Relational Programming with Foundation Models
Abstract
Foundation models have vast potential to enable diverse AI applications. The powerful yet incomplete nature of these models has spurred a wide range of mechanisms to augment them with capabilities such as in-context learning, information retrieval, and code interpreting. We propose Vieira, a declarative framework that unifies these mechanisms in a general solution for programming with foundation models. Vieira follows a probabilistic relational paradigm and treats foundation models as stateless functions with relational inputs and outputs. It supports neuro-symbolic applications by enabling the seamless combination of such models with logic programs, as well as complex, multi-modal applications by streamlining the composition of diverse sub-models. We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement plugins for 12 foundation models including GPT, CLIP, and SAM. We evaluate Vieira on 9 challenging tasks that span language, vision, and structured and vector databases. Our evaluation shows that programs in Vieira are concise, can incorporate modern foundation models, and have comparable or better accuracy than competitive baselines.
1 Introduction
Foundation models are deep neural models that are trained on a very large corpus of data and can be adapted to a wide range of downstream tasks (rishi2021foundationmodels). Exemplars of foundation models include language models (LMs) like GPT (bubeck2023sparks), vision models like Segment Anything (kirillov2023segment), and multi-modal models like CLIP (alec2021transferablevisualmodels). While foundation models are a fundamental building block, they are inadequate for programming AI applications end-to-end. For example, LMs hallucinate and produce nonfactual claims or incorrect reasoning chains (mckenna2023sources). Furthermore, they lack the ability to reliably incorporate structured data, which is the dominant form of data in modern databases. Finally, composing different data modalities in custom or complex patterns remains an open problem, despite the advent of multi-modal foundation models such as ViLT (alec2021transferablevisualmodels) for visual question answering.
Various mechanisms have been proposed to augment foundation models to overcome these limitations. For example, PAL (gao2023pal), WebGPT (reiichiro2021webgpt), and Toolformer (schick2023toolformer) connect LMs with search engines and external tools, expanding their information retrieval and structural reasoning capabilities. LMQL (beurer2022prompting) generalizes pure text prompting in LMs to incorporate scripting. In the domain of computer vision (CV), neuro-symbolic visual reasoning frameworks such as VisProg (Gupta2022VisProg) compose diverse vision models with LMs and image processing subroutines. Despite these advances, programmers lack a general solution that systematically incorporates these methods into a single unified framework.
In this paper, we propose Vieira, a declarative framework for programming with foundation models. Vieira follows a (probabilistic) relational paradigm due to its theoretical and practical versatility. Structured data is commonly stored in relational databases. Relations can also represent structures such as scene graphs in vision and abstract syntax trees in natural and formal languages. Moreover, extensions for probabilistic and differentiable reasoning enable the integration of relational programming with deep learning in neuro-symbolic frameworks like DeepProbLog (robin2018deepproblog) and Scallop (li2023scallop).
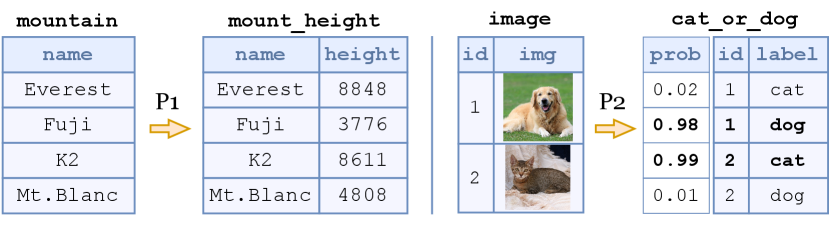
In Vieira, relations form the abstraction layer for interacting with foundation models. Our key insight is that foundation models are stateless functions with relational inputs and outputs. Fig. 1(a) shows a Vieira program which invokes GPT to extract the height of mountains whose names are specified in a structured table. Likewise, the program in Fig. 1(b) uses the image-text alignment model CLIP to classify images into discrete labels such as cat and dog. Fig. 1(c) shows relational input-output examples for the two programs. Notice that the CLIP model also outputs probabilities that allow for probabilistic reasoning.
We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement a customizable and extensible plugin library comprising 12 foundation models including GPT, CLIP, and SAM. The resulting unified interface enables a wide spectrum of applications with benefits such as reduced hallucination, retrieval augmentation, and multi-modal compositionality. We evaluate Vieira on 9 applications that span natural language reasoning, information retrieval, visual question answering, image generation, and image editing. For these applications, we explore diverse methods for programming with foundation models, such as neuro-symbolic reasoning, combining semantic searching with question answering, and modularly composing foundation models. We not only observe on-par or superior performance of our solutions compared to competitive baselines, but also demonstrate their succinctness and ease-of-use.
We summarize our contributions as follows: (1) we introduce a new approach based on relational programming to build applications on top of foundation models; (2) we implement an extensible plugin library of 12 programmable foundation models; and (3) we evaluate Vieira on 9 benchmark tasks, and demonstrate comparable or better no-training accuracy than neural-only as well as task-specific baselines. Our framework, plugin library, and evaluations are open-source and available at https://github.com/scallop-lang/scallop.
2 Related Work
Neuro-symbolic methods.
These methods combine the complementary benefits of neural learning and symbolic reasoning. They include domain-specific solutions (yi2018nsvqa; mao2019nscl; li2020closed; wang2019satnet; xu2022dont; chen2020nerd; minervini2020ctp) as well as general programming frameworks, such as DeepProbLog (robin2018deepproblog) and Scallop (li2023scallop). These methods typically concern training or fine-tuning neural models in the presence of logical programs, whereas we target building applications atop foundation models with zero-shot or few-shot examples. Another recent work, the STAR framework (rajasekharan2023star) also connects a language model (neural) to an answer set programming reasoner (symbolic). It is conceptually similar to Vieira but only focuses on natural language understanding and does not support probabilistic reasoning.
Foundation models.
These models target different modalities and domains (touvron2023llama; openai2023gpt4; alec2021transferablevisualmodels; kirillov2023segment; alec2021transferablevisualmodels). Their reasoning capabilities continue to improve with larger context sizes (ratner2023parallel), smarter data selection (adadi2021survey), and the discovery of new prompting methods, such as chain-of-thought (wei2023chainofthought; kojima2022large), self-consistency (wang2023selfconsistency), and ReAct (yao2023react). Vieira is orthogonal to these techniques and stands to further enhance the robustness and reliability of foundation models in end-to-end AI applications.
Tools aiding language models.
There are many efforts that seek to improve the reasoning abilities of language models (LMs) by incorporating external programs and tools (gao2023pal; schick2023toolformer; reiichiro2021webgpt; davis2023testing). For instance, AutoGPT (autogpt) and TaskMatrix.AI (liang2023taskmatrixai) allows black-box LMs to control symbolic reasoning by invoking commands or calling APIs. On the other hand, many works attempt to extract structured information from LMs for downstream tasks (Gupta2022VisProg; beurer2022prompting). Vieira unifies these two strategies for augmenting model capabilities, and extends them into a glue language for composing multi-modal foundation models.
3 Language
Vieira employs a declarative logic programming language based on Datalog (alice). In this section, we present the core language and its foreign interface for incorporating diverse foundation models.
3.1 Core Language
Relations and data types.
The fundamental data type in Vieira is set-valued relations comprising tuples of statically-typed primitive values. Besides the standard primitive types such as integers (e.g. i32) and string (String), Vieira introduces two additional types for seamless integration of foundation models: Tensor and Algebraic Data Types (ADTs). For example, we can declare a relation named image to store tuples of image IDs and image Tensors:
The contents of this relation can be specified via a set of tuples using the built-in foreign function $load_image:
ADTs in Vieira enable the specification of domain specific languages (DSLs) to bridge structured and unstructured data. For example, the following DSL for visual question answering (VQA) describes queries to retrieve scene objects, count objects, and check the existence of objects:
Logical reasoning.
Being based on Datalog, Vieira supports defining Horn rules, thereby allowing logical reasoning constructs such as conjunction, disjunction, recursion, stratified negation, and aggregation. Recursion is particularly useful for inductively defining the semantics of a DSL. For example, a (partial) semantics for the above DSL is defined as follows, where eval_o and eval_n are recursively defined to evaluate objects and numbers, respectively:
Note that the case-is operator matches patterns of the ADT and the count aggregator counts the number of entities. When combined with foundation models, principled reasoning semantics in this style can compensate for individual foundation models’ lack of reasoning capability.
Probabilistic soft logic.
Tuples can be tagged with probabilities. The example below shows hard-coded probabilities, suggesting that the entity is more likely a dog than a cat:
Soft-logic operations produce probabilities as well. For instance, the soft-eq operator (=̃) on Tensors derives cosine-similarity between tensors, enabling features like soft-join and applications like semantic search. In the following example, we compute similarity scores between distinct documents by performing soft-join on their embeddings:
Notice that in the above rule, a join on a tensor value v is de-sugared into a soft-eq on two individual variables (denoted v1 and v2). Internally, with the provenance framework provided by Scallop (li2023scallop), we use the top--proofs semiring (huang2021scallop) for scalable probabilistic reasoning, thus enabling features such as ranking and uncertainty estimation.
3.2 Foreign Interface
In order to incorporate foundation models, we design a foreign interface with two main programming constructs, called foreign predicate and foreign attribute. They can be defined externally in languages like Python and imported into Vieira for application.
Foreign Predicate (FP).
Foreign predicates can be used in rules just like other relations. However, instead of grounding relational facts from a table, FPs ground facts by invoking external functions. The syntax for defining FPs is as follows:
In addition to the type, each argument is specified either as a bounded argument (using the keyword bound) or a free argument (using free or omitted for brevity). Semantically, FPs are functions that take in a tuple of bounded arguments and return a list of tuples of free arguments. The runtime of Vieira performs memoization on FP results to avoid redundant computation. Optionally, FPs can tag a probability to each returned tuple for further probabilistic reasoning.
Foreign Attribute (FA).
In Vieira, attributes can be used to decorate declarations of predicates. They are higher-order functions that take in the provided arguments and the decorated predicate to return a new predicate. The syntax for using an attribute to decorate a predicate is:
The attribute is applied prior to the compilation of Vieira programs. For interfacing with foundation models, the positional and keyword arguments are particularly helpful in configuring the underlying model, hiding low-level details. Fig. 2 illustrates one succinct implementation of the FA that enables the use of the CLIP model shown in Fig. 1(b).
4 Foundation Models
Vieira provides an extensible plugin framework that adapts to the evolving landscape of foundation models. In this work, we have implemented 7 plugins, covering 12 foundation models, all through the foreign interface. Our design principle for the interface is three-fold: simplicity, configurability, and compositionality. In this section, we present several representative predicates and attributes which substantially support the applicability of Vieira to diverse machine learning tasks.
Text completion.
In Vieira, language models like GPT (openai2023gpt4) and LLaMA (touvron2023llama) can be used as basic foreign predicates for text completion:
In this case, gpt is an arity-2 FP that takes in a String as the prompt and produces a String as the response. It uses the model gpt-3.5-turbo by default. To make the interface more relational and structural, we provide an FA:
Here, we declare a relation named population which produces a population number (num) given a location (loc) as input. Notice that structured few-shot examples are provided through the argument examples.
Semantic parsing.
One can directly configure language models to perform semantic parsing. For instance, the semantic parser for the simple Query DSL (partially defined in the Language section) can be declared as follows:
Internally, the language model is expected to generate a fully structured Query in its string form. Then, Vieira attempts to parse the string to construct actual ADT values. In practice, the success of semantic parsing depends heavily on the design of the DSL, involving factors like intuitiveness (e.g., names and arguments of ADT variants) and complexity (e.g., number of possible ADT variants).
Relational data extraction.
Structural relational knowledge available in free-form textual data can be extracted by language models. We introduce a foreign attribute @gpt_extract_relation for this purpose. For instance, the following declared predicate takes in a context and produces (subject, object, relation) triplets:
This attribute differs from the text completion attribute in that it can extract an arbitrary number of facts. The underlying implementation prompts LMs to respond with JSON-formatted strings, allowing structured facts to be parsed.
Language models for textual embedding.
Textual embeddings are useful in performing tasks such as information retrieval. The following example declares an FP encapsulating a cross-encoder (nogueira2019passage):
In the last line, we compute the cosine-similarity of the encoded embeddings using a soft-join on the variable e. As a result, we obtain a probabilistic fact like 0.9::sim() whose probability encodes the cosine-similarity between the textual embeddings of "cat" and "neko".
Image classification models.
Image-text alignment models, such as CLIP (alec2021transferablevisualmodels), can naturally be used as zero-shot image classification models. Fig. 1(b) shows an example usage of the @clip attribute. We also note that dynamically-generated classification labels can be provided to CLIP via a bounded argument in the predicate.
Image segmentation models.
OWL-ViT (minderer2022simple), Segment Anything Model (SAM) (kirillov2023segment), and DSFD (jian2018dsfd) are included in Vieira as image segmentation (IS) and object localization (LOC) models. IS and LOC models can provide many outputs, such as bounding boxes, classified labels, masks, and cropped images. For instance, the OWL-ViT model can be used and configured as follows:
Here, the find_obj predicate takes in an image, and finds image segments containing “human face” or “rocket”. According to the names of the arguments, the model extracts 3 values per segment: ID, label, and cropped image. Note that each produced fact will be associated with a probability, representing the confidence from the model.
Image generation models.
Visual generative models such as Stable Diffusion (Rombach_2022_diffusion) and DALL-E (ramesh2021zero) can be regarded as relations as well. The following example shows the declaration of the gen_image predicate, which encapsulates a diffusion model:
As can be seen from the signature, it takes in a String text as input and produces a Tensor image as output. Optional arguments such as the desired image resolution and the number of inference steps can be supplied to dictate the granularity of the generated image.
5 Tasks and Solutions
| Task | Dataset | #Test Samples | Metric | Foundation Models Used |
| DR | DR | 369 | EM | GPT-4 |
| TSO | TSO | 150 | EM | GPT-4 |
| KR | CLUTRR | 1146 | EM | GPT-4 |
| MR | GSM8K | 1319 | EM | GPT-4 |
| QA | Hotpot QA | 1000 | EM | GPT-4 |
| ada-002 | ||||
| PS | Amazon ESCI | 1000 | nDCG | GPT-4 |
| ada-002 | ||||
| VQA | CLEVR | 480 | Recall@1 Recall@3 | GPT-4 |
| OWL-ViT | ||||
| GQA | 500 | VilT | ||
| CLIP | ||||
| VOT | VQAR | 100 | MI | OWL-ViT |
| VilT | ||||
| GPT-4 | ||||
| OFCP | 50 | DSFD | ||
| CLIP | ||||
| IGE | OFCP | 50 | MI | DFSD |
| CLIP | ||||
| IGP20 | 20 | GPT-4 | ||
| Diffusion |
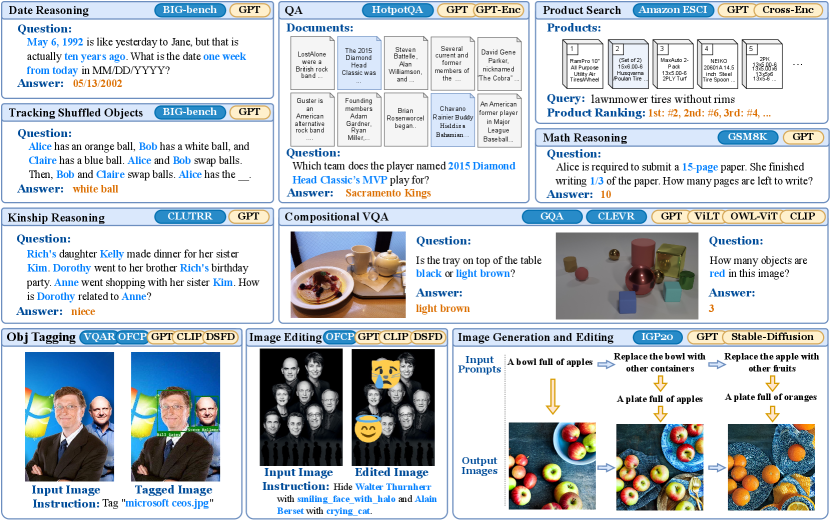
We apply Vieira to solve 9 benchmark tasks depicted in Fig. 3. Table 1 summarizes the datasets, evaluation metrics, and the foundation models used in our solutions. We elaborate upon the evaluation settings and our solutions below.
Date reasoning (DR).
In this task adapted from BIG-bench (srivastava2023imitation), the model is given a context and asked to compute a date. The questions test the model’s temporal and numerical reasoning skills, as well as its grasp of common knowledge. Unlike BIG-bench where multiple-choice answers are given, we require the model to directly produce its answer in MM/DD/YYYY form.
Our solution leverages GPT-4 (5-shot111In this work, in “-shot” means the number of examples provided to the LM component within the full solution. Each example is a ground-truth input-output pair for the LM.) for extracting 3 relations: mentioned dates, duration between date labels, and the target date label. From here, our relational program iterates through durations to compute dates for all date labels. Lastly, the date of the target label is returned as the output.
Tracking shuffled objects (TSO).
In this task from BIG-bench, a textual description of pairwise object swaps among people is given, and the model needs to track and derive which object is in a specified person’s possession at the end. There are three difficulty levels depending on the number of objects to track, denoted by .
Our solution for tracking shuffled objects relies on GPT-4 (1-shot) to extract 3 relations: initial possessions, swaps, and the target person whose final possessed object is expected as the answer. Our reasoning program iterates through all the swaps starting from the initial state and retrieves the last possessed object associated with the target.
Kinship reasoning (KR).
CLUTRR (sinha2019clutrr) is a kinship reasoning dataset of stories which indicate the kinship between characters, and requires the model to infer the relationship between two specified characters. The questions have different difficulty levels based on the length of the reasoning chain, denoted by .
Our solution for kinship reasoning invokes GPT-4 (2-shot) to extract the kinship graph from the context. We also provide an external common-sense knowledge base for rules like “mother’s mother is grandmother”. Our program then uses the rules to derive other kinship relations. Lastly, we retrieve the kinship between the specified pair of people.
Math reasoning (MR).
This task is drawn from the GSM8K dataset of arithmetic word problems (cobbe2021training). The questions involve grade school math word problems created by human problem writers, and the model is asked to produce a number as the result. Since the output can be fractional, we allow a small delta when comparing the derived result with the ground truth.
Our solution to this task prompts GPT-4 (2-shot) to produce step-by-step expressions, which can contain constants, variables, and simple arithmetic operations. We evaluate all the expressions through a DSL, and the result associated with the goal variable is returned. By focusing the LM’s responsibility solely on semantic parsing, our relational program can then achieve faithful numerical computation via DSL evaluation.
Question answering with information retrieval (QA).
We choose HotpotQA (yang2018hotpotqa), a Wikipedia-based question answering (QA) dataset under the “distractor” setting. Here, the model takes in 2 parts of inputs: 1) a question, and 2) 10 Wikipedia paragraphs as the context for answering the question. Among the 10 Wikipedia pages, at most 2 are relevant to the answer, while the others are distractors.
Our solution is an adaptation of FE2H (li2022fe2h), which is a 2-stage procedure. First, we turn the 10 documents into a vector database by embedding each document. We then use the embedding of the question to retrieve the 2 most related documents, which are then fed to a language model to do QA. In this case, the QA model does not have to process all 10 documents, leading to less distraction.
Product search (PS).
We use Amazon’s ESCI Product Search dataset (reddy2022shopping). The model is provided with a natural language (NL) query and a list of products (23 products on average). The goal is to rank the products that best match the query. In the dataset, for each pair of query and product, a label among (exact match), (substitute), (complementary), and (irrelevant) is provided. The metric we use to evaluate the performance is nDCG. The gains are set to be 1.0 for , 0.1 for , 0.01 for , and 0.0 for .
One challenge of this dataset is that many queries contain negative statements. For example, in the query “#1 treadmill without remote”, the “remote” is undesirable. Therefore, instead of computing the embedding of the full query, we decompose the query into positive and negative parts. We then perform semantic search by maximizing the similarity of the positive part while minimizing that of the negative part.
Compositional visual question answering (VQA).
We choose two compositional VQA datasets, GQA (drew2019gqa) and CLEVR (johnson2016clevr). In this task, the model is given an image and a question, and needs to answer the question. For GQA, the majority of questions expect yes/no answers, while CLEVR’s questions demand features like counting and spatial reasoning. We uniformly sample 500 and 480 examples from GQA and CLEVR datasets respectively. Following VQA conventions (kim2021vilt), we use Recall@ where as the evaluation metrics.
Our solution for GQA is an adaptation of VisProg (Gupta2022VisProg). We create a DSL for invoking vision modules such as ViLT and OWL-ViT, and use GPT-4 for converting questions into programs in this DSL. Our solution for CLEVR is similar, directly replicating the DSL provided by the original work. OWL-ViT and CLIP are used to detect objects and infer attributes, while the spatial relations are directly computed using the bounding box data.
Visual object tagging (VOT).
We evaluate on two datasets, VQAR (huang2021scallop) and OFCP. For VQAR, the model is given an image and a programmatic query, and is asked to produce bounding boxes of the queried objects in the image. Our solution composes a relational knowledge base, defining entity names and relationships, with object retrieval (OWL-ViT) and visual QA (ViLT) models.
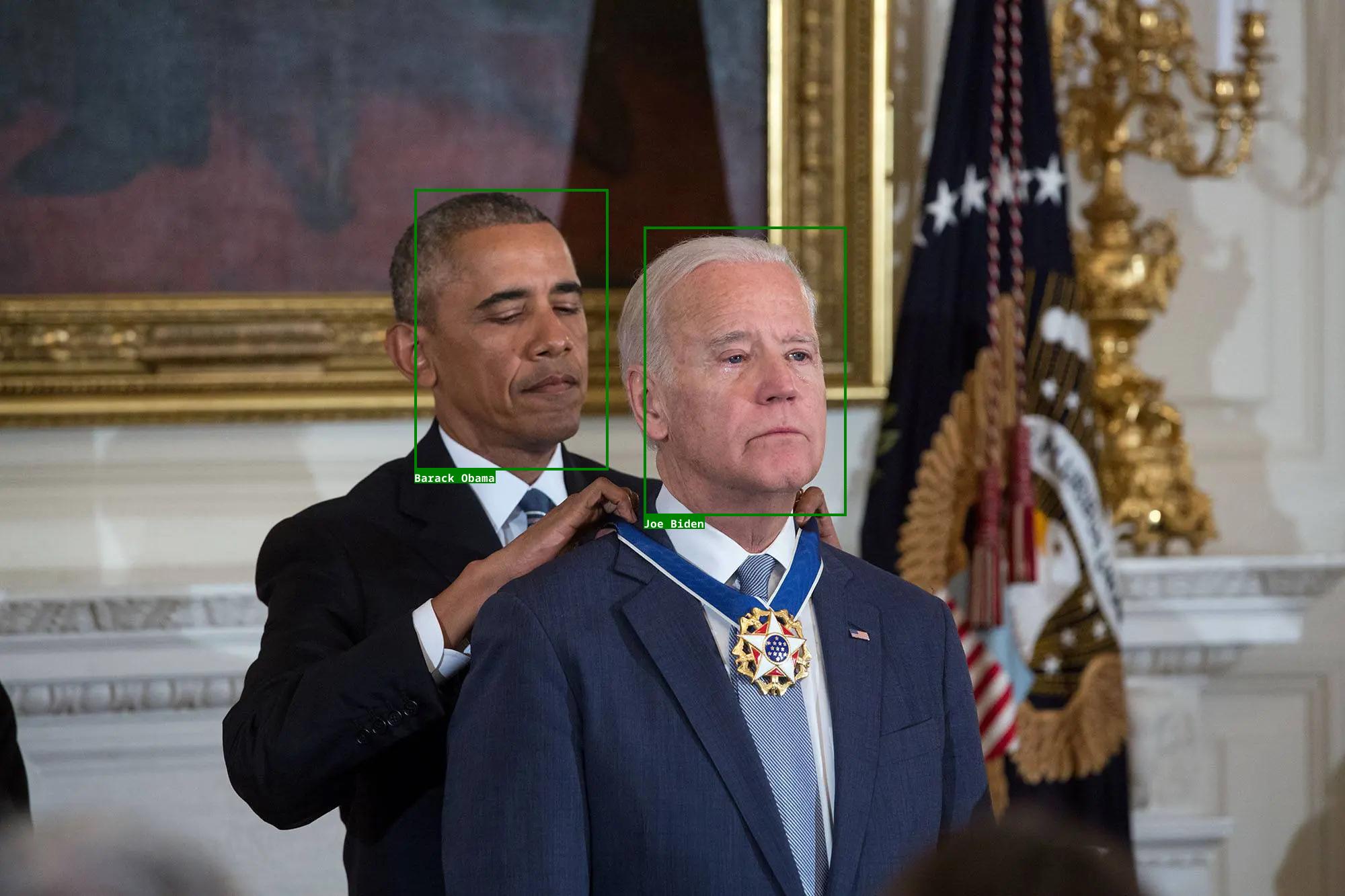
Online Faces of Celebrities and Politicians (OFCP) is a self-curated dataset of images from Wikimedia Commons among other sources. For this dataset, the model is given an image with a descriptive NL filename, and needs to detect faces relevant to the description and tag them with their names. Our solution obtains a set of possible names from GPT-4 and candidate faces from DSFD. These are provided to CLIP for object classification, after which probabilistic reasoning filters the most relevant face-name pairs.
Language-guided image generation and editing (IGE).
We adopt the task of image editing from (Gupta2022VisProg). In this task, the instruction for image editing is provided through NL, and can invoke operations such as blurring background, popping color, and overlaying emojis. Due to the absence of an existing dataset, we repurpose the OFCP dataset by introducing 50 NL image editing prompts. Our solution for this task is centered around a DSL for image editing. We incorporate GPT-4 for semantic parsing, DSFD for face detection, and CLIP for entity classification. Modules for image editing operations are implemented as individual foreign functions.
For free-form generation and editing of images, we curate IGP20, a set of 20 prompts for image generation and editing. Instead of using the full prompt, we employ an LM to decompose complex NL instructions into simpler steps. We define a DSL with high-level operators such as generate, reweight, refine, replace, and negate. We use a combination of GPT-4, Prompt-to-Prompt (hertz2022prompttoprompt), and diffusion model (Rombach_2022_diffusion) to implement the semantics of our DSL. We highlight our capability of grounding positive terms from negative phrases, which enables handling prompts like “replace apple with other fruits” (Fig. 3).
6 Experiments and Analysis
| Dataset | LoC | Prompt LoC | Dataset | LoC | Prompt LoC | |
|---|---|---|---|---|---|---|
| DR | 69 | 48 | CLEVR | 178 | 45 | |
| TSO | 34 | 16 | GQA | 82 | 36 | |
| CLUTRR | 61 | 45 | VQAR | 53 | 11 | |
| GSM8K | 47 | 28 | OFCP (VOT) | 33 | 2 | |
| HotpotQA | 47 | 24 | OFCP (IGE) | 117 | 44 | |
| ESCI | 32 | 7 | IGP20 | 50 | 12 |
| Method | DR | TSO | CLUTRR | GSM8K |
|---|---|---|---|---|
| GPT-4 | 71.00 (0-shot) | 30.00 (0-shot) | 43.10 (3-shot) | 87.10 (0-shot) |
| GPT-4 (CoT) | 87.26 (0-shot) | 84.00 (0-shot) | 24.17 (3-shot) | 92.00 (5-shot) |
| Ours | 92.41 | 100.00 | 72.50 | 90.60 |
We aim to answer the following research questions:
-
RQ1.
Is Vieira programmable enough to be applicable to a diverse range of applications with minimal effort?
-
RQ2.
How do solutions using Vieira compare to other baseline methods in the no-training setting?
| HotpotQA | Amazon ESCI | ||||
|---|---|---|---|---|---|
| Method | Fine-tuned | EM | Method | Fine-tuned | nDCG |
| C2FM | ✓ | 72.07% | BERT | ✓ | 0.830 |
| FE2H | ✓ | 71.89% | CE-MPNet | ✓ | 0.857 |
| — | — | — | MIPS | ✗ | 0.797 |
| Ours | ✗ | 67.3% | Ours | ✗ | 0.798 |
6.1 RQ1: Programmability
While a user study for Vieira’s programmability is out of scope in this paper, we qualitatively evaluate its programmability on three aspects. First, we summarize the lines-of-code (LoC) for each of our solutions in Table 2. The programs are concise, as most are under 100 lines. Notably, natural language prompts (including few-shot examples) take up a significant portion of each solution. Secondly, 8 out of 10 solutions are coded by undergraduate students with no background in logic and relational programming, providing further evidence of Vieira’s user-friendliness. Last but not least, our solutions are interpretable and thus offer debuggability. Specifically, all the intermediate relations are available for inspection, allowing systematic error analysis.
6.2 RQ2: Baselines and Comparisons

We compare the performance of our solutions to existing baselines under the no-training setting. In particular, our solutions achieve better performance than comparable baselines on 6 out of 8 studied datasets with baselines. Below, we classify the tasks into 4 categories and discuss the respective performance and comparisons.
Natural language reasoning.
For the tasks of DR, TSO, CLUTRR, and GSM8K, we pick a generic baseline of GPT-4 under zero-shot, few-shot, and chain-of-thought (CoT) settings. All our solutions also rely on GPT-4 (few-shot), but we note that our shots only include extracted facts, and not the final answer or any reasoning chains. The data in Table 3 indicates that our method can significantly enhance reasoning performance and reduce hallucination, exemplified by achieving a flawless 100% accuracy on the TSO dataset. Note that on GSM8K, our method scores slightly lower than the baseline; we conjecture that our solution demands more from GPT-4 itself to extract structured computation steps. On CLUTRR, our solution even outperforms fCoT (lyu2023faithful), a special prompting technique with external tool use, by 0.6%. In Fig. 5 we illustrate the systematic generalizability of our methods. The performance of our solutions remains relatively consistent even when the problems become harder. We provide illustrative examples in Fig. 4 showing comparisons between our method and GPT-4 (zero-shot CoT).
Retrieval augmentation and semantic search.
For the HotpotQA dataset, our solution is an adaptation of FE2H (li2022fe2h), a retrieval-augmented question answering approach. As seen in Table 4, with no fine-tuning, our method scores only a few percentages lower than fine-tuned methods C2FM (yin2022c2fm) and FE2H. For the Amazon ESCI dataset, our solution performs semantic search for product ranking. While performing slightly lower than the fine-tuned methods (reddy2022shopping; song2020mpnet), our solution outperforms maximum inner product search (MIPS) based on GPT text encoder (text-embedding-ada-002).
| Method | GQA | CLEVR | ||
|---|---|---|---|---|
| Recall@1 | Recall@3 | Recall@1 | Recall@3 | |
| ViLT-VQA | 0.049 | 0.462 | 0.241 | 0.523 |
| PNP-VQA | 0.419 | — | — | — |
| Ours | 0.579 | 0.665 | 0.463 | 0.638 |
Compositional multi-modal reasoning.
For VQA, we pick ViLT-VQA (kim2021vilt) (a pre-trained foundation model) and PNP-VQA (tiong-2022-pnpvqa) (a zero-shot VQA method) as baselines. As shown in Table 5, our method significantly outperforms the baseline model on both datasets. Compared to the neural-only baseline, our approach that combines DSL and logical reasoning more effectively handles intricate logical operations such as counting and numerical comparisons. On GQA, out method outperforms previous zero-shot state-of-the-art, PNP-VQA, by ( to ). For object and face tagging, without training or fine-tuning, our method achieves 67.61% and 60.82% semantic correctness rates (Table 6).

Image generation and editing.
For image generation and editing, we apply our technique to the OFCP and IGP20 datasets. We rely on manual inspection for evaluating our performance on the OFCP dataset, and we observe 37 correctly edited images out of the 50 evaluated ones, resulting in a 74% semantic correctness rate (Table 6). For IGP20, we choose as the baseline a diffusion model, InstructPix2Pix (brooks2023instructpix2pix), which also combines GPT-3 with image editing. We show one example baseline comparison illustrated in Figure 6.
| Method | Visual Object Tagging | Image Editing | |
|---|---|---|---|
| VQAR | OFCP | OFCP | |
| Ours | 67.61% | 60.82% | 74.00% |
7 Conclusion
We introduced Vieira, a declarative framework designed for relational programming with foundation models. Vieira brings together foundation models from diverse domains, providing a unified interface for composition and the ability to perform probabilistic logical reasoning. This results in solutions with comparable and often superior performance than neural-based baselines. In the future, we aim to extend the capabilities of Vieira beyond the current in-context learning settings to weakly-supervised training and fine-tuning of foundation models in an end-to-end manner.
Acknowledgements
We thank the anonymous reviewers for useful feedback. This research was supported by NSF grant #2313010 and DARPA grant #FA8750-23-C-0080. Ziyang Li was supported by an Amazon Fellowship.
Appendix A Full Vieira Language
We present the full surface syntax of the Vieira language in Fig. 7.
Appendix B Detailed Example
In this section, we describe the Vieira program for one of our benchmark applications, CLEVR (johnson2016clevr). We decompose this application into three sub-tasks: 1) extracting a structured scene graph from the input image, 2) extracting an executable query program from the input natural language (NL) question, and 3) combining both to answer the question based on the scene graph. We next describe how we solve each of these sub-tasks. For illustration, we use the example image and question shown in Fig. 8.
B.1 Image to structured scene graph
To convert image to structured scene graph, we use two vision models, namely OWL-ViT (minderer2022simple) and CLIP (alec2021transferablevisualmodels). We use OWL-ViT for obtaining object segments and CLIP models for classifying object properties. The goal is to construct scene graph which contains the following information: the shape, color, material, and size for each object, and the spatial relationships between each pair of objects.
Our object detection predicate is defined as follows:
We are using the @owl_vit foreign attribute to decorate a predicate vit_segment_image. Here, the image has one bounded argument which is the input image, and it produces image segments represented by 5 tuples, containing segment id (id), segmented image (cropped_image), the area of segment (area), the center coordinate (bbox_center_x), and the bottom coordinate (bbox_bottom_y). Specifically, segmented images can be passed to downstream image classifiers, the area is used to classify whether the object is big or small, and the coordinates are used to determine spatial relationships between objects.
Note that the arguments we pass to @owl_vit contain expected labels of cube, sphere, and cylinder. Because OWL-ViT does not perform well at classifying given geometric objects by shape, we do not use it to query the labels associated with each object. Rather, these labels identify the image segments the model extracts from the base image.
We set expand_crop_region to be 10, which expands the cropped images by the given factor. Since the bounding boxes of the objects are tight, enlarging the crop region can help subsequent classifiers to better see the object. With the limit set to 10, OWL-ViT only generates 10 image segments. Lastly, we set flatten_probability to be true. Again, OWL-ViT is not trained on CLEVR, so it produces very low confidence scores on all recognized objects. In order to not let the scores affect downstream computation, we overwrite the probability to 1 for all objects.
We load the image specified by the image directory path using the foreign function $load_image, and then segment the image using the segment_image predicate:
We next define the shape classifier. For this, we repurpose @clip to classify each object segment with a label from three possible shapes: cube, sphere, and cylinder. In order to interface with CLIP, we create a prompt "a {{}} shaped object". Each label is filled into the prompt, producing short phrases like “a cube shaped object”. Then, the three prompts are passed to CLIP along with the object image, and facts with labels are returned with probabilities.
The classifiers for color and material are done similarly:
From here, we just invoke the previous We continue to discuss how do we obtain the size and spatial relationships. In order to obtain the size (small or large) of each object, we use a probabilistic rule for specifying that:
Finally, the spatial relationship (left, right, front, and behind) is derived from object coordinates.
Combining everything together, we have produced the relationships color, shape, material, size, and relate, forming the scene graph of the image.
B.2 NL question to programmatic query
We use the GPT-4 model (openai2023gpt4) for converting a natural language question into a programmatic query. The first step is defining the domain specific language (DSL) for querying the CLEVR dataset:
Notice that the DSL is represented by the user-defined algebraic data type (ADT) Query, which contains constructs for getting objects, counting objects, checking existence of objects, and even comparing counts obtained from evaluating multiple queries. We then create the semantic parser for the DSL by configuring the GPT-4 model:
Other than the model argument which is used to specify the OpenAI model to call, we also pass 3 additional arguments to gpt_semantic_parse: header, prompt, and examples. These arguments construct the first part of the prompt that we pass to GPT-4. Assuming the actual question (“Is there an object to the left of the cube?”) is passed to the foreign predicate parse_expr as the first argument s, the entire prompt becomes:
Then, GPT-4 is prompted to produce the query, which is parsed back into our ADT Query:
B.3 Putting it all together
The last part which brings everything together is the semantics of our Query DSL. The semantics is inductively defined on the Query data structure. We start from defining the variants which return a set of objects. For this, we use the eval_obj binary relation to connect queries with their evaluated object IDs:
We next define the semantics for queries which evaluate to a boolean, producing the eval_bool relation:
We finally define the semantics for queries which evaluate to a number, producing the eval_num relation:
To connect everything together, we apply the eval_* relation on the parsed expression to get the evaluated result:
B.4 A concrete example
We illustrate a concrete example in Fig. 8.

Appendix C Experimental Details
Our experiments are conducted on a machine with two 20-core Intel Xeon CPUs, four GeForce RTX 2080 Ti GPUs, and 768 GB RAM. Note that our experiments do not involve training and therefore do not require high-end computation resources. In this section we elaborate on the foundation models that we used in our experiments and the setup for individual tasks.
C.1 Model setup
GPT.
The default GPT model we use is gpt-4. Depending on the task, there are a few variations we have used which include gpt-3-turbo, text-embedding-ada-002. We set the model temperature to as the default value, and we cache the intermediate result locally for expense-saving purposes. For chain-of-thought (CoT) prompting, we adopt the zero-shot technique introduced by (kojima2022large). Questions that encounter an API server error are manually re-queried. All experiments are performed from June to August 2023.
OWL-ViT.
We use the OWLViTProcessor and OwlViTForObjectDetection models from Hugging Face. We load the pretrained checkpoint google/owlvit-base-patch32. We set the processor’s score_threshold to , score_multiplier to , and expand_crop_region to .
ViLT.
We use the ViltProcessor and ViltForQuestionAnswering models from Hugging Face. We load the pretrained checkpoint dandelin/vilt-b32-finetuned-vqa. We set the default value of top to and score_threshold to .
CLIP.
We use OpenAI’s official implementation with the model set to ViT-B/32.
DSFD.
We use the implementation of DSFD from PyPI’s face-detection package. We set confidence_threshold to 0.5 and nms_iou_threshold to 0.3.
Segment Anything.
We use the Segment Anything Model (SAM) from its official open-source repository. Specifically, we use the ViT-H SAM model checkpoint. We set the default iou_threshold to 0.88, area_threshold to 0, and expand_crop_region to 0.
Prompt2prompt and Diffusion Model.
We adapt Prompt2prompt (hertz2022prompttoprompt) from its official repository to support continuous editing, and we choose the underlying stable diffusion model CompVis/stable-diffusion-v1-4 from Hugging Face. We set the default value of num_inference_steps to 50 for the stable diffusion model, max_num_words to 77, and guidance_scale to 7.5.
Others.
The other integrated models which are not used in our experiments includes chat models like Vicuna (zheng2023vicuna), Llama 2 (touvron2023llama), and text embedding models like Cross-Encoder (nogueira2019passage), and RoBERTa (liu2019roberta).
C.2 Task setup
Date reasoning.
The DR dataset is adapted from BIG-bench’s date understanding task, with 28 of the original 369 questions being corrected for wrong target answers. We solve this task by decomposing it into two sub-tasks: extracting structured information using an LM, followed by logical reasoning over the structured information using relational rules and date arithmetic.
For the first sub-task, we leverage GPT-4 with 5-shot prompting for extracting the following three relations from the given context:
-
1.
mentioned_date(label, date): label is a string label for a date whose MM/DD/YYYY form is explicitly mentioned in the context, and date is the corresponding MM/DD/YYYY string.
-
2.
goal(label): label is the date label whose MM/DD/YYYY form is requested as the answer.
-
3.
relationship(earlier_date, later_date, diff): the first two arguments are a pair of date labels relevant to the question, and diff is the time duration between the dates.
See Table 7 for an example set of extracted relations. The shots for gpt_extract_relation are manually composed to be similar to questions in the dataset. For this task specifically, we configure gpt_extract_relation to use zero-shot CoT (kojima2022large) when extracting relationship, which improves accuracy by over 10%.
After extracting these relations, a symbolic program iterates through derived dates and durations to compute dates for all extracted date labels, including the goal date. Date parsing and date arithmetic is enabled by Vieira’s built-in data types DateTime and Duration.
| Question: Today’s meeting is rescheduled to 11 am tomorrow, 10/16/1924. What is the date one year ago from today in MM/DD/YYYY? | |
|---|---|
| Vieira extracted relations: |
mentioned_date: [("rescheduled-meeting", "1924-10-16")]
relationship: [("1-year-ago", "today", "R12MO PT0S"), ("today", "rescheduled-meeting", "P1D")] goal: [("1-year-ago")] |
| Vieira answer: | 10/15/1923 (CORRECT) |
| GPT-4 response: | Let’s think step by step. First, we need to subtract one year from the given date, 10/16/1924. When we do this, we get 10/16/1923. |
| GPT-4 answer: | 10/16/1923 (INCORRECT) |
Tracking shuffled objects.
The TSO dataset is randomly sampled from a combined dataset of subtasks corresponding to objects from BIG-bench’s tracking shuffled objects task. Specifically, our random sample contains 32 questions where , 59 questions where , and 59 questions where . Our solution relies on GPT-4 with single-shot prompting for extracting three relations:
-
1.
possessions(time, person, object): person possesses object at time step time. We prompt GPT-4 to only extract the initial possessions (where time is 1), which are explicitly described in the context.
-
2.
swaps(time, person_a, person_b): person_a and person_b swap objects at time step time.
-
3.
goal(person): person is the target person whose final possessed object is expected as the answer.
See Table 8 for an example set of extracted relations. We prompt gpt_extract_relation with one shot based on a question from the BIG-bench task but not from our sampled dataset. Our reasoning program then iterates through all the swaps starting from the initial possessions and retrieves the last possessed object associated with the target.
We conjecture that the exemplary performance of our model on TSO is due to the highly consistent syntactic structure of the NL inputs, facilitating relation extraction under a one-shot setting.
| Question: Alice, Bob, Claire, Dave, and Eve are dancers at a square dance. At the start of a song, they each have a partner: Alice is dancing with Ophelia, Bob is dancing with Lola, Claire is dancing with Izzi, Dave is dancing with Karl, and Eve is dancing with Jamie. Throughout the song, the dancers often trade partners. First, Bob and Claire switch partners. Then, Eve and Dave switch partners. Then, Eve and Claire switch partners. Then, Alice and Eve switch partners. Finally, Alice and Bob switch partners. At the end of the dance, Bob is dancing with | |
| Vieira extracted relations: |
possessions: [(1, "Alice", "Ophelia"), (1, "Bob", "Lola"), (1, "Claire", "Izzi"), (1, "Dave", "Karl"), (1, "Eve", "Jamie")]
swaps: [(1, "Bob", "Claire"), (2, "Eve", "Dave"), (3, "Eve", "Claire"), (4, "Alice", "Eve"), (5, "Alice", "Bob")] goal: [("Bob")] |
| Vieira answer: | Lola (CORRECT) |
| GPT-4 response: | Let’s think step by step. At the start, Bob is dancing with Lola. After Bob and Claire switch partners, Bob is dancing with Izzi. After Eve and Dave switch partners, Bob is still dancing with Izzi. After Eve and Claire switch partners, Bob is still dancing with Izzi. After Alice and Eve switch partners, Bob is still dancing with Izzi. Finally, after Alice and Bob switch partners, Bob is dancing with Ophelia. So, the answer is (A) Ophelia. |
| GPT-4 answer: | Ophelia (INCORRECT) |
Kinship reasoning.
We use the CLUTRR (sinha2019clutrr) dataset to perform the kinship reasoning task in NLP. Each data point in this task contains a story that indicates the kinship between characters, and the aim is to infer the relationship between two specified characters. We use all the 1,146 data points in the test dataset of 089907f8.
The intermediate symbolic representation we use GPT-4 model to extract is a kinship graph, whose edge is composed of 20 different relationships, including “father”, “mother”, “uncle”, “niece”. For prompting the GPT-4 model, we first ask the GPT model to yield us all the kinships relations that are mentioned in the context and store it in mentioned_kinship. Then we also need to extract the two target characters, in which we consult gpt and store the answer in the relation query. See Table 9 for an example set of extracted relations.
The resulting kinship graph is then reasoned along with a given external knowledge base, which includes the compositional knowledge like “father’s mother is grandmother”, to obtain the relationship between the two desired people.
| Question: Myrna and her husband Christopher went on a cruise. They had a wonderful time. Christopher and his daughter Lucille took a day off school to go to the zoo. Who is Lucille to Myrna? | |
|---|---|
| Vieira extracted relations: |
mentioned_kinship: [("Christopher",
"Lucille",
"father"),
("Christopher",
"Myrna",
"husband"),
("Lucille",
"Christopher",
"daughter"),
("Myrna",
"Christopher",
"wife")]
query: [("Lucille", "Myrna")] |
| Vieira answer: | daughter (CORRECT) |
| GPT-4 response: | Lucille is Myrna’s stepdaughter. In the given scenario, Christopher is Myrna’s husband, and Christopher is also the father of Lucille. This makes Lucille the daughter of Myrna’s husband, which means she is Myrna’s stepdaughter. |
| GPT-4 answer: | stepdaughter (INCORRECT) |
Math reasoning.
This task is drawn from the GSM8K dataset of arithmetic word problems (cobbe2021training). Both our math and date reasoning datasets have previously served as benchmarks for LLM performance under chain-of-thought prompting (wei2023chainofthought; kojima2022large). The questions involve grade school math word problems created by human problem writers, and the model is asked to produce a number as the result. Since the output can be fractional, we allow a small delta when comparing the derived result with the ground truth. We include GPT-4 (few-shot and CoT) as baselines for this task.
Our solution to this task prompts GPT-4 (2-shot) to produce step-by-step expressions, which can contain constants, variables, and simple arithmetic operations. For example, the fact assign("total_sale", "april_sale + may_sale") represents that total sales are the sum of April and May sales. See Table 10 for an example set of extracted steps.
We evaluate all the expressions through a DSL, and the result associated with the goal variable is returned. By focusing the LM’s responsibility solely on semantic parsing, our relational program can then achieve faithful numerical computation via DSL evaluation.
The semantic parsed result is a Python expression that we can directly call the eval function in Python over the string, and we can obtain the desired outcome. This py_eval function is wrapped as a foreign attribute in .
| Question: If it takes 3 kangaroos traveling at the same speed a total of 18 hours to travel across a highway, how many hours will it take four turtles, each traveling at half the speed of a kangaroo, to do so? | |
|---|---|
| Vieira extracted steps: |
(0, "kangaroo_speed", "1 / (18 / 3)"),
(1, "turtle_speed", "{kangaroo_speed} / 2"), (2, "turtle_time", "1 / {turtle_speed}"), (3, "total_turtle_time", "{turtle_time} * 4") |
| Vieira answer: | 48 (CORRECT) |
| GPT-4 response: | Let’s think step by step. First, we know that the total time it takes for 3 kangaroos to travel across the highway is 18 hours. This means that one kangaroo takes 18 hours to travel across the highway. Then, we know that a turtle travels at half the speed of a kangaroo, which means it takes twice as long for a turtle to travel the same distance. So, one turtle would take 18 hours * 2 = 36 hours to travel across the highway. However, we have four turtles traveling together at the same speed, so they would still take 36 hours to travel across the highway, because they are traveling simultaneously. |
| GPT-4 answer: | 36 (INCORRECT) |
Retrieval augmentation and semantic search.
We have two benchmarks for retrieval augmentation and semantic search: HotpotQA and Amazon’s ESCI Product Search.
The HotpotQA (yang2018hotpotqa) data, a Wikipedia-based question answering (QA) dataset under the “distractor" setting. Here, the model takes in parts of inputs: 1) a question, and 2) Wikipedia paragraphs as the context for answering the question. Among the Wikipedia pages, at most are relevant to the answer, while the others are distractors. This challenges the capability of retrieving information based on the question. Since the QA models produce free-form answers that can vary largely, we use GPT-4 to check the correctness of the derived result against the ground truth. This is aided by the manual inspection of subsets to determine the statistical variance.
We use Amazon’s ESCI Product Search dataset (reddy2022shopping). The model is provided with a natural language (NL) query and a list of products ( products on average). The goal is to rank the products that best match the query. In the dataset, for each pair of query and product, a label among (exact match), (substitute), (complementary), and (irrelevant) is provided. The metric we use to evaluate the performance is nDCG. The gains are set to be for , for , for , and for . We include GPT’s embedding model, text-embedding-ada-002 as baselines for ranking products.
Compositional multi-modal reasoning.
For compositional multi-modal reasoning, we pick tasks of CLEVR and GQA. We choose two compositional VQA datasets, GQA (drew2019gqa) and CLEVR (johnson2016clevr). In this task, the model is given an image and a question, and needs to answer the question. For GQA, the majority of questions expect yes/no answers, while CLEVR’s questions demand features like counting and spatial reasoning. We randomly sample 184 and 480 The images and questions in GQA are collected from real life while that of CLEVR are synthetic.
Visual object tagging.
For VQAR, we consider the top 50 object bounding boxes returned by OWL-ViT. Our relational knowledge base is from (huang2021scallop). When querying ViLT, we take the top response from a score threshold of 0.9. We manually score semantic correctness by finding the percentage of objects returned that match the query. Object bounding boxes are considered correct if they contained any part of an entity matching the query.
For OFCP, we curated 50 examples featuring groups of notable celebrities and politicians from Wikimedia Commons and other Internet sources, and manually assigned descriptive filenames to each image. We obtain the set of possible names by prompting GPT-4 with the filename. We enlarge the face bounding boxes returned by DSFD by a factor of 1.3 before querying CLIP. We tag each face with its most probable name from CLIP, but if the probability is below the 0.8 threshold, then the face is tagged “unknown”. The ground truth of relevant faces and their names were manually assigned based on the filename description. The ground truth label for non-relevant faces is “unknown”. All faces judged to be in the foreground of an image, as well as any additional faces not tagged with “unknown”, are counted for semantic correctness.
Image generation and editing.
We manually wrote prompts image generation and their editing sequences. Each prompt includes one image generation prompt and two consequent image editions. Our domain-specific language for image generation and editing supports operations: Background, ReplaceObject, RefineObject, NotObject, ReweightObject. We use the GPT-4 model to convert the natural language prompts into programmatic queries with 4 shot examples. There are cases among that fail to convert the natural language into executable programs, as the Replace operation requires to have the same token length of the original input text and the updated text, while the GPT-4 model fails to capture the requirement through the few-shot examples.
Appendix D Qualitative Studies
We present exemplars for face tagging in Figure 9, object tagging in Figure 10, image editing in Figure 11, and image generation and editing in Figure 13.