Quantum continual learning of quantum data realizing knowledge backward transfer
Abstract
For the goal of strong artificial intelligence that can mimic human-level intelligence, AI systems would have the ability to adapt to ever-changing scenarios and learn new knowledge continuously without forgetting previously acquired knowledge. When a machine learning model is consecutively trained on multiple tasks that come in sequence, its performance on previously learned tasks may drop dramatically during the learning process of the newly seen task. To avoid this phenomenon termed catastrophic forgetting, continual learning, also known as lifelong learning, has been proposed and become one of the most up-to-date research areas of machine learning. As quantum machine learning blossoms in recent years, it is interesting to develop quantum continual learning. This paper focuses on the case of quantum models for quantum data where the computation model and the data to be processed are both quantum. The gradient episodic memory method is incorporated to design a quantum continual learning scheme that overcomes catastrophic forgetting and realizes knowledge backward transfer. Specifically, a sequence of quantum state classification tasks is continually learned by a variational quantum classifier whose parameters are optimized by a classical gradient-based optimizer. The gradient of the current task is projected to the closest gradient, avoiding the increase of the loss at previous tasks, but allowing the decrease. Numerical simulation results show that our scheme not only overcomes catastrophic forgetting, but also realize knowledge backward transfer, which means the classifier’s performance on previous tasks is enhanced rather than compromised while learning a new task.
1 Introduction
Promoted by the interaction between quantum mechanics and computer science, quantum computation [1] is a brand new computation scheme that manipulates quantum information units following the rules of quantum mechanics. Due to the exponentially increasing Hilbert space and unique properties like superposition and entanglement, quantum computation possesses tremendous potential computing power. Many prominent research achievements have appeared in the realm of quantum computation since the end of last century. In recent years, quantum computation has received high attention and significant investment from the industry.
One of the research focuses in quantum computation is quantum machine learning (QML) [2], which is the mergence between quantum computation and machine learning [3]. The efficiency of machine learning can be enhanced by quantum algorithms such as the quantum algorithm for linear systems of equations [4], quantum algorithm for data fitting [5], quantum support vector machine [6, 7], quantum principal component analysis [8] and quantum recommendation system [9]. On the other hand, using quantum circuits with learnable parameters (a.k.a. variational quantum circuits or parameterized quantum circuits) as ML models is a feasible way to integrate quantum and classical computation in the NISQ [10] era. Two typical pioneering quantum-classical hybrid algorithms are variational quantum eigensolver [11] and quantum approximate optimization algorithm [12]. Various common ML problems have been considered using variational quantum algorithms such as classification [13, 14, 15, 16, 17], generalization [18, 19, 20, 21, 22, 23] and autoencoder [24, 25, 26, 27]. The structure of the variational quantum circuit (layout of gates) is fixed and the parameters of the gates are optimized at the first place. Recently, variational quantum compiling [28, 29, 30] and quantum architecture search [31, 32] try to optimize the structures of variational quantum circuits to obtain more efficient circuits.
Intelligence creatures have the ability to continually learn new knowledge and skills and incrementally adapt to new scenarios over the duration of their lifetime. However, learning of new tasks for an ML model often results in forgetting of old tasks, which is called the catastrophic forgetting phenomenon. Continual learning (a.k.a lifelong learning, incremental learning, sequential learning) [33] is a research topic that provides solutions for acquiring knowledge from continuously changing data stream of multiple tasks. Recently, continual learning has been explored in the context of quantum machine learning [34]. It’s been shown that a quantum classifier’s performance on old tasks may deteriorate when learning a new task. On the assumption that some parameters in variational quantum classifiers are more important than others, the elastic weight consolidation (EWC) [35] method can help to protect those parameters with great importance to the old tasks from being updated drastically. Numerical experiments demonstrate that a quantum classifier can continually learn three different classification tasks without catastrophic forgetting. Another goal of continual learning is to learn a new task faster by utilizing past knowledge acquired from old tasks. Ref. [36] proposed a continual reinforcement learning framework to deal with the constantly changing environment. In this framework, the agent leverages past policies learned from previous noise environments to generate a state preparation quantum circuit for a new noise environment. Without training from scratch, the convergence speed can be much faster.
In this work, we investigate the continual learning of a sequence of quantum state classification tasks. The training and testing data are all quantum states, challenging to classical neural networks because the exponential increasing resources required to represent them classically. We adopt the quantum-classical hybrid computing scheme to train a variational quantum classifier, the parameters of which are updated by a classical gradient descent optimizer. We incorporate the gradient episodic memory (GEM) method [37] to keep the classifier remembering previously learned tasks. Before the gradient is used to update the parameters, it’s modified to avoid the reduction of the classifier’s performance on old tasks. A merit of this method is the possibility of positive backward transfer, which denotes the benefits previous tasks get from the training of new tasks. Numerical results demonstrate that the continual learning of six quantum state classification tasks with GEM has higher accuracy and backward transfer than EWC.
This paper is organized as follows. In section 2, we present the related work of classical and quantum continual learning. In section 3, we describe the quantum state classification tasks, the structure of our variational quantum classifier and the GEM method. In section 4, the numerical experiment results of quantum continual learning with GEM and other strategies are shown and compared. Section 5 presents the concluding remarks.
2 Related work
Elastic weight consolidation (EWC) [35] is a famous continual learning method overcoming catastrophic forgetting phenomenon in neural networks. It adds a penalty term to the loss function to confine the parameter update, because the deviation of important parameters from the optimal solutions of previously trained tasks will compromise the classifier’s performance on those tasks. More specifically, the diagonal elements of the Fisher information matrix at the optimal point are saved when each task has been trained. This information tells about the importance of the parameters to the task and can be used to constrain the update strength of parameters. When training the -th task, the model’s parameter is optimized to minimize the following loss function
| (1) |
where is the original loss function for the -th task, is a hyper-parameter determining how important the old tasks are compared with the new one, is the -th diagonal element of the Fisher information matrix at the optimal point for the -th task. By adding the quadratic penalty term, each parameter is pulled back toward its old values by an amount proportional to its importance for performance on previously learned tasks.
The gradient episodic memory (GEM) method [37] uses samples of previous tasks kept in the memory to modify the gradient of the current task. Unlike EWC, the performance of the old tasks is more likely to increase because the previous samples are rehearsed in the parameter update. This phenomenon is called positive backward transfer. Ref. [37] proposed an evaluation metric
| (2) |
to measure the influence that learning a task has on the performance on a previous task. denotes the number of tasks. denotes the test accuracy of the model on the -th task after learning the -th task. Positive BWT means learning new tasks increases the performance of old tasks, and negative BWT means learning new tasks decreases the performance of old tasks, i.e., catastrophic forgetting. Another evaluation metric we use in this paper is the average accuracy defined by
| (3) |
which is the average accuracy on all tasks after the last task has been learned. This is the most commonly used metric in continual learning.
Continual learning has been investigated in the QML field. Ref. [34] adopted the EWC method to help a quantum classifier overcome catastrophic forgetting and learn a sequence of three classification tasks successfully. Ref. [36] studied quantum state preparation for changing environment by training a reinforcement learning agent that utilizes past policies learned from previous environments.
Another subject called transfer learning, which is similar to continual learning to some extent, has also been studied in the QML field. In transfer learning, a model is trained on task B taking advantage of the knowledge of a similar task A. Unlike continual learning, the model’s performance on only task B is concerned. A generic quantum transfer learning scheme was considered in Ref. [38]. In this scheme, a pre-trained classical or quantum model for task A is truncated by removing some final layers. A new trainable classical or quantum model is connected to the end of the pre-trained model. While keeping the parameters of the pre-trained model constant, the new model’s parameters are optimized using the dataset of task B. Ref. [39] proposed a quantum deep transfer learning scheme for feature-based knowledge transfer, which is composed of a model for generating quantum feature data based on quantum Boltzmann machine [40], an algorithm for computing kernel matrices of mixed quantum states, and a quantum alignment algorithm for comparing the characters of the kernel matrices.
3 Methods
We use a variational quantum classifier to classify quantum states in the continual learning fashion. As far as we know, it’s the first time a quantum classifier is trained to solve up to six quantum state classification problems. Each of the six tasks contains a dataset of quantum states that belong to the positive class or the negative class. After random initialization of parameters, the classifier reads the training data from one task after another. The classifier switches to the next task only when it has read all training samples of the current task. After being trained through all the tasks, the classifier is expected to have good performance on all tasks, i.e., predict the class label for a testing quantum state corresponding to anyone of the trained tasks as accurately as possible.
3.1 Quantum state classification tasks
We use six quantum state classification tasks as benchmark. Task 1 is to classify the symmetry protected topological phases for the following Hamiltonian:
| (4) |
where is the number of spins, are the Pauli operators acting on the -th spin and is the strength of the nearest-neighbor interaction. This model features a quantum phase transition at , between a symmetry protected topological phase characterized by a string order for , and an antiferromagnetic phase with long-range order for . The ground states of comprise the dataset of task 1. We set and obtain 512 samples by picking evenly from 0 to 2.
Ref. [41] provided an entangled dataset for quantum machine learning, which contains quantum states with different amounts of multipartite entanglement. Five classes of 8-qubit states with concentratable entanglement (CE) 0.1, 0.15, 0.25, 0.4 and 0.45 are given. Here we choose the classification between states with CE=0.1 and states with CE=0.25 as task 2, and the classification between quantum states with CE=0.15 and 0.45 as task 3. Each dataset of these two tasks contains 512 quantum states.
The remaining three tasks consider quantum states evolved under the time-dependent two-body transverse field Ising model:
| (5) |
We let and make 512 quantum states by picking evenly from -1 to 1, with fixed for task 4, 5, 6, respectively. The class label is dependent on the sign of .
The order of the above tasks in which they are fed to the classifier can be denoted by a sequence, e.g. 123456. In section 4 we report the numerical experimental results of different orders. We summarize the six quantum state classification tasks in Table 1 for clearness.
| Task name | Description |
|---|---|
| Task 1 | Classify the symmetry protected topological phases |
| Task 2 | Classify between quantum states with CE=0.1 and CE=0.25 |
| Task 3 | Classify between quantum states with CE=0.15 and CE=0.45 |
| Task 4 | Classify states evolved under the transverse field Ising model with |
| Task 5 | Classify states evolved under the transverse field Ising model with |
| Task 6 | Classify states evolved under the transverse field Ising model with |
3.2 Variational quantum classifier
The variational quantum classifier in this study adopts the same hardware-efficient variational ansatz as that in Ref. [34]. The quantum circuit ansatz has repeated layers composed of , and gates. Each layer is defined as
| (6) |
where is the number of qubits, are the rotation gates acting on the -th qubit, the superscript and subscript of denote the control and target qubit, respectively. Before the final measurement, an extra gate is performed on each qubit, so the effect of the whole circuit can be written as
| (7) |
where and denote the input and output state of the circuit, respectively. The rotation angles are learnable parameters which will be updated by a classical optimizer during the training process.
The quantum classifier in Ref. [34] uses the measurement expectation value of only one specified qubit as the prediction value. In order to utilize more information in the final quantum state, we collect the measurement expectation values of all qubits in the form of a vector , with
| (8) |
where is the observable being measured on the -th qubit. Then the prediction value is obtained by a postprocessing transform on through a simple feedforward neural network with only one hidden layer containing neurons. The set of all trainable parameters in our classifier is denoted as with being the weights of the neural network. The prediction for input is denoted as .
3.3 Gradient episodic memory method
We incorporate the gradient episodic memory (GEM) method [37] for continual learning of quantum state classification tasks. In the training process of the -th task, a fraction of the training samples and labels are allocated to an episodic memory . The loss at the episodic memory from the -th task is defined as
| (9) |
In this work, is the cross entropy loss which is commonly used for classification problems.
We require that the parameter update in the training process of the -th task would not decrease the classifier’s performance on previous tasks. This requirement can be expressed by the following constrained optimization problem:
| (10) |
where is the classifier state at the end of learning the -th task. Let be the loss gradient of the -th task, and be the loss gradient of . If the inner product for all , then the parameter update according to is unlikely to increase the loss at previous tasks. Otherwise, the gradient needs to be projected to the closest gradient , by solving
| (11) |
which is a quadratic program in variables (the number of parameters in the classifier). In order to solve this efficiently, GEM works in the dual space which results in a much smaller quadratic program with only variables:
| (12) |
where . After the solution is found, the projected gradient can be obtained by .
4 Results
We conduct numerical simulation experiments on continual learning of six quantum state classification tasks given in section 3.1. We compare the GEM method and the EWC method, along with plainly training the tasks one by one (denoted as ‘Plain’ in the following). The average accuracy (ACC) and backward transfer (BWT) defined in section 2 are calculated to evaluate the performance.
The simulation is carried out using the Pennylane library [42] alongside the PyTorch [43] interface. The stochastic gradient optimizer Adam (Adaptive Moment Estimation) [44] is used to update the classifier’s parameters with the initial learning rate 0.1. Each task contains 512 samples, 400 of which are used as training samples and the remains are used for testing. The variational quantum classifier has layer, and is trained on each task for only 1 epoch with a batch size 10. For the EWC method, 50 samples randomly chosen from the training set are used to calculate the diagonal of the Fisher information matrix. For the GEM method, the capacity of each episodic memory is 50 samples which are randomly picked from the training set of the -th task.
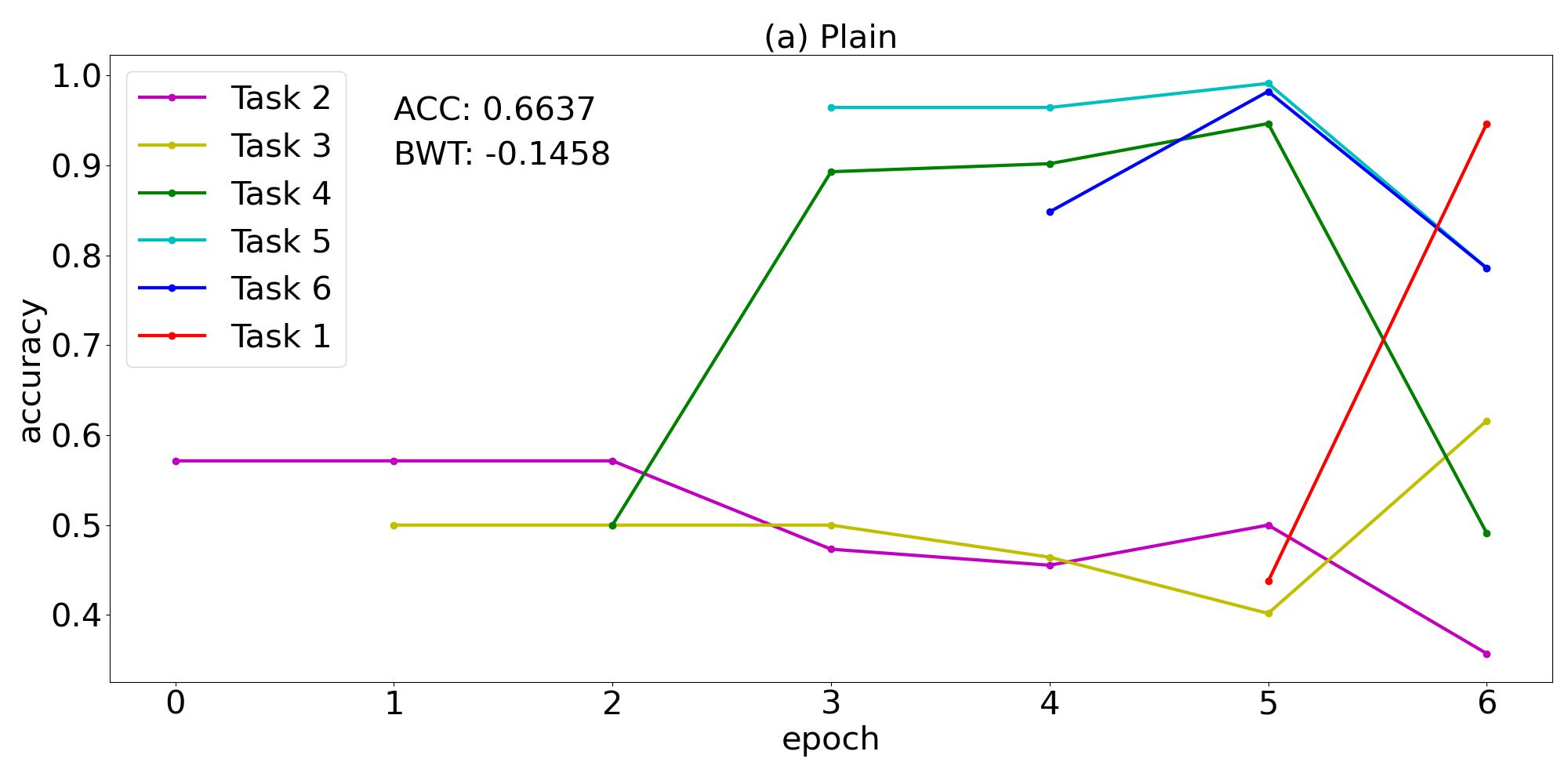
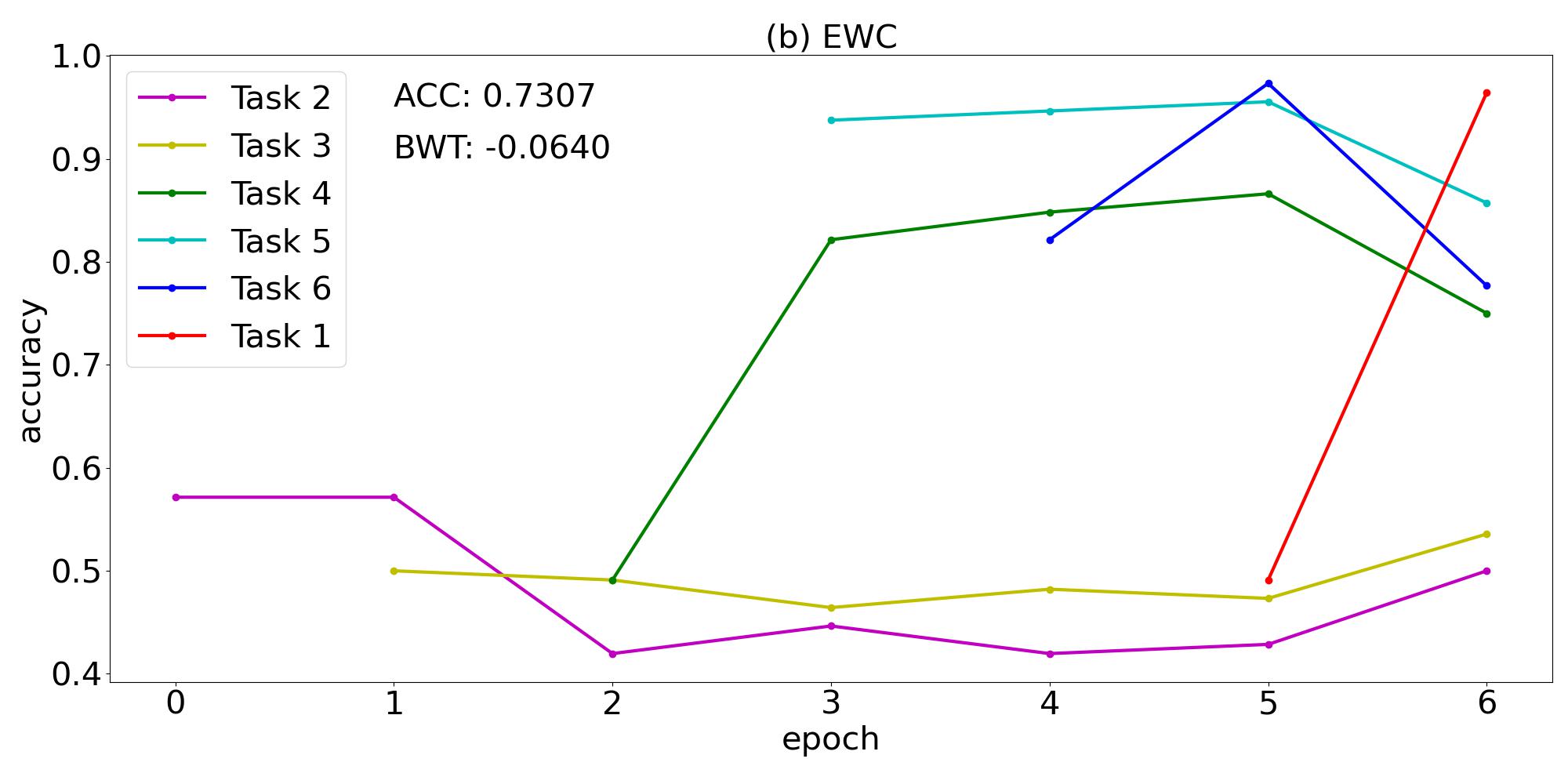
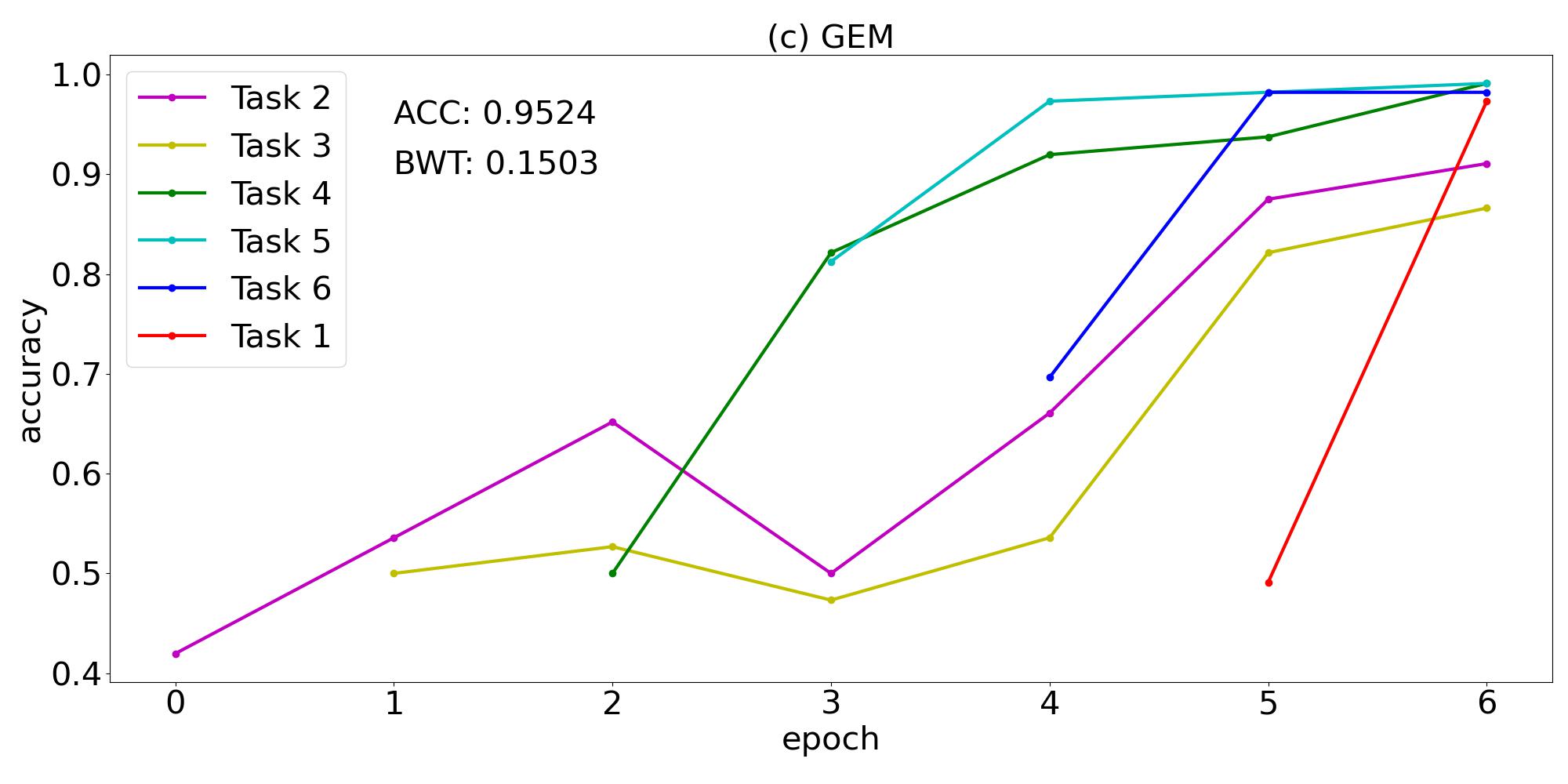
With regard to the training order of the tasks, we first try the lexical order 123456 in which the tasks are introduced in section 3.1, then we pick another four random orders that can be found in the first column of table 2. For each training order and strategy, we train 5 classifiers with different random initialization, and report the one with the highest test ACC. The results are summarized in table 2. It can be seen that for all task sequences, GEM achieves higher ACC than EWC and plain training. GEM results in comparable ACC higher than for all task sequences except 123456, yet the ACC of EWC is lower than for all task sequences. The BWT is all positive in the case of GEM, but all negative for EWC, and even lower in the case of plain training. We can conclude that the overall performance of GEM is significantly better than EWC and plain training.
| Plain | EWC | GEM | ||||
|---|---|---|---|---|---|---|
| Task sequence | ACC | BWT | ACC | BWT | ACC | BWT |
| 123456 | 0.7277 | 0.0268 | 0.7812 | -0.0268 | 0.8482 | 0.0372 |
| 234561 | 0.6637 | -0.1458 | 0.7307 | -0.0640 | 0.9524 | 0.1503 |
| 436251 | 0.6920 | -0.1443 | 0.7693 | -0.0565 | 0.9390 | 0.0699 |
| 312456 | 0.7188 | -0.0714 | 0.7798 | -0.0164 | 0.9554 | 0.1071 |
| 246351 | 0.6310 | -0.1815 | 0.7188 | -0.0223 | 0.9405 | 0.1905 |
The training curve of task sequence 234561 is plotted in figure 1. The catastrophic forgetting phenomenon appears in figure 1(a) which shows the plain training of a sequence of tasks without any continual learning strategy. After the classifier has been trained on a task, the test accuracy of that task will generally drop obviously when the classifier is continually trained on the following tasks. The knowledge acquired from previous tasks are forgotten gradually. It can also be seen that the test accuracy of task 2 and 3 is around , which implies the classifier’s performance is not better than a random guess. The catastrophic forgetting phenomenon can also be observed in figure 1(b) corresponding to the EWC method. Although the ACC has risen from 0.6637 to 0.7307, the classifier still fails to classify the states of task 2 and task 3. Figure 1(c) manifests the effectiveness of the GEM method that successfully overcomes catastrophic forgetting. Although 1 epoch of training on task 2 and 3 cannot result in high test accuracy, the continual training of other tasks help to improve the performance of the classifier on task 2 and 3. After the sixth task has been trained, the model’s test accuracy on task 2 and 3 is above , much better than the other two plots. Every task’s test accuracy is higher at the end of training the last task than immediately after training that task, thus the BWT is positive. The numerical results for other 4 task sequences are depicted in figure 2, which shows similar behaviors.
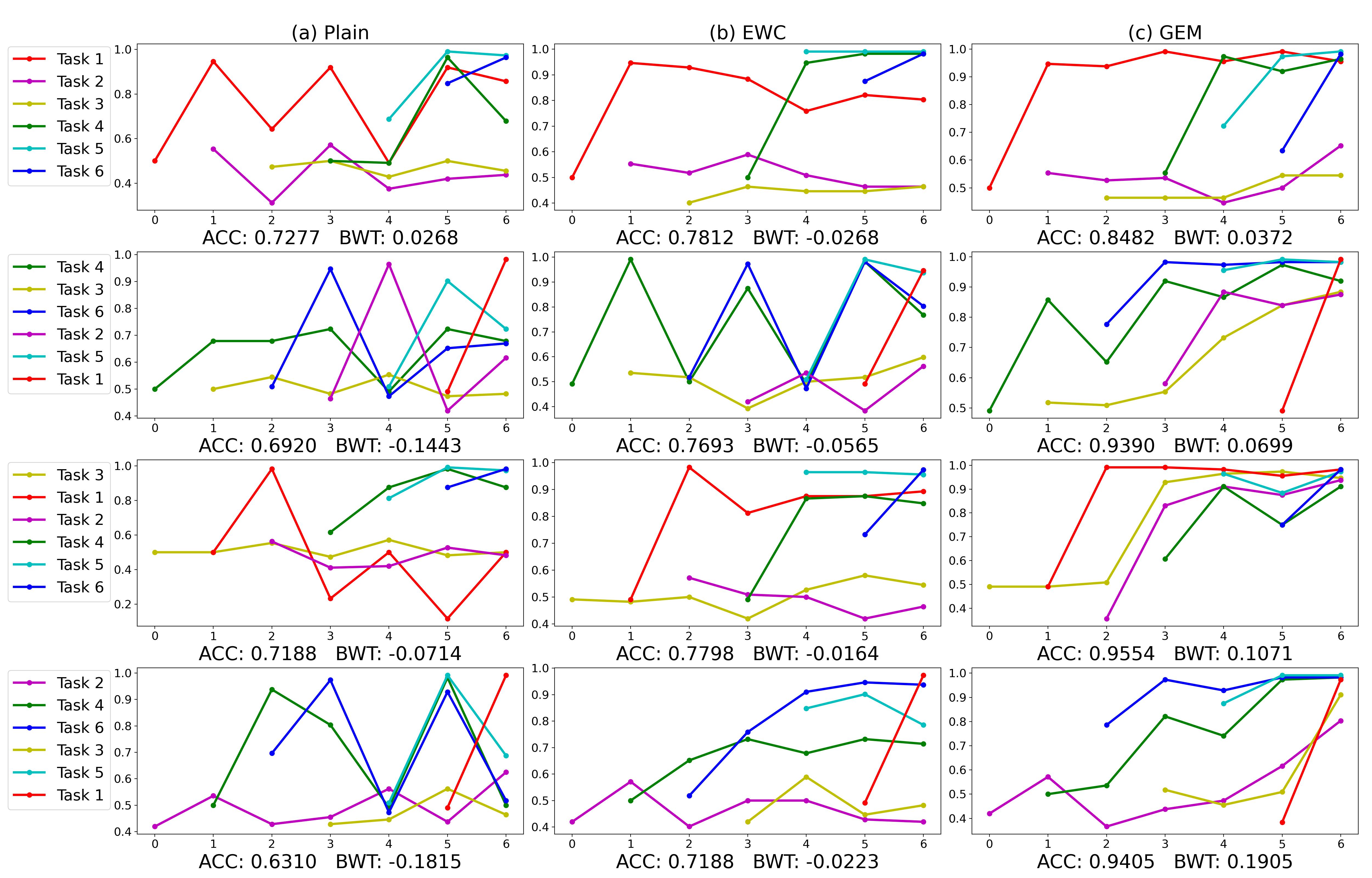
5 Conclusion
Continual learning is a fascinating research topic because it makes artificial intelligence systems learn in a more human-like way. When facing the always changing reality, a machine learning model must be equipped with the capacity of adaptation to new emerging tasks. Previous work [34] has exhibited that a variational quantum classifier can learn a sequence of 3 tasks without catastrophic forgetting. In this work, we move forward to train a variational quantum classifier sequentially on a total of 6 quantum state classification tasks. With resort to the GEM strategy that yields positive knowledge transfer to previous tasks, we have acquired a quantum classifier with better performance. The positive backward transfer explains the improvement brought by GEM. A drawback of GEM is the necessity of computing gradients of previous tasks at each training iteration, while EWC needs to record the diagonal of the Fisher information matrix only at the last training iteration of each task. Another drawback is the episodic memory cost, which would become a heavy burden if the number of tasks is very large. Addressing the two issues will be the focus of our future research. We hope that more exploration and development of quantum continual learning will be done in the future, paving the way to quantum artificial general intelligence.
References
- [1] M. Nielsen, I. Chuang. Quantum Computation and Quantum Information. Cambridge University Press (2000)
- [2] V. Dunjko, P. Wittek. A non-review of quantum machine learning: trends and explorations. Quantum Views 4: 32 (2020)
- [3] I. Goodfellow, Y. Bengio, A. Courville. Deep Learning. MIT Press (2016)
- [4] A. Harrow, A. Hassidim, S. Lloyd. Quantum algorithm for linear systems of equations. Physical Review Letters 103: 150502 (2009)
- [5] N. Wiebe, D. Braun, S. Lloyd. Quantum algorithm for data fitting. Physical Review Letters 109: 050505 (2012)
- [6] P. Rebentrost, M. Mohseni, S. Lloyd. Quantum support vector machine for big data classification. Physical Review Letters 113: 130503 (2014)
- [7] Z. Ye, L. Li, H. Situ, Y. Wang, Quantum speedup of twin support vector machines, Science China Information Sciences 63: 189501 (2020)
- [8] S. Lloyd, M. Mohseni, P. Rebentrost. Quantum principal component analysis. Nature Physics 10: 631 (2014)
- [9] I. Kerenidis, A. Prakash. Quantum recommendation systems. in 8th Innovations in Theoretical Computer Science Conference (ITCS 2017)
- [10] J. Preskill. Quantum computing in the NISQ era and beyond. Quantum 2: 79 (2018)
- [11] A. Peruzzo, J. McClean, P. Shadbolt, et al. A variational eigenvalue solver on a photonic quantum processor. Nature Communications 5: 4213 (2014)
- [12] E. Farhi, J. Goldstone, S. Gutmann. A quantum approximate optimization algorithm. arXiv: 1411.4028 (2014)
- [13] V. Havlíček, A. Córcoles, K. Temme, et al. Supervised learning with quantum-enhanced feature spaces. Nature 567: 209 (2019)
- [14] M. Schuld, N. Killoran. Quantum machine learning in feature Hilbert spaces. Physical Review Letters 122: 040504 (2019)
- [15] I. Cong, S. Choi, M. Lukin. Quantum convolutional neural networks. Nature Physics 15: 1273 (2019)
- [16] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, J. Latorre. Data re-uploading for a universal quantum classifier. Quantum 4: 226 (2020)
- [17] E. Peters, J. Caldeira, A. Ho, et al. Machine learning of high dimensional data on a noisy quantum processor. npj Quantum Information 7: 161 (2021)
- [18] M. Benedetti, D. Garcia-Pintos, O. Perdomo, et al. A generative modeling approach for benchmarking and training shallow quantum circuits. npj Quantum Information 5: 45 (2019)
- [19] H. Situ, Z. He, Y. Wang, L. Li, S. Zheng. Quantum generative adversarial network for generating discrete distribution. Information Sciences 538: 193 (2020); also see arXiv:1807.01235.
- [20] C. Zoufal, A. Lucchi, S. Woerner. Quantum generative adversarial networks for learning and loading random distributions. npj Quantum Information 5: 103 (2019)
- [21] S. Chakrabarti, Y. Huang, T. Li, S. Feizi, X. Wu. Quantum Wasserstein generative adversarial networks. Advances in Neural Information Processing Systems 32 (2019)
- [22] J. Romero, A. Aspuru-Guzik. Variational quantum generators: Generative adversarial quantum machine learning for continuous distributions. Advanced Quantum Technologies 4: 2000003 (2021)
- [23] D. Herr, B. Obert, M. Rosenkranz. Anomaly detection with variational quantum generative adversarial networks. Quantum Science and Technology 6: 045004 (2021)
- [24] J. Romero, J. Olson, A. Aspuru-Guzik. Quantum autoencoders for efficient compression of quantum data. Quantum Science and Techonology 2: 045001 (2017)
- [25] L. Lamata, U. Alvarez-Rodriguez, J. Martín-Guerrero, M. Sanz, E. Solano. Quantum autoencoders via quantum adders with genetic algorithms. Quantum Science and Techonology 4: 014007 (2019)
- [26] A. Pepper, N. Tischler, G. Pryde. Experimental realization of a quantum autoencoder: the compression of qutrits via machine learning. Physical Review Letters 122: 060501 (2019)
- [27] C. Huang, H. Ma, Q. Yin, et al. Realization of a quantum autoencoder for lossless compression of quantum data. Physical Review A 102: 032412 (2020)
- [28] S. Khatri, R. LaRose, A. Poremba, et al. Quantum-assisted quantum compiling. Quantum 3: 140 (2019)
- [29] Y. Zhang, P. Zheng, Y. Zhang, D. Deng. Topological quantum compiling with reinforcement learning. Physical Review Letters 125: 170501 (2020)
- [30] Z. He, L. Li, S. Zheng, Y. Li, H. Situ. Variational quantum compiling with double Q-learning. New Journal of Physics 23: 033002 (2021)
- [31] S. Zhang, C. Hsieh, S. Zhang, H. Yao. Neural predictor based quantum architecture search. Machine Learning: Science and Technology 2: 045027 (2021)
- [32] Z. Lu, P. Shen, D. Deng. Markovian Quantum neuroevolution for machine learning. Physical Review Applied 16: 044039 (2021)
- [33] G. Parisi, R. Kemker, J. Part, C. Kanan, S. Wermter. Continual lifelong learning with neural networks: A review. Neural Networks 113: 54 (2019)
- [34] W. Jiang, Z. Lu, D. Deng. Quantum continual learning overcoming catastrophic forgetting. arXiv: 2108.02786 (2021)
- [35] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences 114: 3521 (2017)
- [36] E. Ye, S. Chen. Quantum architecture search via continual reinforcement learning. arXiv: 2112.05779 (2021)
- [37] D. Lopez-Paz, M. Ranzato. Gradient episodic memory for continual learning. Advances in Neural Information Processing Systems 30 (2017)
- [38] A. Mari, T. Bromley, J. Izaac, M. Schuld, N. Killoran. Transfer learning in hybrid classical-quantum neural networks. Quantum 4: 340 (2020)
- [39] L. Wang, Y. Sun, X. Zhang. Quantum deep transfer learning. New Journal of Physics 23: 103010 (2021)
- [40] M. Amin, E. Andriyash, J. Rolfe, B. Kulchytskyy, R. Melko. Quantum Boltzmann machine. Physical Review X 8: 021050 (2018)
- [41] L. Schatzki, A. Arrasmith, P. Coles, M. Cerezo. Entangled datasets for quantum machine learning. arXiv: 2109.03400 (2021)
- [42] V. Bergholm, J. Izaac, M. Schuld, et al. Pennylane: Automatic differentiation of hybrid quantum-classical computations. arXiv: 1811.04968 (2018)
- [43] A. Paszke, S. Gross, F. Massa, et al. PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems 32 (2019)
- [44] D. Kingma, J. Ba. Adam: a method for stochastic optimization. arXiv: 1412.6980 (2014)