Ranking with Multiple Objectives
Abstract
In search and advertisement ranking, it is often required to simultaneously maximize multiple objectives. For example, the objectives can correspond to multiple intents of a search query, or in the context of advertising, they can be relevance and revenue. It is important to efficiently find rankings which strike a good balance between such objectives. Motivated by such applications, we formulate a general class of problems where
-
•
each result gets a different score corresponding to each objective,
-
•
the results of a ranking are aggregated by taking, for each objective, a weighted sum of the scores in the order of the ranking, and
-
•
an arbitrary concave function of the aggregates is maximized.
Combining the aggregates using a concave function will naturally lead to more balanced outcomes. We give an approximation algorithm in a bicriteria/resource augmentation setting: the algorithm with a slight advantage does as well as the optimum. In particular, if the aggregation step is just the sum of the top results, then the algorithm outputs results which do as well the as the optimal top results. We show how this approach helps with balancing different objectives via simulations on synthetic data as well as on real data from LinkedIn.
1 Introduction
We study the problem of ranking with multiple objectives. Ranking is an important component of many online platforms such as Google, Bing, Facebook, LinkedIn, Amazon, Yelp, and so on. It is quite common that the platform has multiple objectives while choosing a ranking. For instance, in a search engine, when someone searches for “jaguar”, it could refer to either the animal or the car company. Thus there is one set of results that are relevant for jaguar the animal, another for jaguar the car company, and the search engine has to pick a ranking to satisfy both intents.
Another common reason to have multiple objectives is advertising. The final ranking produced has organic results as well as ads, and the objectives are relevance and revenue. Ads contribute to both relevance and revenue, where as organic results only contribute to relevance. While in some cases ads occupy specialized slots, it is becoming more common to have floating ads. Also, in many cases, the same result can qualify both as an ad and as an organic result, and it is not desirable to repeat it. In such cases, one has to produce a single ranking of all the results (the union of organic results and ads) that achieves a certain tradeoff between the two objectives.
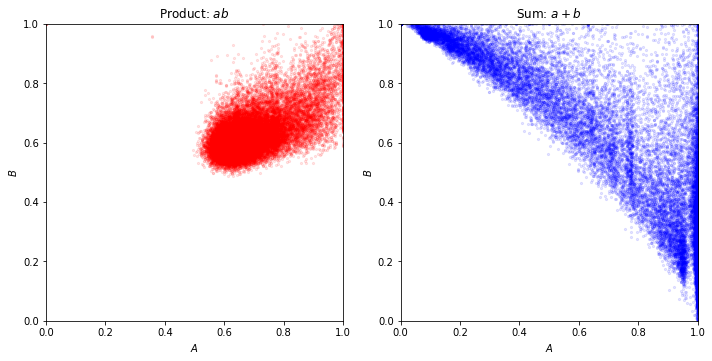
The predominant methodology currently used to handle multiple objectives is to combine them into one objective using a linear combination (Vogt and Cottrell, 1999). The advantage of this is that it can trace out the entire pareto frontier of the achievable objectives. The disadvantage is that you have to choose one linear combination for a large number of instances. This often results in cases where one objective is favored much more than the others. This is illustrated in Figure 1. To explain this figure we introduce some notation.
Suppose that there are instances, and for each instance there are results that are to be ranked. Each result for instance has two numbers associated with it, and , that correspond to the two objectives. Given a ranking , we aggregate the two objective values for instance using cumulative scores defined as
for some non-negative weight vector with (weakly) decreasing weights i.e. 111Throughout the paper, we use the notation policy that is the coordinate of . Further, is the vector . For example, in advertisement ranking, can represent the click rate i.e. the probability that a user clicks the result in the ranking. It is natural that the click rates decrease with the position i.e. it is more probable that a top result is clicked. Suppose represents the revenue generated when ad is clicked, and represents the relevance of the ad to the user query. Then represents the expected revenue generated and represents the expected total relevance for the user when the ads are ranked according to In the figure, the weight vector is the one used in discounted cumulative gain (DCG), and normalized DCG (NDCG) (Burges et al., 2005), which are standard measures often used in evaluating search engine rankings. This weight vector is:
| (1) |
We normalize the cumulative scores by the best possible ranking for each objective. This is motivated by two things: the resulting numbers are all in so they are comparable to each other, and how well the ranking did relative to the best achievable one is often the more meaningful measure. We define
When the weight vector is the one mentioned above, we refer to the normalized cumulative scores as NDCG. Figure 1 shows scatter plots of the NDCGs for the two objectives, for different algorithms: a given algorithm produces ranking for instance , and each dot in the plot is a point
The source of the data is LinkedIn news feed: it is a random sample from one day of results. Here we do not go into the details of what the two objectives are, etc.; Section 4 has more details. On the right, we show the result of ranking using the sum of the two scores. The triangle shape of the scatter plot is persistent across different samples, and different choices of linear combinations. What we wish to avoid are the two corners of the triangle where one of the two NDCGs is rather small. Ideally, we like to be at the apex of the triangle which is at the top right corner of the figure.
On the left, we show the results of our algorithm for the following objective:
The undesirable corners of the triangle have vanished: instances where one objective is much smaller than the other are rare if any. The points are closer to the top right corner.
1.1 Main Results
The key idea is to combine the two cumulative scores using a concave function . (Maximizing the product is the same as maximizing the sum of logs, which is a concave function.) Concave functions tend to favor more balanced outcomes almost by definition: the function at the average of two points is at least as high as the average of the function at the two points, i.e., . Figure 1 is a good demonstration of this.
We allow arbitrary concave functions that are strictly increasing in each coordinate. We define the combined objective score of with weights as
For some objectives, the sum of the cumulative scores across different instances is still an important metric, e.g., the total revenue, or the number of clicks, etc. We allow incorporating such metrics via a global concave function, i.e., a concave function of the sum of all the cumulative scores over all the instances. Let , and for be concave functions in 2 variables. We consider the problem of finding a ranking for each in order to maximize
Our main results are polynomial time bi-criteria approximation algorithms for the problem mentioned above. These are similar in spirit to results with resource augmentation in scheduling, or Bulow-Klemperer style results in mechanism design.
-
•
Consider the special case where we sum the top entries, i.e., the weight vector is ones followed by all zeros. For this case, we allow the algorithm to sum the top entries, and show that the resulting objective is at least as good as the optimum for the sum of the top results.
-
•
For the general case, the algorithm gets an advantage as follows: replace one coordinate of , say , with the immediately preceding coordinate . For the case of summing the top entries, this corresponds to replacing the coordinate which is a 0, with the coordinate which is a 1. The replacement can be different for different . Again, the ranking output by the algorithm with the new weights does as well as the optimum with the original weights . See Theorem 2.2 and Theorem 3.2 for formal statements.
One advantage of such a guarantee is that it does not depend on the parameters of the convex functions, such as the Lipshitz constants, or the range of values, as is usual with other types of guarantees. This allows greater flexibility in the choice of these convex functions.
-
•
When there is no global function , for each , the algorithm just does a binary search (Proposition 2.8). In each iteration of the binary search, we compute a ranking optimal for a linear combination of the two objectives. The running time to solve each ranking problem (i.e. each instance ) is . In practice, the ranking algorithms are required to be very fast, so this is an important property. For the general case, this is still true, provided that we are given 2 additional parameters that are optimized appropriately. In practice, such parameters are tuned ‘offline’ so we can still use the binary search to rank ‘online’ any new instance .
1.2 Related Work
Rank aggregation is much studied, most frequently in the context of databases with ‘fuzzy’ queries (Fagin and Wimmers, 1997) and in the context of information retrieval or web search (Dwork et al., 2001; Aslam and Montague, 2001). There are two main categories of results (Renda and Straccia, 2003), (i) where the input is a set of rankings (Dwork et al., 2001; Renda and Straccia, 2003), and (ii) where the input is a set of scores (Vogt and Cottrell, 1999; Fox and Shaw, 1994). Clearly score based aggregation methods are more powerful, since there is strictly more information; our paper falls in the score based aggregation category.
Among the score based methods, Vogt and Cottrell (1999) uses the same form of cumulative scores as us, and empirically evaluate the usage of a linear combination of cumulative scores. They identify limitations of this method and conditions under which this does well. Fox and Shaw (1994) propose and evaluate several methods for combining the scores for different objectives result by result which are then used to rank. In contrast, we first aggregate the scores for each objective and then combine these cumulative scores.
Azar et al. (2009) also consider rank aggregation motivated by multiple intents in search rankings, but with several differences. They consider a large number of different intents, as opposed to this paper where we focus on just 2. Their objective function also depends on a weight vector but in a different way. For each intent, a result is either ‘relevant’ or not, and given a ranking, the cumulative score for that intent is the weight corresponding to the highest rank at which a relevant result appears. Their objective is a weighted sum of the cumulative scores across all intents.
The rank based aggregation methods are closely related to voting schemes and social choice theory, and a lot of this has focused on algorithms to compute the Kemeny-Young rank aggregation (Young and Levenglick, 1978; Young, 1988; Saari, 1995; Borda, 1784).
Organization:
2 A single instance of ranking with multiple objectives
Let us formally define the problem.
Definition 2.1 ().
Given , find a ranking which maximizes the combined objective i.e. find
It is not clear if can be efficiently solved, because it involves optimization over all rankings and there are exponentially many of them. Our main result shows that when is concave, we can find nearly optimal solutions. We will assume that is differentiable and has continuous derivatives.
Theorem 2.2.
Suppose is a concave function over the range and is strictly increasing in each coordinate in that range. Given an instance of , there is an algorithm that runs in time222This is a Las Vegas algorithm i.e. always output the correct answer but runs in time with high probability. We also give algorithm when are integers bounded by . and outputs a ranking of such that where for some . In other words, is obtained by replacing with in for some .
We have the following corollary for the important special case where the cumulative scores are the sum of scores of top elements, i.e., with exactly ones. In this special case, is called the problem.
Corollary 2.3.
Given such an instance of , there is an efficient algorithm that outputs a subset of at most elements such that
We will now prove Theorem 3.2. We also make the mild assumption that the numbers in are generic for the proof, which can be achieved by perturbing all the numbers with a tiny additive noise. In particular we will assume that . This only perturbs by a tiny amount. By a limiting argument, this shouldn’t affect the result. To prove Theorem 2.2, we create a convex programming relaxation for as shown in (2) and denote its value by .
| (2) | |||||
It is clear that is a relaxation for with By convex programming duality, can be expressed as a dual minimization problem (3) by introducing a dual variable for every constraint in the primal as shown in (2). Note that by Slater’s condition, strong duality holds here Boyd and Vandenberghe (2004). The constraints in the dual correspond to variables in the primal as shown in (3).
| (3) | |||||
Here is the Fenchel dual of defined as
Note that is a convex function since it is the supremum of linear functions. Since is strictly increasing in each coordinate, unless . Since the dual is a minimization problem, the optimum value is attained only when . Hereafter, wlog, we assume that in the dual (3). For example when ,
If is some optimal solution for the primal (2) and is some optimal solution for the dual (3), then they should together satisfy the KKT conditions given in (4). A constraint of primal is tight if the corresponding variable in the dual is strictly positive and vice-versa.
| (4) |
Proposition 2.4.
Proof.
For a fixed , the dual program (3) reduces (after ignoring the fixed additive term ) to the following linear program:
The dual linear program is:
The constraints on correspond to doubly stochastic constraints on the matrix . Therefore by the Birkhoff-von Neumann theorem, the feasible solutions are convex combinations of permutations and the optimum is attained at a permutation. An optimal permutation should sort the values of in decreasing order and convex combinations of such permutations are also optimal solutions. Thus the set of solutions and the value of both the above programs is
∎
Lemma 2.5.
Fix some . Then one of the following is true:
-
1.
There are no ties among i.e. there is a unique such that
-
2.
There is exactly one tie among i.e. there are exactly two permutations such that . Moreover differ by an adjacent transposition i.e. can be obtained from by swapping adjacent elements.
Proof.
where is any permutation which sorts in descending order. There are two cases:
-
Case 1:
If there are no ties among , then the permutation is unique.
-
Case 2:
Suppose there are ties among . Because we assumed that are generic, there can be at most one tie among i.e. there is at most one pair such that . Two such ties impose two linearly independent equations on forcing them to be both zero. Therefore the there are at most two distinct permutations such that . Moreover should be next to each other in and their order is switched in . Therefore they differ by an adjacent transposition.
∎
Remark 2.6.
Remark 2.7.
is a convex function. The gradient333or a subgradient at points where is not differentiable of can be calculated efficiently and therefore can be found efficiently using gradient (or subgradient) descent Bubeck (2015).
It turns out that there is a much more efficient algorithm to find using binary search. We need the notion of a subgradient. For a convex function , the subgradient of at a point is defined as . It is always a convex subset of . If is differentiable at then, .
Proposition 2.8 (Binary search to find ).
Suppose and are integers bounded by in absolute value. We can solve the primal program (2), the dual program (3) and find in time. Moreover there is a strongly polynomial randomized algorithm which runs in time.444Strongly polynomial refers to the fact that the running time is independent of or the actual numbers in . In this model, it is assumed that arithmetic and comparison operations between ’s and ’s take constant time.
Proof.
To solve the primal program (2) and the dual program (3), it is enough to find and which together satisfy all the simplified KKT conditions (5).
Throughout the proof, we drop the subscript from for brevity. is a convex function. So a local minimum is a global minimum and therefore it is enough to find such that .
It is easy to see that . Therefore we rewrite the optimality condition for as:
| (6) |
Thus we need to find a fixed point for a set-valued map. We begin by calculating the subgradient . Note that where is any permutation which sorts in descending order. By Lemma 2.5, there are two cases:
-
Case 1:
If there are no ties among , then the permutation is unique and is differentiable at and
-
Case 2:
Suppose there are ties among . Then there exists exactly two permutations such that . In this case,
We make a few observations. The value of the subgradient only depends on the ratio of and , ; this is because the optimal ranking of only depends on the ratio . And as we change this ratio from to , the subgradient changes at most times. This happens whenever is such that for some . We call the set
the critical set of ’s where the subgradient changes value555 is equal to the number of inversions in w.r.t. , also called the Kendall tau distance.. Let and let be an ordering of the critical set , further define and .
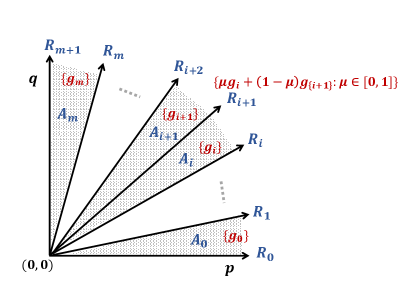
Define the regions
Also define the rays
In the region there is a unique permutation , therefore the subgradient is unique. Denote its value by i.e.
On the ray we have , therefore the subgradient is given by
Figure 2 shows the values of the subgradient as a function of in the regions
Let be the positive quadrant. Since is strictly increasing in each coordinate in , the gradients also lie in the positive quadrant, i.e., . We now define a function as follows:
| (7) |
We now show that it is enough to find some such that one of the following is true.
- 1.
-
2.
. In this case, we claim that there exists some such that . This is because the curve given by starts and ends in opposite sides of the ray as shown in Figure 3, so it should cross it at some point which can be found by binary search (here we need continuity of ). We then set . Since , . Applying to both sides, we get which is the fixed point condition (6). Setting and gives a solution to the simplified KKT conditions (5).
Figure 3: The endpoints of the curve lie on opposite sides of the ray so should cross the ray at some point. 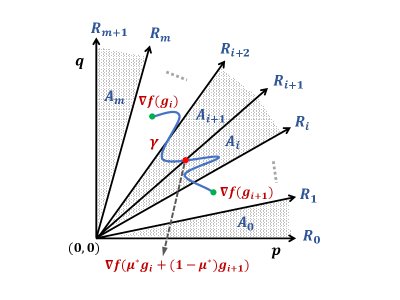
Now if either or , we are done. Otherwise, and . By a simple binary search on we can find a point such that either or .
A naive implementation of the above described binary search will require finding the set of critical values and sorting them. This can take time. To improve this to near-linear time, we need a way do binary search on without listing all values in . See Appendix A for how to achieve this. ∎
We are now ready to prove Theorem 2.2.
Proof of Theorem 2.2.
By Proposition 2.8 and Remark 2.6, we can find a solution to the primal program (2) where is either a permutation or a convex combination of two permutations which differ by an adjacent transposition. If is a permutation then
Thus we just output which is the optimal ranking.
If i.e. a convex combination of which differ in the positions, then
where . Similarly So in this case we output either or , whichever has the higher combined objective.
∎
3 Multiple instances of ranking with global aggregation
Suppose we have several instances of and we want to do well locally in each problem, but we also want to do well when we aggregate our solutions globally. Such a situation arises in the example application discussed in the beginning. For each user we want to solve an instance of , but globally across all the users, we want that the average revenue and average relevance are high as well. We model this as follows.
Let be instances of on sequences of length . Let and let be a sequence of rankings of . The global cumulative a-score and b-score of is defined as
respectively. Suppose is a concave function increasing in each coordinate. The combined objective function is defined as
Definition 3.1 ().
Given , find a sequence of rankings of which maximizes i.e. find
We will assume that the functions are concave and strictly increasing in each coordinate, and that they are differentiable with continuous derivatives. Our main theorem is that we can efficiently find a sequence of rankings which, with a slight advantage, does as well as the optimal sequence of rankings.
Theorem 3.2.
Suppose the functions are concave and strictly increasing in each coordinate. Given an instance of , we can efficiently find a sequence of rankings such that
where and for some i.e., each is obtained by replacing with .
In the special case when the weight vectors are just a sequence of ones followed by zeros i.e. the cumulative scores are calculated by adding the scores of top results, is called the problem.
Corollary 3.3.
Suppose the functions are concave and strictly increasing in each coordinate. Given an instance of , we can efficiently find a sequence of subsets of of size at most (corresponding to the top elements) such that
Our approach to prove Theorem 3.2 is again very similar to how we proved Theorem 2.2. We write a convex programming relaxation and solve its dual program. We will also assume that the sequences are generic which can be ensure by perturbing all entries by tiny additive noise, this will not change by much. By a limiting argument, this will not affect the result. We first develop a convex programming relaxation as shown in (8).
| (8) | |||||
It is clear that is a relaxation for with By convex programming duality, can be expressed as a dual minimization problem (9) by introducing a dual variable for every constraint in the primal as shown in (8). Again by Slater’s condition, strong duality holds Boyd and Vandenberghe (2004). The constraints in the dual correspond to variables in the primal as shown in (9).
| (9) | |||||
Here is the Fenchel dual of and is the Fenchel dual of If is some optimal solution for the primal (8) and is some optimal solution for the dual (9), then they should together satisfy the KKT conditions given in (10). Note that a constraint of primal is tight if the corresponding variable in the dual is strictly positive and vice-versa.
| (10) |
Proposition 3.4.
Proof.
The proof is very similar to the proof of Proposition 2.4 where we write a linear program for each sub-problem and the corresponding dual linear program. We will skip the details. ∎
Remark 3.5.
is a convex function. The gradient (or a subgradient) of can be calculated efficiently and therefore can be found efficiently using gradient (or subgradient) descent. The objective is also amenable to the use of stochastic gradient descent which can be much faster when
Proposition 3.6.
For a fixed we can find
efficiently using binary search.
Proof.
It is enough to the find
for a fixed By convexity of the objective, it is enough to find such that which can be rewritten as:
| (12) |
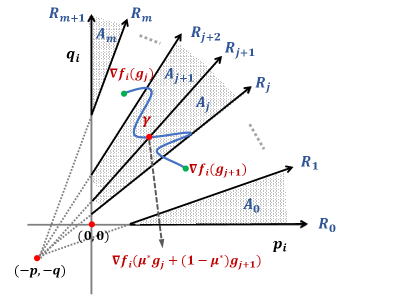
This fixed point equation can be solved using binary search in exactly the same way as in Proposition 2.8. only depends on the ration . Geometrically, this ratio is constant on any line passing through . Figure 4 shows the regions where remains constant. Now the fixed point equation (12) can be solved in exactly the same way as in the proof of Proposition 2.8. We will skip the details.
∎
We are now ready to prove Theorem 3.2.
Proof of Theorem 3.2.
By Proposition 3.6 and 2.6, we can find a solution to the primal program 8 where each is either a permutation or a convex combination of two permutations which differ by an adjacent transposition. If is a permutation then we just output which is the optimal ranking for the ranking problem. If i.e. a convex combination of which differ in the positions, then we output either or as the ranking for the subproblem. ∎
4 Experiments
4.1 Synthetic Data
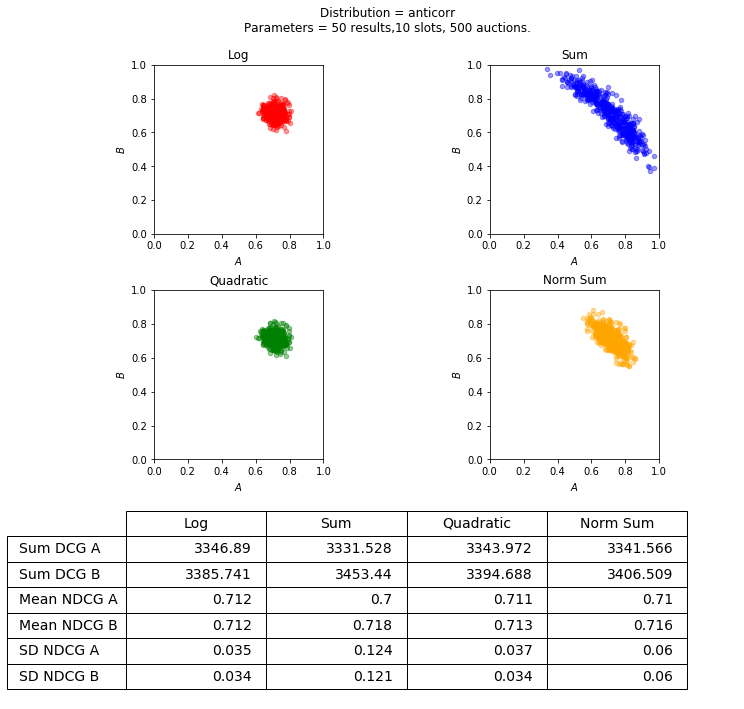
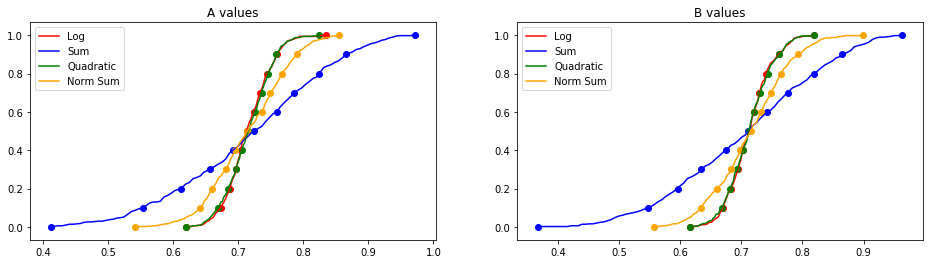
We first present the results on synthetic data. The purpose of this experiment is to illustrate how different objective functions affect the distribution of the NDCGs. These results are summarized in Figures 6 and 7. We present the scatter plot of the NDCGs, just like in Figure 1, as well as the cumulative distribution functions (CDFs).
We aim to capture the multiple intents scenario where the results are likely to be good along one dimension but not both. The values are drawn from a log normal anti-correlated distribution: and the s are drawn from a multivariate Gaussian with mean zero and covariance matrix
A scatter plot of the distribution of these values is shown in Figure 5.
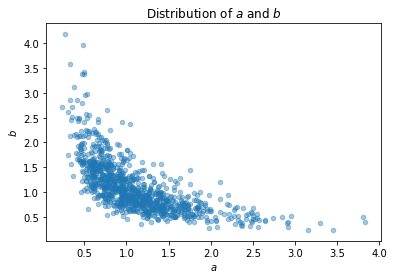
Other parameters of the experiment are as follows: we draw 50 results for each instance, i.e., . The weight vector is the same as in the Introduction, (1), except that we only consider the top 10 results, i.e., the coordinates of after the first 10 are 0. The number of different instances, is 500.
In addition to the product and the sum, we present the result of using two more combining functions: a quadratic and a normalized sum. Since we are plotting the NDCGs, a natural algorithm is to maximize the sum of the NDCGs. This is what the normalized sum does. The quadratic function first normalizes the scores to get the NDCGs, and then applies the function
It can be seen from Figure 6 that the concave functions are quite a bit more clustered than the additive functions. This can also be seen in the table inside the figure, which shows the sum of the cumulative scores, the DCGs, as well as the mean of the normalized cumulative scores, the NDCGs. These quantities are almost the same across all algorithms. We also show the standard deviations of the NDCGs, which quite well captures how clustered the points are, and shows a significant difference between the concave and the additive functions.
We present the CDFs of the NDCGs for the four algorithms in Figure 7. The dots on the curves represent deciles, i.e., the values corresponding to the bottom of the population, , and so on. Recall that a lower CDF implies that the values are higher.666 Recall that a distribution stochastically dominates another distribution iff the cdf of is always below that of . The CDF shows that in the bottom half of the distribution, the concave functions are higher than the additive ones. Also the steeper shape of the CDFs for the concave functions show how they are more concentrated. There is indeed a price to pay in that the top half are worse but this is unavoidable. The additive function picks a point on the Pareto frontier after all; in fact, it maximizes the mean of for a fixed mean of and vice versa. The whole point is that the mean is not necessarily an appropriate metric.
4.2 Real Data
The purpose of the experiment in this section is to show how the ideas from this paper could help in a realistic setting of ranking. We present experiments on real data from LinkedIn, sampled from one day of results from their news feed. The number of instances is about 33,000. The results are either organic or ads. Organic results only have relevance scores, their revenue scores are 0. Ads have both relevance and revenue scores.
The objectives are ad revenue and relevance. We will denote the ad revenue by and relevance by . We use the same weight vector in the introduction, (1), up to 10 coordinates. Ad revenue can be added across instances, so we just sum up the ad revenue across different instances and tune the algorithms so that they all have roughly the same revenue. (The difference is less than .) It makes less sense to add the relevance scores. In fact it is more important to make sure that no instance gets a really bad relevant score, rather than optimize for the mean or even the standard deviation. To do this, we aim to make the bottom quartile (25%) as high as possible.
Motivated by the above consideration, for the relevance objective, we consider a function that has a steep penalty for lower values. We first normalize the scores to get the NDCG, and then apply this function on the normalized value. For revenue, we just add up the cumulative scores. The function we use to combine the two cumulative scores is thus
for some suitable constants and . Higher values of make the curve steeper and make the distribution more concentrated. We choose so that we benefit the bottom quartile as much as possible. The constant is tuned so that the total revenue is close to some target.
We compare this with an additive function. The revenue term is not normalized whereas the relevance term is. This function is
for some suitable choice of . Once again is tuned to achieve a revenue target.
We also add constraints on the ranking to better reflect the real scenario (although not exactly the same constraints as used in reality, for confidentiality reasons). An ad cannot occupy the first position, and the total number of ads in the top 10 positions is at most 4. It is quite easy to see that we can optimize a single objective given these constraints.777Although our guarantees don’t extend, our algorithm extends to handle such constraints, as long as we can solve the problem of optimizing a single objective. In experiments, the algorithm seems to do well. It is an interesting open problem to generalize our guarantees to such settings. We first sort by the score, then slide ads down if the first slot has an ad, and finally remove any ads beyond the top 4.
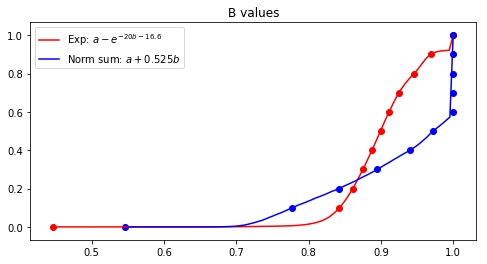
We present the CDFs of the NDCGs for relevance for the two algorithms in Figure 8. The figure shows that in the bottom quartile the exp function does better, and the relation flips above this. For the bottom decile, the difference is significant. As mentioned earlier, this is exactly what we wanted to achieve.
Another important aspect of a ranking algorithm in this context is the set of positions that ads occupy. In Figure 9, we show this distribution: for each position, we show the number of instances for which there was an ad in that position. For the additive function, which is the graph at the bottom, most of the ads are clustered around positions 2 to 4, and the number gradually decreases further down. The distribution in case of the exp function is better spread out. Interestingly, the most common position an ad is shown is the very last one.
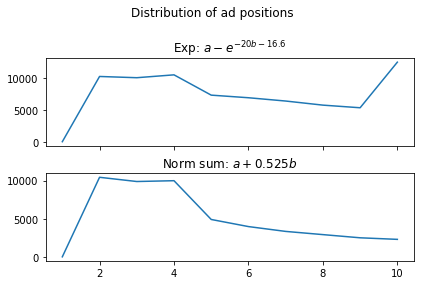
To conclude, the choice of a concave function to combine the different objectives gives a greater degree of freedom to ranking algorithms. This freedom can be used to better control several important metrics in search and ad rankings. This experiment shows how this can be done for the relevance NDCGs in the bottom quartile, or for the distribution of ad positions.
References
- Aslam and Montague [2001] Javed A Aslam and Mark Montague. Models for metasearch. In Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval, pages 276–284. ACM, 2001.
- Azar et al. [2009] Yossi Azar, Iftah Gamzu, and Xiaoxin Yin. Multiple intents re-ranking. In Proceedings of the forty-first annual ACM symposium on Theory of computing, pages 669–678. ACM, 2009.
- Borda [1784] JC de Borda. Mémoire sur les élections au scrutin. Histoire de l’Academie Royale des Sciences pour 1781 (Paris, 1784), 1784.
- Boyd and Vandenberghe [2004] Stephen Boyd and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004.
- Bubeck [2015] Sébastian Bubeck. Convex optimization: Algorithms and complexity. Foundations and Trends® in Machine Learning, 8(3-4):231–357, 2015.
- Burges et al. [2005] Christopher Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Gregory N Hullender. Learning to rank using gradient descent. In Proceedings of the 22nd International Conference on Machine learning (ICML-05), pages 89–96, 2005.
- Dwork et al. [2001] Cynthia Dwork, Ravi Kumar, Moni Naor, and Dandapani Sivakumar. Rank aggregation methods for the web. In Proceedings of the 10th international conference on World Wide Web, pages 613–622. ACM, 2001.
- Fagin and Wimmers [1997] Ronald Fagin and Edward L Wimmers. Incorporating user preferences in multimedia queries. In International Conference on Database Theory, pages 247–261. Springer, 1997.
- Fox and Shaw [1994] Edward A Fox and Joseph A Shaw. Combination of multiple searches. NIST special publication SP, 243, 1994.
- Renda and Straccia [2003] M Elena Renda and Umberto Straccia. Web metasearch: rank vs. score based rank aggregation methods. In Proceedings of the 2003 ACM symposium on Applied computing, pages 841–846. ACM, 2003.
- Saari [1995] Donald G Saari. Basic geometry of voting, volume 12. Springer Science & Business Media, 1995.
- Vogt and Cottrell [1999] Christopher C Vogt and Garrison W Cottrell. Fusion via a linear combination of scores. Information retrieval, 1(3):151–173, 1999.
- Young [1988] H Peyton Young. Condorcet’s theory of voting. American Political science review, 82(4):1231–1244, 1988.
- Young and Levenglick [1978] H Peyton Young and Arthur Levenglick. A consistent extension of condorcet’s election principle. SIAM Journal on applied Mathematics, 35(2):285–300, 1978.
Appendix A Running time of binary search in Proposition 2.8
Getting running time.
Note that the critical set can be of size and doing binary search on this set naively will need us to list all the critical values and then sort them. We can avoid this by doing a binary search directly on the ratio .
Recall that the critical set where and we set . By the assumption that are integers bounded by , and for every . Define as follows:
Claim A.1.
Given , we can compute in time.
Proof.
It is enough to show that we can find such that in time. We can find the ranking which sorts in decreasing order in time. We can then evaluate in time. Now is the first critical point where the sorted order of switches from if we imagine increasing from . Once crosses , some adjacent elements of switch positions in the sorted order of . Therefore
where if the set is empty we set . Note that this can be computed in time. Similarly
where if the set is empty we set . ∎
Now we claim that it is enough to find some such that one of the following is true:
-
1.
or . This is similar to the case when .
-
2.
and . There can be at most one critical point between i.e. there exists a unique such that . Therefore and must belong to adjacent regions. This is similar to the case when
Now if either or , we are done. Otherwise and . Using binary search in the range , one can find such in iterations. Since each iteration runs in time, the total running time is
Getting strongly polynomial randomized running time.
We will only give a proof sketch. In this case we cannot do a binary search over Because all the critical can be concentrated in a small region and we may take a long time to find this region. Before we proceed we make a few claims.
Claim A.2.
Given two (generic) sequences of numbers and of length , let be the set of inversions of w.r.t i.e. . We can find the size in time and we can sample uniformly at random from in time.888Note that there can be as many as inversions and so we cannot list them all.
Proof.
We only give a proof sketch. Wlog, we can assume that is already sorted by applying the same permutation to both We now sort using the merge sort algorithm and it is not hard to see that we can count and sample from inversions during this process. ∎
Claim A.3.
Given any , we can sample uniformly at random from in time.
Proof.
Let be the set of inversions of w.r.t . We claim that
This is because when you imagine increasing from to , is the set of critical points where a switch happens in the sorted order of . Therefore the critical points in correspond exactly to the inversions For each inversion , . ∎
Suppose and (otherwise we are done), where is the function defined in Equation (7). We want to find an such that or . Set . From Claim A.3, we can sample a uniformly random in time. Suppose , then we can find and as shown in Claim A.1 in time. Therefore we can evaluate in time. Now we continue the binary search based on the value of and update the value of the lower bound or the upper bound . In each iteration, the random will eliminate constant fraction of points in i.e. the size of shrinks by a constant factor in expectation. Therefore the algorithm should end in iterations with high probability. In fact, we can stop the sampling process once the size of becomes and then do a regular binary search on them by listing them all. Since the running time of each iteration is the total running time is