Recovering Latent Signals from a Mixture of Measurements using a Gaussian Process Prior
Abstract
In sensing applications, sensors cannot always measure the latent quantity of interest at the required resolution, sometimes they can only acquire a blurred version of it due the sensor’s transfer function. To recover latent signals when only noisy mixed measurements of the signal are available, we propose the Gaussian process mixture of measurements (GPMM), which models the latent signal as a Gaussian process (GP) and allows us to perform Bayesian inference on such signal conditional to a set of noisy mixture of measurements. We describe how to train GPMM, that is, to find the hyperparameters of the GP and the mixing weights, and how to perform inference on the latent signal under GPMM; additionally, we identify the solution to the underdetermined linear system resulting from a sensing application as a particular case of GPMM. The proposed model is validated in the recovery of three signals: a smooth synthetic signal, a real-world heart-rate time series and a step function, where GPMM outperformed the standard GP in terms of estimation error, uncertainty representation and recovery of the spectral content of the latent signal.
Index Terms:
Gaussian process, convolution process, sensing applications, Bayesian inference.I Introduction
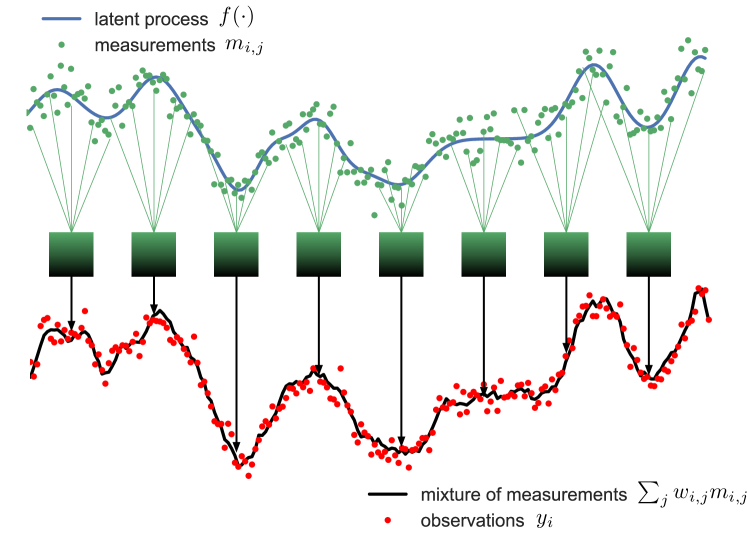
Observations within sensing applications result from the convolution between the latent signal and the sensors’s transfer function, therefore, a desired property of the sensor is to have a transfer function that is close to a Dirac delta function so that the latent signal can be recovered from the observations. We will model this convolution in a discrete manner to give rise to the representation of a sensing application described in fig. 1, where we model the observations as a (noisy) mixture of (again noisy) measurements and aim to recover the latent signal from the observations. Mixing of the latent signal’s values stems from the inability of the sensor to measure the latent signal at the required resolution, this is due to low quality of the sensors that colour the observations which have to then be whiten in order to recover the latent process. Observations composed by mixtures of measurements are commonplace in sensing applications in different areas: in robot localization using radars or sonars [1, 2], in astronomical applications [3], and in super-resolution image recovery [4], to name but a few.
A workaround to the problem of recovering a latent process from observations composed by mixtures of measurements is to define a set of sensing locations (i.e., a grid) and model the observations as a system of linear equations—recall that the measurements are combined in a linear fashion.However, this approach is rather restrictive since it constrains the measurements to be collected at fixed locations, which is rarely the case in real-world applications, and it leads to heavily underdetermined linear systems. In our view, the key to this problem is to assume spatial correlations in the latent signals so that observations of overlapping regions reveal structure in the signal; we do so in a probabilistic manner by placing a Gaussian process (GP) prior [5] on the signal, which is then updated into the posterior density of the latent signal conditional to such observations. However, GPs in their standard form are not suited to deal with observations comprising a mixture of measurements.
In this letter we propose a GP-based mixture-of-measurements model, illustrate how to train it and perform Bayesian inference on the latent signal, establish a connection between the proposed model and the linear system approach to sensing applications, and validate our model on real-world and synthetic data
I-A Background: Gaussian processes and related work
Gaussian processes (GPs) [5] are a nonparametric prior distribution on functions , for any set where a covariance function can be defined (e.g., a metric space), such that for any finite collection of inputs , the corresponding outputs are jointly Gaussian, that is,
| (1) |
where the mean and covariance functions, and respectively, are parametric forms that determine the spatial properties of samples drawn from the GP prior. Training the GP to observed data involves finding the parameters of the mean and covariance functions, then, the posterior distribution of the entire function conditional to a set of observations is Gaussian.
The GP framework is well suited to the sensing setting in fig. 1, since modelling latent signal as a GP results in the posterior distribution of the latent process (given the mixture of measurements) being Gaussian as well. Previous GP-based models for convolution processes [6, 7, 8, 9] model signals a convolution between a continuous-time filter and a white-noise process, which is unsuitable to represent the latent process in the sensing application where the spatial correlation of the process is fundamental. Conversely, [10] allows GPs as latent functions but to address the multi-output case, where the aim is to perform inference on the outputs rather than the latent processes. Furthermore, these methods consider continuous-time convolution filters, which is computationally demanding and requires, e.g., variational approximations [11, 12]. Consequently, closed-form and computationally-efficient Bayesian reconstruction of the latent process is still an open problem in sensing applications.
II The Gaussian Process Mixture of Measurements (GPMM)
Consider a sensing application where each observation is a noisy mixture of, again noisy and hidden, measurements of a latent process measured at locations , that is,
| (2) | ||||
| (3) |
where for the observation , we use the following notation:
-
•
is the value of the latent process at location ,
-
•
is the measurement of acquired by the sensor,
-
•
is the weight of the measurement ,
-
•
is the number of measurements in the observation ,
-
•
is the measurement Gaussian noise, and
-
•
is the observation Gaussian noise.
We use the terms measurement and observation defined here consistently in the rest of the paper—see fig. 1. Note that in general, different observations, i.e. , correspond to different regions and both the locations and the weights might be different due to the sensing procedure.
For observations, we express eq. (3) as a system of linear equations in block matrix notation:
| (4) |
where , and the matrix is an -diagonal matrix. Column vectors are denoted in bold lowercase font and matrices in bold uppercase font.
II-A Solving the linear system
Our approach will consider the weights to be unknown and learn them from the observations, however, let us assume they are known in this section in order to address the problem as a linear system; for ease of notation, we assume there are no common locations across the measurements (i.e., ). With these assumptions, eq. (4) is an underdetermined linear system: there are unknowns and equations, where , in fact, the general solution to such a system has free parameters or degrees of freedom (neglecting the inconsistent case).
This underdetermined system has infinite solutions, with the minimum-norm solution given by , where is the Moore-Penrose pseudoinverse of [13]. Using this solution to recover the latent signal has a number of drawbacks: (i) it requires the weights to be known, (ii) it only recovers the process at the measured locations without providing any insight about regions not measured, and (iii) it does not provide a measure of uncertainty for the estimates, e.g., in the form of error bars.
II-B A novel generative model for the mixture of measurements
As the system in eq. (4) has infinite solutions, a constraint (or regularisation criterion) has to be imposed to reduce the number of solutions, or critically, to find a single solution. The Moore-Penrose pseudoinverse imposes the minimum-norm criterion, we instead assume a probabilistic condition (a prior) on the spatial structure of the solution. Specifically, we (i) place a GP prior on the latent signal to then (ii) find the posterior distribution of the latent signal conditional to the mixture of measurements, even at locations that were not measured. A key property of this approach is that these two steps are performed analytically, since the latent signal and the mixture of measurements are jointly Gaussian. We next present a formal description of the proposed generative model.
We model the latent process in (2) as a GP over the set of locations given by
| (5) |
where and are the GP mean and covariance functions respectively. As the linear combination of jointly-Gaussian random variables (RVs) is Gaussian, the observations in eq. (3) are Gaussian RVs indexed by with mean and covariance respectively given by
| (6) | ||||
| (7) | ||||
where are the variances of the measurement and observation noises respectively. Additionally, note that if measurements are always taken at different locations (which is the case if the set of locations is continuous) we have and
| (8) | ||||
| (9) |
where is the Gram matrix evaluated on and , and .
The covariance of the observations is a mixture of evaluations of the covariance function of the process at the locations measured. This implies that a single entry in common between measurement locations and is enough for the observations and to be correlated. This mixture-of-kernel structure resembles additive GPs [14] and multikernel learning [15, 16, 17], however, these methods combine different kernels (evaluated on a common input) for expressive kernel design, whereas the proposed model combines evaluations of a single kernel on different locations to find the spatial structure of the latent signal. We refer to the presented model as Gaussian processes mixture of measurements (GPMM) and give a graphical model illustration in fig. 2.

III Inference for GPMM and Relationship to the Moore-Penrose Pseudoinverse
Fitting the model to the observations involves finding appropriate hyperparameters for GPMM, , that is, the hyperparameters of the latent signal in eq. (5) and the weights which are now hyperparameters. This can be achieved by minimising the negative log-likelihood :
where is given in (7), , and the optimisation can be performed by, e.g., gradient descent. Notice that the cost of computing in eq. (9) and inverting it are respectively and , meaning that if is dominated by the cost of training GPMM is as standard GPs. With the optimal hyperparameters, we are now ready to calculate the posterior of .
III-A The posterior of the latent process
The posterior density of given the observations , , is Gaussian and determined by (i) the prior mean—assumed to be zero in this case, (ii) the autocovariance of the mixture-of-measurement process —given in eq. (7), and (iii) the covariance between the latent process and the observation at given by , this covariance is
| (10) | ||||
Denoting , the predictive posterior is:
| (11) | ||||
| (12) |
thus, the reconstruction of the latent process can be computed in closed-form (we used the notation ).
III-B The Moore-Penrose solution is a particular case of GPMM
Without loss of generality, let us consider that observations were taken at a grid were only a few weights are nonzero per observation. Furthermore, without evidence for spatial correlation of the latent process , its covariance matrix is the identity multiplied by (signal power)—i.e., . Consequently, denoting the mixing weights by and the input of the observed process, from eqs. (9)-(10) the covariances are given by
| (13) | ||||
| (14) |
Finally, introducing the above two expressions in the posterior mean in eq. (11) gives the solution to the linear system
| (15) |
The connection between solutions to linear systems and GP models is therefore established: when the noise variances are negligible w.r.t. the signal power the ratios in eq. (15) and , and the Moore-Penrose inverse is obtained. On the contrary, when the noise variance is large the estimate decays to zero, or reverts to the prior, since the measurements are not reliable. Furthermore, when the observation noise , eq. (15) is equivalent to the ordinary least squares and when to the regularised least squares (ridge regression).
Finally, we emphasise that, unlike the Moore-Penrose method, the proposed GPMM jointly infers the mixing weights and the complete latent process, while also providing a measure of uncertainty given by the variance in eq. (12).
IV Simulations
The proposed GPMM model was validated using three datasets: A heart-rate time series, a smooth function generated by a GP with square exponential (SE) covariance kernel, and the Heaviside step function. All three experiments consisted in recovering the latent process from noisy mixtures of measurements by fitting GPMM to the observations and then computing the predictive posterior as described in Section III-A, where the learnt weights were constrained to have unit -norm, positive entries and be symmetric to avoid redundant solutions. The proposed GPMM was compared to the standard GP that considers the observations as a single measurement in a single location, which is the common practice in sensing applications.
IV-A Smooth synthetic signal
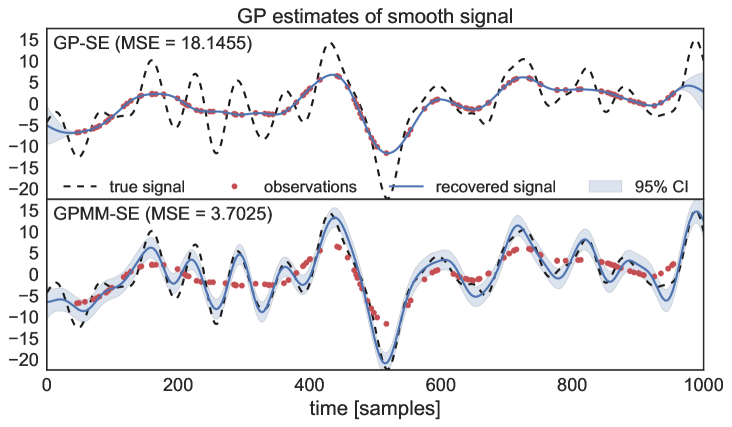
This first toy example considered a draw from a GP with SE covariance as the latent function and 120 observations with 7 measurements per observation. Fig. 3 shows the GP estimates and their mean square error (MSE) for both the standard GP with SE kernel (termed GP-SE) and the proposed GPMM with SE kernel (termed GPMM-SE). Notice how GP-SE fails to recover all the extrema of the latent process and adjust very tightly to the observations, this is because the convolution performed by the sensor smooths out the extrema in the observations which are then trusted as true values by GP-SE. Conversely, the GPMM-SE was able to recover all the extrema, place appropriate error bars on the latent function and report a lower estimation error.
IV-B Heart-rate signal
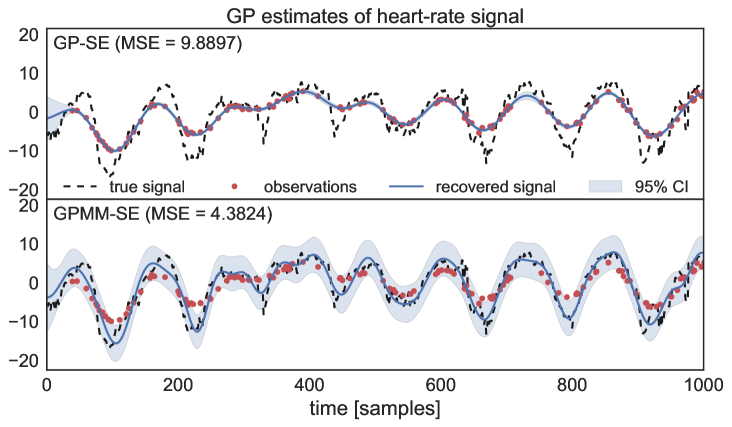
Instantaneous-frequency estimation is performed averaging over a time window thus motivating the use of the proposed GPMM. We used a heart-rate time-series from the MIT-BIH Database [18] (ecg.mit.edu/time-series) and constructed a lower-resolution version of it composed by a mixture of measurements. Fig. 4 shows the recovery of a heart-rate signal from such observations for both the GP-SE and the proposed GPMM-SE, where the GPMM-SE again outperforms the GP-SE in terms of estimation MSE and uncertainty representation. We used 240 observations with 7 measurements each.
IV-C Heaviside step function
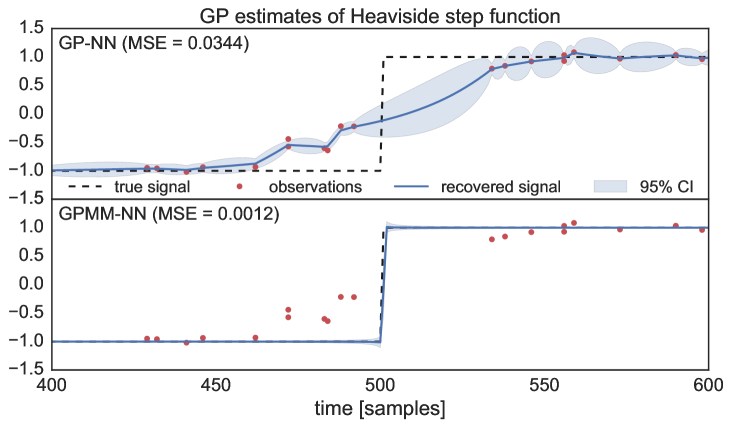
Motivated by edge-detection applications, we then considered the Heaviside step function. To cater for discontinuous signals, we used the neural network (NN) kernel [19] and implemented both the standard GP-NN and the proposed GPMM-NN to recover the latent step function. Observe in 5, how GPMM-NN successfully recovered the discontinuity with low variance. We used 120 observations with 7 measurements each.
IV-D Comparing recovered signals in spectral terms
Our aim is to recover spatial structure in the latent process, in this sense, Fig. 6 shows the PSDs for the smooth, heart-rate, and step function from top to bottom, observe how the GPMM (blue) was able to better recover the spectrum in all the experiments considered unlike the standard GP (red), where the latter failed to identify the spectral content of the latent process that was removed by the convolution sensor.
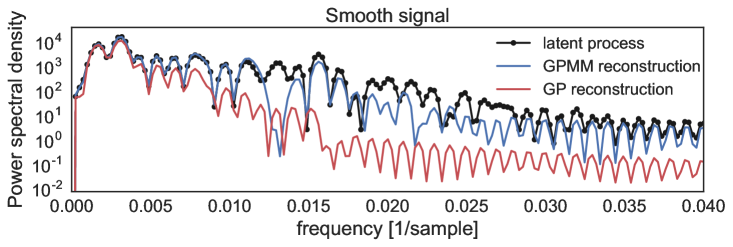
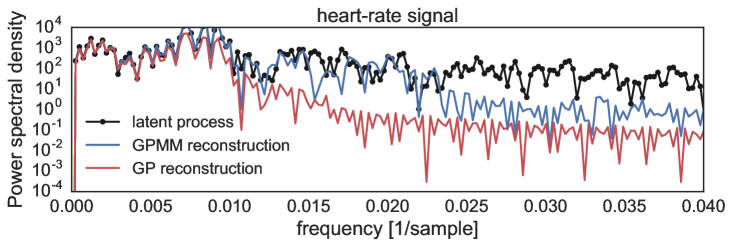
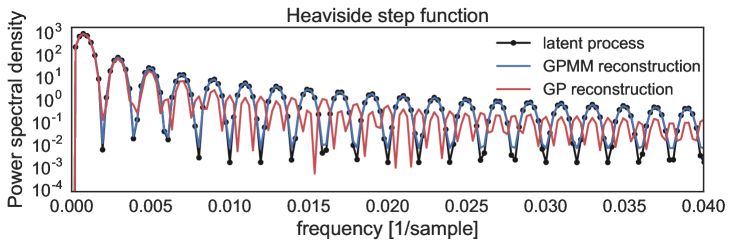
V Conclusions
We have proposed the Gaussian process mixture of measurements (GPMM) to address the problem of recovering a latent signal from a noisy mixture of measurements of such signal, a common setting in sensing applications. Our contributions are (i) to model the latent process and the mixture-of-measurements process as jointly Gaussian, (ii) fitting GPMM, including the mixing weights, and deriving the posterior distribution of the latent function in closed form, (iii) interpreting the solution of the underdetermined linear system generated by the sensing application as a particular case of GPMM, and (iv) validating GPMM against the standard GP for synthetic and real-world signals, where the reconstruction accuracy of GPMM was evidenced both in the time and frequency domains.
References
- [1] M. Adams, J. Mullane, and B.-N. Vo, “Laser and radar based robotic perception,” Foundations and Trends® in Robotics, vol. 1, no. 3, pp. 135–252, 2011.
- [2] H. P. Moravec and A. Elfes, “High resolution maps from wide angle sonar,” in Proc. of the IEEE International Conference on Robotics and Automation, 1985, vol. 2, pp. 116–121.
- [3] J. L. Starck, E. Pantin, and F. Murtagh, “Deconvolution in astronomy: A review,” Publications of the Astronomical Society of the Pacific, vol. 114, no. 800, pp. 1051, 2002.
- [4] L. Baboulaz and P. L. Dragotti, “Exact feature extraction using finite rate of innovation principles with an application to image super-resolution,” IEEE Trans. on Image Processing, vol. 18, no. 2, pp. 281–298, 2009.
- [5] C. E. Rasmussen and C. K. I. Williams, Gaussian Processes for Machine Learning, the MIT Press, 2006.
- [6] F. Tobar, T. D. Bui, and R. E. Turner, “Learning stationary time series using Gaussian processes with nonparametric kernels,” in Advances in Neural Information Processing Systems 28, 2015, pp. 3483–3491.
- [7] F. Tobar, T. D. Bui, and R. E. Turner, “Design of covariance functions using inter-domain inducing variables,” in NIPS 2015 - Time Series Workshop, 2015.
- [8] P. Boyle and M. Frean, “Dependent Gaussian processes,” in In Advances in Neural Information Processing Systems 17, 2005, pp. 217–224.
- [9] D. Higdon, “Space and space-time modeling using process convolutions,” in Quantitative Methods for Current Environmental Issues, pp. 37–56. Springer London, 2002.
- [10] M. Álvarez and N. D. Lawrence, “Sparse convolved Gaussian processes for multi-output regression,” in Advances in Neural Information Processing Systems 21, pp. 57–64. 2009.
- [11] M. K. Titsias, “Variational learning of inducing variables in sparse Gaussian processes,” in International Conference on Artificial Intelligence and Statistics, (AISTATS), 2009, vol. 12, pp. 567–574.
- [12] S. P. Chatzis and D. Kosmopoulos, “A latent manifold Markovian dynamics Gaussian process,” IEEE Trans. on Neural Networks and Learning Systems, vol. 26, no. 1, pp. 70–83, 2015.
- [13] E. H. Moore, “On the reciprocal of the general algebraic matrix,” Bulletin of the American Mathematical Society, vol. 26, pp. 394–395, 1920.
- [14] D. K. Duvenaud, H. Nickisch, and C. E. Rasmussen, “Additive Gaussian processes,” in Advances in Neural Information Processing Systems 24, pp. 226–234. 2011.
- [15] M. Gönen and E. Alpaydın, “Multiple kernel learning algorithms,” Journal of Machine Learning Research, vol. 12, pp. 2211–2268, 2011.
- [16] F. Tobar, S.-Y. Kung, and D. P. Mandic, “Multikernel least mean square algorithm,” IEEE Trans. on Neural Networks and Learning Systems, vol. 25, no. 2, pp. 265–277, 2014.
- [17] M. Yukawa, “Multikernel adaptive filtering,” IEEE Trans. on Signal Processing, vol. 60, no. 9, pp. 4672–4682, 2012.
- [18] A.L. Goldberger and D. R. Rigney, Theory of Heart: Biomechanics, Biophysics, and Nonlinear Dynamics of Cardiac Function, chapter Nonlinear dynamics at the bedside, pp. 583–605, Springer-Verlag, New York, 1991.
- [19] C. K. I. Williams, “Computation with infinite neural networks,” Neural Computation, vol. 10, no. 5, pp. 1203–1216, 1998.