Quickest Changepoint Detection in General Multistream Stochastic Models: Recent Results, Applications and Future Challenges
Abstract
Modern information systems generate large volumes of data with anomalies that occur at unknown points in time and have to be detected quickly and reliably with low false alarm rates. The paper develops a general theory of quickest multistream detection in non-i.i.d. stochastic models when a change may occur in a set of multiple data streams. The first part of the paper focuses on the asymptotic quickest detection theory. Nearly optimal pointwise detection strategies that minimize the expected detection delay are proposed and analyzed when the false alarm rate is low. The general theory is illustrated in several examples. In the second part, we discuss challenging applications associated with the rapid detection of new COVID waves and the appearance of near-Earth space objects. Finally, we discuss certain open problems and future challenges.
1 Introduction
The problem of changepoint detection in multiple data streams (sensors, populations, or multichannel systems) arises in numerous applications that include but are not limited to the medical sphere (detection of an epidemic present in only a fraction of hospitals chang ; frisen-sqa09 ; bock ; tsui-iiet12 ); environmental monitoring (detection of the presence of hazardous materials or intruders fie ; mad ); military defense (detection of an unknown number of targets by multichannel sensor systems Bakutetal-book63 ; Tartakovsky&Brown-IEEEAES08 ); near-Earth space informatics (detection of debris and satellites with telescopes BerenkovTarKol_EnT2020 ; KolessaTartakovskyetal-IEEEAES2020 ; TartakovskyetalIEEESP2021 ); cyber security (detection of attacks in computer networks szor ; Tartakovsky-Cybersecurity14 ; Tartakovskyetal-SM06 ; Tartakovskyetal-IEEESP06 ); detection of malicious activity in social networks Raghavanetal-AoAS2013 ; Raghavanetal-IEEECSS2014 , to name a few.
In many change detection applications, the pre-change (the baseline or in-control) distribution of observed data is known, but the post-change (out-of-control) distribution is not completely known. As discussed in (Tartakovsky_book2020, , Ch 3, 6) there are three conventional approaches in this case: (i) to select a representative value of the post-change parameter and apply efficient detection rules tuned to this value such as the Shiryaev rule, the Shiryaev–Roberts rule or CUSUM, (ii) to select a mixing measure over the parameter space and apply mixture-type rules, (iii) to estimate the parameter and apply adaptive schemes. In Chapters 4 and 6 of Tartakovsky_book2020 , a single stream case was considered. In this paper, we consider a more general case where the change occurs in multiple data streams and the number and location of affected data streams are unknown.
To be more specific, suppose there are data streams observed sequentially in time subject to a change at an unknown point in time , so that the data up to the time are generated by one stochastic model and after by another model. The change in distributions may occur at a subset of streams of a size , where is an assumed maximal number of streams that can be affected, which can be substantially smaller than . A sequential detection procedure is a stopping time with respect to an observed sequence. A false alarm is raised when the detection is declared before the change occurs. One wants to detect the change with as small a delay as possible while controlling the false alarm rate.
We consider a fairly general stochastic model assuming that the observations may be dependent and non-identically distributed (non-i.i.d.) before and after the change and that streams may be mutually dependent.
In the case of i.i.d. observations (in pre-change and post-change modes with different distributions), this problem was considered in felsokIEEEIT2016 ; Mei-B2010 ; TartakovskyIEEECDC05 ; TNB_book2014 ; Tartakovskyetal-SM06 ; Xie&Siegmund-AS13 . Specifically, in the case of a known post-change parameter and (i.e., when only one stream can be affected but it is unknown which one), Tartakovsky TartakovskyIEEECDC05 proposed to use a multi-chart CUSUM procedure that raises an alarm when one of the partial CUSUM statistics exceeds a threshold. This procedure is very simple, but it is not optimal and performs poorly when many data streams are affected. To avoid this drawback, Mei Mei-B2010 suggested a SUM-CUSUM rule based on the sum of CUSUM statistics in streams and evaluated its first-order performance, which shows that this detection scheme is first-order asymptotically minimax minimizing the maximal expected delay to detection when the average run length to false alarm approaches infinity. Fellouris and Sokolov felsokIEEEIT2016 suggested more efficient generalized and mixture-based CUSUM rules that are second-order minimax. Xie and Siegmund Xie&Siegmund-AS13 considered a particular Gaussian model with an unknown post-change mean. They suggested a rule that combines mixture likelihood ratios that incorporate an assumption about the proportion of affected data streams with the generalized CUSUM statistics in streams and then add up the resulting local statistics. They also performed a detailed asymptotic analysis of the proposed detection procedure in terms of the average run length to a false alarm and the expected delay as well as MC simulations. Chan Chan-AS2017 studied a version of the mixture likelihood ratio rule for detecting a change in the mean of the normal population assuming independence of data streams and establishing its asymptotic optimality in a minimax setting as well as dependence of operating characteristics on the fraction of affected streams.
In the present paper, we consider a Bayesian problem with a general prior distribution of the change point and multiple data streams with an unknown pattern, i.e., when the size and location of the affected streams are unknown. It is assumed that the observations can be dependent and non-identically distributed in data streams and even across the streams. Furthermore, in contrast to most previous publications where asymptotically stationary models were considered, we consider substantially non-stationary models, even asymptotically. We address two scenarios when the pre- and post-change distributions are completely known and also a parametric uncertainty when the post-change distribution is known up to an unknown parameter. We introduce mixture detection procedures that mix the Shiryaev–Robers-type statistic over the distributions of the unknown pattern and unknown post-change parameter (in the case of prior uncertainty). The resulting statistics are then compared to appropriate thresholds.
The paper is organized as follows. In Section 2, we present a general theory for very general stochastic models, providing sufficient conditions under which the suggested detection procedures are first-order asymptotically optimal. In Section 3, we provide illustrative examples. In Section 4, we evaluate the performance of proposed mixture detection procedures using Monte Carlo simulations for the non-stationary Gaussian model. In Section 5, theoretical results are applied to rapid detection of the COVID-19 outbreak in Australia based on monitoring the percentage of infections in the total population as well as to rapid detection and extraction of faint near-Earth space objects with telescopes. Section 6 concludes the paper with several remarks, including future research challenges.
2 Asymptotic Theory of Multistream Quickest Change Detection for General Non-i.i.d. Models
In this section, we develop the quickest detection theory in the general multistream non-i.i.d. scenario. We design mixture-based change detection procedures which are nearly optimal in the class of change detection procedures with the prespecified average (weighted) probability of false alarm when this probability is small, assuming that the change point is random with a given prior distribution.
2.1 A General Multistream Model and Basic Notations
We begin with a preliminary description of the scenario of interest and general notation.
Consider the multistream scenario where the observations are sequentially acquired in streams, i.e., in the -th stream one observes a sequence , where . The observations are subject to a change at an unknown time , so that are generated by one stochastic model and by another model when the change occurs in the -th stream. The change in distributions happens at a subset of streams with cardinality , where is an assumed maximal number of streams that can be affected, which can be and often is substantially smaller than . A sequential detection rule is a stopping time with respect to an observed sequence , , i.e., is an integer-valued random variable, such that the event belongs to the sigma-algebra generated by observations .
The observations may have a very general stochastic structure. Specifically, if we let denote the sample of size in the -th stream and if , is a parametric family of conditional densities of given , then when (there is no change) the parameter is equal to the known value , i.e., for all and when , then , i.e., for and for . Not only the point of change , but also the subset , its size , and the post-change parameters are unknown. For further details with a certain change of notation see below.
Let denote the probability measure corresponding to the sequence of observations from all streams when there is never a change () in any of the components and, for and , let denote the measure corresponding to the sequence when and the change occurs in a subset of the set (i.e., , is the first post-change observation). By we denote the hypothesis that the change never occurs and by – the hypothesis that the change occurs at time is the subset of streams . The set is a class of subsets of that incorporates available prior information regarding the subset where the change may occur. For example, in applications frequently it is known that at most streams can be affected, in which case . Hereafter denotes the size of a subset (the number of affected streams under ) and denotes the size of class (the number of possible alternatives in ). Note that takes maximum value when there is no prior information regarding the subset of affected streams, i.e., when , in which case .
The problem is to detect the change as soon as possible after it occurs regardless of the subset , i.e., we are interested in detecting the event that the change has occurred in some subset but not in identifying the subset of streams where it occurs.
Write for the concatenation of the first observations from the -th data stream and for the concatenation of the first observations from all data streams. Let and be sequences of conditional densities of given , which may depend on , i.e., and . We omit the subscript for the sake of brevity. For the general non-i.i.d. changepoint model the joint density under hypothesis can be written as follows
| (1) |
where . Therefore, is the pre-change conditional density and is the post-change conditional density given that the change occurs in the subset .
In most practical applications, the post-change distribution is not completely known – it depends on an unknown (generally multidimensional) parameter , so that the model (1) may be treated only as a benchmark for a more practical case where the post-change densities are replaced by , i.e.,
| (2) |
2.2 Optimality Criterion
In the sequel, we assume that the change point is a random variable independent of the observations with a prior distribution , with for and that a change point may take negative values, but the detailed structure of the distribution for is not important. Only the total probability of the change being in effect before the observations become available matters.
Let and denote expectations under and , respectively, where corresponds to model (2) with an unknown parameter . Define the probability measure on the Borel -algebra in as
Under measure the change point has distribution and the model for the observations is of the form (2), i.e., has conditional density if and conditional density if and the change occurs in the subset with the parameter . Let denote the expectation under .
For the prior distribution of the change point , introduce the average (weighted) probability of false alarm associated with the change detection procedure
| (3) |
that corresponds to the risk due to a false alarm. Note that here we took into account that since the event depends on the observations generated by the pre-change probability measure (recall that by our convention is the last pre-change observation if ).
For , , and the risk associated with the detection delay is measured by the conditional expected delay to detection
| (4) |
Note that if the change occurs before the observations become available, i.e., , then since with probability one.
Next, for the prior distribution and , define the Bayesian class of changepoint detection procedures with the weighed probability of false alarm not greater than a prescribed number :
| (5) |
where stands for the totality of Markov times.
In this section, we are interested in the uniform Bayesian constrained optimization criterion
However, this problem is intractable for arbitrary values of . For this reason, we will consider the following first-order asymptotic problem assuming that the given PFA approaches zero: Find a change detection procedure such that it minimizes the expected detection delay asymptotically to first order as uniformly for all possible values of , subsets , and . That is, our goal it to design such detection procedure that, as ,
| (6) |
where is the class of detection procedures for which the PFA does not exceed a prescribed number defined in (5) and as .
2.3 Multistream Changepoint Detection Procedures
We begin by considering the most general scenario where the observations across streams are dependent.
Parametric Prior Uncertainty
Let . Note that in the general non-i.i.d. case the statistic depends on the change point since the post-change density may depend on . The likelihood ratio (LR) of the hypothesis that the change occurs at in the subset of streams against the no-change hypothesis based on the sample is given by the product
and we set for .
For and , define the generalized Shiryaev–Roberts (SR) statistic
| (7) |
with the initial condition (non-negative head-start) , .
Now, introduce the probability mass function (mixing measure)
| (8) |
where is the prior probability of the change being in effect on the set of streams , and also the mixing probability measure
| (9) |
For a fixed value of , introduce the mixture statistic
| (10) |
where
| (11) |
is the mixture LR.
As discussed in Tartakovsky_book2020 ; TNB_book2014 , when the parameter is unknown there are two main conventional approaches – either to estimate (say maximize) or average (mix) over . Using the mixing measure (prior distribution) given in (9), define the double LR-mixture
| (12) |
and the double-mixture statistic
| (13) |
(with a non-negative head-start ).
The corresponding double-mixture LR-based detection procedure is given by the stopping rule which is the first time such that the statistic exceeds the level :
| (14) |
The main result of our theory is that this changepoint detection procedure is first-order asymptotically optimal under certain very general conditions if threshold is adequately selected, i.e., asymptotic equality (6) holds with .
Known Parameters of the Post-Change Distribution
If the value of the post-change parameter is known or its putative value is of special interest, representing a nominal change, then it is reasonable to turn the double-mixture procedure in single-mixture procedure by taking the degenerate weight function concentrated at , i.e.,
| (15) |
and ask whether or not it has first-order asymptotic optimality properties at the point , i.e., that under certain conditions asymptotic formula (6) holds for .
2.4 Asymptotic Optimality of Mixture-Based Detection Procedures
Basic Conditions
While we consider a general prior and a very general stochastic model for the observations in streams and between streams, to study asymptotic optimality properties we still need to impose certain constraints on the prior distribution and on the general stochastic model (1) that guarantee asymptotic stability of the detection statistics as the sample size increases.
Regarding the prior distribution, we will assume that the following condition holds:
However, this condition being quite general does not cover the case where is positive but may go to zero. Indeed, the distributions with an exponential right tail that satisfy this condition with do not converge as to heavy-tailed distributions with . For this reason, any assertions for heavy-tailed distributions with do not hold if with an arbitrary rate; the rate must be matched with the PFA probability , . Hence, in what follows we consider the scenario with the prior distribution that depends on the PFA constraint and modify the above condition as
. For some such that as
For and , introduce the log-likelihood ratio (LLR) process between the hypotheses () and :
( for ).
Let be an increasing and continuous function and by denote the inverse of , which is also increasing and continuous. We also assume that , and thus, is properly defined on the entire positive real line.
In the rest of the paper, we assume that the strong law of large numbers (SLLN) holds for the LLR with the rate , that is, converges almost surely (a.s.) under probability to a finite and positive number :
| (16) |
Condition (16) is the first main assumption regarding the general stochastic model for observed data.
Notice that if the data in streams and across the streams are independent (but non-stationary), then
where and are pre- and post-change densities of the -th observation in the -th stream, respectively. In other words, the number can be interpreted as the limiting local Kullback-Leibler divergence.
If the function is non-linear we will say that the model is non-stationary (even asymptotically). However, in many applications the observations are non-identically distributed but , in which case we will say that the non-i.i.d. model is asymptotically stationary.
In Subsection 2.4, we establish the asymptotic lower bound (as ) for the minimal value of the expected detection delay in class whenever the almost sure convergence condition (16) holds. To obtain the lower bound it suffices to require the following right-tail condition
This condition holds whenever the SLLN (16) takes place. However, the SLLN is not sufficient to show that this lower bound is attained for the mixture detection procedures (14) and (15). To this end, the SLLN should be strengthened into a complete convergence version.
Definition 1
We say that the process , converges to a random variable uniformly completely under the measure if
The proof of the upper bound presented in Subsection 2.4 shows that if along with the SLLN (16) the following left-tail condition is satisfied
| (17) |
where the “information number” is positive and finite, then the detection procedure (15) is asymptotically optimal for the fixed (prespecified) post-change parameter .
Obviously, both conditions (16) and (17) are satisfied whenever there exist positive and finite numbers (, ) such that the normalized LLR uniformly completely under -probability. Therefore, this condition turns out to be sufficient for asymptotic optimality of the detection procedure (15) when the post-change parameter is known. In the case of the unknown post-change parameter, the left-tail condition is similar to but more sophisticated than condition (17). The details will be given in Subsection 2.4.
Heuristic Argument
We begin with a heuristic argument that allows us to obtain approximations for the expected detection delay when the threshold in the mixture detection procedure is large. For the sake of simplicity, the head-start in the detection statistic is set to zero, . This argument also explains the reason why the condition on the prior distribution is imposed.
Assume first that the change occurs at . It is easy to see that the logarithm of the statistic can be written as
where
Due to the SLLN (16) converges almost surely as under to , so we can expect that for a large
| (18) |
where converges to . Also, , are “slowly changing” and converge to a random variable . Thus, ignoring the overshoot of over , we obtain
| (19) |
If increases sufficiently fast, at least not slower than , then the last two terms can be ignored, and hence,
Taking expectation yields
A similar argument leads to the following approximate formula (for a large ) for the expected delay when the change occurs at :
| (20) |
Next, in Lemma 1 (see Subsection 2.4) it is established that the probability of a false alarm of the procedure satisfies the inequality
where is the mean of the prior distribution . If we assume that as , then this inequality along with approximate equality (20) yields the following approximation for the expected delay to detection:
| (21) |
In subsequent sections, this approximation is justified rigorously.
There are two key points we would like to address. The first one is that if we impose condition on the prior distribution of the change point with that does not depend on and does not converge to , then the lower bound for the expected delay to detection in class has the form
| (22) |
In this case, this lower bound is not attained by the procedure since if we take , then it follows from (21) that
Hereafter we use a conventional notation as if . This can be expected since the detection statistic is based on the uniform prior on a positive half line. However, if , as we assumed in condition , then the lower bound is
and it is attained by .
Yet another key point is that to obtain the lower bound (22) with but , as shown in the proof of Theorem 2.1, we need the function to be either linear or super-linear. Indeed, if now we define the statistic
and the corresponding detection procedure
then instead of (19) we have
So if is sub-linear, i.e., for large , we expect that the prior distribution gives much more contribution than the observations and
as long as , i.e., the prior distribution has an exponential right tail.
Despite the simplicity of the basic ideas and the approximate calculations, the rigorous argument in proving these results is rather tedious.
Asymptotic Lower Bound for Expected Detection Delay
For establishing asymptotic optimality of changepoint detection procedures, we first obtain, under the a.s. convergence condition (16), the asymptotic lower bound for expected detection delay of any detection rule from class . In the following subsections, we show that under certain additional conditions associated with complete convergence of LLR these bounds are attained for the mixture procedures and .
For and , define
| (23) |
The following theorem specifies the asymptotic lower bound for the expected detection delay.
Theorem 2.1
Let the prior distribution of the change point satisfy condition and assume that for some positive and finite numbers (, ) the a.s. convergence condition (16) holds. Suppose in addition that the function increases not slower than , i.e.,
| (24) |
Then for all and
| (25) |
and, as a result, for all , , and
| (26) |
Proof
In the asymptotically stationary case where , the methodology of the proof is analogous to that used by Tartakovsky TartakovskyIEEEIT2017 ; TartakovskyIEEEIT2019 in the proofs of the lower bounds in a single stream change detection problem with slightly different assumptions on the prior distribution. A generalization of the proof in the substantially non-stationary case has several technical details. We present complete proof.
To begin, consider an arbitrary stopping time and note that by Markov’s inequality
If assertion (25) holds, then
| (27) |
Indeed,
where we used the identity . Next, since for any change detection procedure ,
it follows that
| (28) |
where . Hence, we obtain
This inequality yields (27), and we obtain the asymptotic inequality
which holds for arbitrary values of and . By our assumption, the function is continuous, so we may take a limit , which implies inequality (26). Consequently, to show the validity of asymptotic inequality (26), it suffices to prove the equality (25).
Let
and notice that for
where hereafter denotes a restriction of the measure to the sigma-algebra . Therefore, changing the measure and using Wald’s likelihood ratio identity, we obtain for any :
where the last inequality follows from the fact that for any events and , where is the complement event of . Setting
yields
| (29) |
where
and
By the a.s. convergence condition (16),
| (30) |
To evaluate it suffices to note that, by condition , for all sufficiently small , there exists a small such that
and to use inequality (28), which yields that for all sufficiently small
Since by condition (24),
it follows that
for all and every small . Hence, for all and sufficiently small ,
| (31) |
where does not depend on the stopping time and goes to as for any fixed , which implies that
The proof of the lower bound (26) is complete. ∎
Probabilities of False Alarm of Mixture Change Detection Procedures
An important question is how to select threshold in change detection procedures and defined in (15) and (14), respectively, to imbed them into class .
The following lemma provides the upper bounds for the PFA of these procedures.
Lemma 1
For all and any prior distribution of the change point with finite mean , the weighted probabilities of false alarms of the detection procedures and satisfy the inequalities
| (32) | ||||
| (33) |
where . Hence, if , then and , i.e., and .
Proof
We have
and hence, the statistic is a non-negative -submartingale with mean
By Doob’s maximal submartingale inequality, for any ,
| (34) |
which implies
and inequality (32) follows.
Asymptotic Optimality of Mixture Detection Procedure for Known Post-change Parameter
We now proceed with establishing asymptotic optimality properties of the mixture detection procedures in class as assuming that the post-change parameter is prespecified (known or selected).
Throughout this subsection, we assume that there exist positive and finite numbers (, ) such that the normalized LLR converges as to uniformly completely under probability measure , i.e.,
| (36) |
2.4(a) Asymptotic Operating Characteristics of Detection Procedure for Large Threshold Values
The following theorem provides asymptotic operating characteristics of the mixture detection procedure for large values of threshold . Since no constraints are imposed on the false alarm rate (FAR) – neither on the PFA nor any other FAR measure – this result is universal and can be used in a variety of optimization problems. We need to impose some constraints on the behavior of the head-start , which may depend on and approach infinity as in such a way that
| (37) |
We also need to assume that the function increases not too slowly, at least faster than the logarithmic function. Specifically, we assume the following condition on the inverse function
| (38) |
Theorem 2.2
Proof
Similarly to (29)
| (41) |
where
and
Using inequality (34), we obtain
and consequently,
| (42) |
Since, by conditions (37) and (38), for any
it follows from (42) that as for any . Also, as by condition (36). Therefore,
for any fixed . It follows from (2.4) that as
where can be arbitrarily small. This yields the asymptotic lower bound (for any fixed , )
| (43) |
To prove (39) it suffices to show that this bound is attained by , i.e.,
| (44) |
For , define
| (45) |
Recall the definitions of the mixture SR statistic and mixture LR given in (10) and (11), respectively. Obviously, for any and ,
and we have
where for any the last probability does not exceed the probability
Therefore, for , all and all sufficiently large such that , we have
| (46) |
Now, by Lemma A1 in Tartakovsky (Tartakovsky_book2020, , page 239), for any , , and ,
| (47) |
which along with inequality (46) yields
| (48) |
Write
Using (48) and the inequality (see (34)), we obtain
| (49) |
Since due to condition (37) and, by complete convergence condition (36), for all and , inequality (49) implies the asymptotic inequality
Since can be arbitrarily small the asymptotic upper bound (44) follows and the proof of the asymptotic approximation (39) is complete. ∎
2.4(b) Asymptotic Optimality
Since we assume that the prior distribution may depend on the prescribed PFA the mean depends on . We also suppose that the head-start may depend on and may go to infinity as . We further assume that and approach infinity with such a rate that
| (50) |
The following theorem establishes the first-order asymptotic (as ) optimality of the mixture detection procedure for the fixed value of in the general non-i.i.d. case. In this theorem, we assume that satisfies condition (24) in contrast to Theorem 2.2 where this function can be practically arbitrary.
Theorem 2.3
Let the prior distribution of the change point satisfy condition and let the mean of the prior distribution and the head-start of the statistic go to infinity with such a rate that condition (50) hold. Assume that for some () the uniform complete convergence condition (36) holds. If threshold is so selected that and as , in particular as , then for all and as
| (51) | ||||
| (52) |
That is, the detection procedure is first-order asymptotically optimal as in class , minimizing average detection delay uniformly for all and .
Proof
If threshold is so selected that as , then asymptotic approximation (51) follows from Theorem 2.2. This asymptotic approximation coincides with the asymptotic lower bound (26) in Theorem 2.1 if condition (24) on holds. Hence, the lower bound is attained by , proving (52) and the assertion of the theorem.
Remark 1
If the prior distribution of the change point does not depend on and condition is satisfied with , then the assertion of Theorem 2.3 holds if, and only if, , i.e., for heavy-tailed prior distributions, but not for priors with exponential right tail with . This follows from the fact that for the lower bound has the form
Asymptotic Optimality of the Double-Mixture Procedure for Unknown Post-change Parameter
Consider now the case where the post-change parameter is unknown. The goal is to show that the double-mixture detection procedure defined in (14) is asymptotically optimal to first order.
Recall that in the case of the known parameter , the sufficient condition for asymptotic optimality (imposed on the data model) is the uniform complete version of the SLLN (36). The proofs of Theorem 2.1 and Theorem 2.2 show that to establish asymptotic optimality of procedure it suffices to require the following two (right-tail and left-tail) conditions: for all , and
| (53) |
and
| (54) |
Note that the SLLN (16) guarantees right-tail condition (53) and complete version (36) guarantees both conditions (53) and (54).
If the post-change parameter is unknown to obtain the upper bound for the expected detection delay the left-trail condition (54) has to be modified as follows. For , define and assume that there exist positive and finite numbers (, ) such that for any and for all and
| (55) |
We ignore parameter values with -measure null, i.e., without special emphasis we will always assume that
The following theorem generalizes Theorem 2.2 to the case of the unknown post-change parameter.
Theorem 2.4
Proof
The proof of the asymptotic lower bound (for any fixed , and )
| (57) |
is essentially identical to that used to establish the lower bound (43) for the expected delay to detection in the proof of Theorem 2.2. So it is omitted.
To prove asymptotic approximation (56) it suffices to show that the lower bound (57) is attained by , i.e.,
| (58) |
Let be as in (45). Since for any ,
using essentially the same argument as in the proof of Theorem 2.2 that have led to inequality (46) we obtain that for all
Hence, for all and all sufficiently large such that ,
| (59) |
Lemma A1 in Tartakovsky (Tartakovsky_book2020, , Page 239) yields the inequality (for any , , and )
| (60) |
Using (60) and (59), we obtain
| (61) |
where
Next, inequality (61) along with the inequality (see (35)) implies the inequality
| (62) |
Since (see condition (37)) and, by the left-tail condition (55), as for all , , and inequality (62) implies the asymptotic inequality
where can be taken arbitrarily small so that the asymptotic upper bound (58) follows and the proof of the asymptotic approximation (56) is complete. ∎
Using asymptotic approximation (56) in Theorem 2.4 and the lower bound (26) in Theorem 2.1, it is easy to prove that the mixture procedure is asymptotically optimal to first order as in class . We silently assume that is either a linear or super-linear function (see (24)).
Theorem 2.5
Let the prior distribution of the change point satisfy condition . Assume also that the mean value of the prior distribution and the head-start of the statistic approach infinity as with such a rate that condition (50) holds. Suppose further that there exist numbers () such that conditions (53) and (55) are satisfied. If threshold is so selected that and as , in particular as , then for all , and as
| (63) | ||||
| (64) |
that is, the procedure is first-order asymptotically optimal as in class .
Proof
If is so selected that as , then asymptotic approximation (63) follows from asymptotic approximation (56) in Theorem 2.4. Since this approximation is the same as the asymptotic lower bound (26) in Theorem 2.1, this shows that the lower bound is attained by the detection rule , so (64) follows and the proof is complete.
If, in particular, , then and by Lemma 1 . ∎
Remark 2
The assertion of Theorem 2.5 holds when and do not depend on and the condition is satisfied with , i.e., for priors with heavy tails. This could be expected since the detection statistic uses an improper uniform prior distribution of the change point on the whole positive line.
The Case of Independent Streams
Notice that so far we considered a very general stochastic model where not only the observations in streams may be dependent and non-identically distributed, but also the streams may be mutually dependent. In this very general case, computing statistic is problematic even when the statistics in data streams can be computed. Consider now still a very general scenario where the data streams are mutually independent (but have a general statistical structure), which is of special interest for many applications. The computational problem becomes more manageable when the data between data streams are independent.
2.4(a) Computational Issues
In the case where the data across streams are independent, the model has the form
| (65) |
where and are conditional pre- and post-change densities in the -th data stream, respectively, is the unknown post-change parameter (generally multidimensional) in the -th stream (), and is the vector of parameters in the set . So the LR processes are
| (66) |
where .
Recall that is the subclass of for which the cardinality of the sets where the change may occur does not exceed streams, and by denote the subclass of for which the change occurs in exactly streams.
Assume, in addition, that the mixing measure is such that
Then the mixture LR is
and its computational complexity is polynomial in the number of data streams. Moreover, in the special, most difficult case of and , we obtain
| (67) |
so its computational complexity is only . The representation (67) corresponds to the case when each stream is affected independently with probability , the assumption that was made in Xie&Siegmund-AS13 .
2.4(b) Asymptotic Optimality of Detection Procedures
Since the data are independent across streams, for an assumed value of the change point , stream , and the post-change parameter value in the -th stream , the LLR of observations accumulated by time is given by
Define ,
and assume that the following right-tail and left-tail conditions are satisfied for local LLR statistics in data streams: There exist positive and finite numbers , , , such that for any
| (68) |
and
| (69) |
We also assume that for all and .
Let . Recall that
Since the LLR process is the sum of independent local LLRs, (see (66)), it is easy to see that
so that local conditions (68) imply global right-tail condition (53). This is true, in particular, if converge -a.s. to , , in which case the SLLN for the global LLR (16) holds with . Also,
which shows that local left-tail conditions (69) imply global left-tail condition (55).
Theorem 2.5 implies the following results on asymptotic properties of the mixture procedure .
Corollary 1
Assume that for some positive and finite numbers , , , right-tail and left-tail conditions (68) and (69) for local data streams are satisfied. If threshold is so selected that and as , in particular as , and if conditions (24) and (50) are satisfied, then asymptotic formulas (63) and (64) hold with . Therefore, detection procedure is first-order asymptotically optimal as in class .
Remark 3
The assertions of Corollary 1 also hold for different distribution functions , in streams if we assume that for all and . A modification in the proof is trivial.
Remark 4
In the case where the post-change parameter is known, essentially similar corollary follows from Theorem 2.3 if we require the uniform complete version of the SLLN for all streams :
| (70) |
3 Examples
3.1 Detection of Changes in the Mean Values of Multistream Autoregressive Non-stationary Processes
This example related to detecting changes in unknown means of multistream non-stationary AR() processes has a specific real application in addition to several other applications in mathematical statistics. Specifically, it arises in multi-channel sensor systems (such as radars and electro-optic imaging systems) where it is required to detect an unknown number of randomly appearing signals from objects in clutter and sensor noise (cf., e.g., Bakutetal-book63 ; Tartakovsky&Brown-IEEEAES08 ; TNB_book2014 ).
Observations in the -th channel have the form
| (71) |
where are deterministic signals with unknown “amplitudes” that appear at an unknown time in additive noises in an -channel system. Assume that noise processes () are mutually independent -th order Gaussian autoregressive processes AR that obey recursions
| (72) |
where , , are mutually independent i.i.d. normal sequences (), so the observations in channels are independent of each other. For simplicity, let us set zero initial conditions . The coefficients and variances are known and all roots of the equation are in the interior of the unit circle, so that the AR() processes are stable.
For , define the -th order residuals
where if and if . It is easily shown that the conditional pre-change and post-change densities in the -th channel are
and that for all and the LLR in the -th channel has the form
Since under measure the random variables are independent Gaussian random variables , under the LLR is a Gaussian process (with independent but non-identically distributed increments) with mean and variance
| (73) |
Assume that
where . In a variety of signal processing applications this condition holds with , e.g., in radar applications where the signals are the sequences of harmonic pulses. In some applications such as detection, recognition, and tracking of objects on ballistic trajectories that can be approximated by polynomials of order , the function , . Then for all and
so that the SLLN (16) takes place, and therefore, the right-tail condition (68) holds. Furthermore, since the second moment of the LLR is finite it can be shown that uniform complete convergence conditions (70) as well as the left-tail condition (69) also hold. Thus, by Corollary 1, the mixture detection procedure minimizes as the expected delay to detection and asymptotic formulas (63) and (64) hold with
3.2 Change Detection in the Spectrum of the AR( Multistream Process
Consider the problem of detecting the change of the correlation coefficient in the -th order AR process which in the -th stream satisfies the recursion
| (74) |
where
and are i.i.d. (mutually independent) Gaussian random variables with , . Additional notation:
( denotes transpose).
It is easy to see that the pre-change and post-change conditional densities and are given by
| (75) |
where and (, ). Therefore, for any , the LLR is
where
| (76) |
The process (74) is not Markov, but the -dimensional processes
are Markov. Now, for any , define the matrix
Note that
| (77) |
where . Obviously,
Assume that all eigenvalues of the matrices in modules are less than and that belongs to the set
| (78) |
where is the -th eigenvalue of the matrix . Using (77) it can be shown that in this case the processes () are ergodic with stationary normal distributions , where
Taking into account that for any and using techniques developed in PerTar-JMVA2019 it can be shown that the uniform complete convergence conditions (70) as well as the left-tail conditions (69) hold. Therefore, Corollary 1 implies that the mixture detection procedure minimizes as the expected delay to detection for any compact subset of and asymptotic formulas (63) and (64) hold with
In particular, in the purely Markov scalar case where in (74),
4 Monte Carlo
In this section, we perform MC simulations for the example considered in Subsection 3.1, assuming for simplicity (and with a very minor loss of generality) that the noise processes in (71) are i.i.d. Gaussian with mean zero and variances , which is equivalent setting in (72). We also assume that , , pre-change and in the post-change mode when the change occurs in the -th stream.
We suppose that the change in each channel occurs independently with probability , so the probability of the event that streams (out of ) are affected is
The change occurs at time according to the geometric prior distribution
with a parameter .
In MC simulations, we set for the total number of streams, , , and consider three cases: (a) the change occurs in a single stream with , (b) the change occurs in two streams with in each, and (c) the change occurs in three streams with in each.
For each MC run, using equations (66) and (67), we compute the statistics (10) and (13) and get the stopping times for the cases where the parameter of the post-change distribution is known (15) and when the parameter of the post-change distribution is unknown (14). We take uniform prior on with the step . The number of Monte Carlo runs is , which ensures very high accuracy of the estimated characteristics.
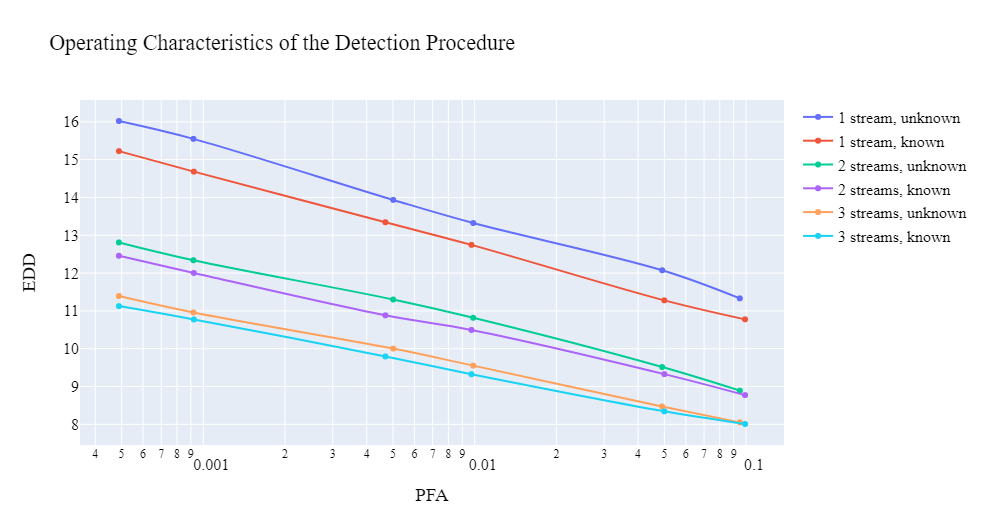
The results are shown in Table 1 and Fig. 1. In Fig. 1, (x-axis) is presented in a logarithmic scale. Marks on the figure mean how many times the value is greater than the previous decimal mark (0.0001, 0.001, or 0.01). It is seen that the detection algorithm has good performance even with such a low signal-to-noise ratio. As expected, in the case when the parameter of the post-change distribution is not known, the algorithm works worse than when it is known, but only slightly – the difference is small. When the change occurs in multiple streams, the expected detection delays and decrease compared to in the case (a), and also becomes smaller than , as expected from theoretical results (see, e.g., (56)). Here denotes the expected detection delay when the change occurs in streams ().
It is also interesting to compare the MC estimates of the expected detection delay with theoretical asymptotic approximations given by (56). In our example, these approximations reduce to
with , . Note that thresholds are different for different to guarantee the same PFA. The data in Table 1 show that the first-order asymptotic approximation is not too bad but not especially accurate.
| 10.77 | 11.28 | 12.76 | 13.34 | 14.68 | 15.22 | |
|---|---|---|---|---|---|---|
| 11.33 | 12.07 | 13.32 | 13.93 | 15.55 | 16.02 | |
| 15.99 | 16.92 | 18.84 | 19.50 | 21.05 | 21.63 | |
| 8.77 | 9.33 | 10.50 | 10.88 | 12.00 | 12.46 | |
| 8.90 | 9.52 | 10.82 | 11.30 | 12.34 | 12.81 | |
| 11.78 | 12.66 | 14.43 | 15.02 | 16.38 | 16.88 | |
| 8.01 | 8.34 | 9.33 | 9.79 | 10.77 | 11.12 | |
| 8.05 | 8.47 | 9.55 | 9.99 | 10.96 | 11.39 | |
| 7.90 | 9.20 | 11.35 | 12.00 | 13.45 | 13.96 |
5 Applications
In this section, we consider two different applications – rapid detection of new COVID-19 epidemic waves and extraction of tracks of low-observable near-Earth space objects in optical images obtained by telescopes.
5.1 Application to COVID Detection
We consider the problem of detecting the emergence of new COVID-19 epidemic waves in Australia based on real data. Note that in pergamenchtchikov2022minimax the algorithm of joint disorder detection and identification has been used not only to detect the start of COVID-19 in Italy but also to identify a region where the outbreak occurs. Here we do not consider identification of the region in which the outbreak occurs. We need only to decide on the occurrence of an epidemic in the whole country based on data from various regions. Also, in contrast to pergamenchtchikov2022minimax where a stationary Markov model has been used, we now propose a substantially different non-stationary model taking into account that a new wave of COVID typically spreads faster than a linear law. This fact has been recently noticed in LiangTarVeerIEEEIT2023 .
We selected data on COVID in Australia, which has 8 regions: Australian Capital Territory, New South Wales, Northern Territory, Queensland, South Australia, Tasmania, Victoria, Western Australia. We propose to use the non-stationary model (71) considered in Subsection 3.1 with super-linear functions , . As an observation, we use the percentage of infections in the total population. We study the COVID outbreak in Australia, which was recorded in the winter of 2021-2022. The data are taken from the World Health Organization and presented in Fig. 2.
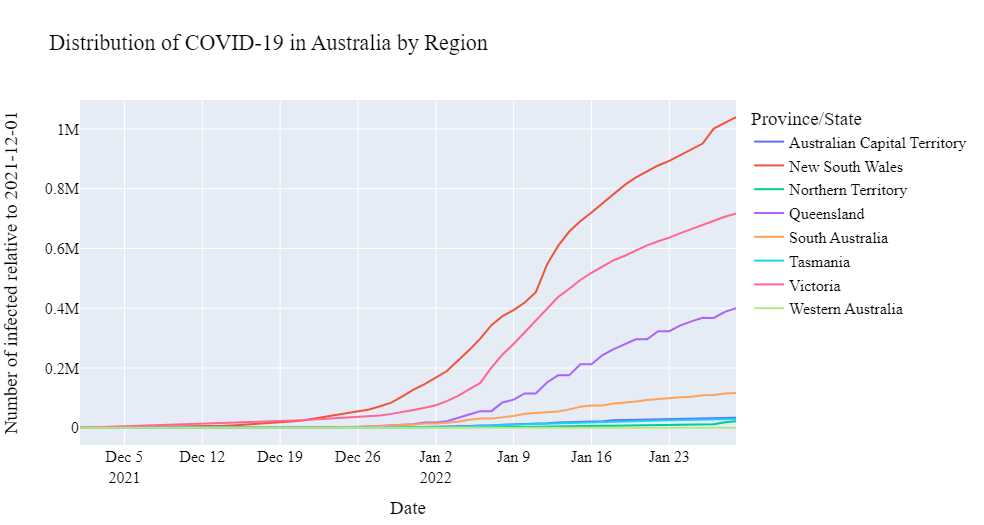
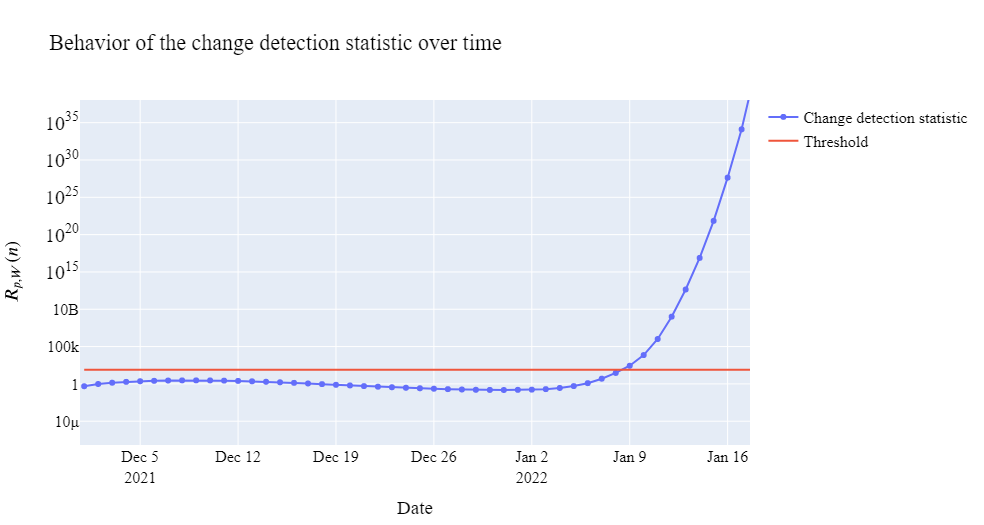
A performed statistical analysis shows that the model with parameters and for New South Wales and Victoria, respectively, describes the beginning of the pandemic outbreak well. We also selected and with in (71). We apply the -stream double mixture detection algorithm discussed above when the parameter of the post-change distribution is not known. We used the discrete uniform prior on with step . The proposed change detection algorithm with a threshold selected so that the probability of false detection does not exceed 0.01 (average detection delay is about 10) decides on the outbreak of the epidemic on January 9, 2022 (see Fig. 3).
The plots in Fig. 3 illustrate the behavior of the change detection statistic defined in (13). The COVID wave is detected at the moment when the statistic crosses the threshold.
The obtained results complement the existing work on the application of changepoint detection algorithms to epidemic detection problems (see, e.g., Baron2004 ; LiangTarVeerIEEEIT2023 ; pergamenchtchikov2022minimax ; Baron2013 ). The results show that the proposed mixture-based change detection algorithm can be useful for governments when deciding whether to impose a total lockdown across the country without regard to a region in the early stages of a pandemic.
5.2 Application to Detection and Extraction of Faint Space Objects
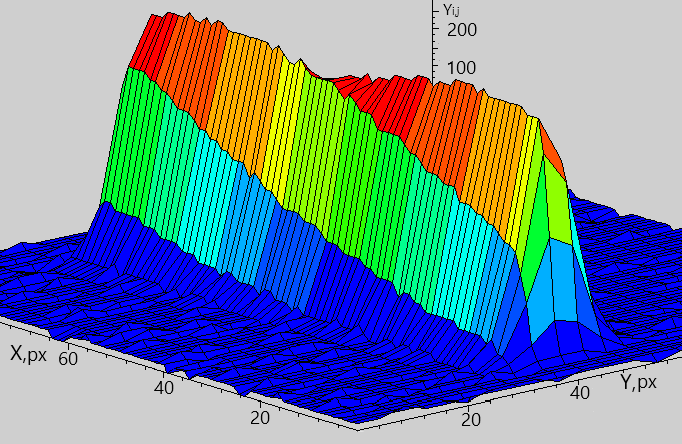
The problem of rapid detection and extraction of streaks of low-observable space objects with unknown orbits in optical images captured with ground-based telescopes is a challenge for Space Informatics. A typical image (digital frame) with a low-contrast streak with the signal-to-noise (SNR) in pixel approximately is shown in Fig. 4.

Since the distribution of observations changes abruptly when the streak starts and ends the problem of object streak extraction can be regarded as the changepoint detection problem in 2-D space (but not in time since we consider a single image).
In realistic situation, the problem is aggravated by the presence of stars and background that produce strong clutter, and special image preprocessing for clutter removal has to be implemented (see, e.g., Tartakovsky&Brown-IEEEAES08 ). We assume that after appropriate preprocessing, the clutter-removed input frame contains Gaussian noise independent from pixel to pixel. For the sake of simplicity, we also consider a scenario where only one streak may be present in the image. We further assume that the satellite has a linear and uniform motion in the frame. The satellite streak is given by the vector , where corresponds to the start point and corresponds to the endpoint. We consider the following model of the observation in pixel of the 2-D frame:
| (79) |
where is an unknown signal intensity from the object, are values of the model profile of the streak that are calculated beforehand assuming the point spread function (PSF) is Gaussian with a certain effective width, which is shown in Fig. 5; and is Gaussian noise after preprocessing with zero mean and known (estimated empirically) local variance . Thus, the observation has normal pre-change distribution when the streak does not cover pixel and normal post-change distribution when the streak covers the pixel .
The problem is to detect the streak with minimal delay or to make a decision that there is no streak in the frame.
We consider only intra-frame detection of faint streaks of subequatorial satellites with unknown orbits with telescopes mounted at the equator. In this case, a signal from a satellite (with unknown intensity, start, and end points) is located almost vertically in a small area at the center of the frame, as shown in Fig. 6.
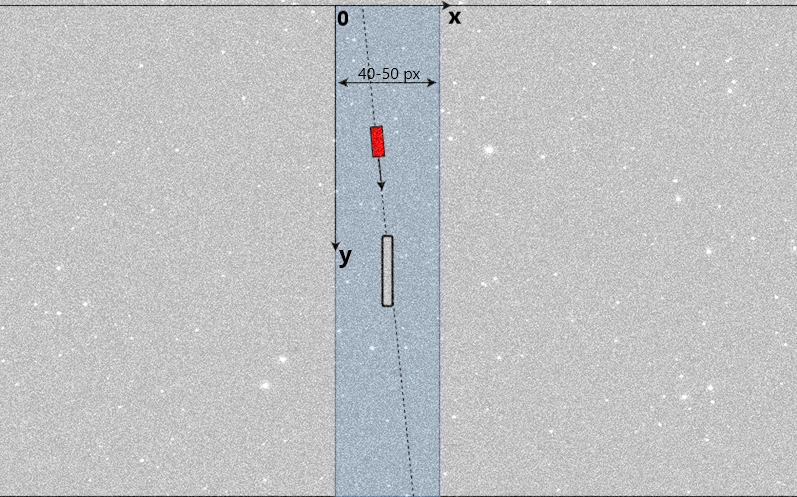
Let denote the streak search area. We define different directions inside . Let denote a certain direction. Since we assume that there may appear only one satellite’s streak in the frame there is no need to mix SR statistics over streak location but rather maximize. However, since the signal intensity is not known we still need to mix over the distribution of , which is a drawback.
A reasonable way to avoid this averaging is to use the so-called Finite Moving Average (FMA) statistics, as suggested in TartakovskyetalIEEESP2021 . Specifically, let stand for a 2-D sliding rectangular window which contains certain pixel numbers at each step in the direction . Window has a fixed length of pixels and a fixed width of pixels (the choice of the parameters depends on the expected SNR and PSF effective width). For the certain direction (), the FMA statistic is defined as
where are values of the Gaussian model profile in the direction and are observed data in the direction . Profile location is given by the vector in the direction . Then the multistream111Here “streams” are not streams per se but rather data in different directions in the search area . FMA detection procedure is defined as
For the Gaussian model, the FMA procedure is invariant to the unknown signal intensity , which is a big advantage over the SR-type versions.
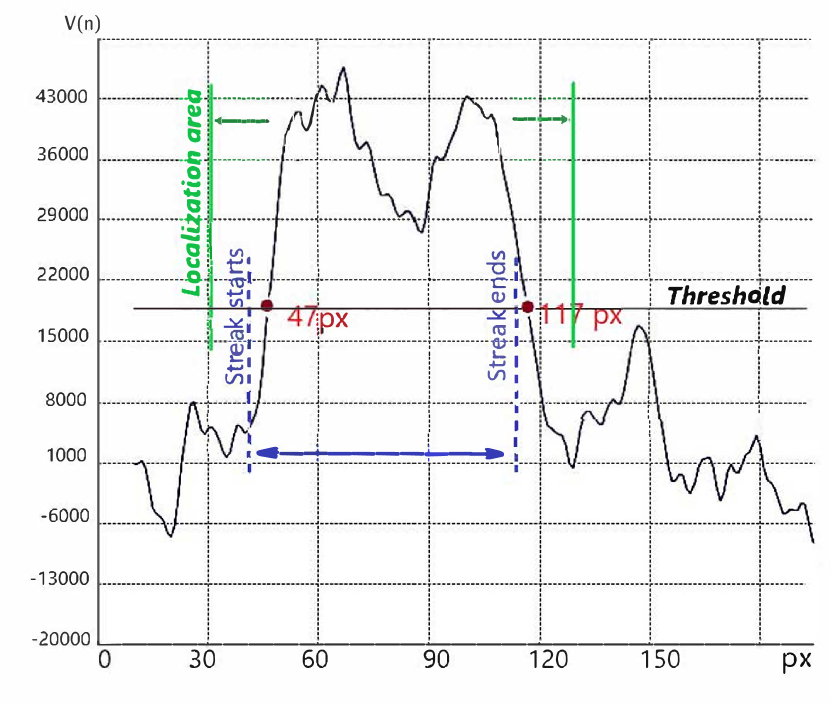
Fig. 7 shows a typical behavior of the statistic along the direction containing the streak in the case of a very low SNR . In this case, the streak is detected with coordinates of start and end at points 47 and 117, respectively, while the true values are 40 and 110 so that the precision is pixels. Experiments show that when sliding the 2-D window in various directions inside and then comparing the largest value to a threshold we typically determine the approximate position of the streak with an accuracy of 5-10 pixels. Therefore, the proposed FMA version of the change detection algorithm turns out to be efficient – it allows us to rapidly determine a localization area, which with a high probability contains the streak.
6 Concluding Remarks and Future Challenges
6.1 Remarks
1. As we already discussed, for general non-i.i.d. models SR-type statistics cannot be computed recursively even in separate streams, so the computational complexity and memory requirements of the mixture detection procedures and , especially in the asymptotically non-stationary case, can be quite high. To avoid this drawback it is reasonable to use either one-stage delayed adaptive procedures or window-limited versions of mixture detection procedures where the summation over potential change points is restricted to the a sliding window of a fixed size . In the window-limited versions of , the statistic is replaced by the window-limited statistic
Following guidelines of Lai LaiIEEE98 and the techniques developed by Tartakovsky (Tartakovsky_book2020, , Sec 3.10, pages 116-122) for the single-stream scenario, it can be shown that the window-limited version of the SR mixture also has first-order asymptotic optimality properties as long as the size of the window approaches infinity as with the rate . Since thresholds, , in detection procedures should be selected in such a way that as , the value of the window size should satisfy .
2. Similar asymptotic optimality results can be obtained for the mixture CUSUM procedure based on thresholding of the sum of generalized LR statistic
and for the corresponding window-limited version.
3. We also conjecture that asymptotic optimality properties hold for the multistream Finite Moving Average (FMA) detection procedure given by the stopping time
where . In cases where the LLR is a monotone function of some statistic, the FMA procedure can be appropriately modified in such a way that it is invariant to the unknown parameters . This is a great advantage over corresponding SR-based and CUSUM-based procedures. See also discussion in Subsection 5.2.
4. The results can be easily generalized to the case where the change points are different for different streams .
5. The Bayesian-type results of this paper can be used to establish asymptotic optimality properties of the detection procedures and in a non-Bayesian setting. In particular, the optimization problem can be solved in the class of procedures with the upper-bounded maximal local probability of false alarms
both in pointwise and minimax settings, by embedding into the Bayesian class, similar to what was done by Pergamenchtchikov and Tartakovsky PerTar-JMVA2019 for the case of a single stream.
6.2 Future Challenges
1. The results of MC simulations in Section 4 show that first-order approximations to EDD and PFA are typically not especially accurate, so higher-order approximations are in order. However, it is not feasible to obtain such approximations in the general non-i.i.d. case considered in this paper. Higher order approximations to the expected detection delay and the probability of false alarm for the i.i.d. models, assuming that the observations in streams are independent and also independent across streams, can be derived based on the renewal and nonlinear renewal theories. This important problem will be considered in the future.
2. The results of this paper cover the scenario where the number of streams is fixed so that for small . In Big Data problems, may be very large and go to infinity. These problems require different approaches and different detection procedures. This challenging problem will be considered in the future.
3. For detecting transient (or intermittent) changes of unknown duration (like object streaks in Subsection 5.2) it is often more reasonable to consider not quickest detection criteria but reliable detection criteria that require minimization of the detection probability in a fixed time (or space) window (see, e.g., BerenkovTarKol_EnT2020 ; TartakovskyetalIEEESP2021 ; Tartakovsky_book2020 and references therein). While certain interesting asymptotic results for single-stream scenarios and i.i.d. data models exist Nikiforov+et+al:2012 ; Nikiforov+et+al:2017 ; Nikiforov+et+al:2023 ; SokolovSpivakTartakSQA2023 ; TartakovskyetalIEEESP2021 ; Tartakovsky_book2020 , to the best of our knowledge this problem has never been considered in the multistream setting and for non-i.i.d. models.
Acknowledgements.
We are grateful to a referee for a comprehensive review and useful comments.References
- (1) Bakut, P.A., Bolshakov, I.A., Gerasimov, B.M., Kuriksha, A.A., Repin, V.G., Tartakovsky, G.P., Shirokov, V.V.: Statistical Radar Theory, vol. 1 (G. P. Tartakovsky, Editor). Sovetskoe Radio, Moscow, USSR (1963). In Russian
- (2) Baron, M.: Early detection of epidemics as a sequential change-point problem. In: V. Antonov, C. Huber, M. Nikulin, V. Polischook (eds.) Longevity, Aging and Degradation Models in Reliability, Public Health, Medicine and Biology, vol. 2, pp. 31–43. St. Petersburg (2004)
- (3) Berenkov, N.R., Tartakovsky, A.G., Kolessa, A.E.: Reliable detection of dynamic anomalies with application to extracting faint space object streaks from digital frames. In: 2020 International Conference on Engineering and Telecommunication (EnT-MIPT 2020). Dolgoprudny, Russia (2020)
- (4) Chan, H.P.: Optimal sequential detection in multi-stream data. Annals of Statistics 45(6), 2736–2763 (2017)
- (5) Chang, F.K.: Structural health monitoring: Promises and challenges. In: Proceedings of the 30th Annual Review of Progress in Quantitative NDE (QNDE), Green Bay, WI, USA. American Institute of Physics (2003)
- (6) Fellouris, G., Sokolov, G.: Second-order asymptotic optimality in multichannel sequential detection. IEEE Transactions on Information Theory 62(6), 3662–3675 (2016). DOI 10.1109/TIT.2016.2549042
- (7) Fienberg, S.E., Shmueli, G.: Statistical issues and challenges associated with rapid detection of bio-terrorist attacks. Statistics in Medicine 24(4), 513–529 (2005)
- (8) Frisén, M.: Optimal sequential surveillance for finance, public health, and other areas (with discussion). Sequential Analysis 28(3), 310–393 (2009)
- (9) Guépié, B.K., Fillatre, L., Nikiforov, I.: Sequential detection of transient changes. Sequential Analysis 31(4), 528–547 (2012). DOI 10.1080/07474946.2012.719443
- (10) Guépié, B.K., Fillatre, L., Nikiforov, I.: Detecting a suddenly arriving dynamic profile of finite duration. IEEE Transactions on Information Theory 63(5), 3039–3052 (2017). DOI 10.1109/TIT.2017.2679057
- (11) Kolessa, A., Tartakovsky, A., Ivanov, A., Radchenko, V.: Nonlinear estimation and decision-making methods in short track identification and orbit determination problem. IEEE Transactions on Aerospace and Electronic Systems 56(1), 301–312 (2020). DOI 10.1109/TAES.2019.2911760
- (12) Lai, T.L.: Information bounds and quick detection of parameter changes in stochastic systems. IEEE Transactions on Information Theory 44(7), 2917–2929 (1998)
- (13) Liang, Y., Tartakovsky, A.G., Veeravalli, V.V.: Quickest change detection with non-stationary post-change observations. IEEE Transactions on Information Theory 69(5), 3400–3414 (2023). DOI 0.1109/TIT.2022.3230583
- (14) Mana, F.E., Guépié, B.K., Nikiforov, I.: Sequential detection of an arbitrary transient change profile by the FMA test. Sequential Analysis pp. 1–21 (2023). DOI 10.1080/07474946.2023.2171056
- (15) Mei, Y.: Efficient scalable schemes for monitoring a large number of data streams. Biometrika 97(2), 419–433 (2010)
- (16) Pergamenchtchikov, S., Tartakovsky, A.G.: Asymptotically optimal pointwise and minimax change-point detection for general stochastic models with a composite post-change hypothesis. Journal of Multivariate Analysis 174(11), 1–20 (2019)
- (17) Pergamenchtchikov, S.M., Tartakovsky, A.G., Spivak, V.S.: Minimax and pointwise sequential changepoint detection and identification for general stochastic models. Journal of Multivariate Analysis 190, 1–22 (2022)
- (18) Raghavan, V., Galstyan, A., Tartakovsky, A.G.: Hidden Markov models for the activity profile of terrorist groups. Annals of Applied Statistics 7, 2402–24,307 (2013)
- (19) Raghavan, V., Steeg, G.V., Galstyan, A., Tartakovsky, A.G.: Modeling temporal activity patterns in dynamic social networks. IEEE Transactions on Computational Social Systems 1, 89–107 (2013)
- (20) Rolka, H., Burkom, H., Cooper, G.F., Kulldorff, M., Madigan, D., Wong, W.K.: Issues in applied statistics for public health bioterrorism surveillance using multiple data streams: research needs. Statistics in Medicine 26(8), 1834–1856 (2007)
- (21) Sokolov, G., Spivak, V.S., Tartakovsky, A.G.: Detecting an intermittent change of unknown duration. Sequential Analysis (2023, to be published)
- (22) Sonesson, C., Bock, D.: A review and discussion of prospective statistical surveillance in public health. Journal of the Royal Statistical Society A 166, 5–21 (2003)
- (23) Szor, P.: The Art of Computer Virus Research and Defense. Addison-Wesley Professional, Upper Saddle River, NJ, USA (2005)
- (24) Tartakovsky, A., Berenkov, N., Kolessa, A., Nikiforov, I.: Optimal sequential detection of signals with unknown appearance and disappearance points in time. IEEE Transactions on Signal Processing 69, 2653–2662 (2021). DOI 10.1109/TSP.2021.3071016
- (25) Tartakovsky, A.G.: Asymptotic performance of a multichart CUSUM test under false alarm probability constraint. In: Proceedings of the 44th IEEE Conference Decision and Control and European Control Conference (CDC-ECC’05), Seville, SP, pp. 320–325. IEEE, Omnipress CD-ROM (2005)
- (26) Tartakovsky, A.G.: Rapid detection of attacks in computer networks by quickest changepoint detection methods. In: N. Adams, N. Heard (eds.) Data Analysis for Network Cyber-Security, pp. 33–70. Imperial College Press, London, UK (2014)
- (27) Tartakovsky, A.G.: On asymptotic optimality in sequential changepoint detection: Non-iid case. IEEE Transactions on Information Theory 63(6), 3433–3450 (2017). DOI 10.1109/TIT.2017.2683496
- (28) Tartakovsky, A.G.: Asymptotic optimality of mixture rules for detecting changes in general stochastic models. IEEE Transactions on Information Theory 65(3), 1413–1429 (2019). DOI 10.1109/TIT.2018.2876863
- (29) Tartakovsky, A.G.: Sequential Change Detection and Hypothesis Testing: General Non-i.i.d. Stochastic Models and Asymptotically Optimal Rules. Monographs on Statistics and Applied Probability 165. Chapman & Hall/CRC Press, Taylor & Francis Group, Boca Raton, London, New York (2020)
- (30) Tartakovsky, A.G., Brown, J.: Adaptive spatial-temporal filtering methods for clutter removal and target tracking. IEEE Transactions on Aerospace and Electronic Systems 44(4), 1522–1537 (2008)
- (31) Tartakovsky, A.G., Nikiforov, I.V., Basseville, M.: Sequential Analysis: Hypothesis Testing and Changepoint Detection. Monographs on Statistics and Applied Probability 136. Chapman & Hall/CRC Press, Taylor & Francis Group, Boca Raton, London, New York (2015)
- (32) Tartakovsky, A.G., Rozovskii, B.L., Blaźek, R.B., Kim, H.: Detection of intrusions in information systems by sequential change-point methods. Statistical Methodology 3(3), 252–293 (2006)
- (33) Tartakovsky, A.G., Rozovskii, B.L., Blaźek, R.B., Kim, H.: A novel approach to detection of intrusions in computer networks via adaptive sequential and batch-sequential change-point detection methods. IEEE Transactions on Signal Processing 54(9), 3372–3382 (2006)
- (34) Tsui, K., Chiu, W., Gierlich, P., Goldsman, D., Liu, X., Maschek, T.: A review of healthcare, public health, and syndromic surveillance. Quality Engineering 20(4), 435–450 (2008)
- (35) Xie, Y., Siegmund, D.: Sequential multi-sensor change-point detection. Annals of Statistics 41(2), 670–692 (2013)
- (36) Yu, X., Baron, M., Choudhary, P.K.: Change-point detection in binomial thinning processes, with applications in epidemiology. Sequential Analysis 32(3), 350–367 (2013)