Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Point Density Level Estimation
Abstract
3D object detection from LiDAR data for autonomous driving has been making remarkable strides in recent years. Among the state-of-the-art methodologies, encoding point clouds into a bird’s eye view (BEV) has been demonstrated to be both effective and efficient. Different from perspective views, BEV preserves rich spatial and distance information between objects. Yet, while farther objects of the same type do not appear smaller in the BEV, they contain sparser point cloud features. This fact weakens BEV feature extraction using shared-weight convolutional neural networks (CNNs). In order to address this challenge, we propose Range-Aware Attention Network (RAANet), which extracts effective BEV features and generates superior 3D object detection outputs. The range-aware attention (RAA) convolutions significantly improve feature extraction for near as well as far objects. Moreover, we propose a novel auxiliary loss for point density estimation to further enhance the detection accuracy of RAANet for occluded objects. It is worth to note that our proposed RAA convolution is lightweight and compatible to be integrated into any CNN architecture used for detection from a BEV. Extensive experiments on the nuScenes and KITTI datasets demonstrate that our proposed approach outperforms the state-of-the-art methods for LiDAR-based 3D object detection, with real-time inference speed of 16 Hz for the full version and 22 Hz for the lite version tested on nuScenes lidar frames. The code is publicly available at our Github repository https://github.com/erbloo/RAAN.
Index Terms:
Object Detection, LiDAR Point Cloud, Bird’s Eye View, Autonomous Driving, Attention Convolution.I Introduction
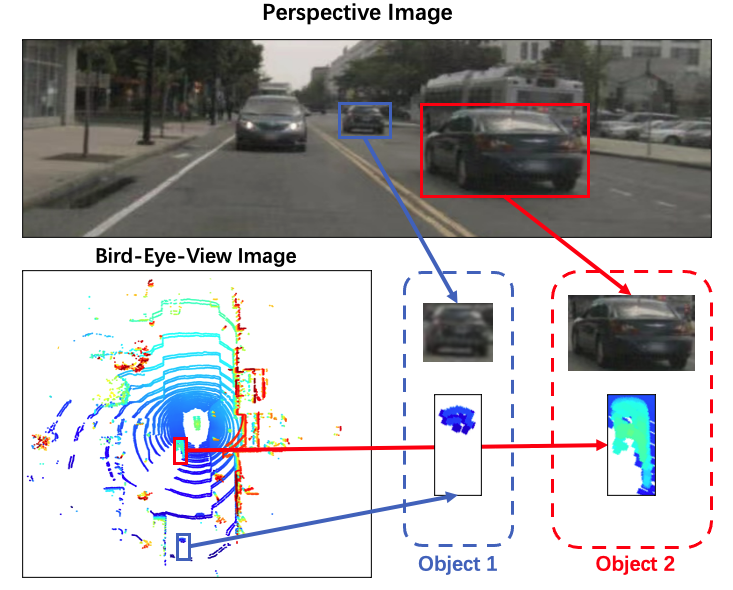
With the rapid improvement of processing units, and thanks to the success of deep neural networks, the perception of autonomous driving has been flourishing in recent years. 3D object detection from LiDAR sensors is one of the important capabilities for autonomous driving. Early works employ 3D convolutional neural networks (CNNs), which have slow processing speeds and large memory requirements. In order to decrease the memory requirements and provide real-time processing, recent methodologies leverage voxelization and bird’s eye view (BEV) projection. Voxelization is widely implemented as a preprocessing method for 3D point clouds because of the computing efficiency, provided by more structured data, and performance accuracy [18][50][49][38][39]. In general, voxelization divides a point cloud into an evenly spaced grid of voxels, and then assigns 3D LiDAR points to their respective voxels. The output space preserves the Euclidean distance between objects and avoids overlapping of bounding boxes. This fact keeps object size variation in a relatively small range, regardless of their distance from the LiDAR, which benefits the shape regression during training. However, as shown in Figure 1, voxels that are farther away from the ego-vehicle contain significantly fewer LiDAR points than the near ones. This leads to a situation where different representations may be extracted for an object at different distances to the ego-vehicle. In contrast to perspective view, where feature elements are location-agnostic, BEV feature maps are location sensitive. Thus, different convolutional kernel weights should be applied to different locations of the feature map. In other words, location information should be introduced to the feature maps, and the convolutional kernels should be adjustable to the location information of corresponding feature maps.
In this paper, we propose the Range-Aware Attention Network (RAANet), which contains the novel Range-Aware Attention Convolutional layer (RAAConv) designed for object detection from LiDAR BEV. RAAConv is composed of two independent convolutional branches and attention maps, which are sensitive to the location information of the input feature map. Our approach is inspired by the properties of BEV images, which are illustrated in Fig. 1. Points get sparser as the distance between an object and ego-vehicle increases. Ideally, for BEV feature maps, elements at different locations should be processed by different convolution kernels. However, applying different kernels will significantly increase the computational expense. In order to utilize the location information during BEV feature extraction, while avoiding heavy computation, we regard a BEV feature map as a composition of sparse features and dense features. We apply two different convolution kernels to simultaneously extract sparse and dense features. Each extracted feature map has half the channel size of the final output. Meanwhile, range and position encodings are generated based on the input shape. Then, each range-aware attention heatmap is computed from the corresponding feature map and the range and position encodings. Finally, the attention heatmaps are applied on the feature maps to enhance feature representation. The feature maps generated from two branches are concatenated channel-wise as the RAAConv output. Details are presented in Sec. III-B.
In addition, effects of occlusion cannot be ignored, since the same object may have different point distributions under different amounts of occlusion. Thus, we propose an efficient auxiliary branch, referred to as the Auxiliary Density Level Estimation Module (ADLE), allowing RAANet to take occlusion into consideration. Since annotating various occlusions is a time consuming and expensive task, we design the ADLE to estimate a point density level for each object. If there is no occlusion, point density levels for near objects are higher than those of far objects. However, if a near object is occluded, its point density level decreases. Therefore, by combining range information and density level information, we are able to estimate existence of the occlusion information. ADLE is only used in the training stage for providing density information guidance, and can be removed in inference state for computational efficiency.
Contributions. The main contributions of this work include the following:
-
•
We propose the RAAConv layer, which allows LiDAR-based detectors to extract more representative BEV features. In addition, RAAConv layer can be integrated into any CNN architecture used for LiDAR BEV.
-
•
We propose a novel auxiliary loss for point density estimation to help the main network learn occlusion related features. This proposed density level estimator further enhances the detection accuracy of RAANet on occluded objects as well.
-
•
We propose the Range-Aware Attention Network (RAANet), which integrates the aforementioned RAA and ADLE modules. RAANet is further optimized by generating anisotropic Gaussian heatmap based on the ground truth, which is introduced in Sec. III-D.
-
•
The code is available at the following GitHub repo [1].
II Related Work
Majority of the object detection works can be categorized into two main groups: object detection with anchors and without anchors. Additionally, there exist works [41][50][18] that encode point cloud data in the early stage, but they are out of scope for object detection network refactorization.
II-A Object detection with anchors
The fixed-shaped anchor regression approach [14][13] [28] has been proposed such that intermediate features can be extracted. Girschick et al. [14] perform independent forward propagation on each region proposal. Region proposal task and object detection task are compounded in [13], which avoids heavy convolution operation overhead and preserves the precision throughout the network. To decrease the computation further, Ren et al. [28] introduce a separate network to predict region proposals. This removes the time-consuming selective search algorithm and lets the network learn the region proposals. These works employ the two-stage detection scheme. However, the region-proposal-joint process (e.g. RPN) is still slow and memory intensive, and thus not compatible with real-time detection. To reduce computation as well as memory footprint during both training and inference phases, one stage detectors are exploited in many works [22][27][20], which can train object classification and bounding box regression directly, without pre-generated region proposals during training, and maintain a lower memory footprint at the same time. Redmon et al. [27] redefine object detection as a single regression problem, which employs an end-to-end neural network to do a single forward propagation to detect objects. Liu et al. [22] develop a multi-resolution-anchor technique to detect objects of a mixture of a scale as well as learn the offset to a certain extent than learning the anchor. Lin et al. [20] present a focal loss to tackle the dense and small object detection problem while dealing with class imbalance and inconsistencies. Zhou and Tuzel [50] and Lang et al. [18] propose neural networks for point clouds, which open up new possibilities for 3D detection tasks. It should be noted that, although the aforementioned studies are real-time detection works, they actually involve the computation of all anchors’ regression corresponding for different anchor scales.
II-B Object detection without anchors
To address the computation overhead and hyperparameter redundancy introduced by anchor regression, and effectively process point cloud encodings, anchor-free object detection has been exploited in many works [33][45][15][52][19][11][48]. Anchor-free object detection can be classified into two broad categories, namely center-based and key point-based approaches.
II-B1 Center-based approach
In this approach [47][44], the center points of an object are used to define positive and negative samples, instead of IoU [33][15][52]. This method significantly reduces the computation cost by predicting four distances from positive samples to boundary of objects to generate a bounding box. Tian et al. [33] predict one point at each position instead of defining several bounding boxes with different scales. Huang et al. [15] propose the DenseBox, a unified fully convolutional neural network, which simultaneously detects multiple objects with confidence scores. This method is primarily applied to face detection and cars detection. Zhu et al. [52] propose to attach online feature selection to each feature pyramid during training by setting up supervision signals through anchor-free branches. This work is demonstrated with feature pyramids of single-shot detectors.
II-B2 Keypoint-based approach
In this approach [19][11][48], the key points are located by several predefined methods or self-learned models, and then generate the bounding boxes to classify the objects. Law and Deng [19] propose corner pooling, which aggregates the features of objects on the corner and groups corners with associative embeddings. Zhou et al. [48] develop a framework to predict four corner coordinates and center points simultaneously. However, the grouping algorithm and key points selection in these works introduce redundant false positive samples and effect the performance of detectors. To address this problem, Duan et al. [11] use both center points and corner points, which directly replace associative embedding with centripetal shifts. Although these paradigms are mainly proposed for optimizing data annotations, we have found that it also plays an essential role in feature representation and detection accuracy. In order to extract representative features, we focus on two major components: range-aware feature extraction and occlusion supervision.
III Range-Aware Attention Network
III-A Overview of the RAANet
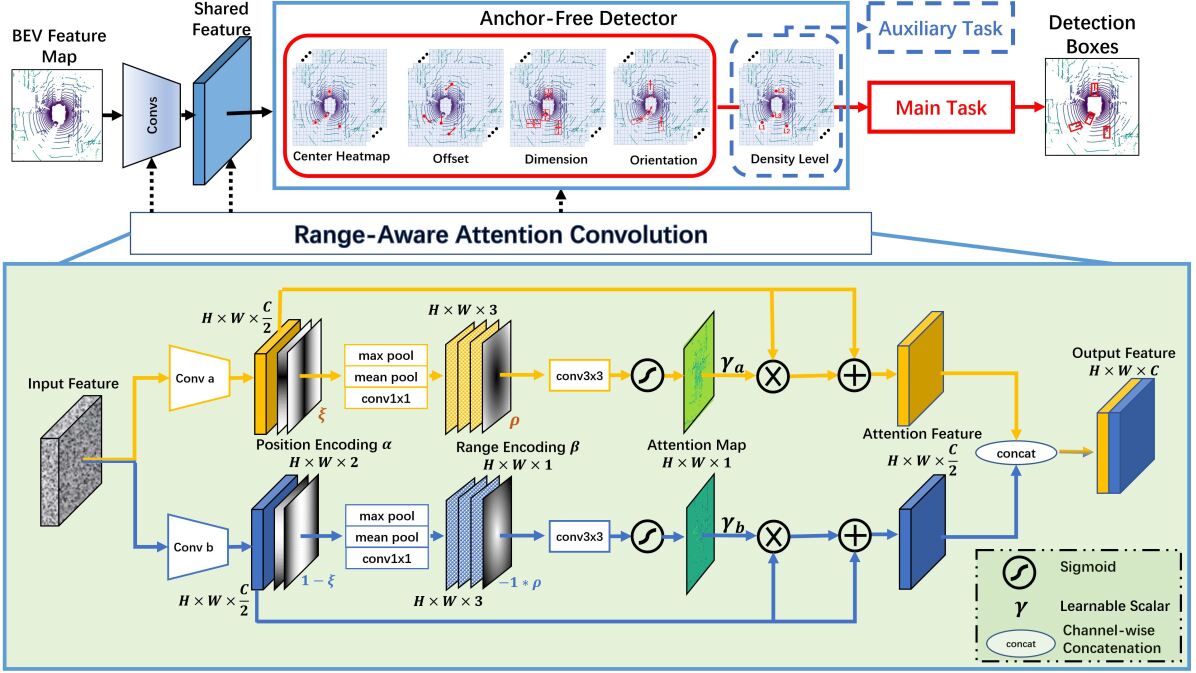
The main architecture of our proposed Range-Aware Attention Network (RAANet) is presented in Fig. 2. We incorporate ideas from CenterNet [47][44] to build an anchor-free detector, and also introduce two novel modules: the Range-Aware Attention Convolutional Layer (RAAConv) and the Auxiliary Density Level Estimation Module (ADLE).
RAANet takes the 3D LiDAR points as input and generates a set of 3D oriented bounding boxes as the output. Inspired by VoxelNet [50], we implement a feature extractor with 3D sparse convolutional network on the voxelized point clouds. This resulting features are reshaped and formed into BEV feature maps, which can be regarded as a multi-channel 2D image. The Region Proposal Network (RPN) takes this BEV feature maps as input and employs multiple down-sample and up-sample blocks to generate a high-dimensional feature map. In addition to the detection heads in main task, we propose an auxiliary task for point density level estimation to achieve better detection performance. Meanwhile, the RAAConv layers are utilized in all convolutional modules. The details of the RAAConv layer are shown in the bottom half of Fig. 2. Center probability heatmap is generated from the detector head, and maximums in local neighborhoods are treated as the centers of ground-truth bounding boxes (bbox). The regression of bbox attributes, including offsets, dimensions and orientations, are computed from the other heads in the main detection task. Parallel to the main task, the proposed ADLE, as an auxiliary task, estimates the point density level for each bounding box. In general, ADLE classifies each bounding box into different density levels, based on the number of points in each bbox. ADLE is a portable block for the whole network, i.e. it is employed only during training and is not used during inference for higher computational efficiency.
For the training phase, the loss components, namely the heatmap classification loss, bbox regression loss and density-level auxiliary loss are denoted as , and , respectively. The total loss function of RAANet is formulated as
| (1) |
where and are scalar weights for balancing the multi-task loss. and are designed as penalty-reduced focal losses [21][47], and is designed as the smooth L1 loss.
III-B Range-Aware Attentional Convolutional Layer
We propose the Range-Aware Attentional Convolutional Layer (RAAConv), which, by leveraging the specially designed attention blocks, becomes sensitive to range and position information. This is the major difference between the proposed RAAConv and a traditional convolutional layer. RAAConv is employed in the aforementioned RPN and detection heads. As shown in Fig. 2, RAAConv first utilizes two sets of convolutional kernels to extract an intermediate feature map for each branch. Then, the position encodings are generated and embedded into intermediate feature maps. Two range-aware heatmaps are calculated by a series of convolution and pooling operations using the intermediate feature maps and range encodings. More specifically, given an input feature map , two separate intermediate feature maps, , are generated by
| (2) |
where represents the convolution operation and denotes the corresponding convolution kernel.
Meanwhile, the position encoding map and range encoding map are generated from the intermediate feature map . and are calculated from shape information and do not depend on the specific values inside the tensor . There are two components of : row encoding and column encoding . and are generated as follows:
| (3) | ||||
Values of are bounded in . Values of are bounded in .
Since the proposed network is designed by using two different convolution kernels, to extract dense and sparse features separately, we append to intermediate feature map channel-wise, and reversely append to . The generated features are denoted by and . Maximum pooling, mean pooling and conv2D are applied on and separately to obtain the spatial embeddings and . Then, similar to positional appending, the range encoding map is appended to , and is appended to . The appended features are processed by a conv2D layer followed by sigmoid activation to obtain the range-aware attention heatmaps and . The heatmaps and are then multiplied by learnable scalars and , respectively. and are initialized as and their values are gradually learned during training [46]. The output feature maps and are calculated from , and using a residual connection, which is defined as:
| (4) |
where is the operation performing channel-wise stacking and element-wise multiplication. The final output for RAAConv is the channel-wise concatenation of and , which has a size of .
It is worth noting that the proposed RAAConv can be readily plugged in any convolutional network for LiDAR BEV detection.
III-C Auxiliary Density Level Estimation Module (ADLE)
The Auxiliary Density Level Estimation Module (ADLE) is an additional classification head that is parallel to the main task heads. The ADLE module indicates the point density level for each bbox. In general, we design the ADLE module to estimate the number of LiDAR points inside a detected bbox. We have empirically found out that this estimation is straightforward yet beneficial for the detector. Moreover, we divide the number of points into three density bins and let the ADLE perform a classification task, instead of a value regression task, which helps training to converge better. More specifically, the three bins are labeled as sparse (label ), adequate (label ) and dense (label ). We have statistically analyzed the distribution of the number of points and employed two thresholds to determine the density level for each object class . The three density levels are defined as:
| (5) |
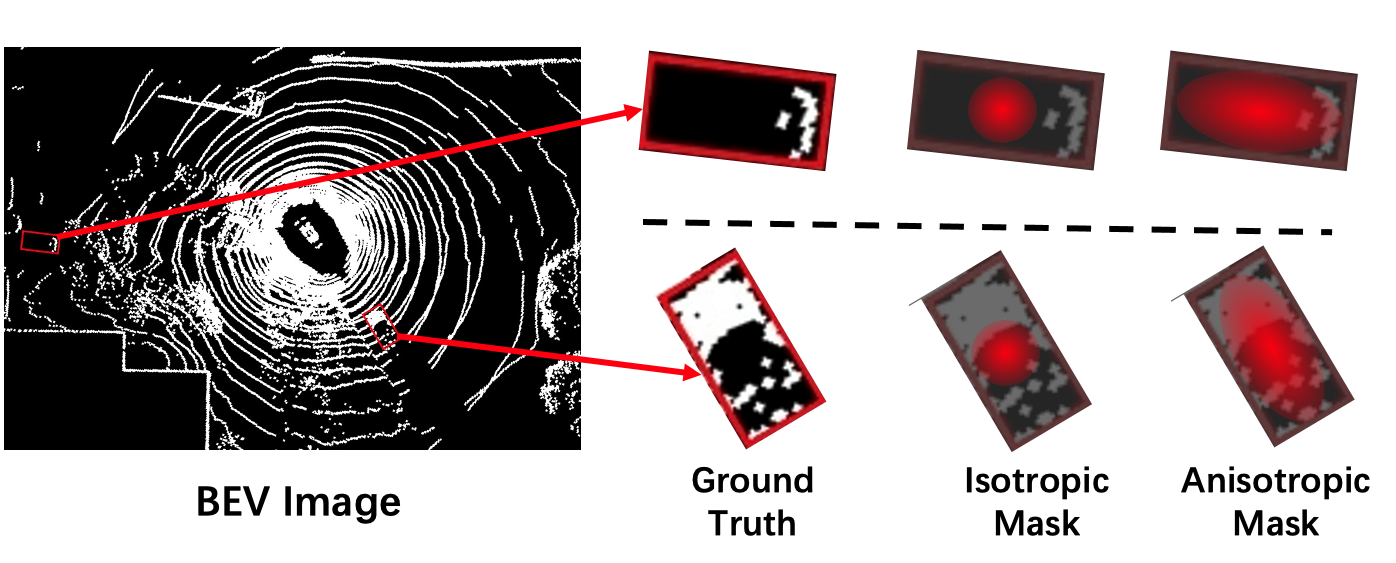
where denotes the number of points, and represents the density level for the -th class. As shown in Fig. 3, the unoccluded instances near the ego-vehicle have high point density levels and faraway instances have low density levels. However, when an instance is occluded, the density level will be lower than the unoccluded case at the same distance. Since we incorporate position and range information into RAAConv, ADLE is able to further help RAANet extract occlusion information by supervising the point density levels.
III-D Anisotropic Gaussian Mask
Anisotropic Gaussian Mask represents the centerness probability for each position in an annotated bbox. The centerness heatmap is generated as the ground truth for the classification head. In this work, we propose an Anisotropic Gaussian Mask, shown in Fig. 3, to generate a 2D Gaussian distribution, to be used for the centerness probabilities of a given oriented bbox. More specifically, the Gaussian distribution is designed in an anisotropic way, i.e. the values for the 2 dimensions, which are the diagonals of , and denoted as , are different, and their values are determined from the length and width of the bbox, respectively. The procedure for generating the center heatmap, denoted by , can be formulated as:
| (6) |
where,
| (7) | ||||
and and denote the center location and dimensions of a bbox, respectively. indicates the ground truth class for the bbox. is the indicator function and denotes the set of locations that are inside the bbox. is a decay factor determining the sharpness of generated heatmap. The value of depends on the class of a given bbox.
III-E Loss Functions
Following Eq. (1), the center heatmap loss is defined as:
| (8) | ||||
where and are the ground-truth and predicted heatmap values, respectively. is a small value for numerical stability. and are the parameters for controlling the penalty-reduced focal loss. For all the experiments, we follow the setting in [32], i.e. , and .
The bounding box head is responsible for the location, dimension and orientation regression, which are represented by the following parameters: , where are the box center offsets with respect to the corresponding voxel centers; and and denote the length, width, height and yaw of a bounding box. We apply smoothed L1 (SL1) losses to regress and for the attribute, and directly regress actual values for other attributes:
| (9) | ||||
| (10) |
where, denotes predicted values corresponding to original symbols. The total loss for box regression is:
| (11) |
where is the number of box samples and equals 1 if the ground truth heatmap value of the th feature map pixel is larger than a threshold , which is set to 0.2 in the experiments.
| Car | Truck | Bus | Trailer |
|
Ped. | M.cyc. | Bicycle |
|
Barrier | mAP | |||||
| PointPillars [18] | 0.760 | 0.310 | 0.321 | 0.366 | 0.113 | 0.640 | 0.342 | 0.140 | 0.456 | 0.564 | 0.401 | ||||
| SA-Det3D [2] | 0.812 | 0.438 | 0.572 | 0.478 | 0.113 | 0.733 | 0.321 | 0.079 | 0.606 | 0.553 | 0.470 | ||||
| InfoFocus [34] | 0.779 | 0.314 | 0.448 | 0.373 | 0.107 | 0.634 | 0.290 | 0.061 | 0.465 | 0.478 | 0.395 | ||||
| CyliNetRG [26] | 0.850 | 0.502 | 0.569 | 0.526 | 0.191 | 0.843 | 0.586 | 0.298 | 0.791 | 0.690 | 0.585 | ||||
| SARPNET [43] | 0.599 | 0.187 | 0.194 | 0.180 | 0.116 | 0.694 | 0.298 | 0.142 | 0.446 | 0.383 | 0.324 | ||||
| PanoNet3D [8] | 0.801 | 0.454 | 0.540 | 0.517 | 0.151 | 0.791 | 0.531 | 0.313 | 0.719 | 0.629 | 0.545 | ||||
| PolarStream [6] | 0.809 | 0.381 | 0.471 | 0.414 | 0.195 | 0.802 | 0.614 | 0.299 | 0.753 | 0.640 | 0.538 | ||||
| MEGVII [51] | 0.811 | 0.485 | 0.549 | 0.429 | 0.105 | 0.801 | 0.515 | 0.223 | 0.709 | 0.657 | 0.528 | ||||
| PointRCNN[30] | 0.810 | 0.472 | 0.563 | 0.510 | 0.141 | 0.766 | 0.422 | 0.134 | 0.667 | 0.614 | 0.510 | ||||
| SSN-v2 [53] | 0.824 | 0.418 | 0.461 | 0.480 | 0.175 | 0.756 | 0.489 | 0.246 | 0.601 | 0.612 | 0.506 | ||||
| ReconfigPP-v2 [35] | 0.758 | 0.272 | 0.395 | 0.380 | 0.065 | 0.625 | 0.152 | 0.002 | 0.257 | 0.349 | 0.325 | ||||
| ReconfigPP-v3 [35][36] | 0.814 | 0.389 | 0.430 | 0.470 | 0.153 | 0.724 | 0.449 | 0.226 | 0.583 | 0.614 | 0.485 | ||||
| HotSpotNet [5] | 0.831 | 0.509 | 0.564 | 0.533 | 0.230 | 0.813 | 0.635 | 0.366 | 0.730 | 0.716 | 0.593 | ||||
| MMDec3D [10] | 0.847 | 0.490 | 0.541 | 0.528 | 0.216 | 0.793 | 0.560 | 0.387 | 0.714 | 0.674 | 0.575 | ||||
| CenterPoint [44] | 0.852 | 0.535 | 0.636 | 0.560 | 0.200 | 0.846 | 0.595 | 0.307 | 0.784 | 0.711 | 0.603 | ||||
| CVCNet-ens [4] | 0.826 | 0.495 | 0.594 | 0.511 | 0.162 | 0.830 | 0.618 | 0.388 | 0.697 | 0.697 | 0.582 | ||||
| RAANet-lite (Ours) | 0.860 | 0.546 | 0.636 | 0.553 | 0.237 | 0.856 | 0.633 | 0.340 | 0.794 | 0.749 | 0.620 | ||||
| RAANet(Ours) | 0.864 | 0.572 | 0.648 | 0.569 | 0.240 | 0.857 | 0.641 | 0.371 | 0.829 | 0.761 | 0.635 |
| mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS | |
| PointPillars | 0.401 | 0.392 | 0.269 | 0.476 | 0.270 | 0.102 | 0.550 |
| SA-Det3D | 0.470 | 0.317 | 0.248 | 0.438 | 0.300 | 0.129 | 0.592 |
| InfoFocus | 0.395 | 0.363 | 0.265 | 1.132 | 1.000 | 0.395 | 0.395 |
| CyliNetRG | 0.585 | 0.272 | 0.243 | 0.383 | 0.293 | 0.126 | 0.661 |
| SARPNET | 0.324 | 0.400 | 0.249 | 0.763 | 0.272 | 0.090 | 0.484 |
| PanoNet3D | 0.545 | 0.298 | 0.247 | 0.393 | 0.338 | 0.136 | 0.631 |
| PolarStream | 0.538 | 0.339 | 0.264 | 0.491 | 0.339 | 0.123 | 0.613 |
| MEGVII | 0.528 | 0.300 | 0.247 | 0.379 | 0.245 | 0.140 | 0.633 |
| PointRCNN | 0.510 | 0.301 | 0.245 | 0.378 | 0.326 | 0.138 | 0.616 |
| SSN-v2 | 0.506 | 0.339 | 0.245 | 0.429 | 0.266 | 0.087 | 0.616 |
| ReconfigPP-v2 | 0.325 | 0.388 | 0.250 | 0.486 | 0.306 | 0.137 | 0.506 |
| ReconfigPP-v3 | 0.485 | 0.328 | 0.244 | 0.439 | 0.274 | 0.244 | 0.590 |
| HotSpotNet | 0.593 | 0.274 | 0.239 | 0.384 | 0.333 | 0.133 | 0.660 |
| MMDec3D | 0.575 | 0.316 | 0.256 | 0.409 | 0.236 | 0.124 | 0.653 |
| CenterPoint | 0.603 | 0.262 | 0.239 | 0.361 | 0.288 | 0.136 | 0.673 |
| CVCNet-ens | 0.582 | 0.284 | 0.241 | 0.372 | 0.224 | 0.126 | 0.666 |
| RAANet-lite (Ours) | 0.620 | 0.277 | 0.244 | 0.365 | 0.212 | 0.126 | 0.687 |
| RAANet (Ours) | 0.635 | 0.259 | 0.240 | 0.326 | 0.210 | 0.125 | 0.702 |
IV Experiments
We introduce the implementation details of the proposed RAANet and evaluate its performance in multiple experiments. The inference results are uploaded to and evaluated by the nuScenes official benchmark [23]. The diagnostic analysis of each component is shown in the ablation studies in Sec. IV-E.
IV-A Datasets
We perform the evaluations on the nuScenes [3] and KITTI [12] datasets, which are publicly available, large-scale and challenging datasets for autonomous driving. The full nuScenes dataset includes approximately 390K LiDAR sweeps and 1.4M object bounding boxes in 40K key frames. The dataset contains 1000 scenes in total, of which 700 are separated for training, 150 for validation and 150 for testing. There are a total of 10 classes: car, truck, bus, trailer, construction vehicle, traffic cone, barrier, motorcycle, bicycle, pedestrian. The scenes of 20 sec. length are manually selected to cover a diverse and interesting set of driving maneuvers, traffic situations and unexpected behaviors. The dataset was captured with a 32-channel spinning LiDAR sensor with 360 degree horizontal and -30 to +10 degree vertical FOV. The sensor captures points, which are within 70 meters with cm accuracy and returns up to 1.39M points per second.
We also use the KITTI dataset to benchmark performance. The 3D object detection dataset consists of 7481 training and 7518 testing samples for the point clouds, including a total of 80256 labeled objects. Following the experimental setting used in [18], we divide the official training samples into 3712 training samples and 3769 validation samples. Meanwhile, considering the test submission requirement, we create 784 samples as a minival validation set, and use the remaining 6697 samples to train. Since the KITTI benchmark only provides the ground truth annotations of objects that are visible in camera images, we followed the standard literature practice on KITTI of only using LiDAR points that project into the image, and trained one network for cars to benchmark our model performance.
IV-B Implementation Details
RAANet is implemented in PyTorch framework [24] with an anchor-free object detection architecture. The weights and in loss function (Eq. 1) are set to and , respectively. The decay factor in Sec. III-D is set to for large size classes (car, truck, bus, trailer, construction_vehicle), to for small object classes (traffic_cone, barrier, motorcycle, bicycle, pedestrian). As for the parameters in Sec. III-E, we set , , and to , , and , respectively.
For nuScenes, all classes are trained end-to-end. The resolution for voxelization is set to and the voxelization region is . The model is trained by 20 epochs. Initial learning rate is set to and then is modified by one-cycle adjuster [31]. Adam optimizer [16] with decay parameters is applied. The models are trained by 8 Nvidia V100 GPUs, and the batch size is set to 4 for each GPU. More details are provided in the configuration files of our Github repository [1].
For KITTI experiments, the resolution for voxelization is set to and the voxelization region is . The model is trained by 80 epochs. Initial learning rate is set to and is decayed by 0.8 for every 15 epochs. Adam optimizer with decay parameters is applied.
Two versions of the RAANet are designed in this work: (i) the full version RAANet applies RAAConv layers throughout all modules; (ii) RAANet-lite version applies RAAConv layers only at the detection heads. Both designs outperform SOTA baselines. Compared to the RAANet, RAANet-lite has faster inference speed, with a small drop in performance in terms of the mAP and NDS metric.
IV-C Training and Inference
RAANet is trained end-to-end from scratch. Several data augmentation strategies are implemented in the training phase. They are random flipping along the -axis, random scaling for the point clouds, and global rotation around the -axis with a random angle sampled from .
During inference, we reuse the checkpoint with the best mean average precision (mAP) value and evaluate on the official lidar-only nuScenes and KITTI evaluation metrics. The detection score threshold is set to and IoU threshold is set to for non-maximal suppression.
The inference speed is tested on the nuScenes. The reason is that the nuScenes data is much closer to the real autonomous driving scenarios, whereas KITTI dataset only stores the front views of the scenes. The latency for the full version of RAANet and RAANet-lite are measured as 62 ms and 45 ms per frame, respectively. Both versions satisfy the real-time 3D detection criteria.
| Method | BEV (AP) | |||
|---|---|---|---|---|
| Easy | Moderate | Hard | AVG | |
| AVOD[17] | 0.898 | 0.850 | 0.783 | 0.843 |
| MV3D[7] | 0.865 | 0.790 | 0.722 | 0.792 |
| PointRCNN[29] | 0.921 | 0.874 | 0.827 | 0.874 |
| Fast PointRCNN[9] | 0.909 | 0.878 | 0.805 | 0.864 |
| F-PointNet[25] | 0.912 | 0.847 | 0.748 | 0.835 |
| F-ConvNet[37] | 0.915 | 0.858 | 0.761 | 0.845 |
| 3DSSD[42] | 0.927 | 0.890 | 0.859 | 0.892 |
| VoxelNet[50] | 0.880 | 0.784 | 0.713 | 0.792 |
| SECOND[40] | 0.894 | 0.838 | 0.786 | 0.839 |
| PointPillars[18] | 0.901 | 0.866 | 0.828 | 0.865 |
| CenterPoint-pcdet[44] | 0.885 | 0.851 | 0.812 | 0.849 |
| RAANet (Ours) | 0.953 | 0.894 | 0.843 | 0.897 |
IV-D Results
IV-D1 Results on the NuScenes Dataset
We present the results obtained on the test set with both our lite-version and full-version models, shown in Table I and II, in terms of different metrics. The architecture of the full version is illustrated in Fig. 2. All detection results are evaluated in terms of mean average precision (mAP), mean Average Translation Error (mATE), mean Average Scale Error (mASE), mean Average Orientation Error (mAOE), Average Velocity Error (AVE), Average Attribute Error (AAE) and nuScenes detection score (NDS). The NDS is weighted summed from mAP, mATE, mASE, mAOE, mAVE and mAAE. It firstly converts the errors to scores by . Then a weight of 5.0 is assigned to mAP, and a weight of 1.0 is assigned to the other five scores. We compare our work with 16 other SOTA models that have open-source codes. As can be seen in Table I, our proposed RAANet outperforms all the other models in terms of mAP, and the RAANet-lite takes the second place. For individual classes, RAANet achieves the best AP for 9 out of 10 classes, and RAANet-lite takes the second place for 7 out of 10 classes. As shown in Table II, the RAANet provides the best performance in terms of mAP, mATE, mAOE, mAVE and NDS metrics, and the 3rd best performance in terms of the mASE and mAAE metrics. The mASE of the RAANet only shows a small gap compared with the top performances on the benchmark. The RAANet-lite takes the second best place for NDS and mAP metrics.
IV-D2 Results on the KITTI Dataset
We present the results, obtained on the test set with our full-version models in Table III. All detection results are evaluated by the average precision (AP) metric for BEV car object detection. We compare our work with other state-of-the-art models that leverage LiDAR points data. As can be seen in Table III, our proposed RAANet outperforms all the other models in terms of the average APs for “Easy”, “Moderate” and “Hard” testing samples, which are defined in the KITTI dataset. Thus, when all these testing samples are considered together, RAANet achieves the best detection performance.
| Model | RAAConv | 2D Gaussian | ADLE | AP (%) | NDS(%) | |||
|---|---|---|---|---|---|---|---|---|
| Dual Branch | Attention | Car | Ped. | All cls. | ||||
| Baseline | - | - | - | - | - | 85.23 | 84.62 | 67.35 |
| + RAAConv | ✓ | ✗ | ✗ | ✗ | ✗ | 85.40 | 84.81 | 68.15 |
| ✗ | ✓ | ✗ | ✗ | ✗ | 85.41 | 84.91 | 68.27 | |
| ✓ | ✓ | ✗ | ✗ | ✗ | 85.85 | 85.52 | 68.51 | |
| ✓ | ✓ | ✓ | ✗ | ✗ | 86.01 | 85.60 | 69.02 | |
| + 2D Gaussian | ✓ | ✓ | ✓ | ✓ | ✗ | 86.25 | - | 69.59 |
| + auxiliary loss | ✓ | ✓ | ✓ | ✓ | ✓ | 86.41 | 85.72 | 70.27 |
| Models | RAAConv | 2D Gaussian | ADLE | AP(%) | |
| Car | Pedestrian | ||||
| Baseline | ✗ | ✗ | ✗ | 83.98 | 82.80 |
| RAANet | ✗ | ✓ | ✗ | 84.32 | - |
| ✓ | ✗ | ✗ | 84.60 | 83.69 | |
| ✓ | ✓ | ✗ | 84.69 | - | |
| ✓ | ✓ | ✓ | 84.80 | 83.79 | |
IV-E Ablation Studies
In this section, we provide the results of the ablation studies for different components and critical parameters of our approach, more specifically the attention module, decay factor (for the anisotropic Gaussian mask) and (weight for the density level estimation loss). The models are evaluated on the nuScenes validation set, since it has much more samples than the KITTI. For computational efficiency, all the experiments in this section are performed on the ‘Car’ and ‘Pedestrian’ classes to represent large and small objects, respectively. The baseline is the CenterPoint [44] with Isotropic Gaussian Mask and traditional convolutions.
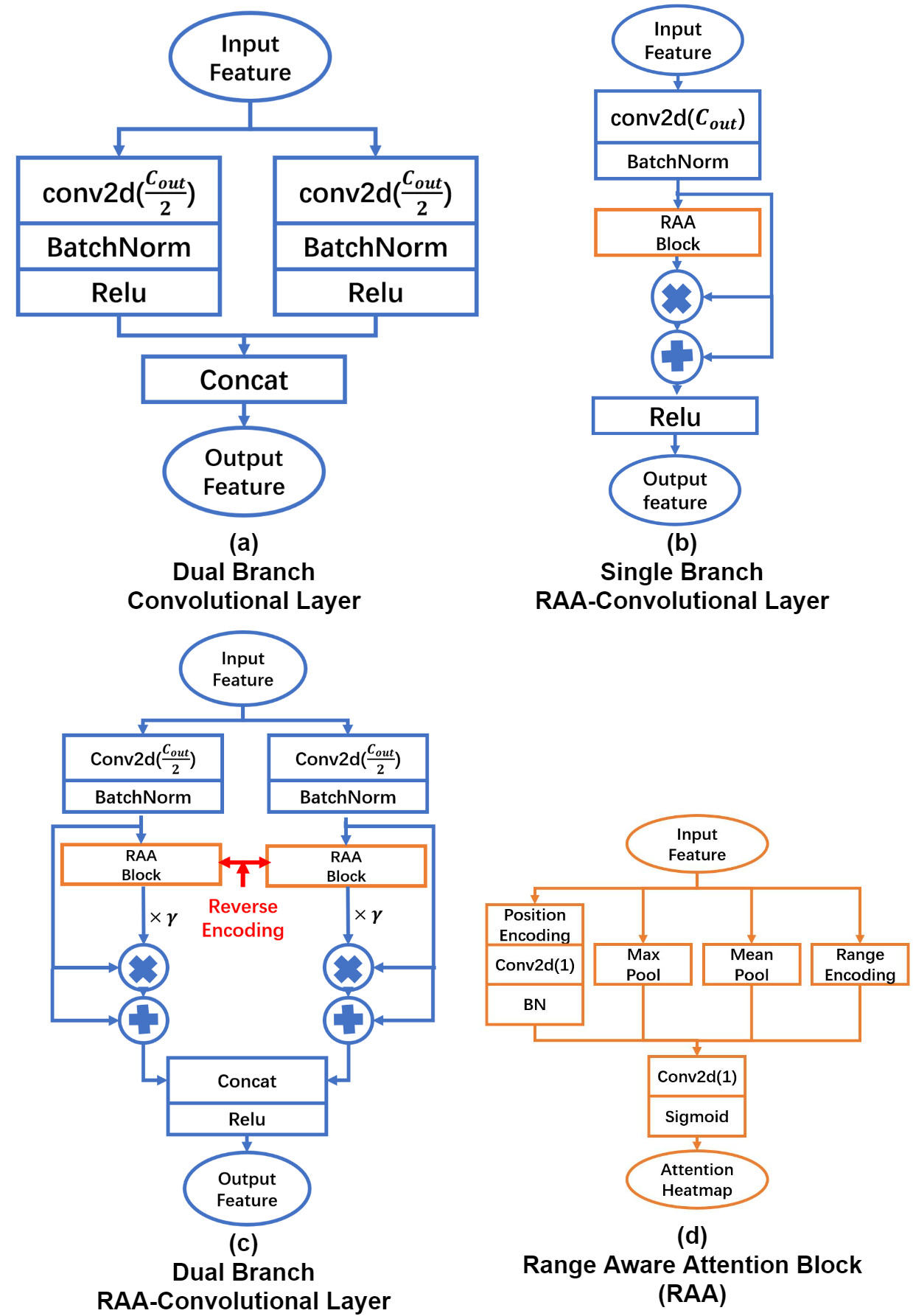
The structures of the RAAConv layers employed in the ablation studies are shown in Fig. 4. In order to evaluate the effectiveness of our proposed RAAConv layer, we test each sub-component inside the RAAConv. Fig. 4 shows three main variants of RAAConv: (a) Dual branch module built with the original convolution, where each branch has half the number of output channels; (b) Single branch module built with range-aware attention, yet without the learnable scalar ; (c) Dual branch module built with all sub-components. The reverse encoding indicates different positional encodings on the two attention branches, in order to extract dense and sparse features separately. The last sub-figure (Fig. 4(d)) shows the structure of the RAA block that is used for generating attention heatmaps.
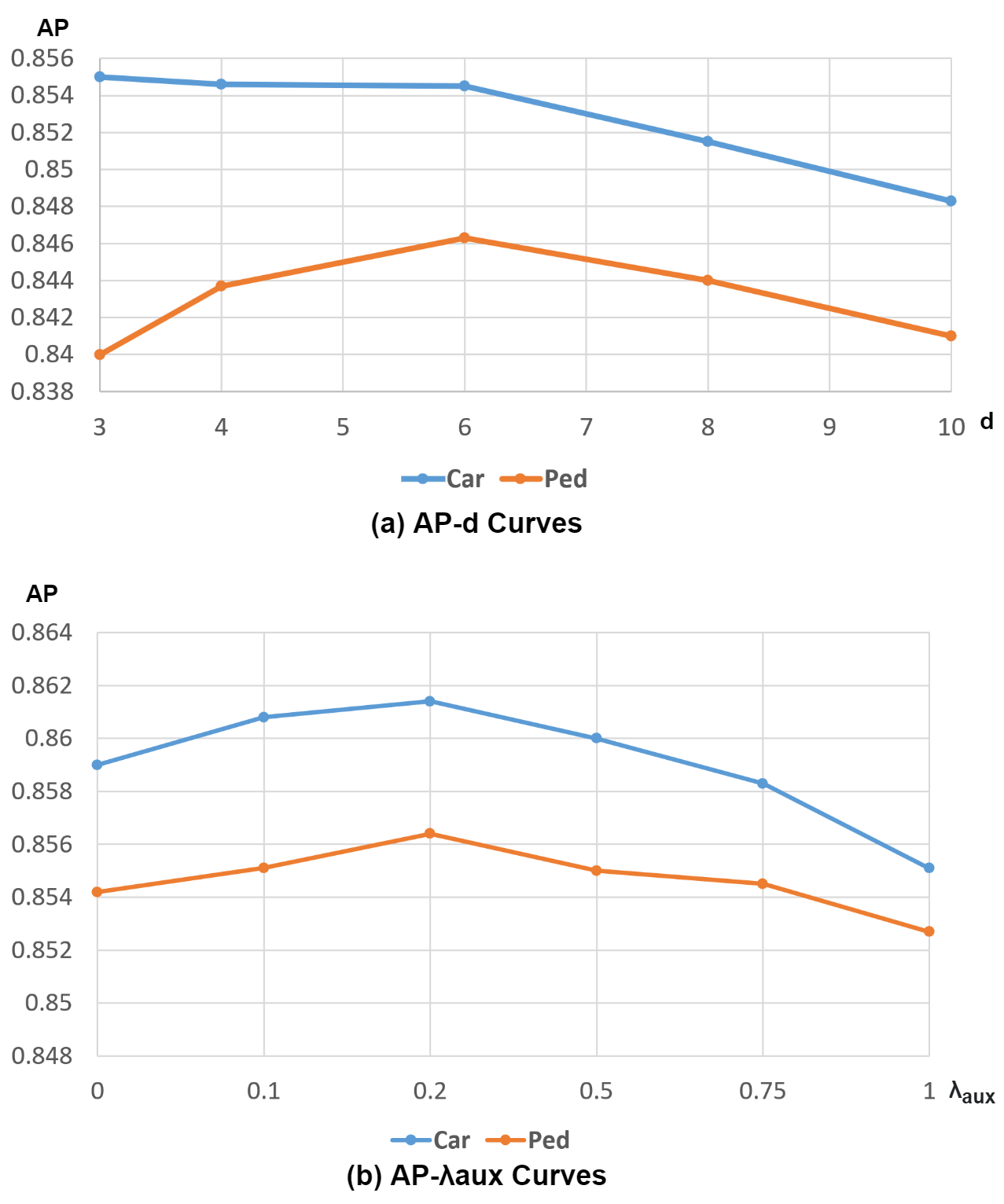
Anisotropic Gaussian Mask. We evaluate the contribution of the Anisotropic Gaussian Mask by varying the decay factor . The ablation study results presented in Fig. 5(a) show that, with anisotropic Gaussian mask, the performance improvement (in terms of AP) for the ‘Car’ class is more compared to the ‘Pedestrian’ class. One of the probable reasons is that the annotated bboxes for the pedestrian class have similar widths and lengths. This leads the anisotropic Gaussian mask to fall back to the original isotropic Gaussian mask. Additionally, we set for large object and for the small objects in our main experiments. In general, IoU-based evaluation is more sensitive on small objects than large objects, and sharper Gaussian masks help achieve higher accuracy values for small objects.
Auxiliary Density Level Estimation Module. The AP results obtained with various weights of the loss for the auxiliary component (), are shown in Fig. 5(b). The loss weight values are chosen between and . Based on these results, We set for the main experiments.
Range-Aware Attentional Convolution. Table IV shows the performance of the baseline as well as several types of the Range-Aware Attention Network. For RAAConv, there are three sub-components: dual branch structure, range-aware attention heatmap and learnable scalar (Fig. 2). Each of these components contributes to the improvement of detection performance. We observe that the combination of dual-branch structure and range-aware attention provides 0.9% gain on the small object. With the learnable scalar , the dual-branch attentions can be adaptive to the variation of the training data resulting in further improvement.
IV-F Generalizability
The proposed RAANet is further evaluated by a different backbone from PointPillar [18]. More specifically, we replace the original 3D voxel-based backbone with a 2D pillar-based backbone. The pillar size is set to . The perception range is set to . The baseline is trained with the CenterPoint-PointPillar version. As shown in Table V, our proposed RAANet still provides a competitive performance with each component contributing to the performance improvement.
IV-G Qualitative Analysis
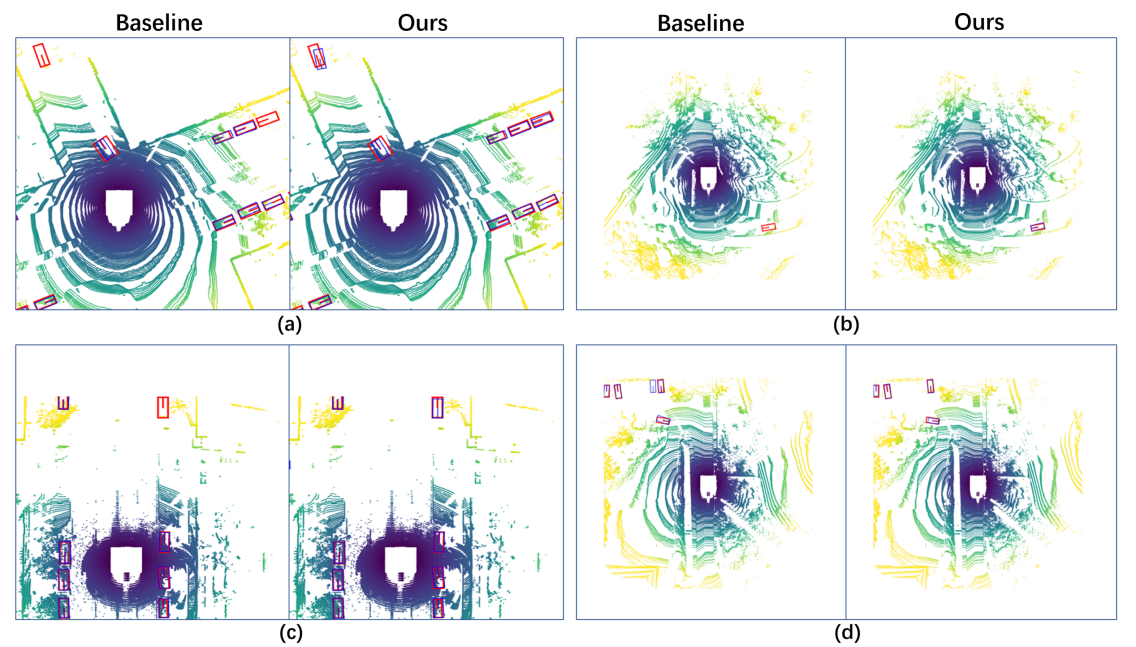
Pairs of example outputs, obtained by the baseline and the proposed RAANet are provided in Fig. 6 for qualitative comparison. The sample data is selected from the nuScenes validation dataset. In a pair, images on the left are the results obtained from the baseline, and the images on the right are the results from the proposed RAANet. It can be observed that RAANet increases true positives and suppresses false positives at far or occluded regions.
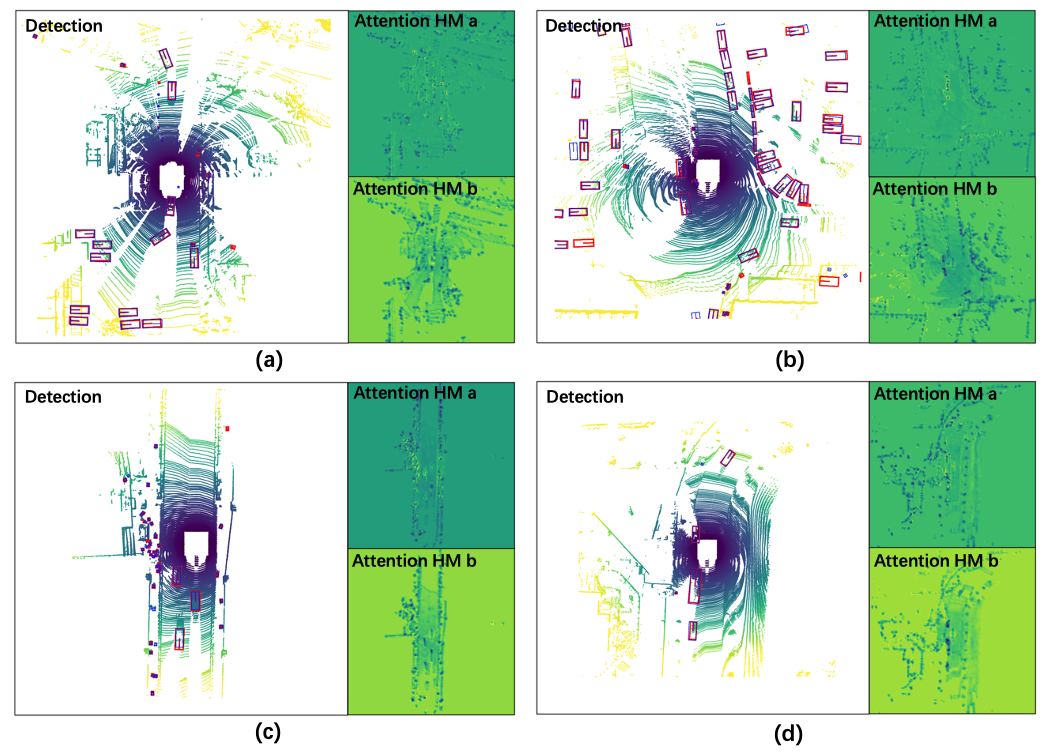
Fig. 7 shows more visualization examples on all-class detection of the RAANet as well as the attention heatmaps generated from RAAConv. For each sub-figure, the image on the left is the all-class detection result obtained from our proposed RAANet, and the two images on the right are the attention maps from both convolutional branches in the RAAConv layer. It can be observed that both attention modules represent the positional heatmaps based on the BEV. In general, the attention heatmap from branch ‘a’, highlights the regions with dense point clouds or the ego-vehicle vicinity. The attention heatmap from branch ‘b’, on the other hand, pays attention to the regions with sparse point clouds or are farther from the ego vehicle. The combination of both branches effectively extracts powerful BEV features and generates superior 3D object detection results.
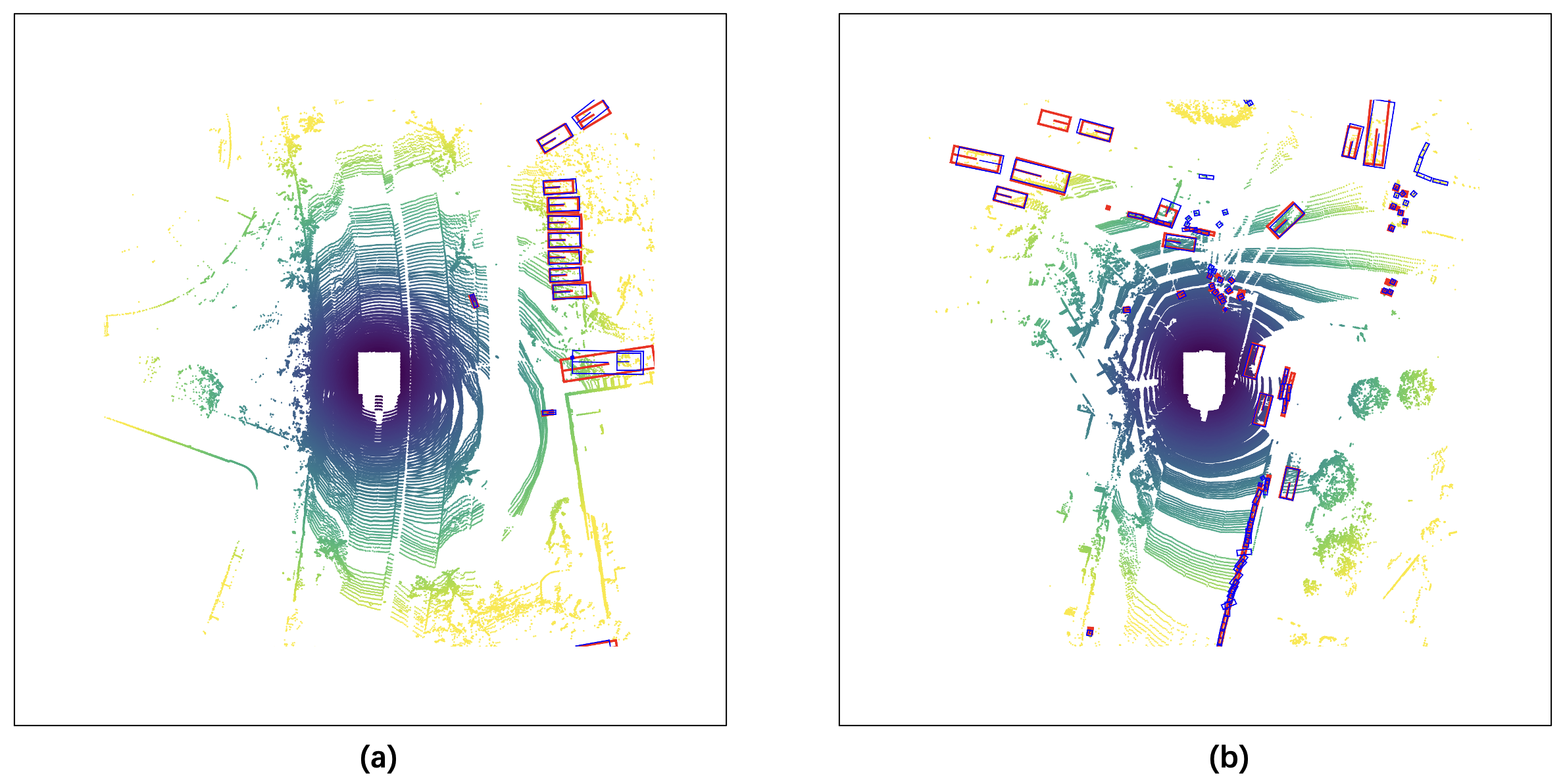
Fig. 8 shows some hard examples that were misjudged by our proposed method. In Fig. 8(a), although our RAANet successfully generates the detection results for all ground truths, some of the detection headings are not regressed accurately enough due to the long distance and sparse points inside the objects. In Fig. 8(b), some false positives appear on severely occluded regions.
V Conclusion
In this paper, we have introduced the Range-Aware Attention Network (RAANet) to improve the performance of 3D object detection from LiDAR point clouds. The motivation behind the RAANet is that, in Bird’s Eye View (BEV) LiDAR images, objects appear very different at various distances to the ego-vehicle, and thus, there is a need to avoid using shared-weight convolutional feature extractors. In particular, we have leveraged position and range encodings to design a RAAConv layer with two independent convolution branches, which separately focus on sparse and dense feature extraction. Moreover, we have proposed the auxiliary density level estimation module (ADLE) to further help RAANet extract occlusion information of objects during training. Since RAAConv sets the channel number for each branch to the half of final output channels, and ADLE is not attached during inference, the proposed RAANet is able to run in real-time. Evaluations on nuScenes and KITTI datasets have shown that our proposed RAANet outperforms the SOTA baselines. The code is available at the following link: https://github.com/erbloo/RAAN.
References
- [1] Anonymized. Anonymized github repository for our code. https://github.com/anonymous0522/RAAN.
- [2] Prarthana Bhattacharyya, Chengjie Huang, and Krzysztof Czarnecki. Sa-det3d: Self-attention based context-aware 3d object detection. arXiv preprint arXiv:2101.02672, 2021.
- [3] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027, 2019.
- [4] Qi Chen, Lin Sun, Ernest Cheung, and Alan L Yuille. Every view counts: Cross-view consistency in 3d object detection with hybrid-cylindrical-spherical voxelization. Advances in Neural Information Processing Systems, 2020.
- [5] Qi Chen, Lin Sun, Zhixin Wang, Kui Jia, and Alan Yuille. Object as hotspots: An anchor-free 3d object detection approach via firing of hotspots. In European Conference on Computer Vision, pages 68–84. Springer, 2020.
- [6] Qi Chen, Sourabh Vora, and Oscar Beijbom. Polarstream: Streaming lidar object detection and segmentation with polar pillars. arXiv preprint arXiv:2106.07545, 2021.
- [7] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1907–1915, 2017.
- [8] Xia Chen, Jianren Wang, David Held, and Martial Hebert. Panonet3d: Combining semantic and geometric understanding for lidar point cloud detection. In 2020 International Conference on 3D Vision (3DV), pages 753–761. IEEE, 2020.
- [9] Yilun Chen, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Fast point r-cnn. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9775–9784, 2019.
- [10] MMDetection3D Contributors. MMDetection3D: OpenMMLab next-generation platform for general 3D object detection. https://github.com/open-mmlab/mmdetection3d, 2020.
- [11] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6569–6578, 2019.
- [12] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- [13] Ross Girshick. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015.
- [14] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014.
- [15] Lichao Huang, Yi Yang, Yafeng Deng, and Yinan Yu. Densebox: Unifying landmark localization with end to end object detection. arXiv preprint arXiv:1509.04874, 2015.
- [16] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [17] Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven L Waslander. Joint 3d proposal generation and object detection from view aggregation. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1–8. IEEE, 2018.
- [18] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12697–12705, 2019.
- [19] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV), pages 734–750, 2018.
- [20] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
- [21] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
- [22] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European conference on computer vision, pages 21–37. Springer, 2016.
- [23] NuScenes. Nuscenes 2d object detection benchmark. https://www.nuscenes.org/object-detection?externalData=no&mapData=no&modalities=Lidar.
- [24] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- [25] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 918–927, 2018.
- [26] Meytal Rapoport-Lavie and Dan Raviv. It’s all around you: Range-guided cylindrical network for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2992–3001, 2021.
- [27] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016.
- [28] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- [29] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3d object progposal generation and detection from point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–779, 2019.
- [30] Shaoshuai Shi, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [31] Leslie N Smith and Nicholay Topin. Super-convergence: Very fast training of neural networks using large learning rates. In Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, volume 11006, page 1100612. International Society for Optics and Photonics, 2019.
- [32] Pei Sun, Weiyue Wang, Yuning Chai, Gamaleldin Elsayed, Alex Bewley, Xiao Zhang, Cristian Sminchisescu, and Dragomir Anguelov. Rsn: Range sparse net for efficient, accurate lidar 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5725–5734, 2021.
- [33] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9627–9636, 2019.
- [34] Jun Wang, Shiyi Lan, Mingfei Gao, and Larry S Davis. Infofocus: 3d object detection for autonomous driving with dynamic information modeling. In European Conference on Computer Vision, pages 405–420. Springer, 2020.
- [35] Tai Wang, Xinge Zhu, and Dahua Lin. Reconfigurable voxels: A new representation for lidar-based point clouds. arXiv preprint arXiv:2004.02724, 2020.
- [36] Tai Wang, Xinge Zhu, Jiangmiao Pang, and Dahua Lin. Probabilistic and geometric depth: Detecting objects in perspective. arXiv preprint arXiv:2107.14160, 2021.
- [37] Zhixin Wang and Kui Jia. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1742–1749. IEEE, 2019.
- [38] Peixi Xiong, Xuetao Hao, Yunming Shao, and Jerry Yu. Adaptive attention model for lidar instance segmentation. In Advances in Visual Computing, pages 141–155. Springer International Publishing, 2019.
- [39] Runsheng Xu, Yi Guo, Xu Han, Xin Xia, Hao Xiang, and Jiaqi Ma. Opencda: an open cooperative driving automation framework integrated with co-simulation. In 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), pages 1155–1162. IEEE, 2021.
- [40] Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection. Sensors, 18(10):3337, 2018.
- [41] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7652–7660, 2018.
- [42] Zetong Yang, Yanan Sun, Shu Liu, and Jiaya Jia. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11040–11048, 2020.
- [43] Yangyang Ye, Houjin Chen, Chi Zhang, Xiaoli Hao, and Zhaoxiang Zhang. Sarpnet: Shape attention regional proposal network for lidar-based 3d object detection. Neurocomputing, 379:53–63, 2020.
- [44] Tianwei Yin, Xingyi Zhou, and Philipp Krähenbühl. Center-based 3d object detection and tracking. CVPR, 2021.
- [45] Feng Zhang, Xueying Wang, Shilin Zhou, and Yingqian Wang. Dardet: A dense anchor-free rotated object detector in aerial images. IEEE Geoscience and Remote Sensing Letters, 2021.
- [46] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. In International conference on machine learning, pages 7354–7363. PMLR, 2019.
- [47] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. In arXiv preprint arXiv:1904.07850, 2019.
- [48] Xingyi Zhou, Jiacheng Zhuo, and Philipp Krahenbuhl. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 850–859, 2019.
- [49] Yin Zhou, Pei Sun, Yu Zhang, Dragomir Anguelov, Jiyang Gao, Tom Ouyang, James Guo, Jiquan Ngiam, and Vijay Vasudevan. End-to-end multi-view fusion for 3d object detection in lidar point clouds. In Conference on Robot Learning, pages 923–932. PMLR, 2020.
- [50] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4490–4499, 2018.
- [51] Benjin Zhu, Zhengkai Jiang, Xiangxin Zhou, Zeming Li, and Gang Yu. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv preprint arXiv:1908.09492, 2019.
- [52] Chenchen Zhu, Yihui He, and Marios Savvides. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 840–849, 2019.
- [53] Xinge Zhu, Yuexin Ma, Tai Wang, Yan Xu, Jianping Shi, and Dahua Lin. Ssn: Shape signature networks for multi-class object detection from point clouds. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 16, pages 581–597. Springer, 2020.