QuantumCircuitOpt: An Open-source Framework for Provably Optimal Quantum Circuit Design
Abstract
In recent years, the quantum computing community has seen an explosion of novel methods to implement non-trivial quantum computations on near-term hardware. An important direction of research has been to decompose an arbitrary entangled state, represented as a unitary, into a quantum circuit, that is, a sequence of gates supported by a quantum processor. It has been well known that circuits with longer decompositions and more entangling multi-qubit gates are error-prone for the current noisy, intermediate-scale quantum devices. To this end, there has been a significant interest to develop heuristic-based methods to discover compact circuits. We contribute to this effort by proposing QuantumCircuitOpt (QCOpt), a novel open-source framework which implements mathematical optimization formulations and algorithms for decomposing arbitrary unitary gates into a sequence of hardware-native gates. A core innovation of QCOpt is that it provides optimality guarantees on the quantum circuits that it produces. In particular, we show that QCOpt can find up to 57% reduction in the number of necessary gates on circuits with up to four qubits, and in run times less than a few minutes on commodity computing hardware. We also validate the efficacy of QCOpt as a tool for quantum circuit design in comparison with a naive brute-force enumeration algorithm. We also show how the QCOpt package can be adapted to various built-in types of native gate sets, based on different hardware platforms like those produced by IBM, Rigetti and Google. We hope this package will facilitate further algorithmic exploration for quantum processor designers, as well as quantum physicists.
Index Terms:
Quantum Circuit Design, Quantum Computing, Discrete Optimization, Open-source SoftwareI Introduction
In the last decade, quantum computing has progressed from a research experiment to a tool on the brink of transforming a variety of computing-intensive industries, including medicine and transportation, to name a few [1]. Quantum computers have achieved rapid DNA sequencing and precise future traffic volumes prediction in urban areas [2]. More importantly, quantum computing has also been recognized to play significant role in the United States’ economic and defense infrastructure applications as stated in the 2018 national strategic overview [3]. The quantum computing market is projected to reach $65 billion by 2030 from just $507 million in 2019.
Perhaps, the best known application of quantum computing is to factor integers, whereas the fastest known classical algorithm is super-polynomial, while Shor’s algorithm solves the problem in polynomial time on a quantum computer [4]. Quantum computers were also proposed for simulating Hamiltonian dynamics and studying phenomena in condensed-matter and high-energy physics [5]. These applications have motivated significant efforts toward building scalable quantum algorithms, typically modeled in the formalism of quantum circuits. Quantum circuits describe a computation as an ordered sequence of elementary quantum logic gates, or hardware-native gates, acting on quantum data, such as qubits. It is well known that any -qubit quantum computation, represented as a target gate, can be achieved using a sequence of one- and two-qubit quantum logic gates [6]. There are many ways of implementing the target gate using available hardware-native gates, and it is advantageous to find an implementation with minimum number of gates to migrate the negative impacts of noise and decoherence in a quantum computer’s computation. Of particular interest is to minimize the two-qubit CNOT gates, as they are orders-of-magnitude more error-prone than implementations of single-qubit gates. However, given a set of native gates, even for two-qubits, finding such optimal implementations with theoretical guarantees can be forbiddingly complex [7]. While heuristics based on machine learning have been shown to achieve good circuits empirically [8, 9, 10], they do not provide a mechanism to measure how close they are to the best possible circuit. The community is lacking both methods and software packages that can provide theoretical guarantees on the solution quality of quantum circuit decompositions. To close this gap, this work proposes the software package QuantumCircuitOpt111https://github.com/harshangrjn/QuantumCircuitOpt.jl, the first software that computes quantum circuit decompositions with numerically provable optimality guarantees, to the best of our knowledge. The key to QuantumCircuitOpt’s success is to formulate the quantum circuit design task as carefully crafted mixed-integer programs (MIPs) that can be solved with state-of-the-art discrete optimization software [11]. Recognizing that different hardware vendors implement different hardware-native gates, QuantumCircuitOpt seamlessly adapts the design task to different user-specified gates. Through these features, QuantumCircuitOpt makes sophisticated mathematical optimization technologies accessible to all quantum computing users.
II QuantumCircuitOpt’s Framework
II-A Success of mixed-integer programming
| (1) |
Mixed-integer programming (MIP), a special case falling under an umbrella of mathematical programming, has been an integral part of important decision making problems such as the classic traveling salesman problem, airline scheduling and energy systems optimization, to name a few [12]. The mathematical theory of MIP, shown in (1), is concerned with finding amongst all solutions of a system of linear algebraic equalities and inequalities, written as functions of decision variables, a variable assignment that minimizes a linear function of those variables. The variables in an MIP can be a mix of continuous and integer values. Model (1) represents a canonical form of an MIP, where and are the continuous and integer variables, respectively. Solving MIPs, while NP-Hard in the worst case, has made dramatic strides in practical applications via state-of-the-art commercial solvers such as CPLEX and Gurobi, where decades of research and development (R&D) have yielded algorithmic performance improvements that even outpaced the hardware improvements from Moore’s Law. For example, CPLEX, since its release in 1991, has seen 200 billion factor speedup in solving MIPs [13].
At their core, MIPs are declarative, they specify what optimization problem to solve and not how to solve it. Hence, a performant mathematical programming language is required to access MIP solvers and to enable a separation from the problem-specific complexities and the underlying algorithms employed by such solvers. For this purpose, JuMP is one of the most widely adopted packages for mathematical programming and provides a declarative domain specific language (DSL) in the Julia programming language for modeling mathematical programs [14], such as MIPs. By taking a “leap of faith” that the problem of optimal quantum circuit design can also be posed as an MIP like shown in (1) (details in section III), we now present the framework of the QuantumCircuitOpt software package to formulate and solve such problems.
II-B Features of the QCOpt package
Building on the recent success of Julia, JuMP and mixed-integer programming, in this work we introduce QuantumCircuitOpt (or QCOpt), a free and open-source toolkit for quantum circuit design. As illustrated in Figure 1, QCOpt is written in Julia, a relatively new and fast dynamic programming language used for technical computing with support for extensible type system and meta-programming [15]. At a high level, QCOpt provides an abstraction layer to achieve two primary goals: (a) to capture user-specified inputs, such as a desired quantum computation and the available hardware gates, and build a JuMP model of an MIP formulation and (b) to extract, analyze and post-process the solution from the JuMP model to provide exact and approximate circuit decompositions, up to a global phase and machine precision. In the remainder of this section, we will highlight a few important features of QCOpt in detail.
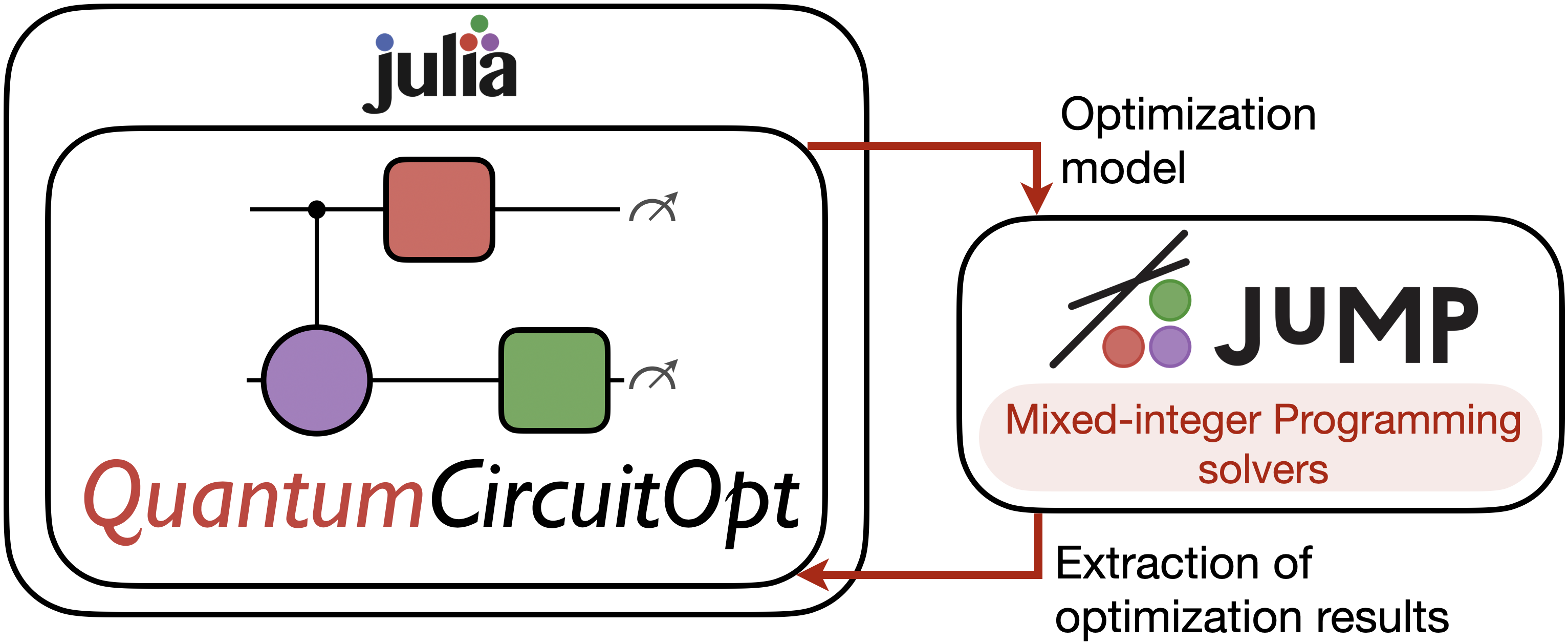
User inputs
QCOpt’s user inputs is a dictionary, with a collection of key-value pairs, where the keys are the options to be set and values are the user inputs. These key-value pairs need not be of the same data type, as seen below. While the below list is not comprehensive, it provides sufficient information to start exploring the package:
-
1.
"num_qubits": Total number of qubits of the circuit.
-
2.
"maximum_depth": Maximum allowable depth for the circuit’s decomposition ( 2). From QCOpt’s perspective, maximum depth is also the total number of input elementary_gates (see below) allowed in the decomposition.
-
3.
"elementary_gates": A vector of all one- and two-qubit elementary gates, native to the hardware. For example, on a three qubits circuit, here is an allowable input: ["H_1", "H_2", "T_2", "Tdagger_3", "CNot_1_2", "CNot_3_2", "CNot_3_1", "Identity"]. Notice that an one-qubit gate is associated with it’s qubit location and a two-qubit gate is associated with it’s control and target qubit locations. For example, inputs "CNot_1_2" and "CNot_3_2" implement the regular and the reverse gates in corresponding qubit locations.
-
4.
"target_gate": A target unitary quantum gate which needs to be compiled/decomposed using the above-mentioned native "elementary_gates".
-
5.
"objective": The options are (a) "minimize_depth" to minimize the total number of one- and two-qubit gates in the decomposition, and (b) "minimize_cnot" to minimize the total number of gates in the decomposition.
-
6.
"decomposition_type": The options are: (a) "exact": finds an exact, optimal circuit decomposition up to a global phase and machine precision, provided it exists, (b) "approximate": Finds an approximate decomposition with best gate fidelity found within the limits of run time.
-
7.
"set_cnot_lower_bound": While this is an optional input, it aids in reducing the size of the search space of MIP and also helps in exploiting theoretical bounds on gate costs from the literature [16].
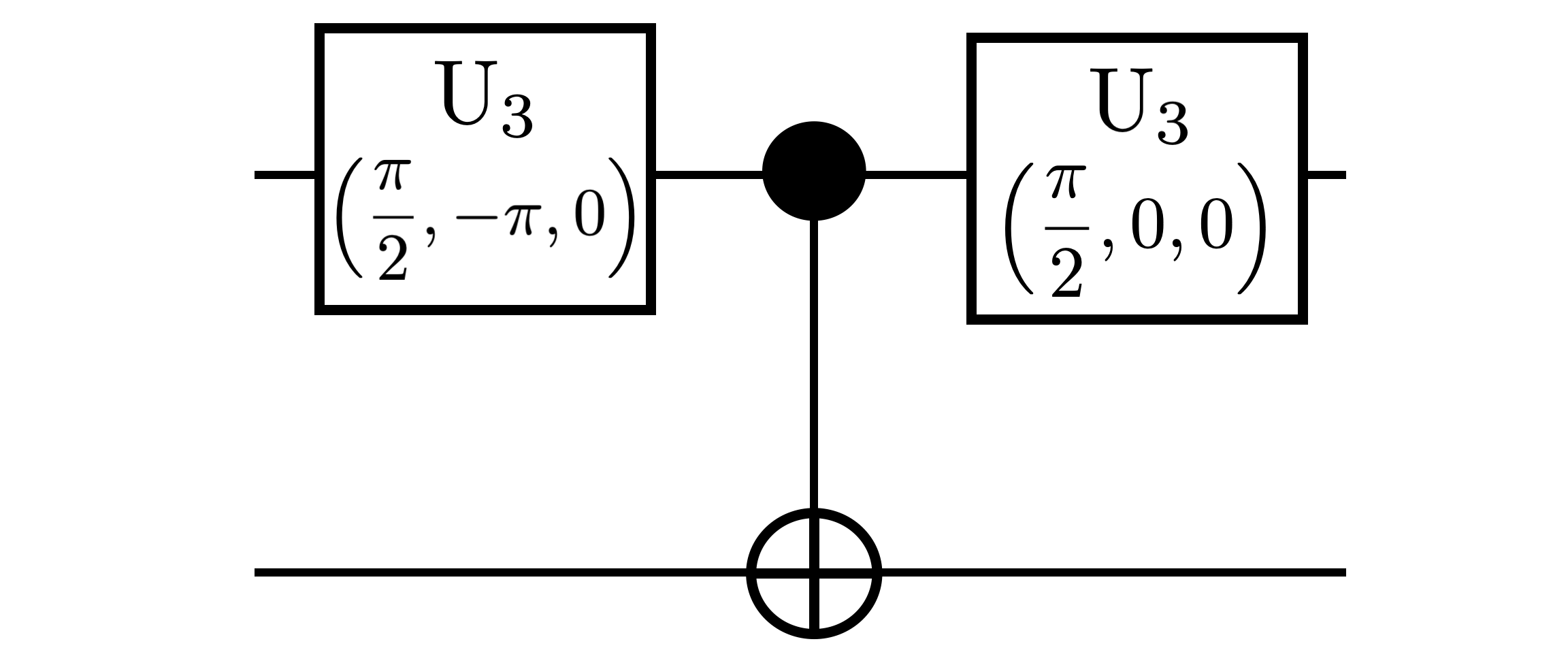
Note that if a gate with continuous angles is in the input elementary_gates, then discretization of these angles have to be specified in the inputs. For example, see figure 2 for specifying the angles for the gate.
Also, it is important to keep in mind that the optimization tasks handled by QCOpt are NP-hard to compute (in worst-case) in the size of the following set of inputs: num_qubits, maximum_depth and elementary_gates.
Available gates set
Currently, QCOpt supports the gates of the Clifford group (), and the phase gate, , and it’s conjugate transpose, , which together are sufficient to arbitrarily approximate any target gate with a finite set of operations. However, for enhanced generality, users can also input universal single-qubit operators such as the rotation gates, ) and the universal gate with three Euler angles, , along with the corresponding angle discretizations. QCOpt also supports various two-qubit gates such as the , , -basis, ’s diffusion operator, , and controlled versions of all the single-qubit gates in the Clifford group, and gates. QCOpt also supports Kronecker products of one- and two-qubit gates as a native gate in the following form: for e.g., on three-qubit circuits, (), ().
Sample implementation
Figure 2 shows a sample implementation for decomposing a two-qubit controlled- gate. The native gates set contains discretized gates which can be located on both the qubits, gate and the gate. The maximum allowable depth for the decomposition is four and Gurobi is specified as an MIP solver. Finally, the results from the optimization model, including an optimal decomposition, run time and solver status, can be accessed from the results dictionary. QCOpt solves this optimization model to optimality, with 72 native gates (after discretization) per depth, in less than 4 seconds on a commodity computing hardware.
II-C Pre-Solving in QCOpt
Pre-processing and transformation of mathematical programs before solving, known as pre-solving, is a well established procedure for improving run time of mathematical optimization algorithms [17]. To that end, before solving the main optimization model (MIP) to optimally, QCOpt preprocesses the user-defined inputs to make them more amenable to the MIP solver’s algorithm. Here we present a few such pre-solving techniques:
-
1.
Elimination of identical gates in the "elementary_gates" input, including the gates obtained via discretization of angle parameters.
-
2.
Implementation a compact, smaller-sized MIP formulation if both the input "elementary_gates" and "target_gate" contain purely real-valued elements.
-
3.
An optional user-given "input_circuit" is preprocessed to map this readily available circuit to warm-start the MIP solver with a feasible decomposition, as this can improve solver run times. During this pre-processing step, if QCOpt recognizes the input circuit as a feasible solution, then it activates the option to emphasize on proving optimality than finding feasibility for the MIP solver. For example, in the Gurobi solver, the MIPFocus parameter is set to “2” to emphasize optimality.

III Underlying Mathematical Programs
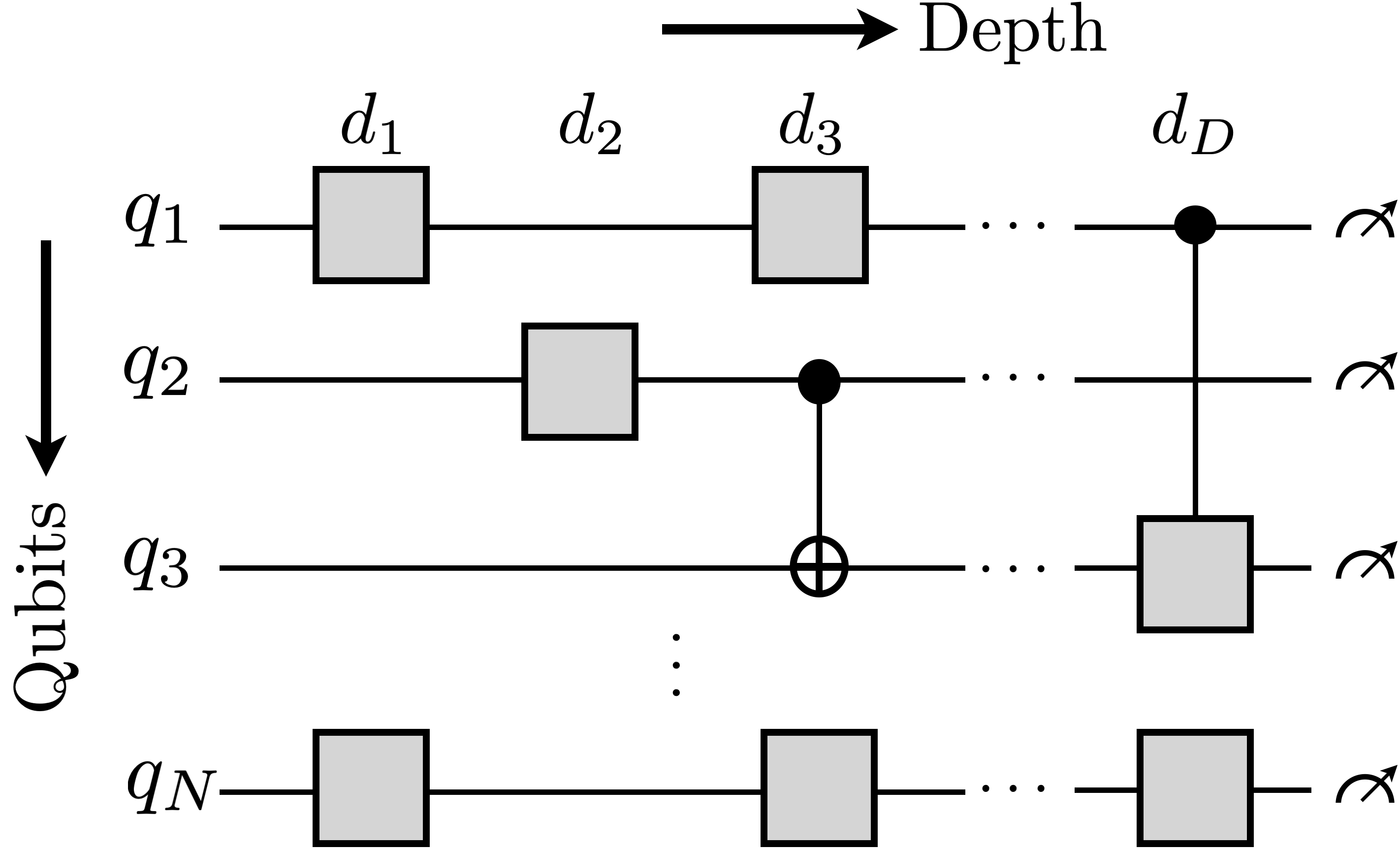
QCOpt focuses on implementing compact and efficient MIP formulations for the design of a generic quantum circuit, represented as an ordered sequence of one- and two-qubit quantum gates as shown in Figure 3. We now present a simplified derivation of the MIP formulation implemented in QCOpt. For clarity purposes, we consider IBM quantum experience’s native gates set [8] in the following exposition. However, the formulation in QCOpt is general enough to support other native gates of a different quantum processor in a straight-forward fashion.
Let the native gates set contain the following one- and two-qubit complex-valued gates:
| (2a) | ||||
| (2b) | ||||
| (2c) | ||||
where is the imaginary constant and and represent discretized angles of continuous angle parameters of the universal gate. From the IBM quantum processor perspective, we consider a special case of this gate, i.e, the phase gate, with and from the set and . For example, if , then the total number of discretized gates considered for optimization is four, in addition to the remaining three native gates with constant parameters. Notice that we discretize the angles instead of handling them as continuous variables in order to circumvent the resulting non-linear, non-convex terms in the optimization model. However, QCOpt’s framework based on JuMP, makes it flexible to interact with existing Julia-based non-linear solvers [18], which will be a future direction of work.
In equation (2c), and represent control and target qubits, respectively. QCOpt follows the convention where higher qubit indices are more significant, and the lesser significant qubit serves as the control qubit for two-qubit controlled gates.
Let , , and be the number of qubits in the circuit, maximum allowable depth of the circuit and the target unitary gate to be decomposed by the optimization model, respectively. Next, we introduce binary variables to choose the location of the these native gates in the circuit:
where , , and an ordered pair represents control and target qubits on which the two-qubit gate can be placed.
Next, let represent the choice of one of the above-described native gates at every depth. Again, for simplicity of exposition, we present in 2-qubits below. However, QCOpt implements the generalized version on qubits. For every depth in ,
| (3a) | ||||
| (3b) | ||||
where represents the Kronecker product of one-qubit gates. Constraint (3b) ensures that only one gate, out of all native gates, is placed per depth of the decomposition. Note that this constraint does not lose the generality of representing any quantum circuit. It is well known that the gates appearing in two consecutive depths and at non-identical qubits can be compressed into an equivalent single-depth circuit.
The multiplicative property of unitary gates, , on a quantum circuit which is intended to represent any computation, given by a target gate , can be mathematically modeled as the following constraint in an optimization model:
| (4) |
where is an initial state of the circuit from which the computation evolves.
The core contribution of QCOpt package also lies in an efficient implementation of the non-linear, non-convex constraint in (4), as this can be crucial in the MIP solver’s performance. Optimization tasks with such constraints with products of variable-matrices is known to be NP-hard to compute [19]. Moreover, state-of-the-art MIP solvers, such as CPLEX and Gurobi, do not support constraints in the above-described form. Hence, we generalize the so-called “recursive linearization” technique to variable-matrix products, akin to handling a multilinear term of scalar variables in the context of deterministic global optimization [20, 21, 22]. Thus, QCOpt reformulates constraint (4) as follows:
| (5a) | |||
| (5b) | |||
In the above reformulation, represents cumulative products of variable unitary gates, thus preserving the property of being an unitary matrix. While the elements of matrix are affine functions of only binary variables (see constraints (3)), the elements of matrix can be values in a complex field , whose real and imaginary parts lie within the box . Thus, the constraints in (5a) are still non-linear, with elements of being bilinear products of a continuous and a binary variable. Let one such product term be where represents either real or an imaginary part of an element of and represents a binary variable associated with any one of the native gates. This product can be efficiently and exactly linearized by applying the following set of four affine constraints with an auxiliary variable per product term:
| (6a) | ||||
| (6b) | ||||
The above linearization reformulation of non-linear constraints in (5), also known as McCormick linearization [23], is named the compact_formulation in QCOpt. However, QCOpt also implements a theoretically stronger linearization formulation based on convex-hull disjunctions proposed by Balas from his theory of disjunctive formulations [24]. Since a stronger formulation leads to a better linear programming relaxation of an MIP [12], this formulation was observed to be faster on smaller qubit circuits. Hence, QCOpt provides this alternative choice of the formulation, which is named the balas_formulation.
III-A Objective function
Currently QCOpt implements two separate objective functions relevant in the field of quantum circuit design. However, the software can easily be extended to support other objectives as needed, such as minimizing the cross-talk noise on quantum processors [25]. To be consistent with the previous derivations, we now present these functions on the two-qubit circuit:
a) To minimize the total depth, which is also the total number of one- and two-qubit gates admitted in the decomposition, as this serves as a proxy for the execution time of the circuit. This objective is modeled as a linear function as follows:
b) To minimize the total number of gates in the decomposition, modeled as a linear function as follows:
Note that it is important to have an gate () in the native gates set in order to obtain a compact circuit decomposition while minimizing the above mentioned objectives. This ensures an optimal decomposition of a depth lesser than the given value of , if such a decomposition is feasible to the optimization model.
To summarize, the optimization model, with the linear objective function and the set of linearized constraints as described earlier in this section, is a mixed-integer program (MIP) which can be solved to global optimality using state-of-the-art MIP solvers. We now provide a brief discussion on the optimality guarantees of these solvers.
III-B MIP optimality guarantees
State-of-the-art solvers such as CPLEX and Gurobi are very well developed technologies with a solid mathematical footing and decades of R&D towards solving generic MIPs with convex constraints. These solvers employ a combination of branch-and-bound (B&B) algorithm and cutting plane generation to solve a MIP to global optimality [26, 12]. In its basic form, a B&B is a divide-and-conquer approach that partitions an exponential search space sequentially into smaller sub-problems, also referred to as nodes of the B&B tree, which are intended to be easier to solve. At each node of this B&B tree, a linear programming (LP) relaxation is solved by relaxing the integrality of the binary variables. During this process of “branching”, the LP relaxation’s objective serves as a lower bound and an integral solution’s objective, obtained using heuristics, serves an upper bound to the optimal solution of the MIP. If at any node, the LP relaxation value is greater than the best integral solution encountered so far, then the search can safely be stopped at that node as none of its children will yield a better solution than the current best solution. Termination criterion for the B&B algorithm is when the obtained LP relaxation is also integral, that is, when the lower and the upper bounds are close enough to each other, thus guaranteeing the global optimality of this integer solution. Despite the theoretical complexity of this algorithm being exponential in the worst-case, it can be accelerated by orders-of-magnitude by incorporation of effective and valid constraints (cutting planes or cuts) into this scheme. State-of-the-art MIP solvers incorporate an array of such generic cuts, like Gomory, mixed-integer rounding and flow-cover cuts, to name a few [12]. While these cuts perform well for generic MIPs, there still remain several technical insights and careful analysis which can lead to problem-specific cuts, which MIP solvers cannot generate automatically. Hence, in the forthcoming section, we summarize a few effective cuts which QCOpt implements to accelerate the convergence to global optimality.
III-C Search space reduction via valid inequalities
QCOpt implements various symmetry-breaking, valid constraints in form of inequalities which have been observed to be very critical in reducing the search space or the number of nodes explored in the B&B tree. For example, these mathematical insights are shown in Section IV-A to provide up to a 180 times improvement in runtime of QCOpt even on two-qubit circuits. Here, we summarize these constraints:
-
1.
Commuting gates: Given any two unitary native gates and , they are said to commute if their commutator, is equal to zero. Thus including the following inequality in a pairwise fashion will forbid the symmetric feasible solution , while not changing the optimal circuit:
Commuting gate constraints can also be further generalized to deeper sub-circuits of equivalent patterns, which can be found extensively in the quantum literature [9, 27, 28]. For example, while the sequence “” is a possible feasible sub-circuit, an equivalent sub-circuit “” can be eliminated from the search space via a valid inequality. QCOpt is currently equipped to identify such classic patterns and apply constraints to forbid equivalent sub-circuits.
-
2.
Involutory gates: Any unitary native gate, is said to be involutory, if and only if is an Identity () gate. Assuming that is already in the native gates set, such consecutive pairs of gate can be eliminated using an inequality similar as above.
-
3.
Idempotent gates: Any unitary native gate, is said to be idempotent, if and only if . Again, such consecutive pairs of gate can be eliminated using an inequality.
-
4.
Redundant gate-pairs: Let the set of native gates be . Any gate-pair index which belongs to the set is considered as a redundant pair, and such pairs can be eliminated via inequalities as described above.
III-D Proving Circuit Infeasibility in QCOpt
In the process of compiling any arbitrary entangled state into a circuit that is supported by a particular quantum processor, analyzing it’s feasibility with minimal measurement errors itself becomes a critical task. Moreover, obtaining insights on cost of noisy gates with feasibility certificates for an entangled target gate can also be very useful for quantum processor designer. To this end, QCOpt can be an incredibly useful diagnostic tool for proving infeasibility of decomposing any arbitrary unitary using hardware-based elementary gates. Although, proving infeasibility of an MIP can be NP-hard in worst case, there are numerous sophisticated techniques in MIP solvers such as conflict graph analysis, dual proof analysis, bound-tightening presolves and isolation of an Irreducible Infeasible Subset of constraints (IIS) from a large set of constraints [29]. These aforementioned methods can also get very efficient by further reducing the search space of feasibility via valid constraints as described in section III-C. Thus, the design philosophy of QCOpt makes it easy to perform this kind of infeasibility analysis, about which we present a result on the classic Toffoli gate in section IV-E.
IV Case Studies using QuantumCircuitOpt
In this section, we provide proof-of-concept case studies to demonstrate the efficacy of using QCOpt for obtaining optimal quantum circuit design. These studies are implemented in QCOpt v0.3.0 using Gurobi v9.1.2 [30] as an underlying MIP solver on an Intel 8 Cores i9 machine running at 2.40 GHz with 32 GB of RAM running a Mac OS. All the input settings for the test target gates in this section are available at this open-source link: https://github.com/harshangrjn/QuantumCircuitOpt.jl/tree/master/examples.
Validation: The correctness of the QCOpt’s implementation has been thoroughly validated on numerous standard gate decompositions from the literature and IBM’s Qiskit library [31]. Moreover, the open-source nature of the Julia ecosystem makes replicating these results effortless.
IV-A Efficacy of QCOpt’s mathematical formulations
Table I summarizes the run times (in seconds) of QCOpt’s implementation for decomposing various target gates as listed in the table. Note that the “Magic basis” and “Grover” gates in this table correspond to the circuits shown in Figures 4(b) and 5(b), respectively. The objective function for all these test gates was to minimize the total number of one and two-qubit gates in the resulting decomposition.
It is clear from Table I that the symmetry-breaking valid constraints (see section III-C) provide huge speedups in runtimes, with up to 180 times, in comparison with the basic MIP formulation derived in section III. However, note that the optimal solutions obtained by both these methods are identical, because the valid constraints are only speeding up the MIP solver by reducing the feasible search space. We also observed in our experiments that the basic MIP formulation (w/o VCs) stalled at much larger optimality gaps (without convergence) for circuits with . Thus, the MIP models and the valid constraints in combination with the pre-solving techniques discussed in section II-C make QCOpt an efficient tool for synthesizing up to medium-scale quantum circuits.
| MIP run times (sec.) | |||||
|---|---|---|---|---|---|
| Target gate | w/o VCs | with VCs | Speedup | ||
| controlled-Z [31] | 72 | 4 | 188.4 | 3.9 | 48.3x |
| controlled-V [31] | 9 | 7 | 63.8 | 12.2 | 5.2x |
| controlled-H [31] | 32 | 5 | 31.1 | 4.6 | 6.7x |
| Magic basis [7] | 72 | 5 | 597.7 | 177.2 | 3.4x |
| iSwap [31] | 9 | 10 | 170.9 | 6.1 | 28.0x |
| Grover [32] | 21 | 10 | 180.1 | 1.0 | 180.1x |
IV-B Compact circuit realizations
We now present new, compact circuit realizations provided by QCOpt on two-qubit circuits for target gates, “magic basis” and “Grover diffusion operator”. The circuits provided here are exact (up to global phase and machine precision) for each of these target gates. Run times for obtaining these realizations are provided in Table I (column 5). In this section, “compressed depth” of a circuit is the depth obtained by compressing the one-qubit gates on adjacent-depths which are acting on non-identical qubits into a single depth.
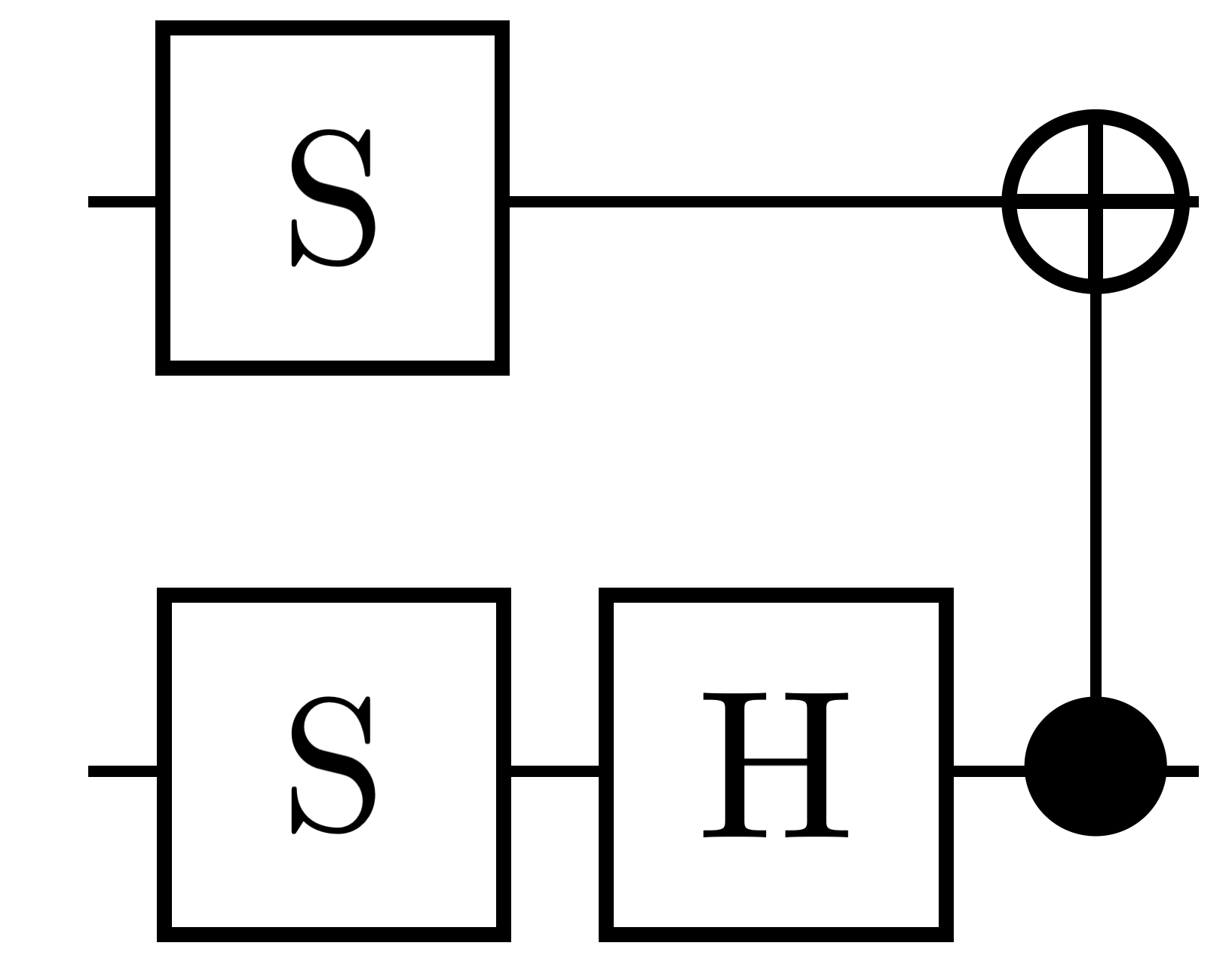
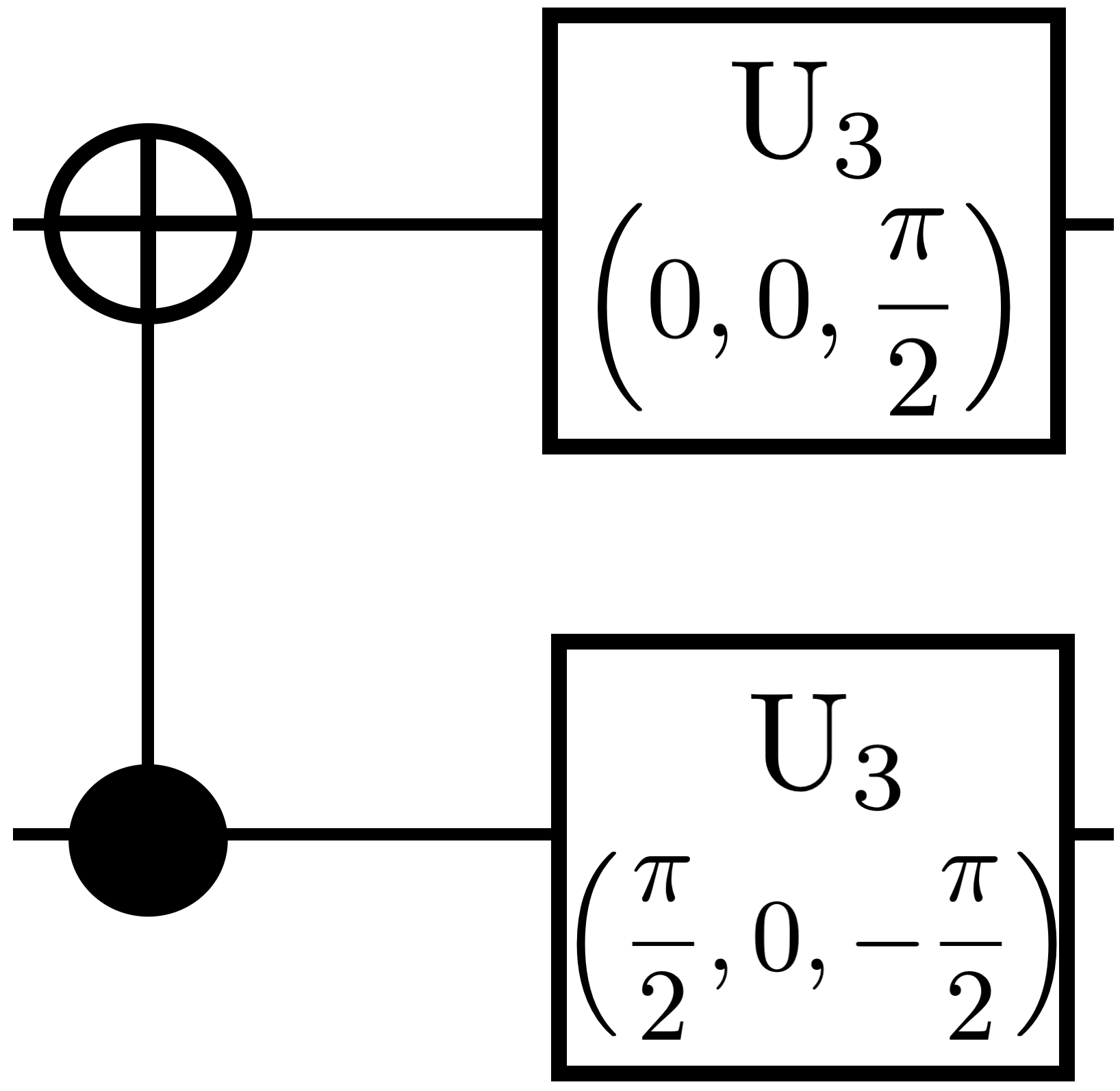
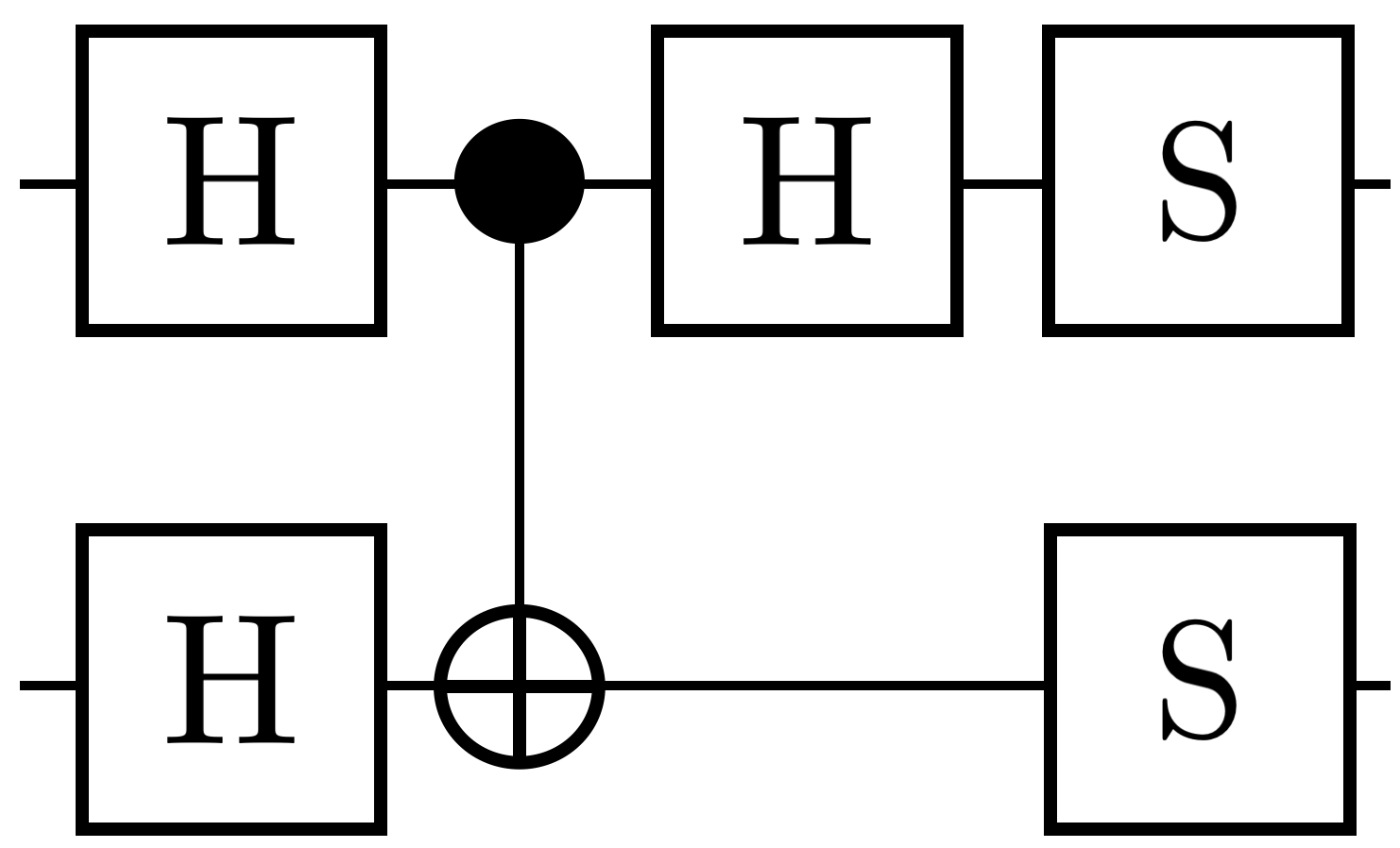
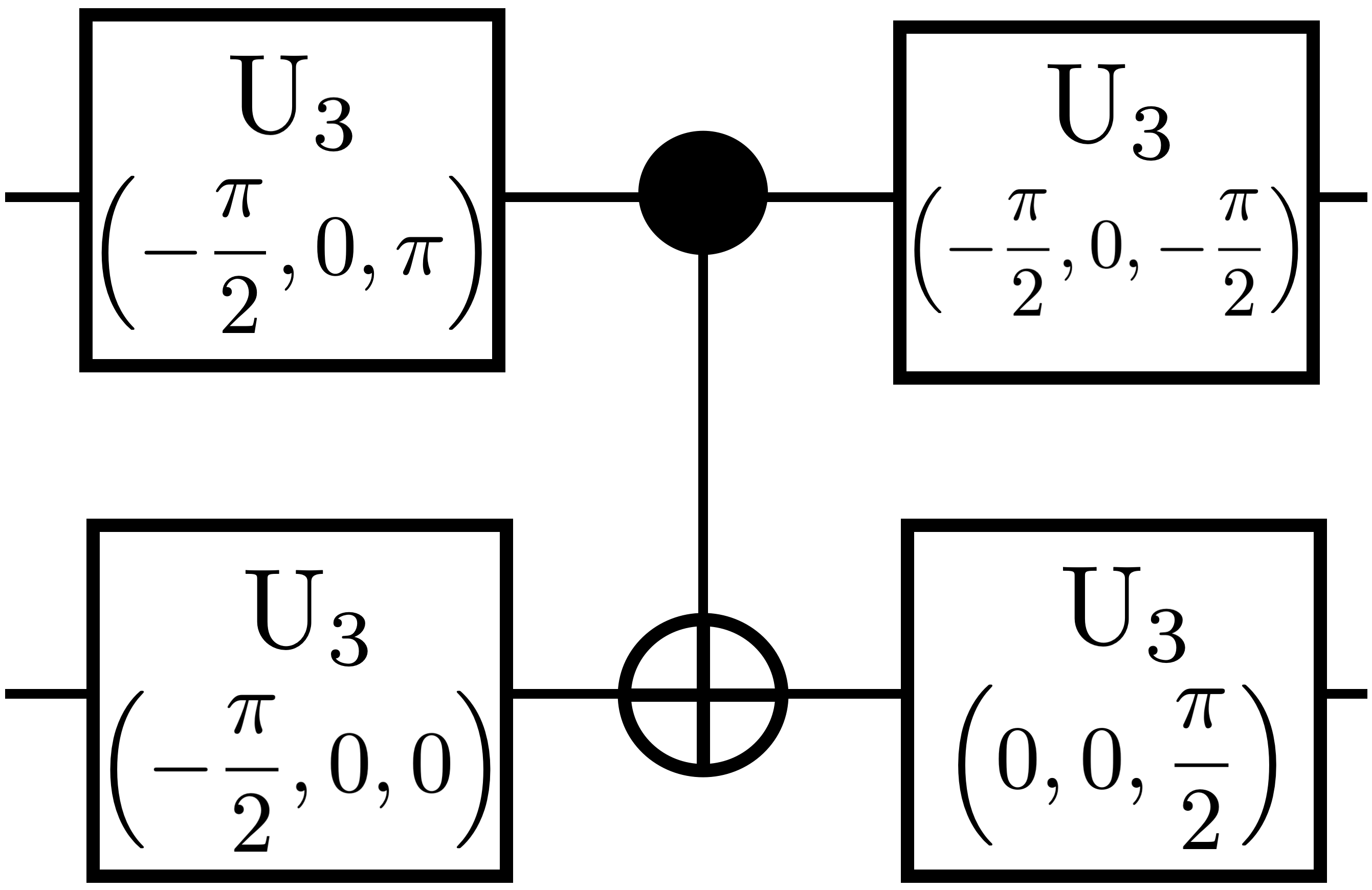
Magic basis This is an Ising-coupling unitary gate which is natively implemented in trapped-ion quantum computers [33]. Although there are numerous ways to define the so-called “magic basis”, we use the one from [34, 7]. In [7], authors provide a way to decompose any two-qubit unitary gate by repeatedly applying the magic basis gate. Theoretical bounds provided in [7] for implementing any two-qubit unitary gate was based on the magic basis circuit implemented with 4 gates and a depth of 3 as shown in Figure 4(a).
Figure 4 presents four equivalent circuit representations for the magic basis gate with different native gate sets. In the circuit in Figure 4(b), obtained using native gates, we observe 33.3% reduction in the compressed depth in comparison with the circuit implemented in [7] (see Figure 4(a)).
Implementing an entangling gate like (like in Figure 4(a) and (b)) itself can be expensive, particularly in IBM-type hardware [31]. It usually necessitates five separate gates using a Hadamard gate on both the qubits and a gate. Hence, we implemented two equivalent circuits for the magic basis using and native gates, respectively. Clearly, by optimizing using gates, as seen in Figure 4(d), QCOpt produces a circuit with one less depth, which also is the most compact way to implement a magic basis gate. To summarize, it is worth to notice that this seemingly simple result in two qubits can provide a substantial improvement in the theoretical bounds for circuit complexity, as derived in [7], when the magic basis is repeatedly applied for realizing other two-qubit gates.
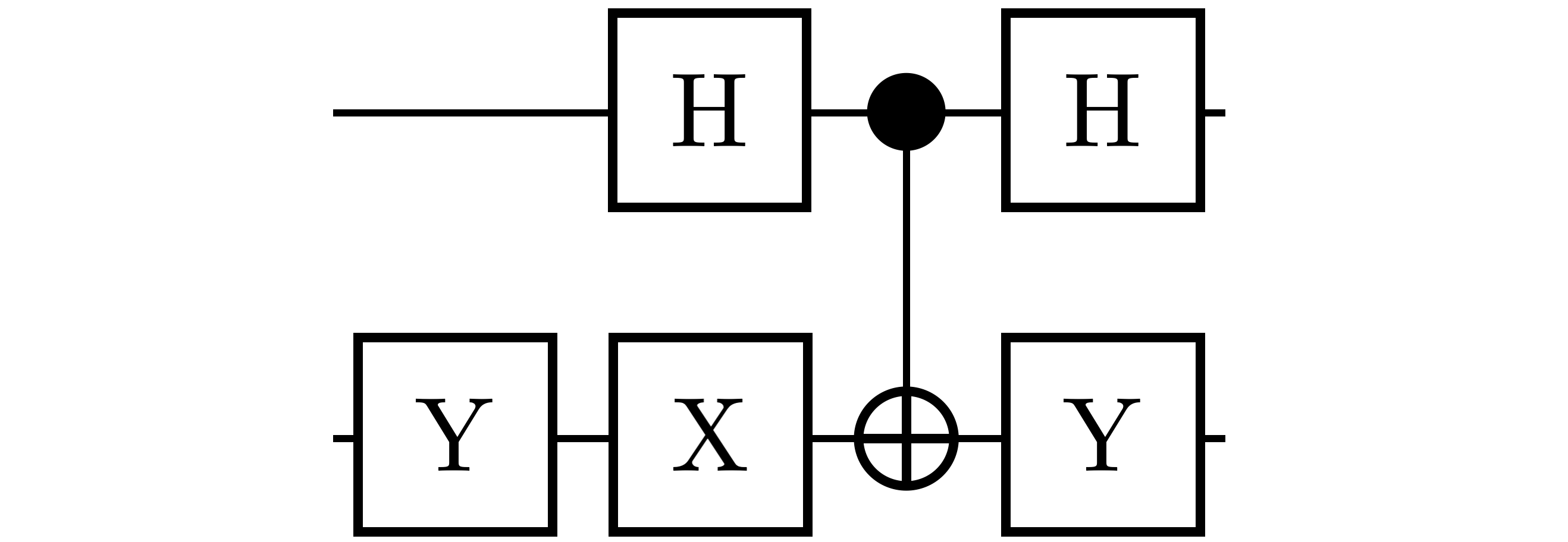
Grover diffusion operator An important part of the Grover’s algorithm is the repeated application of the Grover diffusion operator [32]. In Figure 5, we present two equivalent compact circuit realizations obtained for the Grover operator on two qubits. In Figure 5(a), the circuit is optimal with respect to the native gates in the set . In this realization, we observe a reduction of up to 42.8% in the circuit’s compressed depth, in comparison with the one provided in [32].
In Figure 5(b), the circuit is optimal with respect to the native gates in . To the best of our knowledge, this circuit with three gates is the most compact representation for the Grover operator in the literature. This realization has 57.1% lesser depth in comparison with the circuit provided in [32]. Again, to summarize, compact representations for fundamental two-qubit gates can be very beneficial, particularly when a gate like a Grover operator is applied repeatedly for larger problems as discussed in [32].
IV-C Optimal realizations using two-qubit gates
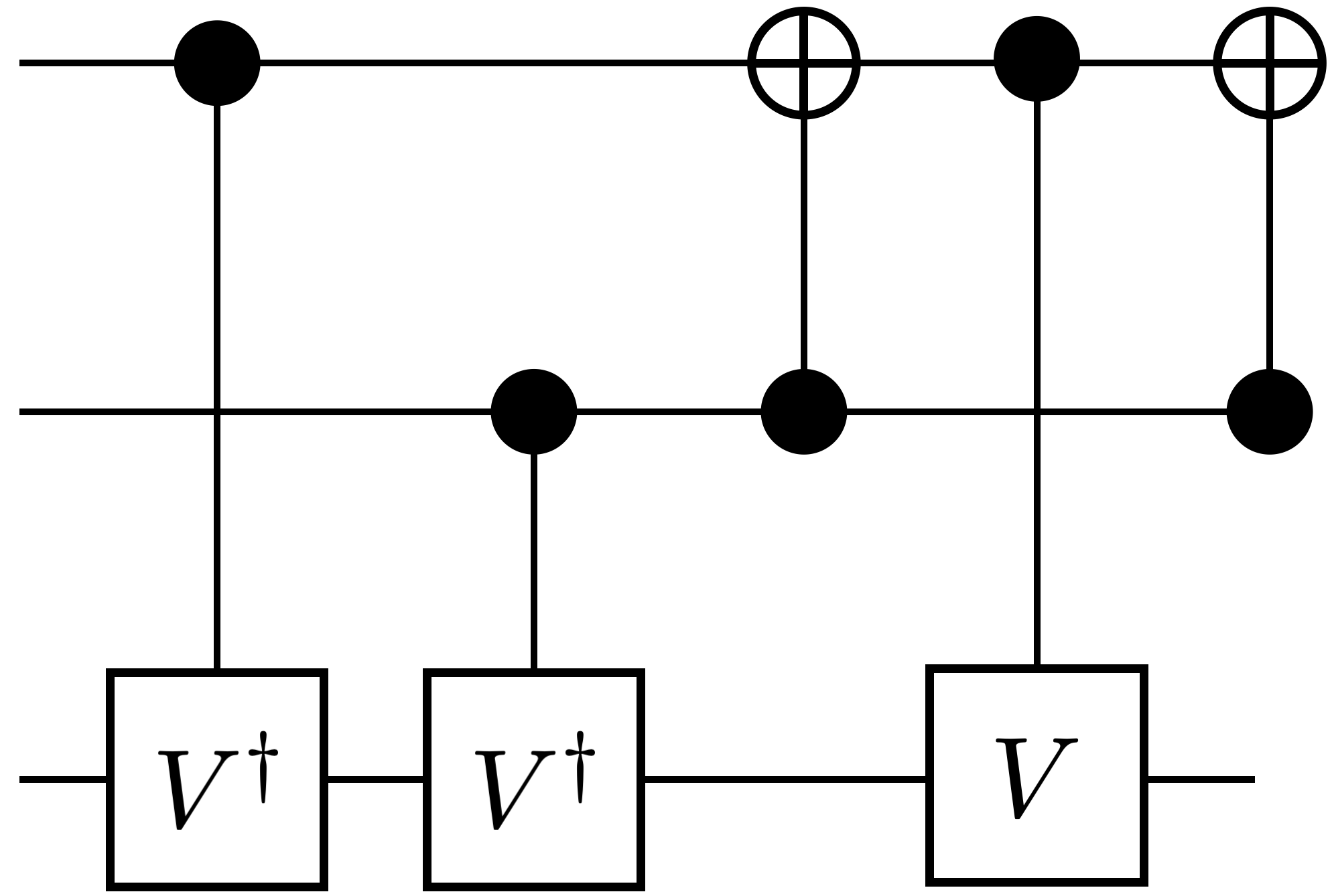
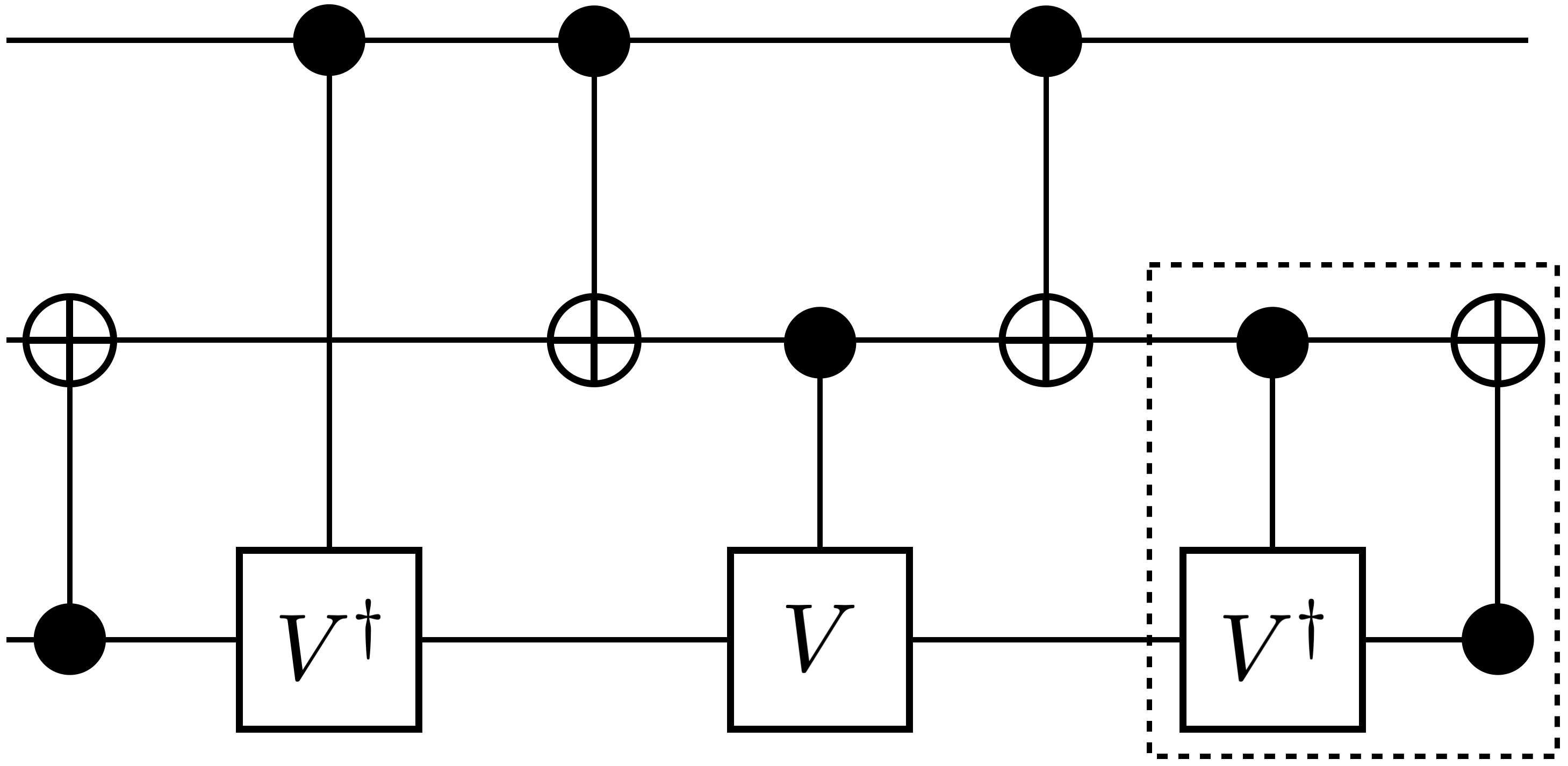
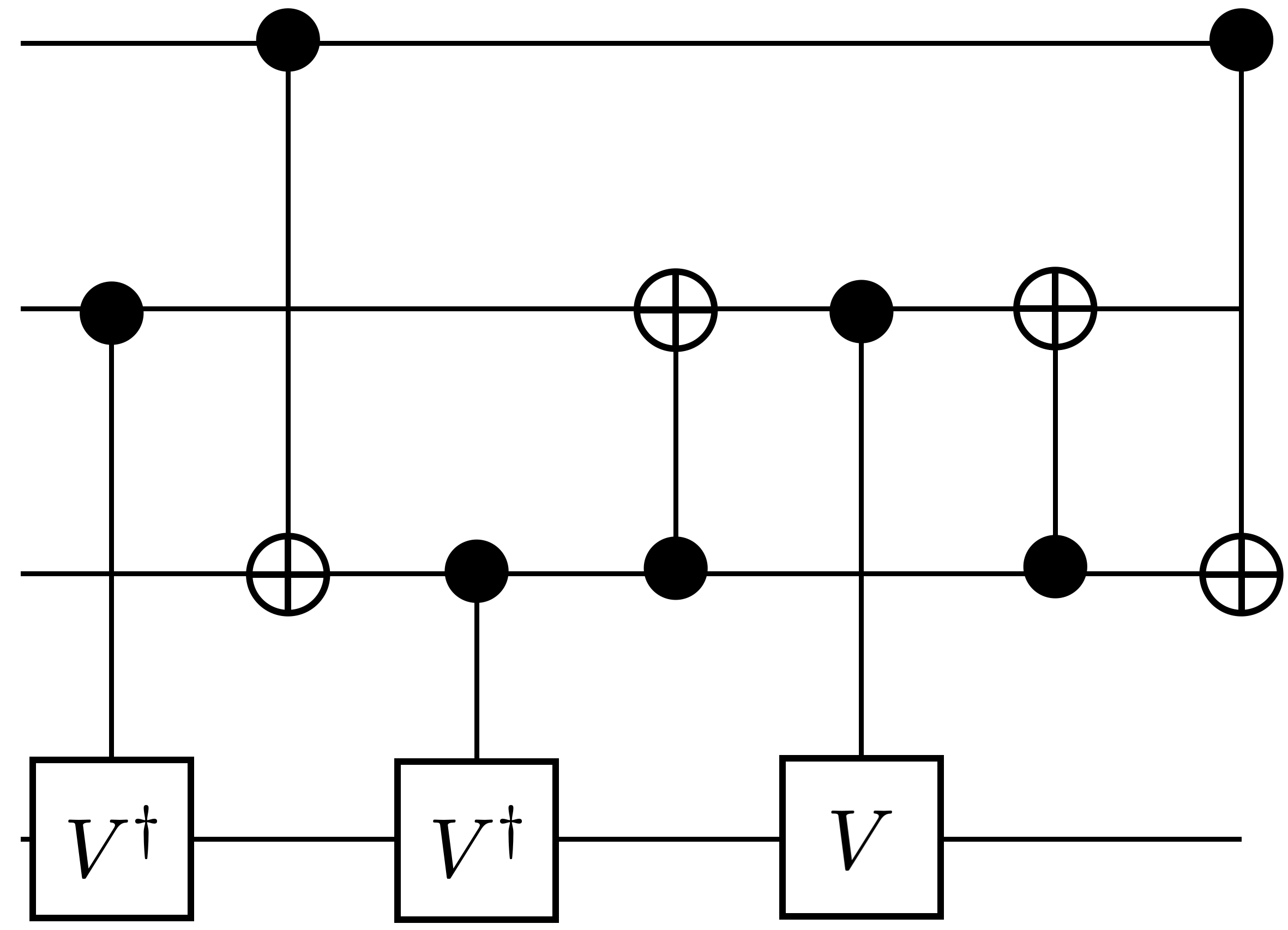
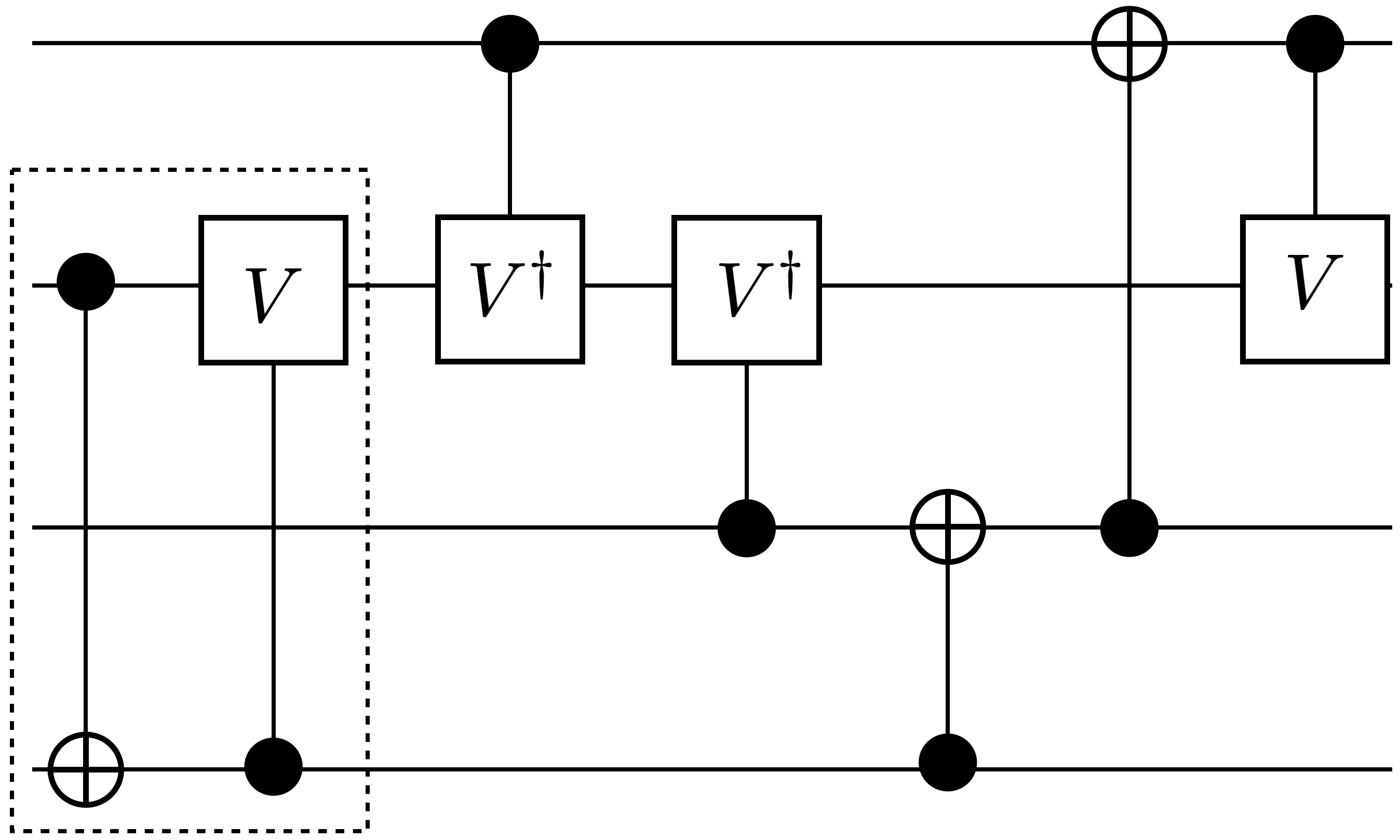
Figure 6 represents QCOpt’s optimal circuit realizations of target unitarites on three and four qubits, using only two-qubit native gates. We present these gates in comparison with [36], where the authors implement a brute-force-type enumeration algorithm, based on so-called “symbolic reachability analysis”, to realize optimal circuits. Thus the circuit realizations in Figure 6 obtained by QCOpt match the ones in [36]. Although, the run times mentioned in [36] were based on older computing platforms, we observe speedups in QCOpt by orders-of-magnitude, due to both improvement in computing platforms and the algorithmic enhancements implemented in QCOpt and state-of-the-art MIP solvers. To be clear, in Figure 6, QCOpt’s run times for decomposing Toffoli, Fredkin, double-Toffoli and quantum full-adder gates are 3.7 s., 72.1 s., 397.4 s., 348.7 s., respectively.
It is also noteworthy to mention that authors in [35] present an implementation for Fredkin gate and mention the following: “However, since the numerical search often gets stuck in local minima, even in cases where it eventually finds a solution, the fact that we were unable to find a smaller implementation of the Fredkin gate is not a proof that one does not exist.”. Using QCOpt, we prove that the decomposition in [35] for the Fredkin gate is indeed globally optimum (in 75 s.), as shown in Figure 6(b).
IV-D QCOpt vs. brute-force enumeration approach
The naïve approach to decomposition of quantum circuits with optimality guarantees is a brute-force enumeration. This approach tries every possible combination of gates and therefore arrives at the optimal decomposition. To verify every possible circuit realization scales for the native gate set of size and a depth of . Additionally, the evaluation of each circuit scales with the complexity of matrix multiplication which grows exponentially with the number of qubits in the circuit. Thus, we implemented an approach which goes through all circuit combinations randomly up to a prescribed time limit. For this purpose, we set a time limit of 500 s.
For the Fredkin gate, the above-described approach could not produce any feasible decomposition (fidelity =1) within the time limit for all three randomized trials. However, for the quantum full-adder gate, out of three randomized trials, it produced an optimal decomposition in just one trial (within 435 s.), and was infeasible for the remaining two trials. For the quantum full-adder gate, as mentioned in section IV-C, QCOpt produces an optimal decomposition in less than 385 seconds. To summarize, in comparison with the above-described naïve approach, rigorous mathematical programming-based methods in QCOpt can be incredibly reliable and robust for quantum circuit applications.
IV-E Proving infeasibility for the Toffoli gate
As discussed in section III-D, QCOpt can not only can prove the existence of an optimal circuit, but can also be used as a tool to prove infeasibility of an existence of an implementation for given target gate. For this purpose, we tested the following: Given a three qubit Toffoli [16] as the target gate, with as the elementary gates, and a maximum depth for an allowable decomposition () equal to , QCOpt provided a proof on infeasibility within 9 minutes that there does not exist an exact decomposition of depth lesser than or equal to . This again shows the efficacy of mathematical models implemented in QCOpt.
V Conclusions
In this work, we proposed QuantumCircuitOpt, which implements provably optimal methods, based on mathematical programming models, to compile any arbitrary quantum unitary into a sequence of hardware-native gates. Results indicate that QCOpt can prove the optimality of several medium-sized circuits such as magic basis, Grover diffusion operator, Toffoli, Fredkin, double-Toffoli and quantum full-adder gates, with run times less than a few minutes on a commodity computing hardware. Moreover, QCOpt produces a new circuit realization for the magic basis gate based on non-trivial angle parameters of the universal gate. We also validated the efficacy of mathematical models in QCOpt and demonstrated it’s advantages over a naïve brute-force enumeration algorithm.
To summarize, we believe that the extensibility and modularity of the Julia language and the function-based architecture of the well-documented QuantumCircuitOpt package enable a robust software infrastructure for the continuously evolving research landscape of quantum computing. Furthermore, while we continue enriching the capabilities of QCOpt, we encourage the quantum computing community to explore the package and also contribute to this novel platform.
VI Acknowledgements
This work was supported by the U.S. DOE through a quantum computing program sponsored by the Los Alamos National Laboratory (LANL) Information Science & Technology Institute and the LANL’s Laboratory Directed Research and Development (LDRD) program under projects “20190590ECR: Discrete Optimization Algorithms for Provably Optimal Quantum Circuit Design” and “20210114ER: Accelerating Combinatorial Optimization with Noisy Analog Hardware”.
References
- [1] J. Preskill, “Quantum computing in the NISQ era and beyond,” Quantum, vol. 2, p. 79, 2018.
- [2] J. Kelly, “A preview of bristlecone, google’s new quantum processor,” Google Research Blog, vol. 5, 2018.
- [3] “National strategic overview for quantum information science,” 2018. [Online]. Available: https://www.quantum.gov/wp-content/uploads/2020/10/2018_NSTC_National_Strategic_Overview_QIS.pdf
- [4] P. W. Shor, “Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer,” SIAM review, vol. 41, no. 2, pp. 303–332, 1999.
- [5] R. P. Feynman, “Simulating physics with computers,” in Feynman and computation. CRC Press, 2018, pp. 133–153.
- [6] A. Barenco, C. H. Bennett, R. Cleve, D. P. DiVincenzo, N. Margolus, P. Shor, T. Sleator, J. A. Smolin, and H. Weinfurter, “Elementary gates for quantum computation,” Physical review A, vol. 52, p. 3457, 1995.
- [7] F. Vatan and C. Williams, “Optimal quantum circuits for general two-qubit gates,” Physical Review A, vol. 69, no. 3, p. 032315, 2004.
- [8] S. Khatri, R. LaRose, A. Poremba, L. Cincio, A. T. Sornborger, and P. J. Coles, “Quantum-assisted quantum compiling,” Quantum, vol. 3, p. 140, 2019.
- [9] Y. Nam, N. J. Ross, Y. Su, A. M. Childs, and D. Maslov, “Automated optimization of large quantum circuits with continuous parameters,” npj Quantum Information, vol. 4, no. 1, pp. 1–12, 2018.
- [10] E. Younis, K. Sen, K. Yelick, and C. Iancu, “QFAST: Quantum synthesis using a hierarchical continuous circuit space,” arXiv preprint: 2003.04462, 2020.
- [11] R. E. Bixby, M. Fenelon, Z. Gu, E. Rothberg, and R. Wunderling, “Mixed-integer programming: A progress report,” in The sharpest cut: the impact of Manfred Padberg and his work. SIAM, 2004, pp. 309–325.
- [12] L. A. Wolsey, “Mixed integer programming,” Wiley Encyclopedia of Computer Science and Engineering, pp. 1–10, 2007.
- [13] D. Bertsimas, “Statistics and machine learning via a modern optimization lens,” in INFORMS Annual Meeting, 2014. [Online]. Available: https://bit.ly/3DdwWw4
- [14] I. Dunning, J. Huchette, and M. Lubin, “JuMP: A modeling language for mathematical optimization,” SIAM review, vol. 59, pp. 295–320, 2017.
- [15] J. Bezanson, A. Edelman, S. Karpinski, and V. B. Shah, “Julia: A fresh approach to numerical computing,” SIAM review, vol. 59, no. 1, pp. 65–98, 2017.
- [16] V. V. Shende and I. L. Markov, “On the CNOT-cost of TOFFOLI gates,” arXiv preprint:0803.2316, 2008.
- [17] T. Achterberg, R. E. Bixby, Z. Gu, E. Rothberg, and D. Weninger, “Presolve reductions in mixed integer programming,” INFORMS Journal on Computing, vol. 32, no. 2, pp. 473–506, 2020.
- [18] O. Kröger, C. Coffrin, H. Hijazi, and H. Nagarajan, “Juniper: an open-source nonlinear branch-and-bound solver in julia,” in International Conference on the Integration of Constraint Programming, Artificial Intelligence, and Operations Research. Springer, 2018, pp. 377–386.
- [19] N. M. Tran and J. Yang, “Antibiotics time machines are hard to build,” Notices of the AMS, vol. 64, no. 10, pp. 1136–1140, 2017.
- [20] H. Nagarajan, M. Lu, S. Wang, R. Bent, and K. Sundar, “An adaptive, multivariate partitioning algorithm for global optimization of nonconvex programs,” Journal of Global Optimization, vol. 74, no. 4, pp. 639–675, 2019.
- [21] H. Nagarajan, M. Lu, E. Yamangil, and R. Bent, “Tightening McCormick relaxations for nonlinear programs via dynamic multivariate partitioning,” in International conference on principles and practice of constraint programming. Springer, 2016, pp. 369–387.
- [22] K. Sundar, H. Nagarajan, J. Linderoth, S. Wang, and R. Bent, “Piecewise polyhedral formulations for a multilinear term,” Operations Research Letters, vol. 49, no. 1, pp. 144–149, 2021.
- [23] G. P. McCormick, “Computability of global solutions to factorable nonconvex programs: Part i—convex underestimating problems,” Mathematical programming, vol. 10, no. 1, pp. 147–175, 1976.
- [24] E. Balas, Disjunctive programming. Springer, 2018.
- [25] P. Murali, D. C. McKay, M. Martonosi, and A. Javadi-Abhari, “Software mitigation of crosstalk on noisy intermediate-scale quantum computers,” in Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, 2020, pp. 1001–1016.
- [26] A. Lodi, “Mixed integer programming computation,” in 50 years of integer programming 1958-2008. Springer, 2010, pp. 619–645.
- [27] D. Maslov, G. W. Dueck, D. M. Miller, and C. Negrevergne, “Quantum circuit simplification and level compaction,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 27, no. 3, pp. 436–444, 2008.
- [28] G. W. Dueck, A. Pathak, M. M. Rahman, A. Shukla, and A. Banerjee, “Optimization of circuits for IBM’s five-qubit quantum computers,” in Euromicro Conference on Digital System Design. IEEE, 2018, pp. 680–684.
- [29] J. Witzig, T. Berthold, and S. Heinz, “Computational aspects of infeasibility analysis in mixed integer programming,” Mathematical Programming Computation, pp. 1–33, 2021.
- [30] L. Gurobi Optimization, Gurobi Optimizer Reference Manual, 2021. [Online]. Available: http://www.gurobi.com
- [31] G. Aleksandrowicz, T. Alexander, P. Barkoutsos, L. Bello, Y. Ben-Haim, D. Bucher, F. J. Cabrera-Hernández, J. Carballo-Franquis, A. Chen, C.-F. Chen et al., “Qiskit: An open-source framework for quantum computing,” Accessed on: Mar, vol. 16, 2019.
- [32] J. Abhijith, A. Adedoyin, J. Ambrosiano, P. Anisimov, A. Bärtschi, W. Casper, G. Chennupati, C. Coffrin, H. Djidjev, D. Gunter et al., “Quantum algorithm implementations for beginners,” arXiv e-prints, pp. arXiv–1804, 2018.
- [33] D. Hanneke, J. P. Home, J. D. Jost, J. M. Amini, D. Leibfried, and D. J. Wineland, “Realization of a programmable two-qubit quantum processor,” Nature Physics, vol. 6, no. 1, pp. 13–16, 2010.
- [34] S. Hill and W. K. Wootters, “Entanglement of a pair of quantum bits,” Physical review letters, vol. 78, no. 26, p. 5022, 1997.
- [35] J. A. Smolin and D. P. DiVincenzo, “Five two-bit quantum gates are sufficient to implement the quantum fredkin gate,” Physical Review A, vol. 53, no. 4, p. 2855, 1996.
- [36] W. N. Hung, X. Song, G. Yang, J. Yang, and M. Perkowski, “Optimal synthesis of multiple output boolean functions using a set of quantum gates by symbolic reachability analysis,” IEEE transactions on Computer-Aided Design of integrated circuits and Systems, vol. 25, no. 9, pp. 1652–1663, 2006.