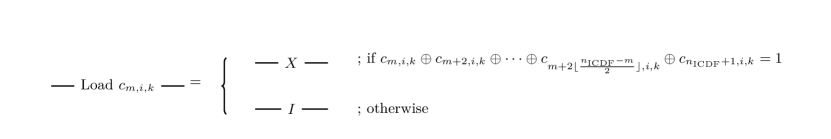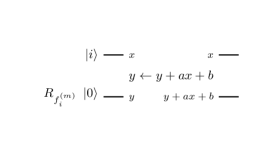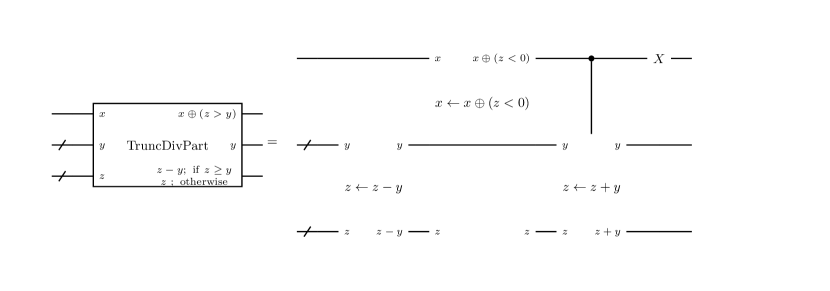Quantum Pricing with a Smile: Implementation of Local Volatility Model on Quantum Computer
Abstract
Applications of the quantum algorithm for Monte Carlo simulation to pricing of financial derivatives have been discussed in previous papers. However, up to now, the pricing model discussed in such papers is Black-Scholes model, which is important but simple. Therefore, it is motivating to consider how to implement more complex models used in practice in financial institutions. In this paper, we then consider the local volatility (LV) model, in which the volatility of the underlying asset price depends on the price and time. We present two types of implementation. One is the register-per-RN way, which is adopted in most of previous papers. In this way, each of random numbers (RNs) required to generate a path of the asset price is generated on a separated register, so the required qubit number increases in proportion to the number of RNs. The other is the PRN-on-a-register way, which is proposed in the author’s previous work. In this way, a sequence of pseudo-random numbers (PRNs) generated on a register is used to generate paths of the asset price, so the required qubit number is reduced with a trade-off against circuit depth. We present circuit diagrams for these two implementations in detail and estimate required resources: qubit number and T-count.
pacs:
Valid PACS appear hereI Introduction
With recent advances of quantum computing technologies, researchers are beginning considering how to utilize them in industries. One major target is finance (see Orus for a review). Since financial institutions are performing enormous tasks of numerical calculation in their daily works, speed-up of such tasks by quantum computer can bring significant benefits to them. One of such tasks is pricing of financial derivatives111As textbooks of financial derivatives and pricing of them, we refer to Hull ; Shreve1 ; Shreve2 . Financial derivatives, or simply derivatives, are contracts in which payoffs are determined in reference to the prices of underlying assets at some fixed times. Large banks typically have a huge number of derivatives written on various types of assets such as stock price, foreign exchange rate, interest rate, commodity and so on. Therefore, pricing of derivatives is an important issue for them.
In derivative pricing, we represent random movements of underlying asset prices using stochastic processes and calculate a derivative price as a expected value of the sum of payoffs discounted by the risk-free interest rate under some specific probability measure. In order to calculate the expected value, Monte Carlo simulation is often used. There are quantum algorithms for Monte Carlo simulationMontanaro ; Suzuki , which bring quadratic speed-up compared with that on classical computers and there already exists some works which discuss application of such quantum algorithms to derivative pricingRebentrost ; Stamatopoulos ; RamosCalderer . However, in order to bring benefits to practice in finance, previous works have some room to be extended. That is, previous works consider the Black-Scholes (BS) modelBlackScholes ; Merton . Although the BS model is the pioneering model for derivative pricing and still used in many situations in today’s financial firms, it is insufficient to consider only the BS model as an application target of Monte Carlo for practical business for some reasons. First, for various types of derivatives, market prices of derivatives are inconsistent with the BS model. This phenomenon is called volatility smile, which we will explain in Section II. In order to precisely price derivatives taking into account volatility smiles, financial firms often use models which have more degree of freedom than the BS models. Second, the BS model is so simple that analytic formulae are available for the price of some types of derivatives in the model. In such cases, Monte Carlo simulation is not necessary. Actually, banks use Monte Carlo simulation mainly for complex models which can take into account volatility smiles. Although it is the natural first step to consider Monte Carlo in the BS model, the above points motivate us to consider how to apply quantum algorithms for Monte Carlo to the advanced models.
In this paper, we will focus on one of the advanced models, that is, the local volatility (LV) modelDupire . The LV model, which we will describe later, is the model in which a volatility of an asset price depends on the price itself and time, so the BS model is included in this category as a special case. With degrees of freedom to adjust the function form of volatility, the LV model can make derivative prices consistent with volatility smiles. So this model is widely used to price derivatives, especially exotic derivatives, which have complex transaction terms such as early redemption, in many banks.
In order to price a derivative by Monte Carlo simulation, we generate paths, that is, random trajectories of time evolution of asset prices, then calculate the expectation value of the sum of discounted payoffs which arise in each path. Since we cannot generate continuous paths on computers, we usually consider evolutions on a discretized time grid, using a random number (RN) for each time step, which represents the stochastic evolution in the step. In this paper, we focus on how to implement such a time evolution in the LV model on quantum computers.
We can consider two ways to implement the time evolution. In this paper, we call them the register-per-RN way and the PRN-on-a-register way. The difference between them is how to generate RNs required to generate a path. The register-per-RN is adopted in previous papersRebentrost ; Stamatopoulos ; RamosCalderer . In this way, following the procedure described in, e.g., Grover , one creates a superposition of bit strings which correspond to binary representations of possible values of a RN, where the probability amplitude of a each bit string is the square root of the possibility that the RN take the corresponding value. The point is that one register is used for one RN, so the required qubit number is proportional to the number of RNs used to generate a path. This can be problematic in terms of qubit number when many RNs are required. The number of RNs is equal to that of time steps times and that of underlying assets222In this paper, we consider arbitrage-free and complete markets, standard assumptions for derivative pricing, so the number of stochastic factors is equal to that of assets. For details, see Shreve1 ; Shreve2 .. The number of time steps can be large for derivatives with long maturity. Maturity can be as long as 30 years, so if we take time grid points monthly, the total number of time steps is 360. The number of underlying assets can be multiple, and furthermore, there are situations where we must simultaneously consider assets concerning different derivative contracts in a portfolio, for example, XVA333XVA is the term which collectively represents various types of Value Adjustment on derivative prices, for example, credit value adjustment (CVA), price subtraction taking into account the default of the counterparty. In this paper, we ignore such technical issues. If you are interested, see Gregory .. Assuming that the number of asset is and that of time steps is , the total number of RNs becomes . If we use a register with qubits for each RN, the total qubit number can be easily. The current state-of-art quantum computers have only qubitsArute . Even if we obtain large-scale fault-tolerant machines in the future, the large qubit overhead might be required to make a logical bit (see Campbell as a review and references therein). Therefore, calculations which require the large number of qubits as above might be prohibitive even in the future. This situation is similar to credit portfolio risk measurement, which is described in Miyamoto .
We are then motivated to consider the PRN-on-a-register way, which is proposed in Miyamoto . In this way, one does not create RNs on different register, but generates a sequence of pseudo-random number (PRN) on a register. At each time step, the PRN sequence is progressed and its value is used to evolve the asset price. Therefore, the required qubit number does not depend on the number of RNs and is largely reduced. The drawback is the circuit depth. Here, we define the circuit depth as the number of layers consisting of gates on distinct qubits that can be performed simultaneously, as T-depth used in Amy2 ; Selinger . Since calculations to update the PRN is sequentially performed on a register, the circuit depth is now proportional to the number of RNs. Since in the fault-tolerant computation some kinds of gates, for example T-gates in the Clifford+T gate set, can take long time to be runBravyi ; Fowler , the sequential run of such gates might be also prohibitive in terms of calculation timeEgger . At any rate, in the current stage, where it is difficult to foresee the spec of future quantum computers, we believe that it is meaningful to consider the implementation which saves qubits but consumes depth as a limit.
When it comes to the LV model, the PRN-on-a-register way becomes more motivating, since its disadvantage on the circuit depth compared with the register-per-RN way is alleviated. In the LV model, the volatility varies over time steps depending on the asset price, so the calculation for the time evolution is necessarily stepwise444In the multi-asset case, parallel computing over assets is possible in the register-per-RN way.. Therefore, the PRN-on-a-register way and the register-per-RN way are equivalent with respect to this point, that is, the circuit depth is proportional to the time step number in both ways. This is different from the situation in credit portfolio risk management Egger , where, in the register-per-RN way, a register is assigned to each random number which determine whether each obligor defaults or not and parallel processing on different registers reduces circuit depth.
In this paper, we design the quantum circuits in the above two way in the level of elementary arithmetic. In doing so, we follow the policies of the two ways to the extent possible. That is, not only with respect to RNs but also in other aspects, we try to reduce qubits accepting some additional procedures in the PRN-on-a-register way, and vice versa in the register-per-RN way. For example, in the PRN-on-a-register way, we have to intermediately output the information of the volatility used to evolve the asset price at each time step and clear it by the next step. Otherwise, we need a register to hold the information per step and the required qubit number becomes proportional to the number of time steps. It is nontrivial to implement such a procedure and we will present how to do this later. Note that such clearing procedure is unnecessary in the register-per-RN way.
We then estimate the resources to implement the proposed circuits. We focus on two metrics: qubit number and T-count. As mentioned above, we see that the qubit number in the PRN-on-a-register way is independent from the time step number and much less than the register-per-RN way. The T-count is proportional to the time step number in the both ways. We see that in some specific setting the both ways yield the T-counts of same order of magnitude, except that in the PRN-on-a-register way is larger by some factor.
The rest of this paper is organized as follows. Section II and III are preliminary sections, the former and the latter briefly explain the LV model and the quantum algorithm for Monte Carlo simulation, respectively. In section IV, we present the circuit diagram in the two way. In section V, we estimate qubit number and T-count of the proposed circuits. Section VI gives a summary.
II LV model
In this paper, we consider only the single-asset case, since it is straightforward to extend the discussion in this paper to the multi-asset case.
II.1 pricing of derivatives
Consider a party A involved in a derivative contract written on some asset. We let denote a stochastic process which represents the asset price at time , which is set as at the present. We assume that the payoffs arise at the multiple times and the -th payoff is given by , where is some function which maps to . The positive payoff means that A receives a money from the counterparty and the negative one means vice versa. For example, the case where A buys an European call option with the strike corresponds to
| (1) |
with a single payment date . Note that this type of derivative contract is too simple to cover all trades in financial markets. For example, callable contracts, in which either of the parties has a right to terminate the contract at some times, are widely dealt in markets. We leave studies for such exotic derivatives for future works and, in this paper, concider only those which can be expressed in the above form.
Following the theory of arbitrage-free pricing, the price of the contract for A is given as follows Shreve1 ; Shreve2 :
| (2) |
where represents the expectation value under some probability measure, the so-called risk-neutral measure. Here and hereafter, we assume that the risk-free interest rate is 0 for simplicity.
II.2 LV model
In the LV model, the evolution of the asset price is modeled by the following stochastic differential equation (SDE)
| (3) |
in the risk-neutral measure555Note that the drift term does not exist since we are now assuming the risk-free rate is 0. is the Wiener process which drives . is the increment of a stochastic process over an infinitesimal time interval . The deterministic function is the local volatility. Note that the BS model corresponds to the case where
| (4) |
where is a positive constant, which we hereafter call a BS volatility.
The LV model was proposed to explain volatility smile. In order to describe this, let us define implied volatility first. In the BS model, a price of a European call option with strike and maturity at is given by the following formula:
| (5) |
where is the cumulative distribution function of the standard normal distribution. We can price the option if we determine the BS volatility. Conversely, given the market price of the option , we can reversely calculate the BS volatility. That is, we can define the following function of and :
We call BS volatilities drawn back from the market option prices by (LABEL:eq:IV) as implied volatilities.
If the market is described well by the BS model, implied volatilities take a same value for any and . Although this is the case for some markets, varies depending on and in many markets. Especially, if depends on , it is said that we observe the volatility smile for the market.
Volatility smiles mean that possible scenarios of asset price evolution in the BS model do not match those which market participants consider. For example, if market participants think that extreme scenarios, big crashes or sharp rises, are more possible than the BS model predicts, the volatility smile arises. In fact, it is often said that the Black Monday, the big crash in the stock markets at 1987, was one of triggers of appearance of volatility smiles.
With the LV model, we can make European option prices given by the model consistent with any market prices, as long as there is no arbitrage in the market. This is intuitively apparent since we can expect that the degree of freedom of the local volatility as a two-dimensional function is available to reproduce the two-dimensional function . In fact, if we can get as a function, that is, the market option prices for continuously infinite strikes and maturities, we can determine which reproduces as followsDupire :
| (7) |
In reality, the market option prices are available only for several strikes and maturities. Therefore, in the practical business, we usually use a specific functional form of with degrees of freedom sufficient to reproduce several available market option prices. In this paper, we use the following form. First, we set the grid points in the time axis, . Second, we set the grid points in the asset price axis for each time grid point, that is, for . Then, is set as follows:
| (8) |
for , where are constants satisfying for any and and . In other words, the two-dimensional space of is divided in the direction of and in each region is set to a function which is piecewise-linear with respect to . In this paper, we assume that are preset to the value for which the option prices in the LV model, which we here write as , match the market prices by some standard. For example, they can be set to
| (9) |
where ’s are several sets of maturity and strike for which the market option prices are available.
II.3 Monte Carlo simulation in the LV model
We here describe how to calculate the derivative price (2) in the LV model by Monte Carlo simulation.
First, we have to discretize the time into sufficiently small meshes, since we can deal with the continuous time on neither classical nor quantum computers. For simplicity, we set the time grid points to the above ’s, those for the LV function. Then, the time evolution given by (3) is approximated as follows:
| (10) |
where are independent standard normal random numbers (SNRNs). Among various ways to discretize the SDE, we here adopt the Euler-Maruyama method Maruyama .
Even after time discretization, we cannot consider all of continuously infinite patterns of SNRNs. One solution for this is discretized approximation of SNRNs. We can choose the finite numbers of the grid points and assign probability to each point so that standard normal distribution is approximately reproduced. Now, the patterns of discretized SNRNs are finite, so we can approximate (2) as
| (11) |
where is the probability that the -th pattern of values of SNRNs are realized and is the asset price at time in the -th pattern.
There are some possible ways to take petterns considered in (11). In the register-per-RN way, we take all patterns. If we take grids to discretize each of SNRNs, the number of possible patterns of SNRNs is . Although this is exponentially large, quantum computers can take into account all patterns with a polynomial number of qubits by quantum superposition.
On the other hand, this cannot be adopted on classical computers, since the number of the SNRN patterns are exponentially large. Usually, Monte Carlo pricing on classical computers is done in the following way, which the PRN-on-a-register way is also based on. We consider sampled patterns of SNRNs. That is, we generate finite but sufficiently many sample sets of and use them to generate sample paths of the asset price which evolves according to (10). We then approximate (2) by the average of sums of payoffs in sample paths,
| (12) |
where is the value of the asset price at time on the -th sample path and is the number of sample paths.
III Quantum Algorithm for Monte Carlo Simulation
III.1 outline of the algorithm
We here review the quantum algorithm for Monte Carlo simulationMontanaro ; Suzuki . It can be divided into the following steps. First, we create a superposition of possible values of a random number used to calculate a sample value of the integrand on a register. If multiple random numbers are necessary to calculate the integrand, one register is assigned per random number. As mentioned above, continuous random numbers must be approximated in some discretized way. Second, we calculate the integrand into another register, using the random numbers. Note that the results for many patterns of random numbers are simultaneously calculated in quantum parallelism. Third, by controlled rotation, the integrand value is reflected into the amplitude of the ancilla. Finally, amplitude estimation Bassard ; Suzuki ; Nakaji on the ancilla gives the expectation value of the integrand.
The quantum state is transformed as follows:
| (13) | |||||
| . |
Here, the first, second and third kets correspond to the random number registers, the integrand register and the ancilla, respectively. represents the binary representation of values of random numbers in the -th pattern and is the probability that it realizes. is the integrand and is its value for . Note that the probability to observe 1 on the ancilla is , the integral value which we want. Although we do not explain how to estimate the probability amplitude in this paper, it is studied in many papers. For example, see Bassard ; Suzuki ; Nakaji . Using such methods, we can estimate the integral with the statistical error which decays as , where is the number of oracle calls. This decay rate is quadratically faster than that in the classical algorithm, .
III.2 the scheme using the PRN generator
We here briefly review the quantum way for Monte Calro simulation using the PRN generator. The calculation flow for the current problem, the time evolution of asset price in the LV model, based on this way is described in Section IV.2.
It is proposed in Miyamoto in order to reduce the required qubits to generate RNs in the application of the quantum algorithm for Monte Carlo to extremely high-dimensional integrations. When it is neccesary to generate many RNs to compute the integrand, the naive way, in which we assign a register to each RN and create a superposition of possible values, leads to the increase of qubit numbers in proportion to the number of RNs. In order to aviod this, we can adopt the following way. First, we prepare two registers, and . Then, we create a superposition of integers, which specify the start point of the PRN sequence, on . With the start point, we sequentially generate PRNs on . This is possible because a PRN sequence is a deterministic sequence whose recursion equation is explicitely given, and in Miyamoto we gave the implementation of one of PRN generators on quantum circuits. Using the PRNs, we compute the integrand step by step, which corresponds to time evolution of the asset price and calculation of payoffs in this paper. Finally, the expectation value of the integrand is estimated by quantum amplitude estimation. In this way, since we need only and to generate PRNs, the required qubit number is now independent from the number of RNs and much smaller than the naive way. The drawback is the increase of the circuit depth.
IV Circuit Design
Now, we present quantum circuits for time evolution of an asset price in the LV model in the two ways: PRN-on-a-register and register-per-RN.
IV.1 elementary gate
Before we present circuits, we here list up elementary gates we use.
-
•
Adder:
-
•
Controlled Adder:
-
•
Multiplier:
-
•
Divider:
We here simply assume their existence. Actually, implementation of such elementary arithmetics are widely studied in previous works: see, for example, Vedral ; Beckman ; Draper ; Cuccaro ; Takahashi ; VanMeter ; Draper2 ; Takahashi2 ; Portugal ; AlvarezSanchez ; Takahashi3 ; Thapliyal ; Thapliyal2 ; Lin ; Babu ; Jayashree ; MunozCoreas ; Khosropour ; Jamal ; Dibbo ; Thapliyal3 . We will discuss the implementation in Section V.1.
With these, we can construct other types of arithmetic we use. For example, subtraction can be done as addition by the method of 2’s complement. Comparison can be done as subtraction in 2’s complement method, since the most significant bit represents whether the result of subtraction is positive or negative. So a comparator is constructed as two adder, including uncomputation.
Note that the above multiplier uses two registers as operands and outputs the product into another register. Most of previously proposed multipliers are of this output-to-other type. On the other hand, we also need the self-update type of multiplier which updates either of input registers with the product, otherwise we have to add a register for each multiplication and qubit number explodes. Such a operation is realized by the following trick. When we want to multiply by , given the two registers holding and and an ancilla register, we can do:
| (14) |
Here, the first step is output-to-other multiplication. The second step is swap between the first and third registers, which is not necessary if we change our recognition on which of two register is ancillary at every multiplication. The third step is the inverse operation of division.
IV.2 the PRN-on-a-register way
IV.2.1 calculation flow
We first present the calculation flow in the PRN-on-a-register way. We consider the flow until calculation of the sum of payoffs, which corresponds to from the first to the third line in (13), since the controlled rotation in the fourth line does not depend on the problem.
In the PRN-on-a-register way, PRNs are used for evolution of the asset price (10). More concretely, we preselect some sequence of pseudo standard normal random numbers (PSNRNs) and divide it into subsequences, then evolve the asset price using them.
Before we present the calculation flow, we explain some setups. We prepare the following register:
-
•
This is a register where a superposition of integers which determine the start point of the PSNRN sequence. We write its qubit number as . is the number of sample paths we generate.
-
•
This is a register where we sequentially generate PSNRNs.
-
•
This is a register where the value of the asset price is stored and which we update for each time step of the evolution, using .
-
•
This is a register into which the payoffs determined by are added.
Note that we need some ancillary registers in addition to the above registers. We assume that the required calculation precision is -bit accuracy and and ancillary registers necessary to update them have qubits.
We assume that the following gates are available to generate a sequence of PSNRNs.
-
•
This progresses a PSNRN sequence by one step. In other words, it acts on and updates to , where is the -th element of the sequence: .
-
•
This lets the PSNRN sequence jump to the starting point. That is, it is input an integer on a register and outputs into another register which is initially set to : . Remember that , the number of time steps, is equal to the number of RNs used to generate one sample path.
The concrete implementation of these gates are discussed later.
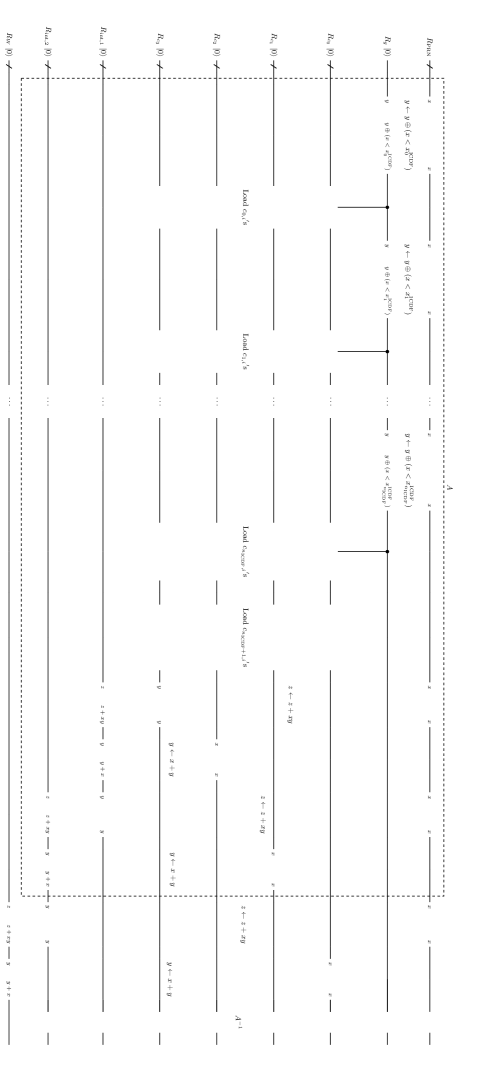
Then, the calculation flow is as follows:
-
1.
Initialize all registers to except , which is initialized to .
-
2.
Generate a equiprobable superposition of , that is, on . This is done by operating a Hadamard gate to each of qubits.
-
3.
Operate to set to , where is determined by the state of . These are the starting points of subsequences.
-
4.
Perform the time evolution (10) using the value on . is updated from to .
-
5.
Calculate the payoff at time and add into .
-
6.
Operate to update from to .
-
7.
Iterate operations similar to 4-6 for each time steps until the time reaches .
- 8.
Here and hereafter, we assume that a payoff arises at each time step, for simplicity.
The flow of state transformation is as follows:
| (15) |
where the first, second, third and fourth kets correspond to and , respectively.
IV.2.2 overview of the circuit
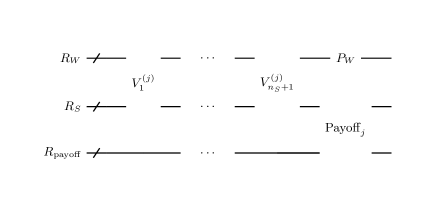
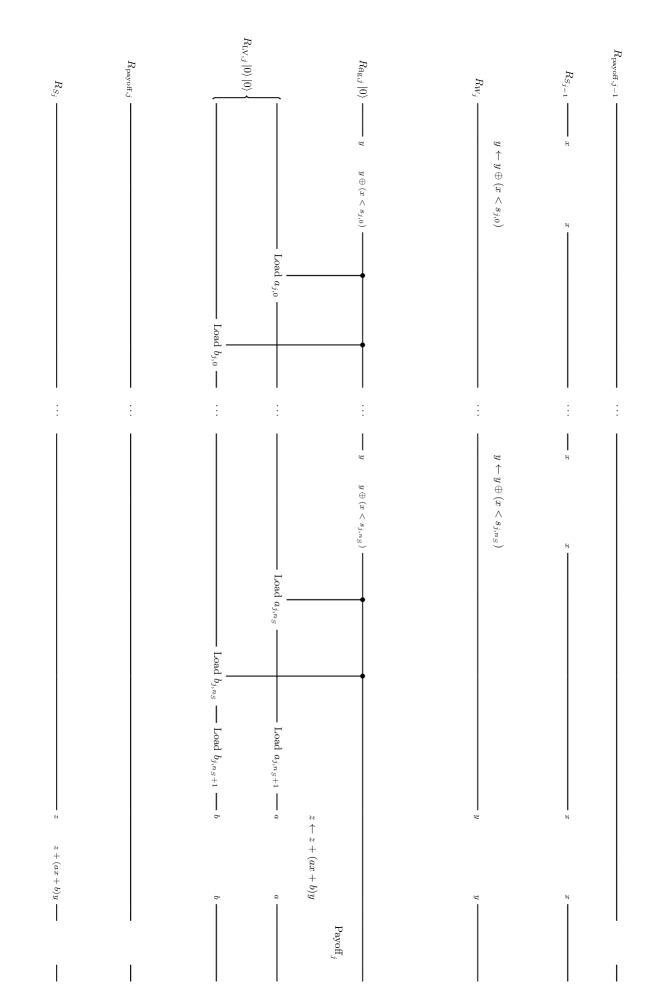
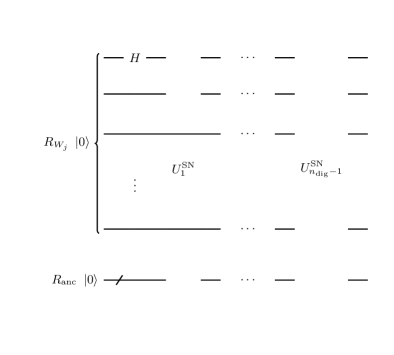
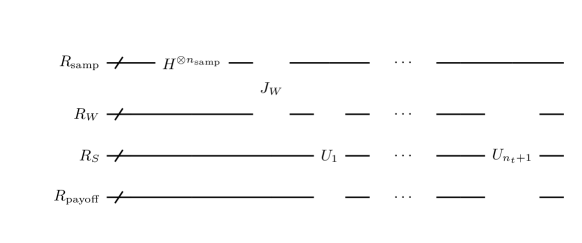
Schematically, the circuit which realizes the flow (15) is as shown in Figure 1. In the figure, the gate corresponds to the -th step of asset price evolution, that is, the -th iteration of step 4-6 in the above calculation flow.
is implemented as shown in Figure 2. is already explained and the gate calculates using and adds it into . In addition to these, has gates , which update .
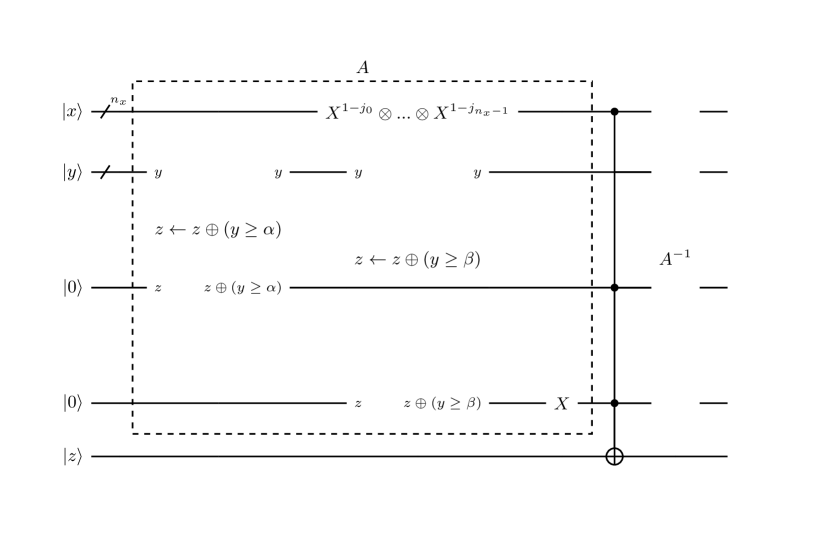
The detail of is shown in Figure 3. This gate (i) checks whether the asset price is in the -th interval , (ii) if so, update using the LV in the interval, (iii) clears the intermediate output. It requires ancillary registers and . They have and 1 qubits respectively. At the start of , takes or and the others take . Then the detailed calculation flow is:
-
1.
If is and is in , flip .
-
2.
If is 1, update as
(16) using the value on and add 1 to .
-
3.
Calculate
(17) into , using the value on as and that on as .
-
4.
If is and is in , flip . This uncomputes .
-
5.
Do the inverse operation of 3.
Let us explain the meaning of this flow. First, is necessary as an indicator of whether the -th step of evolution has been already done or not. Without this, it is possible that the asset price is doubly updated in a time step. If and only if the -th step has not been done, that is, is and the asset price is in , the update of the asset price with the LV function is done. To do this conditional update, the check result is intermediately output to and the gate corresponding (16) is operated on under control by . Besides, the increment of controlled by is also done, so that indicates completion of the -th step if so. Steps 3-5 is necessary to clear . If the asset price has been updated in Step 2, Step 3 draws back it to the value before the update. Conversely, we can determine whether the update has been done in Step 2 from the result of Step 3. That is, for the reason mentioned soon later, the condition that is and is in after Step 3 is equivalent to the condition that is and is in before Step 2. Therefore, Step 4 flip if and only if it is , so it goes back to . In summary, through the sequential operation of , is updated only once at the appropriate , is updated from to and all intermediate outputs on ancillary registers are cleared.
We here mention a restriction on the LV model so that it can be implemented in the PRN-on-a-register way. Note that through , the state is transformed from to , where the first and second kets correspond to and respectively and other registers are omitted since they are unchanged. This means that the map from to must be one-to-one correspondence, since unitarity is violated if not. Actually, this is not so strong restriction. As shown in Appendix, if we set so that is continuous with respect to and we set is small enough that the increment is much smaller than itself, the above condition is satisfied.
This one-to-one correspondence lets Step 3 work. That is, since the map between and is one-to-one correspondence, the result of Step 3 is in if and only if the value on before Step 3 is in the image of under the map.
IV.2.3 implementation of respective gates
We now consider how to implement respective gates in the PRN-on-a-register way to the level of four arithmetic operations.
(i)
Note that most parts of consist of only arithmetic operations, addition, subtraction, multiplication, division and comparison, which mentioned in Sec IV.1.
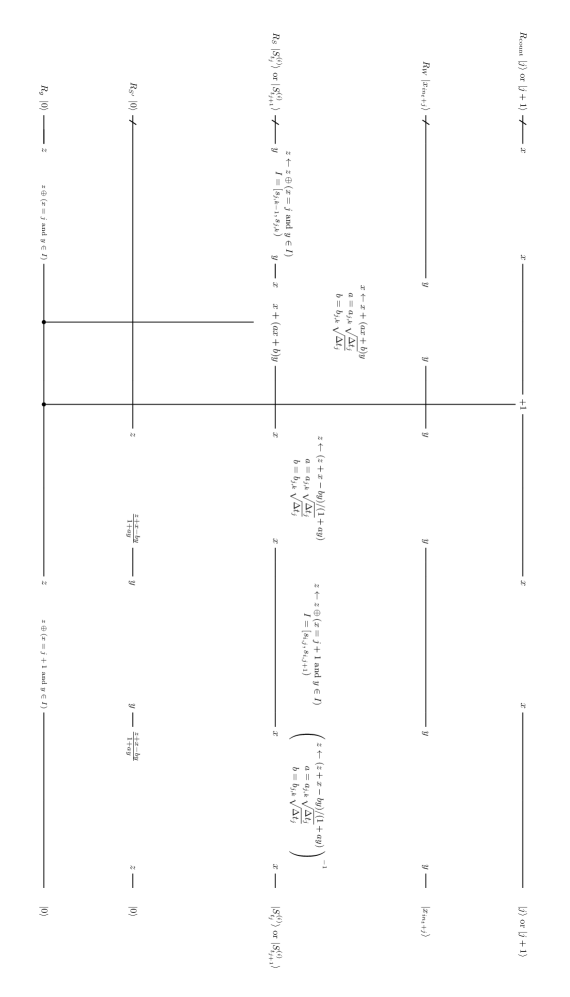
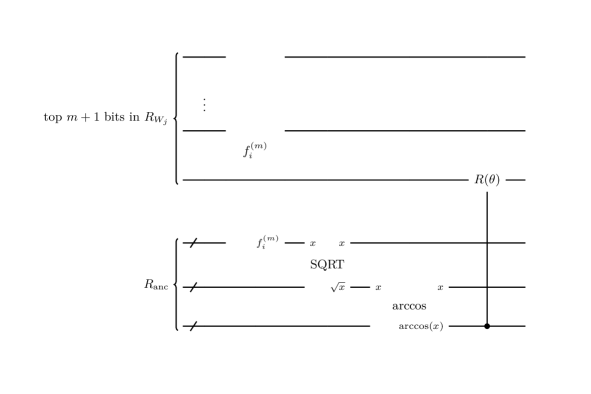
For example, the gate can be divided to two parts. The first part is checking that the value on is equal to and this can be done by the multiple control Toffoli gate, which is studied in Selinger ; Amy ; Maslov . The second part is checking that the asset price is in a given interval, which can be constructed from two comparisons. Combining these, the gate in Figure 3 is constructed as shown in Figure 4. Note that the bitwise flips are operated before the multi control Toffoli. Here, is the -th digit of the binary representation of , so the -th qubit is flipped if and only if . This convert to if and only if .
The operation in Figure 3 can be realized as follows:
| (18) | |||||
where the third ket corresponds to an ancillary register. The first arrow is just setting a constant on a register. The second arrow is the multiplication by a constant . The third arrow is the self-update multiplication, so it needs another ancillary register. The fourth arrow is again multiplication by a constant and the final arrow is uncomputation of the first and second arrows. Note that this is done under control by . In order for this to be controlled, it is sufficient to control only the second, fourth and final arrows, since the third arrow becomes a multiplication by 1 without the second. Also note that multiplication by a -bit constant or can be done by adders, that is, shift-and-add’s: , where is the -th bit of . This saves qubits compared with the case where we use a multiplier, which needs holding on an ancillary register.
The operation in Figure 3 is done as follows:
| (19) | |||||
where the first, second, third and fourth kets are , another ancillary register and , respectively.
Here, the first and second arrows are same as (18), the third is the multiplication by a constant and the final one is division.
Here, we do not have to uncompute and the ancillary register, since the whole of this operation is uncomputed soon later in .
(ii)
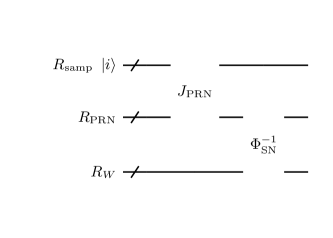
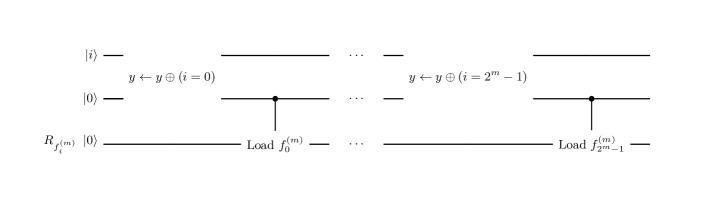
In Miyamoto , implementation of PRN on quantum circuits is presented, using the PRN generator called PCGPCG . Note that this PRN generator generates uniform RNs. We now need PSNRNs, so we must transform uniform distribution to standard normal distribution. There are some method and we adopt the inverse transform sampling. Schematically, and are implemented as shown in Figure 5. Here, is the gate to let the PRN sequence jump to the and is the gate to progress the PRN sequence by a step. They sequentially generate uniform RNs on the ancillary register and they are transformed to PSNRN on .
Although we refer to Miyamoto for the detail of implementation of the PRN generator, we here briefly explain. This generator is combination of linear congruential generator (LCG) and permutation of bit string. For LCG, update of the PRN sequence is done by
| (20) |
where are positive integers and is a nonnegative integer, and the -th element of the sequence is computed from and the initial value by
| (21) |
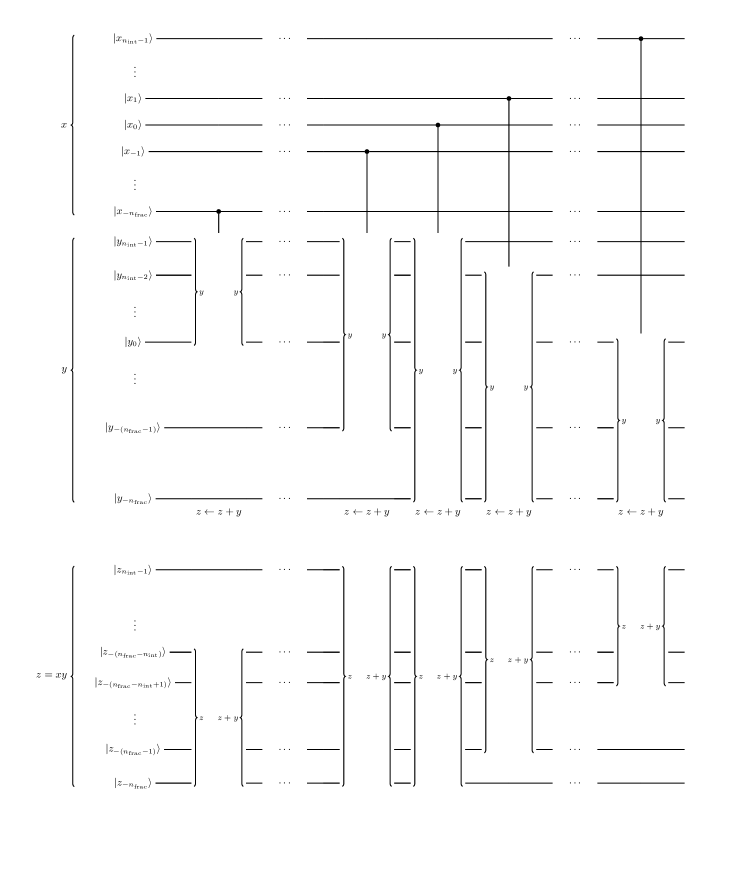
According to Vedral , we can construct the modular adder using 5 plain adders. Modular multiplication by a -bit constant can be done as modular shift-and-add’s. Modular division by a constant can be done as modular multiplication by a constant integer such that , if exists. Modular exponentiation is computed as a sequence controlled modular multiplicationVedral . So, to summarize, we can perform (20) and (21) using only controlled adders. In (20), the state is transformed as
| (22) | |||||
In the circuit we are considering, the first and second registers are and an ancillary register, which interchange their role at every step, and the third is another ancillary register. Each step corresponds to an elementary operation as follows. The first arrow is modular multiplication. The second arrow is the inverse modular multiplication by a integer such that and this clearing step is necessary to avoid increase of ancillas. The third is just loading on an ancillary register, the fourth is modular addition and the last is unloading. (21) progresses as follows:
| (23) | |||||
where the first, third, second and fourth registers are respectively and two ancillary registers. The first arrow is modular exponentiation, the second is modular multiplication, the third is loading, the fourth is modular addition and the last is uncomputation of the first and third.
We do not explain permutation: see Miyamoto for the detail.
We just make a comment that it is implemented by a simple circuit, for example, Xorshift is implemented as a sequence of CNOT.
We also need the gate to calculate , the inverse function of CDF of standard normal distribution. There are some ways to calculate this efficiently and we here adopt the method in Hormann . In the method, is divided into some intervals and is approximated by a polynomial in each interval. We adopt the setting where the number of intervals is 109666if we include and , it is 111 and polynomials are cubic, which realizes the error smaller than . Here, we write the approximated inverse CDF as
| (24) |
for , where are the end points of the intervals and is the number of the interval. Consider that .
Such a piecewise cubic function can be implemented as Figure 6. We here explain how it works. First, the sequence of comparators and “Load ” gates load into the register respectively as follows. The comparators compare the value of and the grid points and flip if . If is 1, the “Load ” gates are activated. They are actually collections of bitwise flips, that is, gates. If , only “Load ” gate is performed and it loads . If , “Load ” and “Load ” are performed. So, we set “Load ” so that it compensates flips done by “Load ” and are successfully loaded. The case where is in another interval is similar. The point is that if , every other gates are activated. That is, the activated gates are “Load ” of if is even and if is odd. This is because every comparator after the -th one flips and takes 0 and 1 alternatingly. Considering this, the gates in “Load ” are set as Figure 7, so that for appropriate are loaded after the sequence of all activated gates. After load of coefficients, the cubic function is calculated in the Horner’s method
| (25) |
This is done by the sequence of adders and multipliers in the latter half of the circuit in Figure 6.
(iii) Payoff
In this paper, we do not consider gates to calculate payoffs in detail, since the resource the gates require is same in both the PRN-on-a-register way and the register-per-RN way. We here make just a short comment. In many cases, a payoff can be expressed in the following form:
| (26) |
where are real constants, that is, a linear function of the asset price with the upper bound (cap) and the lower bound (floor) . For example, a payoff in an European call option (1) corresponds to . Payoffs expressed as (26) can be calculated easily by combination of comparators, adders and multipliers.
IV.3 the register-per-RN way
IV.3.1 calculation flow
Also for the register-per-RN way, we start from presenting the calculation flow, which is somewhat simpler than the PRN-on-a-register way. Again, we consider the flow until calculation of the payoff sum.
Before we present the calculation flow, we explain the required registers.
-
•
This is a register for the -th SNRN. We need such a register per random number, so the total number is .
-
•
This is a register where the value of the asset price at time is held.
-
•
This is a register where the value of the sum of payoffs by is held.
We again omit ancillary registers here and explain them later. Besides, we again assume that these and ancillary registers necessary to update them have qubits.
We here concretely define a superposition of SNRN values as the following state. In advance, we set the equally spaced points for discretization of the distribution , where and are the upper and lower bounds of the distribution and set to, say, -4 and +4, respectively. We here assume for simplicity. Then, we define as
| (27) |
where and is the probability density function of the standard normal distribution. We consider how to create such a state later. Since can be easily calculated from the index by a linear function, we identify as .
Then, the calculation flow is as follows:
-
1.
Initialize all registers to except , which is initialized to .
-
2.
Generate superpositions of SNRNs on . That is, set each of them to .
-
3.
Perform the time evolution (10) using the value on as . The result is output to as .
-
4.
Calculate the payoff at time using and output the sum of it and the previous payoffs to .
-
5.
Iterate operations similar to 3-4 for each time step until the time reaches .
-
6.
Finally we obtain a superposition of states in which the value on is the sum of payoffs for each pattern of values of SNRNs. Estimate the expectation value of to get (11).
The flow of state transformation is as follows. Writing only , and ,
| (28) | |||||
where is the value of the asset price at time evolved by .
IV.3.2 overview of the circuit
The outline of the circuit in the register-per-RN is as shown in Figure 8. First, is created on each by the gate SN, which is considered in detail later. After that, the gate performs -th step of asset price evolution and payoff calculation. For each evolution step, ancillary registers and , which have 1 and qubits respectively, are necessary. is then implemented as Figure 9. In this gate, the sequence of comparators and “Load” gates set in (8) into by the trick similar to that in the circuit in Figure 6. Then, the operation updates the asset price according to (10). Since the register-per-RN way does not aim to uncompute ancillary qubits in order to reduce them, can be done as follows:
| (29) | |||||
where the first ket is , the second is , the third and fourth are , the fifth is an ancillary register and the last is . So, this operation consists of copying a state and three multiplications. At the end of , the payoff is calculated using . Here, the ”” gate performs the following operation
| (30) | |||||
where the first, second and third ket are , and . This is done as copying to followed by calculation and addition of to .
IV.3.3 implementation of the SN gate
Let us now consider implementation of the SN gate, which creates a superposition of SNRN values. The outline was presented in Grover . In addition to this, we here explain some details, which were not explicitely explained in Grover .
We construct the state in the recursive way. We assume that we have already divided by equally-spaced points and created
| (31) |
where . We also assume that we have a gate to efficiently compute with the input , where is
| (32) |
Then, the following state transformation is possible:
| (33) | |||||
where we use the gate to compute at the first arrow and perform the controlled rotation at the second arrow. Repeating this until , we get .
However, as far as the authors know, neither Grover nor other papers present the gate to compute . Here, we propose a way to do this on the basis of a simple Taylor expansion. Consider
| (34) |
We can show that
| (35) |
by simple calculation. So, is well-approximated by a linear function of for small . We can use this to compute , since
| (36) |
Given and large enough that is sufficiently small, this can be approximately seen as a linear function of , since . Actually, we numerically confirmed that for the above approximation gives error smaller than .
We then reach the circuit in Figure 10 for calculation of . For , as shown in Figure 10, the sequence of comparators and “Load” gates set to the output register , using the trick similar to the circuit in Figure 6 again. Note that comparators now check whether the input value is equal to a given integer constant or not, so each of them is actually a combination of bitwise flips and a multi-controlled Toffoli gate, similar to that appeared in Figure 4. Also note that, if the input is , “Load ” gates are activated for . Considering this point, each “Load” gate is set so that operations of it and the following gates are successfully compensated. For , the is just a linear transformation, which is implemented as bitwise flips followed by a constant multiplier. Of course, according to required accuracy, the value of where the two types of are switched should be adjusted and the degree of the Taylor approximation for should be increased.
Using this gate, the SN gate is constructed as Figure 11. First, we operate a Hadamard gate to the most significant bit in to assign probability 1/2 to positive and negative halves of respectively. Then, we operate the sequence of the gates , which corresponds to the -th step of the above recursive calculation. is constructed as a combination of the gate, the gates to calculate square root and arc cosine and the controlled rotation gate .
We here comment on implementation of arccos and square root. The implementation of the inverse trigonometric function based on the piecewise polynomial approximation is proposed in Haner . Although Haner considers not arccos but arcsin, these can be easily related as . We adopt a setting with the polynomial degree 3 and 2 intervals, which leads to accuracy Haner . The circuit for square root is given in MunozCoreas2 .
V Estimation of Required Resources
Then, let us estimate the machine resources required for the implementation in the PRN-on-a-register way and the register-per-RN way. We consider the two metrics, qubit number and T-count, as many papers do.
V.1 elementary gates
| Gate | Qubits | T-count | Reference | |||||
| Total | Operand | Output | Ancilla | |||||
| Adder | 0 (self-update) | 0 | Thapliyal ; Thapliyal2 ; Thapliyal3 | |||||
| Ctrl Adder | 0 (self-update) | 0 | MunozCoreas ; Thapliyal3 | |||||
| Modular Adder777Since we can construct the modular adder using 5 plain addersVedral , we use 5 times the values of the adder for T-count. | 0 (self-update) | 0 | Thapliyal ; Thapliyal2 ; Thapliyal3 ; Vedral | |||||
| Multiplier | 0 | MunozCoreas | ||||||
| Divider | Thapliyal3 | |||||||
| Multi Ctrl Toffoli | 1 | Selinger ; Maslov | ||||||
| Square Root888The circuit given in MunozCoreas2 takes a -bit input and returns the -bit square root and the -bit remainder. In order to keep -bit accuracy, we add 0’s to the input and calculate the -bit square root of the virtual -bit input. We treat the bits added to the input and the bits where the remainder is output as ancillas. | MunozCoreas2 | |||||||
| arccos | 105 | 999Since the value shown in Haner is Toffoli count, we simply multiply it by 7 for converting it to T-count. | Haner | |||||
|
2 (control and target) | Egger ; Kliuchnikov ; Amy | ||||||
We first summarize the resources of the elementary gates which are necessary to construct the LV circuit. We here consider fixed-point arithmetic. Among various implementations proposed previously, we adopt one for each of the elementary gates and summarize their resources when operands are -bit in Table LABEL:tbl:resElem. Since we aim to estimate the orders of the above metrics, we take only the leading term with respect to for required resources. For example, we approximate as ..
We make a comment on multiplication and the division. For these operation, we use modified versions of circuits proposed in MunozCoreas and Thapliyal3 . This is because of the following reason. In order to store the strict value of the product of two -bit numbers, original circuits use -bits. This causes a problem in the situation where we have to sequentially perform multiplication as in the LV circuit, since the required qubit number doubles at every multiplication. Therefore, we have to truncate lower bits of product and keep the digit number constant. In order to do this, we modify the multiplier in MunozCoreas . We also construct the divider, which is dedicated to drawback of the modified multiplication. This is why the qubit number for divider in Table LABEL:tbl:resElem is different from that in MunozCoreas ; Thapliyal3 . We explain the details of the modified multiplier and divider in Appendix.
V.2 assumptions on registers
We assume the following points on qubit numbers of various registers, some of which have already been mentioned.
-
•
Registers which store numerical numbers, etc., and ancillary registers concerning them have qubits. This is determined according to the required accuracy. We hereafter set .
-
•
in Figure 5 exceptionally has qubits, since this is set to so large a value that the PRN sequence has good statistical property, e.g. long period. PCG considers the PRN generators with 64 bits and we also use this value for hereafter. Ancillary registers necessary for calculation of PRN sequence have qubits too. Even if , we use only qubits in for transformation to PSNRN.
-
•
has qubits.
-
•
Other registers, e.g. , have only several qubits and we neglect their contributions to the whole qubit number.
V.3 the PRN-on-a-register way
Then, let us consider the required resources in the PRN-on-a-register way.
V.3.1 qubit number
| Part | Register | Qubit | Note |
| Whole | |||
| ancilla | To hold intermediate outputs; see (21) | ||
| ancilla | To hold the coefficients of the polynomial and the intermediate outputs; see Figure 6 | ||
| ancilla | For and ; see the comment in the body text. | ||
| ancilla | To hold intermediate outputs; see (22). |
In Table LABEL:tbl:qubit, we summarize qubits necessary in each step in the circuit. Registers which hold some values throughout the circuit are as follows: ans . Except these, the following parts in the circuit can consume qubit number most heavily.
-
•
and : qubits
-
•
: qubits
Therefore, the total qubit number required in the PRN-on-a-register way is roughly
| (37) |
Let us comment on some technical points for obtaining Table LABEL:tbl:qubit. We first make a supplementary explanation on the ancillary qubit number in . There are two parts which require ancillas in . First, needs the following ancillas: a -bit register to which is output, a -bit register to which the result is temporally output in the self-update multiplication and a -bit register necessary for the inverse division to clear the input . Second, needs the following: a -bit register to which is output and a -bit register necessary for division. In total, bits are sufficient101010Strictly speaking, comparisons between or and ’s require loading ’s into some register. This does not require another register, since at least one of ancillary registers used in and is empty at loading. .
We also comment on the ancilla number in . As we can see from Figure 6, we need four registers to which coefficients are loaded and two registers for intermediate outputs. Therefore, ancillas are necessary111111Although we also need a register to which ’s are loaded at comparisons between them and , we can use or intermediate output registers, which are empty at comparisons.
V.3.2 T-count
Since we are interested in only the leading contribution, we focus on multiplications, divisions and repeated additions. Besides, we do not consider the T-count of , which is used only once. For the parts in , which is used repeatedly, we specify T-counts as follows:
-
1.
One includes the following parts:-
•
As we can see in (18), this includes one multiplication and one division, which come from one self-update multiplication, and controlled additions, which comes from two controlled multiplications by constant and one inverse. In total, the T-count is . -
•
As we can see in (19), this includes one division and additions, which comes from two multiplications by constant. In total, the T-count is . -
•
Uncomputation of
Similar to the above.
Therefore, the total T-count in one is . Since is used times, the total T-count in them is (only the leading term).
-
•
-
2.
This includes two modular multiplications by constant, which comes from one self-update modular multiplication. These are decomposed into modular additions. So the T-count is roughly . -
3.
and its inverse
Each of them includes additions ( comparisons) and five multiplications. So the T-count for each is roughly .
Summing up these and considering is used in times, the T-count in the whole circuit is roughly
| (38) |
V.4 the register-per-RN way
Next, we consider the required resources in the register-per-RN way.
V.4.1 qubit number
| Register | Qubit | Note | ||
| ancilla used for in | See (29) | |||
| ancilla for | output | for one | ||
| ancilla for SQRT | for one | |||
|
105 for one | |||
In the register-per-RN way, registers shown in Table LABEL:tbl:qubitRN are added per time step. Note that we do not uncompute ancillas. Summing up all registers, the qubit number necessary for one time step is roughly , and for the entire circuit it is
| (39) |
Note that the dominant part comes from the iterative calculation in the SN gates, which prepare superpositions of the values of the SNRNs.
V.4.2 T-count
Again, we focus on operations with large T-count. For each part in the circuit, we estimate the T-count as follows:
-
1.
SN gate
The -th iteration in the SN gate includes the following parts:-
•
square root, arccos, controlled rotation
T-counts are , and , respectively. -
•
For , we use -controlled Toffoli gates to check the value on and load which corresponds to the value. T-count for this is 121212Here, we use , the accurate value of T-count of the -controlled Toffoli gatesSelinger ; Maslov , since the approximation as is too crude for small .. Summing this for leads to about 4000. Since this is much smaller than T-count for arccos in one iteration, we neglect this. For , we do multiplication between a -bit variable and a -bit constant, which is decomposed additions of -bit. Then, T-count is .
Summing up these and taking only dominant contributions, one SN gate has T-count of roughly.
-
•
-
2.
This includes additions ( comparisons) and three multiplications. So one gates has T-count of roughly.
In total, we can estimate T-count of the entire circuit in the register-per-RN way as
| (40) |
V.5 comparison between two ways
| PRN-on-a-register | register-per-RN | |||
|---|---|---|---|---|
| qubit | ||||
| T-count |
| PRN-on-a-register | register-per-RN | |
|---|---|---|
| qubit | ||
| T-count |
We then compare resources necessary in two ways in Table LABEL:tbl:ressum. Naturally, qubit number is independent from in the PRN-on-a-register way but proportional to in the register-per-RN way and T-count is proportional to in the both ways. If we take a setting, which is typically necessary for practical use in derivative pricing131313 corresponds to 65536 sample paths. :
| (41) |
the values in Table LABEL:tbl:ressum becomes as Table LABEL:tbl:ressumspec. The total T-count is of same order of magnitude in the both way but larger for the PRN-on-a-register way by a factor 2 roughly. We here comment on the parts which consume T-count most heavily in each way. In the PRN-on-a-register way, there are two parts which contribute to T-count equally and dominantly. The first is the update of the asset price in . Note that additional operations for reduction of qubits, such as inverse division in self-update multiplication and drawing back the asset price to clear , increase T-count compared with the register-per-RN way. The second is modular multiplications in update of the PRN sequence. Since the PRN generator requires the large bit number, say , in order to it keep good statistical properties such as long period, the T-count of operations for the PRN becomes large. On the other hand, in the register-per-RN way the dominant contribution to T-count comes from arccos’s in preparing SNRNs. Because not only an arccos itself is T-count consuming but also it is used in each iteration in the SN gate, the total T-count piles up.
VI Summary
In this paper, we considered how to implement time evolution of the asset price in the LV model on quantum computers. Similar to other problems in finance, derivative pricing by Monte Carlo simulation requires a large number of random numbers, which is proportional to , the number of time steps for asset price evolution, and this may cause difficulty in implementation. We then considered two ways of implementation: the PRN-on-a-register way and the register-per-RN way. In the former we sequentially generate pseudo random numbers on a register and use them to evolve the asset price. In the latter, standard normal random numbers necessary to time evolution are created as superpositions on separate registers. For both ways, we present the concrete quantum circuits in detail. For not only random number generation but also other aspects, we try to save qubit numbers permitting some additional procedures in the PRN-on-a-register way and do opposite in the register-per-RN way. We then give estimations of qubit number and T-count required in each way. In the PRN-on-a-register way, qubit number is kept constant against . On the other hand, in the register-per-RN way qubit number is proportional to . Each way has T-count consuming parts and the total T-counts for both ways are of same order of magnitude, expect the PRN-on-a-register way has the larger T-count by a factor about 2, in some specific setting.
Note that analyses of resources required for implementation of the LV model in this paper strongly depend on designs of elementary circuits for arithmetic. For example, in the register-per-RN way the dominant contribution to T-count comes from arccos’s in preparing SNRNs. If more efficient circuits are proposed and we replace the current choice with them, required resources may change.
Finally, we would like to notice that this study is not enough for application of quantum algorithm for Monte Carlo simulation to pricing in the LV model. Although we assumed that the LV function is given, in practice we have to calibrate the LV so that the model prices of European options fit to the market prices. Besides, we have not considered how to evaluate terms in exotic derivatives, for example, early exercise. In future works, we will consider such things and aim to present how to apply quantum computers in the whole process of exotic derivative pricing.
Appendix A Sufficient condition on in the PRN-on-a-resigter way
We here show that which is continuous with respect to and takes the form of (8) and sufficiently small lead to one-to-one correspondence between and . We see as a function of and define a function by
| (42) |
for fixed so that holds. Except for the grid points , is differentiable and
| (43) |
Since is bounded in numerical computation, is always positive expect the grid points for sufficiently small . Besides, if is continuous with respect to also at the grid points, so is . Combining these, we find that is strictly increasing for small . Thus, the correspondence between and is one-to-one.
Small is required from another perspective, too. The original dynamics of the asset price is given as the continuous-time evolution (3) and (10) is the discretized approximation of it. Therefore, in order for this approximation to be accurate, the increment of asset price should be sufficiently smaller than the asset price itself: . If this condition is satisfied, , so is met.
Appendix B Truncated multiplier and divider
We here describe the modified version of multiplier and divider. We assume that we consider the fixed-point arithmetic with bits in the integer part and bits in the fractional part, bits in total. We hereafter call such numbers -bit numbers. We want to keep this digit setting before and after multiplication. In order to do this, we adopt the following policy.
-
•
We simply truncate the digits lower than the -th fractional digit in the product. This might cause numerical errors around and the -th fractional digit and such a tiny error might accumulate, but we simply neglect this concern.
-
•
We assume the overflow from the -bit integer part never occurs.
We then approximate the product as follows. Writing a number in binary representation as , where is the -th integer digit of and is the -th fractional digit of , we do
| (44) |
where
| (45) |
This truncated multiplication is implemented as a circuit in Figure 12. Note that the circuit in Figure 12 actually calculates not but
| (46) |
This is equal to if our assumption that the overflow from the -bit integer part never occurs is satisfied.
We define the truncated division as the inverse of the truncated multiplication: . Given two -bit numbers which satisfies , we can find the -bit number as follows:
-
1.
Set , and .
-
2.
Update with
-
3.
If , update with ( returns to the value before step 2) and set . If , set .
-
4.
Decrement by 1.
-
5.
Repeat step 2-4 until becomes at step 4.
-
6.
Output .
Note that . This ensures that sequential subtractions by and checking whether the difference is positive or negative lead to determining each digit of . The above procedure is implemented as the circuit in Figure 13. Note that we add dummy qubits which correspond to the -th to -th integer digits of . Also note that this circuit transforms the dividend register from to . If we want to reserve , we can copy the state to another ancillary register by CNOT gates and use the copy as the dividend state. That is, we can do
| (47) |
Despite the trick to truncate the digits, the structures of the circuits for truncated multiplication and division are similar to that in MunozCoreas and the restoring division circuit in Thapliyal3 respectively. We therefore use the qubit number and T-count of the circuits in MunozCoreas ; Thapliyal3 as those of our truncated arithmetic circuits. The exception is the qubit number of divider, for which we use . This is larger than the value in Thapliyal3 by , reflecting the addition of dummy qubits and the register to which the dividend is copied141414Actually, added qubits are not but , but we consider that qubits are added for simplicity and conservativeness. .
References
- (1) R. Orus et al. ”Quantum computing for finance: overview and prospects”, Reviews in Physics 4, 100028 (2019)
- (2) J. C. Hull, ”Options, Futures, and Other Derivatives”, Prentice Hall (2012)
- (3) S. Shreve, ”Stochastic Calculus for Finance I: The Binomial Asset Pricing Model”, Springer (2004)
- (4) S. Shreve, ”Stochastic Calculus for Finance II: Continuous-Time Models”, Springer (2004)
- (5) A. Montanaro, “Quantum speedup of Monte Carlo methods”, Proc. Roy. Soc. Ser. A, 471, 2181 (2015)
- (6) Y. Suzuki et. al., “Amplitude Estimation without Phase Estimation”, Quantum Information Processing, 19, 75 (2020)
- (7) P. Rebentrost et. al., ”Quantum computational finance: Monte Carlo pricing of financial derivatives”, Phys. Rev. A 98, 022321 (2018)
- (8) N. Stamatopoulos et al., ”Option Pricing using Quantum Computers”, arXiv:1905.02666
- (9) S. Ramos-Calderer et al., ”Quantum unary approach to option pricing”, arXiv:1912.01618
- (10) F. Black and M. Scholes, ”The Pricing of Options and Corporate Liabilities”, Journal of Political Economy 81, 637 (1973).
- (11) R. C. Merton, ”Theory of Rational Option Pricing”, The Bell Journal of Economics and Management Science 4, 141 (1973)
- (12) B. Dupire, ”Pricing with a Smile”, Risk, 7, 18-20 (1994)
- (13) L. Grover et. al., “Creating superpositions that correspond to efficiently integrable probability distributions”, arXiv:quant-ph/0208112
- (14) J. Gregory, ”The xVA Challenge: Counterparty Credit Risk, Funding, Collateral and Capital”, Wiley (2015)
- (15) F. Arute,et al., ”Quantum supremacy using a programmable superconducting processor”, Nature, 574, 505 (2019)
- (16) E. T. Campbell et al., ”Roads towards fault-tolerant universal quantum computation”, Nature, 549, 172 (2017)
- (17) K. Miyamoto and K. Shiohara, ”Reduction of Qubits in Quantum Algorithm for Monte Carlo Simulation by Pseudo-random Number Generator”, arXiv:1911.12469
- (18) M. Amy et al., ”A meet-in-the-middle algorithm for fast synthesis of depth-optimal quantum circuits”, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 32(6): 818-830 (2013)
- (19) P. Selinger, Phys. Rev. A 87, 042302 (2013)
- (20) S. Bravyi and J. Haah, “Magic-state distillation with low overhead,” Phys. Rev. A 86, 052329 (2012)
- (21) A. G. Fowler and C. Gidney, ”Low overhead quantum computation using lattice surgery”, arXiv:1808.06709
- (22) D. J. Egger at al., ”Credit Risk Analysis using Quantum Computers”, arXiv:1907.03044
- (23) G. Maruyama, ”On the Transition Probability Functions of the Markov Process”, Rendiconti del Circolo Matematico di Palermo 4, 48 (1955)
- (24) G. Bassard et. al., “Quantum amplitude amplification and estimation”, Contemporary Mathematics, 305, 53 (2002)
- (25) K. Nakaji, ”Faster Amplitude Estimation”, arXiv:2003.02417
- (26) V. Vedral et. al., “Quantum Networks for Elementary Arithmetic Operations”, Phys. Rev. A 54, 147 (1996)
- (27) D. Beckman et. al., ”Efficient networks for quantum factoring”, Phys. Rev. A, 54, 1034 (1996)
- (28) T. G. Draper, ”Addition on a quantum computer”, arXiv:quant-ph/0008033
- (29) S. A. Cuccaro et. al., ”A new quantum ripple-carry addition circuit”, The Eighth Workshop on Quantum Information Processing (2004)
- (30) Y. Takahashi et. al., ”A linear-size quantum circuit for addition with no ancillary qubits”, Quantum Information and Computation, 5(6), 440–448 (2005)
- (31) R. Van Meter et. al., ”Fast quantum modular exponentiation”, Phys. Rev. A 71(5), 052320 (2005)
- (32) T. G. Draper et. al., ”A logarithmic-depth quantum carry-lookahead adder”, Quantum Information and Computation, 6(4), 351 (2006)
- (33) Y. Takahashi et. al., ”Quantum addition circuits and unbounded fan-out”, Quantum Information and Computation, 10(9&10), 0872 (2010)
- (34) R. Portugal et. al., ”Reversible Karatsubas algorithm”, Journal of Universal Computer Science, 12(5), 499 (2006)
- (35) J. J. Alvarez-Sanchezet. al., ”A quantum architecture for multiplying signed integers”, Journal of Physics: Conference Series, 128(1), 012013 (2008)
- (36) Y. Takahashi et. al., ”A fast quantum circuit for addition with few qubits”, Quantum Information and Computation, 8(6), 636 (2008)
- (37) H. Thapliyal, “Mapping of subtractor and adder-subtractor circuits on reversible quantum gates,” Transactions on Computational Science XXVII. 10, (2016)
- (38) H. Thapliyal and N. Ranganathan, “Design of Efficient Reversible Logic Based Binary and BCD Adder Circuits”, J. Emerg. Technol. Comput. Syst. 9, 17, 1 (2013)
- (39) C.-C. Lin, et al., “Qlib: Quantum module library,” J. Emerg. Technol. Comput. Syst., 11, 1, pp. 7:1–7:20 (2014)
- (40) H. M. H. Babu, “Cost-efficient design of a quantum multiplier–accumulator unit,” Quantum Information Processing, 16, 1, 30 (2016)
- (41) H. V. Jayashree et al., “Ancilla-input and garbage-output optimized design of a reversible quantum integer multiplier,” The Journal of Supercomputing, 72, 4, 1477 (2016).
- (42) E. Muñoz-Coreas and H. Thapliyal, ”Quantum Circuit Design of a T-count Optimized Integer Multiplier”, IEEE Transactions on Computers, 68, 5 (2019)
- (43) A. Khosropour et al., “Quantum division circuit based on restoring division algorithm,” in Information Technology: New Generations (ITNG), 2011 Eighth International Conference on. IEEE, 2011, pp. 1037–1040.
- (44) L. Jamal and H. M. H. Babu, “Efficient approaches to design a reversible floating point divider,” in 2013 IEEE International Symposium on Circuits and Systems (ISCAS2013), May 2013, pp. 3004–3007.
- (45) S. V. Dibbo et al., “An efficient design technique of a quantum divider circuit,” in 2016 IEEE International Symposium on Circuits and Systems (ISCAS), May 2016, pp. 2102–2105.
- (46) H. Thapliyal et al., ”Quantum Circuit Designs of Integer Division Optimizing T-count and T-depth”, IEEE Transactions on Emerging Topics in Computing (2019)
- (47) M. Amy, D. Maslov, and M. Mosca, IEEE Trans. CAD 33(10), 1476 (2014)
- (48) D. Maslov, ”On the advantages of using relative phase Toffolis with an application to multiple control Toffoli optimization”, Phys. Rev. A 93, 022311 (2016)
- (49) M. E. O’Neill, “PCG: A Family of Simple Fast Space-Efficient Statistically Good Algorithms for Random Number Generation”, Harvey Mudd College Computer Science Department Tachnical Report (2014); http://www.pcg-random.org/
- (50) W. Hörmann and J. Leydold, ”Continuous random variate generation by fast numerical inversion”, ACM Transactions on Modeling and Computer Simulation 13(4):347, (2003)
- (51) T. Haner et al., ”Optimizing Quantum Circuits for Arithmetic”, arXiv:1805.12445
- (52) E. Muñoz-Coreas and H. Thapliyal, ”T-count and Qubit Optimized Quantum Circuit Design of the Non-Restoring Square Root Algorithm”, ACM Journal on Emerging Technologies in Computing Systems, 14, 3 (2018)
- (53) V. Kliuchnikov et al., ”Practical approximation of single-qubit unitaries by single-qubit quantum Clifford and T circuits”, IEEE Transactions on Computers, 65, 1, 161 (2016)
- (54) M. Amy et al., “A meet-in-the-middle algorithm for fast synthesis of depth-optimal quantum circuits,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 32, 818 (2013).
.