Reducing ReLU Count for Privacy-Preserving CNN Speedup
Abstract
Privacy-Preserving Machine Learning algorithms must balance classification accuracy with data privacy. This can be done using a combination of cryptographic and machine learning tools such as Convolutional Neural Networks (CNN). CNNs typically consist of two types of operations: a convolutional or linear layer, followed by a non-linear function such as ReLU. Each of these types can be implemented efficiently using a different cryptographic tool. But these tools require different representations and switching between them is time-consuming and expensive. Recent research suggests that ReLU is responsible for most of the communication bandwidth.
ReLU is usually applied at each pixel (or activation) location, which is quite expensive. We propose to share ReLU operations. Specifically, the ReLU decision of one activation can be used by others, and we explore different ways to group activations and different ways to determine the ReLU for such a group of activations.
Experiments on several datasets reveal that we can cut the number of ReLU operations by up to three orders of magnitude and, as a result, cut the communication bandwidth by more than .
Introduction
Deep Learning algorithms have made great progress in recent years. Therein lies the problem. In order to classify an image, a Deep Learning algorithm must be exposed to its content. Yet, an image contains private information that should not be exposed. Protecting the privacy of the data is paramount in the medical, financial, and military domains, to name a few.
Privacy-Preserving Machine Learning algorithms are designed to address this problem. Such an algorithm will protect the privacy of the data, as well as that of the network, while performing the task at hand. For example, assume that Alice owns an image and Bob owns a Convolutional Neural Network (CNN) for image classification. Their goal is to collaborate in classifying the image without revealing any additional information. Alice should learn nothing about the weights of Bob’s network, while Bob should learn nothing about the content of Alice’s image. Only the classification result should be revealed to the agreed upon party.
This problem can be solved using cryptographic tools. The leading approach in recent work is to use secure Multi-Party Computation (MPC) techniques. In this setting, Alice and Bob securely evaluate the network layer by layer until an outcome is reached. At each stage, Alice and Bob hold private shares of the data (or the intermediate results of the network so far). Then, they use Homomorphic Encryption to compute the convolutional and linear component. The non-linear ReLU operation requires a different representation and so Alice and Bob must switch their data representation to compute the ReLU outcome of their operation. And the process repeats for the next layer. Switching to and from ReLU representation is time-consuming and requires considerable communication bandwidth.
The goal of this paper is to develop an algorithm that reduces the ReLU count in a given CNN. Our solution is based on ReLU Sharing - a group of pixels (or activation units down the network) operate based on a single ReLU operation. Today, each activation performs the ReLU operation on the outcome of the convolution at the activation’s site. In ReLU sharing, the ReLU decision at one activation location is shared by others. For example, if we assume that nearby activations are highly correlated, then it is reasonable to assume that their ReLU result will be similar. Therefore, it might be enough to perform ReLU on one activation, and use that result for other activations in its neighborhood.
We consider different methods to group activations and evaluate different ways for a group of activations to perform a shared ReLU operation. We evaluate our algorithm on several data sets and report the results. We find that in some cases we can reduce the ReLU count by up to three orders of magnitude in early layers of the network and cut the total number of ReLU operations by nearly with less than a drop in accuracy.
Background
Secure Multi Party Computation (MPC) was first investigated in Cryptography. Yao (Yao 1982) proposed a Garbled Circuit (GC) to solve the Millionaire Problem: Two Millionaires, Alice and Bob, want to determine which one has more money, without revealing their true wealth. Yao reduced the problem to a circuit that is evaluated jointly and securely by both parties. Observe that the Millionaire Problem is the same as ReLU.
Since every computer program can be reduced to a Boolean circuit, then any computer program can be evaluated securely. Later, Goldreich et al. (Goldreich, Micali, and Wigderson 1987) extended MPC to more than two parties. In practice, GC suffers from two main drawbacks. It requires multiple rounds of communication and is extremely slow to compute.
Alternatively, one can use Fully Homomorphic Encryption (FHE), which is an encryption scheme that supports addition and multiplication of encrypted numbers. This allows Alice to encrypt her image and send it to Bob. Bob, in turn, can run his Convolutional Neural Network (CNN) on the encrypted data and return the result. Because FHE does not support a non-linearity such as ReLU, Bob will have to use an alternative non-linearity such as a low degree polynomial or tanh.
This elegant solution guarantees the privacy of both parties, while minimizing communication bandwidth. Alice simply sends her encrypted image to Bob and gets in return its classification. This solution was adopted in CryptoNets (Dowlin et al. 2016). Unfortunately, FHE is painfully slow and running it on real images is not feasible currently.
Which leads us to present day solutions. Instead of relying on FHE, most methods today evaluate the CNN layer by layer using a combination of GC and Homomorphic Encryption (HE). These algorithms require several rounds of communication and rely on Homomorphic Encryption (HE), which is less demanding than FHE. Specifically, HE supports either addition or multiplication of encrypted data and is much faster to compute. This means that Bob can run the convolutional layers of his network on Alices’s encrypted data, but not the ReLU non-linearity. The ReLU operation can be implemented using a Garbled Circuit. Switching between HE and GC is very time consuming and requires several rounds of communication between Alice and Bob.
Most of the recent progress in Secure Deep Learning mixes and matches these cryptographic tools. DeepSecure (Rouhani, Riazi, and Koushanfar 2018) build on top of Yao’s Garbled Circuit a system for secure Deep Learning, and test it on several data sets from different domains. In the context of Vision, they report results on the MNIST dataset.
SecureML (Mohassel and Zhang 2017) use two-party computation to address the problem. In particular, they develop new techniques to support secure arithmetic operations on shared decimal numbers, and propose MPC-friendly alternatives to non-linear functions such as sigmoid and softmax that are superior to prior work.
MiniONN (Liu et al. 2017) transforms a CNN into an Oblivious CNN. They detail how each component in a CNN can be implemented obliviously and show that some of the computational burden can be shifted to an offline stage. They show considerable improvements over both CryptoNets and SecureML. GAZELLE (Juvekar, Vaikuntanathan, and Chandrakasan 2018) further improved the efficiency of the linear layer computation.
Chamelon (Riazi et al. 2018) combines secure function evaluation with secret sharing for the linear layers and MPC or GC for the nonlinear operations. They report results that are two orders of magnitude faster than CryptoNets (Dowlin et al. 2016) and about four times better than (Liu et al. 2017).
Recently, FALCON (Li et al. 2020) suggested the use of FFT to accelerate the secure computation of the linear layer. They are also the first to introduce a secure softmax evaluation.
The work most closely related to us is that of Shafran et al. (Shafran et al. 2019). They, too, observe that ReLUs are expensive to compute and propose several ways to reduce their count.
Method
Our goal is to reduce the number of ReLU operations, as this is a major factor in the cost of secure inference. Our key insight is that activations are highly correlated with each other and hence the ReLU decision of one can be used for another. The question is how to share ReLU decisions without compromising privacy?
Let denote an , single channel image, and let denote a convolution kernel. The convolution result is given by and the ReLU on top of it is , which is defined element-wise as:
| (1) |
where is (2D) activation location.
We can generalize ReLU such that a ReLU decision of a group of activations is then being used by each activation independently. Formally:
| (2) |
where is a weight vector, the size of , and we treat them both as column vector for ease of notation. If, for , we take to be a one hot vector with then we are back to standard ReLU. If, on the other hand, we take to be a one hot vector with then the ReLU decision for pixel is determined by pixel .
Of course, does not have to be a one hot vector, and we do not have to use just a single vector . A straightforward generalization is to group the activations in the channel plane into patches, assign a different weight vector to each patch and learn the weights.
| (3) |
where is a shorthand for activation belongs to patch .
Figure 1 shows the different ReLU variants that can be used. From left to right we see, first, a regular ReLU, where the ReLU operation is applied directly to the activation itself. Next we show gReLU, where the ReLU decision of activation (green activation) is applied to the red-boundary activation . The last two sub-plots show two different grouping techniques that can be used. In both cases, the gReLU decision of the weighted sum of the green activations is used to determine the ReLU operation of the red-boundary activation.
The first clustering technique is oblivious to data and simply breaks the channel into small patches (i.e., patches). The second clustering technique we consider is based on the training data, as we explain next.
Assume we have training sample and let be a binary vector that denotes the ReLU decision of activation for example . Let denote an dimensional vector of the ReLU response, at pixel of all training examples. The number of such vectors is the number of activations in the channel, which is . We now cluster these vectors to find activations that are correlated with each other.
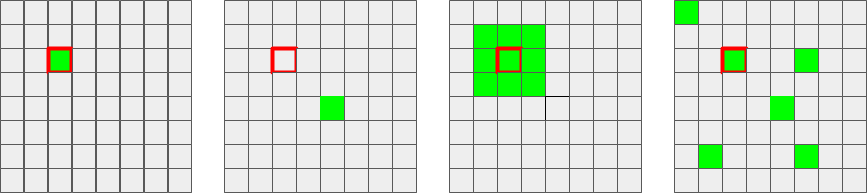
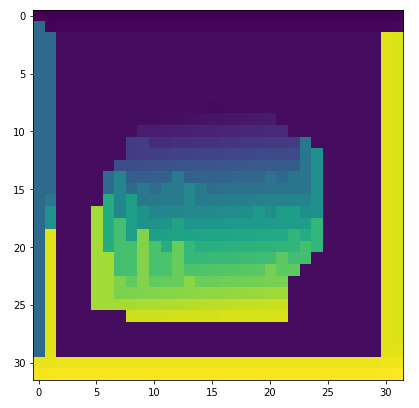
Figure 2 shows an example taken from the CIFAR-10 dataset. On the left we see an example input image, at the center we see its corresponding ReLU activation map for one particular channel in the first layer of the network and on the right we see the clustering map. There is a different weight vector for each color in the clustering map (not shown). The weights are set during training.


One problem with the gReLU operator is that all pixels in the group behave the same. Either they all maintain their input value, or they are all set to zero. If we use a single weight vector per channel, this means that either the entire channel is preserved or zeroed out. To avoid this situation, we introduce a noisy version of gReLU:
| (4) |
where is the Bernoulli distribution with parameter . This way, some activations maintain their value in case the ReLU decision is to zero out. In case the ReLU decision was to keep the activation value, then zero out some of the activations is akin to Dropout, which is a known technique in the literature.
In terms of security, the first clustering method, which is oblivious to the data, preserves the privacy of the data. No additional information is leaked to either party, other than the fact that some activation units share the same ReLU output, which is akin to sharing the overall architecture of the network between the parties. The second clustering method, which is based on the training data, reveals information, but only about the training data and not about the query image at inference time. See, for example, Figure 2 or Figure 4.
Experiments
Datasets
We test our algorithms on the CIFAR-10, SVHN and Fashion-MNIST datasets. They are 10-class classification problems that take as an input an RGB images of size pixels (CIFAR-10, SVHN) or a grayscale image of size (Fashion-MNIST).
Implementation Details
In order to evaluate running times, number of communication rounds and the communication bandwidth in the encrypted settings we used the PySyft library (OpenMined 2018), a framework for secure and private deep learning within the PyTorch framework. PySyft is a 3-party computation settings implementing the secureNN protocol (Wagh, Gupta, and Chandran 2019).
Table 1 gives the round complexity and communication bandwidth of the different operations involved in computing a single layer in a CNN for the secureNN protocol. denotes a matrix multiplication of dimension with . denotes a convolutional layer with input , i input channels, a filter of size , and o output channels. DReLU denotes the binary calculation if a value is greater than 0 for a single value. Mul denotes a single value multiplication. A single ReLU operation is composed of a DReLU and a Mul operations. The round complexity of a convolution layer is 2, while the total round complexity of ReLU layer is 10.
All communication is measured for -bit inputs (64-bit for PySyft) and denotes the field size (67 for PySyft), for more details see (Wagh, Gupta, and Chandran 2019). ReLU clearly dominates the process.
| Protocol | Rounds | Communication |
|---|---|---|
| DReLU | ||
| Mul |
We evaluate the run times of our models on a single Intel Core i5 CPU and 8GB RAM, which lets us evaluate improvement in performance. In our setting both the model and the data are shared between 2 parties (Alice and Bob), the third party doesn’t hold shares but helps with common randomness and computations. In our setting all 3 parties live on the same machine and do not communicate over the network, so all running times do not consider network latency.
CIFAR-10
For the CIFAR-10 dataset, we use a CNN that is based on the architecture proposed in MiniONN (Liu et al. 2017). See table 2. The network consists of a sequence of convolutions, ReLU, max pooling, and fully connected layers. We replaced the max pooling operation with average pooling, to reduce ReLU count. The number of ReLU operations in the first and second layers account for about of all ReLU operations, so we focus on them.
SVHN and Fashion-MNIST
For the SVHN and the Fashion-MNIST datasets, we use the CNNs in tables 3 and 4, respectively. Since they are small networks we focus on the first ReLU layer of the networks. For SVHN the first layer accounts for 92% of all ReLU operations, and for Fashion-MNIST the first layer accounts for 60%.
| Operation | patch size | Output size |
|---|---|---|
| conv | ||
| conv | ||
| Avg Pool | ||
| conv | ||
| conv | ||
| Avg Pool | ||
| conv | ||
| conv | ||
| conv | ||
| FC |
| Operation | patch size | Output size |
|---|---|---|
| conv | ||
| Avg Pool | ||
| conv | ||
| FC |
| Operation | patch size | Output size |
|---|---|---|
| conv | ||
| Avg Pool | ||
| conv | ||
| Avg Pool | ||
| Dropout 0.5 | ||
| FC | ||
| FC |
Reducing ReLU Count
The first set of experiments is designed to measure the impact of reducing ReLU count on the CNN accuracy. This can be achieved by either clustering activations into small image patches (i.e., data agnostic), or clustering together based on their behaviour on the training data (i.e., data dependent).
We start with sharing ReLUs over small patches of activations (i.e., pixels in the first layer). In particular, we evaluate non-overlapping patches of size and activations, and perform this on both the first and second layer. For comparison, we also evaluate the two extreme cases. The first is the regular CNN practice (i.e., patches), the other is the extreme case where the entire image (i.e., patch size of ) is based on a single ReLU.
In each case we assign a weight vector and set its weights during training. All activations in the patch base their ReLU decision on it. This partitioning is agnostic to the content of the images. The top part of Table 5 shows the results of this experiment on the CIFAR-10 model. Observe the nice correlation between the number of ReLUs and the accuracy.
For the SVHN and Fashion-MNIST model see Table 6. We get less than loss in accuracy, compared with the original accuracy of the models but with only ReLUs per channel, compared to and ReLUs per layer, respectively, in the original models.
| Method | Patch size | #ReLU | Noise | Accuracy |
|---|---|---|---|---|
| Original | No | |||
| Uniform | No | |||
| Uniform | No | |||
| Uniform | No | |||
| Layer 1 only | No | |||
| Layer 2 only | No | |||
| Noise | ||||
| FC+Noise |
The next part of Table 5 reports results of keeping one layer intact and replacing the other layer with a single ReLU per layer. We see that performance actually increases in the case of the first layer but degrades in the case of the second layer. As we go deeper into the network we need more and more ReLU decisions in order to maximize the model’s accuracy.
The extreme case of using a single ReLU decision for the whole channel is like a binary choice whether to use this channel in the classification of the image or not, since it either leaves the activation map as is or zeroes-out the entire channel.
As discussed earlier, if the ReLU decision is zero, then the entire patch is zeroed out, leaving no information for the next pooling operation. To battle this phenomenon, we introduce noise into the ReLU result. Specifically, in this experiment both layers use a single ReLU per channel, where the ReLU is carried out on the middle activation of the channel but we add noise to the ReLU decision of the second layer only. Results for CIFAR-10 are reported in Table 5 and for SVHN in Table 6. As can be seen, adding noise helped improve the results compared to working with image patches.
Next we replaced the use of a single activation to determine the ReLU outcome with learned weights of the activations. To do that, we added a fully connected layer and performed a dot-product with the activation map and got a single value that determines the ReLU decision. Then we flipped of the activation decisions and according to this we perform the ReLU on the original activation map. For CIFAR-10, results are shown in table 5. We get less than loss in accuracy, compared with the original accuracy of the model but with only ReLUs per channel per layer, compared to ReLUs per layer in the original model.
| SVHN | ||||
| Method | Patch size | #ReLU | Noise | Accuracy |
| Original | No | |||
| Uniform | No | |||
| Uniform | No | |||
| Adaptive | No | |||
| Noise | ||||
| FC+Noise | ||||
| Fashion-MNIST | ||||
| Method | Patch size | #ReLU | Noise | Accuracy |
| Original | No | |||
| Uniform | No | |||
| Uniform | No | |||
| Noise | ||||
| FC+Noise | ||||
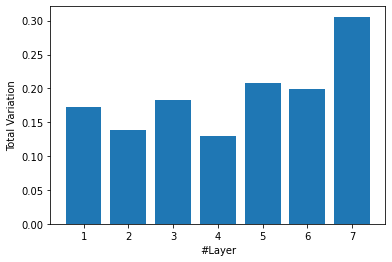
We observe that it is easier to compress the earlier layers of the network and conjecture that this is because the resulting image is smoother. To validate this assumption, we compute the Total Variation (the sum of absolute values of the spatial gradients in the image plane) along the layers. See Figure 3. As can be seen, the Total Variation of the activations increases as we move deeper into the network. This means the activation map is less smooth and therefore the correlation between nearby activations is lower. As a result, we need to increase the ReLU count.

The previous set of experiments used patches to cluster activations. Next, we evaluate the performance of clustering. To this end, we clustered activations into clusters based on the activation maps of all images in the training set. The clustering was done independently for each channel separately.
We use agglomerative clustering. First, we compute a binary activation vector per pixel, then we calculate the correlation matrix according to the hamming distance between the vectors. We initialize each activation as a set and in each iteration we take the two activations with the minimum hamming distance and if they are in different sets we unify their sets, and we stop when we have clusters. The 64 clustering maps for the 64 channels in the second layer can be seen in Figure 4. We can see that many channels have highly correlated background pixels that are unified into a single cluster. The clustering maps reveal information about the training examples and not about the query image.
One can see the results of the clustering experiments in Table 7. In the first experiment we clustered every window into clusters so in total we have clusters for each channel. In the second experiment we use image patches for the first layer where we take the middle pixel in each channel and for the second ReLU layer we use agglomerative clustering with clusters for the whole channel so in total we have the same number of ReLUs in both experiments. The results are slightly worse than the uniform patch experiment reported earlier (See Table 5). The results of agglomerative clustering for SVHN can be seen in table 6.
We conclude that ReLU sharing across small image patches drops the ReLU count with minimal impact on accuracy. We further observe that agglomerative clustering does not outperform simply grouping activations into image patches. We hypothesize that this might be the case because nearby activations in the image plane are already highly correlated.
| Method | Layer #1 | Layer #2 | #ReLU | Accuracy |
|---|---|---|---|---|
| # 1 | 256 | |||
| # 2 | 257 |
| Dataset | Model | Accuracy | Runtime (s) | Rounds | Comm. (MB) |
|---|---|---|---|---|---|
| CIFAR-10 | Original | ||||
| Uniform | |||||
| FC + Noise | |||||
| SVHN | Original | ||||
| Uniform | |||||
| Fashion-MNIST | Original | ||||
| Uniform |
From ReLU Count to Communication Bandwidth
Having established that dropping ReLU count has little impact on network accuracy, we investigate its impact on run-time, round complexity and communication bandwidth.
To do that, we evaluate 3 of the models introduced earlier that presented attractive ReLU count/accuracy trade-offs. This includes the original model, the Uniform with patch size model (where we perform a single ReLU decision for each channel for the first 2 ReLU layers), and the FC + Noise model (where we perform a dot-product with a learned weight vector and add noise to the outcome). We can see the results for CIFAR-10 of classification of 1 test image in Table 8.
In the original model each of the 2 first ReLU layers takes 10 seconds and 46MB of communication bandwidth so just these 2 layers take over of the total time and over of the total communication bandwidth.
In the Uniform model each of the 2 first ReLU layers takes 0.25 seconds and 2.66MB, compared to 10 seconds and 46MB of the original model. This leads to savings in the total time and savings in the total communication (the number of rounds stays the same).
The FC + Noise model takes slightly more communication from the Uniform model (but still less from the original model) since it has an extra fully connected layer and a multiplication with a sampled noise tensor but, as we saw in Table 5, this model has better accuracy so we can see here a trade off between accuracy and efficiency.
We observe similar behaviour for the SVHN data set. The first ReLU layer takes 3.7 seconds and 17.87MB of communication, so over of the total time and over of total communication. In the Uniform model the first ReLU layer takes 0.21 seconds and 1.09MB, 70%-76% less than the original model costs.
For Fashion-MNIST, the first ReLU layer takes 3.49 seconds and 16.66MB of communication, so over of the total time and over of total communication. In the Uniform model the first ReLU layer takes 0.2 seconds and 1.02MB, 45%-50% less than the original model costs. We can see the results for SVHN and Fashion-MNIST of classification of 1 test image in Table 8.
In all three models and across all three datasets we observe that drop in ReLU count translates directly into drop in communication bandwidth.
| Framework | Accuracy | Runtime (s) | Comm. (MB) | |||||
|---|---|---|---|---|---|---|---|---|
| setup | online | total | setup | online | total | |||
| MiniONN | ||||||||
| 2PC | GAZELLE | |||||||
| FALCON | ||||||||
| Chameleon | ||||||||
| 3PC | Shafran et al. | |||||||
| OURS | 0 | 57.86 | 57.86 | |||||
Comparison to other Approaches
It is challenging to compare our method to other methods reported in the literature because we use different hardware and different cryptographic settings.
Specifically, we use the PySyft implementation that, in turn, relies on SecureNN (Wagh, Gupta, and Chandran 2019) protocols. These are 3-party protocols, as opposed to the 2-party protocols used by others, except for Chameleon (Riazi et al. 2018) that uses the third party only in the offline phase.
In our setting all 3 parties live on the same machine and do not communicate over the network, so all running times do not consider network latency. All other frameworks are evaluated in a LAN setting where each party has its own machine so their run time takes into consideration the network latency.
Previous works split their computation into an input independent offline phase and an input dependent online phase. The PySyft implementation of the secureNN protocols does not do this split and counts all cost as online cost – hence, the offline cost is 0. The online run time can be improved by performing the beaver triplet generation for multiplication in an offline phase (Beaver 1992).
We do observe that our work achieves a improvement in online communication and a improvement in total communication over the best results of GAZELLE (Juvekar, Vaikuntanathan, and Chandrakasan 2018) and FALCON (Li et al. 2020). In online run-time our work is roughly slower than the best result of FALCON (Li et al. 2020) and slightly worse in total run-time (since our run-time doesn’t take network latency into consideration).
Shafran et al. (Shafran et al. 2019) used different models in their paper so in order to compare our work with theirs we applied their method on the model in table 2. Specifically, we removed the first ReLU layer and replaced the second ReLU layer with 50% partial activation layer. See results in table 8. Their method does not hurt the accuracy compared to the original model, while our method requires 28% less time and 20% less communication bandwidth, at the cost of a roughly drop in accuracy.
We believe that ReLU sharing can be implemented in other frameworks and improve their run time and communication cost. For example, we can see in the benchmarks table of FALCON (Li et al. 2020) for the ReLU operation that reducing the ReLU count by an order of magnitude leads to a roughly drop in both time and communication costs, for both the offline and online stages. We also observe in the FC layer benchmark there that adding another FC layer will have a negligible effect on costs. This leads us to believe that implementing ReLU sharing within the FALCON, or many other algorithms, will decrease costs.
Conclusions
We propose a method to drastically reduce the ReLU count of a CNN with minimal impact on accuracy. The proposed method groups pixels (or activation units) together and uses a single ReLU operator for all activations in the group. We discuss how to group activations and how to apply the ReLU operation.
Experiments suggest that we can reduce the ReLU count by up to three orders of magnitude which, in turn, cuts the communication bandwidth by more than . Our approach can be used with other Privacy Preserving Machine Learning algorithms and bring us closer to practical algorithms that can be used in the wild.
Acknowledgments
This research was supported in part by a grant made by TATA Consultancy Services.
References
- Beaver (1992) Beaver, D. 1992. Efficient Multiparty Protocols Using Circuit Randomization. In Feigenbaum, J., ed., Advances in Cryptology — CRYPTO ’91, 420–432. Berlin, Heidelberg: Springer Berlin Heidelberg. ISBN 978-3-540-46766-3.
- Dowlin et al. (2016) Dowlin, N.; Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Naehrig, M.; and Wernsing, J. 2016. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. In Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, 201–210. JMLR.org.
- Goldreich, Micali, and Wigderson (1987) Goldreich, O.; Micali, S.; and Wigderson, A. 1987. How to Play any Mental Game or A Completeness Theorem for Protocols with Honest Majority. In Aho, A. V., ed., Proceedings of the 19th Annual ACM Symposium on Theory of Computing, 1987, New York, New York, USA, 218–229. ACM. doi:10.1145/28395.28420.
- Juvekar, Vaikuntanathan, and Chandrakasan (2018) Juvekar, C.; Vaikuntanathan, V.; and Chandrakasan, A. 2018. GAZELLE: A Low Latency Framework for Secure Neural Network Inference. In Proceedings of the 27th USENIX Conference on Security Symposium, SEC’18, 1651–1668. USA: USENIX Association. ISBN 9781931971461.
- Li et al. (2020) Li, S.; Xue, K.; Zhu, B.; Ding, C.; Gao, X.; Wei, D.; and Wan, T. 2020. FALCON: A Fourier Transform Based Approach for Fast and Secure Convolutional Neural Network Predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Liu et al. (2017) Liu, J.; Juuti, M.; Lu, Y.; and Asokan, N. 2017. Oblivious Neural Network Predictions via MiniONN Transformations. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS ’17, 619–631. New York, NY, USA: Association for Computing Machinery. ISBN 9781450349468. doi:10.1145/3133956.3134056. URL https://doi.org/10.1145/3133956.3134056.
- Mohassel and Zhang (2017) Mohassel, P.; and Zhang, Y. 2017. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In 2017 IEEE Symposium on Security and Privacy (SP), 19–38.
- OpenMined (2018) OpenMined. 2018. PySyft: A Python library for secure and private Deep Learning. In https://github.com/OpenMined/PySyft.
- Riazi et al. (2018) Riazi, M. S.; Weinert, C.; Tkachenko, O.; Songhori, E. M.; Schneider, T.; and Koushanfar, F. 2018. Chameleon: A Hybrid Secure Computation Framework for Machine Learning Applications. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, ASIACCS ’18, 707–721. New York, NY, USA: Association for Computing Machinery. ISBN 9781450355766. doi:10.1145/3196494.3196522. URL https://doi.org/10.1145/3196494.3196522.
- Rouhani, Riazi, and Koushanfar (2018) Rouhani, B. D.; Riazi, M. S.; and Koushanfar, F. 2018. Deepsecure: Scalable Provably-Secure Deep Learning. In Proceedings of the 55th Annual Design Automation Conference, DAC ’18. New York, NY, USA: Association for Computing Machinery. ISBN 9781450357005. doi:10.1145/3195970.3196023.
- Shafran et al. (2019) Shafran, A.; Segev, G.; Peleg, S.; and Hoshen, Y. 2019. Crypto-Oriented Neural Architecture Design. CoRR abs/1911.12322. URL http://arxiv.org/abs/1911.12322.
- Wagh, Gupta, and Chandran (2019) Wagh, S.; Gupta, D.; and Chandran, N. 2019. SecureNN: 3-Party Secure Computation for Neural Network Training. In Proceedings on Privacy Enhancing Technologies (PETS).
- Yao (1982) Yao, A. C. 1982. Protocols for Secure Computations. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science, SFCS ’82, 160–164. USA: IEEE Computer Society.