Kyunghoon Ban
Rochester Institution of Technology
Rochester, NY
kban@saunders.rit.edu
and Désiré Kédagni
UNC-Chapel Hill
Chapel Hill, NC
dkedagni@unc.edu
rdid and rdidstag: Stata commands for robust difference-in-differences
Abstract
This article provides a Stata package for the implementation of the robust difference-in-differences (RDID) method developed in Ban and Kédagni (2023). It contains three main commands: rdid, rdid_dy, rdidstag, which we describe in the introduction and the main text. We illustrate these commands through simulations and empirical examples.
keywords:
st0001, rdid, rdid_dy, rdidstag, robust DID1 Introduction
In this article, we present the rdid, rdid_dy, rdidstag commands for estimation and inference on robust difference-in-differences (DID) bounds as developed by Ban and Kédagni (2023). These commands, summarized in Table 1, allows one to analyze the average treatment effects on the treated (ATT) under the canonical DID setting where observational data consist of two different groups (a treatment group and a control group) and two time periods (pre-treatment and post-treatment) as well as the staggered adoption design where there are multiple cohorts with different timings in the treatment adoption.
| Command | Description |
|---|---|
| rdid | Estimates robust DID bounds on the ATT under the canonical DID setting. |
| rdid_dy | Estimates robust DID bounds on the ATTs for each of post-treatment periods under the canonical DID setting. |
| rdidstag | Estimates robust bounds on the cohort-time ATTs under the staggered adoption design. |
Our article contributes to the expanding suite of publicly available software within the DID design community, including Villa (2016), Houngbedji (2016), de Chaisemartin et al. (2019), Rios-Avila et al. (2022, 2023), among others. Specifically, our software is more closely aligned with research exploring alternative identifying assumptions within the DID framework; for instance, Mora and Reggio (2015) examines DID estimations under alternative assumptions and assesses their robustness, while Bravo et al. (2022) discusses methods to bound post-treatment parallel trends (PT) violations using pre-treatment PT violations.
The rest of this article is structured as follows. In section 2, we recap the underlying frameworks of the robust DID bounds by Ban and Kédagni (2023). In sections 3, 4, and 5, we describe the rdid, rdid_dy, rdidstag commands, respectively. In section 6, we illustrate the performance of each command through a series of Monte Carlo simulations.
2 Framework and methodology
Consider the following potential outcome model:
| (1) |
where , represents the observed data, while the vector is latent. The variables are respectively the observed outcomes in the baseline period and the follow-up period 1, while is the observed treatment that occurred between periods 0 and 1, and are the potential outcomes that would have been observed in period 1 had the treatment been externally set to 0 and 1, respectively. denotes the set of all pre-treatment periods. Model (1) assumes that there is no anticipatory effect of the treatment, so that for all baseline periods .
The standard DID estimand is defined as the difference between the OLS estimand in period 1 and the selection bias in period 0:
where is the coefficient of a regression of on the binary ,
and is the selection bias in period ,
for . Recall that is identified with the no anticipatory effect but is an unobserved counterfactual.
Note that the average treatment effect on the treated (ATT),
is identified by under the parallel trend (PT) assumption,
or (bias stability).
Hence, the identification of ATT can be re-framed as imputing the counterfactual selection bias . This observation inspires us to introduce a robust version of the DID estimand.
Define the baseline information set , where is the support of a baseline covariate in period , and is the set of pre-treatment periods. For simplicity, suppose there are no baseline covariates so that .
Definition 1
Given the baseline information set , we define the robust difference-in-differences (RDID) estimand as
| (2) |
where is the convex hull of a generic set , is a function defined as
and is the image of the information set through the function .
When baseline covariates exists, we define the function as
In the above definition, if there is only one element in the information, i.e., , then , and the robust DID estimand is the same as the standard DID estimand.
2.1 Bias set stability
Let us first consider the simple case with no covariates in the model.
Assumption 1 (Bias set stability)
where is defined above.
Assumption 1 is weaker than the standard “parallel/common trends” assumption. Indeed, if is the singleton of a single baseline information , then Assumption 1 is equivalent to which is equivalent to the parallel trends assumption.
Under Assumption 1, robust DID estimand yields the following bounds on the ATT.111Note that the RDID can be generalized by using other correspondences than associated with other assumptions (Ban and Kédagni, 2023).
Proposition 1
The bounds in Proposition 1 are never empty, as they always contain the standard DID estimand under the parallel trends assumption. However, they may not contain the OLS estimand in period 1, , as 0 may not lie within the set . If all pre-treatment periods selection biases are equal, i.e., for all , then our bounds collapse to a point, the standard DID estimand. In case the information set is the set of pre-treatment periods, the above bounds are robust to violations of PT that can be captured in the pre-treatment periods.
2.2 PO-RDID: Best predictor of based on a loss function
Consider a random variable representing the baseline information with a distribution . Provided is known, we are going to assume that the decision maker will choose the selection bias in such a way that a loss function is minimized. By plugging such an optimal selection bias into the definition of the robust DID, we obtain what we call a policy-oriented robust difference-in-differences (PO-RDID) estimand. This estimand may not have a causal interpretation, but it may help the policy-maker in her decision making process.
Assumption 2
Let be the decision maker’s loss function when she observes a (random) baseline information and chooses a selection bias . The decision maker chooses (or ) to minimize the loss : .
In this paper, we consider the class of -norm losses defined as:
where . We are going to derive the optimal selection bias for . We consider those special loss functions because the solutions to the optimization problem have closed-form expressions. Other loss functions can also be considered.
The command rdid with an option rdidtype(1) can be used, and the distribution of is estimated by the proportion of observations at each level of .
loss: Mean absolute error (MAE)
Note that . Given this loss function, under Assumption 2, the decision maker solves the following optimization problem:
The optimal decision is to set the selection to be equal to the median selection bias in the baseline period, i.e., . In such a case, the policy-oriented robust DID estimand is given by
loss: Root mean square error (RMSE)
We have , and minimizing the RMSE is equivalent to minimizing the mean square error (MSE). Therefore, under Assumption 2, the decision maker solves the following optimization problem:
This yields an optimal decision for the selection to be set equal to the average selection bias in the baseline period, i.e., . Hence, we have
loss: Maximal regret
Note that
This optimization problem with the loss is equivalent to a minimax criterion, and yields the mid-point of the bounds on stated in Assumption 1. Hence, the PO-RDID estimand is given by
Note that in all cases, if the information in the baseline period is a singleton, then the optimal is the selection bias in the baseline period , which is equivalent to the parallel trends assumption. Unlike the PO-RDID estimand obtained from and loss functions, that obtained from the loss function does not require the knowledge of the distribution of the information but only its support and is easy to compute. However, when the distribution of is uniform over , then the optimal selection bias is the same in all three cases.
2.3 Forecasting when the baseline information is ordered
Suppose that the baseline information set is ordered (e.g., a set of multiple pre-treatment periods or a continuous baseline covariate like age). We can regress on and use this regression to predict .
For instance, if and the selection bias is increasing over time, Assumption 1 may not hold. The researcher could instead use this increasing trend information about the selection bias to forcast the next period selection bias .
The command rdid with an option rdidtype(2) can be used for a linear predicition model, and an option peval(#) can be used to specify the evaluation point of the prediction.
2.4 Identification with multiple periods
We generalize our analysis to a setting where the treatment receipt occurs at multiple periods. We consider the following multiple treatment periods potential outcome model:
| (3) |
for , where denotes the observed outcome in period , is the observed treatment status in period with by definition, while is the potential outcome when the treatment path is externally set to .222See Robins (1986, 1987), and Han (2021) for a similar definition of the potential outcome model. Under the no-anticipation assumption, we have for all and . That is, we assume that individuals do not anticipate any effects of the treatment before it occurs for the first time in . However, we allow the individuals to anticipate the effects of the treatment for the rest of the period. This assumption is less restrictive than the commonly used no-anticipatory effects assumption.
In the above framework, the parameter of interest is the average treatment effect in period on the treated group following the path to , which is defined as:
Similarly to what we have in the one post-treatment setting, we can write the difference-in-means estimand between the two groups and in period as:
where . We extend Assumption 1 to the current setting.
Assumption 3 (Extended bias set stability)
For each ,
where is the baseline selection bias with respect to the treatment status in period when the information set is equal to .
Assumption 3 is a generalization of Assumption 1, and we have the following identification results for with different treatment paths.
Proposition 2
In a staggered design setting, the average treatment effect in period on units who are treated for the first time in period could be an interesting parameter, as considered in Callaway and Sant’Anna (2021):
By defining as
where denotes the never-treated cohort as our control group, we can write
for , by abusing the notations of and for paths.
3 The rdid command
3.1 Syntax
The rdid command estimates bounds on the ATT under the assumptions discussed above. The syntax for the rdid command is
rdid depvar indepvars if in , treatname(varname) postname(varname) infoname(varname) rdidtype(#) peval(#) level(#) figure brep(#) clustername(varname)
3.2 Options
treatname(varname) specifies the variable name of the treatment indicator. treatname() is required.
postname(varname) specifies the variable name of the post-treatment period indicator. postname() is required.
infoname(varname) specifies the variable name of the information index. infoname() is required.
rdidtype(#) specifies the type of RDID estimator; 0 for the simple RDID, 1 for the policy-oriented (PO) RDID, and 2 for the RDID with linear predictions. The default is rdidtype(0).
peval(#) specifies the evaluation point for the RDID with linear predictions. The default is the mean value of infoname(varname) in the post-treatment period. This option is ignored when rdidtype(#) is not equal to 2.
level(#) specifies the confidence level, as a percentage, for confidence intervals (CIs). The default is level(95). Three different CIs are provided with rdidtype(0); 1) CI for the bounds (Ye et al., 2023), 2) CI for the ATT (Ye et al., 2023), and 3) CI for the bounds (union bounds). Bootstrapped CIs are provided with rdidtype(1) and rdidtype(2).
When figure(string) is specified, rdid saves a scatter plot of estimated selection biases and the information index in the pre-treatment periods as figure(string).png.
brep(#) specifies the number of bootstrap replicates. The default is brep(500).
clustername(varname) specifies the variable name that identifies resampling clusters in bootstrapping.
3.3 Stored results
rdid stores the following in e(). When indepvars is specified, is estimated using post-treatment periods (see Ban and Kédagni, 2023) and stored in e(DR). Otherwise, is estimated and stored in e(OLS). Also, stored scalars depend on rdidtype(#) specification (referred as ‘type’ below). In the following, LB (UB) stands for lower bound (upper bound).
| Scalars (common) | |||
| e(DR) | estimate | e(OLS) | estimate |
| e(N) | number of observations | ||
| Scalars (type=0) | |||
| e(SB_LB) | LB of | e(SB_UB) | UB of |
| e(RDID_LB) | LB of | e(RDID_UB) | UB of |
| e(CI1_LB) | LB of CI-1 | e(CI1_UB) | UB of CI-1 |
| e(CI2_LB) | LB of CI-2 | e(CI2_UB) | UB of CI-2 |
| e(CI3_LB) | LB of CI-3 | e(CI3_UB) | UB of CI-3 |
| Scalars (type=1) | |||
| e(L1_CI_LB) | LB of CI for | e(L1_CI_LB) | UB of CI for |
| e(L2_CI_LB) | LB of CI for | e(L2_CI_LB) | UB of CI for |
| e(Linf_CI_LB) | LB of CI for | e(Linf_CI_LB) | UB of CI for |
| e(L1_PE) | estimate | e(L2_PE) | estimate |
| e(Linf_PE) | estimate | ||
| Scalars (type=2) | |||
| e(SB_hat) | estimate | e(proj_PE) | estimate |
| e(CI_LB) | LB of CI for | e(CI_UB) | UB of CI for |
| Macros | |||
| e(cmd) | rdid | e(indep) | name of independent variable |
| e(depvar) | name of dependent variable(s) | e(clustvar) | name of cluster variable |
| e(level) | confidence level | ||
| Matrices | |||
| e(results) | displayed summary matrix |
4 The rdid_dy command
4.1 Syntax
The rdid_dy command is a wrapper command that implements RDID estimation separately for each levels of a time variable in the post-treatment period and collects the results. The syntax for the rdid_dy command is
rdid_dy depvar indepvars if in , treatname(varname) postname(varname) infoname(varname) tname(varname) rdidtype(#) peval(#) level(#) figure(string) brep(#) clustername(varname) citype(#) losstype(#)
4.2 Options
tname(varname) specifies the variable name for the time. tname() is required.
peval(#) specifies the evaluation point for the RDID with linear predictions. The default is the mean value of infoname(varname) in the post-treatment period. In particular, if infoname(varname) is the same as tname(varname), each RDID estimate is obtained using each level of tname(varname) as the evaluation point. This option is ignored when rdidtype(#) is not equal to 2.
When figure(string) is specified, rdid_dy saves line plots of RDID estimates and confidence intervals over the post-treatment periods as figure(string).png.
citype(varname) specifies the type of confidence intervals to collect for rdidtype(0); 1 yields CI for the RDID bounds (Ye et al., 2023), 2 yields CI for the ATT (Ye et al., 2023), and 3 yields CI for the RDID bounds (Union Bounds). The default is citype(1). This option is ignored when rdidtype(#) is not equal to 0.
losstype(#) specifies the type of loss function for rdidtype(1) (PO-RDID); 1 for , 2 for , and 0 for . The default is losstype(1). This option is ignored when rdidtype(#) is not equal to 1.
4.3 Stored results
rdid_dy stores the following in e(). Stored scalars depend on rdidtype(#) specification; In the following, LB (UB) stands for lower bound (upper bound) and (t) denotes each level of tname(varname).
| Scalars | |||
| e(N) | number of observations | e(RDID_PE_(t)) | estimate for (t) |
| e(RDID_LB_(t)) | LB of for (t) | e(RDID_UB_(t)) | UB of for (t) |
| e(RDID_LB_(t)) | LB of CI for (t) | e(RDID_UB_(t)) | LB of CI for (t) |
| Macros | |||
| e(cmd) | rdid_dy | e(indep) | name of independent |
| variable | |||
| e(depvar) | name of dependent | e(clustvar) | name of cluster variable |
| variable(s) | |||
| e(level) | confidence level | ||
| Matrices | |||
| e(results) | displayed summary matrix |
5 The rdidstag command
5.1 Syntax
The rdidstag command estimates bounds on the ATT over time for different cohorts in the staggered adoption design under the assumptions discussed above. The syntax for the rdidstag command is
rdidstag depvar indepvars if in , gname(varname) tname(varname) postname(varname) infoname(varname) level(#) figure clustername(varname)
5.2 Options
gname(varname) specifies the variable name of the cohort index, , where is assigned for the never-treated group. gname() is required.
tname(varname) specifies the variable name of time index, . tname() is required.
postname(varname) specifies the variable name of the post-treatment period indicator. The default is using units with as post-period units.
infoname(varname) specifies the variable name of the information index. The default is using pre-treatment periods; i.e., .
level(#) specifies the confidence level, as a percentage, for confidence intervals. The default is level(95).
When figure is specified, rdidstag saves line plots of RDID bounds and confidence intervals over the post-treatment periods for each as figure(string).png.
clustername(varname) specifies the variable name that identifies resampling clusters in bootstrapping.
5.3 Stored results
rdidstag stores the following in e(). In the following, LB (UB) stands for lower bound (upper bound). Also, (g) and (t) denote each level of gname(varname) and tname(varname), respectively.
| Scalars | |||
| e(RDID_LB_(g)_(t)) | LB of | e(RDID_UB_(g)_(t)) | UB of |
| e(CI_LB_(g)_(t)) | LB of CI for | e(CI_UB_(g)_(t)) | UB of CI for |
| e(N) | number of observations | ||
| Macros | |||
| e(cmd) | rdidstag | e(indep) | name of independent |
| variable | |||
| e(depvar) | name of dependent | e(clustvar) | name of cluster variable |
| variable(s) | |||
| e(level) | confidence level | ||
| Matrices | |||
| e(results) | displayed summary matrix |
6 Applications
We illustrate usages of rdid, rdid_dy, and rdidstag commands using two applications. We first demonstrate rdid and rdid_dy commands using an application of Cai (2016) in Section 6.1 and then rdidstag command using data from Dube et al. (2016) in Section 6.2.
6.1 Effects of insurance provision on tobacco production
Cai (2016) investigates the impact of insurance provision on tobacco production using a household-level panel dataset provided by the Rural Credit Cooperative (RCC), the main rural bank in China.
Using rdid command
In the following runs, the dependent variable is area_tob and the covariates are hhsize, educ_scale, and age, yielding the doubly-robust estimate (Ban and Kédagni, 2023). Also, treatment variable and the post-treatment period indicator is is treatment and policy2, respectively, and the information set is specified as pre-treatment periods by using year. We use 1,000 bootstrap replicates and cluster the standard errors using hhno. First, the following is yielding the RDID bounds with the three different confidence intervals.
-
. use "analysis.dta" . drop if sector != 1 (20,519 observations deleted) . rdid area_tob hhsize educ_scale age, treat(treatment) post(policy2) /// > info(year) b(1000) cl(hhno) **** RDID Estimation version 1.8 **** Y name: area_tob D name: treatment X name(s): hhsize educ_scale age Y: area_tob LB UB RDID 0.8086 0.9479 CI_1 0.6203 1.1257 CI_2 0.6235 1.1222 CI_3 0.6187 1.1257 * RDID: Point estimates for RDID bounds * CI_1: Confidence interval for the bounds (Ye et al.) * CI_2: Confidence interval for the ATT (Ye et al.) * CI_3: Confidence interval for the bounds (Union Bounds)
Second, by specifying the option rdidtype(1), we can have PO-RDID estimates and their confidence intervals under the three loss functions.
-
. rdid area_tob hhsize educ_scale age, treat(treatment) post(policy2) /// > info(year) rdidtype(1) b(1000) cl(hhno) **** RDID Estimation version 1.8 **** Y name: area_tob D name: treatment X name(s): hhsize educ_scale age Y: area_tob PE CI_LB CI_UB L1 0.8770 0.6732 1.0806 L2 0.8778 0.6911 1.0753 Linf 0.8783 0.6978 1.0710
Lastly, by specifying the option rdidtype(2), we can have an RDID estimate based on a linear prediction with an ordered information set, pre-treatment periods. The predicted value is evaluated at the mean of the post-treatment periods, 2005.5, with the option peval(2005.5).
-
. rdid area_tob hhsize educ_scale age, treat(treatment) post(policy2) /// > info(year) rdidtype(2) peval(2005.5) b(1000) cl(hhno) **** RDID Estimation version 1.8 **** Y name: area_tob D name: treatment X name(s): hhsize educ_scale age PE CI_LB CI_UB TAU_DR SB_hat Y area_tob 0.7239 0.4760 0.9725 1.9154 1.1914
Using rdid_dy command
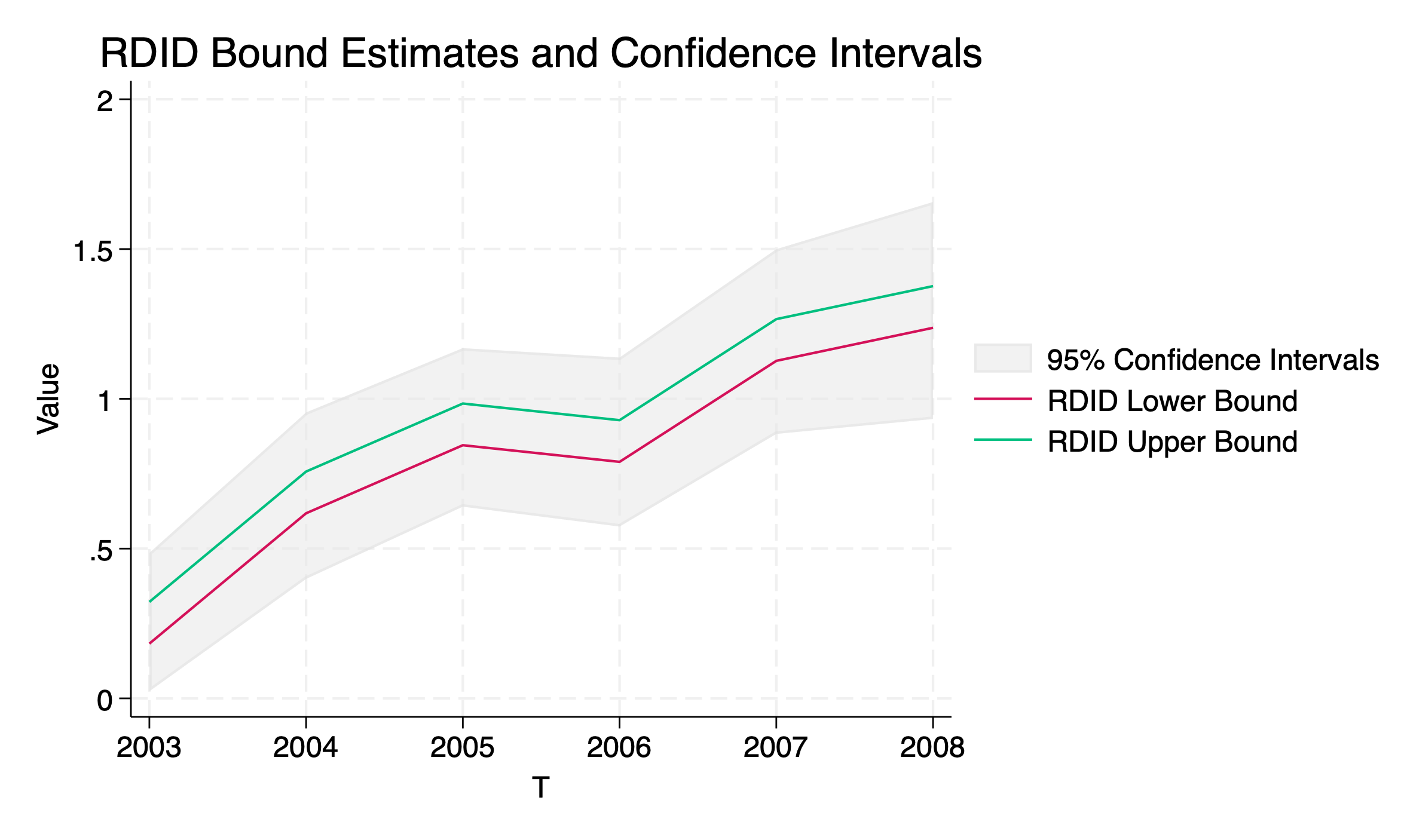
Recall that rdid_dy command is a wrapper command that implements RDID estimation separately for each levels of a time variable in the post-treatment period and collects the results. In the following runs, the same options are specified as before, but the option tname(year) is used to denote the variable for the post-treatment periods. Also, the following run produces Figure 1 that summarizes the output.
-
. use "analysis.dta" . drop if sector != 1 (20,519 observations deleted) . rdid_dy area_tob hhsize educ_scale age, treat(treatment) post(policy2) /// > info(year) tname(year) fig b(1000) cl(hhno) file rdid_dy.png saved as PNG format T: year RDID_LB RDID_UB CI_LB CI_UB 2003 0.1829 0.3221 0.0239 0.4855 2004 0.6181 0.7573 0.3988 0.9545 2005 0.8452 0.9844 0.6401 1.1692 2006 0.7897 0.9289 0.5738 1.1377 2007 1.1269 1.2661 0.8829 1.4996 2008 1.2372 1.3764 0.9328 1.6571 * Confidence intervals are obtained for the bounds (Ye et al.)
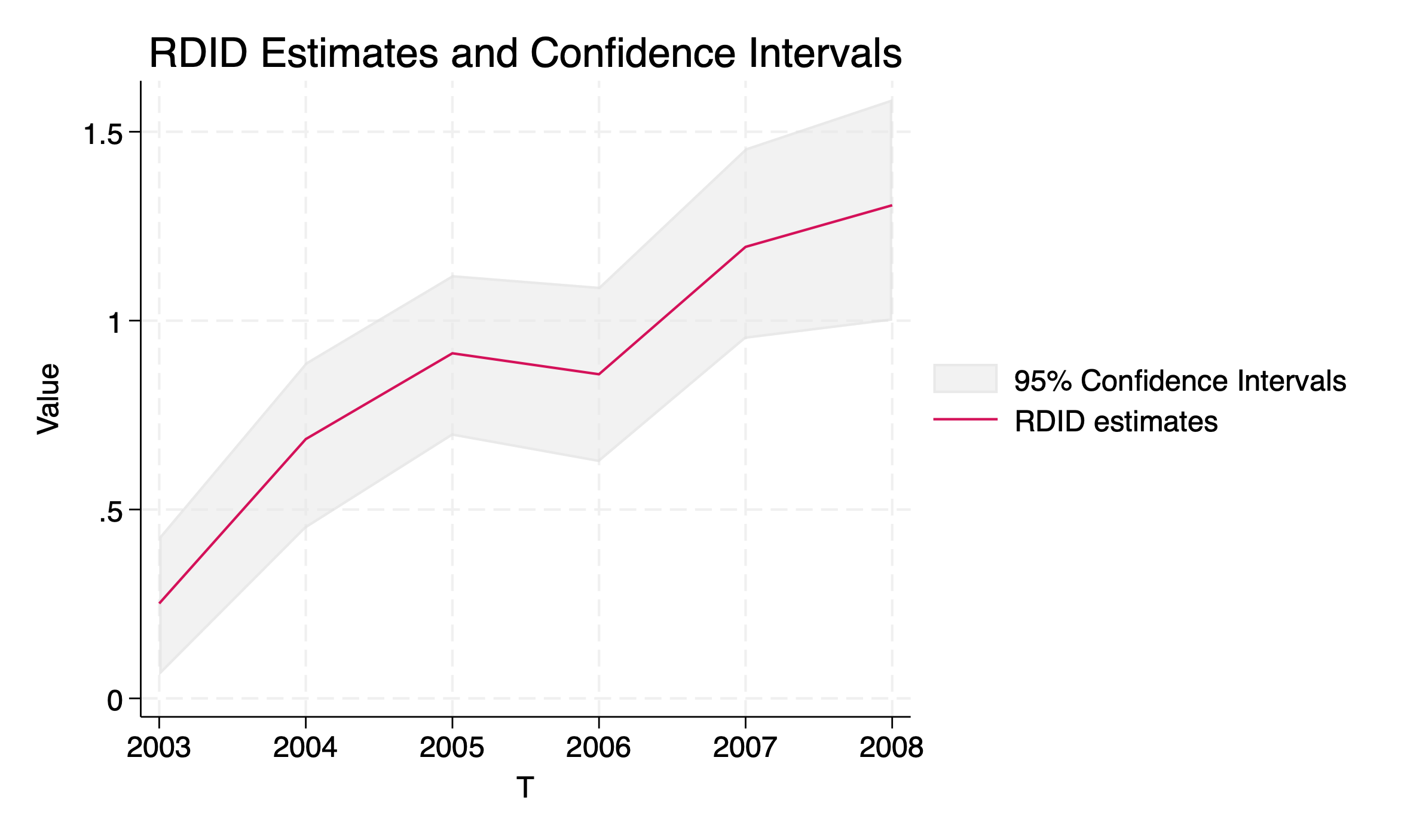
Note that rdid_dy command can be used for the option rdidtype(1) or rdidtype(2), and the following code runs for collecting PO-RDID with (default), producing Figure 2 that summarizes the output.
-
. rdid_dy area_tob hhsize educ_scale age, rdidtype(1) treat(treatment) /// > post(policy2) info(year) tname(year) fig b(1000) cl(hhno) file rdid_dy.png saved as PNG format T: year RDID_PE CI_LB CI_UB 2003 0.2513 0.0605 0.4273 2004 0.6865 0.4497 0.8893 2005 0.9136 0.6951 1.1206 2006 0.8581 0.6253 1.0898 2007 1.1953 0.9517 1.4561 2008 1.3056 0.9999 1.5860 * RDID estimates are obtained as PO-RDID estimates (L1)
6.2 Effects of minimum wage increases on teen employment
Following Callaway and Sant’Anna (2021) and Dube et al. (2016), we used the Quarterly Workforce Indicators (QWI) data to collect the first quarter teen employment as our outcome variable. Callaway and Sant’Anna (2021) considered 7 years of periods between 2001 and 2007 where the federal minimum wage did not change over time, and 3 different control groups of and with states that raised their minimum wage in or right before the beginning of years 2004, 2006, and 2007, respectively. The specific timing of the raise can be found in Callaway and Sant’Anna (2021), and it should be noted that there is some heterogeneity in the size of the minimum wage increase within each group. The control group consists of states that did not raise their minimum wage during this period.
The following code specifies the option gname(G) for the cohort index variable, which has four levels: 0, 2004, 2006, and 2007. Note that because the options postname(varname) and infoname(varname) are not specified, all periods from 2004 onward are treated as post-treatment periods, and all periods before 2004 are treated as informational elements.
-
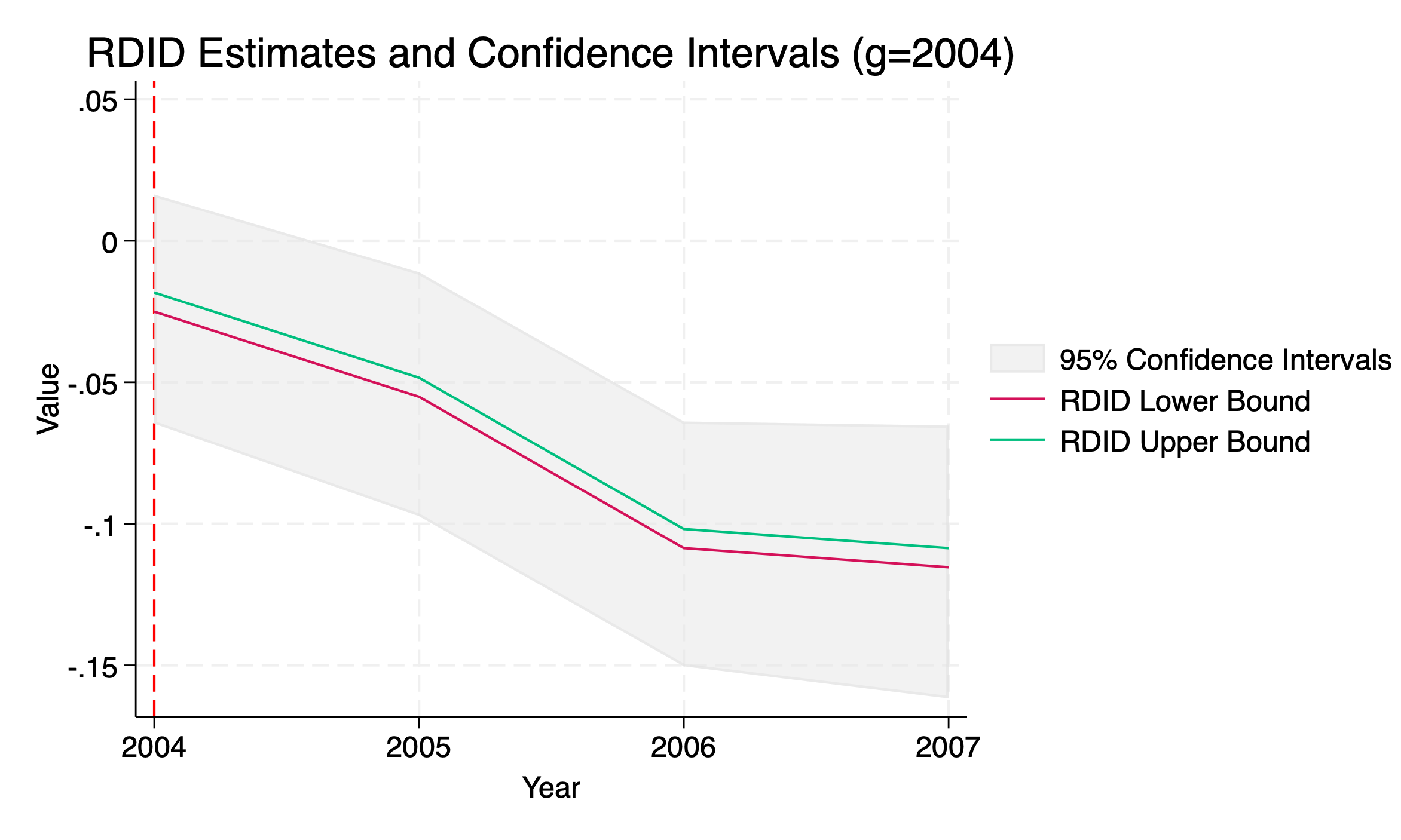
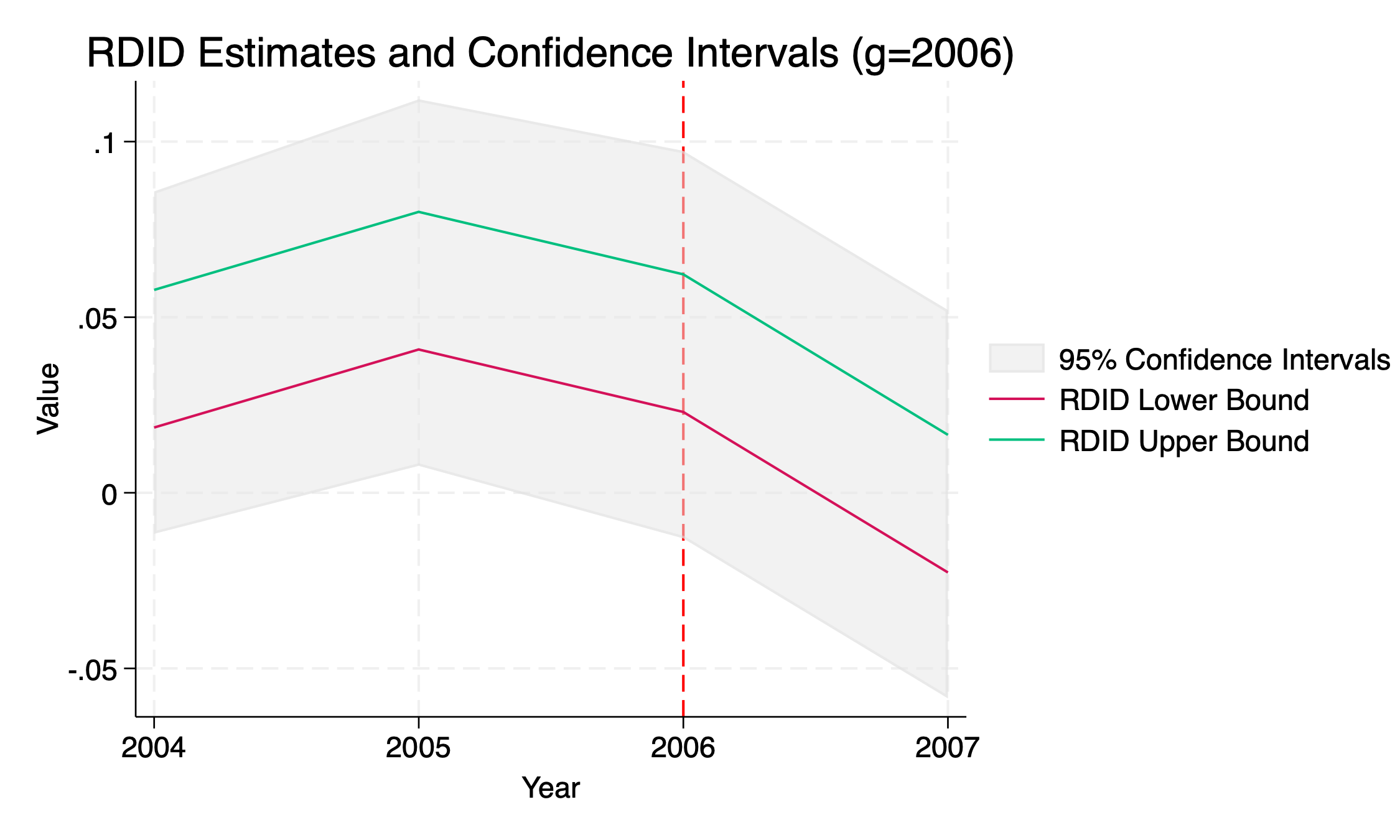
. use "qwi_minwageclean2.dta" . destring years, replace years: all characters numeric; replaced as int . rdidstag lnemp_0A01_BS lnpop lnteenpop lnemp_0A00_BS, gname(G) tname(years) cl(countyfips) fig **** RDID Estimation version 1.7 **** Y name: lnemp_0A01_BS G name: G X name(s): lnpop lnteenpop lnemp_0A00_BS postname is not specified: using units with T >= min(G) as post-period units. infoname is not specified: using pre-period T < min(G) as the information set. ATT(G/T) RDID_LB RDID_UB 95CI_LB 95CI_UB ATT(2004/2004) -0.0250 -0.0183 -0.0646 0.0164 ATT(2004/2005) -0.0551 -0.0484 -0.0973 -0.0111 ATT(2004/2006) -0.1086 -0.1018 -0.1504 -0.0639 ATT(2004/2007) -0.1153 -0.1086 -0.1617 -0.0653 ATT(2006/2004) 0.0186 0.0578 -0.0117 0.0858 ATT(2006/2005) 0.0408 0.0800 0.0077 0.1121 ATT(2006/2006) 0.0230 0.0622 -0.0130 0.0974 ATT(2006/2007) -0.0227 0.0165 -0.0585 0.0520 ATT(2007/2004) 0.0065 0.0422 -0.0301 0.0738 ATT(2007/2005) 0.0013 0.0370 -0.0329 0.0676 ATT(2007/2006) -0.0346 0.0012 -0.0692 0.0383 ATT(2007/2007) -0.0512 -0.0154 -0.0846 0.0207 - Information elements: 2001 2002 2003 - Post-periods: 2004 2005 2006 2007 - Groups: 2004 2006 2007 file rdidstag_g2004.png saved as PNG format file rdidstag_g2006.png saved as PNG format file rdidstag_g2007.png saved as PNG format
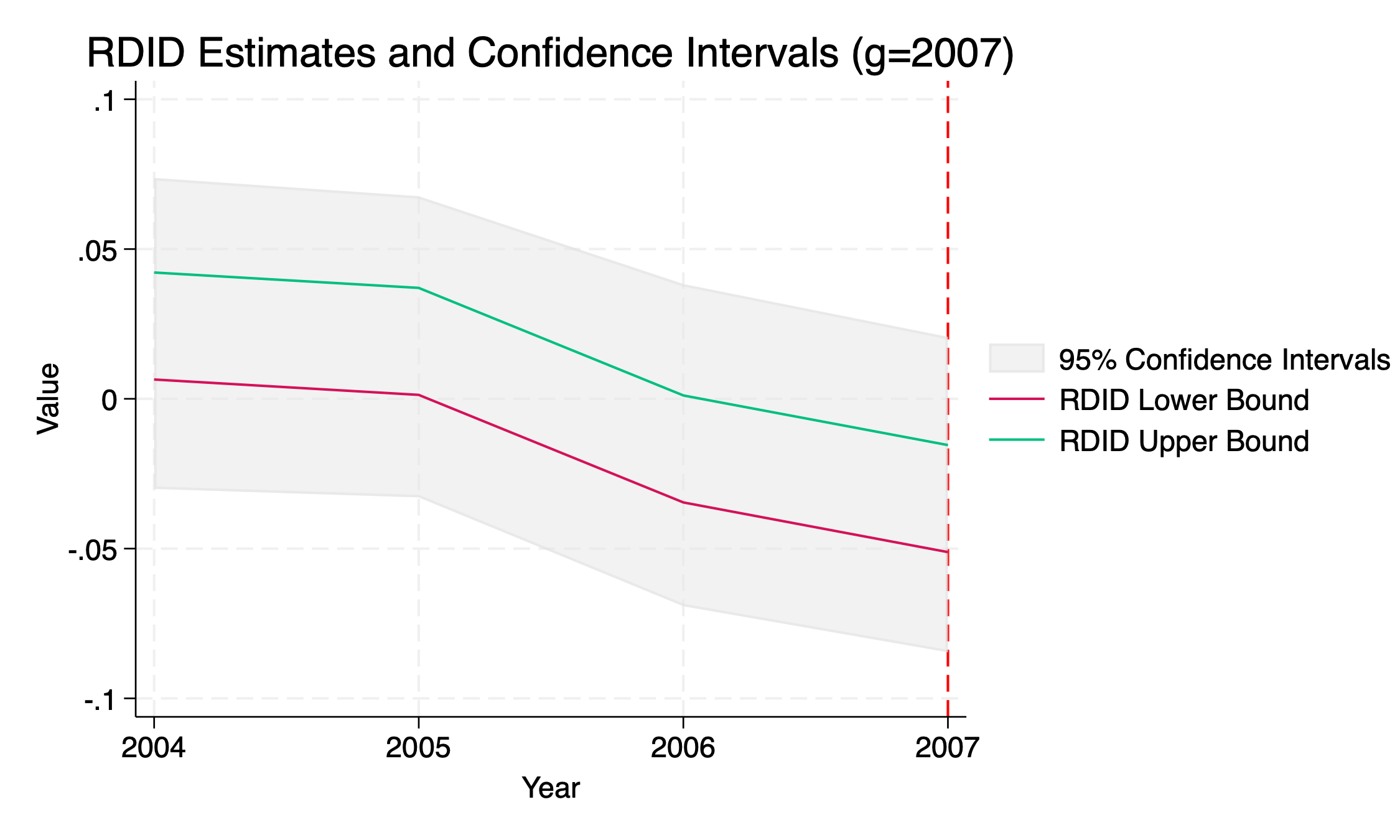
7 Monte-Carlo Simulations
7.1 Modified Example 2: Ashenfelter’s (1978) dip
Consider
for where .
In this model, where and . We have and . So, the standard parallel trends assumption does not hold. However, the selection bias in period 1 belongs to the convex hull of all selection biases in period 0, i.e., . Hence, our identifying assumption holds.
We have , and . The true , and the DID estimand is . Thus, the DID estimand is upward biased and the bias is equal to . The bounds are generally informative about the magnitude of the average treatment effect on the treated (ATT) and can identify the sign of the ATT in some circumstances. For example, when the true ATT is equal to or , our bounds as well as the standard DID estimand identify the correct sign. On the other hand, when the true ATT is equal to , our bounds do not identify any sign, as they contain zero. But, the standard DID estimand identifies a wrong sign, it shows that the ATT is positive while it is actually negative.
The following table shows a series of Monte-Carlo simulations for this DGP for three different confidence intervals (CIs): (1) Ye et al.’s (2023) bootstrap CI for , (2) Ye et al.’s (2023) bootstrap CI for ATT, (3) union bounds for .. The number of bootstrap replicates is 300, and the number of simulations is 1,000 for each case of .
| (1) Ye et al. for bounds | (2) Ye et al. for ATT | (3) Union bounds | ||||
|---|---|---|---|---|---|---|
| Avg. Length | Avg. Length | Avg. Length | ||||
| 0.9300 | 20.7121 | 0.9430 | 20.3115 | 0.9610 | 21.1112 | |
| 0.9540 | 17.1497 | 0.9560 | 16.8730 | 0.9620 | 17.2212 | |
| 0.9490 | 15.1823 | 0.9490 | 14.9536 | 0.9510 | 15.1933 | |
| 0.9510 | 12.8223 | 0.9470 | 12.6881 | 0.9510 | 12.8223 | |
| 0.9680 | 12.2608 | 0.9610 | 12.1640 | 0.9680 | 12.2608 | |
| 0.9640 | 11.4876 | 0.9550 | 11.4448 | 0.9640 | 11.4876 | |
7.2 Example 1 from the article: with a covariate
Consider
where and .
We have , and where and . We have and . So, the standard parallel trends assumption does not hold as . However, the selection bias in period 1 belongs to the convex hull of all selection biases in period 0, i.e., . Hence, our identifying assumption holds. We have , and our new bounds are obtained as . The actual conditional ATT function is , but the standard conditional DID estimand is .
Moreover, using the distribution of , we have an identified set for ATT
where . The simulation is implemented using , and the results are presented in the following table.
| (1) Ye et al. for bounds | (2) Ye et al. for ATT | (3) Union bounds | ||||
|---|---|---|---|---|---|---|
| Avg. Length | Avg. Length | Avg. Length | ||||
| 0.9340 | 5.4190 | 0.9620 | 5.3556 | 0.9340 | 5.4190 | |
| 0.9550 | 4.0948 | 0.9710 | 4.0366 | 0.9550 | 4.0948 | |
| 0.9480 | 3.4183 | 0.9620 | 3.3703 | 0.9480 | 3.4183 | |
| 0.9500 | 2.5282 | 0.9560 | 2.4942 | 0.9500 | 2.5282 | |
| 0.9520 | 2.3183 | 0.9600 | 2.2887 | 0.9520 | 2.3183 | |
| 0.9610 | 2.0405 | 0.9530 | 2.0237 | 0.9610 | 2.0405 | |
7.3 The modified staggered adoption design
Consider
where , , , , , and .
Note that the PT is violated as
for when , especially with for the never-treated cohorts being the control units.
However, note that
and
for all .
In the case of , we have
and
Hence, we have
where .
Under this setup, we implemented a series of Monte-Carlo simulations with various values, and the following tables summarize the coverage probability () and the average length of the 95% confidence interval for each case.
| (1) | (2) | (3) | (4) | |||||
|---|---|---|---|---|---|---|---|---|
| Avg. Len. | Avg. Len. | Avg. Len. | Avg. Len. | |||||
| 0.9670 | 24.9483 | 0.9690 | 25.2785 | 0.9770 | 25.8242 | 0.9770 | 26.7418 | |
| 0.9660 | 23.3114 | 0.9770 | 23.4608 | 0.9810 | 23.6989 | 0.9810 | 24.0988 | |
| 0.9630 | 22.9296 | 0.9710 | 23.0335 | 0.9840 | 23.2027 | 0.9810 | 23.4838 | |
| 0.9720 | 22.4170 | 0.9810 | 22.4637 | 0.9840 | 22.5398 | 0.9880 | 22.6645 | |
| 0.9680 | 22.2932 | 0.9710 | 22.3263 | 0.9820 | 22.3799 | 0.9860 | 22.4681 | |
| (1) | (2) | (3) | (4) | |||||
|---|---|---|---|---|---|---|---|---|
| Avg. Len. | Avg. Len. | Avg. Len. | Avg. Len. | |||||
| 0.9560 | 20.7114 | 0.9660 | 21.0820 | 0.9700 | 21.6513 | 0.9700 | 22.5811 | |
| 0.9580 | 19.1992 | 0.9720 | 19.3615 | 0.9710 | 19.6176 | 0.9740 | 20.0279 | |
| 0.9620 | 18.8385 | 0.9700 | 18.9532 | 0.9690 | 19.1349 | 0.9850 | 19.4250 | |
| 0.9610 | 18.3819 | 0.9750 | 18.4335 | 0.9830 | 18.5146 | 0.9800 | 18.6438 | |
| 0.9700 | 18.2707 | 0.9720 | 18.3071 | 0.9880 | 18.3645 | 0.9830 | 18.4559 | |
| (1) | (2) | (3) | (4) | |||||
|---|---|---|---|---|---|---|---|---|
| Avg. Len. | Avg. Len. | Avg. Len. | Avg. Len. | |||||
| 0.9670 | 16.6965 | 0.9760 | 16.8386 | 0.9680 | 17.4816 | 0.9860 | 18.4511 | |
| 0.9620 | 15.2021 | 0.9780 | 15.2637 | 0.9800 | 15.5432 | 0.9800 | 15.9710 | |
| 0.9580 | 14.8394 | 0.9740 | 14.8832 | 0.9880 | 15.0802 | 0.9830 | 15.3824 | |
| 0.9630 | 14.3781 | 0.9760 | 14.3974 | 0.9790 | 14.4852 | 0.9800 | 14.6201 | |
| 0.9680 | 14.2669 | 0.9730 | 14.2806 | 0.9760 | 14.3425 | 0.9770 | 14.4382 | |
| (1) | (2) | (3) | (4) | |||||
|---|---|---|---|---|---|---|---|---|
| Avg. Len. | Avg. Len. | Avg. Len. | Avg. Len. | |||||
| 0.9690 | 12.7222 | 0.9820 | 12.8685 | 0.9820 | 13.3045 | 0.9830 | 14.3359 | |
| 0.9590 | 11.2131 | 0.9740 | 11.2757 | 0.9820 | 11.4668 | 0.9800 | 11.9167 | |
| 0.9650 | 10.8464 | 0.9710 | 10.8904 | 0.9790 | 11.0256 | 0.9780 | 11.3440 | |
| 0.9620 | 10.3813 | 0.9740 | 10.4005 | 0.9780 | 10.4611 | 0.9760 | 10.6031 | |
| 0.9640 | 10.2689 | 0.9660 | 10.2825 | 0.9800 | 10.3252 | 0.9770 | 10.4256 | |
8 Conclusion
In this article, we introduce the rdid, rdid_dy, and rdidstag commands to implement the RDID framework by Ban and Kédagni (2023) for both the canonical DID settings and staggered adoption designs. By allowing users to specify their information set as pre-treatment periods, the commands enhance robustness to potential violations of the parallel trends assumption in both settings. We anticipate that continued enhancements and community feedback will further increase its effectiveness and adoption in empirical research.
9 Programs and supplemental material
To obtain the latest stable versions of rdid, rdid_dy, and rdidstag from our website, refer to the installation instructions at https://github.com/KyunghoonBan/rdid.
References
- Ashenfelter (1978) Ashenfelter, O. 1978. Estimating the Effect of Training Programs on Earnings. The Review of Economics and Statistics 60(1): 47–57.
- Ban and Kédagni (2023) Ban, K., and D. Kédagni. 2023. Robust Difference-in-differences Models. URL https://arxiv.org/abs/2211.06710.
- Bravo et al. (2022) Bravo, M. C., J. Roth, and A. Rambachan. 2022. Honestdid: Stata module implementing the honestdid r package .
- Cai (2016) Cai, J. 2016. The Impact of Insurance Provision on Household Production and Financial Decisions. American Economic Journal: Economic Policy 8(2): 44–88.
- Callaway and Sant’Anna (2021) Callaway, B., and P. H. Sant’Anna. 2021. Difference-in-Differences with multiple time periods. Journal of Econometrics 225(2): 200–230.
- de Chaisemartin et al. (2019) de Chaisemartin, C., X. D’haultfœuille, and Y. Guyonvarch. 2019. Fuzzy differences-in-differences with stata. The Stata Journal 19(2): 435–458.
- Dube et al. (2016) Dube, A., T. W. Lester, and M. Reich. 2016. Minimum Wage Shocks, Employment Flows, and Labor Market Frictions. Journal of Labor Economics 34(3): 663–704.
- Han (2021) Han, S. 2021. Identification in nonparametric models for dynamic treatment effects. Journal of Econometrics 225: 132–147.
- Houngbedji (2016) Houngbedji, K. 2016. Abadie’s semiparametric difference-in-differences estimator. The Stata Journal 16(2): 482–490.
- Mora and Reggio (2015) Mora, R., and I. Reggio. 2015. didq: A command for treatment-effect estimation under alternative assumptions. The Stata Journal 15(3): 796–808.
- Rios-Avila et al. (2023) Rios-Avila, F., P. Sant’Anna, and B. Callaway. 2023. CSDID: Stata module for the estimation of Difference-in-Difference models with multiple time periods .
- Rios-Avila et al. (2022) Rios-Avila, F., P. Sant’Anna, and A. Naqvi. 2022. DRDID: Stata module for the estimation of doubly robust difference-in-difference models .
- Robins (1986) Robins, J. M. 1986. A new approach to causal inference in mortality studies with a sustained exposure period–application to control of the healthy worker survivor effect. Math. Modelling 7: 1393–1512.
- Robins (1987) . 1987. Addendum to “A new approach to causal inference in mortality studies with a sustained exposure period — application to control of the healthy worker survivor effect”. Comput. Math. Appl. 14(9–12): 923–945.
- Villa (2016) Villa, J. M. 2016. diff: Simplifying the estimation of difference-in-differences treatment effects. The Stata Journal 16(1): 52–71.
- Ye et al. (2023) Ye, T., L. Keele, R. Hasegawa, and D. S. Small. 2023. A Negative Correlation Strategy for Bracketing in Difference-in-Differences. Journal of the American Statistical Association ahead-of-print(ahead-of-print): 1–13.