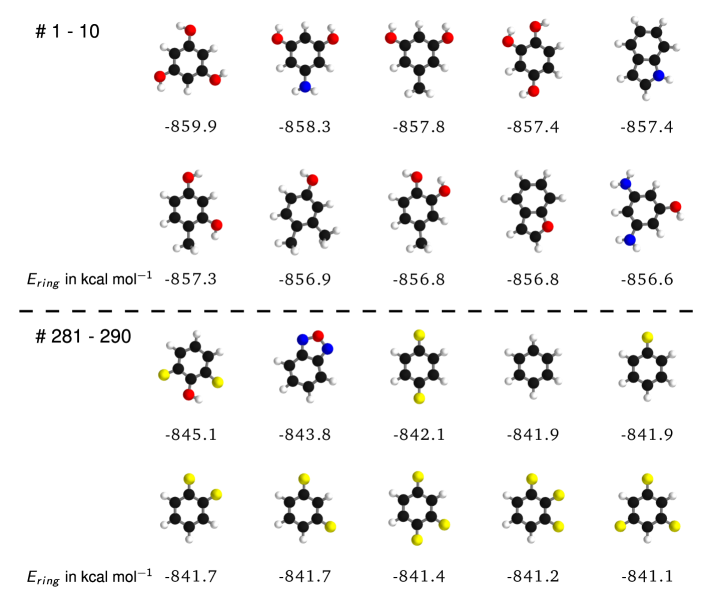
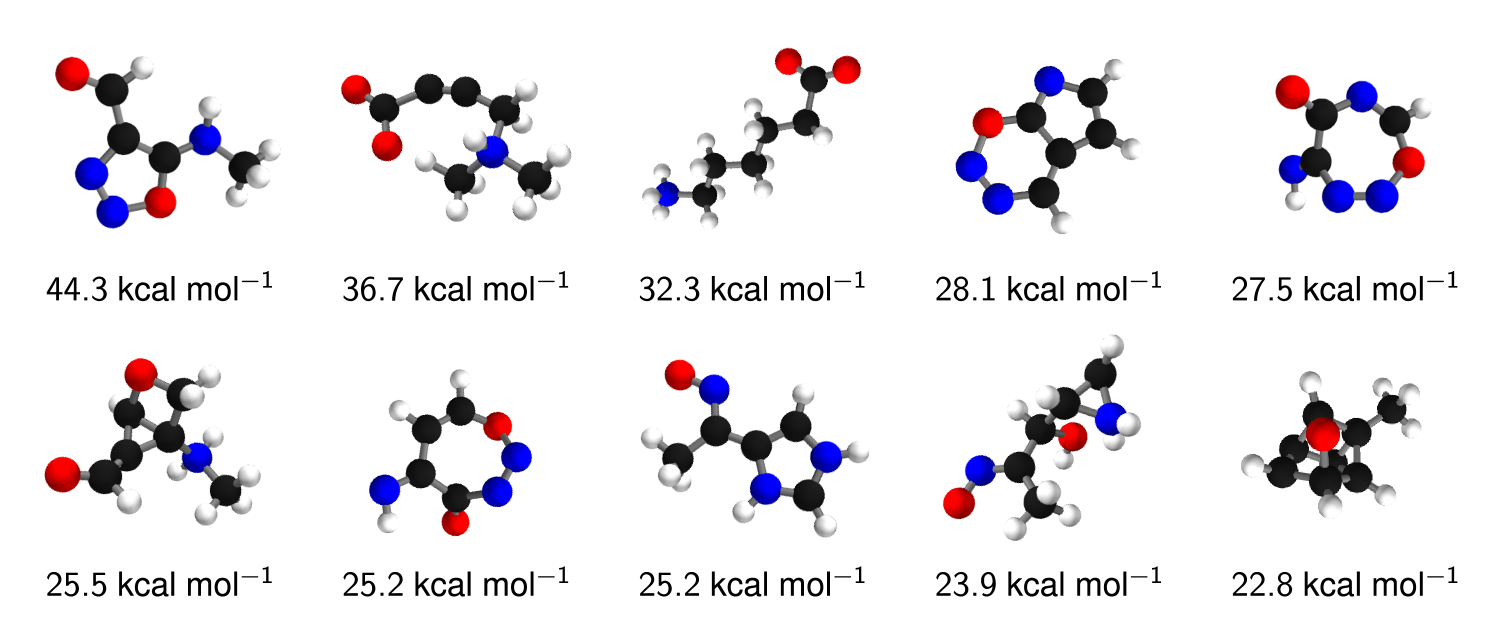
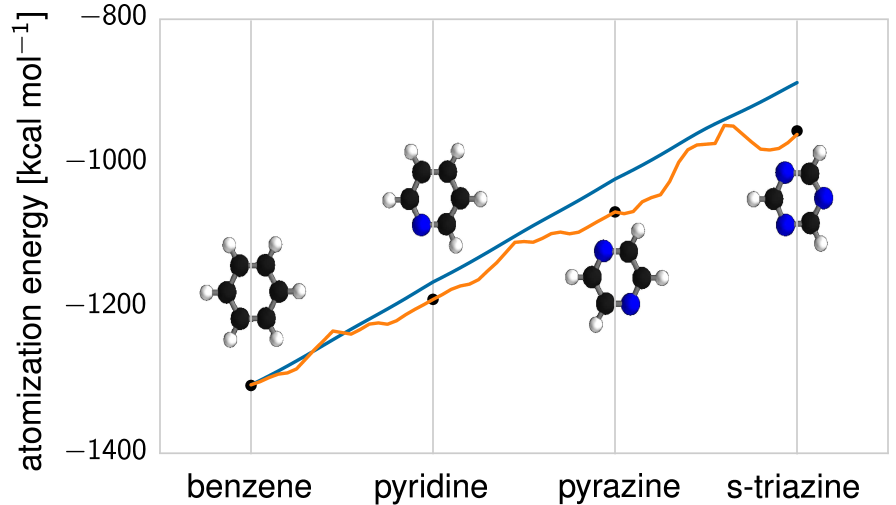
Beyond predicting accurate energies, the true power of DTNN lies in its ability to provide novel quantum-chemical insights. In the context of DTNN, we define a local chemical potential as an energy of a certain atom type , located at a position in the molecule . While the DTNN models the interatomic interactions, we only allow the atoms of the molecule act on the probe atom, while the probe does not influence the molecule matmeth. The spatial and chemical sensitivity provided by our DTNN approach is shown in Fig. 1E for a variety of fundamental molecular building blocks. In this case, we employed hydrogen as a test charge, while the results for are shown in Fig. 2. Despite being trained only on total energies of molecules, the DTNN approach clearly grasps fundamental chemical concepts such as bond saturation and different degrees of aromaticity. For example, the DTNN model predicts the C6O3H6 molecule to be “more aromatic” than benzene or toluene (see Fig. 1E). Remarkably, it turns out that C6O3H6 does have higher ring stability than both benzene and toluene and DTNN predicts it to be the molecule with the most stable aromatic carbon ring among all molecules in the GDB-9 database (see Fig. 3). Further chemical effects learned by the DTNN model are shown in Fig. 2 that demonstrates the differences in the chemical potential distribution of H, C, N, and O atoms in benzene, toluene, salicylic acid, and malonaldehyde. For example, the chemical potentials of different atoms over an aromatic ring are qualitatively different for H, C, N, and O atoms – an evident fact for a trained chemist. However, the subtle chemical differences described by DTNN are accompanied by chemically accurate predictions – a challenging task for humans.
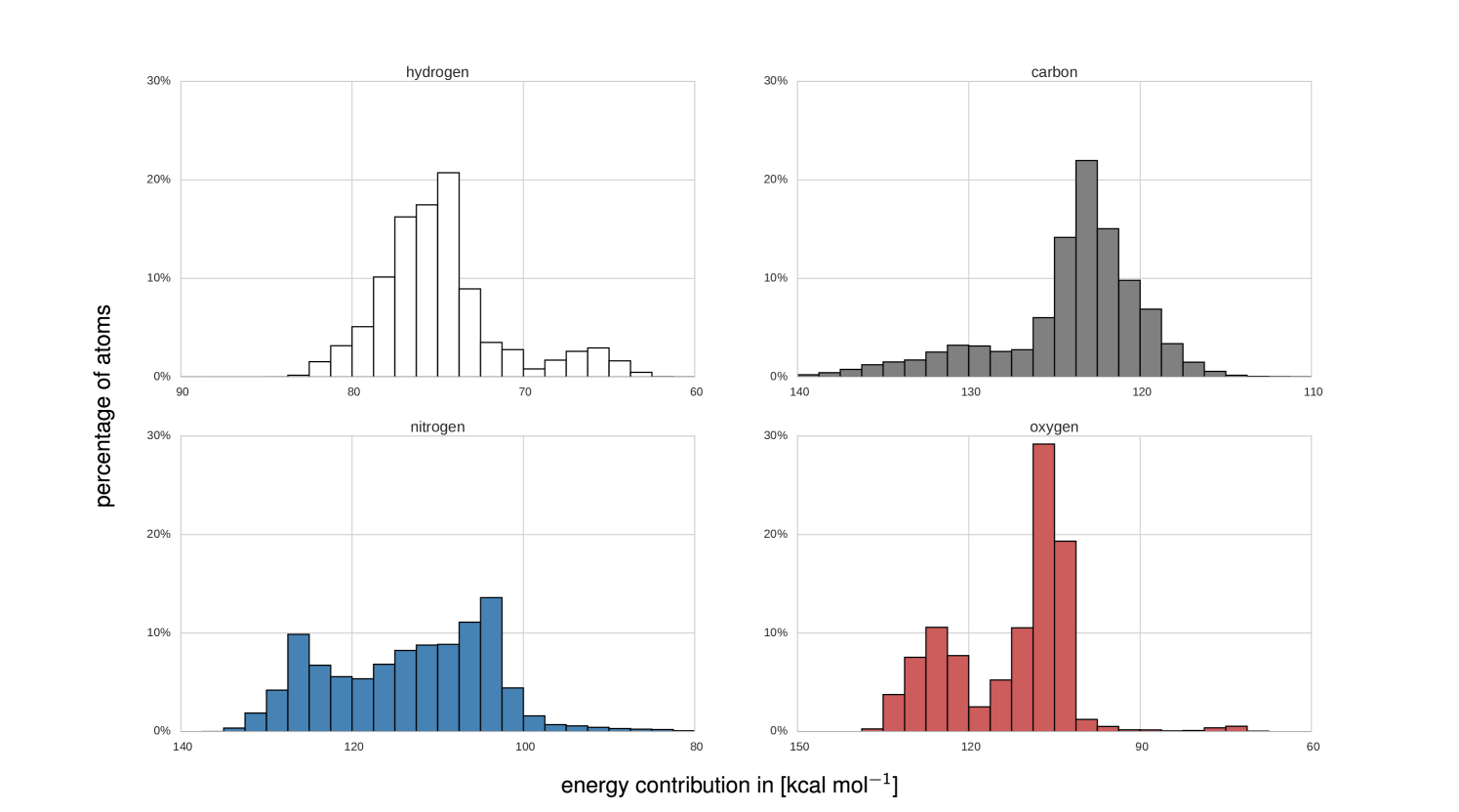
Because DTNN provides atomic energies by construction, it allows us to classify molecules by the stability of different building blocks, for example aromatic rings or methyl groups. An example of such classification is shown in Fig. 3, where we plot the molecules with most stable and least stable carbon aromatic rings in GDB-9. The distribution of atomic energies is shown in Fig. S4, while Fig. S5 lists the full stability ranking. The DTNN classification leads to interesting stability trends, notwithstanding the intrinsic non-uniqueness of atomic energy partitioning. However, unlike atomic projections employed in electronic-structure calculations, the DTNN approach has a firm foundation in statistical learning theory. In quantum-chemical calculations, every molecule would correspond to a different partitioning depending on its self-consistent electron density. In contrast, the DTNN approach learns the partitioning on a large molecular dataset, generating a transferable and global “dressed atom” representation of molecules in chemical space. Recalling that DTNN exhibits errors below 1 kcal/mol, the classification shown in Fig. 3 can provide useful guidance for the chemical discovery of molecules with desired properties. Analytical gradients of the DTNN model with respect to chemical composition or could also aid in the exploration of chemical compound space von2013first.
III.2 Energy predictions for isomers: Towards mapping chemical space
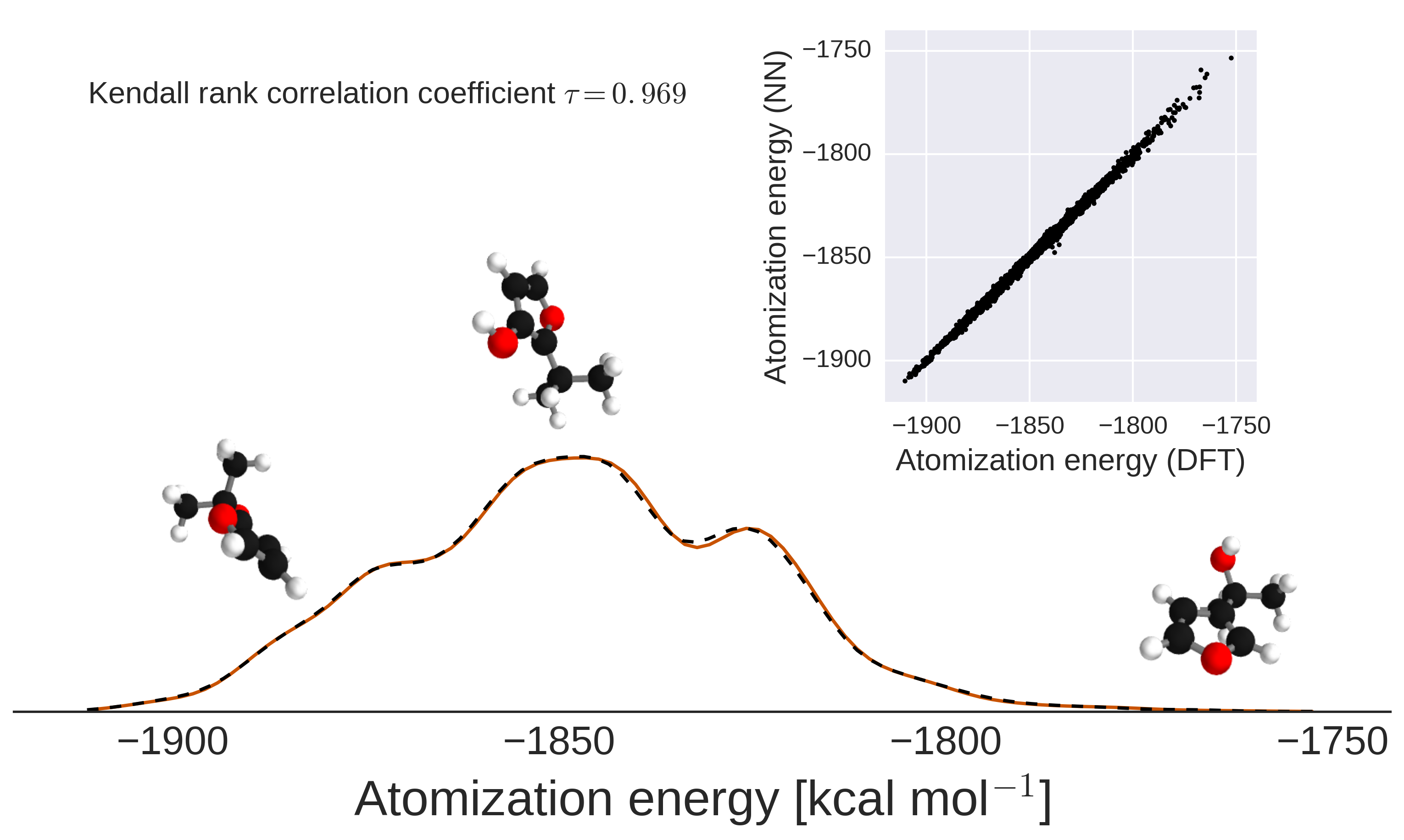
The quantitative accuracy achieved by DTNN and its size extensivity paves the way to the calculation of configurational and conformational energy differences – a long-standing challenge for machine learning approaches rupp2012fast; montavon2013machine; hansen2013assessment; de2015comparing. The reliability of DTNN for isomer energy predictions is demonstrated by the energy distribution in Fig. 4 for molecular isomers with C7O2H10 chemical formula (a total of 6095 isomers in the GDB-9 dataset).
Training a common network for compositional and configurational degrees of freedoms requires a more complex model. Furthermore, it comes with technical challenges such as sampling and multiscale issues since the MD trajectories form clusters of small variation within the chemical compound space. As a proof of principle, we trained the DTNN to predict various MD trajectories of the C7O2H10 isomers. To this end, we calculated short MD trajectories of 5000 steps each for 113 randomly picked isomers as well as consistent total energies for all equilbrium structures. The training set is composed of the isomers in equilibrium as well as 50% of each MD trajectory. The remaining MD calculations are used for validation and testing. Despite the vastly increased complexity, our DTNN model achieves a mean absolute error of 1.7 kcal/mol, providing a proof-of-principle demonstration of describing complex chemical spaces.
IV Discussion
DTNNs provide an efficient way to represent chemical environments allowing for chemically accurate predictions. To this end, an implicit, atom-centered basis is learned from reference ab initio calculations. Employing this representation, atoms can be embedded in their chemical environment within a few refinement steps. Furthermore, DTNNs have the advantage that the embedding is built recursively from pairwise distances. Therefore, all necessary invariances (translation, rotation, permutation) are guaranteed to be exploited by the model.
In previous approaches, potential-energy surfaces were constructed by fitting many-body expansions with neural networks malshe2009development; manzhos2006random; manzhos2008using. However, these methods require a separate NN for each non-equivalent many-body term in the expansion. Since DTNN learns a common basis in which the atom interact, higher-order interactions can obtained more efficiently without separate treament.
Approaches like SOAP bartok2010gaussian; bartok2013representing or manually crafted atom-centered symmetry functions behler2007generalized; behler2011atom; behler2011neural are, like DTNN, based on representing chemical environments. All these approaches have in common that size-extensivity regarding the number of atoms is achieved by predicting atomic energy contributions using a non-linear regression method (e.g., neural networks or kernel ridge regression). However, the previous approaches have a fixed set of basis functions describing the atomic environments. In contrast, DTNNs are able to adapt to the problem at hand in a data-driven fashion. Beyond the obvious advantage of not having to manually select symmetry functions and carefully tune hyper-parameters of the representation, this property of the DTNN makes it possible to gain insights by analyzing the learned representation.
Obviously, more work is required to extend this predictive power for larger molecules, where the DTNN model will have to be combined with a reliable model for long-range interatomic (van der Waals) interactions. The intrinsic interpolation smoothness achieved by the DTNN model can also be used to identify molecules with peculiar electronic structure. Fig. S6 shows a list of molecules with the largest DTNN errors compared to reference DFT calculations. It is noteworthy that most molecules in this figure are characterized by unconventional bonding and the electronic structure of these molecules has potential multi-reference character. The large prediction errors could stem from these molecules being not sufficiently represented by the training data. On the other hand, DTNN predictions might turn out to be closer to the correct answer due to its smooth interpolation in chemical space. Higher-level quantum-chemical calculations would be required to investigate this interesting hypothesis in the future.
V Outlook
We have proposed and developed a deep tensor neural network that enables understanding of quantum-chemical many-body systems beyond properties contained in the training dataset. The DTNN model is scalable with molecular size, efficient, and achieves uniform accuracy of 1 kcal/mol throughout compositional and configuration space for molecules of intermediate size. The DTNN model leads to novel insights into chemical systems, a fact that we illustrated on the example of relative aromatic ring stability, local molecular chemical potentials, relative isomer energies, and the identification of molecules with peculiar electronic structure.
Many avenues remain for improving the DTNN model on multiple fronts. Among these we mention the extension of the model to increasingly larger molecules, predicting alltomic forces and frequencies, and non-extensive electronic and optical properties. We propose the DTNN model as a versatile framework for understanding complex quantum-mechanical systems based on high-throughput electronic structure calculations.
Acknowledgements.
References
Supplementary Materials
Materials and Methods
Data
We employ two subsets of the GDB database blum2009gdb13, referred to in this paper as GDB-7 and GDB-9. GDB-7 contains 7211 molecules with up to 7 heavy atoms out of the elements C, N, O, S and Cl, saturated with hydrogen montavon2013machine. Similarly, GDB-9 includes 133,885 molecules with up to 9 heavy atoms out of C, O, N, F ramakrishnan2014quantum. Both data sets include calculations of atomization energies employing density functional theory DFT with the PBE0 PBE0 and B3LYP B3; LYP; vosko1980accurate; stephens1994ab; becke1993phys exchange-correlation potential, respectively.
The molecular dynamics trajectories are calculated at a temperature of 500 K and resolution of 0.5fs using density functional theory with the PBE exchange-correlation potential PBE. The data sets for benzene, toluene, malonaldehyde and salicylic acid consist of 627k, 442k, 993k and 320k time steps, respectively. In the presented experiments, we predict the potential energy of the MD geometries.
The deep tensor neural network model
The molecular energies of the various data sets are predicted using a deep tensor neural network. The core idea is to represent atoms in the molecule as vectors depending on their type and to subsequently refine the representation by embedding the atoms in their neighborhood. This is done in a sequence of interaction passes where the atom representations influence each other in a pair-wise fashion. While each of these refinements depends only on the pair-wise atomic distances, multiple passes enable the architecture to also take angular information into account. Due to this decomposition of atomic interactions, an efficient representation of embedded atoms is learned following quantum chemical principles.
In the following, we describe the deep tensor neural network step-by-step, including hyper-parameters used in our experiments.
-
1.
Assign initial atomic descriptors
We assign an initial coefficient vector to each atom of the molecule according to its nuclear charge :(4) where B is the number of basis functions. All presented models use atomic descriptors with 30 coefficients. We initialize each coefficient randomly following .
-
2.
Gaussian feature expansion of the inter-atomic distances
The inter-atomic distances are spread across many dimensions by a uniform grid of Gaussians(5) with being the gap between two Gaussians of width .
In our experiments, we set both to Å. The center of the first Gaussian was set to , while was chosen depending on the range of distances in the data (Å for GDB-7 and benzene, Å for toluene, malonaldehyde and salicylic acid and Å for GDB-9).
-
3.
Perform interaction passes Each coefficient vector , corresponding to atom after passes, is corrected by the interactions with the other atoms of the molecule:
(6) Here, we model the interaction as follows:
(7) where the circle () represents the element-wise matrix product. The factor representation in the presented models employs 60 neurons.
-
4.
Predict energy contributions
Finally, we predict the energy contributions from each atom . Employing two fully-connected layers, for each atom a scaled energy contribution is predicted:(8) (9) In our experiments, the hidden layer possesses 15 neurons. To obtain the final contributions, is shifted to the mean and scaled by the standard deviation of the energy per atom estimated on the training set.
(10) This procedure ensures a good starting point for the training.
-
5.
Obtain the molecular energy
The bias parameters as well as are initially set to zero. All other weight matrices are initialized drawing from a uniform distribution according to glorot2010understanding.
The deep tensor neural networks have been trained for 3000 epochs minimizing the squared error, using stochastic gradient descent with 0.9 momentum and a constant learning rate lecun2012efficient. The final results are taken from the models with the best validation error in early stopping.
Computational cost of training and prediction
All DTNN models were trained and executed on an NVIDIA Tesla K40 GPU. The computational cost of the employed models depends on the number of reference calculations, the number of interaction passes as well as the number of atoms per molecule. The training times for all models and data sets are shown in Table 1, ranging from 6 hours for 5.768 reference calculations of GDB-7 with one interaction pass, to 162 hours for 100.000 reference calculations of the GDB-9 data set with 3 interaction passes.
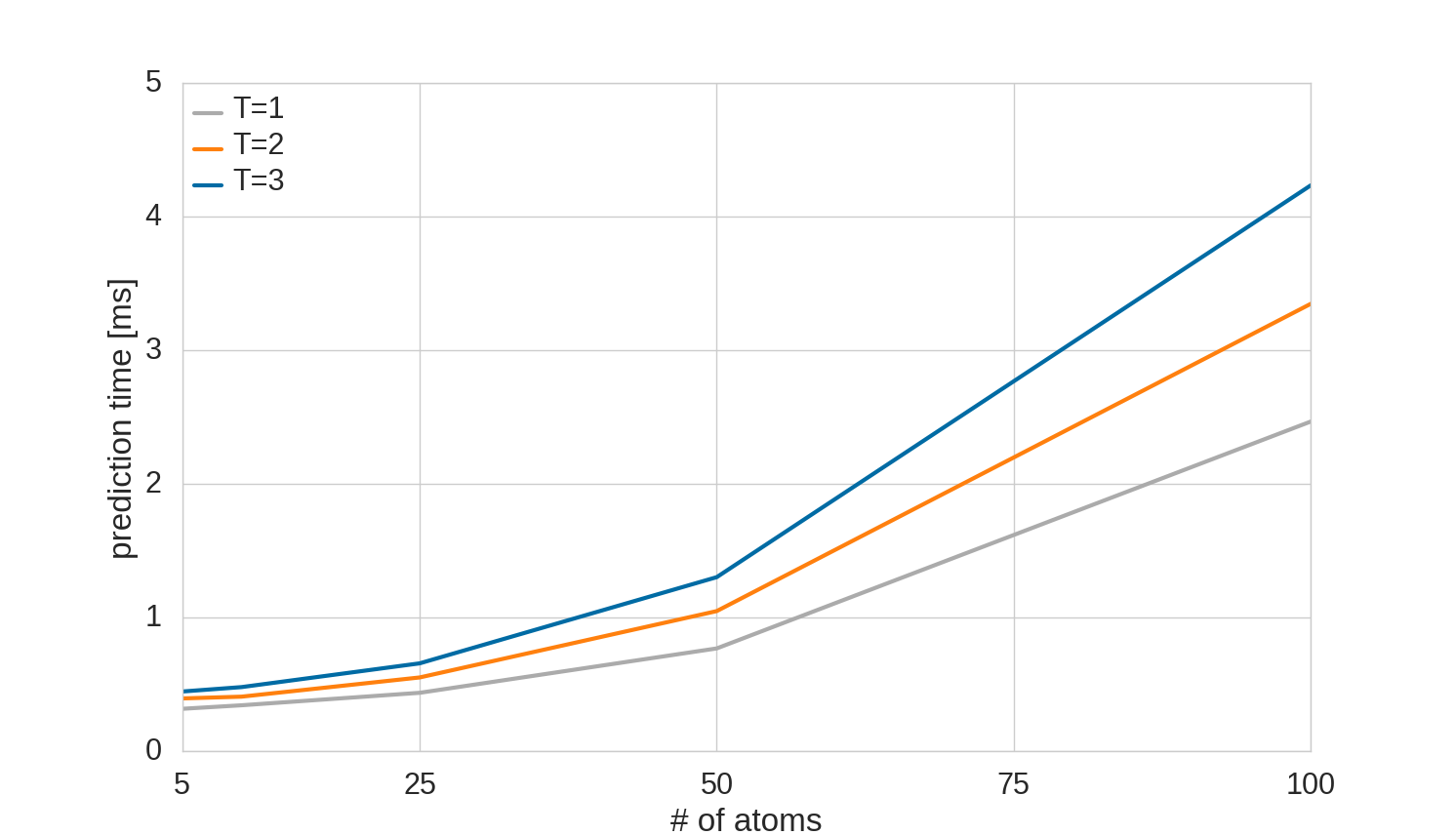
On the other hand, the prediction is instantaneous: all models predict examples from the employed data sets in less than 1 ms. Fig. 12 shows the scaling of the prediction time with the number of atoms and interaction layers. Even for a molecule with 100 atoms, a DTNN with 3 interaction layers requires less than 5 ms for a prediction.
The prediction as well as the training steps scale linearly with the number of interaction passes and quadratically with the number of atoms, since the pairwise atomic distances are required for the interactions. For large molecules it is reasonable to introduce a distance cutoff (future work). In that case, the DTNN will also scale linearly with the number of atoms.
Computing the local potentials of the DTNN
Given a trained neural network as described in the previous section, one can extract the coefficients vectors for each atom and each interaction pass for a molecule of interest. From each final representation , the energy contribution of the corresponding atom to the molecular energy can be obtained. Instead, we let the molecule act on a probe atom, described by its charge and the pairwise distances to the atoms of the molecule:
| (11) |
with . While this is equivalent to how the coefficient vectors of the molecule are corrected, here, the molecule does not get to be influenced by the probe. Now, the energy of the probe atom is predicted as usual from the final representation . Interpreting this as a local potential generated by the molecule, we can use the neural network to visualize the learned interactions as illustrated in Fig. 5. The presented energy surfaces show the potential for different probe atoms plotted on an isosurface of . We used Mayavi ramachandran2011mayavi for the visualization of the surfaces.
Computing an alchemical path with the DTNN
The alchemical paths in Fig. 11 were generated by gradually moving the atoms as well as interpolating between the initial coefficient vectors for changes of atom types. Given two nuclear charges , the coefficient vector for any charge with is given by
| (12) |
Similarly, in order to add or remove atoms, we introduce fading factors for each atom. This way, influences on other atoms
| (13) |
as well as energy contributions to the molecular energy can be faded out.
Supplementary Text
Discussion of the results
Table 2 shows the mean absolute (MAE) and root mean squared errors (RMSE) as well as standard errors over five randomly drawn training sets. For GDB-9 and the MD data sets, 1k reference calculations were used as validation set for early stopping, while the remaining data was used for testing. In case of GDB-7, validation and test set contained 10% of the reference calculations each. With respect to the mean absolute error, chemical accuracy can be achieved on all employed data sets using models with two or three interactions passes.
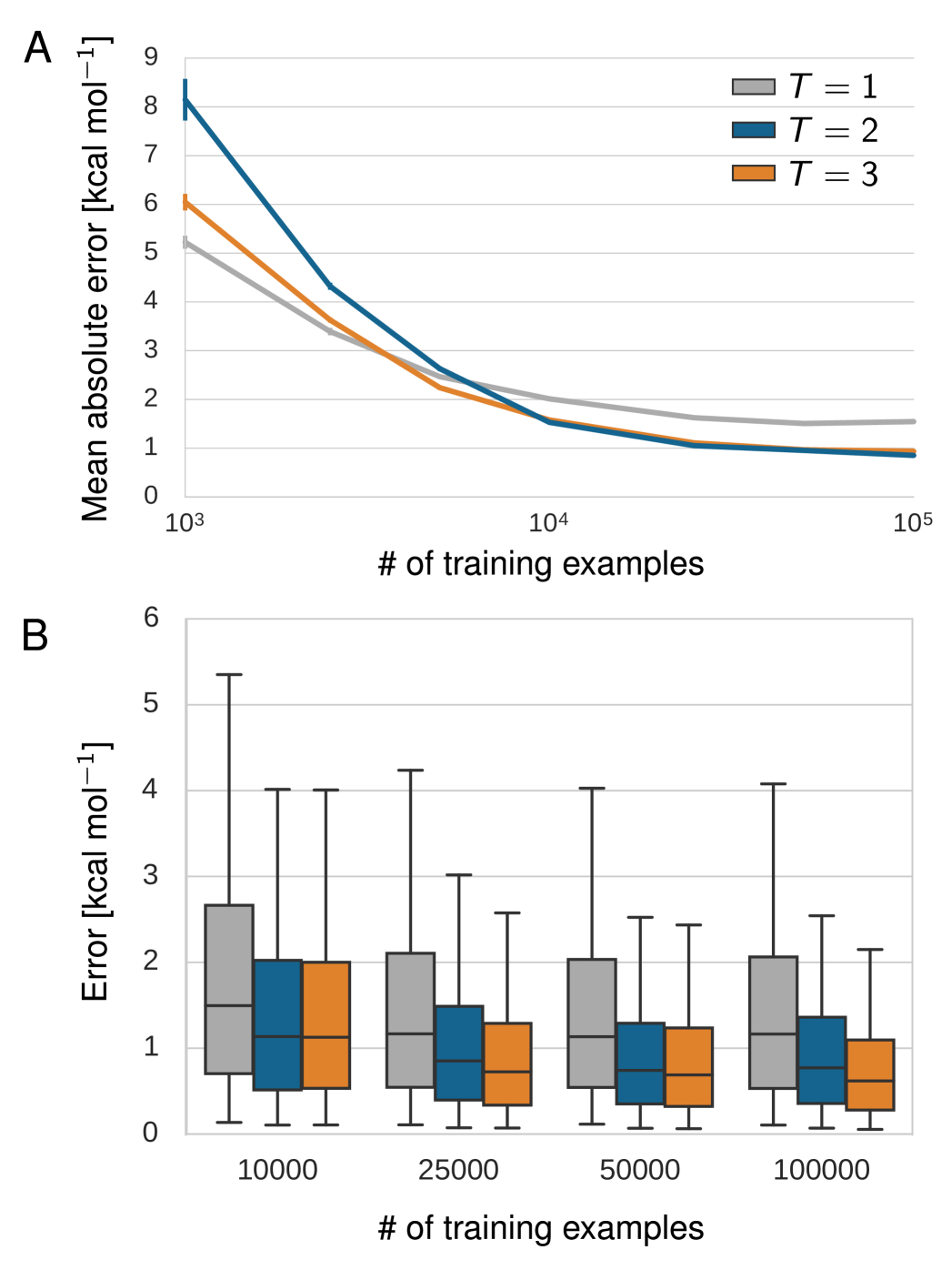
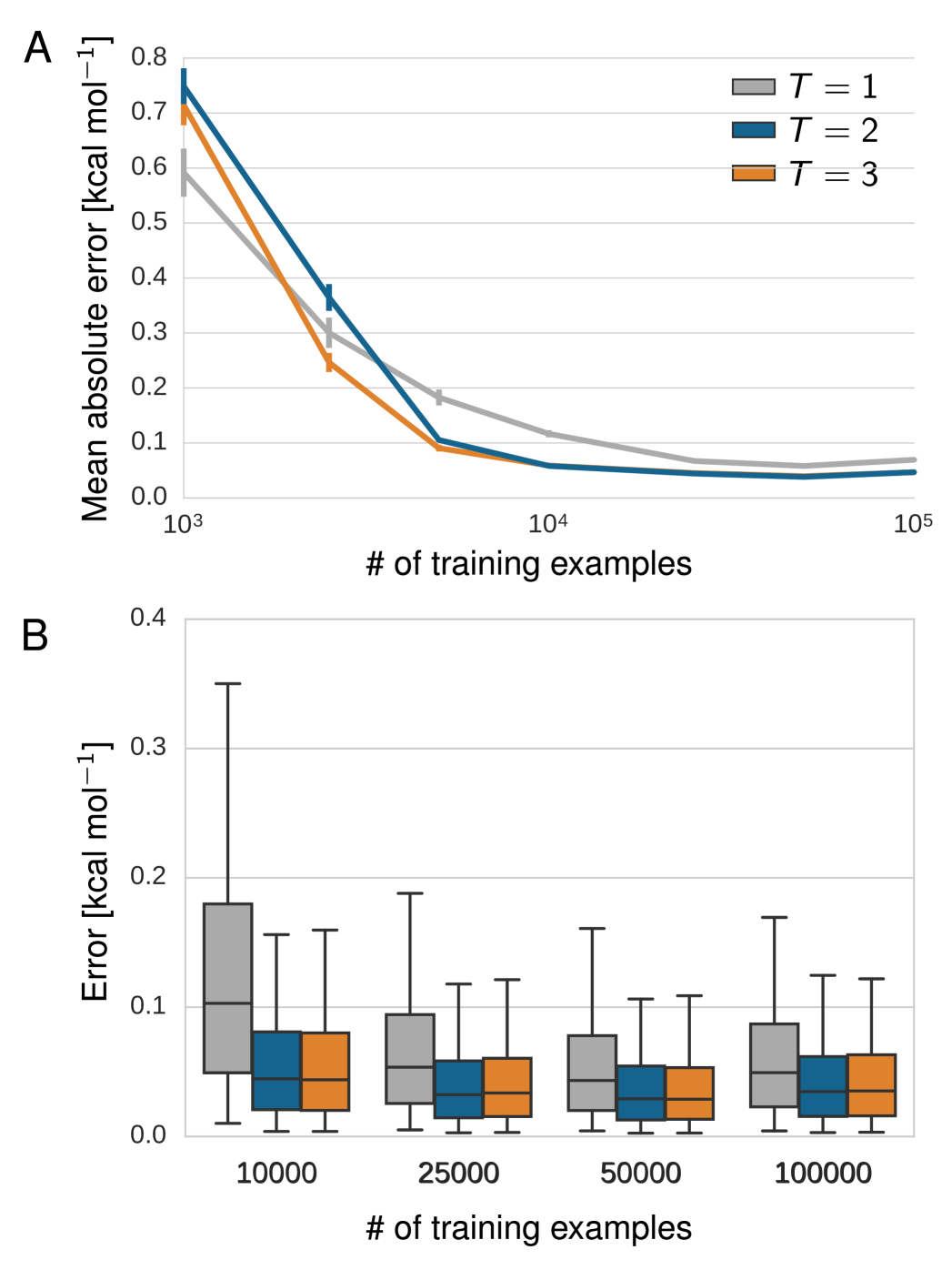
Figs. 6 and 7 show the dependence of the performance on the number of training examples for the benzene MD data set and GDB-9, respectively. In both learning curves (A), an increase from 1.000 to 10.000 training examples reduces the error drastically while another increase to 100.000 examples yields comparatively small improvement. The error distributions (B) show that models with two and three interaction passes trained on at least 25.000 GDB-9 references calculations predict 95% of the unknown molecules with an error of 3.0 kcal/mol or lower. Correspondingly, the same models trained on 25.000 or more MD reference calculations of benzene predict 95% of the unknown benzene configurations with a maximum error lower than 1.3 kcal/mol.
Beyond a certain number of reference calculations, the models with one interaction pass perform significantly worse in all theses respects. Thus, multiple interaction passes indeed enrich the learned feature representation as demonstrated by the increased predictability of previously unseen molecules.
Relations to other deep neural networks
Deep learning has lead to major advances in computer vision, language processing, speech recognition and other applications lecun2015deep. In our model, we embed the atom type in a vector space . This idea is inspired by word embeddings (word2vec) employed in natural language processing mikolov2013distributed. In order to model inter-atomic effects, we need to represent the influence of an atom represented by at the distance . To account for multiple regimes of atomic distances as well as different dimensionality of the two inputs, we apply the Gaussian feature mapping described above. Similar approaches have been applied to the entries of the Coulomb matrix for the prediction of molecular properties before montavon2013machine. A natural way to connect distance and atom representation is a tensor layer as used in text generation sutskever2011generating, reasoning socher2013reasoning or sentiment analysis socher2013recursive. For an efficient computation as well as regularization, we employ a factorized tensor layer, corresponding to a low-rank approximation of the tensor product taylor2009factored.
Convolutional neural networks have been applied to images, speech and text with great success due to their ability to capture local structure ciresan2012multi; krizhevsky2012imagenet; lecun1995convolutional; hinton2012deep; sainath2015deep; collobert2008unified. In a convolution layer, local filters are applied to local environments, e.g., image patches, extracting features relevant to the classification task. Similarly, local correlations of atoms may be exploited in a chemistry setting. The atom interaction in our model can indeed be regarded as a non-linear generalization of a convolution. In contrast to images however, atoms of molecules are not arranged on a grid. Therefore, the convolution kernels need to be continuous. We define a function yielding at the atom positions. Now, we can rewrite the interactions as
| (14) |
with
| (15) |
| (16) |
| (17) |
For being the identity, the sum is equivalent to a discrete convolution.
Figures

Tables
| Data set | # training examples | |||
|---|---|---|---|---|
| GDB-7 | 5768 | 6 | 7 | 8 |
| GDB-9 | 25k | 28 | 35 | 42 |
| 50k | 55 | 71 | 82 | |
| 100k | 110 | 139 | 162 | |
| Benzene | 25k | 21 | 27 | 32 |
| 50k | 44 | 53 | 61 | |
| 100k | 84 | 104 | 121 | |
| Toluene | 25k | 24 | 27 | 32 |
| 50k | 45 | 55 | 64 | |
| 100k | 88 | 108 | 127 | |
| Malonaldehyde | 25k | 21 | 25 | 29 |
| 50k | 41 | 52 | 59 | |
| 100k | 85 | 106 | 117 | |
| Salicylic acid | 25k | 22 | 31 | 32 |
| 50k | 44 | 54 | 65 | |
| 100k | 91 | 109 | 125 |
| Data set | # training examples | T=1 | T=2 | T=3 | ||||
|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | MAE | RMSE | |||
| GDB-7 | 5768 | |||||||
| GDB-9 | 25k | |||||||
| 50k | ||||||||
| 100k | ||||||||
| Benzene | 25k | |||||||
| 50k | ||||||||
| 100k | ||||||||
| Toluene | 25k | |||||||
| 50k | ||||||||
| 100k | ||||||||
| Malonaldehyde | 25k | |||||||
| 50k | ||||||||
| 100k | ||||||||
| Salicylic acid | 25k | |||||||
| 50k | ||||||||
| 100k | ||||||||