ReDi: Efficient Learning-Free Diffusion Inference via Trajectory Retrieval
Abstract
Diffusion models show promising generation capability for a variety of data. Despite their high generation quality, the inference for diffusion models is still time-consuming due to the numerous sampling iterations required. To accelerate the inference, we propose ReDi, a simple yet learning-free Retrieval-based Diffusion sampling framework. From a precomputed knowledge base, ReDi retrieves a trajectory similar to the partially generated trajectory at an early stage of generation, skips a large portion of intermediate steps, and continues sampling from a later step in the retrieved trajectory. We theoretically prove that the generation performance of ReDi is guaranteed. Our experiments demonstrate that ReDi improves the model inference efficiency by 2 speedup. Furthermore, ReDi is able to generalize well in zero-shot cross-domain image genreation such as image stylization. The code and demo for ReDi is available at https://github.com/zkx06111/ReDiffusion.
1 Introduction
Deep generative models are changing the way people create content. Among them, diffusion models have shown great capability in a variety of applications including image synthesis (Ho et al., 2020; Dhariwal & Nichol, 2021), speech synthesis (Liu et al., 2021a), and point cloud generation (Zhou et al., 2021). Latent diffusion models (Rombach et al., 2022) such as Stable Diffusion are able to generate high-quality images given text prompts. However, the basic sampler for diffusion models proposed by Ho et al. (2020) requires a large number of function estimations (NFEs) during inference, making the generation process rather slow. For example, the basic sampler takes 336 seconds on average to run on an NVIDIA 1080Ti, where improving the efficiency of diffusion model inference is crucial.
Previous studies on improving the efficiency of diffusion model inference can be categorized into two types, learning-based ones, and learning-free ones. Learning-based samplers (Salimans & Ho, 2021; Meng et al., 2022; Lam et al., 2022; Watson et al., 2021; Kim & Ye, 2022) require additional training to reduce the number of sampling steps. However, their training is expensive, especially for large diffusion models like Stable Diffusion. In contrast, learning-free samplers do not require training, and are, therefore, applicable to more scenarios. In this paper, we focus on learning-free approaches to speed up inference.
Existing efficient learning-free samplers for diffusion (Liu et al., 2021b; Lu et al., 2022a, b; Zhang & Chen, 2022; Karras et al., 2022) all try to find a more accurate numerical solver for the diffusion ODE (Song et al., 2021), but they do not utilize its sensitivity. The sensitivity of ODEs suggests that under certain conditions, a small perturbation in the initial value does not change the solution too much (Khalil, 2002). This observation motivates the assumption that a previously generated trajectory - if close enough to the current trajectory - can serve as an estimate for it.
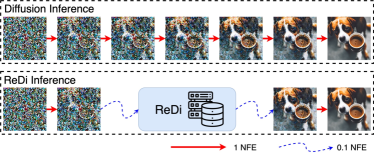
In this paper, we propose ReDi, a learning-free sampling framework based on trajectory retrieval. Figure 1 illustrates the original full diffusion inference and the ReDi inference. Given a pre-trained diffusion model, ReDi does not modify its weights or train new modules. Instead, we fix the model and build a knowledge base of trajectories upon a chosen dataset during the precomputation. During the inference, ReDi first computes the early few steps in the trajectory as they are, and then retrieves a similar trajectory from . In this way, one later step in the retrieved trajectory can surrogate the actual one and serve as an initialization point for the model. By jumping from an early time step to a later time step , ReDi is able to save a larger portion of function estimations (NFEs) any numerical solver.
We first prove that ReDi’s performance is bounded by the distance between the query trajectory and the retrieved neighbor. Then we report results from in-domain experiments to show empirically that with a moderate-sized knowledge base, ReDi is able to achieve comparable performance to recent efficient samplers with a speedup. To demonstrate that ReDi generalizes well in cross-domain adaptation, we propose an extension to ReDi that generates various stylistic images given the same single-style knowledge base. The stylized images generated by ReDi are well-rated by human evaluators. Our ablation studies show that under different settings, the actual results of ReDi correlate well with the theoretical bounds, indicating the bounds are tight enough to estimate the generation quality.
Our contributions are as follows:
-
•
We propose ReDi, a retrieval-based learning-free framework for diffusion models. ReDi is orthogonal to previous learning-free samplers and reduces the number of function estimations (NFEs) by skipping some intermediate steps in the trajectory.
-
•
We prove a theoretical bound for the generation quality of ReDi that correlates well with the actual performance.
-
•
We show empirically that ReDi can improve the inference efficiency with precomputation and perform well in zero-shot domain adaptation.
2 Related Work
Retrieval-Based Diffusion Models Previous studies on retrieval-based diffusion (Blattmann et al., 2022; Sheynin et al., 2022) have different emphases including rare entity generation (Chen et al., 2022), out-of-domain adaptation, semantic manipulation, and parameter efficiency. However, they all need to train a new model instead of building upon a trained model, which requires much computing power and time. They retrieve images and/or text using pre-built similarity measures like CLIP embedding cosine similarity (Radford et al., 2021). But the pre-built measures they use are not specially designed for diffusion models and have no proven performance guarantee.
Learning-Free Diffusion Samplers Most learning-free diffusion samplers are based on the stochastic/ordinary differential equation (SDE/ODE) formulation of the denoising process proposed by Song et al. (2021). This formulation allows the use of better numerical solvers for larger step sizes and fewer model iterations. Under the SDE framework, previous works alter the numerical solver (Song et al., 2021), the initialization point (Chung et al., 2022), the step-size (Jolicoeur-Martineau et al., 2021), and the order of the solver (Karras et al., 2022). The SDE can also be reformulated as an ordinary differential equation which is deterministic and therefore easier to accelerate. Many works (Liu et al., 2021b; Lu et al., 2022a, b; Zhang & Chen, 2022; Karras et al., 2022) hence built upon the ODE formulation and propose better ODE solvers for the problem. Although existing studies have extensively explored how a better numerical solver can be used to accelerate diffusion inference. They have not taken the sensitivity of ODEs into consideration.
3 Background
3.1 Diffusion Models
Assuming data follow an unknown true distribution , diffusion models (Sohl-Dickstein et al., 2015; Ho et al., 2020; Song et al., 2021; Kingma et al., 2021) define a generation process. For any , diffusion models learn a denoising process by iteratively adding noise to original data (denoted as ) from time step until time step . The forward process adds noise to such that at time step , the distribution of conditioned on is
| (1) |
where are real-valued positive functions with bounded derivatives. The signal-to-noise ratio (SNR) is defined as . By making the SNR decreasing, the marginal distribution of approximates a zero-mean Gaussian, i.e.
| (2) |
The noise-adding forward process transforms a data sample from the original distribution to the zero-mean Gaussian , while the backward process randomly samples from and denoises the sample with a neural network parameterized conditional distribution where until it reaches time step .
3.2 The Differential Equation Formulation
Kingma et al. (2021) proves that the forward process is equivalent (in distribution) to the following stochastic differential equation (SDE) in terms of the conditional distribution ,
| (3) | ||||
| (4) | ||||
| (5) |
where is the standard Wiener process.
Song et al. (2021) shows that the forward SDE has an equivalent reverse SDE starting from time with the marginal distribution ,
| (6) |
where is the reverse Wiener process and goes from to .
In practice, is estimated using a noise-predictor function , where is the Gaussian noise added to to obtain , i.e.,
| (7) |
| (8) |
where is a weighting function, and the integral is estimated using random samples.
Song et al. (2021) proves that the following ordinary differential equation (ODE) is equivalent to Equation 6,
| (9) |
When is replaced by its estimation, we obtain the neural network parameterized ODE,
| (10) |
The inference process of diffusion models can be formulated as solving Equation 10 given a random sample from the Gaussian distribution . For each iteration in solving the equation, the noise-predictor function is estimated with the trained neural network . Therefore, the inference time consumption can be approximated by the number of function estimations (NFEs), i.e., how many times is estimated.
4 The ReDi Method
Given a starting sample , a guidance signal , ReDi accelerates diffusion inference by skipping some intermediate samples in the sample trajectory to reduce NFEs.
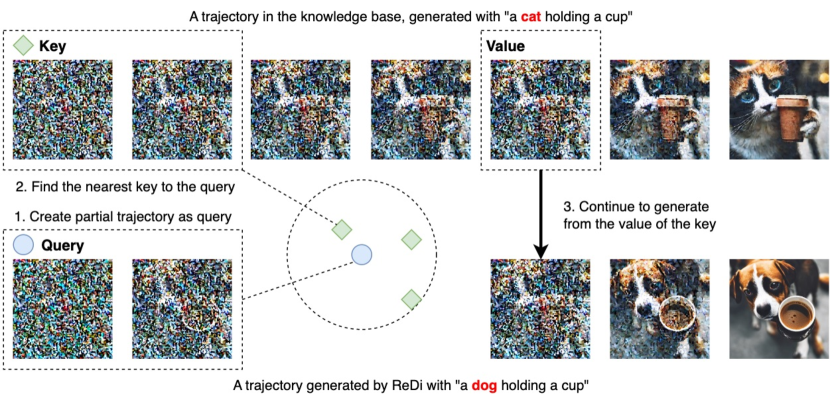
4.1 The Sample Trajectory
Definition 4.1.
Given a starting sample , the sample trajectory of a diffusion model is a sequence of intermediate samples generated in the iterative process from to . For a particular time step size , the sample trajectory is the sequence , where is the initial time step.
The sample trajectory describes the intermediate steps to generate the final data sample (e.g. an image), so the inference time linearly correlates with its length, i.e., the number of estimations used. While previous numerical solvers work towards enlarging the step size , ReDi aims at skipping some intermediate steps to reduce the length of the trajectory. ReDi is able to do so because the first few steps determine only the layout of the image which can be shared by many, and the following steps determine the details (Meng et al., 2021; Wu et al., 2022).
In the following section, we describe the ReDi algorithm with this definition.
4.2 The ReDi Inference framework
Given a trained diffusion model, ReDi does not require any change to the parameters. It only needs access to the sample trajectory of generated images. We show the inference procedure of ReDi in Figure 2. Instead of generating all intermediate samples in the trajectory, ReDi skips some of them to reduce number of function estimations (NFEs) and improve efficiency. This is done by generating the first few samples , using them as a query to retrieve a similar trajectory , and then starting from of the trajectory retrieved. This way, the NFEs spent to go from time step to time step would be unnecessary.
As shown in Figure 2, the retrieval of the similar trajectory depends on a precomputed knowledge base . We formally describe the construction of in Algorithm 1. ReDi first computes the sample trajectories for the data samples in a dataset . For every sample trajectory , a sample early in generation is chosen as the key, while a later sample is chosen as the value. The time consumption for computing one key-value pair is similar to that of one generation of the model. The total time consumption is proportional to . With a moderate-sized , not only can we achieve comparable performance with much less time, we can also perform zero-shot domain adaptation.
The inference process of ReDi is formally described in Algorithm 2. Given a guidance signal (in our case, a text prompt), we want to generate a data sample (in our case, an image) from it. We first generate the first few steps to query the knowledge base with . We find the top- keys that are closest to in terms of the distance measure . Then we find out the set of weights that make the linear combination of the top- keys approximate the best. With , we linearly combine the value and use that combination as the initialization point for the remaining steps of the sampling process.
4.3 Extending ReDi for Zero-Shot Domain Adaptation
One limitation of the ReDi framework described in subsection 4.2 is its generalizability. When the guidance signal contains out-of-domain information that does not exist in , it is difficult to retrieve a similar trajectory from and run ReDi. Therefore, We propose an extension to ReDi in order to generalize it to out-of-domain guidance. For an out-of-domain guidance signal , we break it into 2 parts - the domain-agnostic , and the domain-specific . We use to generate the partial trajectory as the retrieval key. After retrieval, we start from the retrieved value with both and as guidance signal.
For example, under the image synthesis setting, when contains style-free images that are generated without any style specifier in the prompt, it is difficult for ReDi to synthesize images from a stylistic prompt because finding a stylistic trajectory from a style-free knowledge base is hard. However, with the proposed extension, ReDi is able to synthesize stylistic images.
When a stylistic guidance signal is given, the part of describing the content of the image is the domain-agnostic , and the part of specifying the style of the image is the domain-specific . Although it is difficult to find a trajectory similar to one generated by , it is feasible to retrieve a trajectory similar to one generated by . Therefore, we first use the content description to generate the retrieval key and then use the whole prompt for the following sampling steps to make the image stylistic.
5 Theoretical Analysis
We analyze in this section whether ReDi is guaranteed to work. Our theorem is based on two assumptions.
Assumption 5.1.
The noise predictor model is -Lipschitz.
This assumption is used in Lu et al. (2022a) to prove the convergence of DPM-solver. Salmona et al. (2022) also argues that diffusion models are more capable of fitting multimodal distributions than other generative models like VAEs and GANs because of its small Lipschitz constant. The fact that is an estimate of the Gaussian noise added to the original image suggests that a small perturbation in does not change the noise estimation very much.
Assumption 5.2.
The distance between the query and the nearest retrieved key is bounded, i.e. .
This assumes that the nearest neighbor that ReDi retrieves is “near enough”, which we show empirically in section 6.
Given these assumptions, we can prove a theorem saying the distance between the retrieved value and the true sample generated retrieved value is an estimate near enough to the actual .
Theorem 5.3.
If , then .
Here, is the generated early sample used to retrieve from the knowledge base. key is the -th sample from a trajectory stored in the knowledge base. val is the -th sample from the same trajectory as key. is the true -th sample if we generate the full trajectory using the original diffusion sampler starting from .
Proof: We first define and prove it’s Lipschitz continuous. This is equivalent to proving is bounded:
| (11) | ||||
| (12) |
Note that Equation 12 follows from the Lipschitz continuity of . is bounded by the bounds of and , which is determined by the range of .
Since is -Lipschitz, the sensitivity of ODE (Khalil, 2002) suggests that for any two solutions and to Equation 10 satisfies
| (13) |
We summarize the proof of ODE sensitivity in Appendix A.1 to provide a more thorough perspective to our proof. With 13, the theorem is proven because and are and from a solution to Equation 10 according to Algorithm 1.
This theorem can be interpreted as that if the retrieved trajectory is near enough, the retrieved would be a good-enough surrogate for the actual . Note that multiple factors affect the proven bound, namely the Lipschitz constant , the distance to the retrieved trajectory , and the choice of key and value steps and .
6 Experiments
This section presents experiments for ReDi applied in both the inference acceleration setting and the stylization setting. We conduct these experiments to investigate the following research questions:
-
•
Is ReDi capable of keeping the generation quality while speeding up the inference process?
-
•
Is the sample trajectory a better key for retrieval-based generation than text-image representations?
-
•
Is ReDi able to generate data from a new domain without re-constructing the knowledge base?
We conduct our experiments on Stable Diffusion v1.5111https://github.com/CompVis/stable-diffusion, an implementation of latent diffusion models (Rombach et al., 2022) with 1000M parameters. Our inference code is based on Huggingface Diffusers222https://github.com/huggingface/diffusers. To show that ReDi is orthogonal to the choice of numerical solver, we conduct experiments with two widely used numerical solvers - pseudo numerical methods (PNDM) (Liu et al., 2021b) and multistep DPM solvers (Lu et al., 2022a, b). To obtain the top- neighbors, we use ScaNN (Guo et al., 2020), which adds a neglectable overhead to the generation process for retrieving the nearest neighbors.
6.1 ReDi is efficient in precompute and inference
|
|||||
|---|---|---|---|---|---|
| Sampler | 20 | 30 | 40 | 1000 | |
| DDIM | - | - | - | 0.255 | |
| PNDM | 0.274 | 0.268 | 0.262 | - | |
| +ReDi, H=1 | 0.265 | 0.264 | 0.262 | - | |
| +ReDi, H=2 | 0.255 | 0.247 | 0.252 | - | |

To show ReDi’s ability to sample from trained diffusion models efficiently, we use ReDi to sample from Stable Diffusion, with two different numerical solvers, PNDM and DPM-Solver. We build the knowledge base upon MS-COCO (Lin et al., 2014) training set (with 82k image-caption pairs) and evaluate the generation quality on 4k random samples from the MS-COCO validation set. We use the Fréchet inception distance (FID) (Heusel et al., 2017) of the generated images and the real images. In practice, we choose -norm as our distance measure and calculate the optimal combination of neighbors using least square estimation.
Note that although the training of Stable Diffusion costs as much as 17 GPU years on NVIDIA A100 GPUs, constructing with PNDM only requires 1 GPU day, which is much more efficient compared to learning-based methods like progressive distillation (Meng et al., 2022).
For PNDM, we generate 50-sample trajectories to build the knowledge base. We choose the key step to be , making the first 10 samples in the trajectory the key, and alternate the value step from to . Different combinations of key and value steps determine how many NFEs are reduced. For DPM-solver, we choose the length of the trajectory to be and conduct experiments on . To compare the performance of ReDi with the existing numerical solvers. We use them to generate images with the same NFE budget and compare their FIDs with ReDi.
We show the results of our experiments in Table 1 and Table 2. Some samples generated by ReDi are listed in Figure 3. For both PNDM and DPM-Solver, we report the FID scores of the sampler without ReDi, ReDi with top-1 retrieval, and ReDi with top-2 retrieval. The results indicate that with the same number of NFEs, ReDi is able to generate images with a better FID. They also indicate that when ReDi is combined with numerical solvers, we can achieve better performance with only 40% to 50% of the NFEs. In terms of clock time, 50-step PNDM takes 2.94 seconds, while the 30-step ReDi takes 1.75 seconds to generate one sample. The precomputation time for building the vector retrieval index and retrieving top- neighbors, when amortized by 4000 inferences, is 0.0077 seconds, which only takes 0.4% of the inference time. Therefore, ReDi is capable of keeping the generation quality while improving inference efficiency.
We further validate the effectiveness of ReDi with more ablation studies and baselines in Appendix A.6.
|
|||||
|---|---|---|---|---|---|
| Sampler | 10 | 12 | 15 | 17 | |
| DPM-Solver | 0.268 | 0.265 | 0.263 | 0.258 | |
| +ReDi, H=1 | 0.265 | 0.259 | 0.256 | 0.255 | |
| +ReDi, H=2 | 0.261 | 0.257 | 0.253 | 0.252 | |
6.2 Early samples from trajectories are better retrieval keys than text-image representations
One major difference between ReDi and previous retrieval-based samplers is the keys we use. Instead of using text-image representations like CLIP embeddings, we use an early step from the sample trajectory as the key. Theoretically, this is the optimal solution, because we are directly minimalizing the bound from 5.35.3 by minimalizing . In this section, we show empirically that sample trajectory is indeed the better retrieval key.
We compare CLIP embeddings and trajectories by using them alternatively as the key. To use CLIP embeddings as key, we build a knowledge base similar to the one we use in subsection 6.1 with them, where the keys are CLIP embeddings and the values are later samples in the sample trajectory. We run the same inference process except with a different knowledge base.
To evaluate the performance of retrieval keys, we use two criteria - the distance between the actual value and the retrieved value , and the FID scores of the generated images. We report the results in Table 3. Under all NFE settings, the trajectories serve a better purpose as the key for ReDi than CLIP embeddings. This corresponds well to Theorem 5.3.
| NFE | Key | L2 norm ↓ | FID ↓ |
|---|---|---|---|
| 40 | CLIP | 9.03 | 0.2709 |
| Trajectory | 7.95 | 0.2626 | |
| 30 | CLIP | 8.53 | 0.2784 |
| Trajectory | 7.28 | 0.2643 |
6.3 ReDi can perform zero-shot domain adaptation without a domain-specific knowledge base
We use the extended ReDi framework from subsection 4.3 to generate domain-specific images. In particular, we conduct experiments on image stylization (Fu et al., 2022; Feng et al., 2022) with the style-free knowledge base from 6.1. To generate an image with a specific style, we do not build a knowledge base from stylistic images. Instead, we use the content description to generate the partial trajectory as key. After retrieval, we change the prompt from to the combination of and , where is the style description in the prompt.
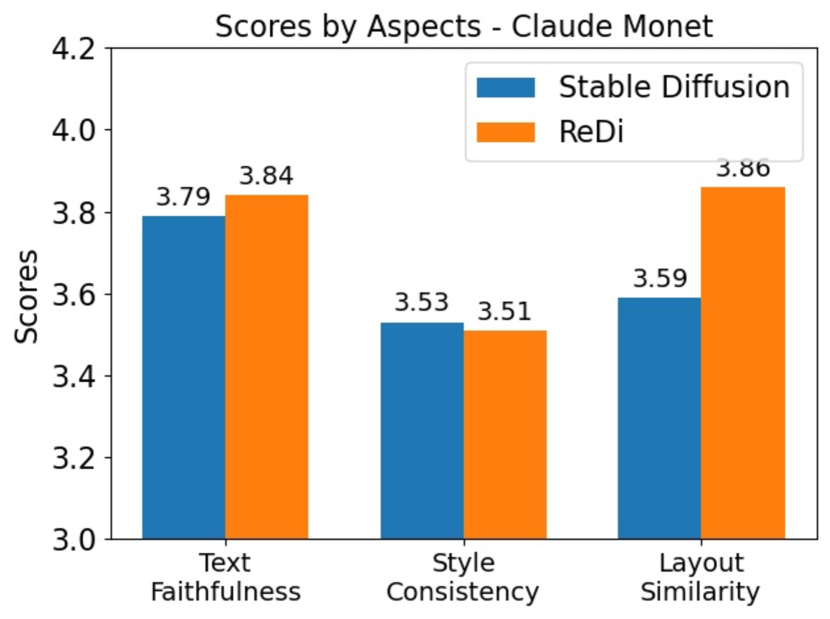
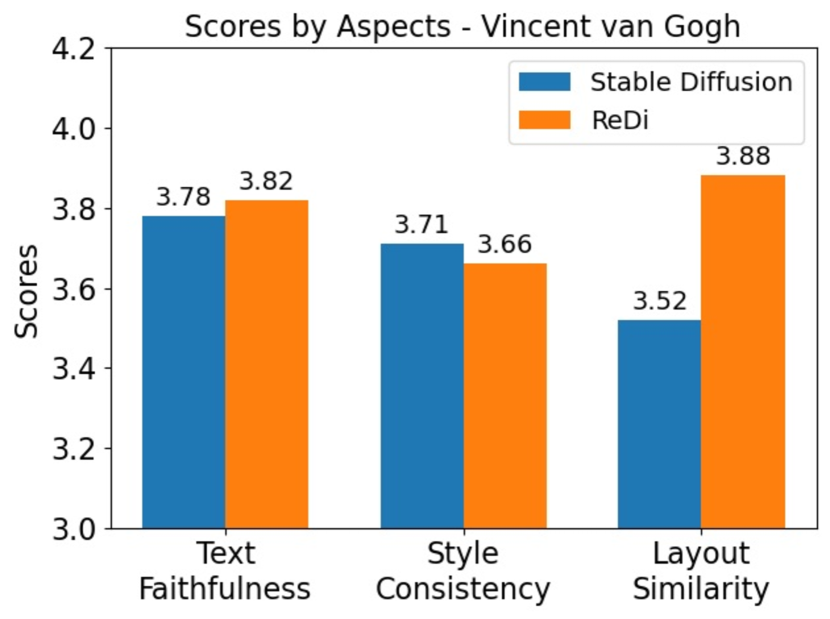
In our experiments, we transfer the validation set of MS COCO to three different styles. The content description directly comes from the image captions, while the style description is appended as a suffix to the prompt. The style descriptions for the three styles are “a Chinese painting”, “by Claude Monet”, and “by Vincent van Gogh”.
Unlike other experiments, in this experiment, we choose and . Because from the preliminary experiments, we find that the style of the image is determined much earlier than its detailed content. For 100 randomly sampled captions from MS COCO validation, we generate the corresponding images in all three styles. To evaluate ReDi’s performance, we compare them with images generated by the original Stable Diffusion with PNDM solver.
We asked human evaluators from Amazon MTurk to evaluate the generated images. They are paid more than the local minimum wage. Every generated image is rated in three aspects, text faithfulness, style consistency, and layout similarity. Every aspect is rated on a scale of 1 to 5 where 5 stands for the highest level. Textual faithfulness represents how faithful the image is depicting the content description. Style consistency represents how consistent the image is to the specified style. Layout similarity represents how similar the layout of the stylistic image is to the layout of the style-free image.

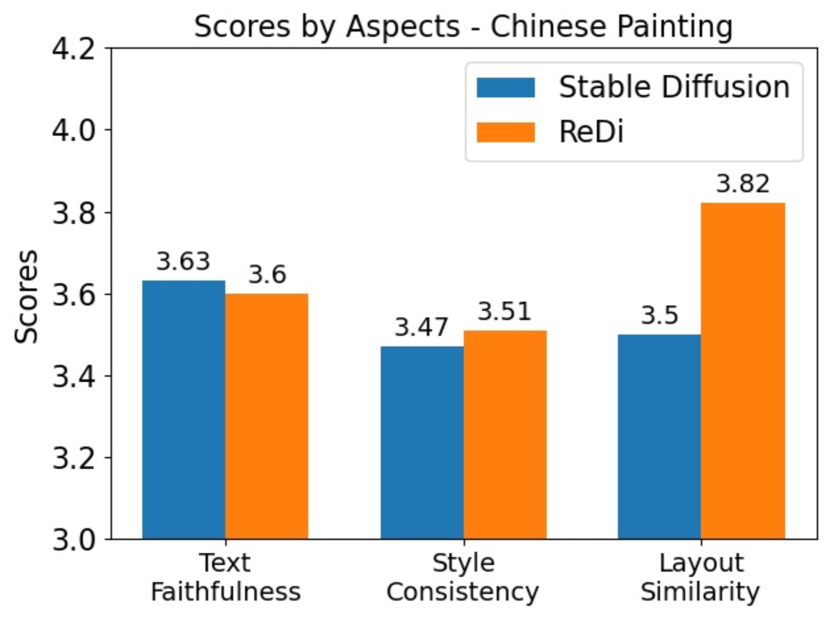
We report the results of the human evaluation of the 3 different styles in Figure 4. In terms of text faithfulness and style, ReDi’s evaluation is comparable to Stable Diffusion. In terms of layout similarity, the images generated by ReDi have significantly more similar layouts. This indicates that by retrieving the early sample in the trajectory, ReDi is able to keep the layout unchanged while transferring the style. This finding is also demonstrated by the qualitative examples in Figure 5.
Furthermore, for stylistic prompts that can not be explicitly decomposed into and , we propose to use prompt engineering techniques from the natural language processing community by asking a large language model to conduct the decomposition for us. We include an example of such method in Appendix A.7.
7 The Tightness of the Theoretical Bound
In this section, we conduct experiments of ReDi on PNDM to show that the proven bound is tight enough to be an estimator of the actual performance. The bound proven in Theorem 5.3 is affected by the following factors:
-
•
The distance to the retrieved neighbor which depends on the size of the knowledge base and the number of nearest neighbors used.
-
•
The difference between the key step and the query step , which depends on and .
-
•
The Lipschitz constant which depends on and .
Therefore, we conduct ablation studies on the knowledge base size, the choice of and , and the number of neighbors to check if the performance ReDi correlates well with the theoretical bound. In all ablation experiments, we use PNDM as the numerical sampler and evaluate the performance using FID scores on samples generated from MSCOCO validation. Our findings indicate that the performance of ReDi correlates well with the theoretical bound. Therefore the proven bound can be a good estimator for model performance.
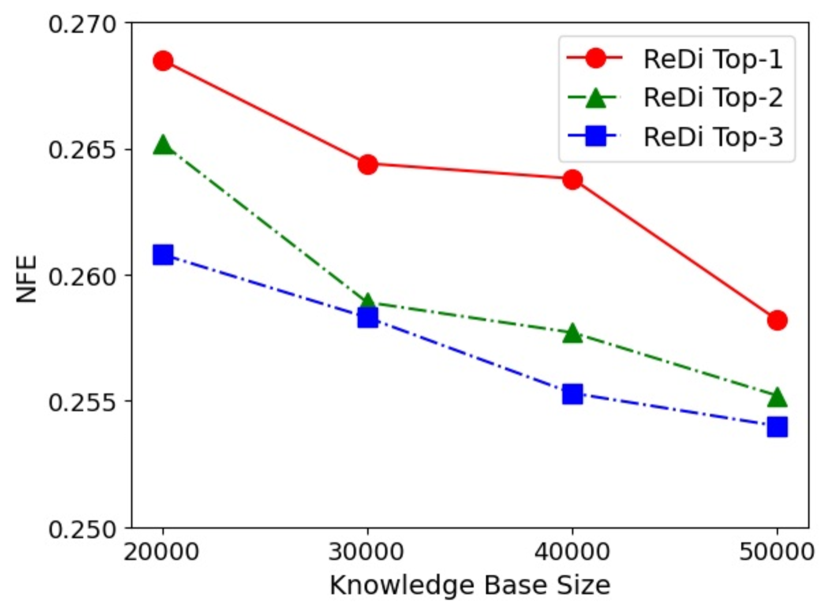
Knowledge base size
We control the size of the knowledge base by randomly sampling from the complete knowledge base described in subsection 6.1. We experiment with knowledge bases of sizes 20K, 30K, 40K and 50K. As shown in 6(a), as the knowledge base size gets smaller, the performance of ReDi drops. This finding is consistent with the theoretical bound since the bound is proportional to .
Key and query steps
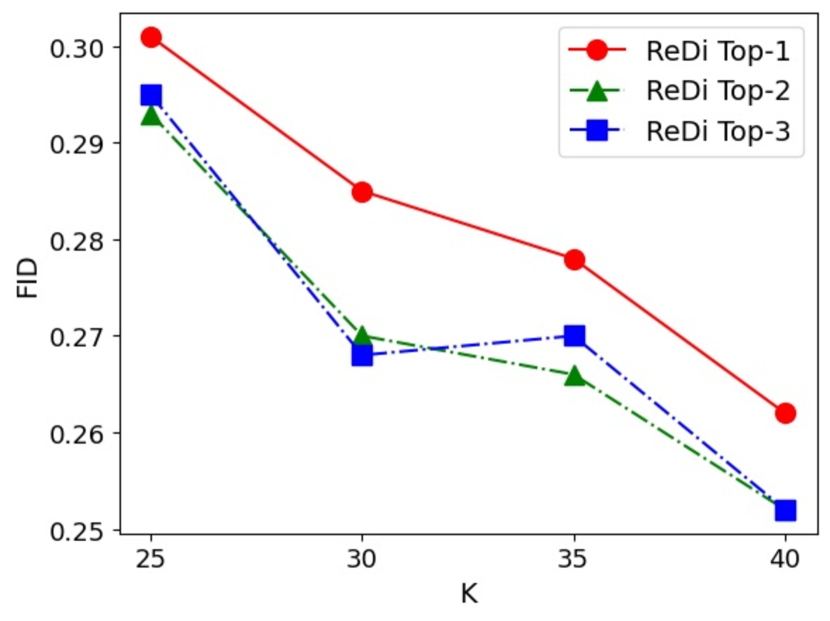
There are two questions to be studied about how key and query steps influence the performance of ReDi - the difference between them , and the choice of . The bound from Theorem 5.3 is proportional to the exponential of . Therefore, we control the difference between the key and the query steps by fixing the key step , and alternating to be . As shown in 6(b), as gets bigger, the performance of ReDi drops. This finding is consistent with the theoretical bound since the bound is proportional to . The bound is also proportional to . Even if the difference between and is fixed, the choice of alone can affect and the performance. We keep and alternate to be . As shown in 6(c), as gets smaller, the performance of ReDi drops. This finding is consistent with the theoretical bound since the bound of Stable Diffusion explodes when (Liu et al., 2021b).
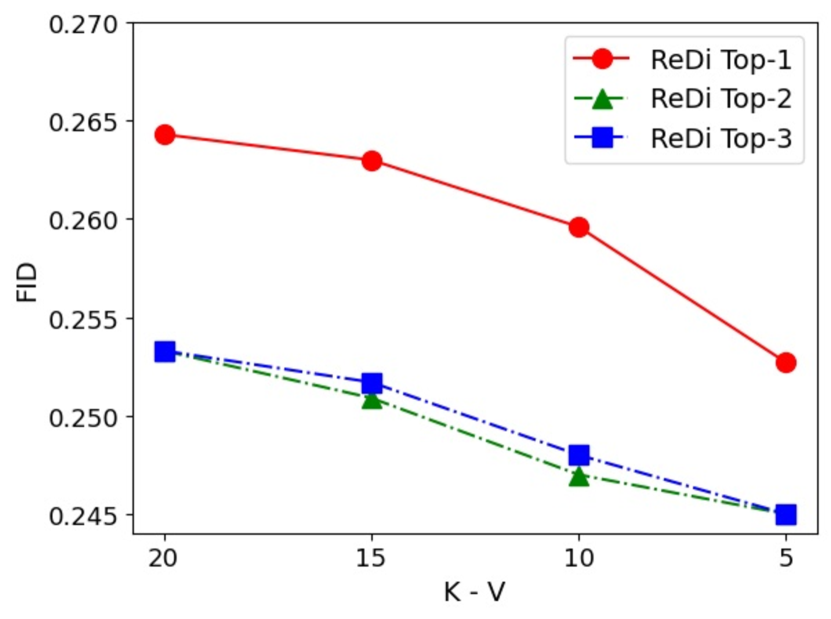
Number of neighbors retrieved
Increasing the number of neighbors can make the approximation of the query more accurate. Therefore, we control the number of neighbors in every ablation experiment to evaluate how affects the performance. As shown in Figure 6, the performance of ReDi rises as the number of neighbors increases. This correlates well with the theoretical bound. We also find the difference between two s converges as gets to .
8 Discussion
Generalizability with respect to guidance scale
The knowledge base for ReDi is built with the guidance scale of 7.5. We investigate whether ReDi works for other guidance scales. The results and generated sample images are listed in Appendix A.2. The results show that ReDi is still able to function and produce similar-quality results when the guidance weight is not the same as the one used in the knowledge base.
Complicated and compositional prompts
Due to the retrieval nature of ReDi, it is possible that when prompted with complicated and compositional prompts, there may not be a trajectory in that’s close enough to the prompt. To qualitatively evaluate ReDi’s performance on complicated prompts, we pick the 4 longest prompts in the test set and compare the generated images of ReDi and PNDM. The samples are shown in Appendix A.3. From the image samples with the longest prompts, we observe that ReDi does not show an inferior ability of compositionality compared with Stable Diffusion. Sometimes it shows better compositionality than Stable Diffusion. However, to enable better compositionality, it’s better to have a larger knowledge base.
Impact on sample diversity
When the knowledge base is small, it’s possible that the diversity of the generated samples can be limited to a smaller space around the data points in the knowledge base. We investigate how ReDi affects the sample diversity by computing the Inception Score (Salimans et al., 2016) for the generated images and the ground truth images in Appendix A.4. The results indicate that ReDi is capable of generating diverse images.
Beyond the image modality
We have only utilized ReDi under the text-to-image setting. However, it may be extended to other modalities. We argue that the extension is possible because DPM-solver, which has the same Lipschitz assumption as ours, is used in other domains. Our theoretical analysis (Theorem 5.3) is based on the Lipschitz assumption (Assumption 5.1), which is also the theoretical basis for the performance of the DPM-Solver (Lu et al., 2022a). Variations of DPM-Solver have demonstrated effectiveness in diverse domains, including audio, video (Ruan et al., 2023), and molecular graph (Huang et al., ). Therefore, we contend that ReDi may also be applicable in these cases.
9 Conclusion
This paper proposes ReDi, a learning-free diffusion inference framework via trajectory retrieval. Unlike previous learning-free samplers that extensively explore more efficient numerical solvers, we focus on utilizing the sensitivity of the diffusion ODE, which leads to our choice of using partial trajectories as query and key for retrieval. We prove a bound for ReDi with the Lipschitz continuity of the diffusion model. The experiments on Stable Diffusion empirically verify ReDi’s capability to generate comparable images with improved efficiency. The zero-shot domain adaptation experiments shed light on further usage of ReDi and call for a better understanding of diffusion inference trajectories. We look forward to future studies built upon ReDi and the properties of the diffusion ODE. To make the best out of the limited knowledge base, it is also desirable to study ReDi in a compositionality setting so that the combination of different trajectories can be more controllable.
Acknowledgements
This work is partially supported by unrestricted gifts from IGSB and Meta via the Institute for Energy Efficiency.
We thank Weixi Feng, Tsu-Jui Fu, Jiabao Ji, Yujian Liu and Qiucheng Wu for helpful discussions and proof-reading.
References
- Bellman (1943) Bellman, R. The stability of solutions of linear differential equations. Duke Math. J., 10(1):643–647, 1943.
- Blattmann et al. (2022) Blattmann, A., Rombach, R., Oktay, K., Müller, J., and Ommer, B. Semi-parametric neural image synthesis. In Advances in Neural Information Processing Systems, 2022.
- Chen et al. (2022) Chen, W., Hu, H., Saharia, C., and Cohen, W. W. Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491, 2022.
- Chung et al. (2022) Chung, H., Sim, B., and Ye, J. C. Come-closer-diffuse-faster: Accelerating conditional diffusion models for inverse problems through stochastic contraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12413–12422, 2022.
- Dhariwal & Nichol (2021) Dhariwal, P. and Nichol, A. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- Feng et al. (2022) Feng, W., He, X., Fu, T.-J., Jampani, V., Akula, A. R., Narayana, P., Basu, S., Wang, X. E., and Wang, W. Y. Training-free structured diffusion guidance for compositional text-to-image synthesis. ArXiv, abs/2212.05032, 2022.
- Fu et al. (2022) Fu, T.-J., Wang, X. E., and Wang, W. Y. Language-driven artistic style transfer. In European Conference on Computer Vision, 2022.
- Gronwall (1919) Gronwall, T. H. Note on the derivatives with respect to a parameter of the solutions of a system of differential equations. Annals of Mathematics, pp. 292–296, 1919.
- Guo et al. (2020) Guo, R., Sun, P., Lindgren, E., Geng, Q., Simcha, D., Chern, F., and Kumar, S. Accelerating large-scale inference with anisotropic vector quantization. In International Conference on Machine Learning, 2020. URL https://arxiv.org/abs/1908.10396.
- Heusel et al. (2017) Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho et al. (2020) Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- (12) Huang, H., Sun, L., Du, B., and Lv, W. Conditional diffusion based on discrete graph structures for molecular graph generation. In NeurIPS 2022 Workshop on Score-Based Methods.
- Jolicoeur-Martineau et al. (2021) Jolicoeur-Martineau, A., Li, K., Piché-Taillefer, R., Kachman, T., and Mitliagkas, I. Gotta go fast when generating data with score-based models. arXiv preprint arXiv:2105.14080, 2021.
- Karras et al. (2022) Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion-based generative models. arXiv preprint arXiv:2206.00364, 2022.
- Khalil (2002) Khalil, H. K. Nonlinear systems third edition. Prentice Hall, 115, 2002.
- Kim & Ye (2022) Kim, B. and Ye, J. C. Denoising mcmc for accelerating diffusion-based generative models. arXiv preprint arXiv:2209.14593, 2022.
- Kingma et al. (2021) Kingma, D., Salimans, T., Poole, B., and Ho, J. Variational diffusion models. Advances in neural information processing systems, 34:21696–21707, 2021.
- Lam et al. (2022) Lam, M. W., Wang, J., Su, D., and Yu, D. Bddm: Bilateral denoising diffusion models for fast and high-quality speech synthesis. In International Conference on Learning Representations, 2022.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In European conference on computer vision, pp. 740–755. Springer, 2014.
- Liu et al. (2021a) Liu, J., Li, C., Ren, Y., Chen, F., and Zhao, Z. Diffsinger: Singing voice synthesis via shallow diffusion mechanism. In AAAI Conference on Artificial Intelligence, 2021a.
- Liu et al. (2021b) Liu, L., Ren, Y., Lin, Z., and Zhao, Z. Pseudo numerical methods for diffusion models on manifolds. In International Conference on Learning Representations, 2021b.
- Lu et al. (2022a) Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., and Zhu, J. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models. arXiv preprint arXiv:2211.01095, 2022a.
- Lu et al. (2022b) Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., and Zhu, J. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. arXiv preprint arXiv:2206.00927, 2022b.
- Meng et al. (2021) Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.-Y., and Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2021.
- Meng et al. (2022) Meng, C., Gao, R., Kingma, D. P., Ermon, S., Ho, J., and Salimans, T. On distillation of guided diffusion models. arXiv preprint arXiv:2210.03142, 2022.
- Radford et al. (2021) Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp. 8748–8763. PMLR, 2021.
- Rombach et al. (2022) Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695, 2022.
- Ruan et al. (2023) Ruan, L., Ma, Y., Yang, H., He, H., Liu, B., Fu, J., Yuan, N. J., Jin, Q., and Guo, B. Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10219–10228, 2023.
- Salimans & Ho (2021) Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models. In International Conference on Learning Representations, 2021.
- Salimans et al. (2016) Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., and Chen, X. Improved techniques for training gans. Advances in neural information processing systems, 29, 2016.
- Salmona et al. (2022) Salmona, A., de Bortoli, V., Delon, J., and Desolneux, A. Can push-forward generative models fit multimodal distributions? arXiv preprint arXiv:2206.14476, 2022.
- Sheynin et al. (2022) Sheynin, S., Ashual, O., Polyak, A., Singer, U., Gafni, O., Nachmani, E., and Taigman, Y. Knn-diffusion: Image generation via large-scale retrieval. arXiv preprint arXiv:2204.02849, 2022.
- Sohl-Dickstein et al. (2015) Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, pp. 2256–2265. PMLR, 2015.
- Song et al. (2021) Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=PxTIG12RRHS.
- Watson et al. (2021) Watson, D., Chan, W., Ho, J., and Norouzi, M. Learning fast samplers for diffusion models by differentiating through sample quality. In International Conference on Learning Representations, 2021.
- Wu et al. (2022) Wu, Q., Liu, Y., Zhao, H., Kale, A., Bui, T., Yu, T., Lin, Z., Zhang, Y., and Chang, S. Uncovering the disentanglement capability in text-to-image diffusion models. arXiv preprint arXiv:2212.08698, 2022.
- Zhang & Chen (2022) Zhang, Q. and Chen, Y. Fast sampling of diffusion models with exponential integrator. arXiv preprint arXiv:2204.13902, 2022.
- Zhou et al. (2021) Zhou, L., Du, Y., and Wu, J. 3d shape generation and completion through point-voxel diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5826–5835, 2021.
Appendix A Appendix
A.1 Proof of ODE Sensitivity
Theorem A.1.
Theorem A.2.
(Sensitivity of ODE (Khalil, 2002))
Let be piecewise continuous in t and L-Lipschitz in on , and let is the solution of
and is the solution of
with respect to for all . Suppose there exists such that for all and further suppose . Then for any ,
Proof: First we can write the solutions of y and z by
Subtracting the above two solutions yields
By letting and , then applying the A.1 to the function gives,
Finally, integrating the last term on the right hand gives,
which finishes the proof.
In our setting, the is simply equal to , so we have the following inequality
A.2 ReDi’s Performance with Different Guidance Signals
We list the FID scores of ReDi with different guidance scales in Table 4. We also show generate samples using different scales in Figure 7.
| Guidance | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
| FID | 0.271 | 0.269 | 0.264 | 0.268 | 0.267 |


A.3 Samples with Complicated Prompts Generated by ReDi
We show the image samples generated by ReDi and PNDM from the longest prompts in Figure 8. ReDi does not show an inferior ability of compositionality compared with Stable Diffusion. Sometimes it shows better compositionality than Stable Diffusion. For example, In row 3, Stable Diffusion incorrectly generated a mask covering the rider’s face when it should be covering the horse’s face. In row 4, Stable Diffusion failed to generate the catcher and umpire in the background, whereas ReDi successfully did. These findings demonstrate the potential of ReDi to handle complex prompts.

A.4 Evaluation of Sample Diversity
As shown in Table 5, the Inception Scores for ReDi are comparable to those of the ground truth images in the MS-COCO validation set. Based on these results, we argue that ReDi is capable of generating diverse images.
| NFE | 20 | 30 | 40 |
|---|---|---|---|
| ReDi | 29.49 | 30.79 | 31.23 |
| Ground Truth | 30.79 | 30.79 | 30.79 |
A.5 The Initial Sample in Knowledge Base Construction
In Algorithm Algorithm 1, the sample to initialize every trajectory in the knowledge base is sampled from a conditional distribution . However, the noise schedule in diffusion models causes the signal-to-noise ratio to approach at time step . This makes sampling from approximately the same as sampling from the unconditional distribution . This makes it possible for ReDi to construct the knowledge base without the ground truth images and with only the prompts. We investigate this possibility by rebuilding the knowledge base with initial samples from the unconditional distribution. The results reported in Table 6 indicate that whether the initial distribution is conditional does not significantly affect the performance of ReDi.
| NFE | 20 | 30 | 40 |
|---|---|---|---|
| 0.268 | 0.263 | 0.265 | |
| 0.265 | 0.264 | 0.262 |
A.6 Validation of Effectiveness
Vanilla skipping from to
We compare it ReDi with a naive substitute - directly approximation of from using any numerical solver, without resorting to retrieval. The average L2 distances to the true value for both the ReDi retrieved and the vanilla skipped is reported in Table 7. It can be noted that ReDi retrieved values are much closer to the true value, indicating the effectiveness of ReDi. We also compute the FID for vanilla skipping under the PNDM setting. The FID of vanilla skipping is 1.58, which is much worse than the 0.267 from ReDi.
| NFE | 20 | 30 | 40 |
|---|---|---|---|
| 7.95 | 18.73 | 7.95 | |
| 44.20 | 24.16 | 44.20 |
Similarity with Original Samples
We compute the distance between ReDi-generated samples and samples generated by the original sampler and list them in Table 8. The distance between ReDi and the original samples is very small (with an average 25% percentage) compared to the distance between the original samples and the ground truth. Therefore we argue that ReDi does not introduce much error to the original sampling trajectory.
| NFE | 20 | 30 | 40 |
|---|---|---|---|
| FID(ReDi, Original) | 0.0745 | 0.0655 | 0.0632 |
| FID(Original, Ground Truth) | 0.274 | 0.268 | 0.272 |
| Percentage | 27.0% | 24.4% | 24.1% |
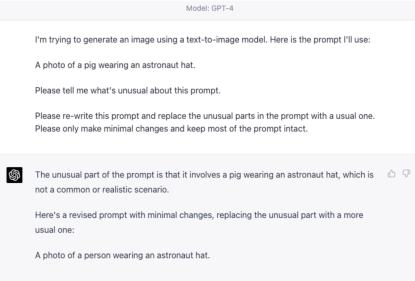
A.7 Prompt Engineering for Explicit Style-Content Decomposition
We demonstrate how we can automatically decompose an out-of-domain prompt into and with the prompt “A photo of a pig wearing an astronaut hat.”.
Unlike prompts with stylistic suffixes, this prompt cannot be easily split into an in-domain prefix and an out-of-domain suffix. Even with the original diffusion model, the generation quality is not satisfactory, as shown in 9(a).


We then asked GPT-4 to re-write the prompt with minimal changes to a more usual one (which is used as ) and then generate the image with ReDi. The response from GPT-4 is shown in Figure 10. GPT-4 is able to find out what is unusual about the prompt and re-write it to “a photo of a person wearing an astronaut hat”. With that, ReDi can generate much better samples as shown in 9(b).