Quasi-conjugate Bayes estimates for GPD parameters and application to heavy tails modelling
Abstract – We present a quasi-conjugate Bayes approach for estimating Generalized Pareto Distribution (GPD) parameters, distribution tails and extreme quantiles within the Peaks-Over-Threshold framework. Damsleth conjugate Bayes structure on Gamma distributions is transfered to GPD. Posterior estimates are then computed by Gibbs samplers with Hastings-Metropolis steps. Accurate Bayes credibility intervals are also defined, they provide assessment of the quality of the extreme events estimates. An empirical Bayesian method is used in this work, but the suggested approach could incorporate prior information. It is shown that the obtained quasi-conjugate Bayes estimators compare well with the GPD standard estimators when simulated and real data sets are studied.
Key words – Extreme quantiles, Gamcon II distribution, Generalized Pareto Distribution, Gibbs Sampler, Peaks over thresholds (POT).
1 Introduction
Motivated by univariate tail and extreme quantile estimation, our goal is to develop new Bayesian procedures for making statistical inference on the shape and scale parameters of Generalized Pareto Distributions (GPD) when used to model heavy tails and estimate extreme quantiles.
Let us assume that observations of a studied phenomenon are issued from independent and identically distributed (i.i.d.) random variables with unknown common distribution function (d.f.) . Suppose that one needs to estimate either extreme quantiles of (i.e., with typically), or the extreme tail of (i.e., for , where denote the ordered observations). It is usually recommended to use the Peaks Over Threshold (POT) method (described for example in Davison and Smith (1990) or in the monographs Embrechts et al. (1997) and Reiss and Thomas (2001)), where only observations exceeding a sufficiently high threshold are considered. In view of the theorem of Balkema and de Haan (1974) and Pickands (1975) the probability distribution of the positive excesses for , where , can be approximated for large by a GPD distribution with scale parameter and shape parameter . The d.f. of GPD is
| (4) |
with , where when , and when .
The shape and scale parameters of the approximating GPD are estimated on the basis of the excesses above . The estimates are then usually plugged into the GPD d.f. and extreme quantile estimates are deduced. In this perspective, good estimation procedures for the shape and scale parameters of a GPD on the basis of approximately i.i.d. observations are necessary for accurate tail estimation. Estimating the shape and scale parameters, and , is not easy. Smith (1987) has shown that estimating GPD parameters by maximum likelihood (ML) is a non regular problem for . Besides, the ML estimators may be numerically hardly tractable, see Davison and Smith (1990) and Grimshaw (1993). Moreover, the properties of MLE’s meet their asymptotic theory only when the sample size (in our case the number of exceedances) is larger than about . Many alternative estimators have been proposed: Hosking and Wallis (1987) linear estimators are based on probability weighted moments (PWM); they are easily computed and reasonably efficient when approximately (see also the comparative study of Singh and Guo, 1997). Castillo and Hadi (1997) have proposed other estimators based on the elemental percentile method (EPM), involving intensive computations. Their numerical simulations show that EPM estimators are more efficient than PWM ones only when .
Semiparametric estimators of along with related estimators of extreme quantiles have been intensively studied. For example, the Hill estimator presented by Hill (1975) and studied in Haeusler and Teugels (1985) and Beirlant and Teugels (1989), among many others. Two classic extensions of the Hill estimator are: The moment tail index estimator (denoted hereafter MTI(DEdH)) of Dekkers, Einmahl and de Haan (1989); The Zipf estimator, see Schultze and Steinebach (1996), and its generalization by Beirlant, Dierckx and Guillou (2001), denoted hereafter ZipfG. Most of these semiparametric estimators do not perform much better than parametric ones when applied to sets of excesses. Only the ZipfG estimator seems to outperform the other ones.
In this paper, a new Bayesian inference approach for GPD’s with is introduced. In a number of application areas such as structural reliability (see for example Grimshaw, 1993) and excess-of-loss reinsurance (see Reiss and Thomas, 2001), tail estimation based on small or moderate data sets is needed. In such situations Bayes procedures can be used to capture and take into account all available information including expert information even when it is loose. Moreover, in the realm of tail inference, evaluating the imprecision of estimates is of vital importance. Bootstrap methods have been suggested to assess this imprecision. But standard bootstrap based on larger values of ordered samples is known to be inconsistent, whereas standard bootstrap based on excess samples has not second-order coverage accuracy and is imprecise when sample sizes are not extremely large (e.g., Bacro and Brito (1993), Caers, Beirlant and Vynckier, 1998). On the contrary, in the Bayesian context, credibility regions and marginal credibility intervals for GPD parameters and related high quantiles provide a non-asymptotic geometry of uncertainty directly based on outputs of the procedure, thus shortcutting bootstrap. For all these reasons (expert information, credibility intervals) easily implementable Bayesian inference procedures for GPD’s are highly desirable to study excess samples in the scope of POT methodology.
The restriction is not too damaging, since several major application areas are connected to heavy-tailed distributions. Our approach can also be tried for data issued from distributions suspected to lie in Gumbel’s maximum domain of attraction (DA(Gumbel)) where . In the latter case, direct Bayesian analysis of the exponential distribution can be made in parallel (see Appendix A).
For other papers on Bayesian approaches to high quantile estimation, see, e.g., Coles and Tawn (1996), Coles and Powell (1996), Reiss and Thomas (1999), Tancredi et al. (2002), Bottolo et al. (2003), and the monographs Reiss and Thomas (2001) and Coles (2001) along with references therein.
Our starting point is a representation of heavy-tailed GPD’s as mixtures of exponential distributions with a gamma mixing distribution. Since the Bayesian conjugate class for gamma distributions is documented (Damsleth, 1975) we only have to transfer it to GPD’s. As described in Section 2, this provides a natural Bayesian quasi-conjugate class for heavy-tailed GPD’s. Even though Bayes estimators have no analytical expressions, the quasi-conjugate structure makes the Bayes computations very simple, the convergence of the MCMC algorithms very quick and gave a high parsimony to the global approach with an intuitive interpretation of the hyperparameters.
Section 3 compares our Bayes estimates to ML, PWM, moment tail index MTI(DEdH) and generalized Zipf (ZipfG) estimates on excess samples through Monte Carlo simulations. Section 4 is devoted to benchmark real data sets. Finally, Section 5 lists some conclusions and presents forthcoming research projects.
2 Bayesian inference for GPD parameters
The standard parameterization of heavy-tailed GPD distributions described by (1) when is now replaced by a more convenient one depending on the two positive parameters and . The re-parameterized version GPD has probability density function (p.d.f.)
| (5) |
We assume in the following that we have observations which are realizations of i.i.d. random variables approximately issued from (5). Typically, they represent excesses above some sufficiently high threshold . The latter means that for each , there exists an integer such that , , where the are assumed i.i.d. and issued from a distribution in Fréchet’s maximum domain of attraction: DA(Fréchet). Remark that the case where the common distribution of the is in DA(Gumbel) can also be covered by considering the limiting situation and with (see Appendix A).
Our starting point is the following mixture representation for (5), see Reiss and Thomas (2001) page 157:
| (6) |
where for , is the density of the Gamma distribution with shape and scale parameters and . The previous representation stands only in DA(Fréchet) as and have to be non-negative (as parameters of a gamma distribution) which implies .
There is no Bayesian conjugate class for GPD’s. Nevertheless, as shown below, the mixture form (6) allows us to make use of the conjugate class for gamma distributions to construct a suitable quasi-conjugate class for GPD’s.
2.1 Transferring conjugate structure from Gamma to GPD
According to Damsleth (1975), the description of the conjugate class for gamma distributions relies on the so-called type II Gamcon distributions: for , the density of the Gamcon II() distribution with parameters and is
| (7) |
where . Let in the following denote a -sample of realizations of i.i.d. random variables issued from Gamma. According to Damsleth (1975), Theorem 2, the conjugate prior density on with hyperparameters and is given by where is the density of Gamcon II() and is the density of Gamma(). Then, the conditional density of given , denoted , is Gamcon II() with
| (8) |
and the conditional density of given and , denoted , is Gamma. Remark 1 . – The hyperparameters and act on the sufficient statistics and , whereas tunes the importance of these modifications. When is a positive integer, the introduction of these prior distributions can loosely be interpreted as artificially adding observations with arithmetic mean in and another observations with geometric mean in with .
Now the question is: How can we deduce the posterior density of the GPD parameters given (assumed in the following to be a sample from GPD) from the gamma conjugate structure, starting with Damsleth prior density ?
In the remaining of this section the following notations are used:
– Let . Consequently and will denote respectively p.d.f.’s of GPD() and Gamma() probability distributions.
– The likelihood function of the observations for writes . Similarly, the likelihood function of for writes .
– We let denote the posterior density of given the observations corresponding to and the prior density (Damsleth prior):
| (9) |
– Similarly, denotes the posterior density of given corresponding to and Damsleth prior density :
| (10) |
– We further denote
| (11) |
Thus, the posterior distribution of given is a mixture of the posterior distributions of given with mixing density :
| (12) |
It follows that each posterior moment given is the integral of the corresponding posterior moment given with respect to . Unfortunately, the functions (see (10)–(11)) and (see (11)–(12)) are not expressible in analytical close form. Therefore, a numerical algorithm is needed. The mixture representation (12) allows us to design a simple and efficient Gibbs sampler. It is presented in the next subsection.
2.2 Gibbs sampling
A Gibbs sampler is used to get approximate simulations from the posterior density of given , . Damsleth’s priors are used for . The proposed sampler generates a Markov chain whose equilibrium density (denoted ) is the joint density of conditionally on where and denote respectively random vectors of independent Gamma(, ) and GPD(, ) random variables. To implement the Gibbs sampler we first note that within the general setting of subsection 2.1, the conditional density of given is independent of : , and the conditional density of given is
| (13) |
It follows that for ,
conditionally on and ,
Gamma
independently.
This yields the following intertwining sampler,
where
denotes the current parameter value
at iteration . The next iteration:
-
1.
independently simulates each from Gamma ;
-
2.
simulates from .
In such a setting, both and are Markov chains. The simulation step of is split into the marginal simulation of and the conditional simulation of given . Finally, the iteration of our Gibbs sampler:
-
1.
independently simulates each from Gamma ;
-
2.
simulates from , i.e. from Gamcon II() with , and computed from using equation (8) ;
-
3.
simulates from Gamma.
When the equilibrium regime is nearly reached, simulated values of are approximately issued from the posterior distribution of given . Implementing the previous algorithm requires simulating Gamcon II distributions and choosing adequate values of the hyperparameters , and of the priors and .
2.3 Simulating Gamcon II distributions
Our sampling scheme involves simulations from Gamcon II distributions with , where and are given by (8), and moderate to large values of . Up to our knowledge, there is no standard algorithm for simulating such distributions. The simulation method that we present is based on a normal approximation to Gamcon II distributions using Laplace’s method.
Gamcon II can be approximated by a normal distribution having the same mode. It is proved in Garrido (2002) that this mode, , is the unique root of the equation
| (14) |
where denotes the digamma function: the derivative of the logarithm of . The standard deviation of the normal approximant distribution is computed through a Taylor expansion of the Gamcon II density in a neighborhood of its mode:
| (15) |
Garrido (2002) has established that . In practice, is numerically approximated through the bisection method.
At each iteration, we simulate Gamcon II with the help of the independent Hastings-Metropolis algorithm, which requires a suitable proposal density. Actually, it is enough to make only one step of Hastings-Metropolis at each iteration of the Gibbs sampler: see Robert (1998). The proposal density must be as close as possible to the simulated density, Gamcon II, and have heavier tails to ensure good mixing. Since Gamcon II densities have gamma-like tails, we cannot directly take the normal approximant density as a proposal. Rather, we have chosen a Cauchy proposal density as close as possible to the normal approximant density to Gamcon II, i.e. with the same mode and modal value. Therefore at each iteration our Hastings-Metropolis step:
-
1.
independently simulates a new from the Cauchy distribution with mode
and modal value ; -
2.
computes the ratio where denotes the density of ;
-
3.
takes with probability and otherwise.
Since all the transition densities involved are positive, the resulting Markov chain is ergodic with unique invariant probability measure equal to the posterior distribution of given . Intensive numerical experiments reported in Garrido (2002) show that for , this Gibbs sampler with one Hastings-Metropolis step at each iteration converges quickly to its invariant distribution. Actually, it seems that discarding the first iterations is sufficient. For , we observed numerical instabilities.
Bayesian inference on the GPD parameters , is based on the outputs of this algorithm when it has approximately reached its stationary regime. We then record a sufficient number of realizations and .
2.4 Choice of hyperparameters
In this paper we suppose that no expert information is available for the choice of priors on the GPD parameters and we thus take an empirical Bayes approach. Introduction of expert information is discussed in Appendix B.
We take both for convenience (for , the prior reduces to a gamma distribution, see below) and because a small value of indicates little confidence in prior information (see Remark 1). Recall that we observed numerical instabilities of our Gibbs sampler for . A natural approach to compute hyperparameter values of priors and is to equate some of their location parameters (e.g. the mean) to frequentist estimates of and , denoted here and . Recall that the mean of the prior distribution is . Taking this mean equal to , the estimate induced by the Hill procedure, and replacing by its Hill estimate yields . When , the prior reduces to Gamma. Its mean is . Solving the equation where this prior mean is set equal to yields
If prior modes are used instead of prior means, a similar approach leads to slightly different formulas for and . Actually, with prior modes explicit expressions can be obtained for all . However, preliminary numerical experiments yielded better estimates with prior means.
2.5 Computation of Bayesian estimates
When the Gibbs sampler approximately
reaches its stationary regime,
values denoted ,
, are saved.
This sample is used to compute posterior
means, medians or modes to estimate ,
leading to Bayesian estimates for and .
Remark 2 . –
The posterior modes are more difficult to compute
since one has first to construct smooth estimates of the joint
posterior density of and .
Numerical experiments reported in Garrido (2002)
for both GPD generated data and excess samples led us to keep only
posterior medians.
Concerning the estimation of an extreme quantile ( is a sample of excesses over a threshold ),
a sample of values is computed using POT
from the simulated ’s:
| (16) |
Means, histograms and credibility intervals can then be computed and represented from (16). Bayesian credibility intervals for , and are obtained by sorting the corresponding simulated values obtained from the Gibbs sampler. See sections 3 and 4 below. The probability distribution of the observed sample can be estimated either by GPD, or by the posterior predictive distribution. Similarly, predictive quantile functions can be approximated through
| (17) |
3 Comparative Monte Carlo simulations
Intensive Monte Carlo simulations were used to compare our Bayes quasi-conjugate estimators (denoted hereafter Bayes-QC) of and with their counterparts when usual estimators of GPD parameters are used: Maximum Likelihood (ML), Moment Tail Index estimator (MTI(DEdH)), Generalized Zipf estimator (ZipfG) and Probability Weighted Moments (PWM).
3.1 The simulation design
Three probability distributions in DA(Fréchet) were considered in order to produce various excess samples:
– The Fréchet(1) distribution, for which and the second-order regular variation parameter (presented below) . The d.f. of Fréchet() for is , .
– The Burr distribution, for which and . The d.f. of Burr() for , , is , .
– The Log-Gamma(2) distribution, for which and . The density of Log-Gamma(2) is , .
The second-order regular variation parameter () indicates the quality of approximation of by a GPD for high values of and suitable ’s. High values of indicate excellent fitting, whereas values of close to indicate bad fitting.
For each one of these three probability distributions, data sets of size were independently generated. For each simulated data set and each value of , we performed iterations of the Gibbs sampler and only the last ones were kept.
3.2 First results
For each simulated data set and each value of Bayes-QC estimates of and , , are computed as the medians of the resulting ’s and ’s given in the 500 last iterations of the Gibbs sampler. Figures 1–3 display the averages over the data sets of these Bayesian estimates of and as functions of . The means and modes were also computed and gave quite similar results. They are not displayed here. ML, MTI(DEdH) and ZipfG estimates of and , , were also computed for each of those simulated data sets and the same values of . Figures 1–3 display the averages over the data sets of these estimates of and .
The left panels of Figures 1–3 show that our estimates of based on posterior medians (continuous line curves) perform rather well compared to the other ones, and give estimates close to ML and ZipfG. The right panels of Figures 1–3 show that our estimates of are very close to those obtained by ML. Both give better estimates than MTI(DEdH) but in general do not perform as well as ZipfG, although they seem to be more stable as functions of . Again, credibility intervals for and and potential improvements when prior information is available are strong arguments supporting the use of our Bayesian procedure.
3.3 Bayes credibility and Monte-Carlo confidence intervals
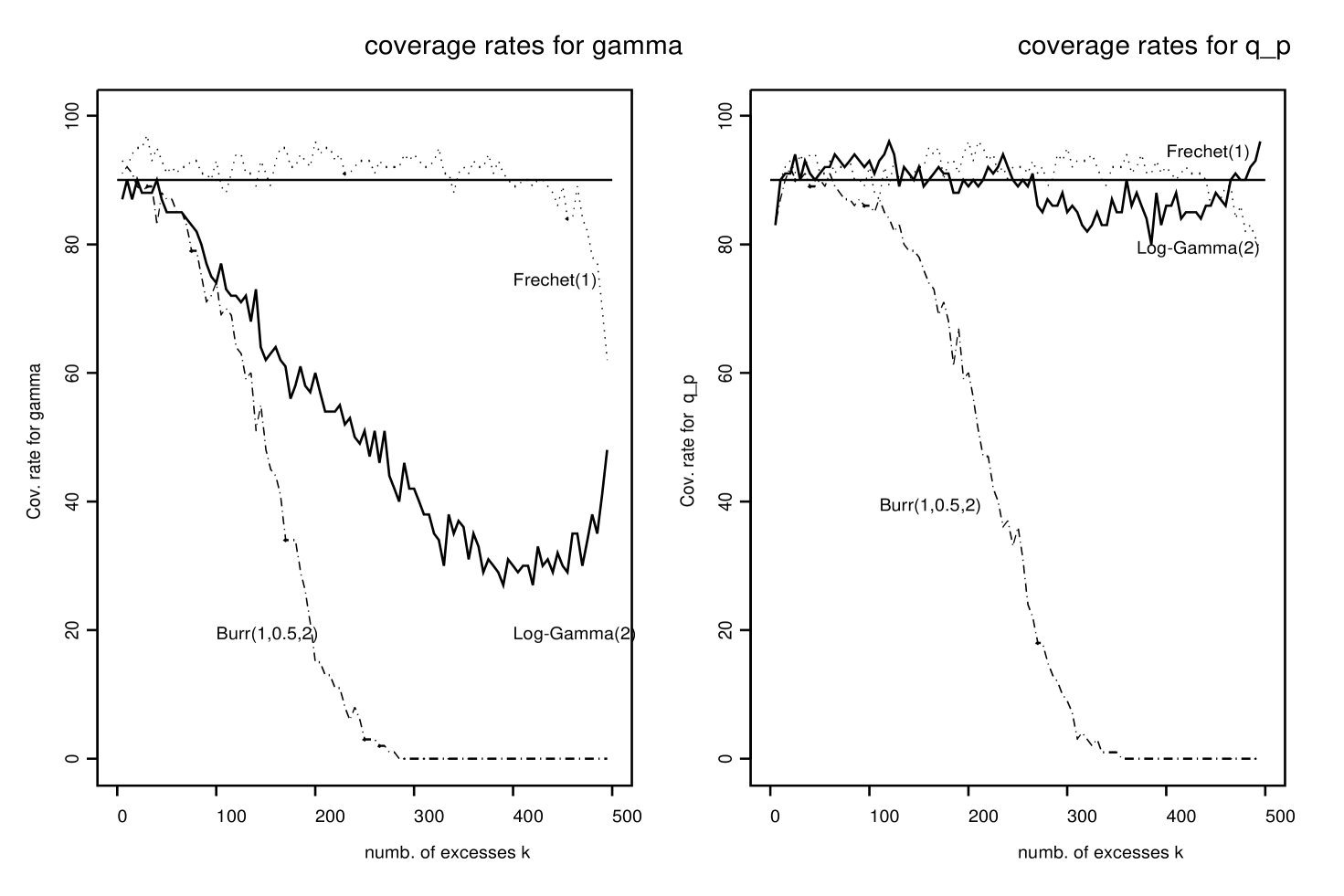
Monte Carlo simulations were also used to study whether Bayesian credibility intervals could be used as approximate frequentist confidence intervals for and . For each simulated data set, the last iterations of our Gibbs sampler provide estimates and estimates , . They can be sorted to provide approximate credibility intervals for and . The precision of these credibility intervals was studied through Monte Carlo simulations: for each one of the three probability distributions considered and for each value of , we counted the number of simulated data sets (out of ) for which the true values of and fell within the corresponding credibility intervals. Figure 4 exhibits the coverage rates for each simulated distribution and for . These credibility intervals are very accurate for the Fréchet distribution. For the Log-Gamma distribution, the credibility intervals have good coverage rates for but not for .
This rather unexpected behavior when can be explained in terms of penultimate approximation, see Diebolt, Guillou and Worms (2003): it can be proved that for , the distribution of excesses is better approximated by a GPD with scale parameter , where is some correction term, than by a GPD with scale parameter (see, e.g., the paper coauthored by Kaufmann, pages 183–190 in Reiss and Thomas (2001) along with references therein and Worms (2001)). This explains why in the case the estimates of strongly deviate from the true value. Furthermore, Diebolt et al. (2003) have established for all sufficiently regular estimators of the parameters such as ML or PWM, that when the estimated survival function is a bias-corrected estimate of . We think that this result partially explains the good and stable coverage rates observed for for the Log-Gamma distribution. These trials show that the credibility intervals computed through our procedure give very promising results.
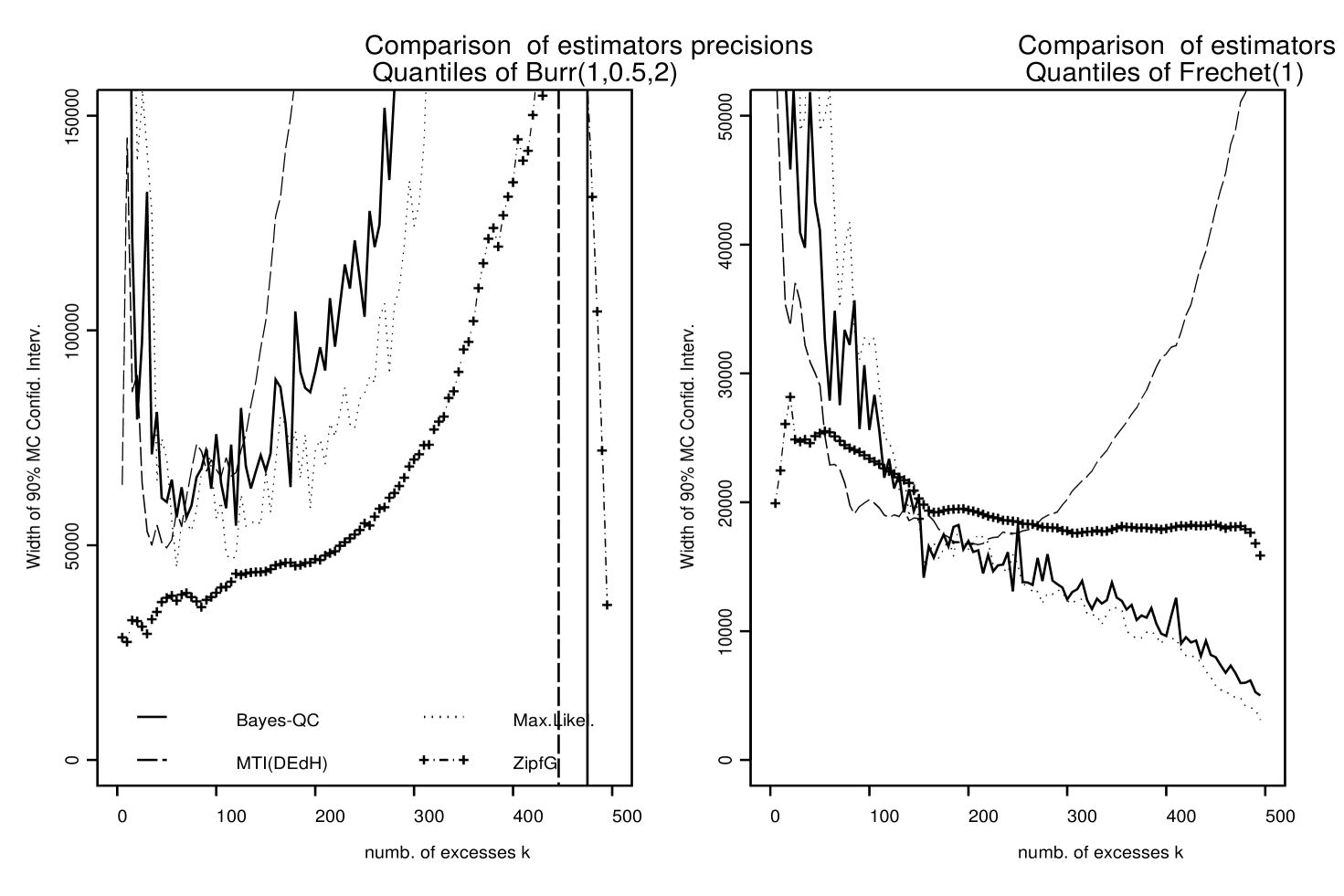
For each one of the three simulated probability distributions and each value of the 100 simulated data sets give 100 estimates of . The empirical 0.05 and 0.95 quantiles of the previous estimates give Monte-Carlo Confidence intervals (MCCI) for . The width of these MCCI’s are used in Figure 5 to compare the precision of our Bayes Quasi-conjugate estimator to ML, ZipfG and MTI(DEdH) estimators. For Burr data sets (left panel of Figure 5) ZipfG gives the most precise quantile estimators, it is followed by ML, Bayes-QC and MTI(DEdH). For Fréchet, Bayes-QC and ML have the best precisions. It is worth noting that the Bayes-QC is used here in its empirical version. Its precision will increase when combined with expert opinions.
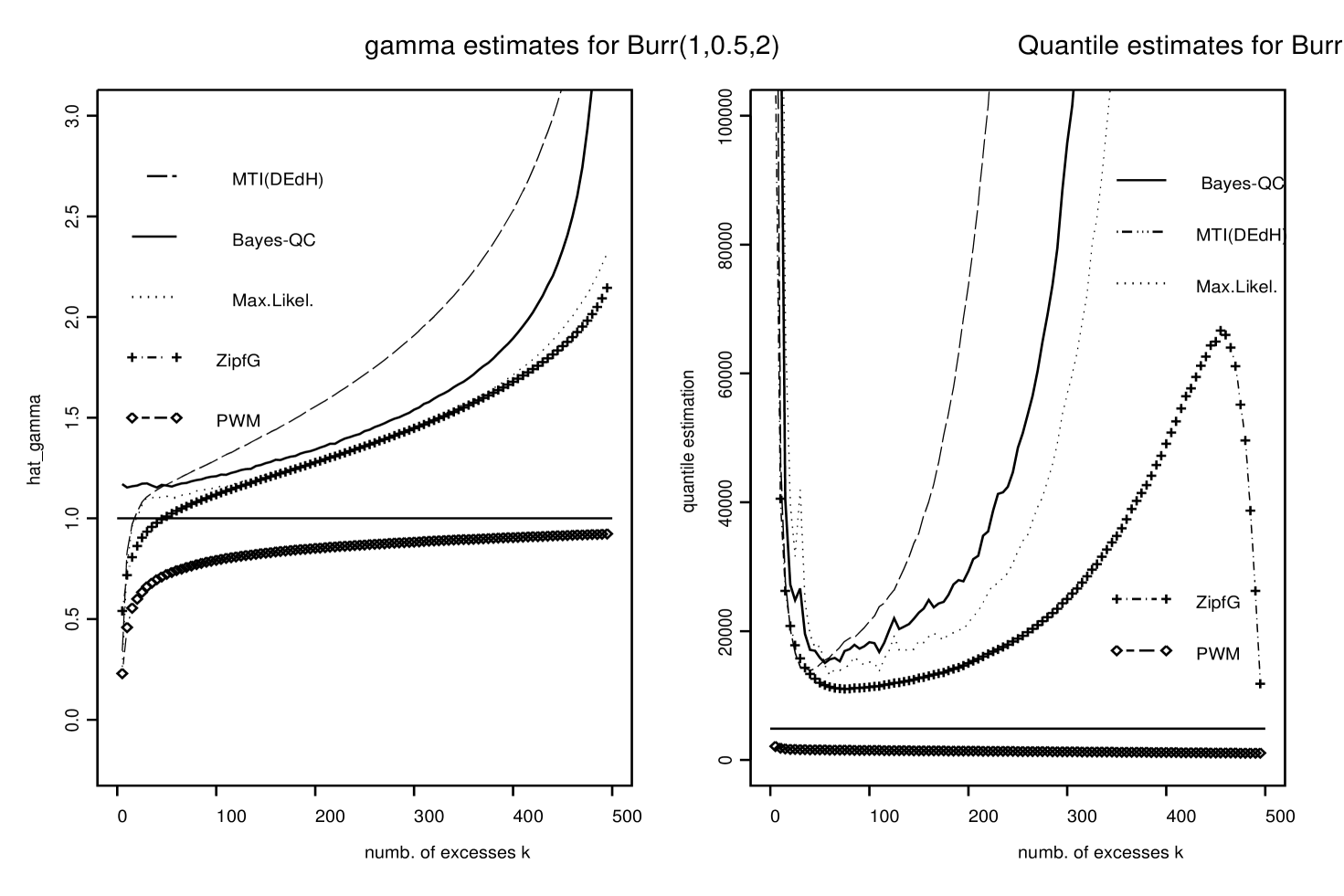
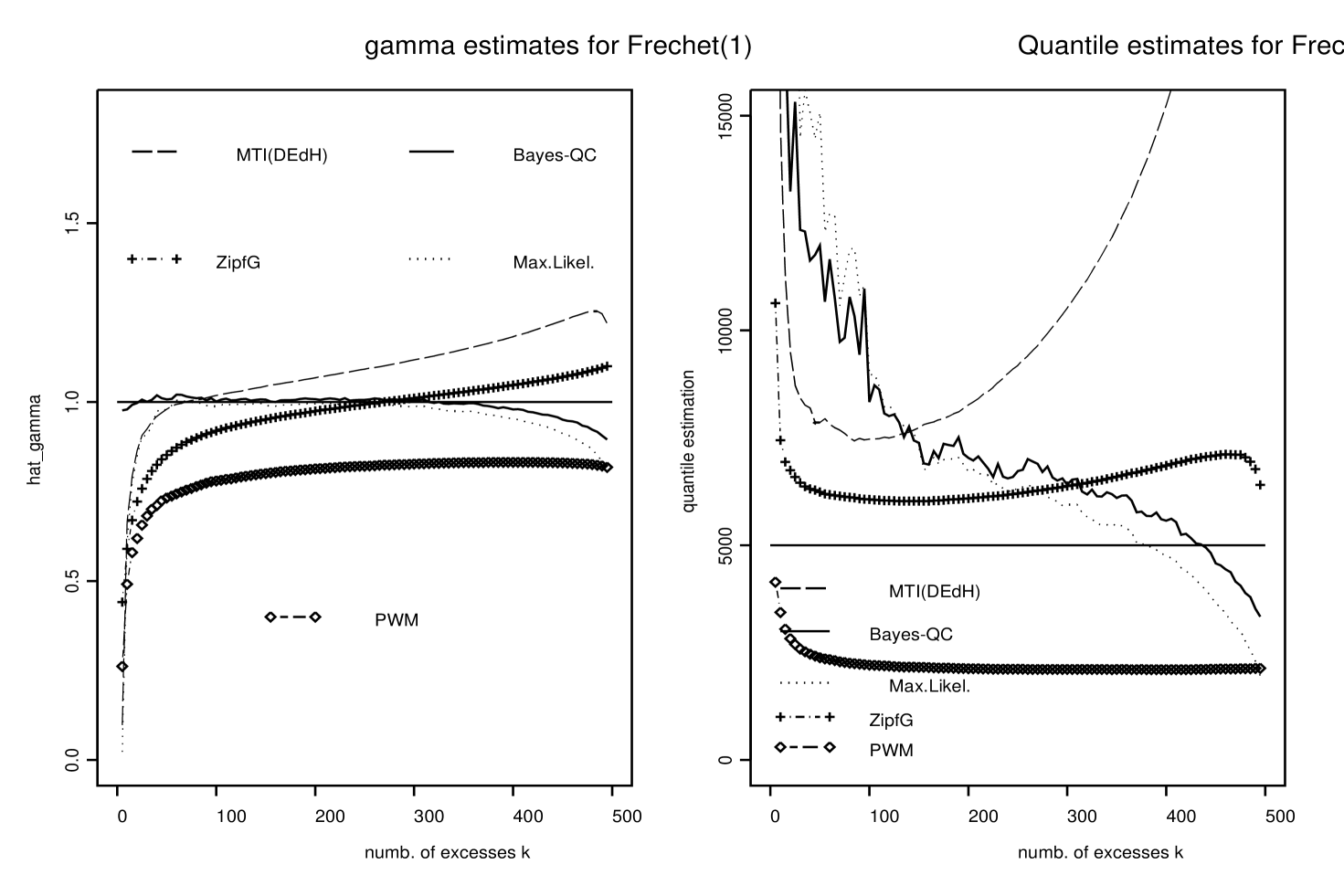
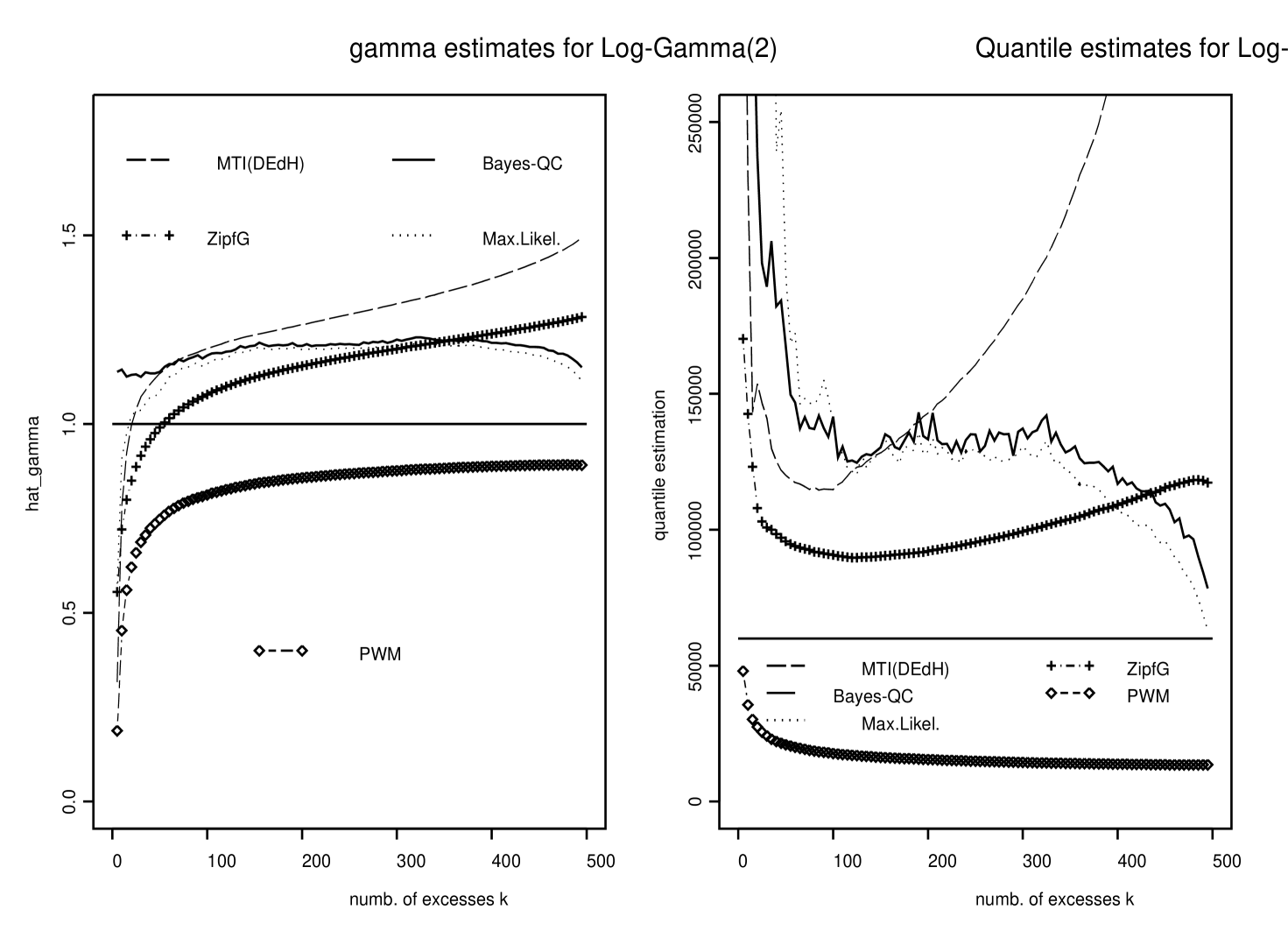
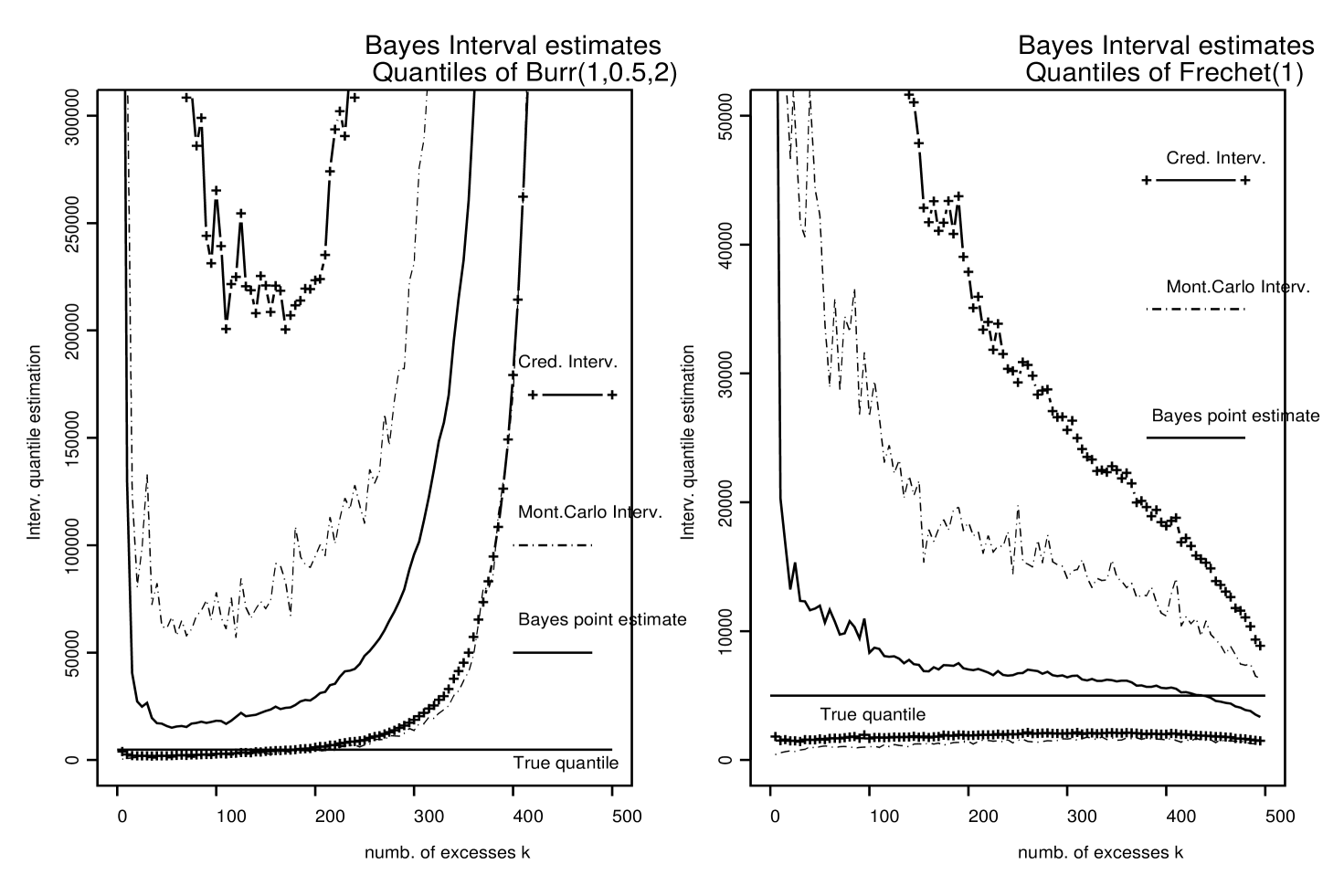
In Figure 6 the average Bayes credibility intervals (averaged over the 100 simulated data sets) are compared to the Monte-Carlo Confidence intervals (MCCI) for our Bayes-QC estimator. For both Burr (left panel) and Fréchet (right panel) ditributions lower bounds of the average Bayes credibility intervals and MCCI are very close. Upper bounds of average Bayes credibility intervals are larger than those of MCCI. It is interesting to note that the width of the average Bayes credibility intervals are the narrowest for where Bayes estimate of is the closest to the true value . This could be used to chose optimal values of the number of excesses . Finally, Figure 1 suggests that the optimal value of in the Burr case is close to . For , the credibility intervals for both and are still satisfactory.
4 Application to real data sets
Here, advantages and good performance of our Bayesian estimators are illustrated through the analysis of extreme events described by two benchmark real data sets.
Nidd river data are widely used in extreme value studies (Hosking and Wallis, 1987 and Davison and Smith, 1990). The raw data consist in exceedances of the level m3s-1 by the river Nidd (Yorkshire, England) during the period 1934-1969 (35 years). The -year return level is the water level which is exceeded on average once in years. Hydrologists need to estimate extreme quantiles in order to predict return levels over long periods (250 years, i.e. , or even 500 years).
Fire reinsurance data were first studied by Schnieper (1993) and Reiss and Thomas (1999). They represent insurance claims exceeding millions of Norwegian Kröner from 1983 to 1992 (1985 prices are used).
Many Goodness-of-fit tools (see for example Embrechts et al. 1997) suggested that excesses from Nidd river data and Fire reinsurance data are well modeled by GPD probability distribution. It was also shown that there are no problems of stationarity violation.
4.1 Nidd river data
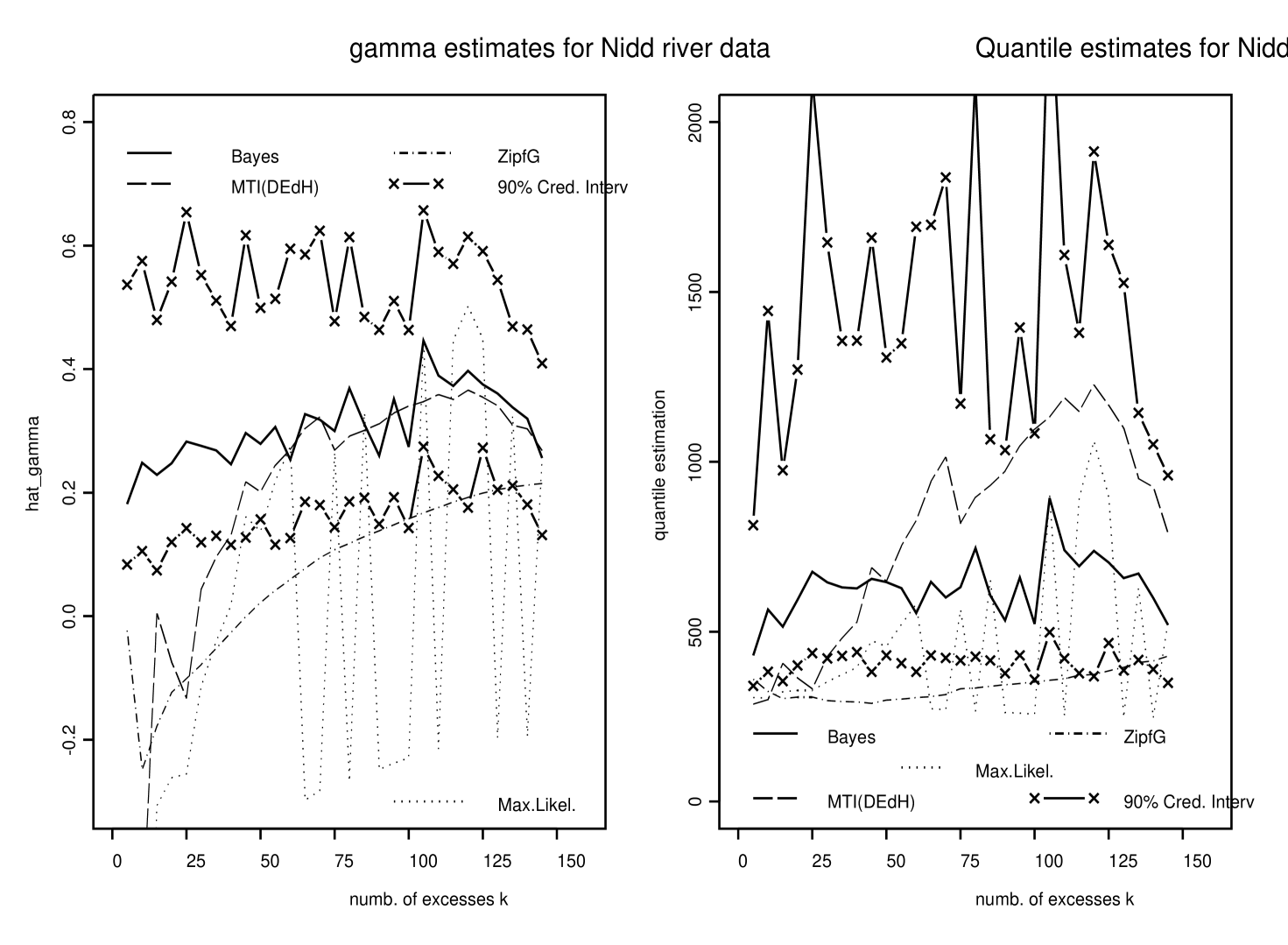
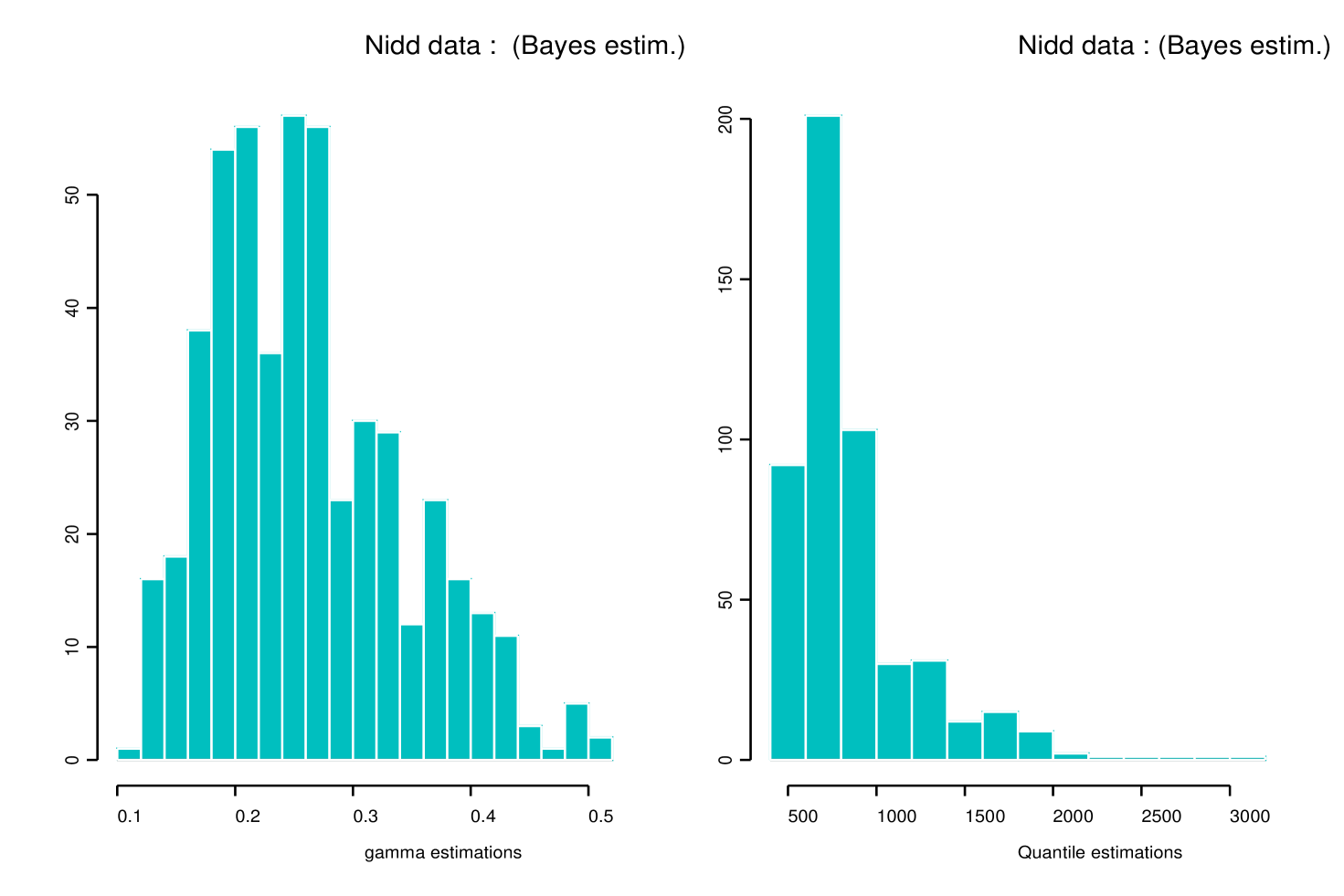
Bayes quasi-conjugate estimates and related credibility intervals for and are depicted in Figure 7 for several values of . Compared to other estimators, our approach provides the most stable estimates as varies. For values of Grimshaw’s algorithm for computing ML estimates did not converge: see the broken ML curves in Figure 7. Histograms of ’s and ’s for are displayed in Figure 8. Table 1 summarizes results of the estimation of the -year and -year return levels of the Nidd river when the threshold is set equal to either () or ().
Remark 3 . – Recall that the -year return level is the water level which is exceeded on average once in years. Equations relating to the return level follow from Davison and Smith (1990): , where it is assumed that the exceedance process is Poisson with annual rate . If we have observed excesses above the threshold during years, then is estimated by . It follows that with . For the Nidd river data, this yields . Therefore, estimating the -year return level is equivalent to estimating by .
As shown in Table 1, our credibility intervals with level (see the last column) compare well to the Bayesian confidence intervals obtained by Davison and Smith (1990), which are based on uniform priors for , and (see Smith and Naylor, 1987 for more details). Actually, ours are slightly narrower.
4.2 Fire reinsurance data and net premium estimation
In the excess-of-loss (XL) reinsurance agreements, the re-insurer pays only for excesses over a high value of the individual claim sizes. The net premium is the expectation of the total claim amounts that the re-insurer will pay during the future period : , where is the random number of claims exceeding during and are the amounts of excesses above . If the ’s are modeled by a GPD(, ) and the exceedance arrival process is modeled by a homogeneous Poisson process with annual rate , then the net premium over the coming year is approximated by . Reiss and Thomas (1999, 2001) estimate the net premium of the Norwegian fire claims reinsurance by analysing a data set (see Table 2) of large Norwegian fire claims between 1983 and 1992 (1985 prices). They use a Bayesian inference method for the GPD parameters and assume that the exceedance process is Poisson. Independent gamma priors are used for and and an inverse-gamma prior, with parameters (, ), is chosen for . Posterior means of , and are computed using Monte Carlo numerical approximations of integrals. Table 3 compares estimates of (, ) and the net premium obtained by our quasi-conjugate approach with those obtained by Reiss and Thomas for ML and Bayesian estimates with different values of the hyperparameters and of the inverse-gamma. Our approach has the advantage of indicating the precision of the estimates.
| Analysis | ML | Bayes-QC | Uniform Bayes | Bayes-QC |
|---|---|---|---|---|
| point Return level estimate | Credibility Intervals | |||
| -year return level | ||||
| 305 | 374 | [210, 775] | [266, 672] | |
| 280 | 403 | [215, 850] | [304, 690] | |
| -year return level | ||||
| 340 | 457 | [220, 935] | [306, 911] | |
| 307 | 499 | [225, 940] | [354, 961] | |
| year | claim sizes | year | claim sizes |
|---|---|---|---|
| (in millions) | (in millions) | ||
| 1983 | 42.719 | 23.208 | |
| 1984 | 105.860 | 1990 | 37.772 |
| 1986 | 29.172 | 34.126 | |
| 22.654 | 27.990 | ||
| 1987 | 61.992 | 1992 | 53.472 |
| 35.000 | 36.269 | ||
| 1988 | 26.891 | 31.088 | |
| 1989 | 25.590 | 25.907 | |
| 24.130 |
| Analysis | Net premium | |||
|---|---|---|---|---|
| Point estimate | credib. interv. | |||
| ML for GPD | 0.254 | 11.948 | 27.23 | |
| Bayes (Reiss and Thomas) | ||||
| Inv.-Gamma(, ) | 0.288 | 11.658 | 27.83 | |
| Inv.-Gamma(, ) | 0.274 | 11.814 | 27.66 | |
| Bayes-QC approach | 0.384 | 10.332 | 30.03 | [17.09, 84.39] |
5 Discussion
The proposed quasi-conjugate Bayes approach has many advantages when compared to standard GPD parameters and extreme quantiles estimators:
– it can incorporate experts prior information and improve estimation of extreme events even when data are scarce,
– it provides Bayes credibility intervals assessing the quality of the extreme events estimation,
– it often gives estimators with weak dependence on the number of used excesses,
– the variances of the empirical quasi-conjugate Bayes estimators compares well to the variances of the standard estimators. This suggests that quasi-conjugate Bayes estimators including experts opinion would give very accurate extreme quantile estimators, this point will be illustrated in a forthcoming paper.
We deeply describe the proposed quasi-conjugate Bayes approach for the most frequent case of DA(Fréchet) where tails are heavy (), the case of DA(Gumbel) is analytically discussed in Appendix A. Future work is needed to extend this approach to the general case where the user has no prior idea on .
The present paper is the first of a series of papers devoted to various developments of the Bayesian inference methodology that we introduced here. In particular, we will study how to determine and compute hyperparameters in a hierarchical structure setting based on the quasi-conjugate class defined here to take into account realistic expert prior information on extreme events.
Finally, note that it would be possible to include a Poisson parameter for the stream of exceedances as in Reiss and Thomas (2000). Also, spatial quantile estimation and multivariate or time-series extensions based on our approach are natural and very promising.
Appendix A
We present here a brief account of the simple case where Bayesian inference is made for exponential distributions, rather than GPD’s with both parameters unknown. This simple setup is of interest since it is the Bayesian analogue of the Exponential Tail (ET) method (Breiman et al. 1990), and all calculations lead to explicit analytical formulas.
Set and . Denote by the prior Gamma density ( ). The posterior density is Gamma, where . Expert information is reflected in the choice of and . The corresponding posterior predictive distribution is GPD , with and . Our first estimate of is based on the posterior mean of :
Our second estimate is based on the posterior predictive distribution:
Our third estimate is based on the transformed posterior distribution. Since the posterior on is an inverse-gamma distribution with density
the corresponding distribution of has a similar shape, and has mean
For large enough, is close to with respect to the standard deviation scale, which is of the order of . On the contrary, a Taylor expansion shows that when is not too large,
The distance between and each of the two other estimates can be significant, and exhibits a positive bias with respect to the other estimates. We have observed a similar behavior when dealing with GPD’s: This is the reason why we have discarded the analogous of in that setting, and selected estimates of based on its posterior distribution.
Appendix B
We propose here two examples for introducing expert opinion in our Bayesian framework. In the first one, we use a partial expert opinion: It acts only on one parameter of the GPD distribution, whereas the second one is derived from the empirical choice made in Subsection 2.4. In the second one, the expert opinion acts on both parameters of the GPD distribution.
Example 1.
In this situation, the expert provides a rare value of the variable as well as an interval containing the probability to overpass and a (small) probability measuring the uncertainty of this opinion. From Pickands theorem, we deduce where
| (18) |
Plugging yields
| (19) |
Replacing by its Hill estimate (similarly to Subsection 2.4), we obtain the following bounds for :
Note that, the converse approach (fixing and bounding ) can also be considered. The prior distribution of given is Gamma. Suppose that and both have probability for this gamma distribution. We thus have two nonlinear equations permitting to obtain and . Approaching the gamma distribution by a Gaussian one yields explicit solutions:
| (20) | |||||
| (21) |
where is the quantile of the standard Gaussian distribution. The parameter is determined by imposing that the gamconII() prior distribution of has mode . From (14), we obtain:
| (22) |
where denotes the digamma function.
Example 2.
Here, the expert provides two rare values and of the variable as well as their associated probabilities and to be overcome. The confidence on this opinion is measured by (see Remark 1). Equation (18) yields two nonlinear equations from which the GPD parameters can be computed. This allows to determinate the hyperparameters and . To this end, we impose and to be respectively the modes of the prior distribution of and given . From (14), we obtain
| (23) | |||||
| (24) |
where denotes the digamma function.
References
- [1] Bacro, J., and Brito, M. Strong limiting behaviour of a simple tail Pareto-index estimator. Statist. Dec. 3, 133–143, (1993).
- [2] Balkema, A., and de Haan, L. Residual life time at a great age. Annals of Probability, 2, 792–804, (1974).
- [3] Beirlant, J., Dierckx, G., and Guillou, A. Estimation of the extreme value index and regression on generalized quantile plots. Preprint, Catholic University of Leuven, Catholic University of Leuven, Belgium. (2001).
- [4] Beirlant, J., and Teugels, J. Asymptotic normality of Hill’s estimator. In Extreme Value Theory (1989), eds., J. Hüsler and R.D. Reiss, Proceedings of the Oberwolfach Conference, 1987. Springer-Verlag New York.
- [5] Bottolo, L., Consonni, G., Dellaportas, P. and Lijoi, A. Bayesian analysis of extreme values by mixture modeling, Extremes 6, 25–47, (2003).
- [6] Breiman, L., Stone, C., and Kooperberg, C. Robust confidence bounds for extreme upper quantiles. J. Statist. Comput. Simul. 37, 127–149, (1990).
- [7] Caers, J., Beirlant, J., and Vynckier, P. Bootstrap confidence intervals for tail indices. Computational Statistics and Data Analysis 26, 259–277, (1998).
- [8] Castillo, E., and Hadi, A. Fitting the Generalized Pareto Distribution to data. J. Amer. Stat. Assoc. 92, 440, 1609–1620, (1997).
- [9] Coles, S. An introduction to statistical modelling of extreme values. Springer series in Statistics, 2001.
- [10] Coles, S., and Powell, E. Bayesian methods in extreme value modelling: A review and new developments. International Statistical Review 64, 1, 119–136, (1996).
- [11] Coles, S., and Tawn, J. A Bayesian analysis of extreme rainfall data. Applied Statistics 45, 4, 463–478, (1996).
- [12] Damsleth, E. Conjugate classes of Gamma distributions. Scandinavian Journal of Statistics: Theory and Applications 2, 80–84, (1975).
- [13] Davison, A., and Smith, R. Models for exceedances over high thresholds. J. R. Statist. Soc. B 52, 3, 393–442, (1990).
- [14] Dekkers, A., Einmahl J.H.J., and de Haan, L. A moment estimator for the index of an extreme-value distribution. The Annals of Statistics 17, 4, 1833–1855, (1989).
- [15] Diebolt, J., Guillou, A., and Worms, R. Asymptotic behaviour of the probability-weighted moments and penultimate approximation. ESAIM: Probability and Statistics 7, 219–238, (2003).
- [16] Dupuis, D. Exceedances over high thresholds: A guide to threshold selection. Extremes 3, 1, 251–261, (1998).
- [17] Embrechts, P., Klüppelberg, C., and Mikosch, T. Modelling Extremal Events. Springer, 1997.
- [18] Garrido, M. Modélisation des évènements rares et estimation des quantiles extrêmes, Méthodes de sélection de modèles pour les queues de distribution. PhD thesis, Université Joseph Fourier de Grenoble (France), 2002.
- [19] Grimshaw, S. Computing maximum likelihood estimates for the Generalized Pareto Distribution. Technometrics 35, 2, May, 185–191, (1993).
- [20] Haeusler, E., and Teugels, J. On asymptotic normality of Hill’s estimator for the exponent of regular variation. The Annals of Statistics 13, 2, 743–756, (1985).
- [21] Hill, B. A simple general approach to inference about the tail of a distribution. The Annals of Statistics, 3, 5, 1163–1174, (1975).
- [22] Hosking, J., and Wallis, J. Parameter and quantile estimation for the Generalized Pareto Distribution. Technometrics 29, 3, August, 339–349, (1987).
- [23] Pickands, J. Statistical inference using extreme order statistics. The Annals of Statistics, 3, 119–131, (1975).
- [24] Reiss, R., and Thomas, M. A new class of Bayesian estimators in paretian excess-of-loss reinsurance. Astin Journal 29, 2, 339–349, (1999).
- [25] Reiss, R., and Thomas, M. Statistical Analysis of Extreme Values. Birkhauser Verlag, 2001.
- [26] Robert, C.P. Discretization and MCMC Convergence Assessment. Lecture Notes in Statistics 135, Springer Verlag, 1998.
- [27] Schnieper, R. Praktische Erfahrungen mit Grossschadenverteilungen. Mitteil. Schweiz. Verein Versicherungsmath, 149–165, (1993).
- [28] Schultze, J., and Steinebach, J. On least squares estimates of an exponential tail coefficient. Statist. Decisions 14, 353–372, (1996).
- [29] Singh, V., and Guo, H. Parameter estimation for 2-parameter Generalized Pareto Distribution by POME. Stochastic Hydrology and Hydraulics 11, 3, 211–227, (1997).
- [30] Smith, R. Estimating tails of probability distributions. The Annals of Statistics 15, 3, 1174–1207, (1987).
- [31] Smith, R., and Naylor, J. A comparison of maximum likelihood and Bayesian estimators for the three-parameter Weibull distribution. Appl. Statist. 36, 3, 358–369, (1987).
- [32] Tancredi, A., Anderson, C. and O’Hagan, A. A Bayesian model for threshold uncertainty in extreme value theory. Working paper 2002.12, Dipartimento di Scienze Statistiche, Universita di Padova. (2002).
- [33] Worms, R. Vitesse de convergence de l’approximation de Pareto Généralisée de la loi des excès. Comptes-Rendus de l’Académie des Sciences, série 1, Tome 333, 65–70, (2001).