Re-weighting Tokens: A Simple and Effective Active Learning Strategy for Named Entity Recognition
Abstract
Active learning, a widely adopted technique for enhancing machine learning models in text and image classification tasks with limited annotation resources, has received relatively little attention in the domain of Named Entity Recognition (NER). The challenge of data imbalance in NER has hindered the effectiveness of active learning, as sequence labellers lack sufficient learning signals. To address these challenges, this paper presents a novel reweighting-based active learning strategy that assigns dynamic smoothed weights to individual tokens. This adaptable strategy is compatible with various token-level acquisition functions and contributes to the development of robust active learners. Experimental results on multiple corpora demonstrate the substantial performance improvement achieved by incorporating our re-weighting strategy into existing acquisition functions, validating its practical efficacy.
1 Introduction
The effectiveness of deep neural networks has been well-established on diverse sequence tagging tasks, including named entity recognition (NER) (Lample et al., 2016). However, the evolving complexity of these models demands substantial labeled data, making annotation a resource-intensive endeavor. Active learning (AL) addresses this by astutely focusing on information-rich sequences, substantially reducing data that needs expert annotation. Such a strategy proves invaluable in NER, as it brings down costs and accelerates learning by honing in on complex or dynamic entities. AL’s iterative process smartly picks subsets from an unlabeled pool, leveraging expert-annotated data to refine the model. Modern AL approaches primarily pivot on model uncertainty (Houlsby et al., 2011; Gal et al., 2017; Shen et al., 2017; Kirsch et al., 2019; Zhao et al., 2021) or data diversity (Sener and Savarese, 2017; Shen et al., 2017; Tan et al., 2021; Hacohen et al., 2022).
The primary challenge in applying active learning to sequence tagging lies in addressing data imbalance at the entity level. Traditional methods of active sequence tagging, such as those referenced by (Shen et al., 2017; Zhang et al., 2020; Shelmanov et al., 2021) , typically generate scores for sentences by summing or averaging the tokens within them, thereby treating each token equally. Radmard et al. (2021) attempted to address this by segmenting sentences for token-level selections, However this led to loss of context and semantic meaning, impairing human understanding. To effectively tackle this data imbalance issue, it is imperative to focus on the token level within the sentences. By implementing a strategy that redistributes sentence selection through assigning weights to the tags of the tokens, a more balanced and efficient handling of the data can be achieved.
In supervised learning (SL) and semi-supervised learning (SSL), re-weighting is a widely researched method to tackle data imbalance. However, they have limitations to be directly applied to active learning. For example, Wei et al. (2021); Cao et al. (2019) assume the labeled data and the unlabeled data have the same label distribution, while we usually have no prior information about the unlabeled data in active learning; Kim et al. (2020) use the confusion matrix on the labeled data to approximate the label distribution of the unlabeled data. In active learning, the labeled data pool can be quite small, so the approximation can cause strong biases; Li et al. (2018) suggest a gradient-based method to compute weights, while computing gradients significantly increases the computational cost for active learning.
In this paper, we focus on the feasibility of adapting reweighting-based methods from SL, SSL to active sequence tagging, which has not been developed in existing works. Our contributions can be summarized as follows:
-
•
We propose a flexible reweighting-based method for active sequence tagging to tackle the data imbalance issue. It is easy to implement, and generic to any token-level acquisition function.
-
•
We conduct extensive experiments to show our method can improve the performance for each baseline, across a large range of datasets and query sizes. We also show that it can indeed mitigate the class imbalance issue, which explains its success.
2 Related works
Active learning for NER. Active learning for NER has seen a variety of methodologies being developed to address its unique challenges (Settles and Craven, 2008; Marcheggiani and Artieres, 2014; Shelmanov et al., 2021). The overarching goal is to reduce the budget for labeling sequence data by selectively querying informative samples. The information content of a sample is typically measured using an acquisition function, which quantifies the potential usefulness of unlabeled data.
Uncertainty-based acquisition functions have gained popularity due to their successful application and their compatibility with neural networks, which can generate a probability distribution using the softmax function over the model’s output. Various acquisition functions have been proposed to represent uncertainty. Least Confidence (LC) (Li and Sethi, 2006), for example, selects the sentence with the lowest model prediction confidence, while Sequence Entropy (SE) (Settles and Craven, 2008) employs the entropy of the output instead of the probability. Alternatively, Margin (Scheffer et al., 2001) defines uncertainty as the difference between the highest and the second-highest probability.
These traditional approaches, however, have their limitations. Shen et al. (2017) pointed out that summing over all tokens, as done in previous methods, can introduce bias towards longer sentences. To overcome this, they proposed Maximum Normalized Log-Probability (MNLP), a normalized version that mitigates this issue. In a more recent development, Lowest Token Probability (LTP) (Liu et al., 2022) selects the sentence containing the token with the lowest probability. Additionally, Bayesian Active Learning by Disagreement (BALD) (Gal et al., 2017) uses Monte-Carlo Dropout to approximate the Bayesian posterior, which makes it feasible to approximate the mutual information (Houlsby et al., 2011) between outputs and model parameters.
It is worth noting that we exclude subsequence-based active learning methods (Wanvarie et al., 2011; Radmard et al., 2021; Liu et al., 2023) from our comparison. In their setting, the query is a subsequence instead of the whole sentence. As they admitted, it may be not practical in the real world because subsequences can be meaningless. Human experts usually need the context to label tokens.
Re-weighting methods for supervised learning and semi-supervised learning. Many real-world datasets exhibit a "long-tailed" label distribution (Van Horn et al., 2018; Liu et al., 2020; Chu et al., 2020). Imbalanced supervised learning has been widely researched. Re-weighting the loss (Khan et al., 2017; Aurelio et al., 2019; Tan et al., 2020) is one of the popular methods on this topic. In recent semi-supervised learning methods, re-weighting is gradually gaining attention. Wei et al. (2021) utilize the unlabeled data with pseudo labels according to an estimated class distribution, Kim et al. (2020) develop a framework to refine class distribution, Lai et al. (2022) use the effective number defined by Cui et al. (2019) to produce adaptive weights.
3 Methodology
3.1 Preliminaries
Consider a multi-class token classification problem with classes. An input is a sequence of tokens, denoted by , and its corresponding label is denoted by . The labeled data contains samples, denoted by , and the unlabeled data contains samples, denoted by , with .
In each active learning iteration, we select data points to form a query , according to some acquisition function :
3.2 Re-weighting Active learning for named entity recognition
Inspired by reweighting-based methods for supervised learning and semi-supervised learning, we propose a new re-weighting strategy for active sequence tagging, which assigns a smoothed weight for each class, which is inversely proportional to the class frequency in the labeled data pool:
where is a hyperparameter controlling the degree of smoothing, is the sample size of class in the labeled data pool, represents the size of the entire labeled data pool. When , weights are strictly the inverse of the class frequencies; when , weights follow a uniform distribution, i.e. no re-weighting is activated. A reasonable value for plays a significant role to combat sampling bias at the early stage of active learning.
Based on this re-weighting function, we generate a sentence-level acquisition score by computing the weighted sum over all tokens. The algorithm is shown in Algorithm 1. It should be noticed that we do not have true labels of unlabeled data in active learning, therefore we use the pseudo label instead. This pseudo label trick is widely used and has been verified as effective in many active learning works (Shen et al., 2017; Ash et al., 2019; Wang et al., 2022; Mohamadi et al., 2022).
Our method has the following advantages: Independent on the label distribution of the unlabeled data. Estimating the label distribution of the unlabeled data can be tricky, especially at the early stage of active learning or the unlabeled data does not have the same distribution as the labeled data. Compared to reweighting-based methods for SSL (Wei et al., 2021; Lai et al., 2022), we do not need to make assumptions on the unlabeled data. Computationally lightweight. The time complexity of computing weights is . Note that in active learning, so it is more efficient compared to the effective number-based reweighting-based method with time complexity (Lai et al., 2022). Generic to any base acquisition function. Since our method is essentially a weighted sum strategy, it can be combined with any base acquisition function for active learning mentioned in section 4.
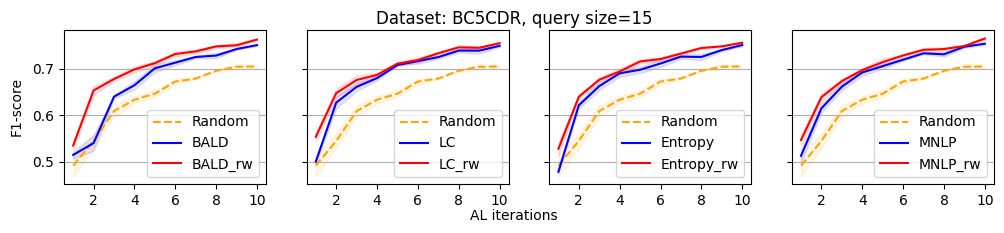
4 Experimental Setups
Datasets: In this section, we evaluate the efficacy of re-weighted active learning on three widely used NER datasets, which are listed as follows, the statistical data of each dataset is provided in the Appendix B.
-
•
Conll2003 (Sang and De Meulder, 2003) is a corpus for NER tasks, with four entity types in BIO format (LOC, MISC, PER, ORG), resulting classes.
-
•
WikiAnn (English) (Pan et al., 2017) is a corpus extracted from Wikipedia data, with three entity types in BIO format (LOC, PER, ORG), resulting classes.
-
•
BC5CDR (Wei et al., 2016) is a biomedical dataset, with two entity types in BIO format (Disease, Chemical), resulting classes.
NER model: We finetuned BERT-base-cased model (Devlin et al., 2018) with an initialized linear classification layer to perform sequence tagging. All experiments share the same settings: we used Adam (Kingma and Ba, 2014) with the constant learning rate at and the weight decay at as the optimizer; the number of training iterations is . All experiments were done with an Nvidia A40 GPU.
Active learning settings: The initial size of the labeled data pool is , the number of active learning iterations is , the query size varies from . In each active learning iteration, we selected a batch of unlabeled data, queried their labels, added them to the labeled data pool, and then re-trained the model. We evaluated the performance of algorithms by their mean F1-scores with confidence interval for five trials on the test dataset.
Baselines: We considered five baselines: (1) randomly querying, (2) Least Confidence (LC) (Li and Sethi, 2006), (3) Maximum Normalized Log-Probability (MNLP) (Shen et al., 2017), (4) Sequence Entropy (SE) (Settles and Craven, 2008), (5) Bayesian Active Learning by Disagreement (BALD) (Gal et al., 2017). The details of the baselines are mentioned in the Appendix A.
Hyperparameter setting: As our reweighting-based methods have a hyperparameter to be tuned, we first conduct a grid search over in the re-weighting LC case on each dataset, and fix the optimal value for all experiments. Please see Appendix C for the performances of all hyperparameters.
5 Experimental Results & Discussions
5.1 Main results
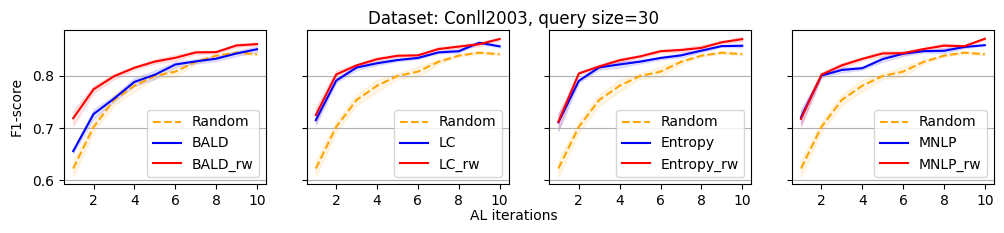
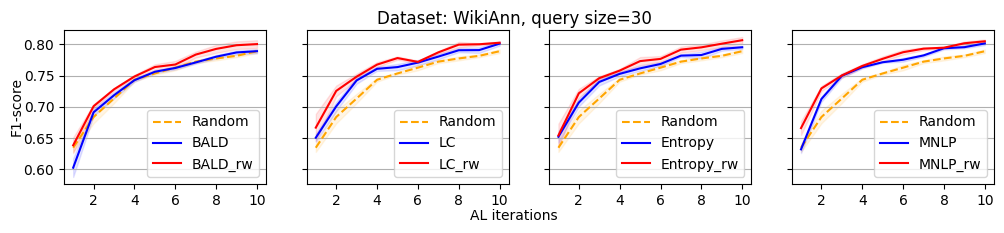
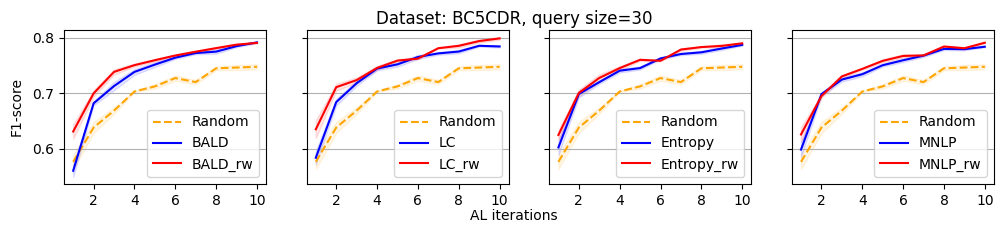
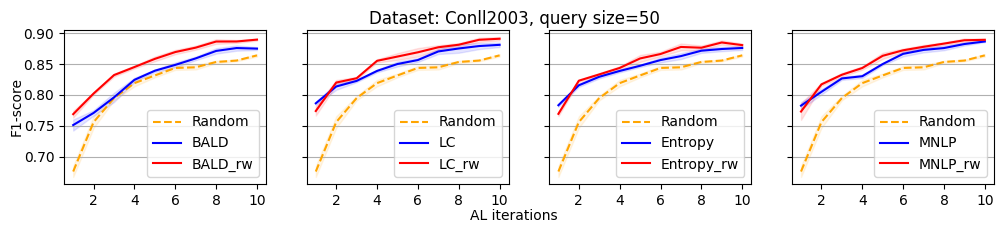
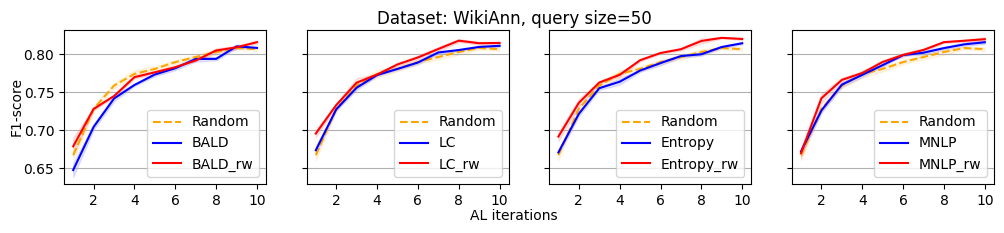
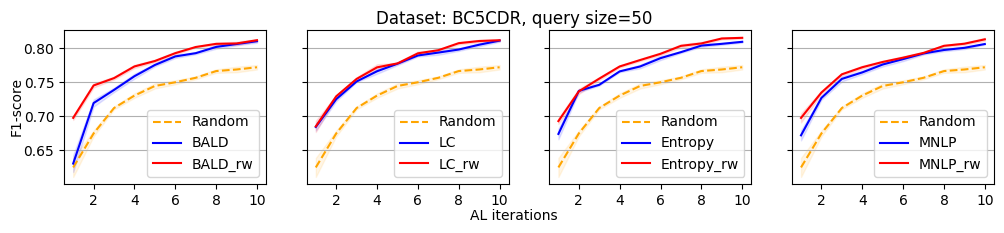
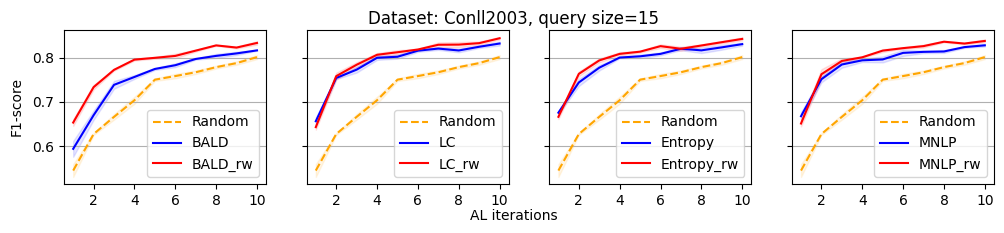
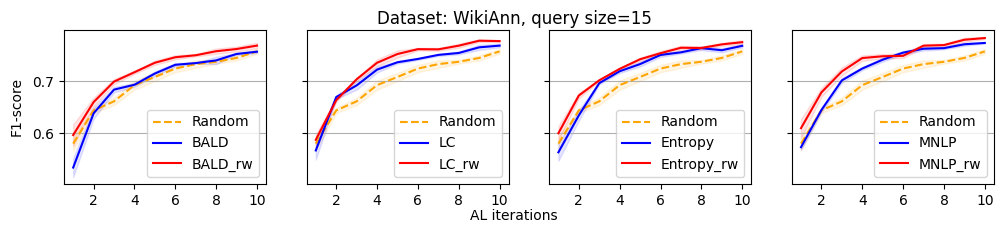
We evaluate the efficacy of our reweighting-based method by comparing the performance of active sequence tagging with and without re-weighting. Figure 1 shows the main results on three datasets with query size 15. We delay the results of other query sizes to Appendix C. It is clear that each re-weighting method consistently outperforms the original method across different datasets and query sizes.
5.2 Analysis of the performance gain
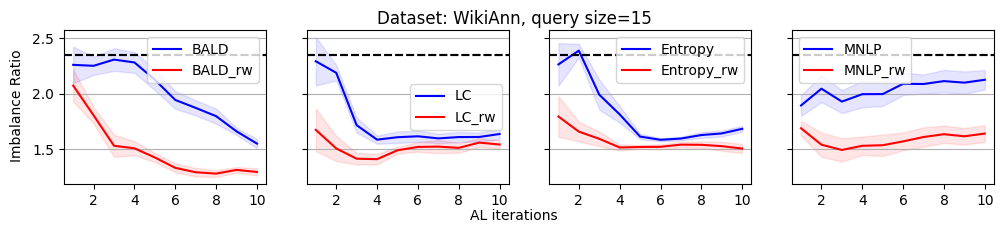
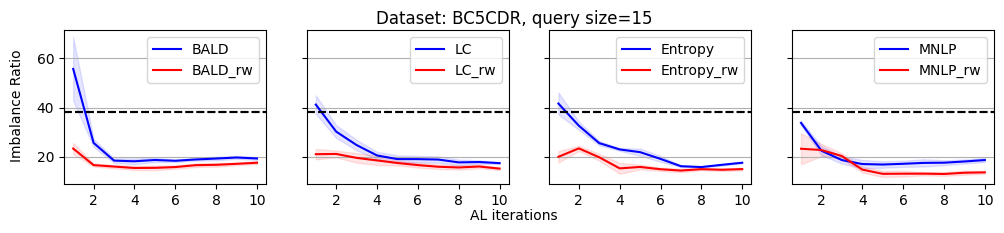
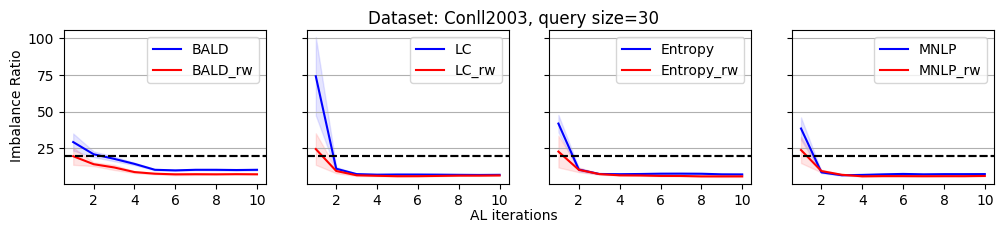
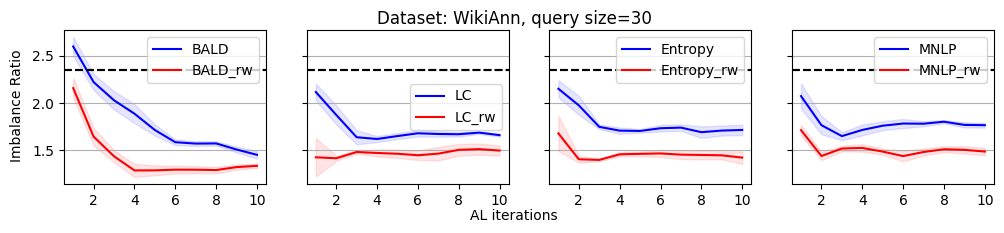
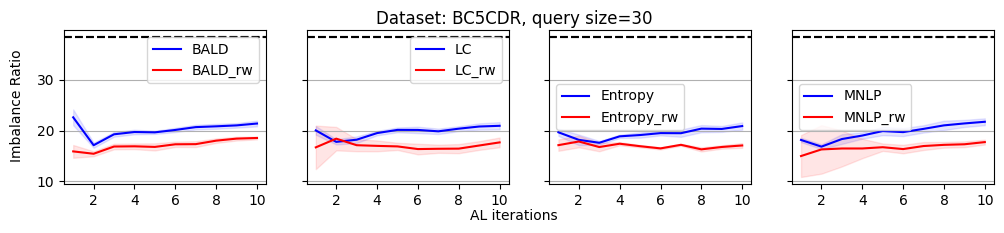
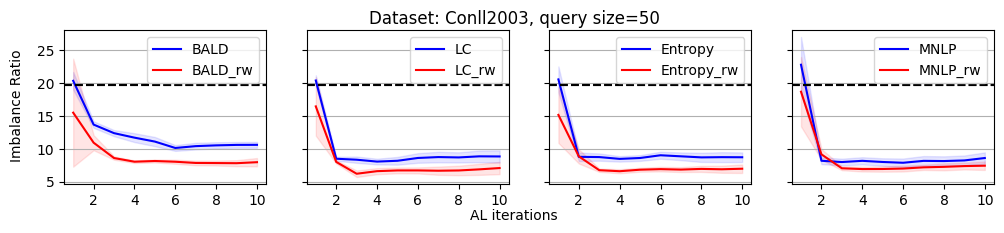
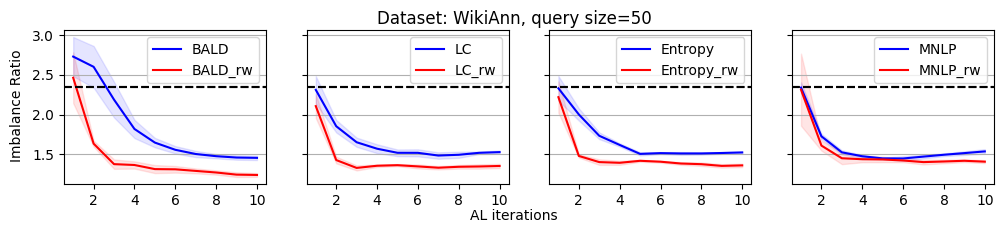
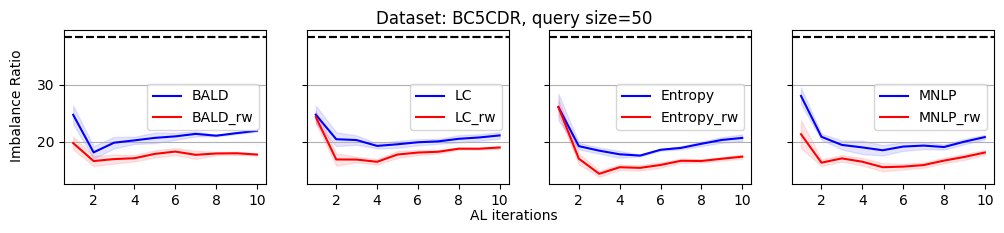
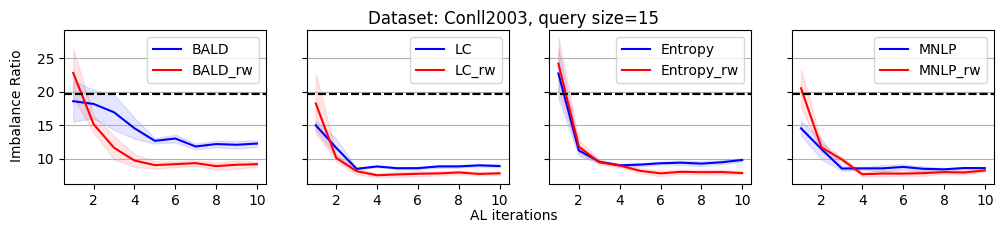
As we discussed, the label imbalance issue occurs commonly in NER datasets, and it potentially damages the performance. We argue that the performance gain of the reweighting-based method is because it can effectively decrease the imbalance ratio. To evaluate this, we define an imbalance ratio as
where is the sample size of class and is the sample size of the class with the minimum number of samples in the labeled dataset. For a balanced label distribution, the imbalance ratio is close to . A larger imbalance ratio indicates a higher class imbalance.
As shown in Figure 2, we plot the variation of the imbalance ratio on Conll2003 during the active learning process. Results on other datasets are put in Appendix C due to space limitations. In general, models have a lower confidence on samples from minority classes. As a result, uncertainty-based acquisition functions bias towards selecting samples from minority classes implicitly. This explains why they can achieve better performance than randomly querying. In contrast, reweighting-based methods further bias towards minority classes explicitly. It leads to more balanced querying, which can cause better performance.
5.3 Ablation study
Effect of smoothing. The first term in the denominator of our re-weighting function , which controls the degree of smoothing, plays a significant role at the early stage of active learning. Not using the smoothed version may encounter sampling bias issues. To verify these views, we report f1-scores of the smoothed version and the non-smoothed version in the first three AL iterations in table 1, across five independent runs. For each experiment, we set LC as the base acquisition function. It can be observed that non-smoothed version has lower performance and higher variance at first. This is what we expect to see in our motivation.
| Iteration# | 1 | 2 | 3 |
|---|---|---|---|
| Smoothed () | 61.20.2 | 76.50.9 | 81.00.3 |
| Non-smoothed | 60.31.0 | 68.91.8 | 78.21.3 |
6 Conclusion
In this work, we pioneered the use of re-weighting in active learning for NER to tackle the label imbalance issue. Our method uses the class sizes in the labeled data pool to generate a weight for each token. We empirically demonstrate that our reweighting-based method can consistently improve performance for each baseline, across a large range of NER datasets and query sizes.
7 Limitations
We acknowledge that the static nature of the hyperparameter is a limitation of our work, particularly when applying the algorithm to new or diverse datasets. Dynamically updating in line with Active Learning iterations can be a promising avenue for future research.
References
- Ash et al. (2019) Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. 2019. Deep batch active learning by diverse, uncertain gradient lower bounds. arXiv preprint arXiv:1906.03671.
- Aurelio et al. (2019) Yuri Sousa Aurelio, Gustavo Matheus De Almeida, Cristiano Leite de Castro, and Antonio Padua Braga. 2019. Learning from imbalanced data sets with weighted cross-entropy function. Neural processing letters, 50:1937–1949.
- Cao et al. (2019) Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. 2019. Learning imbalanced datasets with label-distribution-aware margin loss. Advances in neural information processing systems, 32.
- Chu et al. (2020) Peng Chu, Xiao Bian, Shaopeng Liu, and Haibin Ling. 2020. Feature space augmentation for long-tailed data. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIX 16, pages 694–710. Springer.
- Cui et al. (2019) Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. 2019. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9268–9277.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Gal et al. (2017) Yarin Gal, Riashat Islam, and Zoubin Ghahramani. 2017. Deep bayesian active learning with image data. In International conference on machine learning, pages 1183–1192. PMLR.
- Hacohen et al. (2022) Guy Hacohen, Avihu Dekel, and Daphna Weinshall. 2022. Active learning on a budget: Opposite strategies suit high and low budgets. arXiv preprint arXiv:2202.02794.
- Houlsby et al. (2011) Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. 2011. Bayesian active learning for classification and preference learning. arXiv preprint arXiv:1112.5745.
- Khan et al. (2017) Salman H Khan, Munawar Hayat, Mohammed Bennamoun, Ferdous A Sohel, and Roberto Togneri. 2017. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE transactions on neural networks and learning systems, 29(8):3573–3587.
- Kim et al. (2020) Jaehyung Kim, Youngbum Hur, Sejun Park, Eunho Yang, Sung Ju Hwang, and Jinwoo Shin. 2020. Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning. Advances in neural information processing systems, 33:14567–14579.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kirsch et al. (2019) Andreas Kirsch, Joost Van Amersfoort, and Yarin Gal. 2019. Batchbald: Efficient and diverse batch acquisition for deep bayesian active learning. Advances in neural information processing systems, 32.
- Lai et al. (2022) Zhengfeng Lai, Chao Wang, Henrry Gunawan, Sen-Ching S Cheung, and Chen-Nee Chuah. 2022. Smoothed adaptive weighting for imbalanced semi-supervised learning: Improve reliability against unknown distribution data. In International Conference on Machine Learning, pages 11828–11843. PMLR.
- Lample et al. (2016) Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360.
- Li et al. (2018) Buyu Li, Yu Liu, and Xiaogang Wang. 2018. Gradient harmonized single-stage detector.
- Li and Sethi (2006) Mingkun Li and Ishwar K Sethi. 2006. Confidence-based active learning. IEEE transactions on pattern analysis and machine intelligence, 28(8):1251–1261.
- Liu et al. (2020) Jialun Liu, Yifan Sun, Chuchu Han, Zhaopeng Dou, and Wenhui Li. 2020. Deep representation learning on long-tailed data: A learnable embedding augmentation perspective. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2970–2979.
- Liu et al. (2022) Mingyi Liu, Zhiying Tu, Tong Zhang, Tonghua Su, Xiaofei Xu, and Zhongjie Wang. 2022. Ltp: a new active learning strategy for crf-based named entity recognition. Neural Processing Letters, 54(3):2433–2454.
- Liu et al. (2023) Yang Liu, Jinpeng Hu, Zhihong Chen, Xiang Wan, and Tsung-Hui Chang. 2023. Easal: entity-aware subsequence-based active learning for named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 8897–8905.
- Marcheggiani and Artieres (2014) Diego Marcheggiani and Thierry Artieres. 2014. An experimental comparison of active learning strategies for partially labeled sequences. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 898–906.
- Mohamadi et al. (2022) Mohamad Amin Mohamadi, Wonho Bae, and Danica J Sutherland. 2022. Making look-ahead active learning strategies feasible with neural tangent kernels. arXiv preprint arXiv:2206.12569.
- Pan et al. (2017) Xiaoman Pan, Boliang Zhang, Jonathan May, Joel Nothman, Kevin Knight, and Heng Ji. 2017. Cross-lingual name tagging and linking for 282 languages. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1946–1958.
- Radmard et al. (2021) Puria Radmard, Yassir Fathullah, and Aldo Lipani. 2021. Subsequence based deep active learning for named entity recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4310–4321.
- Sang and De Meulder (2003) Erik F Sang and Fien De Meulder. 2003. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050.
- Scheffer et al. (2001) Tobias Scheffer, Christian Decomain, and Stefan Wrobel. 2001. Active hidden markov models for information extraction. In Advances in Intelligent Data Analysis: 4th International Conference, IDA 2001 Cascais, Portugal, September 13–15, 2001 Proceedings 4, pages 309–318. Springer.
- Sener and Savarese (2017) Ozan Sener and Silvio Savarese. 2017. Active learning for convolutional neural networks: A core-set approach. arXiv preprint arXiv:1708.00489.
- Settles and Craven (2008) Burr Settles and Mark Craven. 2008. An analysis of active learning strategies for sequence labeling tasks. In proceedings of the 2008 conference on empirical methods in natural language processing, pages 1070–1079.
- Shelmanov et al. (2021) Artem Shelmanov, Dmitri Puzyrev, Lyubov Kupriyanova, Denis Belyakov, Daniil Larionov, Nikita Khromov, Olga Kozlova, Ekaterina Artemova, Dmitry V Dylov, and Alexander Panchenko. 2021. Active learning for sequence tagging with deep pre-trained models and bayesian uncertainty estimates. arXiv preprint arXiv:2101.08133.
- Shen et al. (2017) Yanyao Shen, Hyokun Yun, Zachary C Lipton, Yakov Kronrod, and Animashree Anandkumar. 2017. Deep active learning for named entity recognition. arXiv preprint arXiv:1707.05928.
- Tan et al. (2020) Jingru Tan, Changbao Wang, Buyu Li, Quanquan Li, Wanli Ouyang, Changqing Yin, and Junjie Yan. 2020. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11662–11671.
- Tan et al. (2021) Wei Tan, Lan Du, and Wray Buntine. 2021. Diversity enhanced active learning with strictly proper scoring rules. Advances in Neural Information Processing Systems, 34:10906–10918.
- Van Horn et al. (2018) Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. 2018. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8769–8778.
- Wang et al. (2022) Haonan Wang, Wei Huang, Ziwei Wu, Hanghang Tong, Andrew J Margenot, and Jingrui He. 2022. Deep active learning by leveraging training dynamics. Advances in Neural Information Processing Systems, 35:25171–25184.
- Wanvarie et al. (2011) Dittaya Wanvarie, Hiroya Takamura, and Manabu Okumura. 2011. Active learning with subsequence sampling strategy for sequence labeling tasks. Information and Media Technologies, 6(3):680–700.
- Wei et al. (2021) Chen Wei, Kihyuk Sohn, Clayton Mellina, Alan Yuille, and Fan Yang. 2021. Crest: A class-rebalancing self-training framework for imbalanced semi-supervised learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10857–10866.
- Wei et al. (2016) Chih-Hsuan Wei, Yifan Peng, Robert Leaman, Allan Peter Davis, Carolyn J Mattingly, Jiao Li, Thomas C Wiegers, and Zhiyong Lu. 2016. Assessing the state of the art in biomedical relation extraction: overview of the biocreative v chemical-disease relation (cdr) task. Database, 2016.
- Zhang et al. (2020) Rongzhi Zhang, Yue Yu, and Chao Zhang. 2020. Seqmix: Augmenting active sequence labeling via sequence mixup. arXiv preprint arXiv:2010.02322.
- Zhao et al. (2021) Guang Zhao, Edward Dougherty, Byung-Jun Yoon, Francis Alexander, and Xiaoning Qian. 2021. Uncertainty-aware active learning for optimal bayesian classifier. In International Conference on Learning Representations (ICLR 2021).
Appendix A Baselines
For completeness, we list several commonly used acquisition functions below.
Least Confidence (LC) (Li and Sethi, 2006) uses the probability of the model’s prediction to measure the uncertainty:
| (1) | ||||
| (2) |
Sequence Entropy (SE) (Settles and Craven, 2008) utilizes the probability distribution instead of the probability to measure the uncertainty:
| (3) | ||||
| (4) |
Bayesian Active Learning by Disagreement (BALD) (Gal et al., 2017) utilizes MC-dropout samples to approximate the mutual information between outputs and model parameters:
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) | ||||
| (9) |
where is the prediction of the model, denotes MC-dropout samples. Different from the acquisition functions mentioned above, which sum over all tokens, Maximum Normalized Log-Probability (MNLP) (Shen et al., 2017) normalized by the length of the sequence:
Appendix B Dataset statistics
See table 3 for the statistical data for each dataset.
| Dataset | Sentences | Tokens | Average length | Class proportion (B/I/O) | Imbalance ratio |
| Conll2003 | 14041 | 203,621 | 14.5 | 11.5%/5.2%/83.3 | 19.7 |
| WikiAnn | 20000 | 160394 | 8.0 | 17.4%/31.9%/50.7% | 2.35 |
| BC5CDR | 5228 | 109322 | 20.6 | 8.6%/2.9%/88.5% | 38.4 |
Appendix C Additional results
In this section, we present all the remaining experimental results that could not be showcased in the main paper due to the space limitation.
| 0.01 | 0.1 | 0.2 | 0.5 | 1 | |
| Conll2003 | 84.28 | 84.54 | 84.45 | 84.33 | 83.37 |
| WikiAnn | 78.18 | 78.53 | 77.32 | 77.60 | 76.15 |
| BC5CDR | 75.50 | 75.98 | 75.90 | 75.63 | 75.51 |