RAPS: A Novel Few-Shot Relation Extraction Pipeline with Query-Information Guided Attention and Adaptive Prototype Fusion
Abstract
Few-shot relation extraction (FSRE) aims at recognizing unseen relations by learning with merely a handful of annotated instances. To generalize to new relations more effectively, this paper proposes a novel pipeline for the FSRE task based on queRy-information guided Attention and adaptive Prototype fuSion, namely RAPS. Specifically, RAPS first derives the relation prototype by the query-information guided attention module, which exploits rich interactive information between the support instances and the query instances, in order to obtain more accurate initial prototype representations. Then RAPS elaborately combines the derived initial prototype with the relation information by the adaptive prototype fusion mechanism to get the integrated prototype for both train and prediction. Experiments on the benchmark dataset FewRel 1.0 show a significant improvement of our method against state-of-the-art methods.
1 Introduction
Relation extraction (RE) is an important part of information extraction in the field of natural language processing (Bach and Badaskar, 2007). It aims at extracting and classifying the relation between two entities contained in a given text and can be applied in other advanced tasks (Li et al., 2021; Hu et al., 2021), such as knowledge graph (Zhao et al., 2020), machine reading comprehension (Ding et al., 2019; Dua et al., 2020), and question answering (Karpukhin et al., 2020; Zhang et al., 2021). Currently, most researches on RE start from deep learning methods, but these methods rely on large-scale and high-quality annotated datasets. In many real-world applications, it is not possible to collect sufficient instances for model training, which makes them difficult to apply. In order to solve the problem of data scarcity, Few-shot relation extraction (FSRE) task has been widely studied in recent years. In the task, a model is first trained on a large-scale annotated data with known relation types, and then quickly adapts to a small amount of data with new relation types.
Recently, many approaches have been proposed for addressing FSRE problems (Qu et al., 2020; Peng et al., 2020; Wang et al., 2020; Yang et al., 2020; Han et al., 2021). One of the most popular algorithms is Prototypical Network (Snell et al., 2017), which is a metric-based meta-learning framework. The main idea of the prototypical network is that each relation class has a prototype, and the prototype can be learned in the embedding space with given instances (generally average the embedding of the instances in each relation class). Finally all query instances are classified via the nearest neighbor rule.
| Support Set |
|---|
| Class 1 mother: |
| Instance 1 Jinnah and his wife [Rattanbai Petit] had separated soon after their daughter, [Dina Wadia] was born. |
| Instance 2 She married (and murdered) [Polyctor], son of Aegyptus and [Caliadne]. Apollodorus. |
| Class 2 follows: … |
| Class 3 crosses: … |
| Query Instance |
| Dylan and [Caitlin] brought up their three children, [Aeronwy], Llewellyn and Colm. |
Two main lines of research tracks are adopted to improve the FSRE performance. The first line is to integrate the relation information (i.e., relation labels or descriptions) into the model as the external knowledge to assist prototype representation learning. Yang et al. (2020) proposed TD-Proto model, which is an enhanced prototypical network with both relation and entity descriptions. Wang et al. (2020) proposed CTEG model that learns to decouple relations by adding two types of external information. The second line starts from the model structure or training strategy to make model learn good prototypes, that is, to learn intra-class similarity and inter-class dissimilarity. Qu et al. (2020) introduced a global relation graph into the Bayesian meta-learning framework, which makes the model better generalize across different relations. Peng et al. (2020) proposed a contrastive pre-training framework for RE to enhance the ability to grasp entity types and extract relational facts from contexts. Han et al. (2021) introduced a novel supervised contrastive learning method that obtains better prototypes by combining the prototypes, relation labels and descriptions to support model training, and designed a task adaptive focal loss to improve the performance on hard FSRE task.
However, there are two limitations in existing works. Primarily, these prototypical-network-based methods tend to construct the class prototypes simply by averaging representation of support instances of each class, which ignores the informative interaction between the support instances and the query instances. Secondly, in order to learn better representations, these works usually adopt complicated designs or networks, like graphs (Qu et al., 2020), hybrid features (Han et al., 2021), contrastive learning (Wang et al., 2020; Han et al., 2021), or elaborate attention networks (Yang et al., 2021), which may bring too many useless or even harmful parameters.
To address aforementioned issues, this paper proposes a novel pipeline for the FSRE task based on queRy-information guided Attention and adaptive Prototype fuSion, namely RAPS. Concretely, RAPS exploits rich interactive information between the support instances and the query instances by a query-information guided attention module to obtain more accurate relation prototype representations. Furthermore, it elaborately combines the derived relation prototype with the relation information by the adaptive prototype fusion mechanism, which provides more degrees of freedom to learn from data and adjust the weights that the relation prototype and relation information hold, to get the final relation prototype. In this way, the model gains diverse and discriminative prototype representations without introducing too much parameters or computational-demanding modules. Extensive experiments on FewRel (Han et al., 2018) benchmark show that our model significantly outperforms the baselines. Ablation and case studies demonstrate the effectiveness of the proposed modules. Our code is available at https://github.com/zyz0000/RAPS.
The contributions of this paper are summarized as follows:
-
•
We exploit the rich interactive information between the support set and the query set by the proposed query-information guided attention module to get more accurate prototype.
-
•
We present a novel prototype attention fusion mechanism to further combine the useful information from the relation prototypes and the relation information.
-
•
Qualitative and quantitative experiments on FewRel benchmark demonstrate the effectiveness of the proposed RAPS model.
2 Task Definition
We follow the typical -way -shot FSRE task setting, which contains a support set and a query set . The support set includes novel classes (relations), each with labeled instances. The query set contains the same classes as . The task aims to predict the relation of instances in query set . In addition, an auxiliary dataset containing abundant base classes, each of which has a large number of labeled examples, is provided. Note that the relations in and are disjoint. The learner aims to acquire knowledge from the classes in and make fast adaptation on novel classes in . Specifically, in each training iteration, different classes are randomly selected from to form the support set . Meanwhile, instances are sampled from the remaining data of the same classes to form a query set . Each instance in can be represented as a triple , where is a sentence of length , is the head and tail entities and is the semantic relation between and conveyed by , , where is the set of all candidate relation classes. Table 1 is an example of a 3-way 2-shot FSRE task.
3 Methodology
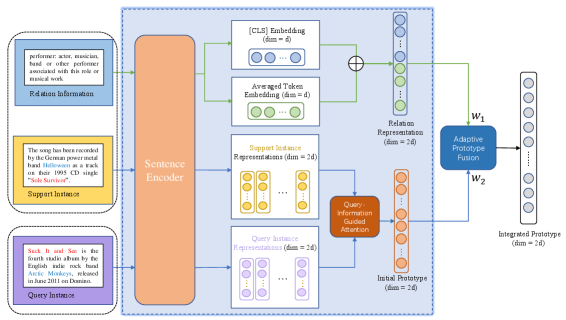
This section provides the details of our proposed RAPS. Figure 1 shows the overall model structure. The inputs are -way -shot tasks sampled from , where each task contains a support set and a query set. Meanwhile, we combine the names and descriptions of these relation classes as inputs as well. We get the integrated relation prototypes with abundant information by the following four steps: First, we encode the sentences and relation information into their embeddings by a shared encoder. Second, we concatenate two aspects of the relation embeddings to obtain the same dimension as instance representations. Third, we calculate the initial prototype of each relation class by the query-information guided attention module. Last, we integrate relation representations into the initial prototypes by the adaptive prototype fusion mechanism to get the integrated relation prototypes.
3.1 Sentence Encoder
We employ BERT (Devlin et al., 2019) as the encoder to map the instances into a low-dimensional vector space and better capture the semantic information of support set and . For instances in and , we concatenate the hidden states corresponding to start tokens of two entity mentions following Baldini Soares et al. (2019), i.e., where and is the size of the representation vector (or euqally, the hidden size of BERT output), as the instance representation.
3.2 Relation Representation
For each relation, we combine its name and description and feed the sequence into the BERT encoder. We treat the embeddings of the [CLS] tokens , and the average embeddings of all tokens , as two components of the relation representation. Then, the final representation of each relation is derived by direct concatenation of and , i.e.,
3.3 Query-Information Guided Attention Module
Traditionally, the naïve prototype for relation is computed simply by averaging the representations of the instances under relation in as
| (1) |
where is the embedding of the th support instance of relation . However, simply averaging all support instances as the relation prototype regardless of the query instances will lose abundant interaction between them. In other words, different relation prototypes will be computed based on the semantic relevance between the support instances and the query instances.
In order to generate more informative prototypes, we propose a query-information guided attention module. This specific module aims to utilize the semantic relevance between the support instances and the query instances to help compute the customized relation prototypes. Specifically, the prototype can be represented as:
| (2) |
where is the attention-based prototype of relation , is the representation of the th support instance of relation , is the weight indicating the semantic relevance between the th support instance of relation and the query instances. The weight is computed by
| (3) |
where is the embedding of the th query instance in the query set, is the total number of instances in , and means the Euclidean distance. We call the prototype obtained in this way Initial Prototype, which is able to store some knowledge about the query. The benefit of the initial prototype for subsequent classification will be proved in Subsection 4.4.
3.4 Adaptive Prototype Fusion
Inspired by the adaptively spatial feature fusion approach proposed by Songtao Liu and Wang (2019), we design a novel adaptive prototype fusion mechanism to obtain the integrated prototype. Specifically, the integrated prototype is an weighted average of and :
| (4) |
where are two learnable weights, which depend on the representation of category information to ensure that the calculated integrated prototype is compatible and not redundant. Unlike Songtao Liu and Wang (2019) forces the sum of the weights equal to 1, our adaptive prototype fusion has no constraint on and . This provides more degrees of freedom to learn from data and adjust the weights. The benefits of mechanism will be demonstrated in Subsection 4.5.
3.5 Training Objective
With the representation of query and integrated prototypes of relations, the model uses the vector dot product way to compute the probability of the relations for the query instance representation as follows:
The training loss is defined as regular cross entropy loss as follows:
In the prediction stage, query is assigned to relation with the highest probability:
4 Experiments
4.1 Datasets and Baselines
Datasets We use FewRel 1.0 (Han et al., 2018) and FewRel 2.0 (the domain adaption portion) (Gao et al., 2019b) to evaluate our model. FewRel 1.0 is a large-scale FSRE dataset, which contains 100 relations with 700 instances each relation. We follow the official split to use 64, 16 and 20 relations for training, validation, and testing. In order to study the domain transferability of RAPS, we also evaluate our model on FewRel 2.0. The training set of FewRel 2.0 is the same as FewRel 1.0, and the validation set is collected from the biomedical domain which contains 10 relations and 100 instances for each relation. We evaluate our model on FewRel 1.0 and FewRel 2.0 in terms of the accuracy under multiple -way -shot meta tasks. We select to be 5 and 10, to be 1 and 5 to form four test scenarios according to Gao et al. (2019a).
| Encoder | Model | 5-way-1-shot | 5-way-5-shot | 10-way-1-shot | 10-way-5-shot |
|---|---|---|---|---|---|
| CNN | Proto-CNN♣ (Snell et al., 2017) | 72.65 / 74.52 | 86.15 / 88.40 | 60.13 / 62.38 | 76.20 / 80.45 |
| Proto-HATT (Gao et al., 2019a) | 75.01 / — — | 87.09 / 90.12 | 62.48 / — — | 77.50 / 83.05 | |
| MLMAN Ye and Ling (2019) | 79.01 / 82.98 | 88.86 / 92.66 | 67.37 / 75.59 | 80.07 / 87.29 | |
| BERT | Proto-BERT∗ (Snell et al., 2017) | 82.92 / 80.68 | 91.32 / 89.60 | 73.24 / 71.48 | 83.68 / 82.89 |
| MAML∗ Finn et al. (2017) | 82.93 / 89.70 | 86.21 / 93.55 | 73.20 / 83.17 | 76.06 / 88.51 | |
| GNN∗ Satorras and Estrach (2018) | — — / 75.66 | — — / 89.06 | — — / 70.08 | — — / 76.93 | |
| BERT-PAIR♣ Gao et al. (2019b) | 85.66 / 88.32 | 89.48 / 93.22 | 76.84 / 80.63 | 81.76 / 87.02 | |
| REGRAB Qu et al. (2020) | 87.95 / 90.30 | 92.54 / 94.25 | 80.26 / 84.09 | 86.72 / 89.93 | |
| TD-Proto Yang et al. (2020) | — — / 84.76 | — — / 92.38 | — — / 74.32 | — — / 85.92 | |
| CTEG Wang et al. (2020) | 84.72 / 88.11 | 92.52 / 95.25 | 76.01 / 81.29 | 84.89 / 91.33 | |
| ConceptFERE Yang et al. (2021) | — — / 89.21 | — — / 90.34 | — — / 75.72 | — — / 81.82 | |
| HCRP Han et al. (2021) | 90.90 / 93.76 | 93.22 / 95.66 | 84.11 / 89.95 | 87.79 / 92.10 | |
| DRK Wang et al. (2022) | — — / 89.94 | — — / 92.42 | — — / 81.94 | — — / 85.23 | |
| RAPS | 92.26 / 94.93 | 94.08 / 96.92 | 87.23 / 90.65 | 89.87 / 93.72 | |
| MTB Baldini Soares et al. (2019) | — — / 91.10 | — — / 95.40 | — — / 84.30 | — — / 91.80 | |
| CP Peng et al. (2020) | — — / 95.10 | — — / 97.10 | — — / 91.20 | — — / 94.70 | |
| MapRE Dong et al. (2021) | — — / 95.73 | — — / 97.84 | — — / 93.18 | — — / 95.64 | |
| HCRP (CP) | 94.10 / 96.42 | 96.05 / 97.96 | 89.13 / 93.97 | 93.10 / 96.46 | |
| RAPS (CP) | 96.28 / 97.39 | 97.74 / 98.00 | 93.86 / 95.21 | 95.39 / 96.32 |
Baselines We compare our model with the following baseline methods: 1) Proto-CNN (Snell et al., 2017), prototypical networks with CNN encoder. 2) Proto-HATT (Gao et al., 2019a), hybrid attention is applied on prototypical networks to focus on the crucial instances and features. 3) MLMAN (Ye and Ling, 2019), a multi-level matching and aggregation prototypical network. 4) Proto-BERT (Snell et al., 2017), prototypical networks with BERT encoder. 5) MAML (Finn et al., 2017), the model-agnostic meta-learning algorithm. 6) GNN (Satorras and Estrach, 2018), a meta-learning approach using graph neural networks. 7) BERT-PAIR (Gao et al., 2019b), a method that measures the similarity of sentence pairs. 8) REGRAB (Qu et al., 2020), a Bayesian meta learning method with an external global relation graph. 9) TD-Proto (Yang et al., 2020), learning the importance distribution of generic content words by a memory network. 10) CTEG (Wang et al., 2020), a model using dependency trees to learn to decouple high co-occurrence relations, where two external information are added. 11) ConceptFERE (Yang et al., 2021), introducing the inherent concepts of entities to provide cludes for relation prediction. 12) HCRP (Han et al., 2021), introducing Hybrid Prototype Learning, Relation-Prototype Contrastive Learining, and Taks Adaptive Focal Loss for the model improvement. 13) DRK (Wang et al., 2022), introducing a logic rule to constrain the inference process, thereby avoiding the adverse effect of shallow text features. Moreover, we compare our model with three pretrained RE methods: 13) MTB (Baldini Soares et al., 2019), pretrained by matching the blank stategy on top of an existing BERT model. 14) CP (Peng et al., 2020), an entity masked contrastive pretraining framework for RE while utilizing prototypical networks for finetuning on FSRE. 15) MapRE (Dong et al., 2021), a framework considering both label-agnostic and label-aware semantic mapping information in pre-training and fine-tuning. Note that MTB (Baldini Soares et al., 2019) employs BERT as the backbone, and CP (Peng et al., 2020) and MapRE (Dong et al., 2021) all employ additional pre-training on BERT with Wikipedia data or contrastive learning to get better contextual representation. This is why we do not compare with MTB, CP, and MapRE directly.
4.2 Training and Evaluation
Training We use BERT and CP (Wang et al., 2020) as the sentence encoder, and set the total train iteration number as 30,000, validation iteration number as 1,000, batch size as 4, learning rate as and for BERT and CP respectively.
Evaluation For FewRel 1.0, we report the accuracy on validation and test sets. For FewRel 2.0, we report the accuracy on test set. Since the labels of two test sets are not publicly available, we submit the prediction file of our best model to the CodaLab platform 111https://codalab.lisn.upsaclay.fr to obtain the final result on the test set.
4.3 Overall Evaluation Results
Table 2 presents the experimental results on FewRel 1.0 validation set and test set. As shown in the upper part of Table 2, our method outperforms the strong baseline models significantly. To be specific, RAPS achieves the average of 1.19 points improvement in terms of accuracy on the test sets of four meta tasks, compared to the second best method (HCRP), demonstrating the superior generalization ability. In addition, we evaluate our approach based on the model CP (Peng et al., 2020), where the BERT encoder is initialized with the pre-trained parameters by a contrastive pre-training approach. The lower part of Table 2 shows that our approach achieves a consistent performance boost when using CP pre-trained model. It is worth to mention that RAPS (CP) has 1.17 and 1.24 points improvement compared with HCRP (CP), under the 5-way 1-shot and 10-way 1-shot scenarios, respectively, which demonstrates that our approach is more suitable for few-shot scenarios. Our method also achieves the competitive performance compared with HCRP on FewRel 2.0, as shown in Table 3, which shows that RAPS is also transferable to the domain adaptation setting. It can be seen that RAPS is overall better than HCRP with the CP as encoder. The possible reason why RAPS is worse than HCRP when using BERT as encoder is that the FewRel 2.0 with domain adaptation setting only provides the name of relations without a specific description, which has a relatively harmful impact on the adaptive fusion mechanism to generate a strong relation representation for the relation prototypes. Nevertheless, HCRP seems to be more robust to the lack of relation description due to the complex hybrid prototype learning module.
| Model | 5-way | 5-way | 10-way | 10-way |
|---|---|---|---|---|
| 1-shot | 5-shot | 1-shot | 5-shot | |
| Proto-CNN∗ | 35.09 | 49.37 | 22.98 | 35.22 |
| Proto-BERT∗ | 40.12 | 51.50 | 26.45 | 36.93 |
| BERT-PAIR∗ | 67.41 | 78.57 | 54.89 | 66.85 |
| Proto-CNN-ADV∗ | 42.21 | 58.71 | 28.91 | 44.35 |
| Proto-BERT-ADV∗ | 41.90 | 54.74 | 27.36 | 37.40 |
| DaFeC+BERT-PAIR♣ | 61.20 | 76.99 | 47.63 | 64.79 |
| Cluster-ccnet† | 67.70 | 84.30 | 52.90 | 74.10 |
| HCRP | 76.34 | 83.03 | 63.77 | 72.94 |
| RAPS | 74.99 | 87.85 | 60.29 | 80.10 |
| RAPS (CP) | 80.61 | 89.59 | 67.51 | 82.52 |
4.4 Effects of Different Adaptive Prototype Fusion Methods
In this subsection, we further explore four different types of adaptive prototype fusion methods, including:
-
•
Unconstrained Adaptive Scalar (UAS): .
-
•
Constrained Adaptive Scalar (CAS): .
-
•
Unconstrained Adaptive Matrix (UAM): .
-
•
Constrained Adaptive Matrix (CAM): .
For UAS and CAS, and are two learnable scalars. For UAM and CAM, and are two learnable matrices, is the identity matrix of order . Note that UAM and CAM are equivalent to add a fully-connected layer without bias term on and , respectively. We evaluate these four types of adaptive prototype fusion methods on FewRel 1.0 validation set. The results are shown in Table 4. We can see that UAS gets the best performance in all scenarios. Compared with CAS, UAS has more degrees of freedom to learn the trade-off between relation prototype and relation information, thus leading to more accurate prototype and better performance than CAS. It can be seen that matrix-based fusion methods (UAM and CAM) are consistently inferior to scalar-based fusion methods (UAS and CAS), which may attribute to the introduction of useless parameters ( for UAM and CAM vs. for UAS and CAS).
| Model | Mean | 5-way | 5-way | 10-way | 10-way |
|---|---|---|---|---|---|
| 1-shot | 5-shot | 1-shot | 5-shot | ||
| UAS | 90.86 | 92.26 | 94.08 | 87.23 | 89.87 |
| CAS | 89.79 | 91.91 | 93.09 | 86.55 | 87.61 |
| UAM | 75.02 | 78.56 | 85.84 | 64.58 | 71.11 |
| CAM | 73.58 | 74.64 | 84.69 | 61.37 | 73.63 |
4.5 Ablation Studies
In this subsection, we conduct an ablation study on 5-way 1-shot and 10-way-1-shot based on BERT with the validation set, to demonstrate the effectiveness of the proposed query-information guided attention module and adaptive prototype fusion mechanism (abbreviated as QIA and APF for further reference, respectively). We consider three ablation experiments including w/o QIA, w/o APF, and w/o QIA and APF.
- •
-
•
w/o APF: calculate using direct addition instead of (4).
- •
From the results in Table 5, We can obtain several observations. First, the model performance drops more or less without any of QIA or APF, which demonstrates the effectiveness of RAPS. Second, QIA seems to be more important under 10-way 1-shot scenario than 5-way 1-shot, with the loss of performance 0.15% and 0.76%, respectively. Third, APF seems to be more important under 5-way 1-shot scenario than 10-way 1-shot, with the loss of performance 1.35% and 1.13%, respectively. Based on the above discussion, it may be a future research direction to choose appropriate prototype computation method under different -way -shot settings.
| Method | 5-way | 10-way |
|---|---|---|
| 1-shot | 1-shot | |
| QIA+APF | 92.26 | 87.23 |
| w/o QIA | 92.11 | 86.47 |
| w/o APF | 91.91 | 86.10 |
| w/o QIA and APF | 91.33 | 86.02 |
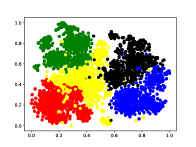
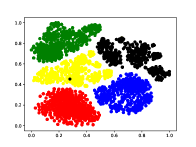
4.6 Visualization
In order to further explore the reason why our proposed method has excellent discriminative capability, we give the visualization results in Figure 2 with BERT on 5-way 1-shot of the validation set of FewRel 1.0. Figure 2 shows the t-SNE (van der Maaten and Hinton, 2008) visualization of query instances, where different colors represent different relation classes. The left subfigure means the original statements of query instances encoded by Proto-BERT (Snell et al., 2017), and the right subfigure means the statements of query instances encoded by RAPS.
It can be seen from the left subfigure that, although the instances can also be divided into different classes, the intra-class distances are not close enough, and there are multiple error points (i.e., yellow points in red cluster). After introducing the relation information and training with the proposed query-information guided attention and adaptive prototype fusion mechanism (right), we can see that the error points are reduced while the representations of the same class are closer, and the inter-class boundaries are more distinct. The observation shows that our proposed method is indeed beneficial to the improvement of the model.
5 Conclusion
In this paper, we propose a novel FSRE pipeline using the proposed query-information guided attention module and adaptive prototype fusion mechanism, called RAPS. It has two advantages: 1) RAPS exploits rich interactive information between the support instances and the query instances to obtain more accurate initial relation prototypes. 2) RAPS dynamically makes the trade-off between the derived relation prototype and the relation information by the adaptive prototype fusion mechanism to get more compatible final relation prototype. Experiments on the FewRel 1.0 and FewRel 2.0 datasets show that RAPS achieves a significant improvement against the modern state-of-the art methods. One possible direction of future work is to generalize the adaptive prototype fusion mechanism to other text classification tasks such as intent classification.
Limitations
There are several limitations of this work. First, RAPS only works under the -way -shot setup, because it requires a support set to calculate the relation class prototype. Second, its effectiveness is only examined on the task of few-shot relation extraction, while the generalization to other text classification tasks, such as intent classification and news classification, is not yet explored in this paper. Third, the model has not been extended to perform non-of-the-above (NOTA) detection (Gao et al., 2019b), where a query instance may not belong to any class in the support set.
Acknowledgements
The research of Yuzhe Zhang, Min Cen, and Tongzhou Wu is partly supported by the postgraduate studentship of USTC. Hong Zhang’s research is partly supported by the National Natural Science Foundation of China (7209121, 12171451).
References
- Bach and Badaskar (2007) Nguyen Bach and Sameer Badaskar. 2007. A review of relation extraction. Literature Review for Language and Statistics II, 2:1–15.
- Baldini Soares et al. (2019) Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. Matching the blanks: Distributional similarity for relation learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2895–2905, Florence, Italy. Association for Computational Linguistics.
- Bansal et al. (2021) Trapit Bansal, Karthick Prasad Gunasekaran, Tong Wang, Tsendsuren Munkhdalai, and Andrew McCallum. 2021. Diverse distributions of self-supervised tasks for meta-learning in NLP. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5812–5824, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Cong et al. (2020) Xin Cong, Bowen Yu, Tingwen Liu, Shiyao Cui, Hengzhu Tang, and Bin Wang. 2020. Inductive unsupervised domain adaptation for few-shot classification via clustering. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 624–639. Springer.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Ding et al. (2019) Ming Ding, Chang Zhou, Qibin Chen, Hongxia Yang, and Jie Tang. 2019. Cognitive graph for multi-hop reading comprehension at scale. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2694–2703, Florence, Italy. Association for Computational Linguistics.
- Dong et al. (2021) Manqing Dong, Chunguang Pan, and Zhipeng Luo. 2021. MapRE: An effective semantic mapping approach for low-resource relation extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2694–2704, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Dua et al. (2020) Dheeru Dua, Sameer Singh, and Matt Gardner. 2020. Benefits of intermediate annotations in reading comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5627–5634, Online. Association for Computational Linguistics.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, pages 1126–1135.
- Gao et al. (2019a) Tianyu Gao, Xu Han, Zhiyuan Liu, and Maosong Sun. 2019a. Hybrid attention-based prototypical networks for noisy few-shot relation classification. In The Thirty-Third AAAI Conference on Artificial Intelligence, pages 6407–6414.
- Gao et al. (2019b) Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. 2019b. FewRel 2.0: Towards more challenging few-shot relation classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6250–6255, Hong Kong, China. Association for Computational Linguistics.
- Han et al. (2021) Jiale Han, Bo Cheng, and Wei Lu. 2021. Exploring task difficulty for few-shot relation extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2605–2616, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Han et al. (2018) Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. FewRel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4803–4809, Brussels, Belgium. Association for Computational Linguistics.
- Hu et al. (2021) Jinpeng Hu, Jianling Li, Zhihong Chen, Yaling Shen, Yan Song, Xiang Wan, and Tsung-Hui Chang. 2021. Word graph guided summarization for radiology findings. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4980–4990.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
- Li et al. (2021) Zhifei Li, Hai Liu, Zhaoli Zhang, Tingting Liu, and Neal N. Xiong. 2021. Learning knowledge graph embedding with heterogeneous relation attention networks. IEEE Transactions on Neural Networks and Learning Systems, pages 1–13.
- Peng et al. (2020) Hao Peng, Tianyu Gao, Xu Han, Yankai Lin, Peng Li, Zhiyuan Liu, Maosong Sun, and Jie Zhou. 2020. Learning from Context or Names? An Empirical Study on Neural Relation Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3661–3672, Online. Association for Computational Linguistics.
- Qu et al. (2020) Meng Qu, Tianyu Gao, Louis-Pascal A. C. Xhonneux, and Jian Tang. 2020. Few-shot relation extraction via bayesian meta-learning on relation graphs. In Proceedings of the 37th International Conference on Machine Learning, pages 7867–7876.
- Satorras and Estrach (2018) Victor Garcia Satorras and Joan Bruna Estrach. 2018. Few-shot learning with graph neural networks. In 6th International Conference on Learning Representations.
- Snell et al. (2017) Jake Snell, Kevin Swersky, and Richard S. Zemel. 2017. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, pages 4077–4087.
- Songtao Liu and Wang (2019) Di Huang Songtao Liu and Yunhong Wang. 2019. Learning spatial fusion for single-shot object detection. arxiv preprint arXiv:1911.09516.
- van der Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of Machine Learning Research, 9(11).
- Wang et al. (2022) Mengru Wang, Jianming Zheng, Fei Cai, Taihua Shao, and Honghui Chen. 2022. DRK: Discriminative rule-based knowledge for relieving prediction confusions in few-shot relation extraction. In Proceedings of the 29th International Conference on Computational Linguistics, pages 2129–2140, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Wang et al. (2020) Yingyao Wang, Junwei Bao, Guangyi Liu, Youzheng Wu, Xiaodong He, Bowen Zhou, and Tiejun Zhao. 2020. Learning to decouple relations: Few-shot relation classification with entity-guided attention and confusion-aware training. In Proceedings of the 28th International Conference on Computational Linguistics, pages 5799–5809, Barcelona, Spain (Online). International Committee on Computational Linguistics.
- Yang et al. (2020) Kaijia Yang, Nantao Zheng, Xinyu Dai, Liang He, Shujian Huang, and Jiajun Chen. 2020. Enhance prototypical network with text descriptions for few-shot relation classification. In The 29th ACM International Conference on Information and Knowledge Management, pages 2273–2276.
- Yang et al. (2021) Shan Yang, Yongfei Zhang, Guanglin Niu, Qinghua Zhao, and Shiliang Pu. 2021. Entity concept-enhanced few-shot relation extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 987–991, Online. Association for Computational Linguistics.
- Ye and Ling (2019) Zhi-Xiu Ye and Zhen-Hua Ling. 2019. Multi-level matching and aggregation network for few-shot relation classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2872–2881, Florence, Italy. Association for Computational Linguistics.
- Zhang et al. (2021) Linhai Zhang, Chao Lin, Deyu Zhou, Yulan He, and Meng Zhang. 2021. A Bayesian end-to-end model with estimated uncertainties for simple question answering over knowledge bases. Computer Speech & Language, 66:101167.
- Zhao et al. (2020) Yu Zhao, Anxiang Zhang, Ruobing Xie, Kang Liu, and Xiaojie Wang. 2020. Connecting embeddings for knowledge graph entity typing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6419–6428, Online. Association for Computational Linguistics.