Quantum decision trees with information entropy
Abstract
We present a classification algorithm for quantum states, inspired by decision-tree methods. To adapt the decision-tree framework to the probabilistic nature of quantum measurements, we utilize conditional probabilities to compute information gain, thereby optimizing the measurement scheme. For each measurement shot on an unknown quantum state, the algorithm selects the observable with the highest expected information gain, continuing until convergence. We demonstrate using the simulations that this algorithm effectively identifies quantum states sampled from the Haar random distribution. However, despite not relying on circuit-based quantum neural networks, the algorithm still encounters challenges akin to the barren plateau problem. In the leading order, we show that the information gain is proportional to the variance of the observable’s expectation values over candidate states. As the system size increases, this variance, and consequently the information gain, are exponentially suppressed, which poses significant challenges for classifying general Haar-random quantum states. Finally, we apply the quantum decision tree to classify the ground states of various Hamiltonians using physically-motivated observables. On both simulators and quantum computers, the quantum decision tree yields better performances when compared to methods that are not information-optimized. This indicates that the measurement of physically-motivated observables can significantly improve the classification performance, guiding towards the future direction of this approach.
I Introduction
The classification of quantum states has been extensively studied in the quantum computing community. With the developments in quantum machine learning (QML) [1, 2, 3, 4], a wide variety of quantum algorithms have been demonstrated to be effective in this task. However, the progress of quantum neural networks (QNNs) [5, 6, 7, 8, 9, 10, 11] is greatly hindered by the barren plateau phenomenon [12, 13, 14, 15, 16, 17], which causes the gradient of a QNN upon random initialization to diminish exponentially as the system size increases. In recent years, several papers investigated various schemes to mitigate the adverse effects of barren plateaus, including shallow circuits [13, 14], symmetry-preserving ansatz [18, 19], local cost functions [13], and many other methods. Recent studies also revealed that most, if not all, existing quantum circuits free of barren plateaus are classically simulable [20, 21]. This stems from the fact that these algorithms operate within polynomially sized subspaces, enabling classical simulation and negating the need for parameterized quantum circuits. Although parameterized quantum circuits are often considered essential for achieving exponential quantum advantage in machine learning, alternative approaches are being explored. One such approach, proposed in Reference [20], involves using quantum computers exclusively for data acquisition, followed by classical simulation of training losses. This work focuses on developing a QML model based on this hybrid strategy, separating the model into two distinct components: one for acquiring information from measurements on quantum systems, and the other for analyzing this information using classical algorithms.
In this paper, we present an ansatz-free classical algorithm that uses quantum measurement results as inputs. Our algorithm, which we tentatively call a quantum decision tree, is heavily inspired by classical decision tree algorithms such as the Iterative Dichotomiser 3 (ID3) [22], C4.5 [23] and classification and regression trees (CART) [24, 25]. The algorithm is designed to correctly label an unknown quantum state from various candidate states by computing the expected information gain in the measurement of possible observables. Since each single quantum measurement only provides a quantized outcome, either or in the computational basis, it is very hard to definitively rule out potential candidate states with just a single measurement. 111It is possible to rule out a candidate state by just one single measurement if the candidate state is an eigenstate of the measured basis. However, such cases are rare if one is dealing with general quantum states, the expectation values of which are continuously distributed between and . To deal with the probabilistic nature of the quantum theory, we use conditional probabilities to quantitatively update the likelihood of each candidate state after a single measurement. With the definition of likelihood, we can compute the information gain of a particular measurement by calculating the change in the information entropy [26, 22, 23, 24, 25].
In this paper, we discuss the algorithm in its simplest form: an optimized searching algorithm that aims to label an unknown state among various candidates with the fewest number of measurement shots. Since our algorithm uses measurements as inputs, it is fundamentally different from traditional quantum search algorithms, such as Grover’s algorithm [27, 28, 29]. We argue that our method is much more robust because it relies solely on the classical treatment of measurement outcomes, rather than on amplitude manipulation techniques [27, 28], which tend to be heavily dependent on hardware and, therefore, are less likely to be realized in the noisy intermediate-scale quantum (NISQ) regime [30]. In the numerical experiment sections, we demonstrate the effectiveness of our method by testing it in a searching problem with Haar-random candidate states in a -qubit system.
Furthermore, we derive the expected information gain per shot and discuss its dependency on the number of qubits. In the leading order, the information gain per shot is proportional to the variance of expectation values in the candidate states. Intuitively, this proves that for Haar random states, we end up with exponentially less information out of each measurement shot with increasing system size, similar to the barren plateau phenomenon in variational quantum algorithms. We claim that barren plateaus are not unique to variational algorithms but are a general phenomenon in all algorithms involving quantum states from large, unstructured quantum systems. To validate our theoretical results, we sampled the information gains in systems of various sizes to observe the exponential suppression. The approximation of information gain using the sample variance is also tested in simulation.
In a broader sense, the working principle of this search algorithm is similar to that of the decision tree and can be easily extended to a classification algorithm that handles unseen data if each class in the training dataset is relatively isolated. In this paper, we also demonstrate how our quantum decision trees can be used to achieve quantum state classification. We update the probability of the test state being each of the training states in the different classes. Eventually, the algorithm stops when one class has its probability weights summed to be above a certain threshold value. We numerically test the algorithm by attempting to classify the ground states of various Hamiltonians. The performance is further enhanced by choosing physically motivated observables for measurements. The results are obtained from both the simulator and the IBM Kawasaki quantum computer.
The paper is organized as follows. In Section II, we discuss the general structure of our quantum decision tree algorithm. The general structure of the algorithm, including conditional probability update and information gain computation, is introduced in Section II.1. The numerical test of our method is shown in Section II.2. In Section III, we deal with the information gain in large systems. The approximation of information gain in large systems is derived in Section III.1, followed by numerical validation in Section III.2. In Section IV, the quantum decision tree is used to classify ground states of various Hamiltonians on both simulators and the IBM Kawasaki quantum computer. In the end, we discuss the results and their implications in Section V.
II Information optimization
In this section, we will use classical information theory to investigate the information obtained in each shot of measurement. First, we set up a typical search problem in which we aim to label a test quantum state selected from a set of candidates states of size . We then measure the expectation values of an observable set of size in all of the candidate states: . To label the test state, we pick observables from the set and measure their values in the test state. The resulting measurement outcomes could then be compared with the expectation value of those in the candidate states to update the probability distribution.
II.1 Optimization process
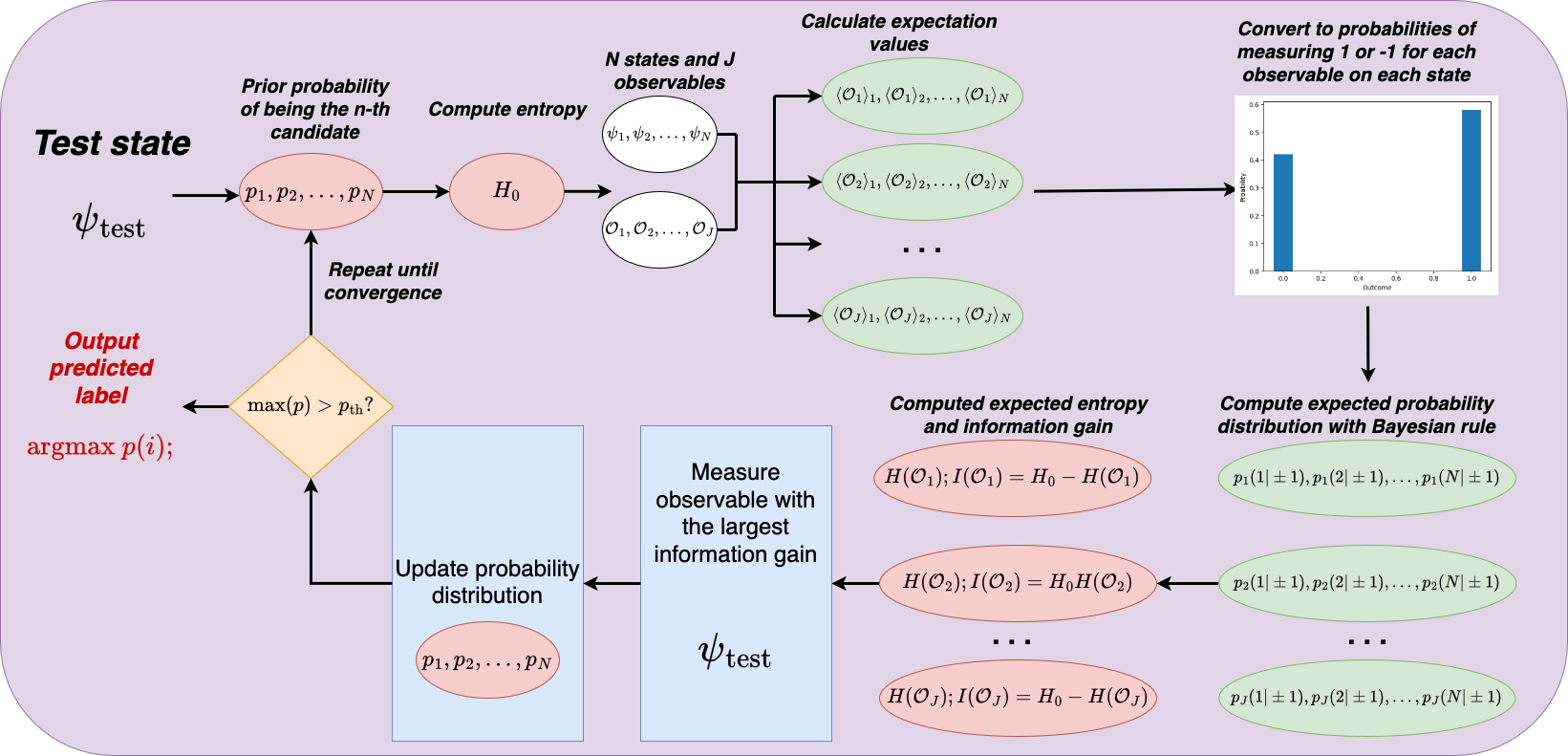
Suppose we have decided to use observable to label the test state, we want to know how much information is obtained when a single shot of measurement is taken. We define the probability of the test state being one of the candidates prior to the measurement to be , where is the index looping through the candidate states.
After a single shot of measurement, the outcome is either or . Since each candidate state has a different expectation value , their probability of yielding as the outcome of measuring is different. Using the Bayesian rule, we update the probability of the test state being the i-th candidate state given the outcome:
| (1) |
The exact derivation of the Bayesian probability update is given in Appendix A.
Now that the probability update is determined, we can proceed to calculate the expected information entropy difference. The information entropy is given by . The expected information gain of measuring one shot of observable is defined as the difference between the prior information entropy, , and the expected information entropy after the measurement, :
| (2) |
where with .
The information-optimized strategy is then given by the following:
-
1.
Start with a probability distribution
-
2.
Compute the expected information gain, , for all available observables, .
-
3.
Pick the observable with the largest information gain and take one shot of measurement.
-
4.
Update the probability distribution using the Bayesian rule and repeat the procedures from step 1 unless one candidate’s probability reaches the desired confidence level (CL) threshold .
A schematic diagram of the strategy is presented in Figure 1, while its algorithmic representation is given in Algorithm 1.
II.2 Quantum state searching
With the method defined in the last subsection, we proceed to demonstrate its effectiveness in a typical searching task.
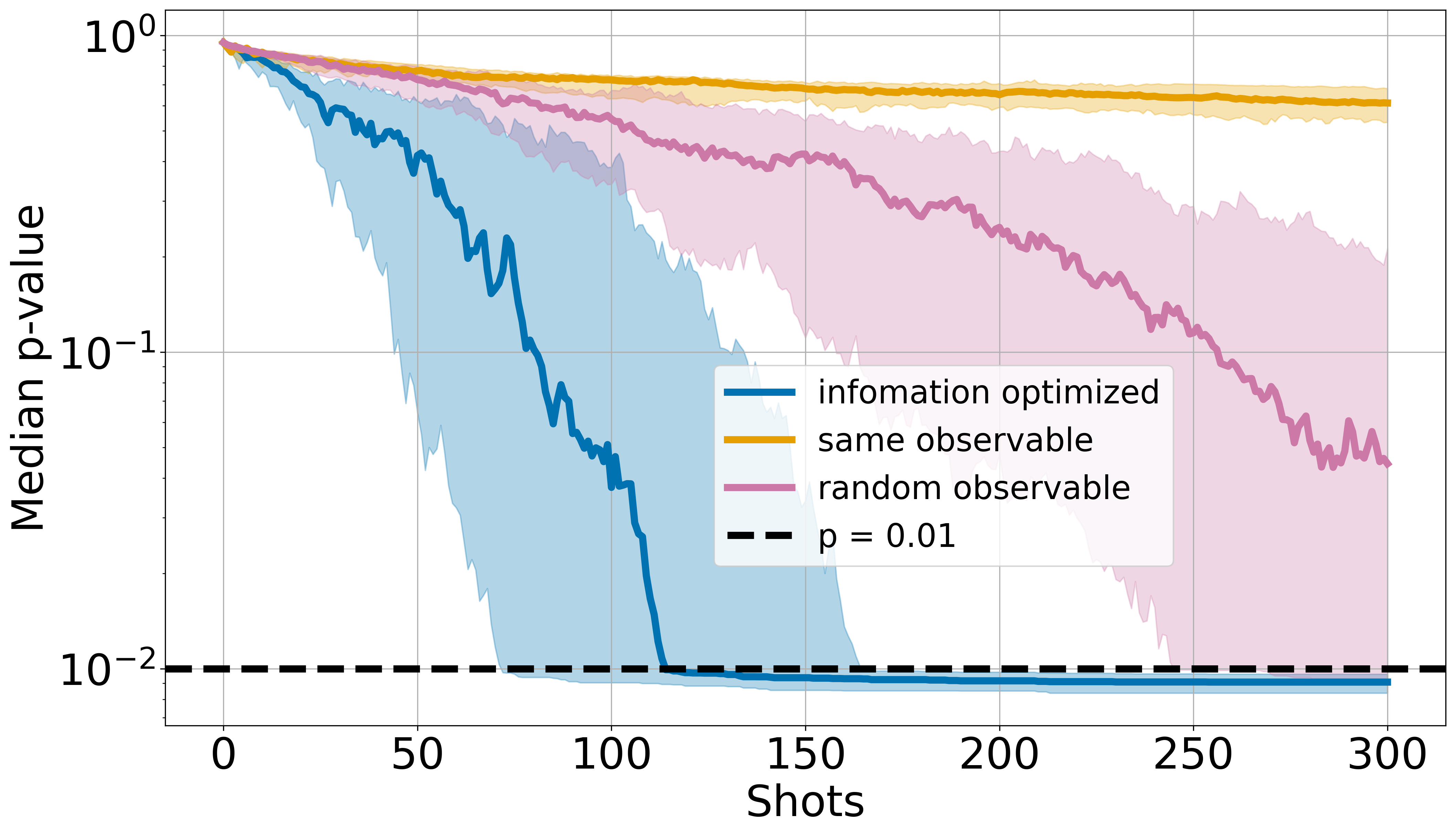
In a simulated -qubit system, we prepared random quantum states and observables for the task. To generate random quantum states, we use a sufficiently deep quantum circuit with random initialization [31, 32]. Our task is to label a randomly drawn test state at CL within shots of measurements. Equivalently, the algorithm stops if the probability of a given candidate state exceeds , which indicates a p-value of . We compare the performances of three methods:
-
1.
Measuring the same observable for as many times as needed. The observable is chosen to be the one that gives the highest information gain in the first iteration.
-
2.
Randomly pick an observable for each shot of measurement.
-
3.
Information-optimized measurement: picking the observable with the highest expected information gain given the current probability distribution.
The experiment runs for test cases, the result of which is shown in Figure 2. The median p-value is plotted against the number of shots taken, while the error bands correspond to and quantiles, respectively. The results show that the information-optimized algorithm converges to CL much faster than the other two alternatives. On average, our quantum decision tree with the information optimization typically converges within shots of measurements.
III Expected information gain in large systems
In this section, we will investigate the scaling of the expected information gain per shot with respect to the number of qubits. The task is to classify the test state among Haar random state candidates [33], silimar to what was shown in Section II. We will derive the approximated information gain that depends on the system size and observe that the expected information gain is proportional to the sample variance of the expectation value of the chosen observable. For Haar random states, this eventually results in the exponential suppression of the expected information gain per shot.
III.1 Approximations of expected information gain
In this section, we will investigate the information gain in the measurement of an arbitrary observable . Before any measurement, the prior probability distribution is uniform across the whole set of candidate states, i.e., . The entropy is therefore:
| (3) |
Given an observable , we first measure its expectation values across the whole set of candidate states: . Now we proceed to measure the expected entropy after measuring one shot of :
| (4) |
where and are the variance and the mean value of across the whole set of candidate states:
| (5) |
In the derivation of Equation 4, we approximate the entropy by taking Taylor expansion to the second order. The full derivation is given in Appendix B. The expected information gain per shot is then given by:
| (6) |
The expected information gain shown in Equation 6 is strictly positive for . This is expected since we started with the uniform probability distribution that yields maximum entropy. In other words, all measurements will yield non-negative information gain since the resulting entropy cannot be higher than the initial one.
| (7) |
| (8) |
where is the number of qubits in the system.
Both and are exponentially suppressed over the Haar random states. Plugging these into Equation 6, we naturally conclude that the expected information gain per shot is decreasing exponentially with respect to the number of qubits.
In the case that we use Pauli operators, which are by definition traceless, becomes zero. And then the information gain per shot is therefore proportional to the variance:
| (9) |
When computing the expectation value of the information gain in the sample, , we note the definition of the variance in Equation 5 is biased. This biased definition of variance is used in the whole derivation, introducing a non-negligible sampling bias when is small. Instead, the unbiased sample variance, , should be used, which is defined as:
| (10) |
where is the sample mean of the observable’s expectation value.
The unbiased sample variance definition satisfies , where is the variance of over the entire Haar-random states. Therefore, we see that an extra factor is introduced in the expectation value :
| (11) |
As a result, we derive the sample information gain with a dependence on :
| (12) |
From the above derivation, we observe that the information obtained from measuring an observable is roughly proportional to the variance of its expectation value across the set of candidate states. Intuitively, higher variance means the observable yields more distinct values for different candidate states, leading to more information obtained per shot.
III.2 Numerical studies
To experimentally verify the theoretical conclusions from the last subsection, we numerically simulate the quantum states using circuits constructed by Qiskit [35]. We used deep circuits and random initializations to produce quasi-Haar-random states for our analysis.
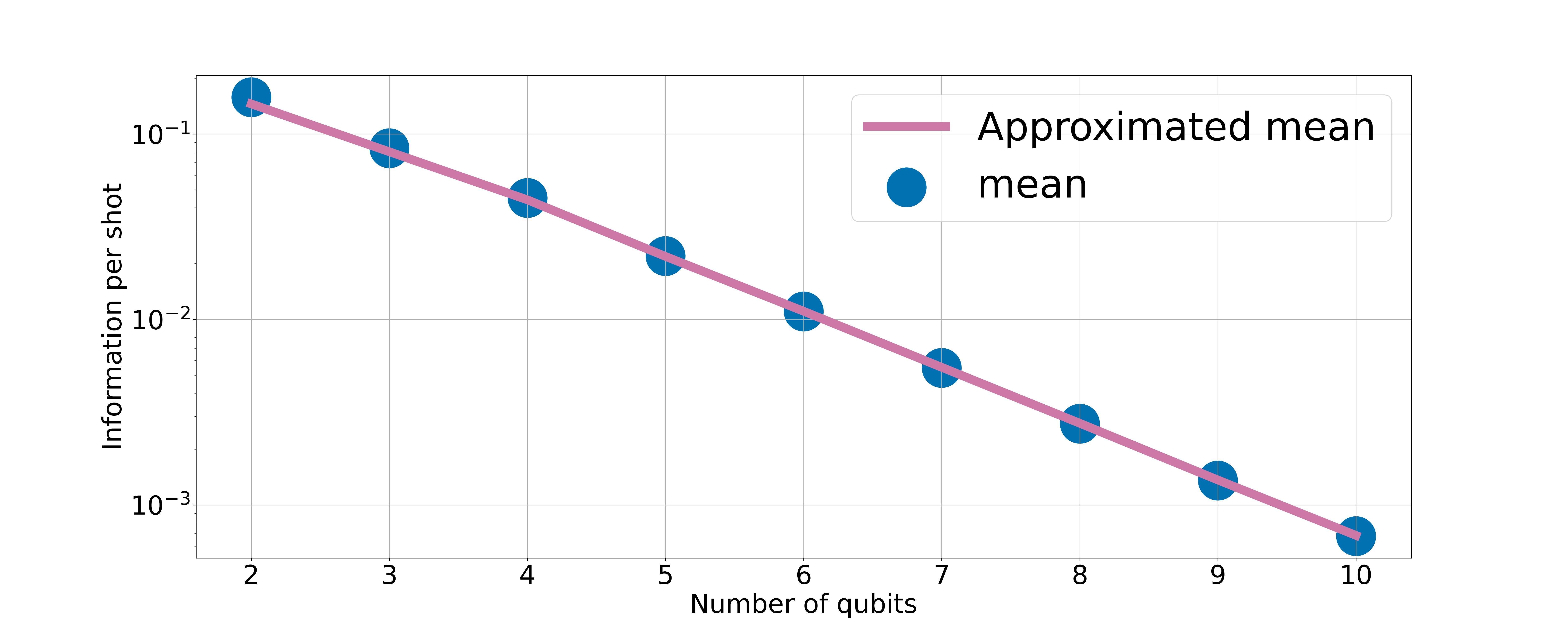
First, we attempt to verify Equation 12 by computing information per shot with varying the number of qubits. For each qubit number, we generate Haar-random states to be distinguished via measuring a set of randomly generated observables. As before, we start with the uniform prior probability over the states and calculate information per shot exactly using Equation 2. In the end, we average the information per shot over all observables to get the mean information per shot for a particular qubit number. Alternatively, we also compute the approximated information per shot according to Equation 12 by evaluating the variance of the expectation values of the observables across the set of Haar-random states, , which is subsequently plugged into Equation 12. The calculations were made for numbers of qubits between and with the results shown in Figure 3(a). We see that Equation 12 reliably approximates the exponentially diminishing information per shot over the entire qubit number range.
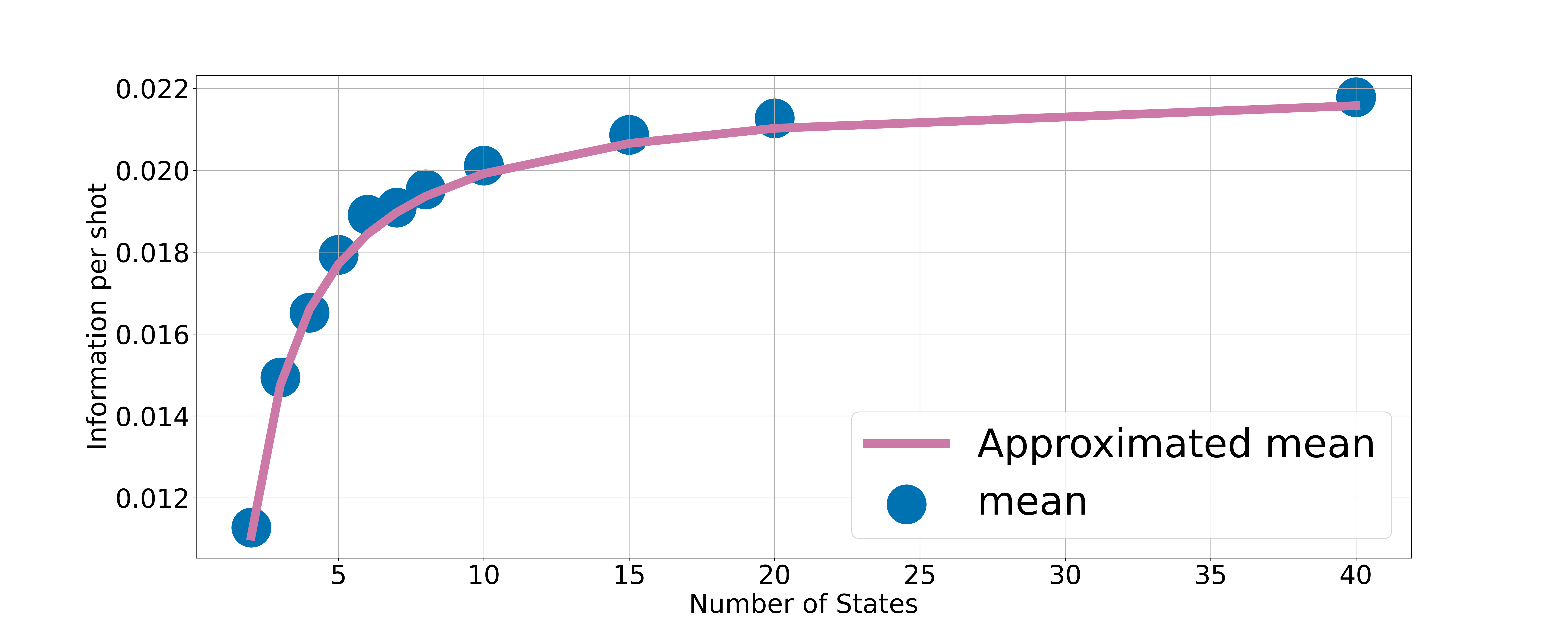
We then proceed to verify the bias factor in Equation 12 by fixing the number of qubits at 5 and computing the mean information over observables on candidate state sets of various sizes. The results of the mean information per shot in sets with the number of states between and are shown in Figure 3(b). The approximated mean uses Equation 12 with the variance over the entire set of Haar-random states. We see that Equation 12 accurately captures the sampling bias in the mean information per shot in small sets.
IV Ground state classifications
In this section, we will adapt our quantum decision tree to handle classification tasks. First, we see that the method in Section II.1 updates the probabilities of the test state being each of the candidates. Assuming that the candidate states are representative of their respective classes, the probability of the test state belonging to a particular class can be determined by summing the probabilities of the test state corresponding to any of the training states within that class. Given distinct classes, each containing training states, the probability of the test state being classified as class c is computed as:
| (13) |
Since our ultimate task is to determine the label of class, we compute the entropy using the class probability distribution and seek to maximize the information gain in the entropy of classes. The entropy with respect to the classes is given by:
| (14) |
It is easy to see that once the entropy gets properly defined, we can proceed to use the methodology in Section II.1 to find the best observable that yields the maximum information gain. As a numerical test, we compute the ground states of four classes of Hamiltonians, each with sets of parameters. We picked states in each class to be the “training set”, where the likelihood is evaluated, and the remaining states in each class to be the test states, which are labeled using our algorithm. For this task, we use four physically-motivated Hamiltonians: the Heisenberg model [36, 37], spin- chain with symmetry-protected topological (SPT) phase [7, 38, 21, 39], the transverse-field Ising model [40], and a synthetically produced Hamiltonian which we call the XYZ Hamiltonian. The Hamiltonians and their parameter ranges are listed below:
-
1.
Heisenberg:
-
•
, where denotes the Pauli X, Y, Z.
-
•
Range of parameters: between and in intervals of .
-
•
-
2.
SPT:
-
•
-
•
Range of parameters: between and in intervals of , between and in intervals of
-
•
-
3.
Transverse-field Ising:
-
•
-
•
Range of parameters: between and in intervals of .
-
•
-
4.
XYZ:
-
•
, where alternates between the three Pauli operators in the order of .
-
•
Range of parameters: between and in intervals of .
-
•
For each of the Hamiltonians listed above, we compute the ground state using variational quantum eigensolver on a simulator with qubits. In this task, since we are dealing with the ground states, it is physically motivated to use observables found in the Hamiltonians. In Section III, we showed that as the system size grows, most observables deliver exponentially diminishing information. By contrast, using Hamiltonian observables exploits the fact that the ground state is more likely to take extreme values in them. Overall, there are distinct observables that appeared in all four Hamiltonians on a qubits system. In comparison, we also execute our algorithm with a set of randomly generated observables by drawing uniformly from all possible combinations of Pauli operators. After the ground states are obtained, we then compute the expectation values of specifically chosen observables used in our algorithms. In this numerical test, we compute the expectation values on both the simulator and the IBM Kawasaki quantum computer. Since it is much less efficient to obtain single-shot measurements on IBM Kawasaki, we measure the estimated mean value and its error on the IBM machine and then use these to simulate the single-shot results offline. To mitigate the noise on IBM Kawasaki, we implement randomized Pauli twirling [41] and zero noise extrapolation [42, 43] using the IBM qiskit package.
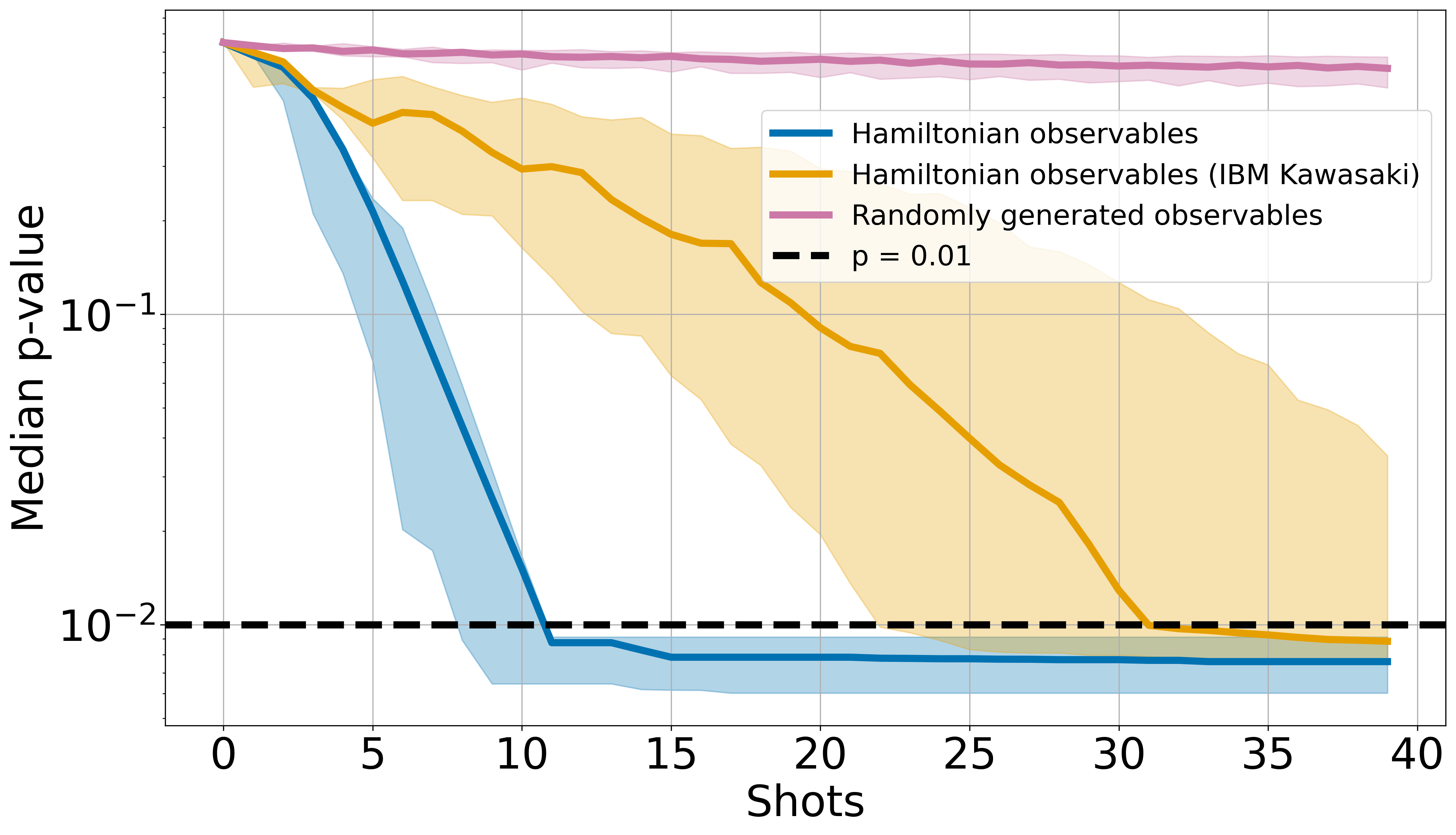
The results of the numerical experiment are shown in Figure 4, where the quantum decision tree classifier yields a faster convergence when it uses the Hamiltonian observables. Since the IBM Kawasaki quantum computer introduces hardware noises, its performance significantly deteriorates. These results confirm our intuition: the observables in the Hamiltonian are information-dense since the ground states are by definition states that yield extreme values in the full Hamiltonian. To the eyes of the other observables not appearing in the Hamiltonian, the ground states are no different from any other Haar-random states, in which the information per shot is greatly suppressed. Therefore, this leads to a significantly poor performance in classifying the ground states when the random observables are used.
V Discussion and conclusions
In this paper, we introduced an algorithm to label unknown quantum states using information gain. Our algorithm chooses the optimal observable, which yields the highest expected information gain, to measure and subsequently updates the likelihoods of each candidate state using conditional probabilities based on their expectation values of the chosen observable and the outcome of the measurement. Our information-optimized algorithm is effective and efficient as shown in Figure 2 and Figure 4. However, further investigations reveal that the expected information gain of a particular observable is proportional to the variance of the candidate states’ expectation values. This introduces an exponential suppression of information gain as the system size increases since the expectation values of observables over general Haar-random quantum states are diminishing exponentially. These results are in good agreement with numerical simulation shown in Figure 3. By computing the inter-class entropy, we are able to adapt the algorithm to perform classifications. As shown in Figure 4, we observe that our algorithm yields good performance on both the simulator and the IBM Kawasaki quantum computer when applied to ground state classification tasks.
One of the main advantages of our method is its robustness. Unlike QNNs [5, 6, 7] that require a quantum circuit to prepare the states and a parameterized quantum circuit to optimize them, our method needs only the former for the classification. As a result, it is less affected by the noisy quantum gates and entanglement operations in NISQ machines. However, the noise in quantum hardware is certainly a non-negligible factor when applying this method. When determining the expectation values of the observables in each candidate state, the real quantum machines could only estimate the values up to the hardware resolutions. As shown in Figure 4, the hardware noise has a non-negligible negative impact on the algorithm performance. In the limit of large system size, the increasing hardware noise in NISQ machines will smear out the information content in the expectation values. An interesting future direction of study will be the development of a good noise model on the information gain such that the responses from real quantum machines can be studied quantitatively.
Aside from the study shown in this paper, it is also crucial to understand how our method could be extended to physically-motivated problems. If the quantum states to be classified are known to have certain properties, one might be able to use this information to cherry-pick the information-dense observables. A clear example is the classification problem in Section IV, where the classes of states are relatively concentrated in subspaces represented by the problem Hamiltonian. As a result, the Hamiltonian observables are shown to give much higher information gain compared to randomly chosen observable sets. This exploits the fact that ground states are by definition states that take extreme values in the operators of their Hamiltonians and thus deviate from the exponentially diminishing expectation values of Haar-random states. We believe that such exploitation could offer a significant increase in the information gain and eventually allow us to deal with large-scale quantum state classifications in a problem-specific fashion.
Acknowledgements.
We would like to thank Dr. Lento Nagano for the discussions and his valuable opinions. This work is supported by the Center of Innovations for Sustainable Quantum AI (Japan Science and Technology Agency Grant Number JPMJPF2221). We acknowledge the usage of IBM quantum computers for this work.Appendix A Bayesian probability update
The expectation value of for a state could be expressed using its probability of obtaining , , as the outcome of measuring :
| (15) |
Therefore, the probability of measuring in this state, , is:
| (16) |
Using the Bayesian rule, the probability of the test state being the i-th candidate state after measuring as the outcome of is given by:
| (17) |
Appendix B Approximating expected information gain per shot
In this Appendix, we will denote and as and in short. In the set of candidate states, these values are defined as:
| (18) |
Since we have taken these candidates to be distributed according to the Haar random distribution, these values will approach the ones derived in Equation 7 and Equation 8 as increases.
First, we examine the approximation of the logarithm term in the expected information gain. When is small, we perform the Taylor expansion:
| (19) |
The prior probability of measuring as the outcome of is given by:
| (20) |
The entropy after measuring as the outcome is:
| (21) |
Similarly, we can work out the entropy after measuring as the outcome:
| (22) |
The overall expected entropy is calculated by summing these two terms with their respective probabilities:
| (23) |
Therefore, the expected information gain after measuring is:
| (24) |
If observable is traceless, we use Equation 7 to conclude that and finally obtain:
| (25) |
References
- Schuld et al. [2014] M. Schuld, I. Sinayskiy, and F. Petruccione, An introduction to quantum machine learning, Contemporary Physics 56, 172–185 (2014), ISSN: 1366-5812, DOI: 10.1080/00107514.2014.964942.
- Biamonte et al. [2017] J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Nature 549, 195–202 (2017), ISSN: 1476-4687, DOI: 10.1038/nature23474.
- Mangini et al. [2021] S. Mangini, F. Tacchino, D. Gerace, D. Bajoni, and C. Macchiavello, Quantum computing models for artificial neural networks, Europhysics Letters 134, 10002 (2021), ISSN:1286-4854 ,DOI:10.1209/0295-5075/134/10002 .
- Cerezo et al. [2022] M. Cerezo, G. Verdon, H.-Y. Huang, L. Cincio, and P. Coles, Challenges and opportunities in quantum machine learning, Nature Computational Science 2 (2022), ISSN: 2662-8547 ,DOI: 10.1038/s43588-022-00311-3 .
- Mitarai et al. [2018] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quantum circuit learning, Physical Review A 98, 10.1103/physreva.98.032309 (2018), ISSN: 2469-9934 , DOI: 10.1103/physreva.98.032309 .
- Schuld et al. [2020] M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Circuit-centric quantum classifiers, Phys. Rev. A 101, 032308 (2020), ISSN: 2469-9926 , DOI: 10.1103/PhysRevA.101.032308 .
- Cong et al. [2019] I. Cong, S. Choi, and M. D. Lukin, Quantum convolutional neural networks, Nature Physics 15, 1273–1278 (2019), ISSN: 1745-2481 , DOI: 10.1038/s41567-019-0648-8 .
- Wu et al. [2021] S. L. Wu, J. Chan, W. Guan, S. Sun, A. Wang, C. Zhou, M. Livny, F. Carminati, A. Di Meglio, A. C. Y. Li, J. Lykken, P. Spentzouris, S. Y.-C. Chen, S. Yoo, and T.-C. Wei, Application of quantum machine learning using the quantum variational classifier method to high energy physics analysis at the LHC on IBM quantum computer simulator and hardware with 10 qubits, Journal of Physics G: Nuclear and Particle Physics 48, 125003 (2021), ISSN: 1361-6471 , DOI: 10.1088/1361-6471/ac1391 .
- Blance and Spannowsky [2021] A. Blance and M. Spannowsky, Quantum machine learning for particle physics using a variational quantum classifier, Journal of High Energy Physics 2021, 10.1007/jhep02(2021)212 (2021), ISSN: 1029-8479 , DOI: 10.1007/jhep02(2021)212 .
- Guan et al. [2021] W. Guan, G. Perdue, A. Pesah, M. Schuld, K. Terashi, S. Vallecorsa, and J.-R. Vlimant, Quantum machine learning in high energy physics, Machine Learning: Science and Technology 2, 011003 (2021), ISSN: 2632-2153, DOI: 10.1088/2632-2153/abc17d .
- Cerezo et al. [2021a] M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Variational quantum algorithms, Nature Reviews Physics 3, 625–644 (2021a).
- McClean et al. [2018] J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Barren plateaus in quantum neural network training landscapes, Nature Communications 9, 10.1038/s41467-018-07090-4 (2018).
- Cerezo et al. [2021b] M. Cerezo, A. Sone, T. Volkoff, L. Cincio, and P. J. Coles, Cost function dependent barren plateaus in shallow parametrized quantum circuits, Nature Communications 12, 10.1038/s41467-021-21728-w (2021b).
- Holmes et al. [2022] Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, Connecting ansatz expressibility to gradient magnitudes and barren plateaus, PRX Quantum 3, 10.1103/prxquantum.3.010313 (2022).
- Arrasmith et al. [2022] A. Arrasmith, Z. Holmes, M. Cerezo, and P. J. Coles, Equivalence of quantum barren plateaus to cost concentration and narrow gorges, Quantum Science and Technology 7, 045015 (2022).
- Larocca et al. [2024] M. Larocca, S. Thanasilp, S. Wang, K. Sharma, J. Biamonte, P. J. Coles, L. Cincio, J. R. McClean, Z. Holmes, and M. Cerezo, A review of barren plateaus in variational quantum computing (2024), arXiv:2405.00781 [quant-ph] .
- Ortiz Marrero et al. [2021] C. Ortiz Marrero, M. Kieferová, and N. Wiebe, Entanglement-induced barren plateaus, PRX Quantum 2, 040316 (2021).
- Pesah et al. [2021] A. Pesah, M. Cerezo, S. Wang, T. Volkoff, A. T. Sornborger, and P. J. Coles, Absence of barren plateaus in quantum convolutional neural networks, Physical Review X 11, 10.1103/physrevx.11.041011 (2021).
- Li et al. [2024] Z. Li, L. Nagano, and K. Terashi, Enforcing exact permutation and rotational symmetries in the application of quantum neural networks on point cloud datasets, Phys. Rev. Res. 6, 043028 (2024).
- Cerezo et al. [2024] M. Cerezo, M. Larocca, D. García-Martín, N. L. Diaz, P. Braccia, E. Fontana, M. S. Rudolph, P. Bermejo, A. Ijaz, S. Thanasilp, E. R. Anschuetz, and Z. Holmes, Does provable absence of barren plateaus imply classical simulability? or, why we need to rethink variational quantum computing (2024), arXiv:2312.09121 [quant-ph] .
- Bermejo et al. [2024] P. Bermejo, P. Braccia, M. S. Rudolph, Z. Holmes, L. Cincio, and M. Cerezo, Quantum convolutional neural networks are (effectively) classically simulable (2024), arXiv:2408.12739 [quant-ph] .
- Quinlan [1986] J. R. Quinlan, Induction of decision trees, Machine Learning 1, 81 (1986).
- Quinlan [1992] J. R. Quinlan, C4.5: Programs for machine learning (1992).
- Breiman et al. [1984] L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone, Classification and regression trees, Biometrics 40, 874 (1984).
- Breiman [2001] L. Breiman, Random forests, Machine Learning 45, 5 (2001).
- Shannon [1948] C. E. Shannon, A mathematical theory of communication, The Bell System Technical Journal 27, 379 (1948).
- Grover [1996] L. K. Grover, A fast quantum mechanical algorithm for database search, in Symposium on the Theory of Computing (1996).
- Nielsen and Chuang [2010] M. A. Nielsen and I. L. Chuang, Quantum Computation and Quantum Information: 10th Anniversary Edition (Cambridge University Press, 2010).
- Boyer et al. [2005] M. Boyer, G. Brassard, P. Hoyer, and A. Tappa, Tight bounds on quantum searching (2005) pp. 187 – 199.
- Preskill [2018] J. Preskill, Quantum Computing in the NISQ era and beyond, Quantum 2, 79 (2018).
- Sim et al. [2019] S. Sim, P. D. Johnson, and A. Aspuru-Guzik, Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum‐classical algorithms, Advanced Quantum Technologies 2 (2019).
- Nakaji and Yamamoto [2021] K. Nakaji and N. Yamamoto, Expressibility of the alternating layered ansatz for quantum computation, Quantum 5, 434 (2021).
- Mele [2024] A. A. Mele, Introduction to haar measure tools in quantum information: A beginner’s tutorial, Quantum 8, 1340 (2024).
- Ipsen [2015] J. R. Ipsen, Products of independent gaussian random matrices (2015), arXiv:1510.06128 [math-ph] .
- [35] Qiskit contributors, Qiskit: An open-source framework for quantum computing, zenodo.org/records/8190968 10.5281/zenodo.2573505.
- Kattemölle and van Wezel [2022] J. Kattemölle and J. van Wezel, Variational quantum eigensolver for the heisenberg antiferromagnet on the kagome lattice, Phys. Rev. B 106, 214429 (2022).
- Oliveira et al. [2024] M. Oliveira, T. Antão, and N. Peres, The two-site heisenberg model studied using a quantum computer: A didactic introduction, Revista Brasileira de Ensino de Física 46 (2024).
- de Groot et al. [2022] C. de Groot, A. Turzillo, and N. Schuch, Symmetry Protected Topological Order in Open Quantum Systems, Quantum 6, 856 (2022).
- Smith et al. [2022] A. Smith, B. Jobst, A. G. Green, and F. Pollmann, Crossing a topological phase transition with a quantum computer, Phys. Rev. Res. 4, L022020 (2022).
- Kim et al. [2023] Y. Kim, A. Eddins, S. Anand, K. Wei, E. Berg, S. Rosenblatt, H. Nayfeh, Y. Wu, M. Zaletel, K. Temme, and A. Kandala, Evidence for the utility of quantum computing before fault tolerance, Nature 618, 500 (2023).
- Endo et al. [2018] S. Endo, S. C. Benjamin, and Y. Li, Practical quantum error mitigation for near-future applications, Phys. Rev. X 8, 031027 (2018).
- Temme et al. [2017] K. Temme, S. Bravyi, and J. M. Gambetta, Error mitigation for short-depth quantum circuits, Phys. Rev. Lett. 119, 180509 (2017).
- Li and Benjamin [2017] Y. Li and S. C. Benjamin, Efficient variational quantum simulator incorporating active error minimization, Phys. Rev. X 7, 021050 (2017).
- Benedetti et al. [2019] M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Parameterized quantum circuits as machine learning models, Quantum Science and Technology 4, 043001 (2019), ISSN: 2058-9565 , DOI: 10.1088/2058-9565/ab4eb5 .
- Terashi et al. [2021] K. Terashi, M. Kaneda, T. Kishimoto, M. Saito, R. Sawada, and J. Tanaka, Event classification with quantum machine learning in high-energy physics, Computing and Software for Big Science 5, 10.1007/s41781-020-00047-7 (2021), ISSN: 2510-2044 , DOI: 10.1007/s41781-020-00047-7 .
- Brassard et al. [2000] G. Brassard, P. Hoyer, M. Mosca, and A. Tapp, Quantum amplitude amplification and estimation, AMS Contemporary Mathematics Series 305 (2000).